applications of rdfs-plus look at projects setting up infrastructure for particular web communities...
TRANSCRIPT

Applications of RDFS-Plus Look at projects setting up infrastructure for particular web
communities
RDFS-Plus is used in the models that describe data in these communities
Not in the everyday use in these communities
Projects originally based on RDF because of the inherently distributed nature of their requirements
As the projects evolved, the need arose to describe the relationships between resources formally
Whence RDFS then RDFS-Plus

SKOS SKOS (Simple Knowledge Organization System) was developed by
the Institute for Learning & Research Technology (Univ. of Bristol)
Provides a way to represent semi-formal knowledge organization systems (KOSs) in a distributed and linkable way
Knowledge organization systems Thesauri, taxonomies, folksonomies
Taxonomy A taxonomy, or taxonomic scheme, is a particular classification ("the
taxonomy of ..."), arranged in a hierarchical structure
Anthropologists: Taxonomies are generally embedded in local cultural and social systems, and serve various social functions

Folksonomy
Folksonomy: a portmanteau of folk and taxonomy
A system of classification derived from the practice and method of collaboratively creating and managing tags to annotate and categorize content
“Collaborative tagging”, “social classification”, “social indexing”, “social tagging”
Folksonomies became popular on the Web around 2004
Part of social software applications such as social bookmarking and photograph annotation

Tagging is one of the defining characteristics of Web 2.0 services
Allows users to collectively classify and find information
Some websites include tag clouds as a way to visualize tags in a folksonomy
An empirical analysis has shown that consensus around stable distributions and shared vocabularies does emerge
Even in the absence of a central controlled vocabulary

Thesaurus First modern thesaurus: Roget's Thesaurus (1852), entries listed
conceptually rather than alphabetically
A thesaurus doesn’t
define words
give a complete list of all the synonyms for a particular word
Entries are also for drawing distinctions between similar words and helping choose exactly the right word

Information retrieval thesauri are formally organized, making relationships between concepts explicit
Terms are sometimes placed in context to help the user draw distinctions
Terms generally arranged hierarchically by themes, topics or facets
Typically focus on one discipline, subject or field of study.
Follow international standards

The key difference between SKOS and thesaurus standards is its basis in the Semantic Web
Designed to allow modelers to create modular knowledge organizations, reused and referenced across the web
Not meant to replace thesaurus standards but to augment them by bringing in the distributed nature of the Semantic Web
A design goal is to allow any thesaurus standard to be mapped straightforwardly to SKOS

SKOS provides a low-cost migration path for porting existing organization systems to the Semantic Web
Also provides a lightweight, intuitive conceptual modeling language for developing and sharing new KOSs
SKOS can also be seen as a bridging technology between
the rigorous logical formalism of ontology languages such as OWL and
the chaotic, informal and weakly-structured world of Web-based collaboration tools—social tagging applications

SKOS Layers SKOS Core: The most mature, maps directly to the thesaurus
standards
SKOS Mapping: Provides a vocabulary to express matching (exact or fuzzy) of concepts from one concept scheme to another
SKOS Extensions: Provide ways to declare relationships between concepts with more specific semantics than the simple "broader-narrower"—e.g., class-instance or partitive relationships
SKOS Mapping and SKOS Extensions are in standby mode until SKOS Core is completed as a W3C Recommendation

Example Fig. 1: A fragment of
the UK Archival System rendered in SKOS
7 concepts related by SKOS-Core properties
Data properties shown in boxes
Each property is defined in relation to other properties Allows useful
inferences

@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix owl: <http://www.w3.org/2002/07/owl#> .
@prefix core: <http://www.w3.org/2004/02/skos/core#> .
@prefix UKAT: <http://www.ncat.edu/UKAT.owl#> .
UKAT:EconomicCooperation a core:Concept ;
core:altLabel "Economic co-operation"@en-US ;
core:broader UKAT:EconomicPolicy ;
core:narrower UKAT:IndustrialCooperation,
UKAT:EconomicIntegration,
UKAT:EuropeanIndustrialCooperation,
UKAT:EuropeanEconomicCooperation ;
core:prefLabel "Economic cooperation"@en-US ;
core:related UKAT:Interdependence ;
core:scopeNote "Includes cooperative measures in banking, trade, industry, etc. between and among countries"@en-US .
Continued

UKAT:EconomicIntegration a core:Concept ;
core:prefLabel "Economic integration"@en-US .
UKAT:EconomicPolicy a core:Concept ;
core:prefLabel "Economic policy"@en-US .
UKAT:EuropeanEconomicCooperation a core:Concept ;
core:prefLabel "European economic cooperation"@en-US .
UKAT:EuropeanIndustrialCooperation a core:Concept ;
core:prefLabel "European industrial cooperation"@en-US .
UKAT:IndustrialCooperation a core:Concept ;
core:prefLabel "Industrial cooperation"@en-US .
UKAT:Interdependence a core:Concept ;
core:prefLabel "Interdependence"@en-US .

SKOS Labels Informal semantics of rdfs:label is a human readable resource name
SKOS provides a more detailed notion of a concept’s label (as per usual thesaurus practice)
3 kinds of label: preferred, alternative, hidden All have values with language tags (e.g., @en-US)
core:prefLabel a rdf:Property ;
rdfs:label "preferred label" ;
rdfs:subPropertyOf rdfs:label .
core:altLabel a rdf:Property ;
rdfs:label "alternative label" ;
rdfs:subPropertyOf rdfs:label .
core:hiddenLabel a rdf:Property ;
rdfs:label "hidden label" ;
rdfs:subPropertyOf rdfs:label .

By subproperty propagation, from any triple using core:prefLable as property, we can infer the same triple with rdfs:label as property
Likewise for core:altLabel and core:hiddenLabel
Some of the triples we can infer UKAT:EconomicCooperation rdfs:label "Economic co-operation"@en-US .
UKAT:EconomicCooperation rdfs:label "Economic cooperation"@en-US .
UKAT:EconomicIntegration rdfs:label "Economic integration"@en-US .
Every SKOS label shows up as an rdfs:label
Sometimes, more than one rdfs:label value inferred (perfectly legal)

SKOS uses this pattern for many of its properties
Of the 7 documentation properties, 6
core:definition
core:scopeNote
core:example
core:historyNote
core:editorialNote
core:changeNote
are subproperties of the 7th
core:note
Similarly, SKOS defines 3 properties relating to symbols
core:altSymbol rdfs:subPropertyOf core:symbol .
core:prefSymbol rdfs:subPropertyOf core:symbol .
As with label properties, any triple using a symbol or documentation property entails a triple using core:symbol or core:note

Semantic Relations in SKOS SKOS defines 3 “Semantic Properties” relating concepts to one another:
broader, narrower, related (from thesaurus standards)
core:broader a owl:TransitiveProperty ;
owl:inverseOf core:narrower ;
rdfs:comment "Broader concepts are typically rendered as parents in a concept hierarchy (tree)."@en-US ;
rdfs:label "has broader"@en-US .
core:narrower a owl:TransitiveProperty ;
owl:inverseOf core:broader ;
rdfs:comment "Narrower concepts are typically rendered as children in a concept hierarchy (tree)."@ en-US ;
rdfs:label "has narrower"@en-US .
core:related a owl:SymmetricProperty ;
rdfs:label "related to"@en-US ;
rdfs:subPropertyOf rdfs:seeAlso .

Since core:narrower is an inverse of core:broader, we can infer, e.g., the following about the UKAT concepts in Fig. 1
UKAT:EconomicPolicy core:narrower UKAT:EconomicCooperation .
UKAT:IndustrialCooperation core:broader UKAT:EconomicCooperation .
Since core:narrower is transitive, we can infer that every concept in Fig. 1 is narrower than that at the top of the tree (UKAT:EconomicPolicy)
UKAT:EconomicPolicy core:narrower UKAT:IndustrialCooperation,
UKAT:EconomicCooperation,
Etc.
Similar triples can be inferred (swapping subject and object) for the inverse property, core:broader, since it too is transitive

core:related isn’t transitive: similarity dissipates as we move out a chain of related concepts
core:related is symmetric, so, if we assert
UKAT:EconomicCooperation core:related UKAT:Interdependence .
we can infer
UKAT:Interdependence core:related UKAT:EconomicCooperation .

Meaning of Semantic Relations Note the similarity between the definitions
of core:narrower & core:broader and
of rdfs:subClassOf & superClassOf
Both model hierarchies traversable upward and downward
The hierarchical structure in both cases is transitive
But the following semantic rule for subClassOf has no analog in SKOS
Given B rdfs:subClassOf C and x rdf:type B, infer x rdf:type C

The absence of such a rule means we must look at the annotations
The core:broader label says “has broader”—e.g.,
:Milk core:broader :Dairy .
means that Dairy is a broader term than Milk
The reverse of what we might think

Special Purpose Inference SKOS includes collections of concepts (common in thesaurus and
indexing standards)
A term index describes agricultural products and includes several kinds of milk
cow milk, goat milk, sheep milk, buffalo milk
A Collection of these concepts is called “milk by source animal”
According to the common practice of cataloguers, “milk by source animal” itself isn’t a concept—just a grouping of concepts
Class core:Collection and property core:member express this situation
See Fig. 2, and the N3 follows

agro:MilkBySourceAnimal a core:Collection ;
rdfs:label "Milk by source animal" ;
core:member agro:CowMilk,
agro:BuffaloMilk,
agro:GoatMilk,
agro:SheepMilk .
agro:BuffaloMilk a core:Concept ;
core:prefLabel "Buffalo milk" .
agro:CowMilk a core:Concept ;
core:prefLabel "Cow milk" .
agro:GoatMilk a core:Concept ;
core:prefLabel "Goat milk" .
agro:SheepMilk a core:Concept ;
core:prefLabel "Sheep milk" .

We can assert triples involving core:narrower with collections—e.g.,
agro:Milk core:narrower agro:MilkBySourceAnimal .
But SKOS has a special-purpose rule for the interaction of core:narrower and core:member in collections
Given A core:narrower C and C core:member B, infer A core:narrower B
Applying this to agro:Milk, we can infer
agro:Milk core:narrower agro:BuffaloMilk .
agro:Milk core:narrower agro:CowMilk .
agro:Milk core:narrower agro:SheepMilk .
agro:Milk core:narrower agro:GoatwMilk .

SKOS represents this constraint as a rule rather than modeling it in RDFS-Plus
RDFS-Plus is not well suited for this problem
Further constructs of OWL can be applied here (later)

Published Subject Indicators A Published Subject Indicator (PSI) is a publication that a community
has agreed to use as a unique identifier for a certain concept
For everyday, non-technical concepts (e.g., Milk, Economic Policy), such agreement is unlikely
But standards bodies often produce such publications—e.g., CDC disease listings, technical standards, government acts
Property core:subjectIndicator links a core:Concept to a published document
Since a PSI is intended as a unique identifier of a concept, we have
core:subjectIndicator a owl:inverseFunctionalProperty .
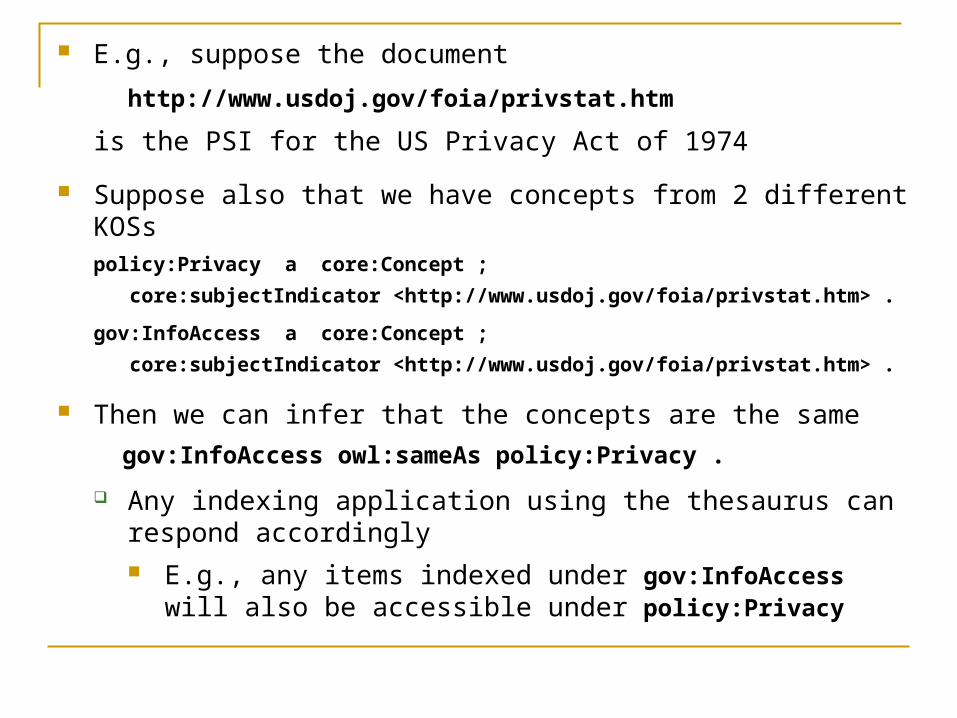
E.g., suppose the document
http://www.usdoj.gov/foia/privstat.htm
is the PSI for the US Privacy Act of 1974
Suppose also that we have concepts from 2 different KOSspolicy:Privacy a core:Concept ;
core:subjectIndicator <http://www.usdoj.gov/foia/privstat.htm> .
gov:InfoAccess a core:Concept ;
core:subjectIndicator <http://www.usdoj.gov/foia/privstat.htm> .
Then we can infer that the concepts are the same
gov:InfoAccess owl:sameAs policy:Privacy .
Any indexing application using the thesaurus can respond accordingly E.g., any items indexed under gov:InfoAccess will also be
accessible under policy:Privacy

SKOS in Action SKOS is an example of a model on the Semantic Web
It models particular standards for how to represent thesauri
An info explosion is taking place on the Web and elsewhere
E.g., libraries are indexing their materials in a way that lets patrons find info from around the world
The Food and Agriculture Organization (FAO) of the UN has been successful with a thesaurus called AGROVOC
Provides multilingual indexing for materials on any aspect of agriculture

Original purpose of AGROVOC was to standardize indexing for the AGRIS Database, making searching simpler and more efficient
AGRIS (International System for Agricultural Science and Technology) is a global public domain database
2.6 million structured bibliographical records on agricultural science and technology.
Lets scientists, researchers, and students do sophisticated searches
FAO acts as a forum where developing and developed countries negotiate agreements and debate policy
A source of knowledge and info
Helps developing countries improve agriculture, forestry and fisheries practices

Member nations have their own indices for agriculture (competing with AGROVOC)
The US National Agriculture Library (NAL) also has an extensive thesaurus for indexing agricultural materials
The UN project to map these thesauri together needed a representation for distinguishing terms from multiple sources in a global way
E.g., the AGROVOC term for Ground Water and the NAL term for Ground Water must be managed separately
But we must be able to represent the relationship between them

Use of URIs in RDF (hence in SKOS) is ideal here
SKOS provides terms for familiar thesaurus relationship broader and narrower
Straightforward to export each thesaurus to SKOS
Both AGROVOC and the NAL independently sponsored exports of their thesauri
Straightforward to represent mappings between the 2 vocabularies in RDF

References The AGROVOC homepage
http://aims.fao.org/agrovoc#.VD7AJlf_pMc
VocBench is a web-based, multilingual, editing and workflow tool that manages thesauri, authority lists and glossaries using SKOS
http://aims.fao.org/vest-registry/tools/vocbench-2#.VD7Aslf_pMc
Sandbox version of VocBench
http://202.73.13.50:55481/vocbench/
The Vocabularies, mEtadata Sets and Tools (VEST) Directory has resources used within the context of agricultural info management
http://aims.fao.org/es/vest-registry/vocabularies/skosmos

Background and Further Developments AGROVOC is being converted
from a term-based knowledge organization system with traditional thesaurus relationships
to a concept-based, OWL-based system, the AGROVOC Concept Server (CS)
Allows the representation of more semantics
Export ontology from OWL format to RDF, XML, TBX, SKOS, and SQL format
An import functionality is envisaged

TBX: TermBase eXchange, a LISA standard republished as ISO 30042
Allows for the interchange of terminology data including detailed lexical information
Based on TM standards
A translation-memory (TM) system stores already translated words, phrases and paragraphs to aid human translators
The Localization Industry Standards Association (LISA)
International forum for organizations doing business globally
Helps governments, NGOs, and multinational corporations implement best practice and language technology standards
Provides info about managing multiple language content efficiently to communicate effectively across cultures
Closed in 2011; the European Telecommunications Standards Institute started an Industry Specification Group (ISG) for localization

The (AGROVOC) Concept Server Workbench (ACWB)
http://naist.cpe.ku.ac.th/agrovoc/ [Dead]
A web-based environment for managing the AGROVOC CS
Accessible to everyone, facilitates collaborative editing
Serves as a pool of agricultural concepts
Starting point for developing specific domain ontologies, where multilingualism and localized representation of info are important
Updated as VocBench, a web-based, multilingual, editing and workflow tool that manages thesauri, authority lists and glossaries using SKOS-XL (see below)
http://vocbench.uniroma2.it/

Validation
People have different background knowledge and their own ways to construct ontologies
Every action (add/edit/delete of a concept/term/relationship) must be approved by 2 types of users: ‘validators’ and ‘publishers’
Consistency Check
The system automatically checks (OWL reasoner) the data
Returns inconsistencies, which are manually fixed

SKOS-XL SKOS eXtension for Labels
See W3C, SKOS Simple Knowledge Organization System eXtension for Labels (SKOS-XL) Namespace Document - HTML Variant, Recommendation, 2009
http://www.w3.org/TR/skos-reference/skos-xl.html
We want to attached metadata to individual terms (not concepts)
But the basic unit of what SKOS manages isn’t a term (what taxonomy management software always managed before) but a concept
Makes internationalized vocabularies much easier to manage

E.g., I can have a single concept with
a German preferred label of "Spirituosen",
a British English preferred label of "spirits",
an American English preferred label of "liquor", and
an American alternative label of "booze"
They all refer to the same concept.
SKOS's extensibility means that you can attach all the metadata you want to a particular concept
But not to a term defined as a label for that concept—labels are strings (“lexical entities”)
SKOS is built on RDF
In RDF triples, strings (literals) can’t be subjects

How can we assign metadata about the labels themselves—e.g.,
the name of the person who added a particular label, or
the date it was last updated?
SKOS-XL defines variations on the SKOS skos:prefLabel and skos:altLabel properties
skosxl:prefLabel and skosxl:altLabel
These extension properties have as range the skosxl:Label class
Members of this class have a skosxl:literalForm property to identify a string that serves as a label for the concept
It can have all the additional properties you want
Next slide: some Turtle syntax for a SKOS-XL representation of the concept described above
Also has :lastEdited and :myCustomProperty properties adding metadata to some of the labels
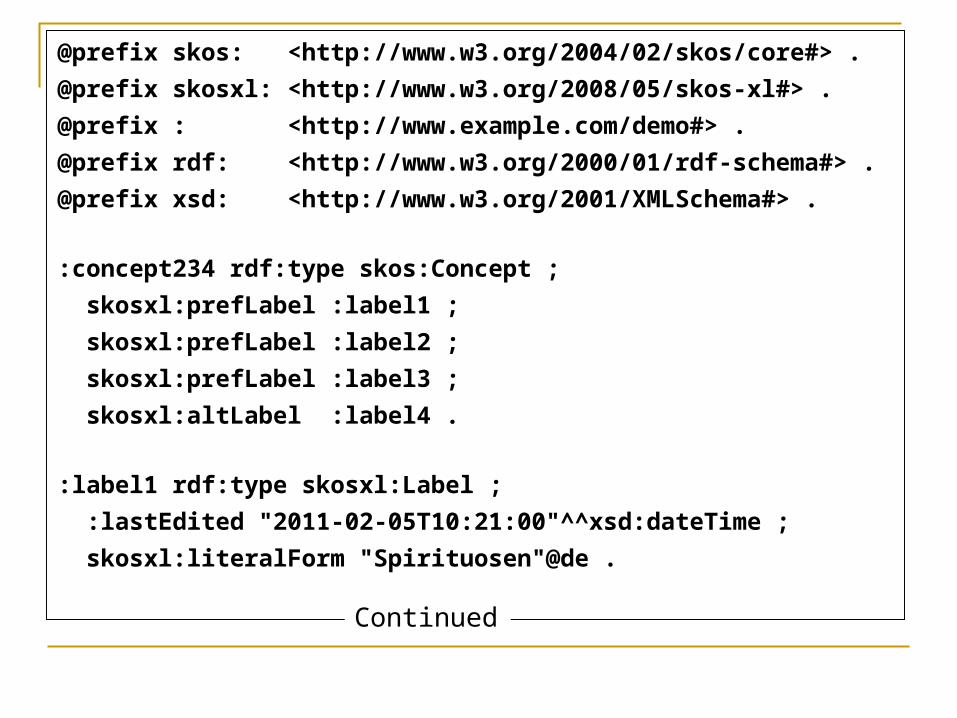
@prefix skos: <http://www.w3.org/2004/02/skos/core#> .
@prefix skosxl: <http://www.w3.org/2008/05/skos-xl#> .
@prefix : <http://www.example.com/demo#> .
@prefix rdf: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
:concept234 rdf:type skos:Concept ;
skosxl:prefLabel :label1 ;
skosxl:prefLabel :label2 ;
skosxl:prefLabel :label3 ;
skosxl:altLabel :label4 .
:label1 rdf:type skosxl:Label ;
:lastEdited "2011-02-05T10:21:00"^^xsd:dateTime ;
skosxl:literalForm "Spirituosen"@de .
Continued
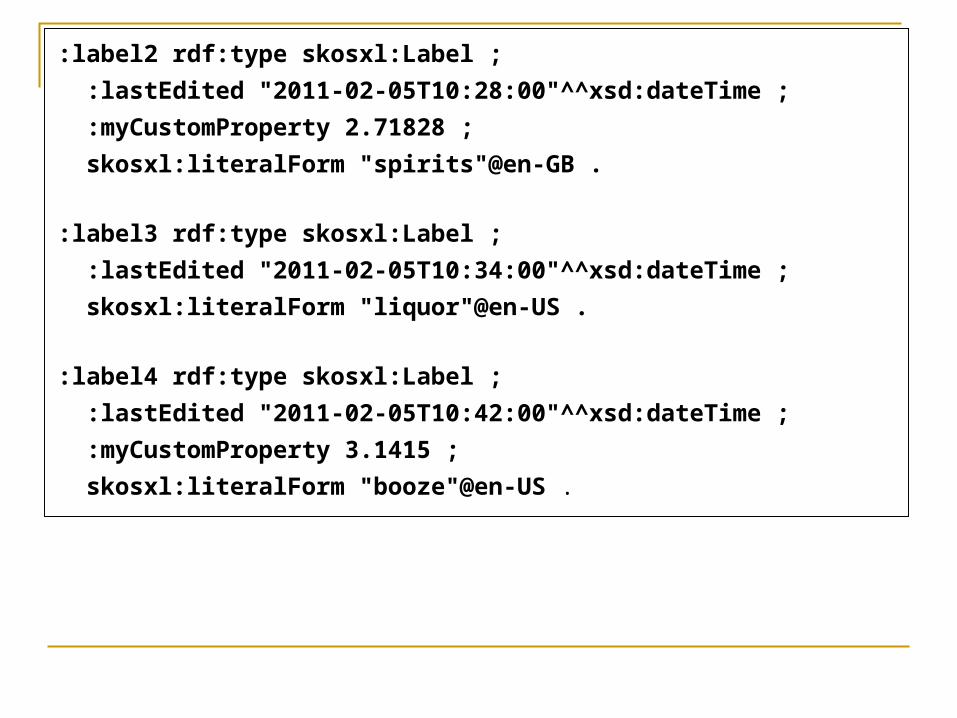
:label2 rdf:type skosxl:Label ;
:lastEdited "2011-02-05T10:28:00"^^xsd:dateTime ;
:myCustomProperty 2.71828 ;
skosxl:literalForm "spirits"@en-GB .
:label3 rdf:type skosxl:Label ;
:lastEdited "2011-02-05T10:34:00"^^xsd:dateTime ;
skosxl:literalForm "liquor"@en-US .
:label4 rdf:type skosxl:Label ;
:lastEdited "2011-02-05T10:42:00"^^xsd:dateTime ;
:myCustomProperty 3.1415 ;
skosxl:literalForm "booze"@en-US .

SKOS References, Services, Etc. SKOS Homepage
http://www.w3.org/2004/02/skos/
SKOS Simple Knowledge Organization System Primer, W3C Working Group Note 18 August 2009
http://www.w3.org/TR/skos-primer/
W3C SKOS Validator
http://www.w3.org/2004/02/skos/validation
Needs the URL of the file to be validated (Have your server running)
Doesn’t work well
Superseded by the PoolParty Consistency Checker

PoolParty Consistency Checks for SKOS Thesauri
http://demo.semantic-web.at:8080/SkosServices/check
Upload the file and select the RDF format
Checks consistency conditions defined in the SKOS spec and some conditions for a thesaurus to be PoolParty-compatible
After checks are finished, a page with check results is displayed
Some checks require the data to be fully entailed So the data is uploaded into a temporary Sesame triple store
with OWL inferencing capabilities

PoolParty http://www.poolparty.biz/ A thesaurus management system & SKOS editor for the Semantic Web
Includes text mining and linked data capabilities
Helps build and maintain multilingual thesauri, easy-to-use interface
Server provides semantic services to integrate semantic search or recommender systems into systems like
CMS (content management systems),
DMS (document management systems), or
Wikis
A thesaurus management system
stores thesauri,
offers interfaces to query them, and
supports creating, updating and maintaining thesauri
You can experiment with demos (after registering)

FOAF The FOAF vocabulary is (and always will be) identified by the
namespace URI http://xmlns.com/foaf/0.1/
The prefix conventionally associated with this URI is foaf:
FOAF Project homepage: http://www.foaf-project.org/
FOAF (Friend of a Friend) is a format for supporting distributed descriptions of people and their relationships
“Friend of a Friend” evokes the fundamental relationship in social networks:
You have direct knowledge of your own friends but only through your network can you access the friends of your friends

FOAF works in the principle of the AAA principle:
Anyone can say Anything about Any topic
Here the topics are related to people and are included in the core FOAF description
Organizations (to which people belong)
Projects (that people work on)
Documents (that people created or that describe them)
Images (that depict people)

Info about a given person is likely distributed across the Web, represented in different forms
On his own webpage, a person likely lists basic info about interests, current projects, some images
Further info is available only on other pages
A photoset taken at a party could include a picture of a person who hasn’t listed it on her own webpage
A conference organizer could include info about a paper listing its authors even if they don’t list it on their own webpages
An office might have a page listing all its members

FOAF leverages the AAA principle as well as the distributed and extensible nature of RDF in an essential way
At any time, FOAF is a work in progress
The semantics of some vocabulary terms is defined only by natural language descriptions in the FOAF standard
The definitions of other terms are in RDFS-Plus, relating them in a formal way to the rest of the description
FOAF is designed to grow in an organic way
Starts with a few intuitive terms, focusing their semantics as they’re used
Needn’t commit early to a set vocabulary
Can use RDFS-Plus to connect new and old vocabulary once we determine the relationship

The core of FOAF now is considered stable
As terms stabilize in usage and documentation, they progress through the categories 'unstable', 'testing' and 'stable‘
FOAF provides a small number of classes and properties as its starting point
These use basic RDF-Plus constructs to maintain consistency and to implement FOAF policies on merging
FOAF is primarily organized around 3 classes
foaf:Person, foaf:Group, foaf:Document

People and Agents Some of what we say of persons can also hold of groups,
companies, etc.
foaf:Person is part of a compact hierarchy under the grouping foaf:Agent
foaf:Person rdfs:subClassOf foaf:Agent .
foaf:Group rdfs:subClassOf foaf:Agent .
foaf:Organization rdfs:subClassOf foaf:Agent .
Most properties holding of persons also hold of agents in general

Names in FOAF FOAF starts with a simple notion of name: a printable label
applicable to anything
foaf:name rdfs:domain owl:Thing .
foaf:name rdfs:range rdfs:Literal .
A foaf:Person’s name is typically their full name
Sometimes we need parts of a person’s name: foaf:firstName, foaf:givenname, foaf:family_name, foaf:surname
Each has an intuitive meaning but no formal semantics

As FOAF evolves, it must encompass different cultures and their use of names
Based on RDF, FOAF needn’t resolve all these issues to begin marking up data with its vocabulary
Usage patterns will determine which terms turn out useful
If 2 properties end up used in exactly the same way, make them equivalent

Nicknames and Online Names Many people described with FOAF will be active in various internet
communities
For screen names on online chat services, there are foaf:aimChatID, foaf:jabberID, etc.
In the spirit of extensibility, new ID properties can be added as needed
Part of the semantics of these terms is given by their natural language descriptions
E.g., foaf:yahooChatID is used for the chat service Yahoo!
FOAF also makes a formal connection between these properties: they’re all sub-properties of foaf:nick

So a foaf:Person active in chat spaces likely has multiple values for foaf:nick
They could have nicknames that aren’t screen names for any chat space
And a person can have a nickname and no screen names

Online Persona FOAF is under constant revision to provide properties to describe the ways
the Internet provides for a person to express himself
foaf:mbox has domain foaf:Agent and range owl:Thing
Many people maintain several webpages: personal webpage, webpage at work, …
Workplaces also have webpages
FOAF uses the same strategy for these properties as for names
It provides a number of properties, defined informally in natural language
foaf:homepage—relates an agent to their primary homepage
foaf:workplaceHomepage—the homepage of a person’s workplace
foaf:workInfoHomepage—the homepage of a person at their workplace, usually hosted by the employer, but about the person’s own work
foaf:schoolHomepage—the homepage of the school the person attends

Any foaf:Agent can have a homepage
The domain of the remaining homepage properties is foaf:Person
Any foaf:Agent can have a blog:
foaf:weblog—the address of the person’s blog
This and all the homepage properties have range foaf:Document

Groups of People A foaf:Group is an individual connected to its members via property
foaf:member
It (like a person) can have a name, chat ID, nickname, e-mail box, homepage, blog, …
Example
:British_Monarchy
a foaf:Group ;
foaf:name "British Monarchy"@en-UK ;
foaf:homepage "http://www.monarchy.com/" ;
foaf:member :Anne, :George_I, :George_II, :George_III, … .

It’s useful to consider the members of a group as instances of a class
foaf:membershipClass links a group to a class—e.g.,
:British_Monarchy foaf:membershipClass :Monarch .
FOAF specifies that, e.g., any individual of type :Monarch should appear as a member of group :British_Monarchy and
any member of group :British_Monarchy should have type :Monarch
So the following should be inferred from the above
:Anne a Monarch .
:George_I a Monarch .
:George_II a Monarch .
:George_III a Monarch .
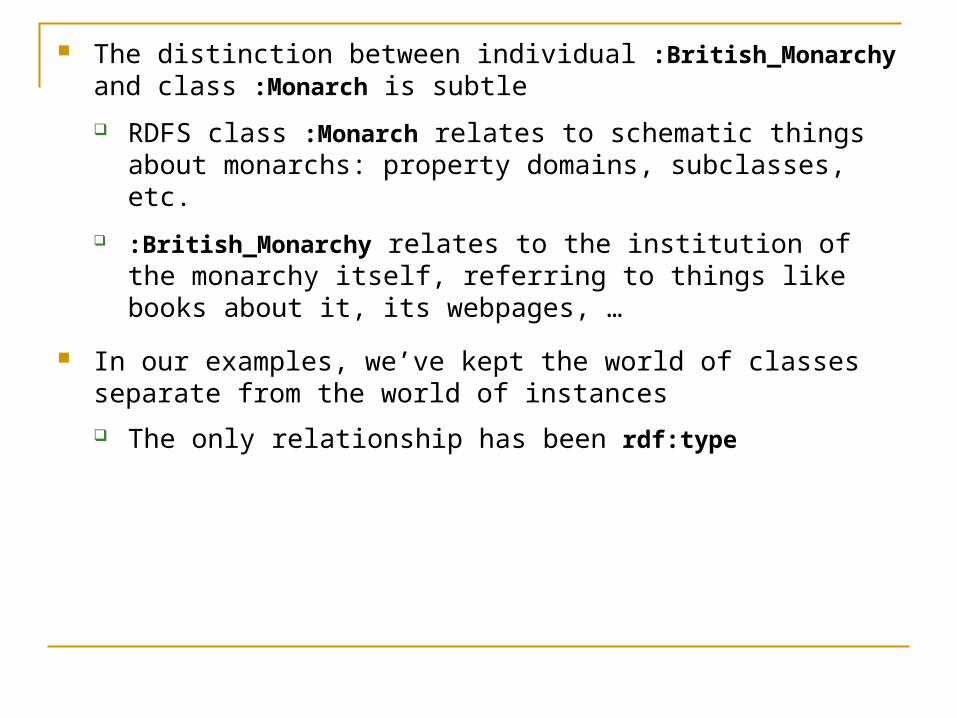
The distinction between individual :British_Monarchy and class :Monarch is subtle
RDFS class :Monarch relates to schematic things about monarchs: property domains, subclasses, etc.
:British_Monarchy relates to the institution of the monarchy itself, referring to things like books about it, its webpages, …
In our examples, we’ve kept the world of classes separate from the world of instances
The only relationship has been rdf:type

Expressing a relationship where we view something
sometimes as an instance (e.g., instance :British_Monarchy of foaf:Group) and
sometimes as a class (e.g., class :Monarch of all instances that are foaf:member of this group)
is an example of meta-modeling
Discussing meta-modeling requires OWL constructs we’ll come to later
Then formalize the relationship between foaf:Group and foaf:membershipClass
And show how the above triples are inferred

Things People Make and Do People create things: books, webpages, works of art, companies,
organizations, …
Two FOAF properties relate people to their creations: foaf:made and foaf:maker
foaf:made rdfs:domain foaf:Agent .
foaf:made rdfs:range owl:Thing .
foaf:maker rdfs:domain owl:Thing .
foaf:maker rdfs:range foaf:Agent .
foaf: made owl:inverseOf foaf:maker .

Property foaf:publications relates a foaf:Person to any foaf:Document published
But FOAF doesn’t specify that a person foaf:made their foaf:publications
Still, in the spirit of the AAA principle, we can assert
foaf:publications rdfs:subPropertyOf foaf:made .

Identity in FOAF If someone else wants to say something about me, how will he refer
to me?
RDF uses URIs to uniquely denote things it describes
This is a simple, elegant, and standard solution to this problem
But it’s inadequate for FOAF
It isn’t common on the Web for people to have their own personal URIs for describing themselves
To lower the barriers to adopting FOAF, need a way to refer to one another that uses some part of the Internet that’s ubiquitous and familiar

The clearest answer is e-mail address
It isn’t a problem if someone has 2 or more e-mail addresses or if one e-mail address is valid for only a limited period
All FOAF requires is that another person doesn’t share the address (simultaneously or later)
Express the role foaf:mbox plays in identifying individuals with
foaf:mbox a owl:inverseFunctionalProperty .
And, similarly, all chat space IDs, homepage, and foaf:weblog are also inverse functional properties

But publishing someone’s e-mail address violates privacy
FOAF also offers an obfuscated version of foaf:mbox, called foaf:sha1sum
The result of applying the SHA-1 hash function to the e-mail address
But FOAF doesn’t offer a standard way to obfuscate the other identifying properties

Knows FOAF provides a single, high-level property for linking one person to
another hence as the basis for a social networking system—foaf:knows
The only triples defined for foaf:knows declare its domain and range to be foaf:Person
foaf:knows is designed to be vague
The relation could be derived from other info
E.g., coauthors are generally assumed to know each other
We usually assume that, if A knows B, then B knows A
But symmetry was intentionally left out for foaf:knows

SKOS and FOAF Both exploit the distributed nature of RDF to allow extension to a
network of info to be distributed across the web
Both rely on the inferencing structure of RDFS-Plus for completeness of their info structure
Both use owl:InversFunctionalProperty to determine identity of key elements
But FOAF (unlike SKOS) has a somewhat evolutionary approach to info extension
Many concepts (e.g., Name) have a broad number of terms
It can be extended as new features are needed—cf. foaf:weblog

SKOS, in contrast, has a much more orderly approach to extension
It has 3 parts
SKOS Core (described here), imported by the other 2
SKOS Mapping includes vocabulary for mapping vocabularies from different sources
SKOS Extensions is for particular vertical applications of SKOS
SKOS Core is an interlingua for thesauri
Designed by a small committee to consolidate the fundamentals of other thesaurus systems into a single Semantic Web model

Consider how they will be extended
FOAF takes the AAA slogan very seriously The actual preferred parts of the representation will be
determined largely by use
SKOS has a stable core designed by an informed committee who performed a detailed commonality/variability analysis of extant vocabulary systems Its architecture has been published and is a roadmap for
development
The technical structure of RDF supports both modes
FOAF’s free extension style and SKOS’s orderly layering are accomplished with the same graph overlay mechanism
The difference is in how the overlay is organized and governed

The SKOS and FOAF efforts are like standards efforts:
they’re maintained by committees who publish policy decisions
But they’re unlike standards efforts in that neither is intended as a complete work providing prescriptive advice to someone designing
a vocabulary control system (like SKOS) or
a social networking systems (like FOAF)
Their role is to provide an exchange mechanism on the Web for sharing this kind of info
This is the power of a model on the Semantic Web:
It doesn’t prescribe how to represent things
Rather, it provides a means of transfer from one representation to another

Dublin Core Diane Hillmann, Using Dublin Core, 2005-11-07
http://dublincore.org/documents/usageguide/
Metadata A metadata record consists of a set of attributes, or elements,
needed to describe a resource
E.g., a metadata system common in libraries—the library catalog— contains a set of metadata records with elements that describe a book or other library item:
author, title, date of creation or publication, subject coverage, and the call number specifying location on the shelf

Linkage between a metadata record and the resource it describes may take 1 of 2 forms:
1. elements may be contained in a record separate from the item (cf. a library's catalog record) or
2. the metadata may be embedded in the resource itself
E.g., the Cataloging In Publication (CIP) data printed on the verso of a book's title page, or the TEI header in an electronic text
Many metadata standards, including the DC standard, don’t prescribe either type of linkage

Introduction to Dublin Core The DC metadata standard is a simple yet effective element set for
describing a wide range of networked resources
Two levels:
Simple DC comprises 15 elements
Qualified DC includes 3 additional elements (Audience, Provenance and
RightsHolder) and a group of element refinements (or qualifiers) that refine the
semantics of the elements in ways useful in resource discovery
The semantics of DC has been established by an international, cross-disciplinary group of professionals from librarianship, computer science, text encoding, the museum community, and other related fields of scholarship and practice

Another way to look at DC is as a "small language for making a particular class of statements about resources"
This language has 2 classes of terms—elements (nouns) and qualifiers (adjectives)—that can be arranged into a simple pattern of statements
The resources themselves (think URIref) are the implied subjects in this language
In the diverse world of the Internet, DC can be seen as a "metadata pidgin for digital tourists":
easily grasped, but not necessarily up to the task of expressing complex relationships or concepts
Each element is optional and may be repeated
Most elements have a limited set of qualifiers or refinements, attributes that may be used to further refine (not extend) its meaning

Three Dublin Core Principles1. The One-to-One Principle DC metadata describes 1 manifestation or version of a resource
Manifestations don’t stand in for one another
E.g., the relationship between the metadata for the original Mona Lisa and that for a reproduction is part of the metadata description
Helps the user determine whether he must go to the Louvre or his need can be met by a reproduction

2. The Dumb-down Principle A client can ignore any qualifier and use the value as if it were
unqualified
May result in some loss of specificity, but the remaining element value must continue to be generally correct and useful for discovery
Qualification only refines, and doesn’t extend, the semantic scope of a property
3. Appropriate values An implementer can’t predict that the interpreter of the metadata will
always be a machine
The requirement of usefulness for discovery should be kept in mind

DC was originally developed for describing document-like objects
But DC metadata can be applied to other resources
Its suitability for particular non-document resources depends on how closely their metadata resembles typical document
metadata and what purpose the metadata is intended to serve

Dublin Core GoalsSimplicity of creation and maintenance The DC element set has been kept as small and simple as possible
Lets a non-specialist create simple descriptive records for info resources easily and inexpensively
Yet provides for effective retrieval of those resources in the networked environment

Commonly understood semantics Discovery of info across the Internet is hindered by differences in
terminology and descriptive practices from one field of knowledge to the next
DC can help the "digital tourist“—a non-specialist searcher—find his way by supporting a common set of elements whose semantics are universally understood and supported
E.g., scientists locating articles by a particular author and art scholars interested in works by a particular artist can agree on the importance of a "creator" element
Such convergence on a common, if slightly more generic, element set increases the visibility of all resources, both within a given discipline and beyond

International scope The DC Element Set was originally developed in English
But versions are being created in many other languages,
The DCMI (DC Metadata Initiative) Localization and Internationalization Special Interest Group is coordinating efforts to link these versions in a distributed registry
The development of the standard considers the multilingual and multicultural nature of the electronic information universe

Extensibility DC developers recognize the importance of providing a mechanism for
extending the DC element set for additional resource discovery needs
Expect that other communities of metadata experts will create and administer additional metadata sets, specialized to their communities
Metadata elements from these sets could be used in conjunction with DC metadata for interoperabilbility
The DCMI Usage Board is working on a model for accomplishing this "application profiles":
Schemas that consist of data elements drawn from 1 or more namespaces, combined by implementers, and optimized for a particular local application
Allows different communities to use the DC elements for core descriptive information

DC Syntax Issues Syntax choices depend on a number of variables,
One-size-fits-all prescriptions rarely apply
DC concepts and semantics are designed to be syntax independent
Equally applicable in a variety of contexts, as long as
the metadata is in a form suitable for interpretation both by search engines and by human beings
(X)HTML can be used to express either simple or qualified DC
But limitations inherent in representing refinements in HTM
Use meta and link element
But typically we use RDF

Metadata Storage and Maintenance Issues Some implementations using DC embed their metadata within the
resource itself
Most often with documents encoded using HTML
But also sometimes possible with other kinds of documents
Simple tools make provision of DC metadata within HTML encoded pages fairly easy
Alternatively, metadata can be stored in any kind of database
Provide a link to the described resource rather than be embedded within it

Element Content and Controlled Vocabularies Each DC element is optional and repeatable
No defined order of elements
The ordering of multiple occurrences of the same element (e.g., creator) may have a significance intended by the provider
But ordering isn’t guaranteed to be preserved in every user environment

Controlled Vocabularies (Vocabulary Encoding Schemes) Content data for some elements may be selected from a controlled
vocabulary (or vocabulary encoding scheme)
A limited set of consistently used and carefully defined terms
Can dramatically improve search results
Without basic terminology control, inconsistent or incorrect metadata can profoundly degrade the quality of search results

One cost of a controlled vocabulary is the need for an administrative body to review, update and disseminate the vocabulary
E.g., the US Library of Congress Subject Headings (LCSH) and the US National Library of Medicine Medical Subject Headings (MeSH) are formal vocabularies
But both require significant support organizations
Another cost is having to train searchers and creators of metadata so that they know when using, e.g., MeSH to enter "myocardial infarction" instead of "heart attack."
More sophisticated implementations can make such tasks easier

Encoding Schemes Using controlled vocabularies can be done most effectively using
encoding schemes
Without an encoding scheme specifically designated, a subject carefully selected from a particular controlled vocabulary can’t be distinguished from a simple keyword

Agent Roles in DC MARC Relator terms are properties describing the various roles
people and organizations play in developing and using of a resource
E.g., "Illustrator" is an agent which provided illustrations for the resource
Roles are expressed as properties (i.e., elements or element refinements)
Most are refinements of the dc:contributor
Library of Congress helped evaluate all 150 MARC Relator Terms
Asked whether they represented "an entity responsible for making contributions to the content of the resource"

DCMI Metadata Termshttp://dublincore.org/documents/dcmi-terms/
Each term is specified with the following minimal set of attributes: Name: A token appended to the URI of a DCMI namespace to create
the URI of the term.
Label: The human-readable label assigned to the term.
URI: The Uniform Resource Identifier uniquely identifying a term
Definition: A statement that represents the concept and essential nature of the term
Type of Term: The type of term as described in the DCMI Abstract Model

Where applicable, the following attributes provide additional info: Comment: Additional information about the term or its application
See: Authoritative documentation related to the term
References: A resource referenced in the Definition or Comment
Refines: A Property of which the described term is a Sub-Property
Broader Than: A Class of which the described term is a Super-Class
Narrower Than: A Class of which the described term is a Sub-Class
Has Domain: A Class of which a resource described by the term is an Instance
Has Range: A Class of which a value described by the term is an Instance
Member Of: An enumerated set of resources (Vocabulary Encoding Scheme) of which the term is a Member
Instance Of: A Class of which the described term is an instance
Version: A specific historical description of a term
Equivalent Property: A Property to which the described term is equivalent
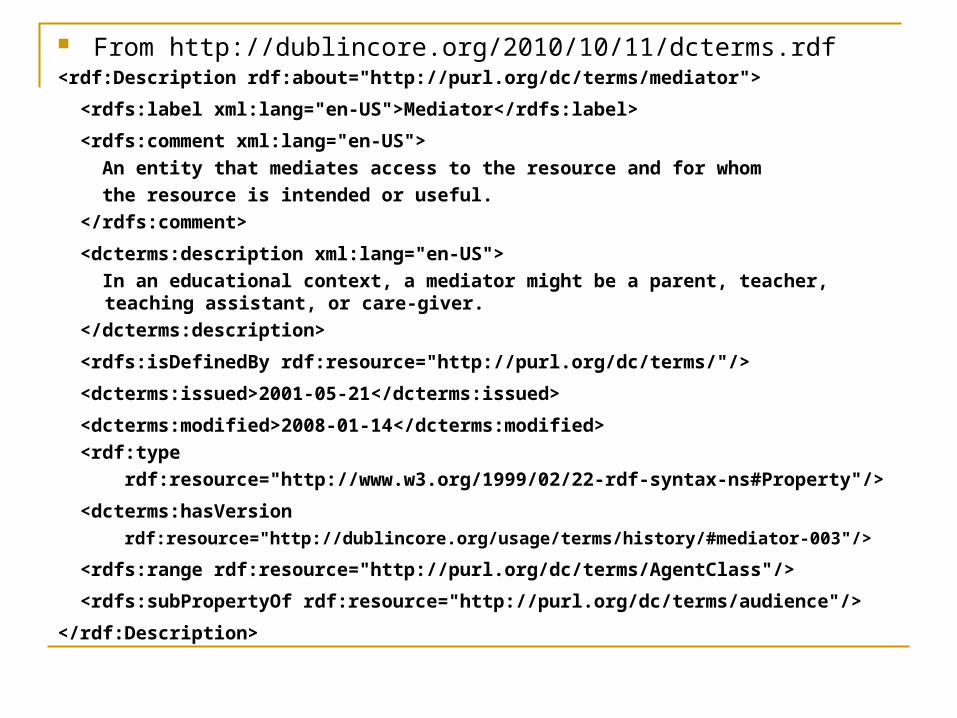
From http://dublincore.org/2010/10/11/dcterms.rdf <rdf:Description rdf:about="http://purl.org/dc/terms/mediator">
<rdfs:label xml:lang="en-US">Mediator</rdfs:label>
<rdfs:comment xml:lang="en-US">
An entity that mediates access to the resource and for whom
the resource is intended or useful.
</rdfs:comment>
<dcterms:description xml:lang="en-US">
In an educational context, a mediator might be a parent, teacher, teaching assistant, or care-giver.
</dcterms:description>
<rdfs:isDefinedBy rdf:resource="http://purl.org/dc/terms/"/>
<dcterms:issued>2001-05-21</dcterms:issued>
<dcterms:modified>2008-01-14</dcterms:modified>
<rdf:type
rdf:resource="http://www.w3.org/1999/02/22-rdf-syntax-ns#Property"/>
<dcterms:hasVersion
rdf:resource="http://dublincore.org/usage/terms/history/#mediator-003"/>
<rdfs:range rdf:resource="http://purl.org/dc/terms/AgentClass"/>
<rdfs:subPropertyOf rdf:resource="http://purl.org/dc/terms/audience"/>
</rdf:Description>
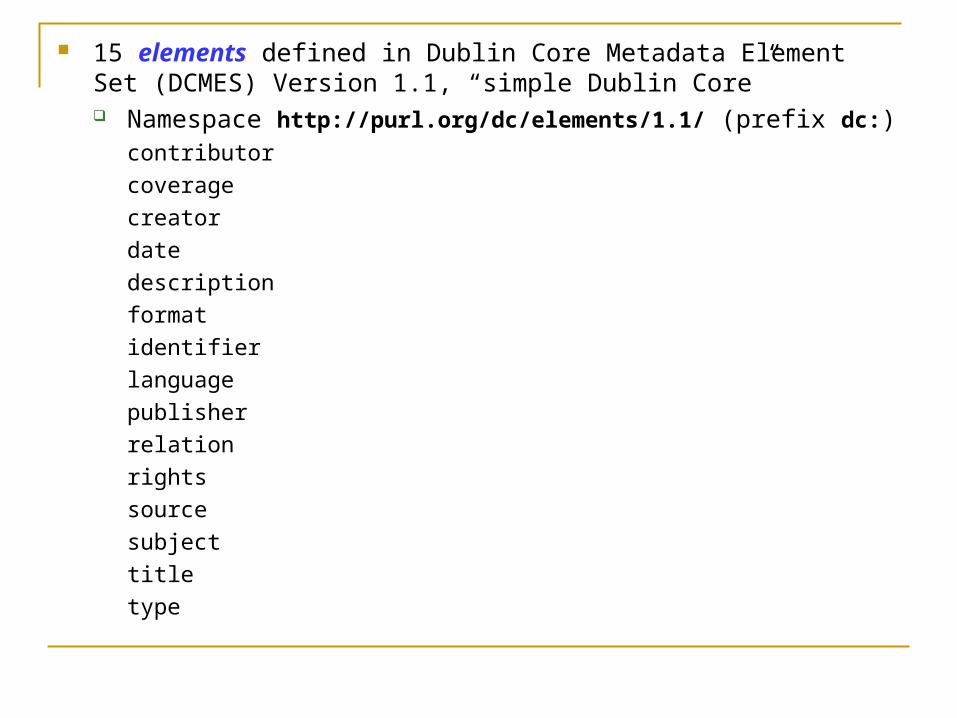
15 elements defined in Dublin Core Metadata Element Set (DCMES) Version 1.1, “simple Dublin Core” Namespace http://purl.org/dc/elements/1.1/ (prefix dc:)
contributor
coverage
creator
date
description
format
identifier
language
publisher
relation
rights
source
subject
title
type

Larger set of “terms” defined in the more comprehensive document "DCMI Metadata Terms"
Terms refine elements (they’re “element refinements”, i.e., sub-properties)
Namespace http://purl.org/dc/terms/ (prefix dcterms:)
abstract, accessRights, accrualMethod,
accrualPeriodicity, accrualPolicy, alternative,
audience, available, bibliographicCitation, conformsTo,
contributor, coverage, created, creator, date,
dateAccepted, dateCopyrighted, dateSubmitted,
description, educationLevel, extent, format, hasFormat,
hasPart, hasVersion, identifier, instructionalMethod,
isFormatOf, isPartOf, isReferencedBy, isReplacedBy,
isRequiredBy, issued, isVersionOf, language, license,
mediator, medium, modified, provenance, publisher,
references, relation, replaces, requires, rights,
rightsHolder, source, spatial, subject, tableOfContents,
temporal, title, type, valid

Classes
Agent, AgentClass, BibliographicResource, FileFormat,
Frequency, Jurisdiction, LicenseDocument,
LinguisticSystem, Location,
LocationPeriodOrJurisdiction, MediaType,
MediaTypeOrExtent, MethodOfAccrual,
MethodOfInstruction, PeriodOfTime, PhysicalMedium,
PhysicalResource, Policy, ProvenanceStatement,
RightsStatement, SizeOrDuration, Standard

Vocabulary Encoding Schemes (Definitions) DCMI Type Vocabulary: The set of classes specified by the DCMI Type
Vocabulary, used to categorize the nature or genre of the resource
See below for details
DDC: The set of conceptual resources specified by the Dewey Decimal Classification
IMT: The set of media types specified by the Internet Assigned Numbers Authority
LCC: The set of conceptual resources specified by the Library of Congress Classification.
LCSH: The set of labeled concepts specified by the Library of Congress Subject Headings.

MeSH: The set of labeled concepts specified by the Medical Subject Headings
NLM: The set of conceptual resources specified by the National Library of Medicine Classification
TGN: The set of places specified by the Getty Thesaurus of Geographic Names
UDC: The set of conceptual resources specified by the Universal Decimal Classification

Look closer at DCMI Type Vocabulary as an example of a vocabulary encoding scheme
http://dublincore.org/documents/dcmi-type-vocabulary/
Provides a general, cross-domain list of approved terms that may be used as values for the Resource Type element to identify the genre of a resource
The terms documented here are also included in the more comprehensive document “DCMI Metadata Terms”
All of these terms are of type Class and are members of
http://purl.org/dc/terms/DCMIType
Collection: An aggregation of resources
Dataset: Data encoded in a defined structure
Event: A non-persistent, time-based occurrence

Image: A visual representation other than text
Examples: images and photographs of physical objects, paintings, prints, drawings, animations and moving pictures, film, diagrams, maps, musical notation
MovingImage: A series of visual representations imparting an impression of motion when shown in succession Narrower than Image
StillImage: A static visual representation. Recommended best practice is to assign the type Text to
images of textual materials Narrower than Image
Text: A resource consisting primarily of words for reading.

InteractiveResource: A resource requiring interaction from the user to be understood, executed, or experienced
Examples: forms on Web pages, applets, multimedia learning objects, chat services, or virtual reality environments.
PhysicalObject: An inanimate, three-dimensional object or substance
Service: A system that provides one or more functions
Examples: a photocopying service, a banking service, an authentication service, interlibrary loans, a Z39.50 or Web server.
Software: A computer program in source or compiled form
Sound: A resource primarily intended to be heard

Syntax Encoding Schemes (Definitions, some) DCMI Box: The set of regions in space defined by their geographic
coordinates according to the DCMI Box Encoding Scheme.
ISO 3166: The set of codes listed in ISO 3166-1 for the representation of names of countries.
ISO 639-2: The three-letter alphabetic codes listed in ISO639-2 for the representation of names of languages.
DCMI Period: The set of time intervals defined by their limits according to the DCMI Period Encoding Scheme.
DCMI Point: The set of points in space defined by their geographic coordinates according to the DCMI Point Encoding Scheme.

URI: The set of identifiers constructed according to the generic syntax for URIs as specified by the Internet Engineering Task Force
W3C-DTF: The set of dates and times constructed according to the W3C Date and Time Formats Specification

DCMI Abstract Modelhttp://dublincore.org/documents/2007/06/04/abstract-model/
The abstract model of the vocabularies in DC metadata descriptions is
A vocabulary is a set of 1 or more terms Each term is a member of 1 or more vocabularies
A term is a property (element), class, vocabulary encoding scheme, or syntax encoding scheme
Each property may be related to one or more classes by a has domain relationship
Each property may be related to one or more classes by a has range relationship
Each resource may be a member of one or more vocabulary encoding schemes

Each class may be related to 1 or more other classes by a sub-class of relationship
Each property may be related to 1 or more other properties by a sub-property of relationship
Each syntax encoding scheme is a class (of literals)