audio-visual speech recognition using an infrared headset
TRANSCRIPT

Speech Communication 44 (2004) 83–96
www.elsevier.com/locate/specom
Audio-visual speech recognition using an infrared headset
Jing Huang *, Gerasimos Potamianos, Jonathan Connell, Chalapathy Neti
IBM Thomas J. Watson Research Center, Yorktown Heights, NY 10598, United States
Received 12 February 2004; received in revised form 17 August 2004; accepted 4 October 2004
Abstract
It is well known that frontal video of the speaker�s mouth region contains significant speech information that, when
combined with the acoustic signal, can improve accuracy and noise robustness of automatic speech recognition (ASR)
systems. However, extraction of such visual speech information from full-face videos is computationally expensive, as it
requires tracking faces and facial features. In addition, robust face detection remains challenging in practical human–
computer interaction (HCI), where the subject�s posture and environment (lighting, background) are hard to control,
and thus successfully compensate for. In this paper, in order to bypass these hindrances to practical bimodal ASR, we
consider the use of a specially designed, wearable audio-visual headset, a feasible solution in certain HCI scenarios.
Such a headset can consistently focus on the speaker�s mouth region, thus eliminating altogether the need for face track-
ing. In addition, it employs infrared illumination to provide robustness against severe lighting variations. We study the
appropriateness of this novel device for audio-visual ASR by conducting both small- and large-vocabulary recognition
experiments on data recorded using it under various lighting conditions. We benchmark the resulting ASR performance
against bimodal data containing frontal, full-face videos collected at an ideal, studio-like environment, under uniform
lighting. The experiments demonstrate that the infrared headset video contains comparable speech information to the
studio, full-face video data, thus being a viable sensory device for audio-visual ASR.
� 2004 Elsevier B.V. All rights reserved.
Keywords: Visual speech; Audio-visual speech recognition; Infrared headset; Feature fusion; Multi-stream HMM; Decision fusion
0167-6393/$ - see front matter � 2004 Elsevier B.V. All rights reserv
doi:10.1016/j.specom.2004.10.007
* Corresponding author. Tel.: +1 914 945 3226; fax: +1 914
945 4490.
E-mail addresses: [email protected] (J. Huang), gpotam@
us.ibm.com (G. Potamianos), [email protected] (J. Con-
nell), [email protected] (C. Neti).
1. Introduction
Motivated by the bimodality (auditory and vi-
sual) of human speech perception (Sumby and Pol-
lack, 1954) and by the need for robust automatic
speech recognition (ASR) in noisy environments,
significant research effort has recently been direc-
ted into the study of audio-visual automatic speech
ed.

84 J. Huang et al. / Speech Communication 44 (2004) 83–96
recognition (AVASR). In addition to the tradi-
tional acoustic input, AVASR utilizes visual
speech information, present in the speaker�s mouth
region. Such information has been successfully ex-
tracted and demonstrated to improve the accuracyand noise robustness of ASR systems for both
small- and large-vocabulary tasks by a number
of authors, including Duchnowski et al. (1994),
Hennecke et al. (1996), Chen and Rao (1998),
Teissier et al. (1999), Dupont and Luettin (2000),
Chen (2001), Chibelushi et al. (2002), Heckmann
et al. (2002), and Nefian et al. (2002), among oth-
ers. For example, Potamianos et al. (2003) reportthat bimodal ASR of a small-vocabulary task un-
der speech babble noise at 0dB signal-to-noise ratio
(SNR) achieves the performance of an acoustic-
only recognizer at 10dB, i.e., the visual modality
provides an ‘‘effective’’ SNR gain of 10dB in
‘‘usable’’ ASR range. The authors also report sig-
nificant gains on the same task even in clean acous-
tic conditions, and furthermore, an 8dB‘‘effective’’ SNR gain for large-vocabulary continu-
ous speech recognition (LVCSR).
However, almost all AVASR research work in
the literature, including the results mentioned
above, has concentrated on databases recorded
under ideal visual conditions. Such sets contain
high-resolution video of the subjects� frontal face,with very limited variation in head pose and sub-ject-camera distance, rather uniform lighting,
and, in most cases, constant background. This
kind of recording is often unrealistic in practical
human–computer interaction (HCI) scenarios,
where the subject�s posture and/or the environ-
ment are hard to control, as could be, for example,
HCI inside automobiles, offices, and in trading
floors, human interaction with intelligent kiosks,cellphones, and PDAs, or audio-visual speech
transcription of lectures, meetings, and broadcast
news. In such scenarios, robust extraction of the
visual speech information given the full-face video
becomes a challenging problem, since it requires
accurate tracking of the speaker�s face and facial
features (e.g., mouth corners, possibly lip con-
tours), as well as successful compensation for headpose and lighting variations in the final visual
speech features. Not surprisingly, preliminary re-
sults by Potamianos and Neti (2003) show that
AVASR performance in visually challenging do-
mains (offices, automobiles) lags significantly com-
pared to the performance achieved on data
recorded in ideal conditions (studio-like environ-
ment), as measured by visual-only word error rate
(WER) and relative WER reduction in bimodal vs.
audio-only ASR in noise.
These facts motivated us to design a special
audio-visual wearable headset as a means to ro-
bustly capture the visual speech information and
thus allow practical AVASR deployment. The
headset can consistently focus on the speaker�smouth region, therefore eliminating altogether theneed for face tracking. Furthermore, by employing
infrared illumination, it captures visual speech even
in extreme lighting conditions. In addition to the
added robustness, bypassing the face tracking step
reduces computational requirements substantially.
For example, in the real-time PC-based AVASR
system of Connell et al. (2003), such tracking con-
sumes about 72% of the visual front end process-ing. Eliminating this step could possibly allow
future real-time AVASR on devices with less avail-
able resources, such as PDAs. The designed head-
set is discussed in more detail in Section 2 of this
paper. Although not the first such device developed
in the literature for AVASR (Adjoudani et al.
(1997)), the proposed design is significantly smaller
and less intrusive.Using a headset for bimodal speech capture in
HCI may at first seem restrictive, however, in
many cases, humans already do wear head-
mounted microphones while communicating with
other humans. Examples include call centers, trad-
ing floors, and aircraft cockpits. All three consti-
tute noisy environments where visual speech can
play a critical role in improving ASR performance,thus enabling automatic transcription. Other pos-
sible scenarios include office dictation and lecture
transcription. In the later case, the lecturer should
be tether-free, so the designed audio-visual headset
allows wireless transmission of its bimodal input.
To reinforce our point, recent work in the litera-
ture has focused in improving ASR robustness to
noise by considering additional head-mountedmicrophone sensors. Indeed, Graciarena et al.
(2003) consider a throat microphone, namely a
skin-vibration transducer, whereas Zhang et al.

J. Huang et al. / Speech Communication 44 (2004) 83–96 85
(2004) utilize a bone-conductive microphone to
capture speech-induced skull vibration. The re-
corded signals are correlated to the subject�sspeech, thus allowing background speech rejection
and improved ASR by using enhancement tech-niques, for example. One possible advantage of
our proposed audio-visual headset over the sen-
sors mentioned above is that the visual signal, in
addition to being correlated to the acoustic one
(Jiang et al., 2002), also contains complementary
information to it (Massaro and Stork, 1998). Such
information contributes to significant ASR
improvements even in clean acoustics.The main focus of this paper is to study the
appropriateness of the novel infrared headset for
AVASR. For this purpose, we utilize our state-
of-the-art bimodal recognizer (Potamianos et al.,
2003) to conduct both small-vocabulary (con-
nected digits) and large-vocabulary (LVCSR) rec-
ognition experiments on data recorded using the
audio-visual headset. We benchmark these tasksagainst AVASR on frontal, full-face videos, col-
lected at an ideal, ‘‘studio’’-like environment. Of
particular interest is the performance of the system
visual front end, as well as its audio-visual fusion
module. The first is measured by visual-only
ASR accuracy on the small-vocabulary task,
whereas the latter by the relative WER reduction,
compared to audio-only performance (for bothrecognition tasks). As our experiments demon-
strate, the headset achieves grossly comparable
performance with the ‘‘studio’’-quality full-face
videos, thus showcasing its appropriateness and
robustness in capturing the visual speech
information.
As we already mentioned, a crucial element in
any AVASR system is the visual speech featureextraction. Our speechreading system utilizes an
appearance-based approach that first estimates a
region-of-interest (ROI), containing the area
around the speaker�s mouth appropriately normal-
ized, and subsequently uses dimensionality reduc-
tion techniques to obtain the visual features. In
the case of video captured by the headset, each en-
tire input frame can be viewed as the ROI. How-ever, due to unavoidable small variations in the
headset placement among subjects, it turns out
that some ROI normalization is desirable. In this
paper, we propose such a scheme, based on track-
ing the subject�s two mouth corners. Notice that
this is a much simpler task compared to tracking
in full-face videos, as the headset images are tightly
constrained (no background objects), and thus thealgorithm can utilize weak models. In addition,
only two facial points need to be detected, com-
pared to the hierarchical face and multiple facial
feature scheme of Senior (1999), required in the
case of full-face videos. A second crucial element
in AVASR is the combination of the extracted vi-
sual features with the traditional acoustic ones.
Here, we consider two main approaches foraudio-visual integration, namely feature and deci-
sion fusion. Thus, compared to an earlier version
of this work (Huang et al., 2003), this paper con-
siders additional techniques for both visual pro-
cessing and audio-visual integration, and, for the
first time, it reports LVCSR on headset data.
The paper is structured as follows: Section 2
presents the novel audio-visual headset. Sections3 and 4 review the main components of the
AVASR system, namely the visual front end and
audio-visual fusion, respectively. Section 5 is de-
voted to the experimental study and comparison
of AVASR performance across two datasets of
interest: full-face studio-quality videos and head-
set-captured data. Finally, Section 6 concludes
the paper.
2. The audio-visual headset
As we mentioned in Section 1, recently there has
been increased interest in the development of
novel head-mounted sensors that supplement the
traditional close-talking microphone input in or-der to improve ASR robustness and performance.
For example, Graciarena et al. (2003) consider a
throat microphone, whereas Zhang et al. (2004)
propose a number of sensors, including a bone-
conductive microphone, an in-ear microphone,
and a device with an infrared light emitter and re-
ceiver pair. The latter aims at the speaker�s mouth
region, seeking to capture the amount of teethvisibility. Therefore, in contrast to the previous de-
vices, it can be considered as a crude sensor for vi-
sual speech capture. Of course, significantly more

86 J. Huang et al. / Speech Communication 44 (2004) 83–96
visual speech information can be obtained by a
regular head-mounted camera. To our knowledge,
the first such audio-visual headset designed for
AVASR has been proposed by Adjoudani et al.
(1997). This device was quite bulky and intrusive,but nevertheless robustly captured the mouth
ROI of the subject. A much more advanced sys-
tem, also commercially available, is reported in
(Gagne et al., 2001). This headset allows wireless
transmission of the captured video to base sta-
tions, where it is displayed on small portable
screens. The system is designed to be worn by lec-
turers in order to improve their intelligibility byhearing-impaired subjects in the audience, taking
advantage of the human speechreading capability.
Fig. 1. (First row) Frontal and side view of the infrared headset; (midd
row) detail of ear-piece and boom.
In our audio-visual headset design, an impor-
tant consideration was to house both microphone
and camera in a single boom with minimal protru-
sion in front of the subject�s mouth. Ideally, the de-
signed headset should not feel much bulkier than atypical close-talking, head-mounted microphone
headset. The current version of the derived
audio-visual headset is depicted in Fig. 1. Frontal
and side views of it are shown, as well as of a sub-
ject wearing it, and details of two of its compo-
nents. The headset contains the audio and video
components in a single adjustable boom. A micro-
phone is placed in the side of the boom, offset fromthe mouth, in order to reduce audio distortion
caused by breath noise. Located in the boom tip
le row) frontal and side view of a subject wearing it; and (lower

Fig. 2. Example video frames from the audio-visual databases considered in this paper for AVASR (see Section 5): (upper row) Data
recorded using the audio-visual headset and (lower row) studio-quality, full-face data, recorded employing a teleprompter. The latter
are used as an AVASR performance benchmark.
J. Huang et al. / Speech Communication 44 (2004) 83–96 87
are a wide-view miniature camera (less than 2.5cm
in cube) and a number of infrared components: On
either side of the camera are two diodes that illu-
minate the speaker�s face with infrared light. Both
camera and infrared diodes sit in a plastic housing,
covered by a rectangular infrared filter, which
blocks visible light and allows only infrared light
to pass through, where it is picked up by the cam-era lens. The design reduces the environmental
lighting effect on captured images, allowing good
visibility of the mouth ROI even in a dark room.
The camera and microphone outputs are con-
nected to a 1.2GHz wireless transmitter placed
next to the headset ear-piece (see also Fig. 1), with
the receiver attached to a base station. This allows
tether-free operation of up to four headsets in sce-narios such as trading floors and lecture rooms.
Also located on the headset are a battery pack that
provides power for it and an auxiliary wireless tele-
phone, which is wired into the headset. This pro-
vides normal telephone conversation with a base
station that is attached to a conventional tele-
phone. The entire headset weighs approximately
480g.The wirelessly transmitted captured audio and
S-video signals are fed into a laptop based AVASR
or audio-visual data collection system (Connell
et al., 2003), the latter after conversion to digital
video via the Firewire interface. The system re-
cords audio at 22kHz and video at a 30frames/s
rate and a 720 · 480 pixel resolution. Example
video frames captured by the headset are depicted
in the upper row of Fig. 2.
3. Visual front end processing
There exist two critical modules in AVASR sys-
tems: the visual front end design and the audio-visual integration strategy. The latter is often tied
to the choice of speech recognition method em-
ployed, for example neural network based classifi-
ers as used by Duchnowski et al. (1994) and
Heckmann et al. (2002), or more conventional hid-
den Markov model (HMM) systems with Gaussian
mixture emission probabilities, as for example in
(Dupont and Luettin, 2000; Nefian et al., 2002;Potamianos et al., 2003). In this paper, we opt
for HMM based recognizers, focusing our atten-
tion instead to the visual feature extraction and
audio-visual fusion modules, which we describe
in more detail in the current and next section,
respectively.
In general, there exist three possibilities for vi-
sual speech representation given the speaker�s vi-deo (Hennecke et al., 1996): Appearance-based
features that typically seek a suitable compressed
representation of the pixel values within a visual
region of interest (ROI) (Duchnowski et al.,
1994, Potamianos et al., 2003), shape-based fea-
tures that consist of a geometric or statistical rep-
resentation of the lip contours and possibly of the

88 J. Huang et al. / Speech Communication 44 (2004) 83–96
lower face (Dupont and Luettin, 2000, Gurbuz
et al., 2001, Heckmann et al., 2002), and combina-
tion of the two strategies. The latter can just con-
catenate features from each category, as in
(Dupont and Luettin, 2000), or seek to build acombined statistical model of face and appearance,
as in (Matthews et al., 2001). Of course, the choice
of visual features dictates the requirements on vi-
sual front end steps that precede their extraction.
Thus, appearance based features require only the
mouth ROI, whereas a geometric representation
of lip shape is dependent on tracking the speaker�slip contours within it. In turn, ROI extraction andits appropriate normalization require successful
face and facial feature detection, and possibly an
estimate of the subject�s head pose within the re-
corded visual scene.
Our AVASR system considered in this work
employs appearance-type features based on the
discrete cosine transform (DCT) of the visual
ROI. Thus, it avoids computationally expensivelip-tracking and face shape estimation. In addi-
tion, using the headset for visual capture elimi-
nates the need for the first module of the visual
front end chain, namely face tracking and localiza-
tion of most of the facial features, as compared to
using full-face videos. Therefore, only the ROI
estimation and the visual feature extraction steps
are required, detailed next. For completeness,and since full-face videos are considered in our
experiments as a benchmark of AVASR perfor-
mance, we also briefly describe face tracking and
ROI extraction for such data.
3.1. ROI extraction on headset captured videos
In our preliminary AVASR work using theaudio-visual headset, reported by Huang et al.
(2003), most of the captured video frame was con-
sidered as the ROI with no normalization applied
to it. In particular, only simple boundary trunca-
tion and subsampling was applied to the original
720 · 480 pixel frame, in order to obtain a
64 · 64 pixel ROI. However, due to the unavoid-
able variations in headset placement among sub-jects, it soon became apparent that some ROI
normalization was desirable. In this paper, we pro-
pose such a scheme, based on tracking two mouth
corners of the recorded subject. This allows cor-
recting slight positioning errors, boom rotation,
and rescaling of the physical mouth size. Recogni-
tion experiments reported in Section 5 demon-
strate the benefits of this approach over ourearlier crude ROI extraction scheme.
Extracting the two mouth corners turns out to
be fairly simple in the headset scenario, since it is
assumed that the camera is already aimed nearly
directly at the mouth. Because the types of features
seen in the captured images are tightly constrained
(i.e., no confusing background objects are ex-
pected in the scene), the algorithms can use veryweak models and hence run quickly.
The first phase of the mouth finding algorithm
estimates the position of the head in the image.
Usually the mouth region is highly illuminated
by the infrared source and the image gets darker
toward the cheeks (even with extra ambient light-
ing). The algorithm starts by histogram equalizing
the entire image to compensate for overall bright-ness changes. Next, only the pixels in a central ver-
tical strip of the equalized image are histogramed
and a binarization threshold is picked. Finally,
the entire image is binarized using this threshold
and projected onto the vertical and horizontal axes
to determine a rough bounding box for the facial
region.
The second phase models the mouth as a darkslit and attempts to determine its extent. Notice
that the mouth appears as a dark slit even when
it is closed, due to the curvature of the lip surfaces.
In detail, the image is first further enhanced using
a horizontal center-surround barmask with a cen-
ter band of 5 pixels in a 17 pixel square (see Fig.
3(d)). An area (yellow box in Fig. 3(d)) within
the face bounding box from the first phase is thenused to obtain another threshold, subsequently
used to binarize the entire image (see Fig. 3(e)).
Then the pixel values within a prospective mouth
box (blue box in Fig. 3(e)) are projected on the
horizontal axis to find the x coordinates of the
mouth corners (see Fig. 3(f)). To find the y coordi-
nates, two independent vertical strips are created
around the lateral mouth bounds, and the binaryimage is projected on the vertical axis in each re-
gion to locate them (see Fig. 3(g,h)). As a sanity
check, the tilt angle between the mouth corners is

Fig. 3. ROI extraction for an example frame captured by the headset: (a) original frame, histogram equalized, with estimated mouth
corners depicted; (b) extracted ROI, normalized on basis of the estimated mouth corners, and subsequently used for DCT-based visual
feature extraction and (c) ROI reconstruction using visual speech features (100 DCT coefficients). Detailed steps for mouth corner
estimation: (d) Barmask-enhanced frame, with a superimposed rectangle over which the binarization threshold is computed; (e)
binarized image after thresholding, with mouth search region depicted; (f) binary image projection within mouth search region, used to
estimate the mouth corner x-coordinates; (g) barmask-enhanced frame with mouth-corner search regions superimposed and (h) image
projection within search regions, used to estimate the mouth corner y-coordinates.
J. Huang et al. / Speech Communication 44 (2004) 83–96 89
computed. If this angle is too steep, the higher of
the two mouth corners is lowered to match the
other one.
The final step is to output a normalized mouth
image. Such image is extracted after the mouth po-
sition, width, and angle have been smoothed over

90 J. Huang et al. / Speech Communication 44 (2004) 83–96
a small, non-causal temporal window. The full im-
age is de-rotated to make the mouth horizontal,
then a portion is extracted and rescaled so that
the mouth spans about 60% of the image width.
A second histogram equalization of just this regionis performed to make the details clearly visible.
The result is a 64 · 64 pixel ROI with an aspect ra-
tio of about 1.7 covering the mouth (see Fig. 3(b)).
3.2. ROI extraction on full-face videos
In the case of full-face videos that possibly in-
clude confusing background, the estimation ofthe speaker�s face location and of landmark facial
features is required preceding the ROI extraction.
In addition to ROI localization, features such as
mouth corners, chin, nose, and eyes can provide
head-pose information, that can be useful in ROI
normalization. In our work, we employ a statisti-
cal approach to this problem, reported in (Senior,
1999).In more detail, given a video frame, face detec-
tion is first performed by searching for face candi-
dates that contain a relatively high proportion of
skin-tone pixels over an image ‘‘pyramid’’ of pos-
sible locations and scales. Each candidate is size-
normalized to a chosen template size (here, an
11 · 11 square), and its greyscale pixel values are
placed into a 121-dimensional face candidate vec-tor. Every vector is given a score based on the
combination of the two-class (face versus non-
face) Fisher linear discriminant, as well as its ‘‘dis-
tance from face space’’ (DFFS), i.e., the face
vector projection error onto a lower, 40-dimen-
sional space, obtained by means of principal
components analysis (PCA). Candidate regions
exceeding a threshold score are considered asfaces. Once a face has been detected, an ensemble
of facial feature detectors are used to estimate the
locations of 26 facial features. Each feature loca-
tion is determined using a within-face restricted
search, based on the feature linear discriminant
and ‘‘distance from feature space’’ (similar to the
DFFS discussed above) scores of 11 · 11 square
candidate features. A training step is required toestimate the Fisher discriminant and PCA eigen-
vectors for both stages, utilizing a number of man-
ually annotated video frames (Senior, 1999).
Face and facial feature tracking provides mouth
location, size, and orientation estimates. These are
subsequently smoothed over time to improve
robustness. Based on the result, a 64 · 64 pixel
ROI is obtained for every video frame. This con-tains the lower face around the speaker�s mouth,
and is properly normalized to compensate for
rotation, size, and lighting variations, the latter
by using histogram equalization of the face.
3.3. Visual feature representation
For both scenarios (headset and full-face vid-eos), an appearance-based representation of the
ROI leads to the final visual features. In more de-
tail, a two-dimensional, separable DCT is applied
to the greyscale 4096-pixel ROI, and 100 DCT
coefficients are retained. The appropriate locations
of the kept coefficients are estimated based on
highest energy over a training set. Notice that
these coefficients retain significant informationabout the mouth shape, teeth and tongue visibility.
This fact is demonstrated in Fig. 3(c), where the
reconstructed ROI on basis of the selected coeffi-
cients is depicted.
To reduce the dimensionality of the DCT repre-
sentation and improve discrimination among the
speech classes of interest, an intra-frame linear dis-
criminant analysis (LDA) projection is applied,resulting in a 30-dimensional feature vector. This
is followed by a maximum likelihood linear trans-
formation (MLLT) that improves maximum likeli-
hood based statistical data modeling (Potamianos
et al., 2003). In order to facilitate audio-visual fu-
sion, linear interpolation is employed that syn-
chronizes the features to the 100Hz rate of their
audio counterpart (see next section), whereas fea-ture mean normalization is used to further com-
pensate for lighting variations, providing the
visual-only static features. In order to capture vi-
sual speech dynamics, 15 consecutive such features
are then concatenated, and subsequently pro-
jected/rotated by means of an inter-frame LDA/
MLLT combination onto a lower-dimensional
space. This final linear transform gives rise to dy-
namic visual features ov,t of dimension 41. These
processing blocks are schematically depicted in
Fig. 4.
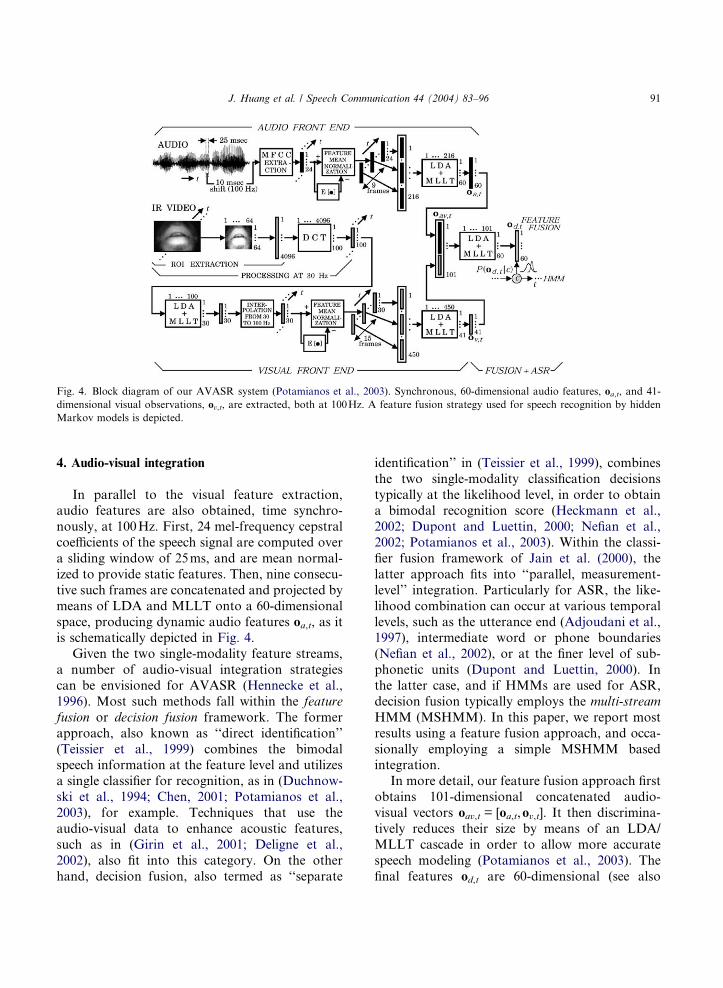
Fig. 4. Block diagram of our AVASR system (Potamianos et al., 2003). Synchronous, 60-dimensional audio features, oa,t, and 41-
dimensional visual observations, ov,t, are extracted, both at 100Hz. A feature fusion strategy used for speech recognition by hidden
Markov models is depicted.
J. Huang et al. / Speech Communication 44 (2004) 83–96 91
4. Audio-visual integration
In parallel to the visual feature extraction,audio features are also obtained, time synchro-
nously, at 100Hz. First, 24 mel-frequency cepstral
coefficients of the speech signal are computed over
a sliding window of 25ms, and are mean normal-
ized to provide static features. Then, nine consecu-
tive such frames are concatenated and projected by
means of LDA and MLLT onto a 60-dimensional
space, producing dynamic audio features oa,t, as itis schematically depicted in Fig. 4.
Given the two single-modality feature streams,
a number of audio-visual integration strategies
can be envisioned for AVASR (Hennecke et al.,
1996). Most such methods fall within the feature
fusion or decision fusion framework. The former
approach, also known as ‘‘direct identification’’
(Teissier et al., 1999) combines the bimodalspeech information at the feature level and utilizes
a single classifier for recognition, as in (Duchnow-
ski et al., 1994; Chen, 2001; Potamianos et al.,
2003), for example. Techniques that use the
audio-visual data to enhance acoustic features,
such as in (Girin et al., 2001; Deligne et al.,
2002), also fit into this category. On the other
hand, decision fusion, also termed as ‘‘separate
identification’’ in (Teissier et al., 1999), combines
the two single-modality classification decisions
typically at the likelihood level, in order to obtaina bimodal recognition score (Heckmann et al.,
2002; Dupont and Luettin, 2000; Nefian et al.,
2002; Potamianos et al., 2003). Within the classi-
fier fusion framework of Jain et al. (2000), the
latter approach fits into ‘‘parallel, measurement-
level’’ integration. Particularly for ASR, the like-
lihood combination can occur at various temporal
levels, such as the utterance end (Adjoudani et al.,1997), intermediate word or phone boundaries
(Nefian et al., 2002), or at the finer level of sub-
phonetic units (Dupont and Luettin, 2000). In
the latter case, and if HMMs are used for ASR,
decision fusion typically employs the multi-stream
HMM (MSHMM). In this paper, we report most
results using a feature fusion approach, and occa-
sionally employing a simple MSHMM basedintegration.
In more detail, our feature fusion approach first
obtains 101-dimensional concatenated audio-
visual vectors oav,t = [oa,t,ov,t]. It then discrimina-
tively reduces their size by means of an LDA/
MLLT cascade in order to allow more accurate
speech modeling (Potamianos et al., 2003). The
final features od,t are 60-dimensional (see also

92 J. Huang et al. / Speech Communication 44 (2004) 83–96
Fig. 4). These are then fed to a suitable HMM
based decoder for speech recognition. The scheme
is referred to in our experiments as ‘‘AVf’’.
In the MSHMM based decision fusion ap-
proach, the single-modality observations are as-sumed generated by audio-only and visual-only
HMMs of identical topologies with class-condi-
tional emission probabilities Pa(oa,t) and Pv(ov,t),
respectively. Both are modeled as mixtures of
Gaussian densities. The class-conditional score of
the concatenated audio-visual observation is then
set to Pav(oav,t) = Pa(oa,t)k · Pv (ov,t)
1�k (Dupont
and Luettin, 2000). Exponent k is used to appro-priately weigh the contribution of each stream,
depending on the ‘‘relative confidence’’ on each
modality. In general, k can vary locally, and thus
model audio-visual inputs in realistic scenarios,
where the quality and speech information content
of each stream changes over time. Here though,
the exponent is assumed constant over a database,
and is estimated by minimizing the WER onappropriate held-out data. This integration
scheme is referred to in our experiments as ‘‘AVd’’.
In both audio-visual fusion algorithms, HMM
parameters are obtained by the traditional maxi-
mum likelihood approach, based on available
data. For decision fusion in particular, the
HMM stream component parameters are sepa-
rately trained and subsequently joined forAVASR, with the MSHMM transition probabili-
ties set equal to the ones of the audio-only
HMM. This approach is simple to implement,
however separate stream training does not enforce
proper audio-visual synchrony in the MSHMM,
and thus it does not fully utilize the advantages
of decision fusion. Indeed, the more complicated
scheme of joint stream training, not consideredin this work, is reported by Potamianos et al.
(2003) to further improve AVASR.
5. Experiments
We now proceed to investigate the appropriate-
ness of the introduced audio-visual headset forAVASR. For that purpose, we use as a compari-
son benchmark the recognition performance on
full face videos, recorded under ideal, ‘‘studio’’-
like conditions. The corresponding audio-visual
databases are briefly discussed next.
5.1. The audio-visual databases
As mentioned in the Introduction, most
AVASR research has concentrated on data col-
lected under ideal visual conditions. One such cor-
pus is the IBM ViaVoiceTM audio-visual database,
recorded in a quiet, studio-like environment, with
uniform lighting and background. The subjects�head pose is ensured to remain frontal with little
variation in the corpus, due to the use of a tele-prompter that displays the dictation text. High-
quality video of the subjects� full frontal face is
captured, and is MPEG2 encoded at 30Hz and a
704 · 480 pixel frame size. In addition to video,
wideband audio is synchronously collected at a
rate of 16kHz using a desktop, omni-directional
microphone. The acoustic SNR is at 20dB. A 50-
subject subset of this database containing con-nected-digit utterances (DIGIT), and a 257-subject
dataset containing ViaVoice training scripts, i.e.,
continuous read speech with mostly verbalized
punctuation (LVCSR), are used here as a reference
for audio-visual ASR under ideal conditions. Four
example video frames from these sets have been
depicted in the lower row of Fig. 2.
The headset data are recorded using a laptop-based audio-visual collection system (Connell
et al., 2003), with the video data received via the
Firewire interface after conversion into DV format
at a base station. As discussed in Section 2, the bi-
modal data are wirelessly transmitted to base from
the headset. The system records audio at 22kHz
and video with a 720 · 480 pixel resolution at
30Hz. Prior to recording, the adjustable boom isused to fine-tune the headset placement with re-
spect to the speaker�s mouth. A preview window
on the laptop is used to correct and verify proper
placement. A total of 79 subjects uttering con-
nected digit strings (DIGIT), and 113 subjects
reading ViaVoice dictation scripts (LVCSR) are
recorded as our experimental datasets. Four exam-
ple video frames from these sets can be viewed inthe upper row of Fig. 2.
Therefore, four audio-visual databases are
available for AVASR experiments, spanning the
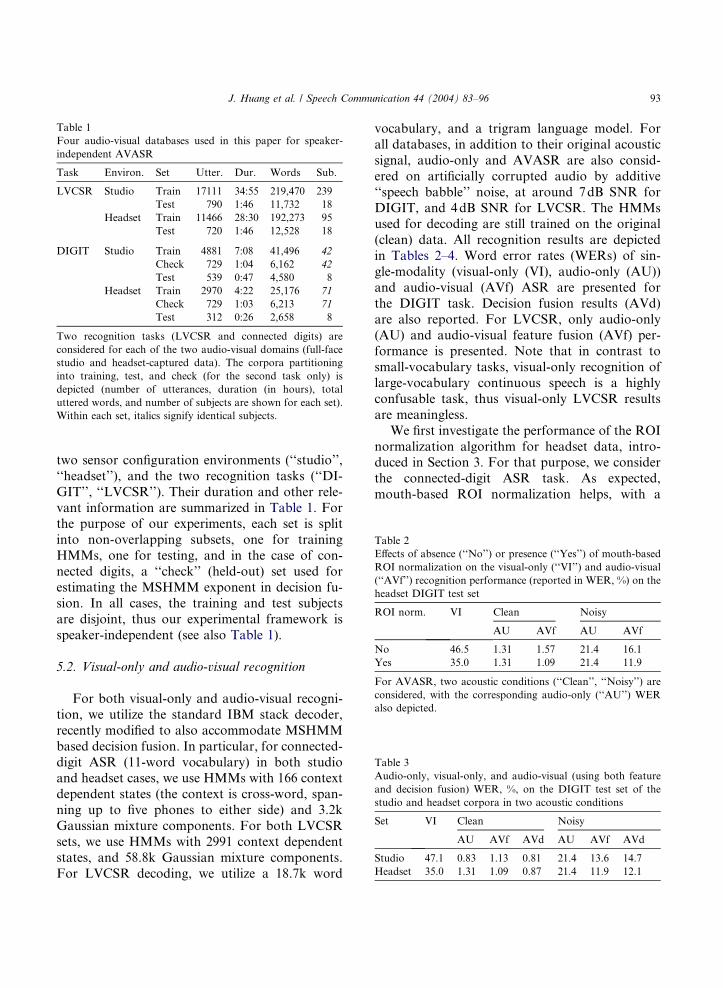
Table 1
Four audio-visual databases used in this paper for speaker-
independent AVASR
Task Environ. Set Utter. Dur. Words Sub.
LVCSR Studio Train 17111 34:55 219,470 239
Test 790 1:46 11,732 18
Headset Train 11466 28:30 192,273 95
Test 720 1:46 12,528 18
DIGIT Studio Train 4881 7:08 41,496 42
Check 729 1:04 6,162 42
Test 539 0:47 4,580 8
Headset Train 2970 4:22 25,176 71
Check 729 1:03 6,213 71
Test 312 0:26 2,658 8
Two recognition tasks (LVCSR and connected digits) are
considered for each of the two audio-visual domains (full-face
studio and headset-captured data). The corpora partitioning
into training, test, and check (for the second task only) is
depicted (number of utterances, duration (in hours), total
uttered words, and number of subjects are shown for each set).
Within each set, italics signify identical subjects.
Table 2
Effects of absence (‘‘No’’) or presence (‘‘Yes’’) of mouth-based
ROI normalization on the visual-only (‘‘VI’’) and audio-visual
(‘‘AVf’’) recognition performance (reported in WER, %) on the
headset DIGIT test set
ROI norm. VI Clean Noisy
AU AVf AU AVf
No 46.5 1.31 1.57 21.4 16.1
Yes 35.0 1.31 1.09 21.4 11.9
For AVASR, two acoustic conditions (‘‘Clean’’, ‘‘Noisy’’) are
considered, with the corresponding audio-only (‘‘AU’’) WER
also depicted.
Table 3
Audio-only, visual-only, and audio-visual (using both feature
and decision fusion) WER, %, on the DIGIT test set of the
studio and headset corpora in two acoustic conditions
Set VI Clean Noisy
AU AVf AVd AU AVf AVd
Studio 47.1 0.83 1.13 0.81 21.4 13.6 14.7
Headset 35.0 1.31 1.09 0.87 21.4 11.9 12.1
J. Huang et al. / Speech Communication 44 (2004) 83–96 93
two sensor configuration environments (‘‘studio’’,
‘‘headset’’), and the two recognition tasks (‘‘DI-
GIT’’, ‘‘LVCSR’’). Their duration and other rele-
vant information are summarized in Table 1. Forthe purpose of our experiments, each set is split
into non-overlapping subsets, one for training
HMMs, one for testing, and in the case of con-
nected digits, a ‘‘check’’ (held-out) set used for
estimating the MSHMM exponent in decision fu-
sion. In all cases, the training and test subjects
are disjoint, thus our experimental framework is
speaker-independent (see also Table 1).
5.2. Visual-only and audio-visual recognition
For both visual-only and audio-visual recogni-
tion, we utilize the standard IBM stack decoder,
recently modified to also accommodate MSHMM
based decision fusion. In particular, for connected-
digit ASR (11-word vocabulary) in both studioand headset cases, we use HMMs with 166 context
dependent states (the context is cross-word, span-
ning up to five phones to either side) and 3.2k
Gaussian mixture components. For both LVCSR
sets, we use HMMs with 2991 context dependent
states, and 58.8k Gaussian mixture components.
For LVCSR decoding, we utilize a 18.7k word
vocabulary, and a trigram language model. For
all databases, in addition to their original acoustic
signal, audio-only and AVASR are also consid-
ered on artificially corrupted audio by additive
‘‘speech babble’’ noise, at around 7dB SNR forDIGIT, and 4dB SNR for LVCSR. The HMMs
used for decoding are still trained on the original
(clean) data. All recognition results are depicted
in Tables 2–4. Word error rates (WERs) of sin-
gle-modality (visual-only (VI), audio-only (AU))
and audio-visual (AVf) ASR are presented for
the DIGIT task. Decision fusion results (AVd)
are also reported. For LVCSR, only audio-only(AU) and audio-visual feature fusion (AVf) per-
formance is presented. Note that in contrast to
small-vocabulary tasks, visual-only recognition of
large-vocabulary continuous speech is a highly
confusable task, thus visual-only LVCSR results
are meaningless.
We first investigate the performance of the ROI
normalization algorithm for headset data, intro-duced in Section 3. For that purpose, we consider
the connected-digit ASR task. As expected,
mouth-based ROI normalization helps, with a

Table 4
Audio-only and audio-visual (using feature fusion) WER, %, on
the LVCSR test set of the studio and headset corpora in two
acoustic conditions
Set Clean Noisy
AU AVf AU AVf
Studio 14.5 12.9 55.8 37.2
Headset 20.6 18.7 55.2 39.7
94 J. Huang et al. / Speech Communication 44 (2004) 83–96
25% relative improvement (from 46.5% ! 35.0%)
in visual-only recognition observed (as depicted
in Table 2). The algorithm also benefits AVASR,
both in clean and noisy acoustic conditions. For
example, in the former, ASR performance de-grades if audio is combined with non-normalized
visual features by means of feature fusion. How-
ever, there is a 17% relative improvement
(1.31% ! 1.09%) when normalized visual features
are used. In addition, for noisy audio, the
improvement is significantly larger in the latter
case (44% vs. 25% relative).
It is expected that by using the infrared headsetone would obtain a better and more accurate ROI
than by face tracking, and thus better visual-only
ASR performance, compared to the full-face stu-
dio video datasets. Indeed (see Table 3), the DI-
GIT visual-only WER improves by 26% relative,
when moving from studio to headset data
(47.1% ! 35.0%). This is so even though headset
data are collected with varying office lighting,whereas in the studio set, both lighting and back-
ground are kept rather uniform. As expected, the
improved visual-only ASR on the headset data
translates to increased relative benefit of the visual
modality to bimodal recognition, both in the clean
and noisy acoustic conditions. Indeed, in the for-
mer, by using audio-visual decision fusion there
is a significant ASR performance improvement inthe headset domain (34% relative, from
1.31% ! 0.87%), whereas a statistically insignifi-
cant improvement is observed in the studio data.
For noisy audio, the relative ASR improvement
due to the visual modality is slightly greater for
the headset (44% vs. 36%). There, feature fusion
slightly outperforms decision fusion, which we be-
lieve is due to the asynchronous (separate) trainingof the MSHMM components. Nevertheless, it is
worth observing that the final AVASR perfor-
mance on the clean studio data is superior to the
headset, because of the better audio-only recogni-
tion (by about 37% relative). The latter is due to
interference in the acoustic signal wireless trans-mission, as well as some degree of breathing noise
in the headset. We are currently working to resolve
these audio problems in future versions of the
prototype.
The audio channel quality issues also become
apparent by comparing the audio-only LVCSR
performance on the headset and studio data. As
depicted in Table 4, audio-only WER on headsetdata is significantly higher than the studio data
WER (20.6% vs. 14.5%), i.e., by about 30% rela-
tive. Nevertheless, the visual modality still helps
improve ASR by about 9% (20.6% ! 18.7%) and
28% (55.2% ! 39.7%), for clean and noisy speech,
respectively. These numbers are quite close but
slightly inferior to the corresponding relative
WER reductions for studio data (11% and 33%,respectively). We believe that this is due to the fact
that, in contrast to the DIGIT sets, a substantially
smaller number of LVCSR training subjects are
available (see Table 1).
Our experimental results clearly demonstrate
that the speech information contained in the head-
set video data can contribute to ASR similarly well
to studio data videos, which have been collectedunder unrealistically controlled conditions. This
conclusion becomes particularly clear by the noisy
ASR experiments, reported above: there, the noise
level has been adjusted to result in approximately
the same audio-only performance across the two
data types. Incorporating the visual information
improves DIGIT ASR by a 36% and 44% relative,
and LVCSR by 33% and 28%, for the studio andheadset data, respectively. Of course, the exact rel-
ative improvements depend heavily on the data-
base specifics, including duration and subject
population. Such factors are practically impossible
to adjust in pre-existing databases.
6. Conclusions
In this paper, we introduced a specially de-
signed audio-visual headset, and investigated its

J. Huang et al. / Speech Communication 44 (2004) 83–96 95
feasibility for AVASR. The headset bypasses the
need for face tracking, thus improving the robust-
ness of visual speech feature extraction in realistic
scenarios and reducing the AVASR computational
requirements. We benchmarked its recognitionperformance against an ideal-case, ‘‘visually
clean’’ data domain, where full-face videos are
captured, and hence face tracking is required. We
reported both small- and large-vocabulary recog-
nition experiments, observing overall that the
headset video contributes significant speech infor-
mation to its audio channel. Compared to the
full-face video, its ASR contribution is superiorin the small-vocabulary recognition experiments
and somewhat inferior for LVCSR, possibly
reflecting the disparate database population sizes.
Nevertheless, the results demonstrate that the
headset constitutes a viable sensory device for
audio-visual ASR, unaffected by head pose and
lighting variations.
Acknowledgment
The authors would like to thank colleagues
Liam Comerford, Luis Elizalde, Tom Picunko,
and Gabriel Taubin for the design and hardware
implementation of the infrared headset, as well
as Larry Sansone for data collection.
References
Adjoudani, A., Guiard-Marigny, T., Le Goff, B., Reveret, L.,
Benoıt, C., 1997. A multimedia platform for audio-visual
speech processing. In: Proc. Europ. Conf. on Speech
Communication Technol., pp. 1671–1674.
Chen, T., 2001. Audiovisual speech processing. Lip reading and
lip synchronization. IEEE Signal Process. Mag. 18 (1), 9–
21.
Chen, T., Rao, R.R., 1998. Audio-visual integration in multi-
modal communication. Proc. IEEE 86 (5), 837–852.
Chibelushi, C.C., Deravi, F., Mason, J.S.D., 2002. A review of
speech-based bimodal recognition. IEEE Trans. Multimedia
4 (1), 23–37.
Connell, J.H., Haas, N., Marcheret, E., Neti, C., Potamianos,
G., Velipasalar, S., 2003. A real-time prototype for small-
vocabulary audio-visual ASR. In: Proc. Internat. Conf. on
Multimedia Expo, pp. 469–472.
Deligne, S., Potamianos, G., Neti, C., 2002. Audio-visual
speech enhancement with AVCDCN (audio-visual code-
book dependent cepstral normalization). In: Proc. Internat.
Conf. on Spoken Lang. Process., pp. 1449–1452.
Duchnowski, P., Meier, U., Waibel, A., 1994. See me, hear me:
Integrating automatic speech recognition and lip-reading.
In: Proc. Internat. Conf. on Spoken Language Process., pp.
547–550.
Dupont, S., Luettin, J., 2000. Audio-visual speech modeling for
continuous speech recognition. IEEE Trans. Multimedia 2
(3), 141–151.
Gagne, J.-P., Laplante-Levesque, A., Labelle, M., Doucet, K.,
2001. Evaluation of an audiovisual-FM system (AudiSee):
The effects of visual distractions on speechreading perfor-
mance. Technical Report, Ecole d�orthophonie et d�audiol-ogie, Faculte de medecine, Universite de Montreal.
Girin, L., Schwartz, J.-L., Feng, G., 2001. Audio-visual
enhancement of speech in noise. J. Acoust. Soc. Amer.
109 (6), 3007–3020.
Graciarena, M., Franco, H., Sonmez, K., Bratt, H., 2003.
Combining standard and throat microphones for robust
speech recognition. IEEE Signal Process. Lett. 10 (3), 72–74.
Gurbuz, S., Tufekci, Z., Patterson, E., Gowdy, J.N., 2001.
Application of affine-invariant Fourier descriptors to lip-
reading for audio-visual speech recognition. In: Proc.
Internat. Conf. Acoust., Speech, Signal Process., pp. 177–
180.
Heckmann, M., Berthommier, F., Kroschel, K., 2002. Noise
adaptive stream weighting in audio-visual speech recogni-
tion. EURASIP J. Appl. Signal Process. 2002 (11), 1260–
1273.
Hennecke, M.E., Stork, D.G., Prasad, K.V., 1996. Visionary
speech: Looking ahead to practical speechreading systems.
In: Stork, D.G., Hennecke, M.E. (Eds.), Speechreading by
Humans and Machines. Springer, Berlin, pp. 331–
349.
Huang, J., Potamianos, G., Neti, C., 2003. Improving audio-
visual speech recognition with an infrared headset. In: Proc.
Work. Audio-Visual Speech Process., pp. 175–178.
Jain, A.K., Duin, R.P.W., Mao, J., 2000. Statistical pattern
recognition: A review. IEEE Trans. Pattern Anal. Machine
Intell. 22 (1), 4–37.
Jiang, J., Alwan, A., Keating, P.A., Chaney, B., Auer Jr., E.T.,
Bernstein, L.E., 2002. On the relationship between face
movements, tongue movements, and speech acoustics.
EURASIP J. Appl. Signal Process. 2002 (11), 1174–1188.
Massaro, D.W., Stork, D.G., 1998. Speech recognition and
sensory integration. Amer. Scient. 86, 236–244.
Matthews, I., Potamianos, G., Neti, C., Luettin, J., 2001. A
comparison of model and transform-based visual features
for audio-visual LVCSR. In: Proc. Internat. Conf. on
Multimedia Expo.
Nefian, A.V., Liang, L., Pi, X., Liu, X., Murphy, K., 2002.
Dynamic Bayesian networks for audio-visual speech recog-
nition. EURASIP J. Appl. Signal Process. 2002 (11), 1274–
1288.
Potamianos, G., Neti, C., 2003. Audio-visual speech recogni-
tion in challenging environments. In: Proc. Europ. Conf. on
Speech Comm. Technol., pp. 1293–1296.

96 J. Huang et al. / Speech Communication 44 (2004) 83–96
Potamianos, G., Neti, C., Gravier, G., Garg, A., Senior, A.W.,
2003. Recent advances in the automatic recognition of
audio-visual speech. Proc. IEEE 91 (9), 1306–1326.
Senior, A.W., 1999. Face and feature finding for a face
recognition system. In: Proc. Internat. Conf. on Audio
Video-based Biometric Person Authentication, pp. 154–159.
Sumby, W.H., Pollack, I., 1954. Visual contribution to speech
intelligibility in noise. J. Acoust. Soc. Amer. 26, 212–215.
Teissier, P., Robert-Ribes, J., Schwartz, J.L., 1999. Comparing
models for audiovisual fusion in a noisy-vowel recognition
task. IEEE Trans. Speech Audio Process 7 (6), 629–642.
Zhang, Z., Liu, Z., Sinclair, M., Acero, A., Deng, L., Droppo,
J., Huang, X., Zheng, Y., 2004. Multi-sensory microphones
for robust speech detection, enhancement and recognition.
In: Proc. IEEE Internat. Conf. on Acoust. Speech Signal
Process., Vol. 3, pp. 781–784.