asynchronous remote execution phd preliminary examination douglas thain university of wisconsin 19...
TRANSCRIPT

AsynchronousRemote Execution
PhD Preliminary ExaminationDouglas ThainUniversity of Wisconsin19 March 2002

Thesis
Asynchronous operations improve the throughput, resiliency, and scalability of remote execution systems.
However, asynchrony introduces new failure modes that must be carefully understood in order to preserve the illusion of synchronous operation.

Proposal
I propose to explore the coupling between asynchrony, failures, and performance in remote execution.
To accomplish this, I will modify an existing system and increase the available asynchrony in degrees.

Contributions
A measurement of the performance benefits through asynchrony.A system design that accommodates asynchrony while tolerating a significant set of expected failure modes.An exploration of the balance between performance, risk, and knowledge in a distributed system.

Outline
IntroductionA Case StudyRemote ExecutionRelated WorkProgress MadeResearch AgendaConclusion

Science NeedsLarge-Scale Computing
Theory, Experiment, ComputationNearly every field of scientific study has a ‘grand challenge” problem: Meteorology Genetics Astronomy Physics

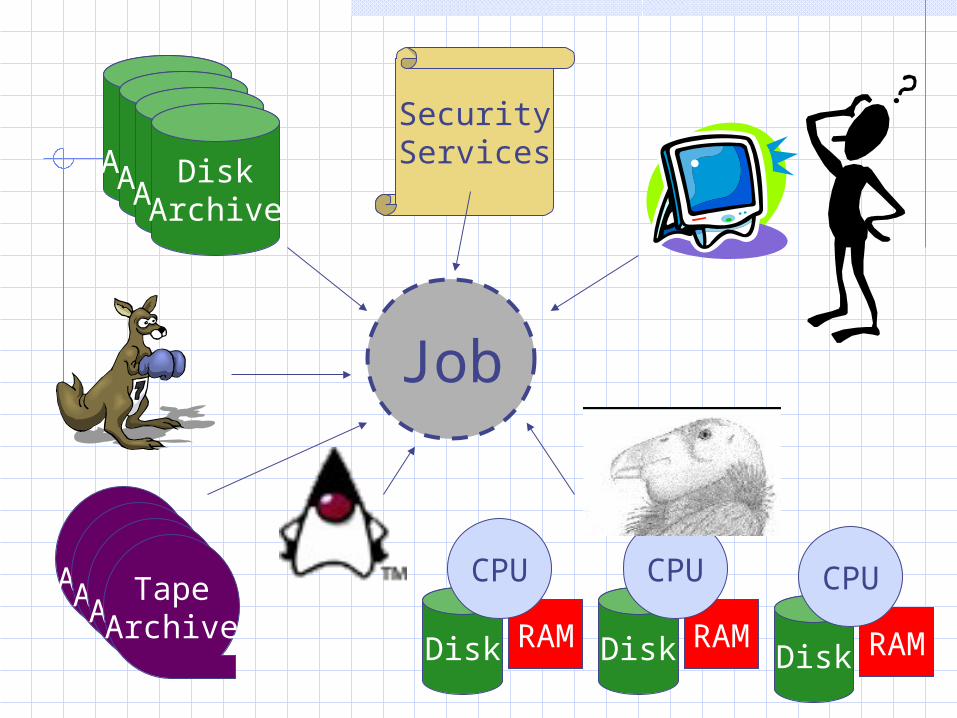
The Grid Vision
Disk RAM
CPU
DiskArchive
TapeArchive
Disk RAM
CPU
Disk RAM
CPU
SecurityServices
DiskArchive
DiskArchive
DiskArchive

The Grid RealitySystems for managing CPUs: Condor, LSF, PBS
Programming Interfaces: POSIX, Java, C#, MPI, PVM....
Systems for managing data: SRB, HRM, SAM, ReqEx (DapMan)
Systems for storing data: NeST, IBP
Systems for moving data: GridFTP, HTTP, Kangaroo
Systems for remote authentication: SSL, GSI, Kerberos, NTSSPI

The Grid RealityHost uptime:
Median: 15.92 days Mean: 5.53 days Local Maximum: 1 day Long et al, “A Longitudinal Study of Internet Host
Reliability,” Symposium on Reliable Distributed Systems, 1995.
Wide-area connectivity: approx 1% chance of 30-sec interruption approx 0.1% chance of a persistent outage Chandra et al, “End-to-end WAN Service Availability”,
Proceedings of 3rd Usenix Symp on Internet Technologies and Systems, 2001.
TapeArchive
Disk RAM
CPU
DiskArchive
DiskArchive
DiskArchive
DiskArchive
TapeArchive
TapeArchive
TapeArchive
Disk RAM
CPU
Disk RAM
CPU
SecurityServices
Job

Usual Approach:Hold and Wait
Request CPU, Wait for SuccessStage Data to CPU, WaitMove Executable to CPU, WaitExecute Program, WaitMissing File -> Stage Data, WaitStage Output Data, WaitFailure? Start over...

Synchronous Systemsare Inflexible
Poor utilization and throughput due to hold-and-wait. CPU idle while disk busy. Disk idle while CPU busy. Disk full? CPU stops.
System sensitive to failures of both performance and correctness. Network down? Everything stops. Network slow? Everything slows. Credentials lost? Everything aborts.

Resiliency Requires Flexibility
Most jobs have weak couplings between all of their components.Asynchrony: Time Decoupling Can’t have network now? Ok, use disk. Can’t have CPU now? Ok, checkpoint. Can’t store data now? Ok, recompute
later.
Time Decoupling -> Space Decoupling

Computing’s Central Challenge:
“How not to make a mess of it.”
- Edsger Dijkstra, CACM March 2001.
How can we harness the advantages of asynchrony while maintaining a coherent and reliable user experience?

Outline
IntroductionA Case Study: The Distributed Buffer CacheRemote ExecutionRelated WorkProgress MadeResearch AgendaConclusion

Case Study:The Distributed Buffer Cache
The Kangaroo distributed buffer cache introduces asynchronous I/O for remote execution.It offers improved job throughput and failure resiliency at the price of increased latency in I/O arrival.A small mess: Jobs and I/O are not recoupled at completion time.

Kangaroo Prototype
KKApp K
An application may contact any node in the system and perform partial-file reads and writes.
Disk
The node may then execute or buffer operations as conditions warrant.
BufferBuffer
A consistency protocol ensures no loss of data due to crash/disconnect.

Distributed Buffer Cache
FileSystem
FileSystem
FileSystem
FileSystem
KKK
K
K
KK
DistributedBuffer CacheApp
Disk

Macrobenchmark:Image Processing
Post-processing of satellite image data: Need to compute various enhancements and produce output for each. Read input image For I=1 to N
Compute transformation of image Write output image
Example: Image size about 5 MB Compute time about 6 sec IO-cpu ratio .91 MB/s

I/O Models for Image Processing
OUTPUT OUTPUT
CPU
OUTPUT
Online Streaming I/O:
Offline Staging I/O:
Kangaroo:
INPUT
OUTPUT
CPU CPU CPU
OUTPUTOUTPUTCPU OUTPUTINPUT OUTPUTCPU CPU CPU
OUTPUT OUTPUTCPU OUTPUTINPUT OUTPUTCPUCPU CPU


A Small MessThe output will make it back eventually, barring the removal of a disk.But, what if... ...we need to know when it arrives? ...the data should be cancelled? ...it never arrives?
There is a hold-and-wait operation (push,) but this defeats much of the purpose.The job result needs to be a function of both the compute and data results.

Lesson
We may decouple CPU and I/O consumption for improved throughput. But, CPU and I/O must be semantically coupled at both dispatch and completion in order to provide useful semantics.Not necessary in a monolithic system: All components fail at once. Integration of CPU and I/O management
(fsync)

Outline
IntroductionA Case StudyRemote Execution Synchronous Execution Asynchronous Execution Failures, Transparency, and Performance
Related WorkProgress MadeResearch AgendaConclusion

Remote Execution
Remote execution is the problem of running a job in a distributed system.A job is a request to consume a set of resources in a coordinated way: Abstract: Programs, Files, Licenses, Users Concrete: CPUs, Storage, Servers, Terminals
A distributed system is a computing environment that is: Composed of autonomous units. Subject to uncoordinated failure. Subject to high performance variability.

About Jobs
Job policy dictates what resources are acceptable to consume: CPU must be a SPARC Must have > 128MB memory Must be within 100ms of a disk server CPU must be owned by a trusted
authority. Input data set X may come from any
trusted replication site.

About Jobs
The components of a job have flexible temporal and spatial requirements.
ProgramImage
CPUInputDevice
OutputDevice
InputData
OutputData
LicenseCreds
read write
presentthroughout
presentat startup
interactivepreferred

Expected Jobs
In this work, I will concentrate on a limited class of jobs: Executable image Single CPU request May checkpoint/restart to manage
CPU. Input data (online/offline) Output data (multiple targets)

Expected SystemsHigh latency I/O operations are ms->sec Process dispatch is seconds->minutes
Performance variation TCP hiccups cause outages of seconds->minutes. By day, network congested, by night->free
Uncoordinated failure File system fails, CPU continues to run. Network fails, but endpoints continue.
Autonomy Users reclaim workstation CPUs. Best-effort storage is reclaimed.

Expected Users
A wide variety of users will have varying degrees of policy aggression.Scientific computation: Maximize long-term utilization/throughput.
Scientific instrument: Minimize use of one device.
Disaster response: Compute this ASAP at any expense!
Graduate student: Finish job before mid-life crisis.

The Synchronous Approach
Grab one resource at a time as they become necessary and available.Assume any other resources are immediately available online.Start with the resource with the most contention.Examples: Condor distributed batch system Fermi Sequential Access Manager (SAM)
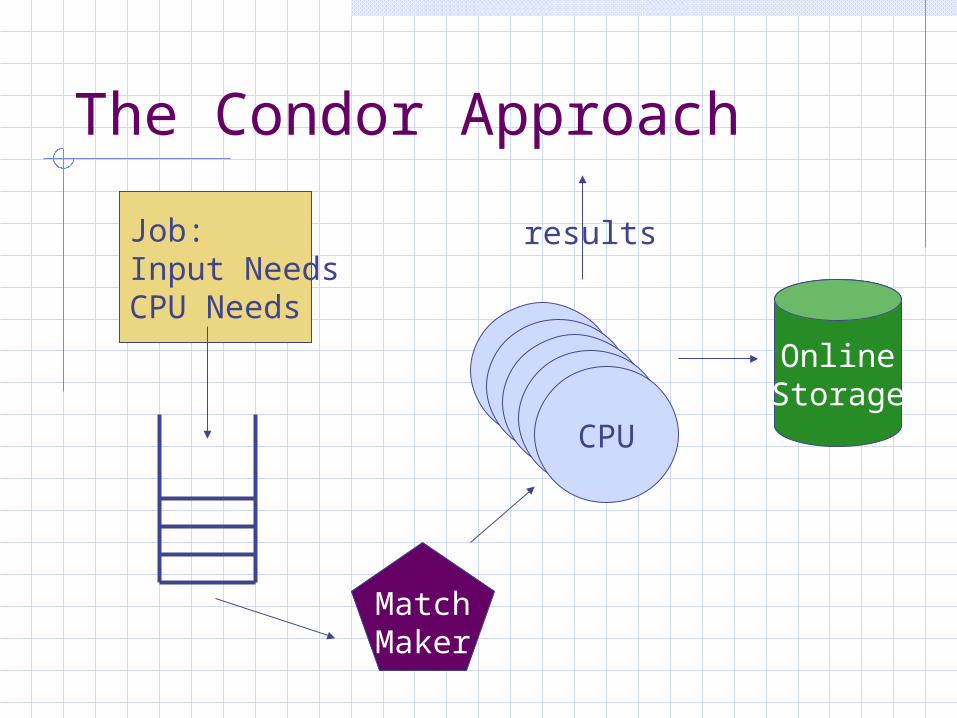
The Condor Approach
Job:Input NeedsCPU Needs
OnlineStorage
CPUCPUCPUCPUCPU
results
MatchMaker

The SAM Approach
Job:Input NeedsCPU Needs
TapeArchive
TempDisk
CPUCPUCPUCPUCPU
results

Problems
What if one resource is not obviously (or consistently) the constraint?What is the expense of holding one resource idle while waiting for another?What if no single resource is under your absolute control?What if all your resource requirements cannot be stated offline?How can we deal with failures without starting everything again from scratch?

Asynchronous Execution
Recognize when a job has loose synchronization requirements.Seek parallelism where available.Synchronize parallel activities at necessary joining points.Allow idle resources to be released and re-allocated for use by others.Consider failures in execution as allocation problems.
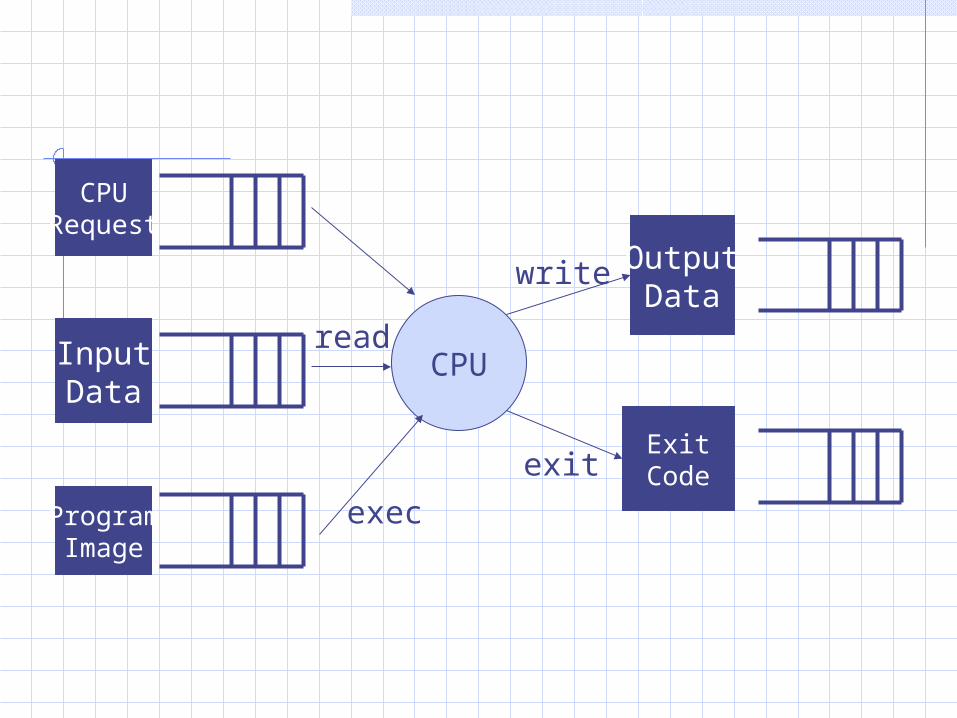
ProgramImage
CPUInputData
OutputData
read
write
ExitCode
exec
CPURequest
exit

The Benefits of Asynchrony
Better utilization of disjoint resources -> higher throughput.More resilient to performance variations.Less expensive recovery from partial system failures.

The Price of Asynchrony
Complexity Many new boundary cases to cover. Is the complexity worth the trouble?
Risk Without appropriate policies, we may:
Oversubscribe (internal fragmentation) Undersubscribe (external fragmentation)

The Problem ofClosing the Loop
ProgramImage
CPUInputData
OutputData
read
write
ExitCode
exec
CPURequest
exit
Job
Su
bm
issi
on Jo
b C
om
ple
tion

Synchronous I/O
CPU Busy
I/O Busy
CPU Idle CPU BusyProgramResult
I/O ResultI/O Dispatch

Asynchronous Open-Loop I/O
CPU Busy
I/O Busy
CPU Busy ProgramResult
I/O Result?I/O Dispatch
I/OResult
I/OValidation
CPUIdle

AsynchronousClosed-Loop I/O
CPU Busy
I/O Busy
CPU Busy ProgramResult
I/O Result?I/O Dispatch
I/OResult
I/OValidation
CPUIdle
JobResult

Outline
AbstractIntroductionRemote ExecutionRelated WorkProgress MadeResearch AgendaConclusion

Related Work
Many components of grid computing: CPUs, storage, networks...
Many traditional research areas: scheduling, file systems, virtual memory...
What systems seek parallelism in operations that would appear to be atomic?What systems exchange one resource for another?How do they deal with failures?

Computer Architecture
These two are remarkably similar: sort -n < infile > outfile ADD [r1+8], [r2+12], [r3]
Each has multiple parts with a loose coupling in time and space.idle -> working -> done -> commitedA failure or an unsuccessful speculation must roll back dependent parts.

Trading Storagefor Communication
Immediate Closure: Synchronous I/O
Bounded Closure: GASS, AFS, transaction
Indeterminate Closure: UNIX buffer cache Imprecise Exceptions
Human Closure: Coda -> Failures invoke email

Trading Computationfor Communication
Time Warp Simulation Model All nodes checkpoint frequently. All messages one-way without synchro. Missed a message? Roll back and send out anti-
messages to undo earlier work. Problems:
When can I throw out a checkpoint? Can’t tolerate message failure.
Virtual Data Grid Data sets have a functional specification. Transfer here, or recompute? Decide at run-time using cost/benefit.

Outline
IntroductionCase StudyRemote ExecutionRelated WorkProgress MadeResearch AgendaConclusion

Progress Made
We have already laid much of the research foundation necessary to explore asynchronous remote execution.Deployable software: Bypass, Kangaroo, NeST
Organizing Concepts: Distributed buffer cache I/O communities Error management theory

Interposition Agents
Application
Standard Library
Kernel
Interposition Agent

The Grid Console
HalfInteractive
Process
UnreliableNetwork
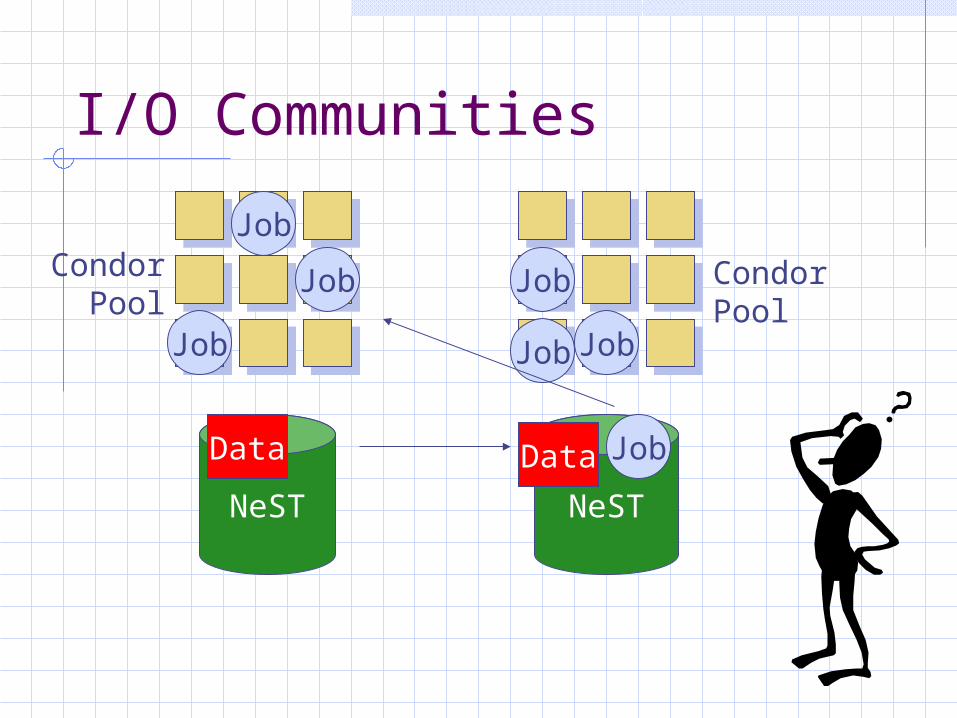
I/O Communities
NeST NeST
CondorPool
CondorPool
Data Job
Job
JobJob
Data
Job
Job
Job

References in ClassAds
MachineMachine NeSTJob
JobAd
MachineAd
StorageAd
matc
h
Refers toNearestStorage.
Knows whereNearestStorage is.

Distributed Buffer Cache
FileSystem
FileSystem
FileSystem
FileSystem
KKK
K
K
KK
DistributedBuffer CacheApp
Disk

Error Management
In preparation: “Error Scope on a Computational Grid: Theory and Practice”An environment for Java in Condor.How do we understand the significance of the many things that may go wrong?Every scope must have a handler.

PublicationsDouglas Thain and Miron Livny, ``Error Scope on a Computational Grid,'' in preparation.Douglas Thain, John Bent, Andrea Arpaci-Dusseau, Remzi Arpaci-Dusseau, and Miron Livny, ``Gathering at the Well: Creating Communities for Grid I/O,'' Proceedings of Supercomputing 2001, Denver, Colorado, November 2001. Douglas Thain, Jim Basney, Se-Chang Son, and Miron Livny, ``The Kangaroo Approach to Data Movement on the Grid,'' in Proceedings of the Tenth IEEE Symposium on High Performance Distributed Computing (HPDC10), San Francisco, California, August 7-9, 2001, pp 325-333.Douglas Thain and Miron Livny, ``Multiple Bypass: Interposition Agents for Distributed Computing,'' Journal of Cluster Computing, Volume 4, Pages 39-47, 2001. Douglas Thain and Miron Livny, ``Bypass: A tool for building split execution systems'', in Proceedings of the Ninth IEEE Symposium in High Performance Distributed Computing (HPDC9), Pittsburgh, Pennsylvania, August 1-4, 2000, pp 79-85.

Outline
IntroductionA Case StudyRemote ExecutionRelated WorkProgress MadeResearch AgendaConclusion

Research Agenda
I propose to create an end-to-end structure for asynchronous remote execution.To accomplish this, I will take an existing remote execution system, and increase the asynchrony by degrees.The focus will be mechanisms, not policies. Suggest points where policies must be
attached. Use simple policies to demonstrate use. Mechanisms must be correct regardless of
policy choices.

Research Environment
The Condor distributed batch system.Local resources: Test Pool - approx 20 workstations. Main Pool - approx 1000 machines. Possible to deploy significant changes to all
partcipating software.
Remote Resources: INFN Bologna - approx 300 workstations. Other pools as necessary. Can only deploy changes within the context of
an interposition agent.

Stage One:Asynchronous Output
Timeline: March-May 2002Goal: Decouple CPU allocation from output data
movement.
Method: Couple Kangaroo with Condor and close the
loop. Job requires a new state: “waiting for output.”
Policy: How long should a job remain in “waiting for
output” before it is re-run?

Stage Two:Asynchronous Input
Timeline: June-August 2002.Goal: Decouple CPU allocation from input data movement.
Method: Modify scheduler to be aware of I/O communities
and seek CPU and I/O allocations independently. Unexpected I/O needs may use checkpointing to
release CPU allocations.
Policy: How long to hold idle before timeout? How to estimate queueing time for each resource?

Stage Three:Disconnected Operation
Timeline: September-December 2002Goal: Permit application to execute without any run-time
dependence on the submitter.
Method: Release umbilical once policy is set. Job requires new state: “presumed alive.” Unexpected policy needs may require reconnection.
Policy: How much autonomy may be delegated tothe
interposition agent? (performance/control)

Stage Four:Dissertation
Timeline: January-May 2003Design What algorithms and data structures are
necessary?
Performance What are the quantitative costs/benefits?
Discussion What are the tradeoffs between performance,
risk, and knowledge? What are the implications of designing for fault-
tolerance?

Evaluation Criteria
Correctness The system must meet its interface obligations.
Reliability Satisfy the user with high probability.
Throughput Improve by avoiding hold-and-wait.
Latency A modest increase is ok for batch workloads.
Knowledge Has my job finished? How much has it consumed?
Complexity

Contributions
Short-term: Improvement of the Condor software. Not the goal, but a necessary validation
Medium-term: Serve as a design resource for grid computing. Key concepts such as “closing the loop” and
“matching interfaces.”
Long-term: Serve as a basis for further research.

Further Work
Should jobs move to data or vice versa? Let’s try both!
Many opportunities for speculation: Potentially stale data in file cache? Keep going.
Partial program completion is useful: DAGMan: dispatch a process based on exit code,
dispatch another based on output data.
What if we change the API? A drastic step, but... MPI, PVM, MW, Linda. Can we admit subprogram failure and maintain a
usable interface?

Outline
IntroductionA Case StudyRemote ExecutionRelated WorkProgress MadeResearch AgendaConclusion

Conclusion
Large-grained asynchrony has yet to be explored in the context of remote program execution.Asynchrony has benefits, but requires careful management of failure modes.This dissertation will contribute a system design and an exploration of performance, risk, and knowledge in a distributed system.

Extra Slides

JVM
Fork
startershadow
HomeFile
System
I/O Library
The Job
I/O Server I/O Proxy
Secure Remote I/O
Local System Calls Local I/O(Chirp)
Execution SiteSubmission Site

RunningProgram
InterpositionAgent
CPU RAMDisk
Network
Remote Resource Interfaces
Application Interface
Few guaranteeson performance, availability, and
reliability.
Explicit descriptions of ordering, reliability,
performance, and availability.
(POSIX, MPI, PVM, MW)

RunningProgram
InterpositionAgent
CPU RAMDisk
Network
In the event of a failure: Retry: Hold the
CPU allocation and try again.
Checkpoint: Release the CPU, with some restart condition.
Abort: Expose the failure to a supervisor.
SupervisorProcess

The Cost of Hiding FailuresEach technique is valid from the standpoint of API conformity.What to use? Depends on cost: Retry: Holds CPU idle while retrying device. Checkpoint: Consumes disk and network, but
releases CPU. Abort: No expense up front, but must re-
consume resources when ready to roll forward.
User policy is vital in determining what costs are acceptable for hiding failures.

RunningProgram
InterpositionAgent
CPU RAMDisk
Network
PolicyDirector
What file should I open?
How long should I try?
May I checkpoint now?
Where should I store the checkpoint image?
Should I stage or stream the output?
FYI, I’ve used 395 service units here.
FYI, I’m about to be evicted from this site.

Disconnected Operation
The policy manager is also an execution resource that is occasionally slow or unavailable.Holding a resource idle while waiting indefinitely for policy direction is still wait-while-idle.A higher degree of asynchrony can be achieved through disconnected operation.Requires each autonomous unit be given an “allowance”.