big data testing: a unified view - east carolina universitycore.ecu.edu/strg/seminars/16 march 2016...
TRANSCRIPT

BIG DATA TESTING: A UNIFIED VIEW BY NAM THAI
ECU, Computer Science Department , March 16, 2016
http://core.ecu.edu/STRG

PRESENTATION CONTENT
1. Overview of Big Data
A. 5 V’s of Big Data
B. Data generation
C. Data acquisition
D. Data pre-processing
E. Data analysis
F. Apache Hadoop
2. Testing Big Data
A. Database Testing
B. Application Testing
C. Performance Testing
D. Traditional Testing vs Big Data Testing
2/30

WHAT? WHY?
Moore’s law (generation / storage)
Industry demand (science, business, etc..)
Traditional RDBMS not enough
Barrack Obama (200$) million
Y. Demchenko; C. Laat; P. Membrey; 2014
H. Hu; Y. Wen; T. Chua; X. Li; 2015
3/30
Comparative Definition:
“ Data sets whose size is beyond the ability of typical database software tools to capture, store, manage and analyze”
-McKinsey Global Institute Report
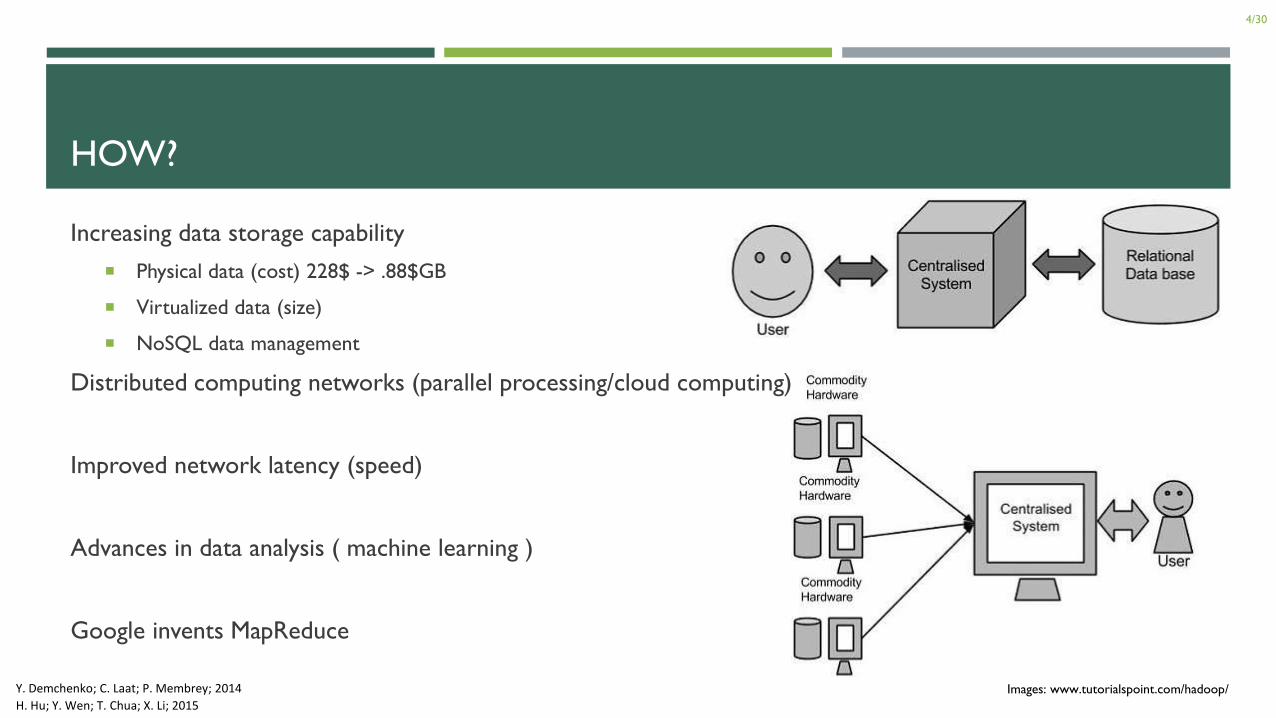
HOW?
Increasing data storage capability
Physical data (cost) 228$ -> .88$GB
Virtualized data (size)
NoSQL data management
Distributed computing networks (parallel processing/cloud computing)
Improved network latency (speed)
Advances in data analysis ( machine learning )
Google invents MapReduce
Y. Demchenko; C. Laat; P. Membrey; 2014 Images: www.tutorialspoint.com/hadoop/
H. Hu; Y. Wen; T. Chua; X. Li; 2015
4/30

WHAT IS BIG DATA?
Attributive Definition:
“ Big Data Technologies describe a new generation of technologies and architectures, designed to
economically extract value from very large volumes of a wide variety of data, by enabling high-
velocity capture, discovery and/or analysis”
-International Data Company
H. Hu; Y. Wen; T. Chua; X. Li; 2015
5/30

THE 4 V’S OF BIG DATA:
Volume:
Terabytes and Petabytes of storage
Database functionality to handle TB & PB
Velocity:
TB/sec. data transfer rates
Variety:
Data Types: text, video, images, speech etc...
Data Source: Many sources, from varying distances, at varying speeds
Value:
Analysis: data analysis applications
Veracity: data must be correct
Data cleansing: removing noise and correcting errors
Demchenko, Y.; de Laat, C.; Membrey, P., "Defining architecture components of the Big Data Ecosystem,"
H. Hu; Y. Wen; T. Chua; X. Li; 2015
6/30
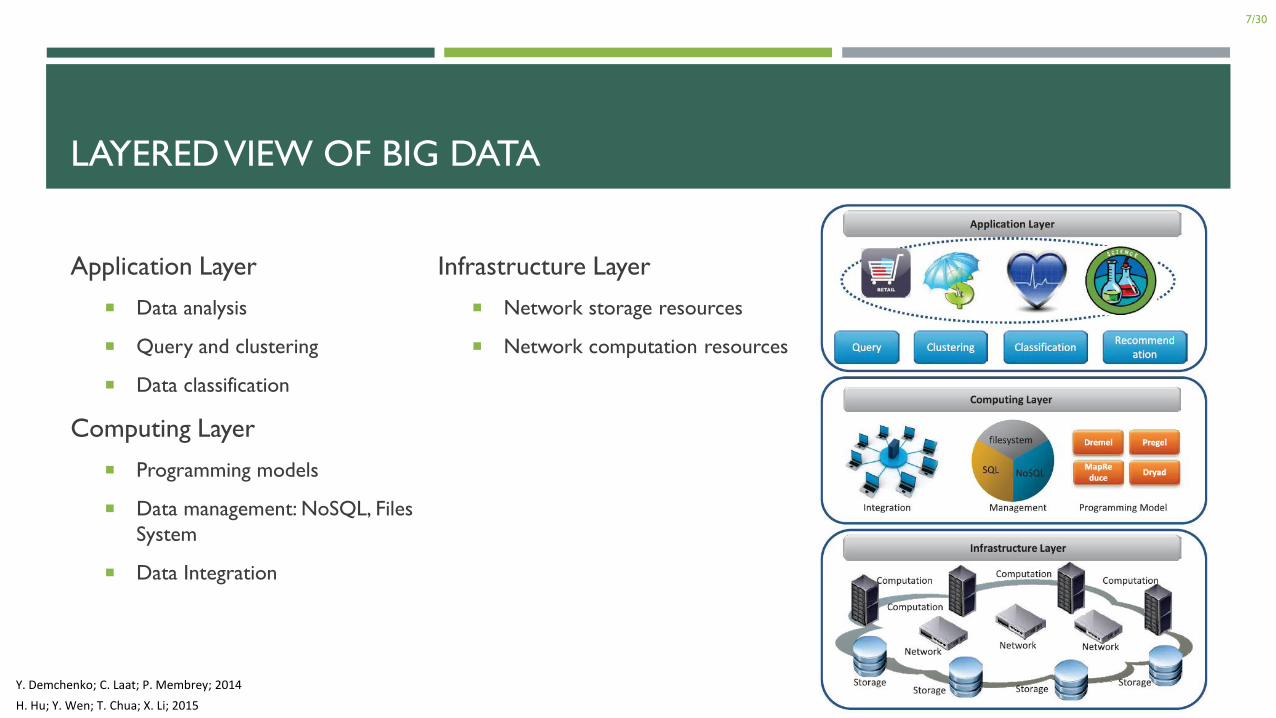
LAYERED VIEW OF BIG DATA
Application Layer
Data analysis
Query and clustering
Data classification
Computing Layer
Programming models
Data management: NoSQL, Files
System
Data Integration
Infrastructure Layer
Network storage resources
Network computation resources
Y. Demchenko; C. Laat; P. Membrey; 2014
H. Hu; Y. Wen; T. Chua; X. Li; 2015
7/30

BIG DATA LIFE CYCLE
1. Data Generation
Attributes
Sources
II. Data Acquisition
Collection
Transmission
Pre-processing
III. Data Storage
File systems
Database technologies
Programming models
IV. Data Analysis
Analysis techniques
Analysis paradigms
Y. Demchenko; C. Laat; P. Membrey; 2014
H. Hu; Y. Wen; T. Chua; X. Li; 2015
8/30
1. DATA GENERATION
The “Data” in Big Data
Volume: Petabytes & Exabytes
Velocity: PB/sec or real-time
Variety: text, image, video, logs, reports
Value: source of data
Domain specificity
H. Hu; Y. Wen; T. Chua; X. Li; 2015
I. Data Generation II. Data Acquisition III. Data Storage IV. Data Analysis 9/30

1. DATA GENERATION CONT.
Business Data:
Stock market, internet purchases, business to business
Billions of transactions per day
Networking Data:
Internet: Google 30 Pb/day
Social Networking: Facebook 30Pb/day
Internet of things: 30 million networked sensors
Scientific Data:
Astronomy: 20 TB of images a night
High-Energy Physics: LHC 2Pb/second
Data is already available!
Amazon RedShift
Petabyte sized data warehouse
http://www.kurzweilai.net/images/ http://bigdatatrainers.com/wp-content/uploads/2013/10/Big-Data-and-Stock-Markets.jpg H. Hu; Y. Wen; T. Chua; X. Li; 2015
I. Data Generation II. Data Acquisition III. Data Storage IV. Data Analysis 10/30

II. DATA ACQUISITION: DATA COLLECTION
Two categories
Pull-Based approach
Push-Based approach
Common Collection methods:
Sensors: Physical to Digital
Pull-Based approach
Log File: Record activity of software systems
Push-Based approach
Web Crawler: Collecting URLs for search engines
Pull-Based approach
https://s.campbellsci.com/images/10-569.png H. Hu; Y. Wen; T. Chua; X. Li; 2015
I. Data Generation II. Data Acquisition III. Data Storage IV. Data Analysis 11/30
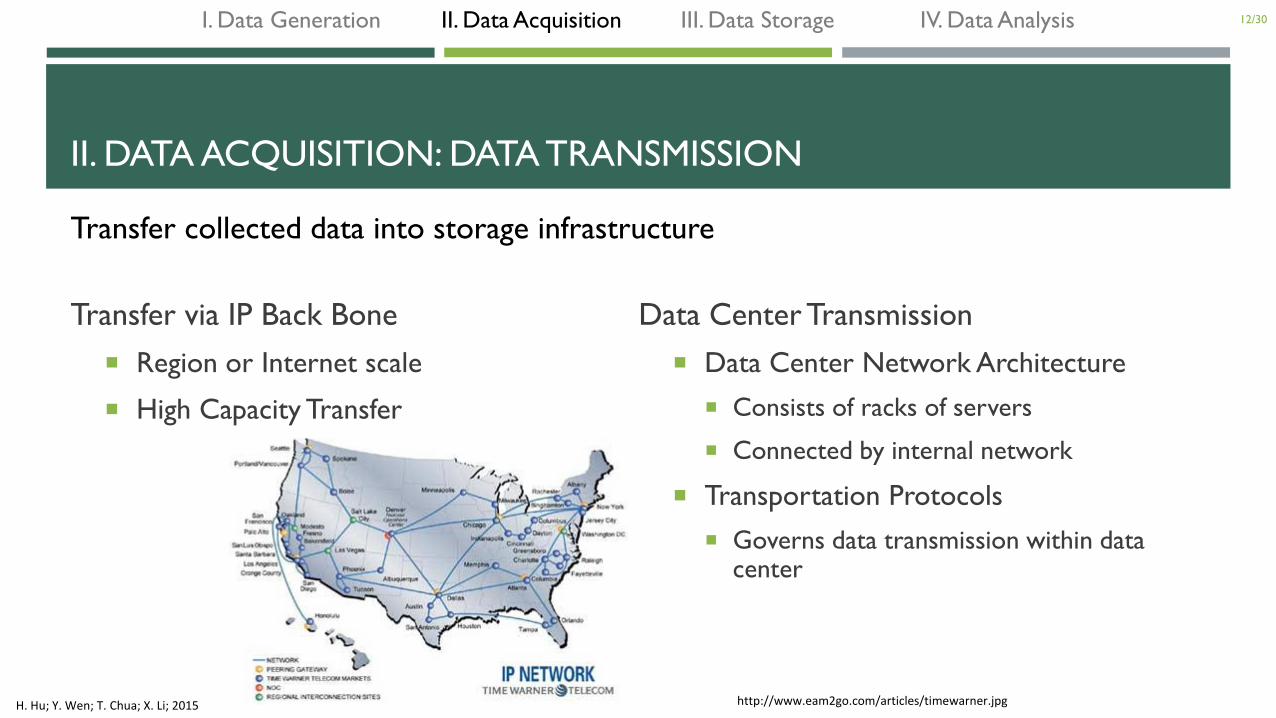
II. DATA ACQUISITION: DATA TRANSMISSION
Transfer via IP Back Bone
Region or Internet scale
High Capacity Transfer
Data Center Transmission
Data Center Network Architecture
Consists of racks of servers
Connected by internal network
Transportation Protocols
Governs data transmission within data center
Transfer collected data into storage infrastructure
http://www.eam2go.com/articles/timewarner.jpg H. Hu; Y. Wen; T. Chua; X. Li; 2015
I. Data Generation II. Data Acquisition III. Data Storage IV. Data Analysis 12/30

II. DATA ACQUISITION: PRE-PROCESSING
Data quality is critical
Reduce noise and redundancy
Increase consistency
Integration
Combining data into a unified view
Distributed sources
Data needs to be standardized
Cleansing
Search for inaccurate, incomplete, irrelevant data
Requires data rules
Amend or remove bad data
Redundancy Elimination
Reduce transmission overhead
Prevent wasted storage space, inconsistency
Data corruption can destroy databases
H. Hu; Y. Wen; T. Chua; X. Li; 2015
I. Data Generation II. Data Acquisition III. Data Storage IV. Data Analysis 13/30

III. DATA STORAGE: STORAGE INFRASTRUCTURE
Store collected data into format for analysis
Physical Storage
Random access memory (RAM)
Magnetic disk (HDD)
Storage class memory (SDD)
Optical / Tape storage (Big Data Obsolete)
Network Infrastructure
Direct Attached Storage (DAS)
Network Attached Storage (NAS)
Storage Area Network (SAN)
Attributes
Persistent and reliable
Infrastructure must be able to scale up and down to meet application demand
SAN networks allows virtualization
Virtualization allows multiple networks to function as a single storage device
http://i.kinja-img.com/gawker-media/image/upload/jltsftzlt6tmfg67vh6m.jpg H. Hu; Y. Wen; T. Chua; X. Li; 2015
I. Data Generation II. Data Acquisition III. Data Storage IV. Data Analysis 14/30
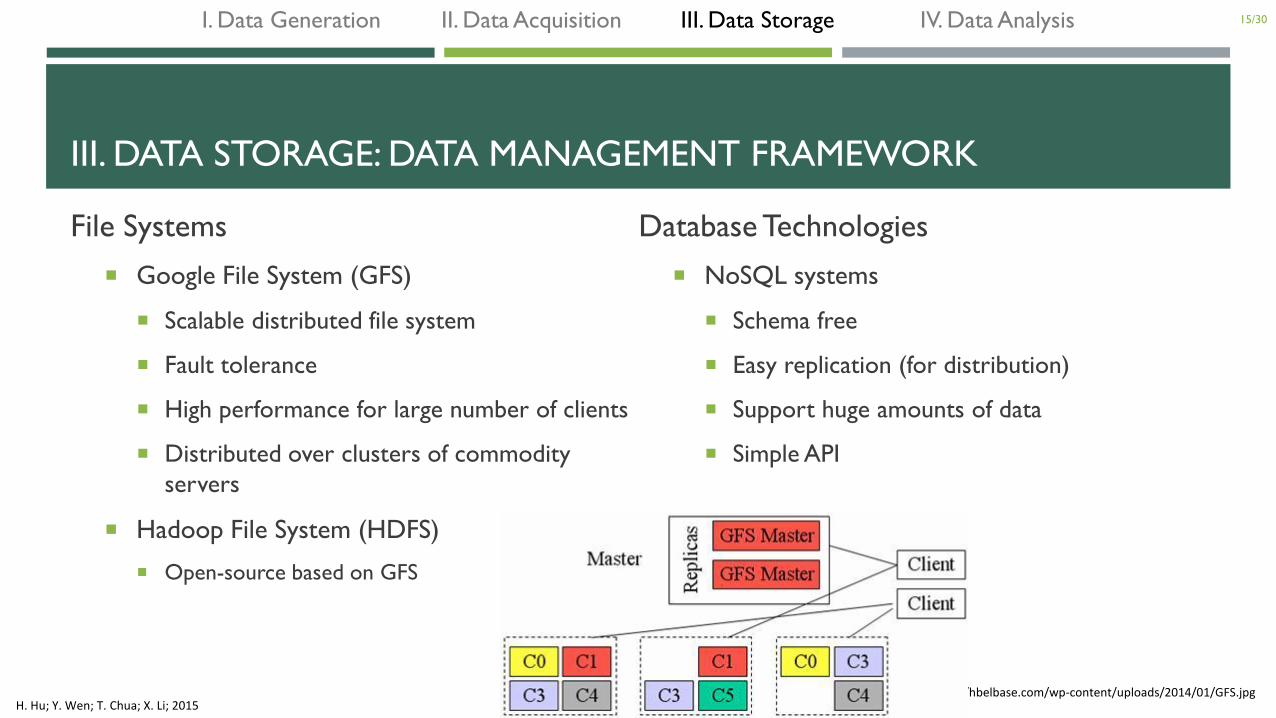
III. DATA STORAGE: DATA MANAGEMENT FRAMEWORK
File Systems
Google File System (GFS)
Scalable distributed file system
Fault tolerance
High performance for large number of clients
Distributed over clusters of commodity
servers
Hadoop File System (HDFS)
Open-source based on GFS
Database Technologies
NoSQL systems
Schema free
Easy replication (for distribution)
Support huge amounts of data
Simple API
http://hbelbase.com/wp-content/uploads/2014/01/GFS.jpg H. Hu; Y. Wen; T. Chua; X. Li; 2015
I. Data Generation II. Data Acquisition III. Data Storage IV. Data Analysis 15/30

III. DATA STORAGE: PROGRAMMING MODELS
Programming models provide application logics that allow large data processing
Generic programming model
Stream programming model
Batch programming model
Generic Process Model
MapReduce invented by google
MapReduce most widely used in big data ecosystem
Allows distributed processing
Can be integrated with SQL
MapReduce consists of three main phases:
Map() - Data objects are mapped based analysis constraints
Shuffle() – Consolidates mapped objects into classes
Reduce() – Aggregate all shuffled objects into one
H. Hu; Y. Wen; T. Chua; X. Li; 2015
I. Data Generation II. Data Acquisition III. Data Storage IV. Data Analysis 16/30

IV. DATA ANALYSIS
Data Analysis methods are domain specific!
Goals of Data analysis
Extrapolate and interpret data
Check legitimacy of data
Assist decision making
Predict future trends
Provide recommendations
Types of Data Analysis
Descriptive analytics
Uses historical data to describe a trend or occurrence
Usually translated to graphical visualizations
Associated with business intelligence
Predictive analytics
Uses data to predict future trends or probabilities
Utilizes data mining to calculate predictions
Statistical techniques used to interpret data
Prescriptive analytics
Uses data to diagnose and infer information to assist decision making
H. Hu; Y. Wen; T. Chua; X. Li; 2015 http://charc-concepts.org/wp-content/uploads/2012/10/Data-Mining-2.jpg
http://www.noaanews.noaa.gov/stories2004/images/frances-radar-melbourne-fla-090404-0334z.jpg
I. Data Generation II. Data Acquisition III. Data Storage IV. Data Analysis 17/30

IV. DATA ANALYSIS: ANALYSIS PARADIGMS
Stream Processing Model (Real-time)
Analyze as soon as possible
Data value relies on data freshness
High processing speed
Little raw data is stored
Batch Processing Model
Analysis of large batches of data
MapReduce is most common batch-
processing model
Processing is scheduled near the data
location
H. Hu; Y. Wen; T. Chua; X. Li; 2015
I. Data Generation II. Data Acquisition III. Data Storage IV. Data Analysis 18/30

IV. DATA ANALYSIS: DATA ANALYSIS TECHNIQUES
Data Mining
Computational process of discovering patterns in data sets
Data mining is used in:
Artificial intelligence, machine learning, pattern recognition,
statistics etc.
Types of data mining algorithms
Classification
Clustering
Regression
Statistical learning
Association analysis
Data Visualization
Information graphics and visualization
Graphical data representation is easy to understand
Due to volume and variety of data, visualization is needed
Visualization can assist
Algorithm design
Software development
https://www.flickr.com/photos/22402885@N00/3821069672/ H. Hu; Y. Wen; T. Chua; X. Li; 2015
I. Data Generation II. Data Acquisition III. Data Storage IV. Data Analysis 19/30

APACHE HADOOP
Leading Big Data Industry and Academia
Open-Sourced
Companies using Hadoop: Amazon, LinkedIn, IBM,
Microsoft and Intel
Adapted from Google’s MapReduce
Scalability & Flexibility
Clusters and servers can be added/removed without
interrupting system
Because of Java base, is compatible on all platforms
Fault tolerance
Does not rely on hardware for FT
Hadoop library designed to detect and handle failures
on application level
http://ecomcanada.org/blog/wp-content/uploads/2014/11/hadoop-architecture.png
H. Hu; Y. Wen; T. Chua; X. Li; 2015
Images: www.tutorialspoint.com/hadoop/
H. Hu; Y. Wen; T. Chua; X. Li; 2015
20/30

BIG DATA TESTING
I. Database Testing
II. Application Testing
III. Performance Testing
IV. Traditional Testing vs Big Data Testing
21/30

DATABASE TESTING: VERIFICATION OF DATABASE
Testing is Domain specific
Testers must know how to cover integrity constraints
Testers must cater data to trigger integrity constraints
Every integrity constraint must be tested
Traditional verification:
Manually filling tables with data copied from other
sources
Random data (Only good for performance and load
testing)
Implementing custom, domain specific, data generators
Big Database Functionality validation requires:
AUTOMATION
Generating formatted and unformatted data
Parse & interpret integrity constraints
Generate data to trigger data rules
Validate the correctness of generated data
Correctness of data structure
Ability to trigger integrity constraints
Sneed, H.M.; Erdoes, K., "Testing big data (Assuring the quality of large databases),"
22/30
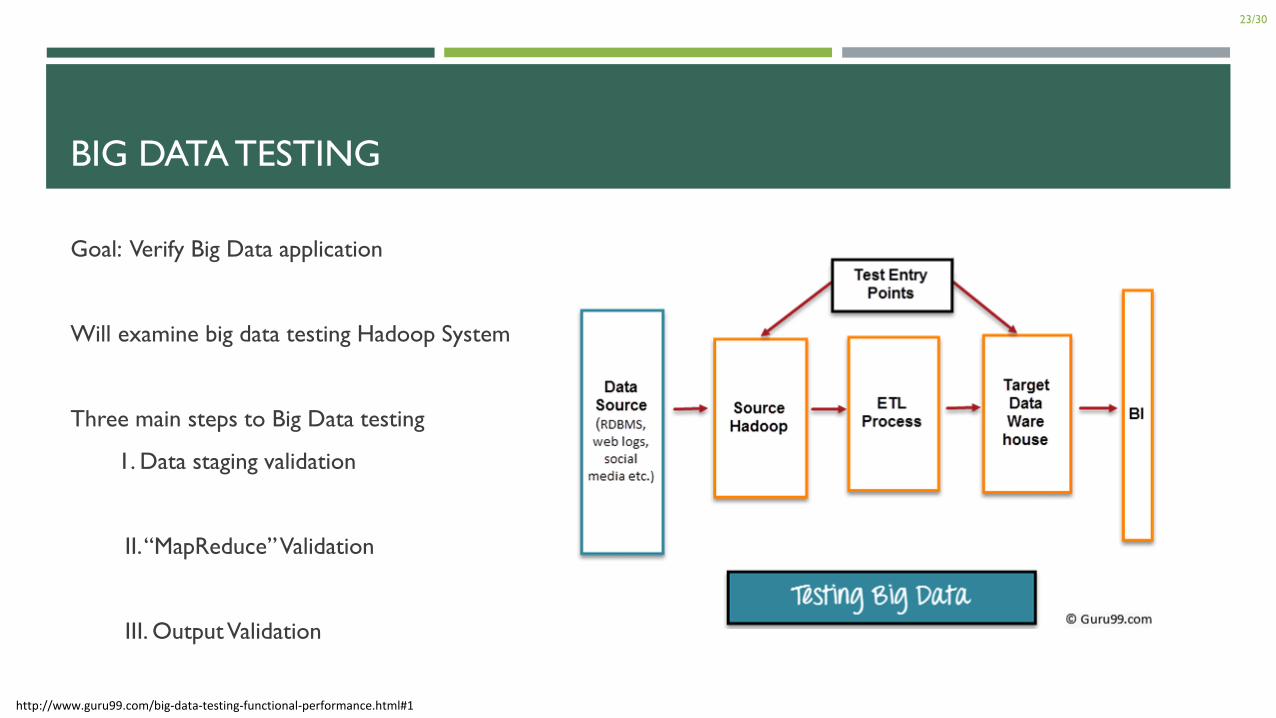
BIG DATA TESTING
Goal: Verify Big Data application
Will examine big data testing Hadoop System
Three main steps to Big Data testing
1. Data staging validation
II. “MapReduce” Validation
III. Output Validation
http://www.guru99.com/big-data-testing-functional-performance.html#1
23/30
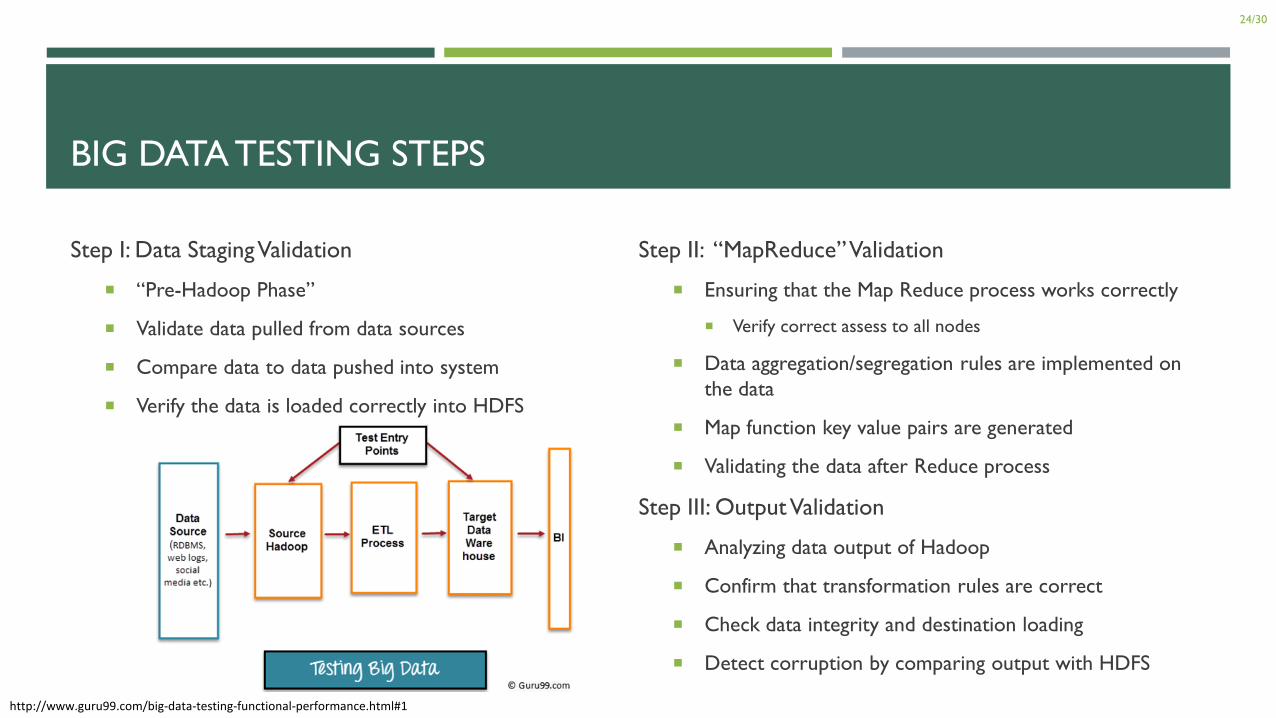
BIG DATA TESTING STEPS
Step I: Data Staging Validation
“Pre-Hadoop Phase”
Validate data pulled from data sources
Compare data to data pushed into system
Verify the data is loaded correctly into HDFS
Step II: “MapReduce” Validation
Ensuring that the Map Reduce process works correctly
Verify correct assess to all nodes
Data aggregation/segregation rules are implemented on
the data
Map function key value pairs are generated
Validating the data after Reduce process
Step III: Output Validation
Analyzing data output of Hadoop
Confirm that transformation rules are correct
Check data integrity and destination loading
Detect corruption by comparing output with HDFS
http://www.guru99.com/big-data-testing-functional-performance.html#1
24/30

PERFORMANCE TESTING
A form of non-functional testing which simulate load
conditions
Detect bottlenecks and performance issues
Provide benchmark data on system
Central Characteristics
Response time (Faster response time)
Resource use (Efficient resource use)
Stability (Reliable Stability)
A. Alexandrov, C. Brücke, and V. Markl, “Issues in Big Data Testing and Benchmarking,”
Sneed, H.M.; Erdoes, K., "Testing big data (Assuring the quality of large databases),"
25/30

PERFORMANCE TESTING
Performance testing focuses on improving the 4 V’s
Performance Test Types
Concurrent test
Tests the concurrent usage of a specific block of the Big Data
system
Determines any problems with many concurrent users
Load testing
Testing the performance of Big Data system in different load levels
to determine levels of performance.
Provides reliability and stability metrics
Focuses on user transactions with the system
Stress testing
Examine system performance in the most extreme
conditions of concurrent users and user transactions
Provides metrics on peak loads and failure conditions
Reveals weaknesses in system
Capacity testing
Determine maximum resource loads available to the
system
Provides metrics on physical limitations of the system
Provides metrics on maximum concurrent users and
maximum simultaneous transactions
A. Alexandrov, C. Brücke, and V. Markl, 2015
26/30

TRADITIONAL VS BIG DATA TESTING
A. Alexandrov, C. Brücke, and V. Markl, 2015 http://www.servermom.org/wp-content/uploads/2014/01/internet-speed-gauge.jpg
Attribute Traditional Database Testing Big Data Testing
Data • Structured
• Testing is well defined & established
• Can use manual sampling of data
• Structured and unstructured data
• Testing requires analysis of big data system domain
• Requires automation
Infrastructure • Does not require test environment • Requires test environment due to large data sizes
Validation Tools • Excel based or UI based automation
tools
• Does not require domain knowledge or
extensive training
• No defined universal tools
• Tools require skills and training
• Requires knowledge of specific big data systems
http://www.guru99.com/big-data-testing-functional-performance.html#1
27/30

BIG DATA TESTING CHALLENGES
Automation*
Much of the testing approaches need to be automated
Due to size, speed, and complexity of data
Automation cannot handle unexpected problems in
testing process
Generating Data
Create very large realistic data sets
Interpreting data rules from data
Requires machine learning and artificial intelligence
Cross-Platform Testing Tools
Testing applications are application/domain specific
Standardized Testing Framework
Testing frameworks for big data in their infancy
Variety of big data systems and system components
creates problems
28/30

CONCLUSIONS
Big Data Attributes
Volume
Velocity
Variety
Value
Big Data Life Cycle
1. Generation
2. Acquisition
3. Storage
4. Analysis
Big Data Application
Google’s MapReduce
Apache Hadoop
Big Data Testing
Database testing
Application testin
Performance Testing
Traditional vs. Big Data Testing
Big Data Testing Challenges
29/30

`
Thank You!