artificial intelligence, scientific discovery, and
TRANSCRIPT

Artificial Intelligence,Scientific Discovery,
and Commercial Innovation
Ajay Agrawal (University of Toronto and NBER)John McHale (National University of Ireland, Galway)Alex Oettl (Georgia Institute of Technology and NBER)
July 2019

Source: https://www.ais.uni-bonn.de/deep_learning/
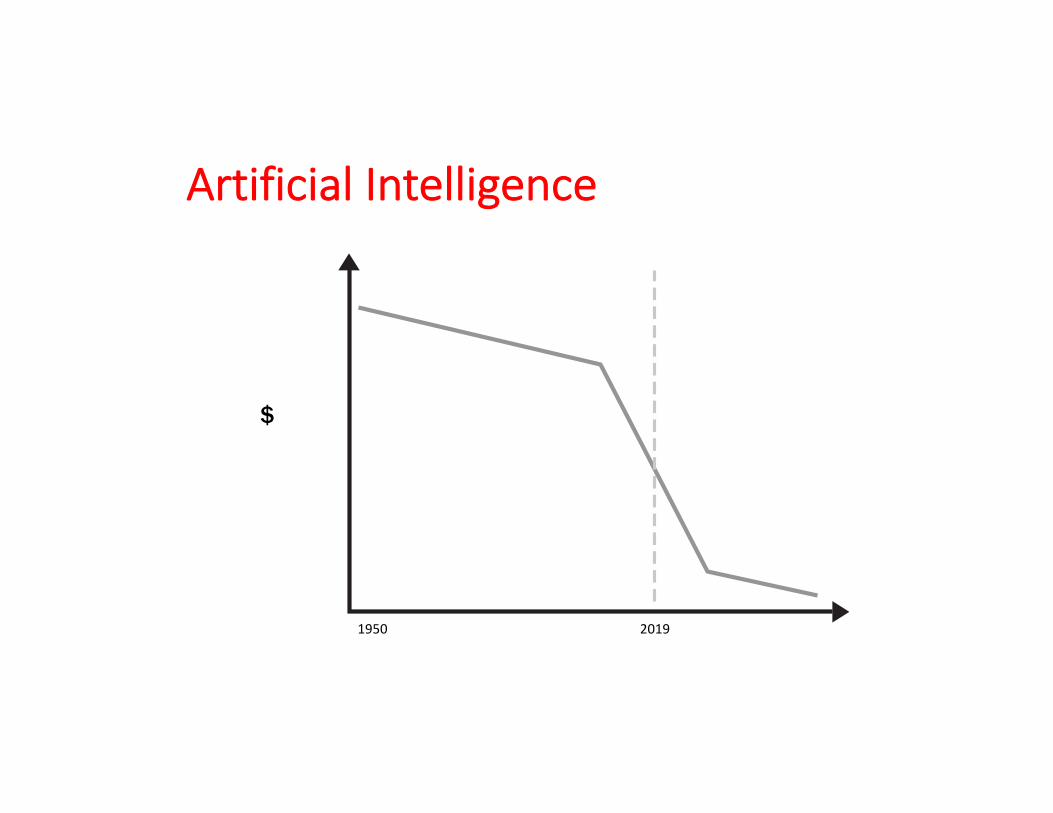
Artificial Intelligence
$
1950 2019

Artificial Intelligence
$Cost of
Prediction
1950 2019

Prediction:Using information that you do have to generate information that you don’t have

12 McKinsey Global Institute 2. Insights from use cases
TWO-THIRDS OF THE OPPORTUNITIES TO USE AI ARE IN IMPROVING THE PERFORMANCE OF EXISTING ANALYTICS USE CASESIn 69 percent of the use cases we studied, deep neural networks can be used to improve performance beyond that provided by other analytic techniques. Cases in which only neural networks can be used, which we refer to here as “greenfield” cases, constituted just 16 percent of the total. For the remaining 15 percent, artificial neural networks provided limited additional performance over other analytics techniques, among other reasons because of data limitations that made these cases unsuitable for deep learning.
Greenfield AI solutions are prevalent in business areas such as customer service management, as well as among some industries in which the data are rich and voluminous and at times integrate human reactions. A key differentiator that often underpins higher AI value potential is the possibility of applying large amounts of audio, video, image, and text data to these problems. Among industries, we found many greenfield use cases in health care, in particular. Some of these cases involve disease diagnosis and improved care, and rely on rich data sets incorporating image and video inputs, including from MRIs.
On average, our use cases suggest that modern deep learning AI techniques have the potential to provide a boost in value above and beyond traditional analytics techniques ranging from 30 percent to 128 percent, depending on industry (Exhibit 6).
In many of our use cases, however, traditional analytics and machine learning techniques continue to underpin a large percentage of the value creation potential in industries including insurance, pharmaceuticals and medical products, and telecommunications, with the potential of AI limited in certain contexts. In part this is due to the way data are used by those industries and to regulatory issues, as we discuss later in this paper.
DATA REQUIREMENTS FOR DEEP LEARNING ARE SUBSTANTIALLY GREATER THAN FOR OTHER ANALYTICS, IN TERMS OF BOTH VOLUME AND VARIETY Making effective use of neural networks in most applications requires large labeled training data sets alongside access to sufficient computing infrastructure. As the size of the training data set increases, the performance of traditional techniques tends to plateau in many cases. However, the performance of advanced AI techniques using deep neural networks, configured and trained effectively, tends to increase. Furthermore, these deep learning techniques are particularly powerful in extracting patterns from complex, multi-dimensional data types such as images, video, and audio or speech. The data will need to be collected in a way that addresses society’s concerns about issues of privacy.
Data volume is essential for neural networks to achieve a high level of accuracy in training algorithms Deep learning methods require thousands of data records for models to become relatively good at classification tasks and, in some cases, millions for them to perform at the level of humans. By one estimate, a supervised deep-learning algorithm will generally achieve acceptable performance with around 5,000 labeled examples per category and will match or exceed human level performance when trained with a data set containing at least 10 million labeled examples.7 In some cases in which advanced analytics is currently used, so much data are available—millions or even billions of rows per data set—that AI usage is the most appropriate technique. However, if a threshold of data volume is not reached, AI may not add value to traditional analytics techniques.
7 Ian Goodfellow, Yoshua Bengio, and Aaron Courville, Deep learning, MIT Press, 2016.

Expanding Range of Use as Input

Expanding Range of Use as Input

Rising AI → Falling Cost of Prediction
• Converting problems that historically were not considered to be AI problems into AI
TranslationDriving Fraud detection Car loans
Email replies HR Inspectionhttps://commons.wikimedia.org/wiki/File:Ultrasonic
_pipeline_test.jpg

Knowledge, combinations, and innovation
! = # $Innovation Knowledge

Knowledge, combinations, and innovation
! = # $
! = % 2'
Innovation Knowledge
Combinatorial view of innovation process

Conceptualisation of the innovation process
• Innovation as search over a potentially vast combinatorial search space
• Science as a map of “fitness landscapes”
• AI generates better maps

Science as a map
• Theory
• Simulation
• Data-based models
• AI
Traditional Science
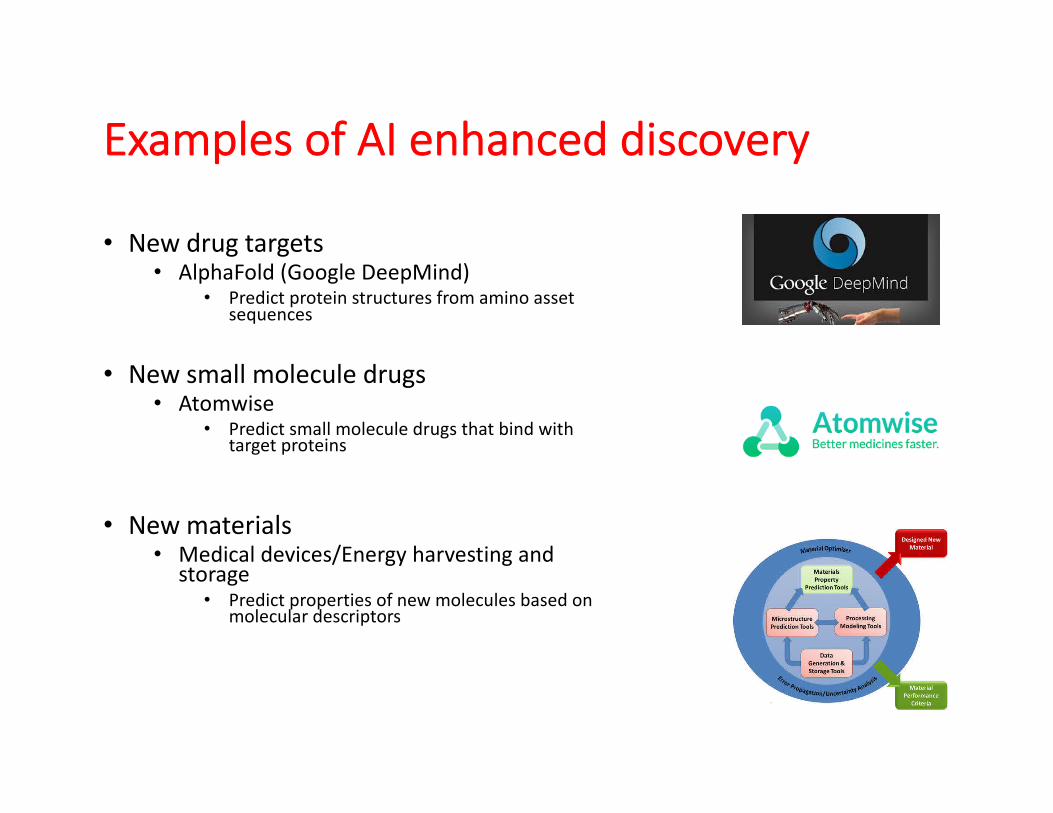
Examples of AI enhanced discovery
• New drug targets• AlphaFold (Google DeepMind)
• Predict protein structures from amino asset sequences
• New small molecule drugs• Atomwise
• Predict small molecule drugs that bind with target proteins
• New materials• Medical devices/Energy harvesting and
storage• Predict properties of new molecules based on
molecular descriptors

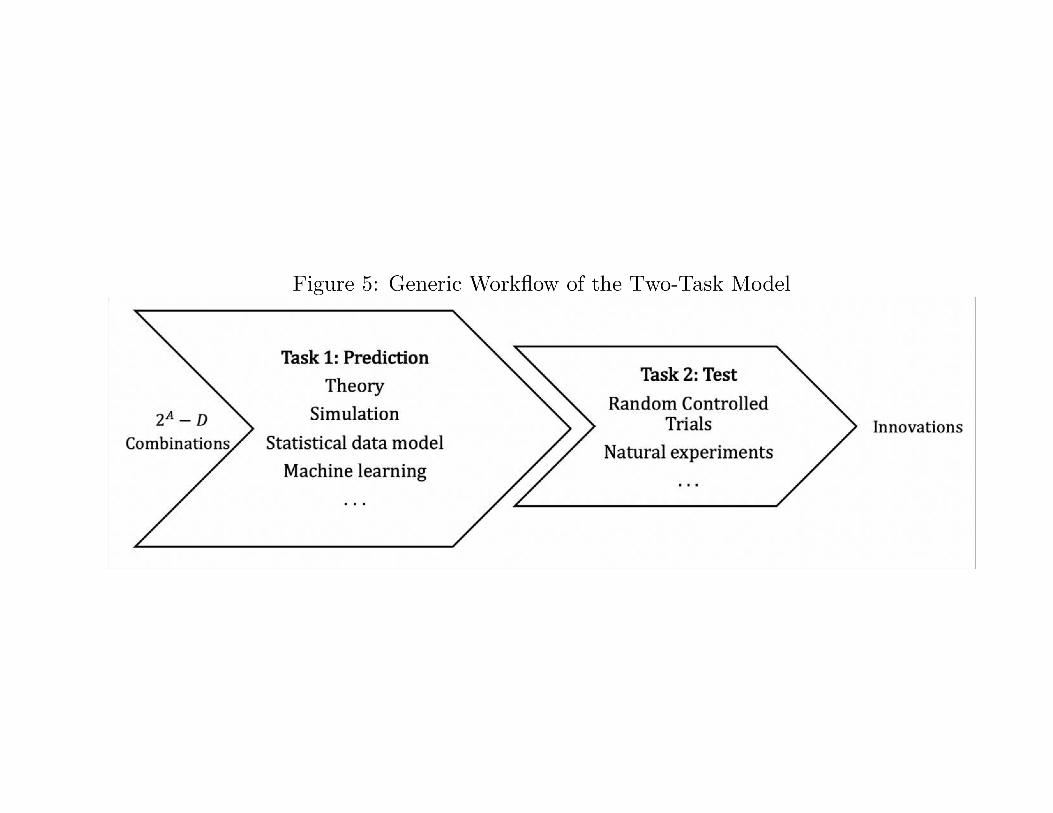
Generic workflow of science-based innovation
Ranking
Innovation
Combinations Fitness Landscape
Experiments
Knowledge
AI

Search space
• Number of potential combinations: 2A-D• A is # ideas the scientist has to combine into new ideas• D is # of observations on prior successes and failures
• Known• Scientist knows that G successes exist to be found• Share of combinations that will be a success: G/(2A-D)

Modelling AI-aided innovation
• A baseline model of exhaustive neighborhood search
• A two-task model• Task 1: Prediction• Task 2: Testing
• Introduce AI as a “shock” to the prediction task
• A multi-task model• The bottleneck problem• AI as a complement and substitute to R&D labor


Ranking function
• Functional form:• Probability of discovering a success when the prediction
model has zero discriminating power = G/(2A-D)• Approaches ground truth as the model approaches perfect
discrimination• Approach ground truth as b -> ∞


Optimal number of tests

Optimal number of tests

Optimal number of tests





Next steps
• Theory• Multi-task innovation process
• Substitute or complement to R&D labour• Closed-loop innovation processes
• Choosing the next experiment• Endogenous growth from data spillovers
• Optimal number and type of tests also considers the value of data spillovers (success/failure feedback data)
• Empirics• Testable hypothesis
• AI increases the productivity of the innovation process• Look for exogenous variation in access to AI

Thank you