biometric authentication via keystroke sound -...
TRANSCRIPT

Biometric Authentication via Keystroke Sound
Joseph Roth Xiaoming Liu Arun RossDepartment of Computer Science and EngineeringMichigan State University, East Lansing MI 48824
{rothjos1,liuxm,rossarun}@msu.edu
Dimitris MetaxasDepartment of Computer Science
Rutgers University, Piscataway, NJ [email protected]
Abstract
Unlike conventional one shot biometric authenticationschemes, continuous authentication has a number of ad-vantages, such as longer time for sensing, ability to rec-tify authentication decisions, and persistent verification ofa user’s identity, which are critical in applications demand-ing enhanced security. However, conventional modalities,e.g., face, fingerprint, and keystroke dynamics, have vari-ous drawbacks in continuous authentication scenarios. Inlight of this, this paper proposes a novel non-intrusive andprivacy-friendly biometric modality that utilizes keystrokesound. Given the keystroke sound recorded by a low-cost microphone, our system extracts discriminative fea-tures and performs matching between a gallery stream anda probe stream. Motivated by the concept of digraphs usedin modeling keystroke dynamics, we learn a virtual alpha-bet from keystroke segments, from which the digraph latencywithin pairs of virtual letters, as well as other statistical fea-tures, are utilized by the score functions. The resultant mul-tiple scores are indicative of the similarities between twosound streams, and are fused to make a final authentica-tion decision. We collect a first-of-its-kind keystroke sounddatabase of 45 subjects typing on a keyboard. Experimentson static text-based authentication, demonstrate the poten-tial as well as limitations of this novel biometric modality.
1. IntroductionBiometric authentication is the process of verifying the
identity of individuals by their physical characteristics, suchas face [8] and fingerprint [16], or behavioral traits, suchas gait and keystroke dynamics [2]. Most biometric au-thentication research has focused on one shot authenticationwhere a subject’s identity is verified only once. However,one shot authentication has a number of drawbacks in manyapplication scenarios. These include short sensing time, in-ability to rectify decisions, and enabled access for poten-tially unlimited periods of time [18]. In contrast, continu-ous authentication aims to continuously verify the identity
Keystroke Sound Biometric
Subject_A is authenticated
to be a legitimate user!
Figure 1. The concept of keystroke sound biometric: The sound ofa user typing on the keyboard is captured by a simple microphoneattached to the PC and is input to our proposed system, which au-thenticates the user by verifying if the characteristic of the acousticsignals is similar to that of the claimed identity.
of a subject over an extended period of time thereby ensur-ing that the integrity of an application is not compromised.It can not only address the aforementioned problems in oneshot authentication, but can also substantially enhance thesecurity of systems, such as computer user authenticationin security-sensitive facilities.
Research on continuous authentication is relativelysparse, and researchers have explored a limited number ofbiometric modalities, such as face, fingerprint, keystrokedynamics, and mouse movement, for this purpose. How-ever, each of these modalities has its own shortcomings. Forexample, face authentication demands uninterrupted sens-ing and monitoring of faces - an intrusive process from auser’s perspective. Similarly, the fingerprint sensor embed-ded on the mouse requires user collaboration in terms ofprecision in holding the mouse [16]. Although being non-intrusive, keystroke dynamics utilizes key-logging to recordall typed texts and thus poses significant privacy risk in thecase of surreptitious usage [14, 2].
To address these problems in continuous authentication,this paper presents a novel biometric modality based onkeystroke acoustics. Nowadays, microphone has becomea standard peripheral device that is embedded in PCs, mon-itors, and webcams. As shown in Figure 1, a microphonecan be used to record the sound of a user typing on thekeyboard, which is then input to the proposed system for
Appeared in Proc. of 6th IAPR International Conference on Biometrics (ICB), (Madrid, Spain), June 2013

Acoustic signal(gallery)
Temporal segmentation & feature extraction
Extracted keystroke features
Convert to virtual letters
Timing and letter of keystrokes
Digraph statistic
Hist. of digraphs
Intra-letter dist.
Biometrictemplate
K-means clustering
Virtual alphabet
All acoustic signals Compute
score distributions
Acoustic signal(probe)
Feature set Score fusion
Score distributions
Yes/No
EnrollmentEnrollmentEnrollmentEnrollmentEnrollmentEnrollmentEnrollmentEnrollmentEnrollment
AuthenticationAuthenticationAuthenticationAuthenticationAuthenticationAuthenticationAuthenticationAuthenticationAuthentication
TrainingTrainingTrainingTrainingTrainingTrainingTrainingTrainingTraining
Top N digraphs
Digraph frequencyLetter frequency
Figure 2. Architecture of the biometric authentication via keystroke sound, where the boldface indicates the output of each stage.
feature extraction and matching. Compared to other bio-metrics modalities, it has a number of advantages. It uti-lizes a readily available sensor without requiring additionalhardware. Unlike face or fingerprint, it is less intrusive anddoes not interfere with the normal computing operation of auser. Compared to keystroke dynamics, it protects the user’sprivacy by avoiding direct logging of any keyboard input.Keystroke acoustics does have the disadvantage of dealingwith environmental noise, but proper audio filtering or a di-rected microphone should help in a noisy environment.
Our technical approach to employ this novel biometricis largely motivated by prior work in keystroke dynamics.One of the most popular features used to model keystrokedynamics is digraph latency [10, 9, 3], which calculates thetime difference between pressing the keys of two adjacentletters. It has been shown that the word-specific digraph ismuch more discriminative than the generic digraph, whichis computed without regard to what letters were typed [15].Considering that the acoustic signal from keystroke doesnot explicitly carry the information of what letter is typed,we propose a novel approach to employ the digraph fea-ture by constructing a virtual alphabet. Given the acous-tic signals from all training subjects, we first detect seg-ments of keystrokes, whose mel-frequency cepstral coeffi-cients (MFCC) [4] are fed into a K-means clustering rou-tine. The resultant set of cluster centroids is considered asa virtual alphabet, which enables us to compute the mostfrequent digraphs (a pair of cluster centroids) and their la-tencies for each subject. Based upon the virtual alphabet,we also consider a number of other feature representationand scoring schemes. Eventually a score level fusion is em-ployed to determine whether a probe stream matches withthe gallery stream. In summary, this paper has three maincontributions:
� We propose a novel keystroke sound-based biometricmodality that offers non-intrusive, privacy-friendly, and po-
tentially continuous authentication for computer users.� We collect a first-of-its-kind sound database of users
typing on a keyboard. The database and the experimentalresults are made publicly available so as to facilitate futureresearch and comparison on this research topic.�We propose a novel virtual alphabet-based approach to
learn various score functions from acoustic signals, and ascore-fusion approach to match two sound streams.
2. Prior WorkTo the best of our knowledge, there is no prior work in
exploring keystroke sound for the purpose of biometric au-thentication. As a result, we focus our literature survey onvarious biometric modalities for continuous authentication,and other applications of keystroke sound.
Face is one of the most popular modalities suggested forcontinuous user authentication, with the benefit of using ex-isting cameras embedded in the monitor and no require-ment for users’ cooperation [16, 12]. However, continu-ously capturing face images creates an intrusive and unfa-vorable computing environment for the user. Similarly, fin-gerprint has been suggested for continuous authenticationby embedding a fingerprint sensor on a specific area of amouse [16]. This can be intrusive since it substantially con-strains the way a user operates a mouse. Mouse dynamicshas been used as a biometric modality due to the distinctivecharacteristics exhibited in its movement when operated bya user [13]. However, as indicated in a recent paper [19],more than 3 minutes of mouse movement on average is re-quired to make a reliable authentication decision, which canbe a bottleneck when the user does not continuously use themouse for an extended period of time.
Keystroke dynamics utilizes the habitual patterns andrhythms a user exhibits while typing on a keyboard. Al-though it has a long history dating back to telegraph in the19th century and Morse Code in World War II, most of theprior work still focuses on static text [7, 20, 2], i.e., all users
Appeared in Proc. of 6th IAPR International Conference on Biometrics (ICB), (Madrid, Spain), June 2013
0 0.01 0.02 0.03 0.04 0.05
−0.1
−0.05
0
0.05
0.1
0.15
Sam
ple
Valu
e
Time (sec)
Keystroke Raw Signal
Key Press
Key Release
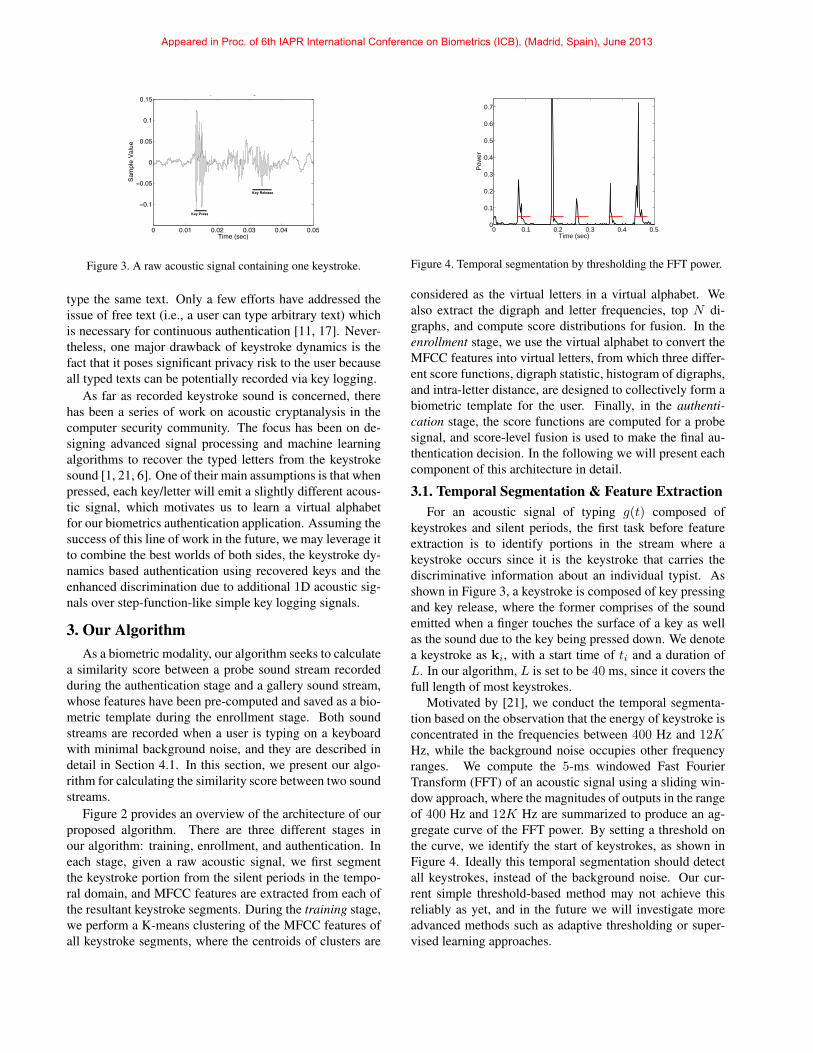
Figure 3. A raw acoustic signal containing one keystroke.
type the same text. Only a few efforts have addressed theissue of free text (i.e., a user can type arbitrary text) whichis necessary for continuous authentication [11, 17]. Never-theless, one major drawback of keystroke dynamics is thefact that it poses significant privacy risk to the user becauseall typed texts can be potentially recorded via key logging.
As far as recorded keystroke sound is concerned, therehas been a series of work on acoustic cryptanalysis in thecomputer security community. The focus has been on de-signing advanced signal processing and machine learningalgorithms to recover the typed letters from the keystrokesound [1, 21, 6]. One of their main assumptions is that whenpressed, each key/letter will emit a slightly different acous-tic signal, which motivates us to learn a virtual alphabetfor our biometrics authentication application. Assuming thesuccess of this line of work in the future, we may leverage itto combine the best worlds of both sides, the keystroke dy-namics based authentication using recovered keys and theenhanced discrimination due to additional 1D acoustic sig-nals over step-function-like simple key logging signals.
3. Our AlgorithmAs a biometric modality, our algorithm seeks to calculate
a similarity score between a probe sound stream recordedduring the authentication stage and a gallery sound stream,whose features have been pre-computed and saved as a bio-metric template during the enrollment stage. Both soundstreams are recorded when a user is typing on a keyboardwith minimal background noise, and they are described indetail in Section 4.1. In this section, we present our algo-rithm for calculating the similarity score between two soundstreams.
Figure 2 provides an overview of the architecture of ourproposed algorithm. There are three different stages inour algorithm: training, enrollment, and authentication. Ineach stage, given a raw acoustic signal, we first segmentthe keystroke portion from the silent periods in the tempo-ral domain, and MFCC features are extracted from each ofthe resultant keystroke segments. During the training stage,we perform a K-means clustering of the MFCC features ofall keystroke segments, where the centroids of clusters are
0 0.1 0.2 0.3 0.4 0.50
0.1
0.2
0.3
0.4
0.5
0.6
0.7
Pow
er
Time (sec)
FFT Keystroke Detection
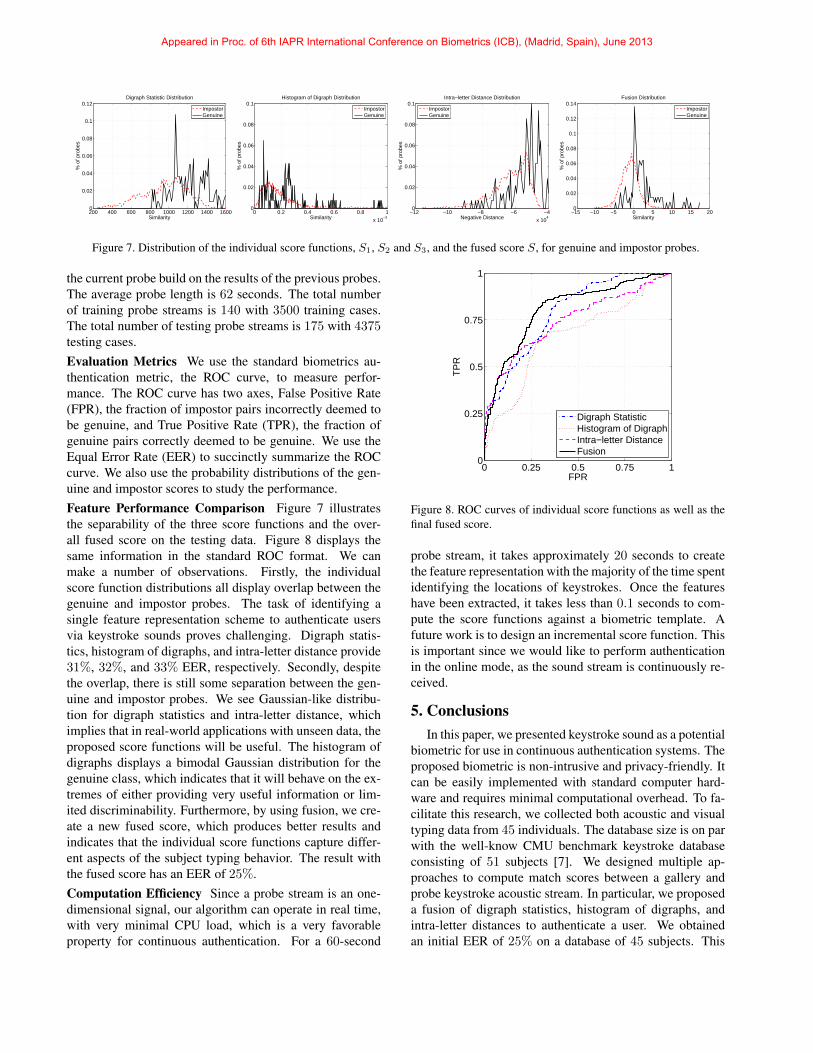
Figure 4. Temporal segmentation by thresholding the FFT power.
considered as the virtual letters in a virtual alphabet. Wealso extract the digraph and letter frequencies, top N di-graphs, and compute score distributions for fusion. In theenrollment stage, we use the virtual alphabet to convert theMFCC features into virtual letters, from which three differ-ent score functions, digraph statistic, histogram of digraphs,and intra-letter distance, are designed to collectively form abiometric template for the user. Finally, in the authenti-cation stage, the score functions are computed for a probesignal, and score-level fusion is used to make the final au-thentication decision. In the following we will present eachcomponent of this architecture in detail.
3.1. Temporal Segmentation & Feature ExtractionFor an acoustic signal of typing g(t) composed of
keystrokes and silent periods, the first task before featureextraction is to identify portions in the stream where akeystroke occurs since it is the keystroke that carries thediscriminative information about an individual typist. Asshown in Figure 3, a keystroke is composed of key pressingand key release, where the former comprises of the soundemitted when a finger touches the surface of a key as wellas the sound due to the key being pressed down. We denotea keystroke as ki, with a start time of ti and a duration ofL. In our algorithm, L is set to be 40 ms, since it covers thefull length of most keystrokes.
Motivated by [21], we conduct the temporal segmenta-tion based on the observation that the energy of keystroke isconcentrated in the frequencies between 400 Hz and 12KHz, while the background noise occupies other frequencyranges. We compute the 5-ms windowed Fast FourierTransform (FFT) of an acoustic signal using a sliding win-dow approach, where the magnitudes of outputs in the rangeof 400 Hz and 12K Hz are summarized to produce an ag-gregate curve of the FFT power. By setting a threshold onthe curve, we identify the start of keystrokes, as shown inFigure 4. Ideally this temporal segmentation should detectall keystrokes, instead of the background noise. Our cur-rent simple threshold-based method may not achieve thisreliably as yet, and in the future we will investigate moreadvanced methods such as adaptive thresholding or super-vised learning approaches.
Appeared in Proc. of 6th IAPR International Conference on Biometrics (ICB), (Madrid, Spain), June 2013

Once the start of a keystroke ti is determined, we convertthe acoustic signal within a keystroke segment, g(ti, ..., ti+L), to a feature representation fi for future processing. Thestandard MFCC feature are utilized due to its wide applica-tions in speech recognition and demonstrated effectivenessin key recovery [21]. Our MFCC implementation uses thesame parameter setup as [21]. That is, we have 32 channelsof the Mel-Scale Filter Bank and use 16 coefficients and 32filters with 10-ms windows that are shifted by 2.5 ms. Theresultant feature of a keystroke ki is a 256-dim vector fi.
3.2. Virtual Alphabet via ClusteringMost of the prior work in keystroke dynamics uses di-
graphs statistics, which is the mean and standard devia-tion of delays between two individual keys or two groupsof keys, or trigraphs, which is the delay across three keys,to model keystroke dynamics. It has also been shownthat word-specific digraph, which is computed on the sametwo keys, is much more discriminative than the generic di-graph [15]. In keystroke dynamics, such word informationis readily available since key logging records the letter asso-ciated with each keystroke. However, this is not the case inour keystroke acoustic signal. Hence, in order to enjoy thebenefit of digraph in our application, we strive to achievetwo goals from the acoustic signal:
• Estimate the starting time of each keystroke;
• Infer or label the letter pressed at each keystroke.
While the first goal is addressed by the temporal seg-mentation process, the second goal requires knowledge ofthe pressed key in order to construct word-specific digraphs.However, as shown in acoustic cryptanalysis [6], preciselyrecognizing the typed key itself is an ongoing researchtopic. Hence, we take a different approach by aiming to as-sociate each keystroke to a unique label, with the hope thatdifferent physical keys will correspond to different labels,and different typists will generate different labels whenpressing the same key. We call each label a virtual letterand the collection of which is called a virtual alphabet. Thelearning of the virtual alphabet is accomplished by applyingK-means clustering to the MFCC features of all keystrokesin the training set.
Assuming the training set includes streams from J sub-jects, each with Ij keystrokes, the input of the K-means is{f ji }, where j ∈ [1, J ] and i ∈ [1, Ij ]. The K-means cluster-ing partitions the input samples into K clusters, with cen-troids mf (k). We set K to be 30 considering that the totalnumber of common keys on a keyboard is around 30.
During all three stages, given an original acoustic sig-nal represented as a collection of keystrokes K = {ki}, wecompute the Euclidean distance between the MFCC featureof a keystroke fi and each of the cluster centroids. The cen-troid with the minimal distance will assign its index to the
−4 −2 0 2 4 6 8 100
1
2
3
4
5
6
7Virtual Letters
1st Principal Component
2nd
Prin
cipa
l Com
pone
nt
−10 −5 0 5 10 15 20−5
0
5
10
15
Virtual Letters
1st Principal Component
2nd
Prin
cipa
l Com
pone
nt
(a) First four virtual letters. (b) All 30 virtual letters.
Figure 5. The mean MFCC features f̄k of each of 20 subjectswithin virtual letters, plotted along the top-2 principle componentsreduced from the original 256-dimensional space. The symbolrepresents a letter and the color in (a) indicates a subject (bestviewed in color).
keystroke as its corresponding virtual letter, i.e., li = k.Thus, in our algorithm a virtual letter is simply a numberbetween 1 and K. Finally, we can represent a keystroke asa triplet ki = {ti, fi, li}.
3.3. Score FunctionsGiven the aforementioned feature representation
scheme, we next investigate a set of score functionsto compute the similarity measure between two sets offeatures, listed as follows.Digraph statistic As a representation of individual typingcharacteristics, digraph statistic refers to the statistics of thelatency, in terms of mean and stand deviation, within fre-quent pairs of letters. A pair of letters is named digraph,with examples such as (t,h), (h,e). In our algorithm, avirtual alphabet with K letters can generate K2 digraphs,such as (2, 5), (7, 1). During the training stage, we countthe frequency of each digraph by passing through adjacentkeystrokes, lji−1 and lji , in the entire training set. Thenwe generate a list of top N most frequent digraphs, eachdenoted as dn = {kn1, kn2}. Given the {ki} representa-tion of an acoustic signal, for each one of N digraphs, wethen compute the mean, {mn}, and the standard deviation,{σn}, of the time difference variable ∆t = ti − ti−1 whereli = kn2 and li−1 = kn1. Finally, the similarity score be-tween two arbitrary length signals, K and K′, is computedusing the following equation:
S1(K,K′) =
N∑n=1
wn1
[∑∆t
√N (∆t;mn, σ2
n)N (∆t;m′n, σ′
n2)
],
(1)which basically summarizes the overlapping region be-tween two Gaussian distributions of the same digraph,weighted by wn
1 . The overlapping region is computed viathe Bhattacharyya coefficient, and wn
1 is the overall fre-quency of each digraph learned from the training set. Weset N to be 50 in our algorithm.Histogram of digraphs In our virtual alphabet represen-
Appeared in Proc. of 6th IAPR International Conference on Biometrics (ICB), (Madrid, Spain), June 2013

Input: A stream g(t), top digraphs dn, clustercentroids mf (k).
Output: A feature set F.Locate keystrokes t = [t1, ..., ti, ...] at times of highenergy using FFT,foreach keystroke time t i do
fi = MFCC(g(ti, ..., ti + L)),li = argmink‖mf (k)− fi‖2,
foreach digraph dn doT = {ti − ti−1 : li = kn2 & li−1 = kn1,∀i ∈[2, |t|]},mn = mean(T),σn = std(T),Compute histogram of digraphs hn via Eqn. (2),
foreach letter k doCompute f̄k via Eqn. (4),
return F = {mn, σn, hn, f̄k}.Algorithm 1: Feature extraction algorithm.
tation, different subjects may produce different virtual let-ters when pressing the same key. This implies that differ-ent subjects are likely to generate different digraphs whentyping the same word. Hence, it is expected that we canuse the frequencies of popular digraphs as a cue for au-thentication. Given that, we compute the histogram h =[h1, h2, ..., hN ]T of top N digraphs, which are the same asthe ones in digraph statistic, for each acoustic signal. Thatis,
hn =
∑i δ(li = kn2)δ(li−1 = kn1)
|K| − 1, (2)
where δ is the indicator function and the numerator is thenumber of digraph dn = {kn1, kn2} within a sequence oflength |K|. The similarity score between two signals is sim-ply the inner product between two histograms of digraphs,
S2(K,K′) = hTh′. (3)
Intra-letter distance We use the virtual letter to repre-sent similar keystrokes from various key pressing of vari-ous subjects. Hence, within a virtual letter, it is very likelythat different subjects will have different distributions. Fig-ure 5 provides evidences for this observation by showingthe mean MFCC features of 20 training subjects within vir-tual letters. It can be seen that 1) there is distinct inter-letter separation among virtual letters; 2) within each vir-tual letter, there is intra-letter separation due to individual-ity. Hence, we would like to utilize this intra-letter sepa-ration in our score function computation. For an acousticsignal, we compute the mean of fi associated with each vir-tual letter, which results in K = 30 mean MFCC features,as follows:
Input: A probe stream g′(t), biometric template F,top digraphs dn, cluster centroids mf (k),score distribution msv, σsv , threshold τ .
Output: An authentication decision d.Compute feature set F′ for probe g′(t) via Alg. 1,Compute digraph statistic score S1 via Eqn. (1),Compute histogram of digraphs score S2 via Eqn. (3),Compute intra-letter distance score S3 via Eqn. (5),Compute normalized score S via Eqn. (6),if S > τ then
return d = genuine.else
return d = impostor.
Algorithm 2: Algorithm in the authentication stage.
f̄k =1
|li = k|∑li=k
fi. (4)
Given two acoustic signals K and K′, we use Equa-tion (5) to compute the Euclidean distance between the cor-responding means and sum up by using a weight wn
3 , whichis the overall frequency of each virtual letter among allkeystroke segments and is computed from the training set.The sign −1 is to make sure that on average the genuineprobe has a larger score than the impostor probe.
S3(K,K′) = −K∑
k=1
wn3 ||̄fk − f̄ ′k||2. (5)
So far we have constructed a new feature set for oneacoustic signal, denoted as {mn, σn, hn, f̄k} where n ∈[1, N ] and k ∈ [1,K]. We summarize the feature extractionalgorithm in Algorithm 1. If the acoustic signal is from thegallery stream, we call the resultant feature set as a biomet-ric template of the gallery subject, which is computed dur-ing enrollment and stored for future matching with a probestream.Score fusion Once the three scores are computed, we fusethem to generate one value to determine whether the au-thentication claim should be accepted or rejected. In oursystem we use a simple score-level fusion where the threenormalized scores are added to create the overall similarityscore between two streams,
S =
3∑v=1
Sv −msv
σsv. (6)
The score normalization is conducted by using the meanmsv and standard deviation σsv of the score distributionlearned from the training data, such that the normalizedscores fall in a standard normal distribution. We summa-rize the algorithm during the authentication stage in Algo-rithm 2. In the future, more advanced fusion mechanisms
Appeared in Proc. of 6th IAPR International Conference on Biometrics (ICB), (Madrid, Spain), June 2013

0 5 10 15 20 25 300
3
6
9
QWERTY experience (years)
Num
ber
of s
ubje
cts
Figure 6. Distribution of subjects’ experience with keyboard.
can be utilized, especially by leveraging previous work inthe biometrics fusion domain [5].
4. ExperimentsIn this section, we present an overview of the database
collected for this experiment which can be used for othertyping based biometrics. We also present our specific exper-imental setup and the results of our static-text experiments.
4.1. Keystroke Sound DatabaseSince keystroke sound is a novel biometric modality
without any prior database, we develop a capture protocolthat ensures the collected database is not only useful forthe current research problem, but also beneficial to otherresearchers on the general topic of typing-based biometrics.
While developing the protocol, our first goal is to studywhether the keystroke sound should be based on static textor free text, i.e., does a subject have to type the same textto be authenticated? The same question was addressed inkeystroke dynamics, where there is substantially more re-search effort on static text than free text [2]. To answer thisquestion, we request each subject to perform typing in twosessions. In the first session, a subject types one paragraphfour times (the first paragraph of “A Tale of Two Cities”by Charles Dickens displayed on the monitor), with a 2–3 seconds break between trials. Multiple typing instancesof the same paragraph enable the study of static text basedauthentication. In the second session, a subject types a half-page letter with any content to his/her family. It can be seenfrom this session that most users make spontaneous pausesduring typing, which mimics well the real-world typing sce-nario. Normally one subject spends around 5–8 minutes oneach session, depending on the typing speed.
A second consideration is the recording environment.The background environment plays an important role in theusability of the data. Low frequency pitches from comput-ers, heaters, and lights can create distractions to the soundof the actual typing. The placement of the sensor relativeto the keyboard as well as in the room can also introducedifferences due to echos. All subjects in the study per-formed the typing with the same computer, keyboard, andmicrophone, in the same room, under reasonably similarconditions. Care was taken to use non-verbal communi-
Age 10–19 20–29 30–39Number of subjects 11 30 4
Table 1. Age distribution of subjects.
cation during the experiments to eliminate human speechfrom corrupting the audio stream. Nevertheless, standardworkplace noises still exist in the background, e.g. doorsopening, chairs rolling, and people walking.
The third consideration is the hardware setup. We usea US standard QWERTY keyboard for data collection. Al-though there are many available options for microphones,we decide to utilize an inexpensive webcam with embed-ded microphone, which is centered on the top of the moni-tor and pointed toward the keyboard. This setup allows usto capture both the video of hand movement and the audiorecording of keyboard typing. Thus, a multi-modal (visualand acoustic) typing-based continuous authentication sys-tem can be developed in the future based on this database.The sound is captured at 48, 000 Hz with a single channel.
Thus far our database contains 45 subjects with differentyears of experience in using the keyboard. The database isformed from students and faculties at Michigan State Uni-versity, whose distributions of typing experience and ageare displayed in Figure 6 and Table 1. The database ofkeystroke sound is available at http://www.cse.msu.edu/˜liuxm/typing, and is intended to facilitate fu-ture research, discussion, and performance comparison onthis topic.
4.2. ResultsWe use the static portion of the database for our exper-
iments and leave the use of the free text for future work.Our algorithm requires a separate training dataset for thepurpose of learning a virtual alphabet, top digraphs, and thestatistics of score distributions. Hence, we randomly par-tition the database into 20 subjects for training and the re-maining 25 subjects for testing our algorithm.
For each subject, we use the first typing trial as thegallery stream and portions of the fourth typing trial as theprobe stream. We choose the first and last paragraph tomaximize the intra-subject differences for the static text.For the probe streams, we need to balance two concerns.Firstly, we want to use as many probes as possible to en-hance the statistical significance of our experiments, whichrequires that we use a shorter partial paragraph. Secondly,we want to use longer probe streams to allow accurate cal-culations of features for a given subject. We decide to form7 continuous probe streams for each user by using 70% ofthe fourth paragraph starting at the 0%, 5%, 10%, 15%,20%, 25%, and 30% mark of the paragraph. This over-lapping nature allows us to balance both concerns, whilealso simulates a continuous environment where the algo-rithm works with an incoming data stream and the results of
Appeared in Proc. of 6th IAPR International Conference on Biometrics (ICB), (Madrid, Spain), June 2013
200 400 600 800 1000 1200 1400 16000
0.02
0.04
0.06
0.08
0.1
0.12Digraph Statistic Distribution
Similarity
% o
f pro
bes
ImpostorGenuine
0 0.2 0.4 0.6 0.8 1
x 10−3
0
0.02
0.04
0.06
0.08
0.1Histogram of Digraph Distribution
Similarity
% o
f pro
bes
ImpostorGenuine
−12 −10 −8 −6 −4
x 104
0
0.02
0.04
0.06
0.08
0.1Intra−letter Distance Distribution
Negative Distance
% o
f pro
bes
ImpostorGenuine
−15 −10 −5 0 5 10 15 200
0.02
0.04
0.06
0.08
0.1
0.12
0.14Fusion Distribution
Similarity
% o
f pro
bes
ImpostorGenuine
Figure 7. Distribution of the individual score functions, S1, S2 and S3, and the fused score S, for genuine and impostor probes.
the current probe build on the results of the previous probes.The average probe length is 62 seconds. The total numberof training probe streams is 140 with 3500 training cases.The total number of testing probe streams is 175 with 4375testing cases.Evaluation Metrics We use the standard biometrics au-thentication metric, the ROC curve, to measure perfor-mance. The ROC curve has two axes, False Positive Rate(FPR), the fraction of impostor pairs incorrectly deemed tobe genuine, and True Positive Rate (TPR), the fraction ofgenuine pairs correctly deemed to be genuine. We use theEqual Error Rate (EER) to succinctly summarize the ROCcurve. We also use the probability distributions of the gen-uine and impostor scores to study the performance.Feature Performance Comparison Figure 7 illustratesthe separability of the three score functions and the over-all fused score on the testing data. Figure 8 displays thesame information in the standard ROC format. We canmake a number of observations. Firstly, the individualscore function distributions all display overlap between thegenuine and impostor probes. The task of identifying asingle feature representation scheme to authenticate usersvia keystroke sounds proves challenging. Digraph statis-tics, histogram of digraphs, and intra-letter distance provide31%, 32%, and 33% EER, respectively. Secondly, despitethe overlap, there is still some separation between the gen-uine and impostor probes. We see Gaussian-like distribu-tion for digraph statistics and intra-letter distance, whichimplies that in real-world applications with unseen data, theproposed score functions will be useful. The histogram ofdigraphs displays a bimodal Gaussian distribution for thegenuine class, which indicates that it will behave on the ex-tremes of either providing very useful information or lim-ited discriminability. Furthermore, by using fusion, we cre-ate a new fused score, which produces better results andindicates that the individual score functions capture differ-ent aspects of the subject typing behavior. The result withthe fused score has an EER of 25%.Computation Efficiency Since a probe stream is an one-dimensional signal, our algorithm can operate in real time,with very minimal CPU load, which is a very favorableproperty for continuous authentication. For a 60-second
0 0.25 0.5 0.75 10
0.25
0.5
0.75
1
FPR
TP
R
ROC Comparison
Digraph StatisticHistogram of DigraphIntra−letter DistanceFusion
Figure 8. ROC curves of individual score functions as well as thefinal fused score.
probe stream, it takes approximately 20 seconds to createthe feature representation with the majority of the time spentidentifying the locations of keystrokes. Once the featureshave been extracted, it takes less than 0.1 seconds to com-pute the score functions against a biometric template. Afuture work is to design an incremental score function. Thisis important since we would like to perform authenticationin the online mode, as the sound stream is continuously re-ceived.
5. ConclusionsIn this paper, we presented keystroke sound as a potential
biometric for use in continuous authentication systems. Theproposed biometric is non-intrusive and privacy-friendly. Itcan be easily implemented with standard computer hard-ware and requires minimal computational overhead. To fa-cilitate this research, we collected both acoustic and visualtyping data from 45 individuals. The database size is on parwith the well-know CMU benchmark keystroke databaseconsisting of 51 subjects [7]. We designed multiple ap-proaches to compute match scores between a gallery andprobe keystroke acoustic stream. In particular, we proposeda fusion of digraph statistics, histogram of digraphs, andintra-letter distances to authenticate a user. We obtainedan initial EER of 25% on a database of 45 subjects. This
Appeared in Proc. of 6th IAPR International Conference on Biometrics (ICB), (Madrid, Spain), June 2013

suggests that more sophisticated features have to be investi-gated in the future. While these are preliminary results, withthe accuracy far below well-researched biometric modali-ties such as face or fingerprint, we wish to emphasize thatthe intent of this feasibility study is to open up a new lineof exciting research on typing-based biometrics. We antic-ipate other interested researchers to commence working onkeystroke acoustics as a biometric modality - either by it-self or in conjunction with other modalities - in continuousauthentication applications.
Our future work on this topic will cover the following as-pects. First, we will increase the subject size of our databaseto provide more training samples. We will continue to col-lect data from a larger number of users as well as more sam-ples from the current users to help obtain a better under-standing of the inter and intra-class variability of this bio-metric. Second, we will explore methods for better iden-tifying keystrokes through supervised learning or context-sensitive thresholding. This will allow for more robust au-thentication in the presence of background noise typical ofa normal work environment. Third, we will explore thechanges that occur when comparing free text, by utilizingthe second session of our database. Finally, we will in-vestigate new feature representation schemes to address theintra-class variability of this biometric.
It is interesting to note a potential attack on this biometricsystem which consists of recording a genuine user’s typingsounds and then replaying the recording while the impos-tor is using the computer in a mainly silent manner throughuse of only the mouse. A means of foiling this attack is tolog only the times of keystrokes and ensure alignment ofthe detected keystroke times from the audio and the actualkeystroke times. It is also desirable to completely fuse thismethod with standard keystroke dynamics methods wherethe audio and virtual digraphs add extra discriminating in-formation to the physical digraphs.
References[1] D. Asonov and R. Agrawal. Keyboard acoustic emanations.
In Proc. of IEEE Symposium on Security and Privacy, pages3 – 11, May 2004.
[2] S. P. Banerjee and D. Woodard. Biometric authenticationand identification using keystroke dynamics: A survey. J. ofPattern Recognition Research, 7(1):116–139, 2012.
[3] F. Bergadano, D. Gunetti, and C. Picardi. User authenticationthrough keystroke dynamics. ACM Trans. Inf. Syst. Secur.,5(4):367–397, Nov. 2002.
[4] S. Davis and P. Mermelstein. Comparison of parametric rep-resentations for monosyllabic word recognition in continu-ously spoken sentences. IEEE Trans. Acoustics, Speech andSignal Processing, 28(4):357 – 366, Aug 1980.
[5] A. Jain, A. Ross, and S. Prabhakar. An introduction to bio-metric recognition. IEEE Trans. CSVT, 14(1):4 – 20, Jan.2004.
[6] A. Kelly. Cracking Passwords using Keyboard Acoustics andLanguage Modeling. Master thesis, University of Edinburgh.2010.
[7] K. S. Killourhy and R. A. Maxion. Comparing anomalydetectors for keystroke dynamics. In Proc. of 39th Inter-national Conference on Dependable Systems and Networks(DSN-2009), pages 125–134, 2009.
[8] X. Liu, T. Chen, and B. V. K. V. Kumar. Face authenticationfor multiple subjects using eigenflow. Pattern Recognition,36(2):313–328, 2003.
[9] F. Monrose, M. Reiter, and S. Wetzel. Password hardeningbased on keystroke dynamics. International Journal of In-formation Security, 1(2):69–83, 2002.
[10] F. Monrose and A. Rubin. Authentication via keystroke dy-namics. In Proceedings of the 4th ACM conference on Com-puter and communications security, pages 48–56, 1997.
[11] T. Mustafic, S. Camtepe, and S. Albayrak. Continuous andnon-intrusive identity verification in real-time environmentsbased on free-text keystroke dynamics. In ICJB, 2011.
[12] K. Niinuma, U. Park, and A. K. Jain. Soft biometric traitsfor continuous user authentication. IEEE Trans. InformationForensics and Security, 5(4):771–780, Dec. 2010.
[13] K. Revett, H. Jahankhani, S. T. Magalhes, and H. M. D.Santos. Global E-Security, volume 12 of Communicationsin Computer and Information Science, chapter A Survey ofUser Authentication Based on Mouse Dynamics, pages 210–219. Springer Berlin Heidelberg, 2008.
[14] D. Shanmugapriya and G. Padmavathi. A survey of bio-metric keystroke dynamics: Approaches, security and chal-lenges. International Journal of Computer Science and In-formation Security, 5(1):115–119, 2009.
[15] T. Sim and R. Janakiraman. Are digraphs good for free-textkeystroke dynamics? In CVPR, Workshop on Biometrics,2007.
[16] T. Sim, S. Zhang, R. Janakiraman, and S. Kumar. Continu-ous verification using multimodal biometrics. IEEE T-PAMI,29(4):687–700, Apr. 2007.
[17] C. C. Tappert, S.-H. Cha, M. Villani, and R. S. Zack. Akeystroke biometric systemfor long-text input. Int. J. of In-formation Security and Privacy (IJISP), 4(1):32–60, 2010.
[18] M. Turk. Grand challenges in biometrics. Presented askeynote at IEEE Int. Conf. on Biometrics: Theory, Appli-cations and Systems (BTAS 10), Washington, DC, 2010.
[19] N. Zheng, A. Paloski, and H. Wang. An efficient user veri-fication system via mouse movements. In Proc. of the 18thACM conference on Computer and communications security,pages 139–150, New York, NY, USA, 2011. ACM.
[20] Y. Zhong, Y. Deng, and A. K. Jain. Keystroke dynamicsfor user authentication. In CVPR, Workshop on Biometrics,2012.
[21] L. Zhuang, F. Zhou, and J. D. Tygar. Keyboard acousticemanations revisited. In Proc. of the 12th ACM conferenceon Computer and communications security, pages 373–382,2005.
Appeared in Proc. of 6th IAPR International Conference on Biometrics (ICB), (Madrid, Spain), June 2013