chapter 16
DESCRIPTION
ECON 6002 Econometrics Memorial University of Newfoundland. Qualitative and Limited Dependent Variable Models. Chapter 16. Adapted from Vera Tabakova’s notes . Chapter 16: Qualitative and Limited Dependent Variable Models. Nested Logit Mixed Logit AKA Random Parameters Logit - PowerPoint PPT PresentationTRANSCRIPT

Chapter 16
Qualitative and Limited Dependent Variable Models
ECON 6002Econometrics Memorial University of Newfoundland
Adapted from Vera Tabakova’s notes

Chapter 16: Qualitative and Limited Dependent Variable Models Nested Logit
Mixed Logit AKA Random Parameters Logit
Generalized Multinomial Logit
Slide 16-2Principles of Econometrics, 3rd Edition

There is the implicit assumption in logit models that the odds between any pair of alternatives is independent of irrelevant alternatives (IIA)
One way to state the assumption If choice A is preferred to choice B out of the choice set {A,B}, then
introducing a third alternative X, thus expanding that choice set to {A,B,X}, must not make B preferable to A.
which kind of makes sense
Slide16-3Principles of Econometrics, 3rd Edition
IIA assumption

There is the implicit assumption in logit models that the odds between any pair of alternatives is independent of irrelevant alternatives (IIA)
In the case of the multinomial logit model, the IIA implies that adding another alternative or changing the characteristics of a third alternative must not affect the relative odds between the two alternatives considered.
This is not realistic for many real life applications involving similar (substitute) alternatives.
Slide16-4Principles of Econometrics, 3rd Edition
IIA assumption

This is not realistic for many real life applications with similar (substitute) alternatives
Examples: Beethoven/Debussy versus another of Beethoven’s Symphonies
(Debreu 1960; Tversky 1972) Bicycle/Pony (Luce and Suppes 1965) Red Bus/Blue Bus (McFadden 1974). Black slacks, jeans, shorts versus blue slacks (Hoffman, 2004) Etc.
Slide16-5Principles of Econometrics, 3rd Edition
IIA assumption

Red Bus/Blue Bus (McFadden 1974).
Imagine commuters first face a decision between two modes of transportation: car and red bus
Suppose that a consumer chooses between these two options with equal probability, 0.5, so
that the odds ratio equals 1.
Now add a third mode, blue bus. Assuming bus commuters do not care about the color of the bus (they are perfect substitutes), consumers are expected to choose between bus and car still with equal probability, so the probability of car is still 0.5, while the probabilities of each of the two bus types should go down to 0.25
However, this violates IIA: for the odds ratio between car and red bus to be preserved, the new probabilities must be: car 0.33; red bus 0.33; blue bus 0.33
Te IIA axiom does not mix well with perfect substitutes
IIA assumption

We can test this assumption with a Hausman-McFadden test which compares a logistic model with all the choices with one with restricted choices (mlogtest, hausman base in STATA, but check option detail too: mlogtest, hausman detail)
However, see Cheng and Long (2007)
Another test is Small and Hsiao’s (1985)STATA’s command is mlogtest, smhsiao (careful: the sample is randomly split every time, so you must set the seed if you want to replicate your results)
See Long and Freese’s book for details and worked examples
IIA assumption

Extensions have arisen to deal with this issue
The multinomial probit and the mixed logit are alternative models for nominal outcomes that relax IIA, by allowing correlation among the errors (to reflect similarity among options) but these models often have issues and assumptions themselves
IIA can also be relaxed by specifying a hierarchical model, ranking the choice alternatives. The most popular of these is called the McFadden’s nested logit model, which allows correlation among some errors, but not all (e.g. Heiss 2002)
Generalized extreme value and multinomial probit models possess another property, the Invariant Proportion of Substitution (Steenburgh 2008), which itself also suggests similarly counterintuitive real-life individual choice behavior
The multinomial probit has serious computational disadvantages too, since it involves calculating multiple (one less than the number of categories) integrals. With integration by simulation this problem is being ameliorated now…
IIA assumption

IIA can also be relaxed by specifying a hierarchical model, ranking the choice alternatives
The most popular of these is called the McFadden’s nested logit model, which allows correlation among some errors, but not all (e.g. Heiss 2002)
IIA assumption

The nested logit is a partial relaxation of the IID and IIA assumptions of the MNL model
It is relatively straightforward to estimate
It also has a closed-form solution
IIA assumption

Most NL models have only two hierarchical levels, Very few NL models are estimated with three levels, and even fewer with four levels
Note that the “tree structure” does not have an actual “sequential” interpretation of any sort
It is only there to allow for differentials in the degree of correlation within and between “nests”
IIA assumption

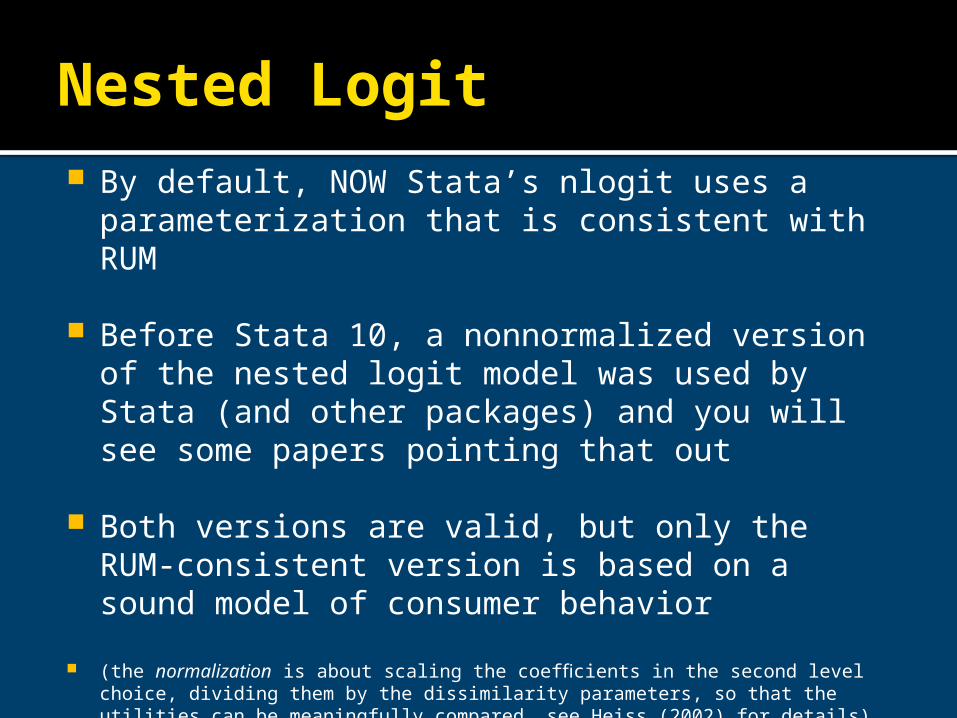
Nested Logit By default, nowadays Stata’s nlogit uses a parameterization
that is consistent with RUM
Before Stata 10, a nonnormalized version of the nested logit model was used by Stata (and other packages) and you will see some papers pointing that out
This can still be requested by specifying the nonnormalized option
nonnormalized requests a nonnormalized parameterization of the model that does not scale the inclusive values by the degree of dissimilarity of the alternatives within each nest. Use this option to replicate results from older versions of Stata (Stata help)
Nested Logit By default, NOW Stata’s nlogit uses a parameterization that
is consistent with RUM
Before Stata 10, a nonnormalized version of the nested logit model was used by Stata (and other packages) and you will see some papers pointing that out
Both versions are valid, but only the RUM-consistent version is based on a sound model of consumer behavior
(the normalization is about scaling the coefficients in the second level choice, dividing them by the dissimilarity parameters, so that the utilities can be meaningfully compared, see Heiss (2002) for details)

Nested Logit
Adapted from Stata’s help file, let us consider a model of restaurant choice
use http://www.stata-press.com/data/r13/restaurant
Or look it up (it is one of Stata’s example datasets)
run describe

Nested Logit
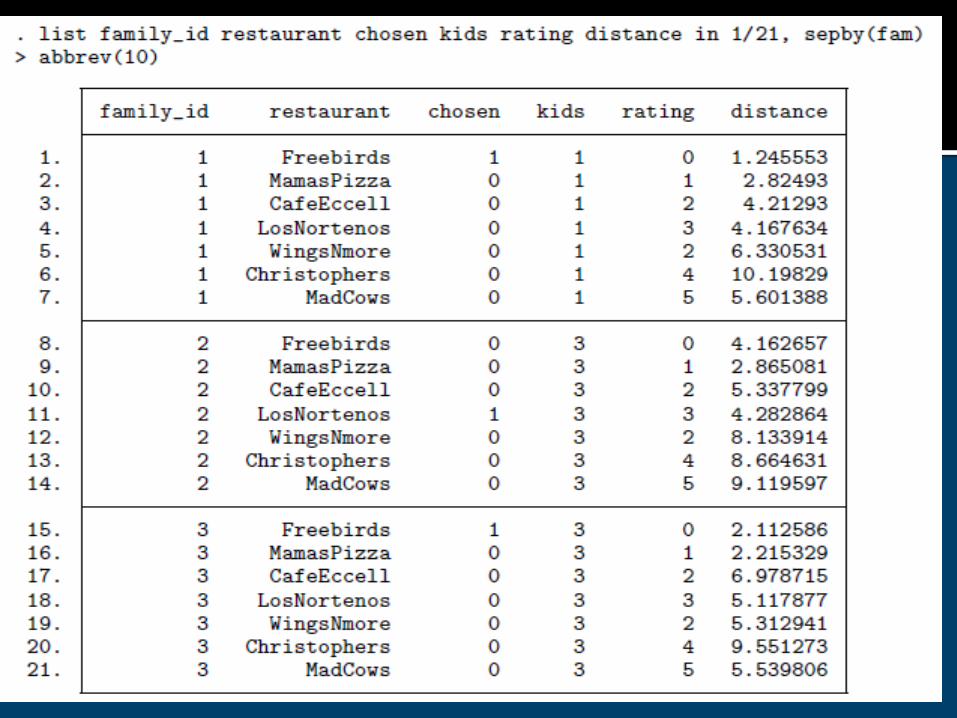
“Fake” data on 300 families and their choice of seven local restaurants: Freebirds and Mama’s Pizza sell fast food Cafe Eccell, Los Nortenos, and Wings ’N
More are family restaurants Christopher’s and Mad Cows are fancy
restaurants

Nested Logit
Model the decision of where to eat as a function of: household income Number of kids rating, of the restaurant (coded 0–5) average meal cost per person distance between the household and the
restaurant

Nested Logit
Note that: income and kids are attributes of the family rating is an attribute of the alternative (the
restaurant) cost and distance are attributes of the
alternative as perceived by the families—that is, each family has its own cost and distance for each restaurant.

Nested Logit
Thus: income and kids are case-specificrating is alternative-specificcost and distance are both

Nested Logit
Why not only 300 obs.?
Nested Logit
Why not only 300 obs.?

Nested Logit
You could fit a conditional logit model to this data as arranged
Since income and kids are case-specific, you would use asclogit instead of clogit*
*asclogit is great…in the “old days” you would need to work a bit harder with dummies and interactions to e able to run a mixed model with the old clogit command. This is still a good exercise tough.

Nested Logit
You could fit a conditional logit model to this data as arranged
However, the conditional logit may be inappropriate, since it assumes that the random errors are independent, and as a result it forces the odds ratio of any two alternatives to be independent of the other alternatives, the IIA!!!

Nested Logit
distance -.085346 .0437514 -1.95 0.051 -.1710973 .0004052 rating .8669793 .0981221 8.84 0.000 .6746635 1.059295 cost -.1543089 .0173858 -8.88 0.000 -.1883845 -.1202333 income 0 (omitted) kids 0 (omitted) chosen Coef. Std. Err. z P>|z| [95% Conf. Interval]
Log likelihood = -537.06643 Pseudo R2 = 0.0800 Prob > chi2 = 0.0000 LR chi2(3) = 93.41Conditional (fixed-effects) logistic regression Number of obs = 2100
Iteration 3: log likelihood = -537.06643 Iteration 2: log likelihood = -537.06643 Iteration 1: log likelihood = -537.06762 Iteration 0: log likelihood = -538.52688
note: income omitted because of no within-group variance.note: kids omitted because of no within-group variance.. clogit chosen kids income cost rating distance , group(family_id)
This is the pure conditional logit!

Nested Logit
.
_cons .8012166 1.821835 0.44 0.660 -2.769514 4.371948 kids -.2062462 .2713623 -0.76 0.447 -.7381066 .3256142 income .0963617 .0221248 4.36 0.000 .052998 .1397254MadCows _cons 1.626207 1.672155 0.97 0.331 -1.651157 4.903571 kids -.0374476 .2535199 -0.15 0.883 -.5343376 .4594424 income .0714976 .021214 3.37 0.001 .029919 .1130763Christophers _cons .6935955 .9268626 0.75 0.454 -1.123022 2.510213 kids .2442661 .2268803 1.08 0.282 -.2004111 .6889434 income .0428583 .0194924 2.20 0.028 .0046538 .0810627WingsNmore _cons 1.483996 .9318191 1.59 0.111 -.3423353 3.310328 kids .1761988 .2257644 0.78 0.435 -.2662912 .6186889 income .0325719 .0193533 1.68 0.092 -.0053599 .0705037LosNortenos _cons .3677203 .9075505 0.41 0.685 -1.411046 2.146486 kids .3486398 .226436 1.54 0.124 -.0951667 .7924463 income .0426504 .0193985 2.20 0.028 .0046301 .0806708CafeEccell _cons -1.228673 1.108607 -1.11 0.268 -3.401503 .944157 kids .3248002 .274624 1.18 0.237 -.2134529 .8630533 income .0239198 .0232255 1.03 0.303 -.0216013 .069441MamasPizza Freebirds (base alternative) distance -.2127489 .0482651 -4.41 0.000 -.3073468 -.1181511 cost -.1330786 .0675342 -1.97 0.049 -.2654432 -.0007141restaurant chosen Coef. Std. Err. z P>|z| [95% Conf. Interval]
Log likelihood = -482.21731 Prob > chi2 = 0.0000 Wald chi2(14) = 60.28
max = 7 avg = 7.0Alternative variable: restaurant Alts per case: min = 7
Case variable: family_id Number of cases = 300Alternative-specific conditional logit Number of obs = 2100
Iteration 4: log likelihood = -482.21731 Iteration 3: log likelihood = -482.21731 Iteration 2: log likelihood = -482.21859 Iteration 1: log likelihood = -483.15644 Iteration 0: log likelihood = -487.34059
. asclogit chosen cost dist, case(family_id) alternatives(restaurant) casevars(income kids)
I could not estimate rating at the same timeIt did not converge
Could you run a Plain MNL With this dataset?
_cons .8012166 1.821835 0.44 0.660 -2.769514 4.371948 kids -.2062462 .2713623 -0.76 0.447 -.7381066 .3256142 income .0963617 .0221248 4.36 0.000 .052998 .1397254MadCows _cons 1.626207 1.672155 0.97 0.331 -1.651157 4.903571 kids -.0374476 .2535199 -0.15 0.883 -.5343376 .4594424 income .0714976 .021214 3.37 0.001 .029919 .1130763Christophers
. asclogit chosen cost dist, case(family_id) alternatives(restaurant) casevars(income kids)
distance -.1922521 .0465579 -4.13 0.000 -.2835039 -.1010003 cost -.1046302 .0656595 -1.59 0.111 -.2333204 .02406restaurant chosen Coef. Std. Err. z P>|z| [95% Conf. Interval]

Nested Logit
Here we suspect that restaurants should be grouped by type (fast, family, or fancy)
Why?

Nested Logit
Assuming that “unobserved stuff” affecting a decision about one alternative has no effect on the choice other alternatives may seem innocuous, but often this assumption is too restrictive
Example: when a family was deciding which restaurant to visit, they were pressed for time because of plans to attend a movie later

Nested Logit
The unobserved shock (being in a hurry) would raise the likelihood that of going to either fast food restaurant (Freebirds or Mama’s Pizza)
Another family might be choosing a restaurant to celebrate a birthday and therefore be inclined to attend a fancy restaurant (Christopher’s or Mad Cows)

Nested Logit
With the nested logit,we are not assuming that families first choose whether to attend a fast, family, or fancy restaurant and then choose the particular restaurant
We assume merely that they choose one of the seven restaurants

Nested Logit We now must first create a variable that
defines the structure of our “decision tree”nlogitgen type = restaurant(fast: Freebirds | MamasPizza, family: CafeEccell | LosNortenos| WingsNmore, fancy: Christophers | MadCows)

Nested Logit We now must first create a variable that
defines the structure of our “decision tree”

Nested Logit
Our new type variable defines the three types of restaurants
We can now see how the alternative-specific attributes (cost, rating, and distance) apply to the bottom alternative set (the seven restaurants)
and how family-specific attributes (income and kid) apply to the alternative set at the first decision level (the three types of restaurants)

Nested Logit
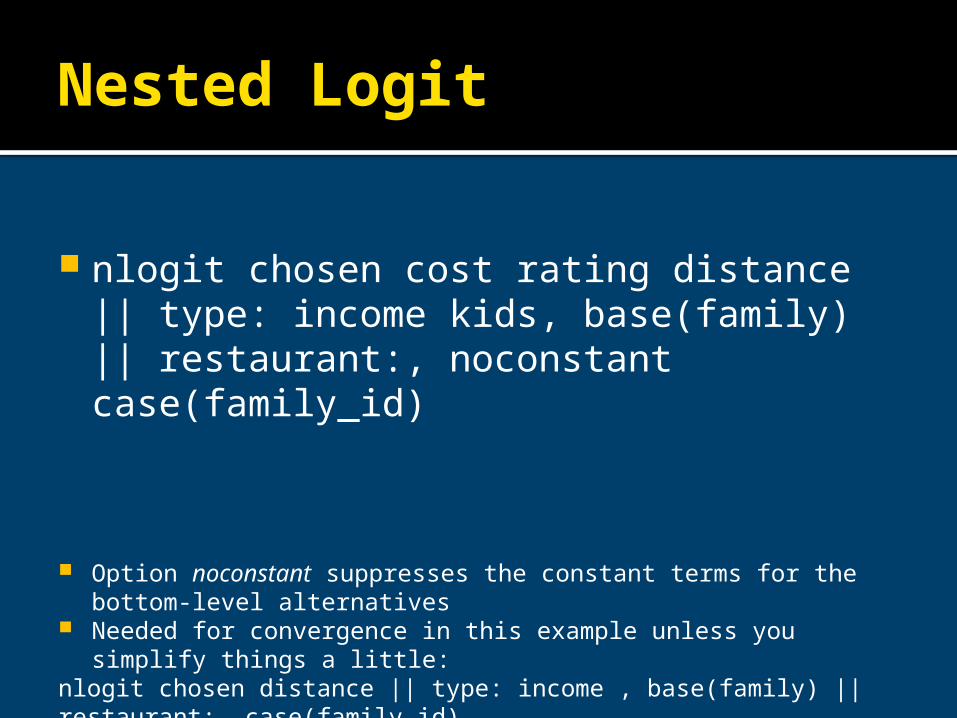
nlogit chosen cost rating distance || type: income kids, base(family) || restaurant:, noconstant case(family_id)

Nested Logit
nlogit chosen cost rating distance || type: income kids, base(family) || restaurant:, noconstant case(family_id)
LR test for IIA (tau = 1): chi2(3) = 6.87 Prob > chi2 = 0.0762 /fancy_tau 4.099844 2.810123 -1.407896 9.607583 /family_tau 2.505113 .9646351 .614463 4.395763 /fast_tau 1.712878 1.48685 -1.201295 4.627051type dissimilarity parameters kids -.3959413 .1220356 -3.24 0.001 -.6351267 -.1567559 income .0461827 .0090936 5.08 0.000 .0283595 .0640059fancy kids 0 (base) income 0 (base)family kids -.0872584 .1385026 -0.63 0.529 -.3587184 .1842016 income -.0266038 .0117306 -2.27 0.023 -.0495952 -.0036123fast type equations distance -.3797474 .1003828 -3.78 0.000 -.5764941 -.1830007 rating .463694 .3264935 1.42 0.156 -.1762215 1.10361 cost -.1843847 .0933975 -1.97 0.048 -.3674404 -.0013289restaurant chosen Coef. Std. Err. z P>|z| [95% Conf. Interval]
Log likelihood = -485.47331 Prob > chi2 = 0.0000 Wald chi2(7) = 46.71
max = 7 avg = 7.0Alternative variable: restaurant Alts per case: min = 7
Case variable: family_id Number of cases = 300RUM-consistent nested logit regression Number of obs = 2100
Nested Logit
nlogit chosen cost rating distance || type: income kids, base(family) || restaurant:, noconstant case(family_id)
Option noconstant suppresses the constant terms for the bottom-level alternatives
Needed for convergence in this example unless you simplify things a little:nlogit chosen distance || type: income , base(family) || restaurant:, case(family_id)

Nested Logit
The error correlation parameters are re-expressed as dissimilarity parameters
In Stata notation nlogit estimates a tau, in this example for each “type” (upper level branch) with subcategories (lower level branches, twigs,…)
In Cameron and Trivedi’s (MMA) notation, dissimilarity parameters are rhos and called scale parameters

Nested Logit In the normalised version of the nlogit model the dissimilarity
parameters are used to scale the logsums or inclusive values:
In Cameron and Trivedi’s (MMA) notation:
Inclusive value or logsum
The inclusive value for the mth nest is the expected value of the maximum utility that Individual i can obtains from choosing an alternative within nest m

Nested Logit Nlogit estimates a tau (dissimilarity parameter, which is the
coefficient of the inclusive value/logsum) for each “type” (upper level branch) with subcategories (lower level branches, twigs,…)
dissimilarity parameters (inversely) measure the degree of correlation (rho =1-tau2 or for the mth nest) of random shocks within each of the three types of restaurants
If greater than one the model is inconsistent with RUM

Nested Logit Dissimilarity parameters must fall between 0 and 1
If one of them (say the one for fast food) were less than zero, something that increased the likelihood of choosing Freebirds would decrease the likelihood of choosing a fast food restaurant, which simply does not make any sense
If the dissimilarity parameter is zero, the changes in restaurant probabilities will not affect the choice of type of restaurant and the correct model is recursive (separated)

Nested Logit
The conditional logit model is a special case of nested logit where all the dissimilarity parameters equal one
Our Likelihood-ratio test of this hypothesis here shows mixed evidence of the null hypothesis that all the dissimilarity parameters are equal to one
IIA holds if and only if all dissimilarity parameters are equal to one

Nested Logit
In LIML (two-step or sequential estimation) it was often assumed for convenience that all of the dissimilarity parameters were equal
This is a restriction you can impose on our stata code too
Nested Logit
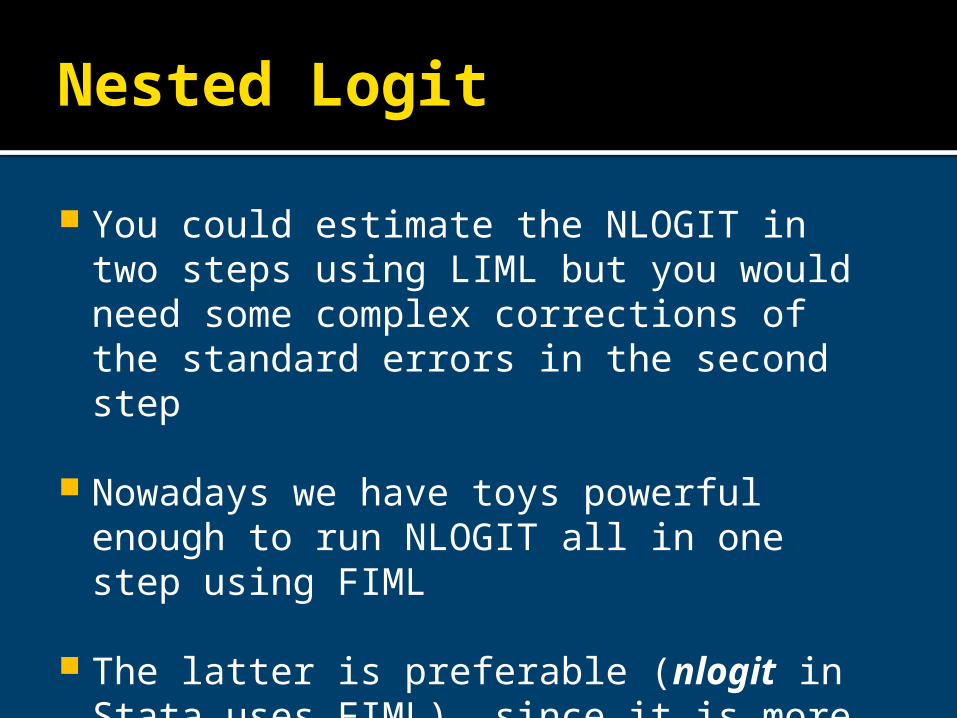
You could estimate the NLOGIT in two steps using LIML but you would need some complex corrections of the standard errors in the second step
Nowadays we have toys powerful enough to run NLOGIT all in one step using FIML
The latter is preferable (nlogit in Stata uses FIML), since it is more efficient
The LIML sequential estimation might still help to provide starting values, as the FIML log-likelihood is not globally concave

Nested Logit
Try:
. nlogit chosen rating distance || type: income kids, base(family) || restaurant: cost, noconstant case(family_id)
. nlogit chosen rating distance cost || type: kids, base(family) || restaurant: income, noconstant case(family_id)

Nested Logit
Issues: you can build your tree in different ways, some will work better than others
Those choices in general will yield different results anyway
No test to choose among trees

Mixed Logit AKA Random Parameters Logit
multinomial logit models with unobserved heterogeneity
They allow the parameters to vary randomly across individuals
See mixlogit command (Hole, A. R. Fitting mixed logit models by using maximum simulated likelihood Stata Journal, 2007, 7,
388-401 )
(find C:/… traindata.dta)
Mixed Logit AKA Random Parameters Logit
multinomial logit models with unobserved heterogeneity
The RPL allows for correlation across alternatives through an individual-specific random effect

Keywords
Slide 16-46Principles of Econometrics, 3rd Edition
binary choice models censored data conditional logit count data models feasible generalized least squares Heckit identification problem independence of irrelevant alternatives
(IIA) index models individual and alternative specific
variables individual specific variables latent variables likelihood function limited dependent variables linear probability model
logistic random variable logit log-likelihood function marginal effect maximum likelihood estimation multinomial choice models multinomial logit odds ratio ordered choice models ordered probit ordinal variables Poisson random variable Poisson regression model probit selection bias tobit model truncated data

References
Cameron and Trivedi’s MMA and MUS Hensher, Rose, and Greene’s (2005) Applied
Choice Analysis: A Primer, available (electronically too) at the QEII
Next
Ordered Choice Count data