co-bdii mi li p aiidt fl designing mpi library and applications for infiniband clusters ·...
TRANSCRIPT

C D i i MPI Lib d A li ti f Co-Designing MPI Library and Applications for InfiniBand Clusters
Application/Architecture Co-design for Extreme-scale Computing (AACEC) Workshop at Cluster ‘10
Dhabaleswar K. (DK) PandaThe Ohio State University
by
yE-mail: [email protected]
http://www.cse.ohio-state.edu/~panda
1AACEC '10
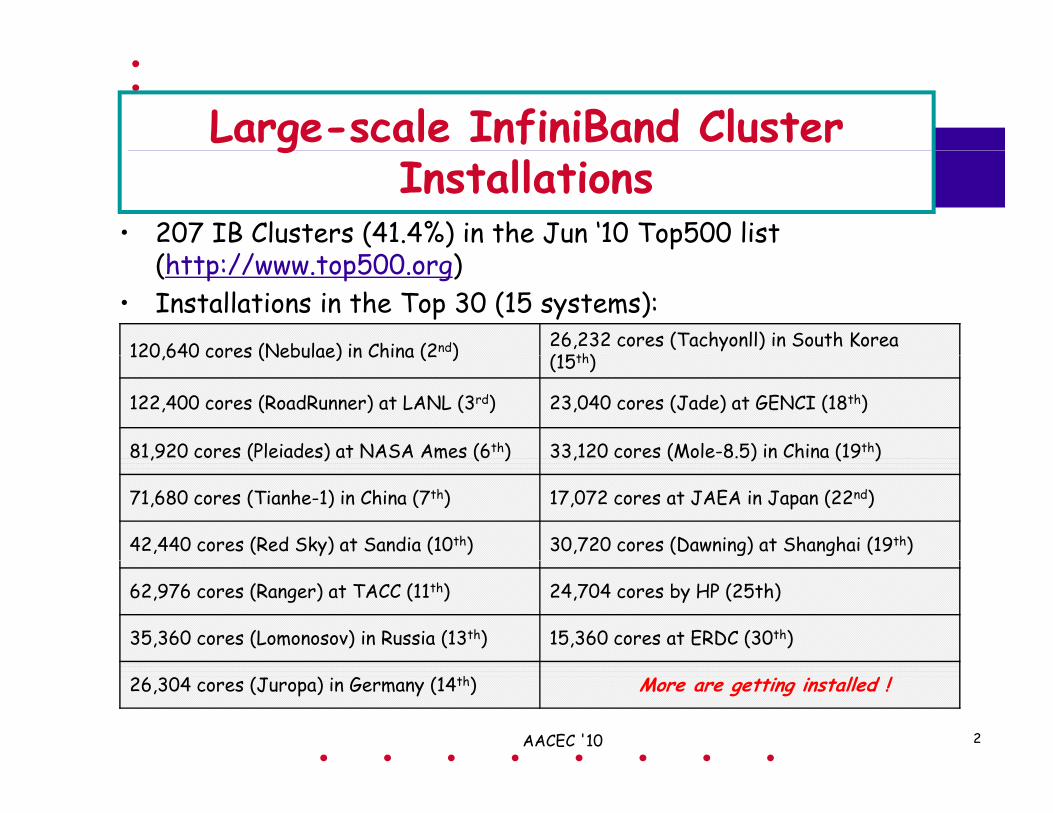
Large-scale InfiniBand Cluster
• 207 IB Clusters (41.4%) in the Jun ‘10 Top500 list //
gInstallations
(http://www.top500.org)• Installations in the Top 30 (15 systems):120 640 cores (Nebulae) in China (2nd) 26,232 cores (Tachyonll) in South Korea
(15th)120,640 cores (Nebulae) in China (2 ) (15th)
122,400 cores (RoadRunner) at LANL (3rd) 23,040 cores (Jade) at GENCI (18th)
81,920 cores (Pleiades) at NASA Ames (6th) 33,120 cores (Mole-8.5) in China (19th),9 c r ( a ) at N m (6 ) , c r (M .5) n h na ( 9 )
71,680 cores (Tianhe-1) in China (7th) 17,072 cores at JAEA in Japan (22nd)
42,440 cores (Red Sky) at Sandia (10th) 30,720 cores (Dawning) at Shanghai (19th)
62,976 cores (Ranger) at TACC (11th) 24,704 cores by HP (25th)
35,360 cores (Lomonosov) in Russia (13th) 15,360 cores at ERDC (30th)
26,304 cores (Juropa) in Germany (14th) More are getting installed !
2AACEC '10

Communication Features of InfiniBand
• Two forms of communication semantics– Channel semantics (Send/Recv)– Memory semantics (RDMA Put, RDMA Get and Atomic
operations)• Potential for overlapping computation with RDMA-based • Potential for overlapping computation with RDMA-based
communication
• New Mellanox ConnectX-2 Adapter provides f ll ffl d ( E D E )support for collective offload (CORE-DIRECT)
• Potential to overlap computation with collective communication
3AACEC '10

Communication in the Memory Semantics (RDMA Put Model)
Memory MemoryProcessor ProcessorM
Memory Memory
MemorySegment
MemorySegment
MemorySegment
Memory
CQQP
Send Recv CQQP
Send Recv
ySegment Initiator processor is involved only to:
1. Post send WQE2. Pull out completed CQE from the send CQ
No involvement from the target processor
InfiniBand DeviceInfiniBand Device
S d WQE i i f i b Hardware ACK
Send WQE contains information about the send buffer (multiple segments)
and the receive buffer (single segment) 4AACEC '10

Collective Offload Support in ConnectX-2 Collective Offload Support in ConnectX-2 (Recv followed by Multi-Send)
Application • Sender creates a task-list consisting of only send and wait WQEs– One send WQE is created for each
registered receiver and is appended Task List
registered receiver and is appended to the rear of a singly linked task-list
– A wait WQE is added to make the ConnectX 2 HCA wait for ACK InfiniBand HCA
Send WaitSendSendSend Wait
MQ ConnectX-2 HCA wait for ACK packet from the receiver
InfiniBand HCA
Physical
Send Q
Send CQ DataData
MCQ
MQ
Physical Link
Recv Q
Q
R CQ
DataData
Recv CQ
5AACEC '10

MVAPICH/MVAPICH2 Software
• High Performance MPI Library for IB and HSE
MVAPICH/MVAPICH2 Software
g y– MVAPICH (MPI-1) and MVAPICH2 (MPI-2.2)
– Used by more than 1,255 organizations in 59 countries
– More than 44,500 downloads from OSU site directly
– Empowering many TOP500 clusters
6th ranked 81 920 core cluster (Pleiades) at NASA• 6th ranked 81,920-core cluster (Pleiades) at NASA
• 7th ranked 71,680-core cluster (Tianhe-1) in China
• 11th ranked 62 976-core cluster (Ranger) at TACC 11 ranked 62,976-core cluster (Ranger) at TACC – Available with software stacks of many IB, HSE and server
vendors including Open Fabrics Enterprise Distribution (OFED)
– http://mvapich.cse.ohio-state.edu
6AACEC '10

Co-Designing Applications and Scientific Libraries with MPI Library
ApplicationsApplications(AWM-ODC)
Co-design Scientific Libraries
MVAPICH2 Library
Co design(3DFFT)
MVAPICH2 Library(two-sided, one-sided, collectives)
RDMA (Put and Get)
Collective Offload I/OAT Network
Loopback Shared memory
7
InfiniBand Features Shared memory designs for multi-core nodes
AACEC '10

AWP-ODCAWP-ODC
• AWP-ODC, a widely used seismic modeling application
• Runs on 100s of thousands of cores
• Consumes millions of CPU hours every year on the TeraGrid y y
• Uses MPI-1 (two-sided communication), spends up to 30% of time in communication
Sh k ut E thqu k Simul ti n1progress• Shows potential for
improvement through overlap
Shakeout Earthquake Simulation1Visualization credits: Amit Chourasia, Visualization Services, SDSCSimulation credits: Kim Olsen et. al. SCEC,Yifeng Cui et. al., SDSCp g p
AACEC '10 8

AWP ODCAWP-ODC
View ofXY plane
• The 3D volume representing the ground area is decomposed into 3D rectangular sub-grids
• Each processor performs stress and velocity calculations each Each processor performs stress and velocity calculations, each element computed from values of neighboring elements from previous iteration
• Ghost cells (two-cell-thick) are used to exchange boundary data Ghost cells (two cell thick) are used to exchange boundary data with neighboring processes – nearest-neighbor communication
AACEC '10 9

AWP-ODC: Application
i l k f h iMAIN LOOP IN AWP-ODC
ppPseudo-code
main loop takes most of the timeMAIN LOOP IN AWP ODCdo i = timestep0, timestepN
Compute Velocities - Tv Swap Velocity data with neighboring sub-grids - Tcv Compute Stresses - Ts Swap Stress data with neighboring sub-grids Tcs
enddo
swap velocity and stressfor each dimension,blocking for completion to
SWAP VELOCITY DATANorth and South Exchange
s2n(u1,north-mpirank, south-mpirank)recv from south, send to northn2s(u1, south-mpirank, north-mpirank)send to south, recv from north. . . repeat for velocity components v1,w1 blocking for completion to
each neighbor. . . p f y mp ,w
East and West Exchangew2e(u1,west-mpirank, east-mpirank)recv from west, send to easte2w(u1, east-mpirank, west-mpirank) send to west, recv from east. . . repeat for velocity components v1,w1
Up and Down Exchange
data needs to be copied into bouncebuffers to send multi-dimensionald
Up and Down Exchange …
S2NCopy 2 planes of data from variable to send buffercopy north boundary excluding the ghost cellsMPI_Isend(sendbuffer, north-mpirank) MPI_Irecv(recvbuffer, south-mpirank) MPI Waitall() dataMPI_Waitall() Copy 2 planes of data from recvbuffer to variable copy into south ghost cells
AACEC '10 10

Exposing overlap in AWP ODCExposing overlap in AWP-ODC
Calculating three velocity components
Calculating six stress components
• Each property has multiple components, each component corresponds to a data grid
• Note that computation of one component is independent of the others!
• However there are data dependencies between stress and
Calculating six stress components
• However, there are data dependencies between stress and velocity
AACEC '10 11

Overlap with Two sided SemanticsOverlap with Two-sided Semantics
Fi st st p initi t t nsf f ll mp n nts t ll n i hb s• First step, initiate transfer of all components to all neighbors– Reduces synchronization
• Wait for completions just before the data is requiredC i f diff i d d• Computation steps for different components are independent
• Exploit this to overlap transfer of one component with computation of another
• However,– Two-sided communication requires rendezvous handshakes for
large messages– What happens when the processes are skewed slightly?– Asynchronous communication is not required of MPI
implementations and most MPI stacks do not do this
AACEC '10 12

Overlap using MPI 2 RMAOverlap using MPI-2 RMA
pre-post window (combined: u, v, w)MPI_Win_post(group, 0, window) ! pre-posting the window to all neighbors p p ( , , )MAIN LOOP IN AWP-ODCCompute velocity component u Start exchanging velocity component u Compute velocity component v Start exchanging velocity component v Compute velocity component w Start exchanging velocity component w
post starts and issue non-blockingMPI Put
Complete Exchanges of u,v and w MPI_Win_post(group, 0, window) ! For the next iteration
START EXCHANGEMPI_Win_start(group, 0, window) s2n(u1,north-mpirank, south-mpirank) ! recv from south send to north MPI_Put
issue completes and waits to finish
! recv from south, send to north n2s(u1, south-mpirank, north-mpirank) ! send to south, recv from north . . . repeat for east-west and up-down
COMPLETE EXCHANGEMPI_Win_complete(window)MPI_Win_wait(window) 2 fill( 1 i d b ff th i k)
ps2nfill(u1, window buffer, south-mpirank) n2sfill(u1, window buffer, north-mpirank) . . . repeat for east-west and up-down
S2NCopy 2 planes of data from variable to sendbuffer! copy north boundary excluding ghost cellsMPI_Put(sendbuffer, north-mpirank)_ ( , p )
S2NFILLCopy 2 planes of data from window buffer to variable! copy into south ghost cells
AACEC '10 13

Experimental Results for AWP ODCExperimental Results for AWP-ODC
• Experiments on TACC Ranger cluster – 64x64x64 data grid ss 25 it ti s 32KB ss sper process – 25 iterations – 32KB messages
• On 4K processes – 11% with Async-2sided and 12% with Async-1sided (RMA)
% h % h • On 8K processes – 6% with Async-2sided and 10% with Async-1sided (RMA)
14AACEC '10

Limiting Factors for Overlap on g pMulti-core Systems
M l b • Multi-core systems are becoming very common– 8/12/16/24 cores per node are common
• Depending on the data distribution and computation-i ti h t i ti i ifi t t f communication characteristics, significant amount of
communication may happen within the node• In AWP-ODC, communication with neighbors in one dimension
ill b ithi dwill be within a node– 1/3 of communication
• Can we provide overlap here?
AACEC '10 15

Overlapping Intra-node pp gCommunication
200 usec200 useccomputation
inserted
• Shared memory communication (copy-based scheme) – gives better performance but poor overlap
• Modern interconnects like InfiniBand provide loop-back (DMA-based scheme) – gives lower performance but provides good overlap
16AACEC '10
– can be used for overlap to hide communication latency completely• I/OAT-like features can be used for similar effect

Overlapping Intra-node pp gCommunication
• Completely hides intra-node communication cost on 48 cores of Magny-Cour systems
• 1600 time steps 128x128x128 data grid per process
17AACEC '10
• 1600 time-steps, 128x128x128 data grid per-process• Similar results with I/OAT technology

Application PerformanceApplication Performance
• 15% improvement in execution time over the original version on 8K cores of TACC Ranger
18AACEC '10
• 100 time-steps – 128x128x128 data grid per-process

2010 Gordon Bell Prize Finalist2010 Gordon Bell Prize Finalist
• AWP-ODC, finalist for 2010 Gordon Bell Prize• Initial two-sided overlap designs using Isend/Irecv improved
elapsed-time on Jaguar by elapsed time on Jaguar by – 21% on 64K cores– 11% at full machine scale
• One-sided designs could not be used because Jaguar does g gnot support MPI-2 one-sided communication yet– Has more potential for performance improvement when this support is
available
19AACEC '10

Collective Communication Primitives with Offload Support
One-to-manyyMulti-send
Multi-receiveMulti receive
Receive-reduce
Other collectives can be Designed with these primitives.
Receive reduce
Receive-replicate
20AACEC '10

Parallel 3 D FFT Application Kernels
• Applications in Direct Numerical Simulations
Parallel 3-D FFT Application Kernels
Applications in Direct Numerical Simulations, Astrophysics , Material Science rely heavily on 3-D FFT kernelsT i h l f (N^3)/P • Transpose operation exchanges a total of (N^3)/P data elements, and is sensitive to network bandwidth
• Takes up to 50% of overall execution time– hard to scale
l l• P3DFFT is a 3-D FFT library developed at the SDSC. Uses a 2D (Pencil) decomposition which improves performance at scalempro s p rformanc at sca
21AACEC '10

Re-Designing P3DFFT with Offloaded g gAlltoall
• Goal: Can we hide the costs associated with the heavy Alltoall operations with collective offload?operations with collective offload?
• Forward and Backward Transform phases operate on independent variables at a time
• We can hide the latency of the transpose phases by • We can hide the latency of the transpose phases by overlapping Alltoall communication with computation of different variables
Alltoall based on Collective Offload - Alltoall based on Collective Offload
22AACEC '10

Alltoall Latency Comparison with 32 Alltoall Latency Comparison with 32 and 64 Processes
Offload Alltoall latency is about 10% better than host-based Alltoall latency for 32 Processes.
23AACEC '10

Overlap Capability of Alltoall Offload
Near Perfect Overlap with Network Offload Alltoall for most medium and large messages with 32 Processes
24AACEC '10

Redesigned Parallel 3D FFT Library Redesigned Parallel 3D FFT Library with Collective Offload Alltoall
Improvement of up to 23% in Application Run-Time with Offload Alltoall with 64 Processes
25AACEC '10

Conclusions and Future WorkConclusions and Future Work
MVAPICH2 lib t k d t f d IB f t • MVAPICH2 library takes advantage of modern IB features for – MPI-2 RMA operations
Loopback intra node communication– Loopback intra-node communication– Collective Offload
• Applications like AWP-ODC can be co-designed with MPI-2 RMA operations and loopback intra-node communication to RMA operations and loopback intra node communication to reduce execution time and provide scalability
• Scientific libraries like P3DFFT can be co-designed with the MPI library with offload capabilityMPI library with offload capability
• Carrying out scalability studies with offload on a larger-scale cluster
• Collective offload support will be available in upcoming • Collective offload support will be available in upcoming MVAPICH2 release
26AACEC '10

Web Pointers
http://www.cse.ohio-state.edu/~pandahttp://nowlab.cse.ohio-state.edu
MVAPICH Web PageMVAPICH Web Pagehttp://mvapich.cse.ohio-state.edu
AACEC '10 27