big data analytics training ati. course contents environment setup required download pig from ...
TRANSCRIPT

Big Data Analytics Training
ATI

Course Contents
Environment Setup required
Download pig from
http://mirrors.ibiblio.org/apache/pig/pig-0.13.0/
Download pig-0.13.0.tar.gz

Pig & SQOOP
Session 1 : Pig- Why another language or interface?- Introduction to Pig
- What is Pig Latin?- Pig Architecture- Components
- Pig Configuration- Data Types- Common Query Algorithms- User Defined Functions- Pig Use Cases
Session 2 : SQOOP
- Introduction to SQOOP- Install and Configure SQOOP- Generate Code- SQOOP Import & Export- Hands On

Why Another Language?
• Map Reduce requires knowledge or expertise of Java
• Need to rewrite the common algorithms like JOIN. FILTER etc.
• Hive is helpful in analyzing structured data – SQL type queries
• Making Hadoop available for other non java programmers

What is Pig Latin
• High Level Language that abstracts Hadoop system complexity from users
• Data Flow language, not a procedural language
• Provides common operators like join, group, sort etc.
• Can use existing user code or libraries for complex non regular algorithms
• Operate on files in HDFS
• Developed by Yahoo for their internal use and later contributed to community and made open source
• They run most of their jobs using Pig

Pig Architecture
Grunt Shell - CLI
Hadoop Cluster
Map Reduce Jobs
Pig Scripts
- No need to install anything on the cluster- Grunt Shell converts Pig scripts into MR programs and submits to the cluster for execution

Pig Configuration
• Download and un-tar the pig file under /home/hadoop• tar -xzf pig-0.13.0.tar.gz
• Configure the PIG Paths• export PIG_INSTALL=/home/hadoop/pig-0.13.0• export PATH=$PATH:$PIG_INSTALL/bin

Pig Configuration
Configure Hadoop Cluster Details
• Using environment variables• export PIG_HADOOP_VERSION=“0.13.0”• export PIG_CLASSPATH=$HADOOP_INSTALL/conf
• Using pig.properties file
• fs.default.name=hdfs://localhost/• mapred.job.tracker=localhost:8021

Running Pig
• pig
• grunt>cust=LOAD ‘retail.cust’ AS (custid:chararray, firstname:chararray, lastname:chararray, age:long, profession:chararray);
grunt>lmt = LIMIT cust 10; grunt>groupByProfession = GROUP cust BY profession; grunt>countByProfession = FOREACH groupByProfession GENERATE
group, count(cust) ; grunt>dump countByProfession; grunt>STORE countByProfession INTO ‘output’;

Pig Data Types – Scalar Types
• INT – Signed 32 bit inetger
• LONG – Signed 64 bit inetger
• FLOAT – 32 bit floating point
• DOUBLE – 64 bit floating point
• CHARARRAY – Character array (String) in Unicode UTF-8
• BYTEARRAY – Byte array (Binary object)

Pig Data Types - Complex
• map• Associative array
• Tuple• Ordered list of data• Ex: (1234, Kim Huston, 54)
• Bag – unordered collection of tuples• {(1234, Kim Huston, 54), (7634, Harry Slater, 41), (4355,
Rod Stewart, 43, architect)}
• Tuples in a Bag are not required to have the same schema or same number of fields
• Can represent semi structured or unstructured data

Pig – LOAD Data
• LOAD• A = LOAD ‘myfile.txt’;• A = LOAD ‘myfile.txt’ AS (f1:int, f2:int, f3:int);• A = LOAD ‘myfile.txt’ USING PigStorage(‘\t’);• A = LOAD ‘myfile.txt’ USING PigStorage(‘\t’) AS (f1:int, f2:int,
f3:int);
• 1 2 3 • 4 2 1 • 8 3 4• DUMP A;• (1, 2, 3)• (4, 2, 1)• (8, 3, 4)

Pig – STORE Data
• STORE• STORE B INTO ‘myoutput’ using PigStorage(‘,’);
• 1 2 3 • 4 2 1 • 8 3 4• cat myoutput;
(1, 2, 3)(4, 2, 1)(8, 3, 4)
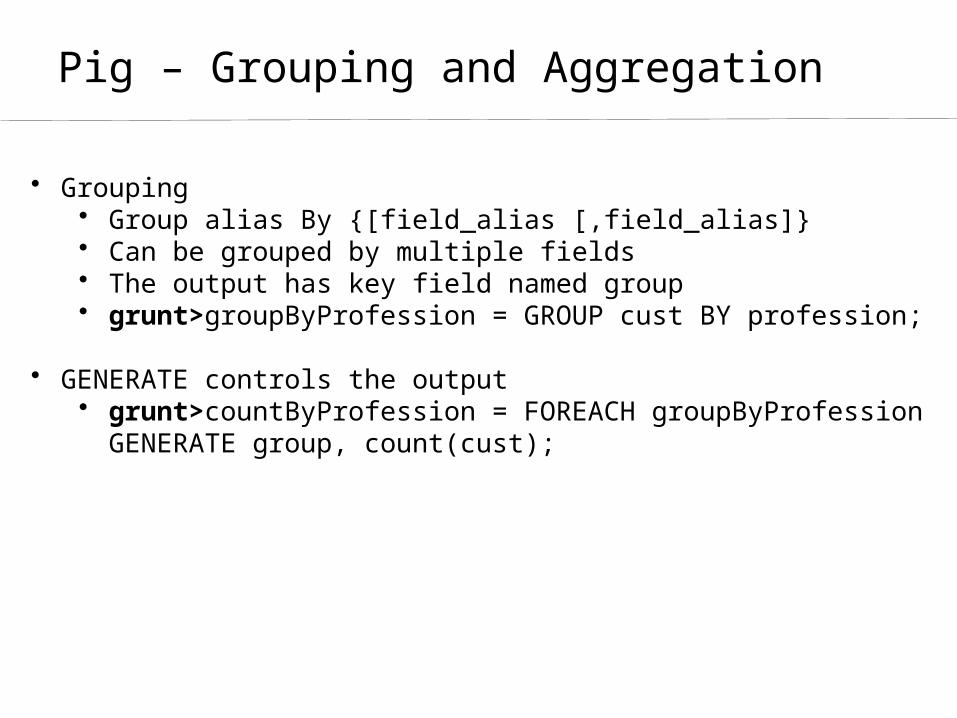
Pig – Grouping and Aggregation
• Grouping• Group alias By {[field_alias [,field_alias]}• Can be grouped by multiple fields• The output has key field named group• grunt>groupByProfession = GROUP cust BY profession;
• GENERATE controls the output• grunt>countByProfession = FOREACH groupByProfession
GENERATE group, count(cust);

Pig – Built-in functions
• AVG, CONCAT, COUNT, DIFF, MAX, MIN, SIZE, SUM, TOKENIZE, IsEmpty

Pig – Filtering and Ordering
• Filtering• Selects tuples based on a boolean expression. Select or
remove tuples
• grunt>teenagers = FILTER cust BY age <20;
• grunt>topProfessions = FILTER countByProfession BY count > 1000;
• Ordering• Sorting – ascending or descending
• Grunt>sorted = ORDER countByProfession By count ASC / DESC;
• Can sort by more than one field

Pig – FOREACH and DISTINCT
• FOREACH
• Iteration through a list
• grunt>countByProfession = FOREACH groupByProfession GENERATE group, count(cust);
• DISTINCT
• Select only distinct tuples
• Removed duplicate entries
• Grunt>distinctProfession = DISTINCT groupByProfession;

Pig – GROUP
• A = LOAD ‘data’ as (f1:chararray, f2:int, f3:int);• DUNP A; (r1, 1, 2) (r2, 2, 1) (r3, 2, 8) (r4, 4, 4)
• In this example, the tuples are grouped using an expression (f2*f3)• X = GROUP A By f2*f3;• DUMP X;(2, {(r1,1,2), (r2,2,1)}(16, {r3, 2,8), (r4, 4, 4)}

Pig – COGROUP
• A = LOAD ‘data1’ AS (owner:chararray, pet:chararray); DUMP A; (Alice, turtle) (Alice, goldfish) (Alice, cat) (Bob, dog) (Bob, cat)
• B = LOAD ‘data2’ AS (friend1:chararray, friend2:chararray);DUMP B;(Cindy, Alice)(Mark, Alice)(Paul, Bob)(Paul, Jane)
• X = COGROUP A BY owner, B BY friend2;(Alice, {(Alice, turtle), (Alice, goldfish), (Alice, cat)}, {(Cindy,Alice),(Mark,Alice)})(Bob, {(Bob,dog),(Bob,cat)},{(Paul,Bob)})(Jane,{},{(Paul,Jane)})

JOINS
DUMP A;
(1,2,3)
(4,2,1)
(8,3,4)
(4,3,3)
(7,2,5)
(8,4,3)
DUMP B;
(2,4)
(8,9)
(1,3)
(2,7)
(2,9)
(4,6)
(4,9)
* X = JOIN A BY a1, B BY b1;DUMP X;
(1,2,3,1,3)
(4,2,1,4,6)
(4,3,3,4,6)
(4,2,1,4,9)
(4,3,3,4,9)
(8,3,4,8,9)
(8,4,3,8,9)

Pig - UNION
DUMP A;
(1,2,3)
(4,2,1)
DUMP B;
(2,4)
(8,9)
(1,3)
* X = UNION A, B;DUMP X;
(1,2,3)
(4,2,1)
(2,4)
(8,9)
(1,3)
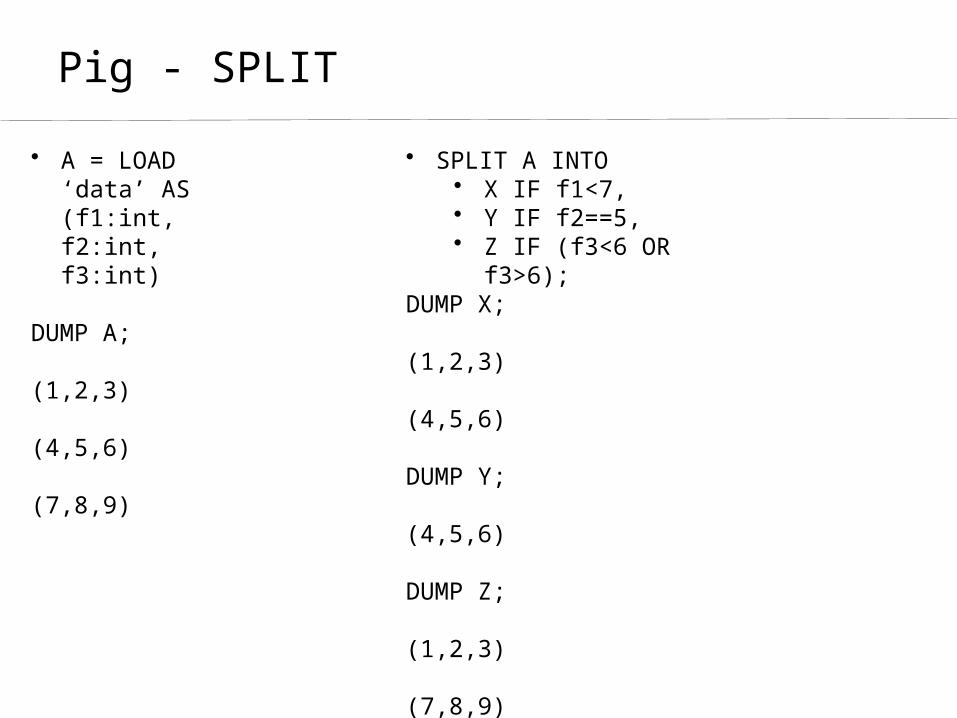
Pig - SPLIT
• A = LOAD ‘data’ AS (f1:int, f2:int, f3:int)
DUMP A;
(1,2,3)
(4,5,6)
(7,8,9)
• SPLIT A INTO • X IF f1<7, • Y IF f2==5, • Z IF (f3<6 OR f3>6);
DUMP X;
(1,2,3)
(4,5,6)
DUMP Y;
(4,5,6)
DUMP Z;
(1,2,3)
(7,8,9)

Pig - Sample
• Creates a sampling of large data set
• Example: 1% of total data set
• A = LOAD ‘data’ AS (f1:int, f2:int, f3:int);
• X = SAMPLE A 0.01

Pig - UDF
• For logic that cannot be done in Pig
• Can be used to do column transformation, filtering, ordering, custom aggregation
• For example, you want to write custom logic to do interest calculation or penalty calculation
• Example:
• Grunt> interest = FOREACH cust GENERATE custid, calculateInterest(custAcc);

Pig – Diagnostic Operators
• DESCRIBE• Display the schema of a relation
• EXPLAIN• Display the execution plan used to compute a relation
• ILLUSTRATE
• Display step-by-step how data is transformed, starting with a load command, to arrive at the resulting relation
• Only a sample of the input data is used to simulate the execution

Pig – Writing Macros
• DEFINE a macro
• DEFINE my_macro(A, sortkey) RETURNS C {B = FILTER $A BY my_filter(*);$C = ORDER B BY $sortkey;}
X = my_macro(a,b);STORE X INTO ‘output’;
• IMPORT a macro into another macro or script
• IMPORT ‘my_macro.pig’;

Hadoop for production environment
• For Development
• Standalone or psedu-distribution
• For Production
• Fully distributed mode• Support platforms – Linux• Can run on commodity hardware. But nor cheap• Can choose from a range of vendors• Hadoop is designed to withstand failure, but too many
failures can affect performance• So choose appropriate hardware
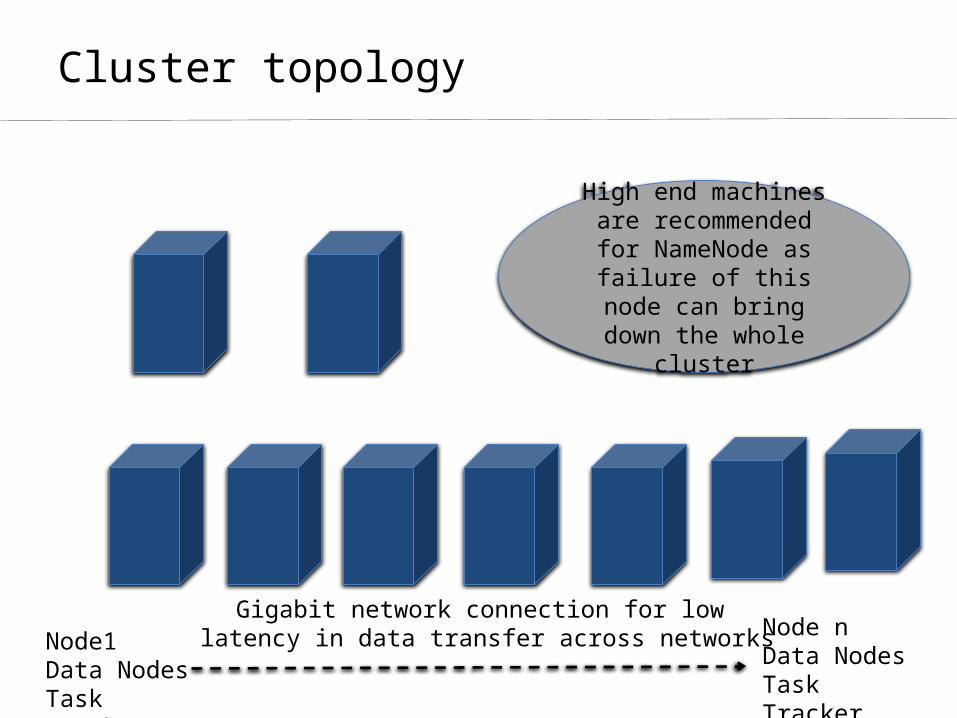
Cluster topology
High end machines are recommended for
NameNode as failure of this node can bring down the
whole cluster
Node1Data NodesTask Tracker
Node nData NodesTask Tracker
Gigabit network connection for low latency in data transfer across networks

Hadoop for production environment
• Several nodes per rack• Single rack or multi-rack configuration• For multiple rack - rack to node mapping
needs to be done• For hadoop to schedule map reduce tasks appropriately• For placing replications in the same rack to avoid transfers across rack

Cluster configuration
• Install Java, Hadoop on all nodes
• Create a single hadoop user across all nodes and configure password less SSH• Configure with Name node
• Masters – specify which nodes will run secondary name node• Slaves – specify which nodes will run data node and task tracker
• Configuring other properties of the nodes• Create one master configuration and use tools like chef and puppet
to configure the whole nodes• Use NFS to store and share configuration files