application-transparent near-memory processing
TRANSCRIPT

Application-Transparent Near-Memory Processing Architecture with Memory
Channel Network
Mohammad Alian1, Seung Won Min1, Hadi Asgharimoghaddam1, Ashutosh Dhar1, Dong Kai Wang1, Thomas Roewer2, Adam McPadden2,
Oliver O'Halloran2, Deming Chen1, Jinjun Xiong2, Daehoon Kim1,Wen-mei Hwu1, and Nam Sung Kim1,3
1University of Illinois Urbana-Champaign2IBM Research and Systems
3Samsung Electronics

Executive Summary
• Processing In Memory (PIM), Near Memory Processing (NMP), …✓EXECUBE’94, IRAM’97, ActivePages’98, FlexRAM’99, DIVA’99, SmartMemories’00, …
• Question: why haven’t they been commercialized yet?✓Demand changes in application code and/or memory subsystem of host processor
2
IRAM’97 ISCA’15SmartMemories’00
Qaud Network
Processing Tile orDRAM Block
Qaud
48MB Memory
48MB Memory
Vector UnitCPU+3M $

Executive Summary
• Processing In Memory (PIM), Near Memory Processing (NMP), …✓EXECUBE’94, IRAM’97, ActivePages’98, FlexRAM’99, DIVA’99, SmartMemories’00, …
• Question: why haven’t they been commercialized yet?✓Demand changes in application code and/or memory subsystem of host processor
• Solution: memory module based NMP + Memory Channel Network (MCN)✓Recognize NMP memory modules as distributed computing nodes over Ethernet
no change in application code or memory subsystem of host processors
✓Seamlessly integrate NMP w/ distributed computing frameworks for better scalability
3

Executive Summary
• Processing In Memory (PIM), Near Memory Processing (NMP), …✓EXECUBE’94, IRAM’97, ActivePages’98, FlexRAM’99, DIVA’99, SmartMemories’00, …
• Question: why haven’t they been commercialized yet?✓Demand changes in application code and/or memory subsystem of host processor
• Solution: memory module based NMP + Memory Channel Network (MCN)✓Recognize NMP memory modules as distributed computing nodes over Ethernet
no change in application code or memory subsystem of host processors
✓Seamlessly integrate NMP w/ distributed computing frameworks for better scalability
• Feasibility & Performance:✓Demonstrate the feasibility w/ an IBM POWER8 + experimental memory module
✓Improve the performance and processing bandwidth by 43% and 4×, respectively
4
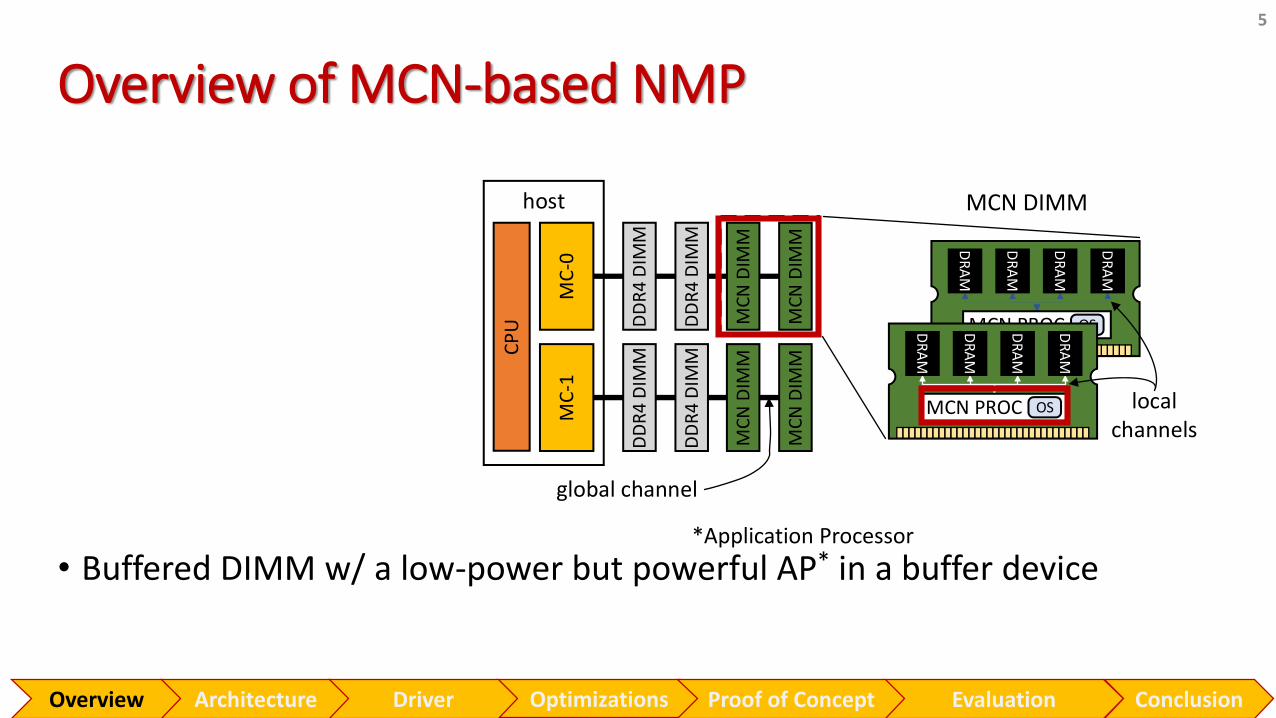
Overview of MCN-based NMP
5
DR
AM
DR
AM
DR
AM
DR
AM
MCN PROC OS
MCN noderegular node
global channel
host
DD
R4
DIM
M
DD
R4
DIM
M
MC
N D
IMM
MC
N D
IMM
MC
-0
DD
R4
DIM
M
DD
R4
DIM
M
MC
N D
IMM
MC
N D
IMM
MC
-1
local channels
CP
U DR
AM
DR
AM
DR
AM
DR
AM
MCN PROC OS
• Buffered DIMM w/ a low-power but powerful AP* in a buffer device
MCN DIMM
*Application Processor
Optimizations Evaluation ConclusionOverview Proof of ConceptArchitecture Driver
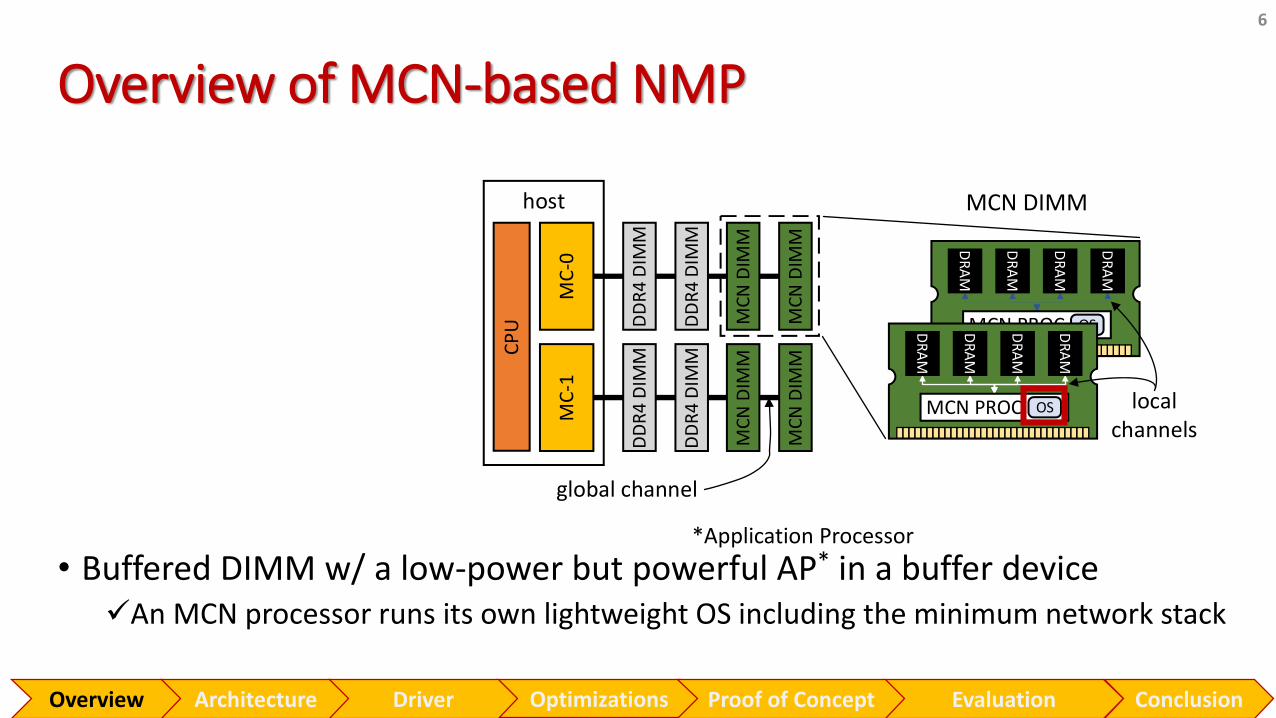
Overview of MCN-based NMP
6
DR
AM
DR
AM
DR
AM
DR
AM
MCN PROC OS
MCN noderegular node
global channel
host
DD
R4
DIM
M
DD
R4
DIM
M
MC
N D
IMM
MC
N D
IMM
MC
-0
DD
R4
DIM
M
DD
R4
DIM
M
MC
N D
IMM
MC
N D
IMM
MC
-1
local channels
CP
U DR
AM
DR
AM
DR
AM
DR
AM
MCN PROC OS
• Buffered DIMM w/ a low-power but powerful AP* in a buffer device✓An MCN processor runs its own lightweight OS including the minimum network stack
MCN DIMM
*Application Processor
Optimizations Evaluation ConclusionOverview Proof of ConceptArchitecture Driver

Overview of MCN-based NMP
7
DR
AM
DR
AM
DR
AM
DR
AM
MCN PROC OS
MCN noderegular node
global channel
host
DD
R4
DIM
M
DD
R4
DIM
M
MC
N D
IMM
MC
N D
IMM
MC
-0
DD
R4
DIM
M
DD
R4
DIM
M
MC
N D
IMM
MC
N D
IMM
MC
-1
local channels
CP
U DR
AM
DR
AM
DR
AM
DR
AM
MCN PROC OS
• Buffered DIMM w/ a low-power but powerful AP* in a buffer device
• Special driver faking memory channels as Ethernet connections
MCN nodeMCN distributed computing
MCN DIMM
*Application Processor
Optimizations Evaluation ConclusionOverview Proof of ConceptArchitecture Driver
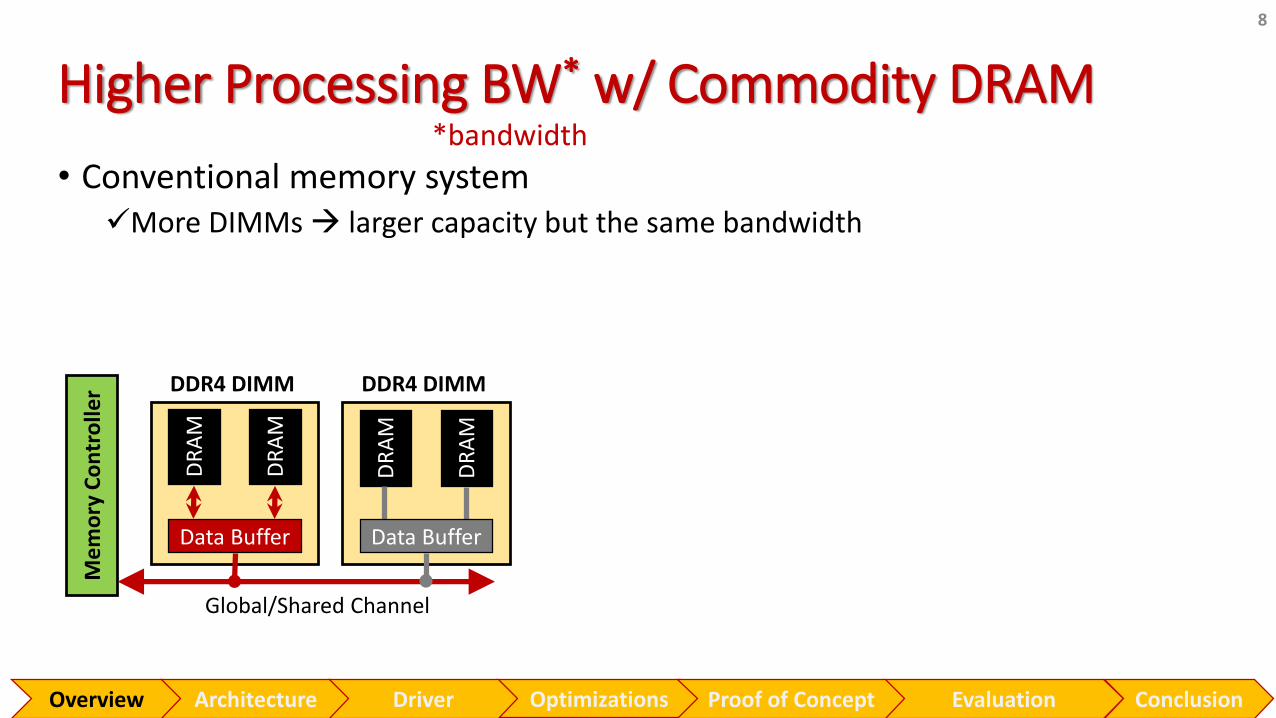
Higher Processing BW* w/ Commodity DRAM
• Conventional memory system✓More DIMMs larger capacity but the same bandwidth
8
Me
mo
ry C
on
tro
ller DDR4 DIMM
DR
AM
DR
AM
Data Buffer
DDR4 DIMMD
RA
M
DR
AM
Data Buffer
Global/Shared Channel
*bandwidth
Optimizations Evaluation ConclusionOverview Proof of ConceptArchitecture Driver
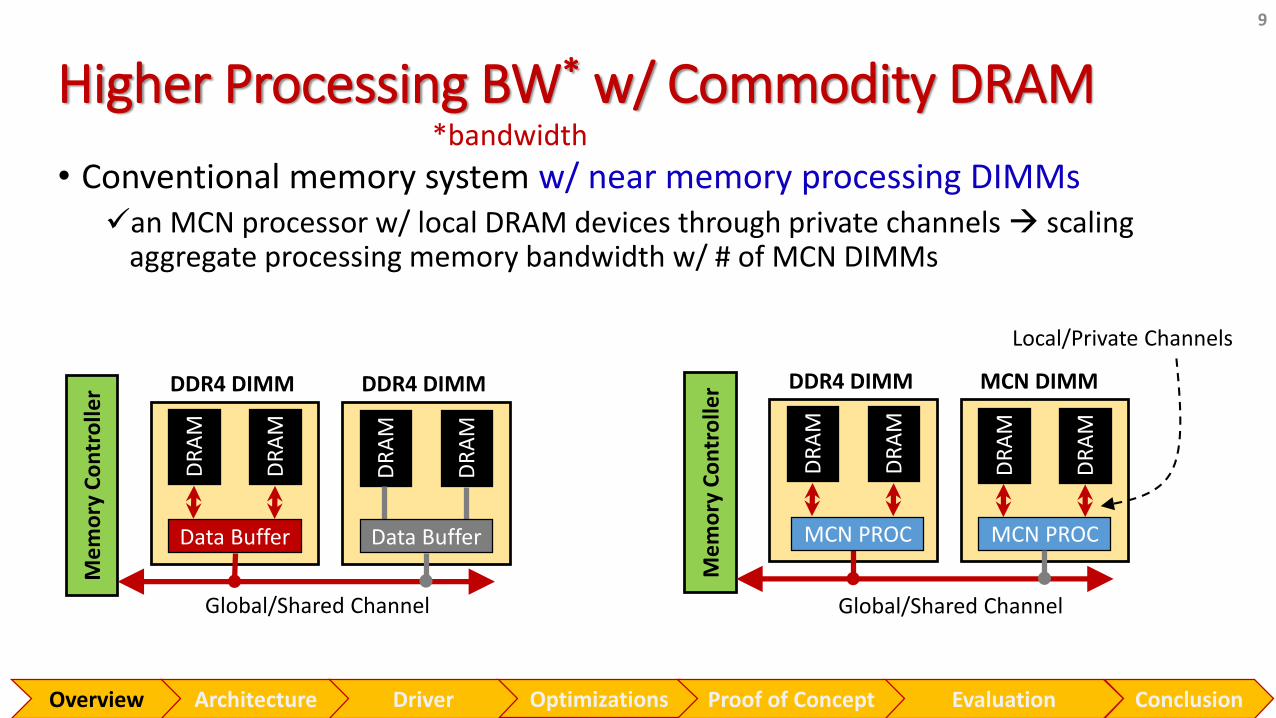
Higher Processing BW* w/ Commodity DRAM
• Conventional memory system w/ near memory processing DIMMs✓an MCN processor w/ local DRAM devices through private channels scaling
aggregate processing memory bandwidth w/ # of MCN DIMMs
9
Me
mo
ry C
on
tro
ller DDR4 DIMM
DR
AM
DR
AM
Data Buffer
DDR4 DIMMD
RA
M
DR
AM
Data Buffer
Me
mo
ry C
on
tro
ller DDR4 DIMM
DR
AM
DR
AM
MCN DIMM
DR
AM
DR
AM
MCN PROC
Global/Shared Channel Global/Shared Channel
Local/Private Channels
*bandwidth
Optimizations Evaluation ConclusionOverview Proof of ConceptArchitecture Driver
MCN PROC
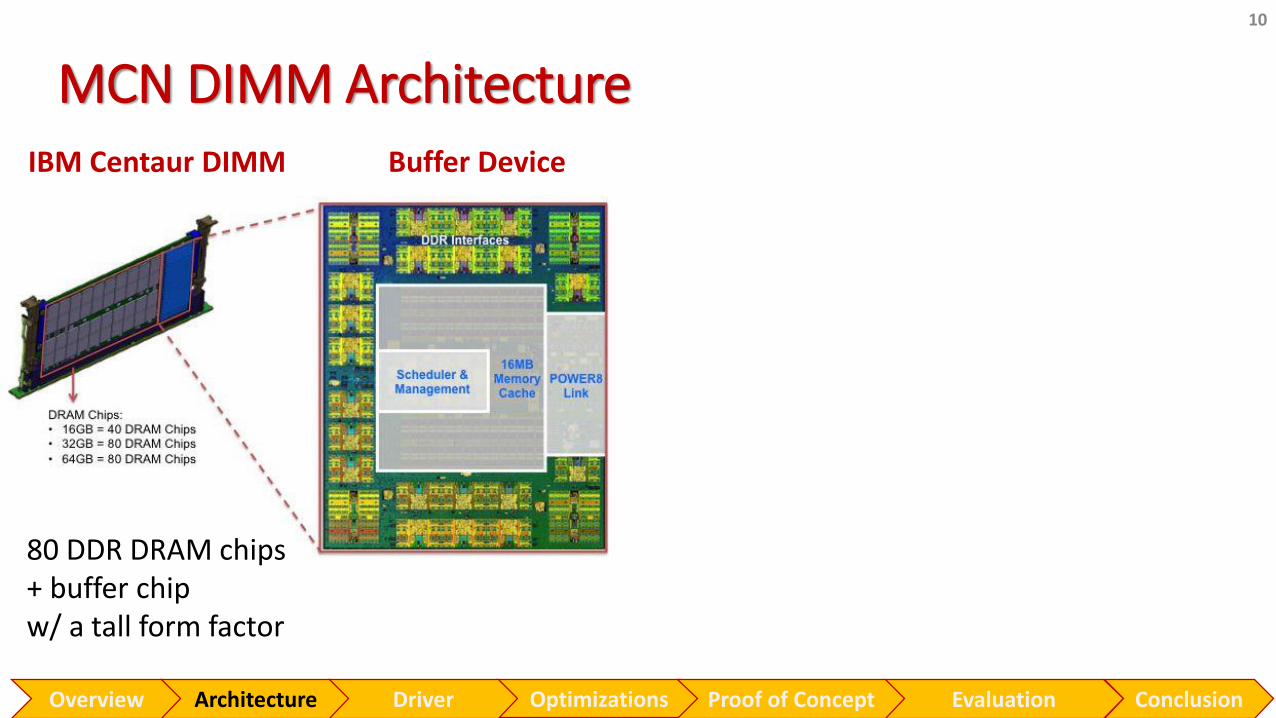
MCN DIMM Architecture
10
IBM Centaur DIMM Buffer Device
80 DDR DRAM chips+ buffer chip w/ a tall form factor
Optimizations Evaluation ConclusionOverview Proof of ConceptArchitecture Driver

MCN DIMM Architecture
11
MCN Processor
core0
core1
core2
core3
LLC / interconnect
MC
globalDDR
channel
dual-port SRAM
DD
R in
terf
ace
MCN PROC
controlTXRX
IRQ
local DRAM
IBM Centaur DIMM Buffer Device
80 DDR DRAM chips+ buffer chip w/ a tall form factor
Near-Memory Processor
Optimizations Evaluation ConclusionOverview Proof of ConceptArchitecture Driver
~20W TDP &~10mm×10mm
Snapdragon AP w/ 4 A57 ARM cores + 2MB LLC, GPU, 2 MCs, etc. @ ~5W & ~8×8mm2 (1.8W & ~2×2mm2)
core0
core1
core2
core3
LLC / interconnect
MC
globalDDR
channel
dual-port SRAM
DD
R in
terf
ace
MCN PROC
controlTXRX
IRQ
local DRAM
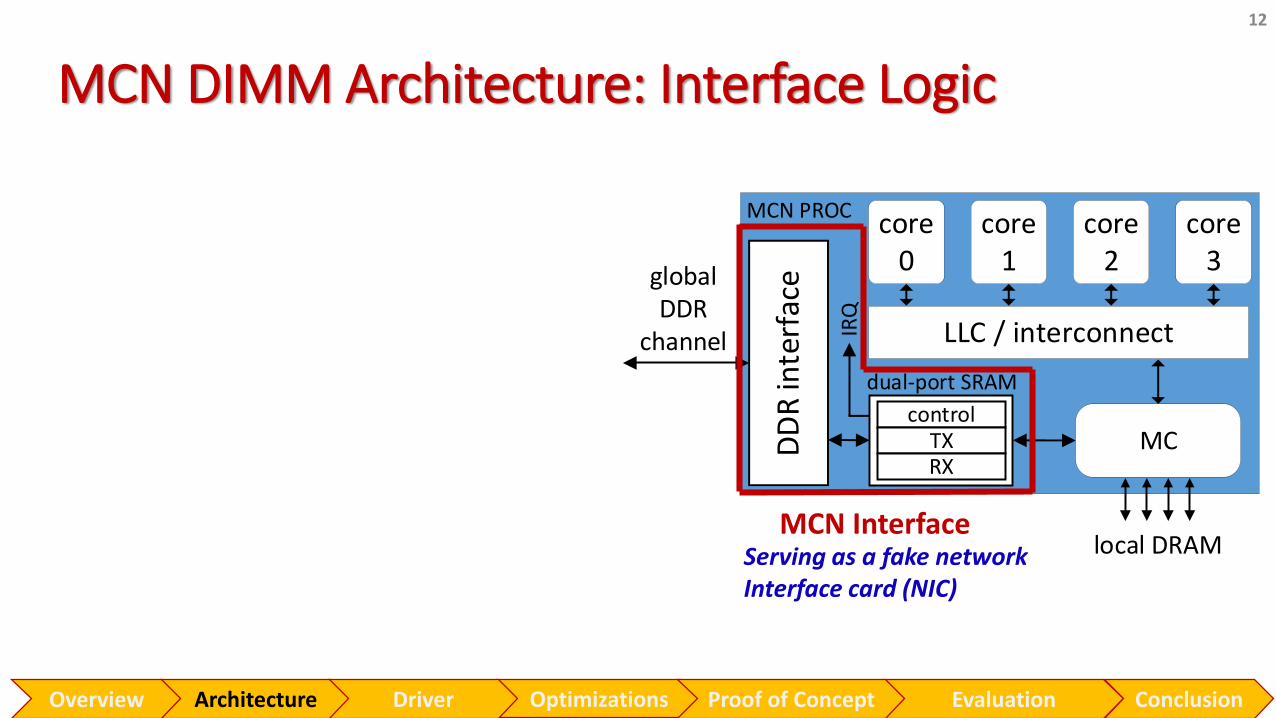
MCN DIMM Architecture: Interface Logic
12
Serving as a fake networkInterface card (NIC)
Optimizations Evaluation ConclusionOverview Proof of ConceptArchitecture Driver
MCN Interface

core0
core1
core2
core3
LLC / interconnect
MC
globalDDR
channel
dual-port SRAM
DD
R in
terf
ace
MCN PROC
controlTXRX
IRQ
local DRAM
MCN DIMM Architecture: Interface Logic
13
Serving as a fake networkInterface card (NIC)
Optimizations Evaluation ConclusionOverview Proof of ConceptArchitecture Driver
MCN Interface
MCN buffer layout
Mapped to a range of physical memory spacedirectly accessed by MC like normal DRAM
Rx circular buffer
reservedRx-poll
48KB
Tx-head
64 Bytes
Tx-tail Tx-poll
0 4 8 12reserved
... 63
Tx circular buffer
Rx-head Rx-tail
48KB

core0
core1
core2
core3
LLC / interconnect
MC
globalDDR
channel
dual-port SRAM
DD
R in
terf
ace
MCN PROC
controlTXRX
IRQ
local DRAM
MCN DIMM Architecture: Interface Logic
14
Serving as a fake networkInterface card (NIC)
Optimizations Evaluation ConclusionOverview Proof of ConceptArchitecture Driver
MCN Interface
MCN buffer layout
Mapped to a range of physical memory spacedirectly accessed by MC like normal DRAM
Rx circular buffer
reservedRx-poll
48KB
Tx-head
64 Bytes
Tx-tail Tx-poll
0 4 8 12reserved
... 63
Tx circular buffer
Rx-head Rx-tail
48KB
DDR memory
kernel space
hardware
user space
memory channel
MCN driver
MCN access regular access
linux network stack
application
polling agent
memcpy
MCN SRAM
forwarding engine
TX RX
host
DD
R4
DIM
M
MC
N D
IMM
MC
-0
DD
R4
DIM
M
MC
N D
IMM
MC
-1
CP
U
SRA
MSR
AM
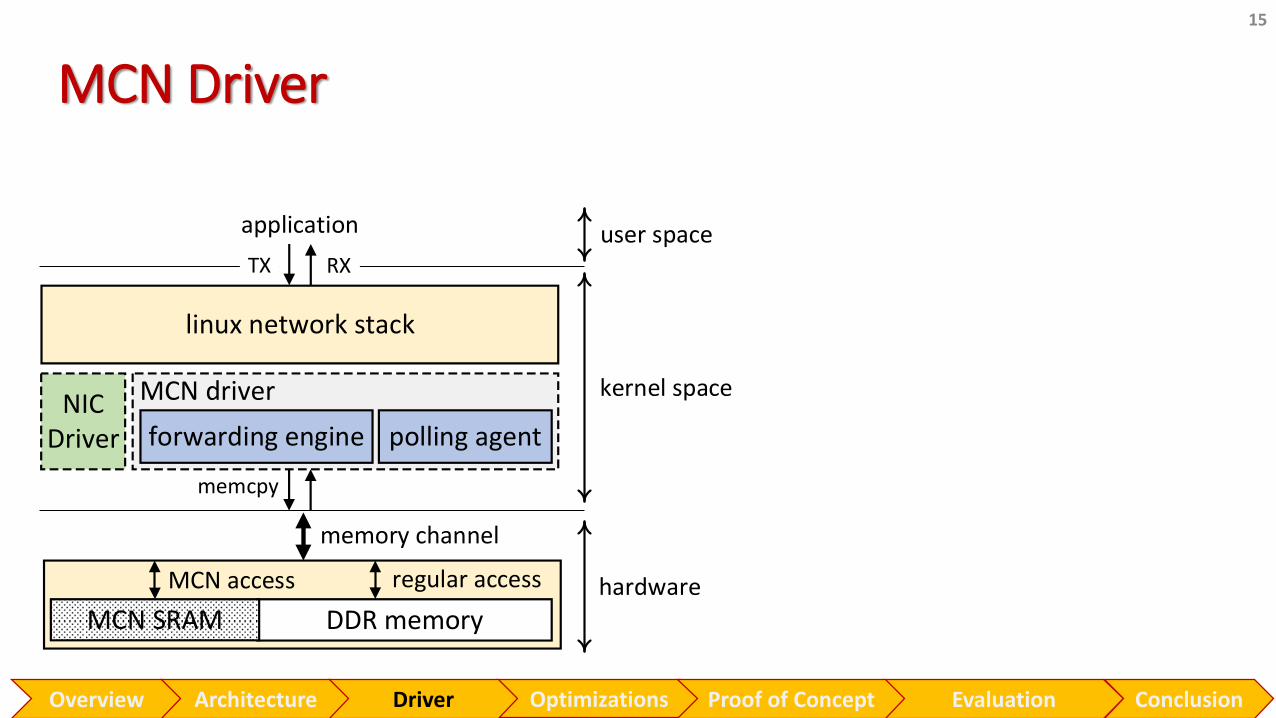
NIC Driver
MCN Driver
15
Optimizations Evaluation ConclusionOverview Proof of ConceptArchitecture Driver

DDR memory
kernel space
hardware
user space
memory channel
MCN driver
MCN access regular access
linux network stack
application
polling agent
memcpy
MCN SRAM
forwarding engine
TX RX
host
DD
R4
DIM
M
MC
N D
IMM
MC
-0
DD
R4
DIM
M
MC
N D
IMM
MC
-1
CP
U
SRA
MSR
AM
NIC Driver
MCN Packet Routing
16
• Host MCN
Header|Data/2
Header|Data/2
Header | Data
IP: X.X.X.X
1. A packet is passed from the host network stack and the packet goes to the corresponding MCN DIMM or NIC
Optimizations Evaluation ConclusionOverview Proof of ConceptArchitecture Driver

DDR memory
kernel space
hardware
user space
memory channel
MCN driver
MCN access regular access
linux network stack
application
polling agent
memcpy
MCN SRAM
forwarding engine
TX RX
host
DD
R4
DIM
M
MC
N D
IMM
MC
-0
DD
R4
DIM
M
MC
N D
IMM
MC
-1
CP
U
SRA
MSR
AM
NIC Driver
MCN Packet Routing
17
• Host MCN
Header|Data/2
Header|Data/2
Header | Data
MAC: AA.AA.AA.AA.AA.AA
2. If the packet needs to be sent to an MCN DIMM, the forwarding engine checks the MAC of the packet stored in main memory
Optimizations Evaluation ConclusionOverview Proof of ConceptArchitecture Driver

DDR memory
kernel space
hardware
user space
memory channel
MCN driver
MCN access regular access
linux network stack
application
polling agent
memcpy
MCN SRAM
forwarding engine
TX RX
host
DD
R4
DIM
M
MC
N D
IMM
MC
-0
DD
R4
DIM
M
MC
N D
IMM
MC
-1
CP
U
SRA
MSR
AM
NIC Driver
MCN Packet Routing
18
• Host MCN
MAC: AA.AA.AA.AA.AA.AA
Header|Data/2
Header|Data/2
Header | Data
3. If the MAC matches w/ that of an MCN DIMM, the packet is copied to the SRAM buffer of the MCN DIMM
Optimizations Evaluation ConclusionOverview Proof of ConceptArchitecture Driver

DDR memory
kernel space
hardware
user space
memory channel
MCN driver
MCN access regular access
linux network stack
application
polling agent
memcpy
MCN SRAM
forwarding engine
TX RX
host
DD
R4
DIM
M
MC
N D
IMM
MC
-0
DD
R4
DIM
M
MC
N D
IMM
MC
-1
CP
U
SRA
MSR
AM
NIC Driver
MCN Packet Routing
19
• Host MCN
Header | Data
4. This data copy triggers IRQ from the MCN DIMM and MCN processor knows there is an arrived packet
Optimizations Evaluation ConclusionOverview Proof of ConceptArchitecture Driver
Header | Data

DDR memory
kernel space
hardware
user space
memory channel
MCN driver
MCN access regular access
linux network stack
application
polling agent
memcpy
MCN SRAM
forwarding engine
TX RX
host
DD
R4
DIM
M
MC
N D
IMM
MC
-0
DD
R4
DIM
M
MC
N D
IMM
MC
-1
CP
U
SRA
MSR
AM
NIC Driver
MCN Packet Routing
20
• MCN Host
Header | Data
Header | Data
1. MCN DIMM writes a packet to its SRAM buffer and set the corresponding TX-poll bit
Optimizations Evaluation ConclusionOverview Proof of ConceptArchitecture Driver

DDR memory
kernel space
hardware
user space
memory channel
MCN driver
MCN access regular access
linux network stack
application
polling agent
memcpy
MCN SRAM
forwarding engine
TX RX
host
DD
R4
DIM
M
MC
N D
IMM
MC
-0
DD
R4
DIM
M
MC
N D
IMM
MC
-1
CP
U
SRA
MSR
AM
NIC Driver
MCN Packet Routing
21
• MCN Host
Header | Data
Header | Data
2. Polling agent from the host recognize the TX-poll bit is set and read the packet from the SRAM buffer
Optimizations Evaluation ConclusionOverview Proof of ConceptArchitecture Driver
DDR memory
kernel space
hardware
user space
memory channel
MCN driver
MCN access regular access
linux network stack
application
polling agent
memcpy
MCN SRAM
forwarding engine
TX RX
host
DD
R4
DIM
M
MC
N D
IMM
MC
-0
DD
R4
DIM
M
MC
N D
IMM
MC
-1
CP
U
SRA
MSR
AM
NIC Driver
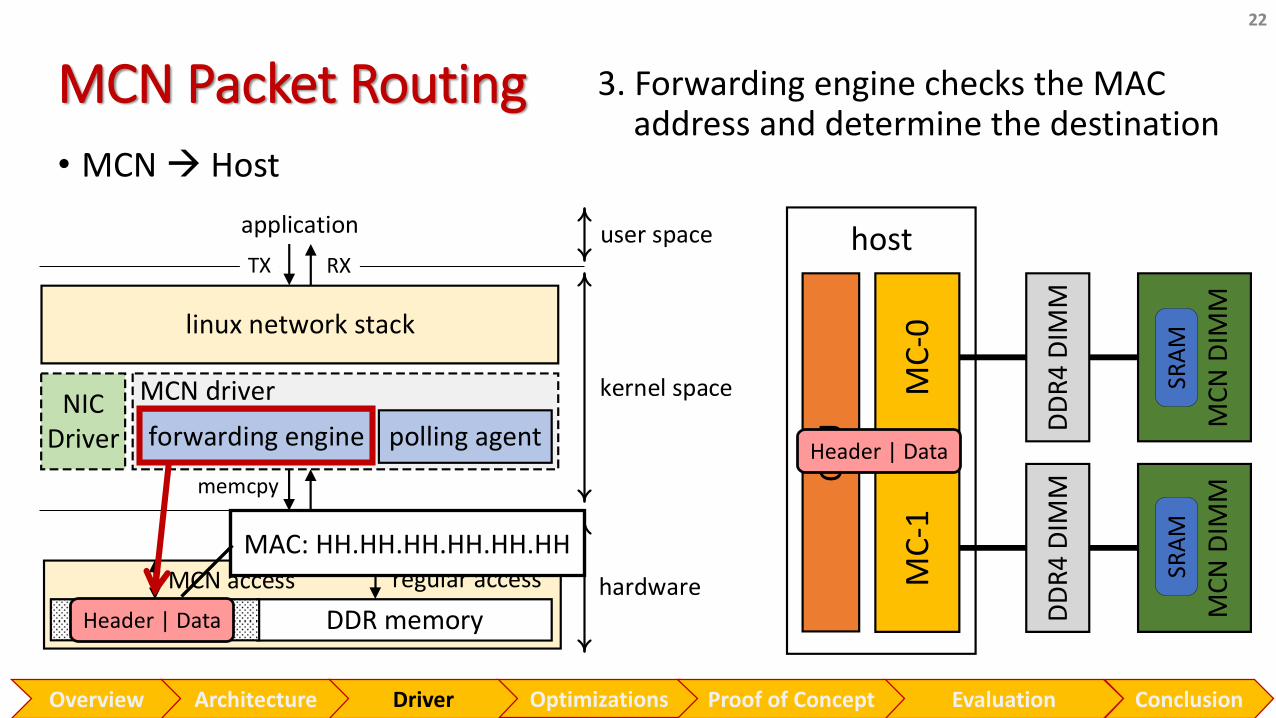
MCN Packet Routing
22
• MCN Host
Header | Data
MAC: HH.HH.HH.HH.HH.HH
Header | Data
3. Forwarding engine checks the MAC address and determine the destination
Optimizations Evaluation ConclusionOverview Proof of ConceptArchitecture Driver
DDR memory
kernel space
hardware
user space
memory channel
MCN driver
MCN access regular access
linux network stack
application
polling agent
memcpy
MCN SRAM
forwarding engine
TX RX
host
DD
R4
DIM
M
MC
N D
IMM
MC
-0
DD
R4
DIM
M
MC
N D
IMM
MC
-1
CP
U
SRA
MSR
AM
NIC Driver
MCN Packet Routing
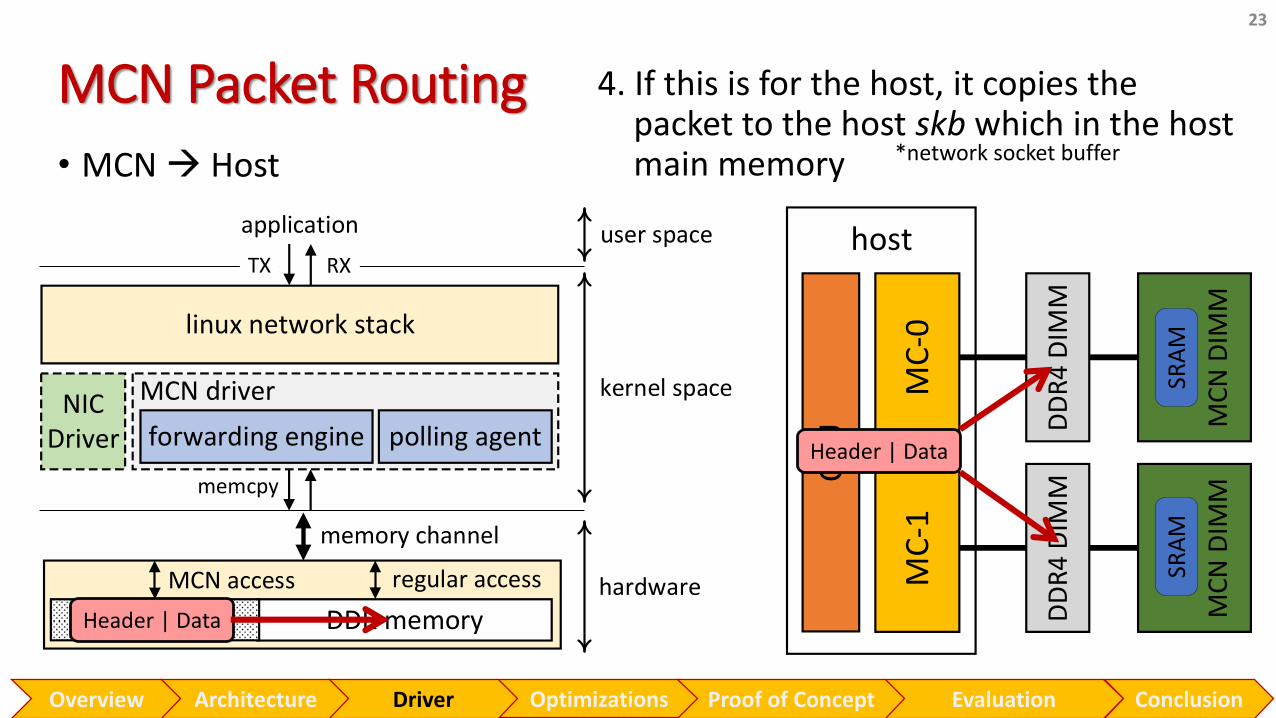
23
• MCN Host
Header | Data
Header | Data
4. If this is for the host, it copies the packet to the host skb which in the host main memory *network socket buffer
Optimizations Evaluation ConclusionOverview Proof of ConceptArchitecture Driver

DDR memory
kernel space
hardware
user space
memory channel
MCN driver
MCN access regular access
linux network stack
application
polling agent
memcpy
MCN SRAM
forwarding engine
TX RX
host
DD
R4
DIM
M
MC
N D
IMM
MC
-0
DD
R4
DIM
M
MC
N D
IMM
MC
-1
CP
U
SRA
MSR
AM
NIC Driver
MCN Packet Routing
24
• MCN Host
Header|Data/2
Header|Data/2
Header | Data
4. If this is for the host, it copies the packet to the host skb which in the host main memory
Optimizations Evaluation ConclusionOverview Proof of ConceptArchitecture Driver
*network socket buffer
DDR memory
kernel space
hardware
user space
memory channel
MCN driver
MCN access regular access
linux network stack
application
polling agent
memcpy
MCN SRAM
forwarding engine
TX RX
host
DD
R4
DIM
M
MC
N D
IMM
MC
-0
DD
R4
DIM
M
MC
N D
IMM
MC
-1
CP
U
SRA
MSR
AM
NIC Driver
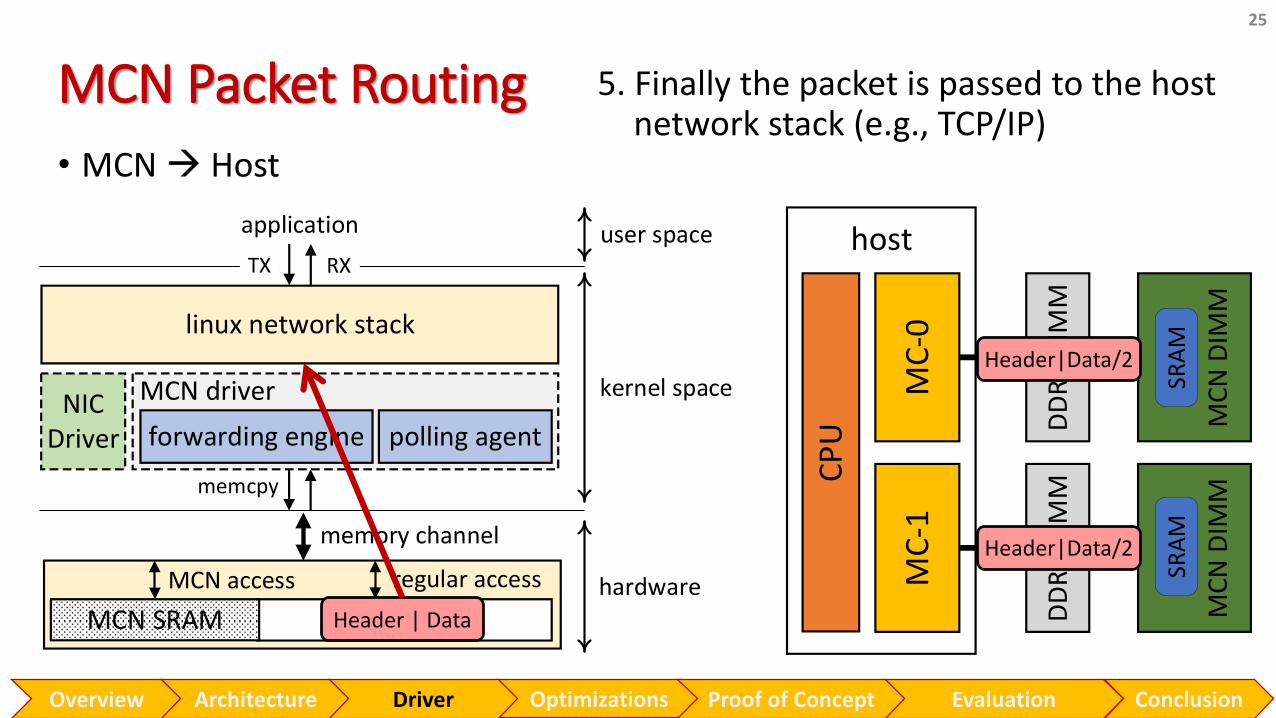
MCN Packet Routing
25
• MCN Host
Header|Data/2
Header|Data/2
Header | Data
5. Finally the packet is passed to the host network stack (e.g., TCP/IP)
Optimizations Evaluation ConclusionOverview Proof of ConceptArchitecture Driver

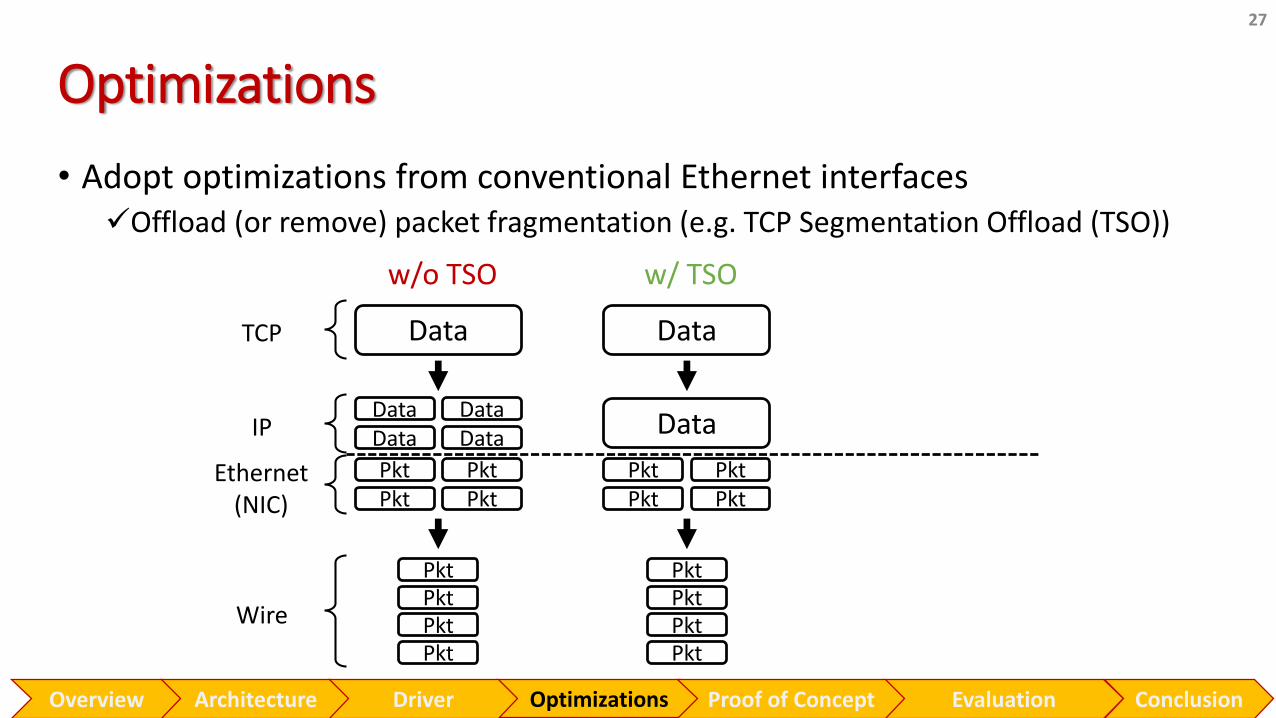
Optimizations
• Adopt optimizations from conventional Ethernet interfaces✓Offload (or remove) packet fragmentation (e.g. TCP Segmentation Offload (TSO))
26
IPDataData Data
Data
Ethernet (NIC)
PktPkt Pkt
Pkt
Data
w/o TSO
PktPktPktPkt
TCP
Wire
Optimizations Evaluation ConclusionOverview Proof of ConceptArchitecture Driver
Optimizations
• Adopt optimizations from conventional Ethernet interfaces✓Offload (or remove) packet fragmentation (e.g. TCP Segmentation Offload (TSO))
27
IPDataData Data
Data
Ethernet (NIC)
PktPkt Pkt
Pkt
Data
w/o TSO w/ TSO
PktPkt Pkt
Pkt
Data
Data
PktPktPktPkt
PktPktPktPkt
TCP
Wire
Optimizations Evaluation ConclusionOverview Proof of ConceptArchitecture Driver

Optimizations
• Adopt optimizations from conventional Ethernet interfaces✓Offload (or remove) packet fragmentation (e.g. TCP Segmentation Offload (TSO))
28
IPDataData Data
Data
Ethernet (NIC)
PktPkt Pkt
Pkt
Data
w/o TSO w/ TSO
PktPkt Pkt
Pkt
Data
Data
PktPktPktPkt
PktPktPktPkt
TCP
Wire
MCN TSO
Data
Data
Reducing the overhead ofsending many small packets
Pkt
Optimizations Evaluation ConclusionOverview Proof of ConceptArchitecture Driver
Optimizations
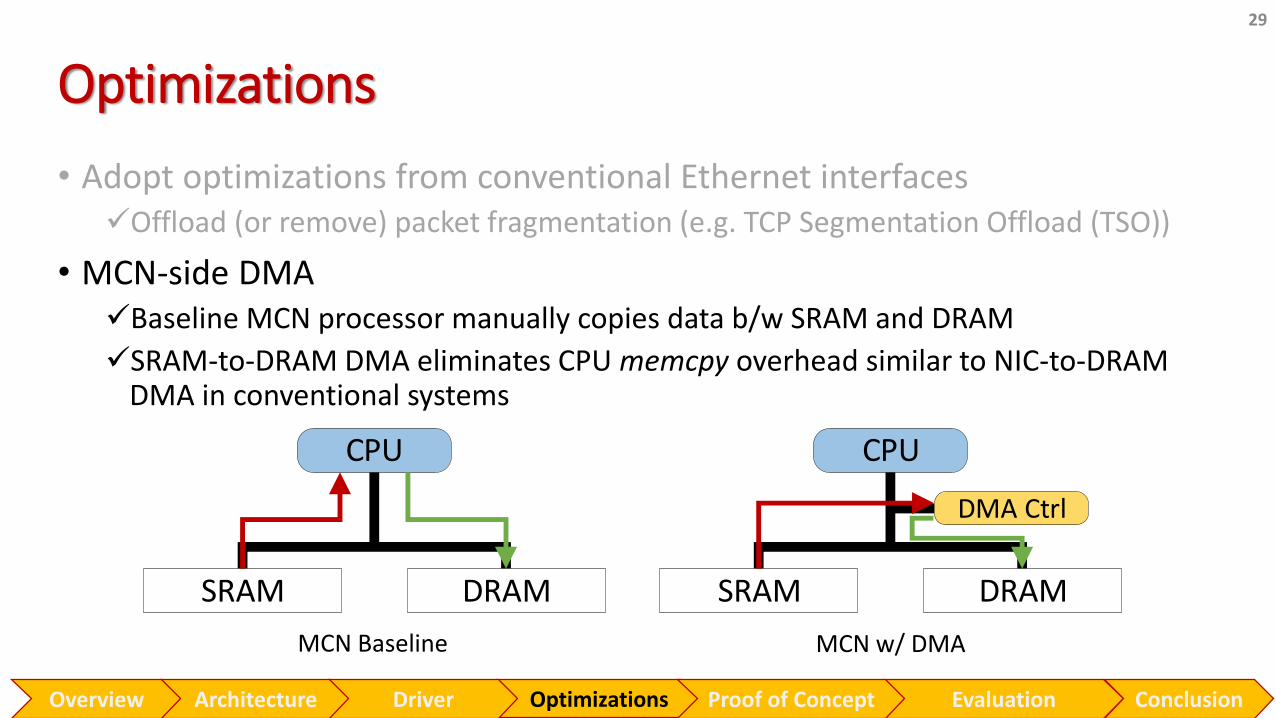
• Adopt optimizations from conventional Ethernet interfaces✓Offload (or remove) packet fragmentation (e.g. TCP Segmentation Offload (TSO))
• MCN-side DMA✓Baseline MCN processor manually copies data b/w SRAM and DRAM
✓SRAM-to-DRAM DMA eliminates CPU memcpy overhead similar to NIC-to-DRAM DMA in conventional systems
29
CPU
SRAM DRAM
CPU
SRAM DRAM
DMA Ctrl
MCN Baseline MCN w/ DMA
Optimizations Evaluation ConclusionOverview Proof of ConceptArchitecture Driver

Proof of Concept HW/SW Demonstration
30
ConTutto top view Contutto plugged in IBM POWER8 server
Stratix V FPGA
Optimizations Evaluation ConclusionOverview Proof of ConceptArchitecture Driver

Proof of Concept HW/SW Demonstration
31
MPI application running through MCN
host
DD
R4
DIM
M
MC
N D
IMM
MC
-0
DD
R4
DIM
M
MC
-1
CP
U
SRA
MD
DR
4 D
IMM
POWER8(Host)
ConTutto(MCN DIMM)
Optimizations Evaluation ConclusionOverview Proof of ConceptArchitecture Driver
MPI case
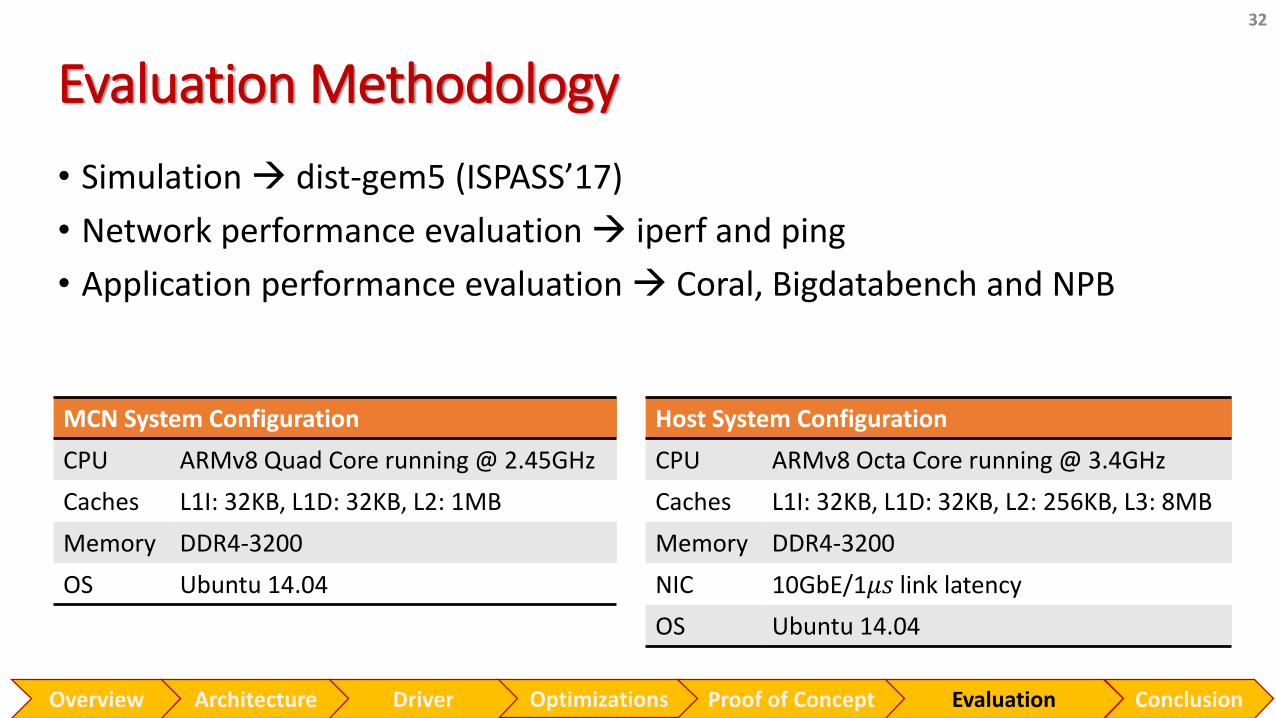
Evaluation Methodology
• Simulation dist-gem5 (ISPASS’17)
• Network performance evaluation iperf and ping
• Application performance evaluation Coral, Bigdatabench and NPB
32
MCN System Configuration
CPU ARMv8 Quad Core running @ 2.45GHz
Caches L1I: 32KB, L1D: 32KB, L2: 1MB
Memory DDR4-3200
OS Ubuntu 14.04
Host System Configuration
CPU ARMv8 Octa Core running @ 3.4GHz
Caches L1I: 32KB, L1D: 32KB, L2: 256KB, L3: 8MB
Memory DDR4-3200
NIC 10GbE/1𝜇𝑠 link latency
OS Ubuntu 14.04
Optimizations Evaluation ConclusionOverview Proof of ConceptArchitecture Driver
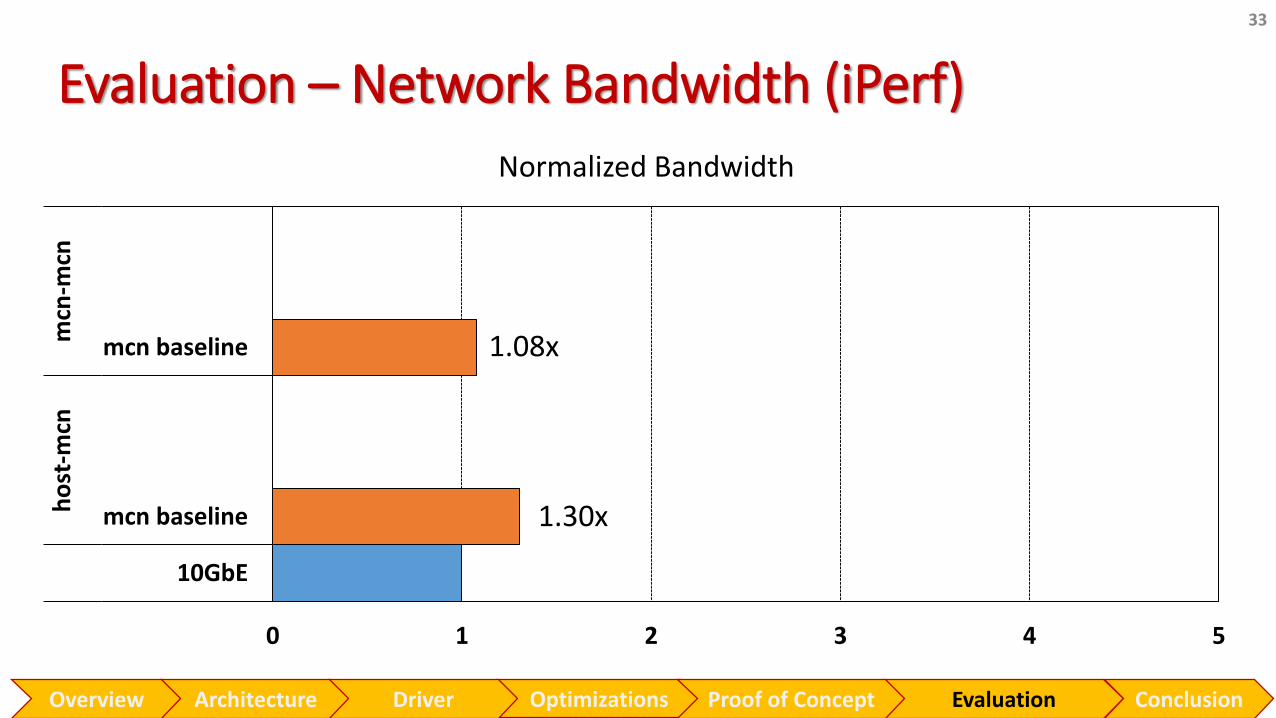
Evaluation – Network Bandwidth (iPerf)
33
Normalized Bandwidth
0 1 2 3 4 5
10GbE
mcn baseline
TSO
mcn dma
mcn baseline
TSO
mcn dma
ho
st-m
cnm
cn-m
cn
1.30x
1.08x
Optimizations Evaluation ConclusionOverview Proof of ConceptArchitecture Driver

Evaluation – Network Bandwidth (iPerf)
34
Normalized Bandwidth
0 1 2 3 4 5
10GbE
mcn baseline
TSO
mcn dma
mcn baseline
TSO
mcn dma
ho
st-m
cnm
cn-m
cn
Optimizations Evaluation ConclusionOverview Proof of ConceptArchitecture Driver

Evaluation – Network Bandwidth (iPerf)
35
Normalized Bandwidth
0 1 2 3 4 5
10GbE
mcn baseline
TSO
mcn dma
mcn baseline
TSO
mcn dma
ho
st-m
cnm
cn-m
cn
3.50x
Optimizations Evaluation ConclusionOverview Proof of ConceptArchitecture Driver

Evaluation – Network Bandwidth (iPerf)
36
Normalized Bandwidth
0 1 2 3 4 5
10GbE
mcn baseline
TSO
mcn dma
mcn baseline
TSO
mcn dma
ho
st-m
cnm
cn-m
cn
4.56x
Optimizations Evaluation ConclusionOverview Proof of ConceptArchitecture Driver

0.0
0.5
1.0
1.5
2.0
16 128 512 4K 8K
No
rmalized
Late
ncy
Packet Size (Bytes)
10GbE mcn baseline TSO mcn dma
Evaluation – Network Latency (Ping)
37
Host ↔ MCN MCN ↔ MCN
19.7%
0.0
0.5
1.0
1.5
2.0
16 128 512 4K 8K
Packet Size (Bytes)
10GbE mcn baseline TSO mcn dma
Optimizations Evaluation ConclusionOverview Proof of ConceptArchitecture Driver

Evaluation – Aggregate Processing Bandwidth
38
0
1
2
3
4
5
6
7
8
9
No
rm. A
gg
reg
ate
Mem
ory
BW
2 4 6 8 MCN DIMMs
1.7
6x
2.5
4x
3.2
9x
3.9
3x
Optimizations Evaluation ConclusionOverview Proof of ConceptArchitecture Driver
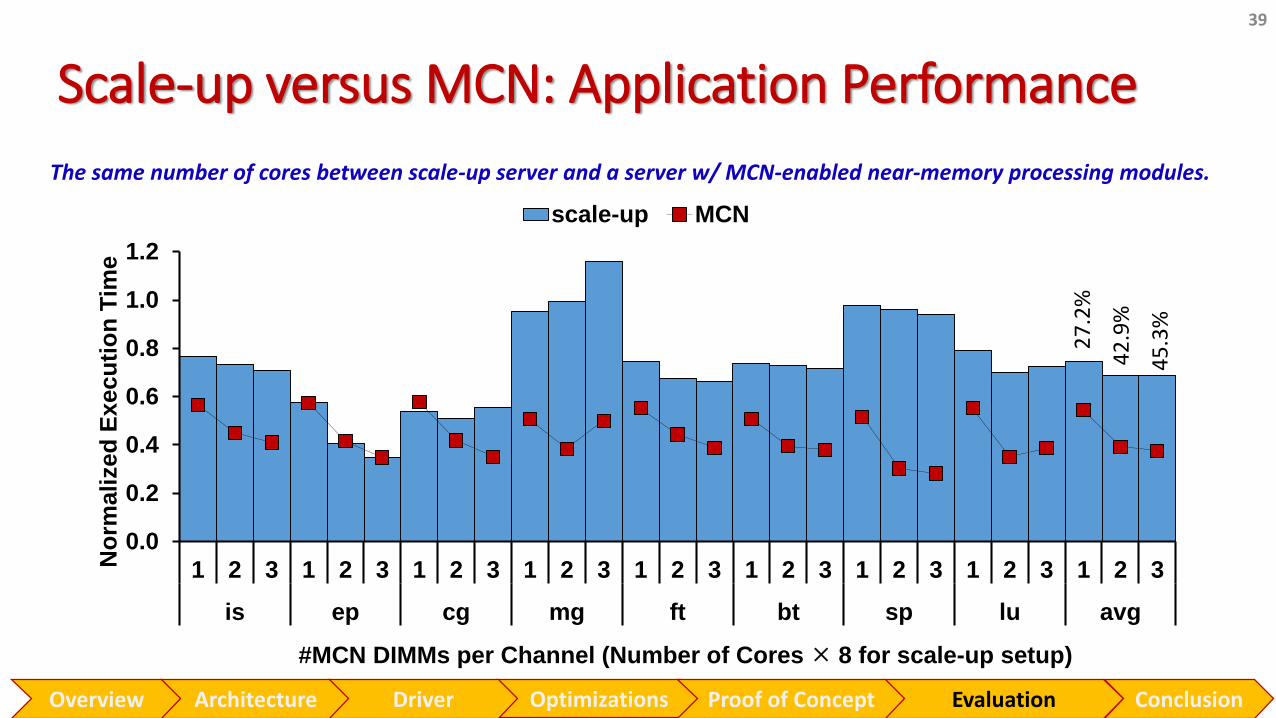
Scale-up versus MCN: Application Performance
39
#MCN DIMMs per Channel (Number of Cores 8 for scale-up setup)
45
.3%
42
.9%
27
.2%
0.0
0.2
0.4
0.6
0.8
1.0
1.2
1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3
is ep cg mg ft bt sp lu avg
No
rmali
ze
d E
xec
uti
on
Tim
e
scale-up MCN
45
.3%
42
.9%
27
.2%
Optimizations Evaluation ConclusionOverview Proof of ConceptArchitecture Driver
The same number of cores between scale-up server and a server w/ MCN-enabled near-memory processing modules.

Conclusion
• MCN is an innovative near-memory processing concept✓No change in host hardware, OS and user applications
✓Seamless integration w/ traditional distributed computing and better scalability
✓Feasibility proven w/ a commercial hardware system
• MCN can provide:✓4.6× higher network bandwidth
✓5.3× lower network latency
✓3.9× higher processing bandwidth
✓45% higher performance
than a conventional system
40
Optimizations Evaluation ConclusionOverview Proof of ConceptArchitecture Driver
Server Node
Server Node
Network
Data
DataMCN
DIMM MCN DIMM
Data
Data
MCN DIMM MCN
DIMM
Data
Data
Mem Channel
Mem Channel

Application-Transparent Near-Memory Processing Architecture with Memory
Channel Network
Mohammad Alian1, Seung Won Min1, Hadi Asgharimoghaddam1, Ashutosh Dhar1, Dong Kai Wang1, Thomas Roewer2, Adam McPadden2,
Oliver O'Halloran2, Deming Chen1, Jinjun Xiong2, Daehoon Kim1,Wen-mei Hwu1, and Nam Sung Kim1,3
1University of Illinois Urbana-Champaign2IBM Research and Systems
3Samsung Electronics

42
Optimizations Evaluation ConclusionOverview Proof of ConceptArchitecture Driver
Any Questions?