"big picture" backgrounder for crowdsourcing ground-truth - factminers, prima, & emop...
TRANSCRIPT

FactMiners, PRImA, & eMOP’sKnight Prototype Fund Entry
Turn Text Soup into Smart Data inNewspaper & Magazine Archives”
A PDF-format compilation of the four “silent Ignite Talk” slide-shows submitted in support of FactMiners &
PRImA’s recent Knight News Challenge entry.
“Big Picture” Backgrounder forStep 1. Crowdsourcing Ground-Truth

FactMiners’ Prototype Fund entry is the 1st step inour “Turn Text Soup into Smart Data” R&D agenda• Originally submitted in support of an unfunded entry in the
current Knight News Challenge, these four short slide-shows provide a “Big Picture” overview of our collaborativeresearch and development agenda
• Problem: Text SoupOCR’s “Dirty” Little Secret
• Goal: Smart DataFrom “Readable” to “Computable”
• Solution: TechnologyMachine Learning & Smart Data
• Solution: PeopleCrowdsourcing Ground-Truth
FactMiners, PRImA, & eMOP: Knight Prototype Fund entry – “Turning Text Soup into Smart Data in Newspaper & Magazine Archives:Step 1. Crowdsourcing Ground-Truth”
Please @KnightFdn folk, don’t deprivemy little boy of a good education. His
Citizen Science teachers need tocreate training materials, tests, &
answer sheets for his school at theInternet Archive.
011010..01.. INIT… Hello, world!Prototype Fund funding will help meserve you better…and this part is all
about what will be done by this project.

Problem: Text SoupOCR’s “Dirty” Little Secret
FactMiners & PRImA’sKnight News Challenge Entry
Turn Text Soup into Smart Data inNewspaper & Magazine Archives”
1Part
Recently submitted in support of our unfunded Knight NewsChallenge entry, this short slide-show describes a key element of
our collaborative R&D agenda. Our current Prototype Fundsubmission is the first strategic step in pursuit of this mission.

Q: What is “Text Soup”?
• A: The uncorrected andusually hidden text “layer”that is generated by OCR(optical character recognition)during bulk scanning anddigitization of historic andcultural heritage documents.
FactMiners & PRImA: Knight News Challenge – “Turning Text Soup into Smart Data in Newspaper & Magazine Archives”
Scanned Imagesor photos of pages!

Q: How is “Text Soup” Used?
• A: Primarily “behind thescenes” to support “full text”search.
• Good for things like:• Show me the pages with the
word “razor” on them in thisbook.
• What books are about shaving?• What words are found in
proximity to the word “strop” ?
FactMiners & PRImA: Knight News Challenge – “Turning Text Soup into Smart Data in Newspaper & Magazine Archives”
ScannedImage of text!
Hidden textlayer…

Q: What are Text Soup’s limits?• Automated OCR
(text recognition) is a“one size fits all” process inthe workflow of bulkscanning and digitization.
• Good for basic books &monographs with simpledocument structure…
FactMiners & PRImA: Knight News Challenge – “Turning Text Soup into Smart Data in Newspaper & Magazine Archives”

Q: What are Text Soup’s limits?
• Newspapers & magazines have complexdocument structures
• Multiple articles, multipleauthors, text continuations,advertisements, images,sidebars, text used as artin design, etc.
• All this data is locked inour archives waitingto be “fact-mined”
FactMiners & PRImA: Knight News Challenge – “Turning Text Soup into Smart Data in Newspaper & Magazine Archives”

Q: What are Text Soup’s limits?• On these pages from Softalk magazine we have lots of
“facts” in ads and a monthly column• We can’t “locate” facts
and assess their meaningbased on the jumbled ormissing info in itsText Soup.
FactMiners & PRImA: Knight News Challenge – “Turning Text Soup into Smart Data in Newspaper & Magazine Archives”
Complexdocumentstructuresnot identified!

We have to “tame” Text Soup to unlock“facts” in archive data.
• Our project will focus on recognizing complexdocument structure and on “fact-revealing”content modeling.
• In the next slideshow, we describe our vision for“fact-mining” Smart Data from newspaper &magazine digital archives…
FactMiners & PRImA: Knight News Challenge – “Turning Text Soup into Smart Data in Newspaper & Magazine Archives”

Goal: Smart DataFrom “readable” to “computable”
FactMiners & PRImA’sKnight News Challenge Entry
Turn Text Soup into Smart Data inNewspaper & Magazine Archives”
2Part
Recently submitted in support of our unfunded Knight NewsChallenge entry, this short slide-show describes a key element of
our collaborative R&D agenda. Our current Prototype Fundsubmission is the first strategic step in pursuit of this mission.

Q: What is Smart Data?• A: Smart Data is self-descriptive
data that can “carry on a conversation”with Smart Programs to supportaccess, editing, and visualization ofthe data itself.
FactMiners & PRImA: Knight News Challenge – “Turning Text Soup into Smart Data in Newspaper & Magazine Archives”
The “actual” data of the database
To access the “actual” data of the database,Smart Programs “talk” to an embedded“database about the database” (AKA a metamodel )
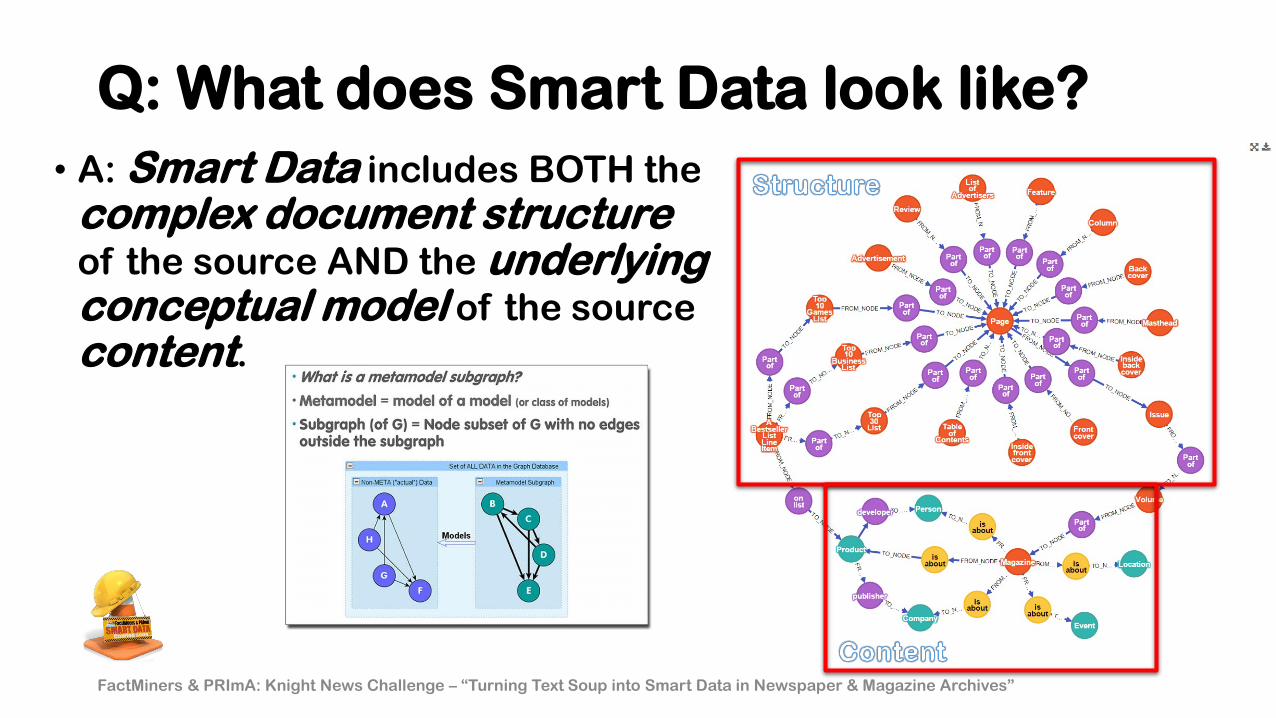
Q: What does Smart Data look like?
FactMiners & PRImA: Knight News Challenge – “Turning Text Soup into Smart Data in Newspaper & Magazine Archives”
• A: Smart Data includes BOTH thecomplex document structureof the source AND the underlyingconceptual model of the sourcecontent.

Q: What can Smart Data do?• A: Turn expensive, time-
consuming, labor-intensiveresearch studies into “Just ask!”queries
• Good for things like:• How did local reporting of race
relations impact public policy inIndiana in the 1950s?
• Did advertising or editorialcoverage account for thepopularity of programs in theSoftalk Bestseller lists?
FactMiners & PRImA: Knight News Challenge – “Turning Text Soup into Smart Data in Newspaper & Magazine Archives”

Q: How “smart” is our Smart Data design?• We spent a year researching
museum informatics andprototyping Smart Data designs.
• Our software architecture is basedon CIDOC-CRM (ConceptualReference Model for Museums)microservice workflows andPRESSoo, the ISSN.orgmetamodel for serial publications
FactMiners & PRImA: Knight News Challenge – “Turning Text Soup into Smart Data in Newspaper & Magazine Archives”
Winter, 2013
Spring, 2014
Fall, 2014
Summer, 2015
Neo4j GraphGist Challenge,a 1st place for MetamodelSubgraph domain model
Semi-finals Ashoka/LEGO“Re-imagine Learning” Challenge.
#MW2014 FactMiners demo.Introduced to #cidocCRM.
Museum Computer NetworkEmerging Professional Scholarship.#MCN2014 paper & demo.“Massively Addressable Text” publishedin peer-reviewed CODE|WORDS.
#HILT2015 Crowdsourcing CourseDPLA Community Reps.
Internet Archive Content Partner.ICOM #cidocCRM SIG member.
Incorporate PRESSoo into design.Begin PRImA Collaboration.

Q: How “open” is our Smart Data design?• Using a metamodel
subgraph designpattern to embed and passinfo about data and its accessand transformation istechnology neutral &future-proof.
FactMiners & PRImA: Knight News Challenge – “Turning Text Soup into Smart Data in Newspaper & Magazine Archives”
Without Smart Data
With Smart Data
Database10 Load X20 Print X30 Goto 10
Domain knowledge writteninto task-specific programs
Metamodel statically storedwithin #TEI header section of
source documents std. text files
<teiHeader><metamodel /><structure /><content />
Any “smart” DB
For dynamic Linked Open Data access,DB need only have import &
ability to represent data structuresread from metamodel header.
10 Load metamodel20 Configure editors30 Do stuff…
“Smart” program inany language

We have a design to “tame” Text Soup andunlock “facts” in archive data.
• An innovative design combining international standardsfor conceptual modeling of museum collections(cidocCRM and PRESSoo) together with a “self-descriptive” software/database design pattern provide thefoundation for mining Smart Data from Text Soup.
• In the next slideshow, we describe our design for thetechnology to “fact-mine” Smart Data fromnewspaper & magazine digital archives…
FactMiners & PRImA: Knight News Challenge – “Turning Text Soup into Smart Data in Newspaper & Magazine Archives”

Recently submitted in support of our unfunded Knight NewsChallenge entry, this short slide-show describes a key element of
our collaborative R&D agenda. Our current Prototype Fundsubmission is the first strategic step in pursuit of this mission.
FactMiners & PRImA’sKnight News Challenge Entry
Turn Text Soup into Smart Data inNewspaper & Magazine Archives”
Solution: TechnologyMachine Learning & Smart Data3
Part

Q: Can Robots* read magazines?• Yes (mostly)…when looking at
layout & text recognition withinthe individual page
• No...in terms of recognizing thecomplex document structure of thewhole issue
• Our challenge is to move fromindividual page to whole-issuedocument structure recognition.
FactMiners & PRImA: Knight News Challenge – “Turning Text Soup into Smart Data in Newspaper & Magazine Archives”
* “Robot” = Software Agent(AKA, a computer program)
From page…
…to pages!

Q: What’s the 1st Step & Where to do it?• We start by teaching Robot
agents to find & understandthe TOC (Table of Contents)and Advertiser Index pagesof newspapers & magazines.
• The best place to do thisapplied research is in thecollections of the InternetArchive.
FactMiners & PRImA: Knight News Challenge – “Turning Text Soup into Smart Data in Newspaper & Magazine Archives”
Bring ‘em on!I can’t get
enough TOC.

Q: Why TOCs & Advertiser Indexes?• A: TOCs (Table of Contents) &
Advertiser Indexes reveal thecomplex document structure ofnewspapers & magazines.
• Like a Sudoku puzzle, the TOC &Ad Index provide helpful “filled-inanswers” about the types ofcontent to be found within pagesof the newspaper or magazine.
FactMiners & PRImA: Knight News Challenge – “Turning Text Soup into Smart Data in Newspaper & Magazine Archives”

Q: Why the Internet Archive?• Thousands of “Text Soup era”
newspaper & magazine collections thatcan be enhanced through research.
• The Archive’s Scanning Service flagsTOC pages & generates a TOC-specific XML-encoded file duringits standard digitization workflow.
• The current Archive TOC OCRanalysis does not “see” &understand the complex TOCs ofmagazines & newspapers.
FactMiners & PRImA: Knight News Challenge – “Turning Text Soup into Smart Data in Newspaper & Magazine Archives”

Q: What TOC Robots will we develop?• TOC-Spotter is an Image/Scene
Recognition software agent to crawlthe Archive in search of TOC &Ad Index pages.
• TOC-Reader is a software agentextending PRImA recognition &evaluation technologies withMachine Learning capabilities to do“deep reading” with the assist of theTOC Pattern Reference Library.
FactMiners & PRImA: Knight News Challenge – “Turning Text Soup into Smart Data in Newspaper & Magazine Archives”
Dot dot dot… Check!Number… Check!
YO! Gotta TOC here!
Great! Let me takea good look at it.

Q: How will this help?• By running our TOC-Agents early in
digitization workflows, we can makesmarter within-page layoutrecognition decisions during bulkOCR of the issue’s subsequent pages.
• We can generate “best guess”structure-revealing meta-tags inappropriate files as part of thestandard Archive scanning workflow.
FactMiners & PRImA: Knight News Challenge – “Turning Text Soup into Smart Data in Newspaper & Magazine Archives”
Let’s see… Based on my notes,that’d be an ad, a feature article,
another ad…and there’s theAd Index!

Q: What will be accomplished?• The structure-mapped text files
generated by the TOC-Readeragent will be ready for FactMiners'Semantic tagging (AKA “fact-mining”) of the issue’s content.
• These files will be compatible withPRImA’s Alethia program for usein crowdsourced Ground-Truthdevelopment of the TOC PatternReference Library.
FactMiners & PRImA: Knight News Challenge – “Turning Text Soup into Smart Data in Newspaper & Magazine Archives”
Welcome to theTOC Pattern Reference Library

We have a design to “tame” Text Soup andunlock “facts” in archive data.
• Our immediate PRImA-inspired technology agenda is todevelop “Robot” assistance (software agents) to find,recognize & deeply understand the TOCs (Table ofContents) and Advertiser Indexes of magazines in theInternet Archive magazine & newspaper collections.
• In our last slideshow, we describe the people dimensionof our strategy to “fact-mine” Smart Data fromnewspaper & magazine digital archives…
FactMiners & PRImA: Knight News Challenge – “Turning Text Soup into Smart Data in Newspaper & Magazine Archives”

Recently submitted in support of our unfunded Knight NewsChallenge entry, this short slide-show describes a key element of
our collaborative R&D agenda. Our current Prototype Fundsubmission is the first strategic step in pursuit of this mission.
FactMiners & PRImA’sKnight News Challenge Entry
Turn Text Soup into Smart Data inNewspaper & Magazine Archives”
Solution: PeopleCrowdsourcing Ground-Truth4
Part

Q: Why do we need people?• If all we had to do was write some
smart “Robot” programs & simply putthem to work, we wouldn’t need people.
• But writing smart code is just the “birth”of a Machine-Learning Robot.
• We have to teach our Robots how toread magazines & newspapers!
FactMiners & PRImA: Knight News Challenge – “Turning Text Soup into Smart Data in Newspaper & Magazine Archives”
011010..01.. INIT…What am I? Who willteach me? What’s a
magazine?

Q: What is Ground-Truth?• Teaching means training; lessons, study
materials, tests & their answer sheets, etc.
• An “answer sheet” in OCR research iscalled a Ground-Truth solution – thehuman-crafted “perfect answer” torecognition of a scanned page.
• To teach our Robots to read magazines,we’ll need a pile of TOC* Ground-Truth!
FactMiners & PRImA: Knight News Challenge – “Turning Text Soup into Smart Data in Newspaper & Magazine Archives”
*TOC being “Table of Contents”See our 3rd Silent Ignite slideshowfor more on TOCs & Technology
Yes, your Honor…That is EXACTLY
what I saw and ONLYwhat I saw on theTable of Contentspage shown to me
as Exhibit A.

Q: What’s the TOC Pattern Reference Library?
• It will be a Special Purpose ResearchCollection at the Internet Archive tobe used to “teach Robots to readmagazines & newspapers.”
• Will Include a TOC Image Dataset,TOC Ground-Truth Solutions, & OpenSource library of TOC-Spotting &TOC-Reading software.
FactMiners & PRImA: Knight News Challenge – “Turning Text Soup into Smart Data in Newspaper & Magazine Archives”
Welcome to theTOC Pattern Reference Library
Yes, counsel, in answer toyour question allow me toreference material from
the Library.

Q: How will Citizen Scientists help?• “Volunpeers” are already generating
Ground-Truth data for the TOC PatternReference Library through ourproject on the Zooniversecrowdsourcing platform.
• In addition to refining the workflow forGround-Truth data collection, thisproject will develop Zooniverse dataexport to PRImA’s Aletheia.
FactMiners & PRImA: Knight News Challenge – “Turning Text Soup into Smart Data in Newspaper & Magazine Archives”

Q: What is Alethia “FactMiners Ed.”?• Aletheia is PRImA’s desktop & web
Ground-Truth Tool.• Funding will allow PRImA to add
features to Aletheia to support“whole issue” modeling inGround-Truth Solutions.
• We get a Power Tool for CitizenScientists who want to “dig deeper”into Internet Archive newspaper &magazine collections as pioneerFactMiners!
FactMiners & PRImA: Knight News Challenge – “Turning Text Soup into Smart Data in Newspaper & Magazine Archives”

We have a design to “tame” Text Soup andunlock “facts” in archive data.
• We are confident that the applied research projectsubmitted as our Knight News Challenge entry willmake substantive contributions to the domain of OpenData by helping to turn Text Soup into Smart Data innewspaper & magazine archives.
• We hope you have enjoyed all four of our “silent Ignite Talk”video slideshows. We welcome your comments, questions,& (of course) “applause” at: https://goo.gl/99Vn5M
FactMiners & PRImA: Knight News Challenge – “Turning Text Soup into Smart Data in Newspaper & Magazine Archives”

FactMiners & PRImA:Our Knight News Challenge Entry
• “Turn Text Soup into Smart Data inNewspaper & Magazine Archives”https://goo.gl/99Vn5M
• Team• Jim Salmons, FactMiners• Timlynn Babitsky, FactMiners• Apostolos Antonacopoulos, PRImA• Christian Clausner, PRImA
FactMiners & PRImA: Knight News Challenge – “Turning Text Soup into Smart Data in Newspaper & Magazine Archives”
This is the final slide for ourprior submission to the News Challengeand not to be confused with our current
Prototype Fund entry…