biological networks woochang hwang. biological networks introduction biological networks...
Post on 21-Dec-2015
227 views
TRANSCRIPT

BIOLOGICAL NETWORKS
Woochang Hwang

BIOLOGICAL NETWORKS Introduction Biological Networks
Protein-Protein Interaction Networks Signaling & Metabolic Pathway Networks Expression Networks
Biological Networks’ Properties Databases Discussion STM Clustering Model

Introduction

Bioinformatics
Informatics
Its carrier is a set of digital codes and a language.
In its manifestation in the
space-time continuum, it has utility (e.g. to decrease entropy of an open system).
Bioinformatics
The essence of life is information (i.e. from digital code to emerging properties of biosystems.)
Bioinformatics is the study of information content of life

Proteomics
Genomics
Proteomics
Structural Proteomics Functional Proteomics
Structure Determination
Database / Knowledge Source
Homology Modeling
Protein-Protein Interaction & Networking
Protein Expression
Post-tranlational Modification
Database / Knowledge Source

From the particular to the universal
A.-L- Barabasi & Z. Oltvai, Science, 2002

Genome Size

Proteom Size (PDB)

Networks are found in biological systems of varying scales:
1. Evolutionary tree of life
2. Ecological networks 3. Expression networks4. Regulatory networks
- genetic control networks of organisms 5. The protein interaction network in cells6. The metabolic network in cells… more biological networks
BIOLOGICAL NETWORK

Why Study Networks? It is increasingly recognized that complex
systems cannot be described in a reductionist view.
Understanding the behavior of such systems starts with understanding the topology of the corresponding network.
Topological information is fundamental in constructing realistic models for the function of the network.

Biological Network Model
Network A linked list of interconnected nodes.
Node Protein, peptide, or non-protein biomolecules.
Edges Biological relationships, etc., interactions, regulations, reactions,
transformations, activation, inhibitions.

Biological Network Model
It is usually represented by a 2-D diagram with characteristic symbols linking the protein and non-protein entities.
A circle indicates a protein or a non-protein biomolecule.
An symbol in between indicates the nature of molecule-molecule process (activation, inhibition, association, disassociation, etc.)

Protein Interaction Network

Proteins in a cell There are thousands of different active
proteins in a cell acting as: enzymes, catalysors to chemical reactions of
the metabolism components of cellular machinery (e.g.
ribosomes) regulators of gene expression Certain proteins play specific roles in special
cellular compartments. Others move from one compartment to
another as “signals”.

Protein Interactions Proteins perform a function as a complex rather
as a single protein. Knowing whether two proteins interact can help
us discover unknown proteins’ functions: If the function of one protein is known, the
function of its binding partners are likely to be related- “guilt by association”.
Thus, having a good method for detecting interactions can allow us to use a small number of proteins with known function to characterize new proteins.

Protein Interactions
P. Uetz, et al. Nature, 2000; Ito et al., PNAS, 2001; …
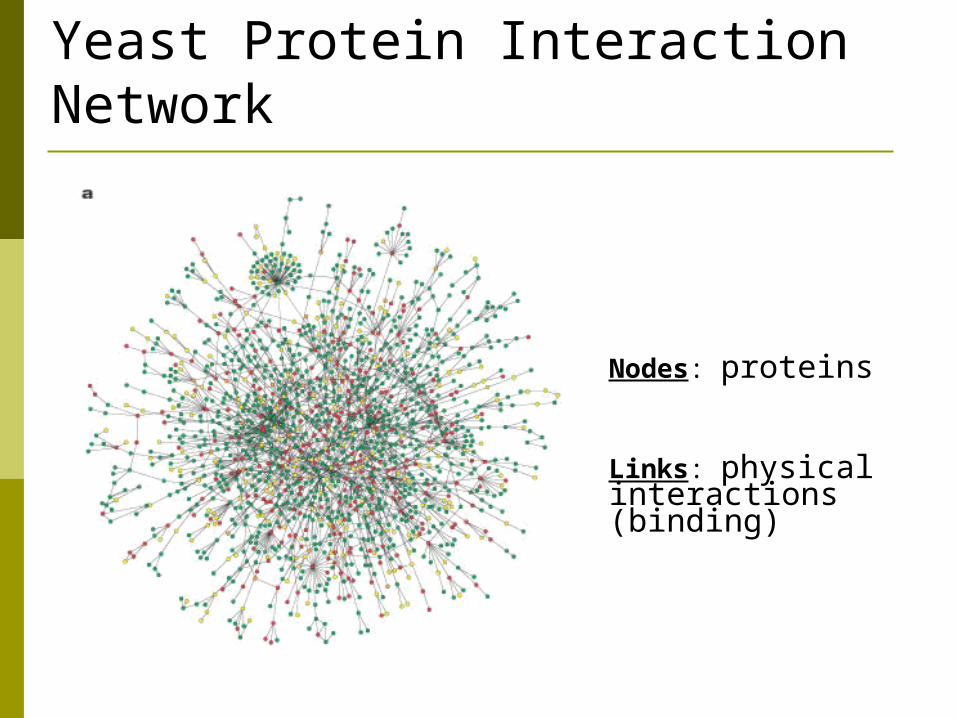
Yeast Protein Interaction Network
Nodes: proteins
Links: physical interactions (binding)

Pathway Networks

Signaling & Metabolic Pathway Network A Pathway can be defined as a modular unit
of interacting molecules to fulfill a cellular function.
Signaling Pathway Networks In biology a signal or biopotential is an electric
quantity (voltage or current or field strength), caused by chemical reactions of charged ions.
refer to any process by which a cell converts one kind of signal or stimulus into another.
Another use of the term lies in describing the transfer of information between and within cells, as in signal transduction.
Metabolic Pathway Networks a series of chemical reactions occurring within a cell,
catalyzed by enzymes, resulting in either the formation of a metabolic product to be used or stored by the cell, or the initiation of another metabolic pathway

A Pathway Example

A Pathway Example

A Pathway Example

Regulatory Network a collection of DNA segments (genes) in a cell
which interact with each other and with other substances in the cell, thereby governing the rates at which genes in the network are transcribed into mRNA.

Regulatory Network

Expression Network A network representation of genomic data. Inferred from genomic data, i.e. microarray.

BIOLOGICAL NETWORK PROPERTY
Interaction Network Pathway Network Regulatory Network Expression Network

Biological Networks Properties
Power law degree distribution: Rich get richer Small World: A small average path length
Mean shortest node-to-node path Robustness: Resilient and have strong
resistance to failure on random attacks and vulnerable to targeted attacks
Hierarchical Modularity: A large clustering coefficient How many of a node’s neighbors are
connected to each other

PREFERENTIAL ATTACHMENT on Growth: the probability that a new vertex will be connected to vertex i depends on the connectivity of that vertex:
( ) ii
jj
kk
k
Power Law Network

The Barabási-Albert [BA] model
ER Model WS Model Actors Power Grid www
The probability of finding a highly connected node decreases exponentially with k:
( ) ~P K K
(a) Random Networks (b) Power law Networks
Power Law Network (Scale Free)

Small World Property A small average path length Any node can be reached within a small
number of edges, 4~5 hops.

Power-law degree distribution & Small world phenomena also observed in: communication networks web graphs research citation networks social networks
Classical -Erdos-Renyi type random graphs do not exhibit these properties: Links between pairs of fixed set of nodes picked
uniformly: Maximum degree logarithmic with network size No hubs to make short connections between nodes
Power Law Network

Attack Tolerance
Complex systems maintain their basic functions even under errors and failures (cell mutations; Internet
router breakdowns)
node failure

Attack Tolerance
Robust. For <3, removing nodes does not break network into islands.
Very resistant to random attacks, but attacks targeting key nodes are more dangerous.
Ma x
Clu
s te r
Siz
e P
ath
Leng
th

Protein Interaction Network
)exp()(~)( 00
k
kkkkkP
H. Jeong, S.P. Mason, A.-L. Barabasi & Z.N. Oltvai, Nature, 2001

Protein Interaction Network
The yeast protein interaction network seems to reveal some basic graph theoretic properties: The frequency of proteins having interactions with
exactly k other proteins follows a power law. The network exhibits the small world phenomena: can
reach any node within small number of hops, usually 4 or 5 hops
Robustness: Resilient and have strong resistance to failure on random attacks and vulnerable to targeted attacks.

Hierarchical Modularity
E. Ravasz et al., Science, 2002

Hierarchical Modularity
Metabolic Networks Protein Networks
E. Ravasz et al., Science, 2002

Implications From Observations
Biological complexity: # states ~2# of genes. Protein hubs critical for cells, 45% . Infections will target highly connected nodes. Cascading node failures could cause a critical
problem. Development of drug and treatment with novel
strategies like targeting effective nodes is indispensable.

Databases

Swiss-Prot (non-redundant database): Release 41.0, 11/4/2003: 124,464 entries. Release 41.5, 23/4/2002: 125,236 entries.
TrEMBL (translations of EMBL nucleotide sequences not yet integrated into Swiss-Prot): Release 23.7, 17/4/2003: 863,248 entries
This number keeps rapidly growing mainly due to large scale sequencing projects.
Protein Databases

Protein Interaction Databases Species-specific
FlyNets - Gene networks in the fruit fly MIPS - Yeast Genome Database RegulonDB - A DataBase On Transcriptional Regulation
in E. Coli SoyBase PIMdb - Drosophila Protein Interaction Map database
Function-specific Biocatalysis/Biodegradation Database BRITE - Biomolecular Relations in Information
Transmission and Expression COPE - Cytokines Online Pathfinder Encyclopaedia Dynamic Signaling Maps EMP - The Enzymology Database FIMM - A Database of Functional Molecular Immunology CSNDB - Cell Signaling Networks Database

Protein Interaction Databases Interaction type-specific
DIP - Database of Interacting Proteins DPInteract - DNA-protein interactions Inter-Chain Beta-Sheets (ICBS) - A database of protein-
protein interactions mediated by interchain beta-sheet formation
Interact - A Protein-Protein Interaction database GeneNet (Gene networks)
General BIND - Biomolecular Interaction Network Database BindingDB - The Binding Database MINT - a database of Molecular INTeractions PATIKA - Pathway Analysis Tool for Integration and
Knowledge Acquisition PFBP - Protein Function and Biochemical Pathways
Project PIM (Protein Interaction Map)

Pathway Databases
KEGG (Kyoto Encyclopedia of Genes and Genomes) http://www.genome.ad.jp/kegg/ Institute for Chemical Research, Kyoto University
PathDB http://www.ncgr.org/pathdb/index.html National Center for Genomic Resources
SPAD: Signaling PAthway Database Graduate School of Genetic Resources Technology. Kyushu
University. Cytokine Signaling Pathway DB.
Dept. of Biochemistry. Kumamoto Univ. EcoCyc and MetaCyc
Stanford Research Institute BIND (Biomolecular Interaction Network Database)
UBC, Univ. of Toronto

KEGG
Pathway Database: Computerize current knowledge of molecular and cellular biology in terms of the pathway of interacting molecules or genes.
Genes Database: Maintain gene catalogs of all sequenced organisms and link each gene product to a pathway component
Ligand Database: Organize a database of all chemical compounds in living cells and link each compound to a pathway component
Pathway Tools: Develop new bioinformatics technologies for functional genomics, such as pathway comparison, pathway reconstruction, and pathway design





Discussion Problems
Network Inference
Micro Array, Protein Chips, other high throughput assay methods
Function prediction
The function of 40-50% of the new proteins is unknown
Understanding biological function is important for: Study of fundamental biological processes Drug design Genetic engineering
Functional module detection Cluster analysis
Topological Analysis Descriptive and Structural Locality Analysis Essential Component Analysis
Dynamics Analysis Signal Flow Analysis Metabolic Flux Analysis Steady State, Response, Fluctuation Analysis
Evolution Analysis Biological Networks are very rich networks with very limited, noisy, and
incomplete information. Discovering underlying principles is very challenging.

Signal Transduction Model Based Functional Module
Detection Algorithm for Protein-Protein Interaction Networks
Woochang Hwang1
Young-Rae Cho1
Aidong Zhang1
Murali Ramanathan2
1Department of Computer Science and Engineering, State University of New York at Buffalo
2Department of Pharmaceutical Sciences, State University of New York at Buffalo
University at Buffalo The State University of New York

Contents
Introduction Protein Interaction Networks Functional Categories Functional Module Detection Algorithm
Signal Transduction Model (STM) Experimental Results Discussion Future Works

Introduction Cellular Functions are coordinately carried out by groups of genes and
gene products.
Detection of such functional modules in a complex molecular network is one of the most challenging problem.
Molecular networks: high data volume, high noise level, sparse connectivity, etc.
PPI data S. Cerevisae full PPI data in DIP: over 4900 proteins and 18000
interactions. PPI data provide us the good opportunity to analyze the underlying
principles and the structure of large living systems.

Cluster Assessment
Clustering Coefficient:
N(v) is the set of the direct neighbors of node v and d(v) is the number of the direct neighbors of node v
Betweeness Centrality:
is the number of shortest paths from node s to t and (v) the number of shortest paths from s to t that pass through the node v.
P-value:
C is the size of the cluster containing k proteins with a given function; G is the size of the universal set of proteins of known proteins and contains n proteins with the function.
The p-value is the probability that a cluster would be enriched with proteins with a particular function by chance alone.
Density:
n is the number of proteins and e is the number of interactions in a sub graph s of a PPI network.
1)()(
,2
)()(,
vdvd
ji
vCvNji
)1(
*2)(
nn
eCDensity
1
0
1k
i
n
G
in
CG
i
C
P
Vvts st
stB
vvC
)(
)(
stst

Protein-Protein Interaction (PPI) Data & MIPS Functional Category Data
DIP Yeast Protein Interaction core data 2521 proteins, 5949 interactions Average clustering coefficient: 0.069 Average path length: 5.47
MIPS Functional Category 457 Hierarchical Functional Categories Sub graphs of each functional categories are
extracted from DIP core data. Average graph density: 0.0025 Average diameter (longest path in a graph): 4.23
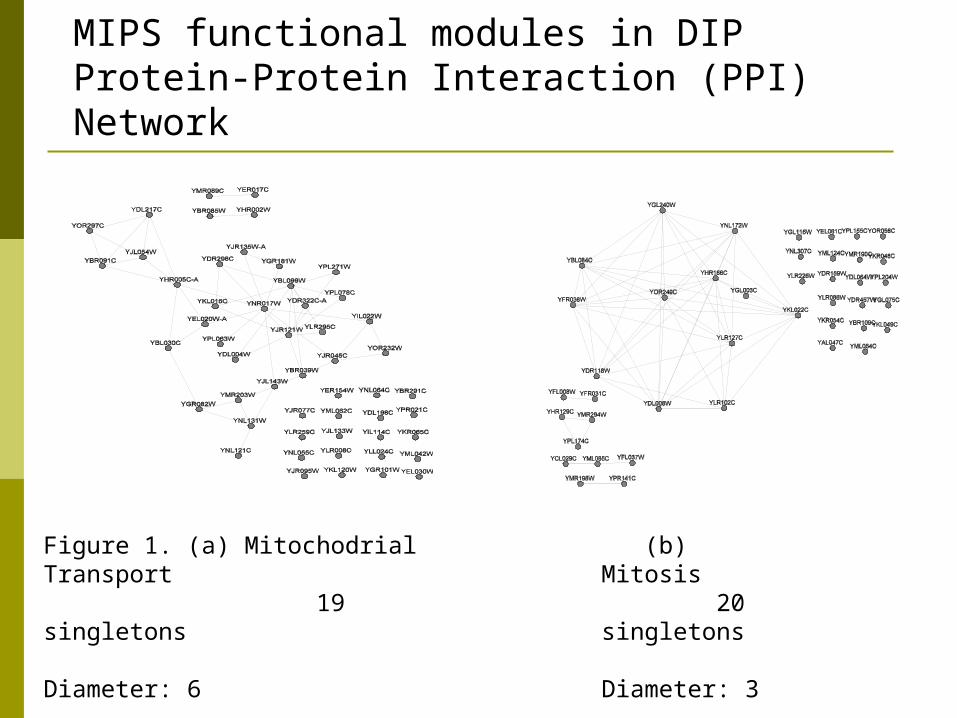
MIPS functional modules in DIP Protein-Protein Interaction (PPI) Network
Figure 1. (a) Mitochodrial Transport 19 singletons Diameter: 6
(b) Mitosis 20 singletons Diameter: 3

Topological Properties of MIPS Functional Modules in DIP Protein Interaction Data
Sparse connectivity : low density, isolated sub graphs and singletons existence.
Longish shape: high diameter

Related works
Distance Based Approaches Several distance metrics were introduced Use traditional clustering algorithms
Graph Based Approaches Density based approaches: Maximal Cliques, Quasi
Cliques, RNSC, HCS, MCODE Statistical approaches: MCL, Samantha

Related works
Suffered by their limited way of clustering. identify only the clusters with specific shapes, e.g., balanced
round shapes, with high density .
But, the actual functional modules are not so densely connected as they expected.
Some members in functional categories do not have direct physical interaction with other members of the functional category they belong to.
Modules that have longish shapes are frequently observed.
The incompleteness of clustering is another distinct drawback of existing algorithms, which produce many clusters with small size and singletons.

Contribution
STM Clustering Model Effective clustering should be able to detect clusters with arbitrary
shape and density if the cluster members share biological and topological similarities.
To take those unexpected properties of PPI networks and actual functional modules into consideration and to conquer the drawbacks of existing approaches effectively:
STM clustering model utilizes a statistical signal transduction model to find the modules whose members share biological common feature even though they are sparsely connected.
STM model also adopts the network’s topological properties into the model.
Unexpected properties of functional categories and sparse connectivity in PPI networks.
A relative excess of emphasis on density in the existing methods can be preferential for detecting clusters with relatively balanced round shapes, high discarding rate, and limit performance.

STM Clustering Model
Process 1: Simulation of dynamic statistical signal transduction behavior in the network.
STM model simulates dynamic signal transduction behavior to find the most influential proteins on each protein in PPI network biologically and topologically.
Process 2: Selection of the putative cluster representatives on each node.
Process 3: Preliminary clusters formation. Preliminary clusters will be formed by accumulating each node
toward its chosen representatives.
Process 4: Cluster merge. So far, STM has considered only the biological features and
topological connectivity of the network and its components, not similarity among preliminary clusters.
Clusters that have significant interconnections between them should have substantial similarity.
In process 4, STM will merge the clusters which has substantial similarity.

Statistical Signal Transduction Model
Signal transduction behavior of the network is modeled by the Erlang distribution, a special case of the Gamma distribution.
(1)
where c > 0 is the shape parameter, b > 0 is the scale parameter, x >= 0 is the independent variable, usually time.
The Erlang distribution with x/b = 1 is used and the value of c is set to the number of nodes between source protein node and the target protein
Setting the value of x/b to unity assesses the perturbation at the target protein when the perturbation reaches 1/e of its initial value at the nearest neighbor of the source protein node.
1
0 !1)(
c
k
k
b
x
k
bxecF

Statistical Signal Transduction Model
Statistically, the Erlang distribution represents the time required to carry out a sequence of c tasks whose durations are identical, exponential probability distributions.
It represents the chance that the actual time to accomplish c tasks will be less than or equal to b.
Figure 2. The pharmacodynamic signal transduction model whose bolus response is an Erlang distribution. The b is the time constant for signal transfer and c is the number of compartments.

Topologically Modified Signal Transduction Model The Erlang distribution was further weighted to reflect network
topology.
(2)
d(i) is the degree of node i, P(v,w) is the set of all visited nodes on the shortest path from node v to node w excluding the source node v and target node w, and F(c) is the signal transduction behavior function.
The perturbation induced by the source protein node was assumed to be proportional to its degree and to follow the shortest path to the target protein node.
Our choice of the shortest path is motivated by the finding that the majority of flux prefers the path of least resistance in many physicochemical and biological systems.
During transduction to the target protein node, the perturbation was assumed to be dissipated at each intermediate node visited in proportion to the reciprocal of the degree of each intermediate node visited.
)()(
)()(
),(
cFid
vdwvS
wvPi

Process 1: Signal Transduction Simulation
Figure 3. Blue arrows are signals from node A and Red ones are from node H. Results for other nodes are not shown.

Process 1: Signal Transduction Simulation
Figure 3. Blue arrows are signal from node A and Red ones are from node H. Results for other nodes are not shown.

Process 1: Signal Transduction Simulation
Figure 3. Blue arrows are signal from node A and Red ones are from node H. Results for other nodes are not shown.

Process 1: Signal Transduction Simulation
Figure 3. Blue arrows are signal from node A and Red ones are from node H. Results for other nodes are not shown.

Process 2: Representatives Selection
Figure 4. A simple network. Each box contains the numerical values obtained from Equation 2, from source nodes A, F, G, and H to other target nodes although signals should be propagated from every node in the network. Results for other nodes are not shown.

Process 3: Preliminary Clusters Formulation
Figure 5. Three preliminary clusters, {A, B, C, D, E, F}, {F, G, L, N}, {G, H, I, J, K, M}, are obtained after the Process 3.

Cluster Merge
Similarity of two clusters i and j
(3)
where interconnectivity(i, j) is the number of connections between clusters i and j, and minsize(i, j) is the size of the smaller cluster among clusters i and j.
The pair of clusters that have the highest similarity are merged in each iteration and the merge process iterates until the highest similarity of all cluster pairs is less than a given threshold.
We see when interconnectivity(i, j)>=minsize(i, j), clusters i and j have substantial interconnections.
),(minsize
),(ctivityinterconne),(Similarity
ji
jiji

Process 4: Cluster Merge
Figure 6. Two clusters, {A, B, C, D, E, F, G, L, N}, {G, H, I, J, K, M}, are obtained after the Merge process when 1.0 is used as the merge threshold.

Process 4: Cluster Merge
Figure 7. Three clusters, {A, B, C, D, E, F}, {F, G, L, N}, {G, H, I, J, K, M}, are obtained after the Process 4 when 2.0 is used as the merge threshold.

Experimental Results Protein Interaction Data
The core data of S. Cerevisiae was obtained from the DIP database.
2526 proteins and 5949 filtered reliable physical interactions.
Species such as S. Cerevisae provide important test beds for the study of the PPI networks since it is a well-studied organism for which most proteomics data is available for the organism, by virtue of the availability of a defined and relatively stable proteome, full genome clone libraries, established molecular biology experimental techniques and an assortment of well designed genomics databases.

Clustering Performance Analysis
60 clustersAverage size: 40.1Average Density: 0.2145Average P-value: 13.7Average Hit %: 51.7Average Unknown %: 5.1
Distribution (%) Cluster Protein no
Density H D U
P-value (-log10)
Function
1 214 0.019 24.7 69.6 5.6 43.9 Nuclear transport 2 188 0.015 69.1 25 5.8 36.4 Cell cycle and DNA processing 3 181 0.022 22.0 72.3 5.5 17.2 Cytoplasmic and nuclear protein degradation 4 170 0.028 46.4 42.9 10.5 31.6 Transported compounds (substrates) 5 131 0.028 37.4 55.7 6.8 28.6 Vesicular transport (Golgi network, etc.) 6 125 0.030 60.8 33.6 5.6 32.2 tRNA synthesis 7 113 0.027 19.4 71.6 8.8 11.8 Actin cytoskeleton 8 79 0.045 17.7 73.4 8.8 12.3 Homeostasis of protons 9 78 0.033 26.9 62.8 10.2 12.5 Ribosome biogenesis 10 76 0.041 38.1 59.2 2.6 20.2 rRNA processing 11 72 0.030 5.55 84.7 9.7 6.23 Calcium binding 12 68 0.064 66.1 25 8.8 44.5 mRNA processing 13 61 0.041 40.9 52.4 6.5 11.5 Cytoskeleton 14 58 0.064 72.4 27.5 0 37.4 General transcription activities 15 53 0.048 15.0 71.6 13.2 7.93 MAPKKK cascade 16 50 0.064 66 32 2 33.5 rRNA processing 17 45 0.055 24.4 73.3 2.2 11.1 Metabolism of energy reserves 18 44 0.058 59.0 36.3 4.5 5.08 Metabolism 19 39 0.072 10.2 89.7 0 7.33 Cell-cell adhesion 20 36 0.125 58.3 36.1 5.5 16.9 Vesicular transport 21 29 0.091 55.1 44.8 0 8.29 Phosphate metabolism 22 28 0.074 14.2 78.5 7.1 4.49 Lysosomal and vacuolar protein degradation 23 27 0.119 29.6 66.6 3.7 7.28 Cytokinesis (cell division) /septum formation 24 26 0.153 53.8 46.1 0 28.6 Peroxisomal transport 25 25 0.09 28 68 4 4.59 Regulation of C-compound and carbohydrate utilization 26 25 0.116 68 28 4 12.9 Cell fate 27 22 0.151 59.0 36.3 4.5 11.4 DNA conformation modification 28 21 0.147 76.1 19.0 4.7 23.9 Mitochondrial transport 29 20 0.2 75 20 5 24.0 rRNA synthesis 30 19 0.228 78.9 15.7 5.2 17.9 Splicing 31 17 0.220 70.5 29.4 0 19.7 Microtubule cytoskeleton 32 17 0.183 23.5 76.4 0 8.17 Regulation of nitrogen utilization 33 15 0.304 86.6 13.3 0 31.3 Energy generation 34 14 0.142 50 42.8 7.1 8.98 Small GTPase mediated signal transduction 35 13 0.564 76.9 23.0 0 15.9 Mitosis 36 13 0.358 84.6 15.3 0 12.4 DNA conformation modification 37 13 0.410 69.2 23.0 7.6 17.6 3'-end processing 38 13 0.179 61.5 30.7 7.6 6.70 DNA recombination and DNA repair 39 12 0.196 16.6 75 8.3 3.92 Unspecified signal transduction 40 12 0.363 58.3 41.6 0 14.7 Posttranslational modification of amino acids 41 12 0.166 16.6 75 8.3 2.35 Autoproteolytic processing 42 11 0.218 54.5 45.4 0 2.91 Transcriptional control 43 11 0.2 72.7 27.2 0 8.16 Enzymatic activity regulation / enzyme regulator 44 10 0.466 80 20 0 14.8 Translation initiation 45 9 0.361 77.7 22.2 0 12.8 Translation initiation 46 8 0.321 50 37.5 12.5 5.60 Metabolism of energy reserves 47 8 0.321 75 25 0 9.00 Modification by ubiquitination, deubiquitination 48 8 0.321 37.5 62.5 0 3.66 Mitosis 49 7 0.333 42.8 57.1 0 3.46 DNA damage response 50 7 0.333 57.1 28.5 14.2 4.09 Vacuolar transport 51 7 0.285 28.5 71.4 0 4.41 Biosynthesis of serine 52 6 0.333 50 33.3 16.6 2.38 Modification by phosphorylation, dephosphorylation, etc. 53 5 0.4 100 0 0 6.99 Meiosis 54 5 0.6 100 0 0 7.01 Vacuolar transport 55 5 0.4 100 0 0 8.53 ER to Golgi transport 56 5 0.4 20 40 40 1.81 cAMP mediated signal transduction 57 5 0.5 40 40 20 3.11 Oxidative stress response 58 5 0.5 80 20 0 4.43 Intracellular signalling 59 5 0.6 40 60 0 4.19 Tetracyclic and pentacyclic triterpenes 60 5 0.4 60 40 0 4.11 Mitochondrial transport
Table 1. all 60 clusters that have more than 4 proteins

Comparative Analysis
Table 2. Performance analyses of the clusters more than size 4.
Methods Number of Clusters
Avg. size of Clusters
Percent of Discarded Nodes (%)
Avg. P-Score Based on Functions (-log10P)
Avg. P-Score Based on Localizations (-log10P)
STM 60 40.1 7.8 13.7 7.42 Maximal Clique 120 5.65 98.4 10.61 7.93 Quasi Clique 103 11.2 80.8 11.50 6.58 Samantha 64 7.9 79.9 9.16 4.89 Minimum Cut 114 13.5 35.0 8.36 4.75 Betweeness Cut 180 10.26 21.0 8.19 4.18 MCL 163 9.79 36.7 8.18 3.97
Other methods can only detect the clusters with small size. Relatively high P-scores regarding their high discarding rates on other methods (e.g., Maximal Clique, Quasi Clique, Samantha)
Due to the mass production of small size clusters which have less than 5 members Due to the discard of sparsely connected proteins. Due to high overlaps among many small clusters which are highly enriched for the same function.

Computational Complexity Our signal transduction based model is fundamentally
established on all pairs shortest path searching algorithm to measure the distance between all pairs of nodes: O(V2logV+VE) where V is the number of nodes and E is the number of edges in a network.
The time required to find the best cluster pair that has the most interconnections is O(k2logk) by using heap-based priority queue, where k is the number of preliminary clusters.
But k is much smaller than V in sparse networks like the Yeast PPI network.
So the total time complexity of our algorithm is bounded by the time consumed in measuring the distance between all pairs of nodes, which is O(V2logV+VE).

Discussion In head-to-head comparisons, our algorithm outperformed
competing approaches and is capable of effectively detecting both dense and sparsely connected, biologically relevant functional modules with fewer discards.
The clusters identified had p-values that are 2.2 orders of magnitude or approximately 125-fold lower than Quasi clique, the best performing alternative clustering method, on biological function.
The incompleteness of clustering is another distinct drawback of existing algorithms, which produce many clusters with small size and singletons.
Our method discarded only about 7.8% of proteins which is tremendously lower than the other approaches did, 59% in average.
In conclusion, our method has strong pharmacodynamics-based underpinnings and is an effective, versatile approach for analyzing protein-protein interactions.

Thanks!