big data analysis
TRANSCRIPT

Nitesh singh

WHAT IS BIG DATA!!!!!!
• LARGE AMOUNT OF DATA
• Lots of data is being collected and warehoused
• Web data, e-commerce
• purchases at department/grocery stores
• Bank/Credit Card transactions
• Social Network

HOW MUCH DATA!!
• Google processes 20 PB a day (2008)
• Wayback Machine has 3 PB + 100 TB/month (3/2009)
• Facebook has 2.5 PB of user data + 15 TB/day (4/2009)
• eBay has 6.5 PB of user data + 50 TB/day (5/2009)
• CERN’s Large Hydron Collider (LHC) generates 15 PB a year

HOW CAN WE ANALYZE THIS MUCH DATA?

WHAT IS APACHE HADOOP
• Apache Hadoop is an open-source software
framework for storage and large-scale processing
of data-sets on clusters ofcommodity hardwareIT IS
DEVELOPED BY “APACHE SOFTWARE FOUNDATION”.
• ITS STABLE RELEASE VERSION IS “2.4.1 ON JUNE
30,2014.
• IT IS WRITTEN IN “JAVA”.
• IT IS DISTRIBUTED FILE SYSTEM.

BASIC COMPONENT OF HADOOP FRAMEWORK!!
• MAP REDUCE
• HIVE
• PIG
• SQOOP
• FLUME

INFRASTRUCTURE PROVIDER
• AWS AMAZON(AMAZON WEB SERVICE).
• CLOUD ERA(LEADING PROVIDER)
• HORTON WORKS
• RACK SPACE.
• MAPR
• SFDC(SALES FOR DOT COM)

MAJOR ROLES OF HADOOP
• HADOOP ADMINISTRATOR
• HADOOP DEVELOPER.

HADOOP DEVELOPER
• RUN THE QUERY
• EXECUTE THE PROGRAM
• MAINTAIN A REPORT.

HADOOP ADMINISTRATOR
• MAINTAIN INFRASTRUCTURE.
• NOT WRITING ANY PROGRAM
• CHECK MEMORY MANAGEMENT AND ALL
• CHECK IF ANY NODE FAILS
• HOW MANY NODES WE HAVE TO CHOOSE.

HADOOP ARCHITECTURE
SQOOP FLUMEHBASE
PIGHIVE
MAP REDUCE
HDFS

HDFS(HADOOP DISTRIBUTED FILE SYSTEM)
CLUSTER
DATA CENTER
RACKS
NODE
BLOCKS
HDFS

WHAT IS HDFS
HDFS IS A WAY TO STORE THE FILES
PREVENTING A DATA TO BE LOOSED.
BASIC COMPONENT OF HADOOP FRAME WORK WHERE
ALL FILES STORED
FILES ARE STORED IN DISTRIBUTED MANNER IN TERMS
OF BLOCK ie CALLED “HADOOP DISTRIBUTED FILE
SYSTEM”.

MAP REDUCE ENGINE
• TECHNOLOGY FROM GOOGLE.
• A MAP REDUCE PROGRAM CONSISTS OF MAP
AND REDUCE FUNCTION
• A MAP REDUCE JOB IS BROKEN IN TO TASK
THAT RUNS IN PARLLEL
• IN HDFS PROCESS IS CALLED “DATA
DISTRIBUTION”
• PROCESS IS MAP RDUCE CALLED “JOB
DISTRIBUTION”.
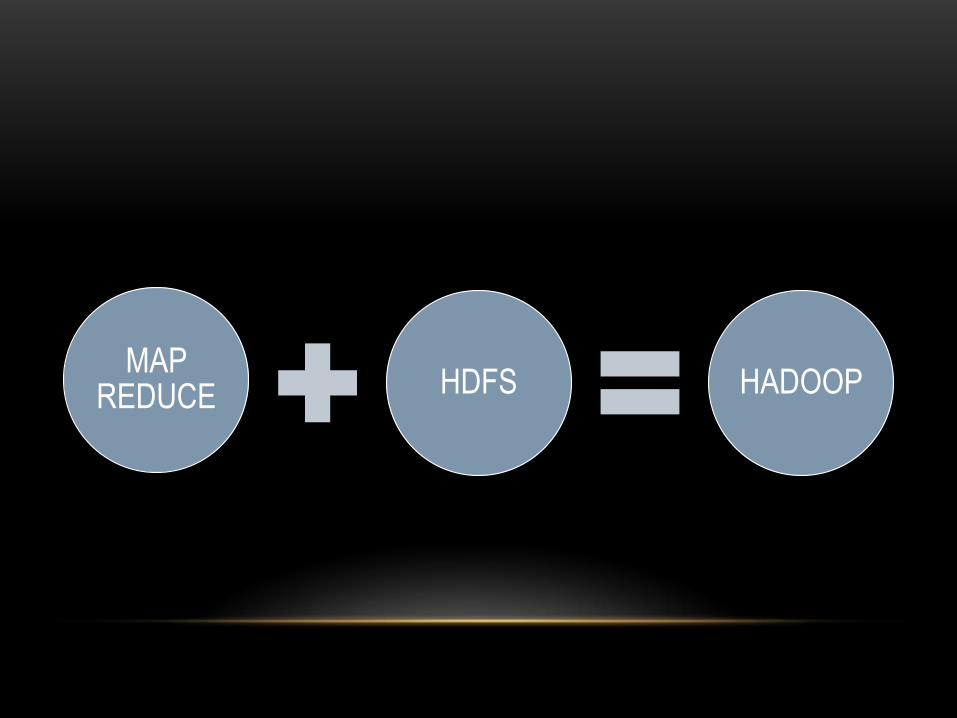
MAP REDUCE HDFS HADOOP

TYPES OF NODE
NODEMASTER
• NAMENODE
• JOB TRACKER
SLAVE
• TASK TRACKER
• DATA NODE

JOB TRACKER NODE
• TAKE THE REQUEST FROM CLIENT
• IT PASS THAT INFORMATION TO NAME NODE.
• IT IS THE PART OF MAPREDUCE ENGINE.
• EVERY CLUSTER HAS ATMOST ON JOB
TRACKER NODE

TASK TRACKER
• MANY PER HADOOP CLUSTER
• EXECUTES MAP REDUCER OPERATION
• READ BLOCK FROM DATABASE.

NAME NODE
• ONE PER HADOOP CLUSTER.
• MAIN NODE OF HADOOP DISTRIBUTED FILE SYSTEM
• IF NAME NODE OR JOB TRACKER NODE FAILS THAN THE WHOLE CLUSTER WILL HALT.
• VERY IMPORTANT NODE SO WE HAVE TO HAVE SECONDRY NODE AS WELL.
• NAME NODE IS VERY IMPORTANT BECAUSE IT THE INTERMEIDATE OF THE JOB TRACKER NODE AND THE DATA NODE.

WRITING THE DATA TO HDFS
• WHEN THE USER SEND REQUEST FOR WRITING THE FILE IN TO
HDFS,JOB TRACKER ACCEPT IT AND SEND REQUEST TO NAME
NODE.
• NAME NODE SEND REQUEST TO THE DATA NODE AND ASK IT TO FIND
THE PARTICULAR BLOCK SO THAT IT CAN ALLOCATE THAT BLOCK
TO THE REQUESTED FILE.
• DATA NODE SENDS ACKNOWLEDGEMENT TO THE NAME NODE
CONATAINS VACANT BLOCK IT HAS.
• THAN NAME NODE SENDS ACKNOWLEDGEMENT TO THE JOB
TRACKER AND ASK IT TO WRITE THE FILE AND DATA NODE ACCEPT
ITS ACESS AND WRITET THE CONTENT IN DATA NODE BLOCKS.
• AFTER SUCCESS POSITIVE ACKNOWEDGEMENT SENDS TO USER .

READING THE FILE FROM HDFS
• WHEN THE USER SENDS REQUEST ,JOB TRACKER ACCEPT IT AND SENDS REQUEST TO NAME NODE
• NAME NODE SENDS REQUEST TO THE DATA NODE ,DATA NODE RETURN ACKNOWLEDGEMENT THAT IS HAD THAT DATA BLOCKS
• NAME NODE SEND ACK TO JOB TRACKER NODE
• JOB TRACKER SENDS THAT ACCESS TO THE TASK TRACKER NODE
• TASK TRACKER NODE READS DATA DIRECTLY FROM THE DATA NODE ,REDIRECT IT TO USER.
• AFTER SUCCESS PROCESS STOP.



MAP REDUCE PROGRAM REDUCER
CLASS
• import java.io.IOException;
• import org.apache.hadoop.io.IntWritable;
• import org.apache.hadoop.io.LongWritable;
• import org.apache.hadoop.io.Text;
• import org.apache.hadoop.mapred.MapReduceBase;
• import org.apache.hadoop.mapred.Mapper;
• import org.apache.hadoop.mapred.OutputCollector;
• import org.apache.hadoop.mapred.Reporter;
• public class mapper extends MapReduceBase implements
• Mapper<LongWritable, Text, Text, IntWritable> {

CONT….
• @Override
• public void map(LongWritable key, Text value,
• OutputCollector<Text, IntWritable> output, Reporter reporter)
• throws IOException {
•
• //1-you have an key value pair for the mapper class input like (0:I am neeraj gupta;1:I am learning hadoop} like this
• //String fix="250000000";
• String s=value.toString();
• String s1[]=s.split(" ");//SPLIT to arrays of word
• //now i have the format fname lname id salary salry 3,7,11,15
• int w=0;
• int last=0;
• for(int i=3;i<s1.length;i=i+7)
• {

CONT……
• w+=Integer.parseInt(s1[i+1])+Integer.parseInt(s1[i+2])+Integer.parseInt(s
1[i+3]);//for total
• //int w=Integer.parseInt(s1[i]);
•
•
• output.collect(new Text(s1[i-2]),new IntWritable(w));
•
• }//end of the for loop
•
•
•
•
•

REDUCER CLASS
• import java.io.IOException;
• import java.util.Iterator;
• import org.apache.hadoop.io.IntWritable;
• import org.apache.hadoop.io.Text;
• import org.apache.hadoop.mapred.OutputCollector;
• import org.apache.hadoop.mapred.MapReduceBase;
• import org.apache.hadoop.mapred.Reducer;
• import org.apache.hadoop.mapred.Reporter;

• public class Reduce extends MapReduceBase implements
• Reducer<Text, IntWritable, Text, IntWritable>{
• int s=0;
• // int count=6;
• String name="";
• @Override
• public void reduce(Text key, Iterator<IntWritable> values,
• OutputCollector<Text, IntWritable> output, Reporter reporter)
• throws IOException {
• int w1=0;
• int i=0;

• IntWritable w=values.next();
• w1+=w.get();
• }//end of the while loop
• if(s<w1)
• {
• s=w1;
• name=key.toString();
• output.collect(new Text(name), new IntWritable(s));
• }
• }

CONFIGURATION FILE
• import org.apache.hadoop.fs.Path;
• import org.apache.hadoop.io.IntWritable;
• import org.apache.hadoop.io.Text;
• import org.apache.hadoop.mapred.FileInputFormat;
• import org.apache.hadoop.mapred.FileOutputFormat;
• import org.apache.hadoop.mapred.JobClient;
• import org.apache.hadoop.mapred.JobConf;
• import org.apache.hadoop.conf.Configured;
• import org.apache.hadoop.util.Tool;
• import org.apache.hadoop.util.ToolRunner;

• public class WordCount extends Configured implements Tool {
• @Override
• public int run(String[] args) throws Exception {
• if (args.length != 2) {
• System.out.printf(
• "Usage: %s [generic options] <input dir> <output dir>\n",
getClass()
• .getSimpleName());
• ToolRunner.printGenericCommandUsage(System.out);
• return -1;
• }

• FileOutputFormat.setOutputPath(conf, new Path(args[1]));
• conf.setMapperClass(mapper.class);
• conf.setReducerClass(Reduce.class);
• conf.setMapOutputKeyClass(Text.class);
• conf.setMapOutputValueClass(IntWritable.class);
• conf.setOutputKeyClass(Text.class);
• conf.setOutputValueClass(IntWritable.class);
• JobClient.runJob(conf);
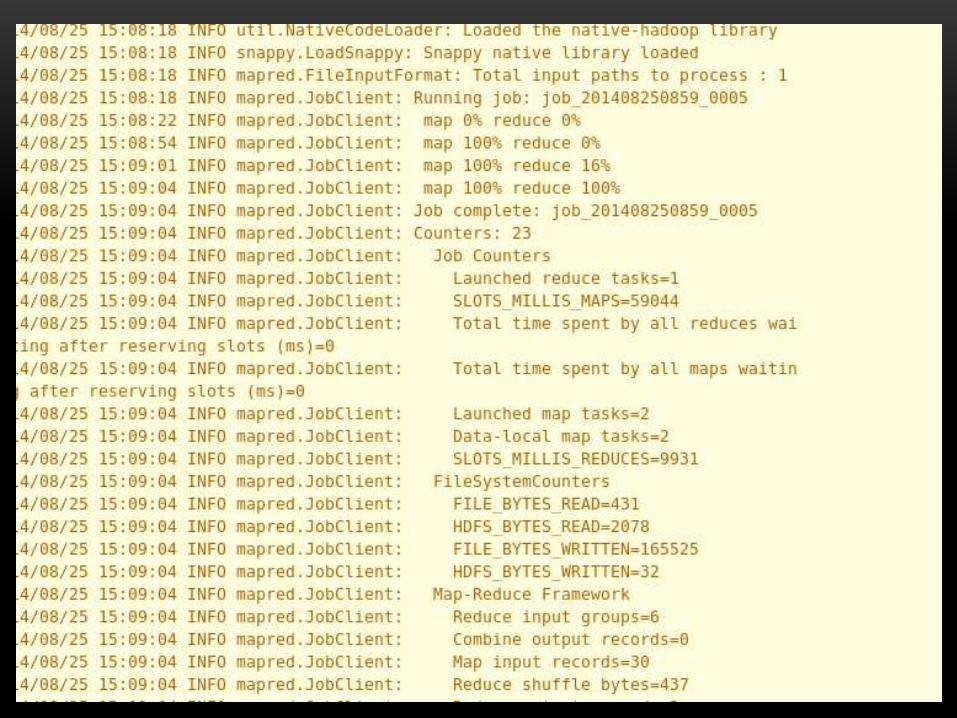

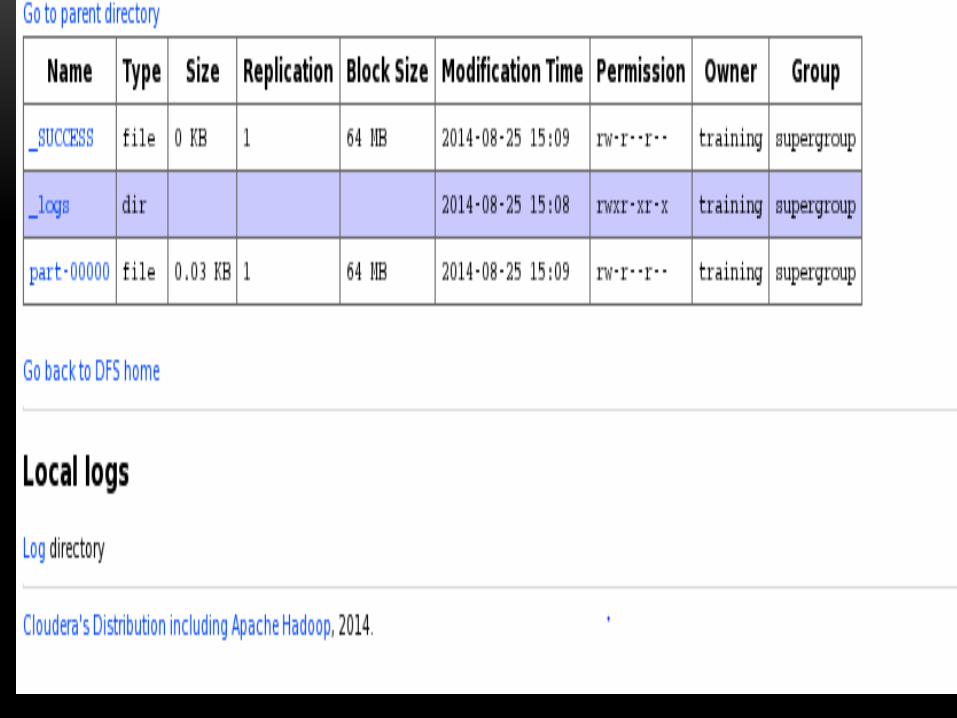


HIVE
• HIVE IS A DATA WARE HOUSE WHICH IS USING FOR READ THE TABLES LANGUAGE “HQL” HIVE QUERY LANGUAGE
• DEFAULT READING FILES FORM HDFS
• BECAUSE HDFS KNOWS ONLY MAP REDUCE PROGRAM
• PERFOMANCE IS SLOWER THAN MAP REDUCE PRGRAM BECAUSE OF COMPARISION
• OUTPUT STORES IN HIVE WARE HOUSE

HIVE WARE HOUSE
HIVE QL
OUTPUT

STEPS TO CREATE TABLES AND LOADING THE
DATA
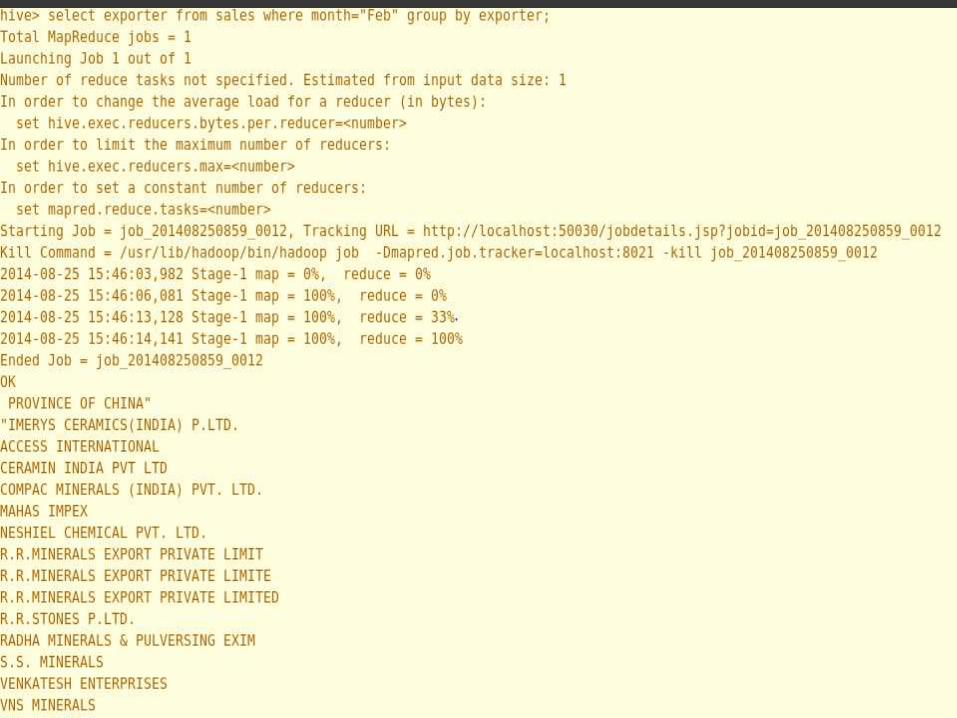
• STEP1:-TYPE HIVE ON CLI
• STEP2:- create table sales(month string,product string,quan string,fc
string,prot string,country string,exporter string,buyer string)row format
delimited fields terminated by ',';
• STEP3:- load data inpath 'spp/docs' overwrite into table docs;
• STEP4:- SELECT * FORM TABLE NAME TO SEE THE OUTPUT.

SALES DATA ANALYSIS PROJECT ON HADOOP
• WE HAVE 1500 ENTRIES IN A CSV FORMAT FILE AND WE NEED TO
ANALYZE THAT WHOLE DATA.
• WE HAVE MULTIPLE SHEETS OF DATA 4 FILES EACH HAVING 1500
ENTRIES
• WE NEED TO MAKE THE REPORT ASKED BY THE USER.
• WE CHOOSE HIVE QUERY LANGUAGE TO DO SO.
• WE EXPORT THAT FILE IN HIVE WARE HOUSE
• WE CONSTUCT THE TABLE IN HIVE
• WE RUN SEVERAL QURIES AND FIND THE DIFFERENT RESULT ASK
BY THE USER
• THIS IS VERY EFFICENT AND FAST




THANK YOU!!!•
•