big metadata: a study of resource description framework (rdf) technologies … · 2015-08-07 ·...
TRANSCRIPT

1
Big Metadata: A study of Resource Description Framework (RDF) technologies to enable machine-interpretable metadata in biomedical science Vladimir Choi
Master's Programme in Health Informatics
Spring Semester 2015
Degree thesis, 30 Credits
Author: Vladimir Choi
Main supervisor: Dr Stefano Bonacina, Department of Learning, Informatics,
Management and Ethics, Karolinska Institutet, Sweden
Co-supervisors: Prof Michel Dumontier & Prof Mark Musen, Center for
Biomedical Informatics Research, School of Medicine, Stanford University, USA
Examiner: Dr Andrzej Kononowicz, Department of Learning, Informatics,
Management and Ethics, Karolinska Institutet, Sweden

2
Master's Programme in Health Informatics
Spring Semester 2015
Degree thesis, 30 Credits
Affirmation I hereby affirm that this Master thesis was composed by myself, that the work
contained herein is my own except where explicitly stated otherwise in the text.
This work has not been submitted for any other degree or professional
qualification except as specified; nor has it been published.
Menlo Park, California, USA, 13 May 2015
Stockholm, Sweden, 3 June 2015
Vladimir Choi __________________________________________________________ Vladimir Choi

3
Master's Programme in Health Informatics
Spring Semester 2015
Degree thesis, 30 Credits
Big Metadata: A study of Resource Description Framework (RDF) technologies to enable machine-interpretable metadata in biomedical science
Abstract
Background: As data becomes ever more complex and voluminous in the
biomedical sciences (in the phenomenon known as Big Data), researchers' ability
to validate findings, discover insights and test novel hypotheses becomes
impaired.
Objective: To demonstrate the use of RDF and RDF constraint languages in
laying the foundations for an ecosystem whereby machine-interpretable metadata
can be annotated and validated in greater scale and with higher accuracy than ever
before, henceforth known as Big Metadata.
Methods: An exploratory feasibility study that surveys the existing RDF
constraint languages, develops a set of requirements for constraining RDF data,
conducts an example validation exercise of sample data from Bio2RDF, and
prototypes a web-based metadata annotation system.
Results: A set of 13 requirements was derived for performing constraints on RDF
graphs from the analysis of existing RDF constraint languages. Sample DrugBank
data from Bio2RDF was found to be mostly valid according to the W3C HCLS
Dataset Description. A web-based prototype was created to allow researchers to
submit metadata according to the W3C HCLS Dataset Description.
Discussion: Existing RDF constraint languages mostly fulfil the ability to perform
basic constraints on RDF data and create a computable representation of the W3C
HCLS Dataset Description, foreshadowing and informing the emerging W3C
standard SHACL. Numerous efforts are ongoing to build upon Semantic Web
technologies for metadata acquisition, discovery, validation, and analysis.
Conclusion: RDF is a feasible data model for machine-interpretable metadata,
with potential as the foundation of an ecosystem of Big Metadata, contingent
upon further awareness, community consensus and standards development.
Keywords: biomedical research, data annotation, user-computer interface, data
machine-readable data files, automatic data processing, biomedical ontologies

4
Acknowledgements
My thanks go to my family, friends, colleagues, and teachers throughout all these
years, but in particular:
Stefano Bonacina & Andrzej Kononowicz – for their helpful and generous
feedback for my thesis
Michel Dumontier – for his unwavering commitment to and guidance for my
research at Stanford
HIMSS Foundation – for its financial support in the form of a HIMSS Foundation
Scholarship
Wei Hu & Tobias Kuhn – for their companionship as my office-mates at Stanford
Sabine Koch – for her support that enabled me to realize my internship at WHO,
scholarship from HIMSS, and research position at Stanford
Mark Musen – for his key role in enabling me to pursue research at Stanford and
to attend the B2DK Hackathon at Scripps, and for his career advice
Martin O’Connor & Mariam Panahiazar – for their help with CEDAR work
Nigam Shah – for his role in facilitating my initial contact with Stanford and
supporting my HIMSS scholarship application

5
Table of Contents
List of abbreviations …………………………...……...………………...page 6
List of figures…………………………………………………….………page 7
List of tables…………………………………………………….……….page 8
1. Introduction……………………………………………………….....page 9
2. Methods…………………………………………………….………page 26
3. Results……………………………………………………………...page 31
4. Discussion…………………………………………………………..page 62
5. Conclusion……………………………………………………..…...page 73
References…………………………………………………………...…page 74
Appendix A - ShEx Implementation of W3C HCLS DD..…………….page 81
Appendix B - Sample DrugBank dataset descriptions from Bio2RDF...page 87

6
List of abbreviations
API Application Programming Interface
CEDAR Center for Expanded Data Annotation and Retrieval
CSS Cascading Style Sheets
CSV Comma-Separated Value
FTP File Transfer Protocol
HCLS Health Care and Life Sciences
HIMSS Healthcare Information and Management Systems Society
HIPC Human Immunology Project Consortium
HTML HyperText Markup Language
HTTP HyperText Transfer Protocol
ICV Integrity Constraint Violations
IEEE Institute of Electrical and Electronics Engineers
IETF Internet Engineering Task Force
ImmPort Immunology Database and Analysis Portal
IRI Internationalized Resource Identifier
JSON JavaScript Object Notation
JSON-LD JSON for Linked Data
MIAME Minimum Information About a Microarray Experiment
MIBBI Minimum Information for Biological and Biomedical Investigations
NCBO National Center for Biomedical Ontology
NIAID National Institute of Allergy and Infectious Diseases
NIH National Institutes of Health
OWL Web Ontology Language
RDF Resource Description Framework
REST Representational State Transfer
SDK Software Development Kit
SHACL Shapes Constraint Language
ShEx Shape Expressions
SIO Semanticscience Integrated Ontology
SNOMED CT Systematized Nomenclature of Medicine – Clinical Terms
SPARQL SPARQL Protocol and RDF Query Language
SPIN SPARQL Inference Notation
SQL Structured Query Language
SW Semantic Web
TSV Tab-Separated Value
UMLS Unified Medical Language System
URI Universal Resource Identifier
W3C World Wide Web Consortium
WHO World Health Organization
WWW World Wide Web
XML eXtensible Markup Language

7
List of figures
Figure 1.1 Sample metadata template containing two metadata elements and their values
Figure 1.2 Investigation-Study-Assay hierarchy as defined by ISA-Tools
Figure 1.3 ImmPort Research Data Model v2.26
Figure 1.4 W3C HCLS Dataset Description Levels
Figure 1.5 Sample rows from the table of W3C HCLS Dataset Description Metadata
Elements
Figure 1.6 RDF triple as a directed Subject-Predicate-Object construct
Figure 1.7 RDF triple where the subject, predicate, and object are represented as IRIs
Figure 1.8 Example of an RDF graph
Figure 3.1 A class representing the Summary Level of the W3C HCLS Dataset
Description with SPIN constraints in TopBraid Composer
Figure 3.2 Constraint violation error message in TopBraid Composer
Figure 3.3 Validation message from Stardog ICV in the command line
Figure 3.4 Constraint violation message from Stardog ICV in the command line
Figure 3.5 The high-level relations between Resource Shapes, Properties, and Allowed
Values
Figure 3.6 Constraint on the type of Predicate 1
Figure 3.7 Constraints on the object node as IRI, literal, or object class
Figure 3.8 Constraints on literal datatype
Figure 3.9 The XML Schema datatype hierarchy
Figure 3.10 Constraints on the cardinality of predicate 1
Figure 3.11 Web-based form converting sample JSON-LD to RDF N-Triples
Figure 3.12 Web-based interface for Core Medata annotation of a Summary Level
description
Figure 3.13 Web-based interface displaying entered metadata in the form of RDF N-Triples
Figure 3.14 Autocompletion input field presenting a list of biomedical ontology terms
retrieved from the BioPortal API
Figure 4.1 Interactive path in SmartAPI connecting Web services from an input parameter
(variant_id) to an output parameter (PFAM)
Figure 4.2 SmartAPI Web-based metadata template form

8
List of tables
Table 2.1 Stakeholders and tools of RDF constraint languages
Table 2.2 Technical details of RDF constraint languages
Table 3.1 XML Schema Datatype Restrictions
Table 3.2 Requirements for RDF constraints as mapped to features of RDF constraint
languages
Table 3.3 Issues identified via Summary Level validation
Table 3.4 Issues identified via Version Level validation
Table 3.5 Issues identified via Distribution Level validation
Table 4.1 Attempts to constrain RDF data in the literature
Table 4.2 Practical considerations of RDF constraint languages

9
1. Introduction
1.1 Background
1.1.1 Big Data and Information Overload
The world is simultaneously enriched and burdened by the growing accumulation
of information, in a phenomenon known as Big Data. It has been remarked that as
of 2013, over 90 percent of the world’s information had been generated in the
previous two years (1). But will all this data necessarily lead to greater insight and
value? In the sciences, research findings have traditionally been disseminated via
papers published in peer-reviewed journals, produced by humans to be read by
humans. Thus far, this paradigm has resulted in innumerable discoveries and
breakthroughs, yet as 2,000 to 4,000 completed references are added to
MEDLINE (the database behind PubMed) every day it is simply unsustainable
and impractical for scientists to digest and keep up with all this information (2).
This can be corroborated through Malthusian principles, which show that as the
volume of information grows, the more difficult and costly it is to find and
comprehend the information we need, eventually leading to an “information
famine” (3). The scientific method is based upon the premise that researchers can
validate, reproduce, and build upon others’ work in other to advance progress – in
other words, “standing on the shoulders of giants” (4). In reality, however, it has
been found that research data is “seldom shared, re-used, or preserved” (5).
Without suitable methods to address the ever-widening gap between our ability to
produce data and our ability to understand it (6), we risk fragmenting and
duplicating scientific efforts, wasting precious research funding, and ultimately
losing opportunities to develop new innovations and insights. We must bring as
much effort to generating and collecting the data as ensuring that it is discoverable
and understandable, both to humans and machines (5).

10
This problem is particularly acute in the biomedical sciences with the rapid rise of
the “omics” fields (genomics, transcriptomics, proteomics, metabolomics,
amongst others) that have led to the explosion of data generated by novel
technologies that analyze and sequence genes, proteins, and other biomolecules in
unprecedented speed and detail. Furthermore, the promise of precision medicine is
dependent on seamless aggregation, analysis, and visualization across biomedical,
clinical, and population-level data (7).
1.1.2 Metadata
Metadata – data that describes other data – is a way to mitigate information
overload and navigate the world of Big Data. In formal terms, metadata is
“structured information that describes, explains, locates, or otherwise makes it
easier to retrieve, use, or manage an information resource” (8). By associating or
tagging data with metadata (in a process known as annotation), the context for
interpretation is communicated to others, allowing them to discover and utilize the
data as intended. Without metadata, the ability to retrieve, share, and understand
valuable data could be lost over time in fields as diverse as astronomy, ecology,
and certainly, biomedicine (5).
Metadata generally contains information (9) regarding:
Identity: how the data should be identified (e.g. name or title)
Content: what the data contains and represents (e.g. type of experiment,
number of test subjects, version of dataset, keywords)
Provenance: where the data comes from, when and how the data was
created, and who created or vetted the data (e.g. author, publication date)
Licensing: how the data is allowed to be used by others
Technical specification (e.g. data format, file size)
These in turn enable the following (9):

11
Linking: datasets can refer to each other, forming a web of knowledge
(Linked Data) and reducing redundancy
Search & discovery: researchers can locate specific data they need,
efficiently and accurately
Integration & analysis: researchers can aggregate and analyze datasets
from disparate sources to test hypotheses, discover new knowledge, or
perform high-level analyses
Just as metadata annotation can be performed manually or automatically,
metadata-driven querying and analysis across vast collections of datasets can be
conducted by humans or machines. A metadata element can be defined as a
discrete descriptor of the data, such as title, author, or date. The metadata value
refers to the actual description of the data, each corresponding to a metadata
element (e.g. “Marie Curie” for “Author”, “1867-11-07” for “Date”) (Figure 1.1).
An empty metadata template is therefore composed of metadata elements and
empty metadata fields, whereas a filled-in metadata template consists of metadata
elements and fields containing metadata values. Templates can be partially or
completely filled-in, affecting the completeness of metadata. The description of
data through the completion of a metadata template is known as annotation.
Figure 1.1 Sample metadata template containing two metadata elements and
their values
Author:
Date:
Metadata element
Metadata template (filled-in)
Marie Curie
1867-11-07
Metadata value
Metadata field (containing value)

12
Metadata is often necessitated due to incompleteness in the dataset itself. For
example, cytokine expression measured from CD4+ cells will most undoubtedly
contain the detected level of each cytokine, but may not necessarily state the cell
type on which the experiment was performed. If this dataset were to be published
on a repository, the metadata field of “Cells” should include “CD4+” so that
scientists searching for cytokine expression in CD4+ cells can actually locate it.
Therefore, metadata should be aim to be:
Complete: all relevant data is annotated to ensure discoverability (e.g. if an
experiment is performed on CD4+ and CD8+ cells, the field for “Cells”
should consist of both cell types, and not merely one or the other)
Accurate & specific: metadata should reflect the data it describes at the
right level of abstraction (e.g. the field for “Cells” should be “CD4+” and
“CD8+”, and not merely “lymphocytes”)
As no term yet exists for the vision for an ecosystem of useful metadata that
accompanies and complements Big Data, the term “Big Metadata” is hereby
declared and utilized.
1.1.3 Communication & Interoperability
The phenomenon of communication can be subdivided into the following four
processes (10):
The sender encodes information as symbols in a language suitable for
transfer
These symbols are transferred across a channel
The receiver translates these symbols into a language he/she understands
The receiver attempts to interpret the intended meaning
In a world where data is expanding at an unprecedented rate and processed by
ever-more complex systems, a breakdown in any of these steps can have severe

13
consequences on data-driven sectors such as retail, finance, transportation, and
science. Interoperability – the ability of data to be exchangeable and mutually-
understandable between two or more disparate systems – therefore is a critical
consideration. It is generally divided into three levels (11)(12):
Technical interoperability (the channel): compatible underlying basis of
data transfer (e.g. bits/bytes, TCP/IP, HTTP) to enable systems to connect
to each other
Syntactic interoperability (the symbols and languages): common data
formats (e.g. XML, JSON) so that systems can find and associate the
appropriate data fields and values
Semantic interoperability (the meanings behind the symbols): common
definitions for terms as defined by one or more ontologies to enable
utilization of data as intended (10)
Therefore, in order to ensure the maximum usefulness and discoverability of
metadata, it follows that it should be encoded using a standardized data model to
allow aggregation, and use concepts that permit shared understanding, in other
words, terms sourced from ontologies.
1.1.4 Scientific experiments
Like most other concepts in science, a singular, uncontested definition of
“experiment” simply does not exist. Here, different models are examined. ISA-
Tools provides a three-level hierarchy (Investigation-Study-Assay) responsible for
its namesake (13)(14), and avoids the term “experiment” altogether (Figure 1.2).
The individual components are described in reverse order, for ease of
comprehensibility:
Assay: an individual test on an experimental subject that yields data (can
be qualitative or quantitative)
Study: a collection of assays that provides a holistic view of the subject
under the effects of different experimental conditions

14
Investigation: a collection of related studies that may reveal insights about
scientific phenomena and/or different experimental subjects
Figure 1.2 Investigation-Study-Assay hierarchy as defined by ISA-Tools (13)
Another model to consider is ImmPort, the public repository of immunology
research data from the National Institute of Allergy and Infectious Diseases
(NIAID). The ImmPort Research Data Model v2.26 (15) is more nuanced than
ISA-Tools, yet is broadly applicable to biomedical science and not merely
restricted to the field of immunology. Instead of tab-separated value (TSV) files
as in ISA-Tools, ImmPort is built as a SQL database containing multiple tables,
each representing a concept that contributes to the notion of an “experiment”,
such as protocol, biological sample, subject, reagent, and lab test (Figure 1.3).

15
Figure 1.3 ImmPort Research Data Model v2.26 (15)
Finally, the BioSharing Initiative brings together information standards in the
biomedical sciences so they can be openly maintained, accessed, and discussed
(16). BioSharing.org is an online repository that consists of:
Policies: data preservation, management and sharing policies from
funding agencies
Standards: reporting guidelines, exchange formats, and terminologies
meant for use by researchers when describing their experiments
Databases: online databases to which researchers can submit their
experimental datasets
BioSharing.org hosts MIBBI (Minimum Information for Biological and
Biomedical Investigations), a set of 40 checklists that outline the minimum
information required to describe an experiment or investigation in various
biomedical sciences (17). Examples include MIAME (Minimum Information
About a Microarray Experiment), BioDBCore (Core Attributes of Biological
Databases), and MIPFE (Minimum Information for Protein Functional
Evaluation). Even though these standards are a step in the right direction, they are

16
only guidelines, and lack concrete implementations that allow unambiguous
human and machine interpretation.
1.1.5 W3C HCLS Dataset Description
The use of standardized metadata facilitates interoperability at the syntactic and
semantic levels. In the biomedical domain, this is the goal that the W3C Health
Care and Life Sciences (HCLS) Interest Group set out to achieve when it
developed the HCLS Dataset Description (HCLS-DD) through community
consensus. The HCLS-DD specifies predefined metadata elements for describing
datasets in biomedical repositories (9), providing a common standard where there
previously was none. The proliferation of unique schemas and data formats had
made it impractical and nearly impossible to query and integrate data across
repositories. The HCLS-DD provides the minimum set of information required to
describe a dataset, and can be extended for domain-specific purposes, such as in
situations where individual experiments need to be annotated by defining test
subjects, conditions, and reagents.
The HCLS-DD is composed of three levels (Figure 1.4):
Summary Level: describes a dataset without referring to a particular
version or data format
Version Level: describes a specific version of a dataset independent of data
format
Distribution Level: describes a specific format of a version of the dataset
Each description level has metadata elements that MUST/SHOULD/MAY/
SHOULD NOT/MUST NOT be used (Figure 1.4). In turn, each metadata element
is represented by one or more predefined predicates (under the “Property”
column) – achieved via community consensus – to be used in order to achieve
shared understanding amongst researchers. These predicates originate from
existing RDF vocabularies and ontologies such as the Dublin Core Metadata
Initiative (DCMI) and Provenance Ontology. The “Value” column denotes the

17
type of the value allowed for the predicate, whether it is an object class
(represented as an IRI) or a literal value datatype (e.g. rdf:langString,
xsd:integer, etc.).
Figure 1.4 W3C HCLS Dataset Description Levels (9)
Figure 1.5 Sample rows from the table of W3C HCLS Dataset Description
Metadata Elements (9)
1.1.6 The Semantic Web
The World Wide Web Consortium (W3C) has been the international standards
body for Web technologies ever since the formation of the World Wide Web
(WWW). Its founder, Sir Tim Berners-Lee, has outlined a vision in which a

18
Semantic Web of discrete units of human- and machine-interpretable information
will connect to each other as Linked Data, gradually supplementing the current
Web where only human-readable pages link to each other (18). Linked Data can
then be aggregated and queried across many different data sources either
automatically by machines, or manually by humans.
The fundamental data model of Linked Data is the Resource Description
Framework (RDF), enabling atomic units of information to be encoded as RDF
triples. A RDF triple is a statement, fact, or assertion that associates a subject with
an object using a predicate, in the construct Subject-Predicate-Object (SPO)
(Figure 1.6), analogous to conventional English grammar, where a basic sentence
takes the form Subject-Verb-Object (19).
Figure 1.6 RDF triple as a directed Subject-Predicate-Object construct
In RDF, each subject, predicate, and object is identified using an Internationalized
Resource Identifier (IRI) (which is mostly interchangeable with its precursor, the
Universal Resource Identifier [URI]) (Figure 1.7), except when the object is a
literal value, such as a string, integer, or date. A resource denotes anything – real
or virtual – that can be described, and includes all subjects, predicates, and
objects, but excludes literal values. An example of an IRI that refers to a
microarray is http://experiment.org/microarray. For convenience
and brevity, a prefix such as exp: can be defined for
http://experiment.org so that the entire IRI can be abbreviated to
exp:microarray. (It should be noted that literal values can also be
represented by IRIs if they have been assigned a priori)

19
Figure 1.7 RDF triple where the subject, predicate, and object are
represented as IRIs
When RDF triples are put together, a “graph consisting of nodes interconnected
by arcs” (20) is formed, in which subjects are connected to numerous objects via
different predicates in a directed way (Figure 1.8). A RDF graph that represents a
high-level model (or view) of the world using classes (or entities) is known as an
ontology, whereas one that also contains instances reflecting actual facts is more
often referred to as a knowledge base. However, this distinction can be blurred in
cases where a graph contains both classes and instances. RDF graphs can be more
richly-described using Web Ontology Language (OWL), and queried using
SPARQL Protocol and Query Language (SPARQL). The inference of new
knowledge can occur if and when a new triple is deduced, or entailed, from
existing triples. This adds tremendous power to Semantic Web technologies, as
machines can now “reason” on their own independently of humans, with their
associated advantages of speed, accuracy, and memory. In the context of
metadata, the superclass-subclass relationships defined in an ontology can
facilitate aggregate analysis by grouping relevant terms (or concepts) together or
joining synonyms in order to high-level insight.
It is worth emphasizing that RDF is an abstract data model, and has numerous
implementations, such as RDF/XML, N-Triples, Turtle, and JSON-LD, that can
be converted between each other.

20
Figure 1.8 Example of an RDF graph
Although the realization of the Semantic Web has not been as rapid as previously
anticipated outside the academic world, momentum is now gathering, bolstered by
emerging standards such as OWL 2, JSON-LD, and microformats. Google’s
Knowledge Graph (21)(22), which complements keyword searches with basic
metadata and related links about people, places, and events, is the most prominent
example of the Semantic Web in action, and is likely to catalyze efforts
elsewhere.
1.2 Problem Description
The proliferation of inadequately annotated and structured experimental data is a
major deterrent to scientific progress. Despite the movement towards open data,
there remains major obstacles towards the vision of interoperable biomedical data
that can easily be shared, aggregated, and queried for the purposes of validating
hypotheses or planning new experiments. First, many researchers are either
unaware of or fail to see the benefits of openly sharing data (5). The abundance
of metadata standards to choose from when describing their experiments and
datasets, as evidenced by the proliferation of standards collected by the
BioSharing Initiative (16), can further discourage researchers. MIBBI standards

21
are published in prestigious journals such as Nature Genetics (23), Immunity (24),
and Nucleic Acids Research (25), but their uptake is limited by verbose,
ambiguous natural language guidelines, and the lack of concrete technical
implementations accompanied by usable interfaces that facilitate the annotation
process. Tools for metadata annotation and data submission remain difficult-to-
use. For example, the ImmPort submission process that consists of filling out
Excel spreadsheets (15) is strenuous, time-consuming, and unappealing –
jeopardizing accuracy and placing unnecessary burden on busy researchers.
There is also an overwhelming number of repositories (or databases) to which
researchers can submit data. The 2015 Nucleic Acids Research (NAR) Database
Issue alone features 56 papers on new biomedical databases (compared to the
previous year) in addition to 115 papers which provide updates on existing
databases (26). These in turn represent only a fraction of the complete list
databases compiled by NAR (27). With different inclusion criteria, schema, and
data formats, submission, aggregation and shared understanding across
repositories are difficult, if not impossible (28).
Even when metadata is present, there can be numerous issues:
Metadata may be incomplete: templates may be insufficiently filled in, or
may not cover the entire scope of the experiment or study.
Metadata may be inaccurate due to lack of time or effort spent in the
annotation process, or poorly-designed metadata annotation interfaces.
Metadata values may be ambiguous: the use of uncontrolled terms or free
text may lead to different and potentially-conflicting interpretations.
Metadata elements are inconsistently defined across repositories, making
comparison and querying difficult.
Efforts are ongoing to tackle the problems associated with metadata annotation.
Starting from one end of the spectrum, Bio2RDF is an initiative that converts

22
biomedical data stored in existing repositories into a standardized data model
(RDF) using common vocabularies such as Semanticscience Integrated Ontology
(SIO) to allow efficient integration and querying (28), removing the need for
additional metadata annotation. Meanwhile, the Center for Expanded Data
Annotation and Retrieval (CEDAR) at Stanford University is a new initiative
funded by the National Institutes of Health (NIH) to create a “unified framework
that researchers in all scientific disciplines can use to create consistent, easily
searchable metadata” (4). CEDAR aims to address the problems of ambiguity,
inaccuracy, and poor usability currently plaguing the metadata annotation process
by:
Standardizing and storing metadata elements and templates
Building intuitive, ontologically-based metadata annotation tools
Continuously improving the templates and annotation tools by studying
metadata annotation patterns
Finally, as previously discussed, the W3C HCLS Dataset Description aims to
standardize metadata for datasets contained in biomedical data repositories (9).
1.3 Research Aims
1.3.1 Improving syntactic interoperability
Meeting the requirement of syntactic interoperability necessitates a flexible and
standardized data model. RDF allows standards-based creation, aggregation, and
sharing built upon the stack of maturing Semantic Web technologies already at
our disposal. RDF can be generated in and converted between various data
formats (e.g. Turtle, N-Triples, JSON-LD), metadata models (as ontologies) can
be defined using OWL, and RDF graphs can be queried using SPARQL. RDF
also necessitates the use of IRIs where resources are unambiguously referenced,

23
and class hierarchies from ontologies can be leveraged, so that child entities can
be appropriately associated with their parent entities.
There is, however, a missing piece to the puzzle. Biomedical researchers must
know what is allowed and not allowed as they annotate their data, just as data
repositories must know what is acceptable or not acceptable when receiving a
dataset submission. Hence, there must be adequate ways to validate metadata that
is in the form of RDF graphs. This necessitates the examination of RDF constraint
languages that define and delimit acceptable RDF graph structures and content,
including but not limited to the “presence of properties, the cardinality of
relations, and restrictions on the allowed values of properties” (20). The W3C
HCLS Dataset Description is an ideal use case, since it has recently been
standardized and is suitably defined by a set of RDF metadata elements.
Whereas data models such as eXtensible Markup Language (XML) and relational
databases have standardized schema languages (XML Schema and Structured
Query Language (SQL), respectively), a schema (or constraint) language for RDF
has yet to be standardized. Moreover, XML Schema only provides interoperability
at the syntactic, but not semantic, level (29).
RDF Schema (30) is unfortunately misnamed, since it is a vocabulary with which
to describe relationships between resources (e.g. rdfs:subClassOf,
rdfs:subPropertyOf, rdfs:domain, rdfs:range) and not a true
schema language that restricts the possible resources or values that a node can
connect to (in a triple or a graph). Furthermore, the use of OWL axioms as
constraints is inhibited by two underlying assumptions of conventional OWL
semantics. First, the Open World Assumption means that the absence of a fact
does not necessarily make it false. Second, the Non-Unique Name Assumption
means that two different identifiers may in fact refer to the same resource (31).
These are essential to OWL’s ability to facilitate automated reasoning and
inference of new knowledge, but is incongruent with the goal of constraining RDF

24
data (32). The resulting vacuum has led to the proliferation of RDF constraint
languages from a multitude of stakeholders. A RDF constraint language should
fulfil the following functions:
Describe the RDF data describe what shapes they conform to
Generate interfaces and input forms for acquisition of valid RDF data
Validate RDF data for acceptance by services or applications
The first and most substantial part of this thesis is therefore a survey of RDF
constraint languages, elucidation of a set of functional requirements, and the
validation of the W3C HCLS Dataset Description with sample Bio2RDF data.
1.3.2 Improving annotation process of metadata
The creation of a prototype to implement the W3C HCLS Dataset Description as a
web-based form comprises the second and final part of the thesis. A web-based
interface is platform-independent and has the advantages of running in any web
browser and being familiar to the vast majority of potential users. Popular
technologies such as HTML, CSS, and JavaScript are open, flexible, and well-
supported languages that have been extended by the wider community through
frameworks such as Bootstrap and AngularJS. Templates written in RDF
constraint languages would ideally power the generation of input forms as well as
provide the basis for constraint validation.
The reuse of existing RDF vocabularies such as Provenance Ontology and
Semanticscience Integrated Ontology (SIO) for metadata elements by the HCLS
Dataset Description is an important step towards ensuring semantic
interoperability and avoiding the creation of yet more standards. Furthermore,
metadata fields should be populated by controlled terms to the greatest extent
possible. The NCBO BioPortal, the world’s most comprehensive collection of
biomedical ontologies, is the most appropriate source for such terms. A web-
based metadata form field (input element) that can be populated with terms via the
BioPortal RESTful API (33) is also prototyped.

25
The vision is an interoperable ecosystem of Big Metadata whereby biomedical
researchers can efficiently and seamlessly annotate and share their datasets in
interchangeable and mutually-interpretable formats, facilitating scientific
hypothesis generation, collaborative experimentation, and knowledge discovery.
This thesis lays some of the groundwork towards achieving this vision, aided by
the recent release of the W3C HCLS Dataset Description.
1.4 Research Questions
To what extent do existing RDF constraint languages meet functional
requirements for validating the W3C HCLS Dataset Description?
How can web technologies be used to create a web-based interface that
performs validation of metadata and source terms from biomedical
ontologies?

26
2. Methods
An exploratory study was performed to assess the current state of RDF constraint
languages and the feasibility of developing a web-based system for metadata
annotation. The W3C HCLS Dataset Description served as the basis for
consolidating a set of requirements for an RDF constraint language and a
validation exercise involving sample metadata from Bio2RDF.
2.1 Survey of RDF constraint languages
The W3C RDF Shapes Working Group was launched in September 2014 with a
mandate to explore the needs surrounding RDF validation and to recommend the
specification of a new RDF constraint language by February 2016 (34). An
“Existing Systems” document (35) had been compiled to provide starting points
for the Working Group, and lists Linked Data Object Model (LDOM), Stardog
ICV (OWL axioms), RDFUnit, Resource Shapes, Shape Expressions (ShEx), and
SPARQL Inference Notation (SPIN).
Table 2.1 Stakeholders and tools of RDF constraint languages
Language Stakeholder(s) Tool(s)
SPIN TopQuadrant
Rensselaer Polytechnic Institute
OpenLink
TopBraid products (incl. TopBraid
Composer)
ShEx W3C experts and others Fancy ShEx Demo (js)
JSShexTest (js)
RDFShape/Shexcala (Scala)
Haws (Haskell)
Stardog ICV Clark & Parsia Stardog
Resource Shape IBM
OSLC
OSLC SDKs (Eclipse Lyo, OSLC4Net)
LDOM is deemed a successor of SPIN yet has no implementations, and has now
evolved into the new candidate language Shapes Constraints Language (SHACL)
(36). RDFUnit is a framework developed by the Agile Knowledge Engineering

27
and Semantic Web (AKSW) group at the University of Leipzig and Institute for
Applied Informatics (InfAI) for validating RDF using automatically-generated test
cases (based on a schema) using SPARQL queries as the underlying execution
mechanism (37). Since LDOM is no longer available and RDFUnit is not strictly a
language, both have been excluded from the survey. The languages of interest in
this thesis are summarized in Tables 2.1 and 2.2.
Table 2.2 Technical details of RDF constraint languages
Language Version Surface syntax Underlying
constraints Vocabulary
ShEx 2013 SHEXc -
SPIN Feb 2011 SPARQL, RDF SPARQL SPIN RDF
Vocabulary
Stardog ICV Dec 2012 OWL, SWRL
SPARQL SPARQL -
Resource
Shape Feb 2014 RDF Resource Shape
Documentation from the W3C website and linked websites for ShEx, SPIN,
Stardog ICV, and Resource Shape were then reviewed with regards to their
abilities to represent the W3C HCLS Dataset Description as well as metadata in
the biomedical domain in general. Sample constraints were created to test
functionality and practicality: ShEx using the W3C FancyShExDemo, SPIN using
TopBraid Composer (TBC), and Stardog ICV OWL constraints using the Stardog
triplestore from Clark & Parsia.
2.2 Elucidation of requirements for RDF constraints
The commonalities and differences between the different RDF constraint
languages were synthesized into a set of requirements for constraining RDF
graphs. These requirements were then mapped to specific features in those
languages in tabular format. Low-level considerations such as computational

28
complexity and in-depth analysis of the logic behind the languages are beyond the
scope of this thesis.
2.3 Evaluation of sample Bio2RDF metadata using a ShEx
implementation of the W3C HCLS Dataset Description
Following the completion of the survey, it was decided that trialling the creation
of metadata templates would be most practical in ShEx. Implementations in ShEx
of the HCLS Dataset Description at all three levels (Summary, Version, and
Distribution) were created, and used to validate sample dataset descriptions
describing DrugBank datasets from Bio2RDF using the W3C FancyShExDemo
validator (38). These descriptions were provided by Prof Michel Dumontier,
Scientific Director of Bio2RDF, and generated using code that converts existing
metadata into the required three levels of dataset descriptions. Validation
messages from FancyShExDemo were consolidated into three tables that highlight
the areas of non-conformance.
2.4 Prototyping of web-based metadata template interface
The theoretical selection of RDF as the data model for machine-interpretable
metadata and RDF constraint languages for metadata validation is not useful until
a concrete implementation can facilitate its creation, validation, and
dissemination. Further, such an implementation needs to be relatively accessible
and user-friendly in order to be widely adopted amongst researchers and
institutions. Thus, a metadata template system was prototyped using a number of
web technologies, such as HTML, CSS and JavaScript. Although they can
ultimately become quite complicated, web-based systems have low barriers to
creation and adoption, with the added advantage of being accessible via the web
for maintenance and testing. The prototype consists of three separate components,
each filling a need in the vision of seamless metadata annotation.

29
2.4.1 Conversion of JSON-LD to RDF
As JSON-LD becomes increasingly adopted as a data exchange format for Linked
Data built on top of the popular JSON, it is important to build in the ability to
convert it into RDF. RDF graphs provide the structure suitable for validation by
RDF constraint languages, offering higher expressivity than existing formats such
as JSON Schema (39). A webpage that takes JSON-LD input and converts it into
RDF triples was created, based on calls to the RDF Translator REST API (40). In
order for these RDF triples to be manipulated within JavaScript, they were parsed
and displayed using N3.js from GitHub (41).
2.4.2 Dynamic generation of HTML form elements using AngularJS
A webpage that dynamically generates HTML form elements based on a JSON
representation of the W3C HCLS Dataset Description was created using
JavaScript and AngularJS. This removes the need to hard-code form elements in
HTML and allows minimal code to generate forms on demand. The form input
can then be converted into and stored as RDF triples into the browser’s
WebStorage using the W3C TriplestoreJS API (42). This is done as so that further
validation can be done on the client side, without requiring a server as the back-
end. The webpage is styled using the Bootstrap framework for navigational and
form interactivity.
2.4.3 Autocompletion of terms from biomedical ontologies
In order to provide a convenient way for users to provide metadata values that
conform to existing ontologies, an input field that suggests biomedical ontology
terms to the user during typing was created by connecting the “allmighty-
autocomplete” AngularJS directive (43) with the NCBO BioPortal API for Class
Search (33). All terms that match the typed string are returned by the BioPortal
API. In addition, a nested API call is performed in order to retrieve the name and
acronym of the ontology using the ontology IRI since those are not returned by
the BioPortal API.

30
2.5 Ethical considerations
There are minimal ethical concerns associated with this study. There is no direct
involvement of human subjects or vertebrate animals. The technologies utilized
are open-source, available from the W3C or on GitHub, and appropriately
attributed. No computers were harmed throughout the course of the thesis.

31
3. Results
3.1 Survey of RDF constraint languages
The term “RDF Shape” can be loosely defined as a structure or pattern, defined by
a RDF constraint language, against which an RDF graph can be validated, with
respect to structure and/or content (34). A shape can act as a template which
specifies the conditions for valid data, by outlining the constraints.
3.1.1 Shape Expressions
ShEx is a language developed following the W3C RDF Validation Workshop in
September 2013 (44) and although it is not itself on recommendation track, it has
been a major influence on the ongoing work of the W3C RDF Shapes Working
Group. It is specified in a small number of conference and ex-journal papers
(45)(46)(47)(48) and W3C webpages (44)(49)(50) as well as implemented by
open-source ShEx validators written in JavaScript, Scala, and Haskell (51). The
lack of a singular specification means that the language is vulnerable to
inconsistent definitions, interpretations, and implementations, although its broad
principles remain consistent throughout.
A ShEx shape consists of predicate-object pairs that are matched against subject-
predicate-object patterns in the data graph, written in SHEXc syntax, which is
similar to RelaxNG (47).
<VersionLevel> {
rdf:type (dctypes:Dataset),
dct:title rdf:langString,
dct:created xsd:dateTime,
dct:creator IRI
}

32
The example above indicates a shape entitled VersionLevel that is defined by
four predicate-object pairs. In other words, any data graph that conforms to
<VersionLevel> must contain those four predicate-object pairs, regardless of
order, where rdf:type connects to dctypes:Dataset, dct:title
connects to a literal of type rdf:langString, dct:created connects to a
literal of type xsd:dateTime, and dct:creator connects to any IRI. The
comma indicates conjunction, as in, all four predicate-object pairs must be present
in the data. However, disjunction can be expressed by separating predicate-object
pairs between pipes written inside parentheses, e.g. (dct:created
xsd:dateTime | dct:created xsd:date) indicates that the creation
event (dct:created) can either be a xsd:dateTime or xsd:date.
Meanwhile, negation is simply demarcated by an exclamation mark in front of the
predicate, e.g. !rdf:type (dcat:Distribution) means that a
<VersionLevel> shape shall never be typed as dcat:Distribution.
Furthermore, a period can stand in place for any object, so that !foaf:logo .
indicates the predicate foaf:logo should not be present at all.
Cardinality can be indicated via symbols following the object, including ? (zero-
or-one), * (zero-or-more), + (one-or-more), {m} (greater-than-or-equal-to-m),
and {m,n} (m-to-n). Modularization is built-in: shapes can take the place of
objects in the predicate-object pairs. For example, <VersionLevel> below
refers to the <AuthorShape> shape:
<VersionLevel> {
(dct:creator IRI | dct:creator @<AuthorShape>)
}
<AuthorShape> {
foaf:name xsd:string
}

33
The creator of the version level dataset can be defined by an IRI, or a sub-graph
that contains the author’s name (foaf:name) as a xsd:string. The following
data (in RDF Turtle syntax) would therefore be valid:
dct:creator [
foaf:name “Marie Curie”^^xsd:string;
];
Semantic actions embedded in ShEx and written in other languages such as
JavaScript or SPARQL introduce complex constraints such as comparing the
values from different triples or performing mathematical operations on them. For
instance, the date of creation of a dataset (dct:created) cannot be after the
date of its publication (dct:issued) (52), and this can be enforced by a
semantic action. Certainly, a validator would need to parse JavaScript in addition
to ShEx were the semantic actions written in JavaScript. ShEx can adopt a
“closed-world” or “open-world” interpretation depending on the settings of the
validator. In ShEx, there is complete dissociation between shapes and data, unless
specific shapes are designated for validation. A full implementation of the W3C
HCLS Dataset Description in ShEx can be found in Appendix A.
3.1.2 SPARQL Inference Notation
SPIN is a W3C member submission (53) by TopQuadrant, a company with a line
of products intended to help customers build applications based on Semantic Web
technologies. It was created in response to the lack of a standardized RDF
constraint language, since a mechanism to constrain and validate RDF was
required.
The principle behind SPIN is the attachment of SPARQL-based constraints to
classes so that all instances of those classes (and its sub-classes) must conform to
those constraints in order to be deemed valid. These constraints can be embedded

34
in the class definitions, or be written as reusable SPIN Templates or SPIN
Functions that are called at run-time, enabling modularization. Because SPIN is
ultimately represented in RDF, the SPIN RDF vocabulary provides the necessary
predicates to codify those SPARQL-based constraints as RDF triples. SPIN’s
dependence on SPARQL gives it the expressivity of SPARQL, but this poses
challenges for those who do not require its full expressivity and those who are not
familiar with its syntax. In addition, validation requires not only a SPARQL
processor but also a system that can interpret the SPARQL RDF vocabulary.
Therefore, SPIN’s use is restricted to the TopBraid suite of products. TopBraid
Composer (TBC) provides an integrated environment where SPIN constraints can
be defined and forms can be generated based on those constraints.
SPIN has three basic properties for expressing constraints: spin:constraint,
spin:rule, and spin:constructor (54).
A spin:constraint is a simple check for whether a constraint is
satisfied or violated via an ASK operation, so that if the ASK query
evaluates to true, the constraint has been violated. A CONSTRUCT query
can be used to return triples that contain information about the nature of
the constraint violation, such as a human-readable label (rdfs:label)
or the identity of the resource or property where the violation occurred.
A spin:rule extends the functionality of SPIN by allowing
computation of values, inference of new triples (insertion into the data
graph), and modification of existing triples in the data graph.
A spin:constructor allows the pre-population of triples at the time
of creation of instances of a class and its sub-classes.
A mini-implementation of the W3C HCLS Dataset Description is performed using
SPIN in TopBraid Composer.

35
A hcls:SummaryLevel class is first created with one spin:constraint
(Figure 3.1). This spin:constraint is built on the SPIN template
spl:Attribute built into TBC that in fact allows one to specify three
constraints (minimum cardinality spl:minCount, maximum cardinality
spl:maxCount, and value type spl:valueType) simultaneously on a
predicate, which here is dct:title. In other words, one and only one
dct:title is valid, and it must be of type xsd:string. (Note: the W3C
HCLS-DD specifies rdf:langString for dct:title, but because it is not
recognized as a datatype in TBC, it has been substituted by xsd:string.)
Figure 3.1 A class representing the Summary Level of the W3C HCLS
Dataset Description with SPIN constraints in TopBraid Composer

36
Next, an instance of hcls:SummaryLevel known as
hcls:SummaryInvalid is created to test the constraints. Here, two titles are
populated, violating the maximum cardinality of 1 and leading to an error
message (Figure 3.2).
Figure 3.2 Constraint violation error message in TopBraid Composer
3.1.3 Stardog ICV
Stardog Integrity Constraint Validation (ICV) is a technology for validating RDF
in Stardog, a light-weight triplestore (RDF database) developed by Clark &
Parsia, LLC (55). The idea to use OWL-based constraints arose in 2008 from the

37
OWL research community and in fact precedes the development of Stardog. ICV
was incorporated into Stardog in 2011 (35).
Interestingly, Stardog ICV allows the flexibility of writing constraints in OWL,
Semantic Web Rule Language (SWRL), or SPARQL, and converts them to
SPARQL for processing. SWRL is a W3C Member Submission that has multiple
implementations, and will not be discussed here (56). SPARQL constraints have
already been discussed as part of SPIN. As a result, this discussion will focus on
Stardog ICV as OWL axioms (OWL ICs) (57).
As previously stated, the use of OWL for constraints presents obstacles as a result
of the Open World Assumption and the Non-Unique Name Assumption (31).
Stardog ICV OWL axioms therefore rely on a different set of semantics, namely,
the Closed World Assumption and the Unique Name Assumption, necessitating
modifications in OWL software as well as the mindset of those who write and
interpret OWL ICs. It is intended that existing OWL ontologies can import OWL
ICs meant for this alternate semantic interpretation as a means of validation, using
the predicate <http://www.w3.org/Submission/owlic/imports> (58).
The workflow for testing Stardog ICV involves:
Authoring RDF files that contain the OWL ICs and RDF data to be
validated
Creating a Stardog database and loading it with RDF data
Loading OWL ICs into the specific Stardog database
Running the validation
A simple example partially implementing a summary level description is
demonstrated. The OWL ICs consist of an OWL class <SummaryLevel>. The
three restrictions (owl:onProperty) are on properties/predicates rdf:type,
dct:title, and dct:description. Each of these is only allowed to be

38
used once, due to the minimum and maximum cardinalities
(owl:minCardinality, owl:maxCardinality) both being set to 1. The
rdf:type property is further defined as an object property
(owl:ObjectProperty), with the only allowed value as
dctypes:Dataset. Finally, both dct:title and dct:description are
data properties (owl:DatatypeProperty), with an rdfs:range of
rdf:langString.
<SummaryLevel> a owl:Class ;
rdfs:subClassOf [owl:onProperty rdf:type;
owl:minCardinality 1;
owl:maxCardinality 1; ],
[owl:onProperty dct:title;
owl:minCardinality 1;
owl:maxCardinality 1; ],
[owl:onProperty dct:description;
owl:minCardinality 1;
owl:maxCardinality 1; ].
rdf:type a owl:ObjectProperty ;
owl:hasValue dctypes:Dataset .
dct:title a owl:DatatypeProperty ;
rdfs:range rdf:langString .
dct:description a owl:DatatypeProperty ;
rdfs:range rdf:langString .
A valid example that validates is shown below.
<SummaryLevel>
rdf:type dctypes:Dataset;
dct:title "Title 1"^^rdf:langString;
dct:description "Description 1"^^rdf:langString;
.

39
Figure 3.3 Validation message from Stardog ICV in the command line
An example that contains two descriptions would be invalid because it exceeds
the maximum cardinality of 1.
<SummaryLevel>
rdf:type dctypes:Dataset;
dct:title "Title 1"^^rdf:langString;
dct:description "Description 1"^^rdf:langString;
dct:description "Description 2"^^rdf:langString;
.
Figure 3.4 Constraint violation message from Stardog ICV in the command
line
3.1.4 Resource Shape
Resource Shape is an RDF vocabulary that allows the specification of shapes
(known as Resource Shapes) represented in RDF itself. Like SPIN, it is also a
W3C Member Submission (20), from staff at IBM who have been involved with
its development and evaluation. Although Resource Shape is intended as a
domain-independent mechanism for verification of RDF data, it was primarily
developed under the Open Services for Lifecycle Collaboration (OSLC) initiative
(59) to facilitate Application Lifecycle Management by describing resources such
as change requests, test cases, and requirements (32).
In principle, Resource Shapes are quite similar to ShEx shapes, except that the
former is defined in RDF and the latter in SHEXc syntax. (In fact,
FancyShExDemo can convert ShEx shapes into Resource Shapes, although bugs
are present.) The RDF syntax however makes Resource Shape more explicit, and
thus more verbose, than ShEx. Resources in the data self-describe by linking (via

40
oslc:instanceShape) to one or more generic Resource Shapes; conversely,
typed Resource Shapes can apply to instances of classes to which they have been
linked (via oslc:describes) (20).
Figure 3.5 The high-level relations between Resource Shapes, Properties, and
Allowed Values
A Resource Shape is constructed as a oslc:ResourceShape resource which
constrains a number of predicates or properties (via oslc:property). These
properties are in turn defined as separate resources (oslc:Property) that
specify the predicates to be constrained (via oslc:propertyDefinition)
and the allowed values (via oslc:allowedValues) (Figure 3.5). Lastly, the
resources that contain the allowed values (oslc:AllowedValues) list any
allowed values via oslc:allowedValue.
Cardinality (oslc:occurs) is specified for each property (oslc:Property)
using oslc:Exactly-one, oslc:One-or-many, oslc:Zero-or-
many, oslc:Zero-or-one. Literal value types are restricted to a set of XML
Schema datatypes, and value sets can also be specified
(oslc:allowedValue). Recommended extensions to the Resource Shape

41
language include provisions for regular expressions and restricting numerical
value and string length. There is limited modularization since Resource Shapes
can be composed of separately-defined Properties and Allowed Values shapes, but
resources cannot refer to more than one Resource Shape, nor can Resource Shapes
reference other Resource Shapes.
Below is an example of a Version Level shape defined as a
oslc:ResourceShape. It is entitled “Version Level Shape” using
dcterms:title, and is set to describe all instances of the class
hcls:versionLevel in the data (not shown here). This Resource Shape
constrains two properties by referencing their shapes: hcls#dct-title and
hcls#dct-created.
<hcls#VersionLevelShape> a oslc:ResourceShape ;
dcterms:title "Version Level Shape" ;
oslc:describes hcls:versionLevel ;
oslc:property
<hcls#dct-title> ,
<hcls#dct-created> .
The two properties, hcls#dct-title and hcls#dct-created, are
described as two separate oslc:Property shapes, restricting the properties to
use the predicates dct:title and dct:created, respectively. Their
expected literal value types are both rdf:langString, and cardinalities both
one and only one (oslc:Exactly-one).
<hcls#dct-title> a oslc:Property ;
oslc:propertyDefinition dct:title ;
oslc:name "Title" ;
rs:valueType rdf:langString ;

42
oslc:occurs oslc:Exactly-one .
<hcls#dct-created> a oslc:Property ;
oslc:propertyDefinition dct:created ;
oslc:name "Creation Date" ;
rs:valueType rdf:langString ;
oslc:occurs oslc:Exactly-one .
The lack of a ready testing environment for Resource Shape meant that a working
example could not be implemented and assessed. Nonetheless, the survey of its
specification reveals sufficient information to compare it to the other RDF
constraint languages.
3.2 Requirements for a RDF constraint language
Following the survey of the four RDF constraint languages, a set of 13
requirements were elucidated, and mapped to the presence or absence of features
in those languages (Table 3.2). These requirements were also influenced by the
list of requirements compiled by the W3C RDF Shapes Working Group (60) and
the Shapes Language Expressivity Questionnaire (61). Requirements are divided
into:
Content constraints: the identities of the predicates, objects, and literal
values.
Structural constraints: the possible structures of RDF graphs, the
configurations of nodes and arcs
Validation characteristics: features that support the validation of RDF
data against the constraints/shapes irrespective of the content or structure
of the RDF graph

43
3.2.1 Content constraints
Requirement 1: Predicate type constraints
When it comes to constraining an RDF graph, one must begin from the
perspective of a focus node, specifically a subject node, from which all connecting
nodes and arcs can be assessed for conformance to the constraints or shape. The
most basic constraint, therefore, is on the predicate types that are allowed to be
associated with this subject node.
Figure 3.6 Constraint on the type of Predicate 1
Requirement 2: Object node constraints
Any node that the subject node connects to can be an IRI, a literal value with a
datatype, or an object class (62). For example:
Untyped IRI: The author field of a dataset should be populated by the IRI
that represents the author. This could be the IRI of the author in an
established database or even the URL of the author’s homepage, such as
http://www.university.edu/authorName.
Literal value with datatype: The title field should be a string of the
datatype xsd:string, such as “Microarray 1”^^xsd:string.
Object class: Any dataset that conforms to the W3C HCLS-DD must have
a rdf:type of dctypes:Dataset.

44
Figure 3.7 Constraints on the object node as IRI, literal, or object class
Requirement 3: Literal value constraints
XML Schema datatypes are most commonly used for literal values, and are rather
intricately defined in a complex hierarchy (Figure 3.9). Fortunately, the W3C
HCLS-DD only utilizes xsd:dateTime, xsd:date, xsd:gYearMonth,
and xsd:gYear for date and time, and xsd:string and xsd:integer for
text and numbers. This removes the need for any entailment regimes (for
datatypes), where, for instance, a value of type xsd:nonNegativeInteger
would need to be recognized as meeting a requirement for xsd:integer.
Figure 3.8 Constraints on literal datatype

45
Figure 3.9 The XML Schema datatype hierarchy (63)
In the W3C HCLS-DD there are no defined value sets from which values must be
taken in order to populate any metadata fields. However, domain- and university-
specific templates (such as those for ImmPort) may need to restrict, for example,
the models of flow cytometry machines based on those available in the
researcher’s immunology department, for the completion of an “equipment” field.
Requirement 4: Literal value facet constraints
There are numerous ways to specify allowed values for literals, such as those
supported by XML Schema Datatype Restrictions (Table 3.1). For strings, the
exact, minimum, and maximum lengths (Requirement 4a) can be specified.
Regular expressions (Requirement 4b) and default values (Requirement 4d) are

46
expected by the community (62). For numbers, a range can be specified with
inclusive or exclusive boundaries (Requirement 4c). It is possible to use XML
Datatypes to restrict values to positive numbers (using
xsd:nonNegativeInteger), but it is less flexible and a more convoluted
way than simply specifying a minimum value of zero. Although the W3C HCLS-
DD does not go to this level of detail, there is good reason for the option to
constrain literal values in these ways. For example, the number of cells in a
sample cannot be a negative number, researchers may want to specify their
institution name as a default value for convenience, and repositories may want to
restrict string length for technical reasons (e.g. database limitations).
Table 3.1 XML Schema Datatype Restrictions (61)(64)
Strings
Exact length xsd:length
Minimum length xsd:minLength
Maximum length xsd:maxLength
Regular expression xsd:pattern
White space xsd:whiteSpace
Numbers
Lower limit xsd:minExclusive, xsd:minInclusive
Upper limit xsd:maxExclusive, xsd:maxInclusive
Total digits xsd:totalDigits
Fraction digits xsd:fractionDigits
Requirement 5: Language constraints
In RDF, strings can be marked with a language tag using the @ sign in order to
designate the language in which the string is written, such as “English
text”@en for English and “Des mots en français”@fr for French
(65). The W3C HCLS-DD specifies that certain elements must be of type
rdf:langString, in other words, that each string is accompanied by a
language tag (9). In addition, for each rdf:langString element, multiple
strings are allowed as long as each language is only represented once. Hence, the
constraint language must be able to: recognize the presence or absence of
language tags (Requirement 4a), to restrict specific language tags (for example, a

47
repository may only want to cater to French researchers) (Requirement 4b) and
to ensure the uniqueness of those languages for each field (to avoid duplicate
strings for any one language) (Requirement 4c).
3.2.2 Structural constraints
Requirement 6: Cardinality constraints
Figure 3.10 Constraints on the cardinality of predicate 1
On the Semantic Web, there is no inherent limit on the number of objects or literal
values that a given subject-predicate can be associated with, hence, adding triples
to a given graph merely extends the knowledge expressed by that graph.
Restricting cardinality – the quantification of such occurrences – is a way to
enforce, for instance, that any dataset may only have one title. Cardinalities are
normally written in square brackets with two numbers, the first denoting the
minimum cardinality, and the second denoting the maximum cardinality, both
inclusive. Typical cardinalities are zero-or-one [0, 1], zero-or-many [0, n], exactly
one [1,1], and one-or-many [1, n] (62). The zero-or-one and zero-or-many
cardinalities give optionality to a specific constraint. The cardinality of zero is
listed as a separate requirement “Absence constraint”.

48
Requirement 7: Absence constraints
Just as the presence of specific RDF predicates is recommended, some predicates
should simply never be used. For example, the logo of a dataset should be
specified using schemaorg:logo and not foaf:logo. The absence of the
foaf:logo predicate must therefore be explicitly stated in the template for
validation to take place correctly.
Requirement 8: Disjunction
In essence, all constraints contribute in a conjunctive (or additive/AND) manner
to the overall shape that the data should take. In other words, the data should be
valid with respect to all stated constraints. Given this, specifying constraints in a
disjunctive (OR) manner could provide additional flexibility for both data creators
and recipients. In this case, data would be valid as long as it conforms to one of
multiple sets of constraints. Disjunctive statements for constraints can be specified
in ShEx as OrRules in relatively straightforward fashion (49), separated by pipes
within a set of parentheses on the same line. This can create:
A combination of different predicates: (dct:contributor IRI |
pav:createdBy IRI) (Figure 3.11)
Figure 3.11 Disjunction of predicates
A combination of different objects/literal datatypes for the same
predicate: (dct:created xsd:gYearMonth | dct:created
xsd:dateTime) (Figure 3.12)
Figure 3.12 Disjunction of literal datatypes

49
Note that it is still up for discussion how the OR in ShEx is to be implemented
(61). For simplicity, the OR here is interpreted to be an exclusive OR.
Combinations of conjunctive and disjunctive statements can add expressivity, but
at the expense of complexity.
3.2.3 Validation characteristics
Requirement 9: Requirement Levels
In the W3C HCLS-DD, the RDF predicates are specified according to the IETF
RFC 2119’s requirement levels (66): MUST, SHOULD, MAY, SHOULD NOT,
and MUST NOT. Whilst MUST and MUST NOT are unambiguous for presence
and absence, respectively, the desired interpretations for SHOULD, MAY, and
SHOULD NOT must be made explicit and machine-executable. The system
performing the validation needs to decide whether or not to accept a submitted
graph, and what validation/error message to display, if the requirement level is a
SHOULD, MAY, or SHOULD NOT.
Requirement 10: Constraints-data validation
There are four principles in which the system validates data against a shape or set
of constraints:
Constraints-in-data embedding: Constraints are directly embedded in the
data itself.
Shape-to-data association: Classes to which a shape applies are written in
the shape definition, so that instances of those classes can be checked
against the constraints in that shape. This requires that the data consists of
instances that have child relationships to classes, and that the creator of the
shapes knows about such instances and relationships in advance.
Data-to-shape association: The second way is to refer to shapes within the
data itself so that the validator knows which shapes the particular data
should be validated against. This requires that the shapes are uniquely
named and discoverable.

50
Data-shape dissociation: Finally, there can be complete disassociation
between shapes and data, so that all nodes in the shape are checked against
all nodes in the data. This creates independence between the data provider,
the data recipient, and the data validator (if separate from the data
recipient). However, unnecessary constraint violations can be generated if
data is matched against shapes that were never meant to apply in the first
place.
Requirement 11: Closed and open shapes
Shapes can specify precisely what is and is not valid, yet there is always the
possibility that data will contain nodes that fall outside of what has been defined.
In order for data to conform to a closed shape, it must match exactly what has
been prescribed, and not contain extraneous nodes or triples. On the other hand,
data conforming to an open shape is valid as long as it contains all matching
nodes as defined by the shape, regardless of the presence of other nodes or triples.
Furthermore, it may be helpful for the validator to highlight those extra nodes or
triples (61). Since the W3C HCLS-DD has been defined as a minimum set of
metadata requirements, it can be interpreted as adhering to the “open shape”
philosophy.
Requirement 12: Modularization
In order to make shapes and constraints as flexible as possible and to minimize
duplication, shapes should ideally be derivable and extensible from other shapes.
Modularization of shapes can be taken to be similar to concepts such as
inheritance, polymorphism, and composition as applied to shapes. This in effect
would allow template creators to build on top of existing templates and to
compose templates from smaller templates.
Requirement 13: Labels
There must be a mechanism that allows appropriate constraint violation messages
to be generated and fed back to data providers (e.g. researchers) and data

51
recipients (e.g. repositories) should validation fail in any way. This requires that
the constraints are labeled in a manner that is easily extractable by the validating
system and automatically composed into an error message (Requirement 13a), or
that a human-readable label is attached to each constraint and displayed if said
constraint has been violated (Requirement 13b).

52
Table 3.2 Requirements for RDF constraints as mapped to features of RDF constraint languages
Requirement ShEx SPIN Stardog ICV OWL axioms Resource Shape Content constraints 1. Predicate type Yes Yes Yes (owl:onProperty) Yes (oslc:propertyDefinition)
2. Object node
2a. Untyped IRI Yes (<IRI>) Yes Yes (xsd:anyURI) Yes (oslc:Reference)
2b. Object class Yes Yes Yes (ObjectHasValue
owl:hasValue)
Yes (oslc:range)
2c. Object class
prefix
Yes (ValueStem) Yes No No
3. Literal value
3a. Literal value type Yes (unrestricted) Yes
(restricted to datatypes in
TBC)
Yes (Data PropertyRange
rdfs:range)
Yes (restricted to rdf:XMLLiteral,
xsd:boolean, xsd:dateTime,
xsd:decimal, xsd:double,
xsd:float, xsd:integer,
xsd:string)
3b. Literal value sets Yes (ValueSet) Yes Yes (DataHasValue
owl:hasValue)
Yes (oslc:allowedValues)
4. Literal value facets
4a. String length No Yes Yes (xsd:length,
xsd:minLength, etc.)
Recommended extension
(xsd:length, xsd:minLength,
etc.)
4b. Regular
expression
No Yes Yes (xsd:pattern) Recommended extension
(xsd:pattern)
4c. Numerical value No Yes Yes (DataSomeValuesFrom
xsd:maxExclusive, etc.)
Recommended extension
(xsd:maxExclusive, etc.)
4d. Default value N/A Yes N/A Yes (oslc:defaultValue)
5. Language
5a. Language tag
presence
No No Yes (rdf:langRange) No

53
5b. Language
selection
No No Yes (rdf:langRange) No
5c. Language tag
uniqueness
No No No No
Structural constraints 6. Cardinality
6a. Exactly one Yes (ArcRule) Yes (minCardinality,
maxCardinality)
Yes (ObjectExactCardinality
owl:cardinality,
ObjectMinCardinality
owl:minCardinality,
, ObjectMaxCardinality
owl:maxCardinality,
DataExactCardinality, etc.)
Yes
(oslc:Exactly-one)
6b. Zero or one Yes (?) Yes
(oslc:Zero-or-one)
6c. Zero or many Yes (*) Yes
(oslc:Zero-or-many)
6d. One or many Yes (+) Yes
(oslc:One-or-many)
6e. Minimum m Yes ({m}) No
6f. Specific range Yes ({m,n}) No
7. Absence constraint Yes (!or – or
{0,0})
Yes (FILTER
expressions)
No
8. Disjunction Yes (OrRule) No No
Validation characteristics 9. Requirement levels No No No
10. Constraints-data
validation
Shape-data
dissociation
Constraints-in-data
embedding
Shape-to-data association, Data-to-
shape association
Shape-to-data association, Data-to-shape
association
11. Closed and open
shapes
Depends on
validation settings
Closed World Assumption Unknown
12. Modularization Yes (<@shape>) Yes (SPIN Templates) Yes Limited
Labels
13a. Labels for
constraint elements
No Yes Yes
13b. Labels for
constraint violations
No Yes No

54
3.3 ShEx implementation of W3C HCLS Dataset Description and
validation of sample Bio2RDF dataset descriptions
A full implementation of the W3C HCLS Dataset Description in all three levels
(Summary, Version, and Distribution) was coded in ShEx manually in a text
editor (Appendix A) by consulting the table of metadata elements specified in the
documentation (9). Since ShEx currently does not encode requirement levels,
SHOULD was interpreted as MUST, and SHOULD NOT interpreted as MUST
NOT, so that the validator flags up any triples that are absent when they
SHOULD be present, as well as those that are present when they SHOULD NOT
be present. MAY was represented by zero-or-one (+) or zero-or-many (*)
cardinalities according to the documentation.
Sample dataset descriptions from Bio2RDF in RDF N-Quads for DrugBank were
obtained from Scientific Director Prof Michel Dumontier and converted to N-
Triples (Appendix B) by removing the IRIs for the graphs, which are unnecessary
for validation and also uninterpretable by the validator. There are two examples of
version and distribution level datasets each, and one example of a summary level
dataset. They were validated as open shapes against the ShEx templates using the
web-based W3C FancyShExDemo (38).
The areas of non-conformance are compiled in Tables 3.3, 3.4, and 3.5 for
Summary, Version and Distribution Levels, respectively. The majority of issues
identified pertain to SHOULD requirements, which are highly-recommended yet
not strictly mandatory. Across all levels one common issue was the type
declaration, which was missing in the summary and distribution levels, and a
different prefix was used in the version level. Overall, many of the missing triples
relate to provenance (e.g. date created, data source provenance), discovery (e.g.
HTML page), and file descriptors (e.g. license, # of triples). The only triples that
were present when they MUST NOT be were identifier pattern, file access pattern,
and example identifier in the summary level.

55
The Summary Level description has two rdf:type predicates, one with the
value <http://bio2rdf.org/lsr:Dataset> and the other
<http://www.w3.org/ns/dcat#Dataset>, none of which satisfy the
required value (MUST) <http://purl.org/dc/dcmitype/Dataset>.
The two Version Level descriptions’ rdf:type predicates have the value
<http://purl.org/dc/terms/Dataset> which is equivalent to
<http://purl.org/dc/dcmitype/Dataset> but is not recognized by
the validator (and thus flagged as non-conformant).
Finally, the two Distribution Level descriptions’ rdf:type predicates have the
required value (MUST)
<http://www.w3.org/ns/dcat#Distribution>, but is missing the
value (SHOULD) <http://purl.org/dc/dcmitype/Dataset>.
Table 3.3 Issues identified from Summary Level validation
Element Predicate Requirement Issue (DrugBank
Bio2RDF)
1.1 Type
declaration
rdf:type
MUST Incorrect value
1.13 Logo schemaorg:logo SHOULD Missing
2.3 Identifier
pattern
idot:identifierPatte
rn
MUST NOT Present
2.5 File access
pattern
idot:accessPattern MUST NOT Present
2.6 Example
identifier
idot:exampleIdentifi
er
MUST NOT Present

56
Table 3.4 Issues identified from Version Level validation
Element Predicate Requirement
Issue
(DrugBank
XML)
Issue
(DrugBank
Bio2RDF)
1.1 Type
declaration
rdf:type
MUST Incorrect
value
Incorrect
value
1.6 Date created dct:created
SHOULD Missing Missing
1.11 Date of
issue
dct:issued SHOULD Missing Missing
1.12 HTML page foaf:page SHOULD Missing Missing
1.13 Logo schemaorg:logo SHOULD Missing Missing
1.15 License dct:license SHOULD Missing Missing
1.17 Language dct:language SHOULD Missing Missing
3.3 Version
linking
pav:previousVersion SHOULD Missing Missing
3.5 Data source
provenance
dct:source or
pav:retrievedFrom or
prov:wasDerivedFrom
SHOULD Missing Missing
3.7 Creation
tool
pav:createdWith SHOULD Missing Missing

57
Table 3.5 Issues identified from Distribution Level validation
Element Predicate Requirement
Issue
(DrugBank
XML)
Issue
(DrugBank
Bio2RDF)
1.1 Type
declaration
rdf:type
SHOULD Missing Missing
1.2 Type
declaration
rdf:type
MUST - -
1.6 Date created dct:created
SHOULD Missing Missing
1.11 Date of
issue
dct:issued SHOULD Missing Missing
1.13 Logo schemaorg:logo SHOULD Missing Missing
1.17 Language dct:language SHOULD Missing Missing
1.20 Vocabulary
used
void:vocabulary SHOULD Missing Missing
1.21 Standards
used
dct:conformsTo
SHOULD Missing Missing
2.6 Example
identifier
idot:exampleIdentifi
er
SHOULD Missing Missing
2.7 Example
resource
void:exampleResource
SHOULD Missing Missing
3.3 Version
linking
pav:previousVersion SHOULD Missing Missing
3.5 Data source
provenance
dct:source or
pav:retrievedFrom or
prov:wasDerivedFrom
SHOULD Missing -
3.7 Creation
tool
pav:createdWith SHOULD Missing Missing
4.5 Byte size dcat:byteSize SHOULD - Missing
4.6 RDF File
URL
void:dataDump SHOULD Missing Missing
4.9 Linkset void:subset SHOULD Missing Missing
5.1 # of triples void:triples SHOULD Missing Missing
5.2 # of typed
entities
void:entities SHOULD Missing Missing
5.3 # of subjects void:distinctSubject
s
SHOULD Missing Missing
5.4 # of
properties
void:properties SHOULD Missing Missing
5.5 # of objects void:distinctObjects SHOULD Missing Missing
5.6 # of classes void:classPartition SHOULD Missing Missing
5.7 # of literals void:classPartition SHOULD Missing Missing
5.8 # of RDF
graphs
void:classPartition SHOULD Missing Missing

58
3.4 Prototyping of metadata template system
As outlined in the Methods section, three separate components of the prototype
were created using web technologies. A web-based form (Figure 3.11) allows a
user to input JSON-LD and convert it into RDF triples, powered by the RDF
Translator API (40). Whilst most users will likely be entering metadata directly
into form fields, this prototype simply demonstrates that this conversion can be
performed, since JSON is a popular data format on the web. There are certain
cases where JSON-LD may need to be converted directly, for instance, ImmPort
is currently converting its data from relational databases into JSON-LD.
Figure 3.11 Web-based form converting sample JSON-LD to RDF N-Triples

59
Next, a web-based form (Figure 3.13) is dynamically generated using HTML and
AngularJS, from a JSON object that has been matched to the metadata elements of
the W3C HCLS Dataset Description. Users can select which level of dataset they
are annotating (Summary, Version, Distribution) by clicking on the appropriate
tab on top. The IRI for the subject needs to be entered manually, for
demonstrative purposes. A submit button at the bottom converts the form data into
RDF triples that are stored in the browser’s WebStorage and then displayed to the
right of the form (Figure 3.12). A “Remove all triples” button is available to clear
this temporary storage to set the stage of new data. Note that a validation
mechanism was not implemented due to time limitations.
Figure 3.12 Web-based interface displaying entered metadata in the form of
RDF N-Triples
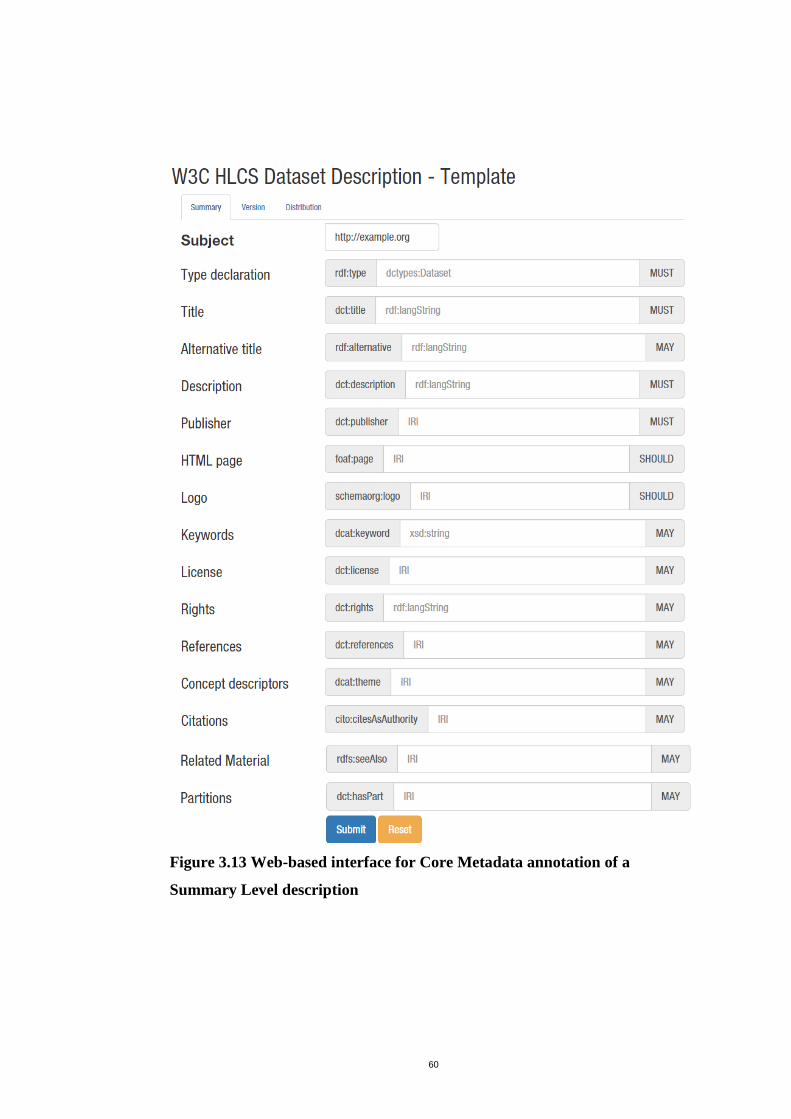
60
Figure 3.13 Web-based interface for Core Metadata annotation of a
Summary Level description

61
Finally, a web-based form input field prototype (Figure 3.14) is connected to the
BioPortal API to display biomedical ontology terms in real-time as the user is
typing on the keyboard. No delay was implemented to prevent premature calls to
the API due to customization difficulties with the “allmighty-autocomplete”
AngularJS directive (43). In a more complete prototype, such autocomplete fields
will need to be generated dynamically within the structure of the form and ideally
support the autosuggestion of terms in a sequential manner (e.g. keywords).
Figure 3.14 Autocompletion input field presenting a list of biomedical
ontology terms retrieved from the BioPortal API

62
4. Discussion
In the information age, we cannot afford to prioritize quantity over quality when it
comes to Big Data. Exchange of information and useful analysis to produce
insight can only be built upon data that is clean, interoperable, and verifiable.
Even though metadata cannot rescue any data that is corrupted, unstructured or
erroneous, it can bridge the gap between data and insight. Metadata provides
information about the identity, content, provenance, discovery, and licensing of
data to enable it to be located, analyzed, and integrated for a multitude of
purposes. It is the enabler of interoperability across disparate sources of data.
RDF is a flexible data model capable of representing any domain – both instances
of data (as in a knowledge base) and conceptual models (as in an ontology).
Representing metadata as RDF brings advantages of using a standardized
representation for data with built-in unique identifiers that allows it to be linked
and integrated with other data in RDF. Yet to this date, there are no standardized
ways of specifying the shapes of, or constraints on, RDF graphs.
4.1 Past efforts
A search on the IEEE Xplore Digital Library revealed a small number of efforts in
the literature over the past 10 years to validate RDF graphs, in the absence of a
standardized RDF constraints language (Table 4.1). On one hand, Wang et al.
(64) and Liu et al. (67) took on the challenge of validating RDF that is consumed
and generated by Web services. On the other, Chen et al. (68), Bouillet et al. (69),
and Fan et al. (70) (71) attempted to validate OWL models that have been derived
from relational databases. Their methods based in XML, OWL, and/or SPARQL
were relatively specific to their use cases and do not offer the generalizability or
expressivity of the RDF constraints languages surveyed in this thesis.
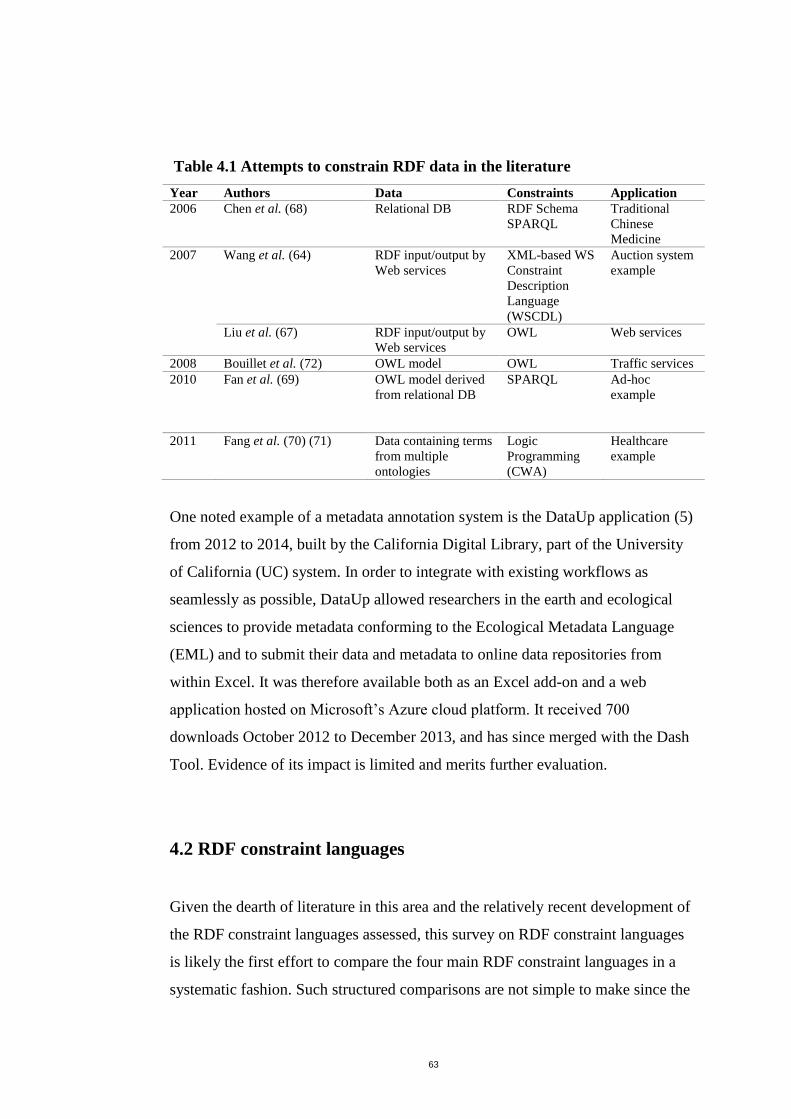
63
Table 4.1 Attempts to constrain RDF data in the literature
Year Authors Data Constraints Application
2006 Chen et al. (68) Relational DB RDF Schema
SPARQL
Traditional
Chinese
Medicine
2007
Wang et al. (64) RDF input/output by
Web services
XML-based WS
Constraint
Description
Language
(WSCDL)
Auction system
example
Liu et al. (67) RDF input/output by
Web services
OWL Web services
2008 Bouillet et al. (72) OWL model OWL Traffic services
2010 Fan et al. (69) OWL model derived
from relational DB
SPARQL Ad-hoc
example
2011 Fang et al. (70) (71) Data containing terms
from multiple
ontologies
Logic
Programming
(CWA)
Healthcare
example
One noted example of a metadata annotation system is the DataUp application (5)
from 2012 to 2014, built by the California Digital Library, part of the University
of California (UC) system. In order to integrate with existing workflows as
seamlessly as possible, DataUp allowed researchers in the earth and ecological
sciences to provide metadata conforming to the Ecological Metadata Language
(EML) and to submit their data and metadata to online data repositories from
within Excel. It was therefore available both as an Excel add-on and a web
application hosted on Microsoft’s Azure cloud platform. It received 700
downloads October 2012 to December 2013, and has since merged with the Dash
Tool. Evidence of its impact is limited and merits further evaluation.
4.2 RDF constraint languages
Given the dearth of literature in this area and the relatively recent development of
the RDF constraint languages assessed, this survey on RDF constraint languages
is likely the first effort to compare the four main RDF constraint languages in a
systematic fashion. Such structured comparisons are not simple to make since the

64
technical specifications and documentation are written and presented in different
ways across those languages. In the end, it was uncovered that the abilities of
ShEx, SPIN, Stardog ICV, and Resource Shape to create constraints on RDF
graphs do not differ significantly from each other, and that their main differences
lie in the their surface syntaxes, as well as practical considerations (discussed
below). With respect to the W3C HCLS Dataset Description, which only requires
relatively basic constraints, all four languages are expected to be able to act as the
validation mechanism. They are also able to meet a large proportion of the
structural and content requirements that were derived. This survey is also likely
the last of its kind due to the expected release of the W3C standard SHACL next
year (discussed below).
Table 4.2 Practical considerations of RDF constraint languages
Language Open-
source Maturity of
implementation
Availability of
validators RDF
representation
ShEx Yes Low Multiple No
SPIN No High One Yes
Stardog ICV No High One Yes
Resource Shape Yes Medium Multiple Yes
Practical considerations play a major role in deciding which language is most
appropriate to use (Table 4.2). The clarity of specification is key to making a
language easy to interpret and write, whilst the availability of implementations or
validators affects the ability to test and create code in that language. Whether or
not the language and its validator software are open-source affects the ability to
have full control over code and its validation, and to improve the specification
through community feedback. An RDF representation allows the templates or
shapes themselves to be connected as Linked Data, extended, queried, and
exchanged by Web services or APIs. ShEx was chosen for the implementation of
the W3C HCLS Dataset Description as a result of its ease of use, interpretability
of shapes, and availability of the validator (FancyShExDemo), despite the rather
fluid nature of its specification.

65
4.3 Shapes Constraint Language
The W3C RDF Shapes Working Group is currently assembling the specification
of a new RDF constraint language, one that aims to be the definitive standard and
put an end to ambiguities and differing specifications, by the deadline of February
2016. The newly-named Shapes Constraint Language (SHACL) inherits features
from ShEx, SPIN, and Resource Shape, and attempts to satisfy as many
stakeholders as possible to maximize adoption. The current specification is being
updated on a near-daily basis, and it is impossible to say how much this will
resemble the final specification, yet the direction in which SHACL is heading is
sufficiently clear enough for discussion here.
In essence, SHACL is an RDF vocabulary similar to Resource Shape with
influence from ShEx, enhanced with the ability to express more complex
constraints using SPARQL. As in Resource Shape and ShEx, a shape here is also
meant to delimit the structure and content of an RDF graph from the perspective
of a focus node. Basic constraints can encompass the literal datatype, node type
(IRI, object class), allowed value sets, as well as refer to other shapes. Since it is
in RDF syntax, SHACL is necessarily more verbose than ShEx. For example,
cardinality constraints are specified as separate triples with the predicates
sh:minCount and sh:maxCount, in contrast to symbols such as * or + in
ShEx. In this respect, SHACL is also more flexible than Resource Shape, since
the cardinality can be denoted with an integer rather than fixed ranges such as
oslc:One-or-many and oslc:Zero-or-one. If SHACL is indeed
finalized within a year’s time, there is no doubt that it will become a core
Semantic Web technology alongside RDF, OWL, and SPARQL.

66
4.4 Metadata annotation system
The prototypes created during the course of this thesis are far from complete. The
next steps would be to combine them into one integrated system that ideally can
display a template form from either JSON, JSON Schema, JSON-LD, or even
RDF, with built-in validation based on a schema such as JSON Schema or the
future SHACL.
A side project related to this thesis was undertaken at the NIH Big Data To
Knowledge (BD2K) Hackathon at The Scripps Research Institute (TSRI) in San
Diego, California from May 7-9, 2015 (73). There, the smartAPI team (Vladimir
Choi, Dmitry Tebaykin, Grant Vousden-Dishington, Chunlei Wu, and Michel
Dumontier) prototyped a platform (74) that allows biomedical API publishers to
semantically annotate their services and input/output parameters in a structured
and identifiable manner, based on a standard JSON-LD format, akin to the W3C
HCLS Dataset Description but for APIs and services. These descriptions are then
indexed and visualized as Linked Data in a MongoDB back-end, using which
researchers can seamlessly identify the services that consume or return desired
parameters, and perhaps even automatically compose services in novel
workflows.
The template system was built on Alpaca Forms (75), a JavaScript and jQuery-
based library that allows form generation from JSON Schema and conversion of
form output into JSON. Customization involved translating the schemas for API
and services in JSON-LD to JSON Schema, and from the JSON output to JSON-
LD again. It is hoped that a library to generate forms based on JSON-LD and then
outputs JSON-LD will be available in the future to eliminate the need for such
customization. In essence, smartAPI aims to become for biomedical APIs and
services what CEDAR aims to become for biomedical experimental datasets.

67
Figure 4.1 Interactive path in smartAPI connecting Web services from an
input parameter (variant_id) to an output parameter (PFAM)
Taking this notion even further is the opportunity to convert completely to a
SHACL-based system, in which metadata templates will be encoded in SHACL
(acting as both the basis for dynamic form generation and data validation), and the
data will be output as RDF, which can then be converted to various formats such
as N-Triples or JSON-LD. A system that utilizes the minimum number of
technologies necessary to achieve its goals is simply more efficient to create and
use, and also reduces the potential for inconsistencies, duplications, and errors.

68
Figure 4.2 SmartAPI Web-based metadata template form

69
Finally, a centerpiece of CEDAR is that machine learning would provide ways to
learn patterns in metadata (both retrospectively and in real-time) in order to lay
out forms and provide autocompletion in a way that makes annotation as seamless
and efficient as possible. The data sources to learn from and the algorithms that
would rank the list of suggested terms for display to the researcher are some of the
issues under consideration. This effort is currently being undertaken by Prof
Olivier Gevaert and Dr Mary Panahiazar at Stanford University.
4.5 RDF in healthcare
Despite the focus on the use of RDF technologies in biomedical science thus far,
the implications for healthcare are no less significant. The advent of precision
medicine, which aims to combine genetic and molecular data for the provision of
patient care, means that a great number of heterogeneous data types and sources
will need to be aggregated, analyzed, and visualized. Clinical data coded with
concepts from the International Classification of Diseases (ICD) and the
Systematized Nomenclature of Medicine Clinical Terms (SNOMED CT) will
need to be reconciled with terms from Gene Ontology (GO) and other biomedical
ontologies. The unique identification characteristic of RDF that gives it the ability
to connect data (as Linked Data) will enable such a process, as long as a
mechanism exists to assign unique IRIs to each term or concept. In turn,
healthcare data that is encoded as RDF has the added advantage of being
machine-interpretable and thus being able to be reasoned automatically by
software powered by ontologies or decision/inference rules. This can facilitate
computerized decision support (CDS) ranging from the basic (e.g. alerts, checks
for drug-drug interactions) to the advanced (e.g. computer-aided diagnosis,
protocol-driven care).
As healthcare data can vary from being highly-structured (e.g. proformas, clinical
trial data) to being wholly-unstructured (e.g. narrative free text), it can certainly

70
be a challenge to convert existing data formats or encode new data into a
structured data model such as RDF, and constraints for such data into templates
based on an RDF constraint language. Certainly, it should be recognized that it is
not necessarily straightforward to convert complex sentences from clinical notes
to RDF, nor is it always appropriate to encode healthcare data in RDF (e.g.
waveforms, images, videos). Natural language processing (NLP) techniques may
useful in extracting meaning from free text, whilst controlled natural languages
(CNLs) may help with creating RDF in the background as natural-sounding
sentences are being written. An alternative approach to NLP taken by Prof Nigam
Shah at Stanford University is to use the BioPortal Annotator to extract clinical
and biomedical terms from free text in EHRs.
Taking this further, the structure and constraints for such RDF data can be
delineated through a RDF constraint language. Harold Solbrig from the Mayo
Clinic has prototyped a sample ShEx template for nephrology data (76) which can
provide a hint of what is to come:
<observation> {
a rdf:Resource ?,
core:hasObservationTime xsd:dateTime ,
}
<renalFunctionObservation> & <observation> {}
<gfrFlowRateObs> & <renalFunctionObservation> {
RenalX:gfrFlowRate { data:value xsd:decimal , data:units
(ucum:mL-per-minute) }
}
<serumCreatinineObs> & <renalFunctionObservation> {
RenalX:serumCreatinine { data:value xsd:decimal , data:units
(ucum:mg_dL) }
}
<urineVolume24hourObs> & <renalFunctionObservation> {
RenalX:urineVolume24hour { data:value xsd:decimal ,
data:units (ucum:L) }
}
The use of RDF for healthcare data provides an elegant solution to syntactic
interoperability by avoiding difficult-to-navigate tree structures (e.g. XML) and

71
complicated fixed-length formats (e.g. HL7 v2). And unlike HL7, Arden syntax,
and other health data formats, RDF also enables semantic interoperability, since
concepts as well as their relationships can be identified unambiguously through
the RDF graph structure and the option of resolving IRIs through Web services
for further interpretation of semantics.
RDF is also flexible enough to accommodate any vocabulary, terminology, or
ontology as long as it has an equivalent representation in RDF. This means that
RDF need not replace existing standards, but provide a common substrate for
healthcare data. The movement to drive RDF adoption in healthcare is outlined in
the Yosemite Manifesto (77) and spearheaded by the Yosemite Project (78). Even
Fast Health Interoperability Resources (FHIR), the latest standard from HL7 that
has recently been gaining momentum, has the term “resources” in its name. It may
therefore not be much of a stretch to imagine that healthcare will eventually adopt
RDF in the future.
4.6 Non-technical considerations
Up to this point, this thesis has dealt primarily with technologies and their ability
to fulfil technical requirements. Yet technologies do not exist in a vacuum, and
are ultimately created to solve real-world needs, with many social elements to
consider (in the context of socio-technical systems). Awareness of the problem of
unchecked information growth and un-annotated data is key, followed by the right
incentives for researchers and institutions to act to address it. For instance, NIAID
researchers are mandated to submit their datasets to ImmPort as part of their grant
conditions. Prominent scientific journals have also taken up the cause by
encouraging authors to submit their experimental data to public repositories in
line with the movement of “open science”. The other side of the equation
necessitates scientists and informaticians to come to a consensus about essential
metadata for different purposes, such as the “minimum information” standards

72
hosted on BioSharing.org. Last but not least, technical organizations such as the
W3C, as well as individual stakeholders, can agree on computable representations
of templates (e.g. W3C HCLS Dataset Description) and come up with standards
(e.g. RDF, ShEx, SHACL) that enable their validation.

73
5. Conclusion
Unrelenting progress in the biological, medical, and health sciences has had the
effect of accumulating volumes and volumes of data that we increasingly struggle
to locate, aggregate, and understand. By providing meaningful context for
interpretation, metadata can be leveraged as a way to mitigate this challenge. This
thesis demonstrates that RDF is a feasible data model for representing machine-
interpretable metadata, and presents a systematic analysis of the major RDF
constraint languages as a way of defining and validating RDF data, paving the
way for the upcoming W3C standard, SHACL. It also outlines how a ShEx
representation of the W3C HCLS Dataset Description is able to validate sample
DrugBank data from Bio2RDF. As the natural progression of these efforts, a web-
based metadata template is prototyped as a proof-of-concept for ongoing metadata
initiatives such as W3C HCLS Dataset Description, CEDAR, and smartAPI. It is
envisioned that through these technologies, an ecosystem of Big Metadata can be
realized, accompanying and complementing Big Data in an effort to maximize its
potential. Finally, it must be realized that technology is only one piece of the
puzzle, and must be supported by social considerations such as community
consensus, standards development, and appropriate incentivization. With all these
pieces in place, we can help ensure that the information revolution is more of a
benefit than a burden to biomedical science and healthcare.

74
References
1. SINTEF. Big Data, for better or worse: 90% of world’s data generated over
last two years. [Internet]. 2013. Available from:
www.sciencedaily.com/releases/2013/05/130522085217.htm
2. National Library of Medicine. Fact Sheet MEDLINE® [Internet]. 2015.
Available from: http://www.nlm.nih.gov/pubs/factsheets/medline.html
3. Coiera E. Information Economics and the Internet. J Am Med Inform Assoc.
2000;7(3):215–21.
4. Warden R. The Internet and science communication: blurring the boundaries.
Ecancermedicalscience. 2010 Dec 14;4(203).
5. Strasser C, Kunze J, Abrams S, Cruse P. DataUp: A tool to help researchers
describe and share tabular data. F1000Res. 2014;3:6.
6. Jonquet C, LePendu P, Falconer S, Coulet A, Noy NF, Musen MA, et al.
NCBO Resource Index: Ontology-based search and mining of biomedical
resources. Web Semantics: Science, Services and Agents on the World Wide
Web. 2011 Sep;9(3):316–24.
7. Sansone S-A, Rocca-Serra P, Field D, Maguire E, Taylor C, Hofmann O, et
al. Toward interoperable bioscience data. Nature Genetics. 2012 Jan
27;44(2):121–6.
8. National Information Standards Organization. Understanding Metadata.
Bethesda, MD: NISO Press; 2004. p. 2014–06.
9. Gray A, Baran J, Marshall MS, Dumontier M. Dataset Descriptions: HCLS
Community Profile [Internet]. 2014. Available from:
http://htmlpreview.github.io/?https://github.com/joejimbo/HCLSDatasetDescr
iptions/blob/master/Overview.html
10. Bittner T, Donnelly M, Winter S. Ontology and semantic interoperability.
Large-scale 3D data integration. London: CRC Press; 2005.
11. Zhu Y, Wang W, Zhou D. Conceptual framework of composable simulation
using multilevel model specification for complex systems. Asia Simulation
Conference - 7th International Conference on System Simulation and
Scientific Computing (ICSC 2008). 2008.

75
12. Lee J, Chae H, Kim C-H, Kim K. Design of product ontology architecture for
collaborative enterprises. Expert Systems with Applications. 2009
Mar;36(2):2300–9.
13. ISA-Tools. Specification | ISA Tools: ISA-Tab Overview [Internet]. 2014
[cited 2015 Apr 20]. Available from: http://www.isa-
tools.org/format/specification/
14. González-Beltrán A, Maguire E, Sansone S-A, Rocca-Serra P. linkedISA:
semantic representation of ISA-Tab experimental metadata. BMC
Bioinformatics. 2014;15 Suppl 14:S4.
15. ImmPort, Northrop Grumman. ImmPort Data Submission User Guide
[Internet]. NIAID; 2014 [cited 2015 Apr 20]. Available from: http://immport-
submission.niaid.nih.gov/downloads/documentation/ImmPort_Data_Submissi
on_Guide.pdf
16. BioSharing. BioSharing - About [Internet]. Available from:
http://www.biosharing.org/pages/about/
17. ISA-Tools, MIBBI Team. BioSharing: MIBBI [Internet]. 2015 [cited 2015
Apr 20]. Available from:
https://www.biosharing.org/standards/?selected_facets=isMIBBI:true
18. Berners-Lee T, Hendler J, Lassila O. The Semantic Web. Scientific American
[Internet]. 2001 May; Available from:
http://www.scientificamerican.com/article/the-semantic-web/
19. Miarka R, Žáč M. Knowledge patterns in RDF graph language for English
sentences. 2012 Federated Conference on Computer Science and Information
Systems (FedCSIS) [Internet]. 2012. p. 109–15. Available from:
http://ieeexplore.ieee.org/xpls/icp.jsp?arnumber=6354372
20. Ryman A. Resource Shape 2.0 [Internet]. 2014. Available from:
http://www.w3.org/Submission/shapes/
21. Suchanek F, Weikum G. Knowledge harvesting from text and Web sources.
2013 IEEE 29th International Conference on Data Engineering (ICDE). 2013.
p. 1250–3.
22. Google. Knowledge - Inside Search - Google [Internet]. [cited 2015 Apr 20].
Available from:
http://www.google.com/insidesearch/features/search/knowledge.html
23. Brazma A, Hingamp P, Quackenbush J, Sherlock G. Minimum information
about a microarray experiment (MIAME)-toward standards for microarray
data. Nat Genet. 2001 Dec;29(4):365–71.

76
24. Janetzi S, Britten C, Kalos M, Levitsky H. “MIATA”-minimal information
about T cell assays. Immunity. 2009 Oct 16;31(4):527–8.
25. Gaudet P, Bairoch A, Field D, Sansone S-A. Towards BioDBcore: a
community-defined information specification for biological databases. Nucl
Acids Res. 2011;39(suppl 1):D7–10.
26. Galperin M, Rigden D, Fernández-Suárez X. The 2015 Nucleic Acids
Research Database Issue and molecular biology database collection. Nucleic
Acids Res. 2015 Jan;43(Database issue):D1–5.
27. Nucleic Acids Research. 2015 NAR Database Summary Paper Alphabetic
List [Internet]. 2014 [cited 2015 Apr 25]. Available from:
http://www.oxfordjournals.org/our_journals/nar/database/a/
28. Callahan A, Cruz-Toledo J, Dumontier M. Ontology-Based Querying with
Bio2RDF’s Linked Open Data. J Biomed Semantics. 2013 Apr 15;4(Suppl
1):S1.
29. Yoo JM, Myaeng SM, Jin Y, Lee HM. Universal information retrieval system
in semantic Web environment. Proceedings of 2005 IEEE International
Conference on Natural Language Processing and Knowledge Engineering,
2005 IEEE NLP-KE ’05. 2005. p. 348–53.
30. Brickley D, Guha RV. RDF Schema 1.1 [Internet]. 2014 [cited 2015 Apr 22].
Available from: http://www.w3.org/TR/rdf-schema/
31. Tao J. Adding Integrity Constraints to the Semantic Web for Instance Data
Evaluation. Proceedings of the 9th International Semantic Web Conference
(ISWC 2010) [Internet]. 2010 Nov 1; Available from: http://www.cs.rpi.edu/
taoj2/2010/iswc2010dc.pdf
32. Ryman A, Le Hors A, Speicher S. OSLC Resource Shape: A language for
defining constraints on Linked Data. LDOW2013 [Internet]. Rio de Janeiro,
Brazil; 2013. Available from:
http://events.linkeddata.org/ldow2013/papers/ldow2013-paper-02.pdf
33. NCBO. BioPortal API Documentation [Internet]. [cited 2015 Apr 22].
Available from: http://data.bioontology.org/documentation
34. Prud’hommeaux E, Archer P, Hawke S. RDF Data Shapes Working Group
Charter [Internet]. 2014 [cited 2015 Apr 27]. Available from:
http://www.w3.org/2014/data-shapes/charter
35. W3C RDF Shapes Working Group. Existing Systems [Internet]. 2015 [cited
2015 Apr 30]. Available from: http://www.w3.org/2014/data-
shapes/wiki/Existing_Systems

77
36. Prud’hommeaux E, Knublauch H. SHACL (Shapes Constraint Language)
Primer [Internet]. [cited 2015 May 11]. Available from:
http://w3c.github.io/data-shapes/data-shapes-primer/
37. Hellmann S. RDFUnit: an RDF Unit-Testing suite [Internet]. 2014 [cited 2015
May 11]. Available from: http://aksw.org/Projects/RDFUnit.html
38. Prud’hommeaux E. FancyShExDemo [Internet]. [cited 2015 May 11].
Available from: http://www.w3.org/2013/ShEx/FancyShExDemo
39. JSON Schema.org. json-schema.org: The home of JSON Schema [Internet].
[cited 2015 May 11]. Available from: http://json-schema.org/
40. RDF Translator [Internet]. [cited 2015 May 11]. Available from: http://rdf-
translator.appspot.com/
41. Verborgh R. RubenVerborgh/N3.js [Internet]. Available from:
https://github.com/RubenVerborgh/N3.js
42. shishimaru/triplestoreJS [Internet]. [cited 2015 May 11]. Available from:
https://github.com/shishimaru/triplestoreJS/
43. Graf G. JustGoscha/allmighty-autocomplete [Internet]. [cited 2015 May 11].
Available from: https://github.com/JustGoscha/allmighty-autocomplete
44. W3C RDF Validation Workshop. Shape Expressions Definition [Internet].
2014. Available from: http://www.w3.org/2013/ShEx/Definition.html
45. Staworko S, Boneva I, Labra Gayo J, Hym S, Prud’hommeaux E, Solbrig H.
Complexity and Expressiveness of ShEx for RDF. Leibniz International
Proceedings in Informatics [Internet]. Germany: Dagstuhl Publishing; 2014.
Available from: http://www.grappa.univ-lille3.fr/~staworko/papers/staworko-
icdt15a.pdf
46. Labra Gayo J, Prud’hommeaux E, Staworko S, Solbrig H. Towards an RDF
validation language based on Regular Expression derivatives [Internet].
Available from: http://labra.github.io/ShExcala/papers/LWDM2015.pdf
47. Prud’hommeaux E, Labra Gayo J, Solbrig H. Shape Expressions: An RDF
validation and transformation language. 10th International Conference on
Semantic Systems. Leipzig, Germany; 2014.
48. Labra Gayo J, Prud’hommeaux E, Solbrig H, Álvarez Rodríguez J. Validating
and Describing Linked Data Portals using RDF Shape Expressions. LDQ
2014 (1st Workshop on Linked Data Quality). Leipzig, Germany; 2014.

78
49. W3C. Shape Expressions Primer [Internet]. 2013 [cited 2015 May 1].
Available from: http://www.w3.org/2013/ShEx/Primer
50. W3C. Shape Expressions Evaluation Logic [Internet]. 2014. Available from:
http://www.w3.org/2013/ShEx/EvaluationLogic.html
51. W3C. ShEx [Internet]. 2014. Available from:
http://www.w3.org/2001/sw/wiki/ShEx
52. DCMI. DCMI Metadata Terms [Internet]. 2015. Available from:
http://dublincore.org/documents/2012/06/14/dcmi-terms/
53. Knublauch H, Hendler JA, Idehen K. SPIN - Overview and Motivation
[Internet]. 2011. Available from:
http://www.w3.org/Submission/2011/SUBM-spin-overview-20110222/
54. Knublauch H, Hendler J, AIdehen K. SPIN - Modeling Vocabulary [Internet].
2011. Available from: http://www.w3.org/Submission/2011/SUBM-spin-
modeling-20110222/
55. Clark K, Sirin E. On RDF Validation, Stardog ICV, and Assorted Remarks
[Internet]. 2013. Available from: http://www.w3.org/2012/12/rdf-
val/submissions/Stardog
56. Horrocks I, Patel-Schneider P, Boley H, Tabet S, Grosof B, Dean M. SWRL:
A Semantic Web Rule Language Combining OWL and RuleML [Internet].
2004 [cited 2015 May 5]. Available from:
http://www.w3.org/Submission/SWRL/
57. Bao J, Kendall E, McGuinness D, Patel-Schneider P. OWL 2 Web Ontology
Language Quick Reference Guide (Second Edition) [Internet]. 2012.
Available from: http://www.w3.org/TR/owl-quick-reference/
58. Pérez-Urbina H, Sirin E, Clark K. Validating RDF with OWL Integrity
Constraints [Internet]. 2012 [cited 2015 May 5]. Available from:
http://docs.stardog.com/icv/icv-specification.html
59. OSLC. Open Services for Lifecycle Collaboration [Internet]. Available from:
http://open-services.net/
60. Solbrig H. Definition of and Requirements for RDF Validation [Internet].
2013. Available from:
http://www.w3.org/2001/sw/wiki/images/d/da/RDFVal_Solbrig.pdf
61. Prud’hommeaux E. Shapes Language Expressivity Questionnaire [Internet].
2015 [cited 2015 May 5]. Available from:
http://www.w3.org/2015/ShExpressivity

79
62. W3C. Requirements - RDF Data Shapes Working Group [Internet]. 2015.
Available from: http://www.w3.org/2014/data-shapes/wiki/Requirements
63. Peterson D, Gao S, Malhotra A, Sperberg-McQueen C, Thompson HS. W3C
XML Schema Definition Language (XSD) 1.1 Part 2: Datatypes [Internet].
2012. Available from: http://www.w3.org/TR/xmlschema11-2/
64. Wang Q, Li M, Meng N, Liu Y, Mei H. A Pattern-Based Constraint
Description Approach for Web Services. Seventh International Conference on
Quality Software, 2007 QSIC ’07. 2007. p. 60–9.
65. Cyganiak R, Wod D, Lanthaler M. RDF 1.1 Concepts and Abstract Syntax
[Internet]. 2014. Available from: http://www.w3.org/TR/rdf11-concepts/
66. Bradner S. Key words for use in RFCs to Indicate Requirement Levels
[Internet]. 1997 [cited 2015 Apr 27]. Available from:
https://www.ietf.org/rfc/rfc2119.txt
67. Liu Z, Ranganathan A, Riabov A. ModelingWeb Services using Semantic
Graph Transformations to aid Automatic Composition. IEEE International
Conference on Web Services, 2007 ICWS 2007. 2007. p. 78–85.
68. Chen H, Wu Z, Wang H, Mao Y. RDF/RDFS-based Relational Database
Integration. Proceedings of the 22nd International Conference on Data
Engineering, 2006 ICDE ’06. 2006. p. 94–94.
69. Fan X, Zhang P, Zhao J. Transformation of relational database schema to
Semantics Web model. 2010 Second International Conference on
Communication Systems, Networks and Applications (ICCSNA). Hong
Kong: IEEE; 2010. p. 379–84.
70. Fang M, Li W, Sunderraman R. Maintaining integrity constraints in relational
to OWL transformations. 2010 Fifth International Conference on Digital
Information Management (ICDIM). 2010. p. 260–5.
71. Fang M, Li W, Sunderraman R. Maintaining Integrity Constraints among
Distributed Ontologies. 2011 International Conference on Complex,
Intelligent and Software Intensive Systems (CISIS). 2011. p. 184–91.
72. Bouillet E, Feblowitz M, Liu Z, Ranganathan A, Riabov A. Semantic Models
for Ad Hoc Interactions in Mobile, Ubiquitous Environments. 2008 IEEE
International Conference on Semantic Computing. Santa Monica, CA; 2008.
p. 589–96.
73. Su A. 1st BD2K 3rd Network of BioThings Hackathon [Internet]. 2015 [cited
2015 May 13]. Available from: https://github.com/Network-of-
BioThings/nob-hq/wiki/1st-BD2K-3rd-Network-of-BioThings-Hackathon

80
74. Wu C. Smart API [Internet]. 2015 [cited 2015 May 13]. Available from:
http://smart-api.info/
75. Gitana Software. Alpaca - Easy Forms for jQuery [Internet]. 2015 [cited 2015
May 8]. Available from: http://www.alpacajs.org/
76. Solbrig H. Renal Transplantation ShEx [Internet]. [cited 2015 Jun 3].
Available from: http://www.w3.org/2013/12/FDA-TA/subject.shex
77. Booth D. Yosemite Manifesto on RDF as a Universal Healthcare Exchange
Language [Internet]. [cited 2015 Jun 3]. Available from:
http://yosemitemanifesto.org/
78. Booth D. The Yosemite Project: A Roadmap for Healthcare Information
Interoperability [Internet]. [cited 2015 Jun 3]. Available from:
http://yosemiteproject.org/

81
Appendix A
ShEx Implementation of W3C HCLS Dataset Description
PREFIX cito: <http://purl.org/spar/cito/>
PREFIX dcat: <http://www.w3.org/ns/dcat#>
PREFIX dctypes: <http://purl.org/dc/dcmitype/>
PREFIX dct: <http://purl.org/dc/terms/>
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
PREFIX freq: <http://purl.org/cld/freq/>
PREFIX idot: <http://identifiers.org/idot/>
PREFIX lexvo: <http://lexvo.org/ontology#>
PREFIX pav: <http://purl.org/pav/>
PREFIX prov: <http://www.w3.org/ns/prov#>
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX schemaorg: <http://schema.org/>
PREFIX sd: <http://www.w3.org/ns/sparql-service-description#>
PREFIX sio: <http://semanticscience.org/resource/>
PREFIX void: <http://rdfs.org/ns/void#>
PREFIX void-ext: <http://ldf.fi/void-ext#>
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
<SummaryLevel> {
#CORE METADATA
rdf:type dctypes:Dataset, #1.1
!rdf:type void:Dataset, #1.2
!rdf:type dcat:Distribution, #1.2
dct:title xsd:string, #1.3
dct:alternative xsd:string*, #1.4 - MAY
dct:description xsd:string, #1.5
!dct:created ., #1.6
!pav:createdOn ., #1.7
!pav:authoredOn ., #1.7
!pav:curatedOn ., #1.7
!dct:creator ., #1.8
!dct:contributor ., #1.9
!pav:createdBy ., #1.9
!pav:authoredBy ., #1.9
!pav:curatedBy ., #1.9
dct:publisher IRI, #1.10
!dct:issued ., #1.11
foaf:page IRI, #1.12 - SHOULD
!foaf:homepage ., #1.12
schemaorg:logo IRI, #1.13 - SHOULD
!foaf:logo ., #1.13
dcat:keyword xsd:string*, #1.14- MAY
dct:license IRI?, #1.15 - MAY
dct:rights xsd:string?, #1.16 - MAY
!dct:language ., #1.17
dct:references IRI*, #1.18 - MAY
dcat:theme IRI*, #1.19 - MAY
!void:vocabulary IRI, #1.20
!dct:conformsTo IRI, #1.21
cito:citesAsAuthority IRI*, #1.22 - MAY
rdfs:seeAlso IRI*, #1.23 - MAY
dct:hasPart IRI*, #1.24 - MAY

82
#IDENTIFIERS
idot:preferredPrefix xsd:string?, #2.1 - MAY
idot:alternatePrefix xsd:string?, #2.2 - MAY
!idot:identifierPattern ., #2.3
!void:uriRegexPattern ., #2.4
!idot:accessPattern ., #2.5
!idot:exampleIdentifier ., #2.6
!void:exampleResource ., #2.7
#PROVENANCE AND CHANGE
!pav:version ., #3.1
!dct:isVersionOf ., #3.2
!pav:previousVersion ., #3.3
pav:hasCurrentVersion IRI?, #3.4 - MAY
!dct:source ., #3.5
!pav:retrievedFrom ., #3.5
!prov:wasDerivedFrom ., #3.5
!sio:has-data-item ., #3.6
!pav:createdWith ., #3.7
dct:accrualPeriodicity IRI?, #3.8 - SHOULD
#AVAILABILITY/DISTRIBUTIONS
!dcat:distribution ., #4.1
!dct:format ., #4.2
dcat:accessURL IRI*, #4.3 - MAY
!dcat:downloadURL IRI, #4.4
!dcat:byteSize ., #4.5
!void:dataDump IRI, #4.6
void:sparqlEndpoint IRI?, #4.7 - SHOULD
!dcat:landingPage ., #4.8
!void:subset ., #4.9
#STATISTICS
!void:triples ., #5.1
!void:entities ., #5.2
!void:distinctSubjects ., #5.3
!void:properties ., #5.4
!void:distinctObjects ., #5.5
!void:classPartition ., #5.6, 5.7, 5.8
!void:propertyPartition . #5.9, 5.10, 5.11, 5.12, 5.13, 5.14
}
<VersionLevel> {
#CORE METADATA
rdf:type dctypes:Dataset, #1.1
!rdf:type void:Dataset, #1.2
!rdf:type dcat:Distribution, #1.2
dct:title xsd:string, #1.3
dct:alternative xsd:string*, #1.4 - MAY
dct:description xsd:string, #1.5
(dct:created xsd:dateTime | dct:created xsd:date | dct:created xsd:gYearMonth
| dct:created xsd:gYear), #1.6 - SHOULD
(dct:creator IRI | dct:creator @<AuthorShape>), #1.8
(pav:createdOn xsd:date?,
pav:createdOn xsd:dateTime?,
pav:createdOn xsd:gYearMonth?,
pav:createdOn xsd:gYear?,

83
pav:createdBy IRI?)*, #1.7 and 1.9 - MAY
(pav:authoredOn xsd:date?,
pav:authoredOn xsd:dateTime?,
pav:authoredOn xsd:gYearMonth?,
pav:authoredOn xsd:gYear?,
pav:authoredBy IRI?)*, #1.7 and 1.9 - MAY
(pav:curatedOn xsd:date?,
pav:curatedOn xsd:dateTime?,
pav:curatedOn xsd:gYearMonth?,
pav:curatedOn xsd:gYear?,
pav:curatedBy IRI?)*, #1.7 and 1.9 - MAY
dct:publisher IRI, #1.10
dct:issued IRI, #1.11 - SHOULD
foaf:page IRI, #1.12 - SHOULD
!foaf:homepage ., #1.12
schemaorg:logo IRI, #1.13 - SHOULD
!foaf:logo ., #1.13
dcat:keyword xsd:string*, #1.14 - MAY
(dct:license IRI+ | dct:license @<UnknownLicenseShape>), #1.15 - SHOULD
dct:rights rdf:langString?, #1.16 - MAY
dct:language IRI, #1.17 - SHOULD - IRI http://lexvo.org/id/iso639-3/{tag}
dct:references IRI*, #1.18 - MAY
dcat:theme IRI*, #1.19 - MAY - IRI type skos:Concept
!void:vocabulary ., #1.20
dct:conformsTo IRI*, #1.21 - MAY
cito:citesAsAuthority IRI*, #1.22 - MAY
rdfs:seeAlso IRI*, #1.23 - MAY
dct:hasPart IRI*, #1.24 - MAY
#IDENTIFIERS
idot:preferredPrefix xsd:string?, #2.1 - MAY
idot:alternatePrefix xsd:string?, #2.2 - MAY
!idot:identifierPattern ., #2.3
!void:uriRegexPattern ., #2.4
!idot:accessPattern ., #2.5
!idot:exampleIdentifier ., #2.6
!void:exampleResource ., #2.7
#PROVENANCE AND CHANGE
pav:version xsd:string, #3.1
dct:isVersionOf IRI, #3.2
pav:previousVersion IRI, #3.3 - SHOULD
!pav:hasCurrentVersion IRI, #3.4
(dct:source IRI | pav:retrievedFrom IRI | pav:wasDerivedFrom IRI)+, #3.5 -
SHOULD
!sio:has-data-item ., #3.6
pav:createdWith IRI, #3.7 - SHOULD
!dct:accrualPeriodicity ., #3.8
#AVAILABILITY/DISTRIBUTIONS
dcat:distribution IRI, #4.1 - SHOULD
!dct:format ., #4.2
dcat:accessURL IRI*, #4.3 - MAY
!dcat:downloadURL ., #4.4
!dcat:byteSize ., #4.5
!void:dataDump ., #4.6
!void:sparqlEndpoint ., #4.7 - SHOULD NOT
dcat:landingPage IRI?, #4.8 - MAY

84
!void:subset ., #4.9
#STATISTICS
!void:triples ., #5.1
!void:entities ., #5.2
!void:distinctSubjects ., #5.3
!void:properties ., #5.4
!void:distinctObjects ., #5.5
!void:classPartition ., #5.6 - #5.9
!void:propertPartition . #5.10 - #5.14
} #end of <VersionLevel>
<DistributionLevel> {
#CORE METADATA
rdf:type dctypes:Dataset, #1.1 - SHOULD
rdf:type void:Dataset, #1.2 - MUST
rdf:type dcat:Distribution?, #1.2 - only for RDF datasets
dct:title xsd:string, #1.3
dct:alternative xsd:string*, #1.4 - MAY
dct:description xsd:string, #1.5
(dct:created xsd:dateTime | dct:created xsd:date | dct:created xsd:gYearMonth
| dct:created xsd:gYear), #1.6 - SHOULD
(dct:creator IRI | dct:creator @<AuthorShape>), #1.8
(pav:createdOn xsd:date?,
pav:createdOn xsd:dateTime?,
pav:createdOn xsd:gYearMonth?,
pav:createdOn xsd:gYear?,
pav:createdBy IRI?)*, #1.7 and 1.9 - MAY
(pav:authoredOn xsd:date?,
pav:authoredOn xsd:dateTime?,
pav:authoredOn xsd:gYearMonth?,
pav:authoredOn xsd:gYear?,
pav:authoredBy IRI?)*, #1.7 and 1.9 - MAY
(pav:curatedOn xsd:date?,
pav:curatedOn xsd:dateTime?,
pav:curatedOn xsd:gYearMonth?,
pav:curatedOn xsd:gYear?,
pav:curatedBy IRI?)*, #1.7 and 1.9 - MAY
dct:publisher IRI, #1.10
dct:issued IRI, #1.11 - SHOULD
foaf:page IRI, #1.12 - SHOULD
!foaf:homepage ., #1.12
schemaorg:logo IRI, #1.13 - SHOULD
!foaf:logo ., #1.13
dcat:keyword xsd:string*, #1.14 - MAY
(dct:license IRI+ | dct:license @<UnknownLicenseShape>), #1.15
dct:rights rdf:langString?, #1.16 - MAY
dct:language IRI, #1.17 - SHOULD - IRI http://lexvo.org/id/iso639-3/{tag}
dct:references IRI*, #1.18 - MAY
dcat:theme IRI*, #1.19 - MAY - IRI type skos:Concept
void:vocabulary IRI, #1.20 - SHOULD
dct:conformsTo IRI, #1.21 - SHOULD
cito:citesAsAuthority IRI*, #1.22 - MAY

85
rdfs:seeAlso IRI*, #1.23 - MAY
!dct:hasPart ., #1.24
#IDENTIFIERS
idot:preferredPrefix xsd:string?, #2.1 - MAY
idot:alternatePrefix xsd:string?, #2.2 - MAY
idot:identifierPattern xsd:string?, #2.3 - MAY
void:uriRegexPattern xsd:string?, #2.4 - MAY
idot:accessPattern @<AccessIdentifierPatternShape>*, #2.5 - MAY
idot:exampleIdentifier xsd:string, #2.6 - SHOULD
void:exampleResource IRI, #2.7 - SHOULD
#PROVENANCE AND CHANGE
pav:version xsd:string, #3.1 - SHOULD
!dct:isVersionOf ., #3.2
pav:previousVersion IRI, #3.3 - SHOULD
!pav:hasCurrentVersion IRI, #3.4
(dct:source IRI | pav:retrievedFrom IRI | pav:wasDerivedFrom IRI)+, #3.5 -
SHOULD
sio:has-data-item IRI?, #3.6 - MAY
pav:createdWith IRI, #3.7 - SHOULD
!dct:accrualPeriodicity ., #3.8
#AVAILABILITY/DISTRIBUTIONS
!dcat:distribution ., #4.1
(dct:format IRI | dct:format xsd:string)+, #4.2
dcat:accessURL IRI*, #4.3 - MAY
dcat:downloadURL IRI+, #4.4 - SHOULD
dcat:byteSize xsd:decimal, #4.5 - SHOULD
void:dataDump IRI+, #4.6 - SHOULD
!void:sparqlEndpoint ., #4.7 - SHOULD NOT
dcat:landingPage IRI?, #4.8 - MAY
void:subset IRI, #4.9 - SHOULD
#STATISTICS (CORE)
void:triples xsd:integer, #5.1 - SHOULD #number of triples
void:entities xsd:integer, #5.2 - SHOULD #number of unique, typed entities
void:distinctSubjects xsd:integer, #5.3 - SHOULD #number of unique subjects
void:properties xsd:integer, #5.4 - SHOULD #number of unique properties
void:distinctObjects xsd:integer, #5.5 - SHOULD #number of unique objects
void:classPartition @<UniqueClassShape>, #5.6 - SHOULD #number of unique
classes
void:classPartition @<UniqueLiteralShape>, #5.7 - SHOULD #number of unique
literals
void:classPartition @<GraphShape> #5.8 - SHOULD
#STATISTICS (ENHANCED)
# not implemented
} #end of <DistributionLevel>
###OTHER SHAPES
<AuthorShape> { #1.6 and 1.7
foaf:name xsd:string
}
<PublisherShape> { #1.10

86
foaf:page IRI
}
<UnknownLicenseShape> { #1.14
rdfs:comment xsd:string #should be "License unknown"
}
<AccessIdentifierPatternShape> { #2.5
idot:primarySource xsd:boolean,
dct:format xsd:string,
dct:publisher IRI,
idot:accessIdentifierPattern xsd:string,
a idot:AccessPattern
}
<LinksetShape> { #4.8
a void:Linkset,
void:subjectsTarget IRI,
void:objectsTarget IRI,
void:linkPredicate IRI, #skos: predicate
void:triples xsd:integer
}
<UniqueClassShape> { #referred by 5.6
void:class rdfs:Class,
void:distinctSubjects xsd:integer
}
<UniqueLiteralShape> { #referred by 5.7
void:class rdfs:Literal,
void:distinctSubjects xsd:integer
}
<GraphShape> { #referred by 5.8
void:class sd:Graph,
void:distinctSubjects xsd:integer
}

87
Appendix B
Sample DrugBank dataset descriptions from Bio2RDF
**** Distribution (Drugbank XML) ****
<http://bio2rdf.org/drugbank_resource:drugbank.xml.2015-03-28.zip>
<http://www.w3.org/2000/01/rdf-schema#label> "DrugBank [2015-03-
27][drugbank.xml.zip]" .
<http://bio2rdf.org/drugbank_resource:drugbank.xml.2015-03-28.zip>
<http://purl.org/dc/terms/title> "DrugBank [2015-03-27][drugbank.xml.zip]" .
<http://bio2rdf.org/drugbank_resource:drugbank.xml.2015-03-28.zip>
<http://www.w3.org/1999/02/22-rdf-syntax-ns#type>
<http://www.w3.org/ns/dcat#Distribution> .
<http://bio2rdf.org/drugbank_resource:drugbank.xml.2015-03-28.zip>
<http://purl.org/dc/terms/description> "DrugBank [2015-03-27][drugbank.xml.zip]
retrieved by Bio2RDF on 2015-03-27T00:50:18-04:00" .
<http://bio2rdf.org/drugbank_resource:drugbank.xml.2015-03-28.zip>
<http://www.w3.org/ns/dcat#downloadURL>
<http://www.drugbank.ca/system/downloads/current/drugbank.xml.zip> .
<http://bio2rdf.org/drugbank_resource:drugbank.xml.2015-03-28.zip>
<http://purl.org/pav/retrievedOn> "2015-03-27T00:50:18-
04:00"^^<http://www.w3.org/2001/XMLSchema#dateTime> .
<http://bio2rdf.org/drugbank_resource:drugbank.xml.2015-03-28.zip>
<http://www.w3.org/ns/dcat#byteSize>
"45240040"^^<http://www.w3.org/2001/XMLSchema#decimal> .
<http://bio2rdf.org/drugbank_resource:drugbank.xml.2015-03-28.zip>
<http://purl.org/dc/terms/creator>
<http://bio2rdf.org/lsr_resource:20508d8bc2a1dcdf713c2b9c48a4d99a> .
<http://bio2rdf.org/drugbank_resource:drugbank.xml.2015-03-28.zip>
<http://purl.org/dc/terms/publisher>
<http://bio2rdf.org/lsr_resource:20508d8bc2a1dcdf713c2b9c48a4d99a> .
<http://bio2rdf.org/drugbank_resource:drugbank.xml.2015-03-28.zip>
<http://xmlns.com/foaf/0.1/page> <http://www.drugbank.ca/> .
<http://bio2rdf.org/drugbank_resource:drugbank.xml.2015-03-28.zip>
<http://purl.org/pav/version> "2015-03-27" .
<http://bio2rdf.org/drugbank_resource:drugbank.xml.2015-03-28.zip>
<http://purl.org/dc/terms/format> "application/xml" .
<http://bio2rdf.org/drugbank_resource:drugbank.xml.2015-03-28.zip>
<http://purl.org/dc/terms/format> "application/zip" .
<http://bio2rdf.org/drugbank_resource:drugbank.xml.2015-03-28.zip>
<http://purl.org/dc/terms/license> <http://www.drugbank.ca/about> .
**** Version 2015-03-27 (Drugbank XML) ****
<http://bio2rdf.org/drugbank_resource:dataset.drugbank.2015-03-28>
<http://www.w3.org/1999/02/22-rdf-syntax-ns#type>
<http://purl.org/dc/terms/Dataset> .
<http://bio2rdf.org/drugbank_resource:dataset.drugbank.2015-03-28>
<http://purl.org/dc/terms/title> "DrugBank [2015-03-27]" .
<http://bio2rdf.org/drugbank_resource:dataset.drugbank.2015-03-28>
<http://purl.org/dc/terms/description> "DrugBank [2015-03-27]" .
<http://bio2rdf.org/drugbank_resource:dataset.drugbank.2015-03-28>
<http://purl.org/pav/version> "2015-03-27" .
<http://bio2rdf.org/drugbank_resource:dataset.drugbank.2015-03-28>
<http://purl.org/dc/terms/creator>
<http://bio2rdf.org/lsr_resource:20508d8bc2a1dcdf713c2b9c48a4d99a> .

88
<http://bio2rdf.org/drugbank_resource:dataset.drugbank.2015-03-28>
<http://purl.org/dc/terms/publisher>
<http://bio2rdf.org/lsr_resource:20508d8bc2a1dcdf713c2b9c48a4d99a> .
<http://bio2rdf.org/drugbank_resource:dataset.drugbank.2015-03-28>
<http://www.w3.org/ns/dcat#distribution>
<http://bio2rdf.org/drugbank_resource:drugbank.xml.2015-03-28.zip> .
<http://bio2rdf.org/drugbank_resource:dataset.drugbank.2015-03-28>
<http://purl.org/dc/terms/isVersionOf> <http://bio2rdf.org/lsr:drugbank> .
**** Distribution (Drugbank Bio2RDF) ****
<http://bio2rdf.org/drugbank_resource:bio2rdf.drugbank.2015-03-28.nq.gz>
<http://www.w3.org/2000/01/rdf-schema#label> "DrugBank by Bio2RDF [2015-03-
28][bio2rdf.drugbank.2015-03-28.nq.gz]" .
<http://bio2rdf.org/drugbank_resource:bio2rdf.drugbank.2015-03-28.nq.gz>
<http://purl.org/dc/terms/title> "DrugBank by Bio2RDF [2015-03-
28][bio2rdf.drugbank.2015-03-28.nq.gz]" .
<http://bio2rdf.org/drugbank_resource:bio2rdf.drugbank.2015-03-28.nq.gz>
<http://www.w3.org/1999/02/22-rdf-syntax-ns#type>
<http://www.w3.org/ns/dcat#Distribution> .
<http://bio2rdf.org/drugbank_resource:bio2rdf.drugbank.2015-03-28.nq.gz>
<http://purl.org/dc/terms/description> "DrugBank by Bio2RDF [2015-03-
28][bio2rdf.drugbank.2015-03-28.nq.gz]" .
<http://bio2rdf.org/drugbank_resource:bio2rdf.drugbank.2015-03-28.nq.gz>
<http://www.w3.org/ns/dcat#downloadURL>
<http://download.bio2rdf.org/data/drugbank/2015-03-28/bio2rdf.drugbank.2015-03-
28.nq.gz> .
<http://bio2rdf.org/drugbank_resource:bio2rdf.drugbank.2015-03-28.nq.gz>
<http://www.w3.org/ns/prov#wasDerivedFrom> <https://github.com/bio2rdf/bio2rdf-
scripts/blob/release3/drugbank/drugbank.php> .
<http://bio2rdf.org/drugbank_resource:bio2rdf.drugbank.2015-03-28.nq.gz>
<http://purl.org/dc/terms/source>
<http://bio2rdf.org/drugbank_resource:drugbank.xml.2015-03-28.zip> .
<http://bio2rdf.org/drugbank_resource:bio2rdf.drugbank.2015-03-28.nq.gz>
<http://purl.org/dc/terms/creator>
<http://bio2rdf.org/lsr_resource:a232e796f6da6823452650bb838429c0> .
<http://bio2rdf.org/drugbank_resource:bio2rdf.drugbank.2015-03-28.nq.gz>
<http://purl.org/dc/terms/publisher>
<http://bio2rdf.org/lsr_resource:a232e796f6da6823452650bb838429c0> .
<http://bio2rdf.org/drugbank_resource:bio2rdf.drugbank.2015-03-28.nq.gz>
<http://xmlns.com/foaf/0.1/page> <http://download.bio2rdf.org/data/drugbank/2015-
03-28/drugbank.html> .
<http://bio2rdf.org/drugbank_resource:bio2rdf.drugbank.2015-03-28.nq.gz>
<http://purl.org/pav/version> "2015-03-28" .
<http://bio2rdf.org/drugbank_resource:bio2rdf.drugbank.2015-03-28.nq.gz>
<http://purl.org/dc/terms/format> "application/gzip" .
<http://bio2rdf.org/drugbank_resource:bio2rdf.drugbank.2015-03-28.nq.gz>
<http://purl.org/dc/terms/format> "application/n-quads" .
<http://bio2rdf.org/drugbank_resource:bio2rdf.drugbank.2015-03-28.nq.gz>
<http://purl.org/dc/terms/license> <http://creativecommons.org/licenses/by/3.0/> .
<http://bio2rdf.org/drugbank_resource:bio2rdf.drugbank.2015-03-28.nq.gz>
<http://purl.org/dc/terms/rights> "use-share-modify" .
<http://bio2rdf.org/drugbank_resource:bio2rdf.drugbank.2015-03-28.nq.gz>
<http://purl.org/dc/terms/rights> "by-attribution" .
<http://bio2rdf.org/drugbank_resource:bio2rdf.drugbank.2015-03-28.nq.gz>
<http://purl.org/dc/terms/rights> "restricted-by-source-license" .
**** Version 2015-03-28 (Drugbank Bio2RDF) ****

89
<http://bio2rdf.org/drugbank_resource:bio2rdf.dataset.drugbank.2015-03-28>
<http://www.w3.org/1999/02/22-rdf-syntax-ns#type>
<http://purl.org/dc/terms/Dataset> .
<http://bio2rdf.org/drugbank_resource:bio2rdf.dataset.drugbank.2015-03-28>
<http://purl.org/dc/terms/title> "DrugBank by Bio2RDF [2015-03-28]" .
<http://bio2rdf.org/drugbank_resource:bio2rdf.dataset.drugbank.2015-03-28>
<http://purl.org/dc/terms/description> "DrugBank by Bio2RDF [2015-03-28]" .
<http://bio2rdf.org/drugbank_resource:bio2rdf.dataset.drugbank.2015-03-28>
<http://purl.org/pav/version> "2015-03-28" .
<http://bio2rdf.org/drugbank_resource:bio2rdf.dataset.drugbank.2015-03-28>
<http://purl.org/dc/terms/creator>
<http://bio2rdf.org/lsr_resource:a232e796f6da6823452650bb838429c0> .
<http://bio2rdf.org/drugbank_resource:bio2rdf.dataset.drugbank.2015-03-28>
<http://purl.org/dc/terms/publisher>
<http://bio2rdf.org/lsr_resource:a232e796f6da6823452650bb838429c0> .
<http://bio2rdf.org/drugbank_resource:bio2rdf.dataset.drugbank.2015-03-28>
<http://www.w3.org/ns/dcat#>
<http://bio2rdf.org/drugbank_resource:bio2rdf.drugbank.2015-03-28.nq.gz> .
<http://bio2rdf.org/drugbank_resource:bio2rdf.dataset.drugbank.2015-03-28>
<http://purl.org/dc/terms/isVersionOf> <http://bio2rdf.org/lsr:drugbank> .
**** Summary (Drugbank Bio2RDF) ****
<http://bio2rdf.org/lsr:drugbank>
<http://purl.org/spar/cito/citesAsAuthority>
<http://bio2rdf.org/pubmed:16381955> .
<http://bio2rdf.org/drugbank_vocabulary:Resource>
<http://semanticscience.org/resource/is-member-of>
<http://bio2rdf.org/lsr:drugbank> .
<http://bio2rdf.org/lsr:drugbank>
<http://purl.org/dc/terms/identifier>
"lsr:drugbank" .
<http://bio2rdf.org/lsr:drugbank>
<http://bio2rdf.org/bio2rdf_vocabulary:uri>
"http://bio2rdf.org/lsr:drugbank"^^<http://www.w3.org/2001/XMLSchema#
string> .
<http://bio2rdf.org/lsr:drugbank>
<http://bio2rdf.org/bio2rdf:identifier>
"drugbank" .
<http://bio2rdf.org/lsr:drugbank>
<http://bio2rdf.org/bio2rdf:namespace>
"lsr" .
<http://bio2rdf.org/lsr:drugbank>
<http://bio2rdf.org/lsr_vocabulary:type> "dataset" .
<http://bio2rdf.org/lsr:drugbank>
<http://www.w3.org/2000/01/rdf-schema#label>
"DrugBank [lsr:drugbank]" .
<http://bio2rdf.org/lsr:drugbank>
<http://purl.org/spar/cito/citesAsAuthority>
<http://bio2rdf.org/pubmed:24203711> .
<http://bio2rdf.org/lsr:drugbank>
<http://purl.org/dc/terms/title>
"DrugBank" .
<http://bio2rdf.org/lsr:drugbank>
<http://www.w3.org/1999/02/22-rdf-syntax-ns#type>
<http://bio2rdf.org/lsr:Dataset> .
<http://bio2rdf.org/lsr:drugbank>
<http://purl.org/dc/terms/identifier>
"lsr:drugbank"^^<http://www.w3.org/2001/XMLSchema#string> .

90
<http://bio2rdf.org/lsr:drugbank>
<http://identifiers.org/idot/accessPattern>
"http://www.drugbank.ca/drugs/$id" .
<http://bio2rdf.org/lsr:drugbank>
<http://purl.org/spar/cito/citesAsAuthority>
<http://bio2rdf.org/pubmed:18048412> .
<http://bio2rdf.org/lsr:drugbank>
<http://bio2rdf.org/lsr_vocabulary:x-miriam>
<http://bio2rdf.org/miriam:00000102> .
<http://bio2rdf.org/lsr:drugbank>
<http://purl.org/spar/cito/citesAsAuthority>
<http://bio2rdf.org/pubmed:21059682> .
<http://bio2rdf.org/lsr:drugbank>
<http://purl.org/dc/terms/alternative>
"DrugBank" .
<http://bio2rdf.org/lsr:drugbank>
<http://www.w3.org/ns/dcat#keyword>
"protein" .
<http://bio2rdf.org/lsr:drugbank>
<http://identifiers.org/idot/exampleIdentifier>
"DB00001" .
<http://bio2rdf.org/lsr:drugbank>
<http://purl.org/dc/terms/publisher>
<http://bio2rdf.org/lsr_resource:20508d8bc2a1dcdf713c2b9c48a4d99a> .
<http://bio2rdf.org/lsr:drugbank>
<http://identifiers.org/idot/preferredPrefix>
"drugbank"^^<http://www.w3.org/2001/XMLSchema#string> .
<http://bio2rdf.org/lsr:drugbank>
<http://rdfs.org/ns/void#inDataset>
<http://bio2rdf.org/lsr_resource:bio2rdf.dataset.lsr.R3> .
<http://bio2rdf.org/lsr:drugbank>
<http://identifiers.org/idot/identifierPattern>
"^DBd{5}$" .
<http://bio2rdf.org/lsr:drugbank>
<http://purl.org/dc/terms/rights>
"commercial license" .
<http://bio2rdf.org/lsr:drugbank>
<http://www.w3.org/1999/02/22-rdf-syntax-ns#type>
<http://www.w3.org/ns/dcat#Dataset> .
<http://bio2rdf.org/lsr:drugbank>
<http://semanticscience.org/resource/has-member>
<http://bio2rdf.org/drugbank_vocabulary:Resource> .
<http://bio2rdf.org/lsr:drugbank>
<http://purl.org/dc/terms/description>
"The DrugBank database is a bioinformatics and chemoinformatics
resource that combines detailed drug (i.e. chemical, pharmacological and
pharmaceutical) data with comprehensive drug target (i.e. sequence, structure, and
pathway) information." .
<http://bio2rdf.org/lsr:drugbank>
<http://bio2rdf.org/bio2rdf_vocabulary:namespace>
"lsr"^^<http://www.w3.org/2001/XMLSchema#string> .
<http://bio2rdf.org/lsr:drugbank>
<http://www.w3.org/ns/dcat#keyword>
"drug" .
<http://bio2rdf.org/lsr:drugbank>
<http://purl.org/dc/terms/license>
<http://www.drugbank.ca/about> .
<http://bio2rdf.org/lsr:drugbank>
<http://www.w3.org/1999/02/22-rdf-syntax-ns#type>
<http://bio2rdf.org/lsr_vocabulary:Resource> .

91
<http://bio2rdf.org/lsr:drugbank>
<http://xmlns.com/foaf/0.1/page>
<http://www.drugbank.ca/> .
<http://bio2rdf.org/lsr:drugbank>
<http://bio2rdf.org/lsr_vocabulary:license-text> "DrugBank is
offered to the public as a freely available resource. Use and re-distribution of
the data, in whole or in part, for commercial purposes requires explicit
permission of the authors and explicit acknowledgment of the source material
(DrugBank) and the original publication" .
<http://bio2rdf.org/lsr:drugbank>
<http://bio2rdf.org/bio2rdf_vocabulary:identifier>
"drugbank"^^<http://www.w3.org/2001/XMLSchema#string> .