big data a small introduction prabhakar tv iit kanpur, india [email protected] much of this content is...
TRANSCRIPT

Big Dataa small introduction
Prabhakar TVIIT Kanpur, India
Much of this content is generously borrowed from all over the Internet

2
Let us start with a storyCan we predict that a customer is expecting a
baby?

3
“As Pole’s(Statistician at Target) computers crawled through the data, he was able to identify about 25 products that, when analyzed together, allowed him to assign each shopper a “pregnancy prediction” score. More important, he could also estimate her due date to within a small window, so Target could send coupons timed to very specific stages of her pregnancy”

4
What is Big Data?How big is Big?
Constantly moving targetMore than 100 petabytes in 2012

5
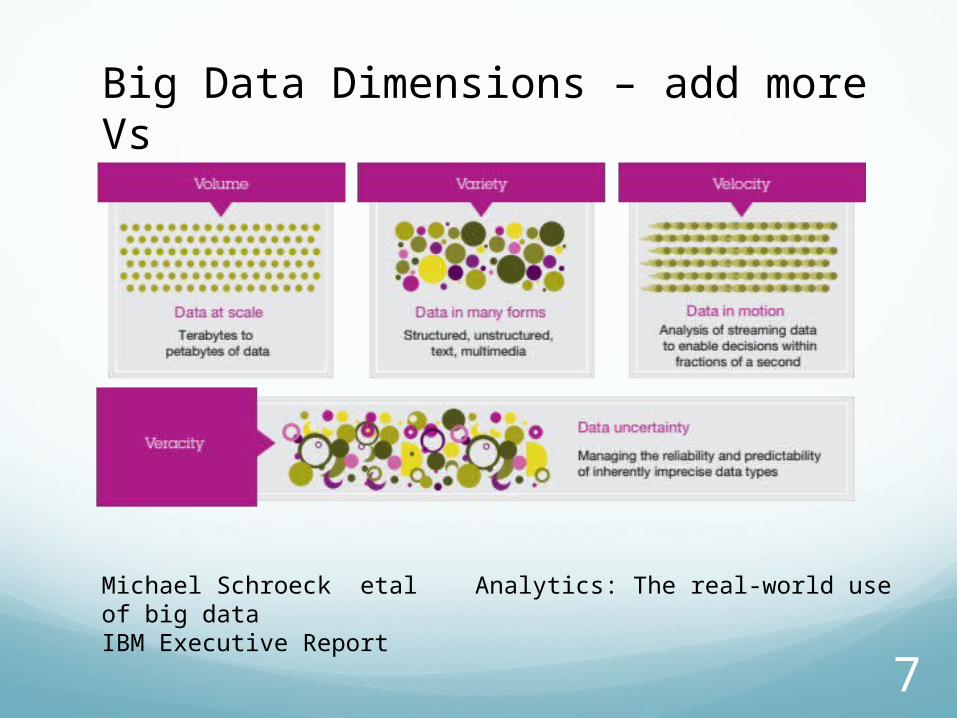
Big in What?Big in Volume
Big in Velocity
Big in Variety

6
Big Data Dimensions
Michael Schroeck etal Analytics: The real-world use of big dataIBM Executive Report
7
Michael Schroeck etal Analytics: The real-world use of big dataIBM Executive Report
Big Data Dimensions – add more Vs

8
Gartner’s Definition"Big data are
high volume, high velocity, high variety information assets that require new forms of processing to enable
enhanced decision making, insight discovery and process optimization."

9
Big data can be very smallThousands of sensors in planes, power stations,
trains…
These sensors have errors(tolerance)
Monitor engine efficiency to safety passenger well being
The size of the dataset is not very large – several Gigabytes, but number of permutations in the source are very large
http://mike2.openmethodology.org/wiki/Big_Data_Definition

10
Large datasets that ain’t bigMedia streaming is generating very large
volumes with increasing amounts of structured metadata.
Telephone calls and internet connections
Petabytes of data, but content is extremely structured.
Relational databases can handle well-structured very well

11
Who coined the term Big Data?
Not clear
An Economist has claims to it (Prof Francis Diebold of Univ of Pennsylvania)
There is even a NYTimes article
http://bits.blogs.nytimes.com/2013/02/01/the-origins-of-big-data-an-etymological-detective-story/

12
But generally speaking..originated as a tag for a class of technology with
roots in high-performance computing
pioneered by Google in the early 2000s
Includes technologies, such as distributed file and database management tools led by the Apache Hadoop project;
Big data analytic platforms, also led by Apache; and integration technology for exposing data to other systems and services.
13
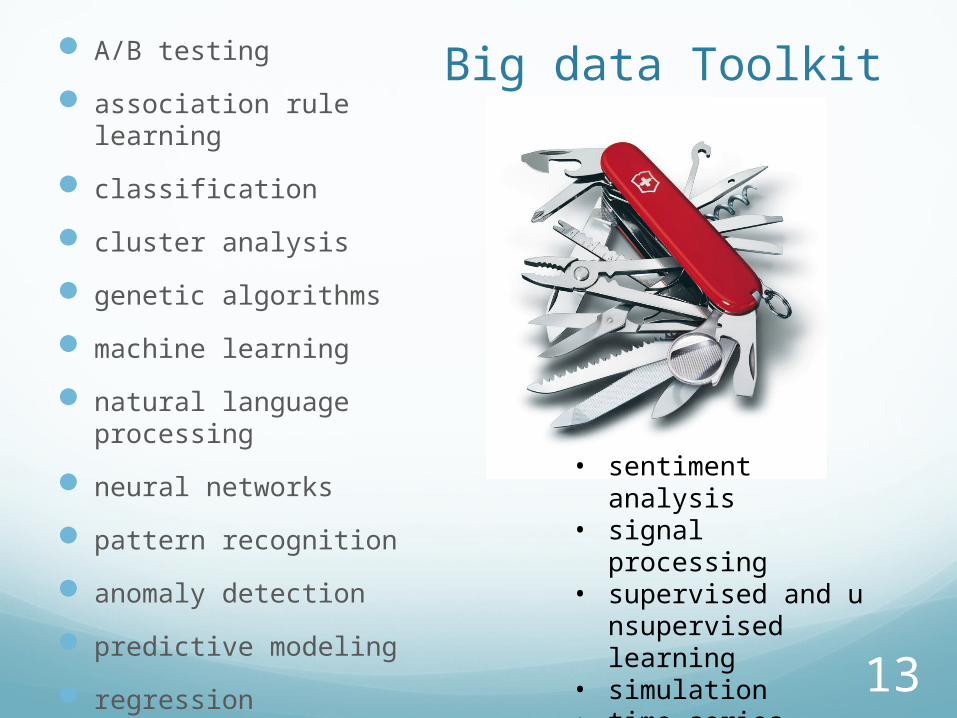
Big data Toolkit A/B testing
association rule learning
classification
cluster analysis
genetic algorithms
machine learning
natural language processing
neural networks
pattern recognition
anomaly detection
predictive modeling
regression
• sentiment analysis• signal processing• supervised and uns
upervised learning• simulation• time series analysis• Visualisation

14
What is special about big data processing?

15
Big Volume - Little Analytics
Well addressed by data warehouse crowd
Who are pretty good at SQL analytics onHundreds of nodesPetabytes of data
From Stonebraker

16
Big Data - Big Analytics
Complex math operations (machine learning, clustering, trend detection, ….)In the market, the world of the “quants”Mostly specified as linear algebra on array data

17
Big Data - Big AnalyticsAn Example
Consider closing price on all trading days for the last 5 years for two stocks A and B
What is the covariance between the two time-series?

18
Now Make It Interesting …
Do this for all pairs of 4000 stocksThe data is the following 4000 x 1000 matrix
Stock
t1 t2 t3 t4 t5 t6 t7…. t1000
S1
S2
…
S4000
Hourly data? All securities?

19
AndNow try it for companies headquartered in
Switzerland!

20
Goal of Big DataGood data management
Integrated with complex analytics

21
How to manage big data?While big data technology may be quite
advanced, everything else surrounding it – best practices, methodologies, organizational structures, etc. – is nascent.

22
What is wrong with Bigdata
End of theoryTraditional Statistics have model – a distribution,
say normalCompute Mean and varianceHere there is no apriori model – it is discoveredLike how many clusters?

23
How companies learn your secrets?
Privacy issues
http://www.forbes.com/sites/kashmirhill/2012/02/16/how-target-figured-out-a-teen-girl-was-pregnant-before-her-father-did/
http://www.nytimes.com/2012/02/19/magazine/shopping-habits.html?pagewanted=1&_r=2&hp

24
Will now talk aboutMap reduce
Hadoop
Bigdata in India – academic scene

Map reduce

26
Map Reduce Inspired by Lisp programming language
programming model for processing large data sets with a parallel, distributed algorithm on a cluster
Many problems can be phrased this way
Easy to distribute across nodes
Google has a patent!! Will it hurt me?

27
The MapReduce ParadigmPlatform for reliable, scalable parallel computing
Abstracts issues of distributed and parallel environment from programmer.
Runs over distributed file systemsGoogle File SystemHadoop File System (HDFS)
Adapted from S. Sudarshan, IIT Bombay

28
MapReduce Consider the problem of counting the number of
occurrences of each word in a large collection of documents
How would you do it in parallel ?
Solution:Divide documents among workersEach worker parses document to find all words, outputs
(word, count) pairsPartition (word, count) pairs across workers based on wordFor each word at a worker, locally add up counts

29
Map - ReduceIterate over a large number of records
Map: extract something of interest from each
Shuffle and sort intermediate results
Reduce: aggregate intermediate results
Generate final output

30
MapReduce Programming Model
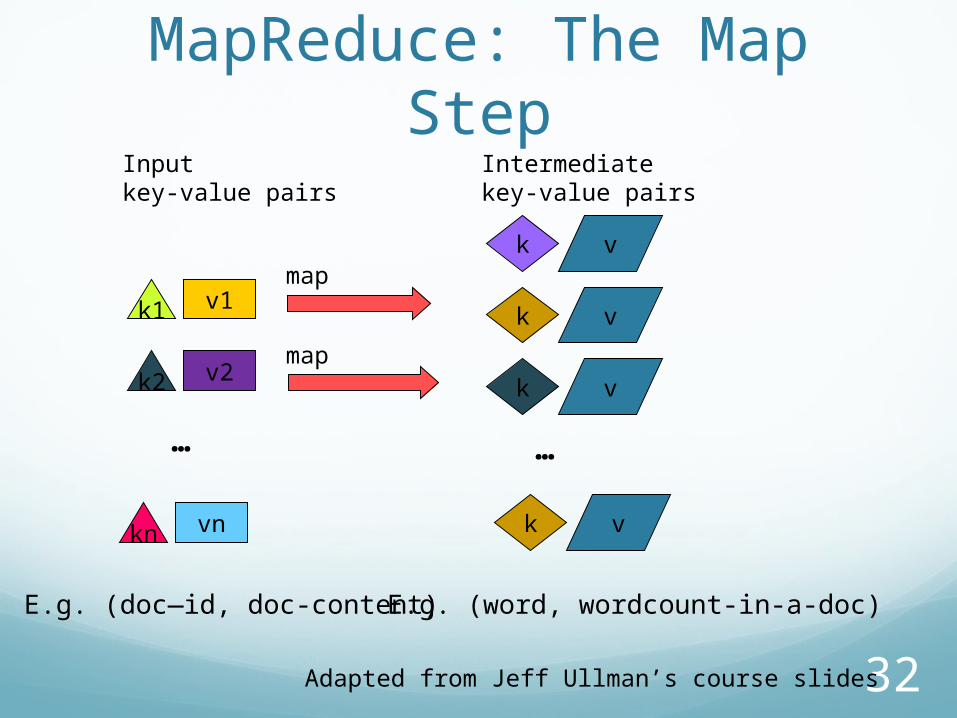
Input: a set of key/value pairs
User supplies two functions:map(k,v) list(k1,v1) reduce(k1, list(v1)) v2
(k1,v1) is an intermediate key/value pair
Output is the set of (k1,v2) pairs

31
MapReduce: Execution overview
32
MapReduce: The Map Step
v2k2
k v
k v
mapv1k1
vnkn
…
k vmap
Inputkey-value pairs
Intermediatekey-value pairs
…
k v
Adapted from Jeff Ullman’s course slides
E.g. (doc—id, doc-content) E.g. (word, wordcount-in-a-doc)
33
MapReduce: The Reduce Step
k v
…
k v
k v
k v
Intermediatekey-value pairs
group
reduce
reduce
k v
k v
k v
…
k v
…
k v
k v v
v v
Key-value groupsOutput key-value pairs
Adapted from Jeff Ullman’s course slides
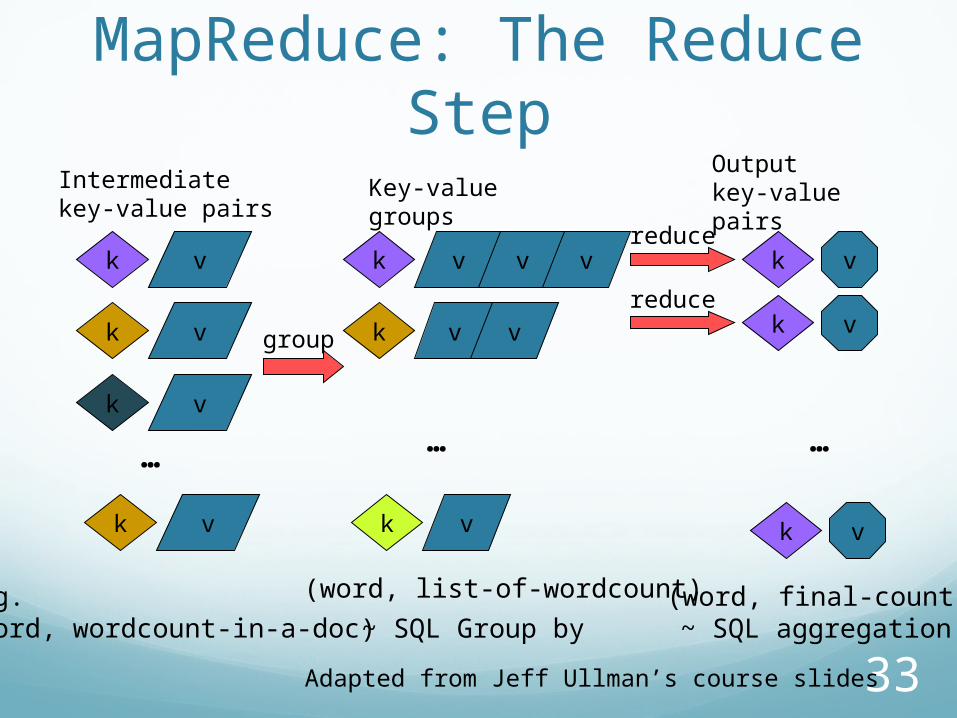
E.g. (word, wordcount-in-a-doc)
(word, list-of-wordcount) (word, final-count)~ SQL Group by ~ SQL aggregation

34
Pseudo-codemap(String input_key, String input_value):
// input_key: document name
// input_value: document contents for each word w in input_value:
EmitIntermediate(w, "1");
// Group by step done by system on key of intermediate Emit above, and // reduce called on list of values in each group.
reduce(String output_key, Iterator intermediate_values):
// output_key: a word
// output_values: a list of counts int result = 0; for each v in intermediate_values:
result += ParseInt(v); Emit(AsString(result));

35
Distributed Execution Overview
UserProgram
Worker
Worker
Master
Worker
Worker
Worker
fork fork fork
assignmap
assignreduce
readlocalwrite
remoteread,sort
OutputFile 0
OutputFile 1
write
Split 0Split 1Split 2
From Jeff Ullman’s course slides
input data fromdistributed filesystem

36
Map Reduce vs. Parallel Databases
Map Reduce widely used for parallel processing Google, Yahoo, and 100’s of other companies Example uses: compute PageRank, build keyword
indices, do data analysis of web click logs, ….
Database people say: but parallel databases have been doing this for decades
Map Reduce people say: we operate at scales of 1000’s of machines We handle failures seamlessly We allow procedural code in map and reduce and allow
data of any type

37
ImplementationsGoogle
Not available outside Google
HadoopAn open-source implementation in JavaUses HDFS for stable storage
Aster DataCluster-optimized SQL Database that also
implements MapReduce
And several others, such as Cassandra at Facebook, ..

38
ReadingJeffrey Dean and Sanjay Ghemawat,
MapReduce: Simplified Data Processing on Large Clusters
http://labs.google.com/papers/mapreduce.html
Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung, The Google File System, http://labs.google.com/papers/gfs.html

39
Map reduce in English Map: In this phase, a User Defined Function (UDF), also called Map, is executed on each
record in a given file. The file is typically striped across many computers, and many processes (called Mappers) work on the file in parallel. The output of each call to Map is a list of <KEY, VALUE> pairs.
Shuffle: This is a phase that is hidden from the programmer. All the <KEY, VALUE> pairs are sent to another group of computers, such that all <KEY, VALUE> pairs with the same KEY go to the same computer, chosen uniformly at random from this group, and independently of all other keys. At each destination computer, <KEY, VALUE> pairs with the same KEY are aggregated together. So if <x; y1>; <x; y>; : : : ;<x; yK> are all the key-value pairs produced by the Mappers with the same key x, at the destination computer for key x, these get aggregated into a large <KEY, VALUE> pair <x;{y1; y2; : : : ; yK}>; observe that there is no ordering guarantee. The aggregated <KEY, VALUE>pair is typically called a Reduce Record, and its key is referred to as the Reduce Key.
Reduce: In this phase, a UDF, also called Reduce, is applied to each Reduce Record, often by many parallel processes. Each process is called a Reducer. For each invocation of Reduce, one or more records may get written into a local output file.

Hadoop

41
Why is Hadoop exciting?Blazing speed at low cost on commodity
hardware
Linear Scalability
Highly scalable data store with a good parallel programming model, MapReduce
Doesn't solve all problems, but it is a strong solution for many tasks.

42
What is Hadoop?For the executives:
Hadoop is an Apache open source software project
Gives you value from the volume/velocity/variety of data you have

43
What is Hadoop?Technical managers
An open source suite of software that
mines the structured and unstructured BigData

44
What is Hadoop?Legal
An open source suite of software that is packaged and supported by multiple suppliers.
licensed under the Apache v2 license

45
Apache V2 A licensee of Apache Licensed V2 software can:
copy, modify and distribute the covered software in source and/or binary forms
exercise patent rights that would normally only extend to the licensor provided that:
all copies, modified or unmodified, are accompanied by a copy of the licensee
all modifications are clearly marked as being the work of the modifier
all notices of copyright, trademark and patent rights are reproduced accurately in distributed copies
the licensee does not use any trademarks that belong to the licensor Furthermore, the grant of patent rights specifically is withdrawn if: the licensee starts legal action against the licensor(s) over patent
infringements within the covered software

46
What is Hadoop?Engineering
A massively parallel, shared nothing, Java-based map-reduce execution environment.
hundreds to thousands of computers working on the same problem, with built-in failure resilience
Projects in the Hadoop ecosystem provide data loading, higher-level languages, automated cloud deployment, and other capabilities.
Kerberos-secured software suite

47
What are the components of Hadoop?
Two core components,
File store called Hadoop Distributed File System (HDFS)
Programming framework called MapReduce

48
HDFS
MapReduce
Hadoop Streaming
Hive and Hue
Pig
Sqoop
Hbase
FlumeNG
Whirr
Mahout
Fuse
Zookeeper

49
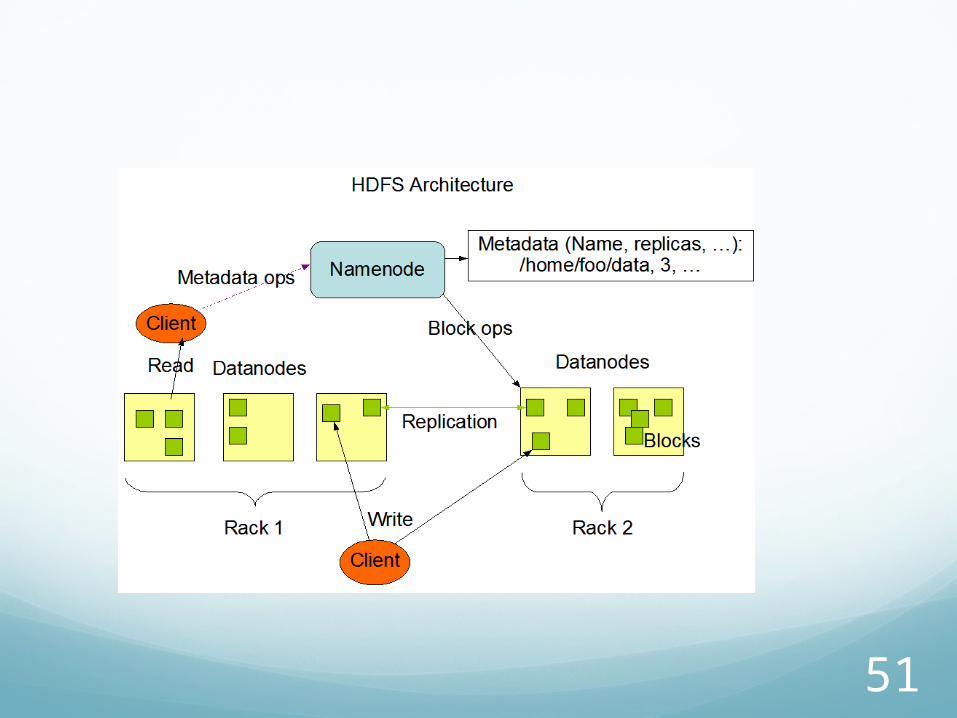
Hadoop ComponentsHDFS: spreads data over thousands of nodes
The Datanodes store your data, and the Namenode keeps track of where stuff is stored.

50
Hadoop ComponentsPig: A higher-level programming environment to
do MapReduce coding
Sqoop: data transfer between Hadoop and relational database
HBase: highly scalable key-value store
Whirr: Cloud provisioning for Hadoop
51

Reduce
Shuffle/sort mapper output
Mapper – read 64+ MB blocks
HDFS
........

53
HDFS, the bottom layer, sits on a cluster of commodity hardware.
For a map-reduce job, the mapper layer reads from the disks at very high speed.
The mapper emits key value pairs that are sorted and presented to the reducer, and
the reducer layer summarizes the key-value pairs

54

55
Hadoop and relational databases?
Hadoop integrates very well with relational database
Apache Sqoop
Used for moving data between Hadoop and relational databases

56
Some elementary references
Open Source Big Data for the Impatient, Part 1: Hadoop tutorial: Hello World with Java, Pig, Hive, Flume, Fuse, Oozie, and Sqoop with Informix, DB2, and MySQL
How to get started with Hadoop and your favorite databasesMarty Lurie ([email protected]), Systems Engineer, Cloudera http://www.ibm.com/developerworks/data/library/techarticle/dm-1209hadoopbigdata/

Bigdata India Scene

58
Big data IndiaWill restrict myself to the academic scene
Almost every institute has courses and researchers in this space
But not with the label Big Data
Found only one ‘course’ with this title
59
Big data Toolkit A/B testing
association rule learning
classification
cluster analysis
genetic algorithms
machine learning
natural language processing
neural networks
pattern recognition
anomaly detection
predictive modeling
regression
sentiment analysis
signal processing
supervised and unsupervised learning
• simulation• time series analysis• Visualisation

60
CoursesMachine Learning
Natural Language Processing
Data Mining
Soft computing
Statistics

61
MOOC on BigdataCoursera
24 March 201310 weeks
Dr. Gautam ShroffDepartment of Computer Science and EngineeringIndian Institute of Technology Delhi

62
http://www.mu-sigma.com/
Mu Sigma, one of the world’s largest Decision Sciences and analytics firms, helps companies institutionalize data-driven decision making and harness Big Data
http://www.veooz.com/

63
64

65
What is Veooz?
• pronounced as "views”• helps you to get a quick
overview, understand and insights from the
• views/opinions by users on different social media platforms like
• Facebook, Twitter, Google+, LinkedIn, News Sites, Blogs, ...
• Track views/opinions expressed by social media users- on people, places, products, movies, events, brands …
• billions of views on millions of topics at one place
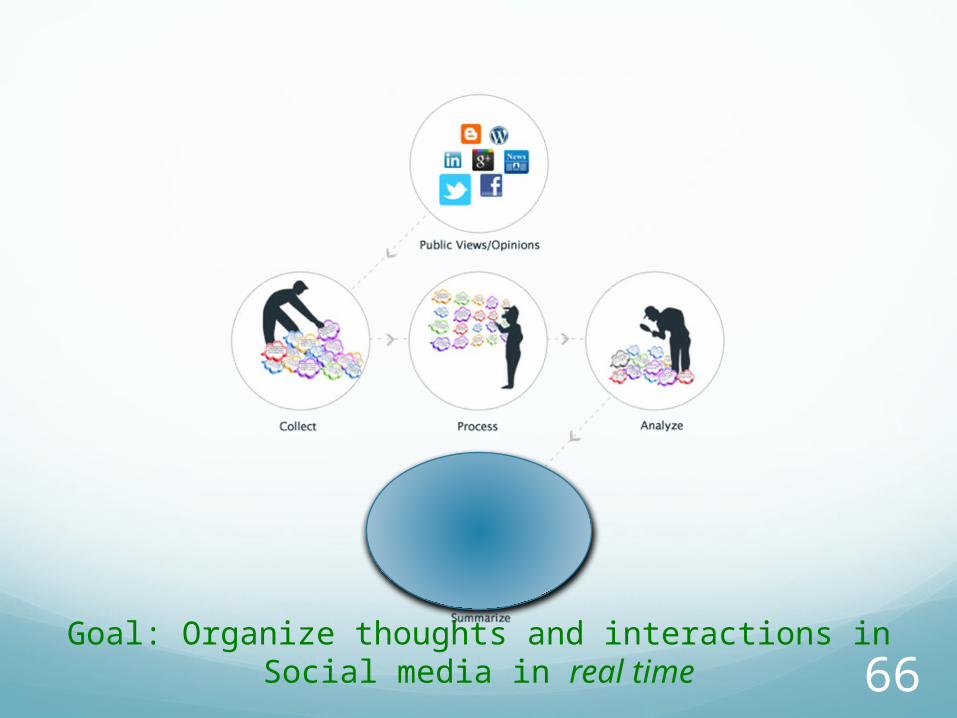
66Goal: Organize thoughts and interactions in Social media
in real time

67veooz: Real time Social Media Search & Analytics Engine

68
Social media is a Good
Proxy for the Real World

69New Power …
Social media monitoring to
Social listening to
Social Intelligence

70Not easy, because…
Most Social Media data
is Noisy

71Noisy Data in Social Media
Short forms and
abbreviationsSemantic equivalents
Spelling errors and variations
messenger and
message problem
Irony, Sarcasm and Negation detection
#HashTagMappingSocial media SPAM

72
Noise? Because it makes sentiment computation and deeper text processing
very hard
Fine grained Text Analysis and
Context/Semantic Processing
Topic level aggregation vs. text level processing
Detecting variations of
the topic
Using Prior Global Sentiment in Computing current sentiment

73
Sentiment Expression Axis
Literal• Non-opinions• Opinion• Intensity/
graded expressions
Special Symbols• Emoticons• Punctuation
Transgression• Grapheme
stretching• Abbreviations
Non-Literal• Metaphor• Sarcasm• Irony• Oxymoron
SPAM• Incorrect/Ill-
intention• Reputation/
Influence• Content
User Engagement• User actions• User
reactions• Social
relations

74
http://www.bda2013.net/Important Dates (Research, Tutorial, Industry):Abstract submission deadline: June 30 2013Paper submission deadline: July 7 2013Notification to authors: August 23 2013Camera ready submission: September 4 2013

75
Conferences on Big Data

76
Indian Institutes of Technology

77
Indian Institutes of Technology (IITs)
IITs are a group of fifteen autonomous engineering and technology oriented institutes of higher education established and declared as Institutes of National Importance by the Parliament of India.

78
IITs were created to train scientists and engineers, with the aim of developing a skilled workforce to support the economic and social development of India after independence in 1947.

79
Original IITs1. As a step towards this
direction, the first IIT was established in 1951, in Kharagpur (near Kolkata) in the state of West Bengal.

80
2. IIT Bombay was founded in 1958 at Powai, Mumbai with assistance from UNESCO and the Soviet Union, which provided technical expertise.

81
3. IIT Madras is located in the city of Chennai in Tamil Nadu. It was established in 1959 with technical assistance from the Government of West Germany.

82
4. IIT Kanpur was established in 1959 in the city of Kanpur, Uttar Pradesh. During its first 10 years, IIT Kanpur benefited from the Kanpur–Indo-American Programme (KIAP), where a consortium of nine US universities.

83
5. Established as the College of Engineering in 1961, located in Hauz Khas was renamed as IIT Delhi.
6. IIT Guwahati was established in 1994 near the city of Guwahati (Assam) on the bank of the Brahmaputra River.

84
7. IIT Roorkee, originally known as the University of Roorkee, was established in 1847 as the first engineering college of the British Empire. Located in Uttarakhand, the college was renamed The Thomson College of Civil Engineering in 1854. It became first technical university of India in 1949 and was renamed University of Roorkee which was included in the IIT system in 2001.

85
New IITs1. Patna (Bihar)
2. Jodhpur(Rajasthan)
3. Hyderabad (Andhra Pradesh)
4. Mandi(Himachal Pradesh)
5. Bhubaneshwar (Orissa)
6. Indore (Madhya Pradesh)
7. Gandhinagar (Gujarat)
8. Ropar (Punjab)

86
Admission
Admission to undergraduate B.Tech., M.Sc., and dual degree (BT-MT) programs are through
Joint Entrance Examination (JEE)
1 out of 100 get in

87
Features
• IITs receive large grants compared to other engineering colleges in India.
• About Rs. 1,000 million per year for each IIT.

88
Features (cont.)
The availability of resources has translated into superior infrastructure and qualified faculty in the IITs and consequently higher competition among students to gain admissions into the IITs.

89
Features (cont.)
The government has no direct control over internal policy decisions of IITs (such as faculty recruitment) but has representation on the IIT Council.

90
Features (cont.)
All over, IIT degrees are respected, largely due to the prestige created by very successful alumni.

91
Success story
Other factors contributing to the success of IITs are stringent faculty recruitment procedures and industry collaboration.
This combination of success factors has led to the concept of the IIT Brand.

92
Success story (cont.)IIT brand was reaffirmed when the United
States House of Representatives passed a resolution honouring Indian Americans and especially graduates of IIT for their contributions to the American society.
Similarly, China also recognised the value of IITs and has planned to replicate the model.

93
Indian Institute of Technology Kanpur
Indian Institute of Technology, Kanpur is one of the premier institutions established in 1959 by the Government of India.

94
IITK (Cont.)“to provide meaningful education, to
conduct original research of the highest standard and to provide leadership in technological innovation for the industrial growth of the country”

95
IITK (Cont.)
Under the guidance of eminent economist John Kenneth Galbraith, IIT Kanpur was the first Institute in India to start Computer Science education.
The Institute now has its own residential campus spread over 420 hectors of land.

96
Statistics Undergraduate 3679
Postgraduate 2039
Ph.D. 1064
Faculty 351
Research Staff 30
Supporting Staff 900
Alumni 26900

97
Departments
Sciences: Chemistry, Physics, Mathematics & Statistics
Engineering: Aerospace, Bio-Sciences and Bioengineering, Chemical, Civil, Computer Science & Engineering, Electrical, Industrial & Management Engineering, Mechanical, Material Science & Engineering
Humanities and Social Sciences
Interdisciplinary: Environmental Engineering & Management, Laser Technology, Master of Design, Materials Science Programme, Nuclear Engineering & Technology

98
Thank you