bigdatabench: benchmarking big data systems -...
TRANSCRIPT

INSTITUTE O
F COM
PUTING
TECHN
OLO
GY
BigDataBench: Benchmarking Big Data Systems
Presented by Yingjie ShiInstitute of Computing Technology, CAS
2013-10-8
1
http://prof.ict.ac.cn/BigDataBench

BPOEBigData 2013
Outline
2/
Background1
Benchmarking Methodology2
Case Studies4
Conclusions5
Scalable Data Generation Tool3

BPOEBigData 2013
Motivation
3/
2.5 quintillion bytes of data are created daily
turning bigTuning data into true treasure relies on massive big data systemsvalues.x
Big Data Solutions
Data Management
Architecture System
Semantic Model
Big Data Benchmark

BPOEBigData 2013
Challenges
4/
•Complexity
• Diversity
•Workload Churns
•Rapid Evolution
Customers, vendors, or researchersfrom academia or even different domains of industry do not know enough about each other.
Big data system softwarestacks cover a broad spectrum.
There are many classes of big data applications lacking of a scientific classification.

BPOEBigData 2013
Requirements
5/
4V: volume, velocity, variety, and veracity
Scalable data volumeCover different data
types and sourcesAdjustable and fast
enough data generating and updating
Reflect the big data
application diversity
Cover state-of-art
techniques
Extensible operations
and algorithms
Data Store
Data Management
Programming
Framework
Easy to be deployed and runEasy to acquire the
performance dataAble to run on the
simulator platforms
Data–centric Workloads
Diverse Applications
Representative Software Stack
Usability

BPOEBigData 2013
Comparison of Big Data Benchmarking Efforts
6/

BPOEBigData 2013
Outline
7/
Background1
Benchmarking Methodology2
Case Studies4
Conclusions5
Scalable Data Generation Tool3

BPOEBigData 2013
Methodology
8/
Representative Real Data Sets
Diverse and Important Workloads
Data SourcesText dataGraph dataTable dataExtended …
Data TypesStructured data Semi-structured dataUnstructured data
Big Data Sets Preserving 4V
BigDataBench
Investigate Typical
Application Domains
Synthetic data generation tool preserving data characteristics
Application TypesOffline analyticsRealtime analyticsOnline services
Basic & Important Operations and Algorithms Extended…
Represent Software Stack Extended…
Big Data Workloads

BPOEBigData 2013
Representative Datasets
9/
Application Domain Data Type Data Source Dataset
Search Engine
unstructured data Text data Wikipedia EntriesGraph data Google Web Graph
Semi-structured data
Table data Profsearch Person Resume
E-commenceunstructured data Text data Amazon Movie
Reviewsstructured data Table data ABC Transaction
DataSocial Network unstructured data Graph data Facebook Social
Graph

BPOEBigData 2013
Considerations of Workloads Characterization
10/
• Covering workloads in diverse and representative application scenarios
• Search Engine, E-commerce, Social Network
• Paying equal attentions to different applications:• online service, real-time data analysis, offline data analysis
• Including different data sources• Text data, Graph data, Tale data
• Covering the representative software stack• Data store system, Data management system, Programming framework
BPOEBigData 2013
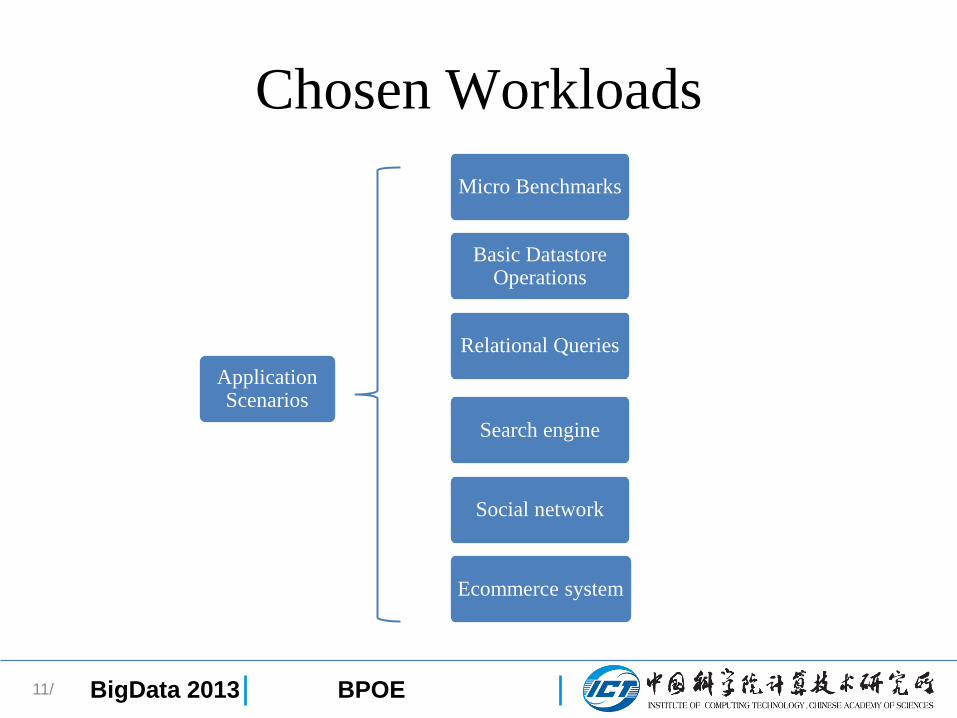
Chosen Workloads
11/
Application Scenarios
Micro Benchmarks
Basic DatastoreOperations
Relational Queries
Search engine
Social network
Ecommerce system

BPOEBigData 2013
Chosen Workloads – Basic Operations
12/
Operations & Algorithms
sort
grep
wordcount
BFS
SoftwareStack
HadoopSparkMPI
HadoopSparkMPI
HadoopSparkMPIMPI
Application Domain
MicroBenchmarks
Data Type
un-structured
Data Source
text
graph
BenchmarkID1-11-21-32-12-22-33-13-23-34

BPOEBigData 2013
Chosen Workloads – Basic DatastoreOperations
13/
SoftwareStackHBase
CassandraMongoDBMySQLHBase
CassandraMongoDBMySQLHBase
CassandraMongoDBMySQL
Application Domain
Basic DatastoreOperations
Data Type
semi-structured
Data Source
table
Operations & Algorithms
Read
Write
Scan
BenchmarkID5-15-25-35-46-16-26-36-47-17-27-37-4
BPOEBigData 2013
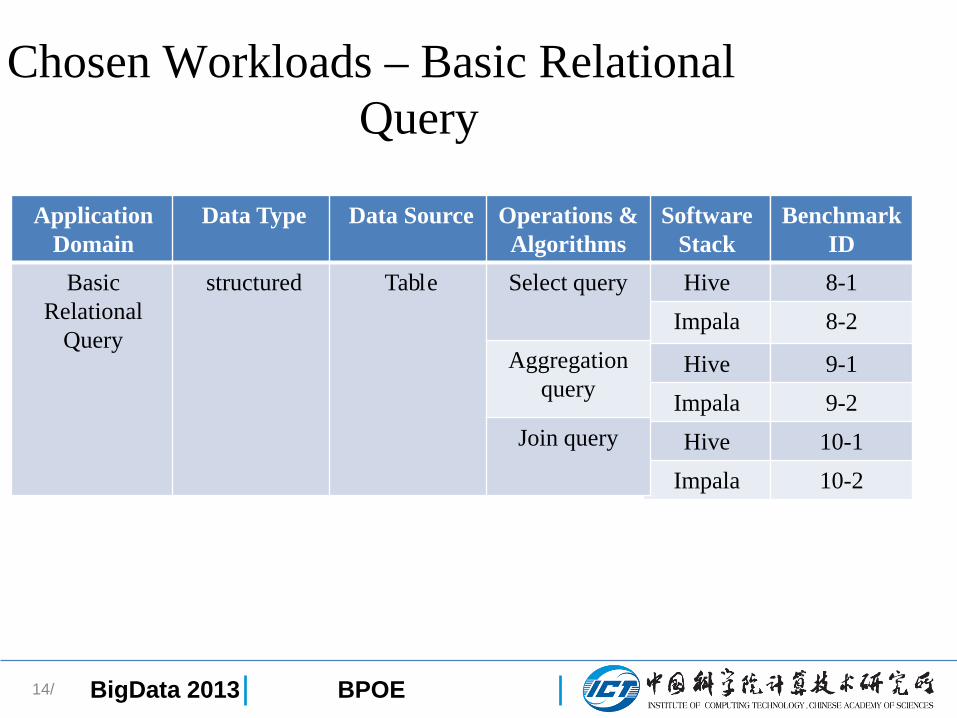
Chosen Workloads – Basic Relational Query
14/
SoftwareStackHive
Impala
HiveImpalaHive
Impala
Application Domain
Basic Relational
Query
Data Type
structured
Data Source
Table
Operations & AlgorithmsSelect query
Aggregationquery
Join query
BenchmarkID8-18-2
9-19-2
10-110-2
BPOEBigData 2013
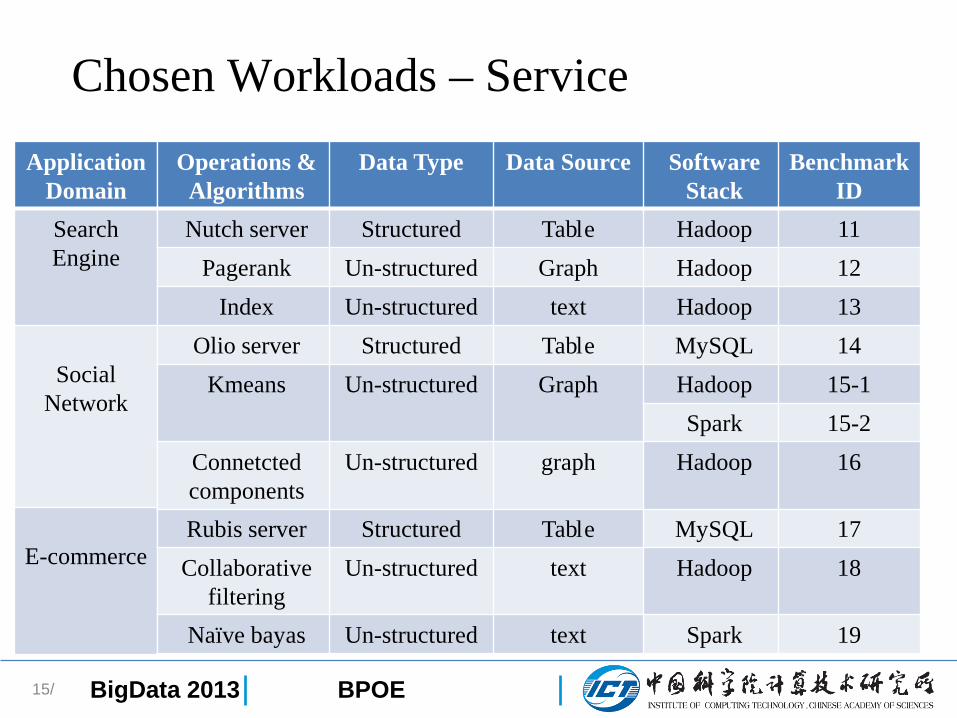
Chosen Workloads – Service
15/
Data Source
TableGraphtext
TableGraph
graph
Tabletext
text
Application DomainSearchEngine
SocialNetwork
E-commerce
Operations & AlgorithmsNutch server
PagerankIndex
Olio serverKmeans
ConnetctedcomponentsRubis serverCollaborative
filteringNaïve bayas
Data Type
StructuredUn-structuredUn-structured
StructuredUn-structured
Un-structured
StructuredUn-structured
Un-structured
SoftwareStack
HadoopHadoopHadoopMySQLHadoopSpark
Hadoop
MySQLHadoop
Spark
BenchmarkID11121314
15-115-216
1718
19
BPOEBigData 2013
Outline
16/
Background1
Benchmarking Methodology2
Case Studies4
Conclusions5
Scalable Data Generation Tool3Text Generator
Graph Generator
Table Generator

BPOEBigData 2013
Text Generator
• Use latent dirichlet allocation to generate text corpus.
• Latent dirichlet allocation (David M Blei, et al.)– topic model – generative probabilistic model – widely used in machine learning and natural
language processing

BPOEBigData 2013
Latent Dirichlet Allocation
David M Blei, et al., “Latent dirichlet allocation,” the Journal of machine Learning research, vol. 3, pp. 993–1022, 2003.
Topic proportion
Topic Word
parameters
Document length
Number of documents in corpus
Graphical model representation of LDA
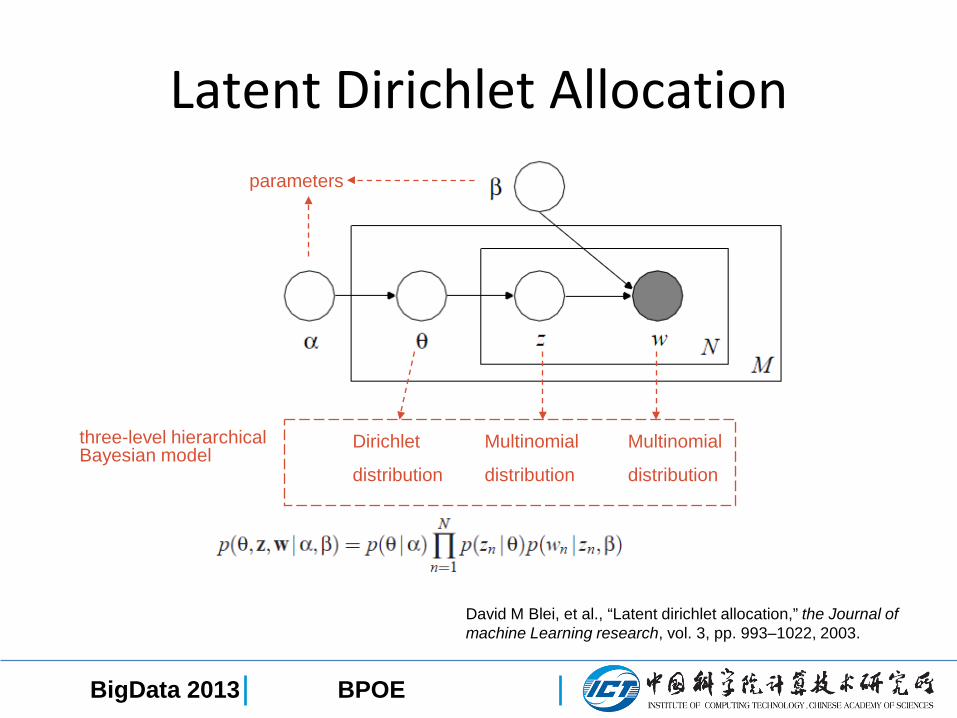
BPOEBigData 2013
Latent Dirichlet Allocation
Dirichlet
distribution
Multinomial
distribution
Multinomial
distribution
parameters
David M Blei, et al., “Latent dirichlet allocation,” the Journal of machine Learning research, vol. 3, pp. 993–1022, 2003.
three-level hierarchical Bayesian model

BPOEBigData 2013
Latent Dirichlet Allocation
The process of document generation

BPOEBigData 2013
Graph Generator
• Use the Stochastic Kronecker Graph model (Jure Leskovec,et al.) to generate graph
• Used also by graph 500, different from Graph 500– Application-specific, the stochastic kronecker
initiator is obtained from real representive data set of specific applications.

BPOEBigData 2013
Deterministic Kronecker Graph
Jure Leskovec,et al. , “Kronecker graphs: An approach to modeling networks,” The Journal of Machine Learning Research, vol. 11, pp. 985–1042, 2010.
self similar
1: has edge
0: no edge

BPOEBigData 2013
Stochastic Kronecker Graph
The probability with which the cell generate a edge
Jure Leskovec,et al. , “Kronecker graphs: An approach to modeling networks,” The Journal of Machine Learning Research, vol. 11, pp. 985–1042, 2010.

BPOEBigData 2013
Application-specific
Specific real data
Estimateparameters
ScaleBig graph
inputSpecific application
Google Web Graph
KronFitStochastic Kronecker Synthetical
Web Graph
inputPagerank
Facebook Social Graph
KronFitStochastic Kronecker Synthetical
Social Graph
inputConnetcted components

BPOEBigData 2013
Table Generator
• Related structured table– Parallel Data Generation Framework (Tilmann
Rabl, et al.)– using XML configuration files for data description
and distribution • Semi-structured resumes
– choose mix of fields, each field follows bernoulli distribution
– choose value of each field, following multinomial distribution.

BPOEBigData 2013
Outline
26/
Background1
Benchmarking Methodology2
Case Studies4
Conclusions5
Evaluating Big Data Systems on Different Hardware Platforms
Evaluating the Rationality of Newly Proposed Power Usage
Effectiveness Metrics
Scalable Data Generation Tool3

BPOEBigData 2013
Outline
27/
Background1
Benchmarking Methodology2
Case Studies4
Conclusions5
Evaluating Big Data Systems on Different Hardware Platforms
Evaluating the Rationality of Newly Proposed Power Usage
Effectiveness Metrics
Scalable Data Generation Tool3

BPOEBigData 2013
New Solutions of Big Data Systems
28/
……
BPOEBigData 2013
A Tradeoff?
29/ 29
Energy consumptionPerformance

BPOEBigData 201330/ 3030
What is the performance of different big data systems under types of applications?
What is the performance of different big data systems under different data volumes?
What is the energy consumption of different big data systems?
Evaluating three respective big data systems
Comparing two of them from performance and energy cost
Analyzing the running features of different big data system, and the underlying reasons

BPOEBigData 2013
Experiment Platforms
31/
• Xeon – Mainstream processor • Atom – Low power processor• Tilera – Many core processor
31
CPU Type Intel Xeon E5310 Intel Atom D510 Tilera TilePro36
CPU Core 4 cores @ 1.6GHz 2 cores @ 1.66GHz 36 cores @ 500MHz
L1 I/D Cache 32KB 24KB 16KB/8KB
L2 Cache 4096KB 512KB 64KB
Basic Configurations

BPOEBigData 2013
Experiment Platforms
32/
• Xeon – Mainstream processor • Atom – Low power processor• Tilera – Many core processor
32
OoOExecution FPU Connection
ModeBuffer
Sharing TDP
Xeon E5310 Yes Yes BUS No 80W
Atom D510 No Yes BUS No 13W
TilePro36 Yes No IMESH Yes 16W
Comparison

BPOEBigData 2013
Experiment Platforms
33/
• Xeon – Mainstream processor • Atom – Low power processor• Tilera – Many core processor
33
Hadoop ClusterInformation Xeon VS Atom Xeon VS Tilera
Master/Slaves 1/7 1/7 and 1/1
Comprison Having the same hardware thread number
Having the same core number
Hadoop setting Following the Hadoop official website

BPOEBigData 2013
The Roles of BigDataBench
Providing various, representative applications Sort, WordCount, Grep, Naive Bayes, SVM From basic applications to complex applications Having different main operations
Offerring a scalable data generation tool Generate data of any size Based on real data, ensure data reality
34/
BPOEBigData 2013
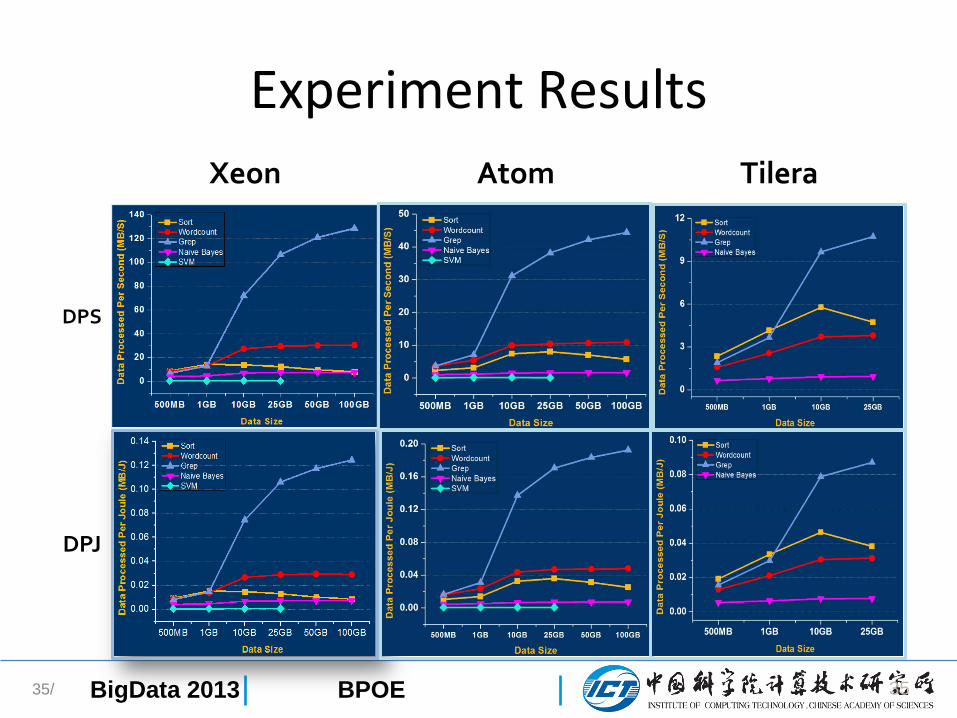
Experiment Results
35/
Xeon Atom Tilera
DPS
DPJ
35

BPOEBigData 2013
Implications from the Results
36/
•Xeon vs. Atom
• Xeon vs. Tilera
Xeon is more powerful than AtomAtom is energy conservation than Xeon when dealing
with some easy applicationAtom doesn’t show energy advantage when dealing
with complex application
Xeon is more powerful than TileraTilera is more energy conservation than Xeon when dealing with
some easy applicationTilera don’t show energy advantage when dealing with complex applicationTilera is more suitable to process I/O intensive application

BPOEBigData 2013
Outline
37/
Background1
Benchmarking Methodology2
Case Studies4
Conclusions5
Evaluating Big Data Systems on Different Hardware Platforms
Evaluating the Rationality of Newly Proposed Power Usage
Effectiveness Metrics
Scalable Data Generation Tool3

BPOEBigData 2013
Greening Data Center
38/
IDC says: Digital Universe will be 35 Zettabytes by 2020
Nature says: Distilling the meaning from big data has never been in such urgent demand.
The data centers consumed about 1.3% electricity of all the electricity use
The energy bill is the largest single item in the “total cost of ownership of a Data Center”

BPOEBigData 2013
Power Usage Effectiveness
39/
If you can not measure it, you can not improve it. – Lord Kelvin
PUE(Power usage effectiveness): a measure of how efficiently a computer data center uses its power; specifically, how much of the power is actually used by the information technology equipment.

BPOEBigData 201340/
PUE
AxPUE

BPOEBigData 2013
ApPUE
41/
• ApPUE (Application Performance Power Usage Effectiveness): a metric that measures the power usage effectiveness of IT equipments, specifically, how much of the power entering IT equipments is used to improve the application performance.
• Computation Formulas:
Application PerformanceApPUEIT Equipment Power
=
Data processing performance of applications
The average rate of IT Equipment Energy consumed

BPOEBigData 2013
AoPUE
42/
• AoPUE (Application ): a metric that measures the power usage effectiveness of the overall data center system, specifically, how much of the total facility power is used to improve the application performance.
• Computation Formulas:
Application PerformanceAoPUETotal Facility Power
=
The average rate of Total Facility Energy UsedApPUEAoPUEPUE
=

BPOEBigData 2013
Experiment Overview
43/
Testbed Data center of 18 racks,362 servers Sample 8 servers
Workloads
Two experiments Different Applications Different Implementation Algorithms

BPOEBigData 2013
The Roles of BigDataBench Conduting the experiments based on BigDataBench
to demonstrate the rationality of the newly proposed AxPUE from two aspects: Adopting the comprehensive workloads of BigDataBench
to design the application category–sensitive experiment. Adopting Sort of BigDataBench to design the algorithm
complexity-sensitive experiment.
44/
BPOEBigData 2013
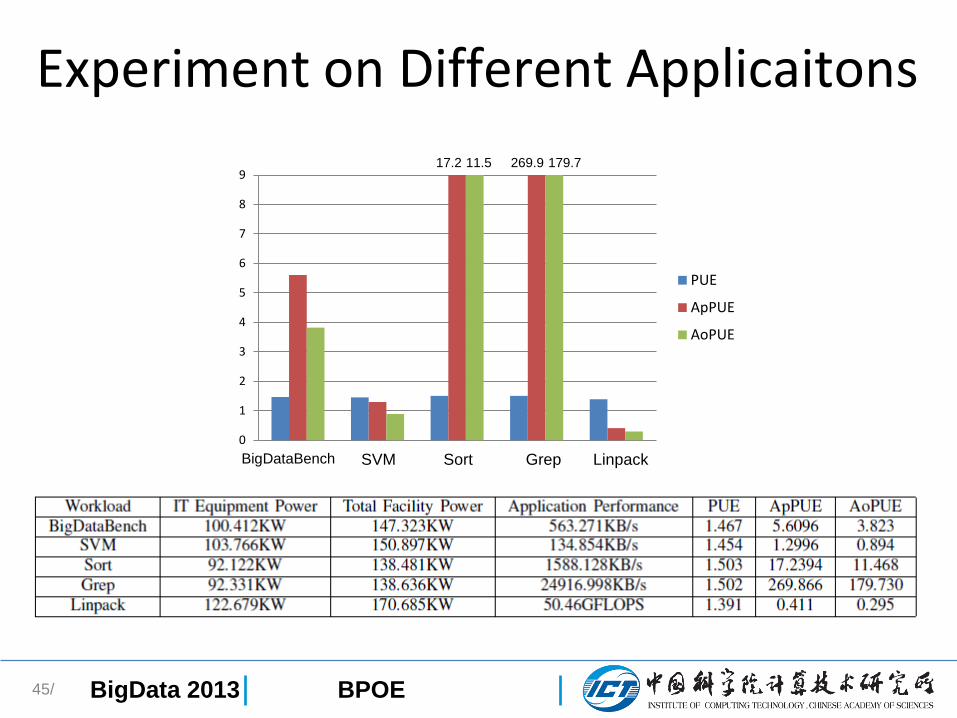
Experiment on Different Applicaitons
45/
0
1
2
3
4
5
6
7
8
9
PUE
ApPUE
AoPUE
BigDataBench SVM Sort Grep Linpack
17.2 11.5 269.9 179.7

BPOEBigData 2013
Experiment on Different Algorithms
46/
Two Implementations for Sort Several reducers with random sampling partitioning One reducer without partitioning
0
5
10
15
20
25
30
10G 25G 50G 100G
PUE(Sort1)ApPUE(Sort1)PUE(Sort2)ApPUE(Sort2)
Data Size
BPOEBigData 2013
Outline
47/
Background1
Benchmarking Methodology2
Case Studies4
Conclusions5
Scalable Data Generation Tool3

BPOEBigData 201348/
BigDataBench
Evaluating Energy Efficiency
Evaluating Performance
Characterizing Workloads
Demonstrate New Metrics
Evaluating New Platforms
Download the BigDataBench: http://prof.ict.ac.cn/BigDataBench/

BPOEBigData 201349/
Please visit BigDataBench homepage for more research information:http://prof.ict.ac.cn/BigDataBench/