biological databases
TRANSCRIPT

Databases

INSDCInternational Nucleotide Sequence Database Collaboration
GenBank EMBL DDBJ
Sequence types:
Eukaryotic gene
Bacterial operon
Artificial Cloning vectors
Plasmid
Repeat element
Transfer RNA

GenBankNucleic Acids Research, 2008, 36, D25-D30

GenBankDoubled in size about every 18 months
80 billion nucleotide bases from more than 76 million individual
sequences

Sequence-based taxonomy

2,60,000 named species
1700 species are being added per month
12 % are human origin & 8% are human EST
The top species
Homo sapiens ------- 12.7 billion
Mus musculus ------- 8.3 billion
Rattus norvegicus ------- 5.8 billion
Bos taurus ------- 3.8 billion
Zea mays ------- 3.6 billion

GenBank Records and Divisions

GenBank records
Partitioned into “divisions”
Traditional BCT, VRL, PRI, ROD
Recent EST, GSS, HTG, HTC, ENV
WGS
Special TPA

WGS Accession numbers are issued to these sequences
eg., AAAA01072744
AAAA Project ID
01 Version number
072744 Contig number
TPA Third party annotation
1. Experimental
2. Inferential

Data submission

BankIt
Use BankIt if: you have one or a few sequence submissions you prefer to use a WWW-based submission tool your sequence annotation is not complicated you do not require sequence analysis tools to submit your sequence(s)

Sequin
Use Sequin if: you are submitting long or complex submissions you are submitting mutation, phylogenetic, population, environmental, or segmented sets you would like graphical viewing and editing options, including the alignment editor you would like network access to related analytical tools

EMBL

EMBLMaintained by EBI
Other databases of EBI
Swiss-Prot
TrEMBL
UniProt
InterPro
E-MSD
ArrayExpress

EMBLTaxonomic
Invertebrates, Organells, Bacteriophages, Plants, Prokaryotes, Rodents
Non-Taxonomic
HTG, HTC, GSS, WGS, EST

EMBL representationFor Genomic data Coding strand
cDNA data RNA sequence
tRNA Mature transcript
WebIn Data submission tool

DDBJ
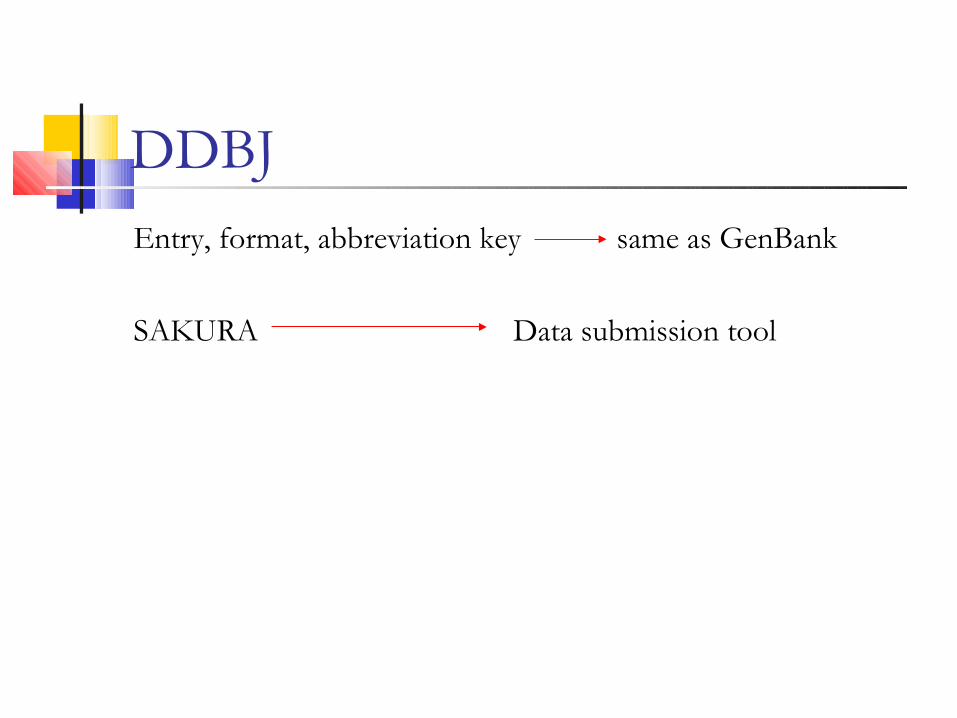
DDBJEntry, format, abbreviation key same as GenBank
SAKURA Data submission tool

Secondary Nucleotide Sequence Databases
UniGene
Database of unique
gene clusters

STACK (Sequence Tag Alignment and Consensus Knowledgebase)
Ribosomal database
HIV sequence database
EPD (Eukaryotic Promoter Database)
REBASE

SwissProtCurated protein sequence database
High level of annotation
Description of the function
Domains structure
PTMs
Variants
TrEMBL
Consists of entries in SWISS-PROT-like format

PIR-PSDProtein Information resource- Protein Sequence Database
World’s first database of classified and funtionally annotated
protein sequences
Grew out of The Atlas of Protein Sequence and Structure

UniProtUniversal Protein Resource
Comprehensive resource for protein sequence and annotated
data

Sequence AlignmentsAlignments:
Pairwise
Multiple
Multiple Sequence Alignments provide information on,
Alignment itself
Consensus Sequences
Conserved residues
Conserved residue patterns
Sequence Profiles

Consensus Sequence DatabasesMultiple Alignment
↓
A single sequence in which each residue is the most common or consensus for the sequence family
↓
Consensus Sequence Database

Consensus Sequence Databases Disadvantage:
Much information from the sequences that do not contain the consensus residue is ignored, even though these hold information about allowed substitutions.

PROSITE Database of sequence patterns Associated with protein family membership. Developed using patterns that best fit particular protein
families and functions.

PROSITE
Serine Protease Family :- Pattern1:
[LIVM]-[ST]-A-[STAG]-H-C Pattern2:
[DNSTAGC]-[GSTAPIMVQH]-x(2)-G-[DE]-S-G-[GS]-[SAPHV]-[LIVMFYWH]-PA-[LIVMFYSTANQH]

PROSITEFeatures:
1.Much shorter than total sequence length
2.Provide information on acceptable substitution.
3.Provide information on shared biological functions.

PROSITEDisadvantage:
1. Lack of specificity.
2. They have no way of attaching
probabilities to the variation.

PRINTS and BLOCKS Contain multiply aligned ungapped segments.
BLOCKS- blocks
PRINTS - motifs

PRINTS and BLOCKS Advantages
1. Potentially more sensitive (more
distant relationships can be found)
2.More specific (fewer false positives
occur)

Specialized Sequence Database rRNA database tRNA database 5S rRNA database Promoter sequence database InBase, a database on inteins

OMIM Online Mendelian Inheritance in Man Comprehensive database of human genes and genetic
disorders. Has numerous links to databases like SWISS- PROT,
PubMed, Mutation databases, Mapviewer.

Structural Databases RCSB
1. PDB
2. NDB



Structural Databases PDBe of EBI
MMDB
Structures derived from the PDB, with value-added features
such as,
Explicit chemical graphs,
Links to literature,
Similar sequences,
Related 3D structures,
Information about chemicals


Structural DatabasesCATH
C- Class
A- Architecture
T- Topology
H- Homologous superfamily
SCOP
Structural Classification of Proteins

Higher Order Functions Databases KEGG (Kyoto Encyclopedia of Genes and Genomes)
Subsidiary Databases
Contains 16 main databases




Higher Order Functions Databases
DIP (Database of Interacting Proteins)
BIND (Biomolecular Interaction Network Database)
Literature Databases PubMed Web of Science BioMedNet

Data retrieval tools
Data retrieval toolsEntrez