bios 6110 applied categorical data analysis - …yuanhuang.org/bios6110_2017fall/notes/11-27.pdf ·...
TRANSCRIPT

BIOS 6110Applied Categorical Data Analysis
Instructor: Yuan Huang, Ph.D.
Department of Biostatistics
Fall 2017

Part VIII
Models for Matched Pairs
1 / 28

Overview
Previously, we have worked on the data where the subjects areindependently collected.
This section introduces methods for comparing categoricalresponses for two samples that have a natural pairing betweeneach subject in one sample and a subject in the other sample.
Because each observation in one sample pairs with anobservation in the other sample, the responses in the twosamples are matched pairs.
Because of the matching, the samples are statisticallydependent.
In this case, methods that treat the two sets of observations asindependent samples are inappropriate
We will focus on 1-1 Match with binary response in this chapter.
2 / 28

Objectives
1. Data display
Population-Average tableSubject-Specific tables
2. Compare two dependent proportions
McNemar test for testing marginal homogeneityEstimate and CI of the proportion differenceMantel-Haenszel odds ratio
3. Logistic regression for matched pairs
Marginal modelsConditional Logistic regression for matched-pairs*Why unconditional logistic model is biased for matched-pairs
Two motivating data examples:
2000 General Social Survey (used in objective 2)
Diabetes-MI Matched Pairs Case-Control Study (used in objective 3)
3 / 28
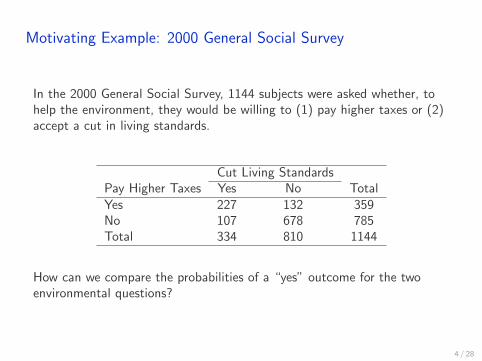
Motivating Example: 2000 General Social Survey
In the 2000 General Social Survey, 1144 subjects were asked whether, tohelp the environment, they would be willing to (1) pay higher taxes or (2)accept a cut in living standards.
Cut Living StandardsPay Higher Taxes Yes No TotalYes 227 132 359No 107 678 785Total 334 810 1144
How can we compare the probabilities of a “yes” outcome for the twoenvironmental questions?
4 / 28

Comparing Dependent Proportions
Generally, we have
Cut Living StandardsPay Higher Taxes Yes No TotalYes n11 n12 n1+No n21 n22 n2+Total n+1 n+2 n
Define sample estimates pij = nij/n, i = 1, 2, j = 1, 2
pi+ = pi1 + pi2, i = 1, 2
p+j = p1j + p2j , j = 1, 2
The population value corresponding to pij is denoted by πij . Whenπ+1 = π1+ and π+2 = π2+, there is marginal homogeneity. From thiscondition, we have
π1+ − π+1 = (π11 + π12)− (π11 + π21) = π12 − π21
That is, marginal homogeneity is equivalent to π12 = π21.5 / 28

Testing Marginal Homogeneity: McNemar Test
For matched pairs data with a binary response, a test of marginalhomogeneity has null hypothesis
H0 : π12 = π21, or equivalently H0 : π+1 = π1+
As off-diagonal counts are n12 + n21, under H0, both n12 and n21 aredistributed as Binomial(n12 + n21, 0.5).
Construct test based on n12. When n12 + n21 is large, the binomial can beapproximately by normal distribution with mean (n12 + n21)× 0.5 andvariance (n12 + n21)× (0.5)× (1− 0.5). Therefore, the z statistics can beconstructed accordingly.
z =n12 − (n12 + n21)× 0.5√
(n12 + n21)× 0.5× 0.5=
n12 − n21√n12 + n21
The z ∼ N(0,1), or z2 is approximately χ2 with df = 1 under H0.
The chi-squared test (z2) for a comparison of two dependent proportions is
called McNemar test.6 / 28
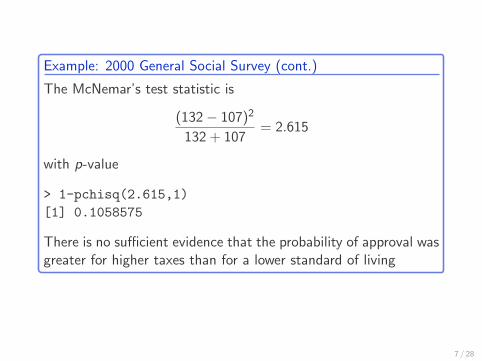
Example: 2000 General Social Survey (cont.)
The McNemar’s test statistic is
(132− 107)2
132 + 107= 2.615
with p-value
> 1-pchisq(2.615,1)
[1] 0.1058575
There is no sufficient evidence that the probability of approval wasgreater for higher taxes than for a lower standard of living
7 / 28

Estimating Differences of Proportions
The point estimate of π1+ − π+1 is p1+ − p+1
The estimated standard error (SE) of p1+ − p+1 is{p1+(1− p1+) + p+1(1− p+1)− 2(p11p22 − p12p21)
n
}1/2
= n−1√
(n12 + n21)− n−1(n12 − n21)2
95% Confidence interval: (p1+ − p+1)± 1.96× SE
Matched-pairs data usually show a positive association, which impliesa odds ratio > 1. A sample odds ratio exceeding 1.0 corresponds top11p22 > p12p21, a negative contribution from the third term.
Thus, an advantage of using dependent samples, rather thanindependent samples, is a smaller variance for the estimateddifference in proportions.
8 / 28
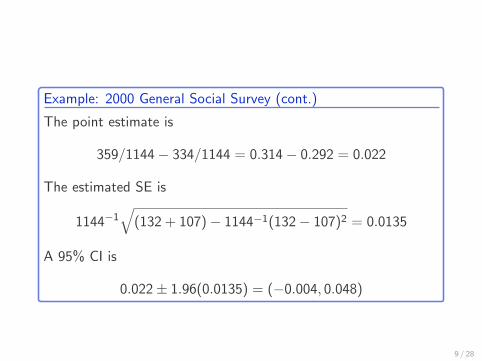
Example: 2000 General Social Survey (cont.)
The point estimate is
359/1144− 334/1144 = 0.314− 0.292 = 0.022
The estimated SE is
1144−1√
(132 + 107)− 1144−1(132− 107)2 = 0.0135
A 95% CI is
0.022± 1.96(0.0135) = (−0.004, 0.048)
9 / 28
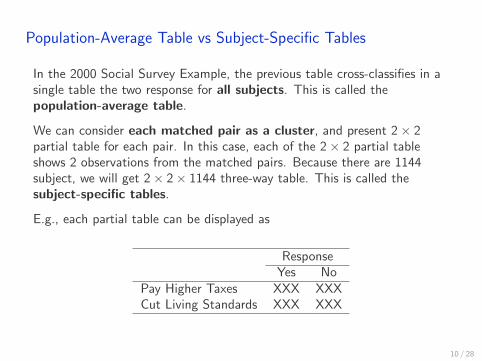
Population-Average Table vs Subject-Specific Tables
In the 2000 Social Survey Example, the previous table cross-classifies in asingle table the two response for all subjects. This is called thepopulation-average table.
We can consider each matched pair as a cluster, and present 2× 2partial table for each pair. In this case, each of the 2× 2 partial tableshows 2 observations from the matched pairs. Because there are 1144subject, we will get 2× 2× 1144 three-way table. This is called thesubject-specific tables.
E.g., each partial table can be displayed as
ResponseYes No
Pay Higher Taxes XXX XXXCut Living Standards XXX XXX
10 / 28
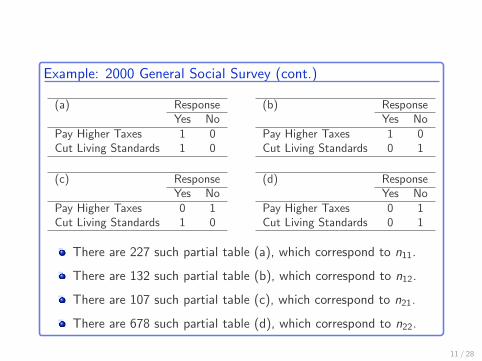
Example: 2000 General Social Survey (cont.)
(a) ResponseYes No
Pay Higher Taxes 1 0Cut Living Standards 1 0
(b) ResponseYes No
Pay Higher Taxes 1 0Cut Living Standards 0 1
(c) ResponseYes No
Pay Higher Taxes 0 1Cut Living Standards 1 0
(d) ResponseYes No
Pay Higher Taxes 0 1Cut Living Standards 0 1
There are 227 such partial table (a), which correspond to n11.
There are 132 such partial table (b), which correspond to n12.
There are 107 such partial table (c), which correspond to n21.
There are 678 such partial table (d), which correspond to n22.
11 / 28

Mantel-Haenszel Odds Ratio - Based on Subject-Specific Tables
Previously in XYZ three-way table, where X is the binary treatment, Y isbinary response, and Z is the centers (k = 1, . . . ,K ).
Diseased Non-diseased TotalsExposed n11k n12k n1+k
Unexposed n21k n22k n2+k
Totals n+1k n+2k n++k
The Mantel-Haenszel method
assumes that there is a true odds ratio which is consistent across k
provides a pooled estimate of the common odds ratio. In essence, it isa weighted average of the odds ratios from the individual strata
The Mantel-Haenszel estimate of the odds ratio is
θ̂MH =
∑Kk=1 n11kn22k/n++k∑Kk=1 n21kn12k/n++k
Note that, in our current matched pair case, the K is number of pairs.12 / 28
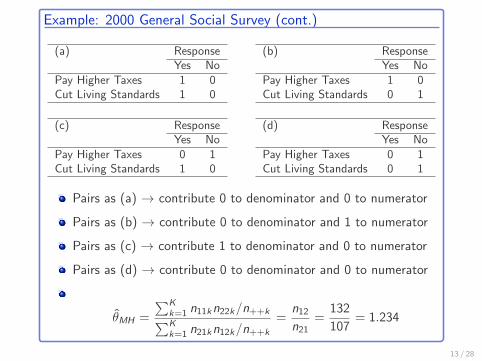
Example: 2000 General Social Survey (cont.)
(a) ResponseYes No
Pay Higher Taxes 1 0Cut Living Standards 1 0
(b) ResponseYes No
Pay Higher Taxes 1 0Cut Living Standards 0 1
(c) ResponseYes No
Pay Higher Taxes 0 1Cut Living Standards 1 0
(d) ResponseYes No
Pay Higher Taxes 0 1Cut Living Standards 0 1
Pairs as (a) → contribute 0 to denominator and 0 to numerator
Pairs as (b) → contribute 0 to denominator and 1 to numerator
Pairs as (c) → contribute 1 to denominator and 0 to numerator
Pairs as (d) → contribute 0 to denominator and 0 to numerator
θ̂MH =
∑Kk=1 n11kn22k/n++k∑Kk=1 n21kn12k/n++k
=n12n21
=132
107= 1.234
13 / 28
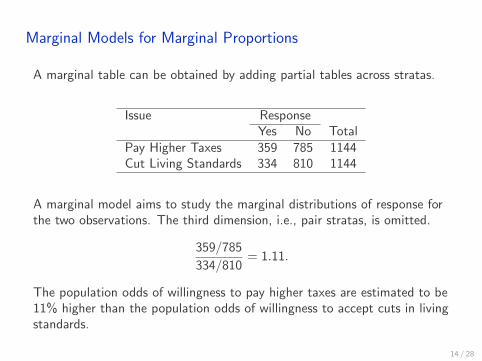
Marginal Models for Marginal Proportions
A marginal table can be obtained by adding partial tables across stratas.
Issue ResponseYes No Total
Pay Higher Taxes 359 785 1144Cut Living Standards 334 810 1144
A marginal model aims to study the marginal distributions of response forthe two observations. The third dimension, i.e., pair stratas, is omitted.
359/785
334/810= 1.11.
The population odds of willingness to pay higher taxes are estimated to be11% higher than the population odds of willingness to accept cuts in livingstandards.
14 / 28

Marginal Models for Marginal Proportions (cont.)
We already know that this analysis can also be obtained by using thefollowing logistic regression
logit[Pr(Y = “Yes”)] = α + βx
where x is an indicator for question 1.
Chapter 9 will discuss marginal models in details.
15 / 28

Objectives
1. Data display
Population-Average tableSubject-Specific tables
2. Compare two dependent proportions
McNemar test for testing marginal homogeneityEstimate and CI of the proportion differenceMantel-Haenszel odds ratio
3. Logistic regression for matched pairs
Marginal modelsConditional Logistic regression for matched-pairs*Why unconditional logistic model is biased for matched-pairs
Two motivating data examples:
2000 General Social Survey (used in objective 2)
Diabetes-MI Matched Pairs Case-Control Study (used in objective 3)
16 / 28
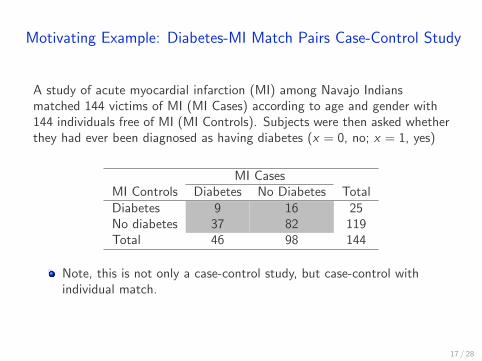
Motivating Example: Diabetes-MI Match Pairs Case-Control Study
A study of acute myocardial infarction (MI) among Navajo Indiansmatched 144 victims of MI (MI Cases) according to age and gender with144 individuals free of MI (MI Controls). Subjects were then asked whetherthey had ever been diagnosed as having diabetes (x = 0, no; x = 1, yes)
MI CasesMI Controls Diabetes No Diabetes TotalDiabetes 9 16 25No diabetes 37 82 119Total 46 98 144
Note, this is not only a case-control study, but case-control withindividual match.
17 / 28
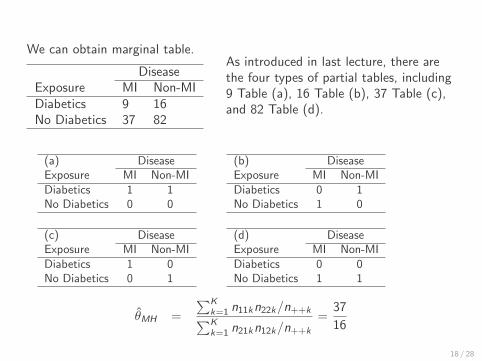
We can obtain marginal table.
DiseaseExposure MI Non-MIDiabetics 9 16No Diabetics 37 82
As introduced in last lecture, there arethe four types of partial tables, including9 Table (a), 16 Table (b), 37 Table (c),and 82 Table (d).
(a) DiseaseExposure MI Non-MIDiabetics 1 1No Diabetics 0 0
(b) DiseaseExposure MI Non-MIDiabetics 0 1No Diabetics 1 0
(c) DiseaseExposure MI Non-MIDiabetics 1 0No Diabetics 0 1
(d) DiseaseExposure MI Non-MIDiabetics 0 0No Diabetics 1 1
θ̂MH =
∑Kk=1 n11kn22k/n++k∑Kk=1 n21kn12k/n++k
=37
16
18 / 28

Conditional logistic regression (Introduction)
To handle stratum/pairs, one possibility is to estimate the following model
logit(Pr(MI = 1)) = αi + β Diabetes,
where
MI =
{1 MI
0 Non-MIDiabetes =
{1 Diabetes
0 No Diabetes
The odds that a subject with diabetes is an MI case equal eβ times theodds of a subject without diabetes is an MI case.
However, it can have a lot of nuisance parameters attributing to αi s.
To get a better estimation of β, we want to use conditional logisticregression. By doing conditioning on a discordant pair, the conditionallikelihood does not involves parameters αi s, it depends only on β.
19 / 28

Conditional logistic regression (Details)
For the i-th stratum/pair, based on logit(Pr(MI = 1)) = αi + β Diabetes,we can fill in probabilities of the following 2 × 2 partial table.
DiseaseMI Non-MI
Diabeticseαi+β
1 + eαi+β1− eαi+β
1 + eαi+β=
1
1 + eαi+β
Non-Diabeticseαi
1 + eαi1− eαi
1 + eαi=
1
1 + eαi
Table (b): MI with diabetes AND Non-MI without diabetes
(b) DiseaseExposure MI Non-MIDiabetics 0 1No Diabetics 1 0
eαi
1 + eαi× 1
1 + eαi+β
Table (c): MI without diabetes AND Non-MI with diabetes
(c) DiseaseExposure MI Non-MIDiabetics 1 0No Diabetics 0 1
eαi+β
1 + eαi+β× 1
1 + eαi
20 / 28

Conditional logistic regression (Details, Cont.)
Instead of modeling probability of observing a partial table, conditionallogistic regression modeling the conditional probability of observing apartial table given a discordant pair.
Therefore, for conditional logistic regression, only discordant stratum/paircan contribute terms to the likelihood.− This is similar to McNemar Test.
A discordant pair means either Table (b) or Table (c)
eαi
1 + eαi× 1
1 + eαi+β+
eαi+β
1 + eαi+β× 1
1 + eαi
P(Table (b)|Discordant pair) =eαi
1+eαi× 1
1+eαi+β
eαi
1+eαi× 1
1+eαi+β + eαi+β
1+eαi+β × 11+eαi
P(Table (c)|Discordant pair) =eαi+β
1+eαi+β × 11+eαi
eαi
1+eαi× 1
1+eαi+β + eαi+β
1+eαi+β × 11+eαi
21 / 28

Conditional logistic regression (Details, Cont.)
P(Table (c)|Discordant pair) =eαi+β
1+eαi+β × 11+eαi
eαi
1+eαi× 1
1+eαi+β + eαi+β
1+eαi+β × 11+eαi
=eαi+β
eαi+β + eαi=
eβ
eβ + 1
P(Table (b)|Discordant pair) = 1− eβ
eβ + 1=
1
eβ + 1
Conditional likelihood depends only on β.
Because there are 16 Table (b) and 37 Table (c), so the conditionallikelihood is (
1
eβ + 1
)16(eβ
eβ + 1
)37
,
which is maximized at eβ = 3716 . the same as θ̂MH .
22 / 28

* An Ordinary Logistic Regression Approach to 1:1 Matching
For 1-1 match, let
y∗i =
{1 when yi1 = 1, yi2 = 0
0 when yi1 = 0, yi2 = 1
Also let
x∗1i = x1i1 − x1i2
. . .
x∗ki = xki1 − xki2
Fit the ordinary logistic regression to the y∗ with predictors {x∗1 , . . . , x∗k },forcing the intercept parameter as 0. The resulting estimates are the sameas the conditional logistic regression.
23 / 28

* Why Ordinary/Unconditional Logistic Regression is Inappropriate
Recall that for the i-th stratum/pair, we have
DiseaseMI Non-MI
Diabeticseαi+β
1 + eαi+β1− eαi+β
1 + eαi+β=
1
1 + eαi+β
Non-Diabeticseαi
1 + eαi1− eαi
1 + eαi=
1
1 + eαi
Without conditioning, all tables (a) - (d) contribute to the likelihood.
There are 9 Table (a): MI with diabetes AND Non-MI with diabetes
(a) DiseaseExposure MI Non-MIDiabetics 1 1No Diabetics 0 0
eαi+β
1 + eαi+β× 1
1 + eαi+β
Regardless of β, the αi is maximized at −β. So for estimating β, it willcontribute to the likelihood the following term
I(a) =
(e−β+β
1 + e−β+β× 1
1 + e−β+β
)9
= (1/4)9
24 / 28

DiseaseMI Non-MI
Diabeticseαi+β
1 + eαi+β1− eαi+β
1 + eαi+β=
1
1 + eαi+β
Non-Diabeticseαi
1 + eαi1− eαi
1 + eαi=
1
1 + eαi
There are 16 Table (b): MI without diabetes AND Non-MI with diabetes
(b) DiseaseExposure MI Non-MIDiabetics 0 1No Diabetics 1 0
eαi
1 + eαi× 1
1 + eαi+β
Regardless of β, the αi is maximized at −β/2. So for estimating β, it willcontribute to the likelihood the following term
I(d) =
(e−β/2
1 + e−β/2× 1
1 + e−β/2+β
)16
=
(1
1 + eβ/2
)2×16
25 / 28

DiseaseMI Non-MI
Diabeticseαi+β
1 + eαi+β1− eαi+β
1 + eαi+β=
1
1 + eαi+β
Non-Diabeticseαi
1 + eαi1− eαi
1 + eαi=
1
1 + eαi
There are 37 Table (c): MI with diabetes AND Non-MI without diabetes
(c) DiseaseExposure MI Non-MIDiabetics 1 0No Diabetics 0 1
eαi+β
1 + eαi+β× 1
1 + eαi
Regardless of β, the αi is maximized at −β/2. So for estimating β, it willcontribute to the likelihood the following term
I(c) =
(e−β/2+β
1 + e−β/2+β× 1
1 + e−β/2
)37
=
(eβ/2
1 + eβ/2
)2×37
26 / 28

DiseaseMI Non-MI
Diabeticseαi+β
1 + eαi+β1− eαi+β
1 + eαi+β=
1
1 + eαi+β
Non-Diabeticseαi
1 + eαi1− eαi
1 + eαi=
1
1 + eαi
There are 82 Table (d): MI without diabetes AND Non-MI withoutdiabetes
(d) DiseaseExposure MI Non-MIDiabetics 0 0No Diabetics 1 1
eαi
1 + eαi× 1
1 + eαi
Regardless of β, the αi is maximized at 0. So for estimating β, it willcontribute to the likelihood the following term
I(d) =
(e0
1 + e0× 1
1 + e0
)82
= (1/4)82
27 / 28

In order to maximize the likelihood function
l = I(a)I(b)I(c)I(d)
it is suffice to maximize I(b)I(c), or equivalently, to maximize
log(I(b)I(c)) = 2× 37× log
(eβ/2
1 + eβ/2
)+ 2× 16× log
(1
1 + eβ/2
)= −2× 37× log(1 + e−β/2)− 2× 16× log(1 + eβ/2)
The partial derivative with respect to β is
37
1 + eβ/2− 16× eβ/2
1 + eβ/2
Setting it to 0, we have
exp(β/2) = 37/16
Orexp(β) = (37/16)2 = (ORMH)2
Therefore, the unconditional logistic regression is not appropriate.28 / 28