big data v4.0
TRANSCRIPT

THE ELEPHANT IN THE ROOM: WHEN DID DATA GET SO BIG?
1

(c) 2013 Ian Brown
WE'LL TALK ABOUT
2

(c) 2013 Ian Brown
WE'LL TALK ABOUT
3

(c) 2013 Ian Brown
WE'LL TALK ABOUT
4
0
(c) 2013 Ian Brown
WE'LL TALK ABOUT
5

(c) 2013 Ian Brown
WE'LL TALK ABOUT
6

(c) 2013 Ian Brown
WE'LL TALK ABOUT
•What is Big Data? What makes it "Big"?
•Who needs Big Data? Where does it come from?
•How does Big Data work? What are the tools and the issues?
•Look at fans and detractors to come to a balanced decision
7

(c) 2013 Ian Brown
WHAT IS BIG DATA?
•To some extent “Big” really means “Difficult to handle”
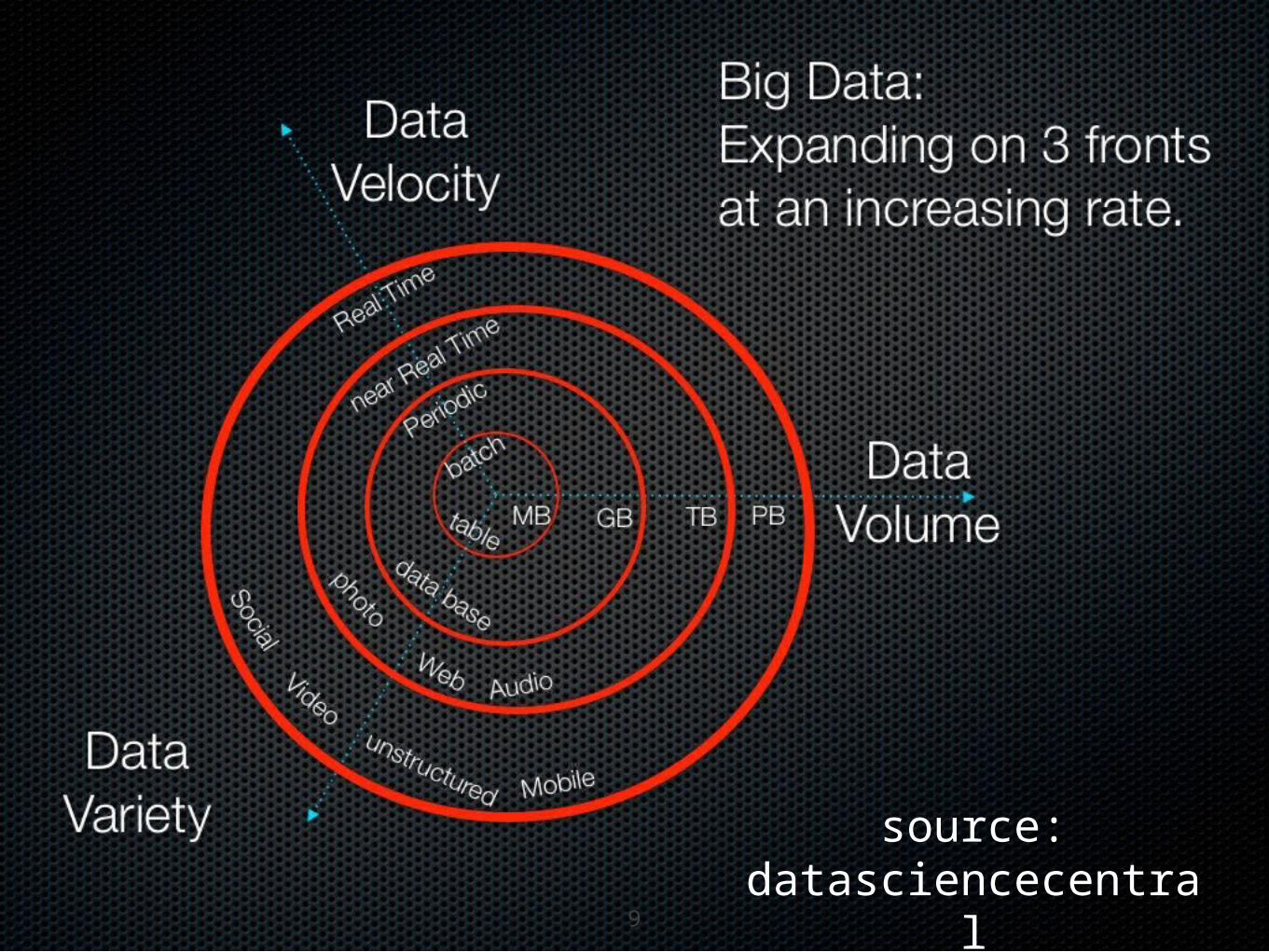
•Something of a misnomer: not only about size as three things distinguish big data:
•Volume (how much capacity you need to process/store)
•Velocity (how quickly you need to process updates)
•Variety (how complicated/non-standard the data is)8
Volume
VelocityVariety
BIG DATA
(c) 2013 Ian Brown
9
source: datasciencecentral

(c) 2013 Ian Brown
VOLUME
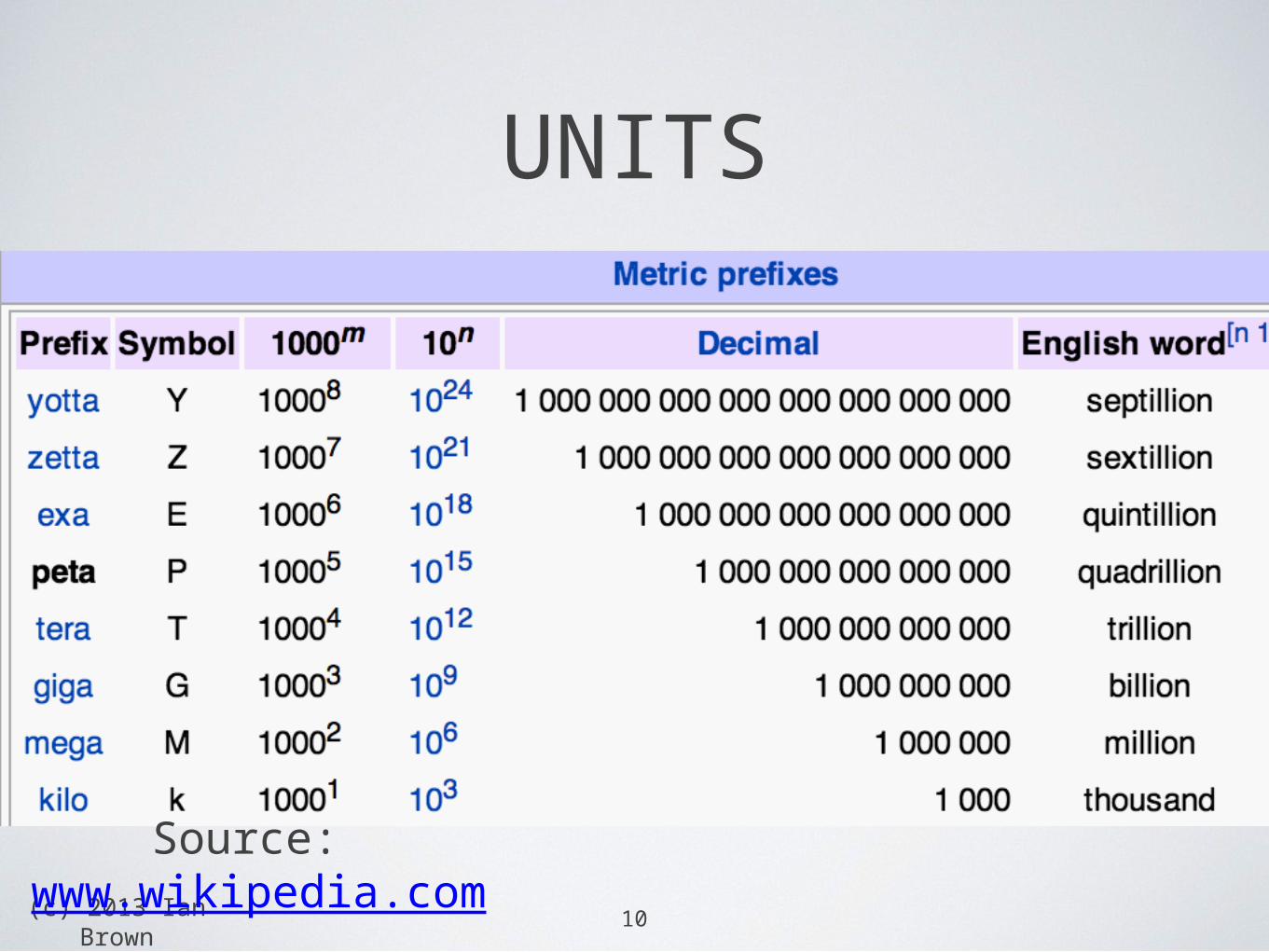
•From pre-history to 2004 the world generated around 5 exabytes of data - we now produce that amount every 2 days
•Data volumes are huge and growing: 1.8 zettabytes in 2011
•= 1’800 Petabytes
•=1.8 billion Terabytes
•Data is predicted to grow x44 by 2020
•>40% every year11

(c) 2013 Ian Brown
VOLUME
•Whilst data has previously been “big” for some people, sometimes in the past - it’s definitely potentially big now (for everyone) and getting bigger every day
•Sources are networks (voice/data/video), social networks, sensors & transducers, GPS, banking, logistics, trade etc
•90% of the World’s digital data was gathered in the last 2 years (source: IBM 2012)
12

(c) 2013 Ian Brown
VARIETY (VARIABILITY)
•Governments and Corporates have always had big databases but the data has always been structured - invoices, customers, inventory etc
•Of the huge increase in data we just mentioned only 10-20% will be structured - the rest (80-90%) will be unstructured:
•Video, email, social media, audio, images/scanned material
•Traditional SQL databases (the clue is in the S) don’t do well with this sort of mixed data
13

(c) 2013 Ian Brown
VELOCITY
•Data is now coming at users constantly from global sources which therefore gives a 24x7 problem.
•Q. When do you stop to summarise/analyse? At what point do you cut-off for the day/week/period to run a report or plan the next action?
•A. Sometimes you can’t! Analysis/processing/Action may have to happen on streaming data and corrections or actions are taken on-the-fly. Sometimes without storing the data!
14

(c) 2013 Ian Brown
HASN’T DATA ALWAYS BEEN “BIG”?
•Maybe.
•Historically computing was done in “batches” where stacks of punchcards or reels of tape (first paper, then magnetic) were processed one file at a time. This had to be done when the business was “closed”.
•If you closed at 18:00 and opened the next day at 09:00 you had a window of 15 hours to do all your calculations and reports before you had to stop and open for the next day’s business.
•If you couldn’t get it done in 15 hours your data was “big”15

(c) 2013 Ian Brown
HASN’T DATA ALWAYS BEEN “BIG”?
•Hence this is a relative question of how much data vs how much computing you can throw at it
•For more than three decades we have seen a constant increase in computing power which made the data generated by most businesses through their local customers look “small”
•Then the Web happened ....
16

(c) 2013 Ian Brown
HASN’T DATA ALWAYS BEEN “BIG”?
•Initially Web 1.0 and eCommerce opened up servers to many millions of events in terms of “hits” on web sites, logs, emails and a global multiplier of who could be a customer and access your system. Analysis of who was searching for what and who was buying what absorbed a lot of computing capacity.
•Web 2.0 has added hundreds of millions of social networking users all broadcasting data in terms of photos, tweets, status updates, blog posts etc which has created a truly vast ocean of data which can be trawled to learn about our behaviours, beliefs and likely future actions.
•If you want to process this data it certainly has volume, it doesn’t stop coming at you when you close for the night and so has tremendous velocity and if you are pulling it in from several sources it quickly starts to exhibit complexity and variety
•Traditional Hardware/Software has not kept pace with the growth of volume/velocity/variety
17

(c) 2013 Ian Brown
WHO NEEDS BIG DATA?
•Generally: anyone who can derive a “big picture” insight by adding up all the small data points and “zooming out”
•How much can you say about one tweet? A thousand tweets?
•Twitter is generating > 9’000 tweets/sec which means it takes around 5 days to add another billion tweets. Source: www.statisticbrain.com (2012)
•What you “reckon” changes into sentiment analysis
18

(c) 2013 Ian Brown
WHO NEEDS BIG DATA?
•Generally: anyone who can derive a “big picture” insight by adding up all the small data points and “zooming out”
•How much can you say about one tweet? A thousand tweets?
•Twitter is generating > 9’000 tweets/sec which means it takes around 5 days to add another billion tweets. Source: www.statisticbrain.com (2012)
•What you “reckon” changes into sentiment analysis
Source
Flickr
19

(c) 2013 Ian Brown
BIG DATA - THE SCALE CHANGES THINGS
•Big Data may be analogous to the difference between the insight in a picture vs. a video
20Source:
slowmotionrunninghorse.com

(c) 2013 Ian Brown
BIG DATA - WHY CARE?•Governments - release of open data: McKinsey est. $300m per year savings in US, $100m savings in Europe
•Banks - fraud detection, algo trading: losses/profits. 2/3rd of 7 Bn US shares a day ..
•Life Sciences - genomics, drug research. 10yrs to seq the human genome
•Retailers - buying patterns, CRM, if you like this ... : cross-selling
•Social - Google, Facebook, LinkedIn,Twitter, Amazon, eBay: - Insight!
•Networks - load management/routing, protecting networks
•Probabalistic outcomes - Google Flu predictions (Nature: 2009)
21

(c) 2013 Ian Brown
Some or All?

(c) 2013 Ian Brown
Some or All?

A MATTER OF PERSPECTIVE
•Here is a traditional photo, the subject, the arrangement and the focus were fixed at the time I took the shot. If I want to look at something else now I'm out of luck.
24

A "BIG DATA" PHOTO
•Here is another photo taken with a "big data" camera called a Lytro. The device takes much more data than it needs for a traditional photo and stores this data to wait for interaction from the user AFTER taking the picture.
25

A "BIG DATA" PHOTO
•Here is another photo taken with a "big data" camera called a Lytro. The device takes much more data than it needs for a traditional photo and stores this data to wait for interaction from the user AFTER taking the picture.
26
(c) 2013 Ian Brown
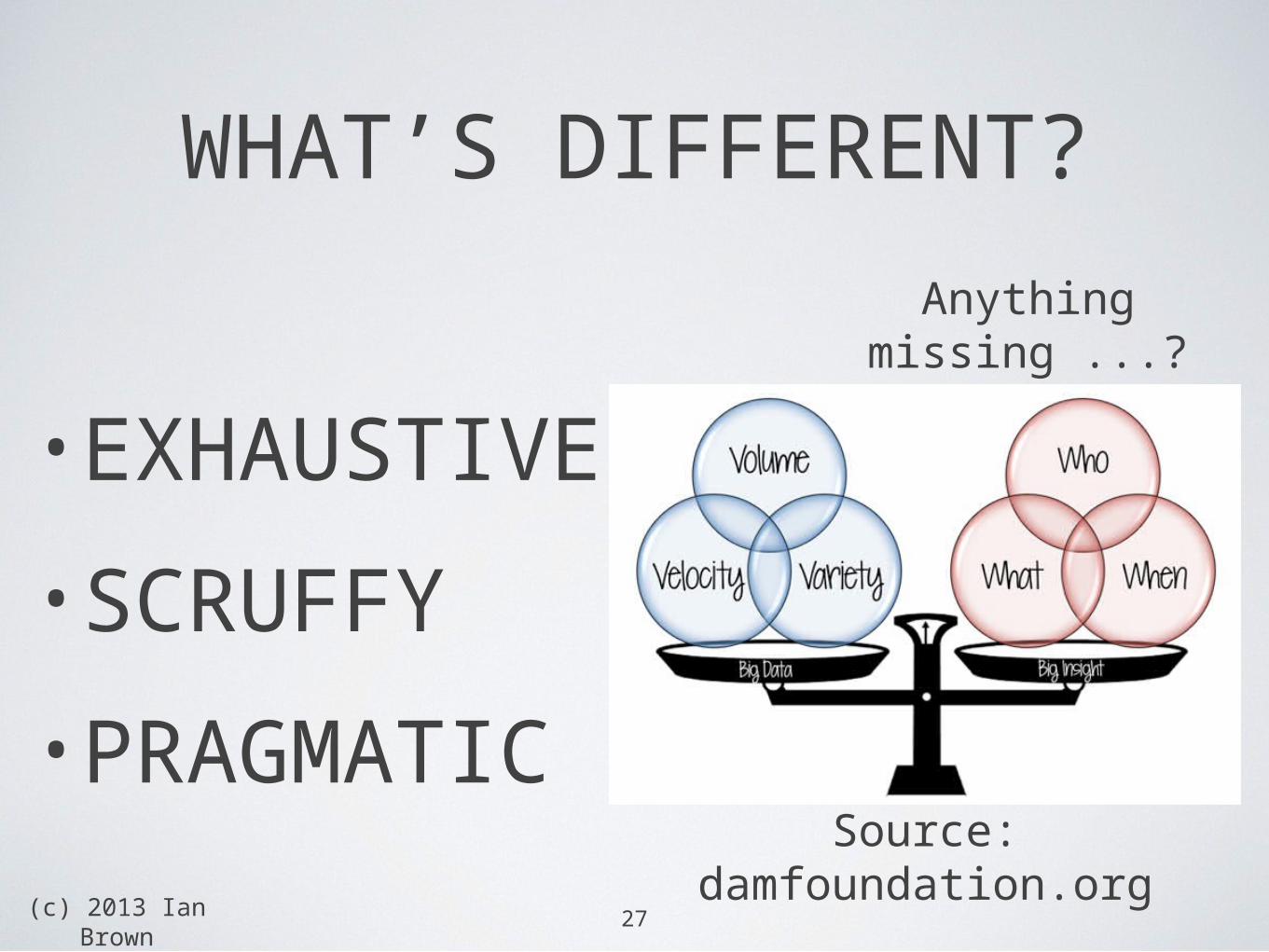
WHAT’S DIFFERENT?
•EXHAUSTIVE
•SCRUFFY
•PRAGMATIC
27
Anything missing ...?
Source: damfoundation.org

(c) 2013 Ian Brown
SO WHAT?
•Three key pieces have shifted:
•A shift from sampling to populations
•A shift from exactness to “gisting”
•A move from causality to correlation
•Data no longer tied to the purpose for which it was collected
28
small, exact & logical
exhaustivemess
y & inferenti
al

(c) 2013 Ian Brown
An example

(c) 2013 Ian Brown
Big Data Art

(c) 2013 Ian Brown
Big Data Art

(c) 2013 Ian Brown
In summary…
32
Source: www.datasciencecentral.com

(c) 2013 Ian Brown
NEW SOURCES OF DATA
•Information is now gathered on events and values that were not traditionally thought of as data: (datafication!)
•Current location (vs. address)
•Whether you “like” someone else’s post
•Things you nearly bought but didn’t
•How much energy your office needs now
•PLUS transactional systems, social media, sensors etc etc
33
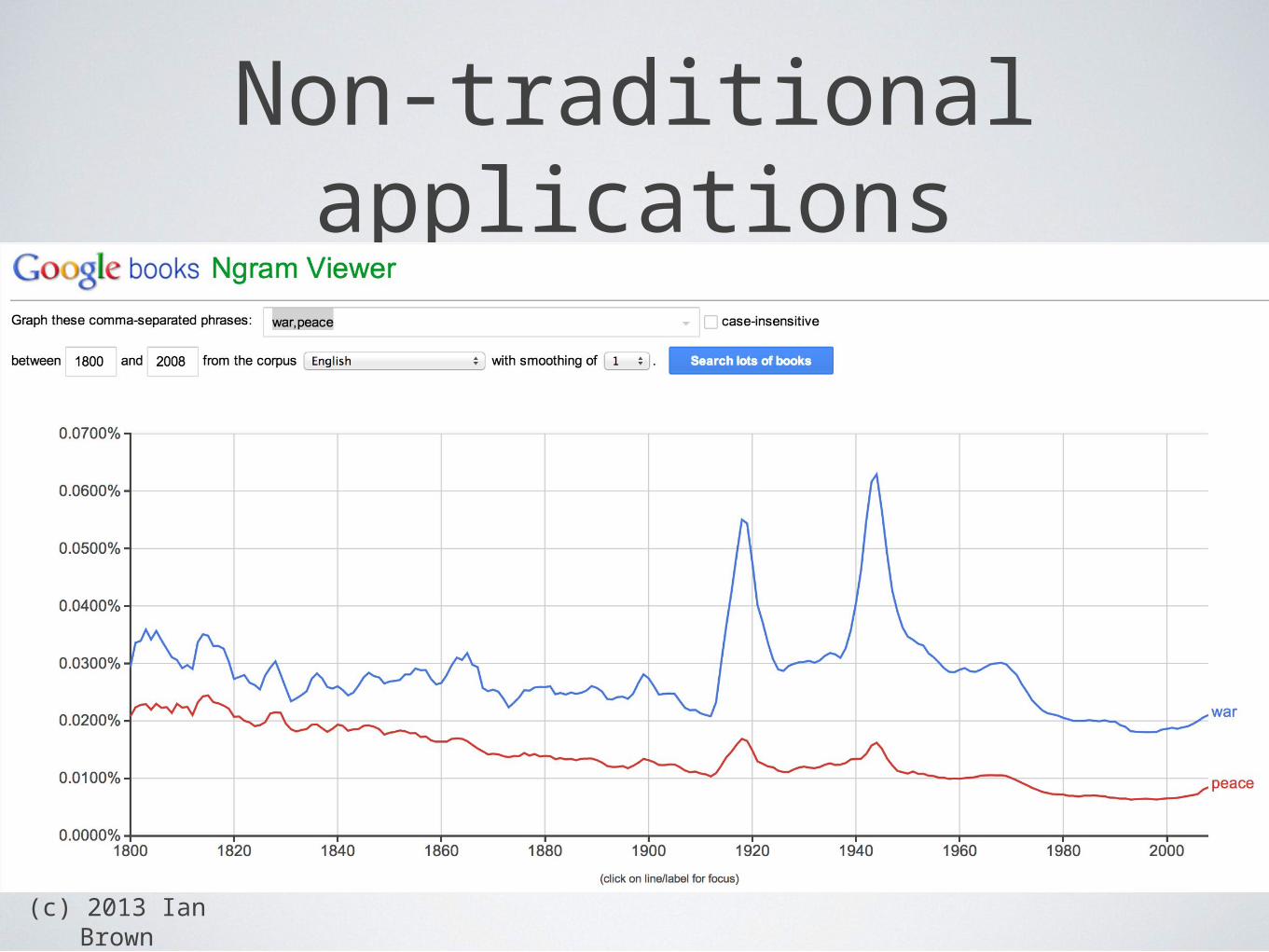
(c) 2013 Ian Brown
Non-traditional applications

(c) 2013 Ian Brown
Not correlation sense might make
Aviva are exploring methods of substituting your social network profile, hobbies and favourite web sites for a blood/urine test.
Your “Likes” obviously don’t cause diabetes but they may correlate!

(c) 2013 Ian Brown
HOW DOES IT WORK?•Is this just a big database running on a powerful machine?
•Not usually. Traditional databases don’t scale to this
•Many hands make light work: Remember S.E.T.I. ?
•Split it up and share it out between many nodes
•Key analysis perspectives:
•Real-time streaming data analysis (detect events and act)
•Business Intelligence (asking specific questions of)
•Data Mining (asking is there anything interesting here?)
36

(c) 2013 Ian Brown
WHAT ARE THE PIECES?•HDFS Hadoop Distributed File system (Google)
•MapReduce (Google)
•Split the problem into chunks
•Spread it out over lots of (cheap) computing nodes
•Reassemble the answer from the parts
38
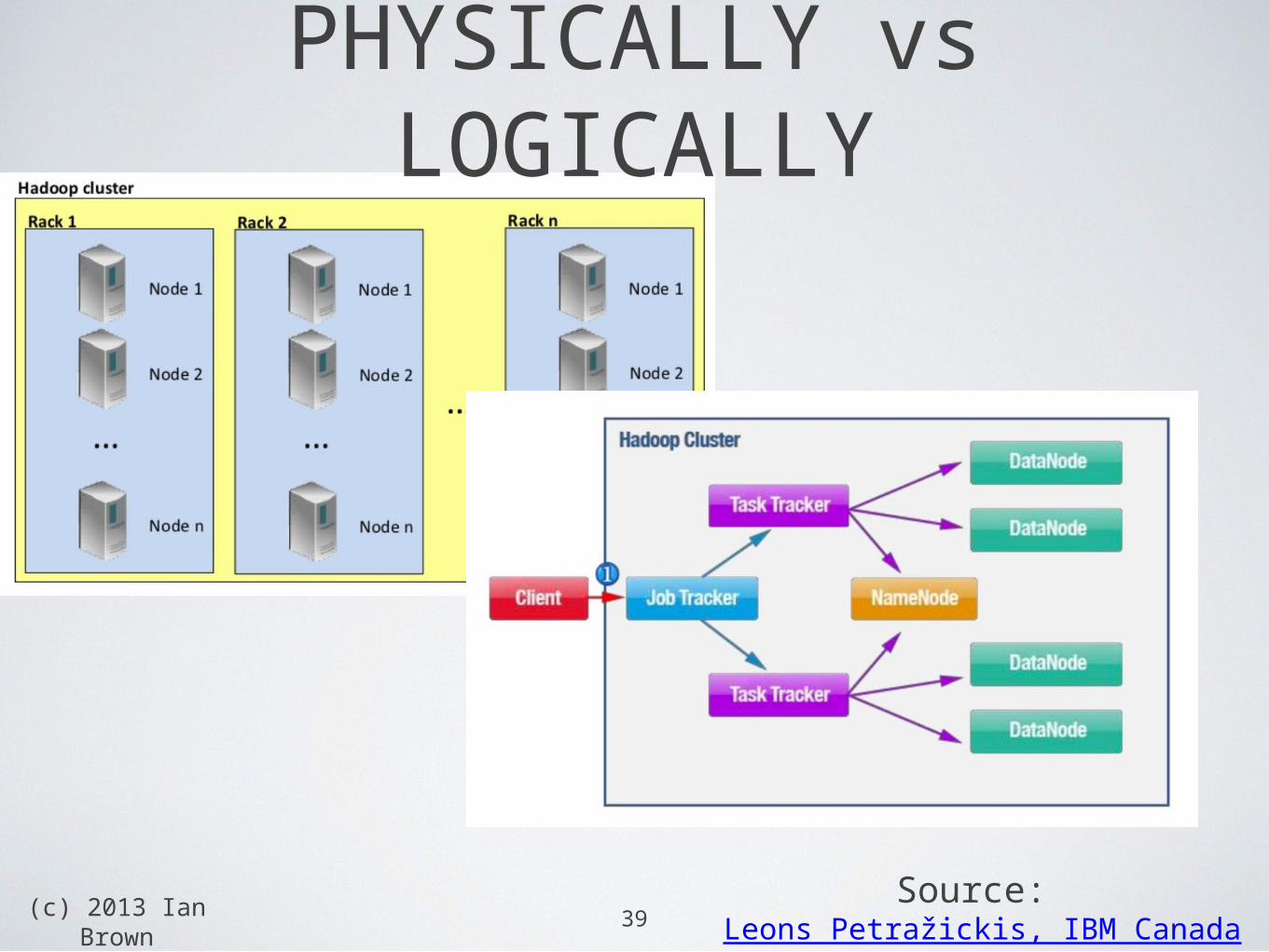
(c) 2013 Ian Brown
39
PHYSICALLY vs LOGICALLY
Source: Leons Petražickis, IBM Canada


(c) 2013 Ian Brown
WHAT IS THE APPROACH?•Somewhere to store it across different systems
•e.g. Distributed File System (HDFS) - batch mode
•Some way of specifying work in pieces/jobs
•e.g. Hadoop (Yahoo) or MapReduce (for low-level jobs)
•e.g. Pig or Hive or Oozie (for high-level apps/queries that translate to MapReduce)
•Some way of reading/processing in real-time vs batch e.g. Hbase and Flume
•Some way mining the data for trends/meaning (Data Mining/Machine learning) e.g. Mahout
•Some way of getting data in/out of SQL databases e.g. Sqoop
41

(c) 2013 Ian Brown
HOW MANY CHUNKS?•eBay had 530 cores in 2010. It’s now in excess of 2’500 cores
•Yahoo has >4’000 cores
•FaceBook have 23’000 cores with 20Pb of storage - be careful what you “like”...
•Google aren’t telling .... (24Pb of data / day)
•LinkedIn offer 100Bn recommendations / week
42

(c) 2013 Ian Brown
WHERE CAN I GET SOME!!•IBM
•ORACLE
•MICROSOFT
•EMC
•Informatica
•Apache - Open source
•Amazon - Elastic computing / cloud-based hadoop
•Small installations are free
43

(c) 2013 Ian Brown
WHAT'S THE FUTURE LIKE?
44
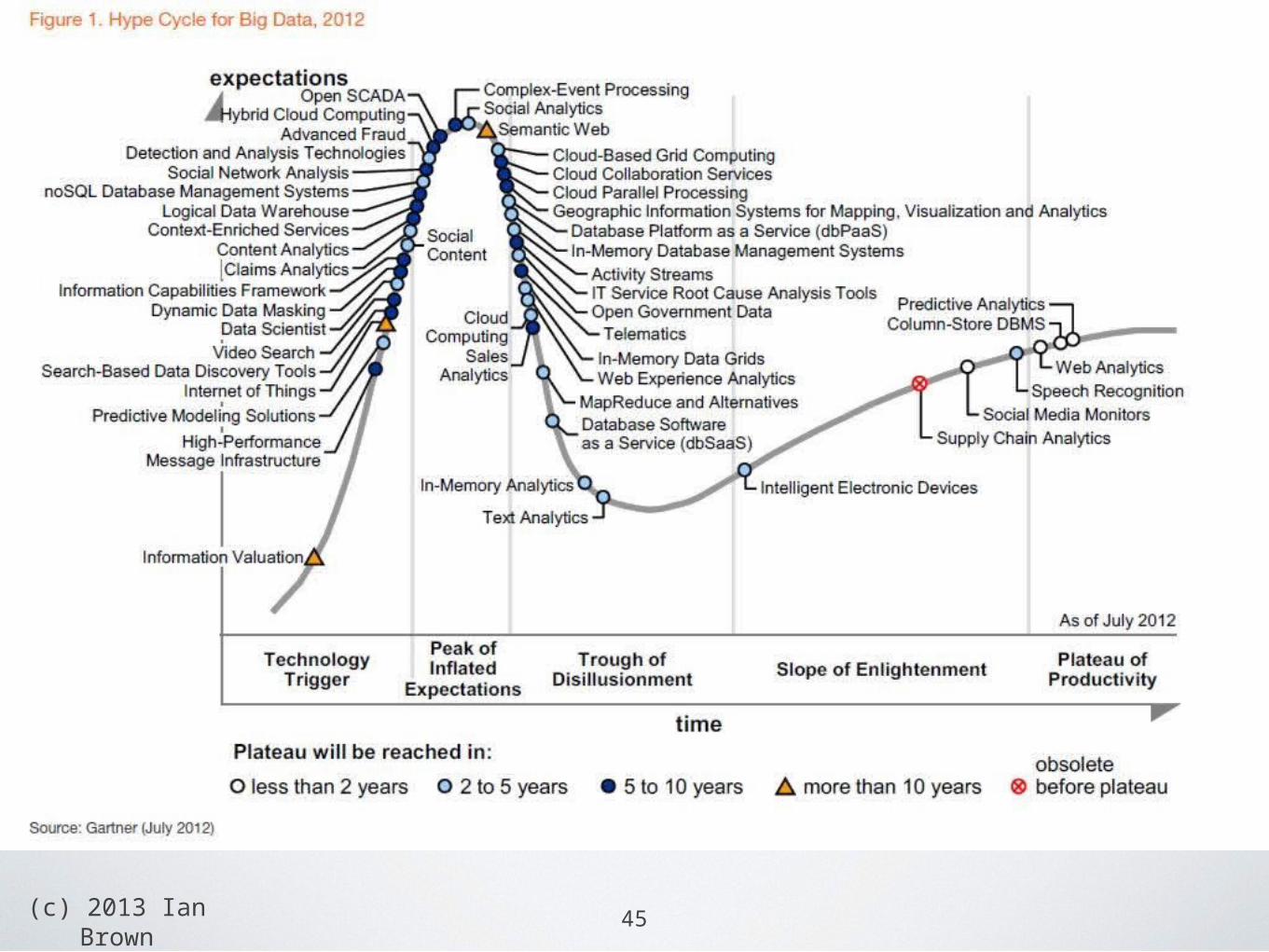
(c) 2013 Ian Brown
THE FUTURE ..
45
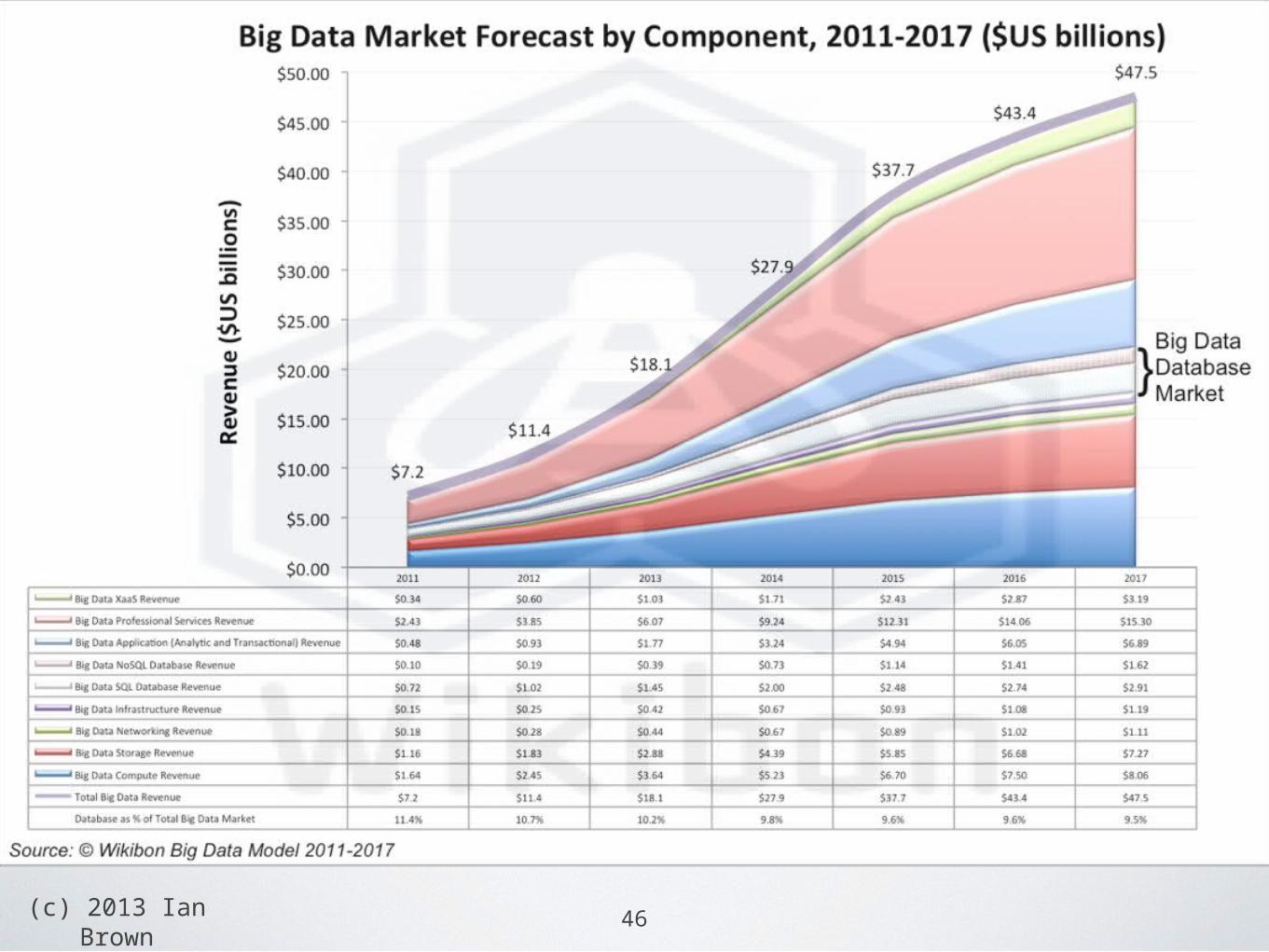
(c) 2013 Ian Brown
46
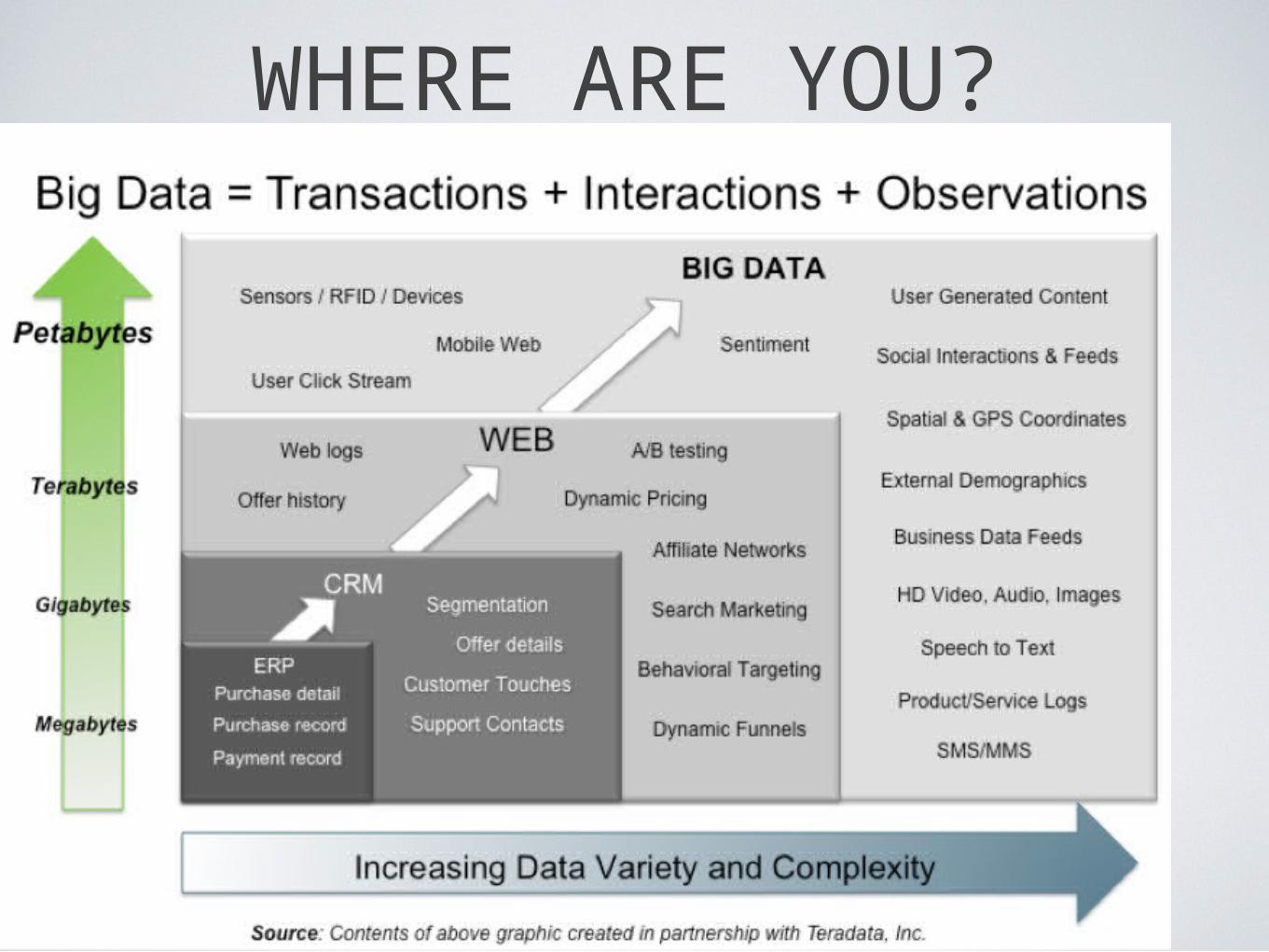
(c) 2013 Ian Brown
WHERE ARE YOU?
47

(c) 2013 Ian Brown
WHAT'S THE FUTURE LIKE?
•More data - MUCH MUCH MORE data
•Internet of Things (IOT) - instrumentation/measurement
•SmartEnergy meters 2005, RFID tags (1.3bn 2011 >30bn 2013)
•each A380 engine gives 10TB every 30m: 640TB JFK->London
•Big Science: Genomics, Pharmacology. LHC experiment gives 40TB/sec!!
•Much more video and unstructured stuff (~60% of Internet traffic video by 2015)
•The re-invention (or demise) of search/SEO
•The need to move from local big data to distributed big data and sense-making networks
•The rise of Observation - the need to filter and gain more control
48

(c) 2013 Ian Brown
WHERE DOES THAT LEAVE YOUR COMPANY?
49
source: sap.com
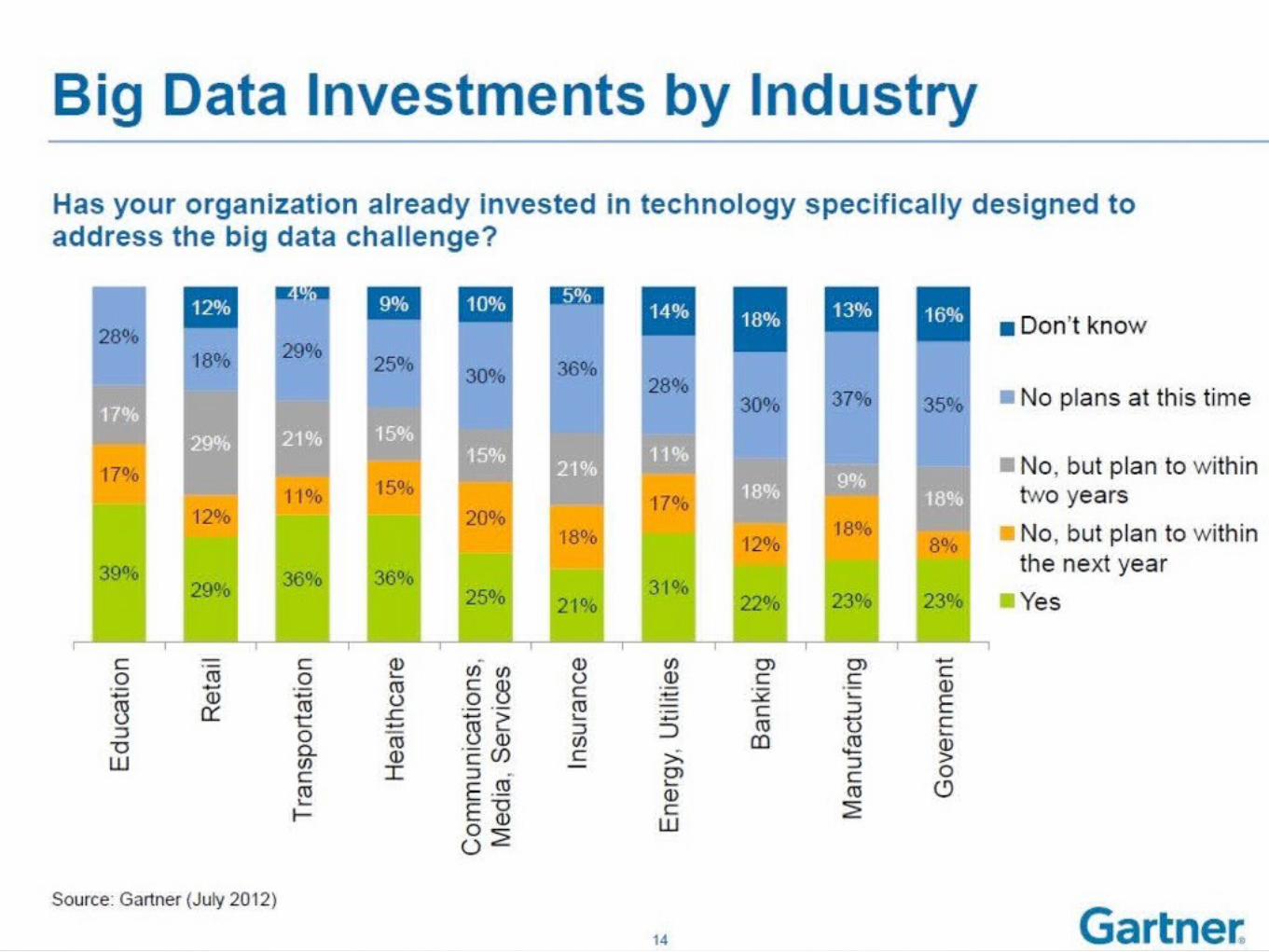
(c) 2013 Ian Brown
WHERE DOES THAT LEAVE YOUR COMPANY?
50
source: sap.com

(c) 2013 Ian Brown
MAGIC BULLET?•Hadoop probably won’t replace your existing database
•It is very good at large files/data sets so you not see so much benefit from large volumes of small files/datasets
•It is very good at dealing with unstructured data so if your data is largely structured or can be made to look structured you may be better to stick with traditional databases
•It doesn’t need to know about how you want to query the data which makes it very flexible but if your queries are always the same you may be able to stick with SQL databases and BI/DW systems
51

(c) 2013 Ian Brown
Ethical Questions
With great power comes great responsibility ..
We can do this – but should we?
-Better medical treatment
-Better security/ law-and-order
-Better Amazon recommends

(c) 2013 Ian Brown
TWO THINGS WORTH REMEMBERING
53
The last “mining” frenzy like this was the California gold rush and whilst a few
people struck gold - a lot of eager miners just found rocks and the people that made more money than anyone else were the companies selling the
shovels ...

(c) 2013 Ian Brown
QUESTIONS?
54