bolasso: model consistent lasso estimation through the bootstrap bach-icml08 presented by sheehan...
Post on 19-Dec-2015
226 views
TRANSCRIPT

Bolasso: Model Consistent Lasso Estimation through the BootstrapBach-ICML08
Presented by Sheehan Khan to “Beyond Lasso” reading groupApril 9, 2009

2
OutlineFollows the structure of the paper
◦Define Lasso◦Comments on scaling the penalty◦Bootstrapping/Bolasso◦Results
A few afterthoughts on the paperSynopsis of 2009 Extended Tech
reportDiscussion2

3
Problem formulationStandard Lasso formulation
◦New notation (consistent with ICML08)
◦Response vector (n samples)◦Design matrix (n samples x p
features)Generative model

4
How should we set μn?
Shows 5 mutual exclusive possibilities1. implies2. means we minimize
implies is not a consistent estimate of

5
How should we set μn?
3. slower than requires
denotes the active set
4. faster thanloose the sparsifying effect of l1 penalty
We saw similar arguments in Adaptive Lasso

6
How should we set μn?
5. we can state:
Prop1:
Prop2:
*Dependence on Q omitted in the body of paperbut appears in the appendix

7
So what?Props 1&2 tell us that
asymptotically:◦We have positive probability
selecting the active features◦We have vanishing probability of
missing active featuresWe may or may not get
additional non-active features based on the dataset◦With many independent sets, the
common features must be the active sets

8
BootstrapIn practice we do not get many
datasetsWe can use m bootstrap
replications of the given set◦For now we use pairs, later we will
used centered residuals

9
Bolasso

10
Asymptotic ErrorProp3:
Given that we have
Can be tightened if

11
Results on Synthetic Data1000 samples16 features (first 8 active)Average over 256 datasetsForce
lasso bolasso (m=128)lasso (black)bolasso (red)
m=2,4,8…256

12
Results on Synthetic Data1000 samples16 features (first 8 active)Average over 256 datasetsForce
lasso bolasso (m=128)lasso (black)bolasso (red)
m=2,4,8…256

13
Results on Synthetic Data64 features (8 active)Error is squared distance
between sparsity pattern vectors averaged over 32 datasets
lasso(black), bolasso(green), forward greedy(magenta), threshold LS(red), adaptive lasso(blue)

14
Results on Synthetic Data64 samples32 features (8 active) Bolasso-S has soft intersection
(90%)MSE prediction 1.24???
15
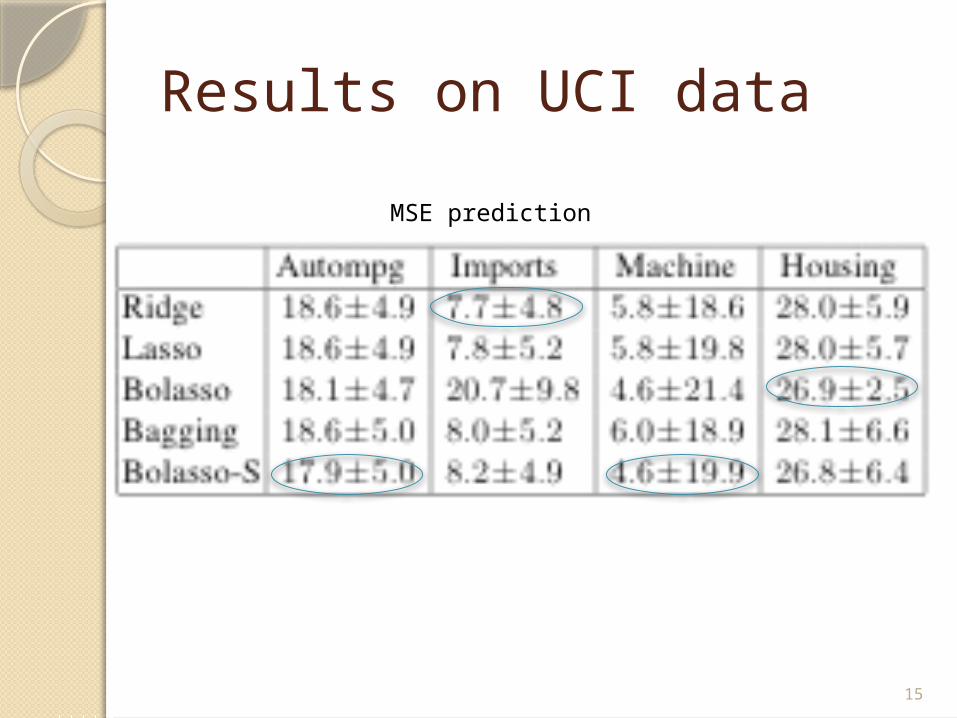
Results on UCI data
MSE prediction

16
Some thoughtsWhy do they compare bolasso variable selection
error to lasso, forward greedy, threshold LS, and adaptive lasso but then compare mean square prediction to lasso, ridge and bagging?
All these results have low dimensional data, we are interested in large amounts of features◦ This is considered in the 2009 tech. rep.
Based on the plots it seems that its best to use as large as possible (in contrast to Prop3)◦ Is there any insight to the size of positive constants
which have a huge impact?◦ Based on the results it seems that we really want to
use bolasso in the problems where we know this bound to be loose

17
2009 Tech ReportMain extensions
◦Fills in the math details omitted previously◦Discusses bootstrap pairs vs. residuals
Proves both consistent in low dimensional data Show empirical results favouring residuals in
high dimensional data
◦New upper and lower bounds for selecting active components in low dimensional data
◦Propose similar method for high dimensions Lasso with high regularization parameter Then bootstrap within the supports
◦Discusses implementation details

18
Bootstrap RecapPreviously we sampled uniformly
from the given dataset with replacement to generate bootstrap set◦Done in parallel
Bootstrapping can also be done sequentially◦We saw this when reviewing
Boosting

19
Bootstrap Residuals
1. Compute residual errors based on lasso using the current dataset
2. Compute centered residuals
3. Create a new dataset from the pairs

20
Synthetic Results in High Dimensional Data64 samples, 128 features (8
active)

21
Varying Replications in High Dimensional Data
lasso(black), bollaso m={2,4,8,16,32,64,128,256}(red), m=512(blue)

22
The EndThanks for your attention and
participationQuestions/Discussion???