chap. 4, formal grammars and parsing j. h. wang oct. 19, 2015
TRANSCRIPT

Chap. 4, Formal Grammars and Parsing
J. H. WangOct. 19, 2015

Outline
• Introduction• Context-Free Grammars• Properties of CFGs• Transforming Extended Grammars• Parsers and Recognizers• Grammar Analysis Algorithms

Introduction
• A natural language’s grammar: to capture a small but important aspect of a sentence’s validity with respect to a natural language
• Regular sets: guiding the actions of automatically constructed scanner– Chap. 3
• Grammar: guiding the actions of the parsers– Chap. 5, 6
• Semantic analysis: enforcing programming language rules that are not easily expressed by grammars– Chap. 7, 8, 9

The Role of the Parser
LexicalAnalyzer
LexicalAnalyzer ParserParser
Symbol Table
source program
Parse treetoken
Get next token
Rest of Front End
Rest of Front End
Intermediate
representation

Context-Free Grammars
• Components: G=(N,,P,S)– A finite terminal alphabet : the set of
tokens produced by the scanner– A finite nonterminal alphabet N: variables of
the grammar– A start symbol S: SN that initiates all
derivations• Goal symbol
– A finite set of productions P: AX1…Xm, where AN, XiN, 1≤i≤m and m≥0.
• Rewriting rules
• Vocabulary V=N– N=

• CFG: recipe for creating strings• Derivation: a rewriting step using the
production A replaces the nonterminal A with the vocabulary symbols in – Left-hand side (LHS): A– Right-hand side (RHS):
• Context-free language of grammar G L(G): the set of terminal strings derivable from S

Notations
Names Beginning with
Represent Symbols In
Examples
Uppercase N A, B, C, Prefix
Lowercase and punctuation
a, b, c, if, then, (, ;
X, Y N Xi, Y3
Other Greek letters
(N)* , ,

• Or notation:– A
| … |
– AA …A
A=>: one step of derivation using the production A– =>+: derives in one or more steps– =>*: derives in zero or more
steps
• S=>*: is a sentential form of the CFG
• SF(G): the set of sentential forms of G
• L(G)={w*|S=>+w}– L(G)=SF(G)*

• Two conventions that nonterminals are rewritten in some systematic order– Leftmost derivation: from left to right– Rightmost derivation: from right to left

Leftmost Derivation
• A derivation that always chooses the leftmost possible nonterminal at each step– =>lm, =>+
lm, =>*lm
– A left sentential form• A sentential form produced via a leftmost
derivation• E.g. production sequence in top-down
parsers• (Fig. 4.1)


• E.g: a leftmost derivation of f ( v + v )– E =>lm Prefix ( E )
=>lm f ( E ) =>lm f ( v Tail ) =>lm f ( v + E ) =>lm f ( v + v Tail ) =>lm f ( v + v )

Rightmost Derivations
• The rightmost possible nonterminal is always expanded– Canonical derivation
– =>rm, =>+rm, =>*rm
– A right sentential form• A sentential form produced via a rightmost
derivation• E.g. produced by bottom-up parsers (Ch. 6)• (Fig. 4.1)

• E.g: a rightmost derivation of f ( v + v )– E =>rm Prefix ( E )
=>rm Prefix ( v Tail ) =>rm Prefix ( v + E ) =>rm Prefix ( v + v Tail ) =>rm Prefix ( v + v ) =>rm f ( v + v )

Parse Trees
• Parse tree: graphical representation of a derivation– Root: start symbol S– Each node: either grammar symbol or λ– Interior nodes: nonterminals
• An interior node and its children: production
– E.g. Fig. 4.2


• Phrase of the sentential form: a sequence of symbols descended from a single nonterminal in the parse tree
• A simple or prime phrase: a phrase that contains no smaller phrase
• Handle of a sentential form: the leftmost simple phrase
• E.g. f ( v Tail ) in Fig. 4.2

Other Types of Grammars
• Regular grammars: less powerful• Context-sensitive and unrestricted
grammars: more powerful

Regular Grammars
• A CFG that is limited to productions of the form AaB or Cd– RHS: either a symbol from {λ}
followed by a nonterminal symbol, or a symbol from {λ}
– Regular set• E.g. {[i]i|i>=1} not regular
– S TT [ T ] | λ
• Regular sets are a proper subset of the context-free languages

Beyond Context-Free Grammars
• Context-sensitive grammar: nonterminals are rewritten only when they appear in a particular context (A), provided the rule never causes the sentential form to contract in length
• Unrestricted grammar (type-0 grammar): the most general

• More powerful, but less useful– Efficient parsers for such grammars do
not exist– It’s difficult to prove properties about
such grammars
• CFGs: a nice balance between generality and practicability

Properties of CFGs
• Some grammars might have problems:– Include useless symbols– Allow multiple, distinct derivations for
some input string– Include strings not in the language, or
exclude strings in the language

Reduced Grammars
• Each of its nonterminals and productions participates in the derivation of some string– Useless nonterminals: can be safely removed– E.g.
• SA | BAaBB bCc
– Algorithms to detect useless nonterminals• Ex.16 and Ex.19

Ambiguity
• Allow a derived string to have two or more different parse trees– E.g.
• Expr Expr – Expr | id
• Two different parse trees for id – id – id– Fig. 4.3
– No algorithm for checking an arbitrary CFG for ambiguity• Undecidable


Faulty Language Definition
• Terminal strings derivable by the grammar do not correspond exactly to the strings in the language
• Determining in general whether two CFGs generate the same language is an undecidable problem

Transforming Extended Grammars
• BNF (Backus-Naur form)– Optional symbols: enclosed in square brackets
• A [X1…Xn]
– Repeated symbols: enclosed in braces• B {X1…Xm}
– E.g. Java-like declaration• Declaration [final][static][const] Type identifier {,
identifier }
– Transforming extended BNF grammars into standard form
• Fig. 4.4

EW ON ERM
EW ON ERM

Parsers and Recognizers
• Recognizer: to determine if input string x L(G)
• Parser: to determine the string’s validity and structure (parse tree)– Top-down: starting at the root, expanding
the tree in a depth-first manner• Preorder traversal, predictive
– Bottom-up: starting at the leaves• Postorder traversal

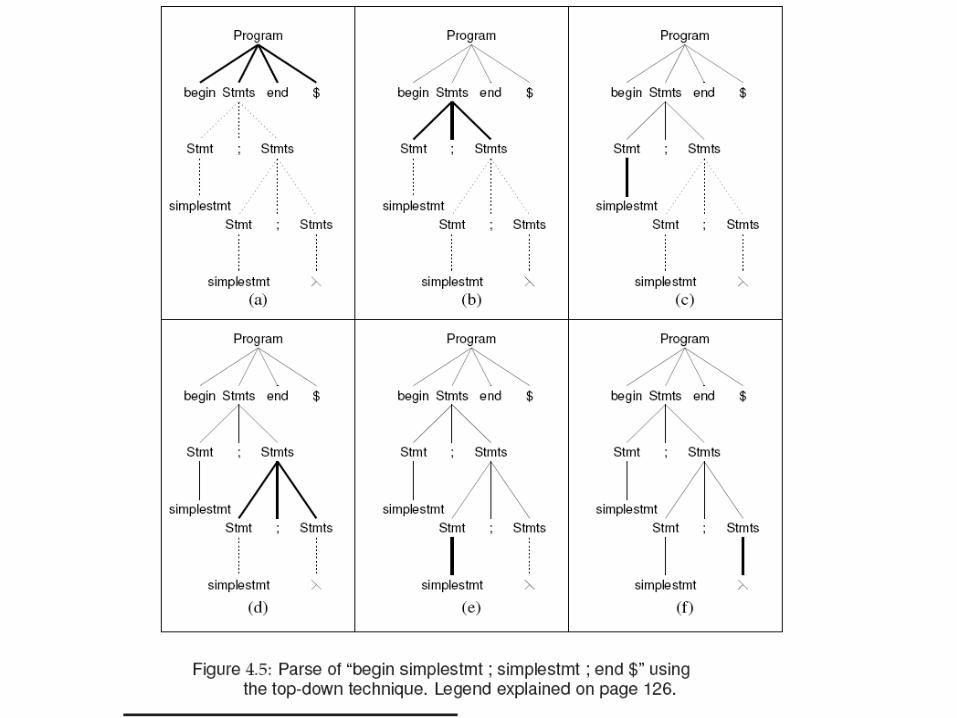
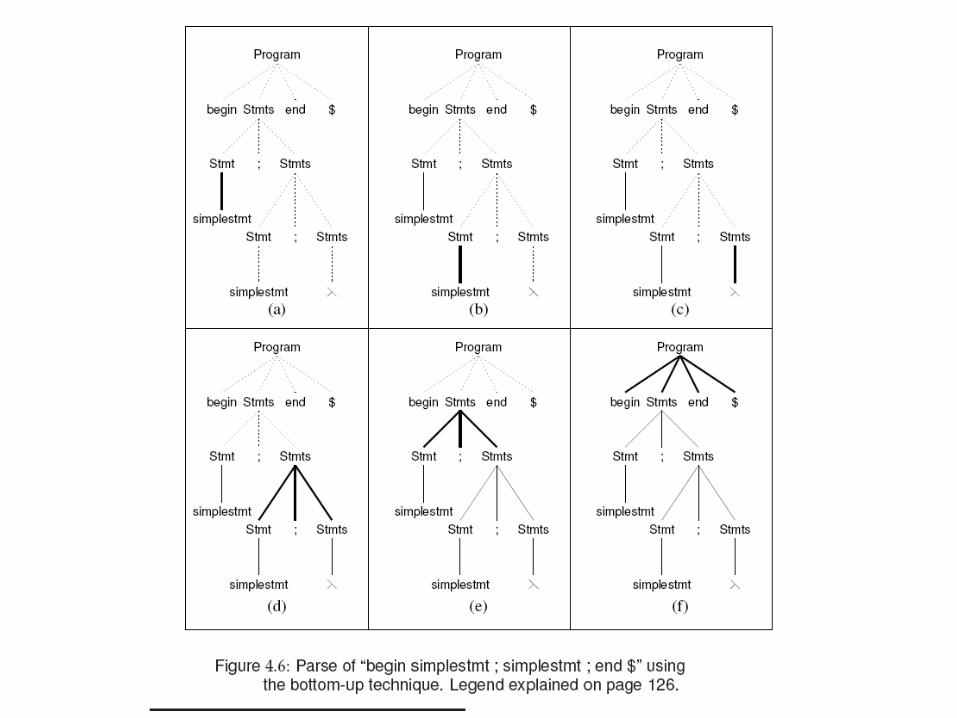
• E.g. grammar– Program begin Stmts end $
Stmts Stmt; Stmts | λStmt simplestmt | begin Stmts end
– String: begin simplestmt; simplestmt; end $• Top-down parse: Fig. 4.5• Bottom-up parse: Fig. 4.6

• Parsing techniques– E.g. LL(1), LR(1) are the best-known top-
down and bottom-up parsing strategies
• L: token sequence is processed from left to right
• L,R: Leftmost or Rightmost parse• 1: the number of lookahead symbols

Grammar Analysis Algorithms
• Grammar representation– Programming language constructs assumed:
• A set: an unordered collection of distinct entities• A list: an ordered collection of entities• An iterator: a construct that enumerates the contents
of a set or list– Observations
• Symbols are rarely deleted from a grammar• Transformations can add symbols and productions to a
grammar• Typically visit all rules for a nonterminal, or visit all
occurrences of a symbol in productions• A production’s RHS processed one symbol at a time
– -> a production is represented by LHS and RHS symbols

Grammar Utilities• Creating or adding:
– Grammar(S)– Production(A, rhs)– Nonterminal(A)– Terminal(x)
• Iterators:– Productions()– Noterminals()– Terminals()– RHS(p)– LHS(p)– ProductionsFor(A)– Occurrences(X)– Tail(y)
• Others– IsTerminal(X)– Production(y)

Deriving the Empty String
• It’s common to determine which nonterminals can derive λ– Not trivial because the derivation can
take more than one step• A=>BCD=>BC=>B=> λ
– Fig. 4.7

ERIVES MPTY TRING
ON ERMINALS
RODUCTIONS
RODUCTION
HECK OR MPTY
HECK OR MPTY
HECK OR MPTY
CCURRENCES

• The algorithm establishes two structures– RuleDerivesEmpty(p)– SymbolDerivesEmpty(A)– Useful in grammar analysis and parsing
algorithms in Chap.4, 5, & 6

First Sets
• The set of all terminal symbols that can begin a sentential form derivable from the string – First()={ a| =>*a }– We never include λ in First() even if
=>*λ– E.g. (in Fig.4.1)
• First(Tail) = {+}• First(Prefix) = {f}• First(E) = {v, f, (}
– Fig.4.8, Fig. 4.9, Fig. 4.10

IRST
NTERNAL IRST
NTERNAL IRST
NTERNAL IRST
NTERNAL IRST
ON ERMINALS



Follow Sets
• The set of terminals that can follow a nonterminal A in some sentential form– For AN,
• Follow(A) = {b|S=>+Ab}
– The right context associated with A– Fig. 4.11

NTERNAL OLLOW
NTERNAL OLLOW
NTERNAL OLLOW
OLLOW
CCURRENCES
IRST AIL
LL ERIVE MPTY
LL ERIVE MPTY
RODUCTION
ON ERMINALS
AIL



• First and Follow sets can be generalized to include strings of length k– Firstk(), Followk(A)
– Useful in parsing techniques that use k-symbol lookaheads (e.g. LL(k), LR(k))

More on FIRST and FOLLOW[Aho, Lam, Sethi, Ullman]
• Two functions FIRST and FOLLOW allow us to choose which production to apply, based on the next input symbol
• FIRST(): the set of terminals that begin strings derived from – Ex: A=>* c, c is in FIRST(A)
• FOLLOW(A): the set of terminals a that can appear immediately to the right of A in some sentential form– Ex: S =>* Aa

• To compute FIRST(X) for all grammar symbols X– If X is a terminal, FIRST(X)={X}
– If X is a nonterminal and XY1Y2…Yk, then place a in FIRST(X) if for some i, a is in FIRST(Yi) and Y1…Yi-1=>* λ
– (If Xλ is a production, add λ to FIRST(X))– (NOTE: In [Fischer 2009], never including
λ in First(X) even if X =>*λ)

• To compute FOLLOW(A) for all nonterminals A– (Place $ in FOLLOW(S))
• (Note: $ not needed in [Fischer 2009])
– If there’s a production AB, then everything in FIRST() except λ is in FOLLOW(B)
– If there’s a production AB, or AB, where FIRST() contains λ, then everything in FOLLOW(A) is in FOLLOW(B)

Example
• Ex: (4.28)– E T E’
E’ + T E’ | λT F T’T’ * F T’ | λF (E) | id
– FIRST(F)=FIRST(T)=FISRT(E)={(,id}– FIRST(E’)={+}– FIRST(T’)={*}– FOLLOW(E)=FOLLOW(E’)={)}– FOLLOW(T)=FOLLOW(T’)={+,)}– FOLLOW(F)={+,*,)}

Thanks for Your Attention!