aws re:invent 2016: real-time data processing using aws lambda (svr301)
TRANSCRIPT

© 2016, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
Cecilia DengSoftware Developer
AWS Lambda
12/01/2016
SVR301
Real-Time Processing Using AWS
Lambda
Anders FritzSenior Manager
ThomsonReuters
Marco PierleoniLead Software Developer
Thomson Reuters

What to Expect from the Session
• What kinds of real time events can trigger lambda?
• How does Lambda pull and process streams?
• What are some stream processing behaviors?
• Hear how Thomson Reuters went real time with AWS
Lambda

Flavors of real time event sources
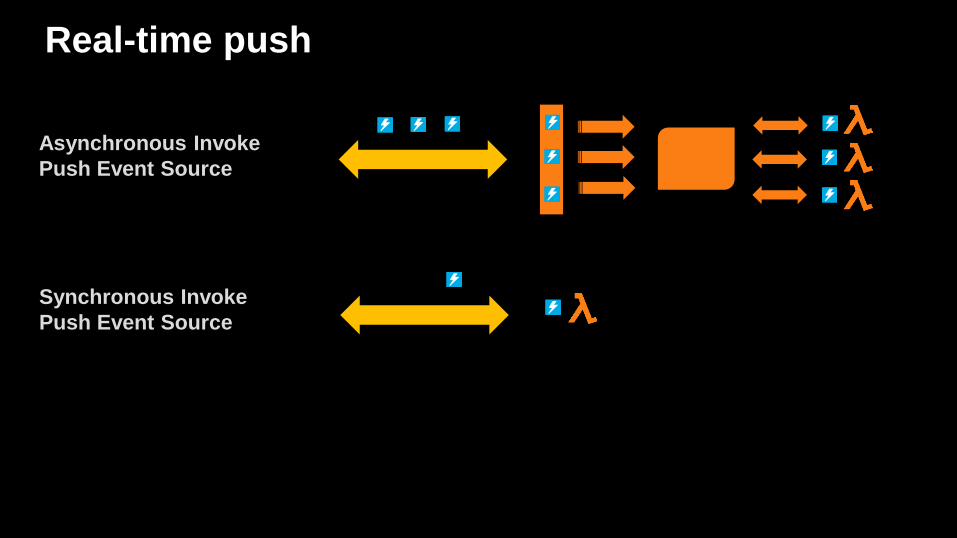
Asynchronous Invoke
Push Event Source
Synchronous Invoke
Push Event Source
Stream
Pull Event Source
S3
async invoke
Alexa skillsync invoke
Pull then sync invoke
DynamoDB
Update Stream

Real-time push

Real-time push
Who?
• Any integrator that uses AWS Lambda invoke API
• E.g., Amazon S3, Amazon SNS, Amazon Alexa, AWS IoT
What?
• Event sources sending events to Lambda for processing
How?
• Real-time triggered events owned by event source
• Real-time processing owned by Lambda invoke methods
Real-time push
Synchronous Invoke
Push Event Source
Asynchronous Invoke
Push Event Source

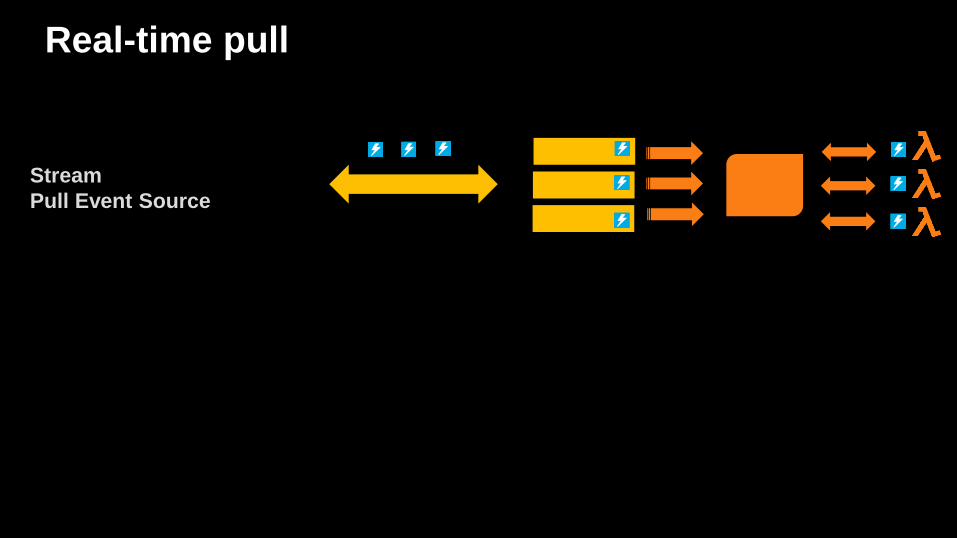
Real-time pull

Real-time pull
Who?
• Amazon Kinesis and DynamoDB update streams
What?
• Lambda grabbing events from a stream for processing
How?
• Mapping maintained by Lambda
• Real-time triggered events owned by DDB or Kinesis
producer
• Real-time processing owned by Lambda stream polling
component and invoke methods
Real-time pull
Stream
Pull Event Source

Processing streams

Processing streams: Kinesis setup
Streams
▪ Made up of shards
▪ Each shard supports writes up to 1 MB/s
▪ Each shard supports reads up to 2 MB/s
▪ Each shard supports 5 reads/s
Data
▪ All data is stored and replayable for 24 hours by default
▪ Make sure partition key distribution is even to optimize parallel throughput
▪ Pick a key with more groups than shards

Processing streams: Lambda setup
Memory
▪ CPU is proportional to the memory
configured
▪ More memory means faster execution,
if CPU bound
▪ More memory means larger sized
record batches can be processed
Timeout
• Increasing timeout allows for longer functions, but more wait in case of
errors
Permission model
• The execution role defined for Lambda must have permission to access
the stream
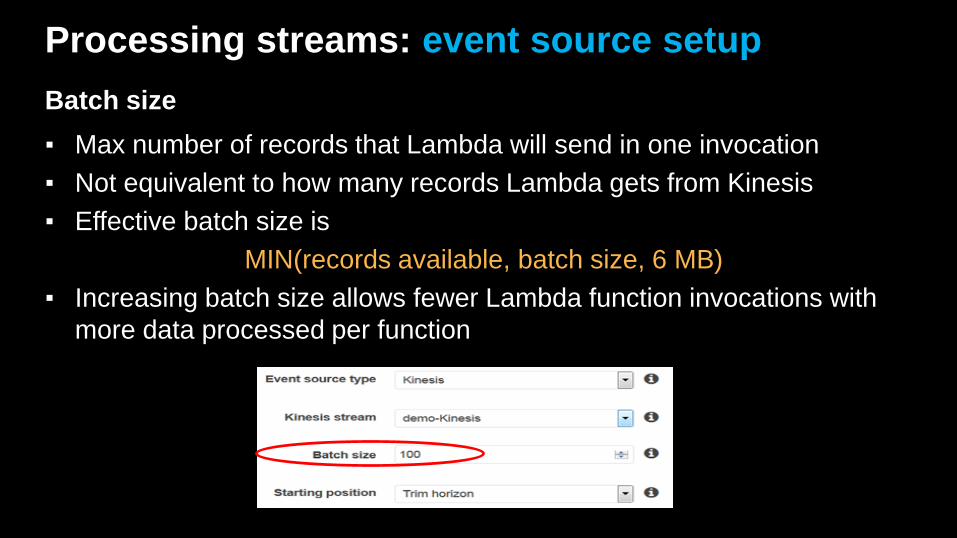
Processing streams: event source setup
Batch size
▪ Max number of records that Lambda will send in one invocation
▪ Not equivalent to how many records Lambda gets from Kinesis
▪ Effective batch size is
MIN(records available, batch size, 6 MB)
▪ Increasing batch size allows fewer Lambda function invocations with
more data processed per function
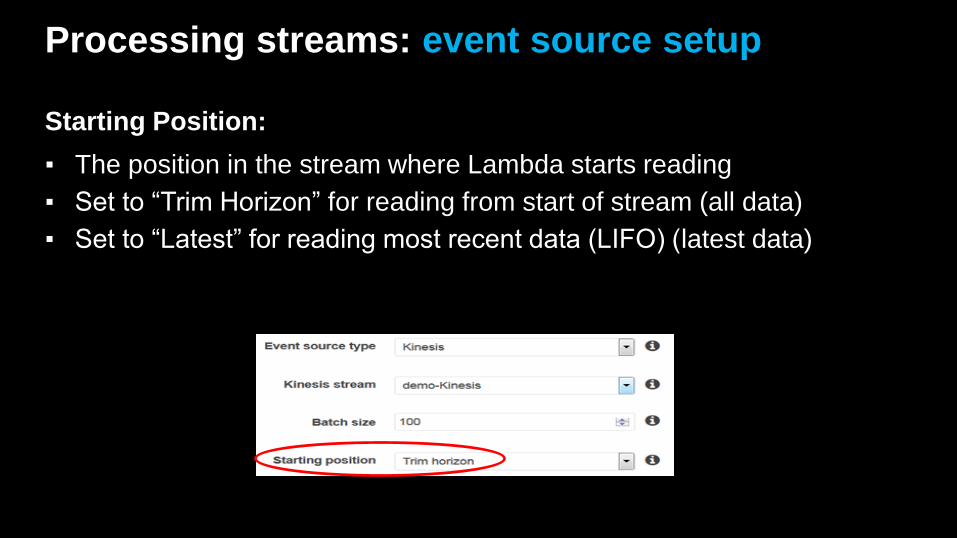
Processing streams: event source setup
Starting Position:
▪ The position in the stream where Lambda starts reading
▪ Set to “Trim Horizon” for reading from start of stream (all data)
▪ Set to “Latest” for reading most recent data (LIFO) (latest data)
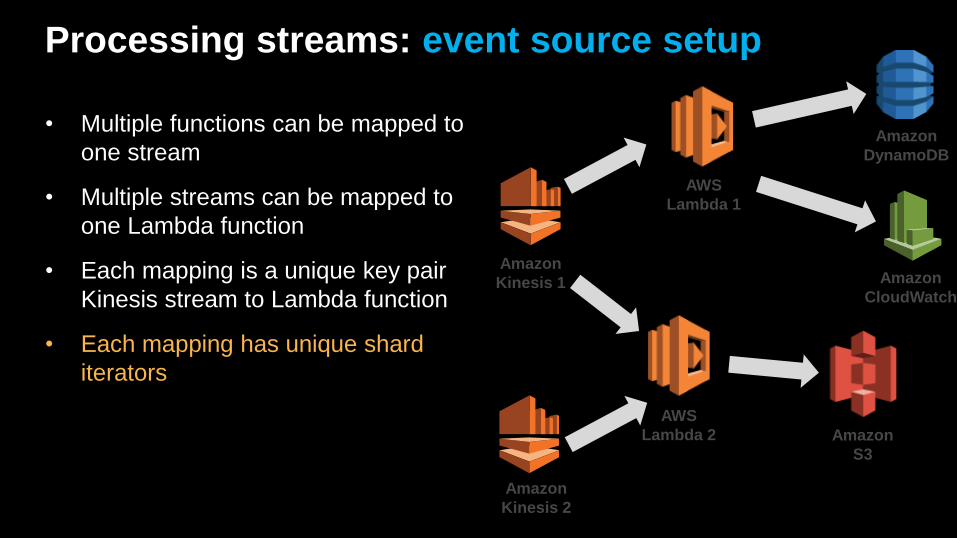
Processing streams: event source setup
Amazon
Kinesis 1
AWS
Lambda 1
Amazon
CloudWatch
Amazon
DynamoDB
AWS
Lambda 2 Amazon
S3
• Multiple functions can be mapped to
one stream
• Multiple streams can be mapped to
one Lambda function
• Each mapping is a unique key pair
Kinesis stream to Lambda function
• Each mapping has unique shard
iterators
Amazon
Kinesis 2

Processing streams: under the hoodEvent received by Lambda function is a collection of records from the stream
{ "Records": [ {
"kinesis": { "partitionKey": "partitionKey-3",
"kinesisSchemaVersion": "1.0",
"data": "SGVsbG8sIHRoaXMgaXMgYSB0ZXN0IDEyMy4=",
"sequenceNumber": "49545115243490985018280067714973144582180062593244200961" },
"eventSource": "aws:kinesis",
"eventID": "shardId-000000000000:49545115243490985018280067714973144582180062593244200961", "invokeIdentityArn": "arn:aws:iam::account-id:role/testLEBRole",
"eventVersion": "1.0",
"eventName": "aws:kinesis:record",
"eventSourceARN": "arn:aws:kinesis:us-west-2:35667example:stream/examplestream",
"awsRegion": "us-west-2" } ] }

Processing streams: under the hood
Polling
▪ Concurrent polling and processing per shard
▪ Polls every 250 ms if no records found
▪ Grab as much as possible in one GetRecords call
Batching
▪ Sub batch in memory for invocation payload
Synchronous invocation
▪ Batches invoked as synchronous RequestResponse type
▪ Lambda honors Kinesis at least once semantics
▪ Each shard blocks on in order synchronous invocation

Processing streams: under the hood
Per Shard:
▪ Lambda calls GetRecords with max limit from Kinesis (10 k or 10 MB)
▪ If no record, wait 250 ms
▪ From in memory, sub batches and formats records into Lambda payload
▪ Invoke Lambda with synchronous invoke
… …Source
Kinesis Lambda Polling Logic
Shards
Lambda will scale automaticallyScale Kinesis by adding shards
Batch sync invokesPolls

Processing streams: how it works
▪ Lambda blocks on ordered processing for each individual shard
▪ Increasing # of shards with even distribution allows increased concurrency
▪ Batch size may impact duration if the Lambda function takes longer to process
more records
… …Source
Kinesis Lambda Polling Logic
Shards
Lambda will scale automaticallyScale Kinesis by adding shards
Batch sync invokesPolls

Processing streams: under the hood
▪ Retry execution failures until the record is expired
▪ Retry with exponential backoff up to 60 s
▪ Throttles and errors impacts duration and directly impacts throughput
Kinesis
…Source
Scale Kinesis by adding shards
Lambda Polling Logic
Lambda will scale automatically
Pollsinvoke fail
invoke fail
invoke success
Batch sync invokes

Processing streams: under the hood
▪ Maximum theoretical throughput:
# shards * 2 MB / (s)
▪ Effective theoretical throughput:
( # shards * batch size (MB) ) / ( function duration (s) * retries until expiry)
▪ If put / ingestion rate is greater than the theoretical throughput, consider
increasing number of shards of optimizing function duration to increase
throughput
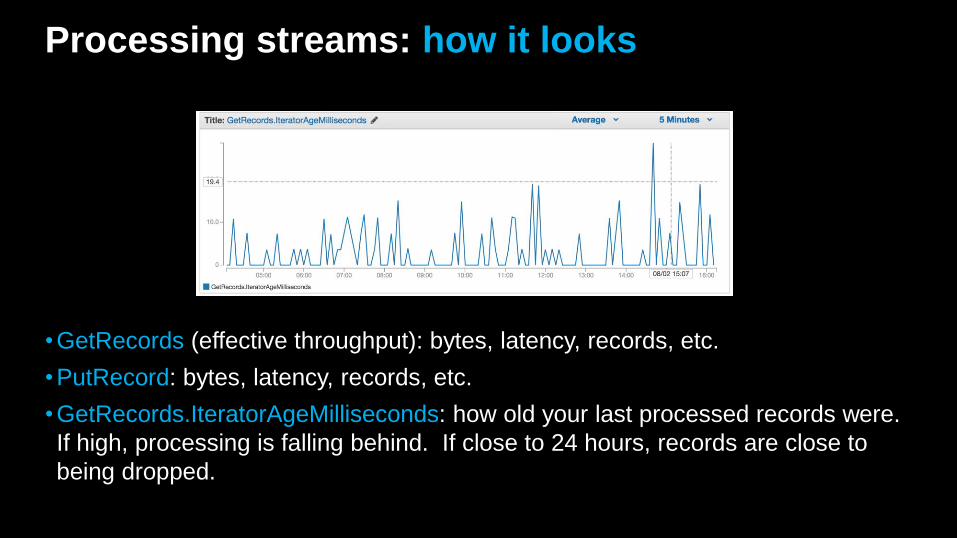
Processing streams: how it looks
•GetRecords (effective throughput): bytes, latency, records, etc.
•PutRecord: bytes, latency, records, etc.
•GetRecords.IteratorAgeMilliseconds: how old your last processed records were.
If high, processing is falling behind. If close to 24 hours, records are close to
being dropped.

Processing streams: how it looks
Amazon CloudWatch Metrics
• Invocation count
• Duration
• Error count
• Throttle count
Amazon CloudWatch Logs
• All Metrics
• Custom logs
• RAM consumed

Processing streams: how it looks
Common observations:
▪ Effective batch size may be less than configured during low throughput
▪ Effective batch size will increase during higher throughput
▪ Increased Lambda duration -> decreased # of invokes and GetRecord calls
▪ Too many consumers of your stream may compete with Kinesis read limits and
induce ReadProvisionedThroughputExceeded errors and metrics

ANALYSING USAGE OF THOMSON
REUTERS PRODUCTS WITH AWS
Anders Fritz & Marco Pierleoni

CHALLENGE
To identify and define a solution for usage analytics tracking that enables product teams to
take ownership of the usage data collected. In addition to tracking and visualizing usage
data it had to;
1. Cross reference Usage
with Business data
4. Require Limited
Maintenance.
3. Auto Scale as data
flow fluctuates.
2. Follow TR Security &
Compliance rules.
5. Launch in 5
months.

SOLUTION

SOLUTION
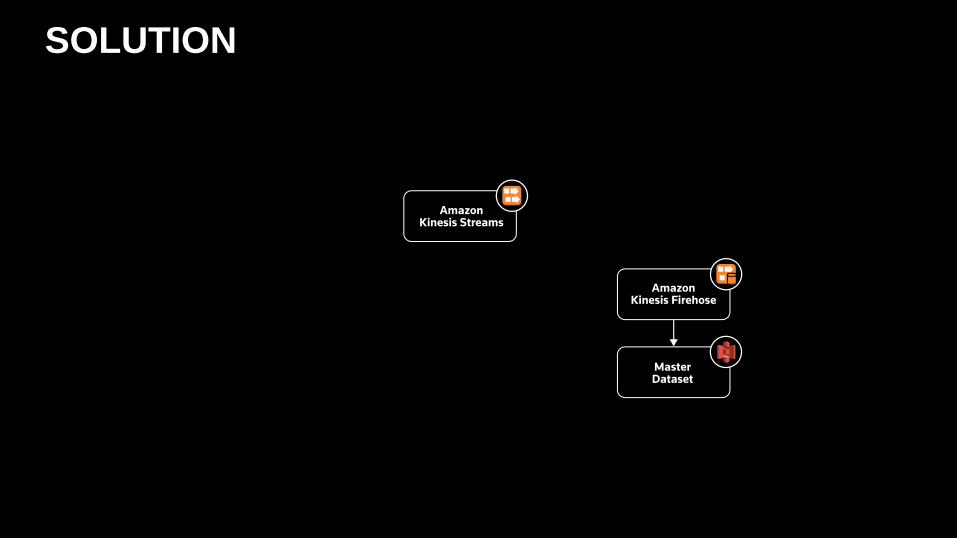
SOLUTION

SOLUTION
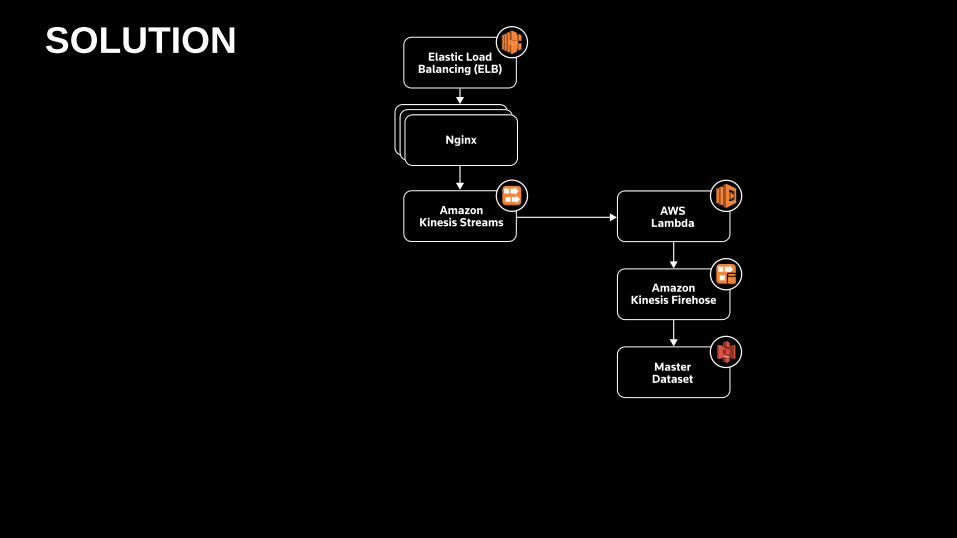
SOLUTION
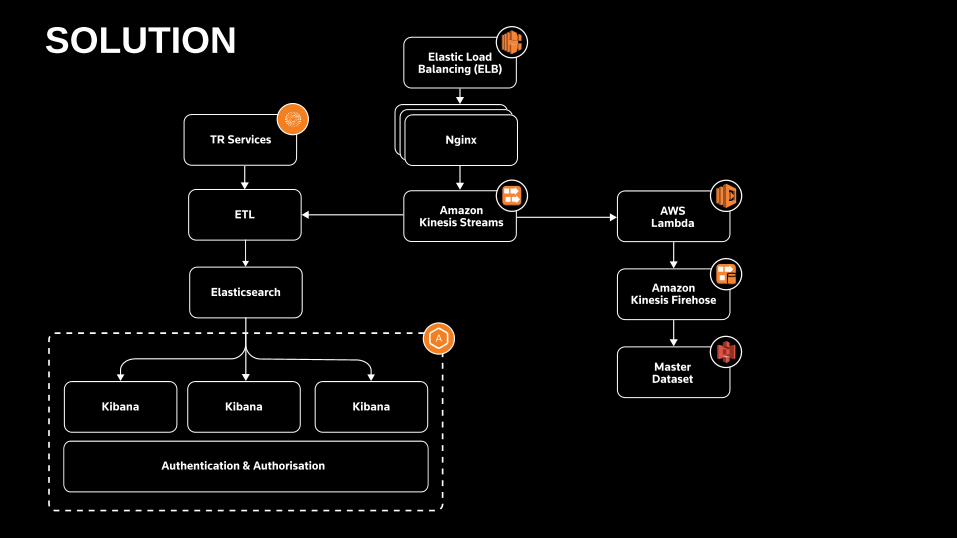
SOLUTION

SOLUTION

• Product Insight is live – adoption rate high.
• Tested 4,000 requests per second while targeting 5bn requests / month.
• Since March – very little maintenance required
• No Outages
• No Downtime
• Cloudwatch monitor everything.
• Latency – Data visible on chart within 10 seconds
• BrExit and US elections tested autoscaling.
• US elections ~16m events – normally ~ 6-8m events / day.
• UK EU referendum (BrExit) ~ 10m events – normally ~ 5m events / day
OUTCOME
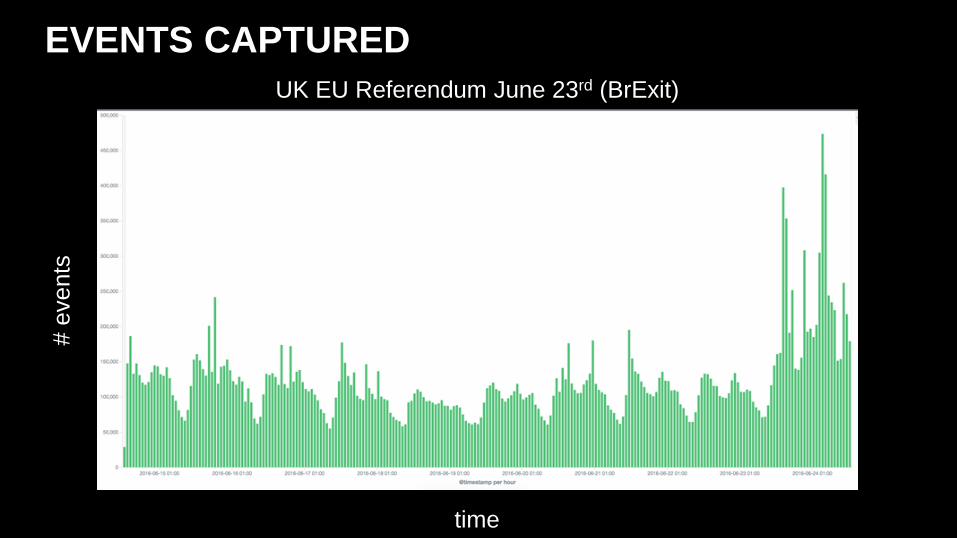
EVENTS CAPTURED
UK EU Referendum June 23rd (BrExit)
time
# e
vents

EVENTS CAPTURED
US Elections November 8th
time
# e
vents

Thank you!

Remember to complete
your evaluations!