beijing engineering research center of mixed reality and ......2018/02/07 · designed by dominic...
TRANSCRIPT

Multi-Level Context Ultra-Aggregation
for Stereo Matching
1 Beijing Institute of Technology 2 TKLNDST, CS, Nankai University
3 National Key Laboratory of Science and Technology on Blind Signal Processing
4 AICFVE, Beijing Film Academy
Guang-Yu Nie1, Ming-Ming Cheng2, Yun Liu2, Zhengfa Liang3,
Deng-Ping Fan2, Yue Liu1,4, and Yongtian Wang1,4
IGTA2019
Beijing Engineering Research Center
of Mixed Reality and Advanced Display

Depth from Stereo
IGTA2019
What is stereo?
Source: http://www.vudream.com/reasons-why-virtual-reality-is-happening-now/3d-brain/
Depth from images is a very intuitive ability
Can we do the same using computers?
Given two images of a scene from (slightly)
different viewpoints, we are able to infer depth
Yes
Designed by Dominic Cheng/Depth from Stereo/February 7, 2018
3D Stereo Scene

IGTA2019
Geometry in stereoDepth from Stereo
Think of images as projections of 3D points
(in the real world) onto a 2D surface (image
plane)
XA is the projection of X, X1, X2, X3, .... onto
the left image
X, X1, X2, X3 will also project onto the right
image
Designed by Dominic Cheng/Depth from Stereo/February 7, 2018
Source: Schairer, Edward, et al. "Measurements of tip vortices from a full-Scale UH-60A rotor by retro-reflective
background oriented schlieren and stereo photogrammetry." (2013).
Left View Right View

IGTA2019
Geometry in stereoDepth from Stereo
Projections of X1, X2, X3 on right image all lie
on a line
This line is known as an epipolar line
Designed by Dominic Cheng/Depth from Stereo/February 7, 2018
Projections of cameras’ optical centers
OA, OB onto the images
Points eA, eB are known as epipoles All epipolar lines will intersect at epipoles
Left image has corresponding epipolar
line
Source: Schairer, Edward, et al. "Measurements of tip vortices from a full-Scale UH-60A rotor by retro-reflective
background oriented schlieren and stereo photogrammetry." (2013).
Left View Right View

IGTA2019
Geometry in stereoDepth from Stereo
What does this give us?
All 3D points that could have resulted in XA
must have a projection on the right image,
and must be on the epipolar line eB− xB
Designed by Dominic Cheng/Depth from Stereo/February 7, 2018
Given just the left/right images and XA, you
can search on the corresponding epipolar
line in the right image. If you can find the
corresponding match XB, you can uniquely
determine the 3D position of X.Source: Schairer, Edward, et al. "Measurements of tip vortices from a full-Scale UH-60A rotor by retro-reflective
background oriented schlieren and stereo photogrammetry." (2013).
Left View Right View

IGTA2019Designed by Dominic Cheng/Depth from Stereo/February 7, 2018
Source: https://www.ivs.auckland.ac.nz/web/calibration.php http://web.stanford.edu/class/cs231a/lectures/lecture6_stereo_systems.pdf
Epipolar lines can be made parallel
through a process called rectification
Simplifies the process of finding a
match and calculating the 3D point
Geometry in stereoDepth from Stereo

IGTA2019
Geometry in stereo
Source: https://docs.opencv.org/3.0-beta/doc/py_tutorials/py_calib3d/py_depthmap/py_depthmap.htmlLeft View
x x'x
Right View
Depth from Stereodisparity = '
Bfx x
Z
'
'
x x f
O O Z
Problem statement, reformulated:
Find the disparity for every pixel in the left (or right)
image by finding matches in the right (or left) image

IGTA2019
Basic stereo matching algorithmRelated Research
1. If necessary, rectify the two stereo
images to transform epipolar lines
into scanlines
2. For each pixel x in the first image:
Find corresponding epipolar scanline in
the right image
Search the scanline and pick the best
match x’
Compute disparity x-x’ and set depth(x) =
Bf/(x-x’)
Matching cost
Disparity
Source: https://courses.cs.washington.edu/courses/cse455/16wi/notes/11_Stereo.pdf
Correspondence search

IGTA2019
Related ResearchFailures of correspondence search
Textureless surfaces Occlusions, repetition
Non-Lambertian surfaces, specularitiesSource: https://courses.cs.washington.edu/courses/cse455/16wi/notes/11_Stereo.pdf
IGTA2019
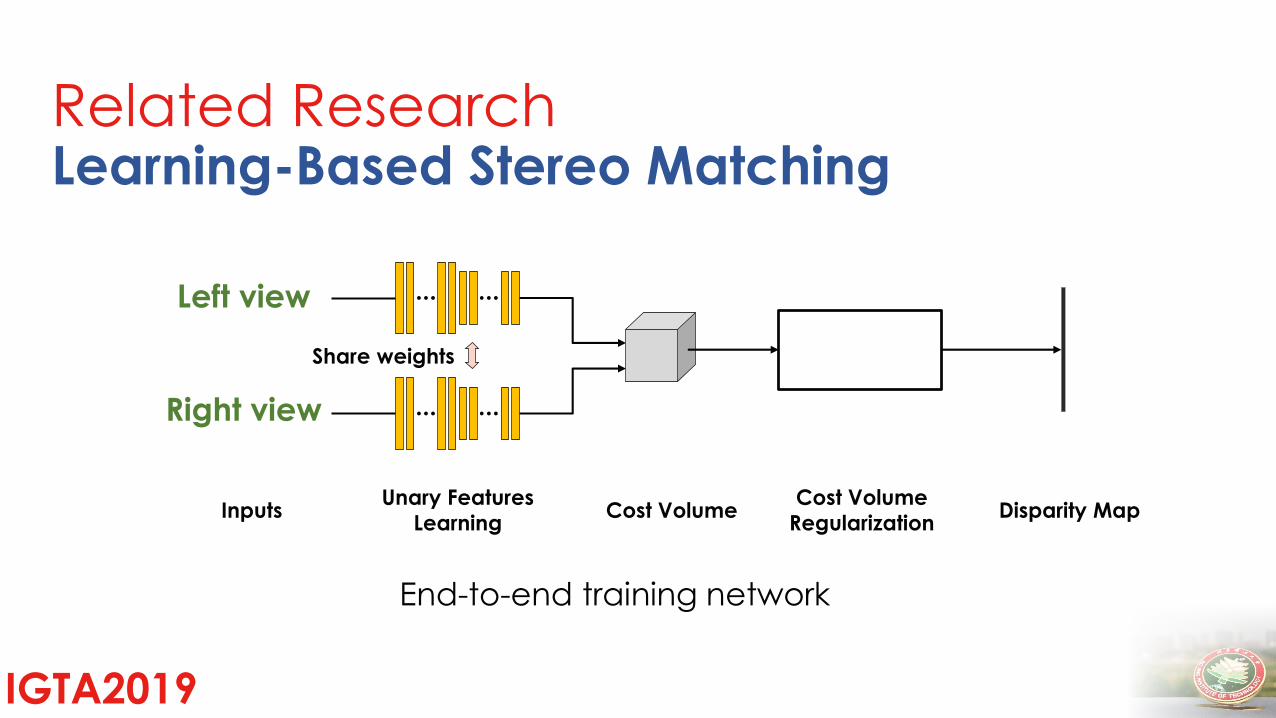
Learning-Based Stereo MatchingRelated Research
Left view
Right view
Share weights
Unary Features
LearningCost Volume Disparity MapInputs
Cost Volume
Regularization
End-to-end training network

Related Research
IGTA2019
GC-Net by Kendall et al.End-to-End Learning of Geometry and Context for Deep Stereo Regression (ICCV’17)

Related Research
IGTA2019
PSM-Net by Chang et al.Pyramid Stereo Matching Network (CVPR’18)

IGTA2019
Learning-Based Stereo MatchingRelated Research
Left view
Right view
Share weights
Unary Features
LearningCost Volume Disparity MapInputs
Cost Volume
Regularization
End-to-end training network
IGTA2019
h0
h1
h2
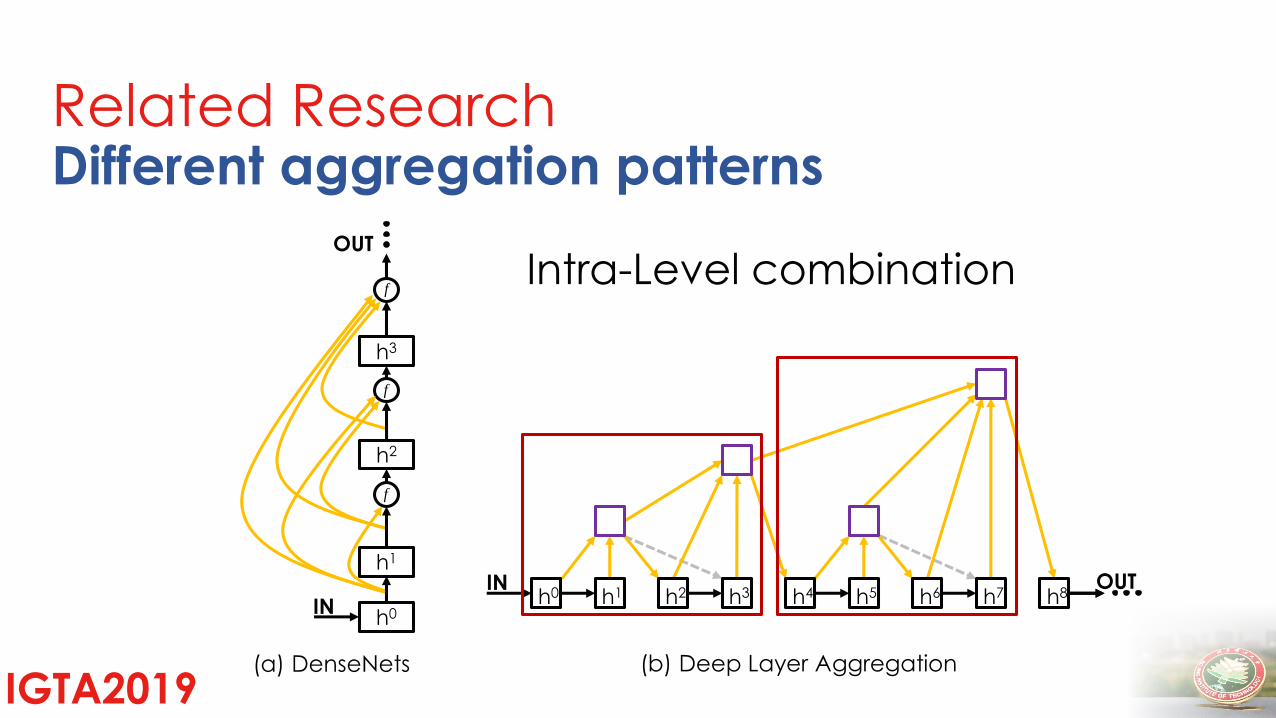
(a) DenseNets (b) Deep Layer Aggregation
INh3h2h1h0 h4 h6h5 h7 h8
OUT
f
f
IN
h3
f
OUT
Related ResearchDifferent aggregation patterns
Intra-Level combination

2-D feature
Receptive field
(a)
F4 F5 F6 F7 F8F0 F1 F2 F3
1
IN
OUT
Method/MCUAMulti-Level Context Ultra-Aggregation
IGTA2019
1
4
1
2
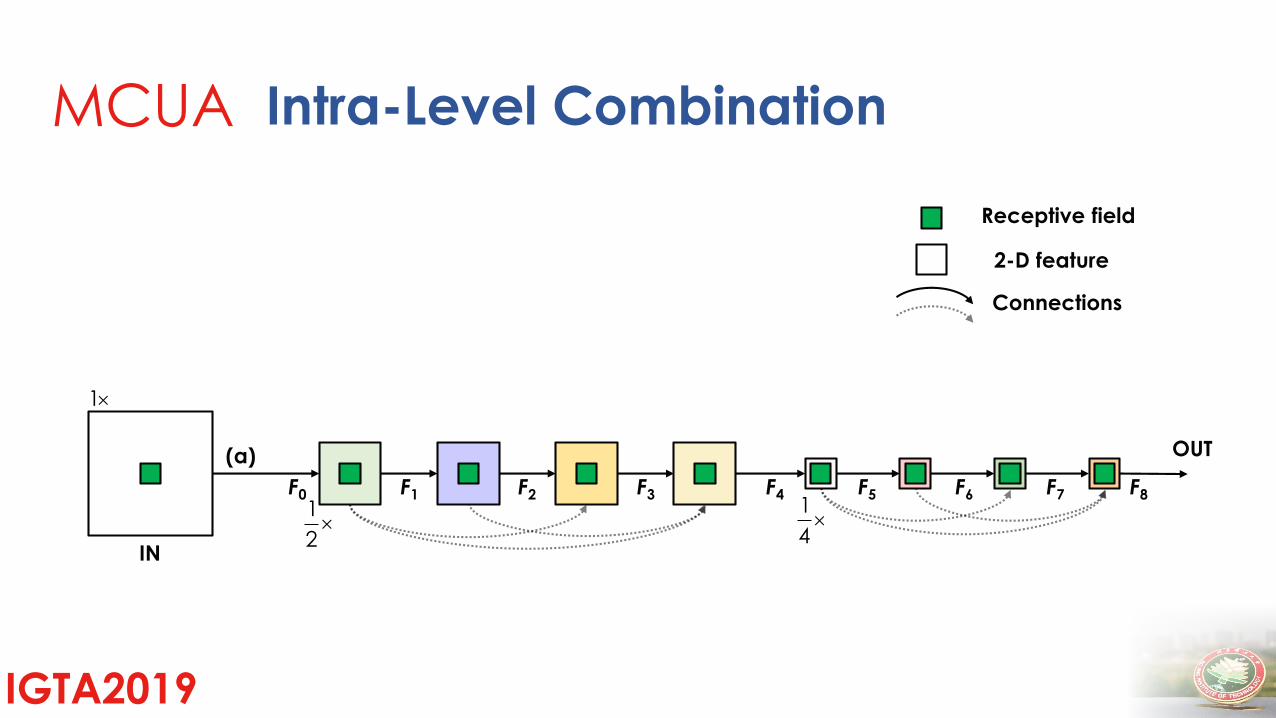
2-D feature
Receptive field
(a)
F4 F5 F6 F7 F8F0 F1 F2 F3
1
IN
OUT
Connections
IGTA2019
1
4
1
2
MCUA Intra-Level Combination

MCUA
(b)
2-D feature
Connections
Receptive field
AvgPool
P0
F0 F1 F2 F3
Share parameters
(a)
F4 F5 F6 F7 F8F0 F1 F2 F3
IN
OUT
IGTA2019
1
4
1
2
1
1
2 1
4
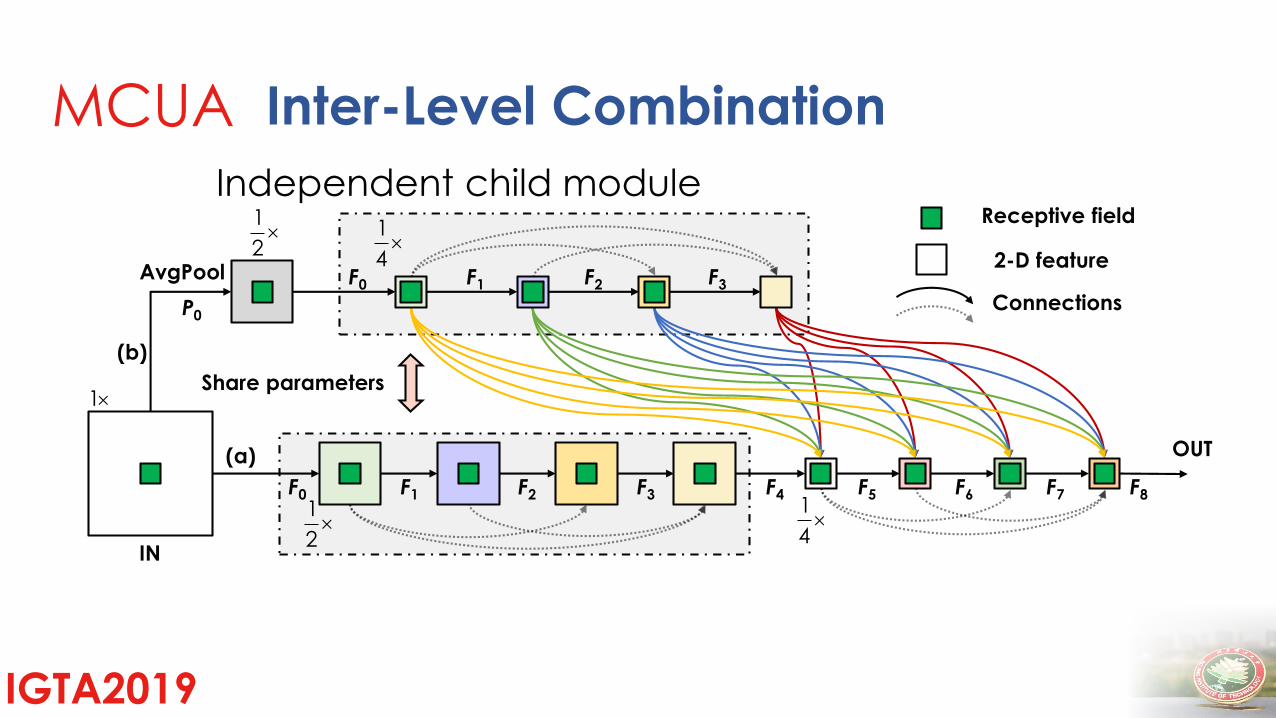
Inter-Level Combination
Independent child module

AvgPool
(b)
2-D feature
Connections
Receptive field
P0
(a)
F4 F5 F6 F7 F8F0 F1 F2 F3
IN
OUT
IGTA2019
MCUA
1
4
1
2
1
1
2
Inter-Level Combination
Independent child module

(b)
2-D feature
Connections
Receptive field
AvgPool
P0
F0 F1 F2 F3
Share parameters
(a)
F4 F5 F6 F7 F8F0 F1 F2 F3
IN
OUT
IGTA2019
MCUA
1
4
1
2
1
1
2 1
4
Inter-Level Combination
Independent child module
IGTA2019
MCUA
(b)
2-D feature
Connections
Receptive field
AvgPool
P0
F0 F1 F2 F3
(a)
F4 F5 F6 F7 F8F0 F1 F2 F3
IN
OUT
1
4
1
2
1
1
2 1
4
Inter-Level Combination
Independent child module
Share parameters
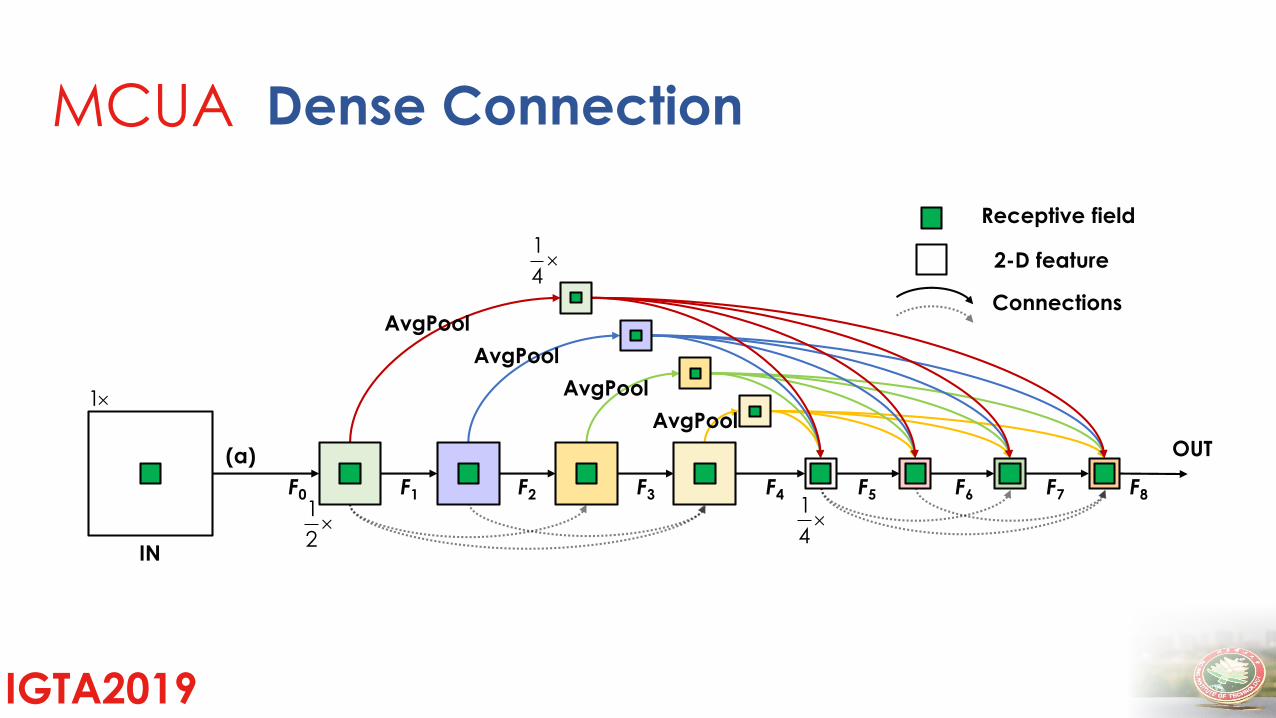
IGTA2019
(a)
2-D feature
Connections
Receptive field
F4 F5 F6 F7 F8F0 F1 F2 F31
4
1
2
IN
OUT
AvgPool
AvgPool
AvgPool
AvgPool1
1
4
MCUA Dense Connection
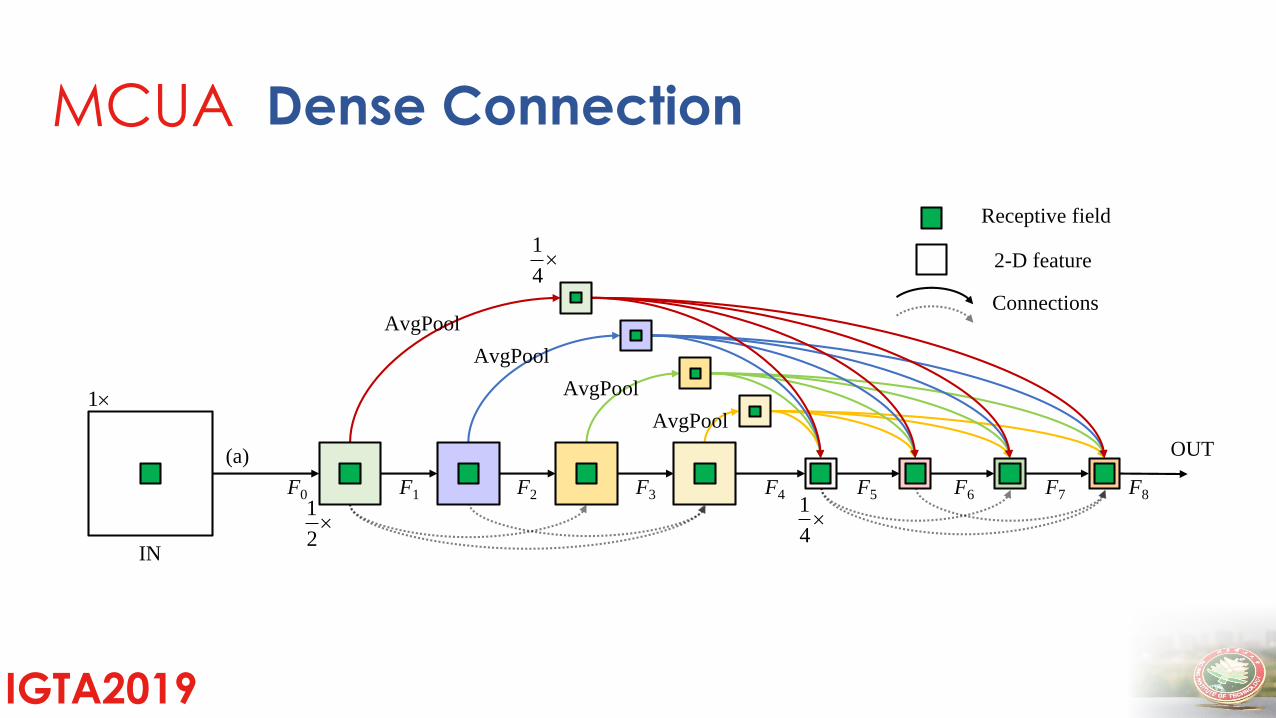
IGTA2019
(a)
2-D feature
Connections
Receptive field
F4 F5 F6 F7 F8F0 F1 F2 F31
4
1
2
IN
OUT
AvgPool
AvgPool
AvgPool
AvgPool1
1
4
MCUA Dense Connection

MCUA
2H
2W
H1
W1
W1
H1
W
H
1 1
1 1
2 2
Receptive Field
IGTA2019
Capture more area

2H
2W
H1
W1
W1
H1
W
H
(a) (b)
IGTA2019

MCUA
IGTA2019
Share weights
Unary Features
LearningCost Volume Disparity MapStereo Images
1
2
1
4
Residual Initial MapInformation
Flow
+
Element-wise
SummationScale
Cost Volume Regularization
Right
Left
Output3
Warped
Map
2-D
Features
3-D
Features
Output1
Output2
1
OutputConcatenation
11
1
1
4
1
2
1
41
Stereo Matching

EMCUA
IGTA2019
Share weights +
Unary Features
LearningCost Volume Disparity MapStereo Images
1
2
1
4
Residual Initial MapInformation
Flow
+
Element-wise
SummationScale
Cost Volume Regularization
Right
Left
Output3
Warped
Map
2-D
Features
3-D
Features
Output1
Output2
1
OutputConcatenation
1
1
1
1
1
4
1
2
1
41
Stereo Matching

Experiment
IGTA2019
Datasets
Left view Right view
Disparity map (Ground truth)
Scene Flow dataset:FlyingThings3D, Driving, Monkaa
KITTI2015/2012 datasets
>39000(35454/4370 train/test) stereo frames
960540 pixel resolution
KITTI2015: 200/200 train/test stereo images
KITTI2012: 194/200 train/test stereo images
1242375 pixel resolutionhttps://lmb.informatik.uni-freiburg.de/resources/datasets/SceneFlowDatasets.en.html
http://www.cvlibs.net/datasets/kitti/eval_scene_flow.php?benchmark=stereo
http://www.cvlibs.net/datasets/kitti/eval_stereo_flow.php?benchmark=stereo
Source:

Experiment
IGTA2019
Train on a lot of data:
Test on Flying Things and KITTI
Scene Flow datasets
Finetuning on KITTI
The training process of EMCUAcontains two steps:
Train MCUA:
Input: 256512 pixel resolution
Optimizer: Adam
Implementation Details
Train EMCUA (+ Residual module)
20+50 epochs on SF dataset (lr=0.01)
600 (lr=0.001) + 400 (lr=0.0001) epochs on KITTI datasets
1 epoch on SF dataset (lr=0.01)
600 (lr=0.001) + 400 (lr=0.0001) epochs on KITTI datasets

Performance
IGTA2019
KITTI2015 dataset
(a) EMCUA (b) PSM-NetIn
pu
tR
esu
ltErr
or
Inp
ut
Re
sult
Err
or
Sample output

Performance
IGTA2019(a) EMCUA (b) PSM-Net
Inp
ut
Re
sult
Err
or
Inp
ut
Re
sult
Err
or
KITTI2012 datasetSample output

Performance
IGTA2019
Residual Module
Residual module is mainly used to improve the performance of
the accuracy of the foreground.
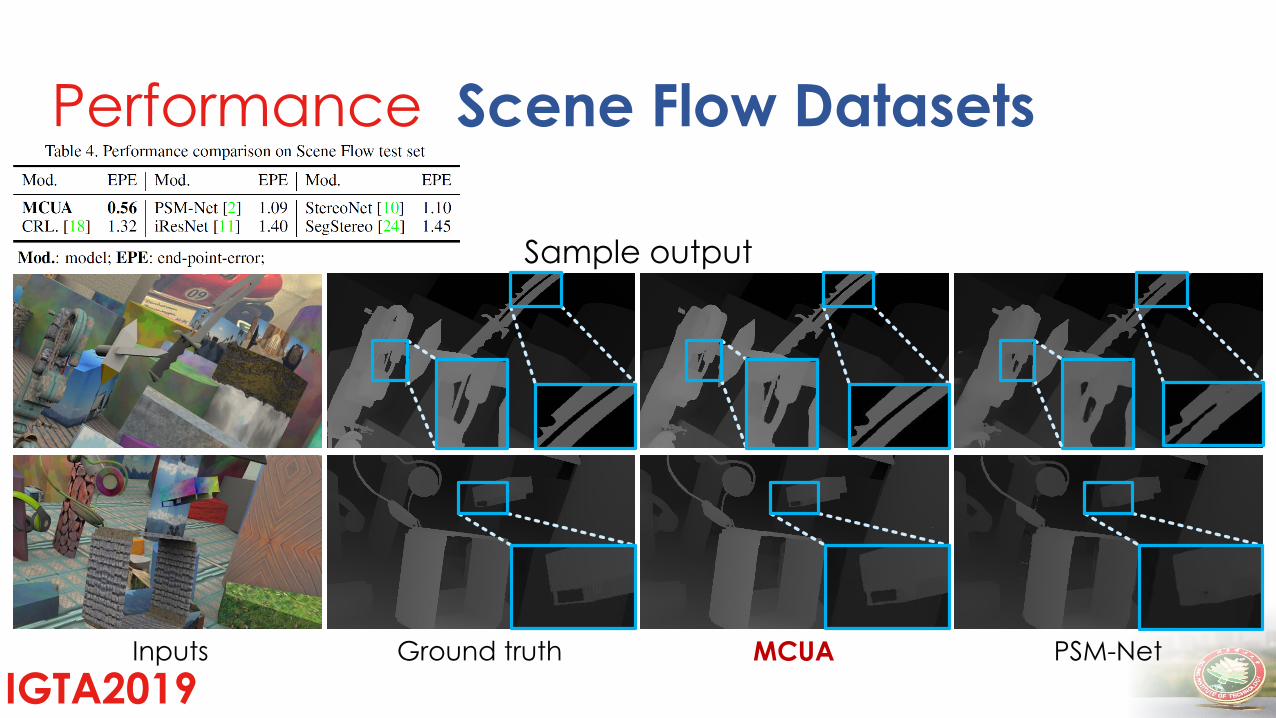
Performance
IGTA2019
MCUAGround truthInputs PSM-Net
Inputs Ground truth MCUA PSM-Net
Scene Flow Datasets
Sample output

Discussion
IGTA2019
Different aggregation schemes
Dense connection
Deep Layer Aggregation
MCUA

Discussion
IGTA2019
Effect of MCUA
(b)
AvgPool
P0
F0 F1 F2 F3
Share parameters
(a)
F4 F5 F6 F7 F8F0 F1 F2 F3
IN
OUT
1
4
1
2
1
1
2 1
4
MCUA

Discussion
IGTA2019
Effect of MCUA
(b)
AvgPool
P0
F0 F1 F2 F3
(a)
F4 F5 F6 F7 F8F0 F1 F2 F3
IN
OUT
1
4
1
2
1
1
2 1
4
UChi

Discussion
IGTA2019
Effect of MCUA
(b)
AvgPool
P0
F0 F1 F2 F3
Share parameters
(a)
F4 F5 F6 F7 F8F0 F1 F2 F3
IN
OUT
1
4
1
2
1
1
2 1
4
Chi
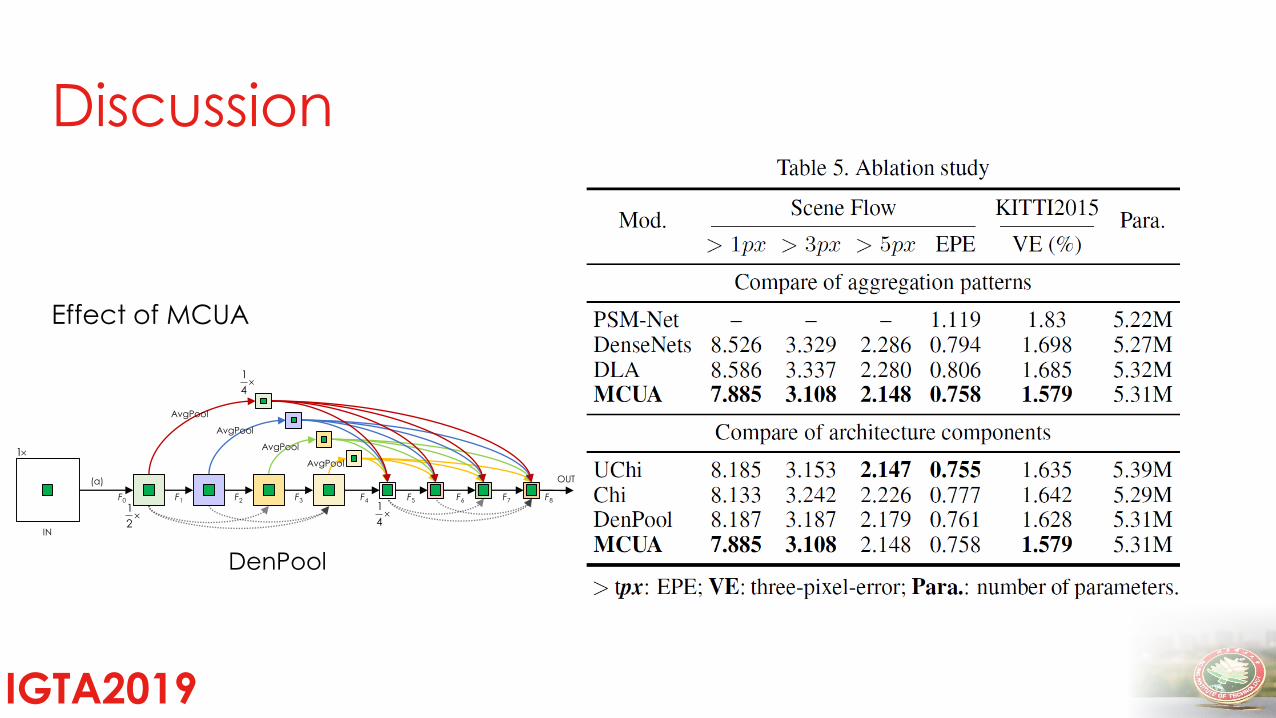
Discussion
IGTA2019
Effect of MCUA
(a)
F4 F5 F6 F7 F8F0 F1 F2 F3
1
4
1
2
IN
OUT
AvgPool
AvgPool
AvgPool
AvgPool1
1
4
DenPool

Conclusion
IGTA2019
We propose a general feature aggregation scheme, MCUA,
which contains both intra- and inter-level feature aggregation,
while DenseNets and DLA contain only intra-level aggregation.
We use an independent child module to introduce inter-level
aggregation, which enlarges the receptive fields and captures
more context information.

Future work
IGTA2019
Dataset bias (Stereo matching Depth estimation)
Real-time stereo matching

IGTA2019
Datasets
Left view Right view
Disparity map (Ground truth)
Scene Flow dataset:FlyingThings3D, Driving, Monkaa
KITTI2015/2012 datasets
>39000(35454/4370 train/test) stereo frames
960540 pixel resolution
KITTI2015: 200/200 train/test stereo images
KITTI2012: 194/200 train/test stereo images
1242375 pixel resolutionhttps://lmb.informatik.uni-freiburg.de/resources/datasets/SceneFlowDatasets.en.html
http://www.cvlibs.net/datasets/kitti/eval_scene_flow.php?benchmark=stereo
http://www.cvlibs.net/datasets/kitti/eval_stereo_flow.php?benchmark=stereo
Source:
Future work

Future work
IGTA2019
Dataset bias (Stereo matching Depth estimation)
Real-time stereo matching
Matching cost
computaion
Cost Aggregation
Disparity Selection
Disparity refinement
Step1 Step2 Step3 Step4
Input images
Disparity map
Framework of traditional stereo vision algorithm
Correspondence search
Matching cost: SSD, SAD, or normalized correlation
2
( , )
SSD , , , ,l r
x y w
x y d I x y I x d y
Source: A. Fusiello, U. Castellani, and V. Murino, “Relaxing symmetric multiple windows stereo using Markov Random Fields,”
in Computer Vision and Pattern Recognition, vol. 2134 of Lecture Notes in Computer Science, pp. 91–105, Springer, 2001.

Future work
IGTA2019
Dataset bias (Stereo matching Depth estimation)
Real-time stereo matching
Qualitative results on the FlyingThings3D test set
StereoNet architecture (ECCV’18)
Source: Khamis, Sameh, et al. "Stereonet: Guided hierarchical refinement for real-time edge-aware depth prediction." Proceedings of
the European Conference on Computer Vision (ECCV). 2018.

Thanks for your watching.
Beijing Engineering Research Center
of Mixed Reality and Advanced Display

Guang-Yu Nie
IGTA201904/19-20/2019
Beijing Engineering Research Center
of Mixed Reality and Advanced Display