apache solr for begginers
TRANSCRIPT

Full text search for lazy guys
STA R R ING APACHE SOLR

Agenda• Introduction
• FTS solutions
• FTS patterns
• Apache Solr
• Architecture
• Client libraries
• data treatment pipeline
• Index modeling
• ingestion
• Searching
• Demo 1
• Solr in clustered environment
• Architecture
• Idexing
• quering
• Demo 2
• Advanced Solr
• Cool features overview
• Performance tuning
• Q&A sessions

FTS solutions attributes
1. Search by content of documents rather than by attributes2. Read-oriented3. Flexible data structure4. 1 dedicated tailored index used further for search5. index contains unique terms and their position in all documents6. Indexer takes into account language-specific nuances like stop words, stemming,
shingling (word-grams, common-grams)
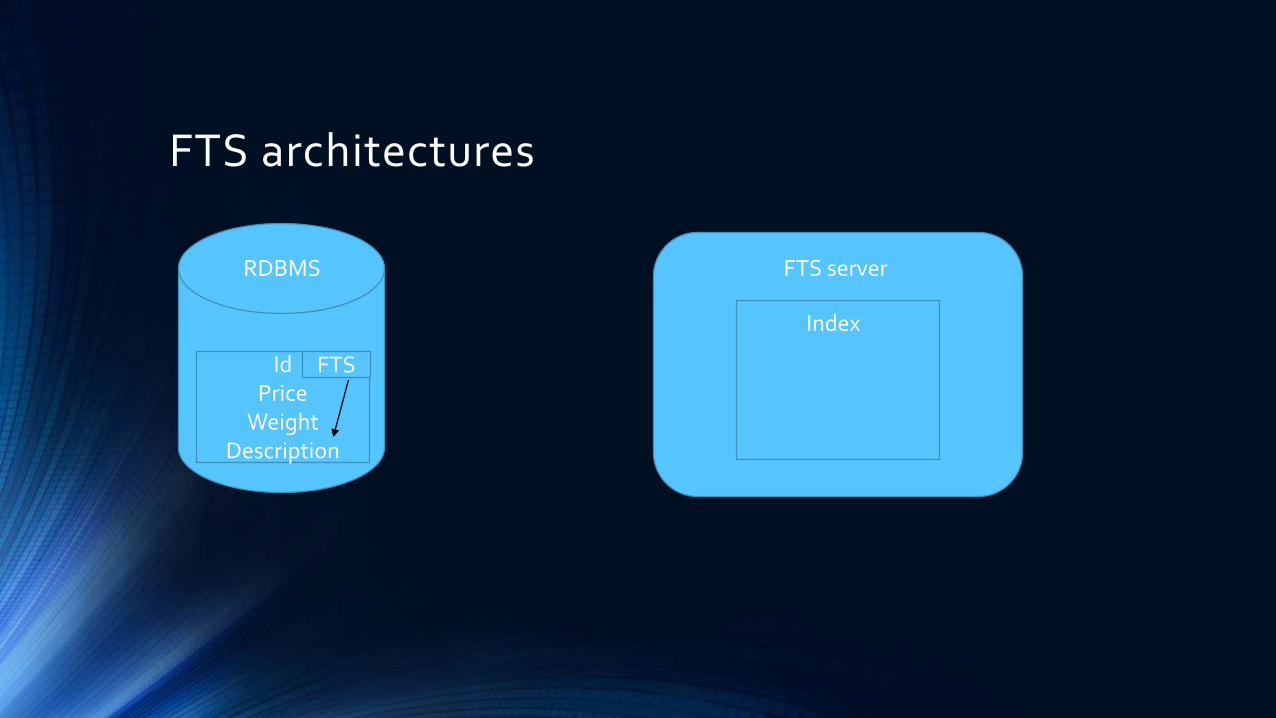
FTS architectures
IdPrice
WeightDescription
RDBMS
FTS
FTS server
Index
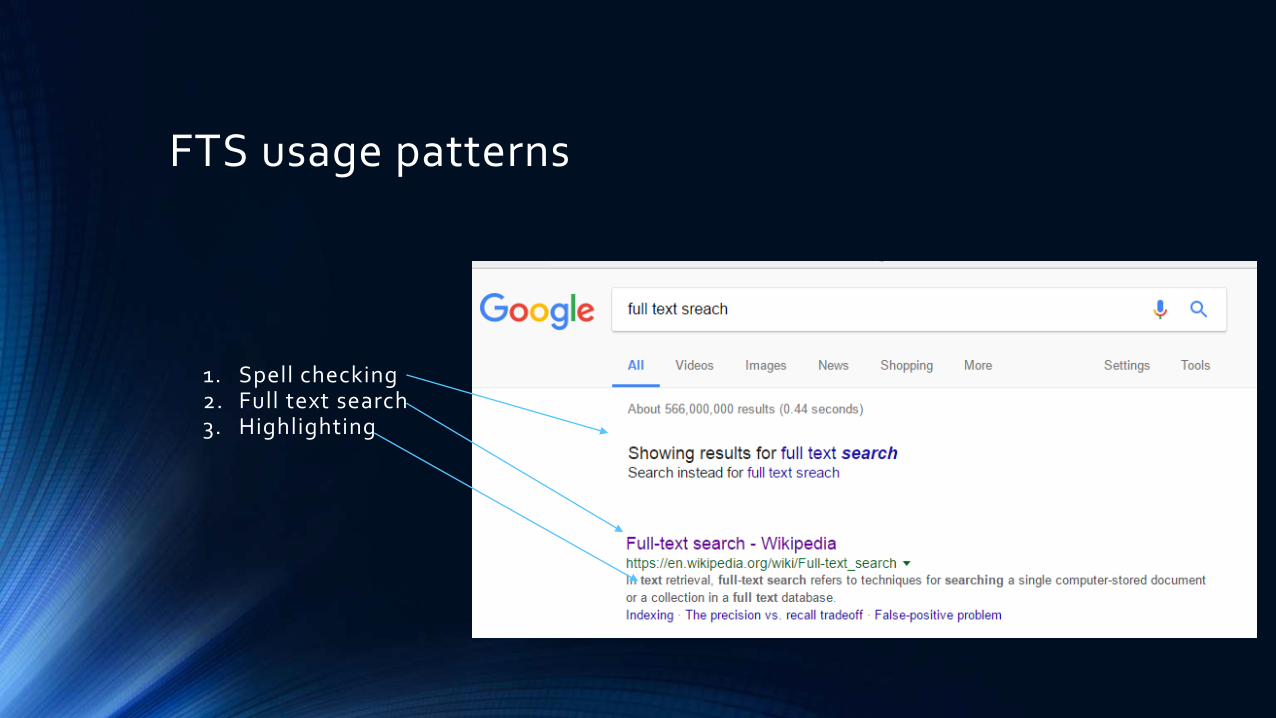
FTS usage patterns
1. Spell checking2. Full text search3. Highlighting
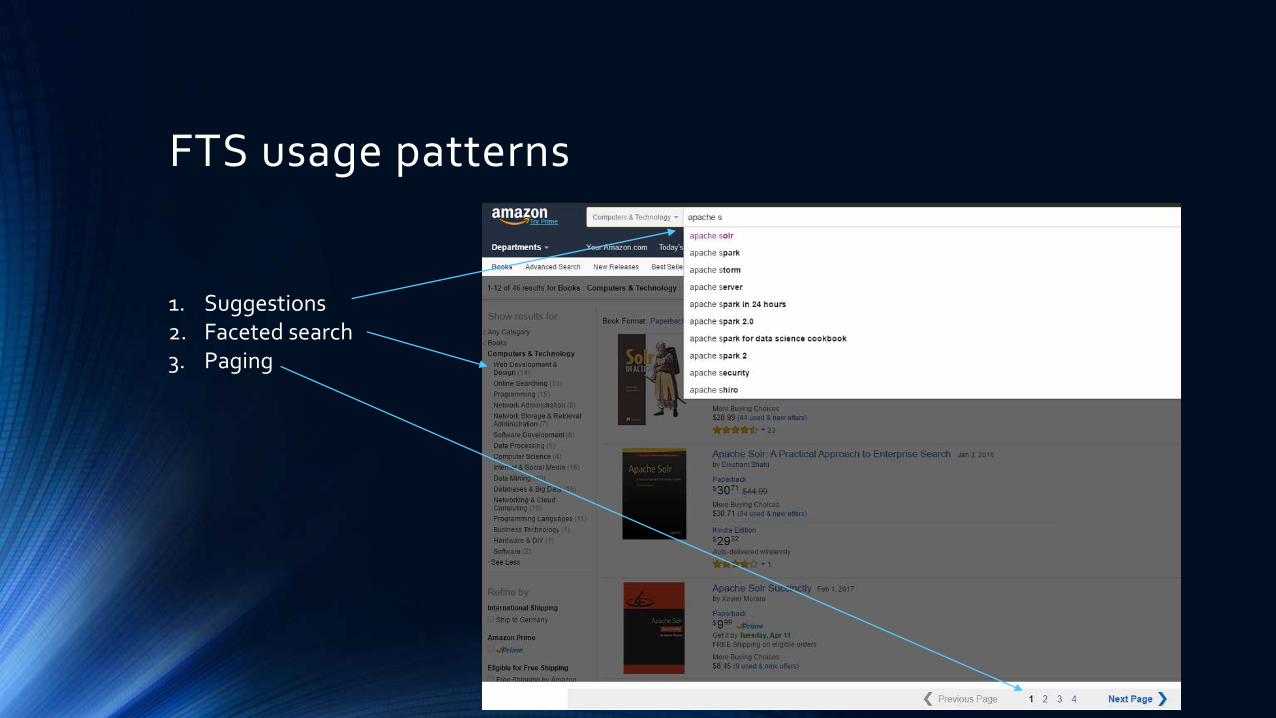
FTS usage patterns
1. Suggestions2. Faceted search3. Paging

Market leaders
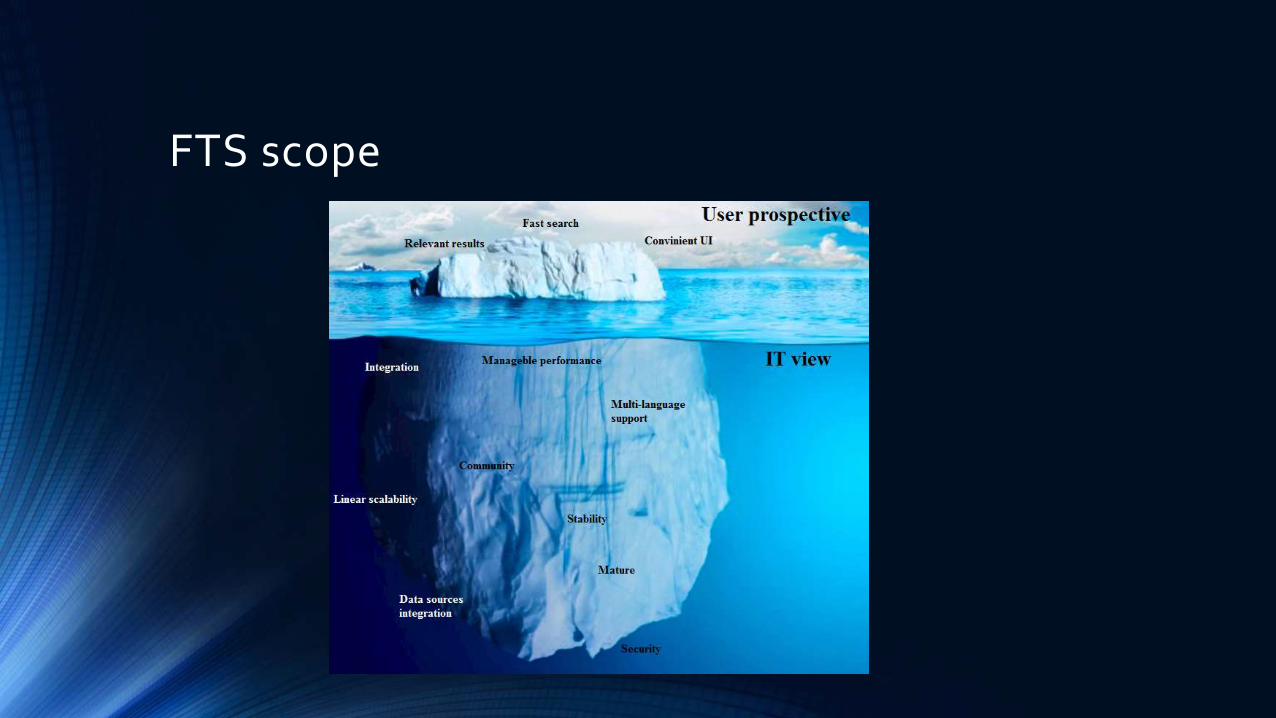
FTS scope

Q&A

Solr
• True open source (under Apache) full text search engine• Built over Lucene• Multi-language support• Rich document parsing (rtf, pdf, …)• Various client APIs• Versatile query language• Scalable• Full of additional features

Well-known Solr users
and many others in https://wiki.apache.org/solr/PublicServers
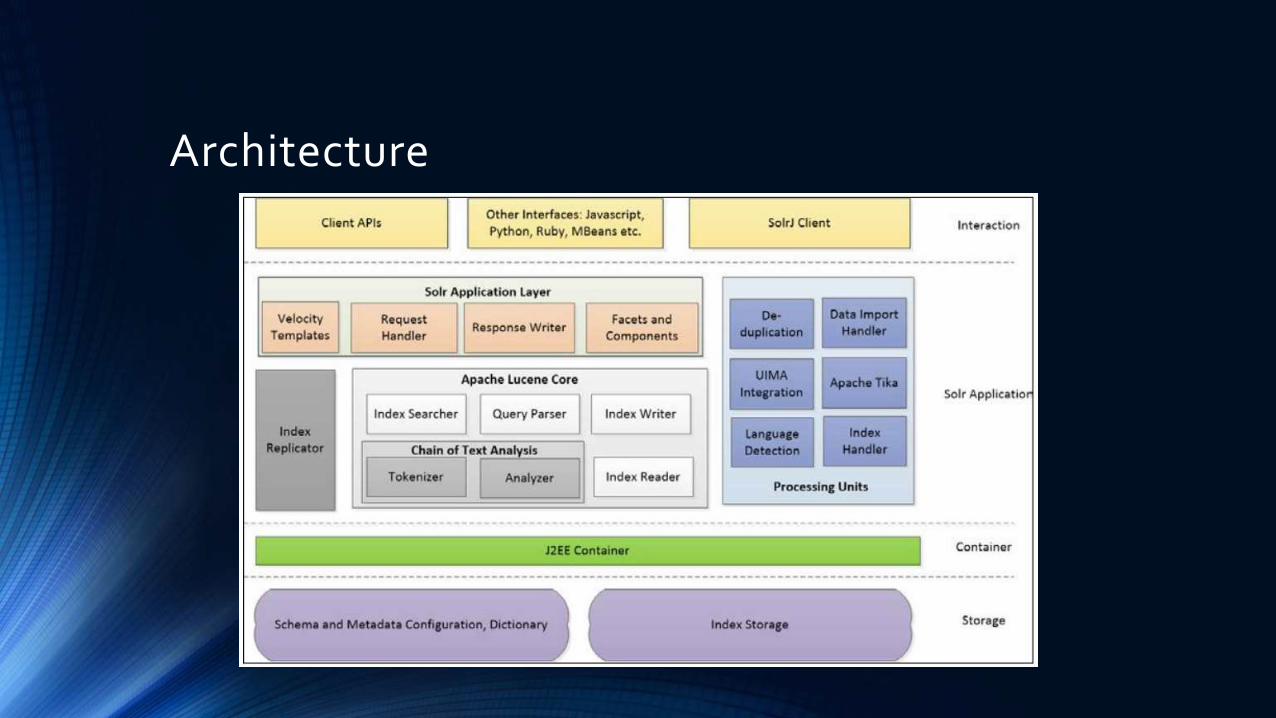
Architecture

Client access
1. Main REST API• Common operations• Schema API• Rebalance/collection API• Search API• Faceted API2. Native JAVA client SolrJ3. Client bindings like Ruby, .Net, Python, PHP, Scala – see
https://wiki.apache.org/solr/IntegratingSolr + https://wiki.apache.org/solr/SolPython
4. Parallel SQL (via REST and JDBC)

Inverted index

Index modeling
Choose Solr mode:1. Schema2. Schema-less
Define field attributes:1. Indexed (query, sort, facet, group by, provide query suggestions for, execute
function)2. Stored – all fields which are intended to be shown in a response3. Mandatory4. Data type5. Multivalued6. Copy field (calculated)
Choose a field for UniqueIdentifier

Field data types
1. Dates2. Strings3. Numeric4. Guid5. Spatial6. Boolean7. Currency and etc

Real life-schema

Text processingIntended to mitigate differences between terms to provide perfect search
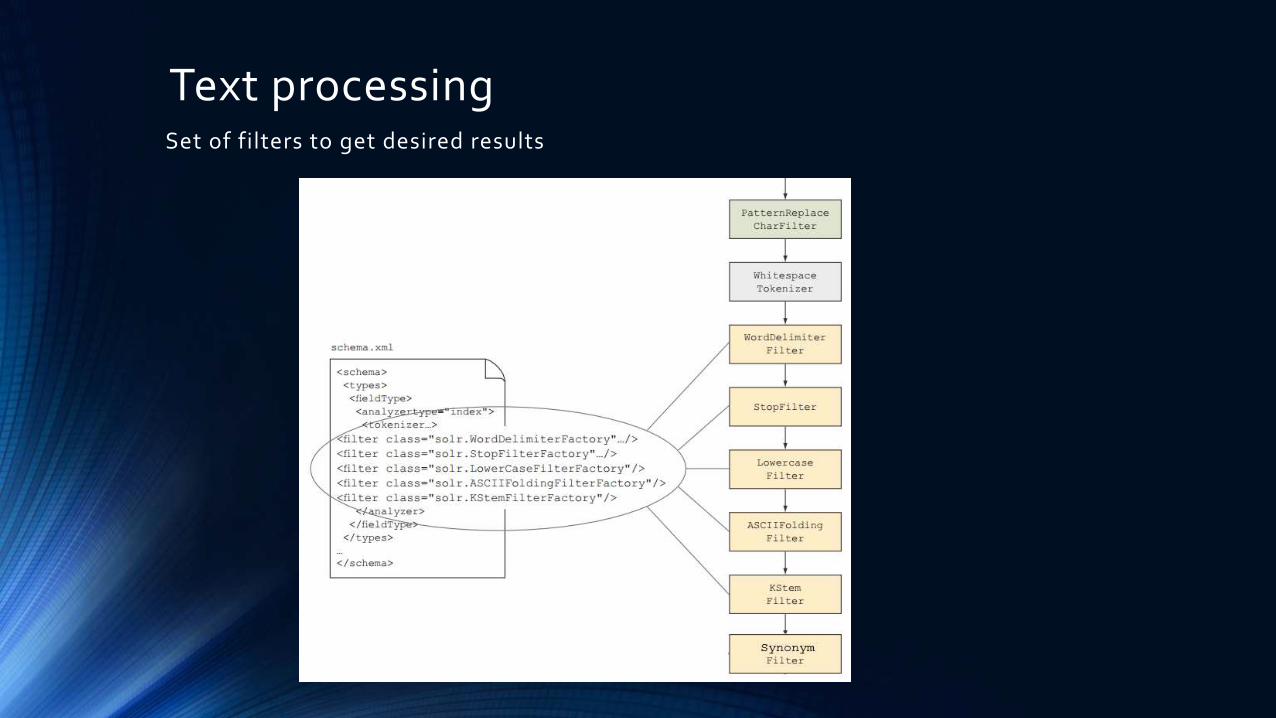
Text processingSet of filters to get desired results

Text processing
Set of filters to get desired results
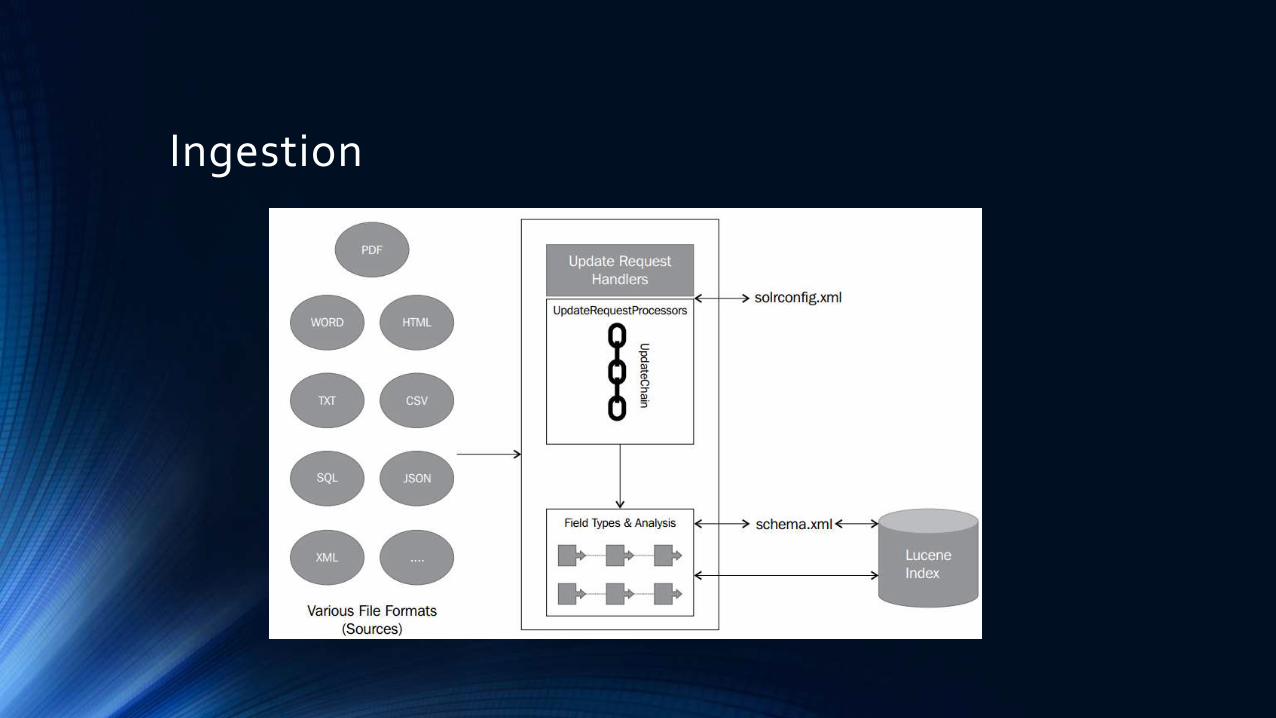
Ingestion

Transaction management
1. Solr doesn’t expose immediately new data as well as not remove deleted2. Commit/rollback should be issued
Commit types:1. Soft
Data indexed in memory1. Hard
It moves data to hard-drive
Risks:1. Commits are slow2. Many simultaneous commits could lead to Solr exceptions (too many commits)< h 2 > H T T P E R R O R : 5 0 3 < / h 2 >< p r e > E r r o r o p e n i n g n e w s e a r c h e r . e x c e e d e d l i m i t o f m a x W a r m i n g S e a r c h e r s = 2 , t r y a g a i n l a t e r . < / p r e >
3. Commit command works on instance level – not on user one

Transaction log
Intention:1. recovery/durability2. Nearly-Real-Time (NRT) update3. Replication for Solr cloud4. Atomic document update, in-place update (syntax is different) 5. Optimistic concurrency
Transaction log could be enabled in solrconfig.xml<updateLog><str name="dir">${solr.ulog.dir:}</str></updateLog>
Atomic update example:{ " i d " : " m y d o c " ," p r i c e " : { " s e t " : 9 9 } ," p o p u l a r i t y " : { " i n c " : 2 0 } ," c a t e g o r i e s " : { " a d d " : [ " t o y s " , " g a m e s " ] } ," p r o m o _ i d s " : { " r e m o v e " : " a 1 2 3 x " } ," t a g s " : { " r e m o v e " : [ " f r e e _ t o _ t r y " , " o n _ s a l e " ] }
}

Data modification Rest API
Rest API accepts:1. Json objects2. Xml-update 3. CSV
Solr UPDATE = UPSERT if schema.xml has <UniqueIdentifier>

Data modification Rest API
c u r l h t t p : / / 1 9 2 . 1 6 8 . 7 7 . 6 5 : 8 9 8 3 / s o l r / s in g l e - c o r e / u p d a t e ? c o m m it = t r u e - H ' C o n t e n t - t y p e : a p p l ic a t io n / j s o n ' - d '
[
{ " id " : " 3 " ," in t e r n a l_ n a m e " : " p o s t 2 " ,} ,
{ " id " : “ 1 " ," in t e r n a l_ n a m e " : " p o s t 1 " ,}] ‘
D a t a . x m l
<a d d ><d o c >
< f ie ld n a m e =' id ' >8 < / f i e l d >< f ie ld n a m e =' in t e r n a l_ n a m e ' >t e s t 1 </ f i e l d >
< d o c >< d o c >
< f ie ld n a m e =' id ' > 9 < / f i e l d >< f ie ld n a m e =' in t e r n a l_ n a m e ' >t e s t 6 </ f i e l d >
< d o c >< / a d d >
c u r l - X P O ST ' h t t p : / / 1 9 2 . 1 6 8 . 7 7 . 6 5 : 8 9 8 3 / s o lr / s in g l e - c o r e / u p d a t e ? c o m m it = t r u e & w t = j s o n ' - H ' C o n t e n t - T y p e : t e x t / x m l ' - d @ d a t a . x m l
D e le t e . x m l<d elet e >
< id >1 1 6 0 4 </ i d >< id >: 1 1 6 0 3 </ i d >
</ d e le t e >
D e le t e _ w it h _ q u e r y . x m l<d e le t e >
<q u e r y > id : [ 1 T O 8 5 ] </ q u e r y ></ d e le t e >

Post utility
1. Java-written utility2. Intended to load files3. Works extremely fast4. Loads csv, json5. Loads files by mask of file-by-file
bin/post -c http://localhost:8983/cloud tags*.json
ISSUE: doesn’t work with Solr Cloud

Data import handler
1. Solr loads data itself2. DIH could access to JDBC, ATOM/RSS, HTTP, XML, SMTP datasource3. Delta approach could be implemented (statements for new, updated and deleted
data)4. Loading progress could be tracked5. Various transformation could be done inside (regexp, conversion, javascript)6. Own datasource loaders could be implemented via Java7. Web console to run/monitor/modify

Data import handler
How to implement:1. Create data config
< da t a C o n f i g >< da t a S o u r c e n a m e =" j db c " dr i v e r =" o r g. po s t g r e s q l . D r i v e r "
u r l = " j db c : po s t gr e s q l : / / l o c a l h o s t / d b "u s e r ="a dm i n " r e a dO n l y ="t r u e " a u t o C o m m i t ="f a l s e " / >
<do c u m e n t ><e n t i t y n a m e ="a r t i s t " da t a S o u r c e = " j db c " pk =" i d"
q u e r y =" s e l e c t * f r o m a r t i s t a "t r a n s f o r m e r =" D a t e F o r m a t T r a n s f o r m e r "
><f i e l d c o l u m n =" i d" n a m e =" i d" / >
<f i e l d c o l um n =" de pa r t m e n t _ c o d e " n a m e =" de pa r t m e n t _ c o d e "/ ><f i e l d c o l u m n =" de pa r t m e n t _ n a m e " n a m e =" de pa r t m e n t _ n a m e "/ >
<f i e l d c o l u m n = " b e gi n _ da t e " da t e T i m e F o r m a t = " y y y y - M M - d d " / >
</ e n t i t y ></ do c u m e n t >
< / da t a C o n f i g >
2. Publish in solrconfig.xml< r e q u e s t H a n dl e r n a m e ="/ j db c "c l a s s =" o r g. a pa c h e . s o l r . h a n dl e r . da t a i m po r t . D a t a I m po r t H a n dl e r " >
< l s t n a m e =“ de f a u l t ">< s t r n a m e =" j db c . x m l </ s t r >
< / l s t >< / r e q u e s t H a n dl e r >
DIH could be started via REST callc u r l h t t p : / / l o c a l h o s t : 8 9 8 3 / c l o u d / j d b c - F c o m m a n d = f u l l - i m p o r t

Data import handler
In process:
< ?xml vers ion="1.0" encoding="U TF -8"?><response>
< lst name=" response Hea der ">< int name="stat us ">0</ in t>< int name=" QTime ">0</ int>
< / lst>< lst name=" ini tArg s ">
< lst name="defaul ts ">< str name=" conf ig">jd bc .xm l</ str>
< / lst>< / lst>< str name="stat us "> b us y< / s tr>< str name=" importRes po nse ">A command is st i l l running. . .</ str>< lst name=" stat u sMes s a ge s ">
< str name="Time Elapsed">0:1:15.4 60 </ s tr><str name="Total Requests made to DataSour ce ">3 9 54 7</ st r>< str name="Total Rows Fetched">59319< / s tr>< str name="Total Documents Processed">197 72</ st r>< str name="Total Documents Sk ipped">0</ str>< str name="Ful l Dump Started">2010 -1 0-03 14:28:00</ str>
< / lst>< str name="WARNIN G">T hi s response format is exper imental . I t i s l ike ly to change in the future.</ str>
</response>

Data import handler
After import:
<?xml version="1.0" encoding="UTF-8"?><response>
<lst name="responseHeader"><int name="status">0</int><int name="QTime">0</int>
</lst><lst name="initArgs">
<lst name="defaults"><str name="config">jdbc.xml</str>
</lst></lst><str name="status">idle</str><str name="importResponse"/><lst name="statusMessages">
<str name="Total Requests made to DataSource">2118645</str><str name="Total Rows Fetched">3177966</str><str name="Total Documents Skipped">0</ str><str name="Full Dump Started">2010 -10-03 14:28:00</str><str name="">Indexing completed. Added/Updated: 1059322 documents. Deleted 0
documents.</str><str name="Committed">2010-10-03 14:55:20</str><str name="Optimized">2010-10-03 14:55:20</str><str name="Total Documents Processed">1059322</ str><str name="Time taken ">0:27:20.325</ str>
</lst><str name="WARNING">This response format is experimental. It is likely to change in the
future.</str></response>
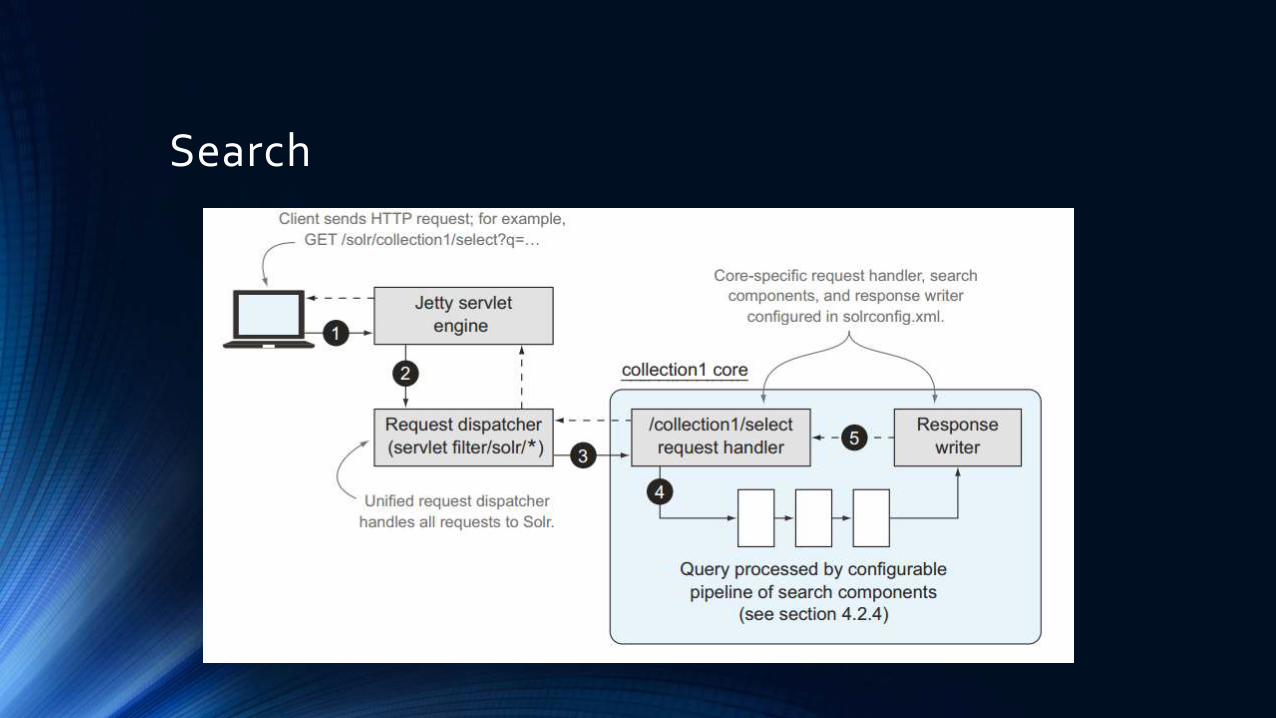
Search
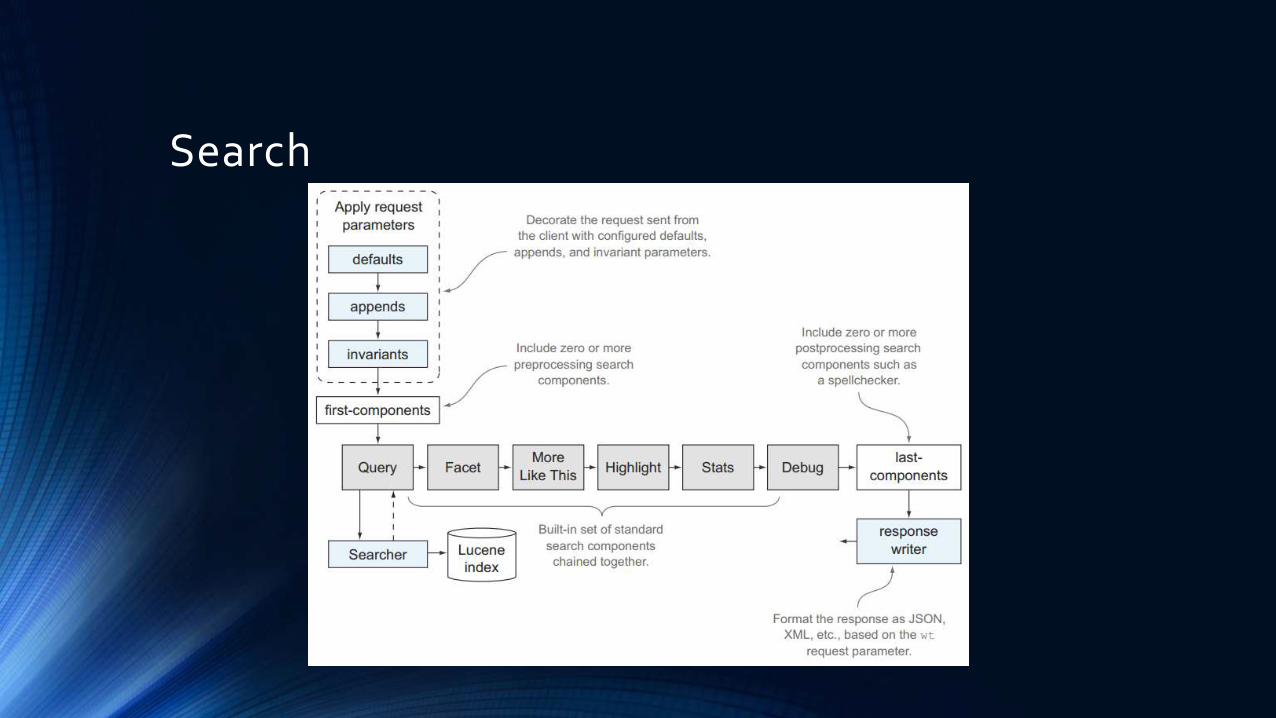
Search

Search typesFuzzy
Developer~ Developer~1 Developer~4It matches developer, developers, development and etc.
Proximity
“solr search developer”~ “solr search developer”~1
It matches: solr search developer, solr senior developer
Wildcard
Deal* Com*n C??t Need *xed? Add ReversedWildcardFilterFactory .
Range
[1 TO25] {23 TO50} {23 TO90]

Search characteristics
1. Similarity2. Term frequency
Similarity could be changed via boosting:
q = t i t l e : ( s o l r f o r d e v e l o p e r s ) ^ 2 . 5 A N D d e s c r i p t i o n : ( p r o f e s s i o n a l )
q = t i t l e : ( j a v a ) ^ 0 . 5 A N D d e s c r i p t i o n : ( p r o f e s s i o n a l ) ^ 3

Search result customization
Field list /query?=&fl=id, genre /query?=&fl=*,score
Sort/query?=&fl=id, name&sort=date, score desc
Pagingselect?q=*:*&sort=id&fl=id&rows=5&start=5
Transformers[docid] [shard]
Debuging/query?=&fl=id&debug=true
Format/query?=&fl=id&wt=json /query?=&fl=id&wt=xml

Search queries examples
Parameter stylec u r l " h t t p : / / l o c a l h o s t : 8 9 8 3 / c l o u d / q u e r y ? q = h e r o y & f q = i n S t o c k : t r u e "
JSON API$ c u r l h t t p : / / l o c a l h o s t : 8 9 8 3 / c l o u d / q u e r y - d '{
q u e r y : " h e r o "" f i l t e r " : " i n S t o c k : t r u e "
} '
Response{
" r e s p o n s e H e a d e r " : {" s t a t u s " : 0 ," QT im e " : 2 ," p a r a m s " : {
" j s o n " : " n { n q u e r y : " h e r o " " f i l t e r " : " in St o c k : t r u e " n } " } } ," r e s p o n s e " : { " n u m F o u n d " : 1 , " s t a r t " : 0 , " d o c s " : [
{" id " : " b o o k 3 " ," a u t h o r " : " B r a n d o n Sa n d e r s o n " ," a u t h o r _ s " : " B r a n d o n Sa n d e r s o n " ," t i t le " : [ " T h e H e r o o f A a g e s " ] ," s e r ie s _ s " : " M i s t b o r n " ," s e q u e n c e _ i" : 3 ," g e n r e _ s " : " f a n t a s y " ," _ v e r s io n _ " : 1 4 8 6 5 8 1 3 5 5 5 3 6 9 7 3 8 2 4
} ]}
}

Q&A

SolrCloud
ALEX 2 turn!!!!

Advanced Solr1. Streaming language
Special language tailored mostly for Solr Cloud, parallel processing, map -reduce style approach. The idea is to process and return big datasets.Commands like: search, jdbc, intersect, parallel, or, and
2. Parallel queryJDBC/REST to process data in SQL style. Works on many Solr nodes in MPP style.
c u r l - - da t a - u r l e n c o de ' s t m t =S E L E C T t o , c o u n t ( * ) F R O M c o l l e c t i o n 4 G R O U P B Y t o O R D E R B Y c o u n t ( * ) de s c L I M I T 1 0 ' h t t p: / / l o c a l h o s t : 8 9 8 3 / s o l r / c l o u d / s q l
3. Graph functionsGraph traversal, aggregations, cycle detection, export to GraphML format
4. Spatial queriesThere is field datatype Location . It permits to deal with spatial conditions like filtering by distance (circle,
square, sphere) and etc.& q =* : * & f q = ( s t a t e : "F L " A N D c i t y : "J a c k s o n v i l l e " ) & s o r t = g e o di s t ( ) + a s c
5. Spellchecking It could be based on a current index, another index, file or using word breaks. Many options what to
return: most similar, more popular etc
h t t p: / / l o c a l h o s t : 8 9 8 3 / s o l r / c l o u d / s p e l l ? d f = t e x t & s p e l l c h e c k . q = d e l l l + u l t r a + s h a r p& s p e l l c h e c k = t r u e
6. Suggestionsh t t p : / / l o c a l h o s t : 8 9 8 3 / s o l r / c l o u d/ a _ t e r m _ s u g g e s t ? q =s m a & w t =j s o n
7. HighlighterMarks fragments in found documenth t t p : / / l o c a l h o s t : 8 9 8 3 / s o l r / c l o u d/ s e l e c t ? h l =o n & q =a ppl e
8. FacetsArrangement of search results into categories based on indexed terms with statistics. Could be done by values, range, dates, interval, heatmap

Performance tuning CacheBe aware of Solr cache types:1. Filter cache
Holds unordered document identifiers associated with filter queries that have been executed (only if fq query parameter is used)
2. Query result cacheHolds ordered document identifiers resulting from queries that have been
executed
3. Document cacheHolds Lucene document instances for access to fields marked as stored
Identify most suitable cache class1. LRUCache – last recently used are evicted first, track time2. FastLRUCache – the same but works in separate thread3. LFUCache – least frequently used are evicted first, track usage count
Play with auto-warm<f i l terCach e class=" solr .F a s t LRU C a c he " s ize=" 512“ in i t ia lSize =“100" autowar mCo un t =“10 "/>
Be aware how auto-warm works internally – doesn’t delete data, repopulated completely

Performance tuning MemoryCare about OS memory for disk caching
Estimate properly Java heap size for Solr – use https://svn.apache.org/repos/asf /lucene/dev/tags/lucene_solr_4_2_0/dev -tools/s i ze-estimator- lucene-solr.xls

Performance tuning Schema design
1. Try to decrease number of stored fields mark as indexed only2. If fields are used only to be returned in search results – use stored only

Performance tuning Ingestion
1. Use bulk sending data rather than per-document2. If you use SolrJ use ConcurentUpdateSolrServer class3. Disable ID uniqueness checking4. Identify proper mergeFactor + maxSegments for Lucene segment merge5. Issue OPTIMIZE after huge bulk loadings 6. If you use DIH try to not use transformers – pass them to DB level in SQL7. Configure AUTOCOMMIT properly

Performance tuning Search
1. Choose appropriate query parser based on use case2. Use Solr pagination to return data without waiting for a long time3. If you return huge data set use Solr cursors rather than pagination4. Use fq clause to speed up queries with one equal condition – time for scoring
isn’t used + results are put in cache5. If you have a lot of stored fields but queries don’t show all of them use field lazy
loading< enableLaz yFie ld Lo adin g >t r ue</ en a ble L az yFie ld Lo adin g >
6. Use shingling to make phrasal search faster
<filter class=" solr.Shingl eF i lt e rFa ct ory “ maxShingleSiz e = " 2" outputUnigra ms = "t ru e" />
<fi lter c lass=" solr.Common G ram sQ u ery Fi lte r Facto ry “ words="commongram s. tx t" ignoreCase ="tr ue" " />

Q&A
