backprojection project update january 2002
DESCRIPTION
Backprojection Project Update January 2002. Haiqian Yu Miriam Leeser Srdjan Coric. Outline. Review of backprojection algorithm Hardware considerations Wildstar implementation and some results Comparison of Wildstar and Firebird Current work Issues and some proposals Future work. - PowerPoint PPT PresentationTRANSCRIPT

1
Backprojection Project Update January 2002
Haiqian Yu
Miriam Leeser
Srdjan Coric

2
Outline
• Review of backprojection algorithm
• Hardware considerations
• Wildstar implementation and some results
• Comparison of Wildstar and Firebird
• Current work
• Issues and some proposals
• Future work
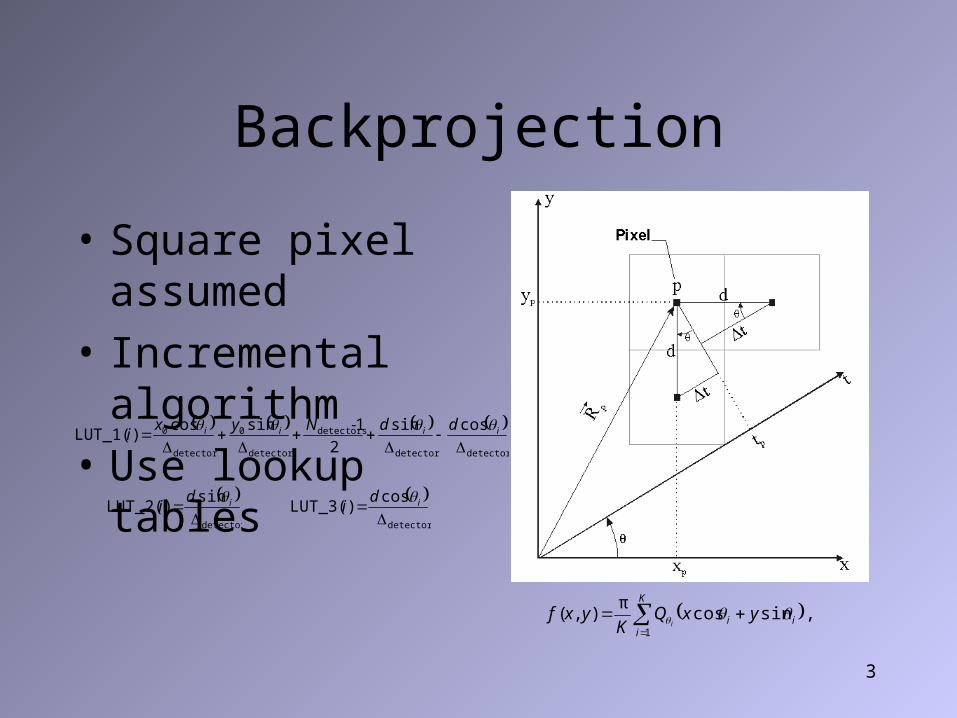
3
Backprojection
• Square pixel assumed
• Incremental algorithm
• Use lookup tables
, sin cosπ
) ,(1
ii
K
i
yxQK
yxfi
detectordetector
detectors
detector
0
detector
0 cossin
2
1sincos)LUT_1(
iiii dd-Nyx
i
detector
sin)LUT_2(
id
i
detector
cos)LUT_3(
id
i

4
Sinogram data address
generation
Sinogram data retrieval
Linearinterpolation
Dataaccumulation
Datawrite
Dataread
Sinogram data prefetch
Data Flow Block Diagram

5
Hardware ImplementationData Flow

6
Parameters selected in our hardware implementation
• Fixed point data is used
• Quantization bits for the sinogram: 9 bits
• Interpolation factor bits: 3 bits
• Restored backprojection data width: 25 bits
• Lookup table width: – table1: 15 bits
– table2: 16 bits
– table3: 17 bits

7
Simple Architecture-One Projection Processing
ROUN D
EVENRAM
ODDRAM
EVENRAM
ODDRAM
SW
AP
SU
B MU
LT
AD
D
LOCALRAM
LOCALRAM
MU
X
LUT 1
LUT 2
LUT 3
PROJECTIONCOUN TER
SU
BMU
X
MU
X
AD
D
DE
MU
X
W RITEADDR ESSCOUN TER
MU
XM
UX
AD
D
10
15
16
17
25
25
25
25
25
5 4
10
9
9
9
MEZZAN INERAM
9
9
10
13
14
25
9
15
25
++

8
Advanced Architecture-Four Projection Parallel Processing
SU
B
ROUND
ROUND
ROUND
SU
BS
UB
LUT 3.1
LUT 3.2
LUT 2.1
LUT 2.2
LUT 1.1
LUT 1.2
LUT 4.1
LUT 4.2
EVENWRITE
COUNTERODD
WRITECOUNTER
ODDRAMODD
RAM
EVENRAMEVEN
RAM
ODDRAMODD
RAM
EVENRAMEVEN
RAM
ODDRAMODD
RAM
EVENRAMEVEN
RAM
ODDRAMODD
RAM
EVENRAMEVEN
RAM
SU
B
SU
BS
UB
SU
BS
UB M
UL
TM
UL
TM
UL
TM
UL
T
AD
D
PROJECTIONCOUNTER
MU
X
AD
D
LUT 1.3
MU
X
AD
D
LUT 2.3
MU
X
AD
D
LUT 3.3
MU
X
AD
D
LUT 4.3
DE
MU
X
ROUND
DE
MU
XD
EM
UX
DE
MU
X
MU
XM
UX
MU
XM
UX
SW
AP
MU
XM
UX
SW
AP
MU
XM
UX
SW
AP
MU
XM
UX
SW
AP
MU
XM
UX
AD
D
AD
DA
DD
AD
D
AD
DA
DD
AD
D LOCALRAM
LOCALRAM
15
16
2525
2525
25
17
5 4
9
9
10
9
9
10
14
1315
16
17
25
25
9
9
8
LEFTMEZZANINE
RAM
RIGHTMEZZANINE
RAM
4 9
4 9

9
Some Results

10
Performance Results on Wildstar: Software vs. FPGA Hardware
A Software - Floating point - 450 MHz Pentium : ~ 240 s
B Software - Floating point - 1 GHz Dual Pentium : ~ 94 s
C Software - Fixed point - 450 MHz Pentium : ~ 50 s
D Software - Fixed point - 1 GHz Dual Pentium : ~ 28 s
E Hardware - 50 MHz : ~ 5.4 s
F Hardware (Advanced Architecture) - 50 MHz : ~ 1.3 s
0
50
100
150
200
250
A B C D E F
Parameters: 1024 projections
1024 samples per projection
512*512 pixels image
9-bit sinogram data
3-bit interpolation factor

11
Board Parameters Compared
WildStar FireBird 3 Xilinx® VIRTEX™ 1000 FPGAs with
3 million system gates (Processing can’t bedistributed to different chips, only one chipis used.)
1 VirtexTM E FPGA Processing Element -XCV2000E with 2 million gates
Processing clock rates up to 100MHz Processing clock rates up to 150MHz
1.6 GB/s I/O bandwidth 4.2 GB/s I/O bandwidth
6.4 GB/s memory bandwidth (1.3GB/s isused)
6.6 GB/s memory bandwidth
40MB of 100MHz Synchronous ZBT SRAM(We only use part of it)
30MB of 150MHz Synchronous ZBT SRAM

12
Logical Block Diagram of WildStar

13
Backprojection on Wildstar• PE1 is the only processor element used
• Not all the memory is used to store the data – Left & Right PE1 Mezzanine Mem0 are used to store sinogram
data, the input data for backprojection
– Left & Right PE1 Local memory banks are used to store the results
• The bottleneck is PE1’s block RAM (on chip memory) size.– XCV1000 has 32 block RAMs, each has 4096 bits,
totaling 131,072 bits
– We used 73,728 bits in our implementation, the maximum bits we can use
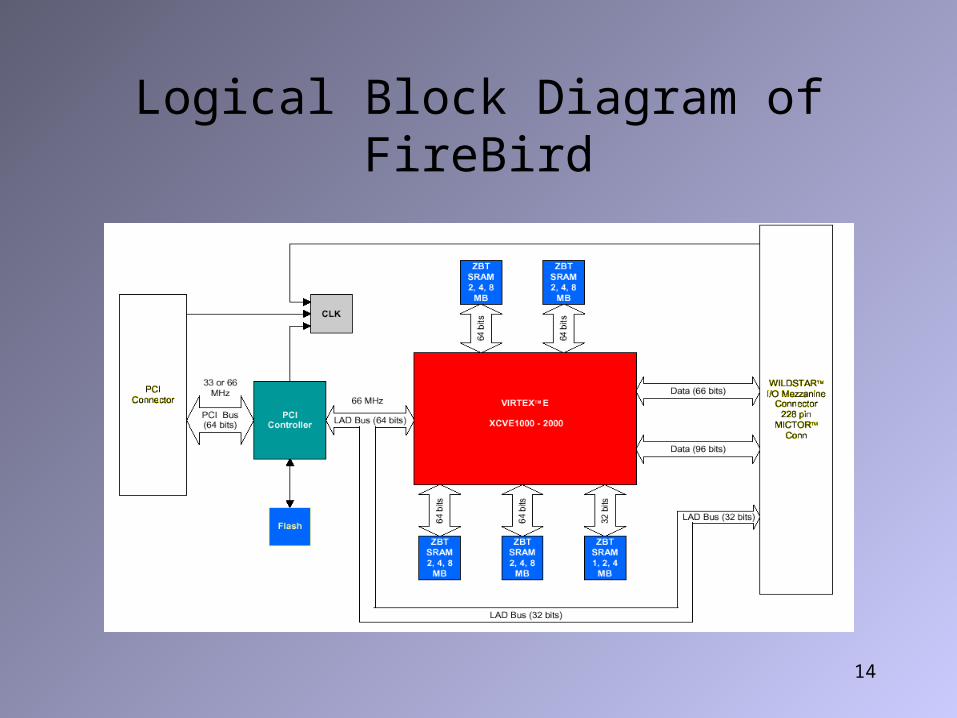
14
Logical Block Diagram of FireBird

15
Backprojection on FireBird
• XCV2000E has 160 block RAMs with totally 655,360 bits, 5 times that of XCV1000.
• FireBird has 5 on board memory banks, 4 that are 64 bits wide, one that is 32 bits wide.
• The memory interface is different from WildStar.

16
Current Work• Firebird configuration:
– parameters setting for simulation scripts– synthesis settings– C environment settings
• Getting familiar with FireBird memory interface.
• Implementing simple architecture of parallel-beam backprojection.

17
Issues• Because of increased CLBs on Virtex2000E:
we can increase parallelism in backprojection processing by a factor of 5 or 20 projection parallelism.
• On chip block RAM is no longer the bottleneck
• Memory bandwidth to off-chip memory is the new bottleneck:– To process 20 projection at one time, we need to load 40
projections (for interpolation), or 2*4*5*9=360 bits in one clock cycle
– Firebird has 4*64-bit memories, we need 6 for 20 projections
– We should be able to achieve 12 projections in parallel

18
Imagerows
Projections
Imagecolumns
Data dependency for backprojection processing
Parallelism Improvement
Imagerows
ProjectionsImage
columns
Current parallelism we used in WildStar
Desired parallelism we would implement in FireBird
Imagerows
ProjectionsImage
columns

19
Example of Using four memory banks to increase the speed
EvenRAM
512*9 bits
OddRAM
512*9 bits
EvenRAM
512*9 bits
OddRAM
512*9 bits
EvenRAM
512*9 bits
OddRAM
512*9 bits
EvenRAM
512*9 bits
OddRAM
512*9 bits
MemoryBank Even64-bit width
9 Bits
9 Bits
9 Bits
9 Bits
MemoryBank Odd
64-bit width
9 Bits
EvenRAM
512*9 bits
OddRAM
512*9 bits
EvenRAM
512*9 bits
OddRAM
512*9 bits
7*9=63BitsMaximum data width provided
by memory banksEvenRAM
512*9 bits
OddRAM
512*9 bits
EvenRAM
512*9 bits
OddRAM
512*9 bits
...
EvenRAM
512*9 bits
OddRAM
512*9 bits
EvenRAM
512*9 bits
OddRAM
512*9 bits
EvenRAM
512*9 bits
OddRAM
512*9 bits
EvenRAM
512*9 bits
OddRAM
512*9 bits
MemoryBank Even64-bit width
9 Bits
9 Bits
9 Bits
9 Bits
MemoryBank Odd
64-bit width
9 Bits
EvenRAM
512*9 bits
OddRAM
512*9 bits
EvenRAM
512*9 bits
OddRAM
512*9 bits
7*9=63BitsMaximum data width provided
by memory banksEvenRAM
512*9 bits
OddRAM
512*9 bits
EvenRAM
512*9 bits
OddRAM
512*9 bits
...
9 Bits
9 Bits
9 Bits
9 Bits
9 Bits
9 Bits
Processing
EvenRAM
512*9 bits
OddRAM
512*9 bits
EvenRAM
512*9 bits
OddRAM
512*9 bits
EvenRAM
512*9 bits
OddRAM
512*9 bits
EvenRAM
512*9 bits
OddRAM
512*9 bits
MemoryBank Even64-bit width
9 Bits
9 Bits
9 Bits
9 Bits
9 Bits
MemoryBank Odd
64-bit width
9 Bits
9 Bits
9 Bits
EvenRAM
512*9 bits
OddRAM
512*9 bits
EvenRAM
512*9 bits
OddRAM
512*9 bits
EvenRAM
512*9 bits
OddRAM
512*9 bits
EvenRAM
512*9 bits
OddRAM
512*9 bits
36Bits
36Bits
Processing

20
More memory issues
• If we use four 64-bit width memory banks to store the sinogram data, we have only one 32-bit memory bank for storing the result
• Since the j-th step results depends on (j-1)-th results, we will have to use read-modify-write method to store the final data. This will decrease the overall speed.
• Possible solution: – fewer projections in parallel
– use more memory to store results

21
Alternatives
• An alternative is to use 2*512 cycles to double the number of projection processed. – However, we need to make sure processing all the data needs more
than 1024 clock cycle.
– That will introduce extra delay for the first time processing, for the consequent processing, data is pre-fetched while processing the current projection.
• We can also modify the hardware structure to see if there are some other ways to explore parallelism.

22
Future Work
• Implement parallel backprojection on FireBird– With bridge to host– Without bridge to host
• Investigate parallelism to optimize performance