big data curation - comadcomad.in/comad2014/keynotes/bigdatacuration-keynote2-comad20… ·...
TRANSCRIPT


RJ Miller, Dec 2014
Evidence-based Art http://www.healthcarefineart.com/2009/03/
Art Curation• acquisition, care and documentation of art,• conduct research based on the art collection,• provide proper packaging of art for transport,• and share that research with the public and scholarly
community through exhibitions and publications…• ensure art maintains its value over time
Data Curation• acquisition, care and documentation of data,• conduct research based on the data,• provide proper packaging of data for reuse,• and share that research with the public and
scholarly community through exhibitions and publications…
• Ensure data maintains its value over timeCurated Databases, Buneman, 2003
Copyright © 2013 by The Atlantic Monthly Group. All Rights Reserved. CDN powered by Edgecast Networks. Insights powered by Parsely .
2
Challenge: Data Curation

RJ Miller, Dec 2014
Evidence-based Art http://www.healthcarefineart.com/2009/03/
Art Curation• acquisition, care and documentation of art,• conduct research based on the art collection,• provide proper packaging of art for transport,• and share that research with the public and scholarly
community through exhibitions and publications…• ensure art maintains its value over time
Data Curation• acquisition, care and documentation of data,• conduct research based on the data,• provide proper packaging of data for reuse,• and share that research with the public and
scholarly community through exhibitions and publications…
• Ensure data maintains its value over timeCurated Databases, Buneman, 2003
3
Challenge: Data Curation

RJ Miller, Dec 2014
© 2012 Biocomicals Biocomicals by Dr. Alper Uzun
Big Data to Data Science
4
DATA SCIENTIST:THE SEXIEST JOB OF THE 21ST CENTURY
Harvard Business ReviewOct. 2012
Data science needs set of trusted tools and methods.
Can we trust the conclusions of our data science?

RJ Miller, Dec 2014
To study data curation, we should become data curators....
•Oktie Hassanzadeh, PhD’12, now IBM• Soheil Hassas Yeganeh, PhD Student• Javed Siddique, PhD Student• Boris Glavic, PostDoc, now at IIT Chicago• Ken Pu, Assoc Prof UOIT• Collaborators at IBM* Tasos Kementsietsidis, Lipyeow Lim, Min Wang * Laura Haas
• Gustavo Alonso, ETH Zurich
We =
5

RJ Miller, Dec 2014
•Nor any drop to drink...
Data, Data Every Where...
6
•Open DataUS: data.gov/NY: data.ny.gov/NYC: cusp.nyu.edu/•Available in variety of semi-structured
formats
RDB

RJ Miller, Dec 2014
Open Linked Data• Open Linked Data• make your data available under an open license• make it available as structured data • use non-proprietary formats (e.g., CSV instead of Excel)• use URIs to denote things, so others can share/re-use• link your data to other data to provide context
7

RJ Miller, Dec 2014
Open Linked Data• Open Linked Data
make your data available under an open licensemake it available as structured data use non-proprietary formats (e.g., CSV instead of Excel)use URIs to denote things, so others can share/re-uselink your data to other data to provide context
8

RJ Miller, Dec 2014
linkedCT.org
Example: Clinical Trials
9
• International clinical trials (153,457 trials, 183 countries)
• Audience: patients, families, health care professionals, researchers
• Access to information on publicly & privately supported clinical studies on a wide range of diseases & conditions
Research-Disease Disparity• Understand and quantify disparity between the
availability of treatment options and the prevalence of diseases in different regions
[Zaveri11]

RJ Miller, Dec 2014
Running Example• Source: ClinicalTrials.gov
– Online registry of international clinical drug trials– 150,000+ XML files, updated daily – Provides web search interface
• Permits downloading relational (static) dump of DB– Permits structured querying – Relatively high cost of ownership– Still stand-alone DB not integrated with other sources or even linked to common
Web knowledge* “Find trials on Alzheimer’s disease near Toronto”* “How many publications are there related to this trial?”
– Although (mostly manually) curated, data still contains errors and inconsistencies
* Thalassemia vs. Thalassaemia* Location of a trial stored in different attributes
10

RJ Miller, Dec 2014
Super Duper IndexesMain Memory DBsColumn Oriented DBs150K Trials = Big Data?Big data encodes semantics that is valuable for curation
Integration is the most scalable way to add value to data
Big data provides opportunity to solve integration problems in new ways
Leveraging the human knowledge embedded in open curated data sets
11
Where’s the Big Data?

RJ Miller, Dec 2014
Talk Themes
12

RJ Miller, Dec 2014
Challenges• Big Data Challenges to Aligning Data
– How to discover links over open data at scale?
• Challenges to Maintaining Data Value – How to maintain alignments?– How to help users understand data and alignments?– How to provide provenance at scale?– How to provide provenance for more than queries?• Provenance for mining [TaPP13]
– How to clean the data and maintain its quality?• Unified model for cleaning data and metadata [ICDE11]
• Continuous data cleaning [ICDE14]
13
Linkage Points[PVLDB13]
LinQuer[CIKM09]
Perm[PVLDB11][Buneman Festschrift13]

RJ Miller, Dec 2014
Open Data Example
14
1 sec_company[j] = 2 { 3 "cik": "0001011006", 4 "name": "YAHOO INC", 5 "director": { 6 "cik": "0001238512", 7 "fullname": "BOBSTOCK ROY J", 8 "number_of_shares": "1995" 9 },10 }
1 freebase_company[i] = 2 { 3 "id": "/business/cik/0001011006", 4 "name": "Yahoo!", 5 "key": ["YHOO","Yahoo"], 6 "founded": "1995", 7 "key_people": [ 8 { 9 "name": { "Roy J. Bobstock" }, 10 "title": "Chairman" 11 }, {12 "name": { "Tim Morse" },13 "title": ["Employee","CEO"]14 } 15 ] 16 }

RJ Miller, Dec 2014
Entity Resolution (most common form of Data Matching)
• Attribute-based Resolution– string similarity & learned attribute weights
• Relational ER– relation similarity & learned relation weights– relation similarity ~ cluster similarity* e.g.,
• Deep and rich topic– Many formulations as both supervised & unsupervised learning task– [Getoor, Machanavajjhala, KDD 2013]
• Basic assumption: attributes and relations are semantically coherent– i.e., data fits a well-designed schema
15

RJ Miller, Dec 2014
Open Company Data
• Unknown schema– SEC data has no given schema, Freebase & DBpedia have dynamic and highly
heterogeneous schemas• Very large schema
– Considering only “company” entities in Freebase & DBpedia*DBpedia has over 3,000 attributes, Freebase 167 attributes, SEC 72 attributes
• Noisy schema– These sources are automatically extracted from text and contain noise
e.g., dateOfDeath & stockTicket [sic] attributes for a Company in DBpedia– These schemas are too heterogeneous and dynamic to meaningfully align– Traditional schema matching methods fail to assist in finding effective linkage rules
* largely assume each attribute used for one (homogeneous) thing
16
(RDF / Web API)(JSON / Web API)
(JSON Files)
RJ Miller, Dec 2014
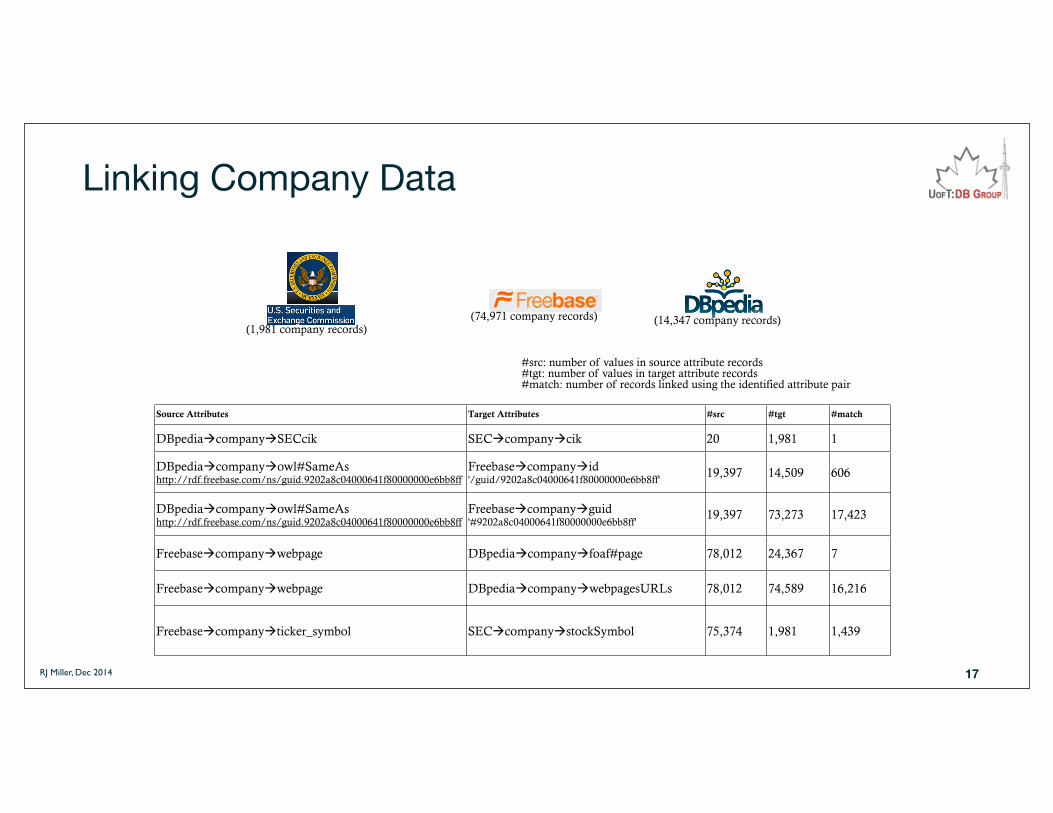
Linking Company Data
17
Source Attributes Target Attributes #src #tgt #match
DBpediaàcompanyàSECcik SECàcompanyàcik 20 1,981 1
DBpediaàcompanyàowl#SameAs http://rdf.freebase.com/ns/guid.9202a8c04000641f80000000e6bb8ff
Freebaseàcompanyàid '/guid/9202a8c04000641f80000000e6bb8ff'
19,397 14,509 606
DBpediaàcompanyàowl#SameAs http://rdf.freebase.com/ns/guid.9202a8c04000641f80000000e6bb8ff
Freebaseàcompanyàguid '#9202a8c04000641f80000000e6bb8ff'
19,397 73,273 17,423
Freebaseàcompanyàwebpage DBpediaàcompanyàfoaf#page 78,012 24,367 7
Freebaseàcompanyàwebpage DBpediaàcompanyàwebpagesURLs 78,012 74,589 16,216
Freebaseàcompanyàticker_symbol SECàcompanyàstockSymbol 75,374 1,981 1,439
(14,347 company records)(74,971 company records)(1,981 company records)
#src: number of values in source attribute records#tgt: number of values in target attribute records#match: number of records linked using the identified attribute pair
RJ Miller, Dec 2014
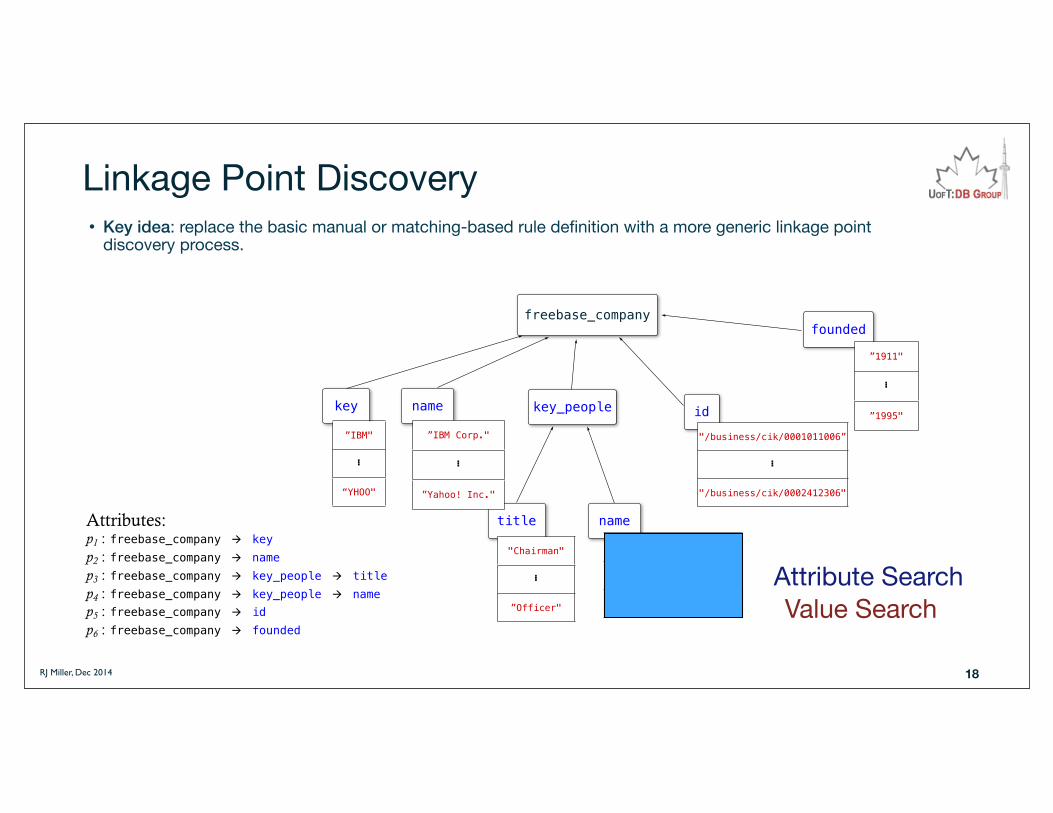
Linkage Point Discovery• Key idea: replace the basic manual or matching-based rule definition with a more generic linkage point
discovery process.
18
key name key_people id
founded freebase_company
title name
”IBM"
...
“YHOO"
”IBM Corp."
...
”Yahoo! Inc."
"Chairman"
...
”Officer"
"Virginia M. Rometty"
...
"Tom Morse”
"/business/cik/0001011006”
...
"/business/cik/0002412306"
”1911"
...
”1995"
Attributes:p1 : freebase_company à keyp2 : freebase_company à namep3 : freebase_company à key_people à titlep4 : freebase_company à key_people à namep5 : freebase_company à idp6 : freebase_company à founded
Value SearchAttribute Search

RJ Miller, Dec 2014
Analyze & Index
19
”http://ibm.com"
...
”http://www.yahoo.com"
Analyze (tokenize) usinga library of analyzers
• Exact: no transformation• Lower: transform strings into lowercase• Split: split strings by whitespace• Word Token: replace special characters with whitespace and then split• Q-gram: split strings into substrings of length q
Index • Given an attribute, retrieve (tokenized) values • Given a value, retrieve record/attributes containing the value
"http://ibm.com" ...
"http://www.yahoo.com"Attributes as Docs
Values as Docs "http://ibm.com"
"http://www.yahoo.com"
...
"http" "ibm" "com" ... "http" "www" "yahoo"
"com"
"http" "ibm" "com"
"http" "www" "yahoo" "com"
...
Word TokenAnalyzerAttribute Search
Value Search
Q-gramAnalyzer
" h”, “ ht" "htt" "ttp" ... ".co" "com" "co " "m"
...
Word TokenAnalyzer

RJ Miller, Dec 2014
Example Linkage Points
20
key name key_people id
founded
freebase_company
title name
"YHOO"
"Yahoo"
"Yahoo!"
"Chairman"
"CEO"
"Employee"
"Roy J. Bobstock"
"Tom Morse”
"/business/cik/0001011006"
”1995"
cik name
director
sec_company
number_of _shares
cik
”1995"
"0001011006"
fullname
"0001238512"
"BOBSTOCK ROY J"
”YAHOO INC"
(freebase_company à key , sec_company à name) using case insensitive substring matching as relevance function
(freebase_company à founded , sec_company à number_of_shares) using exact matching as relevance function

RJ Miller, Dec 2014
Attribute Search - Smash-S
• Treats attribute as a whole• Set similarity measures:
– Intersection Size, Jaccard similarity, Dice coefficient, etc.• Issues:
– Scalability, False positives21
Return (s,t) as a linkage point
"Apple" "Yahoo!” ...
"International" "Business" "Machines"
"Apple" "Corp." "Yahoo!"
"Inc," ... "International"
"Business" "Machines"
"Corporation"
s : freebase_company à name t : sec_company à name
sim(s,t) = Jaccard(Tokens(s),Tokens(t))
= | Tokens(s) ∩ Tokens(t) |
| Tokens(s) ∪ Tokens(t) |
sim(s,t) > ℇ

RJ Miller, Dec 2014
Value Search - Smash-R• Using a sample of values
– Find best match* Use efficient IR index• TF/IDF or Okapi BM25
– Find target attribute with best score over source sample* highest matching attribute:• sec_company à brand
22
s : freebase_company à name
q ß "Apple"
"Apple"
"International Business Machines"
...
"Yahoo!"
"Apple"
"Apple Corp."...
"Apple Cider"
1.0
0.67
0.54sec_company à product à name
sec_company à name
sec_company à product à brand
q ß "Yahoo!"
"Yahoo"
“Yahoo Finance”...
“Yoo-hoo”
0.87
0.54
0.31sec_company à product à name
sec_company à brand
sec_company à product à name

RJ Miller, Dec 2014
Removing the Junk - Smash-X• Attribute and value search return set of candidate linkage points: source à target• Filter out false positives
– Cardinality: size of the linkage set– Coverage: percentage of linked records in source or target data– Strength: percentage of distinct records that appear in the linkage set
23
( freebase_company à name , sec_company à name )Linkage point:
Linkage set:
"Apple"
"International Business Machines"
...
"Yahoo!"
"Apple Corp."
"IBM Corp.”
...
"Yahoo! Inc."
( freebase_company à founded , sec_company à product à release_date )Linkage point:
Linkage set:
"Apple"
"International Business Machines"
...
"Yahoo!"
"Apple Corp."
"IBM Corp.”
...
"Yahoo! Inc."
strong
weak

RJ Miller, Dec 2014
Implementation• Main features
– Transformation module that supports most semi-structured (Web) data – A library of analyzers and an efficient library of similarity functions– Efficient memory-based key-value store for record and value indices
24

RJ Miller, Dec 2014
Experimental Evaluation• Data sets in three domains (Company, Drug, and Movie entities), nine
scenarios
25
• Empirical Results– A relatively small sample value
size works well for value search– The filtering criteria are
effective, & work best when used together
Automated linkage based on linkage point discovery outperforms laborious manual linkage in real-world scenario in bioinformatics domain [American Medical Informatics Assoc, Translational Bioinformatics Summit, 2013]

RJ Miller, Dec 2014
Open Problems• Once linkage points identified, how do we efficiently link large datasets?
– Cannot co-partition data in a single way to enable efficient joins– Deep Sea (work with Jiang Du)* Provide physical data independence for distributed shared nothing
parallel systems* Reuse fault-tolerance mechanisms to improve performance of joins
over massively heterogeneous data• Linkage methods work for some, but not all data
– How do we let users correct mistakes?– How do we maintain links and linkage methods over time?
26

RJ Miller, Dec 2014
Data Linking
27
Clinical Trials (CT) from ClinicalTrials.gov/LinkedCT.org
Patient Visits (PV)
Wikipedia/DBpedia Articles (DP)
Trial Condition Intervention Location Reference
NCT003 Thalassemia Hydrozyurea Sick Kids PubMed14988
NCT005 Hematologic Disease Campath NYU PubMed30582
Visit Diagnosis Therapy Location
VID777 Thalassemia Hydroxyurea NY
VID999 Thalassaemia NULL UK
URI Title Categoryhttp://en.wikipedia.org/wiki/Thalessemia Thalassemia Blood_disorders
http://en.wikipedia.org/wiki/Hydroxyurea Hydroxyurea Chemotherapeutic_agents
http://en.wikipedia.org/wiki/AlemtuzumabAlemtuzumba
Alemtuzumab Cancer_treatments
is_same_as
is_same_as

RJ Miller, Dec 2014
Data Linking
28
Clinical Trials (CT) from ClinicalTrials.gov/LinkedCT.org
Patient Visits (PV)
Wikipedia/DBpedia Articles (DP)
Trial Condition Intervention Location Reference
NCT003 Thalassemia Hydrozyurea Sick Kids PubMed14988
NCT005 Hematologic Disease Campath NYU PubMed30582
Visit Diagnosis Therapy Location
VID777 Thalassemia Hydroxyurea NY
VID999 Thalassaemia NULL UK
URI Title Categoryhttp://en.wikipedia.org/wiki/Thalessemia Thalassemia Blood_disorders
http://en.wikipedia.org/wiki/Hydroxyurea Hydroxyurea Chemotherapeutic_agents
http://en.wikipedia.org/wiki/AlemtuzumabAlemtuzumba
Alemtuzumab Cancer_treatments
NCI_Synonym
is_a_type_of located_in

RJ Miller, Dec 2014
Data Linking7• Linkage point discovery
–finds effective linkage method over massively heterogeneous big datasets
• Lots of other great link discovery work– PSL (UMD), SERF (Stanford), Dedupalog (UW), PSL (UMD), ...
• For curation discovery is not enough– Customize – Correct– Understand* Automation should not obviate understanding!
29

RJ Miller, Dec 2014
LinQuer• Generic, extensible and easy-to-use framework
– LinQL: SQL extension specification of linkage methods– [Hassanzadeh, Kementsietsidis, Lim, M-, Wang 09]– [Hassanzadeh, Xin, M-, Kementsietsidis, Lim, Wang 09]
• Library of large variety similarity functions– Syntactic (string) errors or differences– Semantic relationship or equivalence– A mix of syntactic similarity and semantic relationship
• Efficient implementation and integration with SQL– Declarative approximate string joins [Hassanzadeh 07]
• Open incremental incorporation human knowledge
30

RJ Miller, Dec 2014
Linkage methods• Learned automatically or designed by a curator using languages like
Dedupalog [Arasu, et al 09] or HIL [Hernandez et al 13]
– many make use of similarity measures between different types of data (attribute values of a record or fact)
– measures may be combined in different weighted combinations• String similarity measures
– many are set similarity measures (Jaccard, Dice coefficient)*Jaccard - size of intersection divided by size union
– different tokenizations create sets*characters separated by white space or URL/other separators, normalized to lower case or by stemming...
• Semantic similarity– implemented using SQL to joins with ontology
*synonyms, part-of/isa relationships
31

RJ Miller, Dec 2014
Data Linking in LinQuer
CT PV
Trial Condition Interv...
NCT003 Thalassemia Hydro...
NCT005 Beta-Thalassemia Campa...
Visit Diagnosis Therapy Loc
VID777 Thalassemia Hydroxyurea NY
VID999 Thalassemia Disorder NULL UK
SELECT Trial, Condition, count(Visit) AS #PatientsFROM CT LEFT OUTER JOIN PV WHERE Diagnosis = ConditionGROUP BY Trial, Condition
Trial Condition #Patients
NCT003 Thalassemia 1
NCT005 Beta-Thalassemia 0
• Linkage methods permit approximate join
32

RJ Miller, Dec 2014
Data Linking in LinQuer
CT PV
Trial Condition Interv...
NCT003 Thalassemia Hydro...
NCT005 Beta-Thalassemia Campa...
Visit Diagnosis Therapy Loc
VID777 Thalassemia Hydroxyurea NY
VID999 Thalassemia Disorder NULL UK
Trial Condition #Patients
NCT003 Thalassemia 1
NCT005 Beta-Thalassemia 0
• Linkage methods permit approximate join– Syntactic: tokenizer and similarity
measure (e.g., weighted Jaccard on tokens)
– Semantic: using ontologies such as NCI Thesaurus
– Combinations
33
SELECT Trial, Condition, count(Visit) AS #PatientsFROM CT LEFT OUTER JOIN PV WHERE Diagnosis LINK Condition USING
weightedJaccard(Diagnosis, Condition, .8) GROUP BY Trial, Condition

RJ Miller, Dec 2014
SQL Under the CoversweightedJaccard is syntactic sugar for pure SQL implementation of this approximate join
34
WITH scores(tid1, tid2, score) AS ( SELECT tid1, tid2,
Intersect.inter/(Cweight.sum + Pweight.sum - Intersect.inter) AS score FROM (SELECT C.TID AS tid1, P.TID AS tid2, SUM(C.Weight) AS inter FROM CTConditionTokens C, PVDiagnosisTokens P, WHERE B.Token = P.Token GROUP BY C.TID, P.TID) AS Intersect, (SELECT ID, sum(Weight) AS sum FROM CTConditionTokens, GROUP BY TID) as Cweight, (SELECT TID, sum(Weight) AS sum FROM PVDiagnosisTokens, GROUP BY TID) AS Pweight, WHERE Cweight.tid = Intersect.tid1 and Pweight.tid = Intersect.tid2 )SELECT CT.Trial, CT.Condition, count(PV.Visit)FROM CT, PV, scores SWHERE S.tid1=CT.Trial, S.tid2=PV.Visit and S.score > .8
TID Token WeightNCT003 Thalassemia 0.9NCT005 Beta 0.8NCT005 Thalassemia 0.9
TID Token WeightVID777 Thalassemia 0.9VID999 Disorder 0.1VID999 Thalassemia 0.9
CTConditionTokens
PVDiagnosisTokens

RJ Miller, Dec 2014
Beyond Data Linking• Given link (or any data derived from curation)
– What data is it derived from (data provenance)?– Which linkage methods were used to create it?– Who created it?– Which data sources contributed to it?
• Given an erroneous result, is the error in the base data, the curation (linking) process, or human curation decisions?
35
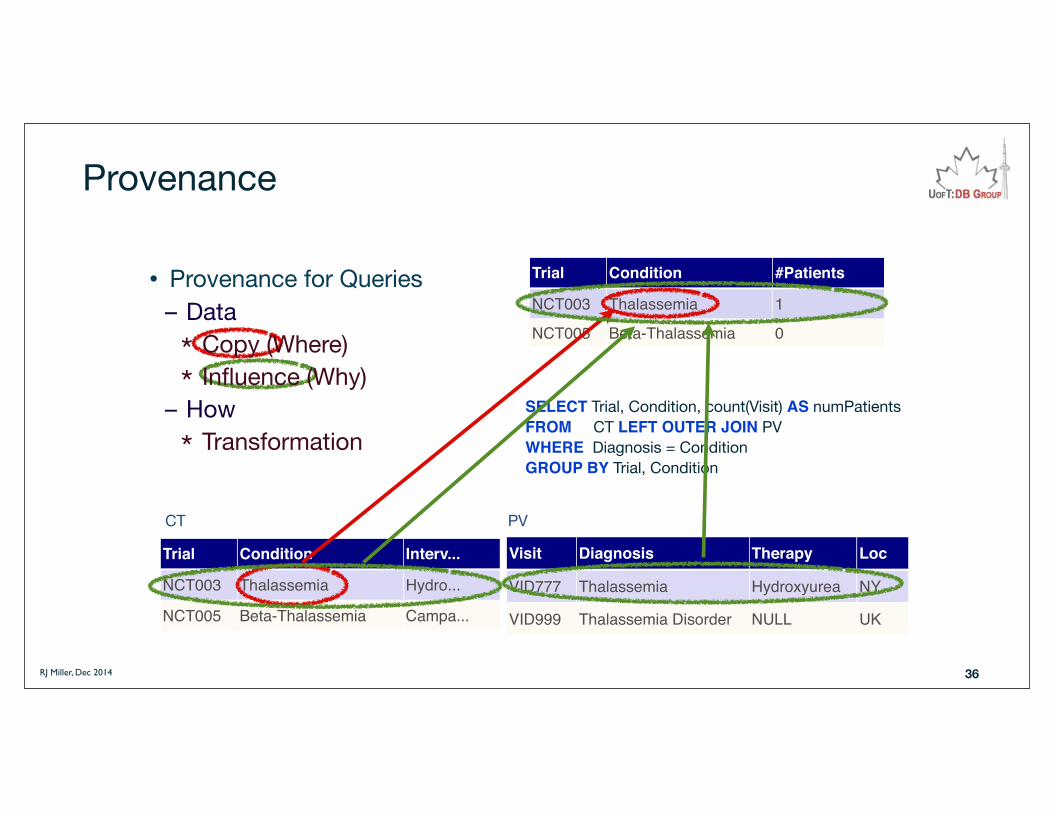
RJ Miller, Dec 2014
Trial Condition Interv...
NCT003 Thalassemia Hydro...
NCT005 Beta-Thalassemia Campa...
Trial Condition #Patients
NCT003 Thalassemia 1
NCT005 Beta-Thalassemia 0
Provenance
CT PV
SELECT Trial, Condition, count(Visit) AS numPatientsFROM CT LEFT OUTER JOIN PV WHERE Diagnosis = ConditionGROUP BY Trial, Condition
36
Visit Diagnosis Therapy Loc
VID777 Thalassemia Hydroxyurea NY
VID999 Thalassemia Disorder NULL UK
• Provenance for Queries– Data* Copy (Where)* Influence (Why)
– How* Transformation

RJ Miller, Dec 2014
Trial Condition Interv...
NCT003 Thalassemia Hydro...
NCT005 Beta-Thalassemia Campa...
Visit Diagnosis Therapy Loc
VID777 Thalassemia Hydroxyurea NY
VID999 Thalassemia Disorder NULL UK
Trial Condition #Patients
NCT003 Thalassemia 2
NCT005 Beta-Thalassemia 2
Provenance over Linked Data
37
CT PV
SELECT Trial, Condition, count(Visit) AS #PatientsFROM CT LEFT OUTER JOIN PV WHERE Diagnosis LINK Condition USING
weightedJaccard(Diagnosis, Condition, .8)GROUP BY Trial, Condition
• Declarative specification of linkage methods enables provenance computation over linked data

RJ Miller, Dec 2014
Visit Token WeightVID777 Thalassemia 0.9VID999 Disorder 0.1VID999 Thalassemia 0.9
Trial Condition Interv...
NCT003 Thalassemia Hydro...
NCT005 Beta-Thalassemia Campa...
Visit Diagnosis Therapy Loc
VID777 Thalassemia Hydroxyurea NY
VID999 Thalassemia Disorder NULL UK
Trial Condition #Patients
NCT003 Thalassemia 2
NCT005 Beta-Thalassemia 2
Provenance over Linked Data
38
CT PV
SELECT Trial, Condition, count(Visit) AS #PatientsFROM CT LEFT OUTER JOIN PV WHERE Diagnosis LINK Condition USING
weightedJaccard(Diagnosis, Condition, .8)GROUP BY Trial, Condition
Trial Token WeightNCT003 Thalassemia 0.9NCT005 Beta 0.2NCT005 Thalassemia 0.9
CTConditionTokens
PV.Diagnosis.Tokens
• Declarative specification of linkage methods enables provenance computation over linked data

RJ Miller, Dec 2014
Visit Token WeightVID777 Thalassemia 0.9VID999 Disorder 0.1VID999 Thalassemia 0.9
Trial Condition Interv...
NCT003 Thalassemia Hydro...
NCT005 Beta-Thalassemia Campa...
Visit Diagnosis Therapy Loc
VID777 Thalassemia Hydroxyurea NY
VID999 Thalassemia Disorder NULL UK
Trial Condition #Patients
NCT003 Thalassemia 2
NCT005 Beta-Thalassemia 2
Provenance over Linked Data
39
CT PV
SELECT Trial, Condition, count(Visit) AS #PatientsFROM CT LEFT OUTER JOIN PV WHERE Diagnosis LINK Condition USING
weightedJaccard(Diagnosis, Condition, .8)GROUP BY Trial, Condition
Trial Token WeightNCT003 Thalassemia 0.9NCT005 Beta 0.2NCT005 Thalassemia 0.9
CTConditionTokens
PV.Diagnosis.Tokens
• Declarative specification of linkage methods enables provenance computation over linked data Suppose Beta-Thalassemia & Thalassemia are different
diseases, can use provenance to correct learned weights

RJ Miller, Dec 2014
Provenance State of the Art• Provenance Semantics
– Why-, Where-, Lineage, How-, ...– Semiring-model: subsumes most of these semantics* Generally most accepted semantics for relational algebra (extended
for aggregates and bag semantics) [Green, Karvounarakis, Tannen 07]
• Provenance Systems– Our contributions: PERM* SQL (including nested queries)* Provenance computation expressed as efficient SQL* Ability to query data and provenance* Programmability of provenance computation• User can control when & how much provenance is computed
40

RJ Miller, Dec 2014
Provenance Representation• General Idea
– Single relation that combines result tuples of query with tuples in its provenance
• Schema– Add additional attributes to query result that store provenance– Determined by query structure
• Instance– Combine each result tuple with all tuples in its provenance– Duplicate tuple to fit in provenance if necessary– For experts: each monomial in provenance polynomial is one row
(sum of products normal form)
41

RJ Miller, Dec 2014
Trial Condition Interv...
NCT003 Thalassemia Hydro...
NCT005 Beta-Thalassemia Campa...
Visit Diagnosis Therapy Loc
VID777 Thalassemia Hydroxyurea NY
VID999 Thalassemia Disorder NULL UK
Trial Condition
#Patients
p1 p2 p3 p4 p5 p6 p7NCT003 Thalasse
mia2 NCT003 Thalass
emiaHydro... VID777 Thalass
emiaHydroxyurea
NYNCT003 Thalasse
mia2 NCT003 Thalass
emiaHydro... VID999 Thalass
emiaNULL UK
NCT005 Beta-Thalassemia
2 NCT005 Beta-Thalassemia
Campa...
VID777 Thalassemia
Hydroxyurea
NYNCT005 Beta-
Thalasse2 NCT005 Beta-
ThalassCampa...
VID999 Thalassemia
NULL UK
Provenance Representation
42
CT PV
SELECT PROVENANCE Trial, Condition, count(Visit) AS #PatientsFROM CT LEFT OUTER JOIN PV WHERE Diagnosis LINK Condition USING
weightedJaccard(Diagnosis, Condition, .8)GROUP BY Trial, Condition
c1c2
p1p2
Shortcut Namep1 prov_CT_Trialp2 prov_CT_Conditionp3 prov_CT_Interv...p4 prov_PV_Visitp5 prov_PV_Diagnosisp6 prov_PV_Therapy
c1 x p1c1 x p2c2 x p1c2 x p2
Each monomial in provenance polynomial is one row (sum of products normal form)

RJ Miller, Dec 2014
Contributions• Relational representation of provenance
– Support querying of provenance– Which links were derived from the assertion that:* (Thalessemia is-type-of Hematologic Disease )?
– Requires not only ability to generate provenance but to represent and query it relationally [Glavic, Alonso, M-- 13]
• What part of a linkage method or transformation program (mapping) contributed to a link?– If data has been mapped (transformed) into another schema, could the
transformation code be wrong? • Using provenance to debug data exchange
* [Glavic, Alonso, Haas M-- VLDB10], [Glavic, Du, M-, Alonso, Haas VLDB11]
43

RJ Miller, Dec 2014
Provenance for Data Mining• Data Mining
– Extract useful information from data* Summarization, simplification, filtering
– Underlies many curation tasks like schema discovery and link discovery
• Raw data mining outputs are often hard to interpret– Drill-down to relevant inputs (Provenance)* Find related inputs and summarize this information (Mine Provenance)
– Quantify amount of responsibility (Responsibility)
• Example: frequent itemset mining [Glavic, Siddique, M-- 13]– One of most notorious mining tasks
44

RJ Miller, Dec 2014
FID Frequent Items Support
1 (Alemtuzumab) 4
2 {Campath} 4
3 (Lemtrada) 4
4 {Cyclosporine} 4
5 {Campath Alemtuzumab Lemtrada} 3
6 {Lemtrada Cyclosporine} 3
34Provenance
45
TID Interventions
1 Campath Alemtuzumab Lemtrada Cyclosporine
2 Campath Alemtuzumab Lemtrada
3 Campath Alemtuzumab Lemtrada Cyclosporine
4 Campath
5 Lemtrada Cyclosporine
6 Alemtuzumab Cyclosporine
• Why is {Campath, Alemtuzumab, Lemtrada} frequent?
ClinicalTrials
Frequent Itemsets
Why ProvenanceFID TIDs
1 {1,2,3,5}
2 {1,2,3,4}
3 {1,2,3,5}
4 {1,3,5,6}
5 {1.2.3}
6 {1,2,5}
TID Funder Location
1 Pfizer NYU
2 Pfizer Columbia
3 Pfizer NYU
4 NIH NYU
Trial Funding
• Mining provenance -> a defining characteristic of these trials were that they were funded by Pfizer at NY locations
• Why-provenance -> appeared in trials {1,2,3}

RJ Miller, Dec 2014
Talk Themes• Curation is ultimately about semantics
– Exploit modeled semantics & be principled in how missing semantics is created
• Curation is for humans– Facilitate human understanding and decision making– People must be able to correct and understand curation decisions
• Curation focus on valuable datasets – Leverage Big Data to add value to curated data– Automation required not just for scale, but to manage deep complexity
of curation tasks
46

RJ Miller, Dec 2014
Future Work• Curation maintains value of data over time
– Incremental/Continuous Linkage Point Discovery– Continuous curation (continuous data quality improvement)
• Data cleaning– Declarative data cleaning (permits explanation of repair)– Unified approach to repairing data & semantics [Chiang, M- VLDB08, ICDE11]– Most work considers cleaning as one step activity* Continuous Data Cleaning [Volkovs,Chiang,Szlichta, M- ICDE14]
• Visualization support for curation– Value imputation [Christodoulakis, Faloutsos, M- ICDE14]– Visual algebra for curation* Focus user’s attention on most impactful curation decisions
47