audio signal recognition for speech, music, and environmental...
TRANSCRIPT

Dan Ellis Audio Signal Reecognition 2003-11-13 - 1 / 25
Audio Signal Recognitionfor Speech, Music,
and Environmental Sounds
Pattern Recognition for Sounds
Speech Recognition
Other Audio Applications
Observations and Conclusions
1
2
3
4
Dan Ellis <[email protected]>
Laboratory for Recognition and Organization of Speech and Audio(Lab
ROSA
)Columbia University, New Yorkhttp://labrosa.ee.columbia.edu/
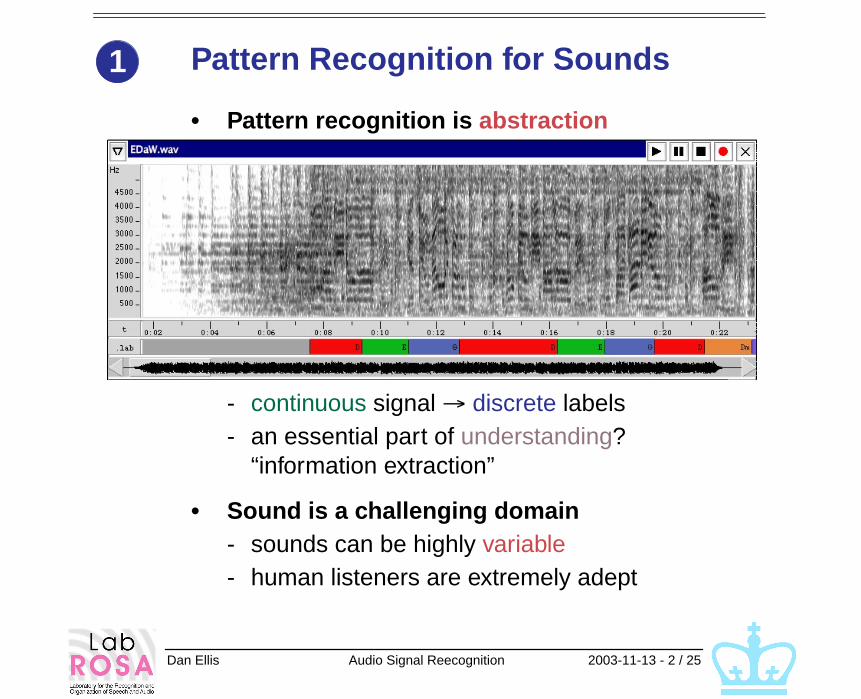
Dan Ellis Audio Signal Reecognition 2003-11-13 - 2 / 25
Pattern Recognition for Sounds
• Pattern recognition is abstraction
- continuous signal
→
discrete labels- an essential part of understanding?
“information extraction”
• Sound is a challenging domain
- sounds can be highly variable- human listeners are extremely adept
1
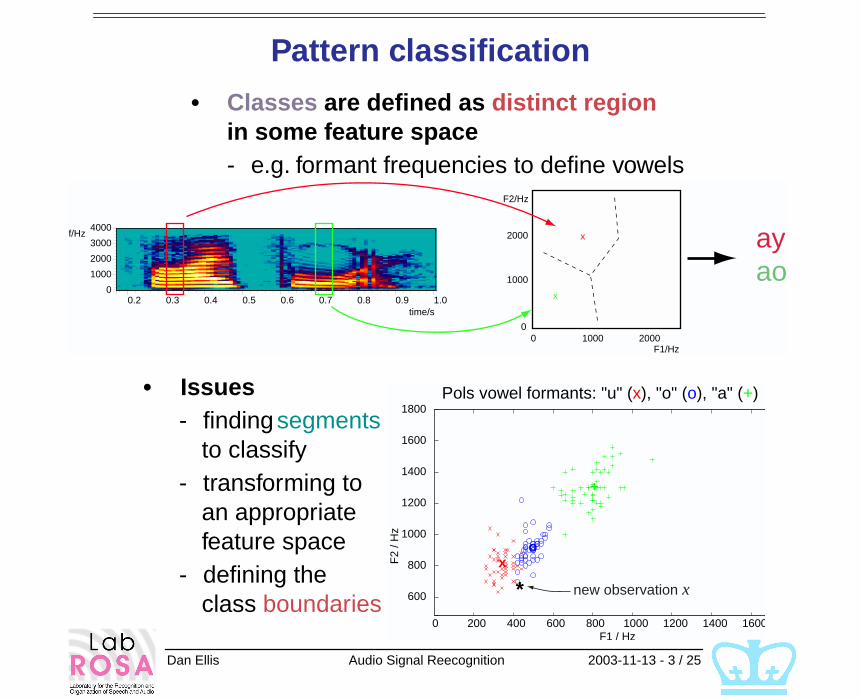
Dan Ellis Audio Signal Reecognition 2003-11-13 - 3 / 25
Pattern classification
• Classes are defined as distinct region in some feature space
- e.g. formant frequencies to define vowels
• Issues
- finding segments to classify
- transforming to an appropriate feature space
- defining the class boundaries
0
00
1000
1000
2000
2000
1000
2000
3000
4000
0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0
f/Hz
time/s
F1/Hz
F2/Hz
x
x ayao
0 200 400 600 800 1000 1200 1400 1600
600
800
1000
1200
1400
1600
1800Pols vowel formants: "u" (x), "o" (o), "a" (+)
F1 / Hz
F2
/ Hz
x
*
+
o
new observation x
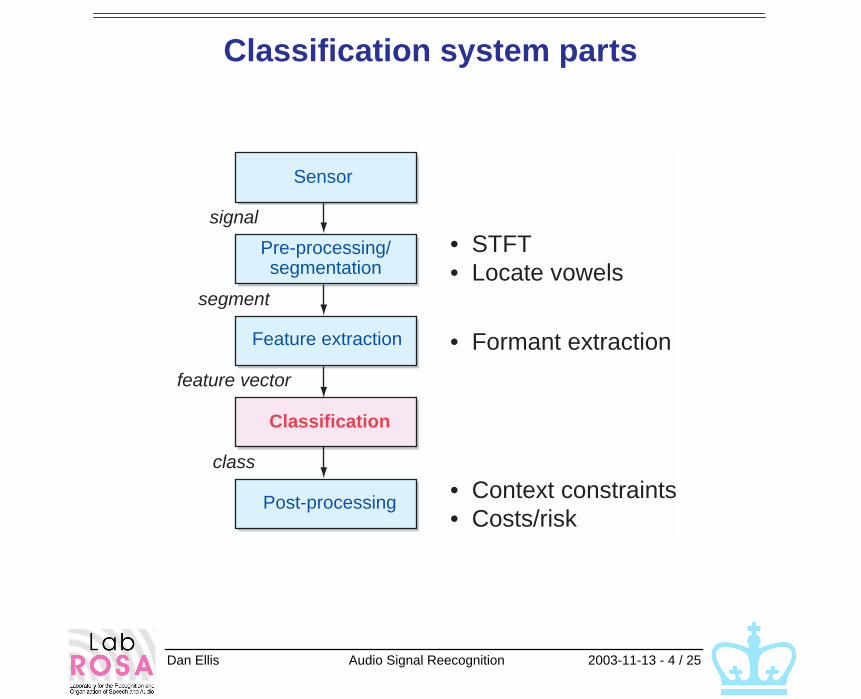
Dan Ellis Audio Signal Reecognition 2003-11-13 - 4 / 25
Classification system parts
signal
segment
feature vector
class
Pre-processing/segmentation
Feature extraction
Classification
Post-processing
Sensor
• STFT• Locate vowels
• Formant extraction
• Context constraints• Costs/risk

Dan Ellis Audio Signal Reecognition 2003-11-13 - 5 / 25
Feature extraction
• Feature choice is critical to performance
- make important aspects explicit, remove irrelevant details
- ‘equivalent’ representations can perform very differently in practice
- major opening for domain knowledge (“cleverness”)
• Mel-Frequency Cepstral Coefficients (MFCCs):Ubiquitous speech features
- DCT of log spectrum on ‘auditory’ scale- approximately decorrelated ...
0 1 2 30
10
20
30
0 1 2 30
5
10
time / sec
freq
. cha
nnel
cep.
coe
f.Mel Spectrogram MFCCs

Dan Ellis Audio Signal Reecognition 2003-11-13 - 6 / 25
Statistical Interpretation
• Observations are random variableswhose distribution depends on the class:
• Source distributions
p
(
x
|
ω
i
)
- reflect variability in feature- reflect noise in observation- generally have to be estimated from data
(rather than known in advance)
Classωi
(hidden)discrete continuous
Observationx
p(x|ωi)Pr(ωi|x)
p(x|ωi)
x
ω1 ω2 ω3 ω4

Dan Ellis Audio Signal Reecognition 2003-11-13 - 7 / 25
Priors and posteriors
• Bayesian inference can be interpreted as updating prior beliefs with new information,
x
:
• Posterior is prior scaled by likelihood & normalized by evidence (so
Σ
(
posteriors
)
= 1)
• Minimize the probability of error by choosing
maximum
a posteriori
(MAP) class:
Pr ωi( )p x ωi( )
p x ω j( ) Pr ω j( )⋅j∑
---------------------------------------------------⋅ Pr ωi x( )=
Posteriorprobability
‘Evidence’ = p(x)
Likelihood
Prior probability
ω̂ Pr ωi x( )ωi
argmax =

Dan Ellis Audio Signal Reecognition 2003-11-13 - 8 / 25
Practical implementation
• Optimal classifier is
but we don’t know
• So, model conditional distributions then use Bayes’ rule to find MAP class
ω̂ Pr ωi x( )ωi
argmax =
Pr ωi x( )
p x ωi( )
Labeledtraining
examples{xn,ωxn}
Sortaccordingto class
Estimateconditional pdf
for class ω1
p(x|ω1)

Dan Ellis Audio Signal Reecognition 2003-11-13 - 9 / 25
Gaussian models
• Model data distributions via parametric model
- assume known form, estimate a few parameters
• E.g. Gaussian in 1 dimension:
• For higher dimensions, need mean vector
µ
i
and
d
x
d
covariance matrix
Σ
i
• Fit more complex distributions with mixtures...
p x ωi( )1
2πσi
---------------- 12---
x µi–
σi------------- 2
–exp⋅=normalization
0
2
4
0
2
4
0
0.5
1
0 1 2 3 4 50
1
2
3
4
5
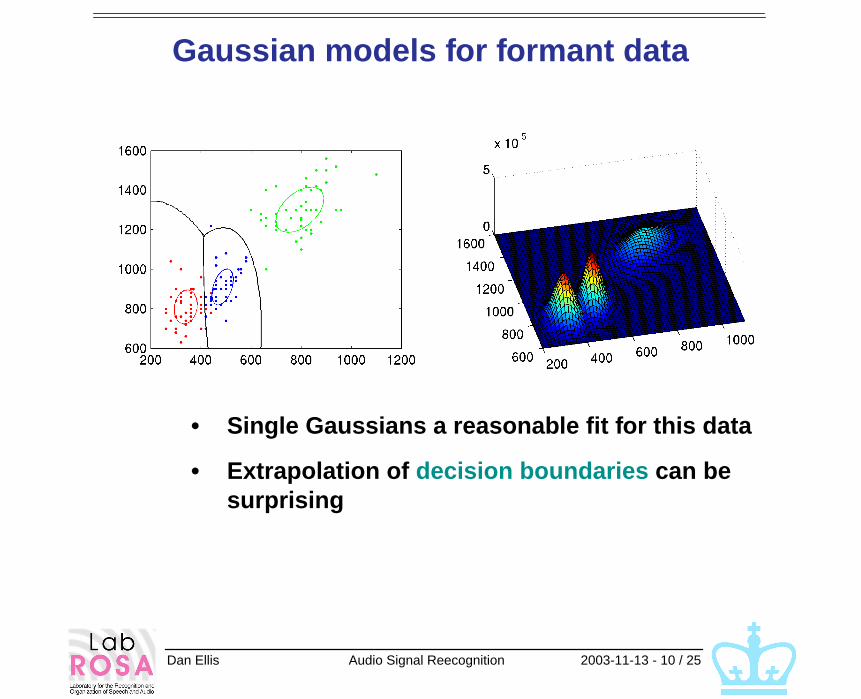
Dan Ellis Audio Signal Reecognition 2003-11-13 - 10 / 25
Gaussian models for formant data
• Single Gaussians a reasonable fit for this data
• Extrapolation of decision boundaries can be surprising

Dan Ellis Audio Signal Reecognition 2003-11-13 - 11 / 25
Outline
Pattern Recognition for Sounds
Speech Recognition- How it’s done- What works, and what doesn’t
Other Audio Applications
Observations and Conclusions
1
2
3
4
Dan Ellis Audio Signal Reecognition 2003-11-13 - 12 / 25
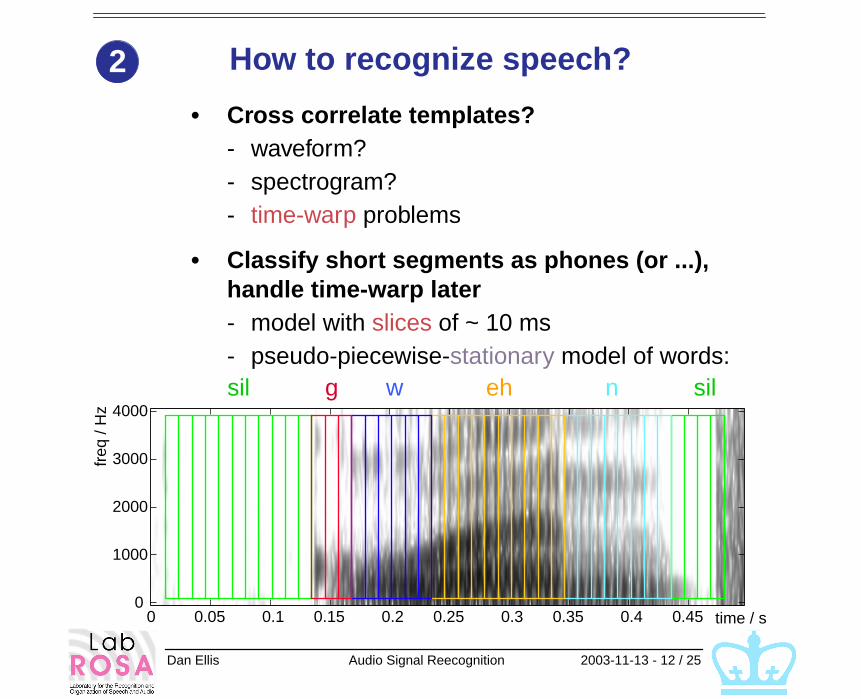
How to recognize speech?
• Cross correlate templates?- waveform?- spectrogram?- time-warp problems
• Classify short segments as phones (or ...), handle time-warp later- model with slices of ~ 10 ms- pseudo-piecewise-stationary model of words:
2
time / s
freq
/ H
z
0 0.05 0.1 0.15 0.2 0.25 0.3 0.35 0.4 0.450
1000
2000
3000
4000sil silg w eh n

Dan Ellis Audio Signal Reecognition 2003-11-13 - 13 / 25
Speech Recognizer Architecture
• Almost all current systems are the same:
• Biggest source of improvement is increase in training data- .. along with algorithms to take advantage
Featurecalculation
sound
Acousticclassifier
feature vectorsAcoustic model
parameters
HMMdecoder
Understanding/application...
phone probabilities
phone / word sequence
Word models
Language modelp("sat"|"the","cat")p("saw"|"the","cat")
s ah t
D A
T A
Dan Ellis Audio Signal Reecognition 2003-11-13 - 14 / 25
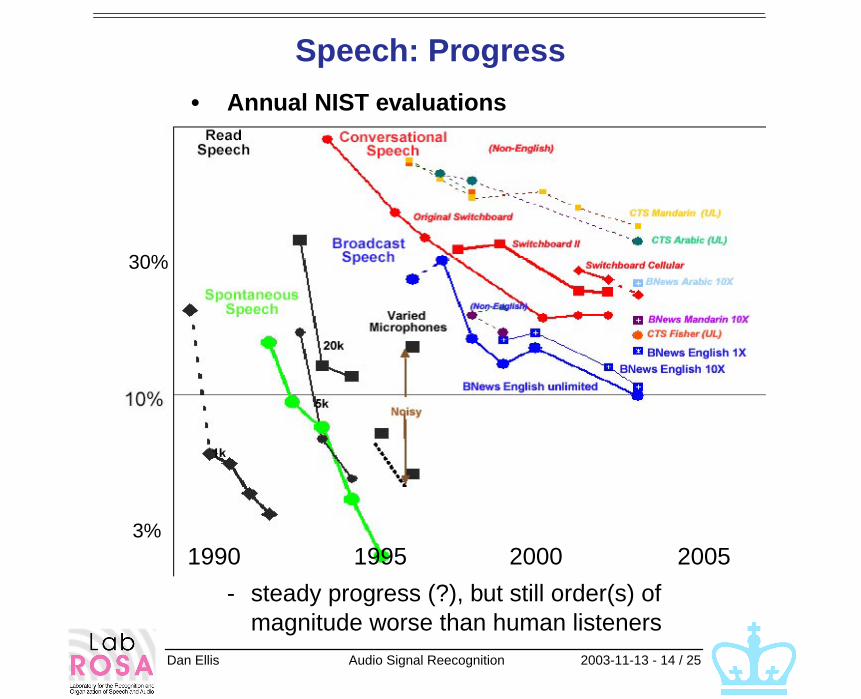
Speech: Progress
• Annual NIST evaluations
- steady progress (?), but still order(s) of magnitude worse than human listeners
1990 1995 2000 2005
30%
3%

Dan Ellis Audio Signal Reecognition 2003-11-13 - 15 / 25
Speech: Problems
• Natural, spontaneous speech is weird!
- coarticulation- deletions- disfluencies→ is word transcription even a sensible approach?
• Other major problems- speaking style, rate, accent- environment / background...

Dan Ellis Audio Signal Reecognition 2003-11-13 - 16 / 25
Speech: What works, what doesn’t
• What works: Techniques:- MFCC features + GMM/HMM systems
trained with Baum-Welch (EM)- Using lots of training dataDomains:- Controlled, low noise environments- Constrained, predictable contexts- Motivated, co-operative users
• What doesn’t work: Techniques:- rules based on ‘insight’- perceptual representations
(except when they do...)Domains:- spontaneous, informal speech- unusual accents, voice quality, speaking style- variable, high-noise background / environment

Dan Ellis Audio Signal Reecognition 2003-11-13 - 17 / 25
Outline
Pattern Recognition for Sounds
Speech Recognition
Other Audio Applications- Meeting recordings- Alarm sounds- Music signal processing
Observations and Conclusions
1
2
3
4

Dan Ellis Audio Signal Reecognition 2003-11-13 - 18 / 25
Other Audio Applications:ICSI Meeting Recordings corpus
• Real meetings, 16 channel recordings, 80 hrs
- released through NIST/LDC
• Classification e.g.: Detecting emphasized utterances based on f0 contour (Kennedy & Ellis ’03)
- per-speaker normalized f0 as unidimensional feature → simple threshold classification
3
Speaker 1 Speaker 2440 f0/Hz f0/Hz440110 176022011055

Dan Ellis Audio Signal Reecognition 2003-11-13 - 19 / 25
Personal Audio
• LifeLog / MyLifeBits / Remembrance Agent:- easy to record everything you
hear
• Then what?- prohibitive to review- applications if access easier?
• Automatic content analysis / indexing...
- find features to classify into e.g. locations
50 100 150 200 2500
2
4
14:30 15:00 15:30 16:00 16:30 17:00 17:30 18:00 18:30
5
10
15
freq
/ H
zfr
eq /
Bar
k
time / min
clock time
Dan Ellis Audio Signal Reecognition 2003-11-13 - 20 / 25
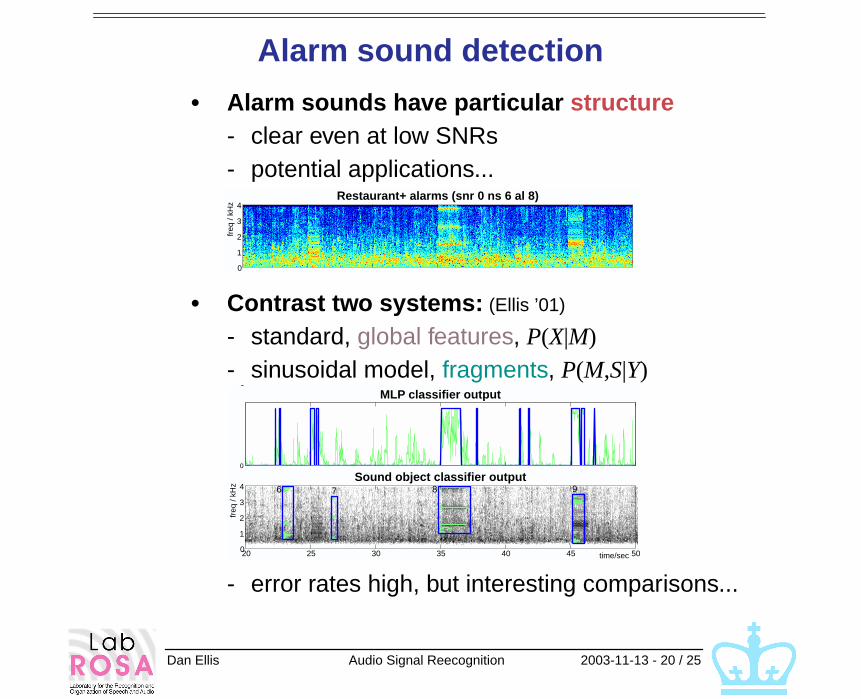
Alarm sound detection
• Alarm sounds have particular structure- clear even at low SNRs- potential applications...
• Contrast two systems: (Ellis ’01)
- standard, global features, P(X|M)- sinusoidal model, fragments, P(M,S|Y)
- error rates high, but interesting comparisons...
0
freq
/ kH
z
1
2
3
4Restaurant+ alarms (snr 0 ns 6 al 8)
20 25 30 35 40 45 50
0
6 7 8 9
time/sec0
freq
/ kH
z
1
2
3
4
0
MLP classifier output
Sound object classifier output

Dan Ellis Audio Signal Reecognition 2003-11-13 - 21 / 25
Music signal modeling
• Use “machine listener” to navigate large music collections- e.g. unsigned bands on MP3.com
• Classification to label:- notes, chords, singing, instruments- .. information to help cluster music
• “Artist models” based on feature distributions
- measure similarity between users’ collections and new music? (Berenzweig & Ellis ’03)
third cepstral coef
fifth
cep
stra
l coe
f
madonnabowie
p
1 0.5 0 0.5
0.8
0.6
0.4
0.2
0
0.2
0.4
0.6
Country
Ele
ctro
nica
madonnabowie
10
5
15 10 5
15
0

Dan Ellis Audio Signal Reecognition 2003-11-13 - 22 / 25
Outline
Pattern Recognition for Sounds
Speech Recognition
Other Audio Applications
Observations and Conclusions- Model complexity- Sound mixtures
1
2
3
4
Dan Ellis Audio Signal Reecognition 2003-11-13 - 23 / 25
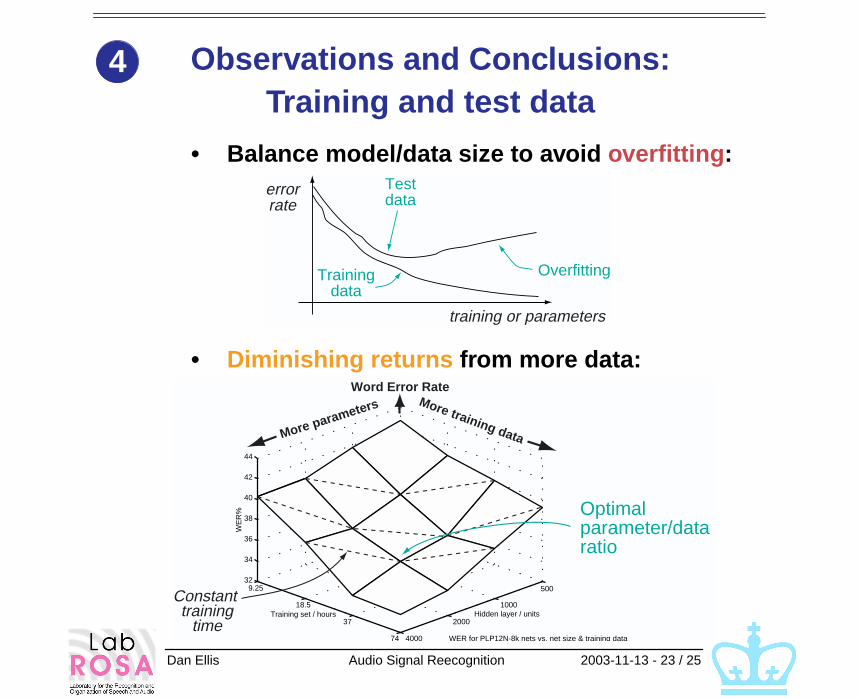
Observations and Conclusions:Training and test data
• Balance model/data size to avoid overfitting:
• Diminishing returns from more data:
4
training or parameters
errorrate
Testdata
Trainingdata
Overfitting
500
1000
2000
4000
9.25
18.5
37
74
32
34
36
38
40
42
44
Hidden layer / unitsTraining set / hours
WE
R%
WER for PLP12N-8k nets vs. net size & training data
Word Error RateMore training dataMore parameters
Optimal parameter/data ratio
Constant training
time

Dan Ellis Audio Signal Reecognition 2003-11-13 - 24 / 25
Beyond classification
• “No free lunch”: Classifier can only do so much- always need to consider other parts of system
• Features- impose ceiling on system performance- improved features allow simpler classifiers
• Segmentation / mixtures- e.g. speech-in-noise:
only subset of feature dimensions available→missing-data approaches...
Y(t)
S1(t)
S2(t)

Dan Ellis Audio Signal Reecognition 2003-11-13 - 25 / 25
Summary
• Statistical Pattern Recognition- exploit training data for probabilistically-correct
classifications
• Speech recognition- successful application of statistical PR- .. but many remaining frontiers
• Other audio applications- meetings, alarms, music- classification is information extraction
• Current challenges- variability in speech- acoustic mixtures

Dan Ellis Audio Signal Reecognition 2003-11-13 - 26 / 25
Extra slides
Dan Ellis Audio Signal Reecognition 2003-11-13 - 27 / 25
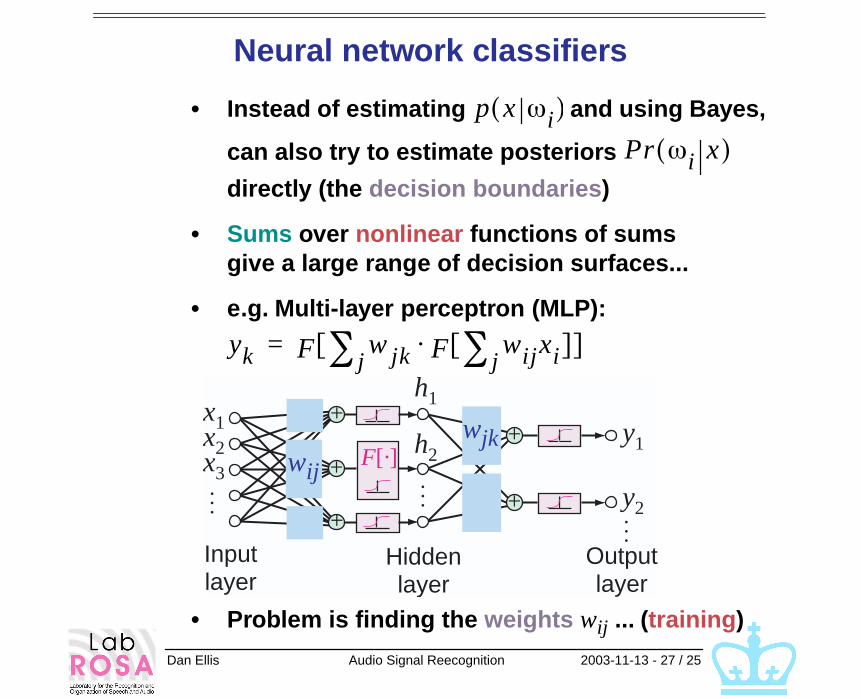
Neural network classifiers
• Instead of estimating and using Bayes,
can also try to estimate posteriors
directly (the decision boundaries)
• Sums over nonlinear functions of sums give a large range of decision surfaces...
• e.g. Multi-layer perceptron (MLP):
• Problem is finding the weights wij ... (training)
p x ωi( )
Pr ωi x( )
yk F w jk F wijxij∑[ ]⋅j∑[ ]=
+
+wij
x1 y1
h1
h2
y2
x2x3
F[·]+
+
+wjk
Inputlayer
Hiddenlayer
Outputlayer
Dan Ellis Audio Signal Reecognition 2003-11-13 - 28 / 25
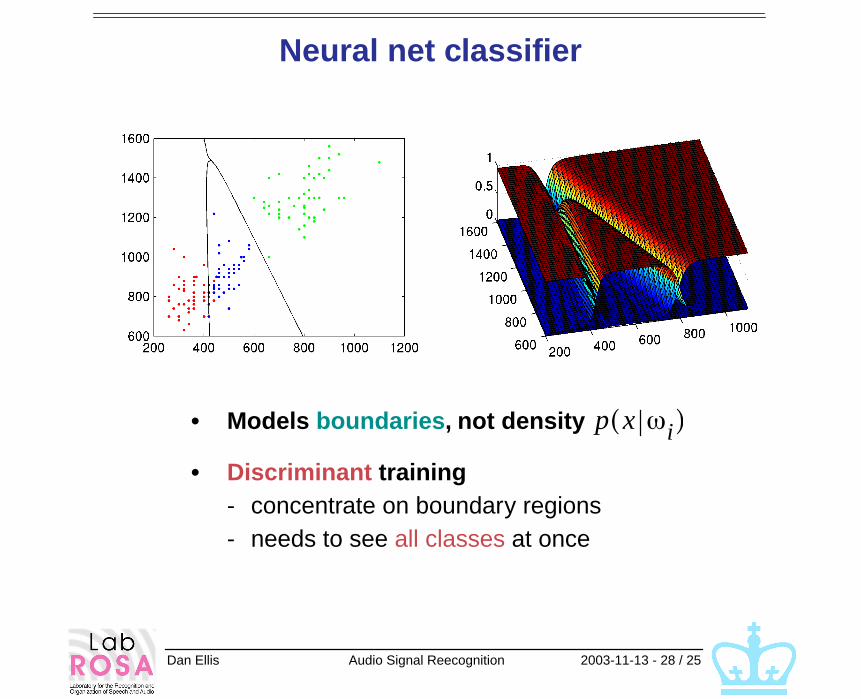
Neural net classifier
• Models boundaries, not density
• Discriminant training- concentrate on boundary regions- needs to see all classes at once
p x ωi( )

Dan Ellis Audio Signal Reecognition 2003-11-13 - 29 / 25
Why is Speech Recognition hard?
• Why not match against a set of waveforms?- waveforms are never (nearly!) the same twice- speakers minimize information/effort in speech
• Speech variability comes from many sources:- speaker-dependent (SD) recognizers must
handle within-speaker variability- speaker-independent (SI) recognizers must also
deal with variation between speakers- all recognizers are afflicted by background noise,
variable channels
→ Need recognition models that:- generalize i.e. accept variations in a range, and- adapt i.e. ‘tune in’ to a particular variant

Dan Ellis Audio Signal Reecognition 2003-11-13 - 30 / 25
Within-speaker variability
• Timing variation:- word duration varies enormously
- fast speech ‘reduces’ vowels
• Speaking style variation:- careful/casual articulation- soft/loud speech
• Contextual effects:- speech sounds vary with context, role:
“How do you do?”
0.5
Fre
quen
cy
00 1.0 1.5 2.0 2.5 3.0
2000
4000
s
SO ITHOUGHT
ABOUTTHAT
ITHINK
IT'S STILL POSSIBLE
AND
ow ayth
aadx
ax b aw plihtstih
kn
ihth
ayn
axth
aa s b ax l
Dan Ellis Audio Signal Reecognition 2003-11-13 - 31 / 25
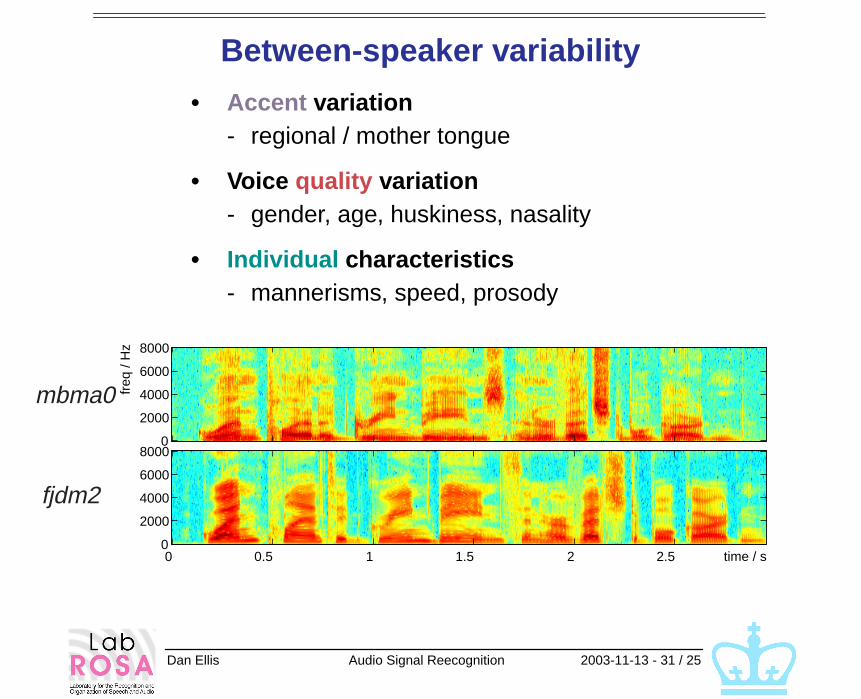
Between-speaker variability
• Accent variation- regional / mother tongue
• Voice quality variation- gender, age, huskiness, nasality
• Individual characteristics- mannerisms, speed, prosody
0
2000
4000
6000
8000
time / s
freq
/ H
z
0 0.5 1 1.5 2 2.50
2000
4000
6000
8000
mbma0
fjdm2

Dan Ellis Audio Signal Reecognition 2003-11-13 - 32 / 25
Environment variability
• Background noise- fans, cars, doors, papers
• Reverberation- ‘boxiness’ in recordings
• Microphone channel- huge effect on relative spectral gain
0
2000
4000
time / s
freq
/ H
z
0 0.2 0.4 0.6 0.8 1 1.2 1.40
2000
4000
Closemic
Tabletopmic