carnegie mellon compiler optimization of memory-resident value communication between speculative...
TRANSCRIPT

Carnegie Mellon
Compiler Optimization of Memory-Resident Value Communication Between Speculative Threads
Antonia Zhai, Christopher B. Colohan,
J. Gregory Steffan† and Todd C. Mowry
School of Computer ScienceCarnegie Mellon University
†Dept. Elec. & Comp. EngineeringUniversity of Toronto

Compiler Optimization of Memory-Resident Value Communication… - 2 - Zhai, Colohan, Steffan and
Mowry
Carnegie Mellon
Motivation
Chip-level multiprocessing is becoming commonplace
We need parallel programs
UntraSPARC IV 2 UltraSparc III cores
IBM Power 4 SUN MAJC Sibyte SB-1250
Can multithreaded processors improve the performance of a single application?

Compiler Optimization of Memory-Resident Value Communication… - 3 - Zhai, Colohan, Steffan and
Mowry
Carnegie Mellon
Why Is Automatic Parallelization Difficult?
One solution: Thread-Level Speculation
Automatic parallelization today
Must statically prove threads are independent
Constructing proofs is difficult due to ambiguous data dependences Complex control flow Pointers and indirect references Runtime inputs
Optimistic compiler?
Limited only by true dependences

Compiler Optimization of Memory-Resident Value Communication… - 4 - Zhai, Colohan, Steffan and
Mowry
Carnegie Mellon
Example
while (...){…x=hash[index1];…hash[index2]=y;...
}
Time…= hash[19]…hash[21] =...check_dep()
Thread 2…= hash[33]…hash[30] =...check_dep()
Thread 3…= hash[3]…hash[10] =...check_dep()
Thread 1
…= hash[10]…hash[25] =...check_dep()
Thread 4
…= hash[31]…hash[12] =...check_dep()
Thread 5
…= hash[9]…hash[44] =...check_dep()
Thread 6
…= hash[27]…hash[32] =...check_dep()
Thread 7
…= hash[10]…hash[25] =...check_dep()
Thread 4 Retry
Processor 1 Processor 2 Processor 3 Processor 4
Compiler Optimization of Memory-Resident Value Communication… - 5 - Zhai, Colohan, Steffan and
Mowry
Carnegie Mellon
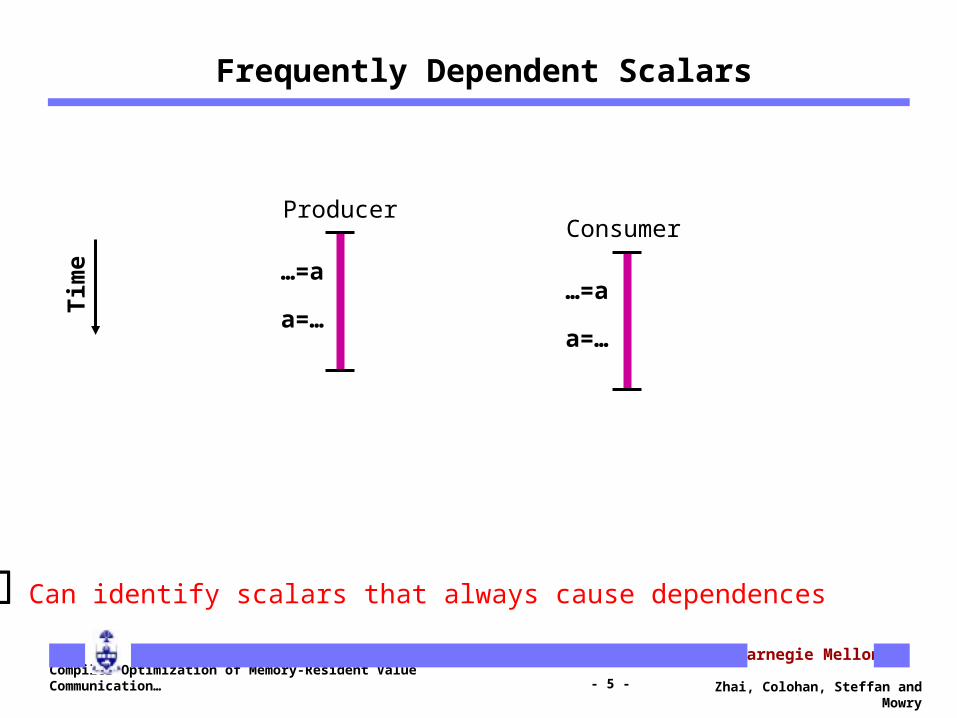
Frequently Dependent Scalars
…=a
a=……=a
a=…
Can identify scalars that always cause dependences
Time
ProducerConsumer

Compiler Optimization of Memory-Resident Value Communication… - 6 - Zhai, Colohan, Steffan and
Mowry
Carnegie Mellon
Frequently Dependent Scalars
…=a
a=…
…=a
a=…
Dependent scalars should be synchronized
[ASPLOS’02]
Time
Signal(a)
Wait(a)
ProducerConsumer

Compiler Optimization of Memory-Resident Value Communication… - 7 - Zhai, Colohan, Steffan and
Mowry
Carnegie Mellon
Frequently Dependent Scalars
…=a
a=…
Dataflow analysis allows us to deal with complex control flow
[ASPLOS’02]
…=a
a=…
Time
ProducerConsumer
Compiler Optimization of Memory-Resident Value Communication… - 8 - Zhai, Colohan, Steffan and
Mowry
Carnegie Mellon
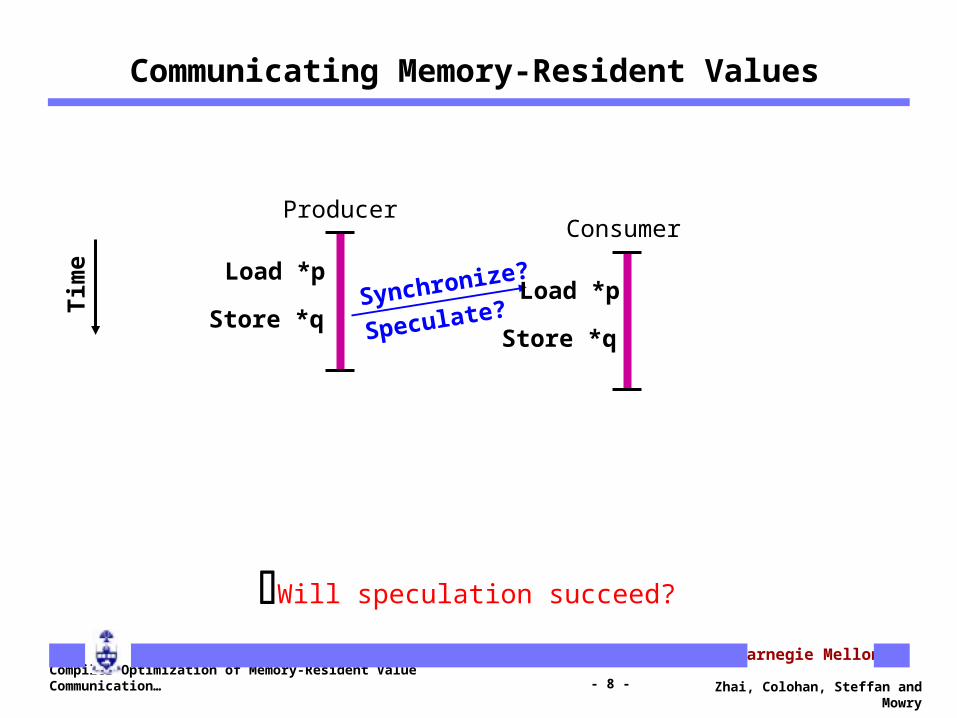
Communicating Memory-Resident Values
Synchronize?
Speculate?
Will speculation succeed?
Time Load *p
Store *qLoad *p
Store *q
ProducerConsumer

Compiler Optimization of Memory-Resident Value Communication… - 9 - Zhai, Colohan, Steffan and
Mowry
Carnegie Mellon
Speculation vs. Synchronization
Sequential Execution Speculative Parallel Execution
Load *p
Speculation succeeds: efficient
Time
Load *p
Load *p
Load *p
Store *q
Store *q
Store *q
Store *q
Load *pLoad *p
Load *pLoad *pStore *q
Store *qStore *q
Store *q

Compiler Optimization of Memory-Resident Value Communication… - 10 - Zhai, Colohan, Steffan and
Mowry
Carnegie Mellon
Speculation vs. Synchronization
Sequential Execution Speculative Parallel Execution
Speculation fails: inefficient
Load *p
Time
Load *p
Load *p
Load *p
Store *q
Store *q
Store *q
Store *q
Load *p
Store *qLoad *p
Store *q
Load *p
Store *q
Load *p
Store *q
Load *p
Store *q
Load *p
Store *q
Load *p
Store *q
Load *p
Store *q
Load *p
Store *q
Load *p
Store *q
violation

Compiler Optimization of Memory-Resident Value Communication… - 11 - Zhai, Colohan, Steffan and
Mowry
Carnegie Mellon
Speculation vs. Synchronization
Sequential Execution Speculative Parallel Execution
Frequent dependences: Synchronize
Infrequent dependences: Speculate
Load *p
Time
Load *p
Load *p
Load *p
Store *q
Store *q
Store *q
Store *q
Load *p
Store *qLoad *pStore *q
Load *pStore *q Load *p
Store *q

Compiler Optimization of Memory-Resident Value Communication… - 12 - Zhai, Colohan, Steffan and
Mowry
Carnegie Mellon
Performance Potential
Reducing failed speculation improves performance
Detailed simulation:• TLS support• 4-processor CMP
• 4-way issue, out-of-order superscalar• 10-cycle communication latency
Original
Perfect memory value
Prediction
Nor
m. R
egio
nal E
xec.
Tim
e
0
100
m88ksim
ijpeg
gzip_comp
gzip_decomp
vpr_place gc
cmcf
crafty
parser
perlbmk
gap
bzip2_comp
go
Compiler Optimization of Memory-Resident Value Communication… - 13 - Zhai, Colohan, Steffan and
Mowry
Carnegie Mellon
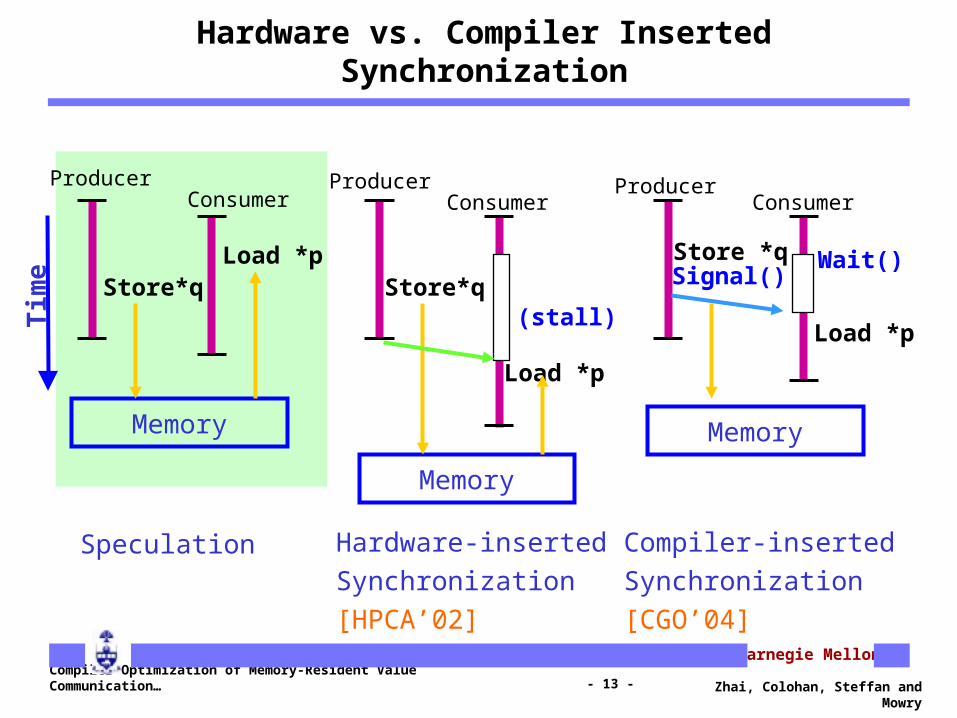
Hardware vs. Compiler Inserted Synchronization
Store*qLoad *p
Memory
Store*q
Load *p
Memory
Store *q
Load *p
Memory
Speculation Hardware-insertedSynchronization[HPCA’02]
Compiler-insertedSynchronization[CGO’04]
Tim
e Signal()
(stall)
ProducerConsumer
ProducerConsumer
ProducerConsumer
Wait()
Compiler Optimization of Memory-Resident Value Communication… - 14 - Zhai, Colohan, Steffan and
Mowry
Carnegie Mellon
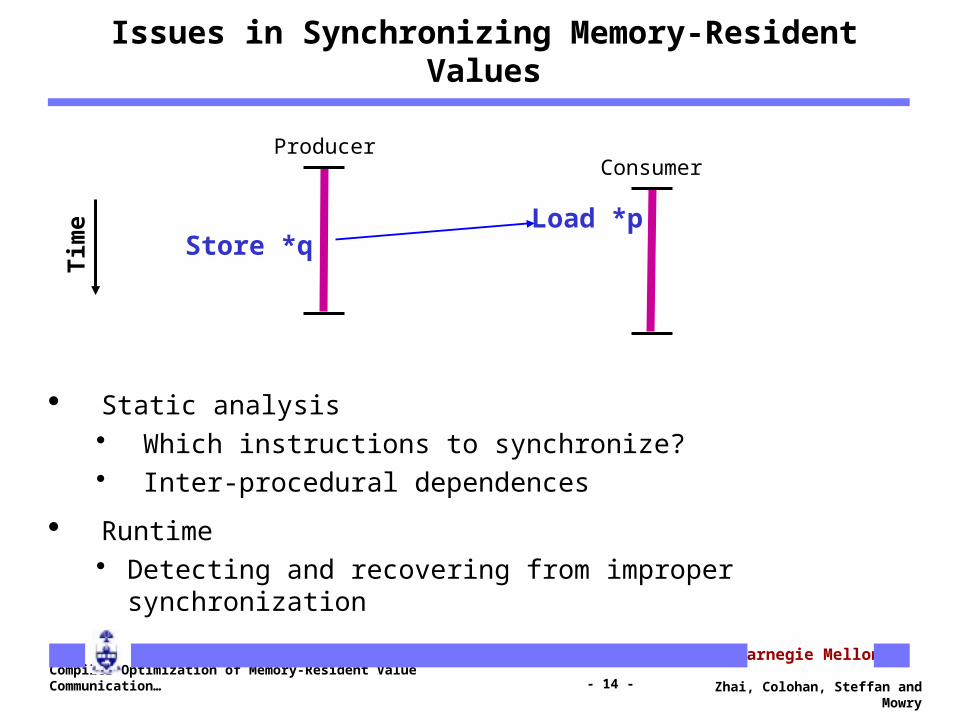
Issues in Synchronizing Memory-Resident Values
Static analysis Which instructions to synchronize? Inter-procedural dependences
Runtime Detecting and recovering from improper synchronization
Store *qLoad *p
ProducerConsumer
Time

Compiler Optimization of Memory-Resident Value Communication… - 15 - Zhai, Colohan, Steffan and
Mowry
Carnegie Mellon
Outline
Static analysis
Runtime checks
Results
Conclusions
Load *p
ProducerConsumer
Store *q
Time
Compiler Optimization of Memory-Resident Value Communication… - 16 - Zhai, Colohan, Steffan and
Mowry
Carnegie Mellon
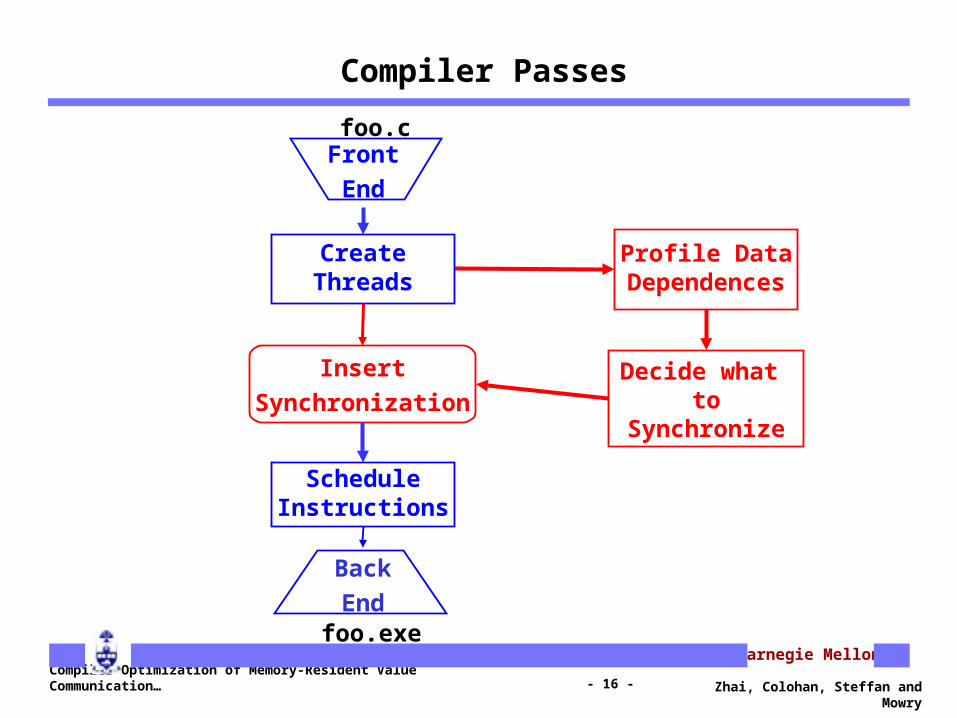
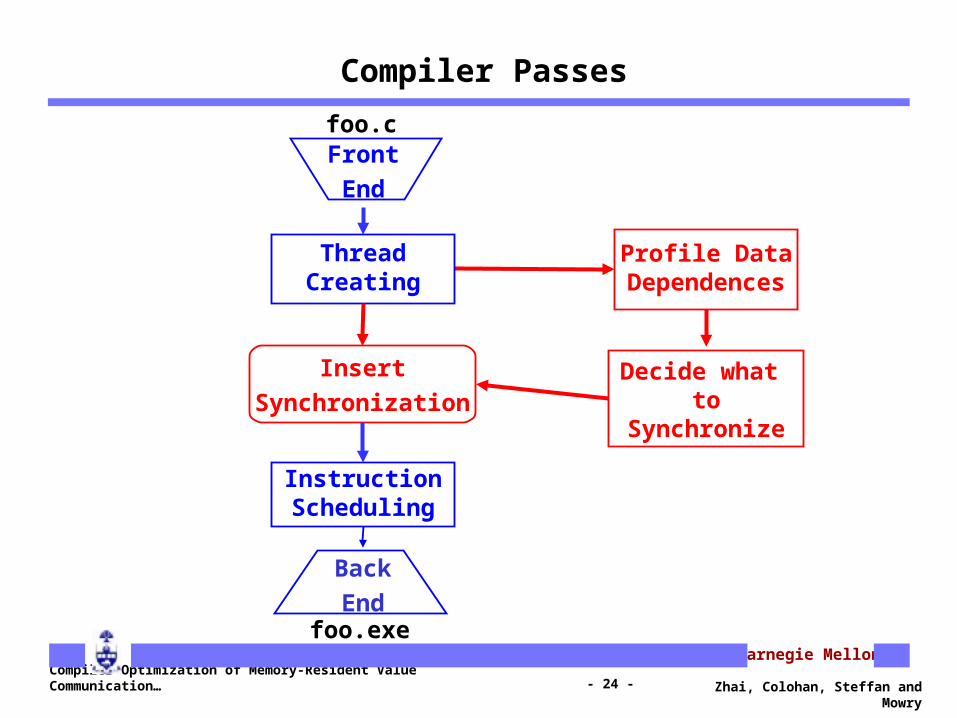
Compiler Passes
Front
End
Back
End
foo.c
foo.exe
Insert
Synchronization
Profile DataDependences
CreateThreads
ScheduleInstructions
Decide what to Synchronize

Compiler Optimization of Memory-Resident Value Communication… - 17 - Zhai, Colohan, Steffan and
Mowry
Carnegie Mellon
Example
work()
push (head, entry)
do { push (&set, element); work(); } while (test);

Compiler Optimization of Memory-Resident Value Communication… - 18 - Zhai, Colohan, Steffan and
Mowry
Carnegie Mellon
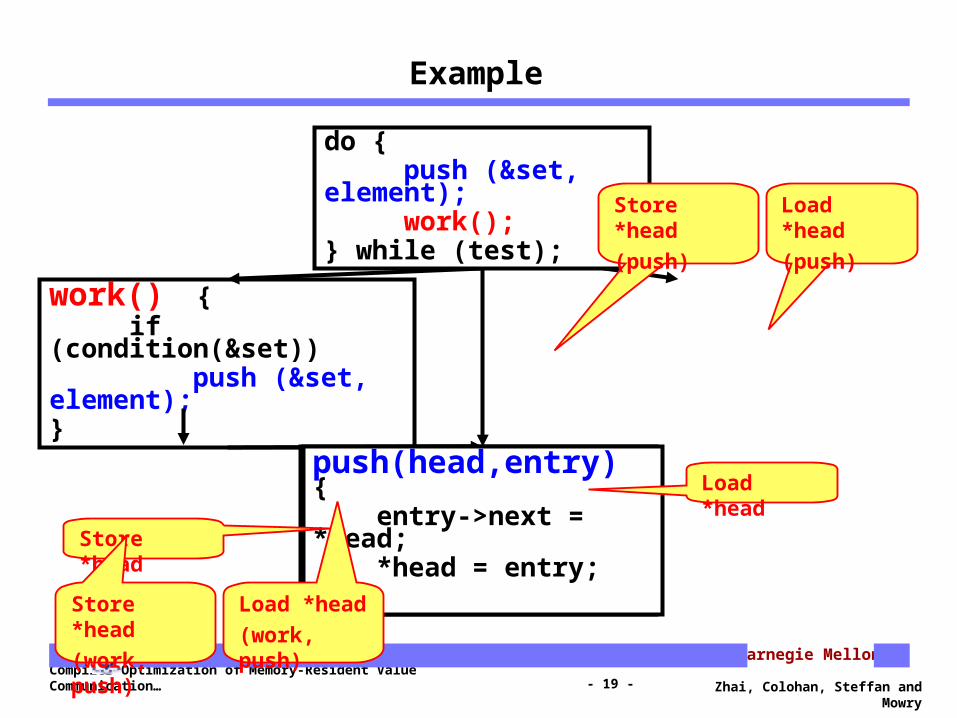
Example
work() { if (condition(&set)) push (&set, element);}
push (head, entry)
do { push (&set, element); work(); } while (test);
Compiler Optimization of Memory-Resident Value Communication… - 19 - Zhai, Colohan, Steffan and
Mowry
Carnegie Mellon
Example
work() { if (condition(&set)) push (&set, element);}
push(head,entry) { entry->next = *head; *head = entry; }
push(head,entry) { entry->next = *head; *head = entry; }
Load *head
Store *head
Load *head
(work, push)
Load *head
(push)
Store *head
(work, push)
do { push (&set, element); work(); } while (test);
Store *head
(push)

Compiler Optimization of Memory-Resident Value Communication… - 20 - Zhai, Colohan, Steffan and
Mowry
Carnegie Mellon
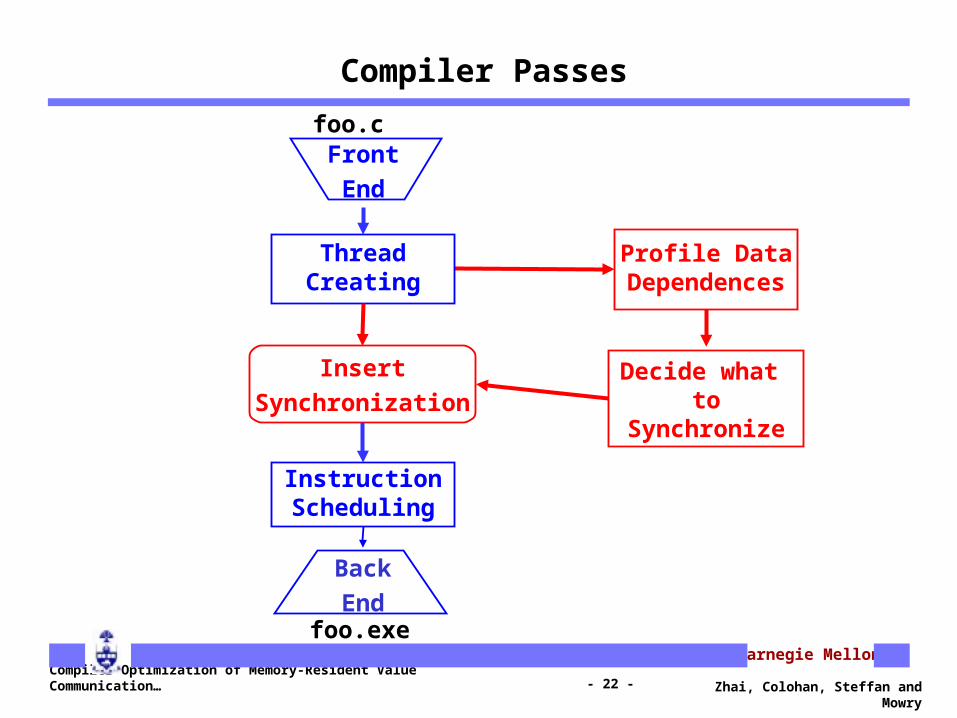
Compiler Passes
Front
End
Back
End
Insert
Synchronization
Profile DataDependences
ThreadCreating
InstructionScheduling
Decide what to Synchronize
foo.exe
foo.c
Compiler Optimization of Memory-Resident Value Communication… - 21 - Zhai, Colohan, Steffan and
Mowry
Carnegie Mellon
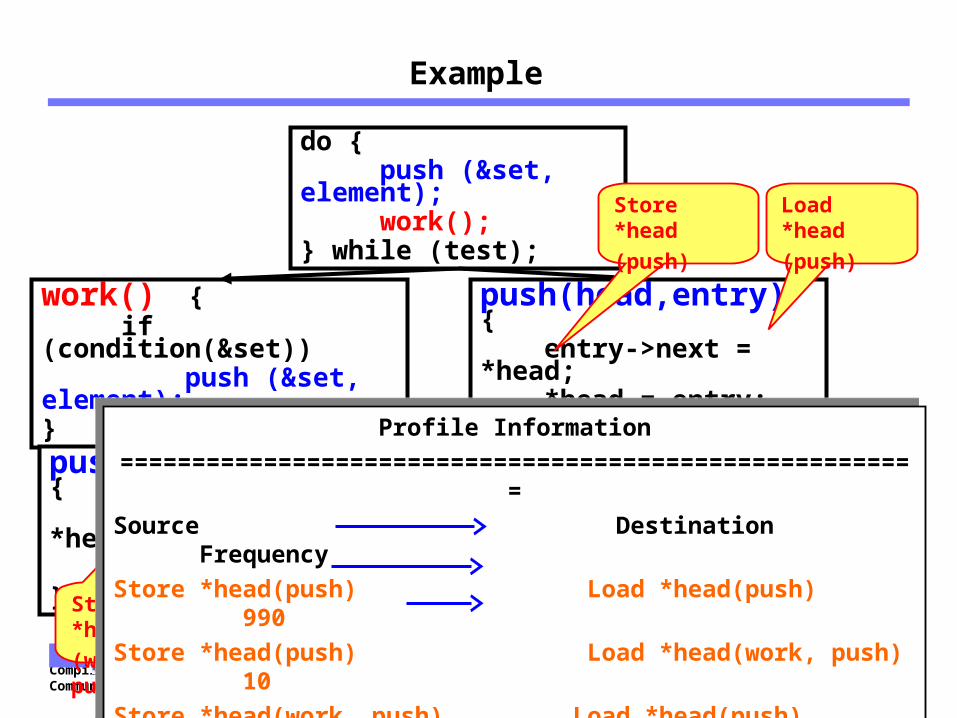
Example
work() { if (condition(&set)) push (&set, element);}
do { push (&set, element); work(); } while (test);
push(head,entry) { entry->next = *head; *head = entry; }
push(head,entry) { entry->next = *head; *head = entry; }
Load *head
(push)
Store *head
(push)
Load *head
(work, push)
Store *head
(work, push)
Profile Information=======================================================
=
Source Destination FrequencyStore *head(push) Load *head(push) 990Store *head(push) Load *head(work, push) 10Store *head(work, push) Load *head(push) 10
Profile Information=======================================================
=
Source Destination FrequencyStore *head(push) Load *head(push) 990Store *head(push) Load *head(work, push) 10Store *head(work, push) Load *head(push) 10
Compiler Optimization of Memory-Resident Value Communication… - 22 - Zhai, Colohan, Steffan and
Mowry
Carnegie Mellon
Compiler Passes
Front
End
Back
End
Insert
Synchronization
Profile DataDependences
ThreadCreating
InstructionScheduling
Decide what to Synchronize
foo.exe
foo.c

Compiler Optimization of Memory-Resident Value Communication… - 23 - Zhai, Colohan, Steffan and
Mowry
Carnegie Mellon
Dependence Graph
Load *head
(work, push)
Store *head
(work, push)
990
10
10
Load *head
(push)
Store *head
(push)
Pairs that need to be synchronized can be extracted
from the dependence graph
Infrequent dependences: occur in less than 5% of iterations
Compiler Optimization of Memory-Resident Value Communication… - 24 - Zhai, Colohan, Steffan and
Mowry
Carnegie Mellon
Compiler Passes
Front
End
Back
End
Insert
Synchronization
Profile DataDependences
ThreadCreating
InstructionScheduling
Decide what to Synchronize
foo.exe
foo.c

Compiler Optimization of Memory-Resident Value Communication… - 25 - Zhai, Colohan, Steffan and
Mowry
Carnegie Mellon
Example
work() { if (condition(&set)) push (&set, element);}
do { push (&set, element); work(); } while (test);
push(head,entry) { entry->next = *head; *head = entry; }
push(head,entry) { entry->next = *head; *head = entry; }
Load *head
(push)
Store *head
(push)990
Load *head
(push)
Store *head
(push)
Synchronize these
push_clone(head,entry) { wait(); entry->next = *head; *head = entry; signal(head, *head);}
push_clone(&set, element);

Compiler Optimization of Memory-Resident Value Communication… - 26 - Zhai, Colohan, Steffan and
Mowry
Carnegie Mellon
Outline
• Static analysis
Runtime checks
Results
Conclusions
ProducerConsumer
Store *qLoad *pT
ime
Compiler Optimization of Memory-Resident Value Communication… - 27 - Zhai, Colohan, Steffan and
Mowry
Carnegie Mellon
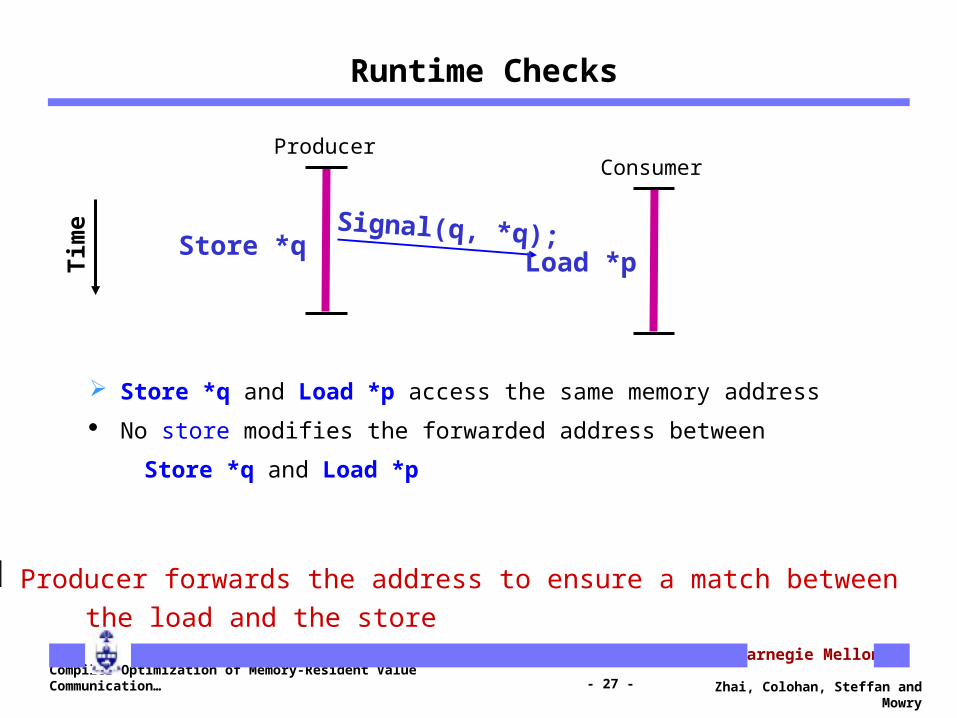
Runtime Checks
Store *q and Load *p access the same memory address
No store modifies the forwarded address between
Store *q and Load *p
Signal(q, *q);
Producer forwards the address to ensure a match between the load and the store
ProducerConsumer
Load *pStore *q
Time
Compiler Optimization of Memory-Resident Value Communication… - 28 - Zhai, Colohan, Steffan and
Mowry
Carnegie Mellon
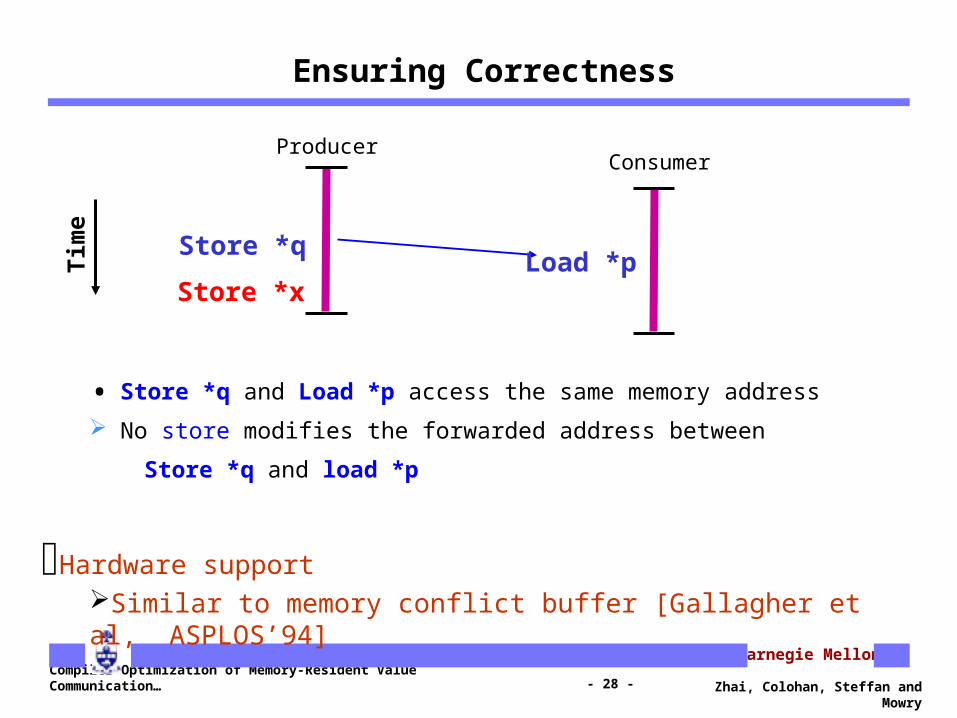
Ensuring Correctness
Store *x
• Store *q and Load *p access the same memory address
No store modifies the forwarded address between
Store *q and load *p
ConsumerProducer
Hardware supportSimilar to memory conflict buffer [Gallagher et al, ASPLOS’94]
Load *pStore *q
Time

Compiler Optimization of Memory-Resident Value Communication… - 29 - Zhai, Colohan, Steffan and
Mowry
Carnegie Mellon
Ensuring Correctness
Hardware support: TLS hardware already knows which locations are stored to
• Store *q and Load *p access the same memory address
No store modifies the forwarded address between
Store *q and load *p
ConsumerProducer
Store *yLoad *p
Store *q
Time

Compiler Optimization of Memory-Resident Value Communication… - 30 - Zhai, Colohan, Steffan and
Mowry
Carnegie Mellon
Outline
• Static analysis
• Runtime checks
Results
Conclusions
ProducerConsumer
Store *qLoad *pT
ime

Compiler Optimization of Memory-Resident Value Communication… - 31 - Zhai, Colohan, Steffan and
Mowry
Carnegie Mellon
Crossbar
Experimental Framework
Underlying architecture 4-processor, single-chip multiprocessor speculation supported through coherence
Simulator superscalar, similar to MIPS R14K 10-cycle communication latency models all bandwidth and contention
Benchmarks SPECint95 and SPECint2000, -O3 optimization
detailed simulationC
C
P
C
P

Compiler Optimization of Memory-Resident Value Communication… - 32 - Zhai, Colohan, Steffan and
Mowry
Carnegie Mellon
Parallel Region CoveragePa
ralle
l Reg
ion
Cov
erag
e
0
100
go
m88ksim
ijpeg
gzip_comp
gzip_decomp
vpr_place gc
cmcf
crafty
parser
perlbmk
gap
bzip2_comp
Coverage is significant
Average coverage: 54%
Compiler Optimization of Memory-Resident Value Communication… - 33 - Zhai, Colohan, Steffan and
Mowry
Carnegie Mellon
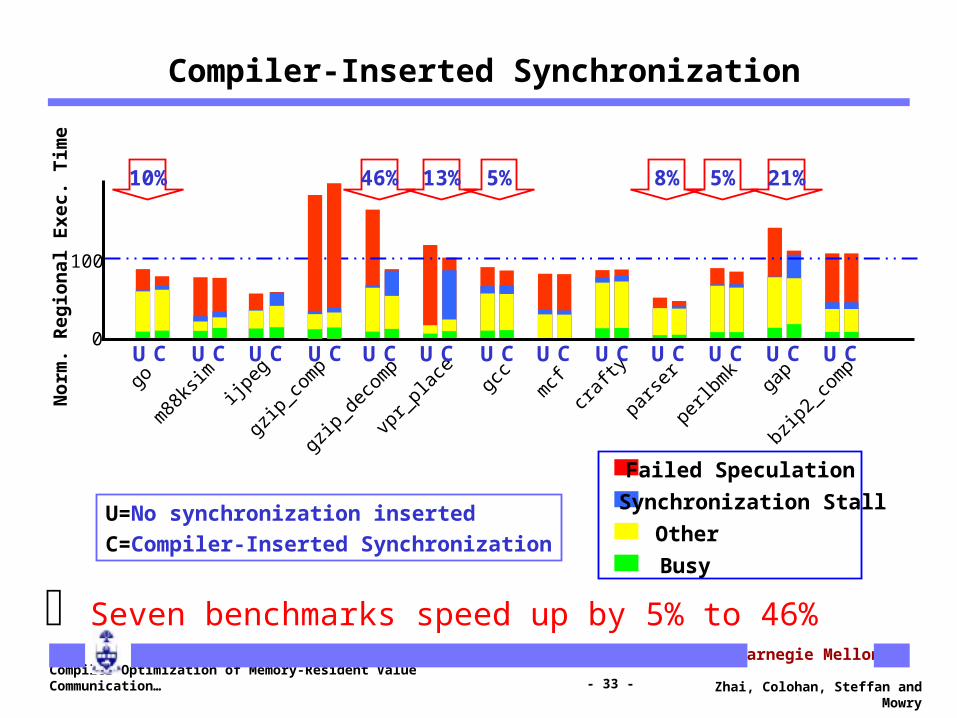
Failed Speculation
Synchronization Stall
Other
Busy
U=No synchronization inserted
C=Compiler-Inserted Synchronization
Seven benchmarks speed up by 5% to 46%
Compiler-Inserted Synchronization
0
100
go
m88ksim
ijpeg
gzip_comp
gzip_decomp
vpr_place gc
cmcf
crafty
parser
perlbmk
gap
bzip2_comp
U C U C U C U C U C U C U C U C U C U C U C U C U C
10% 46% 13% 5% 8% 5% 21%
Nor
m. R
egio
nal E
xec.
Tim
e

Compiler Optimization of Memory-Resident Value Communication… - 34 - Zhai, Colohan, Steffan and
Mowry
Carnegie Mellon
Compiler- vs. Hardware-Inserted Synchronization
0
100
go
m88ksim
ijpeg
gzip_comp
gzip_decomp
vpr_place gc
cmcf
crafty
parser
perlbmk
gap
bzip2_comp
C H C H C H C H C H C H C H C H C H C H C H C H C H
C=Compiler-Inserted Synchronization
H=Hardware-Inserted Synchronization
Compiler and hardware [HPCA’02] each benefits different benchmarks
Nor
m. R
egio
nal E
xec.
Tim
e
Failed Speculation
Synchronization Stall
Other
Busy
Hardwaredoes better
Compilerdoes better

Compiler Optimization of Memory-Resident Value Communication… - 35 - Zhai, Colohan, Steffan and
Mowry
Carnegie Mellon
Combining Hardware and Compiler Synchronization
C=Compiler-inserted synchronization
H=Hardware-inserted synchronization
B=Combining Both
The combination is more robust than each technique individually
0
100
go
m88ksim
gzip_comp
gzip_decomp
perlbmk
gap
C H B C H B C H B C H B C H B C H B
Nor
m. R
egio
nal E
xec.
Tim
e
Failed Speculation
Synchronization Stall
Other
Busy
Compiler Optimization of Memory-Resident Value Communication… - 36 - Zhai, Colohan, Steffan and
Mowry
Carnegie Mellon
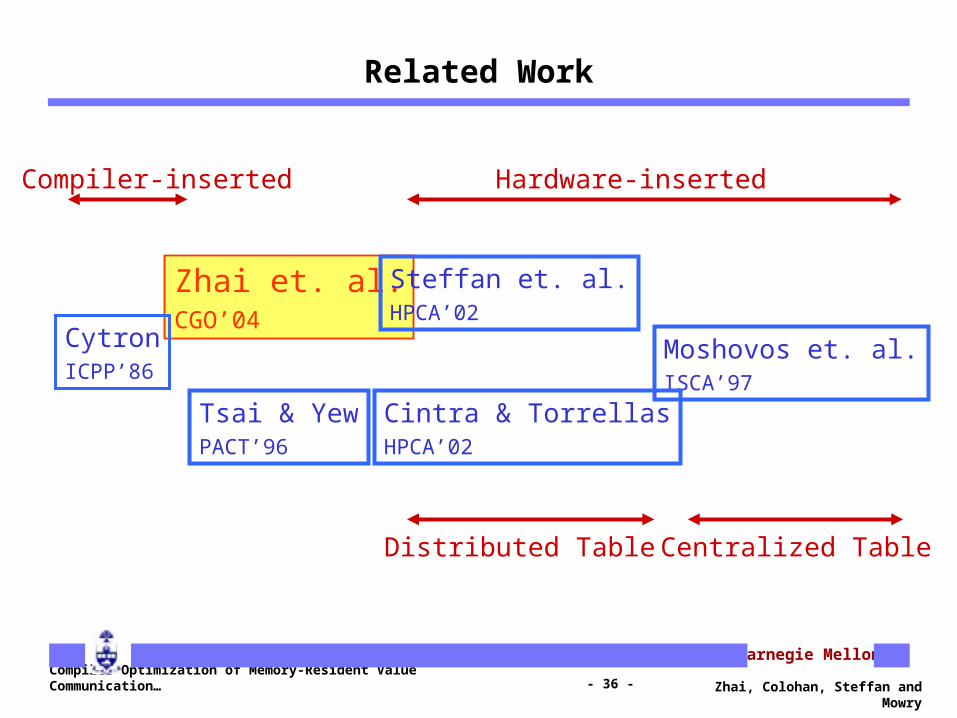
Related Work
Zhai et. al.CGO’04
CytronICPP’86
Compiler-inserted
Moshovos et. al.ISCA’97
Cintra & TorrellasHPCA’02
Steffan et. al.HPCA’02
Hardware-inserted
Centralized TableDistributed Table
Tsai & YewPACT’96

Compiler Optimization of Memory-Resident Value Communication… - 37 - Zhai, Colohan, Steffan and
Mowry
Carnegie Mellon
Conclusions
Compiler-inserted synchronization for memory-resident value communication:
Effective in reducing speculation failure Half of the benchmarks speedup by 5% to 46%
(regional)
Combining hardware and compiler techniques is more robust Neither consistently outperforms the other Can be combined to track the best performer
Memory-resident value communication should be addressed with the combined efforts of the compiler and the hardware
Compiler Optimization of Memory-Resident Value Communication… - 38 - Zhai, Colohan, Steffan and
Mowry
Carnegie Mellon
Questions?
Compiler Optimization of Memory-Resident Value Communication… - 39 - Zhai, Colohan, Steffan and
Mowry
Carnegie Mellon
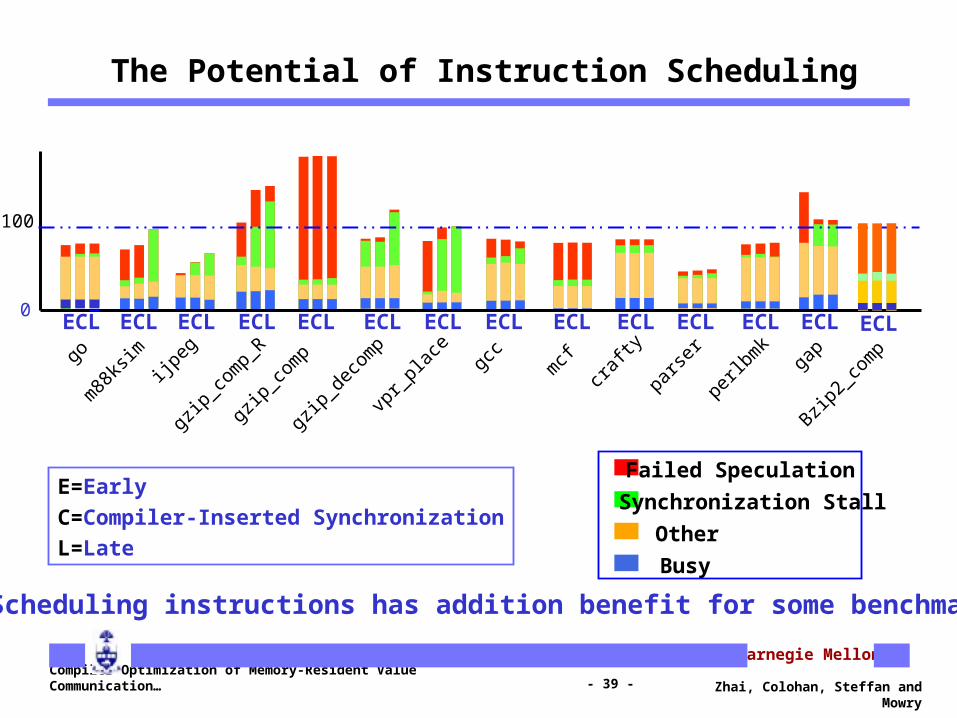
The Potential of Instruction Scheduling
0
100
go
m88ksim
ijpeg
gzip_comp_R
gzip_decomp
vpr_place
mcf
crafty
parser
perlbmk
gap
gzip_comp gc
c
E=Early
C=Compiler-Inserted Synchronization
L=Late
Failed Speculation
Synchronization Stall
Other
Busy
Scheduling instructions has addition benefit for some benchmarks
ECL ECL ECL ECL ECL ECL ECL ECL ECL ECL ECL ECL ECL ECL
Bzip2_comp
Compiler Optimization of Memory-Resident Value Communication… - 40 - Zhai, Colohan, Steffan and
Mowry
Carnegie Mellon
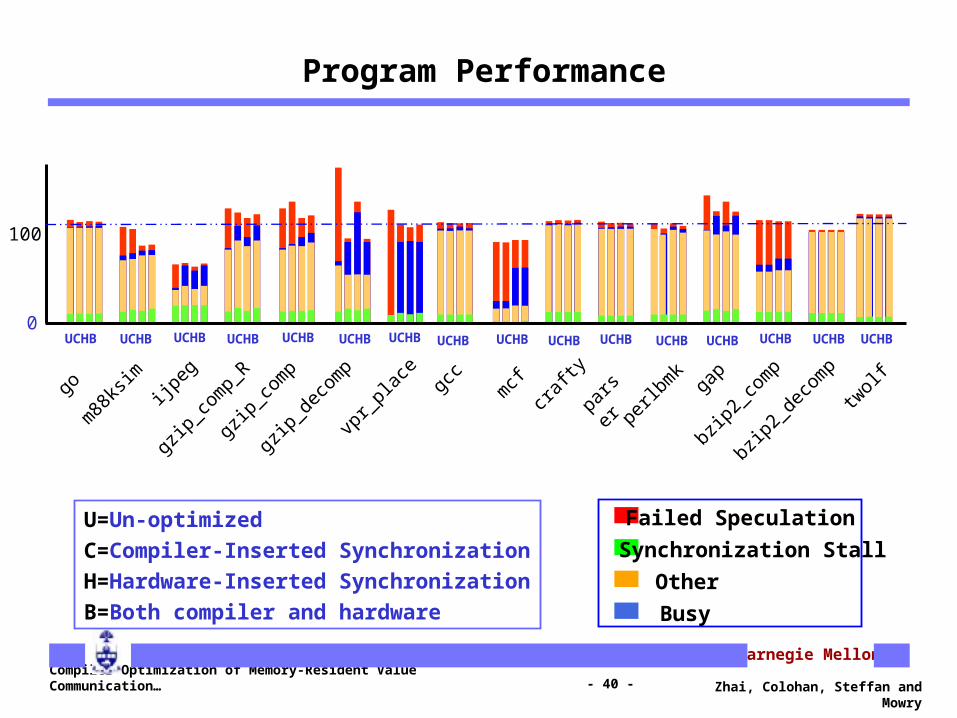
Program Performance
0
100
go
m88ksim
ijpeg
gzip_comp_R
gzip_decomp
vpr_place gc
cmcf
crafty
parser
perlbmk
gap
bzip2_comp
bzip2_decomp
twolf
gzip_comp
U=Un-optimized
C=Compiler-Inserted Synchronization
H=Hardware-Inserted Synchronization
B=Both compiler and hardware
Failed Speculation
Synchronization Stall
Other
Busy
UCHB UCHB UCHB UCHB UCHB UCHB UCHB UCHB UCHB UCHB UCHB UCHB UCHB UCHB UCHB UCHB
Compiler Optimization of Memory-Resident Value Communication… - 41 - Zhai, Colohan, Steffan and
Mowry
Carnegie Mellon
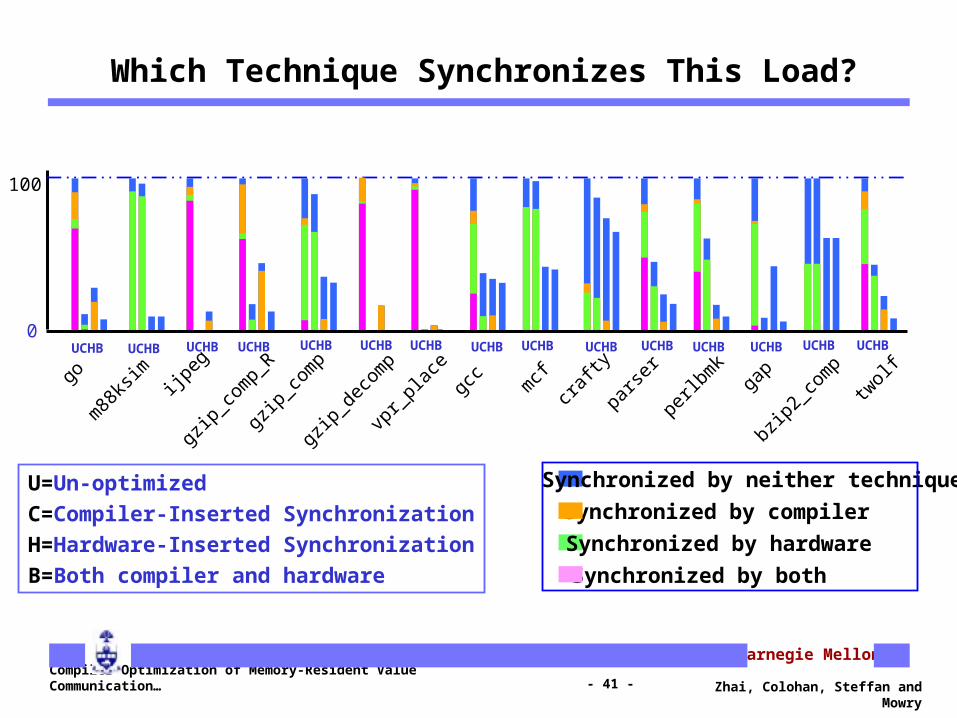
Which Technique Synchronizes This Load?
0
100
go
m88ksim
ijpeg
gzip_comp_R
gzip_decomp
vpr_place gc
cmcf
crafty
parser
perlbmk
gap
bzip2_comp
twolf
UCHB UCHB UCHB UCHB UCHB UCHB UCHB UCHB UCHB UCHB UCHBUCHBUCHBUCHBUCHB
gzip_comp
U=Un-optimized
C=Compiler-Inserted Synchronization
H=Hardware-Inserted Synchronization
B=Both compiler and hardware
Synchronized by neither technique
Synchronized by compiler
Synchronized by hardware
Synchronized by both

Compiler Optimization of Memory-Resident Value Communication… - 42 - Zhai, Colohan, Steffan and
Mowry
Carnegie Mellon
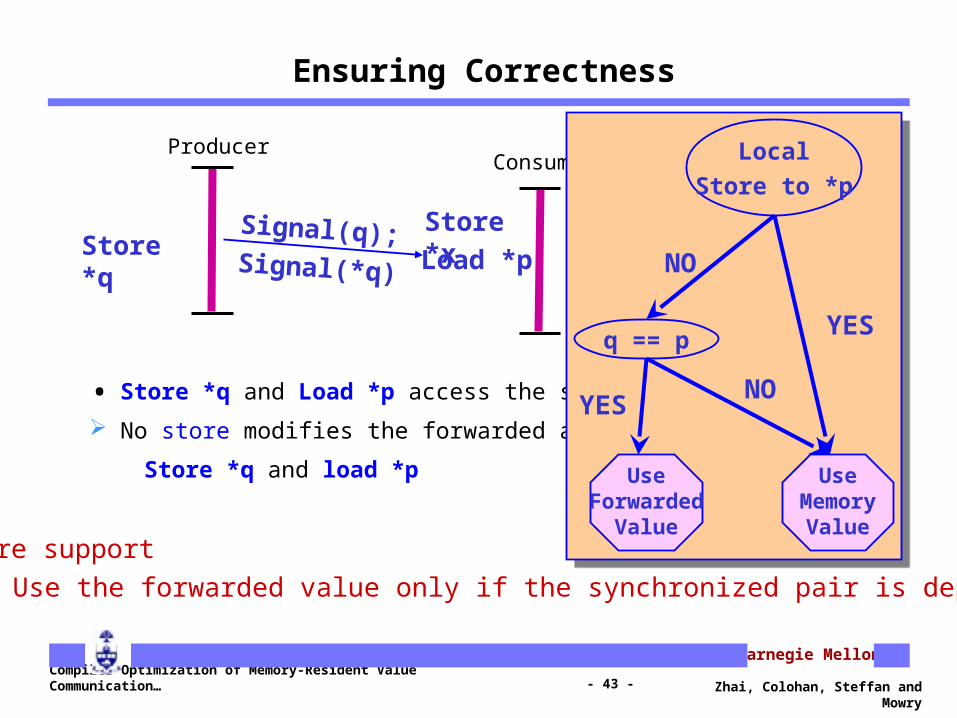
Ensuring Correctness
Hardware supportSimilar to memory conflict buffer [Gallagher et al, ASPLOS’94]
Store *q Load *pStore *x
• Store *q and Load *p access the same memory address
No store modifies the forwarded address between
Store *q and load *p
ConsumerProducer
Compiler Optimization of Memory-Resident Value Communication… - 43 - Zhai, Colohan, Steffan and
Mowry
Carnegie Mellon
Consumer
• Store *q and Load *p access the same memory address
No store modifies the forwarded address between
Store *q and load *p
Ensuring Correctness
Hardware support Use the forwarded value only if the synchronized pair is dependent
UseForwarded
Value
UseMemoryValue
LocalStore to *p
q == p
NO
YES
YESNO
Store *q Load *p
Store *xSignal(q);Signal(*q)
Producer
Compiler Optimization of Memory-Resident Value Communication… - 44 - Zhai, Colohan, Steffan and
Mowry
Carnegie Mellon
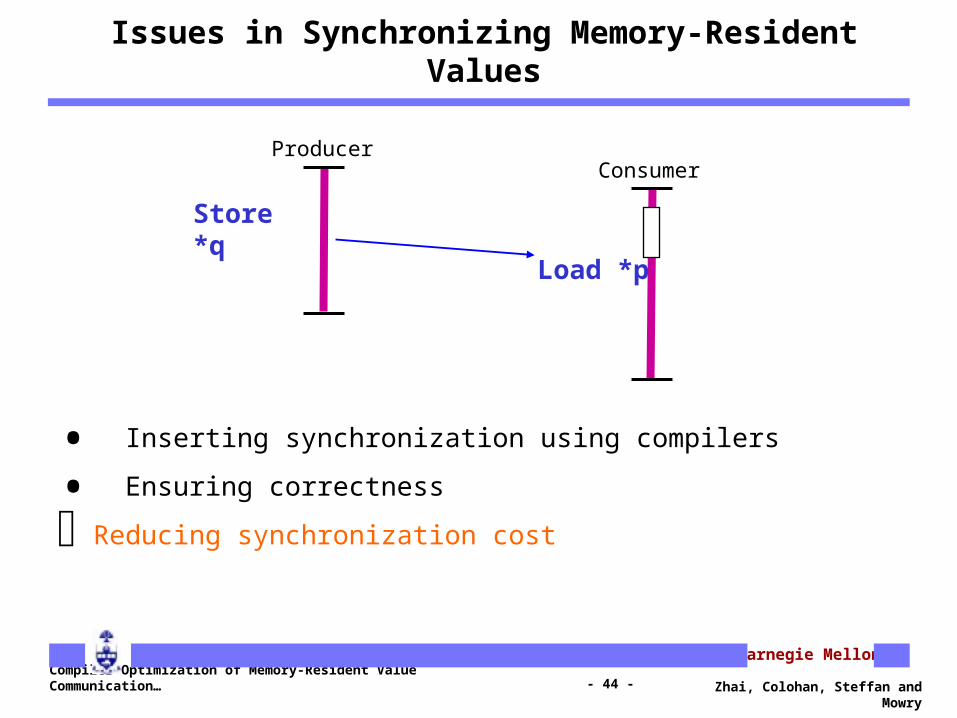
Issues in Synchronizing Memory-Resident Values
• Inserting synchronization using compilers
• Ensuring correctness
Reducing synchronization cost
Store *q
Load *p
ConsumerProducer

Compiler Optimization of Memory-Resident Value Communication… - 45 - Zhai, Colohan, Steffan and
Mowry
Carnegie Mellon
Reducing Cost of Synchronization
Before Instruction Scheduling
Consumer
Producer
Instruction scheduling algorithms are described in [ASPLOS’02]
After Instruction Scheduling
Producer
Consumer

Compiler Optimization of Memory-Resident Value Communication… - 46 - Zhai, Colohan, Steffan and
Mowry
Carnegie Mellon
The Potential of Instruction Scheduling
0
100
m88ksim
ijpeg
gzip_comp
gzip_decomp
vpr_place ga
p
E = Perfectly predicting synchronized
memory-resident values
C = Compiler-inserted synchronization
L = Consumer stalls until previous thread commits
Scheduling instructions could offer additional benefit
E C L E C L E C L E C L E C L E C L
Failed Speculation
Synchronization Stall
Other
Busy
Nor
m. R
egio
nal E
xec.
Tim
e
Compiler Optimization of Memory-Resident Value Communication… - 47 - Zhai, Colohan, Steffan and
Mowry
Carnegie Mellon
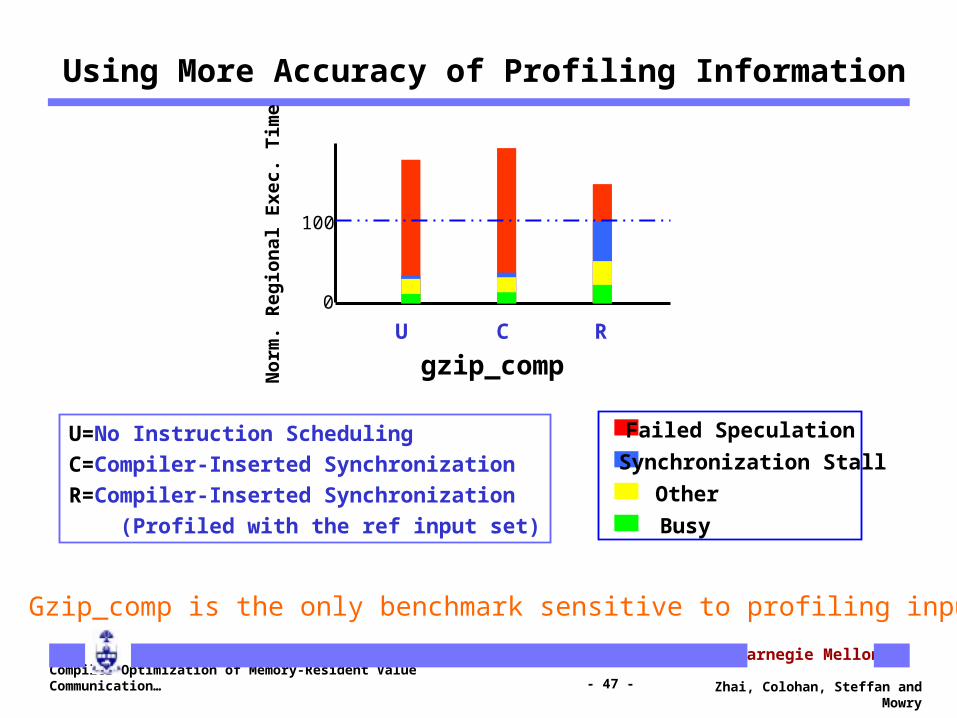
Using More Accuracy of Profiling Information
0
100
C RU
U=No Instruction Scheduling
C=Compiler-Inserted Synchronization
R=Compiler-Inserted Synchronization
(Profiled with the ref input set)
Gzip_comp is the only benchmark sensitive to profiling input
gzip_comp
Failed Speculation
Synchronization Stall
Other
Busy
Nor
m. R
egio
nal E
xec.
Tim
e