cisco systems, inc. a. csaszar - ietf datatracker systems, inc. a. csaszar g. enyedi ericsson july...
TRANSCRIPT

Routing Area Working Group A. Atlas, Ed.Internet-Draft R. KeblerIntended status: Standards Track Juniper NetworksExpires: January 13, 2014 IJ. Wijnands Cisco Systems, Inc. A. Csaszar G. Enyedi Ericsson July 12, 2013
An Architecture for Multicast Protection Using Maximally Redundant Trees draft-atlas-rtgwg-mrt-mc-arch-02
Abstract
Failure protection is desirable for multicast traffic, whether signaled via PIM or mLDP. Different mechanisms are suitable for different use-cases and deployment scenarios. This document describes the architecture for global protection (aka multicast live- live) and for local protection (aka fast-reroute).
The general methods for global protection and local protection using alternate-trees are dependent upon the use of Maximally Redundant Trees. Local protection can also tunnel traffic in unicast tunnels to take advantage of the routing and fast-reroute mechanisms available for IP/LDP unicast destinations.
The failures protected against are single link or node failures. While the basic architecture might support protection against shared risk group failures, algorithms to dynamically compute MRTs supporting this are for future study.
Status of this Memo
This Internet-Draft is submitted in full conformance with the provisions of BCP 78 and BCP 79.
Internet-Drafts are working documents of the Internet Engineering Task Force (IETF). Note that other groups may also distribute working documents as Internet-Drafts. The list of current Internet- Drafts is at http://datatracker.ietf.org/drafts/current/.
Internet-Drafts are draft documents valid for a maximum of six months and may be updated, replaced, or obsoleted by other documents at any time. It is inappropriate to use Internet-Drafts as reference material or to cite them other than as "work in progress."
Atlas, et al. Expires January 13, 2014 [Page 1]

Internet-Draft MRT FRR Architecture July 2013
This Internet-Draft will expire on January 13, 2014.
Copyright Notice
Copyright (c) 2013 IETF Trust and the persons identified as the document authors. All rights reserved.
This document is subject to BCP 78 and the IETF Trust’s Legal Provisions Relating to IETF Documents (http://trustee.ietf.org/license-info) in effect on the date of publication of this document. Please review these documents carefully, as they describe your rights and restrictions with respect to this document. Code Components extracted from this document must include Simplified BSD License text as described in Section 4.e of the Trust Legal Provisions and are provided without warranty as described in the Simplified BSD License.
Atlas, et al. Expires January 13, 2014 [Page 2]

Internet-Draft MRT FRR Architecture July 2013
Table of Contents
1. Introduction . . . . . . . . . . . . . . . . . . . . . . . . . 4 1.1. Maximally Redundant Trees (MRTs) . . . . . . . . . . . . . 4 1.2. MRTs and Multicast . . . . . . . . . . . . . . . . . . . . 6 2. Terminology . . . . . . . . . . . . . . . . . . . . . . . . . 6 3. Use-Cases and Applicability . . . . . . . . . . . . . . . . . 8 4. Global Protection: Multicast Live-Live . . . . . . . . . . . . 9 4.1. Creation of MRMTs . . . . . . . . . . . . . . . . . . . . 10 4.2. Traffic Self-Identification . . . . . . . . . . . . . . . 11 4.2.1. Merging MRMTs for PIM if Traffic Doesn’t Self-Identify . . . . . . . . . . . . . . . . . . . . 12 4.3. Convergence Behavior . . . . . . . . . . . . . . . . . . . 13 4.4. Inter-area/level Behavior . . . . . . . . . . . . . . . . 14 4.4.1. Inter-area Node Protection with 2 border routers . . . 15 4.4.2. Inter-area Node Protection with > 2 Border Routers . . 16 4.5. PIM . . . . . . . . . . . . . . . . . . . . . . . . . . . 17 4.5.1. Traffic Handling: RPF Checks . . . . . . . . . . . . . 17 4.6. mLDP . . . . . . . . . . . . . . . . . . . . . . . . . . . 17 5. Local Repair: Fast-Reroute . . . . . . . . . . . . . . . . . . 17 5.1. PLR-driven Unicast Tunnels . . . . . . . . . . . . . . . . 18 5.1.1. Learning the MPs . . . . . . . . . . . . . . . . . . . 19 5.1.2. Using Unicast Tunnels and Indirection . . . . . . . . 19 5.1.3. MP Alternate Traffic Handling . . . . . . . . . . . . 20 5.1.4. Merge Point Reconvergence . . . . . . . . . . . . . . 21 5.1.5. PLR termination of alternate traffic . . . . . . . . . 21 5.2. MP-driven Unicast Tunnels . . . . . . . . . . . . . . . . 21 5.3. MP-driven Alternate Trees . . . . . . . . . . . . . . . . 22 6. Acknowledgements . . . . . . . . . . . . . . . . . . . . . . . 23 7. IANA Considerations . . . . . . . . . . . . . . . . . . . . . 23 8. Security Considerations . . . . . . . . . . . . . . . . . . . 23 9. Appendix A . . . . . . . . . . . . . . . . . . . . . . . . . . 23 9.1. MP-driven Alternate Trees . . . . . . . . . . . . . . . . 23 9.1.1. PIM details for Alternate-Trees . . . . . . . . . . . 26 9.1.2. mLDP details for Alternate-Trees . . . . . . . . . . . 26 9.1.3. Traffic Handling by PLR . . . . . . . . . . . . . . . 26 9.2. Methods Compared for PIM . . . . . . . . . . . . . . . . . 27 9.3. Methods Compared for mLDP . . . . . . . . . . . . . . . . 27 10. References . . . . . . . . . . . . . . . . . . . . . . . . . . 27 10.1. Normative References . . . . . . . . . . . . . . . . . . . 27 10.2. Informative References . . . . . . . . . . . . . . . . . . 28 Authors’ Addresses . . . . . . . . . . . . . . . . . . . . . . . . 29
Atlas, et al. Expires January 13, 2014 [Page 3]

Internet-Draft MRT FRR Architecture July 2013
1. Introduction
This document describes how the algorithms in [I-D.enyedi-rtgwg-mrt-frr-algorithm], which are used in [I-D.ietf-rtgwg-mrt-frr-architecture] for unicast IP/LDP fast- reroute, can be used to provide protection for multicast traffic. It specifically applies to multicast state signaled by PIM[RFC4601] or mLDP[RFC6388]. There are additional protocols that depend upon these (e.g. VPLS, mVPN, etc.) and consideration of the applicability to such traffic will be in a future version.
In this document, global protection is used to refer to the method of having two maximally disjoint multicast trees where traffic may be sent on both and resolved by the receiver. This is similar to the ability with RSVP-TE LSPs to have a primary and a hot standby, except that it can operate in 1+1 mode. This capability is also referred to as multicast live-live and is a generalized form of that discussed in [I-D.ietf-rtgwg-mofrr]. In this document, local protection refers to the method of having alternate ways of reaching the pre-identified merge points upon detection of a local failure. This capability is also referred to as fast-reroute.
This document describes the general architecture, framework, and trade-offs of the different approaches to solving these general problems. It will recommend how to generally provide global protection and local protection for mLDP and PIM traffic. Where protocol extensions are necessary, they will be defined in separate documents as follows.
o Global 1+1 Protection Using PIM
o Global 1+1 Protection Using mLDP
o Local Protection Using mLDP: [I-D.wijnands-mpls-mldp-node-protection]This document describes how to provide node-protection and the necessary extensions using targeted LDP session.
o Local Protection Using PIM
1.1. Maximally Redundant Trees (MRTs)
Maximally Redundant Trees (MRTs) are described in [I-D.enyedi-rtgwg-mrt-frr-algorithm]; here we only give a brief description about the concept. A pair of MRTs is a pair of directed spanning trees (red and blue tree) with a common root, directed so that each node can be reached from the root on both trees. Moreover, these trees are redundant, since they are constructed so that no
Atlas, et al. Expires January 13, 2014 [Page 4]

Internet-Draft MRT FRR Architecture July 2013
single link or single node failure can separate any node from the root on both trees, unless that failed link or node is splitting the network into completely separated components (e.g. the link or node was a cut-edge or cut-vertex).
Although for multicast, the arcs (directed links) are directed away from the root instead of towards the root, the same MRT computations are used and apply. This is similar to how multicast uses unicast routing’s next-hops as the upstream-hops. Thus this definition slightly differs from the one presented in [I-D.enyedi-rtgwg-mrt-frr-algorithm], since the arcs are directed away and not towards the root. When we need two paths towards a given destination and not two away from it (e.g. for unicast detours for local repair solutions), we only need to reverse the arcs from how they are used for the unicast routing case; thus constructing MRTs towards or away from the root is the same problem. A pair of MRTs is depicted in Figure 1.
[E]---[D]---| |---[J] | | | | | | | | | | [R] [F] [C]---[G] | | | | | | | | | | | [A]---[B]---| |---[H]
(a) a network
[E]<--[D]---| |-->[J] [E]<--[D] [J] ^ | | | | ^ ^ | V V | | | | [R] [F] [C]-->[G] | [R] [F] [C]-->[G] | | | | ^ ^ | | V V V | | | | [A]<--[B] [H] [A]-->[B]---| |-->[H]
(b) Blue MRT of root R (c) Red MRT of root R
Figure 1: A network and two MRTs found in it
It is important to realize that this redundancy criterion does not imply that, after a failure, either of the MRTs remains intact, since a node failure must affect any spanning tree. Redundancy here means that there will be a set of nodes, which can be reached along the blue MRT, and there will be another set, which remains reachable along the red MRT. As an example, suppose that node F goes down; that would separate B and A on the blue MRT and D and E on the red
Atlas, et al. Expires January 13, 2014 [Page 5]

Internet-Draft MRT FRR Architecture July 2013
MRT. Naturally, it is possible that the intersection of these two sets is not empty, e.g. C, G, H and J will remain reachable on both MRTs. Additionally, observe that a single link can be used in both of the trees in different directions, so even a link failure can cut both trees. In this example, the failure of link F<->B leads to the same reachability sets.
Finally, it is critical to recall that a pair of MRTs is always constructed together and they are not SPTs. While it would be useful to have an algorithm that could find a redundant pair for a given tree (e.g. for the SPT), that is impossible in general. Moreover, if there is a failure and at least one of the trees change, the other tree may need to change as well. Therefore, even if a node still receives the traffic along the red tree, it cannot keep the old red tree, and construct a blue pair for it; there can be reconfiguration in cases when traditional shortest-path-based-thinking would not expect it. To converge to a new pair of disjoint MRTs, it is generally necessary to update both the blue MRT and the red MRT.
The two MRTs provide two separate forwarding topologies that can be used in addition to the default shortest-path-tree (SPT) forwarding topology (usually MT-ID 0). There is a Blue MRT forwarding topology represented by one MT-ID; similarly there is a Red MRT forwarding topology represented by a different MT-ID. Naturally, a multicast protocol is required to use the forwarding topologies information to build the desired multicast trees. The multicast protocol can simply request appropriate upstream interfaces, but include the MT-ID when needed.
1.2. MRTs and Multicast
Maximally Redundant Trees (MRT) provide two advantages for protecting multicast traffic. First, for global protection, MRTs are precisely what needs to be computed to have maximally redundant multicast distribution trees. Second, for local repair, MRTs ensure that there will protection to the merge points; the certainty of a path from any merge point to the PLR that avoids the failure node allows for the creation of alternate trees.
A known disadvantage of MRT, and redundant trees in general, is that the trees do not necessarily provide shortest detour paths. Modeling is underway to investigate and compare the MRT lengths for the different algorithm options [I-D.enyedi-rtgwg-mrt-frr-algorithm].
2. Terminology
Atlas, et al. Expires January 13, 2014 [Page 6]

Internet-Draft MRT FRR Architecture July 2013
2-connected: A graph that has no cut-vertices. This is a graph that requires two nodes to be removed before the network is partitioned.
2-connected cluster: A maximal set of nodes that are 2-connected.
2-edge-connected: A network graph where at least two links must be removed to partition the network.
ADAG: Almost Directed Acyclic Graph - a graph that, if all links incoming to the root were removed, would be a DAG.
block: Either a 2-connected cluster, a cut-edge, or an isolated vertex.
cut-link: A link whose removal partitions the network. A cut-link by definition must be connected between two cut-vertices. If there are multiple parallel links, then they are referred to as cut-links in this document if removing the set of parallel links would partition the network.
cut-vertex: A vertex whose removal partitions the network.
DAG: Directed Acyclic Graph - a graph where all links are directed and there are no cycles in it.
GADAG: Generalized ADAG - a graph that is the combination of the ADAGs of all blocks.
Maximally Redundant Trees (MRT): A pair of trees where the path from any node X to the root R along the first tree and the path from the same node X to the root along the second tree share the minimum number of nodes and the minimum number of links. Each such shared node is a cut-vertex. Any shared links are cut-links. Any RT is an MRT but many MRTs are not RTs.
Maximally Redundant Multicast Trees (MRMT): A pair of multicast trees built of the sub-set of MRTs that is needed to reach all interested receivers.
network graph: A graph that reflects the network topology where all links connect exactly two nodes and broadcast links have been transformed into the standard pseudo-node representation.
Redundant Trees (RT): A pair of trees where the path from any node X to the root R along the first tree is node-disjoint with the path from the same node X to the root along the second tree. These can be computed in 2-connected graphs.
Atlas, et al. Expires January 13, 2014 [Page 7]

Internet-Draft MRT FRR Architecture July 2013
Merge Point (MP): For local repair, a router at which the alternate traffic rejoins the primary multicast tree. For global protection, a router which receives traffic on multiple trees and must decide which stream to forward on.
Point of Local Repair (PLR): The router that detects a local failure and decides whether and when to forward traffic on appropriate alternates.
MT-ID: Multi-topology identifier. The default shortest-path-tree topology is MT-ID 0.
MultiCast Ingress (MCI): Multicast Ingress, the node where the multicast stream enters the current transport technology (MPLS- mLDP or IP-PIM) domain. This maybe the router attached to the multicast source, the PIM Rendezvous Point (RP) or the mLDP Root node address.
Upstream Multicast Hop (UMH): Upstream Multicast Hop, a candidate next-hop that can be used to reach the MCI of the tree.
Stream Selection: The process by which a router determines which of the multiple primary multicast streams to accept and forward. The router can decide on a packet-by-packet basis or simply per- stream. This is done for global protection 1+1 and described in [I-D.ietf-rtgwg-mofrr].
MultiCast Egress (MCE): Multicast Egress, a node where the multicast stream exists the current transport technology (MPLS- mLDP or IP-PIM) domain. This is usually a receiving router that may forward the multicast traffic on towards receivers based upon IGMP or other technology.
3. Use-Cases and Applicability
Protection of multicast streams has gained importance with the use of multicast to distribute video, including live video such as IP-TV. There are a number of different scenarios and uses of multicast that require protection. A few preliminary examples are described below.
o When video is distributed via IP or MPLS for a cable application, it is desirable to have global protection 1+1 so that the customer-perceived impact is limited. A QAM can join two multicast groups and determine which stream to use based upon the stream quality. A network implementing this may be custom- engineered for this particular purpose.
Atlas, et al. Expires January 13, 2014 [Page 8]

Internet-Draft MRT FRR Architecture July 2013
o In financial markets, stock ticker data is distributed via multicast. The loss of data can have a significant financial impact. Depending on the network, either global protection 1+1 or local protection can minimize the impact.
o Several solutions exist for updating software or firmwares of a large number of end-user or operator-owned networking equipment that are based on IP multicast. Since IP multicast is based on datagram transport so taking care of lost data is cumbersome and decreases the advantages offered by multicast. Solutions may rely on sending the updates several times: a properly protected network may result in that less repetitions are required. Other solutions rely on the recipent asking for lost data segments explicitly on- demand. A network failure could cause data loss for a significant number of receivers, which in turn would start requesting the the lost data in a burst that could overload the server. Properly engineered multicast fast reroute would minimise such impacts.
o Some providers offer multicast VPN services to their customers. SLAs between the customer and provider may set low packet loss requirements. In such cases interruptions longer than the outage timescales targeted by FRR could cause direct financial losses for the provider.
Global protection 1+1 uses maximally redundant multicast trees (MRMTs) to simultaneously distribute a multicast stream on both MRMTs. The disadvantage is the extra state and bandwidth requirements of always sending the traffic twice. The advantage is that the latency of each MRMT can be known and the receiver can select the best stream.
Local protection provides a patch around the fault while the multicast tree reconverges. When PLR replication is used, there is no extra multicast state in the network, but the bandwidth requirements vary based upon how many potential merge-points must be provided. When alternate-trees are used, there is extra multicast state but the bandwidth requirements on a link can be minimized to no more than once for the primary multicast tree traffic and once for the alternate-tree traffic.
4. Global Protection: Multicast Live-Live
In MoFRR [I-D.ietf-rtgwg-mofrr], the idea of joining both a primary and a secondary tree is introduced with the requirement that the primary and secondary trees be link and node disjoint. This works well for networks where there are dual-planes, as explained in [I-D.ietf-rtgwg-mofrr]. For other networks, it is still desirable to
Atlas, et al. Expires January 13, 2014 [Page 9]

Internet-Draft MRT FRR Architecture July 2013
have two disjoint multicast trees and allow a receiver to join both and make its own decision about which traffic to accept.
Using MRTs gives the ability to guarantee that the two trees are as disjoint as possible and dynamically recomputed whenever the topology changes. The MRTs used are rooted at the MultiCast Ingress (MCI). One multicast tree is created using the Blue MRT forwarding topology. The second multicast tree is created using the Red MRT forwarding topology. This can be accomplished by specifying the appropriate MT-ID associated with each forwarding topology.
There are four different aspects of using MRTs for 1+1 Global Protection that are necessary to consider. They are as follows.
1. Creation of the maximally redundant multicast trees (MRMTs) based upon the forwarding topologies.
2. Traffic Identification: How to handle traffic when the two MRMTs overlap due to a cut-vertex or cut-link.
3. Convergence: How to converge after a network change and get back to a protected state.
4. Inter-area/inter-level Behavior: How to compute and use MRMTs when the multicast source is outside the area/level and how to provide border-router protection.
4.1. Creation of MRMTs
The creation of the two maximally redundant multicast trees occurs as described below. This assumes that the next-hops to the MCI associated with the Blue and Red forwarding topologies have already been computed and stored.
1. A receiving router determines that it wants to join both the Blue tree and the Red tree. The details on how it does this decision are not covered in this document and could be based on configuration, additional protocols, etc.
2. The router selects among the Blue next-hops an Upstream Multicast Hop (UMH) to reach the MCI node. The router joins the tree towards the selected UMH including a multi-topology id (MT-ID) identifying the Blue MRT.
3. The router selects among the Red next-hops an Upstream Multicast Hop (UMH) to reach the MCI node. The router joins the tree towards the selected UMH including a multi-topology id (MT-ID) identifying the Red MRT.
Atlas, et al. Expires January 13, 2014 [Page 10]

Internet-Draft MRT FRR Architecture July 2013
4. When a router receives a tree setup request specifying a particular MT-ID (e.g. Color), then the router selects among the Color next-hops to the MCI a UMH node, creates the necessary multicast state, and joins the tree towards the UMH node.
4.2. Traffic Self-Identification
Two maximally redundant trees will share any cut-vertices and cut- links in the network. In the multicast global protection 1+1 case, this means that the potential single failures of the other nodes and links in the network are still protected against. If each cut-vertex cannot associate traffic to a particular MRMT, then the traffic would be incorrectly replicated to both MRMT resulting in complete duplication of traffic. An example of such MRTs is given earlier in Figure 1 and repeated below in Figure 2, where there are two cut- vertices C and G and a cut-link C<->G.
[E]---[D]---| |---[J] | | | | | | | | | | [R] [F] [C]---[G] | | | | | | | | | | | [A]---[B]---| |---[H]
(a) a network
[E]<--[D]---| |-->[J] [E]<--[D] [J] ^ | | | | ^ ^ | V V | | | | [R] [F] [C]-->[G] | [R] [F] [C]-->[G] | | | | ^ ^ | | V V V | | | | [A]<--[B] [H] [A]-->[B]---| |-->[H]
(b) Blue MRT of root R (c) Red MRT of root R
Figure 2: A network and two MRTs found in it
In this example, traffic from the multicast source R to a receiver G, J, or H will cross link C<->G on both the Blue and Red MRMTs. When this occurs, there are several different possibilities depending upon protocol.
Atlas, et al. Expires January 13, 2014 [Page 11]

Internet-Draft MRT FRR Architecture July 2013
mLDP: Different label bindings will be created for the Blue and Red MRMTs. As specified in [I-D.iwijnand-mpls-mldp-multi-topology], the P2MP FEC Element will use the MT IP Address Family to encode the Root node address and MRT T-ID. Each MRMT will therefore have a different P2MP FEC Element and be assigned an independent label.
PIM: There are three different ways to handle IP traffic forwarded based upon PIM when that traffic will overlap on a link.
A. Different Groups: If different multicast groups are used for each MRMT, then the traffic clearly indicates which MRMT it belongs to. In this case, traffic on the Blue MRMT would use multicast group G-blue and traffic on the Red MRMT would use multicast group G-red.
B. Different Source Loopbacks: Another option is to use different IP addresses for the source S, so S might announce S-red and S-blue. In this case, traffic on the Blue MRMT would have an IP source of S-blue and traffic on the Red MRMT would have an IP source of S-red.
C. Stream Selection and Merging: The third option, described in Section 4.2.1, is to have a router that gets (S,G) Joins for both the Blue MT-ID and the Red MT-ID merge those into a single tree. The router may need to select which upstream stream to use, just as if it were a receiving router.
There are three options presented for PIM. The most appropriate will depend upon deployment scenario as well as router capabilities.
4.2.1. Merging MRMTs for PIM if Traffic Doesn’t Self-Identify
When traffic doesn’t self-identify, the cut-vertices must follow specific rules to avoid traffic duplication. This section describes that behavior which allows the same (S,G) to be used for both the Blue MT-ID and Red MT-ID (e.g. when the traffic doesn’t self-identify as to its MT-ID).
The behavior described in this section differs from the conflict resolution described in [RFC6420] because these rules apply to the Global Protection 1+1 case. Specifically, it is not sufficient for a upstream router to pick only one of the two MT-IDs to join because that does not maximize the protection provided.
As described in [RFC6420], a router that receives (S,G) Joins for both the Blue MT-ID and the Red MT-ID can merge the set of downstream interfaces in its forwarding entry. Unlike the procedures defined in [RFC6420], the router must send a Join upstream for each MT-ID. If a
Atlas, et al. Expires January 13, 2014 [Page 12]

Internet-Draft MRT FRR Architecture July 2013
router has different upstream interfaces for these MRMTs, then the router will need to do stream selection and forward the selected stream to its outgoing interfaces, just as if it were an MCE. The stream selection methods of detecting failures and handle traffic discarding are described in [I-D.ietf-rtgwg-mofrr].
This method does not work if the MRMTs merge on a common LAN with different upstream routers. In this case, the traffic cannot be distinguished on the LAN and will result in duplication on the LAN. The normal PIM Assert procedure would stop one of the upstream routers from transmitting duplicates onto the LAN once it is detected. This, in turn, may cause the duplicate stream to be pruned back to the source. Thus, end-to-end protection in this case of the MRMTs converging on a single LAN with different upstream interfaces can only be accomplished by the methods of traffic self- identification.
4.3. Convergence Behavior
It is necessary to handle topology changes and get back to having two MRMTs that provide global protection. To understand the requirements and what can be computed, recall the following facts.
a. It is not generally possible to compute a single tree that is maximally redundant to an existing tree.
b. The pair of MRTs must be computed simultaneously.
c. After a single link or node failure, there is one set of nodes that can be reached from the root on the Blue MRMT and a second set of nodes that can be reached from the root on the Red MRMT. If the failure wasn’t a cut-vertex or cut-edge, all nodes will be in at least one of these two sets.
To gracefully converge, it is necessary to never have a router where both its red MRMT and blue MRMT are broken. There are three different ways in which this could be done. These options are being more fully explored to see which is most practical and provides the best set of trade-offs.
Ordered Convergence When a single failure occurs, each receiver determines whether it was affected or unaffected. First, the affected receivers identify the broken MRMT color (e.g. blue) and join the MRMT via their new UMH for that MRT color. Once the affected receivers receive confirmation that the new MRMT has been successfully created back to the MCI, then the affected receivers switch to using that MRMT. The affected receivers tear down the old broken MRMT state and join the MRMT via their new UMH for the
Atlas, et al. Expires January 13, 2014 [Page 13]

Internet-Draft MRT FRR Architecture July 2013
other MRT color (e.g. red). Finally, once the affected receivers receive confirmation that the new MRMT has been successfully created back to the MCI, the affected receivers can tear down the old working MRMT state. Once the affected receivers have updated their state, the unaffected receivers need to also do the same staging - first joining the MRMT via their new UMH for the Blue MRT, waiting for confirmation, switching to using traffic from the Blue MRMT, tearing down the old Blue MRMT state, joining the MRMT via their new UMH for the Red MRT, waiting for confirmation, and tearing down the old Red MRMT state. There are complexities remaining, such as determining how an Unaffected Receiver decides that the Affected Receivers are done. When the topology change isn’t a failure, all receivers are unaffected and the same process can apply.
Protocol Make-Before-Break In the control plane, a router joins the tree on the new Blue topology but does not stop receiving traffic on the old Blue topology. Once traffic is observed from the new Blue UMH, then the router accepts traffic on the new Blue UMH and removes the old Blue UMH. This behavior can happen simultaneously with both Blue and Red forwarding topologies. An advantage is that it works regardless of the type of topology change and existing traffic streams aren’t broken. Another advantage is that the complexity is limited and this method is well understood. The disadvantage is that the number of traffic-affecting events depends upon the number of hops to the MCI.
Multicast Source Make-Before-Break On a topology change, routers would create new MRMTs using new MRT forwarding state and leaving the old MRMTs as they are. After the new MRMTs are complete, the multicast source could switch from sending on the old MRMTs to sending on the new MRMTs. After a time, the old MRMTs could be torn down. There are a number of details to still investigate.
4.4. Inter-area/level Behavior
A source outside of the IGP area/level can be treated as a proxy node. When the join request reaches a border router (whether ABR for OSPF or LBR for ISIS), that border router needs to determine whether to use the Blue or Red forwarding topology in the next selected area/ level.
Atlas, et al. Expires January 13, 2014 [Page 14]

Internet-Draft MRT FRR Architecture July 2013
|-------------------| | | |---[S]---| [BR1]-----[ X ] | | | | | | [ A ]-----[ B ] | | | | | [ Y ]-----[BR2]--(proxy for S) | | [BR1]-----[BR2] (b) Area 10 Y’s Red next-hop: BR1 (a) Area 0 Y’s Blue next-hop: BR2 Red Next-Hops to S BR1’s is BR2 BR2’s is B B’s is S
Blue Next-Hops to S BR1’s is A BR2’s is BR1 A’s is S
Figure 3: Inter-area Selection - next-hops towards S
Achieving maximally node-disjoint trees across multiple areas is hard due to the information-hiding and abstraction. If there is only one border router, it is trivial but protection of the border router is not possible. With exactly 2 border routers, inter-area/level node protection is reasonably straightforward but can require that the BR rewrite the (S,G) for PIM. With more than 2 border routers, inter- area node protection is possible at the cost of additional bandwidth and border router complexity. These two solutions are described in the following sub-sections.
4.4.1. Inter-area Node Protection with 2 border routers
If there are exactly two border routers between the areas, then the solution and necessary computation is straightforward. In that specific case, each BR knows that only the other BR must specifically be avoided in the second area when a forwarding topology is selected. As described in [I-D.enyedi-rtgwg-mrt-frr-algorithm], it is possible for a node X to determine whether the Red or Blue forwarding topology should be used to reach a node D while avoiding another node Y.
The results of this computation and the resulting changes in MT-ID from Red to Blue or Blue to Red are illustrated in Figure 3. It shows an example where BR1 must modify joins received from Area 10 for the Red MT-ID to use the Blue MT-ID in Area 0. Similarly, BR2 must modify joins received from Area 10 for the Blue MT-ID to use the
Atlas, et al. Expires January 13, 2014 [Page 15]

Internet-Draft MRT FRR Architecture July 2013
Red MT-ID in Area 0.
For mLDP, modifying the MT-ID in the control-plane is all that is needed. For PIM, if the same (S,G) is used for both the Blue MT-ID and the Red MT-ID, then only control-plane changes are needed. However, for PIM, if different group IDs (e.g. G-red and G-blue) or different source loopback addresses (S-red and S-blue) are used, it is necessary to modify the traffic to reflect the MT-ID included in the join message received on that interface. An alternative could be to use an MPLS label that indicates the MT-ID instead of different group IDs or source loopback addresses.
To summarize the necessary logic, when a BR1 receives a join from a neighbor in area N to a destination D in area M on the Color MT-ID, the BR1:
a. Identifies the BR2 at the other end of the proxy node in area N.
b. Determines which forwarding topology may avoid BR2 to reach D in area M. Refer to that as Color-2 MT-ID.
c. Uses Color-2 MT-ID to determine the next-hops to S. When a join is sent upstream, the MT-ID used is that for Color-2.
4.4.2. Inter-area Node Protection with > 2 Border Routers
If there are more than two BRs between areas, then the problem of ensuring inter-area node-disjointness is not solved. Instead, once a request to join the multicast tree has been received by a BR from an area that isn’t closest to the multicast source, the BR must join both the Red MT-ID and the Blue MT-ID in the area closest to the multicast source. Regardless of what single link or node failure happens, each BR will receive the multicast stream. Then, the BR can use the stream-selection techniques specified in [I-D.ietf-rtgwg-mofrr] to pick either the Blue or Red stream and forward it to downstream routers in the other area. Each of the BRs for the other area should be attached to a proxy-node representing the other area.
This approach ensures that a BR will receive the multicast stream in the closest area as long as the single link or node failure isn’t a single point of failure. Thus, each area or level is independently protected. The BR is required to be able to select among the multicast streams and, if necessary for PIM, translate the traffic to contain the correct (S,G) for forwarding.
Atlas, et al. Expires January 13, 2014 [Page 16]

Internet-Draft MRT FRR Architecture July 2013
4.5. PIM
Capabilities need to be exchanged to determine that a neighbor supports using MRT forwarding topologies with PIM. Additional signaling extensions are not necessary to PIM to support Global Protection. [RFC6420] already defines how to specify an MT-ID as a Join Attribute.
4.5.1. Traffic Handling: RPF Checks
For PIM, RPF checks would still be enabled by the control plane. The control plane can program different forwarding entries on the G-blue incoming interface and on the G-red incoming interface. The other interfaces would still discard both G-blue and G-red traffic.
The receiver would still need to detect failures and handle traffic discarding as is specified in [I-D.ietf-rtgwg-mofrr].
4.6. mLDP
Capabilities need to be exchanged to determine that a neighbor supports using MRT forwarding topologies with mLDP. The basic mechansims for mLDP to support multi-topology are already described in [I-D.iwijnand-mpls-mldp-multi-topology]. It may be desirable to extend the capability defined in this draft to indicate that MRT is or is not supported.
5. Local Repair: Fast-Reroute
Local repair for multicast traffic is different from unicast in several important ways.
o There is more than a single final destination. The full set of receiving routers may not be known by the PLR and may be extremely large. Therefore, it makes sense to repair to the immediate next- hops for link-repair and the next-next-hops for node-repair. These are the potential merge points (MPs).
o If a failure cannot be positively identified as a node-failure, then it is important to repair to the immediate next-hops since they may have receivers attached.
o If a failure cannot be positively identified as a link-failure and node protection is desired, then it is important to repair to the next-next-hops since they may not receive traffic from the immediate next-hops.
Atlas, et al. Expires January 13, 2014 [Page 17]

Internet-Draft MRT FRR Architecture July 2013
o Updating multicast forwarding state may take significantly longer than updating unicast state, since the multicast state is updated tree by tree based on control-plane signaling.
o For tunnel-based IP/LDP approaches, neither the PLR nor the MP may be able to specify which interface the alternate traffic will arrive at the MP on. The simplest reason is the unicast forwarding includes the use of ECMP and the path selection is based upon internal router behavior for all paths between the PLR and the MP.
For multicast fast-reroute, there are three different mechanisms that can be used. As long as the necessary signaling is available, these methods can be combined in the same network and even for the same PLR and failure point.
PLR-driven Unicast Tunnels: The PLR learns the set of MPs that need protection. On a failure, the PLR replicates the traffic and tunnels it to each MP using the unicast route. If desired, an RSVP-TE tunnel could be used instead of relying upon unicast routing.
MP-driven Unicast Tunnels: Each MP learns the identity of the PLR. Before failure, each MP independently signals to the PLR the desire for protection and other information to use. On a failure, the PLR replicates the traffic and tunnels it to each MP using the unicast route. If desired, an RSVP-TE tunnel could be used instead of relying upon unicast routing.
MP-driven Alternate Trees: Each MP learns the identity of the PLR and the failure point (node and interface) to be protected against. Each MP selects an upstream interface and forwarding topology where the path will avoid the failure point; each MP signals a join towards that upstream interface to create that state.
Each of these options is described in more detail in their respective sections. Then the methods are compared and contrasted for PIM and for mLDP.
5.1. PLR-driven Unicast Tunnels
With PLR-driven unicast tunnels, the PLR learns the set of merge points (MPs) and, on a locally detected failure, uses the existing unicast routing to tunnel the multicast traffic to those merge points. The failure being protected against may be link or node failure. If unicast forwarding can provide an SRLG-protecting alternate, then SRLG-protection is also possible.
Atlas, et al. Expires January 13, 2014 [Page 18]

Internet-Draft MRT FRR Architecture July 2013
There are five aspects to making this work.
1. PLR needs to learn the MPs and their associated MPLS labels to create protection state.
2. Unicast routing has to offer alternates or have dedicated tunnels to reach the MPs. The PLR encapsulates the multicast traffic and directs it to be forwarded via unicast routing.
3. The MP must identify alternate traffic and decide when to accept and forward it or drop it.
4. When the MP reconverges, it must move to its new UMH using make- before-break so that traffic loss is minimized.
5. The PLR must know when to stop sending traffic on the alternates.
5.1.1. Learning the MPs
If link-protection is all that is desired, then the PLR already knows the identities of the MPs. For node-protection, this is not sufficient. In the PLR-driven case, there is no direct communication possible between the PLR and the next-next-hops on the multicast tree. (For mLDP, when targeted LDP sessions are used, this is considered to be MP-driven and is covered in Section 5.2.)
In addition to learning the identities of the MPs, the PLR must also learn the MPLS label, if any, associated with each MP. For mLDP, a different label should be supplied for the alternate traffic; this allows the MP to distinguish between the primary and alternate traffic. For PIM, an MPLS label is used to identify that traffic is the alternate. The unicast tunnel used to send traffic to the MP may have penultimate-hop-popping done; thus without an explicit MPLS label, there is no certainty that a packet could be conclusively identified as primary traffic or as alternate traffic.
A router must tell its UMH the identity of all downstream multicast routers, and their associated alternate labels, on the particular multicast tree. This clearly requires protocol extensions. The extensions for PIM are given in [I-D.kebler-pim-mrt-protection].
5.1.2. Using Unicast Tunnels and Indirection
The PLR must encapsulate the multicast traffic and tunnel it towards each MP. The key point is how that traffic then reaches the MP. There are basically two possibilities. It is possible that a dedicated RSVP-TE tunnel exists and can be used to reach the MP for just this traffic; such an RSVP-TE tunnel would be explicitly routed
Atlas, et al. Expires January 13, 2014 [Page 19]

Internet-Draft MRT FRR Architecture July 2013
to avoid the failure point. The second possibility is that the packet is tunneled via LDP and uses unicast routing. The second case is explored here.
It is necessary to assume that unicast LDP fast-reroute [I-D.ietf-rtgwg-mrt-frr-architecture][RFC5714][RFC5286] is supported by the PLR. Since multicast convergence takes longer than unicast convergence, the PLR may have two different routes to the MP over time. When the failure happens, the PLR will have an alternate, whether LFA or MRT, to reach the MP. Then the unicast routing converges and the PLR will have a new primary route to the MP. Once the routing has converged, it is important that alternate traffic is no longer carried on the MRT forwarding topologies. This rule allows the MRT forwarding topologies to reconverge and be available for the next failure. Therefore, it is also necessary for the tunneled multicast traffic to move from the alternate route to the new primary route when the PLR reconverges. Therefore, the tunneled multicast traffic should use indirection to obtain the unicast routing’s current next-hops to the MP. If physical indirection is not feasible, then when the unicast LIB is updated, the associated multicast alternate tunnel state should be as well.
When the PLR detects a local failure, the PLR replicates each multicast packet, swaps or adds the alternate MPLS label needed by the MP, and finally pushes the appropriate label for the MP based upon the outgoing interface selected by the unicast routing.
For PIM, if no alternate labels are supplied by the MPs, then the multicast traffic could be tunneled in IP. This would require unicast IP fast-reroute.
5.1.3. MP Alternate Traffic Handling
A potential Merge Point must determine when and if to accept alternate traffic. There are two critical components to this decision. First, the MP must know the state of all links to its UMH. This allows the MP to determine whether the multicast stream could be received from the UMH. Second, the MP must be able to distinguish between a normal multicast tree packet and an alternate packet.
The logic is similar for PIM and mLDP, but in PIM there is only one RPF-interface or interface of interest to the UMH. In mLDP, all the directly connected interfaces to the UMH are of interest. When the MP detects a local failure, if that interface was the last connected to the UMH and used for the multicast group, then the MP must rapidly switch from accepting the normal multicast tree traffic to accepting the alternate traffic. This rapid change must happen within the same approximately 50 milliseconds that the PLR switching to send traffic
Atlas, et al. Expires January 13, 2014 [Page 20]

Internet-Draft MRT FRR Architecture July 2013
on the alternate takes and for the same reasons. It does no good for the PLR to send alternate traffic if the MP doesn’t accept it when it is needed.
The MP can identify alternate traffic based upon the MPLS label. This will be the alternate label that the MP supplied to its UMH for this purpose.
5.1.4. Merge Point Reconvergence
After a failure, the MP will want to join the multicast tree according to the new topology. It is critical that the MP does this in a way that minimizes the traffic disruption. Whenever paths change, there is also the possibility for a traffic-affecting event due to different latencies. However, traffic impact above that should be avoided.
The MP must do make-before-break. Until the MP knows that its new UMH is fully connected to the MCI, the MP should continue to accept its old alternate traffic. The MP could learn that the new UMH is sufficient either via control-plane mechanisms or data-driven. In the latter case, the reception of traffic from the new UMH can trigger the change-over. If the data-driven approach is used, a time-out to force the switch should apply to handle multicast trees that have long quiet periods.
5.1.5. PLR termination of alternate traffic
The PLR sends traffic on the alternates for a configurable time-out. There is no clean way for the next-hop routers and/or next-next-hop routers to indicate that the traffic is no longer needed.
If better control were desired, each MP could tell its UMH what the desired time-out is. The UMH could forward this to the PLR as well. Then the PLR could send alternate traffic to different MPs based upon the MP’s individual timer. This would only be an advantage if some of the MPs were expected to have a longer multicast reconvergence time than others - either due to load or router capabilities.
5.2. MP-driven Unicast Tunnels
MP-driven unicast tunnels are only relevant for mLDP where targeted LDP sessions are feasible. For PIM, there is no mechanism to communicate beyond a router’s immediate neighbors; these techniques could work for link-protection, but even then there would not be a way of requesting that the PLR should stop sending traffic.
There are three differences for MP-driven unicast tunnels from PLR-
Atlas, et al. Expires January 13, 2014 [Page 21]

Internet-Draft MRT FRR Architecture July 2013
driven unicast tunnels.
1. The MPs learn the identity of the PLR from their UMH. The PLR does not learn the identities of the MPs.
2. The MPs create direct connections to the PLR and communicate their alternate labels.
3. When the MPs have converged, each explicitly tells the PLR to stop sending alternate traffic.
The first means that a router communicates its UMH to all its downstream multicast hops. Then each MP communicates to the PLR(s) (1 for link-protection and 1 for node-protection) and indicates the multicast tree that protection is desired for and the associated alternate label.
When the PLR learns about a new MP, it adds that MP and associated information to the set of MPs to be protected. On a failure, the PLR does the same behavior as for the PLR-driven unicast tunnels.
After the failure, the MP reconverges using make-before-break. Then the MP explicitly communicates to the PLR(s) that alternate traffic is no longer needed for that multicast tree. When the node- protecting PLR hasn’t changed for a MP, it may be necessary to withdraw the old alternate label, which tells the PLR to stop transmitting alternate traffic, and then provide a new alternate label.
5.3. MP-driven Alternate Trees
In this document we have defined different solutions to achieve fast convergence for multicast link and node protection based on MRTs. At a high level these solutions can be separated in Local and Global protections. Alternate Trees, which is a Local protection schema, initially looked like an attractive solution for Multicast node protection since it avoids replicating the packet by the PLR to each of the receivers of the protected node and waisting bandwidth. However, this comes at the expense of extra multicast state and complexity. In order to mitigate the extra multicast state its possible to aggregate the Alternate Trees by creating an Alternate Tree per protected node and reuse it for all the multicast trees going through this node. This further complicates the procedures and upstream assigned labels are required to de-aggregate the trees. With aggregation we are also introducing an unwanted side effect. The receiver population of the aggregated trees will very likely not be the same. That means multicast packets will be forwarded on the Alternate Tree to node(s) that may not have a receiver(s) for the
Atlas, et al. Expires January 13, 2014 [Page 22]

Internet-Draft MRT FRR Architecture July 2013
protected tree. The more protected trees are aggregated, the higher the risk of forwarding unwanted multicast packets, this leads again to waisting bandwidth.
Considering the complexity of this solution and the unwanted side- effects, the authors of this document believe its better to solve Multicast node protection using a Global protection schema, as documented in Section 4. The solution previously defined in this section has been move to Appendix A (Section 9).
6. Acknowledgements
The authors would like to thank Kishore Tiruveedhula, Santosh Esale, and Maciek Konstantynowicz for their suggestions and review.
7. IANA Considerations
This doument includes no request to IANA.
8. Security Considerations
This architecture is not currently believed to introduce new security concerns.
9. Appendix A
9.1. MP-driven Alternate Trees
For some networks, it is highly desirable not to have the PLR perform replication to each MP. PLR replication can cause substantial congestion on links used by alternates to different MPs. At the same time, it is also desirable to have minimal extra state created in the network. This can be resolved by creating alternate-trees that can protect multiple multicast groups as a bypass-alternate-tree. An alternate-tree can also be created per multicast group, PLR and failure point.
It is not possible to merge alternate-trees for different PLRs or for different neighbors. This is shown in Figure 4 where G can’t select an acceptable upstream node on the alternate tree that doesn’t violate either the need to avoid C (for PLR A) or D (for PLR B).
Atlas, et al. Expires January 13, 2014 [Page 23]

Internet-Draft MRT FRR Architecture July 2013
|-------[S]--------| Alternate from A must avoid C V V Alternate from B ust avoid D [A]------[E]-------[B] | | | V | V |--[C]------[F]-------[D]---| | | | | | |-------[G]--------| | | | | | | | |->[R1]-----[H]-------[R2]<-|
(a) Multicast tree from S S->A->C->R1 and S->B->D->R2
Figure 4: Alternate Trees from PLR A and B can’t be merged
A MP that joins an alternate-tree for a particular multicast stream should not expect or request PLR-replicated tunneled alternate traffic for that same multicast stream.
Each alternate-tree is identified by the PLR which sources the traffic and the failure point (node and link) (FP) to be avoided. Different multicast groups with the same PLR and FP may have different sets of MPs - but they are all at most going to include the FP (for link protection) and the neighbors of FP except for the PLR. For a bypass-alternate-tree to work, it must be acceptable to temporarily send a multicast group’s traffic to FP’s neighbors that do not need it. This is the trade-off required to reduce alternate- tree state and use bypass-alternate-trees. As discussed in Section 5.1.3, a potential MP can determine whether to accept alternate traffic based upon the state of its normal upstream links. Alternate traffic for a group the MP hasn’t joined can just be discarded.
[S]......[PLR]--[ A ] | | | 1| |2 | [ FP]--[MP3] | \ | | \ | [MP1]--[MP2]
Figure 5: Alternate Tree Scenario
Atlas, et al. Expires January 13, 2014 [Page 24]

Internet-Draft MRT FRR Architecture July 2013
For any router, knowing the PLR and the FP to avoid will force selection of either the Blue MRT or the Red MRT. It is possible that the FP doesn’t actually appear in either MRT path, but the FP will always be in either the set of nodes that might be used for the Blue MRT path or the set of nodes that might be used for the Red MRT path. The FP’s membership in one of the sets is a function of the partial ordering and topological ordering created by the MRT algorithm and is consistent between routers in the network graph.
To create an alternate-tree, the following must happen:
1. For node-protection, the MP learns from its upstream (the FP) the node-id of its upstream (the PLR) and, optionally, a link identifier for the link used to the PLR. The link-id is only needed for traffic handling in PIM, since mLDP can have targeted sessions between the MP and the PLR.
2. For link-protection, the MP needs to know the node-id of its upstream (the PLR) and, optionally, its identifier for the link used to the PLR.
3. The MP determines whether to use the Blue or Red forwarding topology to reach the PLR while avoiding the FP and associated interface. This gives the MP its alternate-tree upstream interface.
4. The MP signals a backup-join to its alternate-tree upstream interface. The backup-join specifies the PLR, FP and, for PIM, the FP-PLR link identifier. If the alternate-tree is not to be used as a bypass-alternate-tree, then the multicast group (e.g. (S,G) or Opaque-Value) must be specified.
5. A router that receives a backup-join and is not the PLR needs to create multicast state and send a backup-join towards the PLR on the appropriate Blue or Red forwarding topology as is locally determined to avoid the FP and FP-PLR link.
6. Backup-joins for the same (PLR, FP, PLR-FP link-id) that reference the same multicast group can be merged into a single alternate-tree. Similarly, backup-joins for the same (PLR, FP, PLR-FP link-id) that reference no multicast group can be merged into a single alternate-tree.
7. When the PLR receives the backup-join, it associates either the specified multicast group with that alternate-tree, if such is given, or associates all multicast groups that go to the FP via the specified FP-PLR link with the alternate-tree.
Atlas, et al. Expires January 13, 2014 [Page 25]

Internet-Draft MRT FRR Architecture July 2013
For an example, look at Figure 5. FP would send a backup-join to MP3 indicating (PLR, FP, PLR-FP link-1). MP3 sends a backup-join to A. MP1 sends a backup-join to MP2 and MP2 sends a backup-join to MP3.
It is necessary that traffic on each alternate-tree self-identify as to which alternate-tree it is part of. This is because an alternate- tree for a multicast-group and a particular (PLR, FP, PLR-FP link-id) can easily overlap with an alternate-tree for the same multicast group and a different (PLR, FP, PLR-FP link-id). The best way of doing this depends upon whether PIM or mLDP is being used.
9.1.1. PIM details for Alternate-Trees
For PIM, the (S,G) of the IP packet is a globally unique identifier and is understood. To identify the alternate-tree, the most straightforward way is to use MPLS labels distributed in the PIM backup-join messages. A MP can use the incoming label to indicate the set of RPF-interfaces for which the traffic may be an alternate. If the alternate-tree isn’t a bypass-alternate-tree, then only one RPF interface is referenced. If the alternate-tree is a bypass- alternate-tree, then multiple RPF-interfaces (parallel links to FP) might be intended. Alternate-tree traffic may cross an interface multiple times - either because the interface is a broadcast interface and different downstream-assigned labels are provided and/or because a MP may provide different labels.
9.1.2. mLDP details for Alternate-Trees
For mLDP, if bypass-alternate-trees are used, then the PLR must provide upstream-assigned labels to each multicast stream. The MP provides the label for the alternate-tree; if the alternate-tree is not a bypass-alternate-tree, this label also describes the multicast stream. If the alternate-tree is a bypass-alternate-tree, then it provides the context for the PLR-assigned labels for each multicast stream. If there are targeted LDP sessions between the PLR and the MPs, then the PLR could provide the necessary upstream-assigned labels.
9.1.3. Traffic Handling by PLR
An issue with traffic is how long should the PLR continue to send alternate traffic out. With an alternate-tree, the PLR can know to stop forwarding alternate traffic on the alternate-tree when that alternate-tree’s state is torn down. This provides a clear signal that alternate traffic is no longer needed.
Atlas, et al. Expires January 13, 2014 [Page 26]

Internet-Draft MRT FRR Architecture July 2013
9.2. Methods Compared for PIM
The two approaches that are feasible for PIM are PLR-driven Unicast Tunnels and MP-driven Alternate-Trees.
+-------------------------+-------------------+---------------------+ | Aspect | PLR-driven | MP-driven | | | Unicast Tunnels | Alternate-Trees | +-------------------------+-------------------+---------------------+ | Worst-case Traffic | 1 + number of MPs | 2 | | Replication Per Link | | | | PLR alternate-traffic | timer-based | control-plane | | | | terminated | | Extra multicast state | none | per (PLR,FP,S) for | | | | bypass mode | +-------------------------+-------------------+---------------------+
Which approach is prefered may be network-dependent. It should also be possible to use both in the same network.
9.3. Methods Compared for mLDP
All three approaches are feasible for mLDP. Below is a brief comparison of various aspects of each.
+-------------------+---------------+-------------+-----------------+ | Aspect | MP-driven | PLR-driven | MP-driven | | | Unicast | Unicast | Alternate-Trees | | | Tunnels | Tunnels | | +-------------------+---------------+-------------+-----------------+ | Worst-case | 1 + number of | 1 + number | 2 | | Traffic | MPs | of MPs | | | Replication Per | | | | | Link | | | | | PLR | control-plane | timer-based | control-plane | | alternate-traffic | terminated | | terminated | | Extra multicast | none | none | per (PLR,FP,S) | | state | | | for bypass mode | +-------------------+---------------+-------------+-----------------+
10. References
10.1. Normative References
[I-D.enyedi-rtgwg-mrt-frr-algorithm] Atlas, A., Envedi, G., Csaszar, A., and A. Gopalan, "Algorithms for computing Maximally Redundant Trees for
Atlas, et al. Expires January 13, 2014 [Page 27]

Internet-Draft MRT FRR Architecture July 2013
IP/LDP Fast- Reroute", draft-enyedi-rtgwg-mrt-frr-algorithm-03 (work in progress), July 2013.
[I-D.ietf-rtgwg-mrt-frr-architecture] Atlas, A., Kebler, R., Envedi, G., Csaszar, A., Tantsura, J., Konstantynowicz, M., White, R., and M. Shand, "An Architecture for IP/LDP Fast-Reroute Using Maximally Redundant Trees", draft-ietf-rtgwg-mrt-frr-architecture-03 (work in progress), July 2013.
[RFC4601] Fenner, B., Handley, M., Holbrook, H., and I. Kouvelas, "Protocol Independent Multicast - Sparse Mode (PIM-SM): Protocol Specification (Revised)", RFC 4601, August 2006.
[RFC6388] Wijnands, IJ., Minei, I., Kompella, K., and B. Thomas, "Label Distribution Protocol Extensions for Point-to- Multipoint and Multipoint-to-Multipoint Label Switched Paths", RFC 6388, November 2011.
[RFC6420] Cai, Y. and H. Ou, "PIM Multi-Topology ID (MT-ID) Join Attribute", RFC 6420, November 2011.
10.2. Informative References
[I-D.ietf-rtgwg-mofrr] Karan, A., Filsfils, C., Farinacci, D., Wijnands, I., Decraene, B., Joorde, U., and W. Henderickx, "Multicast only Fast Re-Route", draft-ietf-rtgwg-mofrr-02 (work in progress), June 2013.
[I-D.iwijnand-mpls-mldp-multi-topology] Wijnands, I. and K. Raza, "mLDP Extensions for Multi Topology Routing", draft-iwijnand-mpls-mldp-multi-topology-03 (work in progress), June 2013.
[I-D.kebler-pim-mrt-protection] Kebler, R., Atlas, A., Wijnands, IJ., and G. Enyedi, "PIM Extensions for Protection Using Maximally Redundant Trees", draft-kebler-pim-mrt-protection-00 (work in progress), March 2012.
[I-D.wijnands-mpls-mldp-node-protection] Wijnands, I., Rosen, E., Raza, K., Tantsura, J., Atlas, A., and Q. Zhao, "mLDP Node Protection", draft-wijnands-mpls-mldp-node-protection-04 (work in progress), June 2013.
Atlas, et al. Expires January 13, 2014 [Page 28]

Internet-Draft MRT FRR Architecture July 2013
[RFC5286] Atlas, A. and A. Zinin, "Basic Specification for IP Fast Reroute: Loop-Free Alternates", RFC 5286, September 2008.
[RFC5714] Shand, M. and S. Bryant, "IP Fast Reroute Framework", RFC 5714, January 2010.
Authors’ Addresses
Alia Atlas (editor) Juniper Networks 10 Technology Park Drive Westford, MA 01886 USA
Email: [email protected]
Robert Kebler Juniper Networks 10 Technology Park Drive Westford, MA 01886 USA
Email: [email protected]
IJsbrand Wijnands Cisco Systems, Inc.
Email: [email protected]
Andras Csaszar Ericsson Konyves Kalman krt 11 Budapest 1097 Hungary
Email: [email protected]
Atlas, et al. Expires January 13, 2014 [Page 29]

Internet-Draft MRT FRR Architecture July 2013
Gabor Sandor Enyedi Ericsson Konyves Kalman krt 11. Budapest 1097 Hungary
Email: [email protected]
Atlas, et al. Expires January 13, 2014 [Page 30]


Network Working Group A. BashandyInternet Draft B. PithawalaIntended status: Standards Track K. PatelExpires: January 2013 Cisco Systems July 16, 2012
Scalable BGP FRR Protection against Edge Node Failure draft-bashandy-bgp-edge-node-frr-03.txt
Abstract
Consider a BGP free core scenario. Suppose the edge BGP speakers PE1,PE2,..., PEn know about a prefix P/m via the external routers CE1,CE2,..., CEm. If the edge router PEi crashes or becomes totallydisconnected from the core, it is desirable for a core router "P"carrying traffic to the failed edge router PEi to immediately restoretraffic by re-tunneling packets originally tunneled to PEi anddestined to the prefix P/m to one of the other edge routers thatadvertised P/m, say PEj, until BGP re-converges. In doing so, it ishighly desirable to keep the core BGP-free while not imposingrestrictions on external connectivity. Thus (1) a core router shouldnot be required to learn any BGP prefix, (2) the size of theforwarding and routing tables in the core routers should beindependent of the number of BGP prefixes,(3) provisioning overheadshould be kept at minimum, (4) re-routing traffic without waiting forre-convergence must not cause loops, and (4) there should be norestrictions on what edge routers advertise what prefixes. Forlabeled prefixes, (6) the label stack on the packet must allow therepair PEj to correctly forward the packet and (7) there must not beany need to perform more than one label lookup on any edge or corerouter during steady state
Status of this Memo
This Internet-Draft is submitted in full conformance with the provisions of BCP 78 and BCP 79.
This document may contain material from IETF Documents or IETF Contributions published or made publicly available before November 10, 2008. The person(s) controlling the copyright in some of this material may not have granted the IETF Trust the right to allow modifications of such material outside the IETF Standards Process. Without obtaining an adequate license from the person(s) controlling the copyright in such materials, this document may not be modified outside the IETF Standards Process, and derivative works of it may not be created outside the IETF Standards Process, except to format it for publication as an RFC or to translate it into languages other than English.
Bashandy Expires January 16, 2013 [Page 1]

Internet-Draft BGP FRR For Edge Node Failure July 2012
Internet-Drafts are working documents of the Internet Engineering Task Force (IETF), its areas, and its working groups. Note that other groups may also distribute working documents as Internet- Drafts.
Internet-Drafts are draft documents valid for a maximum of six months and may be updated, replaced, or obsoleted by other documents at any time. It is inappropriate to use Internet-Drafts as reference material or to cite them other than as "work in progress."
The list of current Internet-Drafts can be accessed at http://www.ietf.org/ietf/1id-abstracts.txt
The list of Internet-Draft Shadow Directories can be accessed at http://www.ietf.org/shadow.html
This Internet-Draft will expire on January 16, 2013.
Copyright Notice
Copyright (c) 2012 IETF Trust and the persons identified as the document authors. All rights reserved.
This document is subject to BCP 78 and the IETF Trust’s Legal Provisions Relating to IETF Documents (http://trustee.ietf.org/license-info) in effect on the date of publication of this document. Please review these documents carefully, as they describe your rights and restrictions with respect to this document. Code Components extracted from this document must include Simplified BSD License text as described in Section 4.e of the Trust Legal Provisions and are provided without warranty as described in the Simplified BSD License.
Table of Contents
1. Introduction...................................................3 1.1. Conventions used in this document.........................4 1.2. Terminology...............................................5 1.3. Problem definition........................................6 2. Overview of the solution in an MPLS Core.......................7 2.1. Control Plane operation for Automated pNH Assignment......7 2.2. Control Plane operation for Configured pNH...............10 2.3. Forwarding behavior at Steady State (When pPE is reachable)11 2.4. Forwarding behavior when pPE Fails.......................12 3. Overview of the solution in a Pure IP Core....................13 3.1. Control Plane operation..................................13
Bashandy Expires January 16, 2013 [Page 2]

Internet-Draft BGP FRR For Edge Node Failure July 2012
3.2. Forwarding Behavior at Steady State (while pPE is reachable) ..............................................................13 3.3. Forwarding Behavior at Failure (when pPE is not reachable)14 4. Example.......................................................15 4.1. Control Plane............................................16 4.2. Forwarding Plane at Steady State (When PE0 is reachable).16 4.3. Forwarding Plane at Failure (When PE0 is not reachable)..17 5. Inter-operability with Existing IP FRR Mechanisms.............19 6. Security Considerations.......................................19 7. IANA Considerations...........................................19 8. Conclusions...................................................19 9. References....................................................20 9.1. Normative References.....................................20 9.2. Informative References...................................21 10. Acknowledgments..............................................21 Appendix A. How to protect Against Misconfigured pNH.............22 Appendix B. Alternative Approach for advertising (pNH,rNH) to iPE23 Appendix C. Modification History.................................24 A.1.1. Changes from Version 02.............................24 A.1.2. Changes from Version 01.............................24
1. Introduction
In a BGP free core, where traffic is tunneled between edge routers, BGP speakers advertise reachability information about prefixes to other edge routers not to core routers. For labeled address families, namely AFI/SAFI 1/4, 2/4, 1/128, and 2/128, an edge router assigns local labels to prefixes and associates the local label with each advertised prefix such as L3VPN [10], 6PE [11], and Softwire [9]. Suppose that a given edge router is chosen as the best next-hop for a prefix P/m. An ingress router that receives a packet from an external router and destined to the prefix P/m "tunnels" the packet across the core to that egress router. If the prefix P/m is a labeled prefix, the ingress router pushes the label advertised by the egress router before tunneling the packet to the egress router. Upon receiving the packet from the core, the egress router takes the appropriate forwarding decision based on the content of the packet or the label pushed on the packet.
In modern networks, it is not uncommon to have a prefix reachable via multiple edge routers. One example is the best external path [8]. Another more common and widely deployed scenario is L3VPN [10] with multi-homed VPN sites. As an example, consider the L3VPN topology depicted in Figure 1.
Bashandy Expires January 16, 2013 [Page 3]

Internet-Draft BGP FRR For Edge Node Failure July 2012
PE1 .............+ | +--------+---------------+ | | | VPN 1 Network | | | | VPN prefix | | (10.0.0.0/8) | | | +---+--------------------+ | /------CE1 / / BGP-free core P--------PE0 \ \ \------CE2 | +---+--------------------+ | | | VPN 2 Network | | | | VPN prefix | | (20.0.0.0/8) | | | +--------+---------------+ | PE2 .............+
Figure 1 VPN prefix reachable via multiple PEs
As illustrated in Figure 1, the edge router PE0 is the primary NH for both 10.0.0.0/8 and 20.0.0.0/8. At the same time, both 10.0.0.0/8 and 20.0.0.0/8 are reachable through the other edge routers PE1 and PE2, respectively.
1.1. Conventions used in this document
The key words "MUST", "MUST NOT", "REQUIRED", "SHALL", "SHALL NOT", "SHOULD", "SHOULD NOT", "RECOMMENDED", "MAY", and "OPTIONAL" in this document are to be interpreted as described in RFC-2119 [1].
In this document, these words will appear with that interpretation only when in ALL CAPS. Lower case uses of these words are not to be interpreted as carrying RFC-2119 significance.
Bashandy Expires January 16, 2013 [Page 4]

Internet-Draft BGP FRR For Edge Node Failure July 2012
1.2. Terminology
This section defines the terms used in this document. For ease of use, we will use terms similar to those used by L3VPN [10]
o BGP-Free core: A network where BGP prefixes are only known to the edge routers and traffic is tunneled between edge routers
o External prefix: It is a prefix P/m (of any AFI/SAFI) that a BGP speaker has an external path for. The BGP speaker may learn about the prefix from an external peer through BGP, some other protocol, or manual configuration. The protected prefix is advertised to some or all of the internal peers.
o Protectable prefix: It is an external prefix P/m of any AFI/SAFI) that a BGP speaker has an external path to and is eligible to have a repair path.
o Primary Egress PE, "ePE": It is an IBGP peer that can reach the prefix P/m through an external path and advertised the prefix to the other IBGP peers. The primary egress PE was chosen as the best path by one or more internal peers. In other words, the primary egress PE is an egress PE that will normally be used by some ingress PEs when there is no failure. Referring to Figure 1, PE0 is an egress PE.
o Protected egress PE, "pPE" (Protected PE for simplicity): It is an egress PE that has or eligible to have a repair path for some or all of the prefixes to which it has an external path Referring to Figure 1, PE0 is a protected egress PE.
o Protected edge router: Any protected egress PE.
o Protected next-hop (pNH): It is an IPv4 or IPv6 host address belonging to the protected egress PE. Traffic tunneled to this IP address will be protected via the mechanism proposed in this document. Note that the protected next-hop MUST be different from the next-hop attribute in the BGP update message [2][3].
o CE: It is an external router through which an egress PE can reach a prefix P/m. The routers "CE1" and "CE2" in Figure 1 are examples of such CEs.
o Ingress PE, "iPE": It is a BGP speaker that learns about a prefix through another IBGP peer and chooses that IBGP peer as the next-hop for the prefix.
Bashandy Expires January 16, 2013 [Page 5]

Internet-Draft BGP FRR For Edge Node Failure July 2012
o Repairing P router "rP" (Also "Repairing core router" and "repairing router"): A core router that attempts to restore traffic when the primary egress PE is no longer reachable without waiting for IGP or BGP to re-converge. The repairing P router restores the traffic by rerouting the traffic (through a tunnel) towards the pre-calculated repair PE when it detects that the primary egress PE is no longer reachable. Referring to Figure 1, the router "P" is the repairing P router.
o Repair egress PE "rPE" (Repair PE for simplicity): It is an egress PE other than the primary egress PE that can reach the protected prefix P/m through an external neighbor. The repair PE is pre-calculated prior to any failure. Referring to Figure 1, PE1 is the repair PE for 10.0.0.0/8 while PE2 is the repair PE for 20.0.0.0/8.
o Underlying Repair label (rL): The underlying repair label is the label that will be pushed so that the repair PE can forward repaied traffic correctly. A repair label is defined for labeled protected prefixes only.
o Repair next-hop (rNH): It is an IPv4 or IPv6 host address belonging to the repair egress PE. If the protected prefix is advertised via BGP, then the repair next-hop SHOULD be the next- hop attribute in the BGP update message [2][3].
o Repair path (Also Repair Egress Path): It is the repair next- hop. If an underlying repair label exists, the repair path is the repair next-hop together with the underlying repair label.
o Primary tunnel: It is the tunnel from the ingress PE to the primary egress PE
o Repair tunnel: It is the tunnel from the repairing P router to the repair egress PE
1.3. Problem definition
The problem that we are trying to solve is as follows
o Even though multiple prefixes may share the same egress router, they have different repair edge router. In Figure 1 above, both 10.0.0.0/8 and 20.0.0.0/8 share the same primary next hop PE0, the routing protocol(s) must identify that the node protecting repair node for 10.0.0.0/8 is PE1 while the node protecting repair node for 11.0.0.0/8 is PE2
Bashandy Expires January 16, 2013 [Page 6]

Internet-Draft BGP FRR For Edge Node Failure July 2012
o On loosing connection to the edge router, the core router "P" MUST reroute traffic towards the *correct* repair edge router without waiting for IGP or BGP to re-converge and update the routing tables. On the failure of PE0 illustrated in Figure 1, the core router P needs to reroute traffic for 10.0.0.0/8 towards PE1 and traffic for 11.0.0.0/8 towards PE2
o The repairing core router P MUST NOT be forced to learn about the BGP prefixes on any of the edge router. The same applies for all core routers.
o The size of the routing table on any core router MUST be independent of the number of BGP prefixes in the network.
o Rerouting traffic without waiting for IGP and BGP to re-converge after a failure MUST NOT cause loops.
o For labeled prefixes, when a packet gets re-routed to the repair PE, the label stack on the packet MUST ensure correct forwarding.
o Provisioning overhead must be kept at minimum. In addition, misconfiguration should be detectable.
o At steady state, when pPE is reachable, a path taken by traffic flow must not be impacted by enabling the solution proposed in this document on some or all routers
2. Overview of the solution in an MPLS Core
The solution proposed in this document relies on the collaboration of egress PE, ingress PE, penultimate hop routers, and repairing router. This section gives an overview of how to the solution works for labeled and unlabeled protected prefixes in an MPLS core.
2.1. Control Plane operation for Automated pNH Assignment
This section outlines the solution for the case where the protected next hop "pNH" is automatically calculated instead of being assigned by an operator.
1. Each egress router that is capable of handling repaired traffic assigns each protectable labeled prefix a repair label: "rL". "rL" is advertised as optional path attribute. "rL" MUST be per-CE or per-VRF for good BGP attribute packing and forwarding simplicity. For unlabeled prefix, no repair label is needed. A router that is capable of handling repaired traffic is called a repair PE "rPE". The semantics of the repair label "rL" is:
Bashandy Expires January 16, 2013 [Page 7]

Internet-Draft BGP FRR For Edge Node Failure July 2012
a. pop *two* labels
b. If "rL" is per-CE, then and send the packet to the appropriate CE
c. If "rL" is per-VRF, forward the packet based on the contents under the two popped labels
2. If an Egress PE knows that a P/m to which it has an external path is also reachable via another PE and that other PE advertises a repair label "rL" for P/m,
a. It chooses the other PE as a repair PE. Let’s call the chosen repair PE "rPE". The ePE chooses an IP address "rNH" local to or advertised by rPE.
i. "rNH" SHOULD be the next-hop attribute advertised by rPE when it announces reachability to the protected prefix P/m to minimize the number of prefixes advertised into IGP.
ii. if rPE also advertised a protected next-hop (pNH) for any BGP prefix that rPE can protect, then rNH MUST NOT be any protected next-hop (pNH) advertised by rPE.
b. Allocates a local IP address corresponding to the chosen rPE, say "pNH". "pNH" represents the protected NH. I.e. Traffic tunneled to "pNH" will be protected against edge node failure via the BGP FRR mechanism proposed in this document
c. A separate pNH is needed for every rPE (for a given protected PE). Each pNH must be unique within a single BGP-free core.
d. Now that "ePE" has a repair path for P/m, it becomes a protected PE "pPE".
e. Advertise pNH as a prefix into IGP
f. Re-advertise the protected prefix P/m to other iBGP peers with "pNH" as optional non-transitive attribute
g. pPE advertises the mapping (pNH,rNH) separately to all ingress PEs. A method analogous to how tunnel information is advertised [4] can be used to advertise this mapping (pNH,rNH) to ingress PE’s.
h. Once iPE receives the pNH for each prefix and the mapping (pNH,rNH), the iPE can retrieve "rL" for P/m from the advertisement of rPE for P/m.
Bashandy Expires January 16, 2013 [Page 8]

Internet-Draft BGP FRR For Edge Node Failure July 2012
i. "pPE" advertises the pair (pNH,rNH) to candidate repairing core routers.
j. "pPE" advertises the protected next-hop "pNH" to the penultimate hops to indicate that traffic flowing through the tunnel to the tail end "pNH" is protected against the failure of the node "pPE" and requires special processing by the penultimate hop as will be described in the next few steps
k. pPE advertises an explicit label for pNH instead of the usual implicit NULL. This way pPE can carry out the special label popping behavior (described in the next section if the penultimate hop cannot perform this task
3. Ingress PE "iPE"
a. iPE receives the protected prefix P/m with "pNH" as an optional attribute
b. iPE also receives the mapping (pNH,rNH) from pPE
c. When iPE receives "rL" with P/m from rPE, then iPE can associate "rL" with P/m as described in Section 2.1.
As a result of the above steps, the following nodes store the following information
o Ingress PE (iPE)
o Receives from pPE NLRI advertisement for the protected labeled prefix P/m containing the usual next-hop attribute and the optional information "pNH". iPE also receives that mapping (pNH, rNH).
o iPE retrieves "rL" from the advertisement of rPE for the protected prefix P/m.
o Assume that iPE chooses pPE as the primary NH. Then the iPE will use pNH as the tunnel tail end to pPE instead of the usual BGP next-hop
o Penultimate Hop
o Receives the "pNH" from pPE
o As such, it knows that traffic destined to pNH needs certain special forwarding treatment as described in the next few steps
Bashandy Expires January 16, 2013 [Page 9]

Internet-Draft BGP FRR For Edge Node Failure July 2012
o Penultimate hop advertises "pNH" as its own prefix but with one of the following conditions
. For link-state IGPs, "pNH" MAY be advertised with *maximum metric* so as not to affect the path taken by the traffic flowing from iPE’s to pPE’s
. For distance vector IGPs, the penultimate hop MAY advertise the metric of "pNH" as follows
PHP-metric(pNH) =
pPE-metric(pNH) + metric-From-PHP-to-pPE
That is the metric advertised by the penultimate hop for pNH equals the metric advertised by pPE for pNH plus the metric from the penultimate hop to pPE
. This way the advertisement of pNH by the penultimate hop does not impact the path taken by the traffic from iPE’s to pPE’s
o Repairing core router "rP" (which may also be the penultimate hop)
o Receives the pair (pNH,rNH) from pPE
o Installs the following forwarding entry for pNH
. If pNH is not reachable, re-tunnel traffic to rNH
2.2. Control Plane operation for Configured pNH
In Section 2.1, the pPE assigned pNH to a protected prefix P/m based on the chosen rPE. The result of this behavior is the need to re-advertise the protected prefix P/m with the associated "pNH". In this section, we outline the procedure by which the operator can pre- assign pNH to protected prefixes and hence avoid the need to re- advertise protected prefixes.
1. Protected PE "pPE"
a. The operator groups prefixes such that two prefixes belong to the same group if the operator knows that the two prefixes are protected by the same rPE
b. The operator assigns a distinct protected next-hop "pNH" for every group of prefixes. The assignment occurs even a repair path for P/m is not yet known.
Bashandy Expires January 16, 2013 [Page 10]

Internet-Draft BGP FRR For Edge Node Failure July 2012
c. pPE advertises "pNH" as an optional non-transitive attribute with the protected prefix P/m *all the time* even of no other PE advertises P/m
d. When pPE receives an advertisement for P/m from another PE
i. pPE chooses the other PE as rPE
ii. pPE advertises the mapping (pNH,rNH) separately to all ingress PEs. rNH SHOULD be the next-hop attribute advertised by rPE. A method analogous to how tunnel information is advertised [4] can be used to advertise this mapping (pNH,rNH) to ingress PE’s.
e. The rest of the behavior is identical to what specified in Section 2.1.
2. How to Protect the network against misconfigured pNH?
See Appendix A.
What is left it to outline the forwarding behavior before and after "pPE" failure.
2.3. Forwarding behavior at Steady State (When pPE is reachable)
This section outlines the packet forwarding procedure when pPE is still reachable
1. Ingress PE (iPE) receives a packet matching P/m and reachable via pPE
2. The iPE pushes three labels:
o Bottom label: VPN label advertised by pPE
o Second label: rL
o Top label: IGP label towards pNH (not the BGP next-hop attribute)
3. Penultimate Hop
a. Receives a packet with top label bound to pNH
b. Pops *two* labels *all the time*.
Bashandy Expires January 16, 2013 [Page 11]

Internet-Draft BGP FRR For Edge Node Failure July 2012
c. Sends packet to pNH
4. Protected PE (pPE)
a. Receives a packet with top label as VPN label
b. Forwards the packet as usual
c. For unlabeled packets, the iPE only pushes the rL and the IGP label of pNH and the pPE uses the IP header for forwarding.
Thus the packet can be delivered correctly to its destination.
2.4. Forwarding behavior when pPE Fails
The repairing core router directly connected to a failure detects that pNH is no longer reachable. The following steps are applied.
1. Repairing core router "rP"
a. Receives packet with top label bound to pNH
b. pNH is not reachable
c. Swap the top label with the label of rNH
d. Send packet towards rPE
In effect, the repairing router re-tunnels the packet towards the repair PE
2. Penultimate hop of rPE
a. rNH is not a protected NH for rPE
b. Thus the penultimate hop employs the usual penultimate hop popping and then forwards the packet to rPE
3. Repair PE (rPE)
a. Receives packet with top label rL (which rPE advertised) and underneath it the regular VPN label advertised by the protected PE "pPE"
b. Make a lookup on "rL"
c. rL per CE
i. Pop *two* labels.
Bashandy Expires January 16, 2013 [Page 12]

Internet-Draft BGP FRR For Edge Node Failure July 2012
ii. Send to correct CE
d. rL per VRF
i. Pop *two* labels.
ii. Make IP lookup in appropriate VRF
iii. Send to the CE
e. rL is assigned to unlabeled prefix
i. Pop "rL"
ii. Send the packet to the correct CE
3. Overview of the solution in a Pure IP Core
This section provides an overview of the solution when operating in a pure IP core where core routers only understand IPv4 or IPv6 protocols. Thus traffic between PEs is transported using IP tunnels such as [4][6][7].
3.1. Control Plane operation
The control plane behavior in an IP core is identical to its behavior in an MPLS core.
3.2. Forwarding Behavior at Steady State (while pPE is reachable)
1. Ingress PE (iPE) receives a packet matching P/m and reachable via pPE
2. Ingress PE:
o For labeled traffic, Pushes two labels
. Bottom label: VPN label advertised by pPE
. Second label: rL
o For unlabeled traffic, just push "rL"
o Encapsulates the packet into the IP tunnel header towards the pNH
3. Penultimate Hop
Bashandy Expires January 16, 2013 [Page 13]

Internet-Draft BGP FRR For Edge Node Failure July 2012
o No special behavior is needed from the penultimate hop while pPE is reachable
4. Protected PE
a. Receives an IP packet encapsulated in an IP tunnel header with destination address pNH
b. Decapsulate the IP tunnel header and the label right under it (which will be the repair label "rL")
c. For labeled traffic, the VPN label is exposed. So pPE makes a lookup using the VPN label. Otherwise the usual IP forwarding is applied
d. Forwards the packet as usual
3.3. Forwarding Behavior at Failure (when pPE is not reachable)
The repairing router directly connected to a failure detects that pNH is no longer reachable. The following steps are applied.
1. Repairing router "rP"
a. Receives IP packet with a tunnel header destined to pNH
b. pNH is not reachable
c. Replace the tunnel header with a tunnel header with destination address rNH
d. Forward the packet to rNH
2. Repair PE (rPE)
a. Receives IP packet with a tunnel header destined to rNH
b. Decapsulate the tunnel header to expose the repair label "rL"
c. The rest of the behavior is identical to the behavior in an MPLS Core.
Bashandy Expires January 16, 2013 [Page 14]

Internet-Draft BGP FRR For Edge Node Failure July 2012
4. Example
We will use an LDP core as an example. Consider the diagram depicted in Figure 2 below.
+-----------------------------------+ | | | LDP Core | | | | PE1 Lo = 9.9.9.1 | |\ | | \ | | \ | | \ | | CE1.......VRF "Blue" | | / (10.0.0.0/8) | | / (11.0.0.0/8) | | / | |/ PE11 P--------PE0 Lo1 = 1.1.1.1/32 | |\ pNH Range = 2.1.1.0/24 | | \ | | \ | | \ | | CE2.......VRF "Red" | | / (20.0.0.0/8) | | / (21.0.0.0/8) | | / | |/ | PE2 Lo = 9.9.9.2 | | | | +-----------------------------------+ Figure 2 : Edge node BGP FRR in LDP core
o In Figure 2, PE0 is the pPE for VRFs "Blue" and "Red" while PE1 and PE2 are the rPEs for VRFs "Blue" and "Red", respectively. VRF Blue has 10.0.0.0/8 and 11.0.0.0/8 and VRF Red has 20.0.0.0/8 and 21.0.0.0/8
o Assuming PE0 uses per prefix label allocation, PE0 assigns the VPN labels 4100, 4200, 4300, and 4400 to 10.0.0.0/8, 11.0.0.0/8, 20.0.0.0/8, and 21.0.0.0/8 respectively. PE0 advertises the prefixes 10.0.0.0/8, 11.0.0.0/8, 20.0.0.0/8, and 21.0.0.0/8 using MP/BGP as usual
Bashandy Expires January 16, 2013 [Page 15]

Internet-Draft BGP FRR For Edge Node Failure July 2012
4.1. Control Plane
1. rPEs Allocate and advertise Repair labels
a. Acting as a rPE, PE1 allocates (on per-CE basis) and advertises a repair label rL1=3100 with the prefixes 10.0.0.0/8 and 11.0.0.0/8 to all iBGP peers
b. Similarly, PE2 allocates and advertises the repair label rL2=3200 with the prefixes 20.0.0.0/8 and 21.0.0.0/8
2. pPE calculates and advertises the pNHs
a. For prefixes belonging to VRF "blue", PE0 allocates rNH1=2.1.1.1 because all of them are protected by PE1
b. Similarly, for prefixes belonging to VRF "red", PE0 allocates rNH2=2.1.1.2 because VRF "red" is protected by PE2
c. PE0 advertises (pNH1,rNH1)=(2.1.1.1, 9.9.9.1) and (pNH2,rNH2)=(2.1.1.2, 9.9.9.2) to the ingress PE PE11 and the repairing core router "P".
d. PE0 re-advertises 10.0.0.0/8 & 11.0.0.0/8 with the optional attribute pNH1=2.1.1.1, and 20.0.0.0/8 & 21.0.0.0/8 with pNH=2.1.1.2 to the ingress PE PE11
3. The ingress PE "PE11" creates the following forwarding state
a. For prefixes 10.0.0.0/8 & 11.0.0.0/8: Push the VPN labels 4100 and 4200, respectively, followed by rL=3100 then tunnel the packet to 2.1.1.1
b. For prefixes 20.0.0.0/8 & 21.0.0.0/8: Push the VPN labels 4300 and 4400, respectively, followed by rL=3200; then tunnel the packet to 2.1.1.2
4.2. Forwarding Plane at Steady State (When PE0 is reachable)
1. Ingress PE PE11
a. Traffic for VRF "Blue"
i. PE11 receives a packet for VRF Blue with destination address 10.1.1.1 from an external router.
ii. PE11 pushes the following labels
1. The VPN label 4100
Bashandy Expires January 16, 2013 [Page 16]

Internet-Draft BGP FRR For Edge Node Failure July 2012
2. The Repair label 3100
3. The LDP label for the pNH 2.1.1.1
b. Traffic for VRF "Red"
i. PE11 receives a packet for VRF Red with destination address 20.1.1.1 from an external router
ii. PE11 pushes the following labels
1. The VPN label 4300
2. The Repair label 3200
3. The LDP label for the pNH 2.1.1.2
2. Penultimate Hop of PE0 (Which is also the rP "P")
a. Receives a packet with top label for the protected next-hop 2.1.1.1 or 2.1.1.2
b. Pops *2* labels
c. Forwards the packet to pPE which is 1.1.1.1
3. Protected PE PE0
a. Traffic for VRF "Blue"
i. PE0 receives traffic with the top label 4100.
ii. 4100 is the VPN label 10.1.1.1 belonging to VRF "Blue"
iii. PE0 pops the label 4100 and forwards the packet to CE1
b. Traffic for VRF "Red"
i. PE0 receives traffic with the top label 4300.
ii. 4300 is the VPN label for 20.1.1.1 belonging to VRF "Red"
iii. PE0 pops the label 4300 and forwards the packet to CE2
4.3. Forwarding Plane at Failure (When PE0 is not reachable)
1. The ingress PE PE11
Bashandy Expires January 16, 2013 [Page 17]

Internet-Draft BGP FRR For Edge Node Failure July 2012
Does not know about the failure yet and hence it does not change its behavior.
2. Repair PE rP
a. Traffic for VRF "Blue"
i. Receives a packet with the top label being the LDP label for 2.1.1.1
ii. 2.1.1.1 is not reachable
iii. Swap the LDP label for 2.1.1.1 with the LDP label of 9.9.9.1
iv. Forward the packet towards 9.9.9.1
b. Traffic for VRF "Blue"
i. Receives a packet with the top label being the LDP label for 2.1.1.2
ii. 2.1.1.2 is not reachable
iii. Swap the LDP label for 2.1.1.1 with the LDP label of 9.9.9.2
iv. Forward the packet towards 9.9.9.2
3. The repair Router "PE1"
a. The penultimate hop of PE1 performs the usual penultimate hop popping
b. PE1 receives a packet with the top label equals the repair label 3100, which was allocated on per-CE basis and points to CE1
c. PE1 pops *2* labels and forwards the packet to CE1
4. The repair Router "PE2"
a. The penultimate hop of PE2 performs the usual penultimate hop popping
b. PE1 receives a packet with the top label equals the repair label 3200, which was allocated on per-CE basis and points to CE2
Bashandy Expires January 16, 2013 [Page 18]

Internet-Draft BGP FRR For Edge Node Failure July 2012
c. PE2 pops *2* labels and forwards the packet to CE2
5. Inter-operability with Existing IP FRR Mechanisms
Current existing IP FRR mechanisms can be divided into two categories: core protection and edge protection. Core protection techniques, such as [12], [13], and [14], provide protection against internal node and/or link failure. Thus the technique proposed in this document is not related to existing IP FRR mechanisms. If the failure of an internal node or link results in completely disconnecting a protectable edge node, then an administrator MAY configure the repairing router to prefer the technique proposed in this document over existing IP FRR mechanisms.
Edge protection techniques, such as [16] and its practical implementation [15] provide protection against the failure of the link between PE and CE routers. Thus existing PE-CE link protection can co-exist with the techniques proposed in this document because the two techniques are independent of each other.
6. Security Considerations
No additional security risk is introduced by using the mechanisms proposed in this document
7. IANA Considerations
No requirements for IANA
8. Conclusions
This document proposes a method that allows fast re-route protection against edge node failure or complete disconnected from the core in a BGP-free core. The proposed method has few advantages
o Easy to apply protection policies. pPE is the router that chooses the rPE. Hence if an operator wants to control what prefixes/VRFs get to be protected or what router can be chosen as repair PE, the operator needs to apply the policy on the pPE only.
o Simple forwarding plane. The only change in forwarding plane is the need to pop/push two labels on the iPE, rP, and rPEs.
Bashandy Expires January 16, 2013 [Page 19]

Internet-Draft BGP FRR For Edge Node Failure July 2012
o Single label lookup even during failure. Forwarding decisions are taken based on a single label lookup on all routers all the time even during failure
o Immunity to mis-configuration. The only required configuration is to choose non-overlapping address ranges on different pPEs. If an operator configures overlapping IP address ranges on two different pPEs, then one of the pPE will eventually allocate a pNH that is covered by the IP address range of another pPE and hence the mis- configuration can be detected
o No Need for IP or TE FRR: Because the exit point of the repair tunnel from rP to rPE is different from the primary tunnel exit point
o Works in both MPLS core and IP core
o Works with per-CE, per-VRF, and per-prefix label allocation
o Can be incrementally deployed. There is no flag day. Different routers can be upgraded at different times
o Zero impact on the paths taken by traffic: Enabling/deploying the feature described in this document has no effect on the paths taken by traffic at steady state
9. References
9.1. Normative References
[1] Bradner, S., "Key words for use in RFCs to Indicate Requirement Levels", BCP 14, RFC 2119, March 1997.
[2] Rekhter, Y., Li, T., and S. Hares, "A Border Gateway Protocol 4 (BGP-4), RFC 4271, January 2006
[3] Bates, T., Chandra, R., Katz, D., and Rekhter Y., "Multiprotocol Extensions for BGP", RFC 4760, January 2007
[4] Malhotra, P. and Rosen, E., " The BGP Encapsulation Subsequent Address Family Identifier (SAFI) and the BGP Tunnel Encapsulation Attribute", RFC 5512, April 2009
[5] Lau, J., Ed., Townsley, M., Ed., and I. Goyret, Ed., "Layer Two Tunneling Protocol - Version 3 (L2TPv3)", RFC 3931, March 2005.
[6] Farinacci, D., Li, T., Hanks, S., Meyer, D., and P. Traina, "Generic Routing Encapsulation (GRE)", RFC 2784, March 2000.
Bashandy Expires January 16, 2013 [Page 20]

Internet-Draft BGP FRR For Edge Node Failure July 2012
[7] Perkins, C., "IP Encapsulation within IP", RFC 2003, October 1996.
9.2. Informative References
[8] Marques,P., Fernando, R., Chen, E, Mohapatra, P., Gredler, H., "Advertisement of the best external route in BGP", draft-ietf- idr-best-external-04.txt, April 2011.
[9] Wu, J., Cui, Y., Metz, C., and E. Rosen, "Softwire Mesh Framework", RFC 5565, June 2009.
[10] Rosen, E. and Y. Rekhter, "BGP/MPLS IP Virtual Private Networks (VPNs)", RFC 4364, February 2006.
[11] De Clercq, J. , Ooms, D., Prevost, S., Le Faucheur, F., "Connecting IPv6 Islands over IPv4 MPLS Using IPv6 Provider Edge Routers (6PE)", RFC 4798, February 2007
[12] Atlas, A. and A. Zinin, "Basic Specification for IP Fast Reroute: Loop-Free Alternates", RFC 5286, September 2008.
[13] Shand, S., and Bryant, S., "IP Fast Reroute", RFC5714, January 2010
[14] Shand, M. and S. Bryant, "A Framework for Loop-Free Convergence", RFC 5715, January 2010.
[15] Bashandy, A., Pithawala, P., and Heitz, J., "Scalable, Loop- Free BGP FRR using Repair Label", draft-bashandy-idr-bgp- repair-label-02.txt", July 2011
[16] O. Bonaventure, C. Filsfils, and P. Francois. "Achieving sub-50 milliseconds recovery upon bgp peering link failures," IEEE/ACM Transactions on Networking, 15(5):1123-1135, 2007
10. Acknowledgments
Special thanks to Eric Rosen, Clarence Filsfils, Maciek Konstantynowicz, Stewart Bryant, Pradosh Malhotra, Nagendra Kumar, George Swallow, Les Ginsberg, and Anton Smirnov for the valuable comments
This document was prepared using 2-Word-v2.0.template.dot.
Bashandy Expires January 16, 2013 [Page 21]

Internet-Draft BGP FRR For Edge Node Failure July 2012
Appendix A. How to protect Against Misconfigured pNH
Section 2.2 outlines a method by which the operator can configure the protected next-hop "pNH". There is a possibility of a misconfiguration as follows
o The operator configures the same pNH for two protected prefixes P1/m1 and P2/m2 but the two prefixes are protected by different rPEs
o The operator configures two different pNH’s for two protected prefixes P1/m1 and P2/m2 but the two prefixes are protected by same rPE
The second configuration does not cause a lot of harm. Either way, routers implementing the BGP FRR scheme proposed in this document can detect both misconfigurations.
Suppose the operator configures the same "pNH" for P1/m1 and P2/m2 but P1/m1 is protected by rPE1 and P2/m2 is protected by rPE2. In that case, the iPE and misconfigured pPE will detect this inconsistency because both will see that P1/m1 and P2/m2 are assigned the same pNH but are protected by two different rPEs. The reaction to the misconfiguration is beyond the scope of this document.
Similarly, iPE and pPE can detect that the operator configured different pNH’s for P1/m1 and P2/m2 even though they are protected by the same rPE because both iPE and pPE will receive an advertisement for P1/m1 and P2/m2 from the same rPE. Reactions and remedy to the misconfiguration is beyond the scope of this document.
Bashandy Expires January 16, 2013 [Page 22]

Internet-Draft BGP FRR For Edge Node Failure July 2012
Appendix B. Alternative Approach for advertising (pNH,rNH) to iPE
In Section 2.1, pPE re-advertises the protected prefixes with (pNH) as optional non-transitive attribute and advertises mapping (pNH,rNH) separately. Alternatively, iPE can re-advertise the protected prefix P/m to other iBGP peers with the mapping (pNH,rNH) as optional non- transitive attributes. Advertising (pNH) only with the prefixes has some advantages
o Advertising pNH only with the prefixes can easily be used for configured pNH as described in Section 2.2.
o If the repair PE changes from one PE to another, there is no need to re-advertise all the prefixes. Only the mapping (pNH,rNH) needs to be re-advertised plus possibly some of the protected prefixes
o Advertising pNH only with the prefix slightly reduces the BGP message size
Irrespective of whether (pNH,rNH) is advertised with the prefix or separately, (pNH,rNH) is better than advertising (pNH,rL) because there are many rL’s for the same rNH. Hence advertising (pNH,rNH) yields better attribute packing
Bashandy Expires January 16, 2013 [Page 23]

Internet-Draft BGP FRR For Edge Node Failure July 2012
Appendix C. Modification History
C.1.1. Changes from Version 02
The whole scheme has been changed to a single next-hop per pPE-rPE. As a result, unlike version 00 and 01, there will be a need for behavioral changes in pPE, rP, iPE. The behavior for rPE remains almost unchanged
The second important change is requiring rP to advertise the pNH with maximum metric so that traffic does not get disrupted when the pPE disappears
C.1.2. Changes from Version 01
1. Use the term "underlying repair label" instead of just "repair label" to avoid confusion with the term "repair label" used in [15].
2. In version 01, it was assumed in many places that the repairing router is the penultimate hop P router. Although this would probably be the most common case, it is not always true. Hence in this version the repairing router may be any core router
3. Merged handling labeled and unlabeled prefixes into a single algorithm.
4. Allowed sending a repair label for unlabeled prefixes and added the "Push" flag. This ensures loop-free repair even for unlabeled prefixes in case that the repair PE has eiBGP paths as mentioned in Section Error! Reference source not found.
5. In Section Error! Reference source not found. discussing the rules governing the choice of the underlying repair label for labeled prefix, we changed the wording so that the primary egress PE "SHOULD" instead of "MAY" use the repair label advertised according to [15] as an underlying repair label.
6. All occurrences of the term "backup" were replaced by "repair" as the term "repair" is the commonly used term in the IP FRR context such as [14][13][12]
7. Added the definition of primary and repair tunnels in Section 1.2.
8. Added a definition of the term "Repair Next-hop" in Section 1.2.
9. Modified the definition of "repair path" in Section 1.2. to being the repair next-hop plus the underlying repair label instead of being the repair PE plus the underlying repair label.
Bashandy Expires January 16, 2013 [Page 24]

Internet-Draft BGP FRR For Edge Node Failure July 2012
10.Outlined inter-operability with existing IP FRR techniques in Section 5.
11.There were few editorial corrections.
Authors’ Addresses
Ahmed Bashandy Cisco Systems 170 West Tasman Dr, San Jose, CA 95134 Email: [email protected]
Burjiz Pithawala Cisco Systems 170 West Tasman Dr, San Jose, CA 95134 Email: [email protected]
Keyur Patel Cisco Systems 170 West Tasman Dr, San Jose, CA 95134 Email: [email protected]
Bashandy Expires January 16, 2013 [Page 25]


Internet Engineering Task Force U. Herberg, Ed.Internet-Draft FujitsuIntended status: Experimental A. CardenasExpires: November 8, 2013 University of Texas at Dallas T. Iwao Fujitsu M. Dow Freescale S. Cespedes U. Icesi May 7, 2013
Depth-First Forwarding in Unreliable Networks (DFF) draft-cardenas-dff-14
Abstract
This document specifies the "Depth-First Forwarding" (DFF) protocol for IPv6 networks, a data forwarding mechanism that can increase reliability of data delivery in networks with dynamic topology and/or lossy links. The protocol operates entirely on the forwarding plane, but may interact with the routing plane. DFF forwards data packets using a mechanism similar to a "depth-first search" for the destination of a packet. The routing plane may be informed of failures to deliver a packet or loops. This document specifies the DFF mechanism both for IPv6 networks (as specified in RFC2460) and in addition also for LoWPAN "mesh-under" networks (as specified in RFC4944). The design of DFF assumes that the underlying link layer provides means to detect if a packet has been successfully delivered to the next hop or not. It is applicable for networks with little traffic, and is used for unicast transmissions only.
Status of this Memo
This Internet-Draft is submitted in full conformance with the provisions of BCP 78 and BCP 79.
Internet-Drafts are working documents of the Internet Engineering Task Force (IETF). Note that other groups may also distribute working documents as Internet-Drafts. The list of current Internet- Drafts is at http://datatracker.ietf.org/drafts/current/.
Internet-Drafts are draft documents valid for a maximum of six months and may be updated, replaced, or obsoleted by other documents at any time. It is inappropriate to use Internet-Drafts as reference material or to cite them other than as "work in progress."
Herberg, et al. Expires November 8, 2013 [Page 1]

Internet-Draft DFF May 2013
This Internet-Draft will expire on November 8, 2013.
Copyright Notice
Copyright (c) 2013 IETF Trust and the persons identified as the document authors. All rights reserved.
This document is subject to BCP 78 and the IETF Trust’s Legal Provisions Relating to IETF Documents (http://trustee.ietf.org/license-info) in effect on the date of publication of this document. Please review these documents carefully, as they describe your rights and restrictions with respect to this document. Code Components extracted from this document must include Simplified BSD License text as described in Section 4.e of the Trust Legal Provisions and are provided without warranty as described in the Simplified BSD License.
Herberg, et al. Expires November 8, 2013 [Page 2]

Internet-Draft DFF May 2013
Table of Contents
1. Introduction . . . . . . . . . . . . . . . . . . . . . . . . . 5 1.1. Motivation . . . . . . . . . . . . . . . . . . . . . . . . 5 1.2. Experiments to be conducted . . . . . . . . . . . . . . . 6 2. Notation and Terminology . . . . . . . . . . . . . . . . . . . 7 2.1. Notation . . . . . . . . . . . . . . . . . . . . . . . . . 7 2.2. Terminology . . . . . . . . . . . . . . . . . . . . . . . 8 3. Applicability Statement . . . . . . . . . . . . . . . . . . . 9 4. Protocol Overview and Functioning . . . . . . . . . . . . . . 11 4.1. Information Sets Overview . . . . . . . . . . . . . . . . 12 4.2. Signaling Overview . . . . . . . . . . . . . . . . . . . . 12 5. Protocol Dependencies . . . . . . . . . . . . . . . . . . . . 13 6. Information Sets . . . . . . . . . . . . . . . . . . . . . . . 14 6.1. Symmetric Neighbor List . . . . . . . . . . . . . . . . . 14 6.2. Processed Set . . . . . . . . . . . . . . . . . . . . . . 14 7. Packet Header Fields . . . . . . . . . . . . . . . . . . . . . 15 8. Protocol Parameters . . . . . . . . . . . . . . . . . . . . . 16 9. Data Packet Generation and Processing . . . . . . . . . . . . 16 9.1. Data Packets Entering the DFF Routing Domain . . . . . . . 17 9.2. Data Packet Processing . . . . . . . . . . . . . . . . . . 18 10. Unsuccessful Packet Transmission . . . . . . . . . . . . . . . 20 11. Determining the Next Hop for a Packet . . . . . . . . . . . . 21 12. Sequence Numbers . . . . . . . . . . . . . . . . . . . . . . . 22 13. Modes of Operation . . . . . . . . . . . . . . . . . . . . . . 22 13.1. Route-Over . . . . . . . . . . . . . . . . . . . . . . . . 23 13.1.1. Mapping of DFF Terminology to IPv6 Terminology . . . 23 13.1.2. Packet Format . . . . . . . . . . . . . . . . . . . . 23 13.2. Mesh-Under . . . . . . . . . . . . . . . . . . . . . . . . 25 13.2.1. Mapping of DFF Terminology to LoWPAN Terminology . . 25 13.2.2. Packet Format . . . . . . . . . . . . . . . . . . . . 26 14. Scope Limitation of DFF . . . . . . . . . . . . . . . . . . . 27 14.1. Route-Over MoP . . . . . . . . . . . . . . . . . . . . . . 29 14.2. Mesh-Under MoP . . . . . . . . . . . . . . . . . . . . . . 30 15. MTU Exceedance . . . . . . . . . . . . . . . . . . . . . . . . 32 16. Security Considerations . . . . . . . . . . . . . . . . . . . 32 16.1. Attacks Out of Scope . . . . . . . . . . . . . . . . . . . 32 16.2. Protection Mechanisms of DFF . . . . . . . . . . . . . . . 32 16.3. Attacks In Scope . . . . . . . . . . . . . . . . . . . . . 33 16.3.1. Denial of Service . . . . . . . . . . . . . . . . . . 33 16.3.2. Packet Header Modification . . . . . . . . . . . . . 33 16.3.2.1. Return Flag Tampering . . . . . . . . . . . . . . 34 16.3.2.2. Duplicate Flag Tampering . . . . . . . . . . . . 34 16.3.2.3. Sequence Number Tampering . . . . . . . . . . . . 34 17. IANA Considerations . . . . . . . . . . . . . . . . . . . . . 35 18. Acknowledgements . . . . . . . . . . . . . . . . . . . . . . . 35 19. References . . . . . . . . . . . . . . . . . . . . . . . . . . 35 19.1. Normative References . . . . . . . . . . . . . . . . . . . 35
Herberg, et al. Expires November 8, 2013 [Page 3]

Internet-Draft DFF May 2013
19.2. Informative References . . . . . . . . . . . . . . . . . . 36 Appendix A. Examples . . . . . . . . . . . . . . . . . . . . . . 37 A.1. Example 1: Normal Delivery . . . . . . . . . . . . . . . . 37 A.2. Example 2: Forwarding with Link Failure . . . . . . . . . 37 A.3. Example 3: Forwarding with Missed Link Layer Acknowledgment . . . . . . . . . . . . . . . . . . . . . . 38 A.4. Example 4: Forwarding with a Loop . . . . . . . . . . . . 39 Appendix B. Deployment Experience . . . . . . . . . . . . . . . . 40 B.1. Deployments in Japan . . . . . . . . . . . . . . . . . . . 40 B.2. Kit Carson Electric Cooperative . . . . . . . . . . . . . 40 B.3. Simulations . . . . . . . . . . . . . . . . . . . . . . . 40 B.4. Open Source Implementation . . . . . . . . . . . . . . . . 40 Authors’ Addresses . . . . . . . . . . . . . . . . . . . . . . . . 41
Herberg, et al. Expires November 8, 2013 [Page 4]

Internet-Draft DFF May 2013
1. Introduction
This document specifies the Depth-First Forwarding (DFF) protocol for IPv6 networks, both for IPv6 forwarding ([RFC2460], henceforth denoted "route-over"), and also for "mesh-under" forwarding using the LoWPAN adaptation layer ([RFC4944]). The protocol operates entirely on the forwarding plane, but may interact with the routing plane. The purpose of DFF is to increase reliability of data delivery in networks with dynamic topologies and/or lossy links.
DFF forwards data packets using a "depth-first search" for the destination of the packets. DFF relies on an external neighborhood discovery mechanism which lists neighbors of a router that may be attempted as next hops for a data packet. In addition, DFF may use information from the Routing Information Base (RIB) for deciding in which order to try to send the packet to the neighboring routers.
If the packet makes no forward progress using the first selected next hop, DFF will successively try all neighbors of the router. If none of the next hops successfully receives or forwards the packet, DFF returns the packet to the previous hop, which in turn tries to send it to alternate neighbors.
As network topologies do not necessarily form trees, loops can occur. Therefore, DFF contains a loop detection and avoidance mechanism.
DFF may provide information, which may - by a mechanism outside of this specification - be used for updating cost of routes in the RIB based on failed or successful delivery of packets through alternative next hops. Such information may also be used by a routing protocol.
DFF assumes that the underlying link layer provides means to detect if a packet has been successfully delivered to the next hop or not, is designed for networks with little traffic, and is used for unicast transmissions only.
1.1. Motivation
In networks with dynamic topologies and/or lossy links, even frequent exchanges of control messages between routers for updating the routing tables cannot guarantee that the routes correspond to the effective topology of the network at all times. Packets may not be delivered to their destination because the topology has changed since the last routing protocol update.
More frequent routing protocol updates can mitigate that problem to a certain extent, however this requires additional signaling, consuming channel and router resources (e.g., when flooding control messages
Herberg, et al. Expires November 8, 2013 [Page 5]

Internet-Draft DFF May 2013
through the network). This is problematic in networks with lossy links, where further control traffic exchange can worsen the network stability because of collisions. Moreover, additional control traffic exchange may drain energy from battery-driven routers.
The data-forwarding mechanism specified in this document allows for forwarding data packets along alternate paths for increasing reliability of data delivery, using a depth-first search. The objective is to decrease the necessary control traffic overhead in the network, and at the same time to increase delivery success rates.
As this specification is intended for experimentation, the mechanism is also specified for forwarding on the LoWPAN adaption layer (according to Section 11 of [RFC4944]), in addition to IPv6 forwarding as specified in [RFC2460]. Other than different header formats, the DFF mechanism for route-over and mesh-under is similar, and is therefore first defined in general, and then more specifically for both IPv6 route-over forwarding (as specified in Section 13.1), and for LoWPAN adaptation layer mesh-under (as specified in Section 13.2).
1.2. Experiments to be conducted
This document is presented as an Experimental specification that can increase reliability of data delivery in networks with dynamic topology and/or lossy links. It is anticipated that, once sufficient operational experience has been gained, this specification will be revised to progress it on to the Standards Track. This experiment is intended to be tried in networks that meet the applicability described in Section 3, and with the scope limitations set out in Section 14. While experimentation is encouraged in such networks, operators should exercise caution before attempting this experiment in other types of network as the stability of interaction between DFF and routing in those networks has not been established.
Experience reports regarding DFF implementation and deployment are encouraged particularly with respect to:
o Optimal values for the parameter P_HOLD_TIME, depending on the size of the network, the topology and the amount of traffic originated per router. The longer a Processed Tuple is hold, the more memory is consumed on a router. Moreover, if a tuple is hold too long, a sequence number wrap-around may occur, and a new packet may have the same sequence number as one indicated in an old Processed Tuple. However, if the tuple is expired too soon (before the packet has been completed its path to the destination), it may be mistakenly detected as new packet instead of one already seen.
Herberg, et al. Expires November 8, 2013 [Page 6]

Internet-Draft DFF May 2013
o Optimal values for the parameter MAX_HOP_LIMIT, depending on the size of the network, the topology, and the lossyness of the link layer. MAX_HOP_LIMIT makes sure that packets do not unnecessarily traverse in the network; it may be used to limit the "detour" of packets that is acceptable. The value may also be based on a per- packet-basis if hop-count information is available from the RIB or routing protocol. In such a case, the hop-limit for the packet may be a percentage (e.g., 200%) of the hop-count value indicated in the routing table.
o Optimal methods to increase cost of a route when a loop or lost L2 ACK is detected by DFF. While this is not specified as a normative part of this document, it may be of interest in an experiment to find good values of how much to increase link cost in the RIB or routing protocol.
o Performance of using DFF in combination with different routing protocols, such as reactive and proactive protocols. This also implies how routes are updated by the RIB / routing protocol when informed by DFF about loops or broken links.
2. Notation and Terminology
The key words "MUST", "MUST NOT", "REQUIRED", "SHALL", "SHALL NOT", "SHOULD", "SHOULD NOT", "RECOMMENDED", "NOT RECOMMENDED", "MAY", and "OPTIONAL" in this document are to be interpreted as described in [RFC2119].
Additionally, this document uses the notation in Section 2.1 and the terminology in Section 2.2.
2.1. Notation
The following notations are used in this document:
List: A list of elements is defined as [] for an empty list, [element] for a list with one element, and [element1, element2, ...] for a list with multiple elements.
Concatenation of lists: If L1 and L2 are lists, then L1@L2 is a new list with first all elements of L1, followed by all elements of L2 in that order.
Byte order: All packet formats in this specification use network byte order (most significant octet first) for all fields. The most significant bit in an octet is numbered bit 0, and the least significant bit of an octet is numbered bit 7.
Herberg, et al. Expires November 8, 2013 [Page 7]

Internet-Draft DFF May 2013
Assignment: a := b An assignment operator, whereby the left side (a) is assigned the value of the right side (b).
Comparison: c = d A comparison operator, returning true if the value of the left side (c) is equal to the value of the right side (d).
Flags: This specification uses multiple 1-bit flags. A value of ’0’ of a flag means ’false’, a value of ’1’ means ’true’.
2.2. Terminology
The terms "route-over" and "mesh-under", introduced in [RFC6775] are used in this document, where "route-over" is not only limited to 6LoWPANs but applies to general IPv6 networks:
Mesh-under: A topology where nodes are connected to a [6LoWPAN Border Router] 6LBR through a mesh using link-layer forwarding. Thus, in a mesh-under configuration, all IPv6 hosts in a LoWPAN are only one IP hop away from the 6LBR. This topology simulates the typical IP-subnet topology with one router with multiple nodes in the same subnet.
Route-over: A topology where hosts are connected to the 6LBR through the use of intermediate layer-3 (IP) routing. Here, hosts are typically multiple IP hops away from a [6LoWPAN Router] 6LBR. The route-over topology typically consists of a 6LBR, a set of 6LRs, and hosts.
The following terms are used in this document. As the DFF mechanism is specified both for route-over IPv6 and for mesh-under LoWPAN adaptation layer, the terms are generally defined in this section, and then specifically mapped for each of the different modes of operation in Section 13.
Depth-first search: "Depth-first search (DFS) is an algorithm for traversing or searching a tree, tree structure, or graph. One starts at the root (selecting some node as the root in the graph case) and explores as far as possible along each branch before backtracking" [DFS_wikipedia]. In this document, the algorithm for traversing a graph is applied to forwarding packets in a computer network, with nodes being routers.
Routing Information Base (RIB): A table stored in the user-space of an operating system of a router or host. The table lists routes to network destinations, as well as associated metrics with these routes.
Herberg, et al. Expires November 8, 2013 [Page 8]

Internet-Draft DFF May 2013
Mode of Operation (MoP): The DFF mechanism specified in this document can either be used as "route-over" IPv6 forwarding mechanism (Mode of Operation: "route-over"), or as "mesh-under" LoWPAN adaptation layer (Mode of Operation: "mesh-under").
Packet: An IPv6 Packet (for "route-over" MoP) or a "LoWPAN encapsulated packet" (for "mesh-under" MoP) containing an IPv6 Packet as payload.
Packet Header: An IPv6 extension header (for "route-over" MoP) or a LoWPAN header (for "mesh-under" MoP).
Address: An IPv6 address (for "route-over" MoP), or a 16-bit short or EUI-64 link layer address (for "mesh-under" MoP).
Originator: The router which added the DFF header (specified in Section 7) to a Packet.
Originator Address: An Address of the Originator. This Address SHOULD be an Address configured on the interface which transmits the Packet, selected according to [RFC6724].
Destination: The router or host to which a Packet is finally destined. In case this router or host is outside of the routing domain in which DFF is used, the Destination is the router that removes the DFF header (specified in Section 7) from the Packet. This case is described in Section 14.1.
Destination Address: An Address to which the Packet is sent.
Next Hop: An Address of the next hop router to which the Packet is sent along the path to the Destination.
Previous Hop: The Address of the previous hop router from which a Packet has been received. In case the Packet has been received by a router from outside of the routing domain where DFF is used (i.e., no DFF header is contained in the Packet), the Originator Address of the router adding the DFF header to the Packet is used as the Previous Hop.
Hop Limit: An upper bound how many times the Packet may be forwarded.
3. Applicability Statement
This document specifies DFF, a packet forwarding mechanism intended for use in networks with dynamic topology and/or lossy links with the
Herberg, et al. Expires November 8, 2013 [Page 9]

Internet-Draft DFF May 2013
purpose of increasing reliability of data delivery. The protocol’s applicability is determined by its characteristics, which are that this protocol:
o Is applicable for use in IPv6 networks, either as "route-over" forwarding mechanism using IPv6 ([RFC2460]), or as "mesh-under" forwarding mechanism using the frame format for transmission of IPv6 packets defined in [RFC4944].
o Assumes addresses used in the network are either IPv6 addresses (if the protocol is used as "route-over"), or 16-bit short or EUI-64 link layer addresses, as specified in [RFC4944] if the protocol is used as "mesh-under". In "mesh-under" mode, mixed 16- bit and EUI-64 addresses within one DFF routing domain are allowed (if conform with [RFC4944]), as long as DFF is limited to be used within one PAN (Personal Area Network). It is assumed that the "route-over" mode and "mesh-under" mode are mutually exclusive in the same routing domain.
o Assumes that the underlying link layer provides means to detect if a Packet has been successfully delivered to the Next Hop or not (e.g., by L2 ACK messages). Examples for such underlying link layers are IEEE 802.15.4 or IEEE 802.11.
o Is applicable in networks with lossy links and/or with a dynamic topology. In networks with very stable links and fixed topology, DFF will not bring any benefit (but also not be harmful, other than the additional overhead for the Packet header).
o Works in a completely distributed manner, and does not depend on any central entity.
o Is applicable for networks with little traffic in terms of numbers of Packets per second, since each recently forwarded Packet increases the state on a router. The amount of traffic per time that is supported by DFF depends on the memory resources of the router running DFF, on the density of the network, on the loss rate of the channel, and the maximum hop limit for each Packet: for each recently seen Packet, a list of Next Hops that the Packet has been sent to is stored in memory. The stored entries can be deleted after an expiration time, so that only recently received Packets require storage on the router. Implementations are advised to measure and report rates of packets in the network, and also to report memory usage. Thus, operators can determine memory exhaustion because of growing Information Sets or problems because of too rapid sequence number wrap-around.
Herberg, et al. Expires November 8, 2013 [Page 10]

Internet-Draft DFF May 2013
o Is applicable for dense topologies with multiple paths between each source and each destination. Certain topologies are less suitable for DFF: topologies that can be partitioned by the removal of a single router or link, topologies with multiple stub routers that each have a single link to the network, topologies with only a single path to a destination, or topologies where the "detour" that a Packet makes during the depth-first search in order to reach the destination would be too long. Note that the number of retransmissions of a Packet that stipulate a "too long" path depends on the underlying link layer (capacity and probability of Packet loss), as well as how much bandwidth is required for data traffic by applications running in the network. In such topologies, the Packet may never reach the Destination, and therefore unnecessary transmissions of data Packets may occur until the Hop Limit of the Packet reaches zero and the Packet is dropped. This may consume channel and router resources.
o Is used for unicast transmissions only (not for anycast or multicast).
o Is for use within stub networks, and for traffic between a router inside the routing domain in which DFF is used and a known border router. Examples of such networks are LoWPANs. Scope limitations are described in Section 14.
4. Protocol Overview and Functioning
When a Packet is to be forwarded by a router using DFF, the router creates a list of candidate Next Hops for that Packet. This list (created per packet) is ordered, and Section 11 provides recommendations of how to order the list, e.g., first listing Next Hops listed in the RIB, if available, ordered in increasing cost, followed by other neighbors provided by an external neighborhood discovery. DFF proceeds to forward the Packet to the Next Hop listed first in the list. If the transmission was not successful (as determined by the underlying link layer) or if the Packet was "returned" by a Next Hop to which it had been sent before, the router will try to forward the Packet to the next Next Hop on the list. A router "returns" a Packet to the router from which it was originally received, once it has unsuccessfully tried to forward the Packet to all elements in the candidate Next Hop list. If the Packet is eventually returned to the Originator of the Packet, and after the Originator has exhausted all of its Next Hops for the Packet, the Packet is dropped.
For each recently forwarded Packet, a router running DFF stores information about the Packet as entry in an information set, denoted
Herberg, et al. Expires November 8, 2013 [Page 11]

Internet-Draft DFF May 2013
Processed Set. Each entry in the Processed Set contains a sequence number, included in the Packet Header, identifying the Packet (refer to Section 12 for further details on the sequence number). Furthermore, the entry contains a list of Next Hops to which the Packet has been sent. This list of recently forwarded Packets also allows for avoiding loops when forwarding a Packet. Entries in the Processed Set expire after a given expiration timeout, and are removed.
4.1. Information Sets Overview
This specification requires a single set on each router, the Processed Set. The Processed Set stores the sequence number, the Originator Address, the Previous Hop and a list of Next Hops, to which the Packet has been sent, for each recently seen Packet. Entries in the set are removed after a predefined time-out. Each time a Packet is forwarded to a Next Hop, that Next Hop is added to the list of Next Hops of the entry for the Packet.
Note that an implementation of this protocol may maintain the information of the Processed Set in the indicated form, or in any other organization which offers access to this information. In particular, it is not necessary to remove Tuples from a Set at the exact time indicated, only to behave as if the Tuples were removed at that time.
In addition to the Processed Set, a list of symmetric neighbors must be provided by an external neighborhood discovery mechanism, or may be determined from the RIB (e.g., if the RIB provides routes to adjacent routers, and if these one-hop routes are verified to be symmetric).
4.2. Signaling Overview
Information is needed on a per-packet basis by a router running DFF that receives a Packet. This information is encoded in the Packet Header that is specified in this document as IPv6 Hop-by-Hop Options extension header and as LoWPAN header respectively, for the intended "route-over" and "mesh-under" Modes of Operations. This DFF header contains a sequence number used for uniquely identifying a Packet, and two flags: RET (for "return") and DUP (for "duplicated").
While a router successively tries sending a data Packet to one or more of its neighbors, RET = 0. If none of the transmissions of the Packet to the neighbors of a router have succeeded, the Packet is returned to the router from which the Packet has been first received, indicated by setting the return flag (RET := 1). The RET flag is required to discern between a deliberately returned Packet and a
Herberg, et al. Expires November 8, 2013 [Page 12]

Internet-Draft DFF May 2013
looping Packet: if a router receives a Packet with RET = 1 (and DUP = 0 or DUP = 1) that it has already forwarded, the Packet was deliberately returned, and the router will continue to successively send the Packet to routers from the candidate Next Hop list. If that Packet has RET = 0, the router assumes that the Packet is looping and returns it to the router from which it last received it. An external mechanism may use this information for increasing the route cost of the route to the Destination using the Next Hop which resulted in the loop in the RIB or the routing protocol. It is out of scope of this document to specify such a mechanism. Note that once DUP is set to 1, loop detection is not possible any more as the flag is not reset any more. Therefore, a Packet may loop if the RIBs of routers in the domain are inconsistent, until hop limit has reached 0.
Whenever a Packet transmission to a neighbor has failed (as determined by the underlying link layer, e.g., using L2 ACKs), the duplicate (DUP) flag is set in the Packet Header for the following transmissions. The rationale is that the Packet may have been successfully received by the neighbor and only the L2 ACK has been lost, resulting in possible duplicates of the Packet in the network. The DUP flag tags such a possible duplicate. The DUP flag is required to discern between a duplicated Packet and a looping Packet: if a router receives a Packet with DUP = 1 (and RET = 0) that it has already forwarded, the Packet is not considered looping, and successively forwarded to the next router from the candidate Next Hop list. If the received Packet has DUP = 0 (and RET = 0), the router assumes that the Packet is looping, sets RET := 1, and returns it to the Previous Hop. Again, an external mechanism may use this information for increasing route costs and/or informing the routing protocol.
The reason for not dropping received duplicated Packets (with DUP = 1) is that a duplicated Packet may during its path again be duplicated if another L2 ACK is lost. However, when DUP is already set to 1, it is not possible discerning the duplicate from the duplicate of the duplicate. As a consequence, loop detection is not possible after the second lost L2 ACK on the path of a Packet. However, if duplicates are simply dropped, it is possible that the Packet was actually a looping packet (and not a duplicate), and so the Depth First Search would be interrupted.
5. Protocol Dependencies
DFF MAY use information from the Routing Information Base (RIB), specifically for determining an order of preference for to which next hops a packet should be forwarded (e.g., the packet may be forwarded first to neighbors that are listed in the RIB as next hops to the
Herberg, et al. Expires November 8, 2013 [Page 13]

Internet-Draft DFF May 2013
destination, preferring those with the lowest route cost). Section 11 provides recommendations about the order of preference for the next hops of a packet.
DFF MUST have access to a list of symmetric neighbors for each router, provided by a mechanism such as, e.g., NHDP [RFC6130]. That neighborhood discovery protocol is not specified in this document.
6. Information Sets
This section specifies the information sets used by DFF.
6.1. Symmetric Neighbor List
DFF MUST have access to a list of Addresses of symmetric neighbors of the router. This list can be provided by an external neighborhood discovery mechanism, or alternatively may be determined from the RIB (e.g., if the RIB provides routes to adjacent routers, and if these one-hop routes are verified to be symmetric). The list of Addresses of symmetric neighbors is not specified within this document. The Addresses in the list are used to construct a list of candidate Next Hops for a Packet, as specified in Section 11.
6.2. Processed Set
Each router maintains a Processed Set in order to support the loop detection functionality. The Processed Set lists sequence numbers of previously received Packets, as well as a list of Next Hops to which the Packet has been sent successively as part of the depth-first forwarding mechanism. To protect against this situation, it is recommended that an implementation retains the Processed Set in non- volatile storage if such is provided by the router.
The set consists of Processed Tuples
(P_orig_address, P_seq_number, P_prev_hop, P_next_hop_neighbor_list, P_time)
where
P_orig_address is the Originator Address of the received Packet;
P_seq_number is the sequence number of the received Packet;
Herberg, et al. Expires November 8, 2013 [Page 14]

Internet-Draft DFF May 2013
P_prev_hop is the Address of the Previous Hop of the Packet;
P_next_hop_neighbor_list is a list of Addresses of Next Hops to which the Packet has been sent previously, as part of the depth- first forwarding mechanism, as specified in Section 9.2;
P_time specifies when this Tuple expires and MUST be removed.
The consequences when no or not enough non-volatile storage is available on a router (e.g., because of limited resources) or when an implementation chooses not to make the Processed Set persistent, are that Packets that are already in a loop caused by the routing protocol may continue to loop until the hop limit is exhausted. Non- looping Packets may be sent to Next Hops that have already received the Packet previously and will return the Packet, leading to some unnecessary retransmissions. This effect is only temporary and applies only for Packets already traversing the network.
7. Packet Header Fields
This section specifies the information required by DFF in the Packet Header. Note that, depending on whether DFF is used in the "route- over" MoP or in the "mesh-under" MoP, the DFF header is either an IPv6 Hop-by-Hop Options extension header (as specified in Section 13.1.2) or a LoWPAN header (as specified in Section 13.2.2). Section 13.1.2 and Section 13.2.2 specify the precise order, format and encoding of the fields that are listed in this section.
Version (VER) - This 2-bit value indicates the version of DFF that is used. This specification defines value 00. Packets with other values of the version MUST be forwarded using forwarding as defined in [RFC2460] and [RFC4944] for route-over and mesh-under MoP respectively.
Duplicate Packet Flag (DUP) - This 1-bit flag is set in the DFF header of a Packet, when that Packet is being re-transmitted due to a signal from the link-layer that the original transmission failed, as specified in Section 9.2. Once the flag is set to 1, it MUST NOT be modified by routers forwarding the Packet.
Return Packet Flag (RET) - The 1-bit flag MUST be set to 1 prior to sending the Packet back to the Previous Hop. Upon receiving a packet with RET = 1, and before sending it to a new Candidate Next Hop, that flag MUST be set to 0 as specified in Section 9.2.
Herberg, et al. Expires November 8, 2013 [Page 15]

Internet-Draft DFF May 2013
Sequence Number - A 16-bit field, containing an unsigned integer sequence number generated by the Originator, unique to each router for each Packet to which the DFF has been added, as specified in Section 12. The Originator Address concatenated with the sequence number represents an identifier of previously seen data Packets. Refer to Section 12 for further information about sequence numbers.
8. Protocol Parameters
The parameters used in this specification are listed in this section. These parameters are configurable, do not need to be stored in non- volatile storage, and can be varied by implementations at run time. Default values for the parameters depend on the network size, topology, link layer and traffic patterns. Part of the experimentation described in Section 1.2 is to determine suitable default values.
P_HOLD_TIME - Is the time period after which a newly created or modified Processed Tuple expires and MUST be deleted. An implementation SHOULD use a value for P_HOLD_TIME that is high enough that the Processed Tuple for a Packet is still in memory on all forwarding routers while the Packet is transiting the routing domain. The value SHOULD at least be MAX_HOP_LIMIT times the expected time to send a Packet to a router on the same link. The value MUST be lower than the time it takes until the same sequence number is reached again after a wrap-around on the router identified by P_orig_address of the Processed Tuple.
MAX_HOP_LIMIT - Is the initial value of Hop Limit, and therefore the maximum number of times that a Packet is forwarded in the routing domain. When choosing the value of MAX_HOP_LIMIT, the size of the network, the distance between source and destination in number of hops, and the maximum possible "detour" of a Packet SHOULD be considered (compared to the shortest path). Such information MAY be used from the RIB, if provided.
9. Data Packet Generation and Processing
The following sections specify the process of handling a Packet entering the DFF routing domain (i.e., without DFF header) in Section 9.1, as well as forwarding a data Packet from another router running DFF in Section 9.2.
Herberg, et al. Expires November 8, 2013 [Page 16]

Internet-Draft DFF May 2013
9.1. Data Packets Entering the DFF Routing Domain
This section applies for any data Packets upon their first entry into a routing domain, in which DFF is used. This occurs when a new data Packet is generated on this router, or when a data Packet is forwarded from outside the routing domain (i.e., from a host attached to this router or from a router outside the routing domain in which DFF is used). Before such a data Packet (henceforth denoted "current Packet") is transmitted, the following steps MUST be executed:
1. If required, encapsulate the Packet as specified in Section 14.
2. Add the DFF header to the current Packet (to the outer header if the Packet has been encapsulated), with:
* DUP := 0;
* RET := 0;
* Sequence Number := a new sequence number of the Packet (as specified in Section 12).
3. Check that the Packet does not exceed the MTU as specified in Section 15. In case it does, execute the procedures listed in Section 15 and do not further process the Packet.
4. Select the Next Hop (henceforth denoted "next_hop") for the current Packet, as specified in Section 11.
5. Add a Processed Tuple to the Processed Set with:
* P_orig_address := the Originator Address of the current Packet;
* P_seq_number := the sequence number of the current Packet;
* P_prev_hop := the Originator Address of the current Packet;
* P_next_hop_neighbor_list := [next_hop];
* P_time := current time + P_HOLD_TIME.
6. Pass the current Packet to the underlying link layer for transmission to next_hop. If the transmission fails (as determined by the link layer), the procedures in Section 10 MUST be executed.
Herberg, et al. Expires November 8, 2013 [Page 17]

Internet-Draft DFF May 2013
9.2. Data Packet Processing
When a Packet (henceforth denoted the "current Packet") is received by a router, then the following tasks MUST be performed:
1. If the Packet Header is malformed (i.e., the header format is not as expected by this specification), drop the Packet.
2. Otherwise, if the Destination Address of the Packet matches an Address of an interface of this router, deliver the Packet to upper layers and do not further process the Packet as specified below.
3. Decrement the value of the Hop Limit field by one (1).
4. Drop the Packet if Hop Limit is decremented to zero and do not further process the Packet as specified below.
5. If no Processed Tuple (henceforth denoted the "current tuple") exists in the Processed Set, with:
+ P_orig_address = the Originator Address of the current Packet, AND;
+ P_seq_number = the sequence number of the current Packet.
Then:
1. Add a Processed Tuple (henceforth denoted the "current tuple") with:
+ P_orig_address := the Originator Address of the current Packet;
+ P_seq_number := the sequence number of the current Packet;
+ P_prev_hop := the Previous Hop Address of the current Packet;
+ P_next_hop_neighbor_list := [];
+ P_time := current time + P_HOLD_TIME.
2. Set RET to 0 in the DFF header.
Herberg, et al. Expires November 8, 2013 [Page 18]

Internet-Draft DFF May 2013
3. Select the Next Hop (henceforth denoted "next_hop") for the current Packet, as specified in Section 11.
4. P_next_hop_neighbor_list := P_next_hop_neighbor_list@ [next_hop].
5. Pass the current Packet to the underlying link layer for transmission to next_hop. If the transmission fails (as determined by the link layer), the procedures in Section 10 MUST be executed.
6. Otherwise, if a tuple exists:
1. If the return flag of the current Packet is not set (RET = 0) (i.e., a loop has been detected):
1. Set RET := 1.
2. Pass the current Packet to the underlying link layer for transmission to the Previous Hop.
2. Otherwise, if the return flag of the current Packet is set (RET = 1):
1. If the Previous Hop of the Packet is not contained in P_next_hop_neighbor_list of the current tuple, drop the Packet.
2. If the Previous Hop of the Packet (i.e., the address of the router from which the current Packet has just been received) is equal to P_prev_hop of current tuple (i.e., the address of the router from which the current Packet has been first received), drop the Packet.
3. Set RET := 0.
4. Select the Next Hop (henceforth denoted "next_hop") for the current Packet, as specified in Section 11.
5. Modify the current tuple:
- P_next_hop_neighbor_list := P_next_hop_neighbor_list@ [next_hop];
- P_time := current time + P_HOLD_TIME.
Herberg, et al. Expires November 8, 2013 [Page 19]

Internet-Draft DFF May 2013
6. If the selected Next Hop is equal to P_prev_hop of the current tuple, as specified in Section 11, (i.e., all Candidate Next Hops have been unsuccessfully tried), set RET := 1. If this router (i.e., the router receiving the current packet) has the same Address as the Originator Address of the current Packet, drop the Packet.
7. Pass the current Packet to the underlying link layer for transmission to next_hop. If transmission fails (as determined by the link layer), the procedures in Section 10 MUST be executed.
10. Unsuccessful Packet Transmission
DFF requires that the underlying link layer provides information as to whether a Packet is successfully received by the Next Hop. Absence of such a signal is interpreted as delivery failure of the Packet (henceforth denoted the "current Packet"). Note that the underlying link layer MAY retry sending the Packet multiple times (e.g., using exponential back-off) before determining that the Packet has not been successfully received by the Next Hop. Whenever Section 9 explicitly requests it in case of such a delivery failure, the following steps are executed:
1. Set the duplicate flag (DUP) of the DFF header of the current Packet to 1.
2. Select the Next Hop (henceforth denoted "next_hop") for the current Packet, as specified in Section 11.
3. Find the Processed Tuple (the "current tuple") in the Processed Set, with:
+ P_orig_address = the Originator Address of the current Packet, AND;
+ P_seq_number = the sequence number of the current Packet,
4. If no current tuple is found, drop the Packet.
5. Otherwise, modify the current tuple:
* P_next_hop_neighbor_list := P_next_hop_neighbor_list@ [next_hop];
* P_time := current time + P_HOLD_TIME.
Herberg, et al. Expires November 8, 2013 [Page 20]

Internet-Draft DFF May 2013
6. If the selected next_hop is equal to P_prev_hop of the current tuple, as specified in Section 11 (i.e., all neighbors have been unsuccessfully tried):
* RET := 1
* Decrement the value of the Hop Limit field by one (1). Drop the Packet if Hop Limit is decremented to zero.
7. Otherwise
* RET := 0
8. Transmit the current Packet to next_hop. If transmission fails (determined by the link layer), and if the next_hop does not equal P_prev_hop from the current tuple, the procedures in Section 10 MUST be executed.
11. Determining the Next Hop for a Packet
When forwarding a Packet, a router determines a valid Next Hop for that Packet as specified in this section. As a Processed Tuple was either existing when receiving the Packet (henceforth denoted the "current Packet"), or otherwise was created, it can be assumed the a Processed Tuple for that Packet (henceforth denoted the "current tuple") is available.
The Next Hop is chosen from a list of candidate Next Hops in order of decreasing priority. This list is created per Packet. The maximum candidate Next Hop List for a Packet contains all the neighbors of the router (as determined from an external neighborhood discovery process), except for the Previous Hop of the current Packet. A smaller list MAY be used, if desired, and the exact selection of the size of the candidate Next Hop List is a local decision in each router, which does not affect interoperability. Selecting a smaller list may reduce the path length of a Packet traversing the network and reduce required state in the Processed Set, but may result in valid paths that are not explored. If information from the RIB is used, then the candidate Next Hop list MUST contain at least the Next Hop, indicated in the RIB as the Next Hop on the shortest path to the destination, and SHOULD contain all Next Hops, indicated to the RIB as Next Hops on paths to the destination. If a Next Hop from the RIB equals the Previous Hop of the current Packet, it MUST NOT be added to the candidate Next Hop list.
The list MUST NOT contain Addresses which are listed in P_next_hop_neighbor_list of the current tuple, in order to avoid
Herberg, et al. Expires November 8, 2013 [Page 21]

Internet-Draft DFF May 2013
sending the Packet to the same neighbor multiple times. Moreover, an Address MUST NOT appear more than once in the list, for the same reason. Also, Addresses of an interface of this router MUST NOT be added to the list.
The list has an order of preference, where Next Hops at the top of the list being the ones that Packets are sent to first in the depth- first processing specified in Section 9.1 and Section 9.2. The following order is RECOMMENDED, with the elements listed on top having the highest preference:
1. The neighbor that is indicated in the RIB as the Next Hop on the shortest path to the destination of the current Packet;
2. Other neighbors indicated in the RIB as Next Hops on path to the destination of the current Packet;
3. All other symmetric neighbors (except the Previous Hop of the current Packet).
Additional information from the RIB or the list of symmetric neighbors MAY be used for determining the order, such as route cost or link quality.
If the candidate Next Hop list created as specified in this section is empty, the selected Next Hop MUST be P_prev_hop of the current tuple; this case applies when returning the Packet to the Previous Hop.
12. Sequence Numbers
Whenever a router generates a Packet or forwards a Packet on behalf of a host or a router outside the routing domain where DFF is used, a sequence number MUST be created and included in the DFF header. This sequence number MUST be unique locally on each router where it is created. A sequence number MUST start at 0 for the first Packet to which the DFF header is added, and then increase in steps of 1 for each new Packet. The sequence number MUST NOT be greater than 65535 and MUST wrap around to 0.
13. Modes of Operation
DFF can be used either as "route-over" IPv6 forwarding protocol, or alternatively as "mesh-under" data forwarding protocol for the LoWPAN adaptation layer ([RFC4944]). Previous sections have specified the DFF mechanism in general; specific differences for each MoP are
Herberg, et al. Expires November 8, 2013 [Page 22]

Internet-Draft DFF May 2013
specified in this section.
13.1. Route-Over
This section maps the general terminology from Section 2.2 to the specific terminology when using the "route-over" MoP.
13.1.1. Mapping of DFF Terminology to IPv6 Terminology
The following terms are those listed in Section 2.2, and their meaning is explicitly defined when DFF is used in the "route-over" MoP:
Packet - An IPv6 packet, as specified in [RFC2460].
Packet Header - An IPv6 extension header, as specified in [RFC2460].
Address - An IPv6 address, as specified in [RFC4291].
Originator Address - The Originator Address corresponds to the Source address field of the IPv6 header as specified in [RFC2460].
Destination Address - The Destination Address corresponds to the Destination field of the IPv6 header as specified in [RFC2460].
Next Hop - The Next Hop is the IPv6 address of the next hop to which the Packet is sent; the link layer address from that IP address is resolved by a mechanism such as ND [RFC4861]. The link layer address is then used by L2 as destination.
Previous Hop - The Previous Hop is the IPv6 address from the interface of the previous hop from which the Packet has been received.
Hop Limit - The Hop Limit corresponds to the Hop Limit field in the IPv6 header as specified in [RFC2460].
13.1.2. Packet Format
In the "route-over" MoP, all IPv6 Packets MUST conform with the format specified in [RFC2460].
The DFF header, as specified below, is an IPv6 Extension Hop-by-Hop Options header, and is depicted in Figure 1 (where DUP is abbreviated to D, and RET is abbreviated to R because of the limited space in the figure). This document specifies a new option to be used inside the Hop-by-Hop Options header, which contains the DFF fields (DUP and RET flags and sequence number, as specified in Section 7).
Herberg, et al. Expires November 8, 2013 [Page 23]

Internet-Draft DFF May 2013
[RFC6564] specifies:
New options for the existing Hop-by-Hop Header SHOULD NOT be created or specified unless no alternative solution is feasible. Any proposal to create a new option for the existing Hop-by-Hop Header MUST include a detailed explanation of why the hop-by-hop behavior is absolutely essential in the document proposing the new option with hop-by-hop behavior.
[RFC6564] recommends to use Destination Headers instead of Hop-by-Hop Option headers. Destination Headers are only read by the destination of an IPv6 packet, not by intermediate routers. However, the mechanism specified in this document relies on intermediate routers reading and editing the header. Specifically, the sequence number and the DUP and RET flags are read by each router running the DFF protocol. Modifying the DUP flag and RET flag is essential for this protocol to tag duplicate or returned Packets. Without the DUP flag, a duplicate Packet cannot be discerned from a looping Packet, and without the RET flag, a returned Packet cannot be discerned from a looping Packet.
1 2 3 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Next Header | Hdr Ext Len | OptTypeDFF | OptDataLenDFF | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ |VER|D|R|0|0|0|0| Sequence Number | Pad1 | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
Figure 1: IPv6 DFF Header
Field definitions of the DFF header are as follows:
Next Header - 8-bit selector. Identifies the type of header immediately following the Hop-by-Hop Options header. As specified in [RFC2460].
Hdr Ext Len - 8-bit unsigned integer. Length of the Hop-by-Hop Options header in 8-octet units, not including the first 8 octets. As specified in [RFC2460]. This value is set to 0 (zero).
OptTypeDFF - 8-bit identifier of the type of option as specified in [RFC2460]. This value is set to IP_DFF. The two high order bits of the option type MUST be set to ’11’ and the third bit is equal to ’1’. With these bits, according to [RFC2460], routers that do not understand this option on a received Packet discard the packet and, only if the packet’s Destination Address was not a multicast
Herberg, et al. Expires November 8, 2013 [Page 24]

Internet-Draft DFF May 2013
address, send an ICMP Parameter Problem, Code 2, message to the packet’s Source Address, pointing to the unrecognized Option Type. Also, according to [RFC2460], the values within the option are expected to change en route.
OptDataLenDFF - 8-bit unsigned integer. Length of the Option Data field of this option, in octets as specified in [RFC2460]. This value is set to 2 (two).
DFF fields - A 2-bit version field (abbreviated as VER), the DUP (abbreviated as D) and RET (abbreviated as R) flags follow after Mesh Forw, as specified in Section 7. The version specified in this document is 00. All other bits (besides VER, DUP, and RET) of this octet are reserved and MUST be set to 0.
Sequence Number - A 16-bit field, containing an unsigned integer sequence number, as specified in Section 7.
Pad1 - Since the Hop-by-Hop Options header must have a length of multiples of 8 octets, a Pad1 option is used, as specified in [RFC2460]. All bits of this octet are 0.
13.2. Mesh-Under
This section maps the general terminology from Section 2.2 to the specific terminology when using the "mesh-under" MoP.
13.2.1. Mapping of DFF Terminology to LoWPAN Terminology
The following terms are those listed in Section 2.2 (besides "Mode of Operation"), and their meaning is explicitly defined when DFF is used in the "mesh-under" MoP:
Packet - A "LoWPAN encapsulated packet" (as specified in [RFC4944], which contains an IPv6 packet as payload.
Packet Header - A LoWPAN header, as specified in [RFC4944].
Address - A 16-bit short or EUI-64 link layer address, as specified in [RFC4944].
Originator Address - The Originator Address corresponds to the Originator Address field of the Mesh Addressing header as specified in [RFC4944].
Herberg, et al. Expires November 8, 2013 [Page 25]

Internet-Draft DFF May 2013
Destination Address - The Destination Address corresponds to the Final Destination field of the Mesh Addressing header as specified in [RFC4944].
Next Hop - The Next Hop is the destination address of a frame containing a LoWPAN encapsulated packet, as specified in [RFC4944].
Previous Hop - The Previous Hop is the source address of the frame containing a LoWPAN encapsulated packet, as specified in [RFC4944].
Hop Limit - The Hop Limit corresponds to the Deep Hops Left field in the Mesh Addressing header as specified in [RFC4944].
13.2.2. Packet Format
In the "mesh-under" MoP, all IPv6 Packets MUST conform with the format specified in [RFC4944]. All data Packets exchanged by routers using this specification MUST contain the Mesh Addressing header as part of the LoWPAN encapsulation, as specified in [RFC4944].
The DFF header, as specified below, MUST follow the Mesh Addressing header. After these two headers, any other LoWPAN header, e.g., header compression or fragmentation headers, MAY also be added before the actual payload. Figure 2 depicts the Mesh Addressing header defined in [RFC4944], and Figure 3 depicts the DFF header.
1 2 3 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ |1 0|V|F|HopsLft| DeepHopsLeft |orig. address, final address... +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
Figure 2: Mesh Addressing Header
1 2 3 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ |0 1| Mesh Forw |VER|D|R|0|0|0|0| sequence number | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
Figure 3: Header for DFF data Packets
Field definitions of the Mesh Addressing header are as specified in
Herberg, et al. Expires November 8, 2013 [Page 26]

Internet-Draft DFF May 2013
[RFC4944]. When adding that header to the LoWPAN encapsulation on the Originator, the fields of the Mesh Addressing header MUST be set to the following values:
o V := 0 if the Originator Address is an IEEE extended 64-bit address (EUI-64); otherwise, V := 1 if it is a short 16-bit address.
o F := 0 if the Final Destination Address is an IEEE extended 64-bit address (EUI-64); otherwise, F := 1 if it is a short 16-bit address.
o Hops Left := 0xF (i.e., reserved value indicating that the Deep Hops Left field is following);
o Deep Hops Left := MAX_HOP_LIMIT.
Field definitions of the DFF header are as follows:
Mesh Forw - A 6-bit identifier that allows for the use of different mesh forwarding mechanisms. As specified in [RFC4944], additional mesh forwarding mechanisms should use the reserved dispatch byte values following LOWPAN_BCO; therefore, 0 1 MUST precede Mesh Forw. The value of Mesh Forw is LOWPAN_DFF.
DFF fields - A 2-bit version field (abbreviated as VER), the DUP (abbreviated as D) and RET (abbreviated as R) flags follow after Mesh Forw, as specified in Section 7. The version specified in this document is 00. All other bits (besides VER, DUP, and RET) of this octet are reserved and MUST be set to 0.
Sequence Number - A 16-bit field, containing an unsigned integer sequence number, as specified in Section 7.
14. Scope Limitation of DFF
The forwarding mechanism specified in this document MUST be limited in scope to the routing domain in which DFF is used. That also implies that any headers specific to DFF do not traverse the boundaries of the routing domain. This section specifies, both for the "route-over" MoP and the "mesh-under" MoP, how to limit the scope of DFF to the routing domain in which it is used.
Figure 4 to Figure 7 depict four different cases for source and destination of traffic with regards to the scope of the routing domain in which DFF is used. Section 14.2 and Section 14.1 specify how routers limit the scope of DFF for the "route-over" MoP and the
Herberg, et al. Expires November 8, 2013 [Page 27]

Internet-Draft DFF May 2013
"mesh-under" MoP respectively for these cases. In these sections, all nodes "inside the routing domain" are routers and use DFF, and may also be sources or destinations. Sources or destinations "outside the routing domain" do not run DFF and are either hosts attached to a router in the routing domain that is running DFF, or are themselves routers but outside the routing domain and not running DFF.
+-----------------+ | | | (S) ----> (D) | | | +-----------------+ Routing Domain
Figure 4: Traffic within the routing domain (from S to D)
+-----------------+ | | | (S) --------> (R) --------> (D) | | +-----------------+ Routing Domain
Figure 5: Traffic from within the routing domain to outside of the domain (from S to D)
+-----------------+ | | (S) --------> (R) --------> (D) | | | +-----------------+ Routing Domain
Figure 6: Traffic from outside the routing domain to inside the domain (from S to D)
Herberg, et al. Expires November 8, 2013 [Page 28]

Internet-Draft DFF May 2013
+-----------------+ | | (S) --------> (R1) -----------> (R2) --------> (D) | | +-----------------+ Routing Domain
Figure 7: Traffic from outside the routing domain, traversing the domain and then to the outside of the domain (from S to D)
14.1. Route-Over MoP
In Figure 4, both the source and destination of the traffic are routers within the routing domain. If traffic is originated at S, the DFF header is added to the IPv6 header (as specified in Section 13.1.2). The Originator Address is set to S and the Destination Address is set to D. The Packet is forwarded to D using this specification. When router D receives the Packet, it processes the payload of the IPv6 Packet in upper layers. This case assumes that S has knowledge that D is in the routing domain, e.g., because of administrative setting based on the IP address of the Destination. If S has no knowledge about whether D is in the routing domain, IPv6- in-IPv6 tunnels as specified in [RFC2473] MUST be used. These cases are described in the following paragraphs.
In Figure 5, the source of the traffic (S) is within the routing domain, and the destination (D) is outside of the routing domain. The IPv6 Packet, originated at S, MUST be encapsulated according to [RFC2473] (IPv6-in-IPv6 tunnels), and the DFF header added to the outer IPv6 header. S chooses the next router that should process the Packet as the tunnel exit-point (R). Administrative setting, as well as information from a routing protocol may be used to determine the tunnel exit-point. If no information is available which router to choose as tunnel exit-point, the Next Hop MUST be used as tunnel exit-point. In some cases, the tunnel exit-point will be the final router along a path towards the Packet’s Destination, and the Packet will only traverse a single tunnel (e.g., if R is a known border router then S can choose R as tunnel exit- point). In other cases, the tunnel exit-point will not be the final router along the path to D, and the Packet may traverse multiple tunnels to reach the Destination; note that in this case, the DFF mechanism is only used inside each IPv6-in-IPv6 tunnel. The Originator Address of the Packet is set to S and the Destination Address is set to the tunnel exit-point (in the outer IPv6 header). The Packet is forwarded to the tunnel exit-point using this specification (potentially using multiple consecutive IPv6-in-IPv6 tunnels). When router R receives the Packet, it decapsulates the IPv6 Packet and forwards the inner
Herberg, et al. Expires November 8, 2013 [Page 29]

Internet-Draft DFF May 2013
IPv6 Packet to D, using normal IPv6 forwarding as specified in [RFC2460].
In Figure 6, the source of the traffic (S) is outside of the routing domain, and the destination (D) is inside of the routing domain. The IPv6 Packet, originated at S, is forwarded to R using normal IPv6 forwarding as specified in [RFC2460]. Router R MUST encapsulate the IPv6 Packet according to [RFC2473], and add the DFF header (as specified in Section 13.1.2) to the outer IPv6 header. Like in the previous case, R has to select a tunnel exit-point; if it knows that D is in the routing domain (e.g., based on administrative settings), it SHOULD select D as the tunnel exit-point. In case it does not have any information which exit-point to select, it MUST use the Next Hop as tunnel exit-point, limiting the effectiveness of DFF to inside each IPv6-in-IPv6 tunnel. The Originator Address of the Packet is set to R, the Destination Address to the tunnel exit-point (both in the outer IPv6 header), the sequence number in the DFF header is generated locally on R. The Packet is forwarded to D using this specification. When router D receives the Packet, it decapsulates the inner IPv6 Packet and processes the payload of the inner IPv6 Packet in upper layers.
This mechanism is typically not used in transit networks; therefore, this case is discouraged, but described nevertheless for completeness: In Figure 7, both the source of the traffic (S) and the destination (D) are outside of the routing domain. The IPv6 Packet, originated at S, is forwarded to R1 using normal IPv6 forwarding as specified in [RFC2460]. Router R1 MUST encapsulate the IPv6 Packet according to [RFC2473] and add the DFF header (as specified in Section 13.1.2). R1 selects a tunnel exit-point like in the previous cases; if R2 is, e.g., a known border router, then R1 can select R2 as tunnel exit-point. The Originator Address is set to R1, the Destination Address to the tunnel exit-point (both in the outer IPv6 header), the sequence number in the DFF header is generated locally on R1. The Packet is forwarded to the tunnel exit-point using this specification (potentially traversing multiple consecutive IPv6-in- IPv6 tunnels). When router R2 receives the Packet, it decapsulates the inner IPv6 Packet and forwards the inner IPv6 Packet to D, using normal IPv6 forwarding as specified in [RFC2460].
14.2. Mesh-Under MoP
In Figure 4, both the source and destination of the traffic are routers within the routing domain. If traffic is originated at router S, the LoWPAN encapsulated Packet is created from the IPv6 packet as specified in [RFC4944]. Then, the Mesh Addressing header and the DFF header (as specified in Section 13.2.2) are added to the LoWPAN encapsulation on router S. The Originator Address is set to S
Herberg, et al. Expires November 8, 2013 [Page 30]

Internet-Draft DFF May 2013
and the Destination Address is set to D. The Packet is then forwarded using this specification. When router D receives the Packet, it processes the payload of the Packet in upper layers.
In Figure 5, the source of the traffic (S) is within the routing domain, and the destination (D) is outside of the routing domain (which is known by S to be outside the routing domain because D uses a different IP prefix from the PAN). The LoWPAN encapsulated Packet, originated at router S, is created from the IPv6 packet as specified in [RFC4944]. Then, the Mesh Addressing header and the DFF header (as specified in Section 13.2.2) are added to the LoWPAN encapsulation on router S. The Originator Address is set to S and the Destination Address is set to R, which is a known border router of the PAN. The Packet is then forwarded using this specification. When router R receives the Packet, it restores the IPv6 packet from the LoWPAN encapsulated Packet and forwards it to D, using normal IPv6 forwarding as specified in [RFC2460].
In Figure 6, the source of the traffic (S) is outside of the routing domain, and the destination (D) is inside of the routing domain. The IPv6 packet, originated at S, is forwarded to R using normal IPv6 forwarding as specified in [RFC2460]. Router R (which is a known border router to the PAN) creates the LoWPAN encapsulated Packet from the IPv6 packet as specified in [RFC4944]. Then, R adds the Mesh Addressing header and the DFF header (as specified in Section 13.2.2). The Originator Address is set to R, the Destination Address to D, the sequence number in the DFF header is generated locally on R. The Packet is forwarded to D using this specification. When router D receives the Packet, it restores the IPv6 packet from the LoWPAN encapsulated Packet and processes the payload in upper layers.
As LoWPANs are typically no transit networks, this case is discouraged, but described nevertheless for completeness: In Figure 7, both the source of the traffic (S) and the destination (D) are outside of the routing domain. The IPv6 packet, originated at S, is forwarded to R1 using normal IPv6 forwarding as specified in [RFC2460]. Router R1 (which is a known border router of the PAN) creates the LoWPAN encapsulated Packet from the IPv6 Packet as specified in [RFC4944]. Then, it adds the Mesh Addressing header and the DFF header (as specified in Section 13.2.2). The Originator Address is set to R1, the Destination Address to R2 (which is another border router towards the Destination), the sequence number in the DFF header is generated locally on R1. The Packet is forwarded to R2 using this specification. When router R2 receives the Packet, it restores the IPv6 packet from the LoWPAN encapsulated Packet and forwards the IPv6 packet to D, using normal IPv6 forwarding as specified in [RFC2460].
Herberg, et al. Expires November 8, 2013 [Page 31]

Internet-Draft DFF May 2013
15. MTU Exceedance
When adding the DFF header as specified in Section 9.1 or when encapsulating the Packet as specified in Section 14, the Packet size may exceed the MTU. This is described in Section 5 of [RFC2460]. When the Packet size of a Packet to be forwarded by DFF exceeds the MTU, the following steps are executed:
1. The router MUST discard the Packet.
2. The router MAY log the event locally (depending on the storage capabilities of the router).
3. The router MUST send back an ICMP Packet Too Big to the source of the Packet reporting back the Next Hop MTU considering the additional overhead of adding the headers.
16. Security Considerations
Based on the recommendations in [RFC3552], this section describes security threats to DFF, lists which attacks are out of scope, which attacks DFF is susceptible to, and which attacks DFF protects against.
16.1. Attacks Out of Scope
As DFF is a data forwarding protocol, any security issues concerning the payload of the Packets are not considered in this section.
It is the responsibility of upper layers to use appropriate security mechanisms (IPsec, TLS, ...) according to application requirements. As DFF does not modify the contents of IP datagrams, other than the DFF header (which is a Hop-by-Hop Options extension header in the "route-over" MoP, and therefore not protected by IPsec), no special considerations for IPsec have to be addressed.
Any attack that is not specific to DFF, but that applies in general to the link layer (e.g., wireless, PLC), is out of scope. In particular, these attacks are: Eavesdropping, Packet insertion, Packet replaying, Packet deletion, and man-in-the-middle attacks. Appropriate link-layer encryption can mitigate part of these attacks and is therefore RECOMMENDED.
16.2. Protection Mechanisms of DFF
DFF itself does not provide any additional integrity, confidentiality or authentication. Therefore, the level of protection of DFF depends
Herberg, et al. Expires November 8, 2013 [Page 32]

Internet-Draft DFF May 2013
on the underlying link layer security as well as protection of the payload by upper layer security (e.g., IPsec).
In the following sections, whenever encrypting or digitally signing Packets is suggested for protecting DFF, it is assumed that routers are not compromised.
16.3. Attacks In Scope
This section discusses security threats to DFF, and for each describes whether (and how) DFF is affected by the threat. DFF is designed to be used in lossy and unreliable networks. Predominant examples of lossy networks are wireless networks, where routers send Packets via broadcast. The attacks listed below are easier to exploit in wireless media, but can also be observed in wired networks.
16.3.1. Denial of Service
Denial of Service attacks are possible when using DFF by either exceeding the storage on a router, or by exceeding the available bandwidth of the channel. As DFF does not contain any algorithms with high complexity, it is unlikely that the processing power of the router could be exhausted by an attack on DFF.
The storage of a router can be exhausted by increasing the size of the Processed Set, i.e., by adding new tuples, or by increasing the size of each tuple. New tuples can be added by injecting new Packets in the network, or by forwarding overheard Packets.
Another possible DoS attack is to send Packets to a non-existing Address in the network. DFF would perform a depth-first search until the Hop Limit has reached zero. Is is therefore RECOMMENDED to set the Hop Limit to a value that limits the path length.
If security provided by the link layer is used, this attack can be mitigated if the malicious router does not possess valid credentials, since other routers would not forward data through the malicious router.
16.3.2. Packet Header Modification
The following attacks can be exploited by modifying the Packet Header information, unless additional security (such as link layer security) is used:
Herberg, et al. Expires November 8, 2013 [Page 33]

Internet-Draft DFF May 2013
16.3.2.1. Return Flag Tampering
A malicious router may tamper the "return" flag of a DFF Packet, and send it back to the previous hop, but only if that router had been selected as next hop by the receiving router before (as specified in Section 9.2). If the malicious router had not been selected as next hop, then a returned Packet is dropped by the receiving router. If, otherwise, the malicious router had been selected as next hop by the receiving router, and the malicious router has set the return flag, the receiving router would then try alternative neighbors. This may lead to Packets never reaching their Destination, as well as unnecessary depth-first search in the network (bandwidth exhaustion / energy drain).
This attack can be mitigated by using appropriate security of the underlying link layer.
16.3.2.2. Duplicate Flag Tampering
A malicious router may modify the Duplicate Flag of a Packet that it forwards.
If it changes the flag from 0 to 1, the Packet would be detected as duplicate by other routers in the network and not as looping packet.
If the Duplicate Flag is set from 1 to 0, and a router receives that Packet for the second time (i.e., it has already received a Packet with the same Originator Address and sequence number before), it will wrongly detect a loop.
This attack can be mitigated by using appropriate security of the underlying link layer.
16.3.2.3. Sequence Number Tampering
A malicious router may modify the sequence number of a Packet that it forwards.
In particular, if the sequence number is modified to a number of another, previously sent, Packet of the same Originator, this Packet may wrongly be perceived as looping packet.
This attack can be mitigated by using appropriate security of the underlying link layer.
Herberg, et al. Expires November 8, 2013 [Page 34]

Internet-Draft DFF May 2013
17. IANA Considerations
IANA is requested to allocate a value from the Dispatch Type Field registry for LOWPAN_DFF.
IANA is requested to allocate a value from the Destination Options and Hop-by-Hop Options registry for IP_DFF. The first three bits of that value MUST be 111.
18. Acknowledgements
Jari Arkko (Ericsson), Antonin Bas (Ecole Polytechnique), Thomas Clausen (Ecole Polytechnifque), Yuichi Igarashi (Hitachi), Kazuya Monden (Hitachi), Geoff Mulligan (Proto6), Hiroki Satoh (Hitachi), Ganesh Venkatesh (Mobelitix), and Jiazi Yi (Ecole Polytechnique) provided useful reviews of the draft and discussions which helped to improve this document.
The authors also would like to thank Ralph Droms, Adrian Farrel, Stephen Farrell, Ted Lemon, Alvaro Retana, Dan Romascanu, and Martin Stiemerling for their reviews during IETF LC and IESG evaluation.
19. References
19.1. Normative References
[RFC2119] Bradner, S., "Key words for use in RFCs to Indicate Requirement Levels", BCP 14, RFC 2119, March 1997.
[RFC2460] Deering, S. and R. Hinden, "Internet Protocol, Version 6 (IPv6) Specification", RFC 2460, December 1998.
[RFC2473] Conta, A. and S. Deering, "Generic Packet Tunneling in IPv6 Specification", RFC 2473, December 1998.
[RFC4291] Hinden, R. and S. Deering, "IP Version 6 Addressing Architecture", RFC 4291, February 2006.
[RFC4944] Montenegro, G., Kushalnagar, N., Hui, J., and D. Culler, "Transmission of IPv6 Packets over IEEE 802.15.4 Networks", RFC 4944, September 2007.
[RFC6130] Clausen, T., Dearlove, C., and J. Dean, "Mobile Ad Hoc Network (MANET) Neighborhood Discovery Protocol (NHDP)", RFC 6130, April 2011.
Herberg, et al. Expires November 8, 2013 [Page 35]

Internet-Draft DFF May 2013
[RFC6564] Krishnan, S., Woodyatt, J., Kline, E., Hoagland, J., and M. Bhatia, "A Uniform Format for IPv6 Extension Headers", RFC 6564, April 2012.
[RFC6724] Thaler, D., Draves, R., Matsumoto, A., and T. Chown, "Default Address Selection for Internet Protocol Version 6 (IPv6)", RFC 6724, September 2012.
19.2. Informative References
[DFF_paper1] Cespedes, S., Cardenas, A., and T. Iwao, "Comparison of Data Forwarding Mechanisms for AMI Networks", 2012 IEEE Innovative Smart Grid Technologies Conference (ISGT), January 2012.
[DFF_paper2] Iwao, T., Iwao, T., Yura, M., Nakaya, Y., Cardenas, A., Lee, S., and R. Masuoka, "Dynamic Data Forwarding in Wireless Mesh Networks", First IEEE International Conference on Smart Grid Communications (SmartGridComm), October 2010.
[DFS_wikipedia] "Dynamic Data Forwarding in Wireless Mesh Networks", http ://en.wikipedia.org/w/ index.php?title=Depth-first_search&oldid=549733112, March 2013.
[KCEC_press_release] Kit Carson Electric Cooperative (KCEC), "DFF deployed by KCEC (Press Release)", http://www.kitcarson.com/ index.php?option=com_content&view=article&id=45&Itemid=1, 2011.
[RFC3552] Rescorla, E. and B. Korver, "Guidelines for Writing RFC Text on Security Considerations", BCP 72, RFC 3552, July 2003.
[RFC4861] Narten, T., Nordmark, E., Simpson, W., and H. Soliman, "Neighbor Discovery for IP version 6 (IPv6)", RFC 4861, September 2007.
[RFC6775] Shelby, Z., Chakrabarti, S., Nordmark, E., and C. Bormann, "Neighbor Discovery Optimization for IPv6 over Low-Power Wireless Personal Area Networks (6LoWPANs)", RFC 6775, November 2012.
Herberg, et al. Expires November 8, 2013 [Page 36]

Internet-Draft DFF May 2013
Appendix A. Examples
In this section, some example network topologies are depicted, using the DFF mechanism for data forwarding. In these examples, it is assumed that a routing protocol is running which adds or inserts entries into the RIB.
A.1. Example 1: Normal Delivery
Figure 8 depicts a network topology with seven routers A to G, with links between them as indicated by lines. It is assumed that router A sends a Packet to G, through B and D, according to the routing protocol.
+---+ +---+ D +-----+ | +---+ | +---+ | | +---+ B +---+ | | +---+ | | +-+-+ | +---+ +-+-+ | A | +---+ E +---+ G + +-+-+ +---+ +-+-+ | +---+ | +---+ C +---+ | +---+ | | | +---+ | +---+ F +-----+ +---+
Figure 8: Example 1: normal delivery
If no link fails in this topology, and no loop occurs, then DFF forward the Packet along the Next Hops listed in each of the routers RIB along the path towards the destination. Each router adds a Processed Tuple for the incoming Packet, and selects the Next Hop as specified in Section 11, i.e., it will first select the next hop for router G as determined by the routing protocol.
A.2. Example 2: Forwarding with Link Failure
Figure 9 depicts the same topology as the Example 1, but both links between B and D and between B and E are unavailable (e.g., because of wireless link characteristics).
Herberg, et al. Expires November 8, 2013 [Page 37]

Internet-Draft DFF May 2013
+---+ XXX-+ D +-----+ X +---+ | +---+ X | +---+ B +---+ | | +---+ X | +-+-+ X +---+ +-+-+ | A | XXXX+ E +---+ G + +-+-+ +---+ +-+-+ | +---+ | +---+ C +---+ | +---+ | | | +---+ | +---+ F +-----+ +---+
Figure 9: Example 2: link failure
When B receives the Packet from router A, it adds a Processed Tuple, and then tries to forward the Packet to D. Once B detects that the Packet cannot be successfully delivered to D because it does not receive link layer ACKs, it will follow the procedures listed in Section 10, by setting the DUP flag to 1, selecting E as new next hop, adding E to the list of next hops in the Processed Tuple, and then forwarding the Packet to E.
As the link to E also fails, B will again follow the procedure in Section 10. As all possible next hops (D and E) are listed in the Processed Tuple, B will set the RET flag in the Packet and return it to A.
A determines that it already has a Processed Tuple for the returned Packet, reset the RET flag of the Packet and select a new next hop for the Packet. As B is already in the list of next hops in the Processed Tuple, it will select C as next hop and forward the Packet to it. C will then forward the Packet to F, and F delivers the Packet to its Destination G.
A.3. Example 3: Forwarding with Missed Link Layer Acknowledgment
Figure 10 depicts the same topology as the Example 1, but the link layer acknowledgments from C to A are lost (e.g., because the link is uni-directional). It is assumed that A prefers a path to G through C and F.
Herberg, et al. Expires November 8, 2013 [Page 38]

Internet-Draft DFF May 2013
+---+ +---+ D +-----+ | +---+ | +---+ | | +---+ B +---+ | | +---+ | | +-+-+ | +---+ +-+-+ | A | +---+ E +---+ G + +-+-+ +---+ +-+-+ . +---+ | +...+ C +---+ | +---+ | | | +---+ | +---+ F +-----+ +---+
Figure 10: Example 3: missed link layer acknowledgment
While C successfully receives the Packet from A, A does not receive the L2 ACK and assumes the Packet has not been delivered to C. Therefore, it sets the DUP flag of the Packet to 1, in order to indicate that this Packet may be a duplicate. Then, it forwards the Packet to B.
A.4. Example 4: Forwarding with a Loop
Figure 11 depicts the same topology as the Example 1, but there is a loop from D to A, and A sends the Packet to G through B and D.
+-----------------+ | | | +-+-+ | +---+ D + | | +---+ \|/ +---+ | +---+ B +---+ | +---+ | +-+-+ | +---+ +-+-+ | A | +---+ E +---+ G + +-+-+ +---+ +-+-+ | +---+ | +---+ C +---+ | +---+ | | | +---+ | +---+ F +-----+ +---+
Figure 11: Example 4: loop
Herberg, et al. Expires November 8, 2013 [Page 39]

Internet-Draft DFF May 2013
When A receives the Packet through the loop from D, it will find a Processed Tuple for the Packet. Router A will set the RET flag and return the Packet to D, which in turn will return it to B. B will then select E as next hop, which will then forward it to G.
Appendix B. Deployment Experience
DFF has been deployed and experimented with both in real deployments and in network simulations, as described in the following.
B.1. Deployments in Japan
The majority of the large Advanced Metering Infrastructure (AMI) deployments using DFF are located in Japan, but the data of these networks is property of Japanese utilities and cannot be disclosed.
B.2. Kit Carson Electric Cooperative
DFF has been deployed at Kit Carson Electric Cooperative (KCEC), a non-profit organization distributing electricity to about 30,000 customers in New Mexico. As described in a press release [KCEC_press_release], DFF is running on currently about 2000 electric meters. All meters are connected through a mesh network using an unreliable, wireless medium. DFF is used together with a distance vector routing protocol. Metering data from each meter is sent towards a gateway periodically every 15 minutes. The data delivery reliability is over 99%.
B.3. Simulations
DFF has been evaluated in Ns2 and OMNEST simulations, in conjunction with a distance vector routing protocol. The performance of DFF has been compared to using only the routing protocol without DFF. The results published in peer-reviewed academic papers ([DFF_paper1][DFF_paper2]) show significant improvements of the Packet delivery ratio compared to using only the distance vector protocol.
B.4. Open Source Implementation
Fujitsu Laboratories of America is currently working on an open source implementation of DFF, which is to be released in early 2013, and which allows for interoperability testings of different DFF implementations. The implementation is written in Java, and can be used both on real machines and in the Ns2 simulator.
Herberg, et al. Expires November 8, 2013 [Page 40]

Internet-Draft DFF May 2013
Authors’ Addresses
Ulrich Herberg (editor) Fujitsu 1240 E. Arques Avenue, M/S 345 Sunnyvale, CA 94085 US
Phone: +1 408 530-4528 Email: [email protected]
Alvaro A. Cardenas University of Texas at Dallas School of Computer Science, 800 West Campbell Rd, EC 31 Richardson, TX 75080-3021 US
Email: [email protected]
Tadashige Iwao Fujitsu Shiodome City Center, 5-2, Higashi-shimbashi 1-chome, Minato-ku Tokyo, JP
Phone: +81-44-754-3343 Email: [email protected]
Michael L. Dow Freescale 6501 William Cannon Drive West Austin, TX 78735 USA
Phone: +1 512 895 4944 Email: [email protected]
Herberg, et al. Expires November 8, 2013 [Page 41]

Internet-Draft DFF May 2013
Sandra L. Cespedes U. Icesi Calle 18 No. 122-135 Pance Cali, Valle Colombia
Phone: Email: [email protected]
Herberg, et al. Expires November 8, 2013 [Page 42]


Routing Area Working Group G. Enyedi, Ed.Internet-Draft A. CsaszarIntended status: Informational EricssonExpires: April 24, 2014 A. Atlas, Ed. C. Bowers Juniper Networks A. Gopalan University of Arizona October 21, 2013
Algorithms for computing Maximally Redundant Trees for IP/LDP Fast- Reroute draft-enyedi-rtgwg-mrt-frr-algorithm-04
Abstract
A complete solution for IP and LDP Fast-Reroute using Maximally Redundant Trees is presented in [I-D.ietf-rtgwg-mrt-frr- architecture]. This document defines the associated MRT Lowpoint algorithm that is used in the default MRT profile to compute both the necessary Maximally Redundant Trees with their associated next-hops and the alternates to select for MRT-FRR.
Status of This Memo
This Internet-Draft is submitted in full conformance with the provisions of BCP 78 and BCP 79.
Internet-Drafts are working documents of the Internet Engineering Task Force (IETF). Note that other groups may also distribute working documents as Internet-Drafts. The list of current Internet- Drafts is at http://datatracker.ietf.org/drafts/current/.
Internet-Drafts are draft documents valid for a maximum of six months and may be updated, replaced, or obsoleted by other documents at any time. It is inappropriate to use Internet-Drafts as reference material or to cite them other than as "work in progress."
This Internet-Draft will expire on April 24, 2014.
Copyright Notice
Copyright (c) 2013 IETF Trust and the persons identified as the document authors. All rights reserved.
This document is subject to BCP 78 and the IETF Trust’s Legal Provisions Relating to IETF Documents
Enyedi, et al. Expires April 24, 2014 [Page 1]

Internet-Draft MRT FRR Algorithm October 2013
(http://trustee.ietf.org/license-info) in effect on the date of publication of this document. Please review these documents carefully, as they describe your rights and restrictions with respect to this document. Code Components extracted from this document must include Simplified BSD License text as described in Section 4.e of the Trust Legal Provisions and are provided without warranty as described in the Simplified BSD License.
Table of Contents
1. Introduction . . . . . . . . . . . . . . . . . . . . . . . . 3 2. Terminology and Definitions . . . . . . . . . . . . . . . . . 4 3. Algorithm Key Concepts . . . . . . . . . . . . . . . . . . . 6 3.1. Partial Ordering for Disjoint Paths . . . . . . . . . . . 6 3.2. Finding an Ear and the Correct Direction . . . . . . . . 8 3.3. Low-Point Values and Their Uses . . . . . . . . . . . . . 11 3.4. Blocks in a Graph . . . . . . . . . . . . . . . . . . . . 13 3.5. Determining Local-Root and Assigning Block-ID . . . . . . 15 4. Algorithm Sections . . . . . . . . . . . . . . . . . . . . . 16 4.1. MRT Island Identification . . . . . . . . . . . . . . . . 17 4.2. Root Selection . . . . . . . . . . . . . . . . . . . . . 18 4.3. Initialization . . . . . . . . . . . . . . . . . . . . . 18 4.4. MRT Lowpoint Algorithm: Computing GADAG using lowpoint inheritance . . . . . . . . . . . . . . . . . . . . . . . 19 4.5. Augmenting the GADAG by directing all links . . . . . . . 21 4.6. Compute MRT next-hops . . . . . . . . . . . . . . . . . . 23 4.6.1. MRT next-hops to all nodes partially ordered with respect to the computing node . . . . . . . . . . . . 24 4.6.2. MRT next-hops to all nodes not partially ordered with respect to the computing node . . . . . . . . . . . . 24 4.6.3. Computing Redundant Tree next-hops in a 2-connected Graph . . . . . . . . . . . . . . . . . . . . . . . . 25 4.6.4. Generalizing for graph that isn’t 2-connected . . . . 27 4.6.5. Complete Algorithm to Compute MRT Next-Hops . . . . . 28 4.7. Identify MRT alternates . . . . . . . . . . . . . . . . . 30 4.8. Finding FRR Next-Hops for Proxy-Nodes . . . . . . . . . . 34 5. MRT Lowpoint Algorithm: Complete Specification . . . . . . . 36 6. Algorithm Alternatives and Evaluation . . . . . . . . . . . . 37 6.1. Algorithm Evaluation . . . . . . . . . . . . . . . . . . 37 7. Algorithm Work to Be Done . . . . . . . . . . . . . . . . . . 47 8. IANA Considerations . . . . . . . . . . . . . . . . . . . . . 47 9. Security Considerations . . . . . . . . . . . . . . . . . . . 47 10. References . . . . . . . . . . . . . . . . . . . . . . . . . 47 10.1. Normative References . . . . . . . . . . . . . . . . . . 47 10.2. Informative References . . . . . . . . . . . . . . . . . 47 Appendix A. Option 2: Computing GADAG using SPFs . . . . . . . . 49 Appendix B. Option 3: Computing GADAG using a hybrid method . . 53 Authors’ Addresses . . . . . . . . . . . . . . . . . . . . . . . 55
Enyedi, et al. Expires April 24, 2014 [Page 2]

Internet-Draft MRT FRR Algorithm October 2013
1. Introduction
MRT Fast-Reroute requires that packets can be forwarded not only on the shortest-path tree, but also on two Maximally Redundant Trees (MRTs), referred to as the MRT-Blue and the MRT-Red. A router which experiences a local failure must also have pre-determined which alternate to use. This document defines how to compute these three things for use in MRT-FRR and describes the algorithm design decisions and rationale. The algorithm is based on those presented in [MRTLinear] and expanded in [EnyediThesis].
Just as packets routed on a hop-by-hop basis require that each router compute a shortest-path tree which is consistent, it is necessary for each router to compute the MRT-Blue next-hops and MRT-Red next-hops in a consistent fashion. This document defines the MRT Lowpoint algorithm to be used as a standard in the default MRT profile for MRT-FRR.
As now, a router’s FIB will contain primary next-hops for the current shortest-path tree for forwarding traffic. In addition, a router’s FIB will contain primary next-hops for the MRT-Blue for forwarding received traffic on the MRT-Blue and primary next-hops for the MRT- Red for forwarding received traffic on the MRT-Red.
What alternate next-hops a point-of-local-repair (PLR) selects need not be consistent - but loops must be prevented. To reduce congestion, it is possible for multiple alternate next-hops to be selected; in the context of MRT alternates, each of those alternate next-hops would be equal-cost paths.
This document defines an algorithm for selecting an appropriate MRT alternate for consideration. Other alternates, e.g. LFAs that are downstream paths, may be prefered when available and that policy- based alternate selection process[I-D.ietf-rtgwg-lfa-manageability] is not captured in this document.
[E]---[D]---| [E]<--[D]<--| [E]-->[D] | | | | ^ | | | | | V | | V [R] [F] [C] [R] [F] [C] [R] [F] [C] | | | ^ ^ | | | | | | | V | [A]---[B]---| [A]-->[B] [A]---[B]<--|
(a) (b) (c) a 2-connected graph MRT-Blue towards R MRT-Red towards R
Figure 1
Enyedi, et al. Expires April 24, 2014 [Page 3]

Internet-Draft MRT FRR Algorithm October 2013
Algorithms for computing MRTs can handle arbitrary network topologies where the whole network graph is not 2-connected, as in Figure 2, as well as the easier case where the network graph is 2-connected (Figure 1). Each MRT is a spanning tree. The pair of MRTs provide two paths from every node X to the root of the MRTs. Those paths share the minimum number of nodes and the minimum number of links. Each such shared node is a cut-vertex. Any shared links are cut- links.
[E]---[D]---| |---[J] | | | | | | | | | | [R] [F] [C]---[G] | | | | | | | | | | | [A]---[B]---| |---[H]
(a) a graph that isn’t 2-connected
[E]<--[D]<--| [J] [E]-->[D]---| |---[J] | ^ | | | | | ^ V | | | V V V | [R] [F] [C]<--[G] | [R] [F] [C]<--[G] | ^ ^ ^ | ^ | | | | | | V | V | | [A]-->[B]---| |---[H] [A]<--[B]<--| [H]
(b) MRT-Blue towards R (c) MRT-Red towards R
Figure 2
2. Terminology and Definitions
network graph: A graph that reflects the network topology where all links connect exactly two nodes and broadcast links have been transformed into the standard pseudo-node representation.
Redundant Trees (RT): A pair of trees where the path from any node X to the root R on the first tree is node-disjoint with the path from the same node X to the root along the second tree. These can be computed in 2-connected graphs.
Maximally Redundant Trees (MRT): A pair of trees where the path from any node X to the root R along the first tree and the path from the same node X to the root along the second tree share the minimum number of nodes and the minimum number of links. Each such shared node is a cut-vertex. Any shared links are cut-links. Any RT is an MRT but many MRTs are not RTs.
Enyedi, et al. Expires April 24, 2014 [Page 4]

Internet-Draft MRT FRR Algorithm October 2013
MRT-Red: MRT-Red is used to describe one of the two MRTs; it is used to described the associated forwarding topology and MT-ID. Specifically, MRT-Red is the decreasing MRT where links in the GADAG are taken in the direction from a higher topologically ordered node to a lower one.
MRT-Blue: MRT-Blue is used to describe one of the two MRTs; it is used to described the associated forwarding topology and MT-ID. Specifically, MRT-Blue is the increasing MRT where links in the GADAG are taken in the direction from a lower topologically ordered node to a higher one.
cut-vertex: A vertex whose removal partitions the network.
cut-link: A link whose removal partitions the network. A cut-link by definition must be connected between two cut-vertices. If there are multiple parallel links, then they are referred to as cut-links in this document if removing the set of parallel links would partition the network.
2-connected: A graph that has no cut-vertices. This is a graph that requires two nodes to be removed before the network is partitioned.
spanning tree: A tree containing links that connects all nodes in the network graph.
back-edge: In the context of a spanning tree computed via a depth- first search, a back-edge is a link that connects a descendant of a node x with an ancestor of x.
2-connected cluster: A maximal set of nodes that are 2-connected. In a network graph with at least one cut-vertex, there will be multiple 2-connected clusters.
block: Either a 2-connected cluster, a cut-edge, or an isolated vertex.
DAG: Directed Acyclic Graph - a digraph containing no directed cycle.
ADAG: Almost Directed Acyclic Graph - a digraph that can be transformed into a DAG whith removing a single node (the root node).
GADAG: Generalized ADAG - a digraph, which has only ADAGs as all of its blocks. The root of such a block is the node closest to the global root (e.g. with uniform link costs).
Enyedi, et al. Expires April 24, 2014 [Page 5]

Internet-Draft MRT FRR Algorithm October 2013
DFS: Depth-First Search
DFS ancestor: A node n is a DFS ancestor of x if n is on the DFS- tree path from the DFS root to x.
DFS descendant: A node n is a DFS descendant of x if x is on the DFS-tree path from the DFS root to n.
ear: A path along not-yet-included-in-the-GADAG nodes that starts at a node that is already-included-in-the-GADAG and that ends at a node that is already-included-in-the-GADAG. The starting and ending nodes may be the same node if it is a cut-vertex.
X >> Y or Y << X: Indicates the relationship between X and Y in a partial order, such as found in a GADAG. X >> Y means that X is higher in the partial order than Y. Y << X means that Y is lower in the partial order than X.
X > Y or Y < X: Indicates the relationship between X and Y in the total order, such as found via a topological sort. X > Y means that X is higher in the total order than Y. Y < X means that Y is lower in the total order than X.
proxy-node: A node added to the network graph to represent a multi- homed prefix or routers outside the local MRT-fast-reroute- supporting island of routers. The key property of proxy-nodes is that traffic cannot transit them.
3. Algorithm Key Concepts
There are five key concepts that are critical for understanding the MRT Lowpoint algorithm and other algorithms for computing MRTs. The first is the idea of partially ordering the nodes in a network graph with regard to each other and to the GADAG root. The second is the idea of finding an ear of nodes and adding them in the correct direction. The third is the idea of a Low-Point value and how it can be used to identify cut-vertices and to find a second path towards the root. The fourth is the idea that a non-2-connected graph is made up of blocks, where a block is a 2-connected cluster, a cut-edge or an isolated node. The fifth is the idea of a local-root for each node; this is used to compute ADAGs in each block.
3.1. Partial Ordering for Disjoint Paths
Given any two nodes X and Y in a graph, a particular total order means that either X < Y or X > Y in that total order. An example would be a graph where the nodes are ranked based upon their unique IP loopback addresses. In a partial order, there may be some nodes
Enyedi, et al. Expires April 24, 2014 [Page 6]

Internet-Draft MRT FRR Algorithm October 2013
for which it can’t be determined whether X << Y or X >> Y. A partial order can be captured in a directed graph, as shown in Figure 3. In a graphical representation, a link directed from X to Y indicates that X is a neighbor of Y in the network graph and X << Y.
[A]<---[R] [E] R << A << B << C << D << E | ^ R << A << B << F << G << H << D << E | | V | Unspecified Relationships: [B]--->[C]--->[D] C and F | ^ C and G | | C and H V | [F]--->[G]--->[H]
Figure 3: Directed Graph showing a Partial Order
To compute MRTs, the root of the MRTs is at both the very bottom and the very top of the partial ordering. This means that from any node X, one can pick nodes higher in the order until the root is reached. Similarly, from any node X, one can pick nodes lower in the order until the root is reached. For instance, in Figure 4, from G the higher nodes picked can be traced by following the directed links and are H, D, E and R. Similarly, from G the lower nodes picked can be traced by reversing the directed links and are F, B, A, and R. A graph that represents this modified partial order is no longer a DAG; it is termed an Almost DAG (ADAG) because if the links directed to the root were removed, it would be a DAG.
[A]<---[R]<---[E] R << A << B << C << R | ^ ^ R << A << B << C << D << E << R | | | R << A << B << F << G << H << D << E << R V | | [B]--->[C]--->[D] Unspecified Relationships: | ^ C and F | | C and G V | C and H [F]--->[G]--->[H]
Figure 4: ADAG showing a Partial Order with R lowest and highest
Enyedi, et al. Expires April 24, 2014 [Page 7]

Internet-Draft MRT FRR Algorithm October 2013
Most importantly, if a node Y >> X, then Y can only appear on the increasing path from X to the root and never on the decreasing path. Similarly, if a node Z << X, then Z can only appear on the decreasing path from X to the root and never on the inceasing path.
When following the increasing paths, it is possible to pick multiple higher nodes and still have the certainty that those paths will be disjoint from the decreasing paths. E.g. in the previous example node B has multiple possibilities to forward packets along an increasing path: it can either forward packets to C or F.
3.2. Finding an Ear and the Correct Direction
For simplicity, the basic idea of creating a GADAG by adding ears is described assuming that the network graph is a single 2-connected cluster so that an ADAG is sufficient. Generalizing to multiple blocks is done by considering the block-roots instead of the GADAG root - and the actual algorithm is given in Section 4.4.
In order to understand the basic idea of finding an ADAG, first suppose that we have already a partial ADAG, which doesn’t contain all the nodes in the block yet, and we want to extend it to cover all the nodes. Suppose that we find a path from a node X to Y such that X and Y are already contained by our partial ADAG, but all the remaining nodes along the path are not added to the ADAG yet. We refer to such a path as an ear.
Recall that our ADAG is closely related to a partial order, more precisely, if we remove root R, the remaining DAG describes a partial order of the nodes. If we suppose that neither X nor Y is the root, we may be able to compare them. If one of them is definitely lesser with respect to our partial order (say X<<Y), we can add the new path to the ADAG in a direction from X to Y. As an example consider Figure 5.
E---D---| E<--D---| E<--D<--| | | | | ^ | | ^ | | | | V | | V | | R F C R F C R F C | | | | ^ | | ^ ^ | | | V | | V | | A---B---| A-->B---| A-->B---|
(a) (b) (c)
(a) A 2-connected graph (b) Partial ADAG (C is not included) (c) Resulting ADAG after adding path (or ear) B-C-D
Enyedi, et al. Expires April 24, 2014 [Page 8]

Internet-Draft MRT FRR Algorithm October 2013
Figure 5
In this partial ADAG, node C is not yet included. However, we can find path B-C-D, where both endpoints are contained by this partial ADAG (we say those nodes are *ready* in the sequel), and the remaining node (node C) is not contained yet. If we remove R, the remaining DAG defines a partial order, and with respect to this partial order we can say that B<<D, so we can add the path to the ADAG in the direction from B to D (arcs B->C and C->D are added). If B were strictly greater than D, we would add the same path in reverse direction.
If in the partial order where an ear’s two ends are X and Y, X << Y, then there must already be a directed path from X to Y already in the ADAG. The ear must be added in a direction such that it doesn’t create a cycle; therefore the ear must go from X to Y.
In the case, when X and Y are not ordered with each other, we can select either direction for the ear. We have no restriction since neither of the directions can result in a cycle. In the corner case when one of the endpoints of an ear, say X, is the root (recall that the two endpoints must be different), we could use both directions again for the ear because the root can be considered both as smaller and as greater than Y. However, we strictly pick that direction in which the root is lower than Y. The logic for this decision is explained in Section 4.6
A partial ADAG is started by finding a cycle from the root R back to itself. This can be done by selecting a non-ready neighbor N of R and then finding a path from N to R that doesn’t use any links between R and N. The direction of the cycle can be assigned either way since it is starting the ordering.
Once a partial ADAG is already present, we can always add ears to it: just select a non-ready neighbor N of a ready node Q, such that Q is not the root, find a path from N to the root in the graph with Q removed. This path is an ear where the first node of the ear is Q, the next is N, then the path until the first ready node the path reached (that second ready node is the other endpoint of the path). Since the graph is 2-connected, there must be a path from N to R without Q.
Enyedi, et al. Expires April 24, 2014 [Page 9]

Internet-Draft MRT FRR Algorithm October 2013
It is always possible to select a non-ready neighbor N of a ready node Q so that Q is not the root R. Because the network is 2-connected, N must be connected to two different nodes and only one can be R. Because the initial cycle has already been added to the ADAG, there are ready nodes that are not R. Since the graph is 2-connected, while there are non-ready nodes, there must be a non- ready neighbor N of a ready node that is not R.
Generic_Find_Ears_ADAG(root) Create an empty ADAG. Add root to the ADAG. Mark root as IN_GADAG. Select an arbitrary cycle containing root. Add the arbitrary cycle to the ADAG. Mark cycle’s nodes as IN_GADAG. Add cycle’s non-root nodes to process_list. while there exists connected nodes in graph that are not IN_GADAG Select a new ear. Let its endpoints be X and Y. if Y is root or (Y << X) add the ear towards X to the ADAG else // (a) X is root or (b)X << Y or (c) X, Y not ordered Add the ear towards Y to the ADAG
Figure 6: Generic Algorithm to find ears and their direction in 2-connected graph
Algorithm Figure 6 merely requires that a cycle or ear be selected without specifying how. Regardless of the way of selecting the path, we will get an ADAG. The method used for finding and selecting the ears is important; shorter ears result in shorter paths along the MRTs. The MRT Lowpoint algorithm’s method using Low-Point Inheritance is defined in Section 4.4. Other methods are described in the Appendices (Appendix A and Appendix B).
As an example, consider Figure 5 again. First, we select the shortest cycle containing R, which can be R-A-B-F-D-E (uniform link costs were assumed), so we get to the situation depicted in Figure 5 (b). Finally, we find a node next to a ready node; that must be node C and assume we reached it from ready node B. We search a path from C to R without B in the original graph. The first ready node along this is node D, so the open ear is B-C-D. Since B<<D, we add arc B->C and C->D to the ADAG. Since all the nodes are ready, we stop at this point.
Enyedi, et al. Expires April 24, 2014 [Page 10]

Internet-Draft MRT FRR Algorithm October 2013
3.3. Low-Point Values and Their Uses
A basic way of computing a spanning tree on a network graph is to run a depth-first-search, such as given in Figure 7. This tree has the important property that if there is a link (x, n), then either n is a DFS ancestor of x or n is a DFS descendant of x. In other words, either n is on the path from the root to x or x is on the path from the root to n.
global_variable: dfs_number
DFS_Visit(node x, node parent) D(x) = dfs_number dfs_number += 1 x.dfs_parent = parent for each link (x, w) if D(w) is not set DFS_Visit(w, x)
Run_DFS(node root) dfs_number = 0 DFS_Visit(root, NONE)
Figure 7: Basic Depth-First Search algorithm
Given a node x, one can compute the minimal DFS number of the neighbours of x, i.e. min( D(w) if (x,w) is a link). This gives the highest attachment point neighbouring x. What is interesting, though, is what is the highest attachment point from x and x’s descendants. This is what is determined by computing the Low-Point value, as given in Algorithm Figure 9 and illustrated on a graph in Figure 8.
[E]---| [J]-------[I] [P]---[O] | | | | | | | | | | | | [R] [D]---[C]--[F] [H]---[K] [N] | | | | | | | | | | | | [A]--------[B] [G]---| [L]---[M]
(a) a non-2-connected graph
[E]----| [J]---------[I] [P]------[O] (5, ) | (10, ) (9, ) (16, ) (15, ) | | | | | | | | | | | | [R] [D]---[C]---[F] [H]----[K] [N]
Enyedi, et al. Expires April 24, 2014 [Page 11]

Internet-Draft MRT FRR Algorithm October 2013
(0, ) (4, ) (3, ) (6, ) (8, ) (11, ) (14, ) | | | | | | | | | | | | [A]---------[B] [G]----| [L]------[M] (1, ) (2, ) (7, ) (12, ) (13, )
(b) with DFS values assigned (D(x), L(x))
[E]----| [J]---------[I] [P]------[O] (5,0) | (10,3) (9,3) (16,11) (15,11) | | | | | | | | | | | | [R] [D]---[C]---[F] [H]----[K] [N] (0, ) (4,0) (3,0) (6,3) (8,3) (11,11) (14,11) | | | | | | | | | | | | [A]---------[B] [G]----| [L]------[M] (1,0) (2,0) (7,3) (12,11) (13,11)
(c) with low-point values assigned (D(x), L(x))
Figure 8
global_variable: dfs_number
Lowpoint_Visit(node x, node parent, interface p_to_x) D(x) = dfs_number L(x) = D(x) dfs_number += 1 x.dfs_parent = parent x.dfs_parent_intf = p_to_x x.lowpoint_parent = NONE for each interface intf of x: if D(intf.remote_node) is not set Lowpoint_Visit(intf.remote_node, x, intf) if L(intf.remote_node) < L(x) L(x) = L(intf.remote_node) x.lowpoint_parent = intf.remote_node x.lowpoint_parent_intf = intf else if intf.remote_node is not parent if D(intf.remote_node) < L(x) L(x) = D(intf.remote) x.lowpoint_parent = intf.remote_node x.lowpoint_parent_intf = intf
Run_Lowpoint(node root) dfs_number = 0
Enyedi, et al. Expires April 24, 2014 [Page 12]

Internet-Draft MRT FRR Algorithm October 2013
Lowpoint_Visit(root, NONE, NONE)
Figure 9: Computing Low-Point value
From the low-point value and lowpoint parent, there are two very useful things which motivate our computation.
First, if there is a child c of x such that L(c) >= D(x), then there are no paths in the network graph that go from c or its descendants to an ancestor of x - and therefore x is a cut-vertex. This is useful because it allows identification of the cut-vertices and thus the blocks. As seen in Figure 8, even if L(x) < D(x), there may be a block that contains both the root and a DFS-child of a node while other DFS-children might be in different blocks. In this example, C’s child D is in the same block as R while F is not.
Second, by repeatedly following the path given by lowpoint_parent, there is a path from x back to an ancestor of x that does not use the link [x, x.dfs_parent] in either direction. The full path need not be taken, but this gives a way of finding an initial cycle and then ears.
3.4. Blocks in a Graph
A key idea for an MRT algorithm is that any non-2-connected graph is made up by blocks (e.g. 2-connected clusters, cut-links, and/or isolated nodes). To compute GADAGs and thus MRTs, computation is done in each block to compute ADAGs or Redundant Trees and then those ADAGs or Redundant Trees are combined into a GADAG or MRT.
[E]---| [J]-------[I] [P]---[O] | | | | | | | | | | | | [R] [D]---[C]--[F] [H]---[K] [N] | | | | | | | | | | | | [A]--------[B] [G]---| [L]---[M]
(a) A graph with four blocks that are: 3 2-connected clusters and a cut-link
[E]<--| [J]<------[I] [P]<--[O] | | | ^ | ^ V | V | V | [R] [D]<--[C] [F] [H]<---[K] [N] ^ | ^ ^ | V | |
Enyedi, et al. Expires April 24, 2014 [Page 13]

Internet-Draft MRT FRR Algorithm October 2013
[A]------->[B] [G]---| [L]-->[M]
(b) MRT-Blue
[E]---| [J]-------->[I] [P]-->[O] | | | V V V [R] [D]-->[C]<---[F] [H]<---[K] [N] ^ | ^ | ^ | | V | | | V [A]<-------[B] [G]<--| [L]<--[M]
(c) MRT-Red
Figure 10
Consider the example depicted in Figure 10 (a). In this figure, a special graph is presented, showing us all the ways 2-connected clusters can be connected. It has four blocks: block 1 contains R, A, B, C, D, E, block 2 contains C, F, G, H, I, J, block 3 contains K, L, M, N, O, P, and block 4 is a cut-edge containing H and K. As can be observed, the first two blocks have one common node (node C) and blocks 2 and 3 do not have any common node, but they are connected through a cut-edge that is block 4. No two blocks can have more than one common node, since two blocks with at least 2 common nodes would qualify as a single 2-connected cluster.
Moreover, observe that if we want to get from one block to another, we must use a cut-vertex (the cut-vertices in this graph are C, H, K), regardless of the path selected, so we can say that all the paths from block 3 along the MRTs rooted at R will cross K first. This observation means that if we want to find a pair of MRTs rooted at R, then we need to build up a pair of RTs in block 3 with K as a root. Similarly, we need to find another one in block 2 with C as a root, and finally, we need the last one in block 1 with R as a root. When all the trees are selected, we can simply combine them; when a block is a cut-edge (as in block 4), that cut-edge is added in the same direction to both of the trees. The resulting trees are depicted in Figure 10 (b) and (c).
Similarly, to create a GADAG it is sufficient to compute ADAGs in each block and connect them.
It is necessary, therefore, to identify the cut-vertices, the blocks and identify the appropriate local-root to use for each block.
Enyedi, et al. Expires April 24, 2014 [Page 14]

Internet-Draft MRT FRR Algorithm October 2013
3.5. Determining Local-Root and Assigning Block-ID
Each node in a network graph has a local-root, which is the cut- vertex (or root) in the same block that is closest to the root. The local-root is used to determine whether two nodes share a common block.
Compute_Localroot(node x, node localroot) x.localroot = localroot for each DFS child c if L(c) < D(x) //x is not a cut-vertex Compute_Localroot(c, x.localroot) else mark x as cut-vertex Compute_Localroot(c, x)
Compute_Localroot(root, root)
Figure 11: A method for computing local-roots
There are two different ways of computing the local-root for each node. The stand-alone method is given in Figure 11 and better illustrates the concept; it is used by the MRT algorithms given in the Appendices Appendix A and Appendix B. The method for local-root computation is used in the MRT Lowpoint algorithm for computing a GADAG using Low-Point inheritance and the essence of it is given in Figure 12.
Get the current node, s. Compute an ear(either through lowpoint inheritance or by following dfs parents) from s to a ready node e. (Thus, s is not e, if there is such ear.) if s is e for each node x in the ear that is not s x.localroot = s else for each node x in the ear that is not s or e x.localroot = e.localroot
Figure 12: Ear-based method for computing local-roots
Once the local-roots are known, two nodes X and Y are in a common block if and only if one of the following three conditions apply.
o Y’s local-root is X’s local-root : They are in the same block and neither is the cut-vertex closest to the root.
Enyedi, et al. Expires April 24, 2014 [Page 15]

Internet-Draft MRT FRR Algorithm October 2013
o Y’s local-root is X: X is the cut-vertex closest to the root for Y’s block
o Y is X’s local-root: Y is the cut-vertex closest to the root for X’s block
Once we have computed the local-root for each node in the network graph, we can assign for each node, a block id that represents the block in which the node is present. This computation is shown in Figure 13.
global_var: max_block_id
Assign_Block_ID(x, cur_block_id) x.block_id = cur_block_id foreach DFS child c of x if (c.local_root is x) max_block_id += 1 Assign_Block_ID(c, max_block_id) else Assign_Block_ID(c, cur_block_id)
max_block_id = 0 Assign_Block_ID(root, max_block_id)
Figure 13: Assigning block id to identify blocks
4. Algorithm Sections
This algorithm computes one GADAG that is then used by a router to determine its MRT-Blue and MRT-Red next-hops to all destinations. Finally, based upon that information, alternates are selected for each next-hop to each destination. The different parts of this algorithm are described below. These work on a network graph after, for instance, its interfaces are ordered as per Figure 14.
1. Compute the local MRT Island for the particular MRT Profile. [See Section 4.1.]
2. Select the root to use for the GADAG. [See Section 4.2.]
3. Initialize all interfaces to UNDIRECTED. [See Section 4.3.]
4. Compute the DFS value,e.g. D(x), and lowpoint value, L(x). [See Figure 9.]
5. Construct the GADAG. [See Section 4.4]
Enyedi, et al. Expires April 24, 2014 [Page 16]

Internet-Draft MRT FRR Algorithm October 2013
6. Assign directions to all interfaces that are still UNDIRECTED. [See Section 4.5.]
7. From the computing router x, compute the next-hops for the MRT- Blue and MRT-Red. [See Section 4.6.]
8. Identify alternates for each next-hop to each destination by determining which one of the blue MRT and the red MRT the computing router x should select. [See Section 4.7.]
To ensure consistency in computation, all routers MUST order interfaces identically. This is necessary for the DFS, where the selection order of the interfaces to explore results in different trees, and for computing the GADAG, where the selection order of the interfaces to use to form ears can result in different GADAGs. The required ordering between two interfaces from the same router x is given in Figure 14.
Interface_Compare(interface a, interface b) if a.metric < b.metric return A_LESS_THAN_B if b.metric < a.metric return B_LESS_THAN_A if a.neighbor.loopback_addr < b.neighbor.loopback_addr return A_LESS_THAN_B if b.neighbor.loopback_addr < a.neighbor.loopback_addr return B_LESS_THAN_A // Same metric to same node, so the order doesn’t matter anymore. // To have a unique, consistent total order, // tie-break based on, for example, the link’s linkData as // distributed in an OSPF Router-LSA if a.link_data < b.link_data return A_LESS_THAN_B return B_LESS_THAN_A
Figure 14: Rules for ranking multiple interfaces. Order is from low to high.
4.1. MRT Island Identification
The local MRT Island for a particular MRT profile can be determined by starting from the computing router in the network graph and doing a breadth-first-search (BFS), exploring only links that aren’t MRT- ineligible.
MRT_Island_Identification(topology, computing_rtr, profile_id) for all routers in topology rtr.IN_MRT_ISLAND = FALSE
Enyedi, et al. Expires April 24, 2014 [Page 17]

Internet-Draft MRT FRR Algorithm October 2013
computing_rtr.IN_MRT_ISLAND = TRUE explore_list = { computing_rtr } while (explore_list is not empty) next_rtr = remove_head(explore_list) for each interface in next_rtr if interface is not MRT-ineligible if ((interface.remote_node supports profile_id) and (interface.remote_node.IN_MRT_ISLAND is FALSE)) interface.remote_node.IN_MRT_ISLAND = TRUE add_to_tail(explore_list, interface.remote_node)
Figure 15: MRT Island Identification
4.2. Root Selection
In [I-D.atlas-ospf-mrt], a mechanism is given for routers to advertise the GADAG Root Selection Priority and consistently select a GADAG Root inside the local MRT Island. Before beginning computation, the network graph is reduced to contain only the set of routers that support the specific MRT profile whose MRTs are being computed.
Off-line analysis that considers the centrality of a router may help determine how good a choice a particular router is for the role of GADAG root.
4.3. Initialization
Before running the algorithm, there is the standard type of initialization to be done, such as clearing any computed DFS-values, lowpoint-values, DFS-parents, lowpoint-parents, any MRT-computed next-hops, and flags associated with algorithm.
It is assumed that a regular SPF computation has been run so that the primary next-hops from the computing router to each destination are known. This is required for determining alternates at the last step.
Initially, all interfaces must be initialized to UNDIRECTED. Whether they are OUTGOING, INCOMING or both is determined when the GADAG is constructed and augmented.
It is possible that some links and nodes will be marked as unusable, whether because of configuration, IGP flooding (e.g. MRT-ineligible links in [I-D.atlas-ospf-mrt]), overload, or due to a transient cause such as [RFC3137]. In the algorithm description, it is assumed that such links and nodes will not be explored or used and no more discussion is given of this restriction.
Enyedi, et al. Expires April 24, 2014 [Page 18]

Internet-Draft MRT FRR Algorithm October 2013
4.4. MRT Lowpoint Algorithm: Computing GADAG using lowpoint inheritance
As discussed in Section 3.2, it is necessary to find ears from a node x that is already in the GADAG (known as IN_GADAG). There are two methods to find ears; both are required. The first is by going to a not IN_GADAG DFS-child and then following the chain of low-point parents until an IN_GADAG node is found. The second is by going to a not IN_GADAG neighbor and then following the chain of DFS parents until an IN_GADAG node is found. As an ear is found, the associated interfaces are marked based on the direction taken. The nodes in the ear are marked as IN_GADAG. In the algorithm, first the ears via DFS-children are found and then the ears via DFS-neighbors are found.
By adding both types of ears when an IN_GADAG node is processed, all ears that connect to that node are found. The order in which the IN_GADAG nodes is processed is, of course, key to the algorithm. The order is a stack of ears so the most recent ear is found at the top of the stack. Of course, the stack stores nodes and not ears, so an ordered list of nodes, from the first node in the ear to the last node in the ear, is created as the ear is explored and then that list is pushed onto the stack.
Each ear represents a partial order (see Figure 4) and processing the nodes in order along each ear ensures that all ears connecting to a node are found before a node higher in the partial order has its ears explored. This means that the direction of the links in the ear is always from the node x being processed towards the other end of the ear. Additionally, by using a stack of ears, this means that any unprocessed nodes in previous ears can only be ordered higher than nodes in the ears below it on the stack.
In this algorithm that depends upon Low-Point inheritance, it is necessary that every node have a low-point parent that is not itself. If a node is a cut-vertex, that may not yet be the case. Therefore, any nodes without a low-point parent will have their low-point parent set to their DFS parent and their low-point value set to the DFS- value of their parent. This assignment also properly allows an ear between two cut-vertices.
Finally, the algorithm simultaneously computes each node’s local- root, as described in Figure 12. This is further elaborated as follows. The local-root can be inherited from the node at the end of the ear unless the end of the ear is x itself, in which case the local-root for all the nodes in the ear would be x. This is because whenever the first cycle is found in a block, or an ear involving a bridge is computed, the cut-vertex closest to the root would be x itself. In all other scenarios, the properties of lowpoint/dfs parents ensure that the end of the ear will be in the same block, and
Enyedi, et al. Expires April 24, 2014 [Page 19]

Internet-Draft MRT FRR Algorithm October 2013
thus inheriting its local-root would be the correct local-root for all newly added nodes.
The pseudo-code for the GADAG algorithm (assuming that the adjustment of lowpoint for cut-vertices has been made) is shown in Figure 16.
Construct_Ear(x, Stack, intf, type) ear_list = empty cur_node = intf.remote_node cur_intf = intf not_done = true
while not_done cur_intf.UNDIRECTED = false cur_intf.OUTGOING = true cur_intf.remote_intf.UNDIRECTED = false cur_intf.remote_intf.INCOMING = true
if cur_node.IN_GADAG is false cur_node.IN_GADAG = true add_to_list_end(ear_list, cur_node) if type is CHILD cur_intf = cur_node.lowpoint_parent_intf cur_node = cur_node.lowpoint_parent else type must be NEIGHBOR cur_intf = cur_node.dfs_parent_intf cur_node = cur_node.dfs_parent else not_done = false
if (type is CHILD) and (cur_node is x) //x is a cut-vertex and the local root for //the block in which the ear is computed localroot = x else // Inherit local-root from the end of the ear localroot = cur_node.localroot while ear_list is not empty y = remove_end_item_from_list(ear_list) y.localroot = localroot push(Stack, y)
Construct_GADAG_via_Lowpoint(topology, root) root.IN_GADAG = true root.localroot = root Initialize Stack to empty push root onto Stack while (Stack is not empty)
Enyedi, et al. Expires April 24, 2014 [Page 20]

Internet-Draft MRT FRR Algorithm October 2013
x = pop(Stack) foreach interface intf of x if ((intf.remote_node.IN_GADAG == false) and (intf.remote_node.dfs_parent is x)) Construct_Ear(x, Stack, intf, CHILD) foreach interface intf of x if ((intf.remote_node.IN_GADAG == false) and (intf.remote_node.dfs_parent is not x)) Construct_Ear(x, Stack, intf, NEIGHBOR)
Construct_GADAG_via_Lowpoint(topology, root)
Figure 16: Low-point Inheritance GADAG algorithm
4.5. Augmenting the GADAG by directing all links
The GADAG, regardless of the algorithm used to construct it, at this point could be used to find MRTs but the topology does not include all links in the network graph. That has two impacts. First, there might be shorter paths that respect the GADAG partial ordering and so the alternate paths would not be as short as possible. Second, there may be additional paths between a router x and the root that are not included in the GADAG. Including those provides potentially more bandwidth to traffic flowing on the alternates and may reduce congestion compared to just using the GADAG as currently constructed.
The goal is thus to assign direction to every remaining link marked as UNDIRECTED to improve the paths and number of paths found when the MRTs are computed.
To do this, we need to establish a total order that respects the partial order described by the GADAG. This can be done using Kahn’s topological sort[Kahn_1962_topo_sort] which essentially assigns a number to a node x only after all nodes before it (e.g. with a link incoming to x) have had their numbers assigned. The only issue with the topological sort is that it works on DAGs and not ADAGs or GADAGs.
To convert a GADAG to a DAG, it is necessary to remove all links that point to a root of block from within that block. That provides the necessary conversion to a DAG and then a topological sort can be done. Finally, all UNDIRECTED links are assigned a direction based upon the partial ordering. Any UNDIRECTED links that connect to a root of a block from within that block are assigned a direction INCOMING to that root. The exact details of this whole process are captured in Figure 17
Enyedi, et al. Expires April 24, 2014 [Page 21]

Internet-Draft MRT FRR Algorithm October 2013
Set_Block_Root_Incoming_Links(topo, root, mark_or_clear) foreach node x in topo if node x is a cut-vertex or root foreach interface i of x if (i.remote_node.localroot is x) if i.UNDIRECTED i.OUTGOING = true i.remote_intf.INCOMING = true i.UNDIRECTED = false i.remote_intf.UNDIRECTED = false if i.INCOMING if mark_or_clear is mark if i.OUTGOING // a cut-edge i.STORE_INCOMING = true i.INCOMING = false i.remote_intf.STORE_OUTGOING = true i.remote_intf.OUTGOING = false i.TEMP_UNUSABLE = true i.remote_intf.TEMP_UNUSABLE = true else i.TEMP_UNUSABLE = false i.remote_intf.TEMP_UNUSABLE = false if i.STORE_INCOMING and (mark_or_clear is clear) i.INCOMING = true i.STORE_INCOMING = false i.remote_intf.OUTGOING = true i.remote_intf.STORE_OUTGOING = false
Run_Topological_Sort_GADAG(topo, root) Set_Block_Root_Incoming_Links(topo, root, MARK) foreach node x set x.unvisited to the count of x’s incoming interfaces that aren’t marked TEMP_UNUSABLE Initialize working_list to empty Initialize topo_order_list to empty add_to_list_end(working_list, root) while working_list is not empty y = remove_start_item_from_list(working_list) add_to_list_end(topo_order_list, y) foreach interface i of y if (i.OUTGOING) and (not i.TEMP_UNUSABLE) i.remote_node.unvisited -= 1 if i.remote_node.unvisited is 0 add_to_list_end(working_list, i.remote_node) next_topo_order = 1 while topo_order_list is not empty y = remove_start_item_from_list(topo_order_list) y.topo_order = next_topo_order
Enyedi, et al. Expires April 24, 2014 [Page 22]

Internet-Draft MRT FRR Algorithm October 2013
next_topo_order += 1 Set_Block_Root_Incoming_Links(topo, root, CLEAR)
Add_Undirected_Links(topo, root) Run_Topological_Sort_GADAG(topo, root) foreach node x in topo foreach interface i of x if i.UNDIRECTED if x.topo_order < i.remote_node.topo_order i.OUTGOING = true i.UNDIRECTED = false i.remote_intf.INCOMING = true i.remote_intf.UNDIRECTED = false else i.INCOMING = true i.UNDIRECTED = false i.remote_intf.OUTGOING = true i.remote_intf.UNDIRECTED = false
Add_Undirected_Links(topo, root)
Figure 17: Assigning direction to UNDIRECTED links
Proxy-nodes do not need to be added to the network graph. They cannot be transited and do not affect the MRTs that are computed. The details of how the MRT-Blue and MRT-Red next-hops are computed and how the appropriate alternate next-hops are selected is given in Section 4.8.
4.6. Compute MRT next-hops
As was discussed in Section 3.1, once a ADAG is found, it is straightforward to find the next-hops from any node X to the ADAG root. However, in this algorithm, we want to reuse the common GADAG and find not only the one pair of MRTs rooted at the GADAG root with it, but find a pair rooted at each node. This is useful since it is significantly faster to compute. It may also provide easier troubleshooting of the MRT-Red and MRT-Blue.
The method for computing differently rooted MRTs from the common GADAG is based on two ideas. First, if two nodes X and Y are ordered with respect to each other in the partial order, then an SPF along OUTGOING links (an increasing-SPF) and an SPF along INCOMING links (a decreasing-SPF) can be used to find the increasing and decreasing paths. Second, if two nodes X and Y aren’t ordered with respect to each other in the partial order, then intermediary nodes can be used to create the paths by increasing/decreasing to the intermediary and then decreasing/increasing to reach Y.
Enyedi, et al. Expires April 24, 2014 [Page 23]

Internet-Draft MRT FRR Algorithm October 2013
As usual, the two basic ideas will be discussed assuming the network is two-connected. The generalization to multiple blocks is discussed in Section 4.6.4. The full algorithm is given in Section 4.6.5.
4.6.1. MRT next-hops to all nodes partially ordered with respect to the computing node
To find two node-disjoint paths from the computing router X to any node Y, depends upon whether Y >> X or Y << X. As shown in Figure 18, if Y >> X, then there is an increasing path that goes from X to Y without crossing R; this contains nodes in the interval [X,Y]. There is also a decreasing path that decreases towards R and then decreases from R to Y; this contains nodes in the interval [X,R-small] or [R-great,Y]. The two paths cannot have common nodes other than X and Y.
[Y]<---(Cloud 2)<--- [X] | ^ | | V | (Cloud 3)--->[R]--->(Cloud 1)
MRT-Blue path: X->Cloud 2->Y MRT-Red path: X->Cloud 1->R->Cloud 3->Y
Figure 18: Y >> X
Similar logic applies if Y << X, as shown in Figure 19. In this case, the increasing path from X increases to R and then increases from R to Y to use nodes in the intervals [X,R-great] and [R-small, Y]. The decreasing path from X reaches Y without crossing R and uses nodes in the interval [Y,X].
[X]<---(Cloud 2)<--- [Y] | ^ | | V | (Cloud 3)--->[R]--->(Cloud 1)
MRT-Blue path: X->Cloud 3->R->Cloud 1->Y MRT-Red path: X->Cloud 2->Y
Figure 19: Y << X
4.6.2. MRT next-hops to all nodes not partially ordered with respect to the computing node
Enyedi, et al. Expires April 24, 2014 [Page 24]

Internet-Draft MRT FRR Algorithm October 2013
When X and Y are not ordered, the first path should increase until we get to a node G, where G >> Y. At G, we need to decrease to Y. The other path should be just the opposite: we must decrease until we get to a node H, where H << Y, and then increase. Since R is smaller and greater than Y, such G and H must exist. It is also easy to see that these two paths must be node disjoint: the first path contains nodes in interval [X,G] and [Y,G], while the second path contains nodes in interval [H,X] and [H,Y]. This is illustrated in Figure 20. It is necessary to decrease and then increase for the MRT-Blue and increase and then decrease for the MRT-Red; if one simply increased for one and decreased for the other, then both paths would go through the root R.
(Cloud 6)<---[Y]<---(Cloud 5)<------------| | | | | V | [G]--->(Cloud 4)--->[R]--->(Cloud 1)--->[H] ^ | | | | | (Cloud 3)<---[X]<---(Cloud 2)<-----------|
MRT-Blue path: decrease to H and increase to Y X->Cloud 2->H->Cloud 5->Y MRT-Red path: increase to G and decrease to Y X->Cloud 3->G->Cloud 6->Y
Figure 20: X and Y unordered
This gives disjoint paths as long as G and H are not the same node. Since G >> Y and H << Y, if G and H could be the same node, that would have to be the root R. This is not possible because there is only one incoming interface to the root R which is created when the initial cycle is found. Recall from Figure 6 that whenever an ear was found to have an end that was the root R, the ear was directed from R so that the associated interface on R is outgoing and not incoming. Therefore, there must be exactly one node M which is the largest one before R, so the MRT-Red path will never reach R; it will turn at M and decrease to Y.
4.6.3. Computing Redundant Tree next-hops in a 2-connected Graph
The basic ideas for computing RT next-hops in a 2-connected graph were given in Section 4.6.1 and Section 4.6.2. Given these two ideas, how can we find the trees?
Enyedi, et al. Expires April 24, 2014 [Page 25]

Internet-Draft MRT FRR Algorithm October 2013
If some node X only wants to find the next-hops (which is usually the case for IP networks), it is enough to find which nodes are greater and less than X, and which are not ordered; this can be done by running an increasing-SPF and a decreasing-SPF rooted at X and not exploring any links from the ADAG root. ( Traversal algorithms other than SPF could safely be used instead where one traversal takes the links in their given directions and the other reverses the links’ directions.)
An increasing-SPF rooted at X and not exploring links from the root will find the increasing next-hops to all Y >> X. Those increasing next-hops are X’s next-hops on the MRT-Blue to reach Y. An decreasing-SPF rooted at X and not exploring links from the root will find the decreasing next-hops to all Z << X. Those decreasing next- hops are X’s next-hops on the MRT-Red to reach Z. Since the root R is both greater than and less than X, after this increasing-SPF and decreasing-SPF, X’s next-hops on the MRT-Blue and on the MRT-Red to reach R are known. For every node Y >> X, X’s next-hops on the MRT- Red to reach Y are set to those on the MRT-Red to reach R. For every node Z << X, X’s next-hops on the MRT-Blue to reach Z are set to those on the MRT-Blue to reach R.
For those nodes, which were not reached, we have the next-hops as well. The increasing MRT-Blue next-hop for a node, which is not ordered, is the next-hop along the decreasing MRT-Red towards R and the decreasing MRT-Red next-hop is the next-hop along the increasing MRT-Blue towards R. Naturally, since R is ordered with respect to all the nodes, there will always be an increasing and a decreasing path towards it. This algorithm does not provide the complete specific path taken but just the appropriate next-hops to use. The identity of G and H is not determined.
The final case to considered is when the root R computes its own next-hops. Since the root R is << all other nodes, running an increasing-SPF rooted at R will reach all other nodes; the MRT-Blue next-hops are those found with this increasing-SPF. Similarly, since the root R is >> all other nodes, running a decreasing-SPF rooted at R will reach all other nodes; the MRT-Red next-hops are those found with this decreasing-SPF.
E---D---| E<--D<--| | | | | ^ | | | | V | | R F C R F C | | | | ^ ^ | | | V | | A---B---| A-->B---|
Enyedi, et al. Expires April 24, 2014 [Page 26]

Internet-Draft MRT FRR Algorithm October 2013
(a) (b) A 2-connected graph A spanning ADAG rooted at R
Figure 21
As an example consider the situation depicted in Figure 21. There node C runs an increasing-SPF and a decreasing-SPF The increasing-SPF reaches D, E and R and the decreasing-SPF reaches B, A and R. So towards E the increasing next-hop is D (it was reached though D), and the decreasing next-hop is B (since R was reached though B). Since both D and B, A and R will compute the next hops similarly, the packets will reach E.
We have the next-hops towards F as well: since F is not ordered with respect to C, the MRT-Blue next-hop is the decreasing one towards R (which is B) and the MRT-Red next-hop is the increasing one towards R (which is D). Since B is ordered with F, it will find, for its MRT- Blue, a real increasing next-hop, so packet forwarded to B will get to F on path C-B-F. Similarly, D will have, for its MRT-Red, a real decreasing next-hop, and the packet will use path C-D-F.
4.6.4. Generalizing for graph that isn’t 2-connected
If a graph isn’t 2-connected, then the basic approach given in Section 4.6.3 needs some extensions to determine the appropriate MRT next-hops to use for destinations outside the computing router X’s blocks. In order to find a pair of maximally redundant trees in that graph we need to find a pair of RTs in each of the blocks (the root of these trees will be discussed later), and combine them.
When computing the MRT next-hops from a router X, there are three basic differences:
1. Only nodes in a common block with X should be explored in the increasing-SPF and decreasing-SPF.
2. Instead of using the GADAG root, X’s local-root should be used. This has the following implications:
a. The links from X’s local-root should not be explored.
b. If a node is explored in the outgoing SPF so Y >> X, then X’s MRT-Red next-hops to reach Y uses X’s MRT-Red next-hops to reach X’s local-root and if Z << X, then X’s MRT-Blue next- hops to reach Z uses X’s MRT-Blue next-hops to reach X’s local-root.
Enyedi, et al. Expires April 24, 2014 [Page 27]

Internet-Draft MRT FRR Algorithm October 2013
c. If a node W in a common block with X was not reached in the increasing-SPF or decreasing-SPF, then W is unordered with respect to X. X’s MRT-Blue next-hops to W are X’s decreasing aka MRT-Red next-hops to X’s local-root. X’s MRT-Red next- hops to W are X’s increasing aka Blue MRT next-hops to X’s local-root.
3. For nodes in different blocks, the next-hops must be inherited via the relevant cut-vertex.
These are all captured in the detailed algorithm given in Section 4.6.5.
4.6.5. Complete Algorithm to Compute MRT Next-Hops
The complete algorithm to compute MRT Next-Hops for a particular router X is given in Figure 22. In addition to computing the MRT- Blue next-hops and MRT-Red next-hops used by X to reach each node Y, the algorithm also stores an "order_proxy", which is the proper cut- vertex to reach Y if it is outside the block, and which is used later in deciding whether the MRT-Blue or the MRT-Red can provide an acceptable alternate for a particular primary next-hop.
In_Common_Block(x, y) if (((x.localroot is y.localroot) and (x.block_id is y.block_id)) or (x is y.localroot) or (y is x.localroot)) return true return false
Store_Results(y, direction, spf_root, store_nhs) if direction is FORWARD y.higher = true if store_nhs y.blue_next_hops = y.next_hops if direction is REVERSE y.lower = true if store_nhs y.red_next_hops = y.next_hops
SPF_No_Traverse_Root(spf_root, block_root, direction, store_nhs) Initialize spf_heap to empty Initialize nodes’ spf_metric to infinity and next_hops to empty spf_root.spf_metric = 0 insert(spf_heap, spf_root) while (spf_heap is not empty) min_node = remove_lowest(spf_heap) Store_Results(min_node, direction, spf_root, store_nhs) if ((min_node is spf_root) or (min_node is not block_root))
Enyedi, et al. Expires April 24, 2014 [Page 28]

Internet-Draft MRT FRR Algorithm October 2013
foreach interface intf of min_node if (((direction is FORWARD) and intf.OUTGOING) or ((direction is REVERSE) and intf.INCOMING) and In_Common_Block(spf_root, intf.remote_node)) path_metric = min_node.spf_metric + intf.metric if path_metric < intf.remote_node.spf_metric intf.remote_node.spf_metric = path_metric if min_node is spf_root intf.remote_node.next_hops = make_list(intf) else intf.remote_node.next_hops = min_node.next_hops insert_or_update(spf_heap, intf.remote_node) else if path_metric is intf.remote_node.spf_metric if min_node is spf_root add_to_list(intf.remote_node.next_hops, intf) else add_list_to_list(intf.remote_node.next_hops, min_node.next_hops)
SetEdge(y) if y.blue_next_hops is empty and y.red_next_hops is empty if (y.local_root != y) { SetEdge(y.localroot) } y.blue_next_hops = y.localroot.blue_next_hops y.red_next_hops = y.localroot.red_next_hops y.order_proxy = y.localroot.order_proxy
Compute_MRT_NextHops(x, root) foreach node y y.higher = y.lower = false clear y.red_next_hops and y.blue_next_hops y.order_proxy = y SPF_No_Traverse_Root(x, x.localroot, FORWARD, TRUE) SPF_No_Traverse_Root(x, x.localroot, REVERSE, TRUE)
// red and blue next-hops are stored to x.localroot as different // paths are found via the SPF and reverse-SPF. // Similarly any nodes whose local-root is x will have their // red_next_hops and blue_next_hops already set.
// Handle nodes in the same block that aren’t the local-root foreach node y if (y.IN_MRT_ISLAND and (y is not x) and (y.localroot is x.localroot) and ((y is x.localroot) or (x is y.localroot) or (y.block_id is x.block_id))) if y.higher
Enyedi, et al. Expires April 24, 2014 [Page 29]

Internet-Draft MRT FRR Algorithm October 2013
y.red_next_hops = x.localroot.red_next_hops else if y.lower y.blue_next_hops = x.localroot.blue_next_hops else y.blue_next_hops = x.localroot.red_next_hops y.red_next_hops = x.localroot.blue_next_hops
// Inherit next-hops and order_proxies to other components if x is not root root.blue_next_hops = x.localroot.blue_next_hops root.red_next_hops = x.localroot.red_next_hops root.order_proxy = x.localroot foreach node y if (y is not root) and (y is not x) and y.IN_MRT_ISLAND SetEdge(y)
max_block_id = 0 Assign_Block_ID(root, max_block_id) Compute_MRT_NextHops(x, root)
Figure 22
4.7. Identify MRT alternates
At this point, a computing router S knows its MRT-Blue next-hops and MRT-Red next-hops for each destination in the MRT Island. The primary next-hops along the SPT are also known. It remains to determine for each primary next-hop to a destination D, which of the MRTs avoids the primary next-hop node F. This computation depends upon data set in Compute_MRT_NextHops such as each node y’s y.blue_next_hops, y.red_next_hops, y.order_proxy, y.higher, y.lower and topo_orders. Recall that any router knows only which are the nodes greater and lesser than itself, but it cannot decide the relation between any two given nodes easily; that is why we need topological ordering.
For each primary next-hop node F to each destination D, S can call Select_Alternates(S, D, F, primary_intf) to determine whether to use the MRT-Blue next-hops as the alternate next-hop(s) for that primary next hop or to use the MRT-Red next-hops. The algorithm is given in Figure 23 and discussed afterwards.
Select_Alternates_Internal(S, D, F, primary_intf, D_lower, D_higher, D_topo_order)
//When D==F, we can do only link protection if ((D is F) or (D.order_proxy is F))
Enyedi, et al. Expires April 24, 2014 [Page 30]

Internet-Draft MRT FRR Algorithm October 2013
if an MRT doesn’t use primary_intf indicate alternate is not node-protecting return that MRT color else // parallel links are cut-edge return AVOID_LINK_ON_BLUE
if (D_lower and D_higher and F.lower and F.higher) if F.topo_order < D_topo_order return USE_RED else return USE_BLUE
if (D_lower and D_higher) if F.higher return USE_RED else return USE_BLUE
if (F.lower and F.higher) if D_lower return USE_RED else if D_higher return USE_BLUE else if primary_intf.OUTGOING and primary_intf.INCOMING return AVOID_LINK_ON_BLUE if primary_intf.OUTGOING is true return USE_BLUE if primary_intf.INCOMING is true return USE_RED
if D_higher if F.higher if F.topo_order < D_topo_order return USE_RED else return USE_BLUE else if F.lower return USE_BLUE else // F and S are neighbors so either F << S or F >> S else if D_lower if F.higher return USE_RED else if F.lower if F.topo_order < D_topo_order return USE_RED else
Enyedi, et al. Expires April 24, 2014 [Page 31]

Internet-Draft MRT FRR Algorithm October 2013
return USE_BLUE else // F and S are neighbors so either F << S or F >> S else // D and S not ordered if F.lower return USE_RED else if F.higher return USE_BLUE else // F and S are neighbors so either F << S or F >> S
Select_Alternates(S, D, F, primary_intf) if D.order_proxy is not D D_lower = D.order_proxy.lower D_higher = D.order_proxy.higher D_topo_order = D.order_proxy.topo_order else D_lower = D.lower D_higher = D.higher D_topo_order = D.topo_order return Select_Alternates_Internal(S, D, F, primary_intf, D_lower, D_higher, D_topo_order)
Figure 23
If either D>>S>>F or D<<S<<F holds true, the situation is simple: in the first case we should choose the increasing Blue next-hop, in the second case, the decreasing Red next-hop is the right choice.
However, when both D and F are greater than S the situation is not so simple, there can be three possibilities: (i) F>>D (ii) F<<D or (iii) F and D are not ordered. In the first case, we should choose the path towards D along the Blue tree. In contrast, in case (ii) the Red path towards the root and then to D would be the solution. Finally, in case (iii) both paths would be acceptable. However, observe that if e.g. F.topo_order>D.topo_order, either case (i) or case (iii) holds true, which means that selecting the Blue next-hop is safe. Similarly, if F.topo_order<D.topo_order, we should select the Red next-hop. The situation is almost the same if both F and D are less than S.
Enyedi, et al. Expires April 24, 2014 [Page 32]

Internet-Draft MRT FRR Algorithm October 2013
Recall that we have added each link to the GADAG in some direction, so it is impossible that S and F are not ordered. But it is possible that S and D are not ordered, so we need to deal with this case as well. If F<<S, we can use the Red next-hop, because that path is first increasing until a node definitely greater than D is reached, than decreasing; this path must avoid using F. Similarly, if F>>S, we should use the Blue next-hop.
Additionally, the cases where either F or D is ordered both higher and lower must be considered; this can happen when one is a block- root or its order_proxy is. If D is both higher and lower than S, then the MRT to use is the one that avoids F so if F is higher, then the MRT-Red should be used and if F is lower, then the MRT-Blue should be used; F and S must be ordered because they are neighbors. If F is both higher and lower, then if D is lower, using the MRT-Red to decrease reaches D and if D is higher, using the Blue MRT to increase reaches D; if D is unordered compared to S, then the situation is a bit more complicated.
In the case where F<<S<<F and D and S are unordered, the direction of the link in the GADAG between S and F should be examined. If the link is directed S -> F, then use the MRT-Blue (decrease to avoid that link and then increase). If the link is directed S <- F, then use the MRT-Red (increase to avoid that link and then decrease). If the link is S <--> F, then the link must be a cut-link and there is no node-protecting alternate. If there are multiple links between S and F, then they can protect against each other; of course, in this situation, they are probably already ECMP.
Finally, there is the case where D is also F. In this case, only link protection is possible. The MRT that doesn’t use the indicated primary next-hop is used. If both MRTs use the primary next-hop, then the primary next-hop must be a cut-edge so either MRT could be used but the set of MRT next-hops must be pruned to avoid that primary next-hop. To indicate this case, Select_Alternates returns AVOID_LINK_ON_BLUE.
As an example, consider the ADAG depicted in Figure 24 and first suppose that G is the source, D is the destination and H is the failed next-hop. Since D>>G, we need to compare H.topo_order and D.topo_order. Since D.topo_order>H.topo_order, D must be not smaller than H, so we should select the decreasing path towards the root. If, however, the destination were instead J, we must find that H.topo_order>J.topo_order, so we must choose the increasing Blue next-hop to J, which is I. In the case, when instead the destination is C, we find that we need to first decrease to avoid using H, so the Blue, first decreasing then increasing, path is selected.
Enyedi, et al. Expires April 24, 2014 [Page 33]

Internet-Draft MRT FRR Algorithm October 2013
[E]<-[D]<-[H]<-[J] | ^ ^ ^ V | | | [R] [C] [G]->[I] | ^ ^ ^ V | | | [A]->[B]->[F]---|
(a) a 2-connected graph
Figure 24
4.8. Finding FRR Next-Hops for Proxy-Nodes
As discussed in Section 10.2 of [I-D.ietf-rtgwg-mrt-frr-architecture], it is necessary to find MRT- Blue and MRT-Red next-hops and MRT-FRR alternates for a named proxy- nodes. An example case is for a router that is not part of that local MRT Island, when there is only partial MRT support in the domain.
A first incorrect and naive approach to handling proxy-nodes, which cannot be transited, is to simply add these proxy-nodes to the graph of the network and connect it to the routers through which the new proxy-node can be reached. Unfortunately, this can introduce some new ordering between the border routers connected to the new node which could result in routing MRT paths through the proxy-node. Thus, this naive approach would need to recompute GADAGs and redo SPTs for each proxy-node.
Instead of adding the proxy-node to the original network graph, each individual proxy-node can be individually added to the GADAG. The proxy-node is connected to at most two nodes in the GADAG. Section 10.2 of [I-D.ietf-rtgwg-mrt-frr-architecture] defines how the proxy-node attachments MUST be determined. The degenerate case where the proxy-node is attached to only one node in the GADAG is trivial as all needed information can be derived from that attachment node; if there are different interfaces, then some can be assigned to MRT- Red and others to MRT_Blue.
Now, consider the proxy-node that is attached to exactly two nodes in the GADAG. Let the order_proxies of these nodes be A and B. Let the current node, where next-hop is just being calculated, be S. If one of these two nodes A and B is the local root of S, let A=S.local_root and the other one be B. Otherwise, let A.topo_order < B.topo_order.
Enyedi, et al. Expires April 24, 2014 [Page 34]

Internet-Draft MRT FRR Algorithm October 2013
A valid GADAG was constructed. Instead doing an increasing-SPF and a decreasing-SPF to find ordering for the proxy-nodes, the following simple rules, providing the same result, can be used independently for each different proxy-node. For the following rules, let X=A.local_root, and if A is the local root, let that be strictly lower than any other node. Always take the first rule that matches.
Rule Condition Blue NH Red NH Notes 1 S=X Blue to A Red to B 2 S<<A Blue to A Red to R 3 S>>B Blue to R Red to B 4 A<<S<<B Red to A Blue to B 5 A<<S Red to A Blue to R S not ordered w/ B 6 S<<B Red to R Blue to B S not ordered w/ A 7 Otherwise Red to R Blue to R S not ordered w/ A+B
These rules are realized in the following pseudocode where P is the proxy-node, X and Y are the nodes that P is attached to, and S is the computing router:
Select_Proxy_Node_NHs(P, S, X, Y) if (X.order_proxy.topo_order < Y.order_proxy.topo_order) //This fits even if X.order_proxy=S.local_root A=X.order_proxy B=Y.order_proxy else A=Y.order_proxy B=X.order_proxy
if (S==A.local_root) P.blue_next_hops = A.blue_next_hops P.red_next_hops = B.red_next_hops return if (A.higher) P.blue_next_hops = A.blue_next_hops P.red_next_hops = R.red_next_hops return if (B.lower) P.blue_next_hops = R.blue_next_hops P.red_next_hops = B.red_next_hops return if (A.lower && B.higher) P.blue_next_hops = A.red_next_hops P.red_next_hops = B.blue_next_hops return if (A.lower)
Enyedi, et al. Expires April 24, 2014 [Page 35]

Internet-Draft MRT FRR Algorithm October 2013
P.blue_next_hops = R.red_next_hops P.red_next_hops = B.blue_next_hops return if (B.higher) P.blue_next_hops = A.red_next_hops P.red_next_hops = R.blue_next_hops return P.blue_next_hops = R.red_next_hops P.red_next_hops = R.blue_next_hops return
After finding the the red and the blue next-hops, it is necessary to know which one of these to use in the case of failure. This can be done by Select_Alternates_Inner(). In order to use Select_Alternates_Internal(), we need to know if P is greater, less or unordered with S, and P.topo_order. P.lower = B.lower, P.higher = A.higher, and any value is OK for P.topo_order, until A.topo_order<=P.topo_order<=B.topo_order and P.topo_order is not equal to the topo_order of the failed node. So for simplicity let P.topo_order=A.topo_order when the next-hop is not A, and P.topo_order=B.topo_order otherwise. This gives the following pseudo-code:
Select_Alternates_Proxy_Node(S, P, F, primary_intf) if (F is not P.neighbor_A) return Select_Alternates_Internal(S, P, F, primary_intf, P.neighbor_B.lower, P.neighbor_A.higher, P.neighbor_A.topo_order) else return Select_Alternates_Internal(S, P, F, primary_intf, P.neighbor_B.lower, P.neighbor_A.higher, P.neighbor_B.topo_order)
Figure 25
5. MRT Lowpoint Algorithm: Complete Specification
Enyedi, et al. Expires April 24, 2014 [Page 36]

Internet-Draft MRT FRR Algorithm October 2013
This specification defines the MRT Lowpoint Algorithm, which include the construction of a common GADAG and the computation of MRT-Red and MRT-Blue next-hops to each node in the graph. An implementation MAY select any subset of next-hops for MRT-Red and MRT-Blue that respect the available nodes that are described in Section 4.6 for each of the MRT-Red and MRT-Blue and the selected next-hops are further along in the interval of allowed nodes towards the destination.
For example, the MRT-Blue next-hops used when the destination Y >> S, the computing router, MUST be one or more nodes, T, whose topo_order is in the interval [X.topo_order, Y.topo_order] and where Y >> T or Y is T. Similarly, the MRT-Red next-hops MUST be have a topo_order in the interval [R-small.topo_order, X.topo_order] or [Y.topo_order, R-big.topo_order].
Implementations SHOULD implement the Select_Alternates() function to pick an MRT-FRR alternate.
In a future version, this section will include pseudo-code describing the full code path through the pseudo-code given earlier in the draft.
6. Algorithm Alternatives and Evaluation
This specification defines the MRT Lowpoint Algorithm, which is one option among several possible MRT algorithms. Other alternatives are described in the appendices.
In addition, it is possible to calculate Destination-Rooted GADAG, where for each destination, a GADAG rooted at that destination is computed. Then a router can compute the blue MRT and red MRT next- hops to that destination. Building GADAGs per destination is computationally more expensive, but may give somewhat shorter alternate paths. It may be useful for live-live multicast along MRTs.
6.1. Algorithm Evaluation
This section compares MRT and remote LFA for IP Fast Reroute in 19 service provider network topologies, focusing on coverage and alternate path length. Figure 26 shows the node-protecting coverage provided by local LFA (LLFA), remote LFA (RLFA), and MRT against different failure scenarios in these topologies. The coverage values are calculated as the percentage of source-destination pairs protected by the given IPFRR method relative to those protectable by optimal routing, against the same failure modes. More details on alternate selection policies used for this analysis are described later in this section.
Enyedi, et al. Expires April 24, 2014 [Page 37]

Internet-Draft MRT FRR Algorithm October 2013
+------------+-----------------------------+ | Topology | percentage of failure | | | scenarios covered by | | | IPFRR method | | |-----------------------------+ | | NP_LLFA | NP_RLFA | MRT | +------------+---------+---------+---------+ | T201 | 37 | 90 | 100 | | T202 | 73 | 83 | 100 | | T203 | 51 | 80 | 100 | | T204 | 55 | 81 | 100 | | T205 | 92 | 93 | 100 | | T206 | 71 | 74 | 100 | | T207 | 57 | 74 | 100 | | T208 | 66 | 81 | 100 | | T209 | 79 | 79 | 100 | | T210 | 95 | 98 | 100 | | T211 | 68 | 71 | 100 | | T212 | 59 | 63 | 100 | | T213 | 84 | 84 | 100 | | T214 | 68 | 78 | 100 | | T215 | 84 | 88 | 100 | | T216 | 43 | 59 | 100 | | T217 | 78 | 88 | 100 | | T218 | 72 | 75 | 100 | | T219 | 78 | 84 | 100 | +------------+---------+---------+---------+
Figure 26
For the topologies analyzed here, LLFA is able to provide node- protecting coverage ranging from 37% to 95% of the source-destination pairs, as seen in the column labeled NP_LLFA. The use of RLFA in addition to LLFA is generally able to increase the node-protecting coverage. The percentage of node-protecting coverage with RLFA is provided in the column labeled NP_RLFA, ranges from 59% to 98% for these topologies. The node-protecting coverage provided by MRT is 100% since MRT is able to provide protection for any source- destination pair for which a path still exists after the failure.
We would also like to measure the quality of the alternate paths produced by these different IPFRR methods. An obvious approach is to take an average of the alternate path costs over all source- destination pairs and failure modes. However, this presents a problem, which we will illustrate by presenting an example of results for one topology using this approach ( Figure 27). In this table, the average relative path length is the alternate path length for the IPFRR method divided by the optimal alternate path length, averaged
Enyedi, et al. Expires April 24, 2014 [Page 38]

Internet-Draft MRT FRR Algorithm October 2013
over all source-destination pairs and failure modes. The first three columns of data in the table give the path length calculated from the sum of IGP metrics of the links in the path. The results for topology T208 show that the metric-based path lengths for NP_LLFA and NP_RLFA alternates are on average 78 and 66 times longer than the path lengths for optimal alternates. The metric-based path lengths for MRT alternates are on average 14 times longer than for optimal alternates.
+--------+------------------------------------------------+ | | average relative alternate path length | | |-----------------------+------------------------+ |Topology| IGP metric | hopcount | | |-----------------------+------------------------+ | |NP_LLFA |NP_RLFA | MRT |NP_LLFA |NP_RLFA | MRT | +--------+--------+--------+-----+--------+--------+------+ | T208 | 78.2 | 66.0 | 13.6| 0.99 | 1.01 | 1.32 | +--------+--------+--------+-----+--------+--------+------+
Figure 27
The network topology represented by T208 uses values of 10, 100, and 1000 as IGP costs, so small deviations from the optimal alternate path can result in large differences in relative path length. LLFA, RLFA, and MRT all allow for at least one hop in the alterate path to be chosen independent of the cost of the link. This can easily result in an alternate using a link with cost 1000, which introduces noise into the path length measurement. In the case of T208, the adverse effects of using metric-based path lengths is obvious. However, we have observed that the metric-based path length introduces noise into alternate path length measurements in several other topologies as well. For this reason, we have opted to measure the alternate path length using hopcount. While IGP metrics may be adjusted by the network operator for a number of reasons (e.g. traffic engineering), the hopcount is a fairly stable measurement of path length. As shown in the last three columns of Figure 27, the hopcount-based alternate path lengths for topology T208 are fairly well-behaved.
Figure 28, Figure 29, Figure 30, and Figure 31 present the hopcount- based path length results for the 19 topologies examined. The topologies in the four tables are grouped based on the size of the topologies, as measured by the number of nodes, with Figure 28 having the smallest topologies and Figure 31 having the largest topologies. Instead of trying to represent the path lengths of a large set of alternates with a single number, we have chosen to present a histogram of the path lengths for each IPFRR method and alternate selection policy studied. The first eight colums of data represent
Enyedi, et al. Expires April 24, 2014 [Page 39]

Internet-Draft MRT FRR Algorithm October 2013
the percentage of failure scenarios protected by an alternate N hops longer than the primary path, with the first column representing an alternate 0 or 1 hops longer than the primary path, all the way up through the eighth column respresenting an alternate 14 or 15 hops longer than the primary path. The last column in the table gives the percentage of failure scenarios for which there is no alternate less than 16 hops longer than the primary path. In the case of LLFA and RLFA, this category includes failure scenarios for which no alternate was found.
For each topology, the first row (labeled OPTIMAL) is the distribution of the number of hops in excess of the primary path hopcount for optimally routed alternates. (The optimal routing was done with respect to IGP metrics, as opposed to hopcount.) The second row(labeled NP_LLFA) is the distribution of the extra hops for node-protecting LLFA. The third row (labeled NP_LLFA_THEN_NP_RLFA) is the hopcount distribution when one adds node-protecting RLFA to increase the coverage. The alternate selection policy used here first tries to find a node-protecting LLFA. If that does not exist, then it tries to find an RLFA, and checks if it is node-protecting. Comparing the hopcount distribution for RLFA and LLFA across these topologies, one can see how the coverage is increased at the expense of using longer alternates. It is also worth noting that while superficially LLFA and RLFA appear to have better hopcount distributions than OPTIMAL, the presence of entries in the last column (no alternate < 16) mainly represent failure scenarios that are not protected, for which the hopcount is effectively infinite.
The fourth and fifth rows of each topology show the hopcount distributions for two alternate selection policies using MRT alternates. The policy represented by the label NP_LLFA_THEN_MRT_LOWPOINT will first use a node-protecting LLFA. If a node-protecting LLFA does not exist, then it will use an MRT alternate. The policy represented by the label MRT_LOWPOINT instead will use the MRT alternate even if a node-protecting LLFA exists. One can see from the data that combining node-protecting LLFA with MRT results in a significant shortening of the alternate hopcount distribution.
Enyedi, et al. Expires April 24, 2014 [Page 40]

Internet-Draft MRT FRR Algorithm October 2013
+-------------------------------------------------------------------+ | | percentage of failure scenarios | | Topology name | protected by an alternate N hops | | and | longer than the primary path | | alternate selection +------------------------------------+ | policy evaluated | | | | | | | | | no | | | | | | | |10 |12 |14 | alt| | |0-1|2-3|4-5|6-7|8-9|-11|-13|-15| <16| +------------------------------+---+---+---+---+---+---+---+---+----+ | T201(avg primary hops=3.5) | | | | | | | | | | | OPTIMAL | 37| 37| 20| 3| 3| | | | | | NP_LLFA | 37| | | | | | | | 63| | NP_LLFA_THEN_NP_RLFA | 37| 34| 19| | | | | | 10| | NP_LLFA_THEN_MRT_LOWPOINT | 37| 33| 21| 6| 3| | | | | | MRT_LOWPOINT | 33| 36| 23| 6| 3| | | | | +------------------------------+---+---+---+---+---+---+---+---+----+ | T202(avg primary hops=4.8) | | | | | | | | | | | OPTIMAL | 90| 9| | | | | | | | | NP_LLFA | 71| 2| | | | | | | 27| | NP_LLFA_THEN_NP_RLFA | 78| 5| | | | | | | 17| | NP_LLFA_THEN_MRT_LOWPOINT | 80| 12| 5| 2| 1| | | | | | MRT_LOWPOINT_ONLY | 48| 29| 13| 7| 2| 1| | | | +------------------------------+---+---+---+---+---+---+---+---+----+ | T203(avg primary hops=4.1) | | | | | | | | | | | OPTIMAL | 36| 37| 21| 4| 2| | | | | | NP_LLFA | 34| 15| 3| | | | | | 49| | NP_LLFA_THEN_NP_RLFA | 35| 19| 22| 4| | | | | 20| | NP_LLFA_THEN_MRT_LOWPOINT | 36| 35| 22| 5| 2| | | | | | MRT_LOWPOINT_ONLY | 31| 35| 26| 7| 2| | | | | +------------------------------+---+---+---+---+---+---+---+---+----+ | T204(avg primary hops=3.7) | | | | | | | | | | | OPTIMAL | 76| 20| 3| 1| | | | | | | NP_LLFA | 54| 1| | | | | | | 45| | NP_LLFA_THEN_NP_RLFA | 67| 10| 4| | | | | | 19| | NP_LLFA_THEN_MRT_LOWPOINT | 70| 18| 8| 3| 1| | | | | | MRT_LOWPOINT_ONLY | 58| 27| 11| 3| 1| | | | | +------------------------------+---+---+---+---+---+---+---+---+----+ | T205(avg primary hops=3.4) | | | | | | | | | | | OPTIMAL | 92| 8| | | | | | | | | NP_LLFA | 89| 3| | | | | | | 8| | NP_LLFA_THEN_NP_RLFA | 90| 4| | | | | | | 7| | NP_LLFA_THEN_MRT_LOWPOINT | 91| 9| | | | | | | | | MRT_LOWPOINT_ONLY | 62| 33| 5| 1| | | | | | +------------------------------+---+---+---+---+---+---+---+---+----+
Figure 28
Enyedi, et al. Expires April 24, 2014 [Page 41]

Internet-Draft MRT FRR Algorithm October 2013
+-------------------------------------------------------------------+ | | percentage of failure scenarios | | Topology name | protected by an alternate N hops | | and | longer than the primary path | | alternate selection +------------------------------------+ | policy evaluated | | | | | | | | | no | | | | | | | |10 |12 |14 | alt| | |0-1|2-3|4-5|6-7|8-9|-11|-13|-15| <16| +------------------------------+---+---+---+---+---+---+---+---+----+ | T206(avg primary hops=3.7) | | | | | | | | | | | OPTIMAL | 63| 30| 7| | | | | | | | NP_LLFA | 60| 9| 1| | | | | | 29| | NP_LLFA_THEN_NP_RLFA | 60| 13| 1| | | | | | 26| | NP_LLFA_THEN_MRT_LOWPOINT | 64| 29| 7| | | | | | | | MRT_LOWPOINT | 55| 32| 13| | | | | | | +------------------------------+---+---+---+---+---+---+---+---+----+ | T207(avg primary hops=3.9) | | | | | | | | | | | OPTIMAL | 71| 24| 5| 1| | | | | | | NP_LLFA | 55| 2| | | | | | | 43| | NP_LLFA_THEN_NP_RLFA | 63| 10| | | | | | | 26| | NP_LLFA_THEN_MRT_LOWPOINT | 70| 20| 7| 2| 1| | | | | | MRT_LOWPOINT_ONLY | 57| 29| 11| 3| 1| | | | | +------------------------------+---+---+---+---+---+---+---+---+----+ | T208(avg primary hops=4.6) | | | | | | | | | | | OPTIMAL | 58| 28| 12| 2| 1| | | | | | NP_LLFA | 53| 11| 3| | | | | | 34| | NP_LLFA_THEN_NP_RLFA | 56| 17| 7| 1| | | | | 19| | NP_LLFA_THEN_MRT_LOWPOINT | 58| 19| 10| 7| 3| 1| | | | | MRT_LOWPOINT_ONLY | 34| 24| 21| 13| 6| 2| 1| | | +------------------------------+---+---+---+---+---+---+---+---+----+ | T209(avg primary hops=3.6) | | | | | | | | | | | OPTIMAL | 85| 14| 1| | | | | | | | NP_LLFA | 79| | | | | | | | 21| | NP_LLFA_THEN_NP_RLFA | 79| | | | | | | | 21| | NP_LLFA_THEN_MRT_LOWPOINT | 82| 15| 2| | | | | | | | MRT_LOWPOINT_ONLY | 63| 29| 8| | | | | | | +------------------------------+---+---+---+---+---+---+---+---+----+ | T210(avg primary hops=2.5) | | | | | | | | | | | OPTIMAL | 95| 4| 1| | | | | | | | NP_LLFA | 94| 1| | | | | | | 5| | NP_LLFA_THEN_NP_RLFA | 94| 3| 1| | | | | | 2| | NP_LLFA_THEN_MRT_LOWPOINT | 95| 4| 1| | | | | | | | MRT_LOWPOINT_ONLY | 91| 6| 2| | | | | | | +------------------------------+---+---+---+---+---+---+---+---+----+
Figure 29
Enyedi, et al. Expires April 24, 2014 [Page 42]
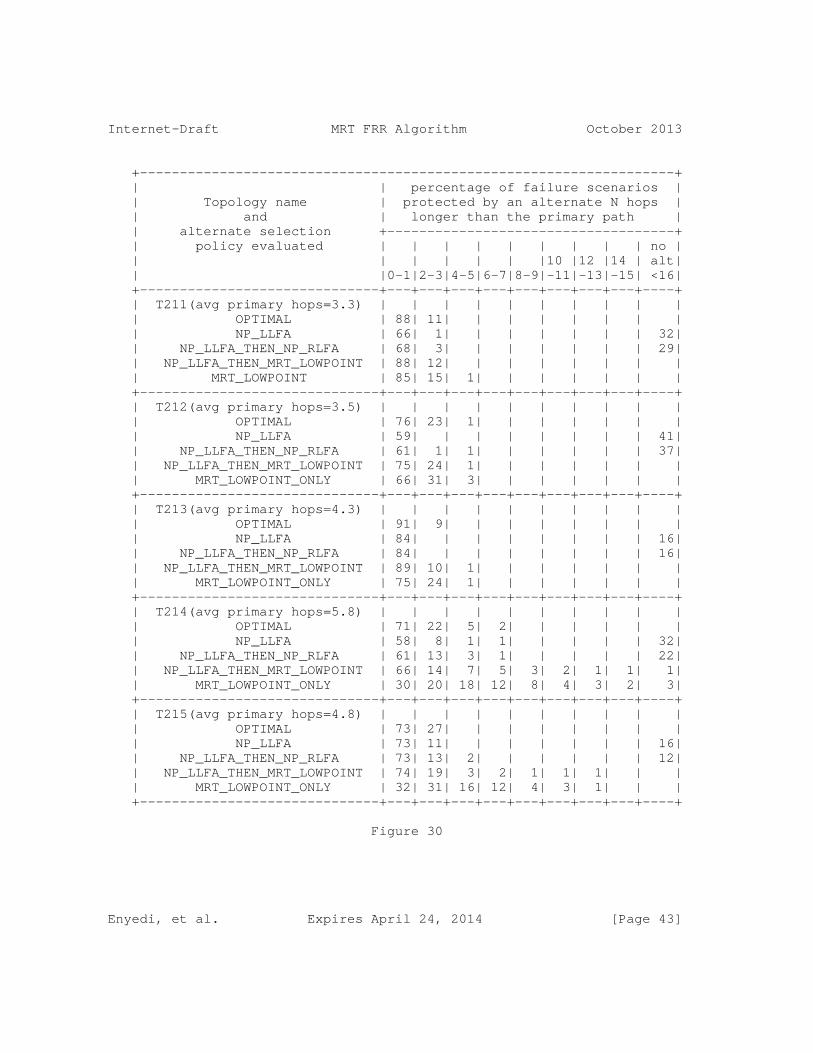
Internet-Draft MRT FRR Algorithm October 2013
+-------------------------------------------------------------------+ | | percentage of failure scenarios | | Topology name | protected by an alternate N hops | | and | longer than the primary path | | alternate selection +------------------------------------+ | policy evaluated | | | | | | | | | no | | | | | | | |10 |12 |14 | alt| | |0-1|2-3|4-5|6-7|8-9|-11|-13|-15| <16| +------------------------------+---+---+---+---+---+---+---+---+----+ | T211(avg primary hops=3.3) | | | | | | | | | | | OPTIMAL | 88| 11| | | | | | | | | NP_LLFA | 66| 1| | | | | | | 32| | NP_LLFA_THEN_NP_RLFA | 68| 3| | | | | | | 29| | NP_LLFA_THEN_MRT_LOWPOINT | 88| 12| | | | | | | | | MRT_LOWPOINT | 85| 15| 1| | | | | | | +------------------------------+---+---+---+---+---+---+---+---+----+ | T212(avg primary hops=3.5) | | | | | | | | | | | OPTIMAL | 76| 23| 1| | | | | | | | NP_LLFA | 59| | | | | | | | 41| | NP_LLFA_THEN_NP_RLFA | 61| 1| 1| | | | | | 37| | NP_LLFA_THEN_MRT_LOWPOINT | 75| 24| 1| | | | | | | | MRT_LOWPOINT_ONLY | 66| 31| 3| | | | | | | +------------------------------+---+---+---+---+---+---+---+---+----+ | T213(avg primary hops=4.3) | | | | | | | | | | | OPTIMAL | 91| 9| | | | | | | | | NP_LLFA | 84| | | | | | | | 16| | NP_LLFA_THEN_NP_RLFA | 84| | | | | | | | 16| | NP_LLFA_THEN_MRT_LOWPOINT | 89| 10| 1| | | | | | | | MRT_LOWPOINT_ONLY | 75| 24| 1| | | | | | | +------------------------------+---+---+---+---+---+---+---+---+----+ | T214(avg primary hops=5.8) | | | | | | | | | | | OPTIMAL | 71| 22| 5| 2| | | | | | | NP_LLFA | 58| 8| 1| 1| | | | | 32| | NP_LLFA_THEN_NP_RLFA | 61| 13| 3| 1| | | | | 22| | NP_LLFA_THEN_MRT_LOWPOINT | 66| 14| 7| 5| 3| 2| 1| 1| 1| | MRT_LOWPOINT_ONLY | 30| 20| 18| 12| 8| 4| 3| 2| 3| +------------------------------+---+---+---+---+---+---+---+---+----+ | T215(avg primary hops=4.8) | | | | | | | | | | | OPTIMAL | 73| 27| | | | | | | | | NP_LLFA | 73| 11| | | | | | | 16| | NP_LLFA_THEN_NP_RLFA | 73| 13| 2| | | | | | 12| | NP_LLFA_THEN_MRT_LOWPOINT | 74| 19| 3| 2| 1| 1| 1| | | | MRT_LOWPOINT_ONLY | 32| 31| 16| 12| 4| 3| 1| | | +------------------------------+---+---+---+---+---+---+---+---+----+
Figure 30
Enyedi, et al. Expires April 24, 2014 [Page 43]

Internet-Draft MRT FRR Algorithm October 2013
+-------------------------------------------------------------------+ | | percentage of failure scenarios | | Topology name | protected by an alternate N hops | | and | longer than the primary path | | alternate selection +------------------------------------+ | policy evaluated | | | | | | | | | no | | | | | | | |10 |12 |14 | alt| | |0-1|2-3|4-5|6-7|8-9|-11|-13|-15| <16| +------------------------------+---+---+---+---+---+---+---+---+----+ | T216(avg primary hops=5.2) | | | | | | | | | | | OPTIMAL | 60| 32| 7| 1| | | | | | | NP_LLFA | 39| 4| | | | | | | 57| | NP_LLFA_THEN_NP_RLFA | 46| 12| 2| | | | | | 41| | NP_LLFA_THEN_MRT_LOWPOINT | 48| 20| 12| 7| 5| 4| 2| 1| 1| | MRT_LOWPOINT | 28| 25| 18| 11| 7| 6| 3| 2| 1| +------------------------------+---+---+---+---+---+---+---+---+----+ | T217(avg primary hops=8.0) | | | | | | | | | | | OPTIMAL | 81| 13| 5| 1| | | | | | | NP_LLFA | 74| 3| 1| | | | | | 22| | NP_LLFA_THEN_NP_RLFA | 76| 8| 3| 1| | | | | 12| | NP_LLFA_THEN_MRT_LOWPOINT | 77| 7| 5| 4| 3| 2| 1| 1| | | MRT_LOWPOINT_ONLY | 25| 18| 18| 16| 12| 6| 3| 1| | +------------------------------+---+---+---+---+---+---+---+---+----+ | T218(avg primary hops=5.5) | | | | | | | | | | | OPTIMAL | 85| 14| 1| | | | | | | | NP_LLFA | 68| 3| | | | | | | 28| | NP_LLFA_THEN_NP_RLFA | 71| 4| | | | | | | 25| | NP_LLFA_THEN_MRT_LOWPOINT | 77| 12| 7| 4| 1| | | | | | MRT_LOWPOINT_ONLY | 37| 29| 21| 10| 3| 1| | | | +------------------------------+---+---+---+---+---+---+---+---+----+ | T219(avg primary hops=7.7) | | | | | | | | | | | OPTIMAL | 77| 15| 5| 1| 1| | | | | | NP_LLFA | 72| 5| | | | | | | 22| | NP_LLFA_THEN_NP_RLFA | 73| 8| 2| | | | | | 16| | NP_LLFA_THEN_MRT_LOWPOINT | 74| 8| 3| 3| 2| 2| 2| 2| 4| | MRT_LOWPOINT_ONLY | 19| 14| 15| 12| 10| 8| 7| 6| 10| +------------------------------+---+---+---+---+---+---+---+---+----+
Figure 31
In the preceding analysis, the following procedure for selecting an RLFA was used. Nodes were ordered with respect to distance from the source and checked for membership in Q and P-space. The first node to satisfy this condition was selected as the RLFA. More sophisticated methods to select node-protecting RLFAs is an area of active research.
Enyedi, et al. Expires April 24, 2014 [Page 44]

Internet-Draft MRT FRR Algorithm October 2013
The analysis presented above uses the MRT Lowpoint Algorithm defined in this specification with a common GADAG root. The particular choice of a common GADAG root is expected to affect the quality of the MRT alternate paths, with a more central common GADAG root resulting in shorter MRT alternate path lengths. For the analysis above, the GADAG root was chosen for each topology by calculating node centrality as the sum of costs of all shortest paths to and from a given node. The node with the lowest sum was chosen as the common GADAG root. In actual deployments, the common GADAG root would be chosen based on the GADAG Root Selection Priority advertised by each router, the values of which would be determined off-line.
In order to measure how sensitive the MRT alternate path lengths are to the choice of common GADAG root, we performed the same analysis using different choices of GADAG root. All of the nodes in the network were ordered with respect to the node centrality as computed above. Nodes were chosen at the 0th, 25th, and 50th percentile with respect to the centrality ordering, with 0th percentile being the most central node. The distribution of alternate path lengths for those three choices of GADAG root are shown in Figure 32 for a subset of the 19 topologies (chosen arbitrarily). The third row for each topology (labeled MRT_LOWPOINT ( 0 percentile) ) reproduces the results presented above for MRT_LOWPOINT_ONLY. The fourth and fifth rows show the alternate path length distibution for the 25th and 50th percentile choice for GADAG root. One can see some impact on the path length distribution with the less central choice of GADAG root resulting in longer path lenghths.
We also looked at the impact of MRT algorithm variant on the alternate path lengths. The first two rows for each topology present results of the same alternate path length distribution analysis for the SPF and Hybrid methods for computing the GADAG. These two methods are described in Appendix A and Appendix B. For three of the topologies in this subset (T201, T206, and T211), the use of SPF or Hybrid methods does not appear to provide a significant advantage over the Lowpoint method with respect to path length. Instead, the choice of GADAG root appears to have more impact on the path length. However, for two of the topologies in this subset(T216 and T219) and for this particular choice of GAGAG root, the use of the SPF method results in noticeably shorter alternate path lengths than the use of the Lowpoint or Hybrid methods. It remains to be determined if this effect applies generally across more topologies or is sensitive to choice of GADAG root.
Enyedi, et al. Expires April 24, 2014 [Page 45]

Internet-Draft MRT FRR Algorithm October 2013
+-------------------------------------------------------------------+ | Topology name | percentage of failure scenarios | | | protected by an alternate N hops | | MRT algorithm variant | longer than the primary path | | +------------------------------------+ | (GADAG root | | | | | | | | | no | | centrality percentile) | | | | | |10 |12 |14 | alt| | |0-1|2-3|4-5|6-7|8-9|-11|-13|-15| <16| +------------------------------+---+---+---+---+---+---+---+---+----+ | T201(avg primary hops=3.5) | | | | | | | | | | | MRT_HYBRID ( 0 percentile) | 33| 26| 23| 6| 3| | | | | | MRT_SPF ( 0 percentile) | 33| 36| 23| 6| 3| | | | | | MRT_LOWPOINT ( 0 percentile) | 33| 36| 23| 6| 3| | | | | | MRT_LOWPOINT (25 percentile) | 27| 29| 23| 11| 10| | | | | | MRT_LOWPOINT (50 percentile) | 27| 29| 23| 11| 10| | | | | +------------------------------+---+---+---+---+---+---+---+---+----+ | T206(avg primary hops=3.7) | | | | | | | | | | | MRT_HYBRID ( 0 percentile) | 50| 35| 13| 2| | | | | | | MRT_SPF ( 0 percentile) | 50| 35| 13| 2| | | | | | | MRT_LOWPOINT ( 0 percentile) | 55| 32| 13| | | | | | | | MRT_LOWPOINT (25 percentile) | 47| 25| 22| 6| | | | | | | MRT_LOWPOINT (50 percentile) | 38| 38| 14| 11| | | | | | +------------------------------+---+---+---+---+---+---+---+---+----+ | T211(avg primary hops=3.3) | | | | | | | | | | | MRT_HYBRID ( 0 percentile) | 86| 14| | | | | | | | | MRT_SPF ( 0 percentile) | 86| 14| | | | | | | | | MRT_LOWPOINT ( 0 percentile) | 85| 15| 1| | | | | | | | MRT_LOWPOINT (25 percentile) | 70| 25| 5| 1| | | | | | | MRT_LOWPOINT (50 percentile) | 80| 18| 2| | | | | | | +------------------------------+---+---+---+---+---+---+---+---+----+ | T216(avg primary hops=5.2) | | | | | | | | | | | MRT_HYBRID ( 0 percentile) | 23| 22| 18| 13| 10| 7| 4| 2| 2| | MRT_SPF ( 0 percentile) | 35| 32| 19| 9| 3| 1| | | | | MRT_LOWPOINT ( 0 percentile) | 28| 25| 18| 11| 7| 6| 3| 2| 1| | MRT_LOWPOINT (25 percentile) | 24| 20| 19| 16| 10| 6| 3| 1| | | MRT_LOWPOINT (50 percentile) | 19| 14| 13| 10| 8| 6| 5| 5| 10| +------------------------------+---+---+---+---+---+---+---+---+----+ | T219(avg primary hops=7.7) | | | | | | | | | | | MRT_HYBRID ( 0 percentile) | 20| 16| 13| 10| 7| 5| 5| 5| 3| | MRT_SPF ( 0 percentile) | 31| 23| 19| 12| 7| 4| 2| 1| | | MRT_LOWPOINT ( 0 percentile) | 19| 14| 15| 12| 10| 8| 7| 6| 10| | MRT_LOWPOINT (25 percentile) | 19| 14| 15| 13| 12| 10| 6| 5| 7| | MRT_LOWPOINT (50 percentile) | 19| 14| 14| 12| 11| 8| 6| 6| 10| +------------------------------+---+---+---+---+---+---+---+---+----+
Figure 32
Enyedi, et al. Expires April 24, 2014 [Page 46]

Internet-Draft MRT FRR Algorithm October 2013
7. Algorithm Work to Be Done
Broadcast Interfaces: The algorithm assumes that broadcast interfaces are already represented as pseudo-nodes in the network graph. Given maximal redundancy, one of the MRT will try to avoid both the pseudo-node and the next hop. The exact rules need to be fully specified.
8. IANA Considerations
This doument includes no request to IANA.
9. Security Considerations
This architecture is not currently believed to introduce new security concerns.
10. References
10.1. Normative References
[I-D.ietf-rtgwg-mrt-frr-architecture] Atlas, A., Kebler, R., Envedi, G., Csaszar, A., Tantsura, J., Konstantynowicz, M., and R. White, "An Architecture for IP/LDP Fast-Reroute Using Maximally Redundant Trees", draft-ietf-rtgwg-mrt-frr-architecture-03 (work in progress), July 2013.
10.2. Informative References
[EnyediThesis] Enyedi, G., "Novel Algorithms for IP Fast Reroute", Department of Telecommunications and Media Informatics, Budapest University of Technology and Economics Ph.D. Thesis, February 2011, <http://www.omikk.bme.hu/ collections/phd/Villamosmernoki_es_Informatikai_Kar/2011/ Enyedi_Gabor/ertekezes.pdf>.
[I-D.atlas-ospf-mrt] Atlas, A., Hegde, S., Chris, C., and J. Tantsura, "OSPF Extensions to Support Maximally Redundant Trees", draft- atlas-ospf-mrt-00 (work in progress), July 2013.
[I-D.ietf-rtgwg-ipfrr-notvia-addresses] Bryant, S., Previdi, S., and M. Shand, "A Framework for IP and MPLS Fast Reroute Using Not-via Addresses", draft- ietf-rtgwg-ipfrr-notvia-addresses-11 (work in progress), May 2013.
Enyedi, et al. Expires April 24, 2014 [Page 47]

Internet-Draft MRT FRR Algorithm October 2013
[I-D.ietf-rtgwg-lfa-manageability] Litkowski, S., Decraene, B., Filsfils, C., and K. Raza, "Operational management of Loop Free Alternates", draft- ietf-rtgwg-lfa-manageability-00 (work in progress), May 2013.
[I-D.ietf-rtgwg-remote-lfa] Bryant, S., Filsfils, C., Previdi, S., Shand, M., and S. Ning, "Remote LFA FRR", draft-ietf-rtgwg-remote-lfa-02 (work in progress), May 2013.
[Kahn_1962_topo_sort] Kahn, A., "Topological sorting of large networks", Communications of the ACM, Volume 5, Issue 11 , Nov 1962, <http://dl.acm.org/citation.cfm?doid=368996.369025>.
[LFARevisited] Retvari, G., Tapolcai, J., Enyedi, G., and A. Csaszar, "IP Fast ReRoute: Loop Free Alternates Revisited", Proceedings of IEEE INFOCOM , 2011, <http://opti.tmit.bme.hu/˜tapolcai /papers/retvari2011lfa_infocom.pdf>.
[LightweightNotVia] Enyedi, G., Retvari, G., Szilagyi, P., and A. Csaszar, "IP Fast ReRoute: Lightweight Not-Via without Additional Addresses", Proceedings of IEEE INFOCOM , 2009, <http://mycite.omikk.bme.hu/doc/71691.pdf>.
[MRTLinear] Enyedi, G., Retvari, G., and A. Csaszar, "On Finding Maximally Redundant Trees in Strictly Linear Time", IEEE Symposium on Computers and Comunications (ISCC) , 2009, <http://opti.tmit.bme.hu/˜enyedi/ipfrr/ distMaxRedTree.pdf>.
[RFC3137] Retana, A., Nguyen, L., White, R., Zinin, A., and D. McPherson, "OSPF Stub Router Advertisement", RFC 3137, June 2001.
[RFC5286] Atlas, A. and A. Zinin, "Basic Specification for IP Fast Reroute: Loop-Free Alternates", RFC 5286, September 2008.
[RFC5714] Shand, M. and S. Bryant, "IP Fast Reroute Framework", RFC 5714, January 2010.
Enyedi, et al. Expires April 24, 2014 [Page 48]

Internet-Draft MRT FRR Algorithm October 2013
[RFC6571] Filsfils, C., Francois, P., Shand, M., Decraene, B., Uttaro, J., Leymann, N., and M. Horneffer, "Loop-Free Alternate (LFA) Applicability in Service Provider (SP) Networks", RFC 6571, June 2012.
Appendix A. Option 2: Computing GADAG using SPFs
The basic idea in this option is to use slightly-modified SPF computations to find ears. In every block, an SPF computation is first done to find a cycle from the local root and then SPF computations in that block find ears until there are no more interfaces to be explored. The used result from the SPF computation is the path of interfaces indicated by following the previous hops from the mininized IN_GADAG node back to the SPF root.
To do this, first all cut-vertices must be identified and local-roots assigned as specified in Figure 12.
The slight modifications to the SPF are as follows. The root of the block is referred to as the block-root; it is either the GADAG root or a cut-vertex.
a. The SPF is rooted at a neighbor x of an IN_GADAG node y. All links between y and x are marked as TEMP_UNUSABLE. They should not be used during the SPF computation.
b. If y is not the block-root, then it is marked TEMP_UNUSABLE. It should not be used during the SPF computation. This prevents ears from starting and ending at the same node and avoids cycles; the exception is because cycles to/from the block-root are acceptable and expected.
c. Do not explore links to nodes whose local-root is not the block- root. This keeps the SPF confined to the particular block.
d. Terminate when the first IN_GADAG node z is minimized.
e. Respect the existing directions (e.g. INCOMING, OUTGOING, UNDIRECTED) already specified for each interface.
Mod_SPF(spf_root, block_root) Initialize spf_heap to empty Initialize nodes’ spf_metric to infinity spf_root.spf_metric = 0 insert(spf_heap, spf_root) found_in_gadag = false while (spf_heap is not empty) and (found_in_gadag is false)
Enyedi, et al. Expires April 24, 2014 [Page 49]

Internet-Draft MRT FRR Algorithm October 2013
min_node = remove_lowest(spf_heap) if min_node.IN_GADAG is true found_in_gadag = true else foreach interface intf of min_node if ((intf.OUTGOING or intf.UNDIRECTED) and ((intf.remote_node.localroot is block_root) or (intf.remote_node is block_root)) and (intf.remote_node is not TEMP_UNUSABLE) and (intf is not TEMP_UNUSABLE)) path_metric = min_node.spf_metric + intf.metric if path_metric < intf.remote_node.spf_metric intf.remote_node.spf_metric = path_metric intf.remote_node.spf_prev_intf = intf insert_or_update(spf_heap, intf.remote_node) return min_node
SPF_for_Ear(cand_intf.local_node,cand_intf.remote_node, block_root, method) Mark all interfaces between cand_intf.remote_node and cand_intf.local_node as TEMP_UNUSABLE if cand_intf.local_node is not block_root Mark cand_intf.local_node as TEMP_UNUSABLE Initialize ear_list to empty end_ear = Mod_SPF(spf_root, block_root) y = end_ear.spf_prev_hop while y.local_node is not spf_root add_to_list_start(ear_list, y) y.local_node.IN_GADAG = true y = y.local_node.spf_prev_intf if(method is not hybrid) Set_Ear_Direction(ear_list, cand_intf.local_node, end_ear,block_root) Clear TEMP_UNUSABLE from all interfaces between cand_intf.remote_node and cand_intf.local_node Clear TEMP_UNUSABLE from cand_intf.local_node return end_ear
Figure 33: Modified SPF for GADAG computation
Assume that an ear is found by going from y to x and then running an SPF that terminates by minimizing z (e.g. y<->x...q<->z). Now it is necessary to determine the direction of the ear; if y << z, then the path should be y->x...q->z but if y >> z, then the path should be y<-x...q<-z. In Section 4.4, the same problem was handled by finding
Enyedi, et al. Expires April 24, 2014 [Page 50]

Internet-Draft MRT FRR Algorithm October 2013
all ears that started at a node before looking at ears starting at nodes higher in the partial order. In this algorithm, using that approach could mean that new ears aren’t added in order of their total cost since all ears connected to a node would need to be found before additional nodes could be found.
The alternative is to track the order relationship of each node with respect to every other node. This can be accomplished by maintaining two sets of nodes at each node. The first set, Higher_Nodes, contains all nodes that are known to be ordered above the node. The second set, Lower_Nodes, contains all nodes that are known to be ordered below the node. This is the approach used in this algorithm.
Set_Ear_Direction(ear_list, end_a, end_b, block_root) // Default of A_TO_B for the following cases: // (a) end_a and end_b are the same (root) // or (b) end_a is in end_b’s Lower Nodes // or (c) end_a and end_b were unordered with respect to each // other direction = A_TO_B if (end_b is block_root) and (end_a is not end_b) direction = B_TO_A else if end_a is in end_b.Higher_Nodes direction = B_TO_A if direction is B_TO_A foreach interface i in ear_list i.UNDIRECTED = false i.INCOMING = true i.remote_intf.UNDIRECTED = false i.remote_intf.OUTGOING = true else foreach interface i in ear_list i.UNDIRECTED = false i.OUTGOING = true i.remote_intf.UNDIRECTED = false i.remote_intf.INCOMING = true if end_a is end_b return // Next, update all nodes’ Lower_Nodes and Higher_Nodes if (end_a is in end_b.Higher_Nodes) foreach node x where x.localroot is block_root if end_a is in x.Lower_Nodes foreach interface i in ear_list add i.remote_node to x.Lower_Nodes if end_b is in x.Higher_Nodes foreach interface i in ear_list add i.local_node to x.Higher_Nodes
Enyedi, et al. Expires April 24, 2014 [Page 51]

Internet-Draft MRT FRR Algorithm October 2013
else foreach node x where x.localroot is block_root if end_b is in x.Lower_Nodes foreach interface i in ear_list add i.local_node to x.Lower_Nodes if end_a is in x.Higher_Nodes foreach interface i in ear_list add i.remote_node to x.Higher_Nodes
Figure 34: Algorithm to assign links of an ear direction
A goal of the algorithm is to find the shortest cycles and ears. An ear is started by going to a neighbor x of an IN_GADAG node y. The path from x to an IN_GADAG node is minimal, since it is computed via SPF. Since a shortest path is made of shortest paths, to find the shortest ears requires reaching from the set of IN_GADAG nodes to the closest node that isn’t IN_GADAG. Therefore, an ordered tree is maintained of interfaces that could be explored from the IN_GADAG nodes. The interfaces are ordered by their characteristics of metric, local loopback address, remote loopback address, and ifindex, as in the algorithm previously described in Figure 14.
The algorithm ignores interfaces picked from the ordered tree that belong to the block root if the block in which the interface is present already has an ear that has been computed. This is necessary since we allow at most one incoming interface to a block root in each block. This requirement stems from the way next-hops are computed as will be seen in Section 4.6. After any ear gets computed, we traverse the newly added nodes to the GADAG and insert interfaces whose far end is not yet on the GADAG to the ordered tree for later processing.
Finally, cut-edges are a special case because there is no point in doing an SPF on a block of 2 nodes. The algorithm identifies cut- edges simply as links where both ends of the link are cut-vertices. Cut-edges can simply be added to the GADAG with both OUTGOING and INCOMING specified on their interfaces.
add_eligible_interfaces_of_node(ordered_intfs_tree,node) for each interface of node if intf.remote_node.IN_GADAG is false insert(intf,ordered_intfs_tree)
check_if_block_has_ear(x,block_id) block_has_ear = false for all interfaces of x if (intf.remote_node.block_id == block_id) && (intf.remote_node.IN_GADAG is true)
Enyedi, et al. Expires April 24, 2014 [Page 52]

Internet-Draft MRT FRR Algorithm October 2013
block_has_ear = true return block_has_ear
Construct_GADAG_via_SPF(topology, root) Compute_Localroot (root,root) Assign_Block_ID(root,0) root.IN_GADAG = true add_eligible_interfaces_of_node(ordered_intfs_tree,root) while ordered_intfs_tree is not empty cand_intf = remove_lowest(ordered_intfs_tree) if cand_intf.remote_node.IN_GADAG is false if L(cand_intf.remote_node) == D(cand_intf.remote_node) // Special case for cut-edges cand_intf.UNDIRECTED = false cand_intf.remote_intf.UNDIRECTED = false cand_intf.OUTGOING = true cand_intf.INCOMING = true cand_intf.remote_intf.OUTGOING = true cand_intf.remote_intf.INCOMING = true cand_intf.remote_node.IN_GADAG = true add_eligible_interfaces_of_node( ordered_intfs_tree,cand_intf.remote_node) else if (cand_intf.remote_node.local_root == cand_intf.local_node) && check_if_block_has_ear (cand_intf.local_node, cand_intf.remote_node.block_id)) /* Skip the interface since the block root already has an incoming interface in the block */ else ear_end = SPF_for_Ear(cand_intf.local_node, cand_intf.remote_node, cand_intf.remote_node.localroot, SPF method) y = ear_end.spf_prev_hop while y.local_node is not cand_intf.local_node add_eligible_interfaces_of_node( ordered_intfs_tree, y.local_node) y = y.local_node.spf_prev_intf
Figure 35: SPF-based GADAG algorithm
Appendix B. Option 3: Computing GADAG using a hybrid method
Enyedi, et al. Expires April 24, 2014 [Page 53]

Internet-Draft MRT FRR Algorithm October 2013
In this option, the idea is to combine the salient features of the above two options. To this end, we process nodes as they get added to the GADAG just like in the lowpoint inheritance by maintaining a stack of nodes. This ensures that we do not need to maintain lower and higher sets at each node to ascertain ear directions since the ears will always be directed from the node being processed towards the end of the ear. To compute the ear however, we resort to an SPF to have the possibility of better ears (path lentghs) thus giving more flexibility than the restricted use of lowpoint/dfs parents.
Regarding ears involving a block root, unlike the SPF method which ignored interfaces of the block root after the first ear, in the hybrid method we would have to process all interfaces of the block root before moving on to other nodes in the block since the direction of an ear is pre-determined. Thus, whenever the block already has an ear computed, and we are processing an interface of the block root, we mark the block root as unusable before the SPF run that computes the ear. This ensures that the SPF terminates at some node other than the block-root. This in turn guarantees that the block-root has only one incoming interface in each block, which is necessary for correctly computing the next-hops on the GADAG.
As in the SPF gadag, bridge ears are handled as a special case.
The entire algorithm is shown below in Figure 36
find_spf_stack_ear(stack, x, y, xy_intf, block_root) if L(y) == D(y) // Special case for cut-edges xy_intf.UNDIRECTED = false xy_intf.remote_intf.UNDIRECTED = false xy_intf.OUTGOING = true xy_intf.INCOMING = true xy_intf.remote_intf.OUTGOING = true xy_intf.remote_intf.INCOMING = true xy_intf.remote_node.IN_GADAG = true push y onto stack return else if (y.local_root == x) && check_if_block_has_ear(x,y.block_id) //Avoid the block root during the SPF Mark x as TEMP_UNUSABLE end_ear = SPF_for_Ear(x,y,block_root,hybrid) If x was set as TEMP_UNUSABLE, clear it cur = end_ear while (cur != y) intf = cur.spf_prev_hop
Enyedi, et al. Expires April 24, 2014 [Page 54]

Internet-Draft MRT FRR Algorithm October 2013
prev = intf.local_node intf.UNDIRECTED = false intf.remote_intf.UNDIRECTED = false intf.OUTGOING = true intf.remote_intf.INCOMING = true push prev onto stack cur = prev xy_intf.UNDIRECTED = false xy_intf.remote_intf.UNDIRECTED = false xy_intf.OUTGOING = true xy_intf.remote_intf.INCOMING = true return
Construct_GADAG_via_hybrid(topology,root) Compute_Localroot (root,root) Assign_Block_ID(root,0) root.IN_GADAG = true Initialize Stack to empty push root onto Stack while (Stack is not empty) x = pop(Stack) for each interface intf of x y = intf.remote_node if y.IN_GADAG is false find_spf_stack_ear(stack, x, y, intf, y.block_root)
Figure 36: Hybrid GADAG algorithm
Authors’ Addresses
Gabor Sandor Enyedi (editor) Ericsson Konyves Kalman krt 11 Budapest 1097 Hungary
Email: [email protected]
Andras Csaszar Ericsson Konyves Kalman krt 11 Budapest 1097 Hungary
Email: [email protected]
Enyedi, et al. Expires April 24, 2014 [Page 55]

Internet-Draft MRT FRR Algorithm October 2013
Alia Atlas (editor) Juniper Networks 10 Technology Park Drive Westford, MA 01886 USA
Email: [email protected]
Chris Bowers Juniper Networks 1194 N. Mathilda Ave. Sunnyvale, CA 94089 USA
Email: [email protected]
Abishek Gopalan University of Arizona 1230 E Speedway Blvd. Tucson, AZ 85721 USA
Email: [email protected]
Enyedi, et al. Expires April 24, 2014 [Page 56]

RTGWG C. Villamizar, Ed.Internet-Draft OCCNC, LLCIntended status: Informational D. McDysan, Ed.Expires: August 10, 2014 Verizon S. Ning Tata Communications A. Malis Huawei L. Yong Huawei USA February 06, 2014
Requirements for Advanced Multipath in MPLS Networks draft-ietf-rtgwg-cl-requirement-16
Abstract
This document provides a set of requirements for Advanced Multipath in MPLS Networks.
Advanced Multipath is a formalization of multipath techniques currently in use in IP and MPLS networks and a set of extensions to existing multipath techniques.
Status of This Memo
This Internet-Draft is submitted in full conformance with the provisions of BCP 78 and BCP 79.
Internet-Drafts are working documents of the Internet Engineering Task Force (IETF). Note that other groups may also distribute working documents as Internet-Drafts. The list of current Internet- Drafts is at http://datatracker.ietf.org/drafts/current/.
Internet-Drafts are draft documents valid for a maximum of six months and may be updated, replaced, or obsoleted by other documents at any time. It is inappropriate to use Internet-Drafts as reference material or to cite them other than as "work in progress."
This Internet-Draft will expire on August 10, 2014.
Copyright Notice
Copyright (c) 2014 IETF Trust and the persons identified as the document authors. All rights reserved.
Villamizar, et al. Expires August 10, 2014 [Page 1]

Internet-Draft Advanced Multipath Requirements February 2014
This document is subject to BCP 78 and the IETF Trust’s Legal Provisions Relating to IETF Documents (http://trustee.ietf.org/license-info) in effect on the date of publication of this document. Please review these documents carefully, as they describe your rights and restrictions with respect to this document. Code Components extracted from this document must include Simplified BSD License text as described in Section 4.e of the Trust Legal Provisions and are provided without warranty as described in the Simplified BSD License.
Table of Contents
1. Introduction . . . . . . . . . . . . . . . . . . . . . . . . 2 1.1. Requirements Language . . . . . . . . . . . . . . . . . . 3 2. Definitions . . . . . . . . . . . . . . . . . . . . . . . . . 3 3. Functional Requirements . . . . . . . . . . . . . . . . . . . 6 3.1. Availability, Stability and Transient Response . . . . . 6 3.2. Component Links Provided by Lower Layer Networks . . . . 8 3.3. Component Links with Different Characteristics . . . . . 8 3.4. Considerations for Bidirectional Client LSP . . . . . . . 9 3.5. Multipath Load Balancing Dynamics . . . . . . . . . . . . 10 4. General Requirements for Protocol Solutions . . . . . . . . . 12 5. Management Requirements . . . . . . . . . . . . . . . . . . . 13 6. Acknowledgements . . . . . . . . . . . . . . . . . . . . . . 14 7. IANA Considerations . . . . . . . . . . . . . . . . . . . . . 14 8. Security Considerations . . . . . . . . . . . . . . . . . . . 14 9. References . . . . . . . . . . . . . . . . . . . . . . . . . 15 9.1. Normative References . . . . . . . . . . . . . . . . . . 15 9.2. Informative References . . . . . . . . . . . . . . . . . 15 Authors’ Addresses . . . . . . . . . . . . . . . . . . . . . . . 16
1. Introduction
There is often a need to provide large aggregates of bandwidth that are best provided using parallel links between routers or carrying traffic over multiple MPLS Label Switched Paths (LSPs). In core networks there is often no alternative since the aggregate capacities of core networks today far exceed the capacity of a single physical link or single packet processing element.
The presence of parallel links, with each link potentially comprised of multiple layers has resulted in additional requirements. Certain services may benefit from being restricted to a subset of the component links or a specific component link, where component link characteristics, such as latency, differ. Certain services require that an LSP be treated as atomic and avoid reordering. Other services will continue to require only that reordering not occur within a flow as is current practice.
Villamizar, et al. Expires August 10, 2014 [Page 2]

Internet-Draft Advanced Multipath Requirements February 2014
Numerous forms of multipath exist today including MPLS Link Bundling [RFC4201], Ethernet Link Aggregation [IEEE-802.1AX], and various forms of Equal Cost Multipath (ECMP) such as for OSPF ECMP, IS-IS ECMP, and BGP ECMP. Refer to the Appendices in [I-D.ietf-rtgwg-cl-use-cases] for a description of existing techniques and a set of references.
The purpose of this document is to clearly enumerate a set of requirements related to the protocols and mechanisms that provide MPLS based Advanced Multipath. The intent is to first provide a set of functional requirements, in Section 3, that are as independent as possible of protocol specifications . A set of general protocol requirements are defined in Section 4. A set of network management requirements are defined in Section 5.
1.1. Requirements Language
The key words "MUST", "MUST NOT", "REQUIRED", "SHALL", "SHALL NOT", "SHOULD", "SHOULD NOT", "RECOMMENDED", "MAY", and "OPTIONAL" in this document are to be interpreted as described in RFC 2119 [RFC2119].
Any statement which requires the solution to support some new functionality through use of [RFC2119] keywords should be interpreted as follows. The implementation either MUST or SHOULD support the new functionality depending on the use of either MUST or SHOULD in the requirements statement. The implementation SHOULD in most or all cases allow any new functionality to be individually enabled or disabled through configuration. A service provider or other deployment MAY enable or disable any feature in their network, subject to implementation limitations on sets of features which can be disabled.
2. Definitions
Multipath The term multipath includes all techniques in which
1. Traffic can take more than one path from one node to a destination.
2. Individual packets take one path only. Packets are not subdivided and reassembled at the receiving end.
3. Packets are not resequenced at the receiving end.
4. The paths may be:
a. parallel links between two nodes, or
Villamizar, et al. Expires August 10, 2014 [Page 3]

Internet-Draft Advanced Multipath Requirements February 2014
b. specific paths across a network to a destination node, or
c. links or paths to an intermediate node used to reach a common destination.
The paths need not have equal capacity. The paths may or may not have equal cost in a routing protocol.
Advanced Multipath Advanced Multipath is a formalization of multipath techniques that meets the requirements defined in this document. A key capability of Advanced Multipath is the support of non- homogeneous component links.
Advanced Multipath Group (AMG) An Advanced Multipath Group (AMG) is a collection of component links where Advanced Multipath techniques are applied.
Composite Link The term Composite Link had been a registered trademark of Avici Systems, but was abandoned in 2007. The term composite link is now defined by the ITU-T in [ITU-T.G.800]. The ITU-T definition includes multipath as defined here, plus inverse multiplexing which is explicitly excluded from the definition of multipath.
Inverse Multiplexing Inverse multiplexing is another method of sending traffic over multiple links. Inverse multiplexing either transmits whole packets and resequences the packets at the receiving end or subdivides packets and reassembles the packets at the receiving end. Inverse multiplexing requires that all packets be handled by a common egress packet processing element and is therefore not useful for very high bandwidth applications.
Component Link The ITU-T definition of composite link in [ITU-T.G.800] and the IETF definition of link bundling in [RFC4201] both refer to an individual link in the composite link or link bundle as a component link. The term component link is applicable to all forms of multipath. The IEEE uses the term member rather than component link in Ethernet Link Aggregation [IEEE-802.1AX].
Client Layer A client layer is the layer immediately above a server layer.
Server Layer A server layer is the layer immediately below a client layer.
Villamizar, et al. Expires August 10, 2014 [Page 4]

Internet-Draft Advanced Multipath Requirements February 2014
Higher Layers Relative to a particular layer, a client layer and any layer above that is considered a higher layer. Upper layer is synonymous with higher layer.
Lower Layers Relative to a particular layer, a server layer and any layer below that is considered a lower layer.
Client LSP A client LSP is an LSP which has been set up over one or more lower layers. In the context of this discussion, one type of client LSP is a LSP which has been set up over an AMG.
Flow A sequence of packets that should be transferred in order on one component link of a multipath.
Flow Identification The label stack and other information that uniquely identifies a flow. Other information in flow identification may include an IP header, pseudowire (PW) control word, Ethernet MAC address, etc. Note that a client LSP may contain one or more Flows or a client LSP may be equivalent to a Flow. Flow identification is used to locally select a component link, or a path through the network toward the destination.
Load Balance Load split, load balance, or load distribution refers to subdividing traffic over a set of component links such that load is fairly evenly distributed over the set of component links and certain packet ordering requirements are met. Some existing techniques better achieve these objectives than others.
Performance Objective Numerical values for performance measures, principally availability, latency, and delay variation. Performance objectives may be related to Service Level Agreements (SLA) as defined in RFC2475 or may be strictly internal. Performance objectives may span links, edge-to-edge, or end-to-end. Performance objectives may span one provider or may span multiple providers.
A Component Link may be a point-to-point physical link (where a "physical link" includes one or more link layer plus a physical layer) or a logical link that preserves ordering in the steady state. A component link may have transient out of order events, but such events must not exceed the network’s Performance Objectives. For
Villamizar, et al. Expires August 10, 2014 [Page 5]

Internet-Draft Advanced Multipath Requirements February 2014
example, a component link may be comprised of any supportable combination of link layers over a physical layer or over logical sub- layers, including those providing physical layer emulation, or over MPLS server layer LSP.
The ingress and egress of a multipath may be midpoint LSRs with respect to a given client LSP. A midpoint LSR does not participate in the signaling of any clients of the client LSP. Therefore, in general, multipath endpoints cannot determine requirements of clients of a client LSP through participation in the signaling of the clients of the client LSP.
This document makes no statement on whether Advanced Multipath is itself a layer or whether an instance of AMG is itself a layer. This is to avoid engaging in long and pointless discussions about what consistitutes a proper layer.
The term Advanced Multipath is intended to be used within the context of this document and the related documents, [I-D.ietf-rtgwg-cl-use-cases] and [I-D.ietf-rtgwg-cl-framework] and any other related document. Other advanced multipath techniques may in the future arise. If the capabilities defined in this document become commonplace, they would no longer be considered "advanced". Use of the term "advanced multipath" outside this document, if referring to the term as defined here, should indicate Advanced Multipath as defined by this document, citing the current document name. If using another definition of "advanced multipath", documents may optionally clarify that they are not using the term "advanced multipath" as defined by this document if clarification is deemed helpful.
3. Functional Requirements
The Functional Requirements in this section are grouped in subsections starting with the highest priority.
3.1. Availability, Stability and Transient Response
Limiting the period of unavailability in response to failures or transient events is extremely important as well as maintaining stability.
FR#1 The transient period between some service disrupting event and the convergence of the routing and/or signaling protocols MUST occur within a time frame specified by Performance Objective values.
Villamizar, et al. Expires August 10, 2014 [Page 6]

Internet-Draft Advanced Multipath Requirements February 2014
FR#2 An AMG MAY be announced in conjunction with detailed parameters about its component links, such as bandwidth and latency. The AMG SHALL behave as a single IGP adjacency.
FR#3 The solution SHALL provide a means to summarize some routing advertisements regarding the characteristics of an AMG such that the updated protocol mechanisms maintain convergence times within the timeframe needed to meet or not significantly exceed existing Performance Objective for convergence on the same network or convergence on a network with a similar topology.
FR#4 The solution SHALL ensure that restoration operations happen within the timeframe needed to meet existing Performance Objective for restoration time on the same network or restoration time on a network with a similar topology.
FR#5 The solution shall provide a mechanism to select a set of paths for an LSP across a network in such a way that flows within the LSP are distributed across the set of paths while meeting all of the other requirements stated above. The solution SHOULD work in a manner similar to existing multipath techniques except as necessary to accommodate Advanced Multipath requirements.
FR#6 If extensions to existing protocols are specified and/or new protocols are defined, then the solution SHOULD provide a means for a network operator to migrate an existing deployment in a minimally disruptive manner.
FR#7 Any load balancing solutions MUST NOT oscillate. Some change in path MAY occur. The solution MUST ensure that path stability and traffic reordering continue to meet Performance Objective on the same network or on a network with a similar topology. Since oscillation may cause reordering, there MUST be means to control the frequency of changing the component link over which a flow is placed.
FR#8 Management and diagnostic protocols MUST be able to operate over AMGs.
Existing scaling techniques used in MPLS networks apply to MPLS networks which support Advanced Multipath. Scalability and stability are covered in more detail in [I-D.ietf-rtgwg-cl-framework].
Villamizar, et al. Expires August 10, 2014 [Page 7]

Internet-Draft Advanced Multipath Requirements February 2014
3.2. Component Links Provided by Lower Layer Networks
A component link may be supported by a lower layer network. For example, the lower layer may be a circuit switched network or another MPLS network (e.g., MPLS-TP)). The lower layer network may change the latency (and/or other performance parameters) seen by the client layer. Currently, there is no protocol for the lower layer network to inform the higher layer network of a change in a performance parameter. Communication of the latency performance parameter is a very important requirement. Communication of other performance parameters (e.g., delay variation) is desirable.
FR#9 The solution SHALL specify a protocol means to allow a server layer network to communicate latency to the client layer network.
FR#10 The precision of latency reporting SHOULD be configurable. A reasonable default SHOULD be provided. Implementations SHOULD support precision of at least 10% of the one way latencies for latency of 1 msec or more.
The intent is to measure the predominant latency in uncongested service provider networks, where geographic delay dominates and is on the order of milliseconds or more. The argument for including queuing delay is that it reflects the delay experienced by applications. The argument against including queuing delay is that if used in routing decisions it can result in routing instability. This tradeoff is discussed in detail in [I-D.ietf-rtgwg-cl-framework].
3.3. Component Links with Different Characteristics
As one means to provide high availability, network operators deploy a topology in the MPLS network using lower layer networks that have a certain degree of diversity at the lower layer(s). Many techniques have been developed to balance the distribution of flows across component links that connect the same pair of nodes or ultimately lead to a common destination.
FR#11 In requirements that follow in this document the word "indicate" is used where information may be provided by either the combination of link state IGP advertisement and MPLS LSP signaling or via management plane protocols. In later documents providing framework and protocol definitions both signaling and management plane mechanisms MUST be defined.
FR#12 The solution SHALL provide a means for the client layer to indicate a requirement that a client LSP will traverse a component link with the minimum latency value. This will provide
Villamizar, et al. Expires August 10, 2014 [Page 8]

Internet-Draft Advanced Multipath Requirements February 2014
a means by which minimum latency Performance Objectives of flows within the client LSP can be supported.
FR#13 The solution SHALL provide a means for the client layer to indicate a requirement that a client LSP will traverse a component link with a maximum acceptable latency value as specified by protocol. This will provide a means by which bounded latency Performance Objectives of flows within the client LSP can be supported.
FR#14 The solution SHALL provide a means for the client layer to indicate a requirement that a client LSP will traverse a component link with a maximum acceptable delay variation value as specified by protocol.
The above set of requirements apply to component links with different characteristics regardless as to whether those component links are provided by parallel physical links between nodes or provided by sets of paths across a network provided by server layer LSP.
Allowing multipath to contain component links with different characteristics can improve the overall load balance and can be accomplished while still accommodating the more strict requirements of a subset of client LSP.
3.4. Considerations for Bidirectional Client LSP
Some client LSP MAY require a path bound to a specific set of component links. This case is most likely to occur in bidirectional client LSP where time synchronization protocols such as Precision Time Protocol (PTP) or Network Time Protocol (NTP) are carried, or in any other case where symmetric delay is highly desirable. There may be other uses of this capability.
Other client LSP may only require that the LSP path serve the same set of nodes in both directions. This is necessary if protocols are carried which make use of the reverse direction of the LSP as a back channel in cases such OAM protocols using IPv4 Time to Live (TTL) or IPv4 Hop Limit to monitor or diagnose the underlying path. There may be other uses of this capability.
Villamizar, et al. Expires August 10, 2014 [Page 9]

Internet-Draft Advanced Multipath Requirements February 2014
FR#15 The solution SHALL provide a means for the client layer to indicate a requirement that a client LSP be bound to a particular component link within an AMG. If this option is not exercised, then a client LSP that is carried over an AMG may be bound to any component link or set of component links matching all other signaled requirements, and different directions of a bidirectional client LSP can be bound to different component links.
FR#16 The solution MUST support a means for the client layer to indicate a requirement that for a specific co-routed bidirectional client LSP both directions of the co-routed bidirectional client LSP MUST be bound to the same set of nodes.
FR#17 A client LSP which is bound to a specific component link SHOULD NOT exceed the capacity of a single component link. This is inherent in the assumption that a network SHOULD NOT operate in a congested state if congestion is avoidable.
For some large bidirectional client LSP it may not be necessary (or possible due to the client LSP capacity) to bind the LSP to a common set of component links but may be necessary or desirable to constrain the path taken by the LSP to the same set of nodes in both directions. Without an entirely new and highly dynamic protocol, it is not feasible to constrain such an bidirectional client LSP to take multiple paths and coordinate load balance on each side to keep both directions of flows within such an LSP on common paths.
3.5. Multipath Load Balancing Dynamics
Multipath load balancing attempts to keep traffic levels on all component links below congestion levels if possible and preferably well balanced. Load balancing is minimally disruptive (see discussion below this section’s list of requirements). The sensitivity to these minimal disruptions of traffic flows within specific client LSP needs to be considered.
FR#18 The solution SHALL provide a means for the client layer to indicate a requirement that a specific client LSP MUST NOT be split across multiple component links.
FR#19 The solution SHALL provide a means local to a node that automatically distributes flows across the component links in the AMG such that Performance Objectives are met as described in prior requirements in Section 3.3.
FR#20 The solution SHALL measure traffic flows or groups of traffic flows and dynamically select the component link on which to place
Villamizar, et al. Expires August 10, 2014 [Page 10]

Internet-Draft Advanced Multipath Requirements February 2014
this traffic in order to balance the load so that no component link in the AMG between a pair of nodes is overloaded.
FR#21 When a traffic flow is moved from one component link to another in the same AMG between a set of nodes, it MUST be done so in a minimally disruptive manner.
FR#22 Load balancing MAY be used during sustained low traffic periods to reduce the number of active component links for the purpose of power reduction.
FR#23 The solution SHALL provide a means for the client layer to indicate a requirement that a specific client LSP contains traffic whose frequency of component link change due to load balancing needs to be bounded by a specific value. The solution MUST provide a means to bound the frequency of component link change due to load balancing for subsets of traffic flow on AMGs.
FR#24 The solution SHALL provide a means to distribute traffic flows from a single client LSP across multiple component links to handle at least the case where the traffic carried in an client LSP exceeds that of any component link in the AMG.
FR#25 The solution SHOULD support the use case where an AMG itself is a component link for a higher order AMG. For example, an AMG comprised of MPLS-TP bi-directional tunnels viewed as logical links could then be used as a component link in yet another AMG that connects MPLS routers.
FR#26 If the total demand offered by traffic flows exceeds the capacity of the AMG, the solution SHOULD define a means to cause some client LSP to move to an alternate set of paths that are not congested. These "preempted LSP" may not be restored if there is no uncongested path in the network.
A minimally disruptive change implies that as little disruption as is practical occurs. Such a change can be achieved with zero packet loss. A delay discontinuity may occur, which is considered to be a minimally disruptive event for most services if this type of event is sufficiently rare. A delay discontinuity is an example of a minimally disruptive behavior corresponding to current techniques.
A delay discontinuity is an isolated event which may greatly exceed the normal delay variation (jitter). A delay discontinuity has the following effect. When a flow is moved from a current link to a target link with lower latency, reordering can occur. When a flow is moved from a current link to a target link with a higher latency, a time gap can occur. Some flows (e.g., timing distribution, PW
Villamizar, et al. Expires August 10, 2014 [Page 11]

Internet-Draft Advanced Multipath Requirements February 2014
circuit emulation) are quite sensitive to these effects. A delay discontinuity can also cause a jitter buffer underrun or overrun affecting user experience in real time voice services (causing an audible click). These sensitivities may be specified in a Performance Objective.
As with any load balancing change, a change initiated for the purpose of power reduction may be minimally disruptive. Typically the disruption is limited to a change in delay characteristics and the potential for a very brief period with traffic reordering. The network operator when configuring a network for power reduction should weigh the benefit of power reduction against the disadvantage of a minimal disruption.
4. General Requirements for Protocol Solutions
This section defines requirements for protocol specification used to meet the functional requirements specified in Section 3.
GR#1 The solution SHOULD extend existing protocols wherever possible, developing a new protocol only where doing so adds a significant set of capabilities.
GR#2 A solution SHOULD extend LDP capabilities to meet functional requirements. This MUST be accomplished without defining LDP Traffic Engineering (TE) methods as decided in [RFC3468]).
GR#3 Coexistence of LDP and RSVP-TE signaled LSPs MUST be supported on an AMG. Function requirements SHOULD, where possible, be accommodated in a manner that supports LDP signaled LSP, RSVP signaled LSP, and LSP set up using management plane mechanisms.
GR#4 When the nodes connected via an AMG are in the same routing domain, the solution MAY define extensions to the IGP.
GR#5 When the nodes are connected via an AMG are in different MPLS network topologies, the solution SHALL NOT rely on extensions to the IGP.
GR#6 The solution SHOULD support AMG IGP advertisement that results in convergence time better than that of advertising the individual component links. The solution SHALL be designed so that it represents the range of capabilities of the individual component links such that functional requirements are met, and also minimizes the frequency of advertisement updates which may cause IGP convergence to occur.
Villamizar, et al. Expires August 10, 2014 [Page 12]

Internet-Draft Advanced Multipath Requirements February 2014
Examples of advertisement update triggering events to be considered include: client LSP establishment/release, changes in component link characteristics (e.g., latency, up/down state), and/or bandwidth utilization.
GR#7 When a worst case failure scenario occurs, the number of RSVP- TE client LSPs to be resignaled will cause a period of unavailability as perceived by users. The resignaling time of the solution MUST support protocol mechanisms meeting existing provider Performance Objective for the duration of unavailability without significantly relaxing those existing Performance Objectives for the same network or for networks with similar topology. For example, the processing load due to IGP readvertisement MUST NOT increase significantly and the resignaling time of the solution MUST NOT increase significantly as compared with current methods.
5. Management Requirements
MR#1 Management Plane MUST support polling of the status and configuration of an AMG and its individual component links and support notification of status change.
MR#2 Management Plane MUST be able to activate or de-activate any component link in an AMG in order to facilitate operation maintenance tasks. The routers at each end of an AMG MUST redistribute traffic to move traffic from a de-activated link to other component links based on the traffic flow TE criteria.
MR#3 Management Plane MUST be able to configure a client LSP over an AMG and be able to select a component link for the client LSP.
MR#4 Management Plane MUST be able to trace which component link a client LSP is assigned to and monitor individual component link and AMG performance.
MR#5 Management Plane MUST be able to verify connectivity over each individual component link within an AMG.
MR#6 Component link fault notification MUST be sent to the management plane.
MR#7 AMG fault notification MUST be sent to the management plane and MUST be distributed via link state message in the IGP.
MR#8 Management Plane SHOULD provide the means for an operator to initiate an optimization process.
Villamizar, et al. Expires August 10, 2014 [Page 13]

Internet-Draft Advanced Multipath Requirements February 2014
MR#9 An operator initiated optimization MUST be performed in a minimally disruptive manner as described in Section 3.5.
6. Acknowledgements
Frederic Jounay of France Telecom and Yuji Kamite of NTT Communications Corporation co-authored a version of this document.
A rewrite of this document occurred after the IETF77 meeting. Dimitri Papadimitriou, Lou Berger, Tony Li, the former WG chairs John Scuder and Alex Zinin, the current WG chair Alia Atlas, and others provided valuable guidance prior to and at the IETF77 RTGWG meeting.
Tony Li and John Drake have made numerous valuable comments on the RTGWG mailing list that are reflected in versions following the IETF77 meeting.
Iftekhar Hussain and Kireeti Kompella made comments on the RTGWG mailing list after IETF82 that identified a new requirement. Iftekhar Hussain made numerous valuable comments on the RTGWG mailing list that resulted in improvements to document clarity.
In the interest of full disclosure of affiliation and in the interest of acknowledging sponsorship, past affiliations of authors are noted. Much of the work done by Ning So occurred while Ning was at Verizon. Much of the work done by Curtis Villamizar occurred while at Infinera. Much of the work done by Andy Malis occurred while Andy was at Verizon.
Tom Yu and Francis Dupont provided the SecDir and GenArt reviews respectively. Both reviews provided useful comments. The current wording of the security section is based on suggested wording from Tom Yu. Lou Berger provided the RtgDir review which resulted in the document being renamed and substantial clarification of terminology and document wording, particularly in the Abstract, Introduction, and Definitions sections.
7. IANA Considerations
This memo includes no request to IANA.
8. Security Considerations
The security considerations for MPLS/GMPLS and for MPLS-TP are documented in [RFC5920] and [RFC6941]. This document does not impact the security of MPLS, GMPLS, or MPLS-TP.
Villamizar, et al. Expires August 10, 2014 [Page 14]

Internet-Draft Advanced Multipath Requirements February 2014
The additional information that this document requires does not provide significant additional value to an attacker beyond the information already typically available from attacking a routing or signaling protocol. If the requirements of this document are met by extending an existing routing or signaling protocol, the security considerations of the protocol being extended apply. If the requirements of this document are met by specifying a new protocol, the security considerations of that new protocol should include an evaluation of what level of protection is required by the additional information specified in this document, such as data origin authentication.
9. References
9.1. Normative References
[RFC2119] Bradner, S., "Key words for use in RFCs to Indicate Requirement Levels", BCP 14, RFC 2119, March 1997.
9.2. Informative References
[I-D.ietf-rtgwg-cl-framework] Ning, S., McDysan, D., Osborne, E., Yong, L., and C. Villamizar, "Advanced Multipath Framework in MPLS", draft- ietf-rtgwg-cl-framework-04 (work in progress), July 2013.
[I-D.ietf-rtgwg-cl-use-cases] Ning, S., Malis, A., McDysan, D., Yong, L., and C. Villamizar, "Advanced Multipath Use Cases and Design Considerations", draft-ietf-rtgwg-cl-use-cases-05 (work in progress), November 2013.
[IEEE-802.1AX] IEEE Standards Association, "IEEE Std 802.1AX-2008 IEEE Standard for Local and Metropolitan Area Networks - Link Aggregation", 2006, <http://standards.ieee.org/getieee802/ download/802.1AX-2008.pdf>.
[ITU-T.G.800] ITU-T, "Unified functional architecture of transport networks", 2007, <http://www.itu.int/rec/T-REC-G/ recommendation.asp?parent=T-REC-G.800>.
[RFC3468] Andersson, L. and G. Swallow, "The Multiprotocol Label Switching (MPLS) Working Group decision on MPLS signaling protocols", RFC 3468, February 2003.
Villamizar, et al. Expires August 10, 2014 [Page 15]

Internet-Draft Advanced Multipath Requirements February 2014
[RFC4201] Kompella, K., Rekhter, Y., and L. Berger, "Link Bundling in MPLS Traffic Engineering (TE)", RFC 4201, October 2005.
[RFC5920] Fang, L., "Security Framework for MPLS and GMPLS Networks", RFC 5920, July 2010.
[RFC6941] Fang, L., Niven-Jenkins, B., Mansfield, S., and R. Graveman, "MPLS Transport Profile (MPLS-TP) Security Framework", RFC 6941, April 2013.
Authors’ Addresses
Curtis Villamizar (editor) OCCNC, LLC
Email: [email protected]
Dave McDysan (editor) Verizon 22001 Loudoun County PKWY Ashburn, VA 20147 USA
Email: [email protected]
So Ning Tata Communications
Email: [email protected]
Andrew Malis Huawei Technologies
Email: [email protected]
Lucy Yong Huawei USA 5340 Legacy Dr. Plano, TX 75025 USA
Phone: +1 469-277-5837 Email: [email protected]
Villamizar, et al. Expires August 10, 2014 [Page 16]

Routing Area Working Group A. AtlasInternet-Draft C. BowersIntended status: Standards Track Juniper NetworksExpires: August 8, 2016 G. Enyedi Ericsson February 5, 2016
An Architecture for IP/LDP Fast-Reroute Using Maximally Redundant Trees draft-ietf-rtgwg-mrt-frr-architecture-10
Abstract
This document defines the architecture for IP and LDP Fast-Reroute using Maximally Redundant Trees (MRT-FRR). MRT-FRR is a technology that gives link-protection and node-protection with 100% coverage in any network topology that is still connected after the failure.
Status of This Memo
This Internet-Draft is submitted in full conformance with the provisions of BCP 78 and BCP 79.
Internet-Drafts are working documents of the Internet Engineering Task Force (IETF). Note that other groups may also distribute working documents as Internet-Drafts. The list of current Internet- Drafts is at http://datatracker.ietf.org/drafts/current/.
Internet-Drafts are draft documents valid for a maximum of six months and may be updated, replaced, or obsoleted by other documents at any time. It is inappropriate to use Internet-Drafts as reference material or to cite them other than as "work in progress."
This Internet-Draft will expire on August 8, 2016.
Copyright Notice
Copyright (c) 2016 IETF Trust and the persons identified as the document authors. All rights reserved.
This document is subject to BCP 78 and the IETF Trust’s Legal Provisions Relating to IETF Documents (http://trustee.ietf.org/license-info) in effect on the date of publication of this document. Please review these documents carefully, as they describe your rights and restrictions with respect to this document. Code Components extracted from this document must include Simplified BSD License text as described in Section 4.e of
Atlas, et al. Expires August 8, 2016 [Page 1]

Internet-Draft MRT Unicast FRR Architecture February 2016
the Trust Legal Provisions and are provided without warranty as described in the Simplified BSD License.
Table of Contents
1. Introduction . . . . . . . . . . . . . . . . . . . . . . . . 3 1.1. Importance of 100% Coverage . . . . . . . . . . . . . . . 4 1.2. Partial Deployment and Backwards Compatibility . . . . . 5 2. Requirements Language . . . . . . . . . . . . . . . . . . . . 5 3. Terminology . . . . . . . . . . . . . . . . . . . . . . . . . 5 4. Maximally Redundant Trees (MRT) . . . . . . . . . . . . . . . 7 5. Maximally Redundant Trees (MRT) and Fast-Reroute . . . . . . 9 6. Unicast Forwarding with MRT Fast-Reroute . . . . . . . . . . 9 6.1. Introduction to MRT Forwarding Options . . . . . . . . . 10 6.1.1. MRT LDP labels . . . . . . . . . . . . . . . . . . . 10 6.1.1.1. Topology-scoped FEC encoded using a single label (Option 1A) . . . . . . . . . . . . . . . . . . . 10 6.1.1.2. Topology and FEC encoded using a two label stack (Option 1B) . . . . . . . . . . . . . . . . . . . 11 6.1.1.3. Compatibility of MRT LDP Label Options 1A and 1B 12 6.1.1.4. Required support for MRT LDP Label options . . . 12 6.1.2. MRT IP tunnels (Options 2A and 2B) . . . . . . . . . 12 6.2. Forwarding LDP Unicast Traffic over MRT Paths . . . . . . 13 6.2.1. Forwarding LDP traffic using MRT LDP Label Option 1A 13 6.2.2. Forwarding LDP traffic using MRT LDP Label Option 1B 14 6.2.3. Other considerations for forwarding LDP traffic using MRT LDP Labels . . . . . . . . . . . . . . . . . . . 14 6.2.4. Required support for LDP traffic . . . . . . . . . . 14 6.3. Forwarding IP Unicast Traffic over MRT Paths . . . . . . 14 6.3.1. Tunneling IP traffic using MRT LDP Labels . . . . . . 15 6.3.1.1. Tunneling IP traffic using MRT LDP Label Option 1A . . . . . . . . . . . . . . . . . . . . . . . 15 6.3.1.2. Tunneling IP traffic using MRT LDP Label Option 1B . . . . . . . . . . . . . . . . . . . . . . . 15 6.3.2. Tunneling IP traffic using MRT IP Tunnels . . . . . . 16 6.3.3. Required support for IP traffic . . . . . . . . . . . 16 7. MRT Island Formation . . . . . . . . . . . . . . . . . . . . 16 7.1. IGP Area or Level . . . . . . . . . . . . . . . . . . . . 17 7.2. Support for a specific MRT profile . . . . . . . . . . . 17 7.3. Excluding additional routers and interfaces from the MRT Island . . . . . . . . . . . . . . . . . . . . . . . . . 18 7.3.1. Existing IGP exclusion mechanisms . . . . . . . . . . 18 7.3.2. MRT-specific exclusion mechanism . . . . . . . . . . 19 7.4. Connectivity . . . . . . . . . . . . . . . . . . . . . . 19 7.5. Algorithm for MRT Island Identification . . . . . . . . . 19 8. MRT Profile . . . . . . . . . . . . . . . . . . . . . . . . . 19 8.1. MRT Profile Options . . . . . . . . . . . . . . . . . . . 19 8.2. Router-specific MRT paramaters . . . . . . . . . . . . . 21
Atlas, et al. Expires August 8, 2016 [Page 2]

Internet-Draft MRT Unicast FRR Architecture February 2016
8.3. Default MRT profile . . . . . . . . . . . . . . . . . . . 21 9. LDP signaling extensions and considerations . . . . . . . . . 22 10. Inter-area Forwarding Behavior . . . . . . . . . . . . . . . 22 10.1. ABR Forwarding Behavior with MRT LDP Label Option 1A . . 23 10.1.1. Motivation for Creating the Rainbow-FEC . . . . . . 24 10.2. ABR Forwarding Behavior with IP Tunneling (option 2) . . 24 10.3. ABR Forwarding Behavior with MRT LDP Label option 1B . . 25 11. Prefixes Multiply Attached to the MRT Island . . . . . . . . 26 11.1. Protecting Multi-Homed Prefixes using Tunnel Endpoint Selection . . . . . . . . . . . . . . . . . . . . . . . 28 11.2. Protecting Multi-Homed Prefixes using Named Proxy-Nodes 29 11.3. MRT Alternates for Destinations Outside the MRT Island . 31 12. Network Convergence and Preparing for the Next Failure . . . 31 12.1. Micro-loop prevention and MRTs . . . . . . . . . . . . . 32 12.2. MRT Recalculation for the Default MRT Profile . . . . . 33 13. Implementation Status . . . . . . . . . . . . . . . . . . . . 34 14. Operational Considerations . . . . . . . . . . . . . . . . . 35 14.1. Verifying Forwarding on MRT Paths . . . . . . . . . . . 35 14.2. Traffic Capacity on Backup Paths . . . . . . . . . . . . 36 14.3. MRT IP Tunnel Loopback Address Management . . . . . . . 38 14.4. MRT-FRR in a Network with Degraded Connectivity . . . . 38 14.5. Partial Deployment of MRT-FRR in a Network . . . . . . . 38 15. Acknowledgements . . . . . . . . . . . . . . . . . . . . . . 39 16. IANA Considerations . . . . . . . . . . . . . . . . . . . . . 39 17. Security Considerations . . . . . . . . . . . . . . . . . . . 40 18. Contributors . . . . . . . . . . . . . . . . . . . . . . . . 40 19. References . . . . . . . . . . . . . . . . . . . . . . . . . 41 19.1. Normative References . . . . . . . . . . . . . . . . . . 41 19.2. Informative References . . . . . . . . . . . . . . . . . 42 Appendix A. Inter-level Forwarding Behavior for IS-IS . . . . . 43 Appendix B. General Issues with Area Abstraction . . . . . . . . 44 Authors’ Addresses . . . . . . . . . . . . . . . . . . . . . . . 45
1. Introduction
This document describes a solution for IP/LDP fast-reroute [RFC5714]. MRT-FRR creates two alternate forwarding trees which are distinct from the primary next-hop forwarding used during stable operation. These two trees are maximally diverse from each other, providing link and node protection for 100% of paths and failures as long as the failure does not cut the network into multiple pieces. This document defines the architecture for IP/LDP fast-reroute with MRT.
[I-D.ietf-rtgwg-mrt-frr-algorithm] describes how to compute maximally redundant trees using a specific algorithm, the MRT Lowpoint algorithm. The MRT Lowpoint algorithm is used by a router that supports the Default MRT Profile, as specified in this document.
Atlas, et al. Expires August 8, 2016 [Page 3]

Internet-Draft MRT Unicast FRR Architecture February 2016
IP/LDP Fast-Reroute with MRT (MRT-FRR) uses two maximally diverse forwarding topologies to provide alternates. A primary next-hop should be on only one of the diverse forwarding topologies; thus, the other can be used to provide an alternate. Once traffic has been moved to one of the MRTs by one point of local repair (PLR), that traffic is not subject to further repair actions by another PLR, even in the event of multiple simultaneous failures. Therefore, traffic repaired by MRT-FRR will not loop between different PLRs responding to different simultaneous failures.
While MRT provides 100% protection for a single link or node failure, it may not protect traffic in the event of multiple simultaneous failures, nor does take into account Shared Risk Link Groups (SRLGs). Also, while the MRT Lowpoint algorithm is computationally efficient, it is also new. In order for MRT-FRR to function properly, all of the other nodes in the network that support MRT must correctly compute next-hops based on the same algorithm, and install the corresponding forwarding state. This is in contrast to other FRR methods where the calculation of backup paths generally involves repeated application of the simpler and widely-deployed shortest path first (SPF) algorithm, and backup paths themselves re-use the forwarding state used for shortest path forwarding of normal traffic. Section 14 provides operational guidance related to verification of MRT forwarding paths.
In addition to supporting IP and LDP unicast fast-reroute, the diverse forwarding topologies and guarantee of 100% coverage permit fast-reroute technology to be applied to multicast traffic as described in [I-D.atlas-rtgwg-mrt-mc-arch]. However, the current document does not address the multicast applications of MRTs.
1.1. Importance of 100% Coverage
Fast-reroute is based upon the single failure assumption - that the time between single failures is long enough for a network to reconverge and start forwarding on the new shortest paths. That does not imply that the network will only experience one failure or change.
It is straightforward to analyze a particular network topology for coverage. However, a real network does not always have the same topology. For instance, maintenance events will take links or nodes out of use. Simply costing out a link can have a significant effect on what loop-free alternates (LFAs) are available. Similarly, after a single failure has happened, the topology is changed and its associated coverage. Finally, many networks have new routers or links added and removed; each of those changes can have an effect on the coverage for topology-sensitive methods such as LFA and Remote
Atlas, et al. Expires August 8, 2016 [Page 4]

Internet-Draft MRT Unicast FRR Architecture February 2016
LFA. If fast-reroute is important for the network services provided, then a method that guarantees 100% coverage is important to accommodate natural network topology changes.
When a network needs to use Ordered FIB[RFC6976] or Nearside Tunneling[RFC5715] as a micro-loop prevention mechanism [RFC5715], then the whole IGP area needs to have alternates available. This allows the micro-loop prevention mechanism, which requires slower network convergence, to take the necessary time without adversely impacting traffic. Without complete coverage, traffic to the unprotected destinations will be dropped for significantly longer than with current convergence - where routers individually converge as fast as possible. See Section 12.1 for more discussion of micro- loop prevention and MRTs.
1.2. Partial Deployment and Backwards Compatibility
MRT-FRR supports partial deployment. Routers advertise their ability to support MRT. Inside the MRT-capable connected group of routers (referred to as an MRT Island), the MRTs are computed. Alternates to destinations outside the MRT Island are computed and depend upon the existence of a loop-free neighbor of the MRT Island for that destination. MRT Islands are discussed in detail in Section 7, and partial deployment is discussed in more detail in Section 14.5.
2. Requirements Language
The key words "MUST", "MUST NOT", "REQUIRED", "SHALL", "SHALL NOT", "SHOULD", "SHOULD NOT", "RECOMMENDED", "MAY", and "OPTIONAL" in this document are to be interpreted as described in [RFC2119].
3. Terminology
network graph: A graph that reflects the network topology where all links connect exactly two nodes and broadcast links have been transformed into the standard pseudo-node representation.
cut-link: A link whose removal partitions the network. A cut-link by definition must be connected between two cut-vertices. If there are multiple parallel links, then they are referred to as cut-links in this document if removing the set of parallel links would partition the network graph.
cut-vertex: A vertex whose removal partitions the network graph.
2-connected: A graph that has no cut-vertices. This is a graph that requires two nodes to be removed before the network is partitioned.
Atlas, et al. Expires August 8, 2016 [Page 5]

Internet-Draft MRT Unicast FRR Architecture February 2016
2-connected cluster: A maximal set of nodes that are 2-connected.
block: Either a 2-connected cluster, a cut-edge, or an isolated vertex.
Redundant Trees (RT): A pair of trees where the path from any node X to the root R along the first tree is node-disjoint with the path from the same node X to the root along the second tree. Redundant trees can always be computed in 2-connected graphs.
Maximally Redundant Trees (MRT): A pair of trees where the path from any node X to the root R along the first tree and the path from the same node X to the root along the second tree share the minimum number of nodes and the minimum number of links. Each such shared node is a cut-vertex. Any shared links are cut-links. In graphs that are not 2-connected, it is not possible to compute RTs. However, it is possible to compute MRTs. MRTs are maximally redundant in the sense that they are as redundant as possible given the constraints of the network graph.
Directed Acyclic Graph (DAG): A graph where all links are directed and there are no cycles in it.
Almost Directed Acyclic Graph (ADAG): A graph with one node designated as the root. The graph has the property that if all links incoming to the root were removed, then resulting graph would be a DAG.
Generalized ADAG (GADAG): A graph that is the combination of the ADAGs of all blocks.
MRT-Red: MRT-Red is used to describe one of the two MRTs; it is used to describe the associated forwarding topology and MPLS multi-topology identifier (MT-ID). Specifically, MRT-Red is the decreasing MRT where links in the GADAG are taken in the direction from a higher topologically ordered node to a lower one.
MRT-Blue: MRT-Blue is used to describe one of the two MRTs; it is used to described the associated forwarding topology and MPLS MT- ID. Specifically, MRT-Blue is the increasing MRT where links in the GADAG are taken in the direction from a lower topologically ordered node to a higher one.
Rainbow MRT: It is useful to have an MPLS MT-ID that refers to the multiple MRT forwarding topologies and to the default forwarding topology. This is referred to as the Rainbow MRT MPLS MT-ID and is used by LDP to reduce signaling and permit the same label to always be advertised to all peers for the same (MT-ID, Prefix).
Atlas, et al. Expires August 8, 2016 [Page 6]

Internet-Draft MRT Unicast FRR Architecture February 2016
MRT Island: The set of routers that support a particular MRT profile and the links connecting them that support MRT.
Island Border Router (IBR): A router in the MRT Island that is connected to a router not in the MRT Island and both routers are in a common area or level.
Island Neighbor (IN): A router that is not in the MRT Island but is adjacent to an IBR and in the same area/level as the IBR.
named proxy-node: A proxy-node can represent a destination prefix that can be attached to the MRT Island via at least two routers. It is named if there is a way that traffic can be encapsulated to reach specifically that proxy node; this could be because there is an LDP FEC (Forwarding Equivalence Class) for the associated prefix or because MRT-Red and MRT-Blue IP addresses are advertised in an undefined fashion for that proxy-node.
4. Maximally Redundant Trees (MRT)
A pair of Maximally Redundant Trees is a pair of directed spanning trees that provides maximally disjoint paths towards their common root. Only links or nodes whose failure would partition the network (i.e. cut-links and cut-vertices) are shared between the trees. The MRT Lowpoint algorithm is given in [I-D.ietf-rtgwg-mrt-frr-algorithm]. This algorithm can be computed in O(e + n log n); it is less than three SPFs. This document describes how the MRTs can be used and not how to compute them.
MRT provides destination-based trees for each destination. Each router stores its normal primary next-hop(s) as well as MRT-Blue next-hop(s) and MRT-Red next-hop(s) toward each destination. The alternate will be selected between the MRT-Blue and MRT-Red.
The most important thing to understand about MRTs is that for each pair of destination-routed MRTs, there is a path from every node X to the destination D on the Blue MRT that is as disjoint as possible from the path on the Red MRT.
For example, in Figure 1, there is a network graph that is 2-connected in (a) and associated MRTs in (b) and (c). One can consider the paths from B to R; on the Blue MRT, the paths are B->F->D->E->R or B->C->D->E->R. On the Red MRT, the path is B->A->R. These are clearly link and node-disjoint. These MRTs are redundant trees because the paths are disjoint.
Atlas, et al. Expires August 8, 2016 [Page 7]

Internet-Draft MRT Unicast FRR Architecture February 2016
[E]---[D]---| [E]<--[D]<--| [E]-->[D]---| | | | | ^ | | | | | | V | | V V [R] [F] [C] [R] [F] [C] [R] [F] [C] | | | ^ ^ ^ | | | | | | | | V | [A]---[B]---| [A]-->[B]---| [A]<--[B]<--|
(a) (b) (c) a 2-connected graph Blue MRT towards R Red MRT towards R
Figure 1: A 2-connected Network
By contrast, in Figure 2, the network in (a) is not 2-connected. If F, G or the link F<->G failed, then the network would be partitioned. It is clearly impossible to have two link-disjoint or node-disjoint paths from G, I or J to R. The MRTs given in (b) and (c) offer paths that are as disjoint as possible. For instance, the paths from B to R are the same as in Figure 1 and the path from G to R on the Blue MRT is G->F->D->E->R and on the Red MRT is G->F->B->A->R.
[E]---[D]---| | | | |----[I] | | | | | [R]---[C] [F]---[G] | | | | | | | | | |----[J] [A]---[B]---|
(a) a non-2-connected graph
[E]<--[D]<--| [E]-->[D] | ^ | [I] | |----[I] V | | | V V ^ [R] [C] [F]<--[G] | [R]<--[C] [F]<--[G] | ^ ^ ^ V ^ | | | | |----[J] | | [J] [A]-->[B]---| [A]<--[B]<--|
(b) (c) Blue MRT towards R Red MRT towards R
Figure 2: A non-2-connected network
Atlas, et al. Expires August 8, 2016 [Page 8]

Internet-Draft MRT Unicast FRR Architecture February 2016
5. Maximally Redundant Trees (MRT) and Fast-Reroute
In normal IGP routing, each router has its shortest path tree (SPT) to all destinations. From the perspective of a particular destination, D, this looks like a reverse SPT. To use maximally redundant trees, in addition, each destination D has two MRTs associated with it; by convention these will be called the MRT-Blue and MRT-Red. MRT-FRR is realized by using multi-topology forwarding. There is a MRT-Blue forwarding topology and a MRT-Red forwarding topology.
Any IP/LDP fast-reroute technique beyond LFA requires an additional dataplane procedure, such as an additional forwarding mechanism. The well-known options are multi-topology forwarding (used by MRT-FRR), tunneling (e.g. [RFC6981] or [RFC7490]), and per-interface forwarding (e.g. Loop-Free Failure Insensitive Routing in [EnyediThesis]).
When there is a link or node failure affecting, but not partitioning, the network, each node will still have at least one path via one of the MRTs to reach the destination D. For example, in Figure 2, C would normally forward traffic to R across the C<->R link. If that C<->R link fails, then C could use the Blue MRT path C->D->E->R.
As is always the case with fast-reroute technologies, forwarding does not change until a local failure is detected. Packets are forwarded along the shortest path. The appropriate alternate to use is pre- computed. [I-D.ietf-rtgwg-mrt-frr-algorithm] describes exactly how to determine whether the MRT-Blue next-hops or the MRT-Red next-hops should be the MRT alternate next-hops for a particular primary next- hop to a particular destination.
MRT alternates are always available to use. It is a local decision whether to use an MRT alternate, a Loop-Free Alternate or some other type of alternate.
As described in [RFC5286], when a worse failure than is anticipated happens, using LFAs that are not downstream neighbors can cause looping among alternates. Section 1.1 of [RFC5286] gives an example of link-protecting alternates causing a loop on node failure. Even if a worse failure than anticipated happens, the use of MRT alternates will not cause looping.
6. Unicast Forwarding with MRT Fast-Reroute
There are three possible types of routers involved in forwarding a packet along an MRT path. At the MRT ingress router, the packet leaves the shortest path to the destination and follows an MRT path
Atlas, et al. Expires August 8, 2016 [Page 9]

Internet-Draft MRT Unicast FRR Architecture February 2016
to the destination. In an FRR application, the MRT ingress router is the PLR. An MRT transit router takes a packet that arrives already associated with the particular MRT, and forwards it on that same MRT. In some situations (to be discussed later), the packet will need to leave the MRT path and return to the shortest path. This takes place at the MRT egress router. The MRT ingress and egress functionality may depend on the underlying type of packet being forwarded (LDP or IP). The MRT transit functionality is independent of the type of packet being forwarded. We first consider several MRT transit forwarding mechanisms. Then we look at how these forwarding mechanisms can be applied to carrying LDP and IP traffic.
6.1. Introduction to MRT Forwarding Options
The following options for MRT forwarding mechanisms are considered.
1. MRT LDP Labels
A. Topology-scoped FEC encoded using a single label
B. Topology and FEC encoded using a two label stack
2. MRT IP Tunnels
A. MRT IPv4 Tunnels
B. MRT IPv6 Tunnels
6.1.1. MRT LDP labels
We consider two options for the MRT forwarding mechanisms using MRT LDP labels.
6.1.1.1. Topology-scoped FEC encoded using a single label (Option 1A)
[RFC7307] provides a mechanism to distribute FEC-Label bindings scoped to a given MPLS topology (represented by MPLS MT-ID). To use multi-topology LDP to create MRT forwarding topologies, we associate two MPLS MT-IDs with the MRT-Red and MRT-Blue forwarding topologies, in addition to the default shortest path forwarding topology with MT- ID=0.
With this forwarding mechanism, a single label is distributed for each topology-scoped FEC. For a given FEC in the default topology (call it default-FEC-A), two additional topology-scoped FECs would be created, corresponding to the Red and Blue MRT forwarding topologies (call them red-FEC-A and blue-FEC-A). A router supporting this MRT transit forwarding mechanism advertises a different FEC-label binding
Atlas, et al. Expires August 8, 2016 [Page 10]

Internet-Draft MRT Unicast FRR Architecture February 2016
for each of the three topology-scoped FECs. When a packet is received with a label corresponding to red-FEC-A (for example), an MRT transit router will determine the next-hop for the MRT-Red forwarding topology for that FEC, swap the incoming label with the outgoing label corresponding to red-FEC-A learned from the MRT-Red next-hop router, and forward the packet.
This forwarding mechanism has the useful property that the FEC associated with the packet is maintained in the labels at each hop along the MRT. We will take advantage of this property when specifying how to carry LDP traffic on MRT paths using multi-topology LDP labels.
This approach is very simple for hardware to support. However, it reduces the label space for other uses, and it increases the memory needed to store the labels and the communication required by LDP to distribute FEC-label bindings. In general, this approach will also increase the time needed to install the FRR entries in the Forwarding Information Base (FIB) and hence the time needed before the next failure can be protected.
This forwarding option uses the LDP signaling extensions described in [RFC7307]. The MRT-specific LDP extensions required to support this option will be described elsewhere.
6.1.1.2. Topology and FEC encoded using a two label stack (Option 1B)
With this forwarding mechanism, a two label stack is used to encode the topology and the FEC of the packet. The top label (topology-id label) identifies the MRT forwarding topology, while the second label (FEC label) identifies the FEC. The top label would be a new FEC type with two values corresponding to MRT Red and Blue topologies.
When an MRT transit router receives a packet with a topology-id label, the router pops the top label and uses that it to guide the next-hop selection in combination with the next label in the stack (the FEC label). The router then swaps the FEC label, using the FEC- label bindings learned through normal LDP mechanisms. The router then pushes the topology-id label for the next-hop.
As with Option 1A, this forwarding mechanism also has the useful property that the FEC associated with the packet is maintained in the labels at each hop along the MRT.
This forwarding mechanism has minimal usage of additional labels, memory and LDP communication. It does increase the size of packets and the complexity of the required label operations and look-ups.
Atlas, et al. Expires August 8, 2016 [Page 11]

Internet-Draft MRT Unicast FRR Architecture February 2016
This forwarding option is consistent with context-specific label spaces, as described in [RFC5331]. However, the precise LDP behavior required to support this option for MRT has not been specified.
6.1.1.3. Compatibility of MRT LDP Label Options 1A and 1B
MRT transit forwarding based on MRT LDP Label options 1A and 1B can coexist in the same network, with a packet being forwarded along a single MRT path using the single label of option 1A for some hops and the two label stack of option 1B for other hops. However, to simplify the process of MRT Island formation we require that all routers in the MRT Island support at least one common forwarding mechanism. As an example, the Default MRT Profile requires support for the MRT LDP Label Option 1A forwarding mechanism. This ensures that the routers in an MRT island supporting the Default MRT Profile will be able to establish MRT forwarding paths based on MRT LDP Label Option 1A. However, an implementation supporting Option 1A may also support Option 1B. If the scaling or performance characteristics for the two options differ in this implementation, then it may be desirable for a pair of adjacent routers to use Option 1B labels instead of the Option 1A labels. If those routers successfully negotiate the use of Option 1B labels, they are free to use them. This can occur without any of the other routers in the MRT Island being made aware of it.
Note that this document only defines the Default MRT Profile which requires support for the MRT LDP Label Option 1A forwarding mechanism.
6.1.1.4. Required support for MRT LDP Label options
If a router supports a profile that includes the MRT LDP Label Option 1A for the MRT transit forwarding mechanism, then it MUST support option 1A, which encodes topology-scoped FECs using a single label. The router MAY also support option 1B.
If a router supports a profile that includes the MRT LDP Label Option 1B for the MRT transit forwarding mechanism, then it MUST support option 1B, which encodes the topology and FEC using a two label stack. The router MAY also support option 1A.
6.1.2. MRT IP tunnels (Options 2A and 2B)
IP tunneling can also be used as an MRT transit forwarding mechanism. Each router supporting this MRT transit forwarding mechanism announces two additional loopback addresses and their associated MRT color. Those addresses are used as destination addresses for MRT- blue and MRT-red IP tunnels respectively. The special loopback
Atlas, et al. Expires August 8, 2016 [Page 12]

Internet-Draft MRT Unicast FRR Architecture February 2016
addresses allow the transit nodes to identify the traffic as being forwarded along either the MRT-blue or MRT-red topology to reach the tunnel destination. For example, an MRT ingress router can cause a packet to be tunneled along the MRT-red path to router X by encapsulating the packet using the MRT-red loopback address advertised by router X. Upon receiving the packet, router X would remove the encapsulation header and forward the packet based on the original destination address.
Either IPv4 (option 2A) or IPv6 (option 2B) can be used as the tunneling mechanism.
Note that the two forwarding mechanisms using LDP Label options do not require additional loopbacks per router, as is required by the IP tunneling mechanism. This is because LDP labels are used on a hop- by-hop basis to identify MRT-blue and MRT-red forwarding topologies.
6.2. Forwarding LDP Unicast Traffic over MRT Paths
In the previous section, we examined several options for providing MRT transit forwarding functionality, which is independent of the type of traffic being carried. We now look at the MRT ingress functionality, which will depend on the type of traffic being carried (IP or LDP). We start by considering LDP traffic.
We also simplify the initial discussion by assuming that the network consists of a single IGP area, and that all routers in the network participate in MRT. Other deployment scenarios that require MRT egress functionality are considered later in this document.
In principle, it is possible to carry LDP traffic in MRT IP tunnels. However, for LDP traffic, it is desirable to avoid tunneling. Tunneling LDP traffic to a remote node requires knowledge of remote FEC-label bindings so that the LDP traffic can continue to be forwarded properly when it leaves the tunnel. This requires targeted LDP sessions which can add management complexity. As described below, the two MRT forwarding mechanisms that use LDP labels do not require targeted LDP sessions.
6.2.1. Forwarding LDP traffic using MRT LDP Label Option 1A
The MRT LDP Label option 1A forwarding mechanism uses topology-scoped FECs encoded using a single label as described in section Section 6.1.1.1. When a PLR receives an LDP packet that needs to be forwarded on the Red MRT (for example), it does a label swap operation, replacing the usual LDP label for the FEC with the Red MRT label for that FEC received from the next-hop router in the Red MRT computed by the PLR. When the next-hop router in the Red MRT
Atlas, et al. Expires August 8, 2016 [Page 13]

Internet-Draft MRT Unicast FRR Architecture February 2016
receives the packet with the Red MRT label for the FEC, the MRT transit forwarding functionality continues as described in Section 6.1.1.1. In this way the original FEC associated with the packet is maintained at each hop along the MRT.
6.2.2. Forwarding LDP traffic using MRT LDP Label Option 1B
The MRT LDP Label option 1B forwarding mechanism encodes the topology and the FEC using a two label stack as described in Section 6.1.1.2. When a PLR receives an LDP packet that needs to be forwarded on the Red MRT, it first does a normal LDP label swap operation, replacing the incoming normal LDP label associated with a given FEC with the outgoing normal LDP label for that FEC learned from the next-hop on the Red MRT. In addition, the PLR pushes the topology-identification label associated with the Red MRT, and forward the packet to the appropriate next-hop on the Red MRT. When the next-hop router in the Red MRT receives the packet with the Red MRT label for the FEC, the MRT transit forwarding functionality continues as described in Section 6.1.1.2. As with option 1A, the original FEC associated with the packet is maintained at each hop along the MRT.
6.2.3. Other considerations for forwarding LDP traffic using MRT LDP Labels
Note that forwarding LDP traffic using MRT LDP Labels can be done without the use of targeted LDP sessions when an MRT path to the destination FEC is used. The alternates selected in [I-D.ietf-rtgwg-mrt-frr-algorithm] use the MRT path to the destination FEC, so targeted LDP sessions are not needed. If instead one found it desirable to have the PLR use an MRT to reach the primary next-next-hop for the FEC, and then continue forwarding the LDP packet along the shortest path tree from the primary next-next- hop, this would require tunneling to the primary next-next-hop and a targeted LDP session for the PLR to learn the FEC-label binding for primary next-next-hop to correctly forward the packet.
6.2.4. Required support for LDP traffic
For greatest hardware compatibility, routers implementing MRT fast- reroute of LDP traffic MUST support Option 1A of encoding the MT-ID in the labels (See Section 9).
6.3. Forwarding IP Unicast Traffic over MRT Paths
For IPv4 traffic, there is no currently practical alternative except tunneling to gain the bits needed to indicate the MRT-Blue or MRT-Red forwarding topology. For IPv6 traffic, in principle one could define bits in the IPv6 options header to indicate the MRT-Blue or MRT-Red
Atlas, et al. Expires August 8, 2016 [Page 14]

Internet-Draft MRT Unicast FRR Architecture February 2016
forwarding topology. However, in this document, we have chosen not to define a solution that would work for IPv6 traffic but not for IPv4 traffic.
The choice of tunnel egress is flexible since any router closer to the destination than the next-hop can work. This architecture assumes that the original destination in the area is selected (see Section 11 for handling of multi-homed prefixes); another possible choice is the next-next-hop towards the destination. As discussed in the previous section, for LDP traffic, using the MRT to the original destination simplifies MRT-FRR by avoiding the need for targeted LDP sessions to the next-next-hop. For IP, that consideration doesn’t apply.
Some situations require tunneling IP traffic along an MRT to a tunnel endpoint that is not the destination of the IP traffic. These situations will be discussed in detail later. We note here that an IP packet with a destination in a different IGP area/level from the PLR should be tunneled on the MRT to the Area Border Router (ABR) or Level Border Router (LBR) on the shortest path to the destination. For a destination outside of the PLR’s MRT Island, the packet should be tunneled on the MRT to a non-proxy-node immediately before the named proxy-node on that particular color MRT.
6.3.1. Tunneling IP traffic using MRT LDP Labels
An IP packet can be tunneled along an MRT path by pushing the appropriate MRT LDP label(s). Tunneling using LDP labels, as opposed to IP headers, has the the advantage that more installed routers can do line-rate encapsulation and decapsulation using LDP than using IP. Also, no additional IP addresses would need to be allocated or signaled.
6.3.1.1. Tunneling IP traffic using MRT LDP Label Option 1A
The MRT LDP Label option 1A forwarding mechanism uses topology-scoped FECs encoded using a single label as described in section Section 6.1.1.1. When a PLR receives an IP packet that needs to be forwarded on the Red MRT to a particular tunnel endpoint, it does a label push operation. The label pushed is the Red MRT label for a FEC originated by the tunnel endpoint, learned from the next-hop on the Red MRT.
6.3.1.2. Tunneling IP traffic using MRT LDP Label Option 1B
The MRT LDP Label option 1B forwarding mechanism encodes the topology and the FEC using a two label stack as described in Section 6.1.1.2. When a PLR receives an IP packet that needs to be forwarded on the
Atlas, et al. Expires August 8, 2016 [Page 15]

Internet-Draft MRT Unicast FRR Architecture February 2016
Red MRT to a particular tunnel endpoint, the PLR pushes two labels on the IP packet. The first (inner) label is the normal LDP label learned from the next-hop on the Red MRT, associated with a FEC originated by the tunnel endpoint. The second (outer) label is the topology-identification label associated with the Red MRT.
For completeness, we note here a potential variation that uses a single label as opposed to two labels. In order to tunnel an IP packet over an MRT to the destination of the IP packet (as opposed to an arbitrary tunnel endpoint), then we could just push a topology- identification label directly onto the packet. An MRT transit router would need to pop the topology-id label, do an IP route lookup in the context of that topology-id , and push the topology-id label.
6.3.2. Tunneling IP traffic using MRT IP Tunnels
In order to tunnel over the MRT to a particular tunnel endpoint, the PLR encapsulates the original IP packet with an additional IP header using the MRT-Blue or MRT-Red loopack address of the tunnel endpoint.
6.3.3. Required support for IP traffic
For greatest hardware compatibility and ease in removing the MRT- topology marking at area/level boundaries, routers that support MPLS and implement IP MRT fast-reroute MUST support tunneling of IP traffic using MRT LDP Label Option 1A (topology-scoped FEC encoded using a single label).
7. MRT Island Formation
The purpose of communicating support for MRT is to indicate that the MRT-Blue and MRT-Red forwarding topologies are created for transit traffic. The MRT architecture allows for different, potentially incompatible options. In order to create consistent MRT forwarding topologies, the routers participating in a particular MRT Island need to use the same set of options. These options are grouped into MRT profiles. In addition, the routers in an MRT Island all need to use the same set of nodes and links within the Island when computing the MRT forwarding topologies. This section describes the information used by a router to determine the nodes and links to include in a particular MRT Island. Some information already exists in the IGPs and can be used by MRT in Island formation, subject to the interpretation defined here.
Other information needs to be communicated between routers for which there do not currently exist protocol extensions. This new information needs to be shared among all routers in an IGP area, so
Atlas, et al. Expires August 8, 2016 [Page 16]

Internet-Draft MRT Unicast FRR Architecture February 2016
defining extensions to existing IGPs to carry this information makes sense. These new protocol extensions will be defined elsewhere.
Deployment scenarios using multi-topology OSPF or IS-IS, or running both IS-IS and OSPF on the same routers is out of scope for this specification. As with LFA, it is expected that OSPF Virtual Links will not be supported.
At a high level, an MRT Island is defined as the set of routers supporting the same MRT profile, in the same IGP area/level and the bi-directional links interconnecting those routers. More detailed descriptions of these criteria are given below.
7.1. IGP Area or Level
All links in an MRT Island are bidirectional and belong to the same IGP area or level. For IS-IS, a link belonging to both level 1 and level 2 would qualify to be in multiple MRT Islands. A given ABR or LBR can belong to multiple MRT Islands, corresponding to the areas or levels in which it participates. Inter-area forwarding behavior is discussed in Section 10.
7.2. Support for a specific MRT profile
All routers in an MRT Island support the same MRT profile. A router advertises support for a given MRT profile using an 8-bit MRT Profile ID value. The registry for the MRT Profile ID is defined in this document. The protocol extensions for advertising the MRT Profile ID value will be defined elsewhere. A given router can support multiple MRT profiles and participate in multiple MRT Islands. The options that make up an MRT profile, as well as the default MRT profile, are defined in Section 8.
The process of MRT Island formation takes place independently for each MRT profile advertised by a given router. For example, consider a network with 40 connected routers in the same area advertising support for MRT Profile A and MRT Profile B. Two distinct MRT Islands will be formed corresponding to Profile A and Profile B, with each island containing all 40 routers. A complete set of maximally redundant trees will be computed for each island following the rules defined for each profile. If we add a third MRT Profile to this example, with Profile C being advertised by a connected subset of 30 routers, there will be a third MRT Island formed corresponding to those 30 routers, and a third set of maximally redundant trees will be computed. In this example, 40 routers would compute and install two sets of MRT transit forwarding entries corresponding to Profiles A and B, while 30 routers would compute and install three sets of MRT transit forwarding entries corresponding to Profiles A, B, and C.
Atlas, et al. Expires August 8, 2016 [Page 17]

Internet-Draft MRT Unicast FRR Architecture February 2016
7.3. Excluding additional routers and interfaces from the MRT Island
MRT takes into account existing IGP mechanisms for discouraging traffic from using particular links and routers, and it introduces an MRT-specific exclusion mechanism for links.
7.3.1. Existing IGP exclusion mechanisms
Mechanisms for discouraging traffic from using particular links already exist in IS-IS and OSPF. In IS-IS, an interface configured with a metric of 2^24-2 (0xFFFFFE) will only be used as a last resort. (An interface configured with a metric of 2^24-1 (0xFFFFFF) will not be advertised into the topology.) In OSPF, an interface configured with a metric of 2^16-1 (0xFFFF) will only be used as a last resort. These metrics can be configured manually to enforce administrative policy, or they can be set in an automated manner as with LDP IGP synchronization [RFC5443].
Mechanisms also already exist in IS-IS and OSPF to discourage or prevent transit traffic from using a particular router. In IS-IS, the overload bit is prevents transit traffic from using a router.
For OSPFv2 and OSPFv3, [RFC6987] specifies setting all outgoing interface metrics to 0xFFFF to discourage transit traffic from using a router.( [RFC6987] defines the metric value 0xFFFF as MaxLinkMetric, a fixed architectural value for OSPF.) For OSPFv3, [RFC5340] specifies that a router be excluded from the intra-area shortest path tree computation if the V6-bit or R-bit of the LSA options is not set in the Router LSA.
The following rules for MRT Island formation ensure that MRT FRR protection traffic does not use a link or router that is discouraged or prevented from carrying traffic by existing IGP mechanisms.
1. A bidirectional link MUST be excluded from an MRT Island if either the forward or reverse cost on the link is 0xFFFFFE (for IS-IS) or 0xFFFF for OSPF.
2. A router MUST be excluded from an MRT Island if it is advertised with the overload bit set (for IS-IS), or it is advertised with metric values of 0xFFFF on all of its outgoing interfaces (for OSPFv2 and OSPFv3).
3. A router MUST be excluded from an MRT Island if it is advertised with either the V6-bit or R-bit of the LSA options not set in the Router LSA.
Atlas, et al. Expires August 8, 2016 [Page 18]

Internet-Draft MRT Unicast FRR Architecture February 2016
7.3.2. MRT-specific exclusion mechanism
This architecture also defines a means of excluding an otherwise usable link from MRT Islands. The protocol extensions for advertising that a link is MRT-Ineligible will be defined elsewhere. A link with either interface advertised as MRT-Ineligible MUST be excluded from an MRT Island. Note that an interface advertised as MRT-Ineligible by a router is ineligible with respect to all profiles advertised by that router.
7.4. Connectivity
All of the routers in an MRT Island MUST be connected by bidirectional links with other routers in the MRT Island. Disconnected MRT Islands will operate independently of one another.
7.5. Algorithm for MRT Island Identification
An algorithm that allows a computing router to identify the routers and links in the local MRT Island satisfying the above rules is given in section 5.2 of [I-D.ietf-rtgwg-mrt-frr-algorithm].
8. MRT Profile
An MRT Profile is a set of values and options related to MRT behavior. The complete set of options is designated by the corresponding 8-bit Profile ID value.
This document specifies the values and options that correspond to the Default MRT Profile (Profile ID = 0). Future documents may define other MRT Profiles by specifying the MRT Profile Options below.
8.1. MRT Profile Options
Below is a description of the values and options that define an MRT Profile.
MRT Algorithm: This identifies the particular algorithm for computing maximally redundant trees used by the router for this profile.
MRT-Red MT-ID: This specifies the MPLS MT-ID to be associated with the MRT-Red forwarding topology. It is allocated from the MPLS Multi-Topology Identifiers Registry.
MRT-Blue MT-ID: This specifies the MPLS MT-ID to be associated with the MRT-Blue forwarding topology. It is allocated from the MPLS Multi-Topology Identifiers Registry.
Atlas, et al. Expires August 8, 2016 [Page 19]

Internet-Draft MRT Unicast FRR Architecture February 2016
GADAG Root Selection Policy: This specifies the manner in which the GADAG root is selected. All routers in the MRT island need to use the same GADAG root in the calculations used construct the MRTs. A valid GADAG Root Selection Policy MUST be such that each router in the MRT island chooses the same GADAG root based on information available to all routers in the MRT island. GADAG Root Selection Priority values, advertised as router-specific MRT parameters, MAY be used in a GADAG Root Selection Policy.
MRT Forwarding Mechanism: This specifies which forwarding mechanism the router uses to carry transit traffic along MRT paths. A router which supports a specific MRT forwarding mechanism must program appropriate next-hops into the forwarding plane. The current options are MRT LDP Label Option 1A, MRT LDP Label Option 1B, IPv4 Tunneling, IPv6 Tunneling, and None. If IPv4 is supported, then both MRT-Red and MRT-Blue IPv4 Loopback Addresses SHOULD be specified. If IPv6 is supported, both MRT-Red and MRT- Blue IPv6 Loopback Addresses SHOULD be specified.
Recalculation: Recalculation specifies the process and timing by which new MRTs are computed after the topology has been modified.
Area/Level Border Behavior: This specifies how traffic traveling on the MRT-Blue or MRT-Red in one area should be treated when it passes into another area.
Other Profile-Specific Behavior: Depending upon the use-case for the profile, there may be additional profile-specific behavior.
When a new MRT Profile is defined, new and unique values should be allocated from the MPLS Multi-Topology Identifiers Registry, corresponding to the MRT-Red and MRT-Blue MT-ID values for the new MRT Profile .
If a router advertises support for multiple MRT profiles, then it MUST create the transit forwarding topologies for each of those, unless the profile specifies the None option for MRT Forwarding Mechanism.
The ability of MRT-FRR to support transit forwarding entries for multiple profiles can be used to facilitate a smooth transition from an existing deployed MRT Profile to a new MRT Profile. The new profile can be activated in parallel with the existing profile, installing the transit forwarding entries for the new profile without affecting the transit forwarding entries for the existing profile. Once the new transit forwarding state has been verified, the router can be configured to use the alternates computed by the new profile in the event of a failure.
Atlas, et al. Expires August 8, 2016 [Page 20]

Internet-Draft MRT Unicast FRR Architecture February 2016
8.2. Router-specific MRT paramaters
For some profiles, additional router-specific MRT parameters may need to be advertised. While the set of options indicated by the MRT Profile ID must be identical for all routers in an MRT Island, these router-specific MRT parameters may differ between routers in the same MRT island. Several such parameters are described below.
GADAG Root Selection Priority: A GADAG Root Selection Policy MAY rely on the GADAG Root Selection Priority values advertised by each router in the MRT island. A GADAG Root Selection Policy may use the GADAG Root Selection Priority to allow network operators to configure a parameter to ensure that the GADAG root is selected from a particular subset of routers. An example of this use of the GADAG Root Selection Priority value by the GADAG Root Selection Policy is given in the Default MRT profile below.
MRT-Red Loopback Address: This provides the router’s loopback address to reach the router via the MRT-Red forwarding topology. It can be specified for either IPv4 or IPv6. Note that this parameter is not needed to support the Default MRT profile.
MRT-Blue Loopback Address: This provides the router’s loopback address to reach the router via the MRT-Blue forwarding topology. It can be specified for either IPv4 and IPv6. Note that this parameter is not needed to support the Default MRT profile.
Protocol extensions for advertising a router’s GADAG Root Selection Priority value will be defined in other documents. Protocol extensions for the advertising a router’s MRT-Red and MRT-Blue Loopback Addresses will be defined elsewhere.
8.3. Default MRT profile
The following set of options defines the default MRT Profile. The default MRT profile is indicated by the MRT Profile ID value of 0.
MRT Algorithm: MRT Lowpoint algorithm defined in [I-D.ietf-rtgwg-mrt-frr-algorithm].
MRT-Red MPLS MT-ID: This value will be allocated from the MPLS Multi-Topology Identifiers Registry. The IANA request for this allocation will be in another document.
MRT-Blue MPLS MT-ID: This value will be allocated from the MPLS Multi-Topology Identifiers Registry. The IANA request for this allocation will be in another document.
Atlas, et al. Expires August 8, 2016 [Page 21]

Internet-Draft MRT Unicast FRR Architecture February 2016
GADAG Root Selection Policy: Among the routers in the MRT Island with the lowest numerical value advertised for GADAG Root Selection Priority, an implementation MUST pick the router with the highest Router ID to be the GADAG root. Note that a lower numerical value for GADAG Root Selection Priority indicates a higher preference for selection.
Forwarding Mechanisms: MRT LDP Label Option 1A
Recalculation: Recalculation of MRTs SHOULD occur as described in Section 12.2. This allows the MRT forwarding topologies to support IP/LDP fast-reroute traffic.
Area/Level Border Behavior: As described in Section 10, ABRs/LBRs SHOULD ensure that traffic leaving the area also exits the MRT-Red or MRT-Blue forwarding topology.
9. LDP signaling extensions and considerations
The protocol extensions for LDP will be defined in another document. A router must indicate that it has the ability to support MRT; having this explicit allows the use of MRT-specific processing, such as special handling of FECs sent with the Rainbow MRT MT-ID.
A FEC sent with the Rainbow MRT MT-ID indicates that the FEC applies to all the MRT-Blue and MRT-Red MT-IDs in supported MRT profiles. The FEC-label bindings for the default shortest-path based MT-ID 0 MUST still be sent (even though it could be inferred from the Rainbow FEC-label bindings) to ensure continuous operation of normal LDP forwarding. The Rainbow MRT MT-ID is defined to provide an easy way to handle the special signaling that is needed at ABRs or LBRs. It avoids the problem of needing to signal different MPLS labels to different LDP neighbors for the same FEC. Because the Rainbow MRT MT-ID is used only by ABRs/LBRs or an LDP egress router, it is not MRT profile specific.
The value of the Rainbow MRT MPLS MT-ID will be allocated from the MPLS Multi-Topology Identifiers Registry. The IANA request for this allocation will be in another document.
10. Inter-area Forwarding Behavior
An ABR/LBR has two forwarding roles. First, it forwards traffic within areas. Second, it forwards traffic from one area into another. These same two roles apply for MRT transit traffic. Traffic on MRT-Red or MRT-Blue destined inside the area needs to stay on MRT-Red or MRT-Blue in that area. However, it is desirable for
Atlas, et al. Expires August 8, 2016 [Page 22]

Internet-Draft MRT Unicast FRR Architecture February 2016
traffic leaving the area to also exit MRT-Red or MRT-Blue and return to shortest path forwarding.
For unicast MRT-FRR, the need to stay on an MRT forwarding topology terminates at the ABR/LBR whose best route is via a different area/ level. It is highly desirable to go back to the default forwarding topology when leaving an area/level. There are three basic reasons for this. First, the default topology uses shortest paths; the packet will thus take the shortest possible route to the destination. Second, this allows a single router failure that manifests itself in multiple areas (as would be the case with an ABR/LBR failure) to be separately identified and repaired around. Third, the packet can be fast-rerouted again, if necessary, due to a second distinct failure in a different area.
In OSPF, an ABR that receives a packet on MRT-Red or MRT-Blue towards destination Z should continue to forward the packet along MRT-Red or MRT-Blue only if the best route to Z is in the same OSPF area as the interface that the packet was received on. Otherwise, the packet should be removed from MRT-Red or MRT-Blue and forwarded on the shortest-path default forwarding topology.
The above description applies to OSPF. The same essential behavior also applies to IS-IS if one substitutes IS-IS level for OSPF area. However, the analogy with OSPF is not exact. An interface in OSPF can only be in one area, whereas an interface in IS-IS can be in both Level-1 and Level-2. Therefore, to avoid confusion and address this difference, we explicitly describe the behavior for IS-IS in Appendix A. In the following sections only the OSPF terminology is used.
10.1. ABR Forwarding Behavior with MRT LDP Label Option 1A
For LDP forwarding where a single label specifies (MT-ID, FEC), the ABR is responsible for advertising the proper label to each neighbor. Assume that an ABR has allocated three labels for a particular destination; those labels are L_primary, L_blue, and L_red. To those routers in the same area as the best route to the destination, the ABR advertises the following FEC-label bindings: L_primary for the default topology, L_blue for the MRT-Blue MT-ID and L_red for the MRT-Red MT-ID, as expected. However, to routers in other areas, the ABR advertises the following FEC-label bindings: L_primary for the default topology, and L_primary for the Rainbow MRT MT-ID. Associating L_primary with the Rainbow MRT MT-ID causes the receiving routers to use L_primary for the MRT-Blue MT-ID and for the MRT-Red MT-ID.
Atlas, et al. Expires August 8, 2016 [Page 23]

Internet-Draft MRT Unicast FRR Architecture February 2016
The ABR installs all next-hops for the best area: primary next-hops for L_primary, MRT-Blue next-hops for L_blue, and MRT-Red next-hops for L_red. Because the ABR advertised (Rainbow MRT MT-ID, FEC) with L_primary to neighbors not in the best area, packets from those neighbors will arrive at the ABR with a label L_primary and will be forwarded into the best area along the default topology. By controlling what labels are advertised, the ABR can thus enforce that packets exiting the area do so on the shortest-path default topology.
10.1.1. Motivation for Creating the Rainbow-FEC
The desired forwarding behavior could be achieved in the above example without using the Rainbow-FEC. This could be done by having the ABR advertise the following FEC-label bindings to neighbors not in the best area: L1_primary for the default topology, L1_primary for the MRT-Blue MT-ID, and L1_primary for the MRT-Red MT-ID. Doing this would require machinery to spoof the labels used in FEC-label binding advertisements on a per-neighbor basis. Such label-spoofing machinery does not currently exist in most LDP implementations and doesn’t have other obvious uses.
Many existing LDP implementations do however have the ability to filter FEC-label binding advertisements on a per-neighbor basis. The Rainbow-FEC allows us to re-use the existing per-neighbor FEC filtering machinery to achieve the desired result. By introducing the Rainbow FEC, we can use per-neighbor FEC-filtering machinery to advertise the FEC-label binding for the Rainbow-FEC (and filter those for MRT-Blue and MRT-Red) to non-best-area neighbors of the ABR.
An ABR may choose to either advertise the Rainbow-FEC or advertise separate MRT-Blue and MRT-Red advertisements. This is a local choice. A router that supports the MRT LDP Label Option 1A Forwarding Mechanism MUST be able to receive and correctly interpret the Rainbow-FEC.
10.2. ABR Forwarding Behavior with IP Tunneling (option 2)
If IP tunneling is used, then the ABR behavior is dependent upon the outermost IP address. If the outermost IP address is an MRT loopback address of the ABR, then the packet is decapsulated and forwarded based upon the inner IP address, which should go on the default SPT topology. If the outermost IP address is not an MRT loopback address of the ABR, then the packet is simply forwarded along the associated forwarding topology. A PLR sending traffic to a destination outside its local area/level will pick the MRT and use the associated MRT loopback address of the selected ABR advertising the lowest cost to the external destination.
Atlas, et al. Expires August 8, 2016 [Page 24]

Internet-Draft MRT Unicast FRR Architecture February 2016
Thus, for these two MRT Forwarding Mechanisms (MRT LDP Label option 1A and IP tunneling option 2), there is no need for additional computation or per-area forwarding state.
10.3. ABR Forwarding Behavior with MRT LDP Label option 1B
The other MRT forwarding mechanism described in Section 6 uses two labels, a topology-id label, and a FEC-label. This mechanism would require that any router whose MRT-Red or MRT-Blue next-hop is an ABR would need to determine whether the ABR would forward the packet out of the area/level. If so, then that router should pop off the topology-identification label before forwarding the packet to the ABR.
For example, in Figure 3, if node H fails, node E has to put traffic towards prefix p onto MRT-Red. But since node D knows that ABR1 will use a best route from another area, it is safe for D to pop the Topology-Identification Label and just forward the packet to ABR1 along the MRT-Red next-hop. ABR1 will use the shortest path in Area 10.
In all cases for IS-IS and most cases for OSPF, the penultimate router can determine what decision the adjacent ABR will make. The one case where it can’t be determined is when two ASBRs are in different non-backbone areas attached to the same ABR, then the ASBR’s Area ID may be needed for tie-breaking (prefer the route with the largest OPSF area ID) and the Area ID isn’t announced as part of the ASBR link-state advertisement (LSA). In this one case, suboptimal forwarding along the MRT in the other area would happen. If that becomes a realistic deployment scenario, protocol extensions could be developed to address this issue.
Atlas, et al. Expires August 8, 2016 [Page 25]

Internet-Draft MRT Unicast FRR Architecture February 2016
+----[C]---- --[D]--[E] --[D]--[E] | \ / \ / \ p--[A] Area 10 [ABR1] Area 0 [H]--p +-[ABR1] Area 0 [H]-+ | / \ / | \ / | +----[B]---- --[F]--[G] | --[F]--[G] | | | | other | +----------[p]-------+ area
(a) Example topology (b) Proxy node view in Area 0 nodes
+----[C]<--- [D]->[E] V \ \ +-[A] Area 10 [ABR1] Area 0 [H]-+ | ^ / / | | +----[B]<--- [F]->[G] V | | +------------->[p]<--------------+
(c) rSPT towards destination p
->[D]->[E] -<[D]<-[E] / \ / \ [ABR1] Area 0 [H]-+ +-[ABR1] [H] / | | \ [F]->[G] V V -<[F]<-[G] | | | | [p]<------+ +--------->[p]
(d) Blue MRT in Area 0 (e) Red MRT in Area 0
Figure 3: ABR Forwarding Behavior and MRTs
11. Prefixes Multiply Attached to the MRT Island
How a computing router S determines its local MRT Island for each supported MRT profile is already discussed in Section 7.
There are two types of prefixes or FECs that may be multiply attached to an MRT Island. The first type are multi-homed prefixes that usually connect at a domain or protocol boundary. The second type represent routers that do not support the profile for the MRT Island.
Atlas, et al. Expires August 8, 2016 [Page 26]

Internet-Draft MRT Unicast FRR Architecture February 2016
The key difference is whether the traffic, once out of the MRT Island, might re-enter the MRT Island if a loop-free exit point is not selected.
FRR using LFA has the useful property that it is able to protect multi-homed prefixes against ABR failure. For instance, if a prefix from the backbone is available via both ABR A and ABR B, if A fails, then the traffic should be redirected to B. This can be accomplished with MRT FRR as well.
If ASBR protection is desired, this has additional complexities if the ASBRs are in different areas. Similarly, protecting labeled BGP traffic in the event of an ASBR failure has additional complexities due to the per-ASBR label spaces involved.
As discussed in [RFC5286], a multi-homed prefix could be:
o An out-of-area prefix announced by more than one ABR,
o An AS-External route announced by 2 or more ASBRs,
o A prefix with iBGP multipath to different ASBRs,
o etc.
See Appendix B for a discussion of a general issue with multi-homed prefixes connected in two different areas.
There are also two different approaches to protection. The first is tunnel endpoint selection where the PLR picks a router to tunnel to where that router is loop-free with respect to the failure-point. Conceptually, the set of candidate routers to provide LFAs expands to all routers that can be reached via an MRT alternate, attached to the prefix.
The second is to use a proxy-node, that can be named via MPLS label or IP address, and pick the appropriate label or IP address to reach it on either MRT-Blue or MRT-Red as appropriate to avoid the failure point. A proxy-node can represent a destination prefix that can be attached to the MRT Island via at least two routers. It is termed a named proxy-node if there is a way that traffic can be encapsulated to reach specifically that proxy-node; this could be because there is an LDP FEC for the associated prefix or because MRT-Red and MRT-Blue IP addresses are advertised (in an as-yet undefined fashion) for that proxy-node. Traffic to a named proxy-node may take a different path than traffic to the attaching router; traffic is also explicitly forwarded from the attaching router along a predetermined interface towards the relevant prefixes.
Atlas, et al. Expires August 8, 2016 [Page 27]

Internet-Draft MRT Unicast FRR Architecture February 2016
For IP traffic, multi-homed prefixes can use tunnel endpoint selection. For IP traffic that is destined to a router outside the MRT Island, if that router is the egress for a FEC advertised into the MRT Island, then the named proxy-node approach can be used.
For LDP traffic, there is always a FEC advertised into the MRT Island. The named proxy-node approach should be used, unless the computing router S knows the label for the FEC at the selected tunnel endpoint.
If a FEC is advertised from outside the MRT Island into the MRT Island and the forwarding mechanism specified in the profile includes LDP, then the routers learning that FEC MUST also advertise labels for (MRT-Red, FEC) and (MRT-Blue, FEC) to neighbors inside the MRT Island. Any router receiving a FEC corresponding to a router outside the MRT Island or to a multi-homed prefix MUST compute and install the transit MRT-Blue and MRT-Red next-hops for that FEC. The FEC- label bindings for the topology-scoped FECs ((MT-ID 0, FEC), (MRT- Red, FEC), and (MRT-Blue, FEC)) MUST also be provided via LDP to neighbors inside the MRT Island.
11.1. Protecting Multi-Homed Prefixes using Tunnel Endpoint Selection
Tunnel endpoint selection is a local matter for a router in the MRT Island since it pertains to selecting and using an alternate and does not affect the transit MRT-Red and MRT-Blue forwarding topologies.
Let the computing router be S and the next-hop F be the node whose failure is to be avoided. Let the destination be prefix p. Have A be the router to which the prefix p is attached for S’s shortest path to p.
The candidates for tunnel endpoint selection are those to which the destination prefix is attached in the area/level. For a particular candidate B, it is necessary to determine if B is loop-free to reach p with respect to S and F for node-protection or at least with respect to S and the link (S, F) for link-protection. If B will always prefer to send traffic to p via a different area/level, then this is definitional. Otherwise, distance-based computations are necessary and an SPF from B’s perspective may be necessary. The following equations give the checks needed; the rationale is similar to that given in [RFC5286]. In the inequalities below, D_opt(X,Y) means the shortest distance from node X to node Y, and D_opt(X,p) means the shortest distance from node X to prefix p.
Loop-Free for S: D_opt(B, p) < D_opt(B, S) + D_opt(S, p)
Loop-Free for F: D_opt(B, p) < D_opt(B, F) + D_opt(F, p)
Atlas, et al. Expires August 8, 2016 [Page 28]

Internet-Draft MRT Unicast FRR Architecture February 2016
The latter is equivalent to the following, which avoids the need to compute the shortest path from F to p.
Loop-Free for F: D_opt(B, p) < D_opt(B, F) + D_opt(S, p) - D_opt(S, F)
Finally, the rules for Endpoint selection are given below. The basic idea is to repair to the prefix-advertising router selected for the shortest-path and only to select and tunnel to a different endpoint if necessary (e.g. A=F or F is a cut-vertex or the link (S,F) is a cut-link).
1. Does S have a node-protecting alternate to A? If so, select that. Tunnel the packet to A along that alternate. For example, if LDP is the forwarding mechanism, then push the label (MRT-Red, A) or (MRT-Blue, A) onto the packet.
2. If not, then is there a router B that is loop-free to reach p while avoiding both F and S? If so, select B as the end-point. Determine the MRT alternate to reach B while avoiding F. Tunnel the packet to B along that alternate. For example, with LDP, push the label (MRT-Red, B) or (MRT-Blue, B) onto the packet.
3. If not, then does S have a link-protecting alternate to A? If so, select that.
4. If not, then is there a router B that is loop-free to reach p while avoiding S and the link from S to F? If so, select B as the endpoint and the MRT alternate for reaching B from S that avoid the link (S,F).
The tunnel endpoint selected will receive a packet destined to itself and, being the egress, will pop that MPLS label (or have signaled Implicit Null) and forward based on what is underneath. This suffices for IP traffic since the tunnel endpoint can use the IP header of the original packet to continue forwarding the packet. However, tunnelling of LDP traffic requires targeted LDP sessions for learning the FEC-label binding at the tunnel endpoint.
11.2. Protecting Multi-Homed Prefixes using Named Proxy-Nodes
Instead, the named proxy-node method works with LDP traffic without the need for targeted LDP sessions. It also has a clear advantage over tunnel endpoint selection, in that it is possible to explicitly forward from the MRT Island along an interface to a loop-free island neighbor when that interface may not be a primary next-hop.
Atlas, et al. Expires August 8, 2016 [Page 29]

Internet-Draft MRT Unicast FRR Architecture February 2016
A named proxy-node represents one or more destinations and, for LDP forwarding, has a FEC associated with it that is signalled into the MRT Island. Therefore, it is possible to explicitly label packets to go to (MRT-Red, FEC) or (MRT-Blue, FEC); at the border of the MRT Island, the label will swap to meaning (MT-ID 0, FEC). It would be possible to have named proxy-nodes for IP forwarding, but this would require extensions to signal two IP addresses to be associated with MRT-Red and MRT-Blue for the proxy-node. A named proxy-node can be uniquely represented by the two routers in the MRT Island to which it is connected. The extensions to signal such IP addresses will be defined elsewhere. The details of what label-bindings must be originated will be described in another document.
Computing the MRT next-hops to a named proxy-node and the MRT alternate for the computing router S to avoid a particular failure node F is straightforward. The details of the simple constant-time functions, Select_Proxy_Node_NHs() and Select_Alternates_Proxy_Node(), are given in [I-D.ietf-rtgwg-mrt-frr-algorithm]. A key point is that computing these MRT next-hops and alternates can be done as new named proxy- nodes are added or removed without requiring a new MRT computation or impacting other existing MRT paths. This maps very well to, for example, how OSPFv2 (see [RFC2328] Section 16.5) does incremental updates for new summary-LSAs.
The remaining question is how to attach the named proxy-node to the MRT Island; all the routers in the MRT Island MUST do this consistently. No more than 2 routers in the MRT Island can be selected; one should only be selected if there are no others that meet the necessary criteria. The named proxy-node is logically part of the area/level.
There are two sources for candidate routers in the MRT Island to connect to the named proxy-node. The first set are those routers in the MRT Island that are advertising the prefix; the named-proxy-cost assigned to each prefix-advertising router is the announced cost to the prefix. The second set are those routers in the MRT Island that are connected to routers not in the MRT Island but in the same area/ level; such routers will be defined as Island Border Routers (IBRs). The routers connected to the IBRs that are not in the MRT Island and are in the same area/level as the MRT island are Island Neighbors(INs).
Since packets sent to the named proxy-node along MRT-Red or MRT-Blue may come from any router inside the MRT Island, it is necessary that whatever router to which an IBR forwards the packet be loop-free with respect to the whole MRT Island for the destination. Thus, an IBR is a candidate router only if it possesses at least one IN whose
Atlas, et al. Expires August 8, 2016 [Page 30]

Internet-Draft MRT Unicast FRR Architecture February 2016
shortest path to the prefix does not enter the MRT Island. A method for identifying loop-free Island Neighbors(LFINs) is given in [I-D.ietf-rtgwg-mrt-frr-algorithm]. The named-proxy-cost assigned to each (IBR, IN) pair is cost(IBR, IN) + D_opt(IN, prefix).
From the set of prefix-advertising routers and the set of IBRs with at least one LFIN, the two routers with the lowest named-proxy-cost are selected. Ties are broken based upon the lowest Router ID. For ease of discussion, the two selected routers will be referred to as proxy-node attachment routers.
A proxy-node attachment router has a special forwarding role. When a packet is received destined to (MRT-Red, prefix) or (MRT-Blue, prefix), if the proxy-node attachment router is an IBR, it MUST swap to the shortest path forwarding topology (e.g. swap to the label for (MT-ID 0, prefix) or remove the outer IP encapsulation) and forward the packet to the IN whose cost was used in the selection. If the proxy-node attachment router is not an IBR, then the packet MUST be removed from the MRT forwarding topology and sent along the interface(s) that caused the router to advertise the prefix; this interface might be out of the area/level/AS.
11.3. MRT Alternates for Destinations Outside the MRT Island
A natural concern with new functionality is how to have it be useful when it is not deployed across an entire IGP area. In the case of MRT FRR, where it provides alternates when appropriate LFAs aren’t available, there are also deployment scenarios where it may make sense to only enable some routers in an area with MRT FRR. A simple example of such a scenario would be a ring of 6 or more routers that is connected via two routers to the rest of the area.
Destinations inside the local island can obviously use MRT alternates. Destinations outside the local island can be treated like a multi-homed prefix and either Endpoint Selection or Named Proxy-Nodes can be used. Named Proxy-Nodes MUST be supported when LDP forwarding is supported and a label-binding for the destination is sent to an IBR.
Naturally, there are more complicated options to improve coverage, such as connecting multiple MRT islands across tunnels, but the need for the additional complexity has not been justified.
12. Network Convergence and Preparing for the Next Failure
After a failure, MRT detours ensure that packets reach their intended destination while the IGP has not reconverged onto the new topology. As link-state updates reach the routers, the IGP process calculates
Atlas, et al. Expires August 8, 2016 [Page 31]

Internet-Draft MRT Unicast FRR Architecture February 2016
the new shortest paths. Two things need attention: micro-loop prevention and MRT re-calculation.
12.1. Micro-loop prevention and MRTs
A micro-loop is a transient packet forwarding loop among two or more routers that can occur during convergence of IGP forwarding state. [RFC5715] discusses several techniques for preventing micro-loops. This section discusses how MRT-FRR relates to two of the micro-loop prevention techniques discussed in [RFC5715], Nearside Tunneling and Farside Tunneling.
In Nearside Tunneling, a router (PLR) adjacent to a failure perform local repair and inform remote routers of the failure. The remote routers initially tunnel affected traffic to the nearest PLR, using tunnels which are unaffected by the failure. Once the forwarding state for normal shortest path routing has converged, the remote routers return the traffic to shortest path forwarding. MRT-FRR is relevant for Nearside Tunneling for the following reason. The process of tunneling traffic to the PLRs and waiting a sufficient amount of time for IGP forwarding state convergence with Nearside Tunneling means that traffic will generally be relying on the local repair at the PLR for longer than it would in the absence of Nearside Tunneling. Since MRT-FRR provides 100% coverage for single link and node failure, it may be an attractive option to provide the local repair paths when Nearside Tunneling is deployed.
MRT-FRR is also relevant for the Farside Tunneling micro-loop prevention technique. In Farside Tunneling, remote routers tunnel traffic affected by a failure to a node downstream of the failure with respect to traffic destination. This node can be viewed as being on the farside of the failure with respect to the node initiating the tunnel. Note that the discussion of Farside Tunneling in [RFC5715] focuses on the case where the farside node is immediately adjacent to a failed link or node. However, the farside node may be any node downstream of the failure with respect to traffic destination, including the destination itself. The tunneling mechanism used to reach the farside node must be unaffected by the failure. The alternative forwarding paths created by MRT-FRR have the potential to be used to forward traffic from the remote routers upstream of the failure all the way to the destination. In the event of failure, either the MRT-Red or MRT-Blue path from the remote upstream router to the destination is guaranteed to avoid a link failure or inferred node failure. The MRT forwarding paths are also guaranteed to not be subject to micro-loops because they are locked to the topology before the failure.
Atlas, et al. Expires August 8, 2016 [Page 32]

Internet-Draft MRT Unicast FRR Architecture February 2016
We note that the computations in [I-D.ietf-rtgwg-mrt-frr-algorithm] address the case of a PLR adjacent to a failure determining which choice of MRT-Red or MRT-Blue will avoid a failed link or node. More computation may be required for an arbitrary remote upstream router to determine whether to choose MRT-Red or MRT-Blue for a given destination and failure.
12.2. MRT Recalculation for the Default MRT Profile
This section describes how the MRT recalculation SHOULD be performed for the Default MRT Profile. This is intended to support FRR applications. Other approaches are possible, but they are not specified in this document.
When a failure event happens, traffic is put by the PLRs onto the MRT topologies. After that, each router recomputes its shortest path tree (SPT) and moves traffic over to that. Only after all the PLRs have switched to using their SPTs and traffic has drained from the MRT topologies should each router install the recomputed MRTs into the FIBs.
At each router, therefore, the sequence is as follows:
1. Receive failure notification
2. Recompute SPT.
3. Install the new SPT in the FIB.
4. If the network was stable before the failure occured, wait a configured (or advertised) period for all routers to be using their SPTs and traffic to drain from the MRTs.
5. Recompute MRTs.
6. Install new MRTs in the FIB.
While the recomputed MRTs are not installed in the FIB, protection coverage is lowered. Therefore, it is important to recalculate the MRTs and install them quickly.
New protocol extensions for advertising the time needed to recompute shortest path routes and install them in the FIB will be defined elsewhere.
Atlas, et al. Expires August 8, 2016 [Page 33]

Internet-Draft MRT Unicast FRR Architecture February 2016
13. Implementation Status
[RFC Editor: please remove this section prior to publication.]
This section records the status of known implementations of the protocol defined by this specification at the time of posting of this Internet-Draft, and is based on a proposal described in [RFC6982]. The description of implementations in this section is intended to assist the IETF in its decision processes in progressing drafts to RFCs. Please note that the listing of any individual implementation here does not imply endorsement by the IETF. Furthermore, no effort has been spent to verify the information presented here that was supplied by IETF contributors. This is not intended as, and must not be construed to be, a catalog of available implementations or their features. Readers are advised to note that other implementations may exist.
According to [RFC6982], "this will allow reviewers and working groups to assign due consideration to documents that have the benefit of running code, which may serve as evidence of valuable experimentation and feedback that have made the implemented protocols more mature. It is up to the individual working groups to use this information as they see fit".
Juniper Networks Implementation
o Organization responsible for the implementation: Juniper Networks
o Implementation name: MRT-FRR
o Implementation description: MRT-FRR using OSPF as the IGP has been implemented and verified.
o The implementation’s level of maturity: prototype
o Protocol coverage: This implementation of the MRT-FRR includes Island identification, GADAG root selection, MRT Lowpoint algorithm, augmentation of GADAG with additional links, and calculation of MRT transit next-hops alternate next-hops based on draft "draft-ietf-rtgwg-mrt-frr-algorithm-00". This implementation also includes the M-bit in OSPF based on "draft- atlas-ospf-mrt-01" as well as LDP MRT Capability based on "draft- atlas-mpls-ldp-mrt-00".
o Licensing: proprietary
Atlas, et al. Expires August 8, 2016 [Page 34]

Internet-Draft MRT Unicast FRR Architecture February 2016
o Implementation experience: Implementation was useful for verifying functionality and lack of gaps. It has also been useful for improving aspects of the algorithm.
o Contact information: [email protected], [email protected], [email protected]
Huawei Technology Implementation
o Organization responsible for the implementation: Huawei Technology Co., Ltd.
o Implementation name: MRT-FRR and IS-IS extensions for MRT.
o Implementation description: The MRT-FRR using IS-IS extensions for MRT and LDP multi-topology have been implemented and verified.
o The implementation’s level of maturity: prototype
o Protocol coverage: This implementation of the MRT algorithm includes Island identification, GADAG root selection, MRT Lowpoint algorithm, augmentation of GADAG with additional links, and calculation of MRT transit next-hops alternate next-hops based on draft "draft-enyedi-rtgwg-mrt-frr-algorithm-03". This implementation also includes IS-IS extension for MRT based on "draft-li-mrt-00".
o Licensing: proprietary
o Implementation experience: It is important produce a second implementation to verify the algorithm is implemented correctly without looping. It is important to verify the IS-IS extensions work for MRT-FRR.
o Contact information: [email protected], [email protected]
14. Operational Considerations
The following aspects of MRT-FRR are useful to consider when deploying the technology in different operational environments and network topologies.
14.1. Verifying Forwarding on MRT Paths
The forwarding paths created by MRT-FRR are not used by normal (non- FRR) traffic. They are only used to carry FRR traffic for a short period of time after a failure has been detected. It is RECOMMENDED that an operator proactively monitor the MRT forwarding paths in
Atlas, et al. Expires August 8, 2016 [Page 35]

Internet-Draft MRT Unicast FRR Architecture February 2016
order to be certain that the paths will be able to carry FRR traffic when needed. Therefore, an implementation SHOULD provide an operator with the ability to test MRT paths with Operations, Administration, and Maintenance (OAM) traffic. For example, when MRT paths are realized using LDP labels distributed for topology-scoped FECs, an implementation can use the MPLS ping and traceroute as defined in [RFC4379] and extended in [RFC7307] for topology-scoped FECs.
14.2. Traffic Capacity on Backup Paths
During a fast-reroute event initiated by a PLR in response to a network failure, the flow of traffic in the network will generally not be identical to the flow of traffic after the IGP forwarding state has converged, taking the failure into account. Therefore, even if a network has been engineered to have enough capacity on the appropriate links to carry all traffic after the IGP has converged after the failure, the network may still not have enough capacity on the appropriate links to carry the flow of traffic during a fast- reroute event. This can result in more traffic loss during the fast- reroute event than might otherwise be expected.
Note that there are two somewhat distinct aspects to this phenomenon. The first is that the path from the PLR to the destination during the fast-reroute event may be different from the path after the IGP converges. In this case, any traffic for the destination that reaches the PLR during the fast-reroute event will follow a different path from the PLR to the destination than will be followed after IGP convergence.
The second aspect is that the amount of traffic arriving at the PLR for affected destinations during the fast-reroute event may be larger than the amount of traffic arriving at the PLR for affected destinations after IGP convergence. Immediately after a failure, any non-PLR routers that were sending traffic to the PLR before the failure will continue sending traffic to the PLR, and that traffic will be carried over backup paths from the PLR to the destinations. After IGP convergence, upstream non-PLR routers may direct some traffic away from the PLR.
In order to reduce or eliminate the potential for transient traffic loss due to inadequate capacity during fast-reroute events, an operator can model the amount of traffic taking different paths during a fast-reroute event. If it is determined that there is not enough capacity to support a given fast-reroute event, the operator can address the issue either by augmenting capacity on certain links or modifying the backup paths themselves.
Atlas, et al. Expires August 8, 2016 [Page 36]

Internet-Draft MRT Unicast FRR Architecture February 2016
The MRT Lowpoint algorithm produces a pair of diverse paths to each destination. These paths are generated by following the directed links on a common GADAG. The decision process for constructing the GADAG in the MRT Lowpoint algorithm takes into account individual IGP link metrics. At any given node, links are explored in order from lowest IGP metric to highest IGP metric. Additionally, the process for constructing the MRT-Red and Blue trees uses SPF traversals of the GADAG. Therefore, the IGP link metric values affect the computed backup paths. However, adjusting the IGP link metrics is not a generally applicable tool for modifying the MRT backup paths. Achieving a desired set of MRT backup paths by adjusting IGP metrics while at the same time maintaining the desired flow of traffic along the shortest paths is not possible in general.
MRT-FRR allows an operator to exclude a link from the MRT Island, and thus the GADAG, by advertising it as MRT-Ineligible. Such a link will not be used on the MRT forwarding path for any destination. Advertising links as MRT-Ineligible is the main tool provided by MRT- FRR for keeping backup traffic off of lower bandwidth links during fast-reroute events.
Note that all of the backup paths produced by the MRT Lowpoint algorithm are closely tied to the common GADAG computed as part of that algorithm. Therefore, it is generally not possible to modify a subset of paths without affecting other paths. This precludes more fine-grained modification of individual backup paths when using only paths computed by the MRT Lowpoint algorithm.
However, it may be desirable to allow an operator to use MRT-FRR alternates together with alternates provided by other FRR technologies. A policy-based alternate selection process can allow an operator to select the best alternate from those provided by MRT and other FRR technologies. As a concrete example, it may be desirable to implement a policy where a downstream LFA (if it exists for a given failure mode and destination) is preferred over a given MRT alternate. This combination gives the operator the ability to affect where traffic flows during a fast-reroute event, while still producing backup paths that use no additional labels for LDP traffic and will not loop under multiple failures. This and other choices of alternate selection policy can be evaluated in the context of their effect on fast-reroute traffic flow and available capacity, as well as other deployment considerations.
Note that future documents may define MRT profiles in addition to the default profile defined here. Different MRT profiles will generally produce alternate paths with different properties. An implementation may allow an operator to use different MRT profiles instead of or in addition to the default profile.
Atlas, et al. Expires August 8, 2016 [Page 37]

Internet-Draft MRT Unicast FRR Architecture February 2016
14.3. MRT IP Tunnel Loopback Address Management
As described in Section 6.1.2, if an implementation uses IP tunneling as the mechanism to realize MRT forwarding paths, each node must advertise an MRT-Red and an MRT-Blue loopback address. These IP addresses must be unique within the routing domain to the extent that they do not overlap with each other or with any other routing table entries. It is expected that operators will use existing tools and processes for managing infrastructure IP addresses to manage these additional MRT-related loopback addresses.
14.4. MRT-FRR in a Network with Degraded Connectivity
Ideally, routers is a service provider network using MRT-FRR will be initially deployed in a 2-connected topology, allowing MRT-FRR to find completely diverse paths to all destinations. However, a network can differ from an ideal 2-connected topology for many possible reasons, including network failures and planned maintenance events.
MRT-FRR is designed to continue to function properly when network connectivity is degraded. When a network contains cut-vertices or cut-links dividing the network into different 2-connected blocks, MRT-FRR will continue to provide completely diverse paths for destinations within the same block as the PLR. For a destination in a different block from the PLR, the redundant paths created by MRT- FRR will be link and node diverse within each block, and the paths will only share links and nodes that are cut-links or cut-vertices in the topology.
If a network becomes partitioned with one set of routers having no connectivity to another set of routers, MRT-FRR will function independently in each set of connected routers, providing redundant paths to destinations in same set of connected routers as a given PLR.
14.5. Partial Deployment of MRT-FRR in a Network
A network operator may choose to deploy MRT-FRR only on a subset of routers in an IGP area. MRT-FRR is designed to accommodate this partial deployment scenario. Only routers that advertise support for a given MRT profile will be included in a given MRT Island. For a PLR within the MRT Island, MRT-FRR will create redundant forwarding paths to all destinations with the MRT Island using maximally redundant trees all the way to those destinations. For destinations outside of the MRT Island, MRT-FRR creates paths to the destination which use forwarding state created by MRT-FRR within the MRT Island and shortest path forwarding state outside of the MRT Island. The
Atlas, et al. Expires August 8, 2016 [Page 38]

Internet-Draft MRT Unicast FRR Architecture February 2016
paths created by MRT-FRR to non-Island destinations are guaranteed to be diverse within the MRT Island (if topologically possible). However, the part of the paths outside of the MRT Island may not be diverse.
15. Acknowledgements
The authors would like to thank Mike Shand for his valuable review and contributions.
The authors would like to thank Joel Halpern, Hannes Gredler, Ted Qian, Kishore Tiruveedhula, Shraddha Hegde, Santosh Esale, Nitin Bahadur, Harish Sitaraman, Raveendra Torvi, Anil Kumar SN, Bruno Decraene, Eric Wu, Janos Farkas, Rob Shakir, Stewart Bryant, and Alvaro Retana for their suggestions and review.
16. IANA Considerations
IANA is requested to create a registry entitled "MRT Profile Identifier Registry". The range is 0 to 255. The Default MRT Profile defined in this document has value 0. Values 1-200 are allocated by Standards Action. Values 201-220 are for Experimental Use. Values 221-254 are for Private Use. Value 255 is reserved for future registry extension. (The allocation and use policies are described in [RFC5226].)
The initial registry is shown below.
Value Description Reference ------- ---------------------------------------- ------------ 0 Default MRT Profile [This draft] 1-200 Unassigned 201-220 Experimental Use 221-254 Private Use 255 Reserved (for future registry extension)
The MRT Profile Identifier Registry is a new registry in the IANA Matrix. Following existing conventions, http://www.iana.org/ protocols should display a new header entitled "Maximally Redundant Tree (MRT) Parameters". Under that header, there should be an entry for "MRT Profile Identifier Registry" with a link to the registry itself at http://www.iana.org/assignments/mrt-parameters/mrt- parameters.xhtml#mrt-profile-registry.
Atlas, et al. Expires August 8, 2016 [Page 39]

Internet-Draft MRT Unicast FRR Architecture February 2016
17. Security Considerations
In general, MRT forwarding paths do not follow shortest paths. The transit forwarding state corresponding to the MRT paths is created during normal operations (before a failure occurs). Therefore, a malicious packet with an appropriate header injected into the network from a compromised location would be forwarded to a destination along a non-shortest path. When this technology is deployed, a network security design should not rely on assumptions about potentially malicious traffic only following shortest paths.
It should be noted that the creation of non-shortest forwarding paths is not unique to MRT.
MRT-FRR requires that routers advertise information used in the formation of MRT backup paths. While this document does not specify the protocol extensions used to advertise this information, we discuss security considerations related to the information itself. Injecting false MRT-related information could be used to direct some MRT backup paths over compromised transmission links. Combined with the ability to generate network failures, this could be used to send traffic over compromised transmission links during a fast-reroute event. In order to prevent this potential exploit, a receiving router needs to be able to authenticate MRT-related information that claims to have been advertised by another router.
18. Contributors
Atlas, et al. Expires August 8, 2016 [Page 40]

Internet-Draft MRT Unicast FRR Architecture February 2016
Robert Kebler Juniper Networks 10 Technology Park Drive Westford, MA 01886 USA Email: [email protected]
Andras Csaszar Ericsson Konyves Kalman krt 11 Budapest 1097 Hungary Email: [email protected]
Jeff Tantsura Ericsson 300 Holger Way San Jose, CA 95134 USA Email: [email protected]
Russ White VCE Email: [email protected]
19. References
19.1. Normative References
[I-D.ietf-rtgwg-mrt-frr-algorithm] Envedi, G., Csaszar, A., Atlas, A., Bowers, C., and A. Gopalan, "Algorithms for computing Maximally Redundant Trees for IP/LDP Fast- Reroute", draft-ietf-rtgwg-mrt-frr- algorithm-06 (work in progress), October 2015.
[RFC2119] Bradner, S., "Key words for use in RFCs to Indicate Requirement Levels", BCP 14, RFC 2119, DOI 10.17487/RFC2119, March 1997, <http://www.rfc-editor.org/info/rfc2119>.
[RFC5226] Narten, T. and H. Alvestrand, "Guidelines for Writing an IANA Considerations Section in RFCs", BCP 26, RFC 5226, DOI 10.17487/RFC5226, May 2008, <http://www.rfc-editor.org/info/rfc5226>.
Atlas, et al. Expires August 8, 2016 [Page 41]

Internet-Draft MRT Unicast FRR Architecture February 2016
[RFC7307] Zhao, Q., Raza, K., Zhou, C., Fang, L., Li, L., and D. King, "LDP Extensions for Multi-Topology", RFC 7307, DOI 10.17487/RFC7307, July 2014, <http://www.rfc-editor.org/info/rfc7307>.
19.2. Informative References
[EnyediThesis] Enyedi, G., "Novel Algorithms for IP Fast Reroute", Department of Telecommunications and Media Informatics, Budapest University of Technology and Economics Ph.D. Thesis, February 2011, <http://timon.tmit.bme.hu/theses/thesis_book.pdf>.
[I-D.atlas-rtgwg-mrt-mc-arch] Atlas, A., Kebler, R., Wijnands, I., Csaszar, A., and G. Envedi, "An Architecture for Multicast Protection Using Maximally Redundant Trees", draft-atlas-rtgwg-mrt-mc- arch-02 (work in progress), July 2013.
[RFC2328] Moy, J., "OSPF Version 2", STD 54, RFC 2328, DOI 10.17487/RFC2328, April 1998, <http://www.rfc-editor.org/info/rfc2328>.
[RFC4379] Kompella, K. and G. Swallow, "Detecting Multi-Protocol Label Switched (MPLS) Data Plane Failures", RFC 4379, DOI 10.17487/RFC4379, February 2006, <http://www.rfc-editor.org/info/rfc4379>.
[RFC5286] Atlas, A., Ed. and A. Zinin, Ed., "Basic Specification for IP Fast Reroute: Loop-Free Alternates", RFC 5286, DOI 10.17487/RFC5286, September 2008, <http://www.rfc-editor.org/info/rfc5286>.
[RFC5331] Aggarwal, R., Rekhter, Y., and E. Rosen, "MPLS Upstream Label Assignment and Context-Specific Label Space", RFC 5331, DOI 10.17487/RFC5331, August 2008, <http://www.rfc-editor.org/info/rfc5331>.
[RFC5340] Coltun, R., Ferguson, D., Moy, J., and A. Lindem, "OSPF for IPv6", RFC 5340, DOI 10.17487/RFC5340, July 2008, <http://www.rfc-editor.org/info/rfc5340>.
[RFC5443] Jork, M., Atlas, A., and L. Fang, "LDP IGP Synchronization", RFC 5443, DOI 10.17487/RFC5443, March 2009, <http://www.rfc-editor.org/info/rfc5443>.
Atlas, et al. Expires August 8, 2016 [Page 42]

Internet-Draft MRT Unicast FRR Architecture February 2016
[RFC5714] Shand, M. and S. Bryant, "IP Fast Reroute Framework", RFC 5714, DOI 10.17487/RFC5714, January 2010, <http://www.rfc-editor.org/info/rfc5714>.
[RFC5715] Shand, M. and S. Bryant, "A Framework for Loop-Free Convergence", RFC 5715, DOI 10.17487/RFC5715, January 2010, <http://www.rfc-editor.org/info/rfc5715>.
[RFC6976] Shand, M., Bryant, S., Previdi, S., Filsfils, C., Francois, P., and O. Bonaventure, "Framework for Loop-Free Convergence Using the Ordered Forwarding Information Base (oFIB) Approach", RFC 6976, DOI 10.17487/RFC6976, July 2013, <http://www.rfc-editor.org/info/rfc6976>.
[RFC6981] Bryant, S., Previdi, S., and M. Shand, "A Framework for IP and MPLS Fast Reroute Using Not-Via Addresses", RFC 6981, DOI 10.17487/RFC6981, August 2013, <http://www.rfc-editor.org/info/rfc6981>.
[RFC6982] Sheffer, Y. and A. Farrel, "Improving Awareness of Running Code: The Implementation Status Section", RFC 6982, DOI 10.17487/RFC6982, July 2013, <http://www.rfc-editor.org/info/rfc6982>.
[RFC6987] Retana, A., Nguyen, L., Zinin, A., White, R., and D. McPherson, "OSPF Stub Router Advertisement", RFC 6987, DOI 10.17487/RFC6987, September 2013, <http://www.rfc-editor.org/info/rfc6987>.
[RFC7490] Bryant, S., Filsfils, C., Previdi, S., Shand, M., and N. So, "Remote Loop-Free Alternate (LFA) Fast Reroute (FRR)", RFC 7490, DOI 10.17487/RFC7490, April 2015, <http://www.rfc-editor.org/info/rfc7490>.
Appendix A. Inter-level Forwarding Behavior for IS-IS
In the description below, we use the terms "Level-1-only interface", "Level-2-only interface", and "Level-1-and-Level-2 interface" to mean in interface which has formed only a Level-1 adjacency, only a Level-2 adjacency, or both Level-1 and Level-2 adjacencies. Note that IS-IS also defines the concept of areas. A router is configured with an IS-IS area identifier, and a given router may be configured with multiple IS-IS area identifiers. For an IS-IS Level-1 adjacency to form between two routers, at least one IS-IS area identifier must match. IS-IS Level-2 adjacencies to not require any area identifiers to match. The behavior described below does not explicitly refer to IS-IS area identifiers. However, IS-IS area identifiers will
Atlas, et al. Expires August 8, 2016 [Page 43]

Internet-Draft MRT Unicast FRR Architecture February 2016
indirectly affect the behavior by affecting the formation of Level-1 adjacencies.
First consider a packet destined to Z on MRT-Red or MRT-Blue received on a Level-1-only interface. If the best shortest path route to Z was learned from a Level-1 advertisement, then the packet should continue to be forwarded along MRT-Red or MRT-Blue. If instead the best route was learned from a Level-2 advertisement, then the packet should be removed from MRT-Red or MRT-Blue and forwarded on the shortest-path default forwarding topology.
Now consider a packet destined to Z on MRT-Red or MRT-Blue received on a Level-2-only interface. If the best route to Z was learned from a Level-2 advertisement, then the packet should continue to be forwarded along MRT-Red or MRT-Blue. If instead the best route was learned from a Level-1 advertisement, then the packet should be removed from MRT-Red or MRT-Blue and forwarded on the shortest-path default forwarding topology.
Finally, consider a packet destined to Z on MRT-Red or MRT-Blue received on a Level-1-and-Level-2 interface. This packet should continue to be forwarded along MRT-Red or MRT-Blue, regardless of which level the route was learned from.
An implementation may simplify the decision-making process above by using the interface of the next-hop for the route to Z to determine the level that the best route to Z was learned from. If the next-hop points out a Level-1-only interface, then the route was learned from a Level-1 advertisement. If the next-hop points out a Level-2-only interface, then the route was learned from a Level-2 advertisement. A next-hop that points out a Level-1-and-Level-2 interface does not provide enough information to determine the source of the best route. With this simplification, an implementation would need to continue forwarding along MRT-Red or MRT-Blue when the next-hop points out a Level-1-and-Level-2 interface. Therefore, a packet on MRT-Red or MRT-Blue going from Level-1 to Level-2 (or vice versa) that traverses a Level-1-and-Level-2 interface in the process will remain on MRT-Red or MRT-Blue. This simplification may not always produce the optimal forwarding behavior, but it does not introduce interoperability problems. The packet will stay on an MRT backup path longer than necessary, but it will still reach its destination.
Appendix B. General Issues with Area Abstraction
When a multi-homed prefix is connected in two different areas, it may be impractical to protect them without adding the complexity of explicit tunneling. This is also a problem for LFA and Remote-LFA.
Atlas, et al. Expires August 8, 2016 [Page 44]

Internet-Draft MRT Unicast FRR Architecture February 2016
50 |----[ASBR Y]---[B]---[ABR 2]---[C] Backbone Area 0: | | ABR 1, ABR 2, C, D | | | | Area 20: A, ASBR X | | p ---[ASBR X]---[A]---[ABR 1]---[D] Area 10: B, ASBR Y 5 p is a Type 1 AS-external
Figure 4: AS external prefixes in different areas
Consider the network in Figure 4 and assume there is a richer connective topology that isn’t shown, where the same prefix is announced by ASBR X and ASBR Y which are in different non-backbone areas. If the link from A to ASBR X fails, then an MRT alternate could forward the packet to ABR 1 and ABR 1 could forward it to D, but then D would find the shortest route is back via ABR 1 to Area 20. This problem occurs because the routers, including the ABR, in one area are not yet aware of the failure in a different area.
The only way to get it from A to ASBR Y is to explicitly tunnel it to ASBR Y. If the traffic is unlabeled or the appropriate MPLS labels are known, then explicit tunneling MAY be used as long as the shortest-path of the tunnel avoids the failure point. In that case, A must determine that it should use an explicit tunnel instead of an MRT alternate.
Authors’ Addresses
Alia Atlas Juniper Networks 10 Technology Park Drive Westford, MA 01886 USA
Email: [email protected]
Chris Bowers Juniper Networks 1194 N. Mathilda Ave. Sunnyvale, CA 94089 USA
Email: [email protected]
Atlas, et al. Expires August 8, 2016 [Page 45]

Internet-Draft MRT Unicast FRR Architecture February 2016
Gabor Sandor Enyedi Ericsson Konyves Kalman krt 11. Budapest 1097 Hungary
Email: [email protected]
Atlas, et al. Expires August 8, 2016 [Page 46]

This Internet-Draft, draft-karan-mofrr-01.txt, has expired, and has beendeleted from the Internet-Drafts directory. An Internet-Draft expires185 days from the date that it is posted unless it is replaced by anupdated version, or the Secretariat has been notified that the documentis under official review by the IESG or has been passed to the RFC Editorfor review and/or publication as an RFC. This Internet-Draft was notpublished as an RFC.
Internet-Drafts are not archival documents, and copies of Internet-Draftsthat have been deleted from the directory are not available. TheSecretariat does not have any information regarding the future plans ofthe authors or working group, if applicable, with respect to this deletedInternet-Draft. For more information, or to request a copy of thedocument, please contact the authors directly.
Draft Authors:Apoorva Karan<[email protected]>Clarence Filsfils<[email protected]>Dino Farinacci<[email protected]>Bruno Decraene<[email protected]>Nicolai Leymann<[email protected]>Thomas Telkamp<[email protected]>

Network Working Group S. BryantInternet-Draft C. FilsfilsIntended status: Standards Track Cisco SystemsExpires: December 3, 2012 M. Shand Independent Contributor N. So Verizon Inc. June 1, 2012
Remote LFA FRR draft-shand-remote-lfa-01
Abstract
This draft describes an extension to the basic IP fast re-route mechanism described in RFC 5286 that provides additional backup connectivity when none can be provided by the basic mechanisms.
Requirements Language
The key words "MUST", "MUST NOT", "REQUIRED", "SHALL", "SHALL NOT", "SHOULD", "SHOULD NOT", "RECOMMENDED", "MAY", and "OPTIONAL" in this document are to be interpreted as described in RFC2119 [RFC2119].
Status of this Memo
This Internet-Draft is submitted in full conformance with the provisions of BCP 78 and BCP 79.
Internet-Drafts are working documents of the Internet Engineering Task Force (IETF). Note that other groups may also distribute working documents as Internet-Drafts. The list of current Internet- Drafts is at http://datatracker.ietf.org/drafts/current/.
Internet-Drafts are draft documents valid for a maximum of six months and may be updated, replaced, or obsoleted by other documents at any time. It is inappropriate to use Internet-Drafts as reference material or to cite them other than as "work in progress."
This Internet-Draft will expire on December 3, 2012.
Copyright Notice
Copyright (c) 2012 IETF Trust and the persons identified as the document authors. All rights reserved.
This document is subject to BCP 78 and the IETF Trust’s Legal
Bryant, et al. Expires December 3, 2012 [Page 1]

Internet-Draft Remote LFA FRR June 2012
Provisions Relating to IETF Documents (http://trustee.ietf.org/license-info) in effect on the date of publication of this document. Please review these documents carefully, as they describe your rights and restrictions with respect to this document. Code Components extracted from this document must include Simplified BSD License text as described in Section 4.e of the Trust Legal Provisions and are provided without warranty as described in the Simplified BSD License.
1. Terminology
This draft uses the terms defined in [RFC5714]. This section defines additional terms used in this draft.
Extended P-space
The union of the P-space of the neighbours of a specific router with respect to the protected link.
P-space P-space is the set of routers reachable from a specific router without any path (including equal cost path splits) transiting the protected link.
For example, the P-space of S, is the set of routers that S can reach without using the protected link S-E.
PQ node A node which is a member of both the extended P-space and the Q-space.
Q-space Q-space is the set of routers from which a specific router can be reached without any path (including equal cost path splits) transiting the protected link.
Repair tunnel A tunnel established for the purpose of providing a virtual neighbor which is a Loop Free Alternate.
Remote LFA The tail-end of a repair tunnel. This tail-end is a member of both the extended-P space the Q space. It is also termed a "PQ" node.
2. Introduction
RFC 5714 [RFC5714] describes a framework for IP Fast Re-route and provides a summary of various proposed IPFRR solutions. A basic mechanism using loop-free alternates (LFAs) is described in [RFC5286] that provides good repair coverage in many
Bryant, et al. Expires December 3, 2012 [Page 2]

Internet-Draft Remote LFA FRR June 2012
topologies[I-D.filsfils-rtgwg-lfa-applicability], especially those that are highly meshed. However, some topologies, notably ring based topologies are not well protected by LFAs alone. This is illustrated in Figure 1 below.
S---E / \ A D \ / B---C
Figure 1: A simple ring topology
If all link costs are equal, the link S-E cannot be fully protected by LFAs. The destination C is an ECMP from S, and so can be protected when S-E fails, but D and E are not protectable using LFAs
This draft describes extensions to the basic repair mechanism in which tunnels are used to provide additional logical links which can then be used as loop free alternates where none exist in the original topology. For example if a tunnel is provided between S and C as shown in Figure 2 then C, now being a direct neighbor of S would become an LFA for D and E. The non-failure traffic distribution is not disrupted by the provision of such a tunnel since it is only used for repair traffic and MUST NOT be used for normal traffic.
S---E / \ \ A \ D \ \ / B---C
Figure 2: The addition of a tunnel
The use of this technique is not restricted to ring based topologies, but is a general mechanism which can be used to enhance the protection provided by LFAs.
3. Repair Paths
As with LFA FRR, when a router detects an adjacent link failure, it uses one or more repair paths in place of the failed link. Repair paths are pre-computed in anticipation of later failures so they can be promptly activated when a failure is detected.
A tunneled repair path tunnels traffic to some staging point in the
Bryant, et al. Expires December 3, 2012 [Page 3]

Internet-Draft Remote LFA FRR June 2012
network from which it is assumed that, in the absence of multiple failures, it will travel to its destination using normal forwarding without looping back. This is equivalent to providing a virtual loop-free alternate to supplement the physical loop-free alternates. Hence the name "Remote LFA FRR". When a link cannot be entirely protected with local LFA neighbors, the protecting router seeks the help of a remote LFA staging point.
3.1. Tunnels as Repair Paths
Consider an arbitrary protected link S-E. In LFA FRR, if a path to the destination from a neighbor N of S does not cause a packet to loop back over the link S-E (i.e. N is a loop-free alternate), then S can send the packet to N and the packet will be delivered to the destination using the pre-failure forwarding information. If there is no such LFA neighbor, then S may be able to create a virtual LFA by using a tunnel to carry the packet to a point in the network which is not a direct neighbor of S from which the packet will be delivered to the destination without looping back to S. In this document such a tunnel is termed a repair tunnel. The tail-end of this tunnel is called a "remote LFA" or a "PQ node".
Note that the repair tunnel terminates at some intermediate router between S and E, and not E itself. This is clearly the case, since if it were possible to construct a tunnel from S to E then a conventional LFA would have been sufficient to effect the repair.
3.2. Tunnel Requirements
There are a number of IP in IP tunnel mechanisms that may be used to fulfil the requirements of this design, such as IP-in-IP [RFC1853] and GRE[RFC1701] .
In an MPLS enabled network using LDP[RFC5036], a simple label stack[RFC3032] may be used to provide the required repair tunnel. In this case the outer label is S’s neighbor’s label for the repair tunnel end point, and the inner label is the repair tunnel end point’s label for the packet destination. In order for S to obtain the correct inner label it is necessary to establish a directed LDP session[RFC5036] to the tunnel end point.
The selection of the specific tunnelling mechanism (and any necessary enhancements) used to provide a repair path is outside the scope of this document. The authors simply note that deployment in an MPLS/ LDP environment is extremely simple and straight-forward as an LDP LSP from S to the PQ node is readily available, and hence does not require any new protocol extension or design change. This LSP is automatically established as a basic property of LDP behavior. The
Bryant, et al. Expires December 3, 2012 [Page 4]

Internet-Draft Remote LFA FRR June 2012
performance of the encapsulation and decapsulation is also excellent as encapsulation is just a push of one label (like conventional MPLS TE FRR) and the decapsulation occurs naturally at the penultimate hop before the PQ node.
When a failure is detected, it is necessary to immediately redirect traffic to the repair path. Consequently, the repair tunnel used must be provisioned beforehand in anticipation of the failure. Since the location of the repair tunnels is dynamically determined it is necessary to establish the repair tunnels without management action. Multiple repairs may share a tunnel end point.
4. Construction of Repair Paths
4.1. Identifying Required Tunneled Repair Paths
Not all links will require protection using a tunneled repair path. If E can already be protected via an LFA, S-E does not need to be protected using a repair tunnel, since all destinations normally reachable through E must therefore also be protectable by an LFA. Such an LFA is frequently termed a "link LFA". Tunneled repair paths are only required for links which do not have a link LFA.
4.2. Determining Tunnel End Points
The repair tunnel endpoint needs to be a node in the network reachable from S without traversing S-E. In addition, the repair tunnel end point needs to be a node from which packets will normally flow towards their destination without being attracted back to the failed link S-E.
Note that once released from the tunnel, the packet will be forwarded, as normal, on the shortest path from the release point to its destination. This may result in the packet traversing the router E at the far end of the protected link S-E., but this is obviously not required.
The properties that are required of repair tunnel end points are therefore:
o The repair tunneled point MUST be reachable from the tunnel source without traversing the failed link; and
o When released, tunneled packets MUST proceed towards their destination without being attracted back over the failed link.
Provided both these requirements are met, packets forwarded over the
Bryant, et al. Expires December 3, 2012 [Page 5]

Internet-Draft Remote LFA FRR June 2012
repair tunnel will reach their destination and will not loop.
In some topologies it will not be possible to find a repair tunnel endpoint that exhibits both the required properties. For example if the ring topology illustrated in Figure 1 had a cost of 4 for the link B-C, while the remaining links were cost 1, then it would not be possible to establish a tunnel from S to C (without resorting to some form of source routing).
4.2.1. Computing Repair Paths
The set of routers which can be reached from S without traversing S-E is termed the P-space of S with respect to the link S-E. The P-space can be obtained by computing a shortest path tree (SPT) rooted at S and excising the sub-tree reached via the link S-E (including those which are members of an ECMP). In the case of Figure 1 the P-space comprises nodes A and B only.
The set of routers from which the node E can be reached, by normal forwarding, without traversing the link S-E is termed the Q-space of E with respect to the link S-E. The Q-space can be obtained by computing a reverse shortest path tree (rSPT) rooted at E, with the sub-tree which traverses the failed link excised (including those which are members of an ECMP). The rSPT uses the cost towards the root rather than from it and yields the best paths towards the root from other nodes in the network. In the case of Figure 1 the Q-space comprises nodes C and D only.
The intersection of the E’s Q-space with S’s P-space defines the set of viable repair tunnel end-points, known as "PQ nodes". As can be seen, for the case of Figure 1 there is no common node and hence no viable repair tunnel end-point.
Note that the Q-space calculation could be conducted for each individual destination and a per-destination repair tunnel end point determined. However this would, in the worst case, require an SPF computation per destination which is not considered to be scalable. We therefore use the Q-space of E as a proxy for the Q-space of each destination. This approximation is obviously correct since the repair is only used for the set of destinations which were, prior to the failure, routed through node E. This is analogous to the use of link-LFAs rather than per-prefix LFAs.
4.2.2. Extended P-space
The description in Section 4.2.1 calculated router S’s P-space rooted at S itself. However, since router S will only use a repair path when it has detected the failure of the link S-E, the initial hop of
Bryant, et al. Expires December 3, 2012 [Page 6]

Internet-Draft Remote LFA FRR June 2012
the repair path need not be subject to S’s normal forwarding decision process. Thus we introduce the concept of extended P-space. Router S’s extended P-space is the union of the P-spaces of each of S’s neighbours. The use of extended P-space may allow router S to reach potential repair tunnel end points that were otherwise unreachable.
Another way to describe extended P-space is that it is the union of ( un-extended ) P-space and the set of destinations for which S has a per-prefix LFA protecting the link S-E. i.e. the repair tunnel end point can be reached either directly or using a per-prefix LFA.
Since in the case of Figure 1 node A is a per-prefix LFA for the destination node C, the set of extended P-space nodes comprises nodes A, B and C. Since node C is also in E’s Q-space, there is now a node common to both extended P-space and Q-space which can be used as a repair tunnel end-point to protect the link S-E.
4.2.3. Selecting Repair Paths
The mechanisms described above will identify all the possible repair tunnel end points that can be used to protect a particular link. In a well-connected network there are likely to be multiple possible release points for each protected link. All will deliver the packets correctly so, arguably, it does not matter which is chosen. However, one repair tunnel end point may be preferred over the others on the basis of path cost or some other selection criteria.
In general there are advantages in choosing the repair tunnel end point closest (shortest metric) to S. Choosing the closest maximises the opportunity for the traffic to be load balanced once it has been released from the tunnel.
There is no technical requirement for the selection criteria to be consistent across all routers, but such consistency may be desirable from an operational point of view.
5. Example Application of Remote LFAs
An example of a commonly deployed topology which is not fully protected by LFAs alone is shown in Figure 3. PE1 and PE2 are connected in the same site. P1 and P2 may be geographically separated (inter-site). In order to guarantee the lowest latency path from/to all other remote PEs, normally the shortest path follows the geographical distance of the site locations. Therefore, to ensure this, a lower IGP metric (5) is assigned between PE1 and PE2. A high metric (1000) is set on the P-PE links to prevent the PEs being used for transit traffic. The PEs are not individually dual-
Bryant, et al. Expires December 3, 2012 [Page 7]

Internet-Draft Remote LFA FRR June 2012
homed in order to reduce costs.
This is a common topology in SP networks.
When a failure occurs on the link between PE1 and P2, PE1 does not have an LFA for traffic reachable via P1. Similarly, by symmetry, if the link between PE2 and P1 fails, PE2 does not have an LFA for traffic reachable via P2.
Increasing the metric between PE1 and PE2 to allow the LFA would impact the normal traffic performance by potentially increasing the latency. | 100 | -P2---------P1- \ / 1000 \ / 1000 PE1---PE2 5
Figure 3: Example SP topology
Clearly, full protection can be provided, using the techniques described in this draft, by PE1 choosing P2 as a PQ node, and PE2 choosing P1 as a PQ node.
6. Historical Note
The basic concepts behind Remote LFA were invented in 2002 and were later included in draft-bryant-ipfrr-tunnels, submitted in 2004.
draft-bryant-ipfrr-tunnels targetted a 100% protection coverage and hence included additional mechanims on top of the Remote LFA concept. The addition of these mechanisms made the proposal very complex and computationally intensive and it was therefore not pursued as a working group item.
As explained in [I-D.filsfils-rtgwg-lfa-applicability], the purpose of the LFA FRR technology is not to provide coverage at any cost. A solution for this already exists with MPLS TE FRR. MPLS TE FRR is a mature technology which is able to provide protection in any topology thanks to the explicit routing capability of MPLS TE.
The purpose of LFA FRR technology is to provide for a simple FRR solution when such a solution is possible. The first step along this simplicity approach was "local" LFA [RFC5286]. We propose "Remote LFA" as a natural second step. The following section motivates its benefits in terms of simplicity, incremental deployment and
Bryant, et al. Expires December 3, 2012 [Page 8]

Internet-Draft Remote LFA FRR June 2012
significant coverage increase.
7. Benefits
Remote LFAs preserve the benefits of RFC5286: simplicity, incremental deployment and good protection coverage.
7.1. Simplicity
The remote LFA algorithm is simple to compute.
o The extended P space does not require any new computation (it is known once per-prefix LFA computation is completed).
o The Q-space is a single reverse SPF rooted at the neighbor.
o The directed LDP session is automatically computed and established.
In edge topologies (square, ring), the directed LDP session position and number is determinic and hence troubleshooting is simple.
In core topologies, our simulation indicates that the 90th percentile number of LDP sessions per node to achieve the significant Remote LFA coverage observed in section 7.3 is <= 6. This is insignificant compared to the number of LDP sessions commonly deployed per router which is frequently is in the several hundreds.
7.2. Incremental Deployment
The establishment of the directed LDP session to the PQ node does not require any new technology on the PQ node. Indeed, routers commonly support the ability to accept a remote request to open a directed LDP session. The new capability is restricted to the Remote-LFA computing node (the originator of the LDP session).
7.3. Significant Coverage Extension
The previous sections have already explained how Remote LFAs provide protection for frequently occuring edge topologies: square and rings. In the core, we extend the analysis framework in section 4.3 of [I-D.filsfils-rtgwg-lfa-applicability]and provide hereafter the Remote LFA coverage results for the 11 topologies:
Bryant, et al. Expires December 3, 2012 [Page 9]

Internet-Draft Remote LFA FRR June 2012
+----------+--------------+----------------+------------+ | Topology | Per-link LFA | Per-prefix LFA | Remote LFA | +----------+--------------+----------------+------------+ | T1 | 45% | 77% | 78% | | T2 | 49% | 99% | 100% | | T3 | 88% | 99% | 99% | | T4 | 68% | 84% | 92% | | T5 | 75% | 94% | 99% | | T6 | 87% | 99% | 100% | | T7 | 16% | 67% | 96% | | T8 | 87% | 100% | 100% | | T9 | 67% | 80% | 98% | | T10 | 98% | 100% | 100% | | T11 | 59% | 77% | 95% | | Average | 67% | 89% | 96% | | Median | 68% | 94% | 99% | +----------+--------------+----------------+------------+
Another study[ISOCORE2010]confirms the significant coverage increase provided by Remote LFAs.
8. Complete Protection
As shown in the previous table, Remote LFA provides for 96% average (99% median) protection in the 11 analyzed SP topologies.
In an MPLS network, this is achieved without any scalability impact as the tunnels to the PQ nodes are always present as a property of an LDP-based deployment.
In the very few cases where P and Q spaces have an empty intersection, one could select the closest node in the Q space (i.e. Qc) and signal an explicitely-routed RSVP TE LSP to Qc. A directed LDP session is then established with Qc and the rest of the solution is identical.
The drawbacks of this solution are:
1. only available for MPLS network;
2. the addition of LSPs in the SP infrastructure.
This extension is described for exhaustivity. In practice, the "Remote LFA" solution should be preferred for three reasons: its simplicity, its excellent coverage in the analyzed backbones and its complete coverage in the most frequent access/aggregation topologies
Bryant, et al. Expires December 3, 2012 [Page 10]

Internet-Draft Remote LFA FRR June 2012
(box or ring).
9. IANA Considerations
There are no IANA considerations that arise from this architectural description of IPFRR.
10. Security Considerations
The security considerations of RFC 5286 also apply.
To prevent their use as an attack vector the repair tunnel endpoints SHOULD be assigned from a set of addresses that are not reachable from outside the routing domain.
11. Acknowledgments
The authors acknowledge the technical contributions made to this work by Stefano Previdi.
12. Informative References
[I-D.filsfils-rtgwg-lfa-applicability] Filsfils, C., Francois, P., Shand, M., Decraene, B., Uttaro, J., Leymann, N., and M. Horneffer, "LFA applicability in SP networks", draft-filsfils-rtgwg-lfa-applicability-00 (work in progress), March 2010.
[ISOCORE2010] So, N., Lin, T., and C. Chen, "LFA (Loop Free Alternates) Case Studies in Verizon’s LDP Network", 2010.
[RFC1701] Hanks, S., Li, T., Farinacci, D., and P. Traina, "Generic Routing Encapsulation (GRE)", RFC 1701, October 1994.
[RFC1853] Simpson, W., "IP in IP Tunneling", RFC 1853, October 1995.
[RFC2119] Bradner, S., "Key words for use in RFCs to Indicate Requirement Levels", BCP 14, RFC 2119, March 1997.
[RFC3032] Rosen, E., Tappan, D., Fedorkow, G., Rekhter, Y., Farinacci, D., Li, T., and A. Conta, "MPLS Label Stack Encoding", RFC 3032, January 2001.
Bryant, et al. Expires December 3, 2012 [Page 11]

Internet-Draft Remote LFA FRR June 2012
[RFC5036] Andersson, L., Minei, I., and B. Thomas, "LDP Specification", RFC 5036, October 2007.
[RFC5286] Atlas, A. and A. Zinin, "Basic Specification for IP Fast Reroute: Loop-Free Alternates", RFC 5286, September 2008.
[RFC5714] Shand, M. and S. Bryant, "IP Fast Reroute Framework", RFC 5714, January 2010.
Authors’ Addresses
Stewart Bryant Cisco Systems 250, Longwater, Green Park, Reading RG2 6GB, UK UK
Email: [email protected]
Clarence Filsfils Cisco Systems De Kleetlaan 6a 1831 Diegem Belgium
Email: [email protected]
Mike Shand Independent Contributor
Email: [email protected]
Ning So Verizon Inc.
Email: [email protected]
Bryant, et al. Expires December 3, 2012 [Page 12]


RTGWG S. NingInternet-Draft Tata CommunicationsIntended status: Informational D. McDysanExpires: December 31, 2012 Verizon E. Osborne Cisco L. Yong Huawei USA C. Villamizar Outer Cape Cod Network Consulting June 29, 2012
Composite Link Framework in Multi Protocol Label Switching (MPLS) draft-so-yong-rtgwg-cl-framework-06
Abstract
This document specifies a framework for support of composite link in MPLS networks. A composite link consists of a group of homogenous or non-homogenous links that have the same forward adjacency and can be considered as a single TE link or an IP link in routing. A composite link relies on its component links to carry the traffic over the composite link. Applicability is described for a single pair of MPLS-capable nodes, a sequence of MPLS-capable nodes, or a set of layer networks connecting MPLS-capable nodes.
Status of this Memo
This Internet-Draft is submitted in full conformance with the provisions of BCP 78 and BCP 79.
Internet-Drafts are working documents of the Internet Engineering Task Force (IETF). Note that other groups may also distribute working documents as Internet-Drafts. The list of current Internet- Drafts is at http://datatracker.ietf.org/drafts/current/.
Internet-Drafts are draft documents valid for a maximum of six months and may be updated, replaced, or obsoleted by other documents at any time. It is inappropriate to use Internet-Drafts as reference material or to cite them other than as "work in progress."
This Internet-Draft will expire on December 31, 2012.
Copyright Notice
Copyright (c) 2012 IETF Trust and the persons identified as the
Ning, et al. Expires December 31, 2012 [Page 1]

Internet-Draft Composite Link Framework June 2012
document authors. All rights reserved.
This document is subject to BCP 78 and the IETF Trust’s Legal Provisions Relating to IETF Documents (http://trustee.ietf.org/license-info) in effect on the date of publication of this document. Please review these documents carefully, as they describe your rights and restrictions with respect to this document. Code Components extracted from this document must include Simplified BSD License text as described in Section 4.e of the Trust Legal Provisions and are provided without warranty as described in the Simplified BSD License.
Table of Contents
1. Introduction . . . . . . . . . . . . . . . . . . . . . . . . . 4 1.1. Architecture Summary . . . . . . . . . . . . . . . . . . . 4 1.2. Conventions used in this document . . . . . . . . . . . . 5 1.2.1. Terminology . . . . . . . . . . . . . . . . . . . . . 5 2. Composite Link Key Characteristics . . . . . . . . . . . . . . 5 2.1. Flow Identification . . . . . . . . . . . . . . . . . . . 6 2.2. Composite Link in Control Plane . . . . . . . . . . . . . 8 2.3. Composite Link in Data Plane . . . . . . . . . . . . . . . 11 3. Architecture Tradeoffs . . . . . . . . . . . . . . . . . . . . 11 3.1. Scalability Motivations . . . . . . . . . . . . . . . . . 12 3.2. Reducing Routing Information and Exchange . . . . . . . . 12 3.3. Reducing Signaling Load . . . . . . . . . . . . . . . . . 13 3.3.1. Reducing Signaling Load using LDP . . . . . . . . . . 14 3.3.2. Reducing Signaling Load using Hierarchy . . . . . . . 14 3.3.3. Using Both LDP and RSVP-TE Hierarchy . . . . . . . . . 14 3.4. Reducing Forwarding State . . . . . . . . . . . . . . . . 14 3.5. Avoiding Route Oscillation . . . . . . . . . . . . . . . . 15 4. New Challenges . . . . . . . . . . . . . . . . . . . . . . . . 16 4.1. Control Plane Challenges . . . . . . . . . . . . . . . . . 16 4.1.1. Delay and Jitter Sensitive Routing . . . . . . . . . . 17 4.1.2. Local Control of Traffic Distribution . . . . . . . . 17 4.1.3. Path Symmetry Requirements . . . . . . . . . . . . . . 17 4.1.4. Requirements for Contained LSP . . . . . . . . . . . . 18 4.1.5. Retaining Backwards Compatibility . . . . . . . . . . 19 4.2. Data Plane Challenges . . . . . . . . . . . . . . . . . . 19 4.2.1. Very Large LSP . . . . . . . . . . . . . . . . . . . . 20 4.2.2. Very Large Microflows . . . . . . . . . . . . . . . . 20 4.2.3. Traffic Ordering Constraints . . . . . . . . . . . . . 20 4.2.4. Accounting for IP and LDP Traffic . . . . . . . . . . 21 4.2.5. IP and LDP Limitations . . . . . . . . . . . . . . . . 21 5. Existing Mechanisms . . . . . . . . . . . . . . . . . . . . . 22 5.1. Link Bundling . . . . . . . . . . . . . . . . . . . . . . 22 5.2. Classic Multipath . . . . . . . . . . . . . . . . . . . . 24
Ning, et al. Expires December 31, 2012 [Page 2]

Internet-Draft Composite Link Framework June 2012
6. Mechanisms Proposed in Other Documents . . . . . . . . . . . . 24 6.1. Loss and Delay Measurement . . . . . . . . . . . . . . . . 24 6.2. Link Bundle Extensions . . . . . . . . . . . . . . . . . . 25 6.3. Fat PW and Entropy Labels . . . . . . . . . . . . . . . . 26 6.4. Multipath Extensions . . . . . . . . . . . . . . . . . . . 26 7. Required Protocol Extensions and Mechanisms . . . . . . . . . 27 7.1. Brief Review of Requirements . . . . . . . . . . . . . . . 27 7.2. Required Document Coverage . . . . . . . . . . . . . . . . 28 7.2.1. Component Link Grouping . . . . . . . . . . . . . . . 28 7.2.2. Delay and Jitter Extensions . . . . . . . . . . . . . 29 7.2.3. Path Selection and Admission Control . . . . . . . . . 29 7.2.4. Dynamic Multipath Balance . . . . . . . . . . . . . . 30 7.2.5. Frequency of Load Balance . . . . . . . . . . . . . . 30 7.2.6. Inter-Layer Communication . . . . . . . . . . . . . . 30 7.2.7. Packet Ordering Requirements . . . . . . . . . . . . . 31 7.2.8. Minimally Disruption Load Balance . . . . . . . . . . 31 7.2.9. Path Symmetry . . . . . . . . . . . . . . . . . . . . 31 7.2.10. Performance, Scalability, and Stability . . . . . . . 32 7.2.11. IP and LDP Traffic . . . . . . . . . . . . . . . . . . 32 7.2.12. LDP Extensions . . . . . . . . . . . . . . . . . . . . 32 7.2.13. Pseudowire Extensions . . . . . . . . . . . . . . . . 33 7.2.14. Multi-Domain Composite Link . . . . . . . . . . . . . 33 7.3. Open Issues Regarding Requirements . . . . . . . . . . . . 34 7.4. Framework Requirement Coverage by Protocol . . . . . . . . 34 7.4.1. OSPF-TE and ISIS-TE Protocol Extensions . . . . . . . 35 7.4.2. PW Protocol Extensions . . . . . . . . . . . . . . . . 35 7.4.3. LDP Protocol Extensions . . . . . . . . . . . . . . . 35 7.4.4. RSVP-TE Protocol Extensions . . . . . . . . . . . . . 35 7.4.5. RSVP-TE Path Selection Changes . . . . . . . . . . . . 35 7.4.6. RSVP-TE Admission Control and Preemption . . . . . . . 35 7.4.7. Flow Identification and Traffic Balance . . . . . . . 35 8. Security Considerations . . . . . . . . . . . . . . . . . . . 35 9. Acknowledgments . . . . . . . . . . . . . . . . . . . . . . . 36 10. References . . . . . . . . . . . . . . . . . . . . . . . . . . 36 10.1. Normative References . . . . . . . . . . . . . . . . . . . 36 10.2. Informative References . . . . . . . . . . . . . . . . . . 37 Authors’ Addresses . . . . . . . . . . . . . . . . . . . . . . . . 40
Ning, et al. Expires December 31, 2012 [Page 3]

Internet-Draft Composite Link Framework June 2012
1. Introduction
Composite Link functional requirements are specified in [I-D.ietf-rtgwg-cl-requirement]. Composite Link use cases are described in [I-D.symmvo-rtgwg-cl-use-cases]. This document specifies a framework to meet these requirements.
Classic multipath, including Ethernet Link Aggregation has been widely used in today’s MPLS networks [RFC4385][RFC4928]. Classic multipath using non-Ethernet links are often advertised using MPLS Link bundling. A link bundle [RFC4201] bundles a group of homogeneous links as a TE link to make IGP-TE information exchange and RSVP-TE signaling more scalable. A composite link allows bundling non-homogenous links together as a single logical link. The motivations for using a composite link are descried in [I-D.ietf-rtgwg-cl-requirement] and [I-D.symmvo-rtgwg-cl-use-cases].
This document describes a composite link framework in the context of MPLS networks using an IGP-TE and RSVP-TE MPLS control plane with GMPLS extensions [RFC3209][RFC3630][RFC3945][RFC5305].
A composite link is a single logical link in MPLS network that contains multiple parallel component links between two MPLS LSR. Unlike a link bundle [RFC4201], the component links in a composite link can have different properties such as cost or capacity.
Specific protocol solutions are outside the scope of this document, however a framework for the extension of existing protocols is provided. Backwards compatibility is best achieved by extending existing protocols where practical rather than inventing new protocols. The focus is on examining where existing protocol mechanisms fall short with respect to [I-D.ietf-rtgwg-cl-requirement] and on extensions that will be required to accommodate functionality that is called for in [I-D.ietf-rtgwg-cl-requirement].
1.1. Architecture Summary
Networks aggregate information, both in the control plane and in the data plane, as a means to achieve scalability. A tradeoff exists between the needs of scalability and the needs to identify differing path and link characteristics and differing requirements among flows contained within further aggregated traffic flows. These tradeoffs are discussed in detail in Section 3.
Some aspects of Composite Link requirements present challenges for which multiple solutions may exist. In Section 4 various challenges and potential approaches are discussed.
Ning, et al. Expires December 31, 2012 [Page 4]

Internet-Draft Composite Link Framework June 2012
A subset of the functionality called for in [I-D.ietf-rtgwg-cl-requirement] is available through MPLS Link Bundling [RFC4201]. Link bundling and other existing standards applicable to Composite Link are covered in Section 5.
The most straightforward means of supporting Composite Link requirements is to extend MPLS protocols and protocol semantics and in particular to extend link bundling. Extensions which have already been proposed in other documents which are applicable to Composite Link are discussed in Section 6.
Goals of most new protocol work within IETF is to reuse existing protocol encapsulations and mechanisms where they meet requirements and extend existing mechanisms such that additional complexity is minimized while meeting requirements and such that backwards compatibility is preserved to the extent it is practical to do so. These goals are considered in proposing a framework for further protocol extensions and mechanisms in Section 7.
1.2. Conventions used in this document
The key words "MUST", "MUST NOT", "REQUIRED", "SHALL", "SHALL NOT", "SHOULD", "SHOULD NOT", "RECOMMENDED", "MAY", and "OPTIONAL" in this document are to be interpreted as described in RFC 2119 [RFC2119].
1.2.1. Terminology
Terminology defined in [I-D.ietf-rtgwg-cl-requirement] is used in this document.
The abbreviation IGP-TE is used as a shorthand indicating either OSPF-TE [RFC3630] or ISIS-TE [RFC5305].
2. Composite Link Key Characteristics
[I-D.ietf-rtgwg-cl-requirement] defines external behavior of Composite Links. The overall framework approach involves extending existing protocols in a backwards compatible manner and reusing ongoing work elsewhere in IETF where applicable, defining new protocols or semantics only where necessary. Given the requirements, and this approach of extending MPLS, Composite Link key characteristics can be described in greater detail than given requirements alone.
Ning, et al. Expires December 31, 2012 [Page 5]

Internet-Draft Composite Link Framework June 2012
2.1. Flow Identification
Traffic mapping to component links is a data plane operation. Control over how the mapping is done may be directly dictated or constrained by the control plane or by the management plane. When unconstrained by the control plane or management plane, distribution of traffic is entirely a local matter. Regardless of constraints or lack or constraints, the traffic distribution is required to keep packets belonging to individual flows in sequence and meet QoS criteria specified per LSP by either signaling or management [RFC2475][RFC3260]. A key objective of the traffic distribution is to not overload any component link, and be able to perform local recovery when one of component link fails.
The network operator may have other objectives such as placing a bidirectional flow or LSP on the same component link in both direction, load balance over component links, composite link energy saving, and etc. These new requirements are described in [I-D.ietf-rtgwg-cl-requirement].
Examples of means to identify a flow may in principle include:
1. an LSP identified by an MPLS label,
2. a sub-LSP [I-D.kompella-mpls-rsvp-ecmp] identified by an MPLS label,
3. a pseudowire (PW) [RFC3985] identified by an MPLS PW label,
4. a flow or group of flows within a pseudowire (PW) [RFC6391] identified by an MPLS flow label,
5. a flow or flow group in an LSP [I-D.ietf-mpls-entropy-label] identified by an MPLS entropy label,
6. all traffic between a pair of IP hosts, identified by an IP source and destination pair,
7. a specific connection between a pair of IP hosts, identified by an IP source and destination pair, protocol, and protocol port pair,
8. a layer-2 conversation within a pseudowire (PW), where the identification is PW payload type specific, such as Ethernet MAC addresses and VLAN tags within an Ethernet PW (RFC4448).
Although in principle a layer-2 conversation within a pseudowire (PW), may be identified by PW payload type specific information, in
Ning, et al. Expires December 31, 2012 [Page 6]

Internet-Draft Composite Link Framework June 2012
practice this is impractical at LSP midpoints when PW are carried. The PW ingress may provide equivalent information in a PW flow label [RFC6391]. Therefore, in practice, item #8 above is covered by [RFC6391] and may be dropped from the list.
An LSR must at least be capable of identifying flows based on MPLS labels. Most MPLS LSP do not require that traffic carried by the LSP are carried in order. MPLS-TP is a recent exception. If it is assumed that no LSP require strict packet ordering of the LSP itself (only of flows within the LSP), then the entire label stack can be used as flow identification. If some LSP may require strict packet ordering but those LSP cannot be distinguished from others, then only the top label can be used as a flow identifier. If only the top label is used (for example, as specified by [RFC4201] when the "all- ones" component described in [RFC4201] is not used), then there may not be adequate flow granularity to accomplish well balanced traffic distribution and it will not be possible to carry LSP that are larger than any individual component link.
The number of flows can be extremely large. This may be the case when the entire label stack is used and is always the case when IP addresses are used in provider networks carrying Internet traffic. Current practice for native IP load balancing at the time of writing were documented in [RFC2991], [RFC2992]. These practices as described, make use of IP addresses. The common practices were extended to include the MPLS label stack and the common practice of looking at IP addresses within the MPLS payload. These extended practices are described in [RFC4385] and [RFC4928] due to their impact on pseudowires without a PWE3 Control Word. Additional detail on current multipath practices can be found in the appendices of [I-D.symmvo-rtgwg-cl-use-cases].
Using only the top label supports too coarse a traffic balance. Using the full label stack or IP addresses as flow identification provides a sufficiently fine traffic balance, but is capable of identifying such a high number of distinct flows, that a technique of grouping flows, such as hashing on the flow identification criteria, becomes essential to reduce the stored state, and is an essential scaling technique. Other means of grouping flows may be possible.
In summary:
1. Load balancing using only the MPLS label stack provides too coarse a granularity of load balance.
2. Tracking every flow is not scalable due to the extremely large number of flows in provider networks.
Ning, et al. Expires December 31, 2012 [Page 7]

Internet-Draft Composite Link Framework June 2012
3. Existing techniques, IP source and destination hash in particular, have proven in over two decades of experience to be an excellent way of identifying groups of flows.
4. If a better way to identify groups of flows is discovered, then that method can be used.
5. IP address hashing is not required, but use of this technique is strongly encouraged given the technique’s long history of successful deployment.
2.2. Composite Link in Control Plane
A composite Link is advertised as a single logical interface between two connected routers, which forms forwarding adjacency (FA) between the routers. The FA is advertised as a TE-link in a link state IGP, using either OSPF-TE or ISIS-TE. The IGP-TE advertised interface parameters for the composite link can be preconfigured by the network operator or be derived from its component links. Composite link advertisement requirements are specified in [I-D.ietf-rtgwg-cl-requirement].
In IGP-TE, a composite link is advertised as a single TE link between two connected routers. This is similar to a link bundle [RFC4201]. Link bundle applies to a set of homogenous component links. Composite link allows homogenous and non-homogenous component links. Due to the similarity, and for backwards compatibility, extending link bundling is viewed as both simple and as the best approach.
In order for a route computation engine to calculate a proper path for a LSP, it is necessary for composite link to advertise the summarized available bandwidth as well as the maximum bandwidth that can be made available for single flow (or single LSP where no finer flow identification is available). If a composite link contains some non-homogeneous component links, the composite link also should advertise the summarized bandwidth and the maximum bandwidth for single flow per each homogeneous component link group.
Both LDP [RFC5036] and RSVP-TE [RFC3209] can be used to signal a LSP over a composite link. LDP cannot be extended to support traffic engineering capabilities [RFC3468].
When an LSP is signaled using RSVP-TE, the LSP MUST be placed on the component link that meets the LSP criteria indicated in the signaling message.
When an LSP is signaled using LDP, the LSP MUST be placed on the component link that meets the LSP criteria, if such a component link
Ning, et al. Expires December 31, 2012 [Page 8]

Internet-Draft Composite Link Framework June 2012
is available. LDP does not support traffic engineering capabilities, imposing restrictions on LDP use of Composite Link. See Section 4.2.5 for further details.
A composite link may contain non-homogeneous component links. The route computing engine may select one group of component links for a LSP. The routing protocol MUST make this grouping available in the TE-LSDB. The route computation used in RSVP-TE MUST be extended to include only the capacity of groups within a composite link which meet LSP criteria. The signaling protocol MUST be able to indicate either the criteria, or which groups may be used. A composite link MUST place the LSP on a component link or group which meets or exceeds the LSP criteria.
Composite link capacity is aggregated capacity. LSP capacity MAY be larger than individual component link capacity. Any aggregated LSP can determine a bounds on the largest microflow that could be carried and this constraint can be handled as follows.
1. If no information is available through signaling, management plane, or configuration, the largest microflow is bound by one of the following:
A. the largest single LSP if most traffic is RSVP-TE signaled and further aggregated,
B. the largest pseudowire if most traffic is carrying pseudowire payloads that are aggregated within RSVP-TE LSP,
C. or the largest source and sink interface if a large amount of IP or LDP traffic is contained within the aggregate.
If a very large amount of traffic being aggregated is IP or LDP, then the largest microflow is bound by the largest component link on which IP traffic can arrive. For example, if an LSR is acting as an LER and IP and LDP traffic is arrving on 10 Gb/s edge interfaces, then no microflow larger than 10 Gb/s will be present on the RSVP-TE LSP that aggregate traffic across the core, even if the core interfaces are 100 Gb/s interfaces.
2. The prior conditions provide a bound on the largest microflow when no signaling extensions indicate a bounds. If an LSP is aggregating smaller LSP for which the largest expected microflow carried by the smaller LSP is signaled, then the largest microflow expected in the containing LSP (the aggregate) is the maximum of the largest expected microflow for any contained LSP. For example, RSVP-TE LSP may be large but aggregate traffic for which the source or sink are all 1 Gb/s or smaller interfaces
Ning, et al. Expires December 31, 2012 [Page 9]

Internet-Draft Composite Link Framework June 2012
(such as in mobile applications in which cell sites backhauls are no larger than 1 Gb/s). If this information is carried in the LSP originated at the cell sites, then further aggregates across a core may make use of this information.
3. The IGP must provide the bounds on the largest microflow that a composite link can accommodate, which is the maximum capacity on a component link that can be made available by moving other traffic. This information is needed by the ingress LER for path determination.
4. A means to signal an LSP whose capacity is larger than individual component link capacity is needed [I-D.ietf-rtgwg-cl-requirement] and also signal the largest microflow expected to be contained in the LSP. If a bounds on the largest microflow is not signaled there is no means to determine if an LSP which is larger than any component link can be subdivided into flows and therefore should be accepted by admission control.
When a bidirectional LSP request is signaled over a composite link, if the request indicates that the LSP must be placed on the same component link, the routers of the composite link MUST place the LSP traffic in both directions on a same component link. This is particularly challenging for aggregated capacity which makes use of the label stack for traffic distribution. The two requirements are mutually exclusive for any one LSP. No one LSP may be both larger than any individual component link and require symmetrical paths for every flow. Both requirements can be accommodated by the same composite link for different LSP, with any one LSP requiring no more than one of these two features.
Individual component link may fail independently. Upon component link failure, a composite link MUST support a minimally disruptive local repair, preempting any LSP which can no longer be supported. Available capacity in other component links MUST be used to carry impacted traffic. The available bandwidth after failure MUST be advertised immediately to avoid looped crankback.
When a composite link is not able to transport all flows, it preempts some flows based upon local management configuration and informs the control plane on these preempted flows. The composite link MUST support soft preemption [RFC5712]. This action ensures the remaining traffic is transported properly. FR#10 requires that the traffic be restored. FR#12 requires that any change be minimally disruptive. These two requirements are interpreted to include preemption among the types of changes that must be minimally disruptive.
Ning, et al. Expires December 31, 2012 [Page 10]

Internet-Draft Composite Link Framework June 2012
2.3. Composite Link in Data Plane
The data plane must first identify groups of flows. Flow identification is covered in Section 2.1. Having identified groups of flows the groups must be placed on individual component links. This second step is called traffic distribution or traffic placement. The two steps together are known as traffic balancing or load balancing.
Traffic distribution may be determined by or constrained by control plane or management plane. Traffic distribution may be changed due to component link status change, subject to constraints imposed by either the management plane or control plane. The distribution function is local to the routers in which a composite link belongs to and is not specified here.
When performing traffic placement, a composite link does not differentiate multicast traffic vs. unicast traffic.
In order to maintain scalability, existing data plane forwarding retains state associated with the top label only. The use of flow group identification is in a second step in the forwarding process. Data plane forwarding makes use of the top label to select a composite link, or a group of components within a composite link or for the case where an LSP is pinned (see [RFC4201]), a specific component link. For those LSP for which the LSP selects only the composite link or a group of components within a composite link, the load balancing makes use of the flow group identification.
The most common traffic placement techniques uses the a flow group identification as an index into a table. The table provides an indirection. The number of bits of hash is constrained to keep table size small. While this is not the best technique, it is the most common. Better techniques exist but they are outside the scope of this document and some are considered proprietary.
Requirements to limit frequency of load balancing can be adhered to by keeping track of when a flow group was last moved and imposing a minimum period before that flow group can be moved again. This is straightforward for a table approach. For other approaches it may be less straightforward but is acheivable.
3. Architecture Tradeoffs
Scalability and stability are critical considerations in protocol design where protocols may be used in a large network such as today’s service provider networks. Composite Link is applicable to networks
Ning, et al. Expires December 31, 2012 [Page 11]

Internet-Draft Composite Link Framework June 2012
which are large enough to require that traffic be split over multiple paths. Scalability is a major consideration for networks that reach a capacity large enough to require Composite Link.
Some of the requirements of Composite Link could potentially have a negative impact on scalability. For example, Composite Link requires additional information to be carried in situations where component links differ in some significant way.
3.1. Scalability Motivations
In the interest of scalability information is aggregated in situations where information about a large amount of network capacity or a large amount of network demand provides is adequate to meet requirements. Routing information is aggregated to reduce the amount of information exchange related to routing and to simplify route computation (see Section 3.2).
In an MPLS network large routing changes can occur when a single fault occurs. For example, a single fault may impact a very large number of LSP traversing a given link. As new LSP are signaled to avoid the fault, resources are consumed elsewhere, and routing protocol announcements must flood the resource changes. If protection is in place, there is less urgency to converging quickly. If multiple faults occur that are not covered by shared risk groups (SRG), then some protection may fail, adding urgency to converging quickly even where protection was deployed.
Reducing the amount of information allows the exchange of information during a large routing change to be accomplished more quickly and simplifies route computation. Simplifying route computation improves convergence time after very significant network faults which cannot be handled by preprovisioned or precomputed protection mechanisms. Aggregating smaller LSP into larger LSP is a means to reduce path computation load and reduce RSVP-TE signaling (see Section 3.3).
Neglecting scaling issues can result in performance issues, such as slow convergence. Neglecting scaling in some cases can result in networks which perform so poorly as to become unstable.
3.2. Reducing Routing Information and Exchange
Link bundling at the very least provides a means of aggregating control plane information. Even where the all-ones component link supported by link bundling is not used, the amount of control information is reduced by the average number of component links in a bundle.
Ning, et al. Expires December 31, 2012 [Page 12]

Internet-Draft Composite Link Framework June 2012
Fully deaggregating link bundle information would negate this benefit. If there is a need to deaggregate, such as to distinguish between groups of links within specified ranges of delay, then no more deaggregation than is necessary should be done.
For example, in supporting the requirement for heterogeneous component links, it makes little sense to fully deaggregate link bundles when adding support for groups of component links with common attributes within a link bundle can maintain most of the benefit of aggregation while adequately supporting the requirement to support heterogeneous component links.
Routing information exchange is also reduced by making sensible choices regarding the amount of change to link parameters that require link readvertisement. For example, if delay measurements include queuing delay, then a much more coarse granularity of delay measurement would be called for than if the delay does not include queuing and is dominated by geographic delay (speed of light delay).
3.3. Reducing Signaling Load
Aggregating traffic into very large hierarchical LSP in the core very substantially reduces the number of LSP that need to be signaled and the number of path computations any given LSR will be required to perform when a major network fault occurs.
In the extreme, applying MPLS to a very large network without hierarchy could exceed the 20 bit label space. For example, in a network with 4,000 nodes, with 2,000 on either side of a cutset, would have 4,000,000 LSP crossing the cutset. Even in a degree four cutset, an uneven distribution of LSP across the cutset, or the loss of one link would result in a need to exceed the size of the label space. Among provider networks, 4,000 access nodes is not at all large.
In less extreme cases, having each node terminate hundreds of LSP to achieve a full mesh creates a very large computational load. The time complexity of one CSPF computation is order(N log N), where L is proportional to N, and N and L are the number of nodes and number of links, respectively. If each node must perform order(N) computations when a fault occurs, then the computational load increases as order(N^2 log N) as the number of nodes increases. In practice at the time of writing, this imposes a limit of a few hundred nodes in a full mesh of MPLS LSP before the computational load is sufficient to result in unacceptable convergence times.
Two solutions are applied to reduce the amount of RSVP-TE signaling. Both involve subdividing the MPLS domain into a core and a set of
Ning, et al. Expires December 31, 2012 [Page 13]

Internet-Draft Composite Link Framework June 2012
regions.
3.3.1. Reducing Signaling Load using LDP
LDP can be used for edge-to-edge LSP, using RSVP-TE to carry the LDP intra-core traffic and also optionally also using RSVP-TE to carry the LDP intra-region traffic within each region. LDP does not support traffic engineering, but does support multipoint-to-point (MPTP) LSP, which require less signaling than edge-to-edge RSVP-TE point-to-point (PTP) LSP. A drawback of this approach is the inability to use RSVP-TE protection (FRR or GMPLS protection) against failure of the border LSR sitting at a core/region boundary.
3.3.2. Reducing Signaling Load using Hierarchy
When the number of nodes grows too large, the amount of RSVP-TE signaling can be reduced using the MPLS PSC hierarchy [RFC4206]. A core within the hierarchy can divide the topology into M regions of on average N/M nodes. Within a region the computational load is reduced by more than M^2. Within the core, the computational load generally becomes quite small since M is usually a fairly small number (a few tens of regions) and each region is generally attached to the core in typically only two or three places on average.
Using hierarchy improves scaling but has two consequences. First, hierarchy effectively forces the use of platform label space. When a containing LSP is rerouted, the labels assigned to the contained LSP cannot be changed but may arrive on a different interface. Second, hierarchy results in much larger LSP. These LSP today are larger than any single component link and therefore force the use of the all-ones component in link bundles.
3.3.3. Using Both LDP and RSVP-TE Hierarchy
It is also possible to use both LDP and RSVP-TE hierarchy. MPLS networks with a very large number of nodes may benefit from the use of both LDP and RSVP-TE hierarchy. The two techniques are certainly not mutually exclusive.
3.4. Reducing Forwarding State
Both LDP and MPLS hierarchy have the benefit of reducing the amount of forwarding state. Using the example from Section 3.3, and using MPLS hierarchy, the worst case generally occurs at borders with the core.
For example, consider a network with approximately 1,000 nodes divided into 10 regions. At the edges, each node requires 1,000 LSP
Ning, et al. Expires December 31, 2012 [Page 14]

Internet-Draft Composite Link Framework June 2012
to other edge nodes. The edge nodes also require 100 intra-region LSP. Within the core, if the core has only 3 attachments to each region the core LSR have less than 100 intra-core LSP. At the border cutset between the core and a given region, in this example there are 100 edge nodes with inter-region LSP crossing that cutset, destined to 900 other edge nodes. That yields forwarding state for on the order of 90,000 LSP at the border cutset. These same routers need only reroute well under 200 LSP when a multiple fault occurs, as long as only links are affected and a border LSR does not go down.
In the core, the forwarding state is greatly reduced. If inter- region LSP have different characteristics, it makes sense to make use of aggregates with different characteristics. Rather than exchange information about every inter-region LSP within the intra-core LSP it makes more sense to use multiple intra-core LSP between pairs of core nodes, each aggregating sets of inter-region LSP with common characteristics or common requirements.
3.5. Avoiding Route Oscillation
Networks can become unstable when a feedback loop exists such that moving traffic to a link causes a metric such as delay to increase, which then causes traffic to move elsewhere. For example, the original ARPANET routing used a delay based cost metric and proved prone to route oscillations [DBP].
Delay may be used as a constraint in routing for high priority traffic, where the movement of traffic cannot impact the delay. The safest way to measure delay is to make measurements based on traffic which is prioritized such that it is queued ahead of the traffic which will be affected. This is a reasonable measure of delay for high priority traffic for which constraints have been set which allow this type of traffic to consume only a fraction of link capacities with the remaining capacity available to lower priority traffic.
Any measurement of jitter (delay variation) that is used in route decision is likely to cause oscillation. Jitter that is caused by queuing effects and cannot be measured using a very high priority measurement traffic flow.
It may be possible to find links with constrained queuing delay or jitter using a theoretical maximum or a probability based bound on queuing delay or jitter at a given priority based on the types and amounts of traffic accepted and combining that theoretical limit with a measured delay at very high priority.
Instability can occur due to poor performance and interaction with protocol timers. In this way a computational scaling problem can
Ning, et al. Expires December 31, 2012 [Page 15]

Internet-Draft Composite Link Framework June 2012
become a stability problem when a network becomes sufficiently large. For this reason, [I-D.ietf-rtgwg-cl-requirement] has a number of requirements focusing on minimally impacting scalability.
4. New Challenges
New technical challenges are posed by [I-D.ietf-rtgwg-cl-requirement] in both the control plane and data plane.
Among the more difficult challenges are the following.
1. requirements related delay or jitter (see Section 4.1.1),
2. the combination of ingress control over LSP placement and retaining an ability to move traffic as demands dictate can pose challenges and such requirements can even be conflicting (see target="sect.local-control" />),
3. path symmetry requires extensions and is particularly challenging for very large LSP (see Section 4.1.3),
4. accommodating a very wide range of requirements among contained LSP can lead to inefficiency if the most stringent requirements are reflected in aggregates, or reduce scalability if a large number of aggregates are used to provide a too fine a reflection of the requirements in the contained LSP (see Section 4.1.4),
5. backwards compatibility is somewhat limited due to the need to accommodate legacy multipath interfaces which provide too little information regarding their configured default behavior, and legacy LSP which provide too little information regarding their requirements (see Section 4.1.5),
6. data plane challenges include those of accommodating very large LSP, large microflows, traffic ordering constraints imposed by a subsent of LSP, and accounting for IP and LDP traffic (see Section 4.2).
4.1. Control Plane Challenges
Some of the control plane requirements are particularly challenging. Handling large flows which aggregate smaller flows must be accomplished with minimal impact on scalability. Potentially conflicting are requirements for jitter and requirements for stability. Potentially conflicting are the requirements for ingress control of a large number of parameters, and the requirements for local control needed to achieve traffic balance across a composite
Ning, et al. Expires December 31, 2012 [Page 16]

Internet-Draft Composite Link Framework June 2012
link. These challenges and potential solutions are discussed in the following sections.
4.1.1. Delay and Jitter Sensitive Routing
Delay and jitter sensitive routing are called for in [I-D.ietf-rtgwg-cl-requirement] in requirements FR#2, FR#7, FR#8, FR#9, FR#15, FR#16, FR#17, FR#18. Requirement FR#17 is particularly problematic, calling for constraints on jitter.
A tradeoff exists between scaling benefits of aggregating information, and potential benefits of using a finer granularity in delay reporting. To maintain the scaling benefit, measured link delay for any given composite link SHOULD be aggregated into a small number of delay ranges. IGP-TE extensions MUST be provided which advertise the available capacities for each of the selected ranges.
For path selection of delay sensitive LSP, the ingress SHOULD bias link metrics based on available capacity and select a low cost path which meets LSP total path delay criteria. To communicate the requirements of an LSP, the ERO MUST be extended to indicate the per link constraints. To communicate the type of resource used, the RRO SHOULD be extended to carry an identification of the group that is used to carry the LSP at each link bundle hop.
4.1.2. Local Control of Traffic Distribution
Many requirements in [I-D.ietf-rtgwg-cl-requirement] suggest that a node immediately adjacent to a component link should have a high degree of control over how traffic is distributed, as long as network performance objectives are met. Particularly relevant are FR#18 and FR#19.
The requirements to allow local control are potentially in conflict with requirement FR#21 which gives full control of component link select to the LSP ingress. While supporting this capability is mandatory, use of this feature is optional per LSP.
A given network deployment will have to consider this pair of conflicting requirements and make appropriate use of local control of traffic placement and ingress control of traffic placement to best meet network requirements.
4.1.3. Path Symmetry Requirements
Requirement FR#21 in [I-D.ietf-rtgwg-cl-requirement] includes a provision to bind both directions of a bidirectional LSP to the same component. This is easily achieved if the LSP is directly signaled
Ning, et al. Expires December 31, 2012 [Page 17]

Internet-Draft Composite Link Framework June 2012
across a composite link. This is not as easily achieved if a set of LSP with this requirement are signaled over a large hierarchical LSP which is in turn carried over a composite link. The basis for load distribution in such as case is the label stack. The labels in either direction are completely independent.
This could be accommodated if the ingress, egress, and all midpoints of the hierarchical LSP make use of an entropy label in the distribution, and use only that entropy label. A solution for this problem may add complexity with very little benefit. There is little or no true benefit of using symmetrical paths rather than component links of identical characteristics.
Traffic symmetry and large LSP capacity are a second pair of conflicting requirements. Any given LSP can meet one of these two requirements but not both. A given network deployment will have to make appropriate use of each of these features to best meet network requirements.
4.1.4. Requirements for Contained LSP
[I-D.ietf-rtgwg-cl-requirement] calls for new LSP constraints. These constraints include frequency of load balancing rearrangement, delay and jitter, packet ordering constraints, and path symmetry.
When LSP are contained within hierarchical LSP, there is no signaling available at midpoint LSR which identifies the contained LSP let alone providing the set of requirements unique to each contained LSP. Defining extensions to provide this information would severely impact scalability and defeat the purpose of aggregating control information and forwarding information into hierarchical LSP. For the same scalability reasons, not aggregating at all is not a viable option for large networks where scalability and stability problems may occur as a result.
As pointed out in Section 4.1.3, the benefits of supporting symmetric paths among LSP contained within hierarchical LSP may not be sufficient to justify the complexity of supporting this capability.
A scalable solution which accommodates multiple sets of LSP between given pairs of LSR is to provide multiple hierarchical LSP for each given pair of LSR, each hierarchical LSP aggregating LSP with common requirements and a common pair of endpoints. This is a network design technique available to the network operator rather than a protocol extension. This technique can accommodate multiple sets of delay and jitter parameters, multiple sets of frequency of load balancing parameters, multiple sets of packet ordering constraints, etc.
Ning, et al. Expires December 31, 2012 [Page 18]

Internet-Draft Composite Link Framework June 2012
4.1.5. Retaining Backwards Compatibility
Backwards compatibility and support for incremental deployment requires considering the impact of legacy LSR in the role of LSP ingress, and considering the impact of legacy LSR advertising ordinary links, advertising Ethernet LAG as ordinary links, and advertising link bundles.
Legacy LSR in the role of LSP ingress cannot signal requirements which are not supported by their control plane software. The additional capabilities supported by other LSR has no impact on these LSR. These LSR however, being unaware of extensions, may try to make use of scarce resources which support specific requirements such as low delay. To a limited extent it may be possible for a network operator to avoid this issue using existing mechanisms such as link administrative attributes and attribute affinities [RFC3209].
Legacy LSR advertising ordinary links will not advertise attributes needed by some LSP. For example, there is no way to determine the delay or jitter characteristics of such a link. Legacy LSR advertising Ethernet LAG pose additional problems. There is no way to determine that packet ordering constraints would be violated for LSP with strict packet ordering constraints, or that frequency of load balancing rearrangement constraints might be violated.
Legacy LSR advertising link bundles have no way to advertise the configured default behavior of the link bundle. Some link bundles may be configured to place each LSP on a single component link and therefore may not be able to accommodate an LSP which requires bandwidth in excess of the size of a component link. Some link bundles may be configured to spread all LSP over the all-ones component. For LSR using the all-ones component link, there is no documented procedure for correctly setting the "Maximum LSP Bandwidth". There is currently no way to indicate the largest microflow that could be supported by a link bundle using the all-ones component link.
Having received the RRO, it is possible for an ingress to look for the all-ones component to identify such link bundles after having signaled at least one LSP. Whether any LSR collects this information on legacy LSR and makes use of it to set defaults, is an implementation choice.
4.2. Data Plane Challenges
Flow identification is briefly discussed in Section 2.1. Traffic distribution is briefly discussed in Section 2.3. This section discusses issues specific to particular requirements specified in
Ning, et al. Expires December 31, 2012 [Page 19]

Internet-Draft Composite Link Framework June 2012
[I-D.ietf-rtgwg-cl-requirement].
4.2.1. Very Large LSP
Very large LSP may exceed the capacity of any single component of a composite link. In some cases contained LSP may exceed the capacity of any single component. These LSP may the use of the equivalent of the all-ones component of a link bundle, or may use a subset of components which meet the LSP requirements.
Very large LSP can be accommodated as long as they can be subdivided (see Section 4.2.2). A very large LSP cannot have a requirement for symetric paths unless complex protocol extensions are proposed (see Section 2.2 and Section 4.1.3).
4.2.2. Very Large Microflows
Within a very large LSP there may be very large microflows. A very large microflow is a very large flows which cannot be further subdivided. Flows which cannot be subdivided must be no larger that the capacity of any single component.
Current signaling provides no way to specify the largest microflow that a can be supported on a given link bundle in routing advertisements. Extensions which address this are discussed in Section 6.4. Absent extensions of this type, traffic containing microflows that are too large for a given composite link may be present. There is no data plane solution for this problem that would not require reordering traffic at the composite link egress.
Some techniques are susceptible to statistical collisions where an algorithm to distribute traffic is unable to disambiguate traffic among two or more very large microflow where their sum is in excess of the capacity of any single component. Hash based algorithms which use too small a hash space are particularly susceptible and require a change in hash seed in the event that this were to occur. A change in hash seed is highly disruptive, causing traffic reordering among all traffic flows over which the hash function is applied.
4.2.3. Traffic Ordering Constraints
Some LSP have strict traffic ordering constraints. Most notable among these are MPLS-TP LSP. In the absence of aggregation into hierarchical LSP, those LSP with strict traffic ordering constraints can be placed on individual component links if there is a means of identifying which LSP have such a constraint. If LSP with strict traffic ordering constraints are aggregated in hierarchical LSP, the hierarchical LSP capacity may exceed the capacity of any single
Ning, et al. Expires December 31, 2012 [Page 20]

Internet-Draft Composite Link Framework June 2012
component link. In such a case the load balancing for the containing may be constrained to look only at the top label and the first contained label. This and related issues are discussed further in Section 6.4.
4.2.4. Accounting for IP and LDP Traffic
Networks which carry RSVP-TE signaled MPLS traffic generally carry low volumes of native IP traffic, often only carrying control traffic as native IP. There is no architectural guarantee of this, it is just how network operators have made use of the protocols.
[I-D.ietf-rtgwg-cl-requirement] requires that native IP and native LDP be accommodated. In some networks, a subset of services may be carried as native IP or carried as native LDP. Today this may be accommodated by the network operator estimating the contribution of IP and LDP and configuring a lower set of available bandwidth figures on the RSVP-TE advertisements.
The only improvement that Composite Link can offer is that of measuring the IP and LDP traffic levels and automatically reducing the available bandwidth figures on the RSVP-TE advertisements. The measurements would have to be significantly filtered. This is similar to a feature in existing LSR, commonly known as "autobandwidth" with a key difference. In the "autobandwidth" feature, the bandwidth request of an RSVP-TE signaled LSP is adjusted in response to traffic measurements. In this case the IP or LDP traffic measurements are used to reduce the link bandwidth directly, without first encapsulating in an RSVP-TE LSP.
This may be a subtle and perhaps even a meaningless distinction if Composite Link is used to form a Sub-Path Maintenance Element (SPME). A SPME is in practice essentially an unsignaled single hop LSP with PHP enabled [RFC5921]. A Composite Link SPME looks very much like classic multipath, where there is no signaling, only management plane configuration creating the multipath entity (of which Ethernet Link Aggregation is a subset).
4.2.5. IP and LDP Limitations
IP does not offer traffic engineering. LDP cannot be extended to offer traffic engineering [RFC3468]. Therefore there is no traffic engineered fallback to an alternate path for IP and LDP traffic if resources are not adequate for the IP and/or LDP traffic alone on a given link in the primary path. The only option for IP and LDP would be to declare the link down. Declaring a link down due to resource exhaustion would reduce traffic to zero and eliminate the resource exhaustion. This would cause oscillations and is therefore not a
Ning, et al. Expires December 31, 2012 [Page 21]

Internet-Draft Composite Link Framework June 2012
viable solution.
Congestion caused by IP or LDP traffic loads is a pathologic case that can occur if IP and/or LDP are carried natively and there is a high volume of IP or LDP traffic. This situation can be avoided by carrying IP and LDP within RSVP-TE LSP.
It is also not possible to route LDP traffic differently for different FEC. LDP traffic engineering is specifically disallowed by [RFC3468]. It may be possible to support multi-topology IGP extensions to accommodate more than one set of criteria. If so, the additional IGP could be bound to the forwarding criteria, and the LDP FEC bound to a specific IGP instance, inheriting the forwarding criteria. Alternately, one IGP instance can be used and the LDP SPF can make use of the constraints, such as delay and jitter, for a given LDP FEC. [Note: WG needs to discuss this and decide first whether to solve this at all and then if so, how.]
5. Existing Mechanisms
In MPLS the one mechanisms which support explicit signaling of multiple parallel links is Link Bundling [RFC4201]. The set of techniques known as "classis multipath" support no explicit signaling, except in two cases. In Ethernet Link Aggregation the Link Aggregation Control Protocol (LACP) coordinates the addition or removal of members from an Ethernet Link Aggregation Group (LAG). The use of the "all-ones" component of a link bundle indicates use of classis multipath, however the ability to determine if a link bundle makes use of classis multipath is not yet supported.
5.1. Link Bundling
Link bundling supports advertisement of a set of homogenous links as a single route advertisement. Link bundling supports placement of an LSP on any single component link, or supports placement of an LSP on the all-ones component link. Not all link bundling implementations support the all-ones component link. There is no way for an ingress LSR to tell which potential midpoint LSR support this feature and use it by default and which do not. Based on [RFC4201] it is unclear how to advertise a link bundle for which the all-ones component link is available and used by default. Common practice is to violate the specification and set the Maximum LSP Bandwidth to the Available Bandwidth. There is no means to determine the largest microflow that could be supported by a link bundle that is using the all-ones component link.
[RFC6107] extends the procedures for hierarchical LSP but also
Ning, et al. Expires December 31, 2012 [Page 22]

Internet-Draft Composite Link Framework June 2012
extends link bundles. An LSP can be explicitly signaled to indicate that it is an LSP to be used as a component of a link bundle. Prior to that the common practice was to simply not advertise the component link LSP into the IGP, since only the ingress and egress of the link bundle needed to be aware of their existence, which they would be aware of due to the RSVP-TE signaling used in setting up the component LSP.
While link bundling can be the basis for composite links, a significant number of small extension needs to be added.
1. To support link bundles of heterogeneous links, a means of advertising the capacity available within a group of homogeneous needs to be provided.
2. Attributes need to be defined to support the following parameters for the link bundle or for a group of homogeneous links.
A. delay range
B. jitter (delay variation) range
C. group metric
D. all-ones component capable
E. capable of dynamically balancing load
F. largest supportable microflow
G. abilities to support strict packet ordering requirements within contained LSP
3. For each of the prior extended attributes, the constraint based routing path selection needs to be extended to reflect new constraints based on the extended attributes.
4. For each of the prior extended attributes, LSP admission control needs to be extended to reflect new constraints based on the extended attributes.
5. Dynamic load balance must be provided for flows within a given set of links with common attributes such that NPO are not violated including frequency of load balance adjustment for any given flow.
Ning, et al. Expires December 31, 2012 [Page 23]

Internet-Draft Composite Link Framework June 2012
5.2. Classic Multipath
Classic multipath is defined in [I-D.symmvo-rtgwg-cl-use-cases].
Classic multipath refers to the most common current practice in implementation and deployment of multipath. The most common current practice makes use of a hash on the MPLS label stack and if IPv4 or IPv6 are indicated under the label stack, makes use of the IP source and destination addresses [RFC4385] [RFC4928].
Classic multipath provides a highly scalable means of load balancing. Adaptive multipath has proven value in assuring an even loading on component link and an ability to adapt to change in offerred load that occurs over periods of hundreds of milliseconds or more. Classic multipath scalability is due to the ability to effectively work with an extremely large number of flows (IP host pairs) using relatively little resources (a data structure accessed using a hash result as a key or using ranges of hash results).
Classic multipath meets a small subset of Composite Link requirements. Due to scalability of the approach, classic multipath seems to be an excellent candidate for extension to meet the full set of Composite Link forwarding requirements.
Additional detail can be found in [I-D.symmvo-rtgwg-cl-use-cases].
6. Mechanisms Proposed in Other Documents
A number of documents which at the time of writing are works in progress address parts of the requirements of Composite Link, or assist in making some of the goals achievable.
6.1. Loss and Delay Measurement
Procedures for measuring loss and delay are provided in [RFC6374]. These are OAM based measurements. This work could be the basis of delay measurements and delay variation measurement used for metrics called for in [I-D.ietf-rtgwg-cl-requirement].
Currently there are two additional Internet-Drafts that address delay and delay variation metrics.
draft-wang-ccamp-latency-te-metric [I-D.wang-ccamp-latency-te-metric] is designed specifically to meet this requirement. OSPF-TE and ISIS-TE extensions are defined to indicate link delay and delay variance. The RSVP-TE ERO is extended to include service level requirements. A latency
Ning, et al. Expires December 31, 2012 [Page 24]

Internet-Draft Composite Link Framework June 2012
accumulation object is defined to provide a means of verification of the service level requirements. This draft is intended to proceed in the CCAMP WG. It is currently and individual submission. The 03 version of this draft expired in September 2012.
draft-giacalone-ospf-te-express-path This document proposes to extend OSPF-TE only. Extensions support delay, delay variance, loss, residual bandwidth, and available bandwidth. No extensions to RSVP-TE are proposed. This draft is intended to proceed in the CCAMP WG. It is currently and individual submission. The 02 version will expire in March 2012.
A possible course of action may be to combine these two drafts. The delay variance, loss, residual bandwidth, and available bandwidth extensions are particular prone to network instability. The question as to whether queuing delay and delay variation should be considered, and if so for which diffserv Per-Hop Service Class (PSC) is not addressed.
Note to co-authors: The ccamp-latency-te-metric draft refers to [I-D.ietf-rtgwg-cl-requirement] and is well matched to those requirements, including stability. The ospf-te-express-path draft refers to the "Alto Protocol" (draft-ietf-alto-protocol) and therefore may not be intended for RSVP-TE use. The authors of the two drafts may be able to resolve this. It may be best to drop ospf- te-express-path from this framework document.
6.2. Link Bundle Extensions
A set of link bundling extensions are defined in [I-D.ietf-mpls-explicit-resource-control-bundle]. This document provides extensions to the ERO and RRO to explicitly control the labels and resources within a bundle used by an LSP.
The extensions in this document could be further extended to support indicating a group of component links in the ERO or RRO, where the group is given an interface identification like the bundle itself. The extensions could also be further extended to support specification of the all-ones component link in the ERO or RRO.
[I-D.ietf-mpls-explicit-resource-control-bundle] does not provide a means to advertise the link bundle components. It is not certain how the ingress LSR would determine the set of link bundle component links available for a given link bundle.
[I-D.ospf-cc-stlv] provides a baseline draft for extending link
Ning, et al. Expires December 31, 2012 [Page 25]

Internet-Draft Composite Link Framework June 2012
bundling to advertise components. A new component TVL (C-TLV) is proposed, which must reference a Composite Link Link TLV. [I-D.ospf-cc-stlv] is intended for the OSPF WG and submitted for the "Experimental" track. The 00 version expired in February 2012.
6.3. Fat PW and Entropy Labels
Two documents provide a means to add entropy for the purpose of improving load balance. MPLS encapsulation can bury information that is needed to identify microflows. These two documents allow a pseudowire ingress and LSP ingress respectively to add a label solely for the purpose of providing a finer granularity of microflow groups.
[RFC6391] allows pseudowires which carry a large volume of traffic, where microflows can be identified to be load balanced across multiple members of an Ethernet LAG or an MPLS link bundle. This is accomplished by adding a flow label below the pseudowire label in the MPLS label stack. For this to be effective the link bundle load balance must make use of the label stack up to and including this flow label.
[I-D.ietf-mpls-entropy-label] provides a means for a LER to put an additional label known as an entropy label on the MPLS label stack. As defined, only the LER can add the entropy label.
Core LSR acting as LER for aggregated LSP can add entropy labels based on deep packet inspection and place an entropy label indicator (ELI) and entropy label (EL) just below the label being acted on. This would be helpful in situations where the label stack depth to which load distribution can operate is limited by implementation or is limited for other reasons such as carrying both MPLS-TP and MPLS with entropy labels within the same hierarchical LSP.
6.4. Multipath Extensions
The multipath extensions drafts address one aspect of Composite Link. These drafts deal with the issue of accommodating LSP which have strict packet ordering constraints in a network containing multipath. MPLS-TP has become the one important instance of LSP with strict packet ordering constraints and has driven this work.
[I-D.villamizar-mpls-tp-multipath] outlines requirements and gives a number of options for dealing with the apparent incompatibility of MPLS-TP and multipath. A preferred option is described.
[I-D.villamizar-mpls-tp-multipath-te-extn] provides protocol extensions needed to implement the preferred option described in [I-D.villamizar-mpls-tp-multipath].
Ning, et al. Expires December 31, 2012 [Page 26]

Internet-Draft Composite Link Framework June 2012
Other issues pertaining to multipath are also addressed. Means to advertise the largest microflow supportable are defined. Means to indicate the largest expected microflow within an LSP are defined. Issues related to hierarchy are addressed.
7. Required Protocol Extensions and Mechanisms
Prior sections have reviewed key characteristics, architecture tradeoffs, new challenges, existing mechanisms, and relevant mechanisms proposed in existing new documents.
This section first summarizes and groups requirements. A set of documents coverage groupings are proposed with existing works-in- progress noted where applicable. The set of extensions are then grouped by protocol affected as a convenience to implementors.
7.1. Brief Review of Requirements
The following list provides a categorization of requirements specified in [I-D.ietf-rtgwg-cl-requirement] along with a short phrase indication what topic the requirement covers.
routing information aggregation FR#1 (routing summarization), FR#20 (composite link may be a component of another composite link)
restoration speed FR#2 (restoration speed meeting NPO), FR#12 (minimally disruptive load rebalance), DR#6 (fast convergence), DR#7 (fast worst case failure convergence)
load distribution, stability, minimal disruption FR#3 (automatic load distribution), FR#5 (must not oscillate), FR#11 (dynamic placement of flows), FR#12 (minimally disruptive load rebalance), FR#13 (bounded rearrangement frequency), FR#18 (flow placement must satisfy NPO), FR#19 (flow identification finer than per top level LSP), MR#6 (operator initiated flow rebalance)
backward compatibility and migration FR#4 (smooth incremental deployment), FR#6 (management and diagnostics must continue to function), DR#1 (extend existing protocols), DR#2 (extend LDP, no LDP TE)
Ning, et al. Expires December 31, 2012 [Page 27]

Internet-Draft Composite Link Framework June 2012
delay and delay variation FR#7 (expose lower layer measured delay), FR#8 (precision of latency reporting), FR#9 (limit latency on per LSP basis), FR#15 (minimum delay path), FR#16 (bounded delay path), FR#17 (bounded jitter path)
admission control, preemption, traffic engineering FR#10 (admission control, preemption), FR#14 (packet ordering), FR#21 (ingress specification of path), FR#22 (path symmetry), DR#3 (IP and LDP traffic), MR#3 (management specification of path)
single vs multiple domain DR#4 (IGP extensions allowed within single domain), DR#5 (IGP extensions disallowed in multiple domain case)
general network management MR#1 (polling, configuration, and notification), MR#2 (activation and de-activation)
path determination, connectivity verification MR#4 (path trace), MR#5 (connectivity verification)
The above list is not intended as a substitute for [I-D.ietf-rtgwg-cl-requirement], but rather as a concise grouping and reminder or requirements to serve as a means of more easily determining requirements coverage of a set of protocol documents.
7.2. Required Document Coverage
The primary areas where additional protocol extensions and mechanisms are required include the topics described in the following subsections.
There are candidate documents for a subset of the topics below. This grouping of topics does not require that each topic be addressed by a separate document. In some cases, a document may cover multiple topics, or a specific topic may be addressed as applicable in multiple documents.
7.2.1. Component Link Grouping
An extension to link bundling is needed to specify a group of components with common attributes. This can be a TLV defined within the link bundle that carries the same encapsulations as the link bundle. Two interface indices would be needed for each group.
Ning, et al. Expires December 31, 2012 [Page 28]

Internet-Draft Composite Link Framework June 2012
a. An index is needed that if included in an ERO would indicate the need to place the LSP on any one component within the group.
b. A second index is needed that if included in an ERO would indicate the need to balance flows within the LSP across all components of the group. This is equivalent to the "all-ones" component for the entire bundle.
[I-D.ospf-cc-stlv] can be extended to include multipath treatment capabilities. An ISIS solution is also needed. An extension of RSVP-TE signaling is needed to indicate multipath treatment preferences.
If a component group is allowed to support all of the parameters of a link bundle, then a group TE metric would be accommodated. This can be supported with the component TLV (C-TLV) defined in [I-D.ospf-cc-stlv].
The primary focus of this document, among the sets of requirements listed in Section 7.1 is the "routing information aggregation" set of requirements. The "restoration speed", "backward compatibility and migration", and "general network management" requirements must also be considered.
7.2.2. Delay and Jitter Extensions
A extension is needed in the IGP-TE advertisement to support delay and delay variation for links, link bundles, and forwarding adjacencies. Whatever mechanism is described must take precautions that insure that route oscillations cannot occur. [I-D.wang-ccamp-latency-te-metric] may be a good starting point.
The primary focus of this document, among the sets of requirements listed in Section 7.1 is the "delay and delay variation" set of requirements. The "restoration speed", "backward compatibility and migration", and "general network management" requirements must also be considered.
7.2.3. Path Selection and Admission Control
Path selection and admission control changes must be documented in each document that proposes a protocol extension that advertises a new capability or parameter that must be supported by changes in path selection and admission control.
The primary focus of this document, among the sets of requirements listed in Section 7.1 are the "load distribution, stability, minimal disruption" and "admission control, preemption, traffic engineering"
Ning, et al. Expires December 31, 2012 [Page 29]

Internet-Draft Composite Link Framework June 2012
sets of requirements. The "restoration speed" and "path determination, connectivity verification" requirements must also be considered. The "backward compatibility and migration", and "general network management" requirements must also be considered.
7.2.4. Dynamic Multipath Balance
FR#11 explicitly calls for dynamic load balancing similar to existing adaptive multipath. In implementations where flow identification uses a coarse granularity, the adjustments would have to be equally coarse, in the worst case moving entire LSP. The impact of flow identification granularity and potential adaptive multipath approaches may need to be documented in greater detail than provided here.
The primary focus of this document, among the sets of requirements listed in Section 7.1 are the "restoration speed" and the "load distribution, stability, minimal disruption" sets of requirements. The "path determination, connectivity verification" requirements must also be considered. The "backward compatibility and migration", and "general network management" requirements must also be considered.
7.2.5. Frequency of Load Balance
IGP-TE and RSVP-TE extensions are needed to support frequency of load balancing rearrangement called for in FR#13, and FR#15-FR#17. Constraints are not defined in RSVP-TE, but could be modeled after administrative attribute affinities in RFC3209 and elsewhere.
The primary focus of this document, among the sets of requirements listed in Section 7.1 is the "load distribution, stability, minimal disruption" set of requirements. The "path determination, connectivity verification" must also be considered. The "backward compatibility and migration" and "general network management" requirements must also be considered.
7.2.6. Inter-Layer Communication
Lower layer to upper layer communication called for in FR#7 and FR#20. This is addressed for a subset of parameters related to packet ordering in [I-D.villamizar-mpls-tp-multipath] where layers are MPLS. Remaining parameters, specifically delay and delay variation, need to be addressed. Passing information from a lower non-MPLS layer to an MPLS layer needs to be addressed, though this may largely be generic advice encouraging a coupling of MPLS to lower layer management plane or control plane interfaces. This topic can be addressed in each document proposing a protocol extension, where applicable.
Ning, et al. Expires December 31, 2012 [Page 30]

Internet-Draft Composite Link Framework June 2012
The primary focus of this document, among the sets of requirements listed in Section 7.1 is the "restoration speed" set of requirements. The "backward compatibility and migration" and "general network management" requirements must also be considered.
7.2.7. Packet Ordering Requirements
A document is needed to define extensions supporting various packet ordering requirements, ranging from requirements to preservce microflow ordering only, to requirements to preservce full LSP ordering (as in MPLS-TP). This is covered by [I-D.villamizar-mpls-tp-multipath] and [I-D.villamizar-mpls-tp-multipath-te-extn].
The primary focus of this document, among the sets of requirements listed in Section 7.1 are the "admission control, preemption, traffic engineering" and the "path determination, connectivity verification" sets of requirements. The "backward compatibility and migration" and "general network management" requirements must also be considered.
7.2.8. Minimally Disruption Load Balance
The behavior of hash methods used in classic multipath needs to be described in terms of FR#12 which calls for minimally disruptive load adjustments. For example, reseeding the hash violates FR#12. Using modulo operations is significantly disruptive if a link comes or goes down, as pointed out in [RFC2992]. In addition, backwards compatibility with older hardware needs to be accommodated.
The primary focus of this document, among the sets of requirements listed in Section 7.1 is the "load distribution, stability, minimal disruption" set of requirements.
7.2.9. Path Symmetry
Protocol extensions are needed to support dynamic load balance as called for to meet FR#22 (path symmetry) and to meet FR#11 (dynamic placement of flows). Currently path symmetry can only be supported in link bundling if the path is pinned. When a flow is moved both ingress and egress must make the move as close to simultaneously as possible to satisfy FR#22 and FR#12 (minimally disruptive load rebalance). If a group of flows are identified using a hash, then the hash must be identical on the pair of LSR at the endpoint, using the same hash seed and with one side swapping source and destination. If the label stack is used, then either the entire label stack must be a special case flow identification, since the set of labels in either direction are not correlated, or the two LSR must conspire to use the same flow identifier. For example, using a common entropy
Ning, et al. Expires December 31, 2012 [Page 31]

Internet-Draft Composite Link Framework June 2012
label value, and using only the entropy label in the flow identification would satisfy this requirement.
The primary focus of this document, among the sets of requirements listed in Section 7.1 are the "load distribution, stability, minimal disruption" and the "admission control, preemption, traffic engineering" sets of requirements. The "backward compatibility and migration" and "general network management" requirements must also be considered. Path symetry simplifies support for the "path determination, connectivity verification" set of requirements, but with significant complexity added elsewhere.
7.2.10. Performance, Scalability, and Stability
A separate document providing analysis of performance, scalability, and stability impacts of changes may be needed. The topic of traffic adjustment oscillation must also be covered. If sufficient coverage is provided in each document covering a protocol extension, a separate document would not be needed.
The primary focus of this document, among the sets of requirements listed in Section 7.1 is the "restoration speed" set of requirements. This is not a simple topic and not a topic that is well served by scattering it over multiple documents, therefore it may be best to put this in a separate document and put citations in documents called for in Section 7.2.1, Section 7.2.2, Section 7.2.3, Section 7.2.9, Section 7.2.11, Section 7.2.12, Section 7.2.13, and Section 7.2.14. Citation may also be helpful in Section 7.2.4, and Section 7.2.5.
7.2.11. IP and LDP Traffic
A document is needed to define the use of measurements native IP and native LDP traffic levels to reduce link advertised bandwidth amounts.
The primary focus of this document, among the sets of requirements listed in Section 7.1 are the "load distribution, stability, minimal disruption" and the "admission control, preemption, traffic engineering" set of requirements. The "path determination, connectivity verification" must also be considered. The "backward compatibility and migration" and "general network management" requirements must also be considered.
7.2.12. LDP Extensions
Extending LDP is called for in DR#2. LDP can be extended to couple FEC admission control to local resource availability without providing LDP traffic engineering capability. Other LDP extensions
Ning, et al. Expires December 31, 2012 [Page 32]

Internet-Draft Composite Link Framework June 2012
such as signaling a bound on microflow size and LDP LSP requirements would provide useful information without providing LDP traffic engineering capability.
The primary focus of this document, among the sets of requirements listed in Section 7.1 is the "admission control, preemption, traffic engineering" set of requirements. The "backward compatibility and migration" and "general network management" requirements must also be considered.
7.2.13. Pseudowire Extensions
PW extensions such as signaling a bound on microflow size and PW requirements would provide useful information.
The primary focus of this document, among the sets of requirements listed in Section 7.1 is the "admission control, preemption, traffic engineering" set of requirements. The "backward compatibility and migration" and "general network management" requirements must also be considered.
7.2.14. Multi-Domain Composite Link
DR#5 calls for Composite Link to span multiple network topologies. Component LSP may already span multiple network topologies, though most often in practice these are LDP signaled. Component LSP which are RSVP-TE signaled may also span multiple network topologies using at least three existing methods (per domain [RFC5152], BRPC [RFC5441], PCE [RFC4655]). When such component links are combined in a Composite Link, the Composite Link spans multiple network topologies. It is not clear in which document this needs to be described or whether this description in the framework is sufficient. The authors and/or the WG may need to discuss this. DR#5 mandates that IGP-TE extension cannot be used. This would disallow the use of [RFC5316] or [RFC5392] in conjunction with [RFC5151].
The primary focus of this document, among the sets of requirements listed in Section 7.1 are "single vs multiple domain" and "admission control, preemption, traffic engineering". The "routing information aggregation" and "load distribution, stability, minimal disruption" requirements need attention due to their use of the IGP in single domain Composite Link. Other requirements such as "delay and delay variation", can more easily be accomodated by carrying metrics within BGP. The "path determination, connectivity verification" requirements need attention due to requirements to restrict disclosure of topology information across domains in multi-domain deployments. The "backward compatibility and migration" and "general network management" requirements must also be considered.
Ning, et al. Expires December 31, 2012 [Page 33]

Internet-Draft Composite Link Framework June 2012
7.3. Open Issues Regarding Requirements
Note to co-authors: This section needs to be reduced to an empty section and then removed.
The following topics in the requirements document are not addressed. Since they are explicitly mentioned in the requirements document some mention of how they are supported is needed, even if to say nother needed to be done. If we conclude any particular topic is irrelevant, maybe the topic should be removed from the requirement document. At that point we could add the management requirements that have come up and were missed.
1. L3VPN RFC 4364, RFC 4797,L2VPN RFC 4664, VPWS, VPLS RFC 4761, RFC 4762 and VPMS VPMS Framework (draft-ietf-l2vpn-vpms-frmwk-requirements). It is not clear what additional Composite Link requirements these references imply, if any. If no additional requirements are implied, then these references are considered to be informational only.
2. Migration may not be adequately covered in Section 4.1.5. It might also be necessary to say more here on performance, scalability, and stability as it related to migration. Comments on this from co-authors or the WG?
3. We may need a performance section in this document to specifically address #DR6 (fast convergence), and #DR7 (fast worst case failure convergence), though we do already have scalability discussion. The performance section would have to say "no worse than before, except were there was no alternative to make it very slightly worse" (in a bit more detail than that). It would also have to better define the nature of the performance criteria.
7.4. Framework Requirement Coverage by Protocol
As an aid to implementors, this section summarizes requirement coverage listed in Section 7.2 by protocol or LSR functionality affected.
Some documentation may be purely informational, proposing no changes and proposing usage at most. This includes Section 7.2.3, Section 7.2.8, Section 7.2.10, and Section 7.2.14.
Section 7.2.9 may require a new protocol.
Ning, et al. Expires December 31, 2012 [Page 34]

Internet-Draft Composite Link Framework June 2012
7.4.1. OSPF-TE and ISIS-TE Protocol Extensions
Many of the changes listed in Section 7.2 require IGP-TE changes, though most are small extensions to provide additional information. This set includes Section 7.2.1, Section 7.2.2, Section 7.2.5, Section 7.2.6, and Section 7.2.7. An adjustment to existing advertised parameters is suggested in Section 7.2.11.
7.4.2. PW Protocol Extensions
The only suggestion of pseudowire (PW) extensions is in Section 7.2.13.
7.4.3. LDP Protocol Extensions
Potential LDP extensions are described in Section 7.2.12.
7.4.4. RSVP-TE Protocol Extensions
RSVP-TE protocol extensions are called for in Section 7.2.1, Section 7.2.5, Section 7.2.7, and Section 7.2.9.
7.4.5. RSVP-TE Path Selection Changes
Section 7.2.3 calls for path selection to be addressed in individual documents that require change. These changes would include those proposed in Section 7.2.1, Section 7.2.2, Section 7.2.5, and Section 7.2.7.
7.4.6. RSVP-TE Admission Control and Preemption
When a change is needed to path selection, a corresponding change is needed in admission control. The same set of sections applies: Section 7.2.1, Section 7.2.2, Section 7.2.5, and Section 7.2.7. Some resource changes such as a link delay change might trigger preemption. The rules of preemption remain unchanged, still based on holding priority.
7.4.7. Flow Identification and Traffic Balance
The following describe either the state of the art in flow identification and traffic balance or propose changes: Section 7.2.4, Section 7.2.5, Section 7.2.7, and Section 7.2.8.
8. Security Considerations
The security considerations for MPLS/GMPLS and for MPLS-TP are
Ning, et al. Expires December 31, 2012 [Page 35]

Internet-Draft Composite Link Framework June 2012
documented in [RFC5920] and [I-D.ietf-mpls-tp-security-framework].
The types protocol extensions proposed in this framework document provide additional information about links, forwarding adjacencies, and LSP requirements. The protocol semantics changes described in this framework document propose additional LSP constraints applied at path computation time and at LSP admission at midpoints LSR. The additional information and constraints provide no additional security considerations beyond the security considerations already documented in [RFC5920] and [I-D.ietf-mpls-tp-security-framework].
9. Acknowledgments
Authors would like to thank Adrian Farrel, Fred Jounay, Yuji Kamite for his extensive comments and suggestions regarding early versions of this document, Ron Bonica, Nabil Bitar, Eric Gray, Lou Berger, and Kireeti Kompella for their reviews of early versions and great suggestions.
Authors would like to thank Iftekhar Hussain for review and suggestions regarding recent versions of this document.
In the interest of full disclosure of affiliation and in the interest of acknowledging sponsorship, past affiliations of authors are noted. Much of the work done by Ning So occurred while Ning was at Verizon. Much of the work done by Curtis Villamizar occurred while at Infinera. Infinera continues to sponsor this work on a consulting basis.
10. References
10.1. Normative References
[RFC2119] Bradner, S., "Key words for use in RFCs to Indicate Requirement Levels", BCP 14, RFC 2119, March 1997.
[RFC3209] Awduche, D., Berger, L., Gan, D., Li, T., Srinivasan, V., and G. Swallow, "RSVP-TE: Extensions to RSVP for LSP Tunnels", RFC 3209, December 2001.
[RFC3630] Katz, D., Kompella, K., and D. Yeung, "Traffic Engineering (TE) Extensions to OSPF Version 2", RFC 3630, September 2003.
[RFC4201] Kompella, K., Rekhter, Y., and L. Berger, "Link Bundling in MPLS Traffic Engineering (TE)", RFC 4201, October 2005.
Ning, et al. Expires December 31, 2012 [Page 36]

Internet-Draft Composite Link Framework June 2012
[RFC4206] Kompella, K. and Y. Rekhter, "Label Switched Paths (LSP) Hierarchy with Generalized Multi-Protocol Label Switching (GMPLS) Traffic Engineering (TE)", RFC 4206, October 2005.
[RFC5036] Andersson, L., Minei, I., and B. Thomas, "LDP Specification", RFC 5036, October 2007.
[RFC5305] Li, T. and H. Smit, "IS-IS Extensions for Traffic Engineering", RFC 5305, October 2008.
[RFC5712] Meyer, M. and JP. Vasseur, "MPLS Traffic Engineering Soft Preemption", RFC 5712, January 2010.
[RFC6107] Shiomoto, K. and A. Farrel, "Procedures for Dynamically Signaled Hierarchical Label Switched Paths", RFC 6107, February 2011.
[RFC6374] Frost, D. and S. Bryant, "Packet Loss and Delay Measurement for MPLS Networks", RFC 6374, September 2011.
[RFC6391] Bryant, S., Filsfils, C., Drafz, U., Kompella, V., Regan, J., and S. Amante, "Flow-Aware Transport of Pseudowires over an MPLS Packet Switched Network", RFC 6391, November 2011.
10.2. Informative References
[DBP] Bertsekas, D., "Dynamic Behavior of Shortest Path Routing Algorithms for Communication Networks", IEEE Trans. Auto. Control 1982.
[I-D.ietf-mpls-entropy-label] Drake, J., Kompella, K., Yong, L., Amante, S., and W. Henderickx, "The Use of Entropy Labels in MPLS Forwarding", draft-ietf-mpls-entropy-label-01 (work in progress), October 2011.
[I-D.ietf-mpls-explicit-resource-control-bundle] Zamfir, A., Ali, Z., and P. Dimitri, "Component Link Recording and Resource Control for TE Links", draft-ietf-mpls-explicit-resource-control-bundle-10 (work in progress), April 2011.
[I-D.ietf-mpls-tp-security-framework] Niven-Jenkins, B., Fang, L., Graveman, R., and S. Mansfield, "MPLS-TP Security Framework", draft-ietf-mpls-tp-security-framework-02 (work in progress), October 2011.
Ning, et al. Expires December 31, 2012 [Page 37]

Internet-Draft Composite Link Framework June 2012
[I-D.ietf-rtgwg-cl-requirement] Malis, A., Villamizar, C., McDysan, D., Yong, L., and N. So, "Requirements for MPLS Over a Composite Link", draft-ietf-rtgwg-cl-requirement-05 (work in progress), January 2012.
[I-D.kompella-mpls-rsvp-ecmp] Kompella, K., "Multi-path Label Switched Paths Signaled Using RSVP-TE", draft-kompella-mpls-rsvp-ecmp-01 (work in progress), October 2011.
[I-D.ospf-cc-stlv] Osborne, E., "Component and Composite Link Membership in OSPF", draft-ospf-cc-stlv-00 (work in progress), August 2011.
[I-D.symmvo-rtgwg-cl-use-cases] Malis, A., Villamizar, C., McDysan, D., Yong, L., and N. So, "Composite Link USe Cases and Design Considerations", draft-symmvo-rtgwg-cl-use-cases-00 (work in progress), February 2012.
[I-D.villamizar-mpls-tp-multipath] Villamizar, C., "Use of Multipath with MPLS-TP and MPLS", draft-villamizar-mpls-tp-multipath-01 (work in progress), March 2011.
[I-D.villamizar-mpls-tp-multipath-te-extn] Villamizar, C., "Multipath Extensions for MPLS Traffic Engineering", draft-villamizar-mpls-tp-multipath-te-extn-00 (work in progress), July 2011.
[I-D.wang-ccamp-latency-te-metric] Fu, X., Betts, M., Wang, Q., McDysan, D., and A. Malis, "GMPLS extensions to communicate latency as a traffic engineering performance metric", draft-wang-ccamp-latency-te-metric-03 (work in progress), March 2011.
[RFC2475] Blake, S., Black, D., Carlson, M., Davies, E., Wang, Z., and W. Weiss, "An Architecture for Differentiated Services", RFC 2475, December 1998.
[RFC2991] Thaler, D. and C. Hopps, "Multipath Issues in Unicast and Multicast Next-Hop Selection", RFC 2991, November 2000.
[RFC2992] Hopps, C., "Analysis of an Equal-Cost Multi-Path
Ning, et al. Expires December 31, 2012 [Page 38]

Internet-Draft Composite Link Framework June 2012
Algorithm", RFC 2992, November 2000.
[RFC3260] Grossman, D., "New Terminology and Clarifications for Diffserv", RFC 3260, April 2002.
[RFC3468] Andersson, L. and G. Swallow, "The Multiprotocol Label Switching (MPLS) Working Group decision on MPLS signaling protocols", RFC 3468, February 2003.
[RFC3945] Mannie, E., "Generalized Multi-Protocol Label Switching (GMPLS) Architecture", RFC 3945, October 2004.
[RFC3985] Bryant, S. and P. Pate, "Pseudo Wire Emulation Edge-to- Edge (PWE3) Architecture", RFC 3985, March 2005.
[RFC4385] Bryant, S., Swallow, G., Martini, L., and D. McPherson, "Pseudowire Emulation Edge-to-Edge (PWE3) Control Word for Use over an MPLS PSN", RFC 4385, February 2006.
[RFC4655] Farrel, A., Vasseur, J., and J. Ash, "A Path Computation Element (PCE)-Based Architecture", RFC 4655, August 2006.
[RFC4928] Swallow, G., Bryant, S., and L. Andersson, "Avoiding Equal Cost Multipath Treatment in MPLS Networks", BCP 128, RFC 4928, June 2007.
[RFC5151] Farrel, A., Ayyangar, A., and JP. Vasseur, "Inter-Domain MPLS and GMPLS Traffic Engineering -- Resource Reservation Protocol-Traffic Engineering (RSVP-TE) Extensions", RFC 5151, February 2008.
[RFC5152] Vasseur, JP., Ayyangar, A., and R. Zhang, "A Per-Domain Path Computation Method for Establishing Inter-Domain Traffic Engineering (TE) Label Switched Paths (LSPs)", RFC 5152, February 2008.
[RFC5316] Chen, M., Zhang, R., and X. Duan, "ISIS Extensions in Support of Inter-Autonomous System (AS) MPLS and GMPLS Traffic Engineering", RFC 5316, December 2008.
[RFC5392] Chen, M., Zhang, R., and X. Duan, "OSPF Extensions in Support of Inter-Autonomous System (AS) MPLS and GMPLS Traffic Engineering", RFC 5392, January 2009.
[RFC5441] Vasseur, JP., Zhang, R., Bitar, N., and JL. Le Roux, "A Backward-Recursive PCE-Based Computation (BRPC) Procedure to Compute Shortest Constrained Inter-Domain Traffic Engineering Label Switched Paths", RFC 5441, April 2009.
Ning, et al. Expires December 31, 2012 [Page 39]

Internet-Draft Composite Link Framework June 2012
[RFC5920] Fang, L., "Security Framework for MPLS and GMPLS Networks", RFC 5920, July 2010.
[RFC5921] Bocci, M., Bryant, S., Frost, D., Levrau, L., and L. Berger, "A Framework for MPLS in Transport Networks", RFC 5921, July 2010.
Authors’ Addresses
So Ning Tata Communications
Email: [email protected]
Dave McDysan Verizon 22001 Loudoun County PKWY Ashburn, VA 20147
Email: [email protected]
Eric Osborne Cisco
Email: [email protected]
Lucy Yong Huawei USA 5340 Legacy Dr. Plano, TX 75025
Phone: +1 469-277-5837 Email: [email protected]
Curtis Villamizar Outer Cape Cod Network Consulting
Email: [email protected]
Ning, et al. Expires December 31, 2012 [Page 40]


RTGWG S. NingInternet-Draft Tata CommunicationsIntended status: Informational A. MalisExpires: December 22, 2012 D. McDysan Verizon L. Yong Huawei USA C. Villamizar Outer Cape Cod Network Consulting June 20, 2012
Composite Link Use Cases and Design Considerations draft-symmvo-rtgwg-cl-use-cases-01
Abstract
This document provides a set of use cases and design considerations for composite links.
Composite link is a formalization of multipath techniques currently in use in IP and MPLS networks and a set of extensions to multipath techniques.
Note: symmvo in the draft name is the initials of the set of authors: So, Yong, McDysan, Malis, Villamizar, Osborne. This paragraph will be removed when/if this document is adopted as a WG item.
Status of this Memo
This Internet-Draft is submitted in full conformance with the provisions of BCP 78 and BCP 79.
Internet-Drafts are working documents of the Internet Engineering Task Force (IETF). Note that other groups may also distribute working documents as Internet-Drafts. The list of current Internet- Drafts is at http://datatracker.ietf.org/drafts/current/.
Internet-Drafts are draft documents valid for a maximum of six months and may be updated, replaced, or obsoleted by other documents at any time. It is inappropriate to use Internet-Drafts as reference material or to cite them other than as "work in progress."
This Internet-Draft will expire on December 22, 2012.
Copyright Notice
Ning, et al. Expires December 22, 2012 [Page 1]

Internet-Draft Composite Link Use Cases June 2012
Copyright (c) 2012 IETF Trust and the persons identified as the document authors. All rights reserved.
This document is subject to BCP 78 and the IETF Trust’s Legal Provisions Relating to IETF Documents (http://trustee.ietf.org/license-info) in effect on the date of publication of this document. Please review these documents carefully, as they describe your rights and restrictions with respect to this document. Code Components extracted from this document must include Simplified BSD License text as described in Section 4.e of the Trust Legal Provisions and are provided without warranty as described in the Simplified BSD License.
Table of Contents
1. Introduction . . . . . . . . . . . . . . . . . . . . . . . . . 3 2. Conventions used in this document . . . . . . . . . . . . . . 3 2.1. Terminology . . . . . . . . . . . . . . . . . . . . . . . 3 3. Composite Link Foundation Use Cases . . . . . . . . . . . . . 4 4. Delay Sensitive Applications . . . . . . . . . . . . . . . . . 7 5. Large Volume of IP and LDP Traffic . . . . . . . . . . . . . . 7 6. Composite Link and Packet Ordering . . . . . . . . . . . . . . 8 6.1. MPLS-TP in network edges only . . . . . . . . . . . . . . 10 6.2. Composite Link at core LSP ingress/egress . . . . . . . . 11 6.3. MPLS-TP as a MPLS client . . . . . . . . . . . . . . . . . 12 7. Security Considerations . . . . . . . . . . . . . . . . . . . 12 8. Acknowledgments . . . . . . . . . . . . . . . . . . . . . . . 13 9. References . . . . . . . . . . . . . . . . . . . . . . . . . . 13 9.1. Normative References . . . . . . . . . . . . . . . . . . . 13 9.2. Informative References . . . . . . . . . . . . . . . . . . 13 Appendix A. More Details on Existing Network Operator Practices and Protocol Usage . . . . . . . . . . . . 15 Appendix B. Existing Multipath Standards and Techniques . . . . . 17 B.1. Common Multpath Load Spliting Techniques . . . . . . . . . 18 B.2. Simple and Adaptive Load Balancing Multipath . . . . . . . 19 B.3. Traffic Split over Parallel Links . . . . . . . . . . . . 20 B.4. Traffic Split over Multiple Paths . . . . . . . . . . . . 20 Appendix C. Characteristics of Transport in Core Networks . . . . 20 Authors’ Addresses . . . . . . . . . . . . . . . . . . . . . . . . 22
Ning, et al. Expires December 22, 2012 [Page 2]

Internet-Draft Composite Link Use Cases June 2012
1. Introduction
Composite link requirements are specified in [I-D.ietf-rtgwg-cl-requirement]. A composite link framework is defined in [I-D.so-yong-rtgwg-cl-framework].
Multipath techniques have been widely used in IP networks for over two decades. The use of MPLS began more than a decade ago. Multipath has been widely used in IP/MPLS networks for over a decade with very little protocol support dedicated to effective use of multipath.
The state of the art in multipath prior to composite links is documented in Appendix B.
Both Ethernet Link Aggregation [IEEE-802.1AX] and MPLS link bundling [RFC4201] have been widely used in today’s MPLS networks. Composite link differs in the following caracteristics.
1. A composite link allows bundling of non-homogenous links together as a single logical link.
2. A composite link provides more information in the TE-LSDB and supports more explicit control over placement of LSP.
2. Conventions used in this document
The key words "MUST", "MUST NOT", "REQUIRED", "SHALL", "SHALL NOT", "SHOULD", "SHOULD NOT", "RECOMMENDED", "MAY", and "OPTIONAL" in this document are to be interpreted as described in RFC 2119 [RFC2119].
2.1. Terminology
Terminology defined in [I-D.ietf-rtgwg-cl-requirement] is used in this document.
In addition, the following terms are used:
classic multipath: Classic multipath refers to the most common current practice in implementation and deployment of multipath (see Appendix A). The most common current practice makes use of a hash on the MPLS label stack and if IPv4 or IPv6 are indicates under the label stack, makes use of the IP source and destination addresses [RFC4385] [RFC4928].
Ning, et al. Expires December 22, 2012 [Page 3]

Internet-Draft Composite Link Use Cases June 2012
classic link bundling: Classic link bundling refers to the use of [RFC4201] where the "all ones" component is not used. Where the "all ones" component is used, link bundling behaves as classic multipath does. Classic link bundling selects a single component link on which to put any given LSP.
Among the important distinctions between classic multipath or classic link bundling and Composite Link are:
1. Classic multipath has no provision to retain order among flows within a subset of LSP. Classic link bundling retains order among all flows but as a result does a poor job of splitting load among components and therefore is rarely (if ever) deployed. Composite Link allows per LSP control of load split characteristics.
2. Classic multipath and classic link bundling do not provide a means to put some LSP on component links with lower delay. Composite Link does.
3. Classic multipath will provide a load balance for IP and LDP traffic. Classic link bundling will not. Neither classic multipath or classic link bundling will measure IP and LDP traffic and reduce the advertised "Available Bandwidth" as a result of that measurement. Composite Link better supports RSVP-TE used with significant traffic levels of native IP and native LDP.
4. Classic link bundling cannot support an LSP that is greater in capacity than any single component link. Classic multipath and Composite Link support this capability but will reorder traffic on such an LSP. Composite Link can retain order of an LSP that is carried within an LSP that is greater in capacity than any single component link if the contained LSP has such a requirement.
None of these techniques, classic multipath, classic link bundling, or Composite Link, will reorder traffic among IP microflows. None of these techniques will reorder traffic among PW, if a PWE3 Control Word is used [RFC4385].
3. Composite Link Foundation Use Cases
A simple composite link composed entirely of physical links is illustrated in Figure 1, where a composite link is configured between LSR1 and LSR2. This composite link has three component links.
Ning, et al. Expires December 22, 2012 [Page 4]

Internet-Draft Composite Link Use Cases June 2012
Individual component links in a composite link may be supported by different transport technologies such as wavelength, Ethernet VLAN. Even if the transport technology implementing the component links is identical, the characteristics (e.g., bandwidth, latency) of the component links may differ.
The composite link in Figure 1 may carry LSP traffic flows and control plane packets. Control plane packets may appear as IP packets or may be carried within a generic associated channel (G-Ach) [RFC5586]. A LSP may be established over the link by either RSVP-TE [RFC3209] or LDP [RFC5036] signaling protocols. All component links in a composite link are summarized in the same forwarding adjacency LSP (FA-LSP) routing advertisement [RFC3945]. The composite link is summarized as one TE-Link advertised into the IGP by the composite link end points. This information is used in path computation when a full MPLS control plane is in use. The individual component links or groups of component links may optionally be advertised into the IGP as sub-TLV of the composite link advertisement to indicate capacity available with various characteristics, such as a delay range.
Management Plane Configuration and Measurement <------------+ ^ | | | +-------+-+ +-+-------+ | | | | | | CP Packets V | | V CP Packets | V | | Component Link 1 | | ^ | | | |=|===========================|=| | | | +----| | Component Link 2 | |----+ | | |=|===========================|=| | Aggregated LSPs | | | | | ˜|˜˜˜˜˜˜>| | Component Link 3 | |˜˜˜˜>˜˜|˜˜ | |=|===========================|=| | | | | | | | | LSR1 | | LSR2 | +---------+ +---------+ ! ! ! ! !<------ Composite Link ------->!
Figure 1: a composite link constructed with multiple physical links between two LSR
[I-D.ietf-rtgwg-cl-requirement] specifies that component links may themselves be composite links. Figure 2 shows three three forms of component links which may be deployed in a network.
Ning, et al. Expires December 22, 2012 [Page 5]

Internet-Draft Composite Link Use Cases June 2012
+-------+ 1. Physical Link +-------+ | |-|----------------------------------------------|-| | | | | | | | | | | +------+ +------+ | | | | | | | MPLS | 2. Logical Link | MPLS | | | | | |.|.... |......|.....................|......|....|.| | | | |-----| LSR3 |---------------------| LSR4 |----| | | | | | +------+ +------+ | | | | | | | | | | | | | | | | | | +------+ +------+ | | | | | | |GMPLS | 3. Logical Link |GMPLS | | | | | |.|. ...|......|.....................|......|....|.| | | | |-----| LSR5 |---------------------| LSR6 |----| | | | | +------+ +------+ | | | LSR1 | | LSR2 | +-------+ +-------+ |<------------- Composite Link ------------------->|
Figure 2: Illustration of Various Component Link Types
The three forms of component link shown in Figure 2 are:
1. The first component link is configured with direct physical media.
2. The second component link is a TE tunnel that traverses LSR3 and LSR4, where LSR3 and LSR4 are the nodes supporting MPLS, but supporting few or no GMPLS extensions.
3. The third component link is formed by lower layer network that has GMPLS enabled. In this case, LSR5 and LSR6 are not the nodes controlled by the MPLS but provide the connectivity for the component link.
A composite link forms one logical link between connected LSR and is used to carry aggregated traffic [I-D.ietf-rtgwg-cl-requirement]. Composite link relies on its component links to carry the traffic over the composite link. The endpoints of the composite link maps incoming traffic into component links.
For example, LSR1 in Figure 1 distributes the set of traffic flows including control plane packets among the set of component links. LSR2 in Figure 1 receives the packets from its component links and sends them to MPLS forwarding engine with no attempt to reorder packets arriving on different component links. The traffic in the opposite direction, from LSR2 to LSR1, is distributed across the set of component links by the LSR2.
Ning, et al. Expires December 22, 2012 [Page 6]

Internet-Draft Composite Link Use Cases June 2012
These three forms of component link are only example. Many other examples are possible. A component link may itself be a composite link. A segment of an LSP (single hop for that LSP) may be a composite link.
4. Delay Sensitive Applications
Most applications benefit from lower delay. Some types of applications are far more sensitive than others. For example, real time bidirectional applications such as voice communication or two way video conferencing are far more sensitive to delay than unidirectional streaming audio or video. Non-interactive bulk transfer is almost insensitive to delay if a large enough TCP window is used.
Some applications are sensitive to delay but unwilling to pay extra to insure lower delay. For example, many SIP end users are willing to accept the delay offerred to best effort services as long as call quality is good most of the time.
Other applications are sensitive to delay and willing to pay extra to insure lower delay. For example, financial trading applications are extremely sensitive to delay and with a lot at stake are willing to go to great lengths to reduce delay.
Among the requirements of Composite Link are requirements to advertise capacity available within configured ranges of delay within a given composite link and the support the ability to place an LSP only on component links that meeting that LSP’s delay requirements.
The Composite Link requirements to accommodate delay sensitive applications are analogous to diffserv requirements to accomodate applications requiring higher quality of service on the same infrastructure as applications with less demanding requirements. The ability to share capacity with less demanding applications, with best effort applications being the least demanding, can greatly reduce the cost of delivering service to the more demanding applications.
5. Large Volume of IP and LDP Traffic
IP and LDP do not support traffic engineering. Both make use of a shortest (lowest routing metric) path, with an option to use equal cost multipath (ECMP). Note that though ECMP is prohibited in LDP specifications, it is widely implemented. Where implemented for LDP, ECMP is generally disabled by default for standards compliance, but often enabled in LDP deployments.
Ning, et al. Expires December 22, 2012 [Page 7]

Internet-Draft Composite Link Use Cases June 2012
Without traffic engineering capability, there must be sufficient capacity to accomodate the IP and LDP traffic. If not, persistent queuing delay and loss will occur. Unlike RSVP-TE, a subset of traffic cannot be routed using constraint based routing to avoid a congested portion of an infrastructure.
In existing networks which accomodate IP and/or LDP with RSVP-TE, either the IP and LDP can be carried over RSVP-TE, or where the traffic contribution of IP and LDP is small, IP and LDP can be carried native and the effect on RSVP-TE can be ignored. Ignoring the traffic contribution of IP is certainly valid on high capacity networks where native IP is used primarily for control and network management and customer IP is carried within RSVP-TE.
Where it is desireable to carry native IP and/or LDP and IP and/or LDP traffic volumes are not negligible, RSVP-TE needs improvement. The enhancement offerred by Composite Link is an ability to measure the IP and LDP, filter the measurements, and reduce the capacity available to RSVP-TE to avoid congestion. The treatment given to the IP or LDP traffic is similar to the treatment when using the "auto- bandwidth" feature in some RSVP-TE implementations on that same traffic, and giving a higher priority (numerically lower setup priority and holding priority value) to the "auto-bandwidth" LSP. The difference is that the measurement is made at each hop and the reduction in advertised bandwidth is made more directly.
6. Composite Link and Packet Ordering
A strong motivation for Composite Link is the need to provide LSP capacity in IP backbones that exceeds the capacity of single wavelengths provided by transport equipment and exceeds the practical capacity limits acheivable through inverse multiplexing. Appendix C describes characteristics and limitations of transport systems today. Section 2 defines the terms "classic multipath" and "classic link bundling" used in this section.
For purpose of discussion, consider two very large cities, city A and city Z. For example, in the US high traffic cities might be New York and Los Angeles and in Europe high traffic cities might be London and Amsterdam. Two other high volume cities, city B and city Y may share common provider core network infrastructure. Using the same examples, the city B and Y may Washington DC and San Francisco or Paris and Stockholm. In the US, the common infrastructure may span Denver, Chicago, Detroit, and Cleveland. Other major traffic contributors on either US coast include Boston, northern Virginia on the east coast, and Seattle, and San Diego on the west coast. The capacity of IP/MPLS links within the shared infrastructure, for
Ning, et al. Expires December 22, 2012 [Page 8]

Internet-Draft Composite Link Use Cases June 2012
example city to city links in the Denver, Chicago, Detroit, and Cleveland path in the US example, have capacities for most of the 2000s decade that greatly exceeded single circuits available in transport networks.
For a case with four large traffic sources on either side of the shared infrastructure, up to sixteen core city to core city traffic flows in excess of transport circuit capacity may be accomodated on the shared infrastructure.
Today the most common IP/MPLS core network design makes use of very large links which consist of many smaller component links, but use classic multipath techniques rather than classic link bundling or Composite Link. A component link typically corresponds to the largest circuit that the transport system is capable of providing (or the largest cost effective circuit). IP source and destination address hashing is used to distribute flows across the set of component links as described in Appendix B.3.
Classic multipath can handle large LSP up to the total capacity of the multipath (within limits, see Appendix B.2). A disadvantage of classic multipath is the reordering among traffic within a given core city to core city LSP. While there is no reordering within any microflow and therefore no customer visible issue, MPLS-TP cannot be used across an infrastructure where classic multipath is in use, except within pseudowires.
These capacity issues force the use of classic multipath today. Classic multipath excludes a direct use of MPLS-TP. The desire for OAM, offerred by MPLS-TP, is in conflict with the use of classic multipath. There are a number of alternatives that satisfy both requirements. Some alternatives are described below.
MPLS-TP in network edges only
A simple approach which requires no change to the core is to disallow MPLS-TP across the core unless carried within a pseudowire (PW). MPLS-TP may be used within edge domains where classic multipath is not used. PW may be signaled end to end using single segment PW (SS-PW), or stitched across domains using multisegment PW (MS-PW). The PW and anything carried within the PW may use OAM as long as fat-PW [RFC6391] load splitting is not used by the PW.
Composite Link at core LSP ingress/egress
The interior of the core network may use classic link bundling, with the limitation that no LSP can exceed the capacity of a
Ning, et al. Expires December 22, 2012 [Page 9]

Internet-Draft Composite Link Use Cases June 2012
single circuit. Larger non-MPLS-TP LSP can be configured using multiple ingress to egress component MPLS-TP LSP. This can be accomplished using existing IP source and destination address hashing configured at LSP ingress and egress, or using Composite Link configured at ingress and egress. Each component LSP, if constrained to be no larger than the capacity of a single circuit. can make use of MPLS-TP and offer OAM for all top level LSP across the core.
MPLS-TP as a MPLS client
A third approach involves modifying the behavior of LSR in the interior of the network core, such that MPLS-TP can be used on a subset of LSP, where the capacity of any one LSP within that MPLS-TP subset of LSP is not larger than the capacity of a single circuit. This requirement is accommodated through a combination of signaling to indicate LSP for which traffic splitting needs to be constrained, the ability to constrain the depth of the label stack over which traffic splitting can be applied on a per LSP basis, and the ability to constrain the use of IP addresses below the label stack for traffic splitting also on a per LSP basis.
The above list of alternatives allow packet ordering within an LSP to be maintained in some circumstances and allow very large LSP capacities. Each of these alternatives are discussed further in the following subsections.
6.1. MPLS-TP in network edges only
Classic MPLS link bundling is defined in [RFC4201] and has existed since early in the 2000s decade. Classic MPLS link bundling place any given LSP entirely on a single component link. Classic MPLS link bundling is not in widespread use as the means to accomodate large link capacities in core networks due to the simplicity and better multiplexing gain, and therefore lower network cost of classic multipath.
If MPLS-TP OAM capability in the IP/MPLS network core LSP is not required, then there is no need to change existing network designs which use classic multipath and both label stack and IP source and destination address based hashing as a basis for load splitting.
If MPLS-TP is needed for a subset of LSP, then those LSP can be carried within pseudowires. The pseudowires adds a thin layer of encapsulation and therefore a small overhead. If only a subset of LSP need MPLS-TP OAM, then some LSP must make use of the pseudowires and other LSP avoid them. A straihtforward way to accomplish this is with administrative attributes [RFC3209].
Ning, et al. Expires December 22, 2012 [Page 10]

Internet-Draft Composite Link Use Cases June 2012
6.2. Composite Link at core LSP ingress/egress
Composite Link can be configured only for large LSP that are made of smaller MPLS-TP component LSP. This approach is capable of supporting MPLS-TP OAM over the entire set of component link LSP and therefore the entire set of top level LSP traversing the core.
There are two primary disadvantage of this approach. One is the number of top level LSP traversing the core can be dramatically increased. The other disadvantage is the loss of multiplexing gain that results from use of classic link bundling within the interior of the core network.
If component LSP use MPLS-TP, then no component LSP can exceed the capacity of a single circuit. For a given composite LSP there can either be a number of equal capacity component LSP or some number of full capacity component links plus one LSP carrying the excess. For example, a 350 Gb/s composite LSP over a 100 Gb/s infrastructure may use five 70 Gb/s component LSP or three 100 Gb/s LSP plus one 50 Gb/s LSP. Classic MPLS link bundling is needed to support MPLS-TP and suffers from a bin packing problem even if LSP traffic is completely predictable, which it never is in practice.
The common means of setting composite link bandwidth parameters uses long term statistical measures. For example, many providers base their LSP bandwidth parameters on the 95th percentile of carried traffic as measured over a one week period. It is common to add 10-30% to the 95th percentile value measured over the prior week and adjust bandwidth parameters of LSP weekly. It is also possible to measure traffic flow at the LSR and adjust bandwidth parameters somewhat more dynamically. This is less common in deployments and where deployed, make use of filtering to track very long term trends in traffic levels. In either case, short term variation of traffic levels relative to signaled LSP capacity are common. Allowing a large overallocation of LSP bandwidth parameters (ie: adding 30% or more) avoids overutilization of any given LSP, but increases unused network capacity and increases network cost. Allowing a small overallocation of LSP bandwidth parameters (ie: 10-20% or less) results in both underutilization and overutilization but statistically results in a total utilization within the core that is under capacity most or all of the time.
The classic multipath solution accomodates the situation in which some composite LSP are underutilizing their signaled capacity and others are overutilizing their capacity with the need for far less unused network capacity to accomodate variation in actual traffic levels. If the actual traffic levels of LSP can be described by a probability distribution, the variation of the sum of LSP is less
Ning, et al. Expires December 22, 2012 [Page 11]

Internet-Draft Composite Link Use Cases June 2012
than the variation of any given LSP for all but a constant traffic level (where the variation of the sum and the components are both zero).
There are two situations which can motivate the use of this approach. This design is favored if the provider values MPLS-TP OAM across the core more than efficiency (or is unaware of the efficiency issue). This design can also make sense if transport equipment or very low cost core LSR are available which support only classic link bundling and regardless of loss of multiplexing gain, are more cost effective at carrying transit traffic than using equipment which supports IP source and destination address hashing.
6.3. MPLS-TP as a MPLS client
Accomodating MPLS-TP as a MPLS client requires a small change to forwarding behavior and is therefore most applicable to major network overbuilds or new deployments. The change to forwarding is an ability to limit the depth of MPLS labels used in hashing on the label stack on a per LSP basis. Some existing hardware, particularly microprogrammed hardware, may be able to accomodate this forwarding change. Providing support in new hardware is not difficult, a much smaller change than, for example, changes required to disable PHP in an environment where LSP hierarchy is used.
The advantage of this approach is an ability to accommodate MPLS-TP as a client LSP but retain the high multiplexing gain and therefore efficency and low network cost of a pure MPLS deployment. The disadvantage is the need for a small change in forwarding.
7. Security Considerations
This document is a use cases document. Existing protocols are referenced such as MPLS. Existing techniques such as MPLS link bundling and multipath techniques are referenced. These protocols and techniques are documented elsewhere and contain security considerations which are unchanged by this document.
This document also describes use cases for Composite Link, which is a work-in-progress. Composite Link requirements are defined in [I-D.ietf-rtgwg-cl-requirement]. [I-D.so-yong-rtgwg-cl-framework] defines a framework for Composite Link. Composite Link bears many similarities to MPLS link bundling and multipath techniques used with MPLS. Aditional security considerations, if any, beyond those already identified for MPLS, MPLS link bundling and multipath techniques, will be documented in the framework document if specific to the overall framework of Composite Link, or in protocol extensions
Ning, et al. Expires December 22, 2012 [Page 12]

Internet-Draft Composite Link Use Cases June 2012
if specific to a given protocol extension defined later to support Composite Link.
8. Acknowledgments
Authors would like to thank [ no one so far ] for their reviews and great suggestions.
In the interest of full disclosure of affiliation and in the interest of acknowledging sponsorship, past affiliations of authors are noted. Much of the work done by Ning So occurred while Ning was at Verizon. Much of the work done by Curtis Villamizar occurred while at Infinera. Infinera continues to sponsor this work on a consulting basis.
9. References
9.1. Normative References
[RFC2119] Bradner, S., "Key words for use in RFCs to Indicate Requirement Levels", BCP 14, RFC 2119, March 1997.
9.2. Informative References
[I-D.ietf-rtgwg-cl-requirement] Villamizar, C., McDysan, D., Ning, S., Malis, A., and L. Yong, "Requirements for MPLS Over a Composite Link", draft-ietf-rtgwg-cl-requirement-04 (work in progress), March 2011.
[I-D.so-yong-rtgwg-cl-framework] So, N., Malis, A., McDysan, D., Yong, L., Villamizar, C., and T. Li, "Composite Link Framework in Multi Protocol Label Switching (MPLS)", draft-so-yong-rtgwg-cl-framework-04 (work in progress), June 2011.
[IEEE-802.1AX] IEEE Standards Association, "IEEE Std 802.1AX-2008 IEEE Standard for Local and Metropolitan Area Networks - Link Aggregation", 2006, <http://standards.ieee.org/getieee802/ download/802.1AX-2008.pdf>.
[ITU-T.G.694.2] ITU-T, "Spectral grids for WDM applications: CWDM wavelength grid", 2003,
Ning, et al. Expires December 22, 2012 [Page 13]

Internet-Draft Composite Link Use Cases June 2012
<http://www.itu.int/rec/T-REC-G.694.2-200312-I>.
[ITU-T.G.800] ITU-T, "Unified functional architecture of transport networks", 2007, <http://www.itu.int/rec/T-REC-G.800-200709-I>.
[ITU-T.Y.1540] ITU-T, "Internet protocol data communication service - IP packet transfer and availability performance parameters", 2007, <http://www.itu.int/rec/T-REC-Y.1540/en>.
[ITU-T.Y.1541] ITU-T, "Network performance objectives for IP-based services", 2006, <http://www.itu.int/rec/T-REC-Y.1541/en>.
[RFC1717] Sklower, K., Lloyd, B., McGregor, G., and D. Carr, "The PPP Multilink Protocol (MP)", RFC 1717, November 1994.
[RFC2475] Blake, S., Black, D., Carlson, M., Davies, E., Wang, Z., and W. Weiss, "An Architecture for Differentiated Services", RFC 2475, December 1998.
[RFC2597] Heinanen, J., Baker, F., Weiss, W., and J. Wroclawski, "Assured Forwarding PHB Group", RFC 2597, June 1999.
[RFC2615] Malis, A. and W. Simpson, "PPP over SONET/SDH", RFC 2615, June 1999.
[RFC2991] Thaler, D. and C. Hopps, "Multipath Issues in Unicast and Multicast Next-Hop Selection", RFC 2991, November 2000.
[RFC2992] Hopps, C., "Analysis of an Equal-Cost Multi-Path Algorithm", RFC 2992, November 2000.
[RFC3209] Awduche, D., Berger, L., Gan, D., Li, T., Srinivasan, V., and G. Swallow, "RSVP-TE: Extensions to RSVP for LSP Tunnels", RFC 3209, December 2001.
[RFC3260] Grossman, D., "New Terminology and Clarifications for Diffserv", RFC 3260, April 2002.
[RFC3809] Nagarajan, A., "Generic Requirements for Provider Provisioned Virtual Private Networks (PPVPN)", RFC 3809, June 2004.
[RFC3945] Mannie, E., "Generalized Multi-Protocol Label Switching (GMPLS) Architecture", RFC 3945, October 2004.
Ning, et al. Expires December 22, 2012 [Page 14]

Internet-Draft Composite Link Use Cases June 2012
[RFC4201] Kompella, K., Rekhter, Y., and L. Berger, "Link Bundling in MPLS Traffic Engineering (TE)", RFC 4201, October 2005.
[RFC4301] Kent, S. and K. Seo, "Security Architecture for the Internet Protocol", RFC 4301, December 2005.
[RFC4385] Bryant, S., Swallow, G., Martini, L., and D. McPherson, "Pseudowire Emulation Edge-to-Edge (PWE3) Control Word for Use over an MPLS PSN", RFC 4385, February 2006.
[RFC4928] Swallow, G., Bryant, S., and L. Andersson, "Avoiding Equal Cost Multipath Treatment in MPLS Networks", BCP 128, RFC 4928, June 2007.
[RFC5036] Andersson, L., Minei, I., and B. Thomas, "LDP Specification", RFC 5036, October 2007.
[RFC5586] Bocci, M., Vigoureux, M., and S. Bryant, "MPLS Generic Associated Channel", RFC 5586, June 2009.
[RFC6391] Bryant, S., Filsfils, C., Drafz, U., Kompella, V., Regan, J., and S. Amante, "Flow-Aware Transport of Pseudowires over an MPLS Packet Switched Network", RFC 6391, November 2011.
Appendix A. More Details on Existing Network Operator Practices and Protocol Usage
Often, network operators have a contractual Service Level Agreement (SLA) with customers for services that are comprised of numerical values for performance measures, principally availability, latency, delay variation. Additionally, network operators may have Service Level Sepcification (SLS) that is for internal use by the operator. See [ITU-T.Y.1540], [ITU-T.Y.1541], RFC3809, Section 4.9 [RFC3809] for examples of the form of such SLA and SLS specifications. In this document we use the term Network Performance Objective (NPO) as defined in section 5 of [ITU-T.Y.1541] since the SLA and SLS measures have network operator and service specific implications. Note that the numerical NPO values of Y.1540 and Y.1541 span multiple networks and may be looser than network operator SLA or SLS objectives. Applications and acceptable user experience have an important relationship to these performance parameters.
Consider latency as an example. In some cases, minimizing latency relates directly to the best customer experience (e.g., in TCP closer is faster). In other cases, user experience is relatively insensitive to latency, up to a specific limit at which point user
Ning, et al. Expires December 22, 2012 [Page 15]

Internet-Draft Composite Link Use Cases June 2012
perception of quality degrades significantly (e.g., interactive human voice and multimedia conferencing). A number of NPOs have. a bound on point-point latency, and as long as this bound is met, the NPO is met -- decreasing the latency is not necessary. In some NPOs, if the specified latency is not met, the user considers the service as unavailable. An unprotected LSP can be manually provisioned on a set of to meet this type of NPO, but this lowers availability since an alternate route that meets the latency NPO cannot be determined.
Historically, when an IP/MPLS network was operated over a lower layer circuit switched network (e.g., SONET rings), a change in latency caused by the lower layer network (e.g., due to a maintenance action or failure) this was not known to the MPLS network. This resulted in latency affecting end user experience, sometimes violating NPOs or resulting in user complaints.
A response to this problem was to provision IP/MPLS networks over unprotected circuits and set the metric and/or TE-metric proportional to latency. This resulted in traffic being directed over the least latency path, even if this was not needed to meet an NPO or meet user experience objectives. This results in reduced flexibility and increased cost for network operators. Using lower layer networks to provide restoration and grooming is expected to be more efficient, but the inability to communicate performance parameters, in particular latency, from the lower layer network to the higher layer network is an important problem to be solved before this can be done.
Latency NPOs for point-to-point services are often tied closely to geographic locations, while latency for multipoint services may be based upon a worst case within a region.
Section 7 of [ITU-T.Y.1540] defines availability for an IP service in terms of loss exceeding a threshold for a period on the order of 5 minutes. However, the timeframes for restoration (i.e., as implemented by pre-determined protection, convergence of routing protocols and/or signaling) for services range from on the order of 100 ms or less (e.g., for VPWS to emulate classical SDH/SONET protection switching), to several minutes (e.g., to allow BGP to reconverge for L3VPN) and may differ among the set of customers within a single service.
The presence of only three Traffic Class (TC) bits (previously known as EXP bits) in the MPLS shim header is limiting when a network operator needs to support QoS classes for multiple services (e.g., L2VPN VPWS, VPLS, L3VPN and Internet), each of which has a set of QoS classes that need to be supported. In some cases one bit is used to indicate conformance to some ingress traffic classification, leaving only two bits for indicating the service QoS classes. The approach
Ning, et al. Expires December 22, 2012 [Page 16]

Internet-Draft Composite Link Use Cases June 2012
that has been taken is to aggregate these QoS classes into similar sets on LER-LSR and LSR-LSR links.
Labeled LSPs and use of link layer encapsulation have been standardized in order to provide a means to meet these needs.
The IP DSCP cannot be used for flow identification since RFC 4301 Section 5.5 [RFC4301] requires Diffserv transparency, and in general network operators do not rely on the DSCP of Internet packets. In addition, the use of IP DSCP for flow identification is incompatible with Assured Forwarding services [RFC2597] or any other service which may use more than one DSCP code point to carry traffic for a given microflow.
A label is pushed onto Internet packets when they are carried along with L2/L3VPN packets on the same link or lower layer network provides a mean to distinguish between the QoS class for these packets.
Operating an MPLS-TE network involves a different paradigm from operating an IGP metric-based LDP signaled MPLS network. The multipoint-to-point LDP signaled MPLS LSPs occur automatically, and balancing across parallel links occurs if the IGP metrics are set "equally" (with equality a locally definable relation).
Traffic is typically comprised of a few large (some very large) flows and many small flows. In some cases, separate LSPs are established for very large flows. This can occur even if the IP header information is inspected by a LSR, for example an IPsec tunnel that carries a large amount of traffic. An important example of large flows is that of a L2/L3 VPN customer who has an access line bandwdith comparable to a client-client composite link bandwidth -- there could be flows that are on the order of the access line bandwdith.
Appendix B. Existing Multipath Standards and Techniques
Today the requirement to handle large aggregations of traffic, much larger than a single component link, can be handled by a number of techniques which we will collectively call multipath. Multipath applied to parallel links between the same set of nodes includes Ethernet Link Aggregation [IEEE-802.1AX], link bundling [RFC4201], or other aggregation techniques some of which may be vendor specific. Multipath applied to diverse paths rather than parallel links includes Equal Cost MultiPath (ECMP) as applied to OSPF, ISIS, or even BGP, and equal cost LSP, as described in Appendix B.4. Various mutilpath techniques have strengths and weaknesses.
Ning, et al. Expires December 22, 2012 [Page 17]

Internet-Draft Composite Link Use Cases June 2012
the term Composite Link is more general than terms such as Link Aggregation which is generally considered to be specific to Ethernet and its use here is consistent with the broad definition in [ITU-T.G.800]. The term multipath excludes inverse multiplexing and refers to techniques which only solve the problem of large aggregations of traffic, without addressing the other requirements outlined in this document, particularly those described in Section 4 and Section 5.
B.1. Common Multpath Load Spliting Techniques
Identical load balancing techniqes are used for multipath both over parallel links and over diverse paths.
Large aggregates of IP traffic do not provide explicit signaling to indicate the expected traffic loads. Large aggregates of MPLS traffic are carried in MPLS tunnels supported by MPLS LSP. LSP which are signaled using RSVP-TE extensions do provide explicit signaling which includes the expected traffic load for the aggregate. LSP which are signaled using LDP do not provide an expected traffic load.
MPLS LSP may contain other MPLS LSP arranged hierarchically. When an MPLS LSR serves as a midpoint LSR in an LSP carrying other LSP as payload, there is no signaling associated with these inner LSP. Therefore even when using RSVP-TE signaling there may be insufficient information provided by signaling to adequately distribute load based solely on signaling.
Generally a set of label stack entries that is unique across the ordered set of label numbers in the label stack can safely be assumed to contain a group of flows. The reordering of traffic can therefore be considered to be acceptable unless reordering occurs within traffic containing a common unique set of label stack entries. Existing load splitting techniques take advantage of this property in addition to looking beyond the bottom of the label stack and determining if the payload is IPv4 or IPv6 to load balance traffic accordingly.
MPLS-TP OAM violates the assumption that it is safe to reorder traffic within an LSP. If MPLS-TP OAM is to be accommodated, then existing multipth techniques must be modified. Such modifications are outside the scope of this document.
For example,a large aggregate of IP traffic may be subdivided into a large number of groups of flows using a hash on the IP source and destination addresses. This is as described in [RFC2475] and clarified in [RFC3260]. For MPLS traffic carrying IP, a similar hash can be performed on the set of labels in the label stack. These
Ning, et al. Expires December 22, 2012 [Page 18]

Internet-Draft Composite Link Use Cases June 2012
techniques are both examples of means to subdivide traffic into groups of flows for the purpose of load balancing traffic across aggregated link capacity. The means of identifying a set of flows should not be confused with the definition of a flow.
Discussion of whether a hash based approach provides a sufficiently even load balance using any particular hashing algorithm or method of distributing traffic across a set of component links is outside of the scope of this document.
The current load balancing techniques are referenced in [RFC4385] and [RFC4928]. The use of three hash based approaches are described in [RFC2991] and [RFC2992]. A mechanism to identify flows within PW is described in [RFC6391]. The use of hash based approaches is mentioned as an example of an existing set of techniques to distribute traffic over a set of component links. Other techniques are not precluded.
B.2. Simple and Adaptive Load Balancing Multipath
Simple multipath generally relies on the mathematical probability that given a very large number of small microflows, these microflows will tend to be distributed evenly across a hash space. Early very simple multipath implementations assumed that all component links are of equal capacity and perform a modulo operation across the hashed value. An alternate simple multipath technique uses a table generally with a power of two size, and distributes the table entries proportionally among component links according to the capacity of each component link.
Simple load balancing works well if there are a very large number of small microflows (i.e., microflow rate is much less than component link capacity). However, the case where there are even a few large microflows is not handled well by simple load balancing.
An adaptive load balancing multipath technique is one where the traffic bound to each component link is measured and the load split is adjusted accordingly. As long as the adjustment is done within a single network element, then no protocol extensions are required and there are no interoperability issues.
Note that if the load balancing algorithm and/or its parameters is adjusted, then packets in some flows may be briefly delivered out of sequence, however in practice such adjustments can be made very infrequent.
Ning, et al. Expires December 22, 2012 [Page 19]

Internet-Draft Composite Link Use Cases June 2012
B.3. Traffic Split over Parallel Links
The load spliting techniques defined in Appendix B.1 and Appendix B.2 are both used in splitting traffic over parallel links between the same pair of nodes. The best known technique, though far from being the first, is Ethernet Link Aggregation [IEEE-802.1AX]. This same technique had been applied much earlier using OSPF or ISIS Equal Cost MultiPath (ECMP) over parallel links between the same nodes. Multilink PPP [RFC1717] uses a technique that provides inverse multiplexing, however a number of vendors had provided proprietary extensions to PPP over SONET/SDH [RFC2615] that predated Ethernet Link Aggregation but are no longer used.
Link bundling [RFC4201] provides yet another means of handling parallel LSP. RFC4201 explicitly allow a special value of all ones to indicate a split across all members of the bundle. This "all ones" component link is signaled in the MPLS RESV to indicate that the link bundle is making use of classic multipath techniques.
B.4. Traffic Split over Multiple Paths
OSPF or ISIS Equal Cost MultiPath (ECMP) is a well known form of traffic split over multiple paths that may traverse intermediate nodes. ECMP is often incorrectly equated to only this case, and multipath over multiple diverse paths is often incorrectly equated to ECMP.
Many implementations are able to create more than one LSP between a pair of nodes, where these LSP are routed diversely to better make use of available capacity. The load on these LSP can be distributed proportionally to the reserved bandwidth of the LSP. These multiple LSP may be advertised as a single PSC FA and any LSP making use of the FA may be split over these multiple LSP.
Link bundling [RFC4201] component links may themselves be LSP. When this technique is used, any LSP which specifies the link bundle may be split across the multiple paths of the LSP that comprise the bundle.
Appendix C. Characteristics of Transport in Core Networks
The characteristics of primary interest are the capacity of a single circuit and the use of wave division multiplexing (WDM) to provide a large number of parallel circuits.
Wave division multiplexing (WDM) supports multiple independent channels (independent ignoring crosstalk noise) at slightly different
Ning, et al. Expires December 22, 2012 [Page 20]

Internet-Draft Composite Link Use Cases June 2012
wavelengths of light, multiplexed onto a single fiber. Typical in the early 2000s was 40 wavelengths of 10 Gb/s capacity per wavelength. These wavelengths are in the C-band range, which is about 1530-1565 nm, though some work has been done using the L-band 1565-1625 nm.
The C-band has been carved up using a 100 GHz spacing from 191.7 THz to 196.1 THz by [ITU-T.G.694.2]. This yields 44 channels. If the outermost channels are not used, due to poorer transmission characteristics, then typcially 40 are used. For practical reasons, a 50 GhZ or 25 GHz spacing is used by more recent equipment, yielding. 80 or 160 channels in practice.
The early optical modulation techniques used within a single channel yielded 2.5Gb/s and 10 Gb/s capacity per channel. As modulation techniques have improved 40 Gb/s and 100 Gb/s per channel have been acheived.
The 40 channels of 10 Gb/s common in the mid 2000s yields a total of 400 Gb/s. Tighter spacing and better modulations are yielding up to 8 Tb/s or more in more recent systems.
Over the optical is an electrical encoding. In the 1990s this was typically Synchronous Optical Networking (SONET) or Synchronous Digital Hierarchy (SDH), with a maximum defined circuit capacity of 40 Gb/s (OC-768), though the 10 Gb/s OC-192 is more common. More recently the low level electrical encoding has been Optical Transport Network (OTN) defined by ITU-T. OTN currently defines circuit capacities up to a nominal 100 Gb/s (ODU4). Both SONET/SDH and OTN make use of time division multiplexing (TDM) where the a higher capacity circuit such as a 100 Gb/s ODU4 in OTN may be subdivided into lower fixed capacity circuits such as ten 10 Gb/s ODU2.
In the 1990s, all IP and later IP/MPLS networks either used a fraction of maximum circuit capacity, or at most the full circuit capacity toward the end of the decade, when full circuit capacity was 2.5 Gb/s or 10 Gb/s. Beyond 2000, the TDM circuit multiplexing capability of SONET/SDH or OTN was rarely used.
Early in the 2000s both transport equipment and core LSR offerred 40 Gb/s SONET OC-768. However 10 Gb/s transport equipment was predominantly deployed throughout the decade, partially because LSR 10GbE ports were far more cost effective than either OC-192 or OC-768 and became practical in the second half of the decade.
Entering the 2010 decade, LSR 40GbE and 100GbE are expected to become widely available and cost effective. Slightly preceeding this transport equipment making use of 40 Gb/s and 100 Gb/s modulations
Ning, et al. Expires December 22, 2012 [Page 21]

Internet-Draft Composite Link Use Cases June 2012
are becoming available. This transport equipment is capable or carrying 40 Gb/s ODU3 and 100 Gb/s ODU4 circuits.
Early in the 2000s decade IP/MPLS core networks were making use of single 10 Gb/s circuits. Capacity grew quickly in the first half of the decade but more IP/MPLS core networks had only a small number of IP/MPLS links requiring 4-8 parallel 10 Gb/s circuits. However, the use of multipath was necessary, was deemed the simplest and most cost effective alternative, and became thoroughly entrenched. By the end of the 2000s decade nearly all major IP/MPLS core service provider networks and a few content provider networks had IP/MPLS links which exceeded 100 Gb/s, long before 40GbE was available and 40 Gb/s transport in widespread use.
It is less clear when IP/MPLS LSP exceeded 10 Gb/s, 40 Gb/s, and 100 Gb/s. By 2010, many service providers have LSP in excess of 100 Gb/s, but few are willing to disclose how many LSP have reached this capacity.
At the time of writing 40GbE and 100GbE LSR products are being evaluated by service providers and contect providers and are in use in network trials. The cost of components required to deliver 100 GbE products remains high making these products less cost effective. This is expected to change within years.
The important point is that IP/MPLS core network links have long ago exceeded 100 Gb/s and a small number of IP/MPLS LSP exceed 100 Gb/s. By the time 100 Gb/s circuits are widely deployed, IP/MPLS core network links are likely to exceed 1 Tb/s and many IP/MPLS LSP capacities are likely to exceed 100 Gb/s. Therefore multipath techniques are likely here to stay.
Authors’ Addresses
So Ning Tata Communications
Email: [email protected]
Ning, et al. Expires December 22, 2012 [Page 22]

Internet-Draft Composite Link Use Cases June 2012
Andrew Malis Verizon 117 West St. Waltham, MA 02451
Phone: +1 781-466-2362 Email: [email protected]
Dave McDysan Verizon 22001 Loudoun County PKWY Ashburn, VA 20147
Email: [email protected]
Lucy Yong Huawei USA 5340 Legacy Dr. Plano, TX 75025
Phone: +1 469-277-5837 Email: [email protected]
Curtis Villamizar Outer Cape Cod Network Consulting
Email: [email protected]
Ning, et al. Expires December 22, 2012 [Page 23]


Network Working Group M. XuInternet-Draft J. WuExpires: September 2, 2012 S. Yang Tsinghua University D. Wang Hong Kong Polytechnic University Mar 2012
Two Dimensional IP Routing Architecture draft-xu-rtgwg-twod-ip-routing-00
Abstract
This document describes Two Dimensional IP (TwoD-IP) routing, a new Internet routing architecture which makes forwarding decisions based on both source address and destination address. This presents a fundamental extension from the current Internet, which makes forwarding decisions based on the destination address, and provides shortest single-path routing towards destination. Such extension provides rooms to solve fundamental problems of the past and foster great innovations in the future.
We present the TwoD-IP routing framework and its two underpinning schemes. The first is a new hardware-based forwarding table structure for TwoD-IP, FIST, which achieves line-speed lookup with acceptable storage space. The second is a policy routing protocol that flexibly diverts traffic.
Status of this Memo
This Internet-Draft is submitted in full conformance with the provisions of BCP 78 and BCP 79.
Internet-Drafts are working documents of the Internet Engineering Task Force (IETF). Note that other groups may also distribute working documents as Internet-Drafts. The list of current Internet- Drafts is at http://datatracker.ietf.org/drafts/current/.
Internet-Drafts are draft documents valid for a maximum of six months and may be updated, replaced, or obsoleted by other documents at any time. It is inappropriate to use Internet-Drafts as reference material or to cite them other than as "work in progress."
This Internet-Draft will expire on September 2, 2012.
Copyright Notice
Xu, et al. Expires September 2, 2012 [Page 1]

Internet-Draft TwoD-IP Routing Architecture Mar 2012
Copyright (c) 2012 IETF Trust and the persons identified as the document authors. All rights reserved.
This document is subject to BCP 78 and the IETF Trust’s Legal Provisions Relating to IETF Documents (http://trustee.ietf.org/license-info) in effect on the date of publication of this document. Please review these documents carefully, as they describe your rights and restrictions with respect to this document. Code Components extracted from this document must include Simplified BSD License text as described in Section 4.e of the Trust Legal Provisions and are provided without warranty as described in the Simplified BSD License.
This document may contain material from IETF Documents or IETF Contributions published or made publicly available before November 10, 2008. The person(s) controlling the copyright in some of this material may not have granted the IETF Trust the right to allow modifications of such material outside the IETF Standards Process. Without obtaining an adequate license from the person(s) controlling the copyright in such materials, this document may not be modified outside the IETF Standards Process, and derivative works of it may not be created outside the IETF Standards Process, except to format it for publication as an RFC or to translate it into languages other than English.
Xu, et al. Expires September 2, 2012 [Page 2]

Internet-Draft TwoD-IP Routing Architecture Mar 2012
Table of Contents
1. Introduction . . . . . . . . . . . . . . . . . . . . . . . . . 4 2. Benefits of Introducing TwoD-IP Routing . . . . . . . . . . . 5 2.1. Multi-homing . . . . . . . . . . . . . . . . . . . . . . . 5 2.2. Load Balancing . . . . . . . . . . . . . . . . . . . . . . 6 2.3. Diagnosis . . . . . . . . . . . . . . . . . . . . . . . . 7 2.4. Policy Routing . . . . . . . . . . . . . . . . . . . . . . 7 2.5. Others . . . . . . . . . . . . . . . . . . . . . . . . . . 7 3. Framework . . . . . . . . . . . . . . . . . . . . . . . . . . 9 3.1. Data Plane . . . . . . . . . . . . . . . . . . . . . . . . 9 3.2. Control Plane . . . . . . . . . . . . . . . . . . . . . . 9 4. Forwarding Table Design . . . . . . . . . . . . . . . . . . . 11 4.1. Design Goals . . . . . . . . . . . . . . . . . . . . . . . 11 4.2. Forwarding Table Structure . . . . . . . . . . . . . . . . 11 4.3. Lookup Action . . . . . . . . . . . . . . . . . . . . . . 13 4.4. Update Action . . . . . . . . . . . . . . . . . . . . . . 14 4.5. Scalability Improvements . . . . . . . . . . . . . . . . . 14 5. Routing Protocol Design . . . . . . . . . . . . . . . . . . . 15 5.1. Protocol Overview . . . . . . . . . . . . . . . . . . . . 15 5.2. Router Actions . . . . . . . . . . . . . . . . . . . . . . 16 5.3. TwoD-IP Routing Table Construction . . . . . . . . . . . . 17 6. Deployment . . . . . . . . . . . . . . . . . . . . . . . . . . 19 7. Implementation Status . . . . . . . . . . . . . . . . . . . . 20 8. Security Considerations . . . . . . . . . . . . . . . . . . . 21 9. IANA Considerations . . . . . . . . . . . . . . . . . . . . . 22 10. References . . . . . . . . . . . . . . . . . . . . . . . . . . 23 10.1. Normative References . . . . . . . . . . . . . . . . . . . 23 10.2. Informative References . . . . . . . . . . . . . . . . . . 23 Authors’ Addresses . . . . . . . . . . . . . . . . . . . . . . . . 24
Xu, et al. Expires September 2, 2012 [Page 3]

Internet-Draft TwoD-IP Routing Architecture Mar 2012
1. Introduction
Since IP routing took place, the current Internet has been making forwarding decisions based on destination addresses. The destination-based routing system provides limited semantics with only a single path towards each destination. Many services, such as multi-homing, multi-path and traffic engineering, face difficulties within the current Internet routing system. Due to the important semantics of source address, recent years see increasing works on adding source addresses into routing controls.
IP source routing [3] carries the routes in packet header. However, IP source routing is disabled in most networks due to security reasons. MPLS [4] uses label switching to manage traffic per-flow. However, MPLS raises scalability issues when the number of label switching paths (LSPs) increases [5]. What’s more, many ISPs prefer pure-IP networks.
In this draft, we describe Two Dimensional IP (TwoD-IP) routing, which makes forwarding decisions based on both source and destination addresses. TwoD-IP routing presents a fundamental extension of the semantics from the current Internet. The network will become more flexible, manageable, reliable, etc. Such extension provides rooms to solve problems of the past and foster innovations in the future.
TwoD-IP routing framework is divided into data plane and control plane. In data plane, packet forwarding needs to check both source and destination addresses. Though current TCAM-based forwarding table can match line speeds with parallel search over the table, with one more dimension in the table, the forwarding table will explode and exceed the maximum storage space of current TCAM. We devise a new forwarding table structure for TwoD-IP, FIB Structure for TwoD-IP (FIST). The new structure makes a separation between TCAM and SRAM, where TCAM contributes to fast lookup speeds and SRAM contributes to a larger memory space. In the control plane, we devise a simple policy based routing protocol. For the traffic of a customer network of an ISP, this policy routing protocol can flexibly divert the traffic from one edge router to another edge router.
This document also presents the deployment issues and objectives of the TwoD-IP routing.
Xu, et al. Expires September 2, 2012 [Page 4]

Internet-Draft TwoD-IP Routing Architecture Mar 2012
2. Benefits of Introducing TwoD-IP Routing
In this section, we list the use cases that can benefit from TwoD-IP routing.
2.1. Multi-homing
Multi-homing is prevalent among ISPs for better traffic distribution and reliability. Traditionally, Provider Independent (PI) address is used. Because PI address can not be aggregated by higher level ISPs, it will cause explosion of routing table. To solve the problem, Provider Aggregatable (PA) address is proposed. However, PA address complicates network configurations for ISP operators. Besides, due to destination-based routing in traditional networks, PA address has difficulties when facing failures, i.e., the network has to re- compute a new path when failures happen.
+--------------------+ | | | Internet | | | +--+---------------+-+ | | | l3 | l4 | | +------+----+ +--+--------+ | ISP1 | | ISP2 | | Prefix P1 | | Prefix P2 | +--------+--+ +-+---------+ | | | l1 | l2 +--+------------+--+ | | | Multi-homed Site | +---------+ | +--------+ Host | +------------------+ +---------+ ISP1 address: A ISP2 address: B
Figure 1: TwoD-IP routing for multi-homing
For example, in Figure 1, assume a multi-homed site is connected to two ISPs: ISP1 and ISP2. ISP1 has a prefix P1, and ISP2 has a prefix P2. A host connect to the multi-homed site has two addresses,
Xu, et al. Expires September 2, 2012 [Page 5]

Internet-Draft TwoD-IP Routing Architecture Mar 2012
address A that can be aggregated into P1, and address B that can be aggregated into P2. With TwoD-IP routing, the multi-homed site can deliver the traffic from A towards the Internet to ISP1, and deliver the traffic from B towards the Internet to ISP2. If the host is using address A, and the link l1 or l3 fails. Then the host can immediately detect the failure, then switch to address B, and continue to communicate with the Internet via ISP2. With TwoD-IP, the host does not have to wait for routing convergence in the multi- homed site when failures happen.
2.2. Load Balancing
Compared to destination-based routing, TwoD-IP routing can manipulate traffic in a finer-grained granularity. Such that TwoD-IP can achieve better traffic distribution. For example, in Figure 2, assume that there are 5 hosts that are communicating with the same server at 10Mbps. Our goal is to minimize the maximum link utilization over the network. Within destination-based routing, traffic towards the same destination has to travel along the same path in the network. Thus the best traffic distribution is to let all traffic take the north route via router b, and the Min-max link utilization is 83.3%.
+-----+ |Host1+---+ +-----+ | +-----+ | 60Mbps +-----+ 60Mbps |Host2+---+ +--------+ b +---------+ +-----+ | | +-----+ | +-----+ | +--+--+ +--+--+ +------+ |Host3+---+---+ a | | c +--------+Server| +-----+ | +--+--+ +--+--+ +------+ +-----+ | | +-----+ | |Host4+---+ +________+ d |_________+ +-----+ | 40Mbps +-----+ 40Mbps +-----+ | |Host5+---+ +-----+
Figure 2: TwoD-IP routing for load balancing
With TwoD-IP routing, we can let the traffic of three hosts (e.g., Host1, Host2 and Host3) take the north route via b, and let the traffic of the other two hsots (e.g., Host4 and Host5) take the south route via d. Thus the Min-max link utilization is only 50.0%.
Xu, et al. Expires September 2, 2012 [Page 6]

Internet-Draft TwoD-IP Routing Architecture Mar 2012
2.3. Diagnosis
In Figure 3, assume a network has four routers: a, b, c and d. The operator wants to monitor the status of the link between b and d. Thus the operator sets up a monitor at router a, and sends probe packets to d. Theoretically, the probe packets will flow on the shortest path, i.e., a-b-d. However, the network provides traffic engineering capabilities. If there is congestion on the link between b and d, and router b moves the traffic towards d to the north path via c. Thus, the probe packets will flow on the path a-b-c-d, which does not include the link between b and d.
+------+ +-------+ c +-----+ | +------+ | | | | | +------+ +--+---+ +---+--+ | a +----------+ b +------------+ d | +------+ +------+ +------+
Figure 3: TwoD-IP routing for Diagnosability
With TwoD-IP routing, router b can identify the probe packets from a towards d, and deliver them directly to router d. Thus the link between b and d can be easily monitored.
2.4. Policy Routing
Assume in an ISP network, ISP operator wants that the traffic from source address A towards destination address B passes by router C. With TwoD-IP routing, routers make forwarding decisions based on both destination and source addresses, thus can easily identify the traffic from A towards B, and divert it to the next hop towards C.
2.5. Others
Besides the above-mentioned use cases, TwoD-IP routing is beneficial in many other use-cases. We list the other use-cases briefly.
o Reliability: TwoD-IP provides multiple paths towards destination, rather than the shortest path only. When one path breaks down, routers can immediately switch to another path.
o Multi-path: TwoD-IP can forward packets towards the same destination, and from different sources to different next hops.
Xu, et al. Expires September 2, 2012 [Page 7]

Internet-Draft TwoD-IP Routing Architecture Mar 2012
If a host has multiple source addresses, the host will have multiple paths towards the same destination.
o Security: Traditional network pushes the security devices to the border routers, the intermediate network just delivers the packets. With TwoD-IP, intermediate routers also have source checking functionality. Thus, the whole network rather than the border network, can defense attacks.
o Measurability: With TwoD-IP, ISP operators can explicitly control the routing paths of probe packets. Thus the number of monitors, and the additional traffic caused by the probe packets, can be reduced [6].
Xu, et al. Expires September 2, 2012 [Page 8]

Internet-Draft TwoD-IP Routing Architecture Mar 2012
3. Framework
Similar with traditional routing, TwoD-IP routing can be separated into two parts: data plane and control plane.
3.1. Data Plane
Data plane contains the forwarding table, that decides what to do when a packet arrives. Different with traditional destination-based routing, each entry in the TwoD-IP routing forwarding table is a 3-tuple: {destination address, source address, next hop}. When a packet arrives, routers extract both destination and source addresses from the packet, then lookup the forwarding table, and output a matched entry. Finally, routers will forward the packet to the next hop associated with the matched entry.
With a new dimension, the size of forwarding table will increase to be O(N^2) (where N is the size of source/destination address space), which is too large for current TCAM-based storage to accomodate. To avoid forwarding table explosion, we design a new forwarding table structure in Section 4.
3.2. Control Plane
In traditional routing, the control plane is concerned with the network status, e.g., network topology. Within TwoD-IP routing, the control plane is concerned with both network status and user demands. TwoD-IP routing not only provides basic connectivity service, but also satisfies kinds of user demands, e.g., policy routing, multi- path and traffic engineering. TwoD-IP routing protocol has two components:
o Destination-based routing protocol: To be compatible with traditional routing (especially when most networks only support destination-based routing), TwoD-IP routing protocol should support destination-based routing. Such that ISPs can provide the same connectivity service, while upgrading routers with TwoD-IP functionality. To provide better connectivity services, destination-based routing protocol should respond instantly to the changes of network topology.
o Source-related routing protocol: Combined with source addresses, TwoD-IP routing can make better forwarding decisions for users. Source-related routing protocols focus on providing services that are related with source addresses. They may need to collect demands from users, and compute the routing table to satisfy these demands. Depending on the specific user demands, some source- related routing protocols need real-time updates, while others do
Xu, et al. Expires September 2, 2012 [Page 9]

Internet-Draft TwoD-IP Routing Architecture Mar 2012
not. The newly designed source-related routing protocols should be:
* Consistent, they should be consistent with other routing protocols, including the destination-based routing protocol and other new source-related routing protocols;
* Efficient, they should not bring lots of additional overheads to the network.
Xu, et al. Expires September 2, 2012 [Page 10]

Internet-Draft TwoD-IP Routing Architecture Mar 2012
4. Forwarding Table Design
4.1. Design Goals
The forwarding table stores a set of 3-tuple rules, {pd, ps, nh}, where pd is a destination prefix, ps is a source prefix, and nh indicates the next hop. When a packet arrives, if its destination address matches pd according to LMF (longest match first) rule among all rules, and its source address matches ps according to LMF rule among all rules that are associated with pd. Then the router will forward the packet to the next hop nh.
The new forwarding table should satisfy the following requirements.
o Storage requirement: The new forwarding table should not cause forwarding table explosion problem. Current storage technology should be able to accomodate the table.
o Speed requirement: The new forwarding table should match line- speeds.
4.2. Forwarding Table Structure
We design a new TwoD-IP forwarding table structure, called FIST. As shown in Figure 4, FIST consists of four parts.
Xu, et al. Expires September 2, 2012 [Page 11]

Internet-Draft TwoD-IP Routing Architecture Mar 2012
Source +-------+------+------+------+------+ Table |default| 111* | 101* | 100* | 11** | +-------+------+------+------+------+ | 0 | 1 | 2 | 3 | 4 | +-------+------+------+------+------+ Destination Table | | | | | | +-------+---+ --+------+------+------+------+------+--- | 111* | 0 | | 1 | 0 | | 1 | | +-------+---+ --+------+------+------+------+------+--- | 100* | 1 | | 0 | 2 | | | | +-------+---+ --+------+------+------+------+------+--- | 101* | 2 | | 1 | | | | 2 | +-------+---+ --+------+------+------+------+------+--- | 11** | 3 | | 2 | | | | | +-------+---+ --+------+------+------+------+------+--- | 10** | 4 | | 2 | | | | 3 | +-------+---+ --+------+------+------+------+------+--- | | | | | | TD-table
+------+---------+ |Index |Next hop | +------+---------+ | 0 |1.0.0.0 | +------+---------+ Mapping | 1 |1.0.0.1 | Table +------+---------+ | 2 |1.0.0.2 | +------+---------+ | 3 |1.0.0.3 | +------+---------+
Figure 4: Forwarding Table for TwoD-IP
o Destination table: It resides in TCAM, and stores the destination prefixes. Each destination prefix in destination table corresponds to a row number.
o Source table: It resides in TCAM, and stores the source prefixes. Each source prefix in source table corresponds to a column number.
o Two Dimensional Table (TD-table): It is a two dimensional array that resides in SRAM. Given a row and column numbers, we can find a cell in TD-table. Each cell in TD-table stores an index value, that can be mapped to a next hop.
Xu, et al. Expires September 2, 2012 [Page 12]

Internet-Draft TwoD-IP Routing Architecture Mar 2012
o Mapping table: It resides in SRAM, and maps index values to next hops.
For example, in Figure 4, the destination table contains 5 destination prefixes, and the destination prefix 101* corresponds to a row number 2. The source table contains 4 source prefixes and a default one (can be see as "****"), the source prefix 11** corresponds to a column number 4. The TD-table has 5 rows and 5 columns, the cell that is in the 2nd row and the 4th column has index value 2. In the mapping table, we can see that the index value 2 is related with the next hop 1.0.0.2.
If destination prefix pd outputs row number n, and source prefix ps outputs column number m, we use (pd, ps) to denote a cell in the nth row and mth column of the TD-table.
4.3. Lookup Action
When a packet arrives at a router, the lookup action is as follows.
1. Extract the destination address d and source address s from the packet;
2. Perform the following two operations in parallel:
* Lookup the destination address d in the destination table using the LMF rule, and output the row number n;
* Lookup the source address s in the source table using the LMF rule, and output the column number m;
3. Lookup the cell that is in the nth row and mth column of the TD- table, and output the index value v;
4. Lookup v in the mapping table, and ouput the corresponding next hop;
5. Forward the packet to the next hop.
The 2nd step takes one TCAM clock cycle to match both d and s, and one SRAM clock cycle to get the row/column number. The 3rd step takes one SRAM clock cycle to get the index value, the 4th step takes one SRAM clock cycle to get the next hop. Thus, the lookup speed is one TCAM clock cycle plus three SRAM clock cycles. Beside, the lookup process can be pipelined to achieve higher speed.
Xu, et al. Expires September 2, 2012 [Page 13]

Internet-Draft TwoD-IP Routing Architecture Mar 2012
4.4. Update Action
Although FIST can reduce TCAM storage space, and achieve fast lookup speed, it also faces new challenges. The challenges are caused by performing LMF rule on source addresses. Assume a packet should match destination prefix pd, and source prefix ps. However, if the source table contains a source prefix ps’ that also mathces the packet and is longer than ps, then the packet will match (pd, ps’) within FIST.
For example, if the forwarding table on a router is shown in Figure 4, and a packet with destination address of 1011 and source address of 1111 arrives on the router. According to the matching rule, destination prefix 101* is matched first, and source prefix 11** should be matched. However, within FIST, destination prefix 101* and source prefix 111* are matched. But the cell (101*, 111*) is empty.
To resolve the confliction, we should pre-compute and fill the empty cell with appropriate index value. For example, in Figure 4, we should fill the cell (101*, 111*) with the index value 2, that is the index value of cell (101*, 11**). We will discuss the update action in the next version of this document.
4.5. Scalability Improvements
In Section 4.2, we design the FIST structure, where each destination prefix corresponds to a row, and each source prefix corresponds to a column. Considering the large number of address prefixes, we can make improvements in the following two aspects:
o Not every destination prefix need to be mapped to a row, because ISPs only need to divert traffic for part of the destination prefixes. The destination table of FIST should be divided into two parts, each destination prefixes in the first part points to a row and each destination prefix in the second part points directly to an index value.
o Different destination/source prefixes can be mapped to the same row/column, because ISPs may implement the same policy on different prefixes. For example, ISPs wants to divert the traffic of some customer network, which has multiple prefixes, to another path.
Xu, et al. Expires September 2, 2012 [Page 14]

Internet-Draft TwoD-IP Routing Architecture Mar 2012
5. Routing Protocol Design
5.1. Protocol Overview
In this section, to illustrate TwoD-IP routing protocol, we design a simple policy routing protocol. The routing protocol provides a flexible tool for ISPs to divert traffic (that is from some customer networks towards the foreign Internet) to another path.
+---------+ |0.0.0.* | +-----------------------+ +----------+ | +-----+-B0 I3 ------ E0-+-----+ | +---------+ | ) ( | | 1.0.0.* | Domain number=0 | ) ( | | | The first customer | I0 | | 1.0.1.* | +---------+ | ) ( | | | |0.0.1.* | | ) ( | | 1.0.2.* | | +-----+-B1 I1---I2---E1-+-----+ | +---------+ +-----------------------+ +----------+ Domain number=1 ISP network Foreign Internet The second customer
Figure 5: A simple policy routing protocol
For example, in Figure 5, the ISP has two customer networks, the first customer network has domain number of 0 and one prefix of 0.0.0.*, the second customer network has domain number of 1 and one prefix of 0.0.1.*. The first customer network is conneted to provider edge router (PE router) B0 and the second customer network is connected to PE router B1. The ISP is connected to the foreign Internet through two edge routers, E0 and E1, besides, it has four intermediate routers (P router), I0, I1, I2 and I3. The shortest paths from the customer networks to the foreign Internet are B0-I0- I3-E0 and B1-I0-I3-E0. However, due to congestion on E0, the ISP operator wants to divert the traffic of the second customer network (behind B1) to the path through E1, i.e., B1-I0-I1-I2-E1.
We design the protocol based on the extension of OSPF [2], which can disseminate the information within the network. To illustrate the protocol, we first clarify the following aspects.
o Through e-BGP, edge routers know the prefixes of foreign Internet, e.g., both E0 and E1 know that there are three foreign Internet prefixes, 1.0.0.*, 1.0.1.*, 1.0.2.*;
Xu, et al. Expires September 2, 2012 [Page 15]

Internet-Draft TwoD-IP Routing Architecture Mar 2012
o Through OSPF, PE routers know the prefixes of the customer networks behind them, e.g., B0 knows that prefix 0.0.0.* belong to the first customer network in Figure 5. Besides, PE routers know the customer domain number of the customer networks behind them, e.g, B0 knows that the customer domain number of the first customer network is 0. Through manual configuration or automatic selection (e.g., selecting the router that has lower utilization), edge routers know the preferences of customer networks on edge routers, e.g., B1 knows that the second customer network in Figure 5 prefers to pass by E1.
With these preconditions, each edge router can announce the foreign Internet prefixes combined with its own router identification to the network, each PE router can announce the customer prefixes combined with the corresponding customer domain number, PE routers are also responsible for announcing the preference of customer networks on edge routers. When receiving all necessary information, both PE and P routers will construct the routing table, which can be used to generate the forwarding table.
5.2. Router Actions
We first define three types of messages.
Announce(Prefixes, Router_ID): Edge routers send this message, to announce the binding relations between foreign IP perfixes and the edge router identification (can be represented by the IP address of the edge router). This message indicates that traffic can reach the foreign Internet through the edge router.
Bind(Prefixes, Domain_Number): PE routers send this message, to announce the binding relations between customer network IP prefixes and customer domain number. This message indicates that the customer network IP prefixes belong to the cusomter network that owns the Domain_Number.
Pref(Domain_Number, Router_ID): PE routers send this message, to announces the preference of a customer network on an edge router. This message indicates that the customer network that owns the Domain_Number prefers to pass by the edge router that owns the Router_ID.
Then the actions on different types of routers are as follows.
Edge Routers: Edge routers have to send Announce(Prefixes, Router_ID) to announce the foreign Internet prefixes to the network. For example, in Figure 5, E0 will send Announce(1.0.0.*, E0), Announce(1.0.1.*, EO) and Announce(1.0.2.*, EO). E1 will
Xu, et al. Expires September 2, 2012 [Page 16]

Internet-Draft TwoD-IP Routing Architecture Mar 2012
send Announce(1.0.0.*, E1), Announce(1.0.1.*, E1) and Announce(1.0.2.*, E1).
PE Routers:
1. PE routers have to send Bind(Prefixes, Domain_Number) to announce the customer network prefixes to the network. For example, B0 will send Bind(0.0.0.*, 0), B1 will send Bind(0.0.1.*, 1).
2. PE routers have to send Pref(Domain_Number, Router_ID) to announce the preference of the cusomter network on an edge routers. For example, B1 will send Pref(1, E1).
3. After receiving Announce(Prefixes, Router_ID) from edge routers, PE routers should construct the routing table.
Intermediate Routers: After receiving Announce(Prefixes, Router_ID) from edge routers, Bind(Prefixes, Domain_Number) and Pref(Domain_Number, Router_ID) from PE routers, P routers should construct the routing table.
5.3. TwoD-IP Routing Table Construction
Receiving the necessary information (including customer network prefixes, foreign Internet prefixes and preferences of customer networks), both PE and P routers should construct the routing table. Edge routers do not need to construct the routing table, unless they also belong to PE/P routers.
The routing table consists of two parts, the first part (traditional routing table) is constructed based on OSPF, the second part (TwoD-IP routing table) is construted based on our TwoD-IP policy routing protocol. When forwarding a packet to the destination, routers first lookup the TwoD-IP routing table, if there does not exist a matched entry, routers will lookup the traditional routing table. We focus on the construction of TwoD-IP routing table in this document. For simplicity, we assume that there are only threee fields in each entry of TwoD-IP routing table, i.e., (Destination, Source, Next hop). Both the destination and source fields represent an IP prefix, the next hop field denotes the outgoing router interface to use (see Section 11 of [1] for more details).
The routing table construction process is as follows.
1. For each received Pref(Domain_Number, Router_ID), lookup the traditional table, and obtain the next hop towards the edge router that owns Router_ID. We use Next_Hop to denote the
Xu, et al. Expires September 2, 2012 [Page 17]

Internet-Draft TwoD-IP Routing Architecture Mar 2012
obtained next hop.
2. For each foreign Internet prefix (Foreign_Prefix), lookup the traditional table, and obtain the next hop towards the Foreign_Prefix. We use Next_Hop’ to denote the obtained next hop.
3. If Next_Hop!=Next_Hop’, for each customer network prefix (Customer_Prefix) that belongs to the customer network that own Domain_Number, we add a new entry (Foreign_Prefix, Customer_Prefix, Next_Hop) to the TwoD-IP routing table.
For example, we continue the example in Figure 5, the TwoD-IP routing table on the P router I0 is shown in Figure 6.
Destination Source Next hop _______________________________________________________ 1.0.0.* 0.0.1.* I1 1.0.1.* 0.0.1.* I1 1.0.2.* 0.0.1.* I1
Figure 6: TwoD-IP routing table on the P router I0
Xu, et al. Expires September 2, 2012 [Page 18]

Internet-Draft TwoD-IP Routing Architecture Mar 2012
6. Deployment
TwoD-IP should support incremental deployment, and during deployment, the following requirements should be satisfied.
Backward compatibility: During deployment, reachability should be guaranteed, and loops should be avoided.
Incentive: After deploying partial routers, ISPs should be able to see visible gains, e.g., their policies are implemented, traffic distribution is improved or security level is enhanced.
Effectivity: The deployment should maximize the benefits for ISPs, e.g., the deployment sequence should be carefully scheduled, such that ISPs can obtain maximum benefits in each step.
Xu, et al. Expires September 2, 2012 [Page 19]

Internet-Draft TwoD-IP Routing Architecture Mar 2012
7. Implementation Status
We have developed a prototype of the TwoD-IP policy routing protocol (see Section 5) on a commercial router, and set up small scale tests under VegaNet [7], a high performance virtualized testbed.
Currently, we are developing the prototype of TwoD-IP router, that uses the FIST forwarding table strucute (see Section 4.2).
Xu, et al. Expires September 2, 2012 [Page 20]

Internet-Draft TwoD-IP Routing Architecture Mar 2012
8. Security Considerations
TwoD-IP routing will enhance the security level of the networks, because routers will check source addresses, which is an important identity of the senders. Distributed attack defenses will be an important topic of TwoD-IP routing, because source checking functionality is deployed deeper in the network.
However, TwoD-IP routing protocols must be carefully designed, to avoid to be used by hackers.
Xu, et al. Expires September 2, 2012 [Page 21]

Internet-Draft TwoD-IP Routing Architecture Mar 2012
9. IANA Considerations
Some newly designed TwoD-IP routing protocols may need new protocol numbers assigned by IANA.
Xu, et al. Expires September 2, 2012 [Page 22]

Internet-Draft TwoD-IP Routing Architecture Mar 2012
10. References
10.1. Normative References
[1] Moy, J., "OSPF Version 2", STD 54, RFC 2328, April 1998.
[2] Zinin, A., Roy, A., Nguyen, L., Friedman, B., and D. Yeung, "OSPF Link-Local Signaling", RFC 5613, August 2009.
[3] Estrin, D., Li, T., Rekhter, Y., Varadhan, K., and D. Zappala, "Source Demand Routing: Packet Format and Forwarding Specification (Version 1)", RFC 1940, May 1996.
[4] Rosen, E., Viswanathan, A., and R. Callon, "Multiprotocol Label Switching Architecture", RFC 3031, January 2001.
[5] Yasukawa, S., Farrel, A., and O. Komolafe, "An Analysis of Scaling Issues in MPLS-TE Core Networks", RFC 5439, February 2009.
10.2. Informative References
[6] Breitbart, Y., Chan, Chee-Yong., Garofalakis, M., Rastogi, R., and A. Silberschatz, "Efficiently monitoring bandwidth and latency in IP networks", INFOCOM 2001, Apr 2001.
[7] Chen, Wenlong., Xu, Mingwei., Yang, Yang., Li, Qi., and Dongchao. Ma, "Virtual Network with High Performance: VegaNet", Chinese Journal of Computers vol. 33, no. 1, 2010.
Xu, et al. Expires September 2, 2012 [Page 23]

Internet-Draft TwoD-IP Routing Architecture Mar 2012
Authors’ Addresses
Mingwei Xu Tsinghua University Department of Computer Science, Tsinghua University Beijing 100084 P.R. China
Phone: +86-10-6278-5822 Email: [email protected]
Jianping Wu Tsinghua University Department of Computer Science, Tsinghua University Beijing 100084 P.R. China
Phone: +86-10-6278-5983 Email: [email protected]
Shu Yang Tsinghua University Department of Computer Science, Tsinghua University Beijing 100084 P.R. China
Phone: +86-10-6278-5822 Email: [email protected]
Dan Wang Hong Kong Polytechnic University Department of Computing, Hong Kong Polytechnic University Hong Kong P.R. China
Phone: +852-2766-7267 Email: [email protected]
Xu, et al. Expires September 2, 2012 [Page 24]