automated design of collective variables using supervised
TRANSCRIPT

1
Automated design of collective variablesusingsupervisedmachinelearningMohammadM.Sultan1,&VijayS.Pande2†1DepartmentofChemistry,StanfordUniversity,318CampusDrive,Stanford,California94305,USA.2Department of Bioengineering, Stanford University, 318 Campus Drive, Stanford, California94305,USA.†[email protected]:Selectionof appropriate collective variables for enhancing sampling ofmolecular simulationsremainsanunsolvedproblemincomputationalmodeling.Inparticular,pickinginitialcollectivevariables (CVs) is particularly challenging in higher dimensions.Which atomic coordinates ortransformsthereoffromalistofthousandsshouldonepickforenhancedsamplingruns?Howdoesamodelerevenbegintopickstartingcoordinatesforinvestigation?Thisremainstrueeveninthecaseofsimpletwostatesystemsandonlyincreasesindifficultyformulti-statesystems.Inthiswork,wesolvethe“initial”CVproblemusingadata-drivenapproachinspiredbythefiledofsupervisedmachine learning. Inparticular,weshowhowthedecisionfunctions insupervisedmachinelearning(SML)algorithmscanbeusedasinitialCVs(!"#$%)foracceleratedsampling.UsingsolvatedalaninedipeptideandChignolinmini-proteinasourtestcases,weillustratehowthe distance to the Support Vector Machines’ decision hyperplane, the output probabilityestimatesfromLogisticRegression,theoutputsfromdeepneuralnetworkclassifiers,andotherclassifiersmaybeusedtoreversiblysampleslowstructuraltransitions.Wediscusstheutilityofother SML algorithms that might be useful for identifying CVs for accelerating molecularsimulations.Introduction:Efficientconfigurationspacesamplingofproteinsorothercomplexphysicalsystemsremainsanopenchallengeincomputationalbiophysics.DespiteadvancesinMDcodebases1,hardware,andalgorithms2,routineaccesstomicrotomillisecondtimescaleeventsis impossibleforallbutafew3–7.As an alternative to unbiased molecular simulations, enhanced sampling methods such asMetadynamics8–11orUmbrellasampling12,13offerpromise.However,theserequireidentificationof a set of slow collective variables (CV) to sample along. Recently we14–17 proposed usingmethodsfromtheMarkovmodeling literature,namelythetime-structurebased independentcomponent analysis method (tICA)14,15,18–20 or the variational auto-encoder method frommachine learning (ML) literature16,17, for identifying optimal linear and non-linear low-dimensionalCVsforacceleratedsampling.However,theseproposedmethodsareintendedfor

2
awild-typesimulation thathasbeensufficiently sampled.Whileweshowed14 that fullphasespaceconvergencewasnotnecessaryforapproximatingsuchCVs,themodels,andthustheCVs,becamemorerobustasmoredatawasinput.Alternatively, other groups21,22 have proposed using spectral gap or re-weighting basedapproaches to identify appropriateCVs in an iterative fashion. However, the lattermethodsrequireeffectivegoodinitialCVssincepoorCVsmightinadvertentlyintroduceorthogonalmodestherebyslowingconvergence.Inthiswork,wewishtoanswerthequestion:Howdoweselectinitialcollectivevariables?Thereisobviouslynocorrectapriorianswertothisproblem.Arguably,an effective starting CV should be continuously defined and differentiable, low dimensional,capableofseparatingouttargetstatesofinterestwhileminimizingthenumberoforthogonaldegreesoffreedom23.Previousapproachesforproteinsystemshaveincludedexpertlychosendistancesordihedrals24,pathbasedCVs25,26,andmoregenericCVssuchasalphaorbetasheetcharacteretc.Similarly,theuseofMLbasedmethodsforfindingCVsisnotnew.Forexample,several groups have proposedmethods to use linear or non-linear dimensionality reductionbased methods8,10,27 to find low dimensional CVs. In contrast to unsupervised learning,supervised machine learning can use the state labels, enabling efficient metric learning fordistinguishingbetweenthestartandendstates.Therefore,inthispaper,weproposeapproachingtheCVselectionproblemusinganautomateddata driven scheme. Formolecular systemswhere the end states are known,we re-cast theproblem into a supervised machine learning (!"#$%) problem. SML are machine learningalgorithmscapableof learningamappingbetweenahighdimensional inputtooutput.ThesealgorithmsareroutinelyusedinMLtosayclassifypicturesofcatsfromdogs.Similartocatsanddogs,wefirstshowhowvariousclassificationalgorithms28 fromtheML literaturecan learnadecisionboundary(Figure1)separatingproteinstatesandhowthisenablesustodefineCVsforenhancedsampling.Wefirstdemonstratethisusingasupportvectormachine(!&"),andhowto use a configuration’s distance to the decision boundary(!&"$%) as a CV. Second, wedemonstratethesameprincipleusingalogisticregression(#*)classifier,andhowitspredictedstate probabilities (#*$%)can be used as a CV. Thirdly,we showhowdeep neural networks(DNNs)basedclassifiersproduceun-normalizedstateprobabilities(+,,$%)thatcanbeusedasCVs. Fourthly, we show how to include data from multiple states by combining multiclassclassification with multidimensional enhanced sampling.We end the paper by sampling thefoldinglandscapeoftheChignolinminiproteinusing!&"$%.

3
Figure1:Pictorialrepresentationoftheproposedmethodandtwocommonclassificationalgorithms.a).Step-wiseprocessforgeneratingacollectivevariable(CV)usingsupervisedmachinelearning(SML)onknownendstates.b).Insupportvectormachines(SVM),thealgorithmfindsadividinghyperplaneboundarybetweenthetwostatesofinterest.Thesigneddistanceofanypointtothisplanebecomesthecollectivevariable.c).Bycontrastlogisticregression(LR)classifiersmodelstheoutputprobabilityasasigmoidtransformoftheweightedinputfeatures.Inthisinstance,thepredictedprobabilitybecomesthecollectivevariable.d).InthecaseoftheNeuralnetwork,theoutputofafullyconnecteddeepnetworkistheun-normalizedprobabilityofbeingineitherstate.Inthisinstance,thedecisionfunctionishighlynon-linearfunctionthatmapstheinputframeXtotheun-normalizedoutputprobability.Lightgreycirclesindicatehiddenlayers/nodes.
Methods:Allofourmethodsassumethatthemodelerhasaccesstoshorttrajectoriesfromtheknownstartandendstates.Afterrunningshortdynamics(ontheorderofnstomicrosecondsforproteinsystems) in the start (StateA) andend (StateB) states (Figure1b-c),we train a classifier todistinguishbetweenthestartandendstates.Todothis,wefirstprojectthetrajectoriesontocomplete list of possible order parameters/ features. For proteins, this listmight include allbackboneand side chaindihedrals, alpha carbonpseudodihedrals, contactdistancesetc.An
Simulate startandendstatesforshorttimescale
Calculate proteinfeatures(Dihedrals,distancesetc.)
Train aclassifiertodistinguishbetweenthestartandend
states
Runenhancedsampling usingtheclassifier’sdecision function
asthecollectivevariable
d(point, plane)
StateB
StateA
StateA
StateB
ab
c
XStateA
StateB
d

4
attractiveadvantageofusingSMLalgorithmstobuildtheseCVsisthatmostofthesealgorithmscanbeexplicitlyregularized(viaL-1regularizationforinstance)toreducemodelcomplexity.Forexample,ifacertaindihedralordistanceisincapableofdistinguishingbetweenthestartandendstates,thentheL-1regularizer’spenaltyfunctionwillallowtheSMLalgorithmtodiscardthatfeature.Moreconcretely,thiswouldsetthemodel’scoefficient(seebelow)forthatfeaturetobe0.Intheexamplesbelow,weusedanL-1regularizationforthealaninedipeptideexamplesandanL-2regularizationschemefortheChignolinexample.IncontrasttoL-1,L-2regularizationpushesallof themodel coefficients towardsanaveragevalue.A secondbenefit comes fromrealizing that the depositing Metadynamics bias will simultaneously accelerate all includeddegreesoffreedom(Figure2b,4b,and5b)whichcanaccelerateconvergenceandallowformoreaggressivebiasingschemes.Again,moreconcretely, ifgettingfromproteinstateAtostateBrequiresbothadihedralandan interatomicdistancetochange, thenusingthe!"#$%wouldallowustoaddexternalbiasingforcestobothofthesefeaturesusingasinglecollectivevariable.Intraditionalmethods,themodelerwouldeitherrunmulti-dimensionalenhancedsamplingorjudiciouslypickandhopeforthebest.Multi-dimensionalsamplingcannotscaletomorethan3dimensionswhilepickingandhopingscalesevenworse.Although,thereareawidevarietyofpossible SML algorithms,we focus on three ofmost common classificationmethods namelySVMs,LR,andDNNclassifiers.SupportVectorMachines.SVMsare linearclassifiers that find theseparatinghyperplane thatmaximizes the distance between the closest points of the two classes (Figure 1b).Mathematically,theypredicttheoutputlabelasfollows:
y = /[ w2X + b > 0]
whereyistheoutputlabel,Xisthehighdimensionalinputvector,/istheindicatorfunction,wisthelearntvectorofcoefficients,andbisthescalarbias.SVM’soptimizationisoutsidethescopeofthispaperbutitisworthnotingthatthesemodelscanbeeasilyfittedviaAPIcallstomodernML software such as scikit-learn29. The accompanying online IPython Notebooks30 provideexamplesonhowthesemodelscanbeconstructed.ThedirectindicatorfunctionbasedoutputfromSVMsisnotdifferentiableandthuscannotbeusedasacollectivevariableforenhancedsampling.Thisisbecauseanon-differentiablefunctionof the input coordinates would have discontinuous derivative at the corresponding decisionboundary.Thisderivative,whichcanbedirectlyrelatedtotheextraforcesappliedtotheatomicpositions,wouldbezeroeverywhereinsidetheboundarysincemovinginanydirectionwouldn’tcauseanumericalchangeinpredictedoutputstate.However,whentheparticleisatthedecisionboundary,thederivativewouldriserapidlyduetoasuddenchangeinthestate.Thisislikelytocausethesimulationtocrash.However,wecanusethesignedclosestdistance to theSVM’shyperplaneasourcollectivevariableinstead.Intuitivelyspeaking(Figure1b),alargerdistanceineitherdirectionwouldmeanthatourcurrentsimulationframeisfurtherinonebasinoranother.Thusourcollectivevariablebecomes:

5
SVM<= = distance point, plane = w2X + b
wJ
wherewedivideby K
Jbecausetheweightvectorisnotnormalinmostcircumstances.Itis
alsopossibletosimplyusethenumerator,alsocalledthedecisionvalueorthesoftnessfieldinglassdynamics31,asthecollectivevariable.LogisticRegression.TheLRclassifier(Figure1c)modelstheprobabilityofthedatabymaximizingthedistanceofeachdatapointtotheseparatinghyperplane.
P y = 1 x) = σ w2X + b
whereσisasigmoidfunction:
σ(x) =1
1 + e-Q
WhileSVMstrytomaximizethemarginbetweenthetwoclasses,LRalgorithmsmaximizetheposterior probability of the classes. However, unlike SVMs, now we can directly use thedifferentiableprobabilityoutputfromthemodelasourcollectivevariableforMetadynamicsorotherenhancedsamplingalgorithms.
LRTU = P V = 1 W) = σ w2X + Y
Whileweareusingtheprobabilityofbeinginstate1asourcollectivevariable,wecanalsousetheconditionallikelihood(oddsratio)ofbeingineitherstateasacollectivevariableaswell.Inthatinstance,theCVbecomes:
LRTU =P y = 1 x)
1 − P y = 1 x)
Incorporatingnon-linearityviakernelsordeepneuralnetworks.Itisentirelypossiblethatthelinearmodelspresentedaboveareinadequateforseparatingthetraining simulation given the feature space. This can be diagnosed via hysteresis during theenhancedsamplingsimulations.Inthatcase,werecommendtwopossibleextensions.1)Usingakernelfunction32,33toimplicitlyencodetheinputfeaturevectoruntoahighdimensionalspace.However,it isworthnotingthatkernelfunctionsoftenrequirepickinglandmark19,32,34proteinconfigurationsforefficientpredictionandpreventingover-fitting.2)Alternatively,non-linearitycanbeachievedviadeepneuralnetworks15(DNNs).DNNsareuniversalfunctionapproximators.Typical DNNs consist of a series of fully connected affine transformation layers (Figure 1d)interspersedwith non-linear activation function, such as the Sigmoid, ReLU, Swish35.Previousworks have already highlighted the expressive power of neural networks for dimensionalityreduction16,36andsampling17,37.Herewearguethatgivensomelabeledstate/trajectorydata,theun-normalizedoutputfromthesenetworkscouldnowbeusedasasetofdifferentiablecollectivevariablesforacceleratingmolecularsimulations.

6
DNNTU = UnnormalizedDeepNeuralNetworkOutput = G X
Wheree X is the non-linear transformation learnt by the DNN to accurately separate thetraining examples. However,we caution users against constructing arbitrarily deep networkssincetheymightbedifficulttotrainormaketheforcecalculationscomputationallyexpensive,therebynegatingthespeedupsfromacceleratedsampling.Extensiontomultiplestatesviabias-exchange:Uptonowwehaveonlyconsideredtheproblemofgeneratingacollectivevariableforatwostate system. However, most large biophysical3,4 and non-biological systems have multiplemetastable states. In several instances, theses states are known before hand fromcrystallography or NMR data but the relative free energies or kinetics of inter-conversionbetweenthosestatesarenotknown.Toincorporatethesestatesintoourmodel,werecommendgeneratingamulticlassclassification28model.GivenNstates,theoutputfromourSMLalgorithmwouldnowbeaN-dimensionalprobabilityvector,andwecanuse themultipleoutputsasNindividualcoordinatesinabias-exchangesimulation38oracceleratethemsimultaneouslyusingmulti-dimensionalGaussians (if thenumberofstates is<3).Whilecertainalgorithms,suchasDNNs,naturallyallowforpredictionofmultipleoutputs,otherSMLalgorithmsadopta“one-vs-rest” (OVR)strategy. InOVR,webuildaseriesofmodels foreachoutputstatesuchthat themodellearnsahyperboundariesordecisionfunctionsthatseparatethecurrenttargetstatefromalltheotherstates.ThuswegetNsub-modelsfortheNstates,andgivenanewdatapoint,wecomputeitsdistancetoeachofthosehyperplanesandassignittoitscloseststate.However,in-lieuof prediction,we cannowuse the same set ofdecision functionsas individual collectivevariablesinanenhancedsamplingsimulation.Forexample,inthecaseofa3-stateSVM,the3collectivevariableswouldbe:
CVg = State1vsrest = distance point, State1hyperplane = wg2X + bg
wgJ
CVJ = State2vsrest = distance point, State2hyperplane = wJ2X + bJ
wJJ
CVk = State3vsrest = distance point, State3hyperplane = wk2X + bk
wkJ
Wherewg,wJ, andwkandbg, bJ, andbkaretherespectiveweightvectorsandbiasingscalarsforthehyperplanesthatseparatetheirrespectivestatesfromtherestoftheensemble.SimilarexpressionscanbederivedforotherSMLmethodssuchasLogisticregressionclassifiers.Ontheotherhand,sinceDNNscandirectlyoutputanun-normalizedprobabilityvectoroflengthequaltothenumberofstates,thereisnoneedtouseOVRbasedstrategies.

7
Notesonimplementationandmodelcross-validationIt is worth recognizing that using this SML based CVs requires existing enhanced samplingsoftware to have native machine learning libraries built in so that the collective variabledefinitions proposed above can be utilized. However, at their core, these machine learningmodelsarenothingmorethanaseriesofvectoroperationswhosecomputegraphcanbeeasilybroken down and implemented in a step wise fashion in most modern enhanced samplingengines.Tohighlightthis,ouropensourceimplementationattheendofthemanuscriptprovidesexamplesonhowtheSVM,multiclass-SVM,LR,orevenDNNscanbewrittenasaseriesofcustomscriptssuchthatenhancedsamplingpackagessuchasPlumedandOpenMM39,1caninterpretandutilize the mathematical transforms that connect the current simulation frame’s atomiccoordinatestoasetofscalars—akathecollectivevariables.Topreventoverfitting,wealsorecommendk-fold(k=3-10)cross-validationtoidentifyoptimalmodelhyperparameters.Incross-validation,themodelistrainedonasubsetofthedata(thetrainingdata),anditsaccuracyisscoredonaheldoutset(validationdata).Arangeofmodelswith varying hyper-parameters andmodel complexity are built, and parameters for the bestscoringmodelaresaved.Thebestmodelcanthenberetrainedonthefulltrainingandvalidationsetsbeforereportingitsperformanceonaheldouttestset.Sincethe“test”forourmodelisitsabilitytoacceleratesampling,wechosetosimplydo3-foldcross-validationwithoutaheldouttestset.TheSupportingInformationcontainsvalidationsetaccuraciesforarangeofdifferentmodelsandsystems.Ingeneral,acrossseveralreasonableparametervalues(SupportingFigure3-5), our models’ accuracies never drop below .92 (92%) for either example. For alanine(Supporting Figure 3-4), allmodels reported accuracies of 100%because the alpha and betaregionsareeasilylinearlyandnon-linearlyseparable.Asspecifiedabove,aftercross-validation,were-trainedthemodelsonthefulltrainandvalidationdataset.Results:ApplicationtoalaninedipeptideusingSVMsWeshowcaseourmethodsforthreedifferentlinearclassifiersonsolvatedalaninedipeptide.Thetrainingsimulationswerepreviouslygenerated14,andconsistedoftwo2nstrajectoriesstartingfromthemandnobasinsontheRamachandranplot(Figure2).Similartopreviouswork,weusedthesin-cosinetransformofthebackbonepandqdihedrals19,40as inputtoourmodels.Thuseach training simulation frame was represented as 4 numbers. The control simulations(SupportingFigure1-2)wereacceleratedonlyalongthebackbonepandqdihedral.Allmodelsweretrainedusingscikit-learn29orPyTorch41.FortheSVMandLRmodels,weperformed3-foldcross-validation to determine the best hyper-parameters and regularization strengths(SupportingFigures3-4)butfoundthatourdatasetwassimpleenoughthatalargerangeofhyperparametersettingsgaveverysimilarresults.Ultimately,wepickedreasonablemodelparameters(SupportingFigure3-4)andthenre-trainedthemodelontheentireavailable4ns.FortheSVMandtheLRmodels,weusedaL-1regularizationwithatheregularizationstrength(C-parameter)of1.0.TheSupporting Informationcontains the fullmodelparametersandtheonlineGithubrepositorycontainsthefittedmodels.Themodelwastrainedonceandkeptfixedthroughoutthesimulation.Thepre-fittedmodelswerewrittenascustomscriptstoperformMetadynamicsusingPlumed39 and OpenMM1. The Metadynamics simulations were well-tempered42 with the

8
parametersshowninSupportingTable1.Thesimulationswerestartedfromthembasin,runforatotallengthof45nsapiece,andsavedevery10ps.Allothersimulationparameterswerekeptthe same as before14. The trajectories were analyzed and plotted using standard pythonlibararies19,29,43,30whilereweightingwasdoneusingthetime-independentestimatorofTiwary11.Theresultsfromour!&"$%simulationsareshowninFigure2.Baseduponthe4nsoftrainingdata (Figure2a), theSVMmodel isable to findahyperplaneseparating themandnoregions(Figure 2a). The distance to this hyper plane (Figure 2a color bar) now becomes our CV foracceleratingsamplingviaMetadynamics (Figure2c).Overa45ns run,wesample theslowestcoordinatem tonotransition tensof times, allowing for robustestimationof the freeenergysurfaceviareweighting(Figure2d).Additionally,sincethesimulationswereconverged,weareabletoefficientlysamplethefasterorthogonalqdegreeoffreedomaswell.SimilartotheSVM,we also used the Logistic Regression Classifiers (LRs) to define CVs (#*$%) for acceleratedsimulations.TheSupportingNote1andSupportingFigure6containdetailsontrainingandusingthesemodelsfordefiningCVs.WerecommendmodelersstartwithsimplerlinearmodelsbeforemovingtothemorecomplexDNNbasedapproachesshownnext.
Figure2:Resultsfrom!&"$%basedsampling.a)Thetwo2nstrainingtrajectoriesprojecteduntotheRamachandranplot.Notethatnotransitionwasobservedfromthemtothenobasins.Thetrainingframesarecoloredaccordingtotheframe’sdistancetothe SVM’s decision boundary in 4 dimensional feature space. The contours show the decision boundary for each region. b)DecomposingtheSVM’scoefficientsvectorintotheoriginaltrainingfeaturesshowsthemodelassignshigherweightstothepfeaturesthantheqfeatures.TheL-1regularizationdropsthecosinetransformoftheqbackbonedihedraltoinducesparsity.c)
a b
c d!
"#
!
"#

9
Runningwell-temperedMetadynamics simulations along the!&"$% efficiently samples them tonotransition repeatedly. d)ReweightingallowsustorecoverthefullfreeenergysurfacealongtheRamachandranplot.
ApplicationtoalaninedipeptideusingDNNsWenextlookedintousingdeepneuralnetworks(DNNs)tofindnon-linearboundariesbetweenthestartandendstates.Toshowthis,wetrainedasimple5-layeredDNNandusedtheresultingmodelasacollectivevariableforenhancedsamplingviaPlumedandOpenMM1,39.TheDNN’slayers alternated (Figure 3b) between fully connected affine transformations and non-linearactivationfunctions.Forthenon-linearactivationlayer,weusedtherecentlydevelopedSwish35non-linearfunction.Wetrainedthemodel(Figure3b)onhalfofthe4nsalaninedipeptidedatasetusingPyTorch.Wenotethattheoutputlayerofthismodelgivestwovalueswhicharetheun-normalizedprobabilityoftheinputframebeingineitherstate.Either(orboth)oftheseoutputnodescanbeusedasacollectivevariablesince,oncenormalized,theysumupto1.Totrainthemodel,weminimizedthecross-entropybetweenthemodels’outputandthetrainingdata.ThiswasdoneusingtheAdamoptimizer44withan initial learningrateof0.1.Wetrainedthemodel for1epochusingbatchsizeof32.TheoptimizationwasperformedusingPytorchontheCPUplatformandtrainingtook less thanaminute.After1epoch,ourmodel’s trainingerrorwasbelow0.1andmodelreported 100% accuracy on a held out 2ns test set. Therefore, we stopped training at thisinstance,andusedthismodelgoingforward.Oncethemodelhadbeentrained(Figure3a),wewrotecustomstringexpressionstoconvertthePytorchDNNmodelintoaformatthatPlumedcanprocess.Again,theMetadynamicssimulationswerewell-tempered42withtheparametersshowninSupportingTable1.TheonlineGithubrepoprovidesexamplesonhowsuchmodelscanbetrainedandtransferredtoPlumed.TheresultsareinFigure3c-d,runningMetadynamicssimulationsalongtheoutputprobability,+,,$%,allowsustoobserve>15transitions(Figure3c)alongalanine’sslowerpcoordinateinjust45nsofsampling.SimilartotheSVMmodel,therobusttransitionstatisticscombinedwith
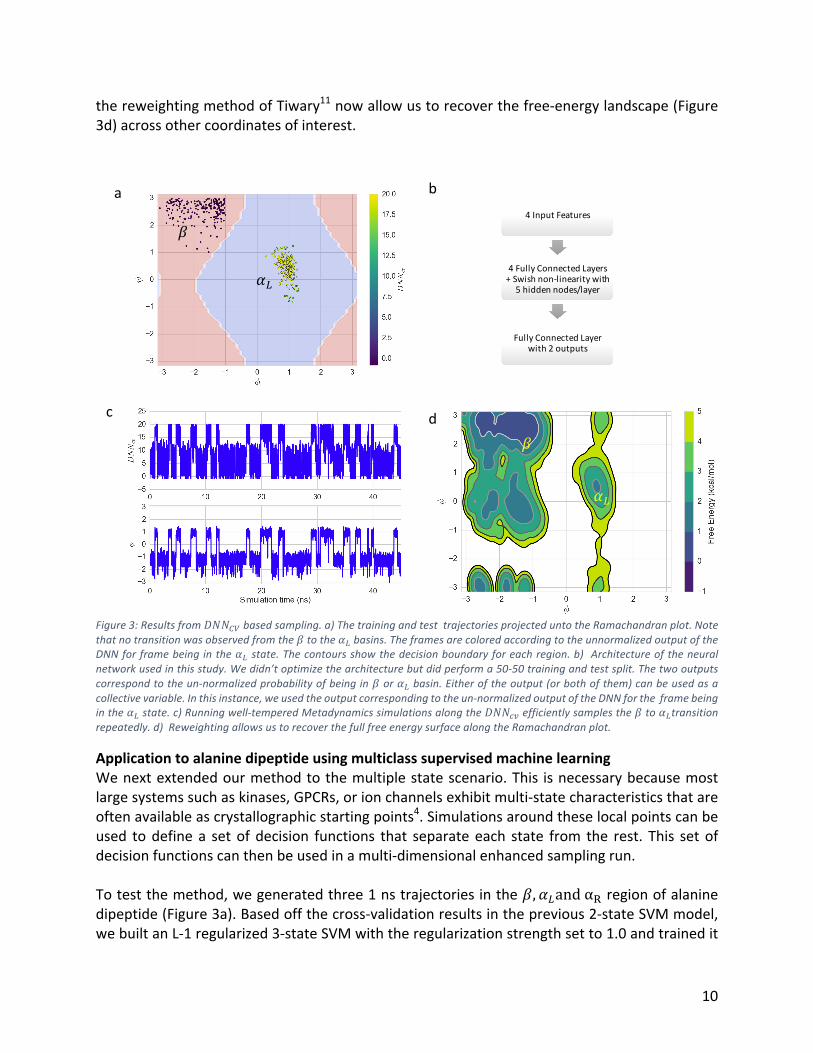
10
thereweightingmethodofTiwary11nowallowustorecoverthefree-energylandscape(Figure3d)acrossothercoordinatesofinterest.
Figure3:Resultsfrom+,,rsbasedsampling.a)ThetrainingandtesttrajectoriesprojecteduntotheRamachandranplot.Notethatnotransitionwasobservedfromthemtothenobasins.TheframesarecoloredaccordingtotheunnormalizedoutputoftheDNNforframebeinginthenostate.Thecontoursshowthedecisionboundaryforeachregion.b) Architectureoftheneuralnetworkusedinthisstudy.Wedidn’toptimizethearchitecturebutdidperforma50-50trainingandtestsplit.Thetwooutputscorrespondtotheun-normalizedprobabilityofbeinginmornobasin.Eitheroftheoutput(orbothofthem)canbeusedasacollectivevariable.Inthisinstance,weusedtheoutputcorrespondingtotheun-normalizedoutputoftheDNNfortheframebeinginthenostate.c)Runningwell-temperedMetadynamicssimulationsalongthe+,,$%efficientlysamplesthemtonotransitionrepeatedly.d)ReweightingallowsustorecoverthefullfreeenergysurfacealongtheRamachandranplot.
ApplicationtoalaninedipeptideusingmulticlasssupervisedmachinelearningWenextextendedourmethodtothemultiplestatescenario.This isnecessarybecausemostlargesystemssuchaskinases,GPCRs,orionchannelsexhibitmulti-statecharacteristicsthatareoftenavailableascrystallographicstartingpoints4.Simulationsaroundtheselocalpointscanbeused todefinea setofdecision functions that separateeach state from the rest. This setofdecisionfunctionscanthenbeusedinamulti-dimensionalenhancedsamplingrun.Totestthemethod,wegeneratedthree1nstrajectoriesinthem, noandαuregionofalaninedipeptide(Figure3a).Basedoffthecross-validationresultsintheprevious2-stateSVMmodel,webuiltanL-1regularized3-stateSVMwiththeregularizationstrengthsetto1.0andtrainedit
a b
c d!
"#
!
"#
4InputFeatures
4FullyConnectedLayers+Swishnon-linearitywith5hiddennodes/layer
FullyConnectedLayerwith2outputs
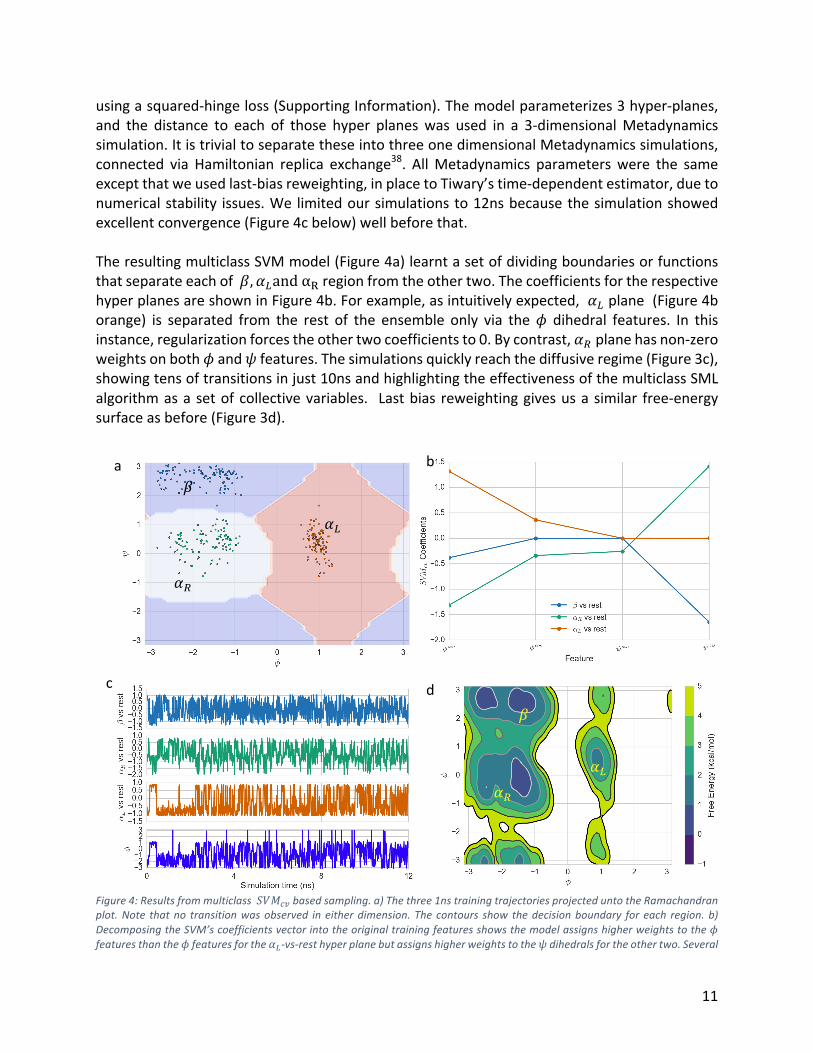
11
usingasquared-hingeloss(SupportingInformation).Themodelparameterizes3hyper-planes,and the distance to each of those hyper planeswas used in a 3-dimensionalMetadynamicssimulation.ItistrivialtoseparatetheseintothreeonedimensionalMetadynamicssimulations,connected via Hamiltonian replica exchange38. AllMetadynamics parameterswere the sameexceptthatweusedlast-biasreweighting,inplacetoTiwary’stime-dependentestimator,duetonumericalstability issues.We limitedoursimulationsto12nsbecausethesimulationshowedexcellentconvergence(Figure4cbelow)wellbeforethat.TheresultingmulticlassSVMmodel(Figure4a)learntasetofdividingboundariesorfunctionsthatseparateeachofm, noandαuregionfromtheothertwo.ThecoefficientsfortherespectivehyperplanesareshowninFigure4b.Forexample,asintuitivelyexpected,noplane(Figure4borange) is separated from the rest of the ensemble only via thep dihedral features. In thisinstance,regularizationforcestheothertwocoefficientsto0.Bycontrast,nvplanehasnon-zeroweightsonbothpandqfeatures.Thesimulationsquicklyreachthediffusiveregime(Figure3c),showingtensoftransitionsinjust10nsandhighlightingtheeffectivenessofthemulticlassSMLalgorithmasasetofcollectivevariables. Lastbias reweightinggivesusasimilar free-energysurfaceasbefore(Figure3d).
Figure4:Resultsfrommulticlass!&"$%basedsampling.a)Thethree1nstrainingtrajectoriesprojecteduntotheRamachandranplot.Note thatno transitionwasobserved ineitherdimension.Thecontours show thedecisionboundary foreach region.b)DecomposingtheSVM’scoefficientsvectorintotheoriginaltrainingfeaturesshowsthemodelassignshigherweightstothepfeaturesthanthepfeaturesfortheno-vs-resthyperplanebutassignshigherweightstotheqdihedralsfortheothertwo.Several
a b
c d!
"#
!
"#
"$
"$

12
coefficientsaredroppedduetoregularization.c)Runningwell-temperedMetadynamicssimulationsalongthe!&"$%efficientlysamples the m to notransition repeatedly. d) Reweighting allows us to recover the full free energy surface along theRamachandranplot.
To compare our simulations to a baseline,we ran two control 12+ns simulation (SupportingFigure1)whereweacceleratedthedynamicsoftheqorpdihedralalone.qisabadstartingCVsincetheslowesttransitionsinalaninearedominatedbythepdihedral.Thus,inourfirstcontrolsimulation,weonlyobservedthreetransitionsalongthepplane.Bycontrast,bothvariantsof!"#$% were able to observe at least 5 transitions in the same amount of simulation time.Additionally,allsimulations,includingthecontrol,werealsoabletodrivetheslowuphillmtonotransitionmuchmorequickly(<5ns)thantheunbiased43nsmeanfirstpassagetimeestimatepreviouslyreported45.However, it isworthnotingthatsomeofourSMLbasedCVarenotasefficientassimplydirectlyacceleratingthepdihedral(SupportingFigure2).ThislikelyindicatesthatwedonothavethemostefficientpossibleCV,butit isentirelypossibletonowturnourinitialSMLbasedCVintoabetterCVbycombiningitwiththeSGOOPformalism21.Intriguingly,knowledgeaboutthepcouldalsopotentiallybeincorporatedasBayesianpriorintothe!"#rs formalism.ApplicationtoproteinfoldingusingSVMsWenext sought to fold the10 residueChignolinmini-protein46 using theAmber forcefield47,TIP3P48 water model, and vanilla NVT simulations. To that end, we obtained the all atomChignolintrajectoriesfromD.E.Shawresearch46,49.Wethensliced1000frames(2wxtrajectory)fromthefoldedandunfolded(Figure5a)states(4wxtotal)respectively,ensuringthatnoactualfoldingevent(Figure5a)wasseeninthosetrajectories.Tofeaturizethese2000frames,weuseda combination of the sin-cosine transform of the backbonep,q dihedrals,ncarbon contactdistancesforresiduesatleast3apartinsequence,andthecosinetransformoffourconsecutiven carbon atoms. Thus each frame in our simulationwas represented using 78 features.WenormalizedthesefeaturestohaveclosetozeromeanandunitvarianceusingaStandardscalartrainedontheShawsimulations7,46.ThisscalingisnecessarybecausemostSMLalgorithmshaveissueswith varied feature scaling—for example dihedrals going from negative pi to pi whiledistancesgoinguptotensofangstroms.DecisiontreesandRandomForestsdonotrequirethisfeaturescalingbecauseunlikeSVMs,LR,orDNNstheydonotlearna“distance”metricandareinvarianttomonotonicfeaturescaling.WetrainedaSVM(Figure5b)onthese2000frames(1000foldedand1000unfolded),usingcross-validated parameters (Supporting Figure 5), via Scikit-learn29. For this model, we used L-2regularizationwiththeregularizationstrengthsetto1.0.However,changingtheregularizationbyafactorof10ineitherdirectionhadminimaleffectonthefinaldecisionboundary(SupportingFigure5).Thensimilartothealanineexample,weusedthedistancetotheSVM’shyperplaneasour collective variable. In this instance,we started25Metadynamicsusingwell-temperedmetadynamics9,42.Eachofourwalkerswasrunfor100ns(~18hrsofparallelizedsampling oncommodity K40 GPUs). Thus the total amount of sampling was 2.5 µs.We ran vanilla NVTMetadynamicssimulationsusinga2fsLangevinintegratorwithafrictioncoefficientof1/ps,and
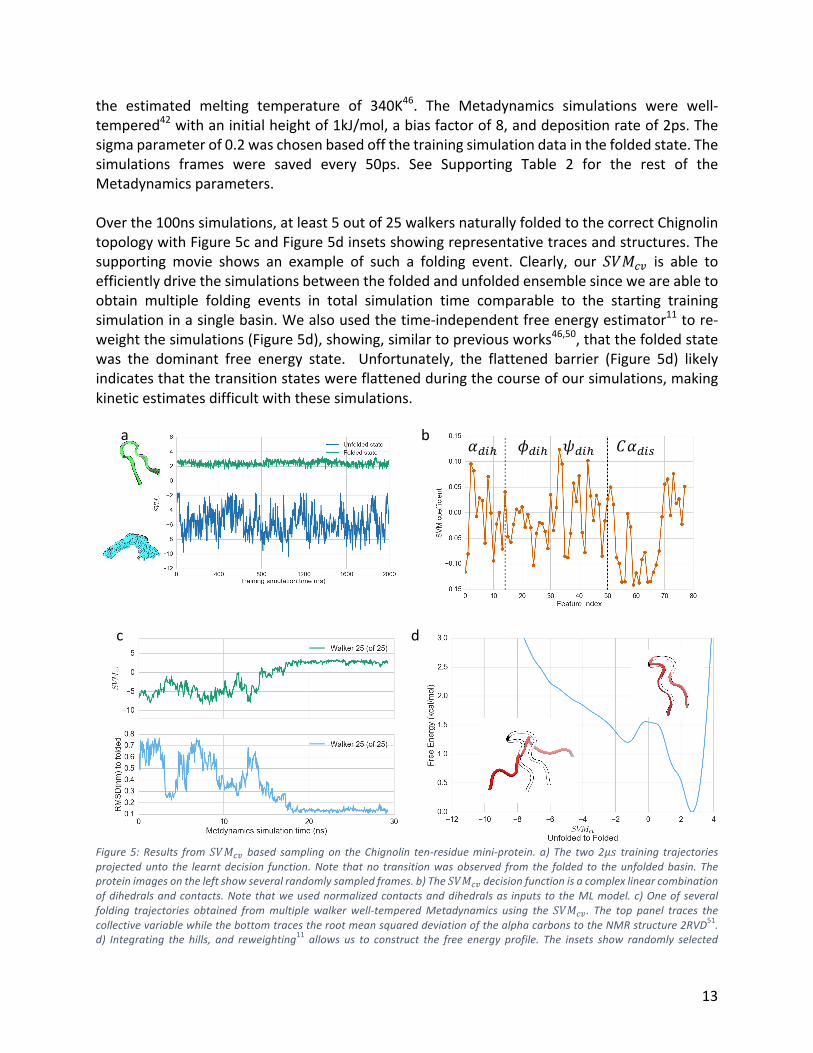
13
the estimated melting temperature of 340K46. The Metadynamics simulations were well-tempered42withaninitialheightof1kJ/mol,abiasfactorof8,anddepositionrateof2ps.Thesigmaparameterof0.2waschosenbasedoffthetrainingsimulationdatainthefoldedstate.Thesimulations frames were saved every 50ps. See Supporting Table 2 for the rest of theMetadynamicsparameters.Overthe100nssimulations,atleast5outof25walkersnaturallyfoldedtothecorrectChignolintopologywithFigure5candFigure5dinsetsshowingrepresentativetracesandstructures.Thesupporting movie shows an example of such a folding event. Clearly, our !&"$% is able toefficientlydrivethesimulationsbetweenthefoldedandunfoldedensemblesinceweareabletoobtain multiple folding events in total simulation time comparable to the starting trainingsimulationinasinglebasin.Wealsousedthetime-independentfreeenergyestimator11tore-weightthesimulations(Figure5d),showing,similartopreviousworks46,50,thatthefoldedstatewas the dominant free energy state. Unfortunately, the flattened barrier (Figure 5d) likelyindicatesthatthetransitionstateswereflattenedduringthecourseofoursimulations,makingkineticestimatesdifficultwiththesesimulations.
Figure5:Results from!&"$% based samplingon theChignolin ten-residuemini-protein.a) The two2wx training trajectoriesprojectedunto the learntdecision function.Note thatno transitionwasobserved fromthe folded to theunfoldedbasin.Theproteinimagesontheleftshowseveralrandomlysampledframes.b)The!&"$%decisionfunctionisacomplexlinearcombinationofdihedralsandcontacts.Notethatweusednormalizedcontactsanddihedralsas inputstotheMLmodel.c)Oneofseveralfolding trajectories obtained frommultiple walker well-temperedMetadynamics using the!&"$%. The top panel traces thecollectivevariablewhilethebottomtracestherootmeansquareddeviationofthealphacarbonstotheNMRstructure2RVD51.d) Integrating the hills, and reweighting11 allows us to construct the free energy profile. The insets show randomly selected
!"#$ %"#$'"#$ (!"#)a b
c d

14
unfolded and folded structures in red with the NMR structure in white. This image was generated using IPythonnotebook30,MSMBuilder19,MSMEplorer43,andVMD52.
Conclusion:Webelieve thepowerofourmethod!"#$% comes inautomating theCVselectionproblem,providingasystematicwaytoincludenon-linearityandregularization,andminimizingtheworkthatneedstobedonetofindstartingpoints forenhancedsamplingruns.Ourresults furtheropenupsignificantopportunitiesforbothbenchmarkingexistingSMLalgorithms,anddevelopingnovelalgorithmsorlossfunctionsinspiredfromstatisticalmechanics.Forexample,otherSMLtechniques, such as the naïve Bayes classifier, might present interesting starting points forbuilding classification schemes better suited for accelerated sampling. However, not all SMLalgorithmsareamenabletobeingusedasCVs.Forexample,whiledecisiontreesandrandomforestclassifiers53,54areusefulforunderstandingmolecularsystems54,their indicatorfunctionbasedoptimizationprocedureisnotdifferentiable,makingtheirdecisionfunctionunlikelytobeusedasaCV.Ourproposedmethod(!"#$%)isintendedtoproduceafirstestimateofCVsfromverylimiteddatacollectedfromlocallysamplingeachbasin,andassuchwilllikelynotbeabletogenerateanidealCV.Inalllikelihood,themodelmightaccidentlyinduceorthogonaldegreesoffreedomineither state thereby slowing convergence. However, this problemwould exist for any of theexistingmethodsinliterature.Whilewehavefocusedonpre-trainingandgenerationofCVs,wealsobelievethatsupervisedmachinelearningbasedcollectivevariables(!"#$%)mightbeexcellentstartingcoordinatesforfurtheroptimizationviaSGOOP21orVAC22.Thiswouldmaketheentireprocessintoanonlinelearningsetupwhereeachadditionalroundofsimulationimprovesthedividinghyperboundary.Additionally, these coordinates are likely to be transferable15,17 across related systemswhichwouldmakethemusefulfor investigatingdrugbinding/unbindingkinetics,mutationaleffects,modest force field effects etc. However, when and where transfer learning might fail is anunsolvedproblem. Lastly,wehypothesizethattheautomatedorderparameter identificationmightmakeiteasiertoconvergechain-of-statesbasedmethodssuchasnudgedelasticbandorstringbasedmethod25,55–57sincetheseparatinghyperplanecannowbeusedtomoreefficientlyguide the iterative minimum free energy path finding algorithms—similar to kernel-SVMapproachofPozunetal58.We hopethattheseresultsprovidestimulatingstartingpoints forautomaticCVoptimizationprotocols,allowingmodelers to focusmoreontheresultsof free-energysimulationsratherthantheirinitialdesign.SupplementaryMaterial:Thesupplementarymaterial contains severaladditional figureswhicharecomparisonsof the!"#$% results againsthandpicked collective variables for alaninedipeptide, results of 3-foldcross-validation for the givenmodels, and results fromusing a Logistic regression classifier’sdecisionfunctionasacollectivevariableforacceleratedsampling.

15
Acknowledgements:Theauthorswould liketothankvariousmembersofthePande labforusefuldiscussionsandfeedback on the manuscript. M.M.S. would like to acknowledge support from the NationalScience Foundation grant NSF-MCB-0954714. This work used the XStream computationalresource, supported by the National Science Foundation Major Research Instrumentationprogram(ACI-1429830).TheauthorswouldliketothankD.E.ShawandDESERESforgraciouslyproviding the Chignolin folding trajectories. VSP is a consultant and SAB member ofSchrodinger,LLCandGlobavir,sitsontheBoardofDirectorsofApeelInc,FreenomeInc,OmadaHealth,PatientPing,Rigetti Computing, and is a General Partner at AndreessenHorowitz.Supportingvideos:Due to size restrictions the supporting video have been uploaded online:https://www.youtube.com/watch?v=jgor4xbAai8andhttps://youtu.be/D1cXDKrHMCACodeanddataavailability:All themodelsandcodeneeded to reproduce themain resultsof thispaperareavailableathttps://github.com/msultan/SML_CV/References:(1) Eastman,P.;Swails,J.;Chodera,J.D.;McGibbon,R.T.;Zhao,Y.;Beauchamp,K.A.;Wang,
L.P.;Simmonett,A.C.;Harrigan,M.P.;Stern,C.D.;etal.OpenMM7:RapidDevelopmentofHighPerformanceAlgorithmsforMolecularDynamics.PLoSComput.Biol.2017,13(7),e1005659.
(2) Bowman,G.R.;Pande,V.S.;Noé,F.AnIntroductiontoMarkovStateModelsandTheirApplicationtoLongTimescaleMolecularSimulation;2014;Vol.797.
(3) Sultan,M.M.;Kiss,G.;Pande,V.TowardsSimpleKineticModelsofFunctionalDynamicsforaKinaseSubfamily.bioRxiv2017,228528.
(4) Sultan,M.M.;Denny,R.A.;Unwalla,R.;Lovering,F.;Pande,V.S.MillisecondDynamicsofBTKRevealKinome-WideConformationalPlasticitywithintheApoKinaseDomain.Sci.Rep.2017,7(1).
(5) Dror,R.O.;Dirks,R.M.;Grossman,J.P.;Xu,H.;Shaw,D.E.BiomolecularSimulation:AComputationalMicroscopeforMolecularBiology.Annu.Rev.Biophys.2012,41,429–452.
(6) Silva,D.-A.;Weiss,D.R.;PardoAvila,F.;Da,L.-T.;Levitt,M.;Wang,D.;Huang,X.MillisecondDynamicsofRNAPolymeraseIITranslocationatAtomicResolution.Proc.Natl.Acad.Sci.2014,111(21),7665–7670.
(7) Shaw,D.;Maragakis,P.;Lindorff-Larsen,K.Atomic-LevelCharacterizationoftheStructuralDynamicsofProteins.Science(80-.).2010,330(October),341–347.
(8) Laio,A.;Gervasio,F.L.Metadynamics:AMethodtoSimulateRareEventsandReconstructtheFreeEnergyinBiophysics,ChemistryandMaterialScience.ReportsProg.Phys.2008,71(12),126601.
(9) Raiteri,P.;Laio,A.;Gervasio,F.L.;Micheletti,C.;Parrinello,M.EfficientReconstructionofComplexFreeEnergyLandscapesbyMultipleWalkersMetadynamics.J.Phys.Chem.B

16
2006,110(8),3533–3539.(10) Abrams,C.;Bussi,G.EnhancedSamplinginMolecularDynamicsUsingMetadynamics,
Replica-Exchange,andTemperature-Acceleration.Entropy2013,16(1),163–199.(11) Tiwary,P.;Parrinello,M.ATime-IndependentFreeEnergyEstimatorforMetadynamics.
J.Phys.Chem.B2015,119(3),736–742.(12) Kästner,J.UmbrellaSampling.WileyInterdiscip.Rev.Comput.Mol.Sci.2011,1(6),932–
942.(13) Jo,S.;Suh,D.;He,Z.;Chipot,C.;Roux,B.LeveragingtheInformationfromMarkovState
ModelstoImprovetheConvergenceofUmbrellaSamplingSimulations.J.Phys.Chem.B2016,120(33),8733–8742.
(14) Sultan,M.M.;Pande,V.S.TICA-Metadynamics:AcceleratingMetadynamicsbyUsingKineticallySelectedCollectiveVariables.J.Chem.TheoryComput.2017,13(6),2440–2447.
(15) Sultan,M.M.;Pande,V.S.TransferLearningfromMarkovModelsLeadstoEfficientSamplingofRelatedSystems.J.Phys.Chem.B2017,acs.jpcb.7b06896.
(16) Hernández,C.X.;Wayment-Steele,H.K.;Sultan,M.M.;Husic,B.E.;Pande,V.S.VariationalEncodingofComplexDynamics.arXivPrepr.2017,arXiv:1711.08576.
(17) Sultan,M.M.;Wayment-Steele,H.K.;Pande,V.S.TransferableNeuralNetworksforEnhancedSamplingofProteinDynamics.arXivPrepr.2018,arXiv:1801.00636.
(18) Pande,V.S.;Beauchamp,K.;Bowman,G.R.EverythingYouWantedtoKnowaboutMarkovStateModelsbutWereAfraidtoAsk.Methods2010,52(1),99–105.
(19) Harrigan,M.P.;Sultan,M.M.;Hernández,C.X.;Husic,B.E.;Eastman,P.;Schwantes,C.R.;Beauchamp,K.A.;Mcgibbon,R.T.;Pande,V.S.MSMBuilder:StatisticalModelsforBiomolecularDynamics.Biophys.J.2016,112(1),10–15.
(20) Pérez-Hernández,G.;Paul,F.;Giorgino,T.;DeFabritiis,G.;Noé,F.;Perez-hernandez,G.;Paul,F.IdentificationofSlowMolecularOrderParametersforMarkovModelConstruction.J.Chem.Phys.2013,139(1),15102.
(21) Tiwary,P.;Berne,B.J.SpectralGapOptimizationofOrderParametersforSamplingComplexMolecularSystems.Proc.Natl.Acad.Sci.U.S.A.2016,113(11),2839–2844.
(22) McCarty,J.;Parrinello,M.AVariationalConformationalDynamicsApproachtotheSelectionofCollectiveVariablesinMetadynamics.J.Chem.Phys.2017,147(20),204109.
(23) Fiorin,G.;Klein,M.L.;Hénin,J.UsingCollectiveVariablestoDriveMolecularDynamicsSimulations.Mol.Phys.2013,111(22–23),3345–3362.
(24) Lovera,S.;Sutto,L.;Boubeva,R.;Scapozza,L.;Dölker,N.;Gervasio,F.L.TheDifferentFlexibilityofc-Srcandc-AblKinasesRegulatestheAccessibilityofaDruggableInactiveConformation.J.Am.Chem.Soc.2012,134(5),2496–2499.
(25) Pan,A.C.;Sezer,D.;Roux,B.FindingTransitionPathwaysUsingtheStringMethodwithSwarmsofTrajectories.J.Phys.Chem.B2008,112(11),3432–3440.
(26) Meng,Y.;Lin,Y.L.;Roux,B.ComputationalStudyofthe“DFG-Flip”conformationalTransitioninc-Ablandc-SrcTyrosineKinases.J.Phys.Chem.B2015,119(4),1443–1456.
(27) Ceriotti,M.;Tribello,G.A.;Parrinello,M.DemonstratingtheTransferabilityandtheDescriptivePowerofSketch-Map.J.Chem.TheoryComput.2013,9(3),1521–1532.
(28) Tan,P.-N.Classification:BasicConcepts,DecisionTreesandModelEvaluation.Introd.toDataMin.2006,145–205.

17
(29) Pedregosa,F.;Varoquaux,G.Scikit-Learn:MachineLearninginPython.J.Mach.Learn.2011,12,2825–2830.
(30) Pérez,F.;Granger,B.E.IPython:ASystemforInteractiveScientificComputing.Comput.Sci.Eng.2007,9(3),21–29.
(31) Schoenholz,S.S.;Cubuk,E.D.;Sussman,D.M.;Kaxiras,E.;Liu,A.J.AStructuralApproachtoRelaxationinGlassyLiquids.Nat.Phys.2016,12(5),469–471.
(32) Hofmann,T.;Schölkopf,B.;Smola,A.J.KernelMethodsinMachineLearning.AnnalsofStatistics.2008,pp1171–1220.
(33) Müller,K.R.;Mika,S.;Rätsch,G.;Tsuda,K.;Schölkopf,B.AnIntroductiontoKernel-BasedLearningAlgorithms.IEEETrans.NeuralNetw.2001,12(2),181–201.
(34) Harrigan,M.P.;Pande,V.S.LandmarkKerneltICAForConformationalDynamics.bioRxiv2017.
(35) Ramachandran,P.;Zoph,B.;Le,Q.V.SearchingforActivationFunctions.arXivPrepr.2017,arXiv:1710.05941.
(36) Ma,A.;Dinner,A.R.AutomaticMethodforIdentifyingReactionCoordinatesinComplexSystems.J.Phys.Chem.B2005,109(14),6769–6779.
(37) Chen,W.;Ferguson,A.L.MolecularEnhancedSamplingwithAutoencoders:On-the-FlyCollectiveVariableDiscoveryandAcceleratedFreeEnergyLandscapeExploration.arXivPrepr.2018,arXiv:1801.00203.
(38) Piana,S.;Laio,A.ABias-ExchangeApproachtoProteinFolding.J.Phys.Chem.B2007,111(17),4553–4559.
(39) Tribello,G.A.;Bonomi,M.;Branduardi,D.;Camilloni,C.;Bussi,G.PLUMED2:NewFeathersforanOldBird.Comput.Phys.Commun.2014,185(2),604–613.
(40) McGibbon,R.T.;Beauchamp,K.A.;Harrigan,M.P.;Klein,C.;Swails,J.M.;Hernández,C.X.;Schwantes,C.R.;Wang,L.P.;Lane,T.J.;Pande,V.S.MDTraj:AModernOpenLibraryfortheAnalysisofMolecularDynamicsTrajectories.Biophys.J.2015,109(8),1528–1532.
(41) Paszke,A.;Chanan,G.;Lin,Z.;Gross,S.;Yang,E.;Antiga,L.;Devito,Z.AutomaticDifferentiationinPyTorch.Adv.NeuralInf.Process.Syst.302017,No.Nips,1–4.
(42) Barducci,A.;Bussi,G.;Parrinello,M.Well-TemperedMetadynamics:ASmoothlyConvergingandTunableFree-EnergyMethod.Phys.Rev.Lett.2008,100(2).
(43) Hernández,C.X.;Harrigan,M.P.;Sultan,M.M.;Pande,V.S.MSMExplorer:DataVisualizationsforBiomolecularDynamics.J.OpenSourceSoftw.2017,2(12).
(44) Kingma,D.P.;Ba,J.Adam:AMethodforStochasticOptimization.arXivPrepr.2014,arXiv:1412.6980.
(45) Trendelkamp-Schroer,B.;Noé,F.EfficientEstimationofRare-EventKinetics.Phys.Rev.X2016,6(1).
(46) Lindorff-Larsen,K.;Piana,S.;Dror,R.O.;Shaw,D.E.HowFast-FoldingProteinsFold.Science(80-.).2011,334(6055),517–520.
(47) Lindorff-Larsen,K.;Piana,S.;Palmo,K.;Maragakis,P.;Klepeis,J.L.;Dror,R.O.;Shaw,D.E.ImprovedSide-ChainTorsionPotentialsfortheAmberff99SBProteinForceField.Proteins2010,78(8),1950–1958.
(48) Jorgensen,W.L.;Chandrasekhar,J.;Madura,J.D.;Impey,R.W.;Klein,M.L.ComparisonofSimplePotentialFunctionsforSimulatingLiquidWater.J.Chem.Phys.1983,79(2),

18
926.(49) Shaw,D.E.;Chao,J.C.;Eastwood,M.P.;Gagliardo,J.;Grossman,J.P.;Ho,C.R.;Ierardi,
D.J.;Kolossváry,I.;Klepeis,J.L.;Layman,T.;etal.Anton,aSpecial-PurposeMachineforMolecularDynamicsSimulation.InProceedingsofthe34thannualinternationalsymposiumonComputerarchitecture-ISCA’07;ACMPress:NewYork,NewYork,USA,2007;Vol.35,p1.
(50) McKiernan,K.A.;Husic,B.E.;Pande,V.S.ModelingtheMechanismofCLN025Beta-HairpinFormation.J.Chem.Phys.2017,147(10),104107.
(51) Honda,S.;Akiba,T.;Kato,Y.S.;Sawada,Y.;Sekijima,M.;Ishimura,M.;Ooishi,A.;Watanabe,H.;Odahara,T.;Harata,K.CrystalStructureofaTen-AminoAcidProtein.J.Am.Chem.Soc.2008,130(46),15327–15331.
(52) Humphrey,W.;Dalke,A.;Schulten,K.VMD:VisualMolecularDynamics.J.Mol.Graph.1996,14(1),33–38,27–28.
(53) Breiman,L.RandomForests.Mach.Learn.2001,45,5–32.(54) Sultan,M.M.;Kiss,G.;Shukla,D.;Pande,V.S.AutomaticSelectionofOrderParameters
intheAnalysisofLargeScaleMolecularDynamicsSimulations.J.Chem.TheoryComput.2014,10(12),5217–5223.
(55) E,W.;Ren,W.;Vanden-Eijnden,E.SimplifiedandImprovedStringMethodforComputingtheMinimumEnergyPathsinBarrier-CrossingEvents.J.Chem.Phys.2007,126(16),164103.
(56) E,W.;Ren,W.;Vanden-Eijnden,E.StringMethodfortheStudyofRareEvents.Phys.Rev.B2002,66(5),52301.
(57) Rohrdanz,M.A.;Zheng,W.;Clementi,C.DiscoveringMountainPassesviaTorchlight:MethodsfortheDefinitionofReactionCoordinatesandPathwaysinComplexMacromolecularReactions.Ann.Rev.Phys.Chem.2013,64(December2012),295–316.
(58) Pozun,Z.D.;Hansen,K.;Sheppard,D.;Rupp,M.;Müller,K.R.;Henkelman,G.OptimizingTransitionStatesviaKernel-BasedMachineLearning.J.Chem.Phys.2012,136(17).

SupportingInformation
Modelparameters:
AllofourSVMandLRmodelsweregeneratedusingscikit-learn.TheDNNmodelwasgenerated
usingPytorch.Thefollowingparameterswereusedforeachofthemodels.
Alanine2-stateSVMmodel(Figure2):
LinearSVC(C=1,class_weight=None,dual=False,fit_intercept=True,
intercept_scaling=1,loss='squared_hinge',max_iter=1000,
multi_class='ovr',penalty='l1',random_state=None,tol=0.0001,
verbose=0)
AlanineDNNmodel(Figure3):
Seethemainmanuscriptforfulldetails.
Alanine3-stateSVMmodel(Figure4):
LinearSVC(C=1,class_weight=None,dual=False,fit_intercept=True,
intercept_scaling=1,loss='squared_hinge',max_iter=1000,
multi_class='ovr',penalty='l1',random_state=None,tol=0.0001,
verbose=0)
AlanineLRmodel(SIFigure6):
LogisticRegression(C=1.0,class_weight=None,dual=False,fit_intercept=True,
intercept_scaling=1,max_iter=100,multi_class='ovr',n_jobs=1,
penalty='l1',random_state=None,solver='liblinear',tol=0.0001,
verbose=0,warm_start=False)
ChignolinSVMmodel(Figure5):
SVC(C=1.0,cache_size=200,class_weight=None,coef0=0.0,
decision_function_shape=None,degree=3,gamma='auto',kernel='linear',
max_iter=-1,probability=False,random_state=None,shrinking=True,
tol=0.001,verbose=False)
Parameter Value
GaussianHeight 1kj/mol
Gaussianwidth 0.5(DNN),0.1(SVM),
0.01(LR)
BiasFactor 8
GaussianDroprate 2ps
FeatureSpace Dihedrals+SinCos
Transform
NormalizedFeatures False(allfeatures
havesimilarscale)

Table1:SetofparametersusedfortheSML-MetadynamicssimulationsofAlaninedipeptide
across3differentCV.
Parameter Value
GaussianHeight 1kj/mol
Gaussianwidth 0.2(SVMbasedCV)
Walkers 25
Walkersreadrate 50ps
BiasFactor 8
GaussianDroprate 2ps
SimulationTemp. 340K
FeatureSpace Dihedrals(sin-cosine
transform)+alpha
contacts+alpha
carbondihedrals(sin-
cosinetransform)
NormalizedFeatures Yes
Table2:SetofparametersusedfortheSML-MetadynamicssimulationsofChignolin
The fitted models and code are available as pickle files on the following github page:
https://github.com/msultan/SML_CV/
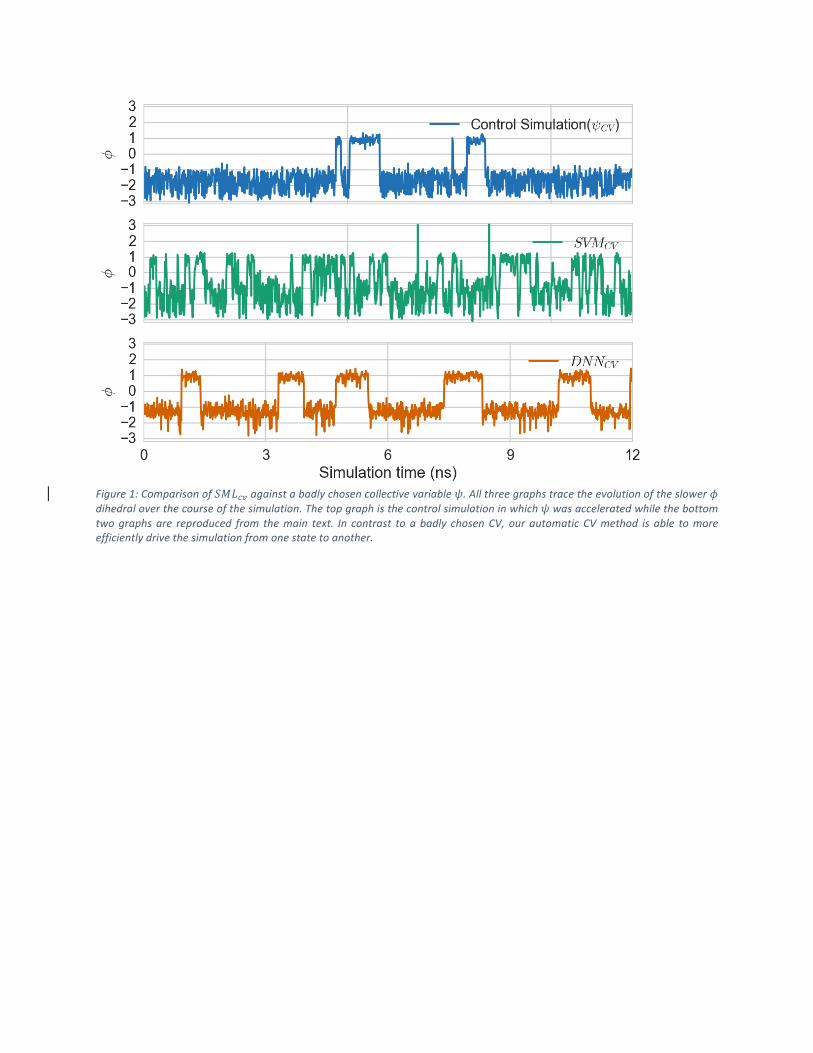
Figure1:Comparisonof!"#$%againstabadlychosencollectivevariable&.Allthreegraphstracetheevolutionoftheslower'dihedraloverthecourseofthesimulation.Thetopgraphisthecontrolsimulationinwhich&wasacceleratedwhilethebottom
twographsare reproduced from themain text. In contrast toabadly chosenCV, ourautomaticCVmethod is able tomore
efficientlydrivethesimulationfromonestatetoanother.
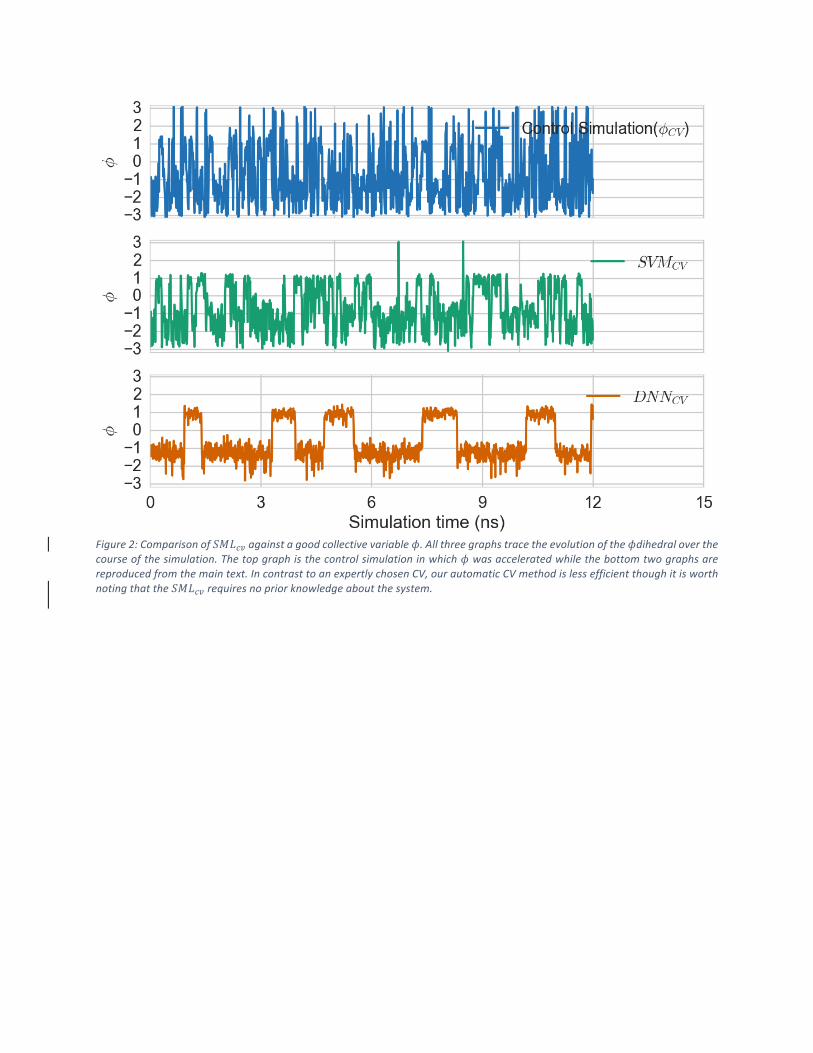
Figure2:Comparisonof!"#$%againstagoodcollectivevariable'.Allthreegraphstracetheevolutionofthe'dihedraloverthecourseofthesimulation.Thetopgraphisthecontrolsimulationinwhich'wasacceleratedwhilethebottomtwographsare
reproducedfromthemaintext.IncontrasttoanexpertlychosenCV,ourautomaticCVmethodislessefficientthoughitisworth
notingthatthe!"#$%requiresnopriorknowledgeaboutthesystem.

Figure3:SensitivityanalysisfortheL-1regularizedalanineSVMmodel.a).Resultsfrom3-foldcross-validationshowsthatthe
modelhasaveryhighvalidationaccuracy(~1)acrossseveralmagnitudechangesintheC-parameter.Theerrorbarsarenegligible
inthevalidationdataset(n=3).Thegoldcircleisthemodelpresentedinthepaperafterithasbeenfittothecompletedataset.
b).ChangingtheSVM’sL1regularization/slackparameterbyordersofmagnitudehasminimaleffectontheSVMcoefficient.In
thiscase,werandomlyremoved20%ofthedatatoshowthatthemodelwasstillrobusttoperturbations.c).Thisresultremains
consistentwith100%ofthedataacrossseveralmagnitudechangesintheC-parameter.
a b
c
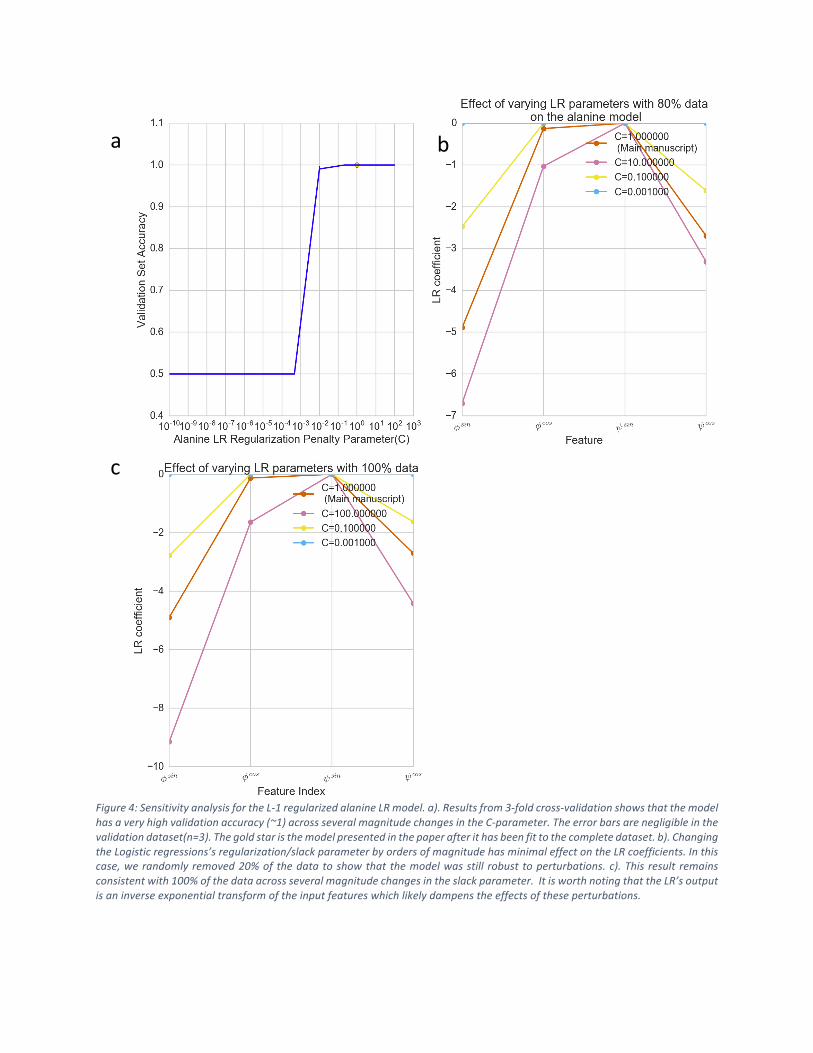
Figure4:SensitivityanalysisfortheL-1regularizedalanineLRmodel.a).Resultsfrom3-foldcross-validationshowsthatthemodel
hasaveryhighvalidationaccuracy(~1)acrossseveralmagnitudechangesintheC-parameter.Theerrorbarsarenegligibleinthe
validationdataset(n=3).Thegoldstaristhemodelpresentedinthepaperafterithasbeenfittothecompletedataset.b).Changing
theLogisticregressions’sregularization/slackparameterbyordersofmagnitudehasminimaleffectontheLRcoefficients.Inthis
case,werandomlyremoved20%ofthedatatoshowthatthemodelwasstill robusttoperturbations.c).Thisresult remains
consistentwith100%ofthedataacrossseveralmagnitudechangesintheslackparameter.ItisworthnotingthattheLR’soutput
isaninverseexponentialtransformoftheinputfeatureswhichlikelydampenstheeffectsoftheseperturbations.
a b
c
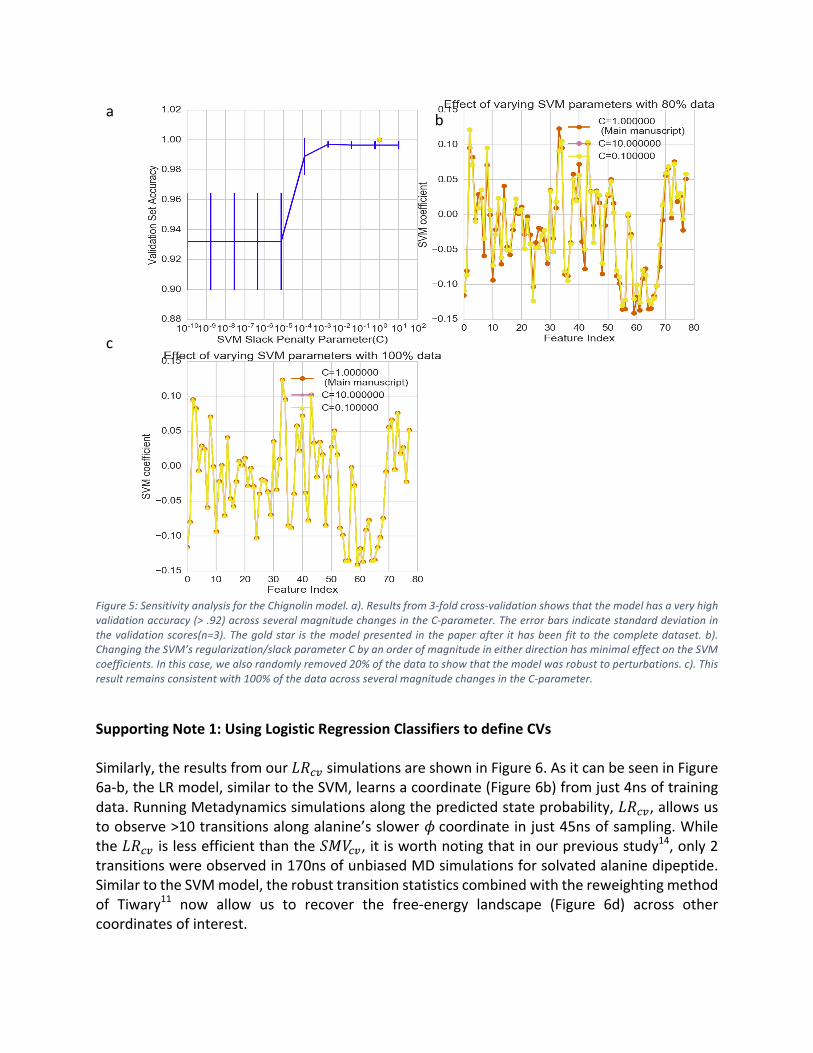
Figure5:SensitivityanalysisfortheChignolinmodel.a).Resultsfrom3-foldcross-validationshowsthatthemodelhasaveryhigh
validationaccuracy(>.92)acrossseveralmagnitudechangesintheC-parameter.Theerrorbarsindicatestandarddeviationin
thevalidationscores(n=3).Thegoldstar isthemodelpresented inthepaperafter ithasbeenfittothecompletedataset.b).
ChangingtheSVM’sregularization/slackparameterCbyanorderofmagnitudeineitherdirectionhasminimaleffectontheSVM
coefficients.Inthiscase,wealsorandomlyremoved20%ofthedatatoshowthatthemodelwasrobusttoperturbations.c).This
resultremainsconsistentwith100%ofthedataacrossseveralmagnitudechangesintheC-parameter.
SupportingNote1:UsingLogisticRegressionClassifierstodefineCVs
Similarly,theresultsfromour#($%simulationsareshowninFigure6.AsitcanbeseeninFigure
6a-b,theLRmodel,similartotheSVM,learnsacoordinate(Figure6b)fromjust4nsoftraining
data.RunningMetadynamicssimulationsalongthepredictedstateprobability,#($%,allowsustoobserve>10transitionsalongalanine’sslower'coordinateinjust45nsofsampling.While
the#($%islessefficientthanthe!"*$%,itisworthnotingthatinourpreviousstudy14,only2transitionswereobservedin170nsofunbiasedMDsimulationsforsolvatedalaninedipeptide.
SimilartotheSVMmodel,therobusttransitionstatisticscombinedwiththereweightingmethod
of Tiwary11 now allow us to recover the free-energy landscape (Figure 6d) across other
coordinatesofinterest.
a b
c
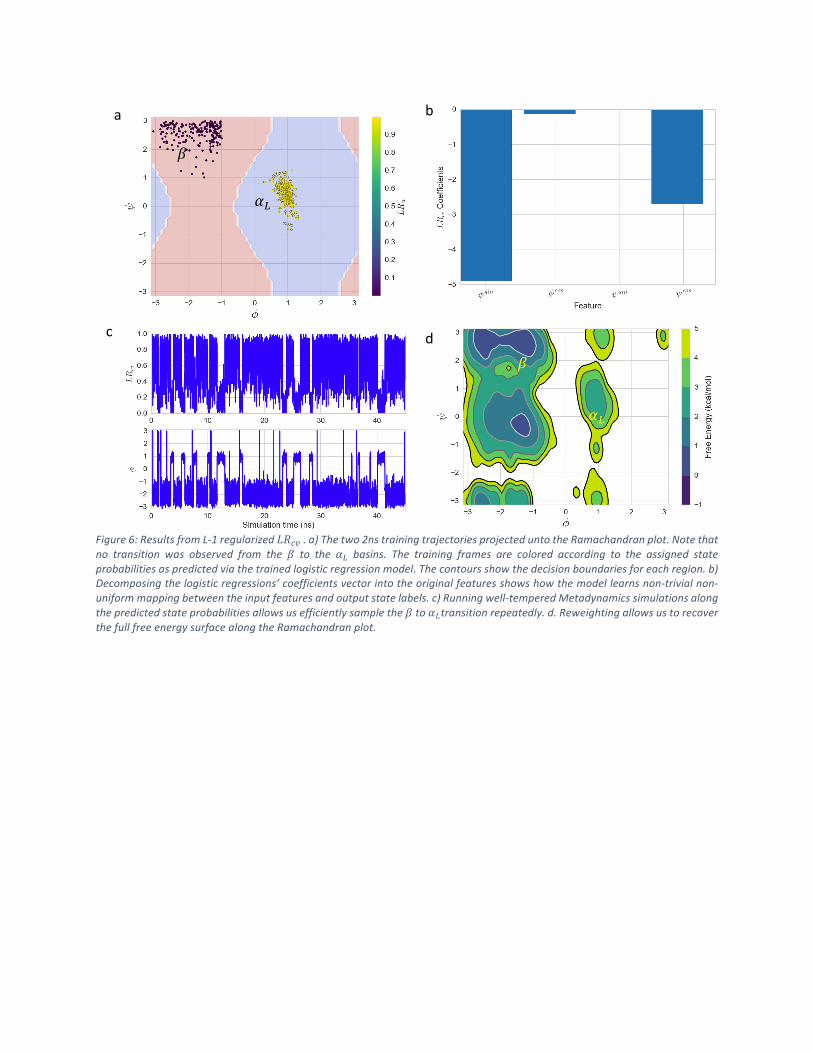
Figure6:ResultsfromL-1regularized#($%.a)Thetwo2nstrainingtrajectoriesprojecteduntotheRamachandranplot.Notethat
no transition was observed from the + to the ,- basins. The training frames are colored according to the assigned state
probabilitiesaspredictedviathetrainedlogisticregressionmodel.Thecontoursshowthedecisionboundariesforeachregion.b)
Decomposingthelogisticregressions’coefficientsvectorintotheoriginalfeaturesshowshowthemodellearnsnon-trivialnon-
uniformmappingbetweentheinputfeaturesandoutputstatelabels.c)Runningwell-temperedMetadynamicssimulationsalong
thepredictedstateprobabilitiesallowsusefficientlysamplethe+to,-transitionrepeatedly.d.ReweightingallowsustorecoverthefullfreeenergysurfacealongtheRamachandranplot.
a b
c d!
"#
!
"#