colloquim report - rotto link web crawler
DESCRIPTION
A report of project named "Rotto Link Web Crawler" .This crawler is to find the list of all broken links in your website.TRANSCRIPT

Rotto Link Web Crawler Summer Internship Report
Submitted By
Akshay Pratap Singh 2011ECS01
Under the Guidance of Mr. Saurabh Kumar Senior Developer
Ophio Computer Solutions Pvt. Ltd.
in partial fulfillment of Summer Internship for the award of the degree of
Bachelor of Technology in
Computer Science & Engineering
SHRI MATA VAISHNO DEVI UNIVERSITY KATRA, JAMMU & KASHMIR
JUNEJULY 2014

UNDERTAKING
I hereby certify that the Colloquium Report entitled “Rotto Link Web Crawler”, submitted in
the partial fulfillment of the requirements for the award of Bachelor of Technology in Computer
Science And Engineering to the School of Computer Science & Engineering of Shri Mata
Vaishno Devi University, Katra, J&K is an authentic record of my own study carried out during
a period from JuneJuly, 2014.
The matter presented in this report has not been submitted by me for the award of any other
degree elsewhere. The content of the report does not violate any copyright and due credit is
given in to the source of information if any.
Name : Akshay Pratap Singh
Entry Number : 2011ECS01
Place : SMVDU, Katra
Date: 1 December 2014

Certificate

About the Company
Ophio is a private company where passionate, dedicated programmers and creative designers team develop outstanding services and applications for Web, iPhone, iPad, Android and the Mac. Their approach is simple, they take well designed products make them function beautifully. Specializing in the creation of unique, immersive and stunning web and mobile applications, videos and animations. At Ophio, they literally make digital dreams, reality. The Ophio team are a core group of skilled development experts, allowing us to bring projects to life, adding an extra dimension of interactivity into all our work. Whether it be responsive builds, CMS sites, microsites or full eCommerce systems, they have the team to create superb products. With launch of iPhone 5 and opening of 3G spectrum in asian countries, there is huge demand for iPhones. They help others product owner reach out to your customers with creative & interactive applications built by our team of experts. Future lies in the open source. Android platform is a robust opening system meant for rapid development, developers at Ophio exploit it to full and build content rich application for your mobile device. Ophio is comprising of 20 members team, out of which 16 are developers, 2 are motion designers and 2 are QA Analyst. Team is best defined as youthful, ambitious, amiable and passionate. Delivering high quality work on time, bringing value to the project and our clients.

Table of Contents
1. Abstract 2. Project Description
2.1 Web Crawler 2.2 Rotto Link Web Crawler 2.3 BackEnd
2.3.1 Web Api 2.3.2 Crawler Module
2.3.2.1 GRequests 2.3.2.2 BeautifulSoup 2.3.2.3 NLTK 2.3.2.4 SqlAlchemy 2.3.2.5 Redis 2.3.2.6 LogBook 2.3.2.2 Smtp
2.4 FrontEnd 2.5 Screenshots of Application
3. Scope 4. Conclusion

Abstract Rotto(a.k.a Broken) link web crawler is an application tool to extract the broken link (i.e dead links) within a complete website. This application takes a seed link, a link of a website to be crawl, and visits every page of a website and search for broken links. As the crawler visits these URLs, it identifies all the hyperlinks in the page and adds the nonbroken hyperlinks to the list of URLs to visit, called the crawl frontier (i.e Worker Queue).And, broken links are added into the database alongwith the matched keywords in the content of a webpage. This process continues untill site crawl completey. This application follow REST architecture to design its web API. Web API take a target/seed url and set of keywords to be searched in a page having broken hyperlinks and return a result containing a set of link of pages having broken hyperlinks. Web API has two endpoints, which performs two actions :
● An HTTP GET request containing a seed/target url and a array of keywords in an JSON form.This returns a user a JOB ID which can be used to get the results.
● An HTTP GET request containing a jobId .This returns a result as a set of pages matched a keywords sent by earlier request and also having a broken links.
All request and response are in JSON form. Application uses two Reddis workers for dispatching websites from database those are pending to a worker queue and crawling websites in queue. As the crawler visits all pages of website and stores all result in database with their respective JOB ID. Application is using sqlite engine. Database implements SqlAlchemy for doing database events. For UI purpose, Application interface is designed using AngularJS framework.

Project Description
2.1 Web Crawler
A Web crawler starts with a list of URLs to visit, called the seeds. As the crawler visits these
URLs, it identifies all the hyperlinks in the page and adds them to the list of URLs to visit, called
the crawl frontier. URLs from the frontier are recursively visited according to a set of policies. If
the crawler is performing archiving of websites it copies and saves the information as it goes.
Such archives are usually stored such that they can be viewed, read and navigated as they were
on the live web, but are preserved as ‘snapshots'.
The large volume implies that the crawler can only download a limited number of the Web pages
within a given time, so it needs to prioritize its downloads. The high rate of change implies that
the pages might have already been updated or even deleted.
Fig. A sequence flow of a web crawler

2.2 Rotto Link Web Crawler
Rotto(a.k.a Broken) link web crawler extracts the broken link (i.e dead links) within a complete website. This application takes a seed link, a link of a website to be crawl, and visits every page of a website and search for broken links. As the crawler visits these URLs, it identifies all the hyperlinks in the web page and these hyperlinks are distributed into two parts :
● internal links(i.e refer to internal site web page) and, ● external links(i.e refer to outside site web page)
Then , all hyperlinks are checked by requesting header and checks that is hyperlink return 404 error or not. Here, HTTP Error Code 404 considered as broken. All internal nonbroken hyperlinks are pushed into the list of URLs to visit, called the crawl frontier (i.e Worker Queue). A content of web page is also extracted and cleaned it to process and search the keywords in a content within the keywords given by user.For searching/matching a keyword out of web page content, a very popular algorithm is implements named as AhoCorasick String Matching Algorithm. “ Aho–Corasick string matching algorithm is a string searching algorithm invented by Alfred V. Aho and Margaret J. Corasick. It is a kind of dictionarymatching algorithm that locates elements of a finite set of strings (the "dictionary") within an input text. It matches all patterns simultaneously. The complexity of the algorithm is linear in the length of the patterns plus the length of the searched text plus the number of output matches.” A separate python module is written for implementing this algorithm in this application.This module has a class named as AhoCorasick, and have methods to search a list of keywords in a text .So, this module is used by crawler to search/match a keywords from a web page content.If If the broken links are found in the page then matched keywords alongwith list of all broken links are stored in the database. This whole process iteratively follow above sequence flow untill all the web pages in the worker queue is processed. This application is primarily divided into two parts : Backend section that deals with crawling and frontend section that provides data set for crawling.

Fig. A Flowchart of a Crawler
2.3 Back End Backend of the application is designed on Flask Python Microframework.
Flask is a lightweight web application framework written in Python and based on the WSGI
toolkit and Jinja2 template engine. It is BSD licensed.
Flask takes the flexible Python programming language and provides a simple template for web
development. Once imported into Python, Flask can be used to save time building web
applications. An example of an application that is powered by the Flask framework is the
community web page for Flask.

Back end of an application further consist two parts, REST web API and crawler modules.
● WEB API act an interface between Frontend and backend of an application.
● Crawler modules consists of whole works like dispatching, scraping, storing data,
mailing.
2.3.1 WEB API
An application web api conforms REST standard and has two main endpoints, one for taking
input the request of a website to be crawled and other one , for returning result on requesting by
input job id.Web API only accepts a HTTP JSON request and responds with a JSON object as
output.
The detailed description of these two endpoints are as follows:
● /api/v1.0/crawl/ Takes input a three fields i.e seed url of website, a array of keywords,
and a emailid of an user in JSON object.Returns an JSON object containing serialized
Website class object having fields like website/job id, status etc.
Example of HTTP GET request:
Example of HTTP GET Response:

● /api/v1.0/crawl/<website/jobid> Takes an input a website/job id as prepended in the
endpoint.Returns an JSON object containing an Website class model object .This object
contains many fields related to website as described above. Results are return as a field of
object as an array of hyperlinks of web pages contains broken links , a list of all broken
links are returns alongwith these pages and the a set of keywords matched on a particular
web page out of entered keywords by the user.
Example of HTTP GET Response:

Web Api also returns an decriptive HTTP Errors in response headers alongwith a message containing error :
● HTTP Error Code 500 : Internal server error ● HTTP Error Code 405 : Method not allowed ● HTTP Error Code 400 : Bad Request ● HTTP Error Code 404 : Not Found
Example of HTTP Error Response:
2.3.2 Crawler Module Crawler module is the heart of this application which performs several vital process like Dispatching set of websites from the database to worker queue, crawling a webpage popped from worker queue, store data into database and mail back the result link to the user. In implementing the web crawler, several python packages are used to extracting, manipulating the web pages. The list of python packages which are used in this application are as follows:
● GRequest to fetch a content of a web page by giving input as a url of web page. ● BeautifulSoup to extract the plain text and links from contents of web page ● Nltk to convert the utf8 text into plain text. ● SqlAlchemy an ORM (Object Relational Mapper) for database intensive tasks. ● Redis for implementing workers to spawn a crawling process from worker queue. ● LogBook for logging of an application. ● Smtp Python mailing module for sending mail.
2.3.2.1 GRequest GRequests allows you to use Requests with Gevent to make asynchronous HTTP Requests easily.

2.3.2.2 BeautifulSoup Beautiful Soup sits atop an HTML or XML parser, providing Pythonic idioms for iterating, searching, and modifying the parse tree.

2.3.2.3 NLTK NLTK is a leading platform for building Python programs to work with human language data. It provides easytouse interfaces to over 50 corpora and lexical resources such asWordNet, along with a suite of text processing libraries for classification, tokenization, stemming, tagging, parsing, and semantic reasoning.
2.3.2.4 SqlAlchemy SQLAlchemy is the Python SQL toolkit and Object Relational Mapper that gives application
developers the full power and flexibility of SQL.
It provides a full suite of well known enterpriselevel persistence patterns, designed for efficient and
highperforming database access, adapted into a simple and Pythonic domain language.
There are two class model which are used for storing data related to user and websites results.
● Website Class Model: List of fields related to website results.
○ id : Unique id of website.
○ url : root url of website
○ last_time_crawled : time stamp of last crawled.
○ status : status of website
○ keywords : keywords to be searched in webpage
○ result : result of website in json form
○ userid : id of a user who requested crawling process of this website

● User Class Model: List of fields related to user.
○ id : unique id of user.
○ email_id : Mail id of user where result will be mailed.
○ websites : users requested website.
2.3.2.5 Reddis RQ (Redis Queue) is a simple Python library for queueing jobs and processing them in the background with workers. It is backed by Redis and it is designed to have a low barrier to entry. It should be integrated in your web stack easily. This application uses two reddis worker.
● DISPATCHER Dispatcher is a worker which pops out five websites to be crawled from the database and pushed into the worker queue.

● CRAWLER Crawler is a worker which pops a web hyperlink from a worker queue and process the page, extract the broken links, enqueue new hyperlinks to be crawl into the worker queue, insert the result into the database and mail a link back to the user to access the result.

2.3.2.6 LogBook Logbook is based on the concept of loggers that are extensible by the application.Each logger and
handler, as well as other parts of the system, may inject additional information into the logging record
that improves the usefulness of log entries.
It also supports the ability to inject additional information for all logging calls happening in a specific
thread or for the whole application. For example, this makes it possible for a web application to add
requestspecific information to each log record such as remote address, request URL, HTTP method
and more.

The logging system is (besides the stack) stateless and makes unit testing it very simple. If context
managers are used, it is impossible to corrupt the stack, so each test can easily hook in custom log
handlers.
2.3.2.7 SMTP The smtplib module defines an SMTP client session object that can be used to send mail to any Internet machine with an SMTP or ESMTP listener daemon.

2.4. FrontEnd For Application User Interface more interacting, AngularJS Front end framework is used. HTML is great for declaring static documents, but it falters when we try to use it for declaring dynamic views in webapplications. AngularJS lets you extend HTML vocabulary for your application. The resulting environment is extraordinarily expressive, readable, and quick to develop. AngularJS is a toolset for building the framework most suited to your application development. It is fully extensible and works well with other libraries. Every feature can be modified or replaced to suit your unique development workflow and feature needs. UI of Application takes input in 3 stages :
● Target Website URL : Contains Valid Hyperlink to be crawled. ● Keywords : Keywords to be searched on pages contains dead links. ● User Mail : Mail id of user to mail back the result link after crawling done.
This UI application make a HTTP GET request to the backend web API on submitting the form by user. The request contains above described three input fields and their respected value in a JSON form.
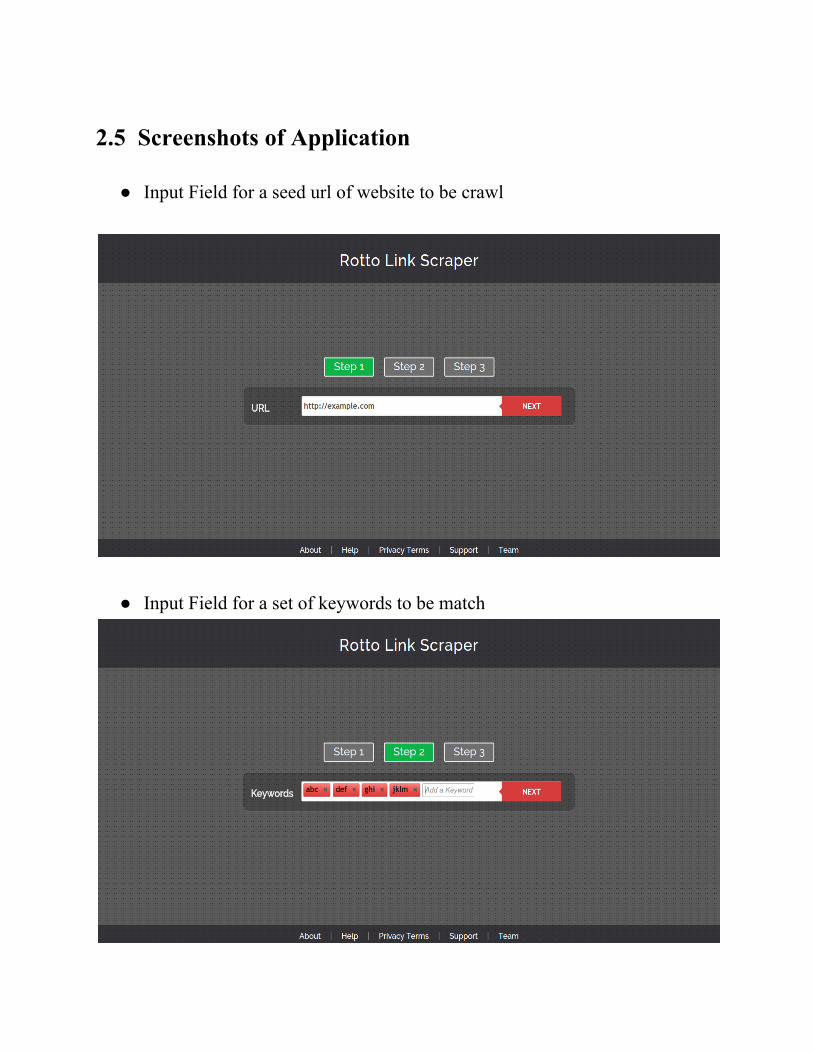
2.5 Screenshots of Application
● Input Field for a seed url of website to be crawl
● Input Field for a set of keywords to be match

● Input Field for a emailid of user as result hyperlink is to be sent to this email on completing crawling
● Confirm Details and Submit Request Page

● Result Page shows the list of hyperlinks of pages contains broken links and also show the broken links and set of keywords matched in a page in a nested form.

Scope
Hidden Web data integration is a major challenge nowadays. Because of autonomous and heterogeneous nature of hidden web content, traditional search engine has now become an ineffective way to search this kind of data. They can neither integrate the data nor they can query the hidden web sites. Hidden Web data needs syntactic and semantic matching to achieve fully automatic integration. Rotto Web Crawler can be widely used in the web industry to search for links and contents. Many companies have a heavy website like news, blogging, Educational sites, Government sites etc. They add large number of pages and hyperlinks refer to internal links or to other websites daily. Old Content in these sites are never reviewed by the admin to check for correctness. As the time pass by, the url mentioned in pages turns into dead link and it never notified to admin. Here Application like this can be very useful for searching broken links in their website and this is helpful for the admin of the site in maintaining with less flaw contents. Application search keywords service helps owner of the site to find an article around which links are broken. This helps owner to maintain pages related to specific topic errorless. This crawler enhances overall user experience and robustness of web platform.

Conclusion
During the project development, We studied Web crawling at many different levels. Our main objectives were to develop a model for Web crawling, to study crawling strategies and to build a Web crawler implementing them. In this work, various challenges in the area of Hidden web data extraction and their possible solutions have been discussed. Although this system extracts, collects and integrates the data from various websites successfully, this work could be extended in near future. In this work, a search crawler has been created which was tested on a particular domain i.e ( text and hyperlinks). This work could be extended for other domains by integrating this work with the unified search interface.