bioinformatics t9-t10-biocheminformatics v2014
TRANSCRIPT


FBW
9-12-2014
Wim Van Criekinge


Examen
<html>
<title>Examen Bioinformatica</title>
<center>
<head>
<script>
rnd.today=new Date();
rnd.seed=rnd.today.getTime();
function rnd() {
rnd.seed = (rnd.seed*9301+49297) % 233280;
return rnd.seed/(233280.0);
};
function rand(number) {
return Math.ceil(rnd()*number);
};
</SCRIPT>
</head>
<body bgcolor="#FFFFFF" text="#00FF00" link="#00FF00">
<script language="JavaScript">
document.write('<table>');
document.write('<tr>');
document.write('<td><a href="index.html" ><img border=0 src="' + rand(713) + '.jpg" width="520" height="360"></a></td>');
rand(98);
document.write('<td><a href="index.html" ><img border=0 src="' + rand(713) + '.jpg" width="520" height="360"></a></td>');
rand(98);
document.write('<td><a href="index.html" ><img border=0 src="' + rand(713) + '.jpg" width="520" height="360"></a></td>');
rand(98);
document.write('<td><a href="index.html" ><img border=0 src="' + rand(713) + '.jpg" width="520" height="360"></a></td>');
rand(98);
document.write('</tr>');

• The keywords can be
– genome structure
– gene-organisation
– known promoter regions
– known critical amino acid residues.
• Combination of functional
modelorganism knowledge
• Structure-function
• Identify similar areas of biology
• Identify orthologous pathways (might
have different endpoints)
Comparative Genomics: The biological Rosetta


Example: Agro
Known “lethal” genes
from worm, drosphila
Sequence Genome
Filter for drugability”,
tractibility & novelty

Example: Extremophiles
Known lipases
Filter for
“workable”lipases
at 90º C
Look for species
with interesting
phenotypes
Clone and produce in large quantities
Washing Powder additives
Sequence Genome
Functional Foods
Convert Highly Energetic Monosaccharides to Dextrane


Drug Discovery: Design new drugs by computer ?
Problem: pipeline cost rise linear, NCE steady
Money: bypassing difficult, work on attrition
Every step requires specific computational tools

• Drugs are generally defined as molecules which affect biological processes.
• In order to be effective, the molecule must be present in the body at an adequate concentration for it to act at the specific site in the body where it can exert its effect.
• Additionally, the molecule must be safe -- that is, metabolized and eliminated from the body without causing injury.
• Assumption: next 50 years still a big market in small chemical entities which can be administered orally in form of a pill (in contrast to antibodies) or gene therapy …
Drug Discovery: What is a drug ?





• Taxol a drug which is an unmodified natural compound, is the exception
• Most drugs require “work” -> need for target driven pipeline
• Humane genome is available so all target are identified
• How to validate (within a given disease area) ?

• target - a molecule (often a protein) that is instrumental
to a disease process (though not necessarily directly
involved), which may be targeted with a potential
therapeutic.
• target identification - identifying a molecule (often a
protein) that is instrumental to a disease process (though
not necessarily directly involved), with the intention of
finding a way to regulate that molecule's activity for
therapeutic purposes.
• target validation - a crucial step in the drug
development process. Following the identification of a
potential disease target, target validation verifies that a
drug that specifically acts on the target can have a
significant therapeutic benefit in the treatment of a given
disease.
Drug Discovery: What is a target ?
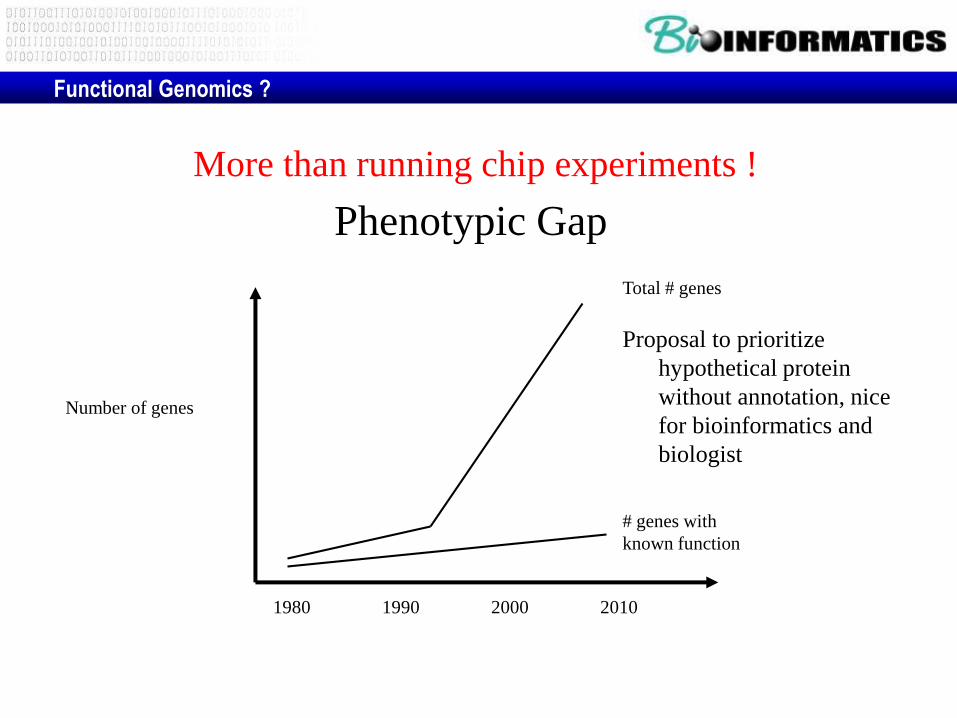
Phenotypic Gap
# genes with
known function
Total # genes
Number of genes
1980 1990 2000 2010
Functional Genomics ?
More than running chip experiments !
Proposal to prioritize
hypothetical protein
without annotation, nice
for bioinformatics and
biologist


“Optimal” drug target
Predict side effect
Where is optimal drug target ?
How to correct disease state
Side effects ?






Genome-wide RNAi
RNAI vector
bacteria producing ds RNA for
each of the 20.000 genes
proprietary nematode
responding to RNAi
20.000 responses
20.000 genes insert
library



Normal insulin signaling
Reduced insulin signaling
fat storage LOW
fat storage HIGH
Type-II Diabetes

20,000 bacteria
each containing
selected
C. elegans gene
select genes with desired phenotypes
proprietary C.elegans strains
• sensitized to silencing
• sensitized to relevant pathway
Industrialized knock-downs

Pharma is conservative


Molecular functions of 26 383 human genes
Structural Genomics


Lipinsky for the target ?
Database of all “drugable” human genes

Drug Discovery: Design new drugs by computer ?

screening - the automated examination and
testing of libraries of synthetic and/or organic
compounds and extracts to identify potential drug
leads, based on the compound's binding affinity
for a target molecule.
screening library - a large collection of
compounds with different chemical properties or
shapes, generated either by combinatorial
chemistry or some other process or by collecting
samples with interesting biological properties.
High Throughput Screening: Quick and Dirty…
from 5000 compounds per day
Drug Discovery: Screening definitions

• At the beginning of the 1990s, when the
term "high-throughput screening" was
coined, a department of 20 would
typically be able to screen around 1.5
million samples in a year, each
researcher handling around 75,000
samples. Today, four researchers using
fully automated robotic technology can
screen 50,000 samples a day, or around
2.5 million samples each year.
Drug Discovery: Screening Throughput

Robotic arm
Read-out
Fluorescence /
luminescence
Distribution
96 / 384 wells
Optical Bank
for stability
Drug Discovery: HTS – The Wet Lab

• Available molecules collections from pharma,
chemical and agro industry, also from
academics (Eastern Europe)
• Natural products from fungi, algae, exotic
plants, Chinese and ethnobotanic medicines
• Combinatorial chemistry: it is the generation
of large numbers of diverse chemical
compounds (a library) for use in screening
assays against disease target molecules.
• Computer drug design (from model
substrates or X-ray structure)
Drug Discovery: Chemistry Sources

Drug Discovery
HIT LEAD

• initial screen established
• Compounds screened
• IC50s established
• Structures verified
• Minimum of three independent
chemical series to evaluate
• Positive in silico PK data
Drug Discovery: HIT

• When the structure of the target is unknown,
the activity data can be used to construct a
pharmacophore model for the positioning of
key features like hydrogen-bonding and
hydrophobic groups.
• Such a model can be used as a template to
select the most promising candidates from the
library.
Drug Discovery: Hit/lead computational approaches

• lead compound - a potential drug candidate emerging from a screening process of a large library of compounds.
• It basically affects specifically a biological process. Mechanism of activity (reversible/ irreversible, kinetics) established
• Its is effective at a low concentration: usually nanomolar activity
• It is not toxic to live cells
• It has been shown to have some in vivo activity
• It is chemically feasible. Specificity of key compound(s) fromeach lead series against selected number of receptors/enzymes
• Preliminary PK in vivo (rodent) to establish benchmark for in vitro SAR
• In vitro PK data good predictor for in vivo activity
• Its is of course New and Original.
Drug Discovery: Lead ?

Christopher A. Lipinski, Franco Lombardo, Beryl W. Dominy, Paul J. Feeney
"Experimental and computational approaches to estimate solubility and
permeability in drug discovery and development settings":
"In the USAN set we found that the sum of Ns and Os in the molecular formula was
greater than 10 in 12% of the compounds. Eleven percent of compounds had
a MWT of over 500. Ten percent of compounds had a CLogP larger than 5 (or
an MLogP larger than 4.15) and in 8% of compounds the sum of OHs and NHs
in the chemical structure was larger than 5. The "rule of 5" states that: poor
absorption or permeation is more likely when:
A. There are less than 5 H-bond donors (expressed as the sum of OHs and
NHs);
B. The MWT is less than 500;
C. The LogP is less than 5 (or MLogP is < 4.15);
D. There are less than 10 H-bond acceptors (expressed as the sum of Ns and
Os).
Compound classes that are substrates for biological transporters are exceptions to
the rule."
Lipinski: « rule of 5 »

• A quick sketch with ChemDraw, conversion to a
3D structure with Chem3D, and processing by
QuikProp, reveals that the problem appears to be
poor cell permeability for this relatively polar
molecule, with predicted PCaco and PMDCK
values near 10 nm/s.
• Free alternative (Chemsketch / PreADME)

(Celebrex)
Methyl in this position makes it a weaker cox-2 inhibitor,
but site of metabolic oxidation and ensures an acceptable clearance
Drug-like-ness

To assist combinatorial chemistry, buy specific compunds


Structural Descriptors: (15 descriptors)
Molecular Formula, Molecular Weight, Formal Charge, The Number of Rotatable Bonds, The Number of Rigid Bonds, The Number of Rings, The Number of Aromatic Rings, The Number of H Bond Acceptors, The Number of H Bond Donors, The Number of (+) Charged Groups, The Number of (-) Charged Groups, No. single, double, triple, aromatic bonds
Topological Descriptors:(350 descriptors)
• Topological descriptors on the adjustancy and distance matrix
• Count descriptors
• Kier & Hall molecular connectivity Indices
• Kier Shape Indices
• Galvez topological charge Indices
• Narumi topological index
• Autocorrelation descriptor of atomic masses, atomic polarizability, Pauling electronegativity and van der Waals radius
• Information content descriptors
• Electrotopological state index (E-state)
• Atomic-Level-Based AI topological descriptors
Physicochemical Descriptor:(10 descriptors)
AlogP98 (calculated logP), SKlogP (calculated logP), SKlogS in pure water (calculated water solubility), SKlogS in buffer system (calculated water solubility),SK vap (calculated vapor pressure), SK bp (calculated boiling point), SK mp (calculated meling point), AMR (calculated molecular refractivity), APOL(calculated polarizability), Water Solvation Free Energy
Geometrical Descriptor:(9 descriptors)
Topological Polar Surface Area, 2D van der Waals Volume, 2D van der Waals Surface Area, 2D van der Waals Hydrophobic Surface Area, 2D van der Waals Polar Surface Area, 2D van der Waals H-bond Acceptor Surface Area, 2D van der Waals H-bond Donor Surface Area, 2D van der Waals (+) Charged Groups Surface Area, 2D van der Waals (-) Charged Groups Surface Area

• What can you do with these descriptors ?
• Cluster entire chemical library
– Diversity set
– Focused set
Drug Discovery: Hit/lead computational approaches

• Structure is known, virtual screening -> docking
• Many different approaches– DOCK
– FlexX
– Glide
– GOLD
• Including conformational sampling of the ligand
• Problem: – host flexibility
– solvatation
• Example: Bissantz et al.– Hit rate of 10% for single scoring function
– Up to 70% with triple scoring (bagging)
Drug Discovery: Docking

• Given the target site:
• Docking + structure generator
• Specialized approach: growing substituent on a core– LUDI
– SPROUT
– BOMB (biochemical and organic model builder)
– SYNOPSIS
• Problem is the scoring function which is different for every protein class
Drug Discovery: De novo design / rational drug design

Drug Discovery: Novel strategies using bio/cheminformatics
- HTS ? Chemical space is big (1041)
- Biased sets/focussed libraries -> bioinformatics !!!
- How ? Use phylogenetics and known structures to define
accesible (conserved) functional implicated residues to
define small molecule pharmacophores (minimal
requirements)
- Desciptor search (cheminformatics) to construct/select
biased compound set
- ensure serendipity by iterative screening of these
predesigned sets

Drug Discovery
Toxigenomics
Metabogenomics


• Preclinical - An early phase of development
including initial safety assessment
Phase I - Evaluation of clinical pharmacology,
usually conducted in volunteers
Phase II - Determination of dose and initial
evaluation of efficacy, conducted in a small
number of patients
Phase III - Large comparative study
(compound versus placebo and/or established
treatment) in patients to establish clinical
benefit and safety
Phase IV - Post marketing study
Drug Discovery: Clinical studies



Drug Discovery & Development: IND filing

Hapmap

Pharmacogenomics
Predictive/preventive – systems biology

Sneak preview
Bioinformatics (re)loaded

Sneak preview
Bioinformatics (re)loaded
• Relational datamodels
– BioSQL (MySQL)
• Data Visualisation
– Interface
• Apache
• PHP
• Large Scale Statistics
– Using R