combinatoria 1 principios b¶asicos - universidad nacional ... de clase/completo.pdf · ... (de...
TRANSCRIPT

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 1
Combinatoria
1 Principios basicos
La combinatoria es una disciplina que se ocupa de estudiar tecnicas de conteo y enumeracion deconjuntos, en especial cuando la cantidad de elementos que poseen es muy grande (de modo que unalista extensiva serıa imposible o impractica). Aplicada a la teorıa de probabilidades permite en muchoscasos determinar la cantidad de elementos de un espacio muestral finito y la cantidad de elementos dealgun evento de interes.Presentamos dos reglas basicas de la combinatoria:
Principio de la multiplicacionSupongamos que un experimento consta de dos etapas. Si como resultado de la primera etapa puedendarse n resultados posibles y si, independientemente del resultado particular de la primera etapa, lasegunda etapa puede dar lugar a m resultados posibles, entonces la cantidad de posibles resultadosdel experimento es n · mEl principio se extiende de manera natural a un experimento en r etapas, donde la i-esima etapatiene una cantidad ni de posibles resultados (independientemente de los resultados particularesde las etapas anteriores), donde i = 1, 2, · · · , r. Entonces la cantidad de posibles resultados del
experimento esr∏
i=1
ni
Ejemplo: Una caja contiene 5 cartas distintas de una baraja espanola. Se extraen dos cartas al azar.Si se realiza la extraccion con reposicion ¿De cuantas maneras distintas es posible realizarlo? Rta: 5·5 = 25 maneras distintas.Si se realiza la extraccion sin reposicion ¿De cuantas maneras distintas es posible realizarlo? Rta: 5 ·4 = 20 maneras distintas.
Principio de la adicionUn experimento puede llevarse a cabo de dos formas. Cuando se lo realiza de una forma conducea n resultados posibles. Cuando se lo realiza de la otra forma conduce a m resultados posibles.Entonces eligiendo una u otra forma para realizarlo, el experimento da lugar a n + m resultadosposibles.El principio de la adicion tambien se generaliza a un experimento que se realiza de una entre r manerasposibles, siendo ni la cantidad de posibles resultados cuando se lo realiza de la i-esima forma, donde
i = 1, 2, · · · , r. Entonces la cantidad de posibles resultados del experimento esr∑
i=1
ni
Ejemplo: Para viajar de Buenos Aires a San Pablo se puede optar por tres companıas aereas o porcinco empresas de omnibus ¿Cuantas maneras diferentes existen para contratar el viaje? Rta: 3 +5 = 8 maneras distintas.
2 Variaciones
Se tienen n objetos diferentes y se quiere ordenar k de ellos en fila, siendo k ≤ n. Cada posibleordenamiento se denomina una variacion de los n objetos tomados de a k. Para calcular la cantidadtotal de variaciones utilizamos el principio de la multiplicacion: Para el primer lugar de la fila hayn posibles maneras de llenarlo con un objeto. Independientemente de cual sea el objeto que ocupeel primero lugar, para llenar el segundo lugar de la fila disponemos ahora de n − 1 objetos dado queuno de los objetos ya fue utilizado para cubrir el primer lugar. Independientemente de cuales hayansido los objetos que llenan los dos primeros lugares de la fila, para cubrir el tercer lugar disponemos den − 2 objetos pues dos ya han sido utilizados. Ası sicesivamente de modo que aplicando el principio
Prof.J.Gaston Argeri 1

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 2
de la multiplicacion, la cantidad total de posibles variaciones de n tomados de a k resulta ser:
(n)k = n · (n − 1) · (n − 2) · · · · · [n − (k − 1)] =n!
(n − k)!
Ejemplo: En un club se postulan cinco miembros, digamos A,B,C,D y E, para ocupar las posiciones depresidente y secretario. Para identificar todas las posibles maneras de elegir entre ellos un presidentey un secretario, formamos las variaciones de 5 tomadas de a 2. En este caso la ”fila” tiene en primerlugar al presidente y en segundo lugar al secretario. El listado de las 5 · 4 = 20 variaciones es elsiguiente:
AB AC AD AEBA BC BD BECA CB CD CEDA DB DC DEEA EB EC ED
3 Permutaciones
Un caso particular de variaciones de n objetos tomados de a k se presenta cuando k = n. En talcaso las variaciones reciben el nombre de permutaciones de n objetos y corresponden a las diferentesmaneras de ordenar en fila n objetos diferentes. La cantidad de permutaciones de n objetos resultaentonces ser:
n · (n − 1) · (n − 2) · · · · · [n − (n − 1)] = n!
Ejemplo: La cantidad de numeros de cuatro cifras que pueden formarse a partir de los dıgitos3, 5, 6, 8 sin repetir ninguno de ellos resulta ser 4! = 24. Damos un listado de dichos numeros:
3568 5368 5638 56833586 5386 5836 58633658 6358 6538 65833685 6385 6835 68533856 8356 8536 85633865 8365 8635 8653
4 Combinaciones
Dados n objetos diferentes, cada conjunto formado por k de los n elementos se dice una combinacionde los n elementos tomados de a k. La diferencia entre variaciones y combinaciones reside en el hechoque las combinaciones no tienen en cuenta el orden relativo entre los elementos (ya no podemos pensaren un ”fila”). Por ejemplo, si se tienen cuatro objetos A,B,C y D las posibles combinaciones de a 2son:
AB AC ADBC BDCD
Comparese esto con las posibles variaciones de 4 tomados de a 2:
AB BA AC CA AD DABC CB BD DBCD DC
Para determinar la cantidad de combinaciones de n tomados de a k procedemos de modo indirecto delmodo siguiente: Anotemos provisoriamente x a dicha cantidad. Para una dada combinacion existenk! maneras diferentes de ordenar sus elementos en una fila. Ademas, combinaciones diferentes daran
Prof.J.Gaston Argeri 2

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 3
lugar a filas con diferentes configuraciones, dado que diferiran en al menos uno de los objetos presentes.De esta manera, tomando todas las posibles combinaciones y ordenando en fila los k objetos en cadauna de ellas, obtendremos la totalidad de posibles ordenamientos en fila de k de los n objetos, esdecir la totalidad de variaciones de n tomados de a k. Por lo tanto: x · k! = n!
(n−k)!
Despejando x resulta que la cantidad de posibles combinaciones de n objetos tomados de a k,numero que representaremos con el sımbolo
(nk
)es:
(n
k
)
=n!
k!(n − k)!
Este numero se denomina numero combinatorio n sobre k.En el ejemplo precedente n = 4 , k = 2 de modo que la cantidad de posibles combinaciones es(42
)= 4!
2!2!= 4!
4= 3! = 6
Propiedad 1 (n
k
)
=
(n
n − k
)
Dem:La demostracion queda a cargo del lector.
Propiedad 2 (n
j − 1
)
+
(n
j
)
=
(n + 1
j
)
Dem:
( nj−1
)+
(nj
)= n!
(j−1)!(n−j+1)!+ n!
j!(n−j)!=
= n!(j−1)!(n−j)!(n−j+1)
+ n!(j−1)!j(n−j)!
=
= n!(j−1)!(n−j)!
(1
n−j+1+ 1
j
)
=
= n!(j−1)!(n−j)!
· j+n−j+1j(n−j+1)
=
= n!(n+1)(j−1)!j(n−j)!(n+1−j)
= (n+1)!j!(n+1−j)!
=(n+1
j
)
¥
5 Binomio de Newton
Dados numeros a, b ∈ R sabemos que el desarrollo del cuadrado del binomio a + b viene dado por:
(a + b)2 = a2 + 2ab + b2
Podemos reescribir este desarrollo como:
(a + b)2 =
(2
0
)
a0 b2 +
(2
1
)
a1 b1 +
(2
2
)
a2 b0 =2∑
k=0
(2
k
)
ak b2−k
Analogamente para el desarrollo del cubo de un binomio:
(a + b)3 = a3 + 3a2b + 3ab2 + b3
Prof.J.Gaston Argeri 3

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 4
que tambien puede reescribirse como:
(a + b)3 =
(3
0
)
a0 b3 +
(3
1
)
a1 b2 +
(3
2
)
a2 b1 +
(3
3
)
a3b0 =3∑
k=0
(3
k
)
ak b3−k
La formula del binomio de Newton generaliza lo anterior al desarrollo de cualquier potencia naturalde un binomio y se expresa de la siguiente manera.
Teorema 1 (Formula del binomio de Newton)Para cualesquiera numeros a, b ∈ R y cualquier numero n ∈ N se verifica:
(a + b)n =
n∑
k=0
(n
k
)
ak bn−k
Dem:Por induccion respecto de n demostraremos que la proposicion
p(n) : ∀a, b ∈ R, (a + b)n =n∑
k=0
(n
k
)
ak bn−k
es verdadera para todo numero natural n.Paso base: Probemos que p(1) es V.
p(1) : ∀a, b ∈ R, (a + b)1 =1∑
k=0
(1
k
)
ak b1−k
El miembro izquierdo de la igualdad es simplemente a + b. El miembro derecho es:
(1
0
)
a0b1 +
(1
1
)
a1b0 = b + a
de modo que p(1) es verdadera.(HI)Hipotesis inductiva: Supongamos que p(n) es verdadera.Ahora probaremos que necesariamente p(n + 1) es verdadera, bajo el supuesto (HI). Para ello
Prof.J.Gaston Argeri 4

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 5
procedemos ası:
(a + b)n+1 = (a + b)(a + b)n = (a + b)n∑
k=0
(nk
)akbn−k =
= an∑
k=0
(nk
)akbn−k + b
n∑
k=0
(nk
)akbn−k =
=n∑
k=0
(nk
)ak+1bn−k +
n∑
k=0
(nk
)akbn−k+1 =
=n+1∑
j=1
( nj−1
)ajbn−j+1 +
n∑
j=0
(nj
)ajbn−j+1 =
=(nn
)an+1 +
n∑
j=1
( nj−1
)ajbn−j+1 +
(n0
)bn+1 +
n∑
j=1
(nj
)ajbn−j+1 =
=(n0
)bn+1 +
n∑
j=1
[( nj−1
)+
(nj
)]
ajbn−j+1
+(nn
)an+1 =
=(n0
)bn+1 +
n∑
j=1
(n+1j
)ajbn−j+1 +
(nn
)an+1 =
=(n+1
0
)a0bn+1 +
n∑
j=1
(n+1j
)ajbn−j+1 +
(n+1n+1
)an+1b0 =
=n+1∑
j=0
(n+1j
)ajbn+1−j
que muestra que p(n + 1) es verdadera. Luego, por induccion completa p(n) es verdadera paratodo n ∈ N ¥
6 Permutaciones con repeticion
Supongamos que queremos determinar cuantas palabras de cuatro letras pueden formarse con las le-tras de la palabra AZAR. Aquı entendemos por ”palabra” cualquier secuencia que utilice las cuatroletras de AZAR, tenga o no significado en algun lenguaje. Para averiguar cuantas pueden formarse,digamos x (a determinar), consideremos el siguiente razonamiento: Si bien la palabra AZAR poseesolo tres letras diferentes, a saber A,Z,R, momentaneamente distingamos las dos apariciones de laletra A, por ejemplo podrıamos ”pintar” de dos colores diferentes las dos letras A. En tal caso yasabemos que la cantidad de posibles ordenamientos de las cuatro letras distintas es 4!. Ahora bien,cada ordenamiento de los x (que no distinguen entre ambas A) da lugar de manera natural a 2!ordenamientos (que sı distinguen entre ambas A), por simple permutacion de las dos letras A entresı. Por lo tanto podemos afirmar que: x · 2! = 4! Se deduce que: x = 4!
2!El mismo tipo de razonamiento se generaliza cuando hay varias letras (objetos) repetidas. For-malmente: Si se tienen r objetos diferentes de los cuales se va a repetir el primero n1 veces,el segundo n2 veces, · · · , el r-esimo nr veces, la cantidad total de configuraciones en fila den = n1 + · · · + nr objetos con las repeticiones especificadas anteriormente es:
(n1 + n2 + · · · + nr)!
n1! n2! · · · nr!
Prof.J.Gaston Argeri 5

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 6
El numero anterior se denomina coeficiente multinomial y suele anotarse tambien como
(n
n1, n2, · · · , nr
)
=(n1 + n2 + · · · + nr)!
n1! n2! · · · nr!
Por ejemplo, con las letras de la palabra AZAR pueden formarse 4!2!
= 12 palabras diferentes. Paraconvencernos las listamos todas:
AZAR AZRA AAZRAARZ ARZA ARAZZAAR ZARA ZRAARAAZ RAZA RZAA
Teorema 2 (Teorema multinomial) Para cualesquiera numeros x1, x2, · · · , xr ∈ R y cualquiernumero n ∈ N se verifica
(x1 + x2 + · · · + xr)n =
∑
0≤k1,··· ,kr≤nk1+···+kr=n
(n
k1, · · · , kr
)
xk11 · · · xkr
r
7 Distribucion de bolillas en urnas
Diversos problemas de ındole combinatorio pueden representarse mediante problemas ”modelo” basa-dos en disposiciones de bolillas en urnas.
7.1 Disposiciones de n bolillas distintas en r urnas distintas
7.1.1 Mas de una bolilla es admisible por urna
En este caso simplemente se trata de un experimento en n etapas: La primera etapa consiste enubicar la primera bolilla en alguna de las r posibles urnas. La segunda etapa consiste en colocar lasegunda bolilla en alguna de las r urnas aun disponibles, etc. De manera que la cantidad de posiblesdisposiciones es en total
r · r · · · r︸ ︷︷ ︸
n
= rn
7.1.2 A lo sumo una bolilla es admisible por urna
Este caso exige que n ≤ r. Para la primera bolilla hay r posibles urnas donde ubicarla, para lasegunda bolilla hay solo r − 1 urnas vacıas para ubicarla, para la tercer bolilla hay solo r − 2 urnasvacıas disponibles, etc. De modo que la cantidad total de posibles disposiciones es r · (r − 1) · (r −2) · · · [r − (n − 1)] es decir igual al numero de variaciones de r tomados de a n.
7.2 Disposiciones de n bolillas identicas en r urnas distintas
7.2.1 No pueden quedar urnas vacıas
En este caso debe ser n ≥ r pues de lo contrario necesariamente quedarıan urnas vacıas. Podemosasimilar este problema de combinatoria representando las bolillas indistinguibles por asteriscos ”∗” ylas separaciones entre urnas mediante barras ”|” Ası por ejemplo una configuracion con tres urnas ycinco bolillas podrıa representarse por: ∗ ∗ | ∗ | ∗ ∗ Esto quiere simbolizar de algun modo que en laprimera urna hay exactamente dos bolillas, en la segunda urna exactamente una bolilla y en la terceraurna exactamente dos bolillas.Si disponemos las bolillas en una hilera, ubicar las n bolillas identicas en las r urnas diferentesequivale a ubicar r − 1 separadores ”|” en los n − 1 espacios entre bolillas consecutivas. Esto
Prof.J.Gaston Argeri 6

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 7
puede realizarse de(n−1
r−1
)maneras distintas.
Ejemplo: Distribuir seis bolillas identicas en tres urnas diferentes, sin permitir urnas vacıas. Listamoslas posibilidades:
∗| ∗ | ∗ ∗ ∗ ∗ ∗| ∗ ∗| ∗ ∗∗ ∗| ∗ ∗ ∗ | ∗ ∗ ∗| ∗ ∗ ∗ ∗|∗ ∗ ∗ | ∗ | ∗ ∗∗∗ ∗ | ∗ ∗| ∗ ∗ ∗ ∗ | ∗ ∗ ∗ |∗ ∗ ∗ ∗| ∗ | ∗ ∗ ∗ ∗ ∗| ∗ ∗|∗ ∗ ∗ ∗ ∗ | ∗ |∗
Ejemplo: Hallar todas las descomposiciones del numero 8 como suma de tres numeros naturales.Considerar que el orden relativo de los tres terminos en la descomposicion es relevante.Se tendran las siguientes posibles descomposiciones:
1|1|111111 1|11|11111 1|111|1111 1|1111|111 1|11111|11 1|111111|1 11|1|111111 + 1 + 6 1 + 2 + 5 1 + 3 + 4 1 + 4 + 3 1 + 5 + 2 1 + 6 + 1 2 + 1 + 511|11|1111 11|111|111 11|1111|11 11|11111|1 111|1|1111 111|11|111 111|111|112 + 2 + 4 2 + 3 + 3 2 + 4 + 2 2 + 5 + 1 3 + 1 + 4 3 + 2 + 3 3 + 3 + 2111|1111|1 1111|1|111 1111|11|11 1111|111|1 11111|1|11 11111|11|1 111111|1|13 + 4 + 1 4 + 1 + 3 4 + 2 + 2 4 + 3 + 1 5 + 1 + 2 5 + 2 + 1 6 + 1 + 1
Es decir un total de(8−13−1
)=
(72
)= 7!
2!5!= 21 descomposiciones.
7.2.2 Pueden quedar urnas vacıas
Tambien aquı podemos pensar en bolillas ∗ y separadores entre urnas |, pero a diferencia de lasituacion previa, en este caso los separadores pueden quedar contiguos, como por ejemplo en la con-figuracion siguiente: ∗ ∗ || ∗ | ∗ ∗ ∗ | que corresponde a n = 6 bolillas identicas en r = 5 urnasdistintas, donde hay 2 bolillas en la primer urna, la segunda urna esta vacıa, 1 bolilla en la tercerurna, 3 bolillas en la cuarta urna y la quinta urna esta vacıa.Se trata pues de disponer en fila n sımbolos ∗ y r − 1 sımbolos | Es decir en un total den + r − 1 lugares. Luego, la cantidad de posibles disposiciones es
(n+r−1n
)=
(n+r−1r−1
)puesto
que basta con elegir los lugares que seran ocupados por ∗ (o equivalentemente elegir los lugares a serocupados por |).Ejemplo: Se desea invertir un capital de $20.000 en cuatro posibilidades de inversion (negocios). Sedesea ademas que las inversion se realice en multiplos de $1.000a) Si se quiere invertir la totalidad del capital, ¿ de cuantas formas diferentes puede realizarse?Si ∗ representa una inversion de $1.000 el problema se asimila al de n = 20 bolillas yr = 4 urnas y donde pueden quedar urnas vacıas (negocios en los cuales se decide no invertirningun monto). Entonces la cantidad total de maneras posibles de invertir el capital de $20.000 es(20+4−1
20
)=
(2320
)= 1.771
b) Si se quiere invertir la totalidad o parte del capital, ¿ de cuantas formas diferentes puede realizarse?El analisis es similar al anterior solo que ahora no es obligatorio invertir todo el capital disponible.Podemos entonces pensar que la parte del capital que se decida no invertir es un ”quinto negocioposible”. De este modo se trata de un problema de disposicion de n = 20 bolillas en r = 5 urnas ydonde no pueden quedar urnas vacıas. Hay un total de
(20+5−120
)=
(2420
)= 10.626 posibles maneras
de invertir el capital (Una de dichas maneras consiste en no invertirlo en absoluto).
Prof.J.Gaston Argeri 7

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 8
Teorıa axiomatica de probabilidades
8 Experimentos aleatorios - Espacio muestral - Eventos
Denominaremos experimento aleatorio a todo proceso (procedimiento, experimento, etc.) que con-duzca a un resultado que cumpla con las siguientes caracterısticas:
• El proceso es repetible en identicas condiciones una cantidad ilimitada de veces. Cada realizacionparticular del proceso conduce a un unico resultado.
• Se conoce a priori (es decir previamente a cualquier realizacion particular) todos los posiblesresultados del experimento.
• El resultado del experimento esta sujeto al azar. Es decir que es imposible determinar a priori(es decir previamente a cualquier realizacion particular) cual de todos los resultados posibles delexperimento ocurrira.
Definicion 1 Llamaremos espacio muestral asociado a un experimento aleatorio a cualquier conjuntoque caracterice todos los posibles resultados de dicho experimento. El espacio muestral frecuentementese anota mediante la letra griega omega mayuscula Ω.
En este contexto caracterizar significa que cada elemento del espacio muestral se corresponde con unoy solo un posible resultado del experimento y a todo posible resultado del experimento le correspondeuno y solo un elemento del espacio muestral. En este sentido podrıamos decir que un espacio muestrales una forma de ”codificar” los posibles resultados del experimento.
Ejemplo:
1) Se arroja un dado una vez y se observa el numero que sale. Claramente es un experimentoaleatorio pues cada realizacion particular conduce a un unico numero saliente (es imposible quearrojemos el dado y salgan simultaneamente dos o mas numeros) y ademas:
• El experimento es reproducible en identicas condiciones una cantidad arbitraria de veces(Al menos una version idealizada del experimento, por ejemplo con un dado imaginario quenunca se desgasta o deforma).
• Antes de arrojar el dado se sabe de antemano que los posibles resultados son los numeros1, 2, 3, 4, 5, 6.
• El resultado del lanzamiento es al azar puesto que es imposible determinar el numero quesaldra, con anterioridad al lanzamiento.
Un espacio muestral asociado a este experimento puede ser Ω = 1, 2, 3, 4, 5, 6
2) Se arroja un dado dos veces y se anota el puntaje total (suma de los numeros obtenidos en amboslanzamientos). En este caso un espacio muestral es Ω = 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12
3) Se arroja un dado hasta obtener por primera vez un 1 y se registra la cantidad de lanzamientosnecesarios. En este ejemplo un espacio muestral es Ω = N
4) Desde una distancia de 3 metros se arroja un dardo a un blanco circular de radio 0, 25 metros.Suponiendo que el dardo da en el blanco, se registra la distancia desde el punto de impacto hastael centro del blanco. En este caso un espacio muestral es Ω = [0 ; 0, 25]
Un conjunto infinito A se dice numerable si sus elementos pueden ponerse en correspondencia 1-1
con los numeros naturales, es decir si existe alguna funcion Nf→ A con las propiedades siguientes:
Prof.J.Gaston Argeri 8

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 9
i) ∀a ∈ A , ∃n ∈ N tal que a = f(n)
ii) ∀m, n ∈ N m 6= n ⇒ f(m) 6= f(n)
En tal caso la funcion f determina una ”enumeracion” de A. Si en lugar de f(n) anotamosan entonces los elementos de A son precisamente los de la secuencia infinita a1, a2, a3, · · · . Esdecir A = a1, a2, a3, · · · . Un conjunto que o bien sea finito o bien sea infinito numerable se diceun conjuto a lo sumo numerable. Si se omite la condicion ii) pero conservando la i), se dice que f esuna funcion suryectiva o sobre A. Se puede demostrar que A es a lo sumo numerable sii existe algunafuncion de N sobre A.
Ejemplo: Mostremos que los siguientes conjuntos infinitos son numerables: N, Z, 2N, Q
• Basta considerarla funcion identidad Nf→ N
• Por ejemplo tomando la funcion Nf→ Z dada por f(n) = (−1)n
[n2
]
• Tomando Nf→ 2N dada por f(n) = 2n
• En este caso es mas engorroso encontrar una formula explıtica para una fucion de N sobre Q.Es mas secillo presentar un grafico ilustrativo de tal funcion:
0
²²1/1 // 1/2
||zzzzzzzz
1/3 // 1/4
||zzzzzzzz
1/5 // · · ·
2/1 // 2/2
<<z
zz
zz
zz
z
2/3
||zzzzzzzz
2/4
<<z
zz
zz
zz
z
2/5
||zzzzzzzz
· · ·
3/1
²²
3/2oo 3/3
<<z
zz
zz
zz
z
3/4
||zzzzzzzz
3/5
==
· · ·
4/1 // 4/2
<<z
zz
zz
zz
z
4/3
||zzzzzzzz
4/4
<<z
zz
zz
zz
z
4/5
||zzzzzzzz
· · ·
5/1
²²
5/2oo 5/3
<<z
zz
zz
zz
z
5/4
5/5
==
· · ·
~~||||||||||
...// ...
==
......
==
...
Vamos a distinguir dos tipos de espacios muestrales de acuerdo a su cardinalidad (es decir su cantidadde elementos):
Ω
Finito o infinito numerable
Infinito no numerable
En los ejemplos 1) y 2) los espacios muestrales considerados son finitos. En el ejemplo 3) el espaciomuestral es infinito numerable. En el ejemplo 4) el espacio muestral es infinito no numerable.Momentaneamente llamaremos evento o suceso a cualquier subconjunto del espacio muestral Ω. Masadelante precisaremos este concepto. Dos eventos de particular interes son el evento Ω (denominadoevento seguro o cierto) y el evento ∅ (denominado evento vacıo o imposible). Los elementos ω ∈ Ω del
Prof.J.Gaston Argeri 9

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 10
espacio muestral dan lugar a los denominados eventos simples, que son los eventos de la forma ω.Todo evento no simple se dice compuesto. Los eventos suelen anotarse empleando las primeras letrasdel alfabeto en mayusculas: A, B, C, D, etc.
Ejemplo:
1) Lanzamiento de un dado. Podemos considerar los siguientes eventos:
A = ”sale numero par” = 2, 4, 6B = ”sale multiplo de tres” = 3, 6C = ”sale 3” = 3 (suceso elemental)
2) Lanzamiento de dos dados. Podemos considerar los siguientes eventos:
A = ”el puntaje total excede 8” = 9, 10, 11, 12B = ”sale un par y un impar” = 3, 5, 7, 9, 11
3) Arrojar una moneda hasta obtener ”cara” por primera vez y registrar la cantidad de lanzamientosque fueron necesarios. Eventos que podrıan interesarnos:
A = ”se requiere a lo sumo 5 lanzamientos” = 1, 2, 3, 4, 5B = ”se requiere una cantidad impar de lanzamientos” = 3, 5, 7, 9, 11, 13, · · ·
3) Lanzamiento del dardo descrito anteriormente. Un evento en el que podemos estar interesadoses A = x ∈ Ω : x ≤ 0, 2
Consideremos un evento A en el contexto de un experimento aleatorio. Supongamos que la realizaciondel experimento conduce a un resultado ω ∈ Ω. Cuando ω ∈ A se dice que el resultado delexperimento es favorable a A o que ha ocurrido A en dicha realizacion. Caso contrario se diceque el resultado ω es desfavorable a A o que no ha ocurrido A en dicha realizacion. Notemosque el hecho de que ocurra cierto evento no quita la posibilidad que ocurran tambien, en la mismarealizacion, otros eventos.
Ejemplo: Un experimento consiste en lanzar una moneda dos veces de modo que
Ω = (C, C), (C, S), (S, C), (S, S)
donde C = ”sale cara” , S = ”sale ceca”, entonces si en determinada realizacion es ω = (C, C) y siA = ”la primera moneda sale cara” = (C, C), (C, S) y B = ”la segunda moneda sale ceca” =(C, C), (S, C), entonces han ocurrido tanto el evento A como el evento B. Es decir que elresultado del experimento ha sido favorable tanto al evento A como al evento B.
9 Algebra de eventos
Sean A, B eventos. A partir de ellos construimos nuevos eventos del modo siguiente:
• El complemento de A es el evento Ac = ω ∈ Ω : ω 6∈ A. Es el evento que ocurre cada vezque no ocurre A. Los resultados favorables a Ac son los desfavorables al A y viceversa. Elcomplemento de A tambien suele anotarse A′.
• La union de A con B es el evento A ∪ B = ω ∈ Ω : ω ∈ A ∨ ω ∈ B. Es el eventoque ocurre cuando al menos uno de los dos sucesos A, B ocurre. Es decir que A ∪ B ocurresii o bien ocurre A pero no ocurre B, o bien ocurre B pero no ocurre A, o bien ocurrensimultaneamente tanto A como B.
Prof.J.Gaston Argeri 10

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 11
• La interseccion de A con B es el evento A ∩ B = ω ∈ Ω : ω ∈ A ∧ ω ∈ B. Esel evento que ocurre cuando A y B ocurren simultaneamente. La interseccion de A conB tambien suele anotarse AB
• La diferencia de A con B es el evento A \ B = ω ∈ Ω : ω ∈ A ∧ ω 6∈ B. Es elevento que ocurre cuando ocurre A y simultaneamente no ocurre B.
Ejemplo: En el ultimo ejemplo se tiene:
Ac = (S, C), (S, S)
A ∪ B = (C, C), (C, S), (S, S)
A ∩ B = (C, S)
A \ B = (C, S) y B \ A = (S, C)
Mas generalmente, sean A1, A2, · · · , An eventos.
• La union de tales eventos es el evento
n⋃
i=1
Ai = A1 ∪ · · · ∪ An = ω ∈ Ω : ω ∈ A1 ∨ · · · ∨ ω ∈ An
• La interseccion de tales eventos es el evento
n⋂
i=1
Ai = A1 ∩ · · · ∩ An = ω ∈ Ω : ω ∈ A1 ∧ · · · ∧ ω ∈ An
Dicha interseccion tambien se anota A1A2 · · · An
Mas generalmente aun necesitaremos definir uniones e intersecciones de una cantidad numerable deeventos: Sea An una sucesion de eventos.
• La union de dichos eventos es el evento que ocurre cuando ocurre al menos uno de los eventosde la sucesion: ∞⋃
n=1
An = ω ∈ Ω : ∃n ∈ N , ω ∈ An
• La interseccion de dichos eventos es el evento que ocurre cuando ocurren simultaneamente todosy cada uno de los eventos de la sucesion:
∞⋂
n=1
An = ω ∈ Ω : ∀n ∈ N , ω ∈ An
Ejemplo: Un experimento aleatorio consistente en arrojar una moneda tantas veces como sea necesariohasta obtener por primera vez ”cara”. Podemos considerar:
Ω = C, SC, SSC, SSSC, SSSSC, · · ·
Consideremos los siguientes eventos: An = ”sale C en el lanzamiento 2n-esimo”En este caso: ∞⋃
n=1
An = ”sale C en una cantidad par de lanzamientos”
Prof.J.Gaston Argeri 11

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 12
Definicion 2 Los eventos A y B se dicen incompatibles o (mutuamente) excluyentes o disjuntossi es imposible que ocurran simultaneamente. Es decir que cada vez que ocurre A no ocurre B ycada vez que ocurre B no ocurre A. Para destacar tal situacion nosotros anotaremos el evento unionA ∪ B como A
⊎B.
Mas generalmente dada una sucesion An de eventos, se dice que dichos eventos son dos a dosincompatibles o (mutuamente) excluyentes o disjuntos dos a dos sii se verifica:
∀m, n ∈ N , m 6= n ⇒ Am ∩ An = ∅
Para destacar tal situacion anotaremos la union∞⋃
n=1An como
⊎∞n=1 An
Dados eventos A, B se dice que A esta contenido o incluido en B o tambien que B contiene oincluye a A sii cada vez que ocurre A tambien ocurre B (pero no necesariamente a la inversa). Talrelacion entre eventos se simboliza A ⊆ B o tambien B ⊇ A. En otras palabras: A ⊆ B sii todoresultado favorable a A es tambien favorable a B. En la practica para demostrar que A ⊆ B esfrecuente tomar un elemento generico (es decir, no un elemento particular) de A y demostrar quenecesariamente tambien pertenece a B. Naturalmente, dos eventos son iguales sii A ⊆ B y B ⊆ A.Por lo tanto una manera de probar la igualdad entre dos eventos consiste en probar que cada uno deellos esta contenido en el otro.Damos a continuacion un listado de propiedades muy sencillas cuyas demostraciones formales omiti-mos:
A ⊆ A
A ⊆ B ∧ B ⊆ C ⇒ A ⊆ C
A ∩ A = A ; A ∪ A = A
A ∪ B = B ∪ A ; A ∩ B = B ∩ A
A ∪ (B ∪ C) = (A ∪ B) ∪ C ; A ∩ (B ∩ C) = (A ∩ B) ∩ C
∅ ⊆ A ⊆ Ω
A ∩ B ⊆ A ⊆ A ∪ B
∅ ∩ A = ∅ ; ∅ ∪ A = A
Ω ∩ A = A ; Ω ∪ A = Ω
(Ac)c = A
(A ∪ B)c = Ac ∩ Bc ; (A ∩ B)c = Ac ∪ Bc
A ∪ B = A ∪ (B \ A)
B = (B ∩ A) ] (B \ A)
A ∪ (B ∩ C) = (A ∪ B) ∩ (A ∪ C) ; A ∩ (B ∪ C) = (A ∩ B) ∪ (A ∩ C)
n⋃
i=1
Ai = A1 ](
n⊎
i=2
Ac1 · · · Ac
n−1An
)
( ∞⋃
n=1An
)c
=∞⋂
n=1Ac
n ;
( ∞⋂
n=1An
)c
=∞⋃
n=1Ac
n
Prof.J.Gaston Argeri 12

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 13
10 Algebras y σ-algebras de subconjuntos de Ω - Espacio de prob-
abilidad
Todos hemos en algun momento realizado mediciones. Como ejemplo concreto supongamos que de-seamos medir areas de rectangulos. Como se sabe, el area de un rectangulo es un numero positivoigual al producto base × altura. Supongamos ahora que construimos figuras planas a partir de unacantidad finita de rectangulos. Podemos asignar un area a cada una de tales figuras del modo sigu-iente: Primero descomponemos la figura en una union finita de rectangulos disjuntos dos a dos yluego sumamos las areas de tales rectangulos. Finalmente, supongamos que todos los rectangulosque consideramos estan contenidos dentro de un ”gran” rectangulo que llamamos Ω. Cada vez quepodamos medir el area de cierta figura contenida en Ω tambien podremos medir el area de la ”figuracomplementaria”, es decir la figura que se obtiene a partir de todos los puntos de Ω que no pertenecena la figura original. En otros terminos, si podemos medir el area de una figura tambien podemos medirel area de su complemento. Queda tambien claro que si hemos podido asignar un area A(F ) a lafigura F ⊆ Ω entonces tendremos A(F c) = A(Ω) − A(F ). Es decir que hay una cantidad depropiedades basicas que esperamos de todo numero que represente una manera de medir. Para reflejarestas propiedades elementales es necesario determinar una cierta clase de conjuntos, que podrıamosdenominar ”medibles” que seran precisamente aquellos a los cuales asignaremos una medida. Ennuestro ejemplo precedente, no queda claro en absoluto como podrıamos medir el area de un cırculocontenido en Ω, pero sı podremos asignar areas de modo sencillo tomando como conjuntos medibles laclase de todos los subconjuntos de Ω que sean o bien rectangulos, o bien uniones finitas de rectanguloso bien sus complementos sean uniones finitas de rectangulos. Una clase de subconjuntos de Ω conestas caracterısticas es lo que denominaremos un algebra de subconjuntos de Ω.
Definicion 3 Dados un conjunto no vacıo Ω y una clase A de subconjuntos de Ω, diremos queA es un algebra de subconjuntos de Ω sii satisface las siguiente condiciones:
i) Ω ∈ Aii) ∀A ∈ A , Ac ∈ A
iii) ∀n ∈ N , ∀A1, · · · , An ∈ A ,n⋃
i=1
Ai ∈ A
Ejemplo: Sea Ω cualquier rectangulo no vacıo. Definamos, como vimos anteriormente, la siguienteclase de subconjuntos de Ω:
A = A ⊆ Ω : A es union finita de rectangulosVeamos que A tiene las propiedades de un algebra de subconjuntos de Ω:
i) Ω ∈ A pues Ω es union finita de rectangulos ya que es un rectangulo.
ii) Supongamos que A ∈ A. Queremos ver que Ac es tambien union finita de rectangulos.En primer lugar notemos que si R ⊆ Ω es un rectangulo entonces Rc = Ω \ R es union finitade rectangulos (Esto le resultara evidente cuando dibuje el gran rectangulo Ω y un rectanguloarbitrario R contenido en el).
Ademas, si B =n⋃
i=1
Ri y C =m⋃
j=1
R∗j son uniones finitas de rectangulos entonces:
B ∩ C =⋃
1≤i≤n1≤j≤m
(
Ri ∩ R∗j
)
de modo que B ∩ C es union finita de rectangulos (notar que Ri ∩ R∗j es un rectangulo).
Esto se extiende a la interseccion de un numero finito de uniones finitas de rectangulos. Por lo
Prof.J.Gaston Argeri 13

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 14
tanto podemos afirmar que la interseccion de un numero finito de miembros de A es tambienmiembro de A.
Como A ∈ A podemos escribir A =n⋃
i=1
Ri donde los Ri son ciertos subrectangulos de Ω.
Entonces:
Ac =
(n⋃
i=1
Ri
)c
=n⋂
i=1
Rci
y dado que los Rci son uniones finitas de rectangulos, la interseccion de ellos tambien lo es. Por
lo tanto Ac es union finita de rectangulos de modo que Ac ∈ A.
iii) Fijemos n ∈ N y sean A1, · · · , An ∈ A. Sabemos que cada Ai es union finita de rectangulos.
Pero entonces evidentemente A =n⋃
i=1
Ai tambien es union finita de rectangulos, de donde re-
sulta que A ∈ A.
Consideremos ahora un ejemplo que nos servira para generalizar la definicion de algebra de subcon-juntos de Ω.
Ejemplo: Supongamos que se tiene una secuencia Rn de rectangulos contenidos en el granrectangulo Ω. Mas aun, supongamos que los Rn son disjuntos dos a dos. Parece intuitivamente
claro que tambien se le puede asignar un area al conjunto∞⊎
n=1Rn, de la manera siguiente:
Cada Rn tiene asignada un area A(Rn)
Podemos asignar area al conjunto R1 ] R2 como A(R1 ] R2) = A(R1) + A(R2)
Podemos asignar area al conjunto R1]R2]R3 como A(R1]R2]R3) = A(R1)+A(R2)+A(R3)
etc. En genral: A
(n⊎
i=1
Ri
)
=n∑
i=1
A(Ri)
De este modo vemos como asignar un area al conjunto Sn =n⊎
i=1
Ri, cualquiera sea n ∈ N. Natu-
ralmente los numeros A(S1), A(S2), A(S3), · · · forman una sucesion creciente de numeros realespositivos. Ademas, dado que todos los Sn ⊆ Ω resulta A(Sn) ≤ A(Ω). Un resultado matematicoasegura que toda sucesion de numeros reales que sea creciente y acotada superiormente, posee unlımite finito. Por lo tanto existe y es finito el numero:
limn →∞
A(Sn)
Resulta entonces natural definir
A
( ∞⊎
n=1Rn
)
= limn →∞
A
(n⊎
i=1
Ri
)
= limn →∞
A(Sn) =
= limn →∞
n∑
i=1
A(Ri) =∞∑
n=1A(Rn)
Este ejemplo muestra que podemos ampliar la definicion de algebra de conjuntos para permitir queno solo las uniones finitas de conjuntos medibles sean medibles, sino tambien las uniones infinitasnumerables. Esto conduce a la definicion siguiente.
Prof.J.Gaston Argeri 14

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 15
Definicion 4 Una clase Σ de subconjuntos de un conjunto no vacıo Ω se dice una σ-algebra desubconjuntos de Ω sii verifica las siguientes condiciones:
i) Ω ∈ Σ
ii) ∀A ∈ Σ , Ac ∈ Σ
iii) ∀ An sucesion en Σ ,∞⋃
n=1An ∈ Σ
Ejemplo: Consideremos un conjunto no vacıo Ω. La clase que consta de todos los subconjuntos deΩ se denomina el conjunto de ”partes” de Ω y se suele anotar P(Ω). Claramente es una σ-algebrade subconjuntos de Ω. De hecho es la mas grande de todas.
Propiedad 3 Sea Σ una σ-algebra de subconjuntos de Ω. Entonces ∅ ∈ Σ
Dem:Puesto que Ω ∈ Σ resulta ∅ = Ωc ∈ Σ ¥
Propiedad 4 Sea Σ una σ-algebra de subconjuntos de Ω. Supongamos que Ω es finito o infinitonumerable. Se verifica:
∀ω ∈ Ω , ω ∈ Σ ⇒ Σ = P(Ω)
Dem:Sea A ⊆ Ω. Puesto que Ω es finito o infinito numerable, lo mismo es cierto de A. Dado que:A =
⋃
ω∈A
ω resulta inmediatamente que A ∈ Σ puesto que la union anterior es a lo sumo
numerable y cada ω pertenece a Σ ¥
Propiedad 5 Sea Σ una σ-algebra de subconjuntos de Ω y sean A1, · · · , An ∈ Σ. Entoncesn⋃
i=1
Ai ∈ Σ
Dem:Definamos An+1 = An+2 = · · · = ∅. Entonces la secesion Ai esta en Σ. Se tiene pues:
n⋃
i=1
Ai =∞⋃
i=1
Ai ∈ Σ ¥
Propiedad 6 Sea Σ una σ-algebra de subconjuntos de Ω y sea An una sucesion en Σ.
Entonces∞⋂
n=1An ∈ Σ
Dem:∞⋂
n=1
An =
( ∞⋃
n=1
Acn
)c
∈ Σ dado que cada Acn ∈ Σ ¥
Propiedad 7 Sea Σ una σ-algebra de subconjuntos de Ω y sean A1, · · · , An ∈ Σ.
Entoncesn⋂
i=1
Ai ∈ Σ
Dem:Definamos An+1 = An+2 = · · · = Ω. Tenemos ası una sucesion An en Σ. Por la propiedadanterior resulta:
n⋂
i=1
Ai =
∞⋂
i=1
Ai ∈ Σ ¥
Prof.J.Gaston Argeri 15

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 16
Propiedad 8 Sean Ω un conjunto no vacıo y Σii∈I una familia no vacıa, donde cada Σi esuna σ-algebra de subconjuntos de Ω. Entonces
⋂
i∈I
Σi es una σ-algebra de subconjuntos de Ω.
Dem: Anotemos Σ =⋂
i∈I
Σi. Debemos probar que Σ satisface los axiomas de σ-algebra de
subconjuntos de Ω. Sabiendo que cada Σi satisface dichos axiomas, se deduce que:
• Ω ∈ Σ pues ∀i ∈ I , Ω ∈ Σi
• Si A ∈ Σ entonces ∀i ∈ I , A ∈ Σi. Luego: ∀i ∈ I , Ac ∈ Σi. Entonces Ac ∈ Σ
• Sea An sucesion en Σ. Entonces ∀i ∈ I , An es una sucesion en Σi. Por lo tanto
∀i ∈ I ,∞⋃
n=1An ∈ Σi. Luego:
∞⋃
n=1An ∈ Σ ¥
Propiedad 9 Dados un conjunto no vacıo Ω y un subconjunto G de P(Ω), existe una mınimaσ-algebra de subconjuntos de Ω que contiene a GDem: Basta considerar la familia de todas las σ-algebras de subconjuntos de Ω que contienen aG (una de ellas es P(Ω)) y aplicarle la propiedad anterior ¥
Estamos ahora en condiciones de definir la nocion axiomatica de probabilidad.
Definicion 5 Sean Ω un conjunto no vacıo y Σ una σ-algebra de subconjuntos de Ω. Una medidade probabilidad o funcion de probabilidad o simplemente una probabilidad sobre Σ es una funcionP : Σ → R que verifica los siguientes axiomas:
i) ∀A ∈ Σ , P (A) ≥ 0
ii) P (Ω) = 1
iii) Para toda sucesion An de elementos de Σ disjuntos dos a dos se cumple:
P
( ∞⊎
n=1
An
)
=
∞∑
n=1
P (An)
Nota: Parte del supuesto en esta igualdad es que la serie en el miembro de la derecha seaconvergente.
Un espacio de probabilidad es una terna ordenada (Ω, Σ, P ) donde P es una probabilidad sobre Σ.
Ejemplo: Sea Ω un conjunto no vacıo a lo sumo numerable, que podemos anotar Ω = ωn. SeaΣ una σ-algebra de subconjuntos de Ω tal que ∀n , ωn ∈ Σ. Como vimos antes esto implica queΣ = P(Ω). Si P es una probabilidad sobre Σ notemos que:
• Las probabilidades pn = P (ωn) determinan la probabilidad de cualquier evento aleatorio.En efecto: Sea A ⊆ Ω. Entonces A =
⊎
ωn∈A
ωn. Por lo tanto:
P (A) = P
(⊎
ωn∈A
ωn)
=∑
ωn∈A
P (ωn) =∑
ωn∈A
pn
• Dada una sucesion pn de numeros reales tal que:
a) ∀n , pn ≥ 0
b)∞∑
n=1pn = 1
existe una unica probabilidad P sobre Σ tal que P (ωn) = pn
Prof.J.Gaston Argeri 16

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 17
11 Espacios de equiprobabilidad
Si Ω = ω1, · · · , ωN es finito y si definimos ∀n ∈ 1, · · · , N , pn = 1N
entonces se cumplenlas condiciones a) y b) del item anterior, de manera que queda definida una unica probabilidad sobreΣ = P(Ω) tal que ∀n ∈ 1, · · · , N , P ωn = 1
N= 1
#(Ω). Esta manera de asignar probabili-
dades sobre un espacio muestral finito es lo que se conoce como espacio de equiprobabilidad. Enun espacio de equiprobabilidad se tiene para cuanlquier evento A ⊆ Ω
P (A) = P
(⊎
ω∈A
ω)
=∑
ω∈A
P (ω) =∑
ω∈A
1
#(Ω)=
#(A)
#(Ω)
Esta manera de asignar probabilidades en un espacio muestral finito suele resumirse del modo siguiente:
P (A) =# resultados favorables al evento A
# resultados posibles del experimentoEn la practica cuando asociamos determinado espacio muestral Ω a un experimento aleatorio con unacantidad finita de resultados posibles, la asignacion de probabilidades a dichos eventos elementales nosiempre se reduce a considerar resultados equiprobables. Volviendo a uno de nuestros primeros ejem-plos: Se lanzan dos dados ”normales” y se anota el puntaje total obtenido. En este caso podrıamostomar como espacio muestral Ω = 2, 3, 4, · · · , 12. Sin embargo no es correcto asignar probabili-dades del modo siguiente:
∀n ∈ 2, · · · , 12 , P (n) =1
11
¿Que inconvenientes observa acerca de esta asignacion de probabilidad?El mismo experimento aleatorio podrıa modelizarse mediante el siguiente espacio muestral:
Ω = (i, j) : 1 ≤ i, j ≤ 6
Con este espacio muestral sı es adecuada la asignacion de probabilidad en forma equiprobable:
∀(i, j) tal que 1 ≤ i, j ≤ 6 , P ((i, j)) =1
36
Calculemos en este ejemplo la probabilidad de que el puntaje total obtenido sea 7. En este casoA = (i, j) : 1 ≤ i, j ≤ 6 ; i + j = 7 = (1, 6), (2, 5), (3, 4), (4, 3), (5, 2), (6, 1). Por lo
tanto P (A) = #(A)#(Ω)
= 636
= 16
Ejemplo: Una urna contiene 3 bolillas blancas y 2 bolillas negras. Se extraen al azar dos bolillas sinreposicion. Calculemos P (A) y P (C) siendo:A = ”ambas bolillas son blancas” y C = ”ambas bolillas son negras”Una posible representacion del espacio muestral asociado a este experimento aleatorio podrıa ser Ω =BB, BN, NB, NN. Sin embargo, dada esta representacion es evidente que no resulta naturalconsiderar los cuatro posibles resultados como equiprobables puesto que hay mas bolillas blancas quenegras. De hecho, si utilizaramos el artificio de numerar las bolillas blancas como B1, B2, B3 ynumerar las bolillas negras como N1, N2 resulta claro que el resultado A se da en mas casos que elresultado C. De hecho:A = (B1, B2), (B1, B3), (B2, B1), (B2, B3), (B3, B1), (B3, B2) tiene 6 elementosC = (N1, N2), (N2, N1) tiene 2 elementosLo natural entonces es elegir una representacion del espacio muestral en la que resulte natural laequiprobabilidad. Tal representacion podrıa ser la siguiente:
Ω = (x, y) : x, y ∈ B1, B2, B3, N1, N2 , x 6= y
Prof.J.Gaston Argeri 17

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 18
Con este espacio muestral es natural plantear equiprobabilidad. Se tiene:
P (A) = #(A)#(Ω)
= 3·25·4 = 3
10= 0, 3
P (C) = #(C)#(Ω)
= 2·15·4 = 1
10= 0, 1
Otra posible representacion del espacio muestral es la siguiente, que prescinde del orden en que seextraen las bolillas:
Ω = x, y : x, y ∈ B1, B2, B3, N1, N2 , x 6= y
Tambien en este caso es natural la equiprobabilidad. Se tiene:
P (A) = #(A)#(Ω)
=(32)
(52)
= 310
= 0, 3
P (C) = #(C)#(Ω)
=(22)
(52)
= 110
= 0, 1
Como era de esperar, se obtienen las mismas probabilidades que cuando se tiene en cuenta el orden deextraccion. Ejemplo: Nuevamente consideremos una urna con 3 bolillas blancas y dos bolillas negras.Se extraen al azar dos bolillas, pero esta vez con reposicion. Calculemos las probabilidades de losmismos eventos A y C del ejemplo anterior.En este caso conviene representar el espacio muestral como:
Ω = (x, y) : x, y ∈ B1, B2, B3, N1, N2
Entonces:P (A) = #(A)
#(Ω)= 3·3
5·5 = 925
= 0, 36
P (C) = #(C)#(Ω)
= 2·25·5 = 4
25= 0, 16
12 Propiedades de una probabilidad
Una cantidad de resultados utiles se desprenden de la definicion axiomatica de probabilidad dada enel paragrafo anterior.
Propiedad 10 P (∅) = 0
Dem:Definamos ∀n , An = ∅. Claramente estos eventos son dos a dos disjuntos, de manera que:
P (∅) = P
( ∞⊎
n=1
An
)
=∞∑
n=1
P (An) =∞∑
n=1
P (∅)
Puesto que la serie a la derecha de la ultima igualdad es convergente, necesariamente su terminogeneral debe tender a 0. Pero dicho termino general, siendo constantemente igual a P (∅), tiende aP (∅). Por lo tanto: P (∅) = 0 ¥
Propiedad 11 Sean A1, · · · , An ∈ Σ dos a dos disjuntos. Entonces:
P
(n⊎
i=1
Ai
)
=n∑
i=1
P (Ai)
Prof.J.Gaston Argeri 18

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 19
Dem:Definamos An+1 = An+2 = · · · = ∅. Se tiene:
P
(n⊎
i=1
Ai
)
= P
( ∞⊎
i=1
Ai
)
=∞∑
i=1
P (Ai) =n∑
i=1
P (Ai) ¥
Propiedad 12 Sean A, B ∈ Σ tales que A ⊆ B. Se verifica:
P (B \ A) = P (B) − P (A)
Dem:Podemos escribir B = A](B \ A) siendo la union disjunta. Por lo tanto: P (B) = P (A ] (B \ A)) =P (A) + P (B \ A). Despejando se tiene: P (B \ A) = P (B) − P (A) ¥
Propiedad 13 Sean A, B ∈ Σ (no necesariamente disjuntos). Se verifica:
P (A ∪ B) = P (A) + P (B) − P (AB)
Dem:Primeramente notemos que BAc = B \ AB. Ahora bien, por la propiedad anterior y teniendo encuenta que AB ⊆ B se tiene:P (BAc) = P (B \ AB) = P (B) − P (AB). Luego:
P (A ∪ B) = P (A ] BAc) = P (A) + P (BAc) = P (A) + P (B) − P (AB) ¥
Corolario 1 Para cualesquiera eventos A, B ∈ Σ se verifica la siguiente desigualdad:
P (A ∪ B) ≤ P (A) + P (B)
Dem: P (A ∪ B) = P (A) + P (B) − P (AB) ≤ P (A) + P (B) pues P (AB) ≥ 0 ¥
Propiedad 14 Dados A, B, C ∈ Σ se verifica:
P (A ∪ B ∪ C) = P (A) + P (B) + P (C) − P (AB) − P (AC) − P (BC) + P (ABC)
Dem:
P (A ∪ B ∪ C) = P (A ∪ B) + P (C) − P ((A ∪ B) C) =
= P (A) + P (B) − P (AB) + P (C) − P (AC ∪ BC) =
= P (A) + P (B) + P (C) − P (AB) − (P (AC) + P (BC) − P (ACBC)) =
= P (A) + P (B) + P (C) − P (AB) − (P (AC) + P (BC) − P (ABC)) =
= P (A) + P (B) + P (C) − P (AB) − P (AC) − P (BC) + P (ABC) ¥
Propiedad 15 Sea (Ω, Σ, P ) un espacio de probabilidad. Dados A1, · · · , An ∈ Σ se cumple:
P (A1 ∪ · · · ∪ An) =n∑
i=1
P (Ai) − ∑
1≤i1<i2≤n
P (Ai1Ai2) + · · ·
+ (−1)r+1∑
1≤i1<i2<···<ir≤n
P (Ai1Ai2 · · · Air) + · · · +
+ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . +
+ (−1)n+1 P (A1A2 · · · An)
(1)
Prof.J.Gaston Argeri 19

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 20
Dem:Por induccion sobre n.
• Paso base: n = 2 ya fue demostrada.
• Hipotesis inductiva (HI): Suponemos valida (1) para n.
• Supongamos A1, · · · , An+1 ∈ Σ.
P (A1 ∪ · · · ∪ An+1) = P (A1 ∪ · · · ∪ An) + P (An+1) − P ((A1 ∪ · · · ∪ An)An+1) =
=n∑
i=1
P (Ai) − ∑
1≤i1<i2≤n
P (Ai1Ai2) + · · ·
+ (−1)r+1∑
1≤i1<i2<···<ir≤n
P (Ai1Ai2 · · · Air) + · · · +
+ (−1)n+1 P (A1A2 · · · An) + P (An+1) − P (A1An+1 ∪ · · · ∪ AnAn+1) =
=n+1∑
i=1
P (Ai) − ∑
1≤i1<i2≤n
P (Ai1Ai2) + · · ·
+ (−1)r+1∑
1≤i1<i2<···<ir≤n
P (Ai1Ai2 · · · Air) + · · · +
+ (−1)n+1 P (A1A2 · · · An) − n∑
i=1
P (AiAn+1) − ∑
1≤i1<i2≤n
P (Ai1Ai2An+1) + · · ·
+ (−1)n+1P (A1A2 · · · AnAn+1)
=n+1∑
i=1
P (Ai) − ∑
1≤i1<i2≤n+1
P (Ai1Ai2) + · · ·
+ (−1)r+1∑
1≤i1<i2<···<ir≤n+1
P (Ai1Ai2 · · · Air) + · · · +
+ (−1)n+2 P (A1A2 · · · An+1) ¥
Propiedad 16 Dados A, B ∈ Σ con A ⊆ B se tiene P (A) ≤ P (B)
Dem:Como A ⊆ B resulta B = A ] BAc. Luego: P (B) = P (A) + P (BAc) ≥ P (A) ¥
Corolario 2 Para todo A ∈ Σ es P (A) ≤ 1
Dem:Como A ⊆ Ω y dado que P (Ω) = 1 resulta P (A) ≤ P (Ω) = 1 ¥
Propiedad 17 Para cualquier A ∈ Σ se verifica:
P (Ac) = 1 − P (A) ; P (A) = 1 − P (Ac)
Dem:Puesto que Ω = A ] Ac resulta 1 = P (Ω) = P (A) + P (Ac) ¥
Prof.J.Gaston Argeri 20

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 21
13 Propiedades de continuidad
Propiedad 18 Sea An una sucesion en Σ. Supongamos dicha sucesion de eventos es creciente,es decir: A1 ⊆ A2 ⊆ A3 ⊆ · · · . Se verifica:
P
( ∞⋃
n=1
An
)
= limn →∞
P (An)
Dem:Definamos los siguientes eventos:
B1 = A1
B2 = A2 \ A1
B3 = A3 \ A2
· · · · · · · · ·Bn = An \ An−1
· · · · · · · · ·Se tiene ası una sucesion Bn en Σ tal que:
n⋃
i=1
Ai =n⊎
i=1
Bi y∞⋃
i=1
Ai =∞⊎
i=1
Bi
Por conveniencia definamos tambien Ao = ∅. Entonces:
P
(n⋃
i=1
Ai
)
= P
(n⋃
i=1
Bi
)
=n∑
i=1
P (Bi) =
=n∑
i=1
P (Ai \ Ai−1) =n∑
i=1
(P (Ai) − P (Ai−1)) =
= P (An) − P (Ao) = P (An) − P (∅) = P (An)
Luego:
limn →∞
P (An) = limn →∞
n∑
i=1
P (Bi) =∞∑
i=1
P (Bi) =
= P
( ∞⊎
i=1
Bi
)
= P
( ∞⋃
i=1
Ai
)
¥
Propiedad 19 Sea An una sucesion en Σ. Supongamos dicha sucesion de eventos es decreciente,es decir: A1 ⊇ A2 ⊇ A3 ⊇ · · · . Se verifica:
P
( ∞⋂
n=1
An
)
= limn →∞
P (An)
Dem:Notemos que dado que los An decrecen entonces los Ac
n crecen.
P
( ∞⋂
n=1An
)
= 1 − P
([ ∞⋂
n=1An
]c)
=
= 1 − P
( ∞⋃
n=1Ac
n
)
= 1 − limn →∞
P (Acn) =
= limn →∞
(1 − P (Ac
n))
= limn →∞
P (An) ¥
Prof.J.Gaston Argeri 21

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 22
Probabilidad condicional - Sucesos independientes
14 Probabilidad condicional
Seguramente al lector no se le habra pasado por alto, cuando definimos los axiomas de una probabili-dad, la relacion intuitiva que existe entre estos y lo que se conoce como el enfoque ”frecuentista” delas probabilidades, que pasamos a explicar someramente.Supongamos, en el contexto de un experimento aleatorio concreto, que se desea asignar probabilidad acierto evento A. El enfoque frecuentista consiste en repetir el experimento un numero finito y grandede veces, digamos N veces. A continuacion determina lo que se conoce como frecuencia relativa delevento A en esas N realizaciones del experimento. Dicha frecuencia relativa, que anotaremos fA,se define por:
fA =numero de veces que ha ocurrido A en las N realizaciones
numero total N de realizaciones
Intuitivamente fA es un reflejo de la chance de ocurrencia de A en dichas repeticiones delexperimento. En otro capıtulo formalizaremos esta idea intuitiva. Por el momento nos conformamoscon admitirla como natural y motivadora. Esta frecuencia relativa posee las siguientes propiedades:Dados eventos A, B se verifica
i) fA ≥ 0
ii) fΩ = 1
iii) Si A y B son disjuntos entonces fA∪B = fA + fB
Las propiedades anteriores nos hacen recordar propiedades analogas a las de la definicion axiomaticade probabilidad.Basados intuitivamente en esta idea frecuentista vamos a introducir el concepto de probabilidad condi-cional. La importancia de este concepto se debe a dos motivos principales:
• Frecuentemente estamos interesados en calcular probabilidades cuando disponemos de algunainformacion parcial adicional acerca del resultado del experimento. En tal caso dichas probabil-idades se dicen condicionales (a la informacion adicional).
• Aun en situaciones en las cuales no disponemos de tal informacion parcial adicional, es frecuenteel uso de la probabilidad condicional como herramienta que permite calcular las probabilidadesdeseadas de un modo mas sencillo.
Para fijar ideas consideremos el ejemplo que sigue.
Ejemplo: Se arrojan dos dados normales, de manera que cada uno de los 36 resultados posibles sonequiprobables. Supongamos que se observa ademas que el primer dado es un 3. Con esta informacionadicional, ¿ cual es la probabilidad de que el puntaje total obtenido sea 8 ?Primeramente observemos que ”el primer dado es un 3” es un evento, que podemos anotar H. Dadoque ha ocurrido H, el experimento se limita a arrojar el segundo dado y determinar el numero quesale. Sabemos que los posibles resultados de este experimento parcial seran solo seis y definiran unespacio muestral parcial: ΩH = (3, 1), (3, 2), (3, 3), (3, 4), (3, 5), (3, 6). Es natural considerarestos seis resultados como equiprobables, es decir que podemos definir una probabilidad PH de modoque ∀j ∈ 1, · · · , 6 , PH ((3, j)) = 1/6. Esta probabilidad sobre el espacio muestral Ω∗ puedepensarse como una probabilidad ”condicional a H” en el espacio muestral Ω asociado al experimentooriginal, definiendo:
• La probabilidad condicional de (3, j) como 1/6. Anotamos P ((3, j) |H) = 1/6
Prof.J.Gaston Argeri 22

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 23
• La probabilidad condicional de (i, j) como 0 si i 6= 3. Anotamos P ((i, j) |H) = 0 sii 6= 3
Por lo tanto, la probabilidad condicional de obtener puntaje total 8 sera
P (”se obtiene puntaje 8”|H) = P ((3, 5) |H) = 1/6
Ejemplo: Mas generalmente consideremos dos eventos E y H en el contexto de un experimentoaleatorio. Queremos asignar una probabilidad al evento E bajo el supuesto o condicion que hayaocurrido H. Intuitivamente lo que podrıamos hacer es repetir el experimento un gran numero N deveces y contar en cuantas de ellas ha ocurrido H, digamos NH veces, y luego contar en cuantas deestas NH ha ocurrido tambien E, digamos NEH veces. Entonces podrıamos considerar el numero:NEHNH
Equivalentemente, dividiendo numerador y denominador por N se obtiene: NEH/NNH/N
= fEH
fH
Dado que las frecuencias relativas son base intuitiva para las probabilidades, este cociente motiva ladefinicion siguiente.
Definicion 6 Sean (Ω, Σ, P ) un espacio de probabilidad y H ∈ Σ tal que P (H) > 0. Dado unevento E ∈ Σ se define la probabilidad de E condicional a F como:
P (E|F ) =P (EF )
P (F )
Ejemplo: Se lanza dos veces una moneda normal. Calculemos:
a) La probabilidad de que ambas salgan cara.
b) La probabilidad condicional de que ambas salgan cara dado que la primera sale cara.
Para responder a) consideramos el espacio muestral Ω = CC, CS, SC, SS y naturalmenteasignamos probabilidades uniformemente, de modo que cada uno de los cuatro resultados elementalestiene probabilidad 1/4. Luego:
P (”ambas salen cara”) = P (CC) =1
4
Para responder a b) utilizamos la definicion de probabilidad condicional. Sean E = ”ambas salen cara” yH = ”la primera sale cara”. Entonces:
P (E|H) =P (EF )
P (F )=
P (CC)
P (CC, CS)=
1/4
1/2=
1
2
Propiedad 20 Sean (Ω, Σ, P ) un espacio de probabilidad y H ∈ Σ tal que P (H) > 0.
Sea ΣP (·|H)−→ R la funcion que asigna a cada E ∈ Σ el numero real P (E|H). Entonces
(Ω, Σ, P (·|H)) es un espacio de probabilidad.
Dem:La demostracion se propone como ejercicio al final del capıtulo ¥
Propiedad 21 Sean Σ una σ-algebra de subconjuntos de Ω y H ∈ Σ. Sea ΣH la siguiente clasede subconjuntos de H:
ΣH = EH : E ∈ ΣEntonces ΣH es una σ-algebra de subconjuntos de H.
Dem:
i) Dado que H ∈ Σ y H = HH resulta H ∈ ΣH
Prof.J.Gaston Argeri 23

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 24
ii) Supongamos que B ∈ ΣH . Luego, existe cierto E ∈ Σ tal que B = EH. Dado que tantoE como H son miembros de Σ tambien lo es B. Luego, tambien Bc ∈ Σ. Entonces elcomplemento de B relativo a H es H \ B = BcH. Por ende este complemento pertenece aΣH , siendo este complemento la interseccion entre H y un miembro de Σ.
iii) Sea Bn una sucesion en ΣH . Luego, existe una sucesion En en Σ tal que ∀n , Bn =EnH. Luego:
∞⋃
n=1
Bn =∞⋃
n=1
EnH =
( ∞⋃
n=1
En
)
∩ H
Sea E =∞⋃
n=1En. Dado que los En son miembros de Σ resulta E ∈ Σ. Pero como
∞⋃
n=1Bn = EH resulta que
∞⋃
n=1Bn ∈ ΣH ¥
Definicion 7 La σ-algebra ΣH definida arriba se denomina la relativizacion de Σ a H o lareduccion de Σ a H.
Propiedad 22 Dados (Ω, Σ, P ) espacio de probabilidad y H ∈ Σ tal que P (H) > 0, la funcion
ΣhPH−→ R definida por
PH(B) =P (B)
P (H)
es una probabilidad sobre (H, ΣH). Mas aun, se verifica: ∀E ∈ Σ , PH(EH) = P (E|H)
Dem:La demostracion se propone como ejercicio al final del capıtulo ¥
Definicion 8 Se dice que el espacio de probabilidad (H, ΣH , PH) se ha obtenido reduciendo a H elespacio de probabilidad (Ω, Σ, P ).
La idea es la siguiente: Calcular en Σ probabilidades condicionalmente a H equivale a calcular enΣH probabilidades sin condicionar. En determinados ejemplos es mas sencillo calcular probabilidadescondicionales por definicion mientras que en otros es mas facil calcularlas trabajando directamentesobre el espacio muestral reducido.
Teorema 3 (Regla del producto)Sea (Ω, Σ, P ) espacio de probabilidad.
i) Si A, B ∈ Σ con P (B) > 0 entonces P (AB) = P (A|B) · P (B)
ii) Mas generalmente, dados A1, · · · , An+1 ∈ Σ con P (A1 · · · An) > 0 se verifica:
P (A1 · · · An+1) = P (A1) · P (A2|A1) · P (A3|A1A2) · · · · · P (An+1|A1A2 · · · An)
Dem:Por induccion sobre n.Paso base: n = 1Este caso corresponde a demostrar i). Sean A1, A2 ∈ Σ con P (A) > 0. Se tiene:
Como P (A2|A1) =P (A1A2)
P (A1)se deduce P (A1A2) = P (A1)P (A2|A1)
Prof.J.Gaston Argeri 24

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 25
Hipotesis inductiva: Suponemos la propiedad valida para nAhora queremos demostrar que vale para n + 1. Sean A1, · · · , An+2 ∈ Σ. Se tiene:
P (A1A2 · · · An+1︸ ︷︷ ︸
A
An+2︸ ︷︷ ︸
B
) = P (A1 · · · An+1︸ ︷︷ ︸
A
)P (An+2︸ ︷︷ ︸
B
| A1 · · · An+1︸ ︷︷ ︸
A
)HI=
HI= P (A1)P (A2|A1) · · · P (An+1|A1 · · · An)P (An+2|A1 · · · An+1)
Esto demuestra que la propiedad es verdadera para n + 1 bajo el supuesto que sea verdadera paran. Luego, por induccion es valida para todo n ∈ N ¥
Ejemplo: Una urna contiene inicialmente r bolillas rojas y b bolillas blancas. Se realiza el siguienteexperimento aleatorio: Se extrae una bolilla al azar y se completa la urna con c bolillas de ese mismocolor. Se extrae nuevamente una bolilla al azar y se completa la urna con c bolillas del mismocolor, etc. Se quiere calcular la probabilidad de que las tres primeras extracciones resulten en bolillasrojas. Para resolverlo, dado que el experimento se lleva a cabo en tres etapas y cada etapa afecta lacomposicion de la urna de extraccion, es adecuado condicionar una extraccion a los resultados de lasextracciones previas.Definamos Ri = ”la i-esima extraccion resulta bolilla roja” (i = 1, 2, 3). Entonces lo que pretende-mos calcular es precisamente P (R1R2R3). Planteamos la regla del producto:
P (R1R2R3) = P (R1)P (R2|R1)P (R3|R1R2)
Por la composicion inicial de la urna es claro que
P (R1) =r
r + b
Por la composicion de la urna inmediatamente luego que ha ocurrido R1 es claro que
P (R2|R1) =r + c
r + c + b
Por la composicion de la urna inmediatamente luego que han ocurrido R1, R2 se tiene analogamente
P (R3|R1R2) =r + 2c
r + 2c + b
Por lo tanto:
P (R1R2R3) =r
r + b· r + c
r + c + b· r + 2c
r + 2c + b
Definicion 9 Sea (Ω, Σ, P ) un espacio de probabilidad. Una sucesion An en Σ se dice unaparticion de Ω sii se verifican:
i) ∀n ∈ N , P (An) > 0
ii) Ω =∞⋃
n=1An
iii) ∀n, n ∈ N , n 6= m ⇒ An ∩ Am = ∅
Ejemplo: Consideremos un espacio de equiprobabilidad Ω = 1, 2, · · · , 12. Es decir: ∀i ∈Ω , P (i) = 1/n > 0. Una posible particion de Ω es A1, A2, A3 donde
A1 = 1, 3, 5, 7, 9, 11 ; A2 = 6, 12 ; A3 = 2, 4, 8, 10
Prof.J.Gaston Argeri 25

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 26
Teorema 4 (Teorema de la probabilidad total)Sean (Ω, Σ, P ) un espacio de probabilidad y Hn una particion de Ω. Entonces para cualquierB ∈ Σ se verifica:
P (B) =∞∑
n=1
P (B|Hn)P (Hn)
Dem:
Dado que Hn es una particion de Ω, sabemos que∞⋃
n=1An = Ω. Por lo tanto
B = B ∩ Ω = B ∩( ∞⋃
n=1
Hn
)
=∞⋃
n=1
BHn
Ademas esta union es disjunta dos a dos:
n 6= m ⇒ (BHn)(BHm) = BHnHm = B∅ = ∅Luego:
P (B) =∞∑
n=1
P (BHn)
Pero como ∀n ∈ N , P (Hn) > 0 podemos escribir P (BHn) = P (B|Hn)P (Hn). Entonces:
P (B) =∞∑
n=1
P (BHn) =∞∑
n=1
P (B|Hn)P (Hn) ¥
Nota: El teorema de la probabilidad total es tambien valido para particiones finitas.
Ejemplo: Una caja C1 contiene n1 fichas marcadas con un 1 y n2 fichas marcadas con un 2.Se extrae una ficha al azar. Si sale 1 se extrae una bolilla al azar de una urna U1 que contiener1 bolillas rojas y b1 bolillas blancas. En cambio, si sale 2 se extrae una bolilla al azar de una urnaU2 que contiene r2 bolillas rojas y b2 bolillas blancas. Calcular la probabilidad de extraer unabolilla roja.La composicion de la urna de la que se extrae la bolilla depende de la primera etapa del experimento(extraccion de ficha). Por lo tanto es de esperar que necesitemos condicionar al resultado de la primeraetapa. Definamos F1 = ”sale ficha 1” y F2 = ”sale ficha 2”. Entonces F1, F2 es claramente unaparticion de Ω. Definamos tambien R = ”sale bolilla roja”. Por lo tanto:
P (R) =2∑
n=1
P (R|Fn)P (Fn) = P (R|F1)P (F1) + P (R|F2)P (F2)
Es claro queP (F1) = n1
n1+n2; P (F2) = n2
n1+n2
Tambien es claro que:
P (R|F1) = r1
r1+b1; P (R|F2) = r2
r2+b2
Por lo tanto:P (R) =
r1
r1 + b1· n1
n1 + n2+
r2
r2 + b2· n2
n1 + n2
Teorema 5 (Regla de Bayes)Sean (Ω, Σ, P ) un espacio de probabilidad y Hn una particion de Ω. Para cualquier B ∈ Σ talque P (B) > 0 y para cualquier j ∈ N se verifica:
P (Hj|B) =P (B|Hj)P (Hj)
∞∑
n=1P (B|Hn)P (Hn)
Prof.J.Gaston Argeri 26

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 27
Dem:Se tiene:
P (Hj|B) =P (BHj)
P (B)=
P (B|Hj)P (Hj)∞∑
n=1P (B|Hn)P (Hn)
¥
Nota: La regla de Bayes tambien es valida para particiones finitas.
Ejemplo: Una caja contiene N = n1 + n2 + n3 fichas, de las cuales n1 estan numeradas con”1”, n2 estan numeradas con ”2” y n3 estan numeradas con ”3”. Se dispone ademas de tres urnasU1, U2, U3. La urna Ui contiene ri bolillas rojas y bi bolillas blancas (i = 1, 2, 3). Se extrae alazar una ficha de la caja. Acto seguido se elige al azar una bolilla de la urna rotulada con el mismonumero que la ficha extraida. Sabiendo que la bolilla extraida fue roja, ¿ cual es la probabilidad deque haya provenido de la urna U2 ?Sean
Fi = ”sale ficha i” ; i = 1, 2, 3R = ”sale bolilla roja” y B = ”sale bolilla blanca”
Se pretende calcular P (F2|R). Aca se quiere averiguar la probabilidad de un evento que ocurrioen una etapa previa del experimento basados en infromacion de una etapa posterior. Es naturalentonces ”revertir” este condicionamiento, para lo cual utilizamos el teorema de Bayes. Notemos queF1, F2, F3 es una particion de Ω. Entonces:
P (F2|R) = P (R|F2)P (F2)P (R|F1)P (F1)+P (R|F2)P (F2)+P (R|F3)P (F3)
=
=r2
r2+b2· n2n1+n2+n3
r1r1+b1
· n1n1+n2+n3
+r2
r2+b2· n2n1+n2+n3
+r3
r3+b3· n3n1+n2+n3
=
=r2n2
r2+b2r1n1
r1+b1+
r2n2r2+b2
+r3n3
r3+b3
Ejemplo: Un procedimiento llamado fluoroscopıa cardıaca (FC) se utiliza para determinar si existecalcificacion en las arterias coronarias. El test permite detectar si hay 0,1,2,o 3 arterias coronariascalcificadas. Anotemos:
T +i : la FC detecta i arterias calcificadas (i = 0, 1, 2, 3)
D+ : hay enfermedad coronaria ; D− : no hay enfermedad coronaria
Supongamos que se conocen los datos de la siguiente tabla
i P (T +i |D+) P (T +
i |D−)
0 0.41 0.961 0.24 0.022 0.20 0.023 0.15 0.00
a) Si P (D+) = 0.05 calcular P (D+|T +i ) para i = 0, 1, 2, 3
b) Si P (D+) = 0.92 calcular P (D+|T +i ) para i = 0, 1, 2, 3
En ambos casos el calculo se reduce a utilizar la regla de Bayes:
P (D+|T +i ) =
P (T +i |D+)P (D+)
P (T +i |D+)P (D+) + P (T +
i |D−)P (D−)
Prof.J.Gaston Argeri 27

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 28
donde P (D−) = 1 − P (D+)Se obtienen los resultados siguientes:
i P (D+|T +i ) cuando P (D+) = 0.05 P (D+|T +
i ) cuando P (D+) = 0.92
0 0.022 0.8311 0.387 0.9932 0.345 0.9913 1.000 1.000
15 Independencia estocastica
Sean A, B eventos con P (A) > 0 y P (B) > 0. Intuitivamente podemos decir que dichos eventosson independientes (entre sı) si el hecho que ocurra A no influye sobre la chance de ocurrir B yrecıprocamente, el hecho que ocurra B no influye sobre la chance de ocurrir A. Es decir si laocurrencia de A ni afecta ni es afectada por la ocurrencia de B. Podemos expresar esta idea intuitivadiciendo que A y B son independientes sii P (B|A) = P (B) y P (A|B) = P (A). Expresandomediante intersecciones podemos reducir estas dos condiciones a una sola, con la ventaja adicionalde no requerir que los eventos tengan probabilidades positivas. Esta idea es la base de la siguientedefinicion.
Definicion 10 Los eventos A y B se dicen independientes sii P (AB) = P (A) · P (B)
Nota: No debe confundirse la nocion de independencia con la de eventos excluyentes. De hecho, siA y B son mutuamente excluyentes y si P (A) > 0 y P (B) > 0, entonces A y B distan muchode ser independientes pues P (AB) = P (∅) = 0 6= P (A)P (B)
Ejemplo: Se elige al azar una carta de un mazo de 52 cartas francesas. Consideremos los eventos
A : ”sale un as” ; C : ”sale una carta de corazones”
Analicemos la independencia entre ellos:
P (A) = 452
P (C) = 1352
P (AC) = 152
P (AC) = 152
= 452
· 1352
= P (A)P (C)
Por lo tanto A y C son independientes.
Ejemplo: Se arrojan dos dados equilibrados, uno blanco y otro rojo. Consideremos los eventos
A : ”puntaje total 6” ; B : ”el dado rojo sale 4”
Analicemos la independencia entre ellos:
P (A) = 536
P (B) = 16
P (AB) = 136
P (AB) = 136
6= 536
· 136
= P (A)P (B)
Por lo tanto A y C no son independientes.
Propiedad 23 Los eventos A y B son independientes sii los eventos A y B′ son independientes
Dem:⇒) Supongamos A y B independientes. Luego: P (AB) = P (A)P (B). Entonces:
P (AB′) = P (A\B) = P (A)−P (AB) = P (A)−P (A)P (B) = P (A)(1−P (B)) = P (A)P (B′)
Prof.J.Gaston Argeri 28

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 29
Luego, A y B′ son independientes.⇐) Si ahora suponemos A y B′ independientes, podemos aplicarles la parte ⇒) ya demostrada.Se deduce que A y (B′)′ = B son independientes ¥
Corolario 3 Los eventos A y B son independientes sii A′ y B′ son independientes
Generalicemos la nocion de independencia a tres eventos A, B, C. Imaginemos que C represente lapresencia de cierta enfermedad y que A y B representen la presencia de dos sıntomas clınicos.Supongamos que dichos sıntomas se presentan independientemente (que un paciente presente unsıntoma no lo hace mas ni menos proclive a presentar el otro sıntoma). Supongamos tambien queA y C sean independientes y que B y C sean independientes. Podrıa sin embargo ocurrirque la presencia simultanea de ambos sıntomas sı aumentara (o disminuyera) la chance de tener laenfermedad. En tal caso los eventos AB y C no serıan independientes. Esto motiva la siguientesdefinicion.
Definicion 11 Los eventos A, B, C se dicen independientes sii se verifican
P (AB) = P (A)P (B) , P (AC) = P (A)P (C) , P (BC) = P (B)P (C)
P (ABC) = P (A)P (B)P (C)
Ejemplo: Sea Ω = 1, 2, 3, 4 un espacio de equiprobabilidad. Definamos los eventos:
A = 1, 4 , B = 2, 4 , C = 3, 4
Entonces:
P (A) = 12
, P (B) = 12
, P (C) = 12
P (AB) = 14
= P (A)P (B) , P (AC) = 14
= P (A)P (C) , P (BC) = 14
= P (B)P (C)
P (ABC) = 14
6= 18
= P (A)P (B)P (C)
Luego A, B, C no son independientes.
Ejemplo: Sea Ω = 1, 2, 3, 4, 5, 6, 7, 8 un espacio de equiprobabilidad. Definamos los eventos:
A = 1, 2, 3, 4 , B = 1, 2, 7, 8 , C = 1, 5, 6, 7
Entonces:
P (A) = 12
, P (B) = 12
, P (C) = 12
P (AB) = 14
= P (A)P (B) , P (BC) = 14
= P (B)P (C) , P (AC) = 18
6= 14
= P (A)P (C)
P (ABC) = 18
= P (A)P (B)P (C)
Luego A, B, C no son independientes.
Definicion 12 Se dice que los eventos A1, · · · , An son independientes sii para cualquier secuenciaestrictamente creciente 1 ≤ i1 < · · · < ir ≤ n de enteros, se verifica
P (Ai1 · · · Air) =r∏
j=1
P (Aij)
Prof.J.Gaston Argeri 29

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 30
Nota: Vemos que en general es necesario verificar(n2
)+
(n3
)+ · · ·+ (n
n
)= 2n − (n+1) condiciones
para asegurar la independencia de n eventos.
Propiedad 24 Supongamos que A1, · · · , An son independientes. Sean B1, · · · , Bn eventos talesque
Bi = Ai o Bi = A′i (i = 1, · · · , n)
Entonces B1, · · · , Bn son independientes.
Prof.J.Gaston Argeri 30

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 31
Variables aleatorias - Distribuciones de probabilidad
16 Funciones
Sea ΩX→ C una funcion. Recordemos que esto significa que X establece una correspondencia entre
elementos de Ω y elementos de C con la caracterıstica que a cada elemento de Ω le asigna uno y soloun elemento de C. Si dicha correspondencia asigna al elemento ω ∈ Ω el elemento c ∈ C decimosque c es el valor de X en ω o la imagen de ω por X, situacion que se anota X(ω) = c.El conjunto Ω se denomina dominio de la funcion y suele anotarse Dom(X). La imagen o rango (oa veces el recorrido) de X es el conjunto de todos los valores de X, es decir el conjunto formado portodos los valores X(ω) cuando ω recorre Ω. Anotaremos la imagen de X como RX . Es decir:
RX = X(ω) : ω ∈ Ω = c ∈ C : ∃ω ∈ Ω , c = X(ω)Dado B ⊆ C definimos la imagen inversa de B por X como el conjunto de todos los elementos deΩ cuyas imagenes por X pertenecen a B. Si anotamos X−1(B) a la imagen inversa de B porX esta definicion establece que
X−1(B) = ω ∈ Ω : X(ω) ∈ B
Ejemplo: Sea RX→ R dada por X(t) = t2. En este caso la imagen o rango de X es RX = [0, ∞).
Por otra parte:
X−1 (4) = 2, −2 , X−1 ([4, ∞)) = (−∞, −2] ∪ [2, ∞)
X−1 (0) = 0 , X−1 (0, 2, 4, 7) =
0, ±√2, ±2, ±√
7
X−1 ((−∞, 0)) = ∅ , X−1 (R) = R
Ejemplo: Sea ω1, ω2, ω3, ω4 X→ R dada mediante la siguiente tabla de valores:
ω X(ω)
ω1 2
ω2 1
ω3 1
ω4 0
Entonces por ejemplo:X−1 (2) = ω1 X−1 (1) = ω2, ω3X−1 (0) = ω4 X−1 ((−∞, 0]) = ω4X−1 ((−∞, 1]) = ω2, ω3, ω4 X−1 ((−∞, −1]) = ∅
Dado A ⊆ R se denomina funcion indicadora o funcion caracterıstica de A a la funcion IA : R →R dada por
IA(x) =
1 si x ∈ A
0 si x 6∈ A
17 Variables aleatorias y funciones de distribucion
Cuando se realiza un experimento aleatorio existen diversas caracterısticas observables o medibles. Noobstante ello, generalmente el experimentador centra su interes en algunas de estas caracterısticas. Porejemplo, si el experimento consiste en lanzar un dado N = 10 veces, podrıamos interesarnos en lassiguientes caracterısticas: ”cantidad de dados que salen 3”, ”puntaje total obtenido”, ”mınimo numeroobtenido”,etc. Cada una de estas caracterısticas relaciona cada posible resultado del experimentocon un numero real. Ası por ejemplo podemos considerar que ”puntaje total obtenido” relaciona elresultado ω = (1, 5, 4, 3, 4, 6, 5, 1, 2, 2) con el numero real 1+5+4+3+4+6+5+1+2+2 = 33.Esto motiva la siguiente definicion.
Prof.J.Gaston Argeri 31

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 32
Definicion 13 Se denomina variable aleatoria (va) sobre un espacio de probabilidad (Ω, Σ, P ) atoda funcion X : Ω → R con la siguiente propiedad:
∀a ∈ R , X−1 ((−∞, a]) ∈ Σ (2)
Las variables aleatorias suelen designarse mediante las ultimas letras del abecedario y en mayusculas:· · · , P, · · · , X, Y, Z. Tambien se las designa mediante alguna de estas letras junto con uno o massubındices, por ejemplo: X1, X2, S12
Nota: Dados un numero real a y una variables aleatoria X, puesto que segun la definicion X esuna funcion de Ω en R, tiene sentido calcular la imagen inversa de B = (−∞, a] por X, que esprecisamente:
X−1 ((−∞, a]) = ω ∈ Ω : X(ω) ∈ (−∞, a] = ω ∈ Ω : X(ω) ≤ aEn el contexto de variables aleatorias es frecuente una notacion alternativa y mucho mas frecuentepara las imagenes inversas por X. En general, para B ⊆ R la imagen inversa de B por X se anotatambien X ∈ B. Es decir:
X ∈ B = ω ∈ Ω : X(ω) ∈ B = X−1(B)
Por lo tanto la definicion establece que una funcion X : Ω → R es una variable aleatoria sobre(Ω, Σ, P ) sii se cumple
∀x ∈ R , X ≤ x ∈ Σ
Tengamos presente que cuando el espacio de probabilidad es finito (es decir cuando #(Ω) es finito)y Σ = P(Ω) es la σ-algebra de todos los subconjuntos de Ω, entonces la condicion (2) es superfluapuesto que se satisface automaticamente. Lo mismo ocurre cuando Ω = ω1, ω2, · · · es infinitonumerable y cada ωn ∈ Σ puesto que:
X ≤ x = ωn : X(ωn) ≤ x =∞⋃
n=1X(ωn)≤x
ωn
Siendo la union a lo sumo numerable y cada ω ∈ Σ se deduce que X ≤ x ∈ Σ.Luego, en los casos donde el espacio de probabilidad es discreto, la nocion de variable aleatoria coincidecon la de funcion X : Ω → R.
Definicion 14 Sea X v.a. definida sobre un espacio de probabilidad (Ω, Σ, P ). Se dice que X esdiscreta sii existe A ∈ Σ, A a lo sumo numerable y tal que P (X ∈ A) = 1.
Observemos que cuando el espacio muestral es finito cualquier variable aleatoria es discreta, pues bastatomar A = Ω.
Propiedad 25 Dada una v.a. discreta X existe un mınimo A ∈ Σ con la propiedad que P (X ∈A) = 1
Dem:Siendo X discreta, sea A ∈ Σ tal que A es a lo sumo numerable y P (X ∈ A) = 1. DefinamosSX = x ∈ R : P (X = x) > 0. Entonces:
A = SX ] (A \ SX)
de manera que 1 = PX(A) = PX(SX) + PX(A \ SX). Mostraremos que PX(A \ SX) = 0. Enefecto: Anotemos B = A \ SX . En primer lugar, como B ⊆ Sc
X resulta ∀x ∈ B , PX (x) = 0.Dado que A es a lo sumo numerable resulta B a lo sumo numerable. Luego:
PX(B) = PX
(⊎
x∈B
x)
=∑
x∈B
PX (x) = 0
Prof.J.Gaston Argeri 32

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 33
Es decir que hemos demostrado que si A es a lo sumo numerable y P (X ∈ A) = 1 entoncesP (A \ SX) = 0En particular: PX(SX) = 1. Es decir P (X ∈ SX) = 1.Supongamos ahora que SX 6⊆ A. Entonces existirıa xo ∈ SX con xo 6∈ A. Luego: P (X = xo) >0. Entonces PX(X ∈ A ] xo) = PX(A) + P (X = xo) > PX(A) = 1. Absurdo. Entoncesnecesariamente es SX ⊆ A. Esto demuestra que:
P (X ∈ SX) = 1
Si A es a lo sumo numerable y P (X ∈ A) = 1 entonces SX ⊆ A
Por lo tanto SX es el mınimo conjunto buscado ¥
Definicion 15 Dada una variable aleatoria discreta X se denomina soporte (o rango esencial osimplemente rango) de X al mınimo A tal que P (X ∈ A) = 1. Anotaremos RX al rango de X.
Cuando un experimento conduce a medir cantidades como ”peso”, ”altura”, ”temperatura”, ”du-racion”, etc, es de esperar que dichas variables aleatorias no esten restringidas a un rango a lo sumonumerable. Una posible clasificacion de las variables aleatorias es la siguiente:
variables aleatorias
discretascontinuasmixtas
Son discretas aquellas variables aleatorias cuyo rango es a lo sumo numerable. Son continuas aquellasque poseen una ”densidad” (concepto que precisaremos mas adelante). Las mixtas son aquellas queni son discretas ni son continuas.
Ejemplo: Se lanza una moneda tantas veces como sea necesario hasta que sale ”cara”. En este casoΩ = C, SC, SSC, SSSC, · · · y consideramos Σ = P(Ω).Sea X = ”lanzamientos necesarios hasta obtener cara”. Esta va. discreta tiene rango RX = N. Parafamiliarizarnos con la notacion de imagen inversa vemos como ejemplo que:
X ≤ 0 = ∅ , X ≤ 5 = C, SC, SSC, SSSC, SSSSC
Ejemplo: Se lanza una moneda. Se tiene Ω = C, S. Consideramos Σ = P(Ω). Sea X =”cantidad de caras obtenidas”. Entonces RX = 0, 1. En este caso:
X ≤ x =
∅ si x < 0S si 0 ≤ x < 1
C, S si x ≥ 1
Recordemos que una bola abierta en Rn es el conjunto de todos los puntos de Rn que distan de unpunto fijo ~xo ∈ Rn (llamado el centro de dicha bola) en menos que una cantidad ε > 0 (el radio dela bola). Es decir
Bε(~xo) = ~x ∈ Rn : ‖~x − ~xo‖ < εUn subconjunto A ⊆ Rn se dice abierto sii para cada ~x = (x1, · · · , xn) ∈ A existe al menos unan−bola abierta en Rn centrada en ~x y completamente contenida en A. Formalmente: A ⊆ Rn esabierto sii se verifica
∀~x ∈ A , ∃ε > 0 , ∀~y ∈ Rn , ‖~y − ~x‖ < ε ⇒ y ∈ A
Definicion 16 Se denomina σ-algebra de Borel en R a la mınima σ-algebra de subconjuntos deR que contiene a todos los conjuntos de la forma (−∞, x] con x ∈ R. Anotaremos B a estaσ-algebra de subconjuntos de R.
Prof.J.Gaston Argeri 33

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 34
Propiedad 26 Dada una variable aleatoria discreta X, se verifica:
∀B ∈ B , P (X ∈ B) =∑
x∈B∩RX
P (X = x)
Dem:Como B = (B ∩ RX) ] (
B ∩ RcX
)se deduce que:
PX(B) = PX(B ∩ RX) + PX(B ∩ RcX)
Pero como PX(RX) = 1 entonces PX(RcX) = 0. Luego: PX(B ∩ Rc
X) = 0, de manera que
PX(B) = PX(B ∩ RX) =∑
x∈B∩RX
P (X = x)
Definicion 17 Sea (Ω, Σ, P ) un espacio de probabilidad. Consideremos una variable aleatoriaX : Ω → R. La funcion PX : B → R dada por E 7−→ P (X ∈ E) se denomina funcion dedistribucion de X.
Propiedad 27 La funcion de distribucion PX de una variable aleatoria X es una funcion deprobabilidad sobre (R, B).
Dem: En lo que sigue B, Bn ∈ BPX(R) = P (X ∈ R) = P (Ω) = 1
PX(B) = P (X ∈ B) ≥ 0 pues P es una probabilidad y X ∈ B ∈ Σ
Supongamos Bn sucesion en B, tal que n 6= m ⇒ Bn ∩ Bm = ∅. Entonces:
PX
( ∞⋃
n=1Bn
)
= P
(
X ∈∞⋃
n=1Bn
)
= P
(
X−1
( ∞⋃
n=1Bn
))
=
= P
( ∞⋃
n=1X−1(Bn)
)
=∞∑
n=1P
(X−1(Bn)
)=
∞∑
n=1P (X ∈ Bn)
puesto que los eventos X ∈ Bn son disjuntos dos a dos. ¥
Definicion 18 Sean X e Y variables aleatorias definidas sobre un mismo espacio de probabilidad.Se dice que X e Y son equidistribuidas o identicamente distribuidas sii ambas poseen la mismafuncion de distribucion, i.e. ∀B ∈ B , PX(B) = PY (B)
Nota: El hecho de ser X e Y equidistribuidas no significa que sean iguales. Esto se vera masadelante. Ejemplo: Un fabricante produce un artıculo en dos variedades A y B. Desea recabarinformacion acerca de la preferencia de los consumidores. Para ello seleccionara al azar 30 clientes aquienes se les preguntara si prefieren A o B. Se trata de un experimento aleatorio en el cual el espaciomuestral Ω puede definirse como el conjunto de todas las 30-uplas de 1’s y/o 0’s, donde un 1 en lai-esima coordenada de la 30-upla indica que el i-esimo cliente encuestado prefiere la variedad A sobrela B. Supongamos que estos 230 posibles resultados de la encuesta sean equiprobables. ConsideremosX = ”cantidad de consumidores que prefieren A”. Se tiene RX = 0, 1, · · · , 30. Calculemos paracada 0 ≤ k ≤ 30, las probabilidades siguientes:
P (X = k) = #X=k#(Ω)
=(30
k )230
(k = 0, 1, · · · , 30)
P (X ≤ k) =k∑
j=0
P (X = j)
Grafiquemos los valores de X sobre el eje de abscisas y las probabilidades halladas anteriormentesobre el eje de ordenadas:
Prof.J.Gaston Argeri 34

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 35
k
P(X=
k)
0 5 10 15 20 25 30
0.00.0
20.0
40.0
60.0
80.1
00.1
20.1
4
kP(
X<=k
)
0 5 10 15 20 25 30
0.00.2
0.40.6
0.81.0
Definicion 19 Dada una variable aleatoria X : Ω → R se denomina funcion de distribucionacumulada (fda) de X a la funcion designada FX y definida por:
FX : R → R dada por FX(x) = P (X ≤ x)
Nota: Para indicar que la variable aleatoria posee fda F anotamos X ∼ F .
Ejemplo: Se arroja tres veces una moneda normal. Sea X = cantidad de caras obtenidas. EntoncesRX = 0, 1, 2, 3. La funcion de distribucion acumulada de X es
FX(x) =
0 si x < 01/8 si 0 ≤ x < 11/2 si 1 ≤ x < 27/8 si 2 ≤ x < 31 si x ≤ 3
Distribucion binomial acumulada
x
F(x
)
-1 0 1 2 3 4
0.0
0.2
0.4
0.6
0.8
1.0
)
)
)
)
Prof.J.Gaston Argeri 35

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 36
Ejemplo: Se arroja una moneda normal hasta que sale cara.Sea X = ”cantidad de lanzamientos antes que salga cara”. Se tiene RX = 0, 1, 2, 3, · · · . La fdade X es:
FX(x) =
0 si x < 01/2 si 0 ≤ x < 1
1/2 + 1/4 si 1 ≤ x < 21/2 + 1/4 + 1/8 si 2 ≤ x < 3
......
...k+1∑
i=1
(12
)isi k ≤ x < k + 1
......
...
Propiedad 28 Sea X una variable aleatoria con funcion de distribucion acumulada FX . Se cumple:
i) ∀x ∈ R , 0 ≤ FX(x) ≤ 1
ii) FX es no decreciente, es decir: ∀x, y ∈ R , x < y ⇒ FX(x) ≤ FX(y)
iii) FX es continua por la derecha, es decir: ∀x ∈ R , limt → x+
FX(t) = FX(x)
iv) limx →−∞
FX(x) = 0 y limx →∞
FX(x) = 1
Dem:
i) Evidente pues FX(x) = P (X ≤ x) es una probabilidad.
ii) Sean x, y ∈ R con x < y. Entonces X ≤ x ⊆ X ≤ y. Por lo tanto FX(x) =P (X ≤ x) ≤ P (X ≤ y) = FX(y)
iii) Siendo FX no decreciente sabemos que para todo x ∈ R , limt → x+
FX(t) existe (es finito). Comox + 1
n
es una sucesion de terminos a la derecha de x y tal que lim
n →∞
(x + 1
n
)= x, en-
tonces limt → x+
FX(t) = limn →∞
FX
(x + 1
n
). Pero: X ≤ x =
∞⋂
n=1
X ≤ x + 1
n
. Como esta
interseccion es decreciente, pues
X ≤ x + 1n+1
⊆ X ≤ x + 1
n
, entonces por propiedad
de una funcion de probabilidad es P (X ≤ x) = limn →∞
P(X ≤ x + 1
n
). Luego:
FX(x) = P (X ≤ x) = limn →∞
P
(
X ≤ x +1
n
)
= limn →∞
FX
(
x +1
n
)
= limt → x+
FX(t)
iv) Dado que Ω = X ∈ R =∞⋃
n=1X ≤ n y siendo la union creciente, por propiedad de una
funcion de probabilidad se tiene limn →∞
FX(n) = limn →∞
P (X ≤ n) = P (Ω) = 1. Pero siendo
FX no decreciente y acotada resulta limx →∞
FX(x) = limn →∞
FX(n). Entonces:
limx →∞
FX(x) = limn →∞
FX(n) = 1
La demostracion del otro lımite es analoga y queda a cargo de ustedes. ¥
Teorema 6 Sea F : R → R una funcion. Se cumple:F satisface las propiedades siguientes:
i) F es no decreciente en R.
Prof.J.Gaston Argeri 36

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 37
ii) F es continua a derecha en R
iii) limx →−∞
F (x) = 0 y limx →∞
F (x) = 1
si y solo si F es la funcion de distribucion de probabilidad acumulada de cierta variable aleatoria.
Dem: ⇐) Ya se demostro (Prop. anterior)⇒) La demostracion excede el alcance y los objetivos de este curso de modo que la omitimos. Solocomentare que es necesario demostrar que existe cierto espacio de probabilidad (Ω, Σ, P ) y ciertavariable aleatoria X en dicho espacio, tal que FX = F ¥
Ejemplo: Consideremos la funcion
F (x) =
1 − e− x si x ≥ 0
0 si x < 0
El teorema anterior permite demostrar la existencia de una variable aleatoria X (definida en ciertoespacio de probabilidad) tal que F = FX . En efecto:
F es no decreciente.
F es continua a derecha en R. De hecho F continua en R
Se tiene
limx →−∞
F (x) = limx →−∞
0 = 0 y limx →∞
F (x) = limx →∞
(1 − e− x
)= 1
La grafica de F tiene el siguiente aspecto:
x
F(x
)
-2 0 2 4 6 8 10
0.0
0.2
0.4
0.6
0.8
1.0
Propiedad 29 Sean X una variable aleatoria, xo ∈ R. Se cumple:
i) FX(xo) − FX(xo−) = P (X = xo)
ii) FX es continua a izquierda en xo sii P (X = xo) = 0
iii) FX posee una cantidad a lo sumo numerable de discontinuidades.
Prof.J.Gaston Argeri 37

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 38
Dem:i) Utilizando las propiedades de continuidad de una probabilidad resulta:
FX(xo−) = limx → xo−
FX(x) = limx → xo−
P (X ≤ x) = limn →∞
P (X ≤ xo − 1/n) =
= P
( ∞⋃
n=1X ≤ xo − 1/n
)
= P (X < xo)
Por lo tanto: P (X = xo) = P (X ≤ xo) − P (X < xo) = FX(xo) − FX(xo−)ii) Evidente a partir de i).iii) Si FX es discontinua en xo entonces P (X = xo) > 0. Anotemos A = x0 ∈ R : P (X = xo) > 0.Queremos ver que A es a lo sumo numerable. Pero:
A =∞⋃
k=1
Ak donde Ak = x0 ∈ R : P (X = xo) > 1/k
Bastara entonces mostrar que los Ak son finitos. Supongamos por el absurdo que existiera k talque Ak fuera infinito. Entonces existirıa una sucesion de terminos todos distintos xn tal que∀n , xn ∈ Ak. Luego:
P (A) ≥ P
( ∞⊎
n=1
xn)
=∞∑
n=1
P (xn) = ∞
dado que la serie posee termino general que no tiende a cero. Absurdo. Luego los Ak son todosfinitos, con lo cual A es a lo sumo numerable ¥
Propiedad 30 Sea X una variable aleatoria y sea FX su fda. Dados a, b ∈ R , a ≤ b, se cumple:
i) P (a < X ≤ b) = FX(b) − FX(a)
ii) P (a ≤ X ≤ b) = FX(b) − FX(a−)
iii) P (a < X < b) = FX(b−) − FX(a)
iv) P (a ≤ X < b) = FX(b−) − FX(a−)
Dem:Demostremos i):
a < X ≤ b = X ≤ b \ X ≤ aEntonces
P (a < X ≤ b) = P (X ≤ b) − P (X ≤ a) = FX(b) − FX(a) ¥
Definicion 20 Para n ∈ N, se denomina sucesion de n ensayos de Bernoulli a todo experimentoaleatorio que consiste en repetir n veces un ensayo sujeto a las siguientes condiciones:
• Las n repeticiones son independientes entre sı.
• Cada ensayo tiene solo dos posibles resultados, digamos E (”exito”) y F (”fracaso”).
• La probabilidad de E es la misma en cada uno de los n ensayos.
Prof.J.Gaston Argeri 38

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 39
Es frecuente denotar la probabilidad de fracaso en cada ensayo individual por q. De modo quep+q = 1, es decir q = 1−p. El espacio muestral asociado a una sucesion de n ensayos de Bernoullies Ω = (ω1, · · · , ωn) : ωi ∈ E, F , 1 ≤ i ≤ n. Ası, el experimento consta de 2n posiblesresultados. Notemos que, salvo cuando p = 1/2, los eventos elementales no son equiprobables. Dehecho:
P (ω) = pr · qn−r sii ω posee exactamente r exitos
Ejemplo: Se arroja 5 veces un dado normal. En cada lanzamiento llamemos E = ”sale 3”, de modoque F = ”no sale 3”. Se trata de una sucesion de n = 5 ensayos de Bernoulli con probabilidad deexito p = 1/6 en cada ensayo. Entonces, por ejemplo:
P ((3, 1, 1, 3, 6)) =
(1
6
)2
·(
5
6
)3
Ejemplo: Se arroja 5 veces un dado normal. En cada lanzamiento llamemos E = ”sale multiplo de 3”,de modo que F = ”no sale multiplo de 3”. Se trata de una sucesion de n = 5 ensayos de Bernoullicon probabilidad de exito p = 1/3 en cada ensayo. Entonces, por ejemplo:
P ((3, 1, 1, 3, 6)) =
(1
3
)3
·(
2
3
)2
Ejemplo: Dada un sucesion de n ensayos de Bernoulli, con probabilidad de exito p en cada ensayo,sea X = ”cantidad de exitos en los n ensayos”. Esta variable aleatoria tiene RX = 0, 1, 2, · · · , n.El evento X = k estara formado por todos aquellos resultados elementales que consten exac-tamente de k ”exitos” y n − k ”fracasos”. Dado que cada uno de ellos tiene probabilidadindividual pk(1 − p)n−k, para calcular la probabilidad de X = k bastara multiplicar dichaprobabilidad individual por la cantidad total de resultados elementales que consten de exactamentek ”exitos” y n − k ”fracasos”, es decir
(nk
). Entonces se tiene: P (X = k) =
(nk
)pk(1 − p)n−k
(k = 0, 1, · · · , n)
Ejemplo: Consideremos un ensayo aleatorio con dos resultados posibles ”exito” y ”fracaso”, donde laprobabilidad de ”exito” es 0 < p < 1. Nuestro experimento aleatorio consiste en repetir el ensayo enforma independiente hasta obtener el primer ”exito”. El espacio muestral puede representarse comoΩ = E, FE, FFE, FFFE, · · · . Los resultados elementales no son equiprobables. De hecho:
P
F · · · F︸ ︷︷ ︸
k
E
= (1 − p)kp
Sea X = ”cantidad de ensayos hasta obtener exito”, de modo que RX = N. Se tiene: P (X = k) =(1 − p)k−1p , k = 1, 2, · · · Hallemos la fda de la variable aleatoria X. Para x ≥ 0 se tiene:
FX(x) = P (X ≤ x) =
[x]∑
k=1
(1 − p)k−1p = p · 1 − q[x]
1 − q= 1 − q[x]
donde [x] simboliza la ”parte entera de x”, es decir el mayor entero que es menor o igual que x. Porejemplo: [4] = 4 , [4, 1] = 4 , [3, 9] = 3. Entonces:
FX(x) =
0 si x < 1
1 − q[x] si x ≥ 1
Definicion 21 Dada una variable aleatoria X se denomina funcion de probabilidad puntual o funcionde masa de probabilidad (fmp) de X a la funcion
pX : R → R dada por pX(x) = P (X = x)
Prof.J.Gaston Argeri 39

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 40
Nota: Cuando la variable aleatoria X es discreta, con rango RX = xn, la fmp pX deX queda unıvocamente determinada conociendo los valores pn = pX(xn). Por este motivo nosreferiremos indistintamente a pX o a pn cuando X sea discreta. Ejemplo: Consideremosuna sucesion de n ensayos de Bernoulli con probabilidad de exito p en cada ensayo. Sea X =”cantidad de exitos en los n ensayos”. En este caso RX = 0, 1, · · · , n. La fmp de X es:
pX(x) =
(nx
)px(1 − p)n−x si x ∈ 0, 1, · · · , n
0 si x 6∈ 0, 1, · · · , n
Grafiquemos esta fdp en el caso n = 10, para p = 1/2 y luego para p = 1/4
p=0.5
x
fdp(x)
0 2 4 6 8 10
0.00.0
50.1
00.1
50.2
00.2
50.3
0
p=0.25
x
fdp(x)
0 2 4 6 8 10
0.00.0
50.1
00.1
50.2
00.2
50.3
0
Propiedad 31 Para toda variable aleatoria X se cumple: ∀x ∈ R , pX(x) = FX(x) − FX(x−)
Dem: Podemos escribir X < x =∞⋃
n=1
X ≤ x − 1
n
. Esta union es creciente de manera que
por propiedades de las funciones de probabilidad vale: P (X < x) = limn →∞
P(X ≤ x − 1
n
)=
limn →∞
FX
(x − 1
n
)= FX(x−). Entonces pX(x) = P (X = x) = P (X ≤ x) − P (X < x) =
FX(x) − FX(x−) ¥
Nota: Observese que FX(xo)−FX(xo−) representa el valor del ”salto” de la fda de X en el puntox = xo. Cuando FX es continua en xo entonces no hay salto allı y en consecuencia la fmp de X esnula en x = xo.
Propiedad 32 Sean X e Y variables aleatorias definidas sobre un mismo espacio de probabilidad.Se verifica: X e Y son identicamente distribuidas sii ∀x ∈ R , FX(x) = FY (x)
Dem: ⇒) Supongamos X e Y identicamente distribuidas. Sea x ∈ R arbitrario. Entonces(−∞, x] ∈ B de modo que FX(x) = P (X ∈ (−∞, x]) = P (Y ∈ (−∞, x]) = FY (x). Luego,X e Y poseen la misma fda.⇐) Supongamos que FX = FY . Consideremos la clase G de todos los miembros de B dondePX coincide con PY , es decir:
G = B ∈ B : PX(B) = PY (B) = B ∈ B : P (X ∈ B) = P (Y ∈ B)
Prof.J.Gaston Argeri 40

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 41
Por construccion es G ⊆ B. Ademas por hipotesis, tomando B = (−∞, x] se tiene PX(B) =FX(x) = FY (x) = PY (B), de modo que G contiene a todos los subconjuntos de R de la forma(−∞, x] con x ∈ R. Pero dado que B es la mınima σ-algebra de subconjuntos de R que contienea todos los conjuntos de la forma (−∞, x], resulta G ⊇ B. Por lo tanto: G = B. Esto significa que∀B ∈ B , PX(B) = PY (B) ¥
Ejemplo: Se arroja una moneda normal 3 veces. Sean X = ”cantidad de caras obtenidas” e Y =”cantidad de cecas obtenidas”. Veamos que X e Y son identicamente distribuidas. En efecto, dadoque en cada ensayo la probabilidad de cara es igual a la probabilidad de ceca, se tiene:
FX(x) =
[x]∑
k=0
(3
k
) (1
2
)3
= FY (x)
Observemos, de paso, que X 6= Y . Por ejemplo, para ω = (C, C, S) es X(Ω) = 2 en tanto queY (ω) = 1
Propiedad 33 Sea X una variable aleatoria discreta con rango RX = xn. La fmp de X verificalas propiedades siguientes:
i) ∀x ∈ R , pX(x) ≥ 0
ii)∞∑
n=1pX(xn) = 1
Dem:
Ω = X ∈ RX =∞⋃
n=1X = xn siendo la union disjunta. Por lo tanto: 1 = P (Ω) =
∞∑
n=1P (X = xn) =
∞∑
n=1pX(xn) ¥
Propiedad 34 Sea X una variable aleatoria discreta con rango RX = xn. La fmp de X determinaunıvocamente su fda. En efecto:
FX(x) = P (X ≤ x) = P
∞⋃
n=1xn≤x
X = xn
=
∞∑
n=1xn≤x
P (X = xn) =∞∑
n=1xn≤x
pX(xn)
Ejemplo: Se lanzan dos dados. Consideremos la variable aleatoria Xi = ”numero del dado i” (i =1, 2). Sea X = ”maximo numero en los dos dados”. Es decir: X = max X1, X2. Hallemos lafmp y la fda de X.Hallemos primeramente las fmp de X1 y X2. Se tiene: RX1 = RX2 = 1, 2, · · · , 6 y porequiprobabilidad vale:
pX1(k) = pX2(k) = 1/6 (k = 1, 2, · · · , 6)
Por lo tanto:
FX1(x) = FX2(x) =
6∑
k=1k≤x
1
6=
[x]
6
Observemos ahora queX ≤ x = X1 ≤ x ∩ X2 ≤ x
Por lo tanto y teniendo en cuenta la independencia de ambos lanzamientos:
FX(x) = P (X ≤ x) = P (X1 ≤ x ∩ X2 ≤ x) =
= P (X1 ≤ x)P (X2 ≤ x) = FX1(x)FX2(x) =(
[x]6
)2= [x]2
36
Prof.J.Gaston Argeri 41

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 42
Luego, para k = 1, 2, · · · , 6 se tiene:
pX(k) = P (X ≤ k) − P (X ≤ k − 1) = FX(k) − FX(k − 1) =k2 − (k − 1)2
36=
2k − 1
36
Generalicemos esta situacion para el experimento que consiste en arrojar una dado normal n-veces.Definamos:
Xi = ”numero obtenido en el i-esimo lanzamiento”
X = ”maximo numero obtenido en los n lanzamientos”
Como antes: X ≤ k =n⋂
i=1
Xi ≤ k Por lo tanto, teniendo en cuenta la independencia de los
n lanzamientos, resulta:
P (X ≤ x) = P
(n⋂
i=1
Xi ≤ x)
=n∏
i=1
P (Xi ≤ x) =
=n∏
i=1
FXi(x) =n∏
i=1
[x]6
=(
[x]6
)n
Luego, para k = 1, 2, · · · , 6 se tiene:
pX(k) = FX(k) − FX(k − 1) =
(k
6
)n
−(
k − 1
6
)n
=kn − (k − 1)n
6n
La propiedad anterior no es valida para variables aleatorias no discretas. De hecho, existen fda que sonfunciones continuas en todo R. Si X una tal variable aleatoria entonces ∀x ∈ R , FX(x) = FX(x−).Por lo tanto:
P (X = x) = P (X ≤ x) − P (X < x) = FX(x) − FX(x−) = 0
Es decir, para variables aleatorias continuas la fmp carece por completo de interes dado que esidenticamente nula.
Propiedad 35 Sea pn una sucesion tal que:
i) ∀n ∈ N , pn ≥ 0
ii)∞∑
x=1pn = 1
Entonces pn es una fmp.
Dem:
Definamos F (x) =∞∑
n=1n≤x
pn. Dejo a cargo de ustedes verificar que F satisface las condiciones para
ser una fda (Teorema 1) ¥
Motivaremos ahora la nocion de variable aleatoria continua.
Ejemplo: Consideremos una poblacion formada por un gran numero N = 1000 de personas. Supong-amos que nos interesa la distribucion de la variable aleatoria X que mide la altura de un individuoseleccionado al azar dentro de esta poblacion. Supongamos para fijar ideas que las alturas se midenen cm y que se encuentran en el intervalo [150, 190] Dado el gran numero de personas en la poblacionpodemos tener una idea aproximada de la distribucion de alturas dividiendo el intervalo [150, 190]
Prof.J.Gaston Argeri 42
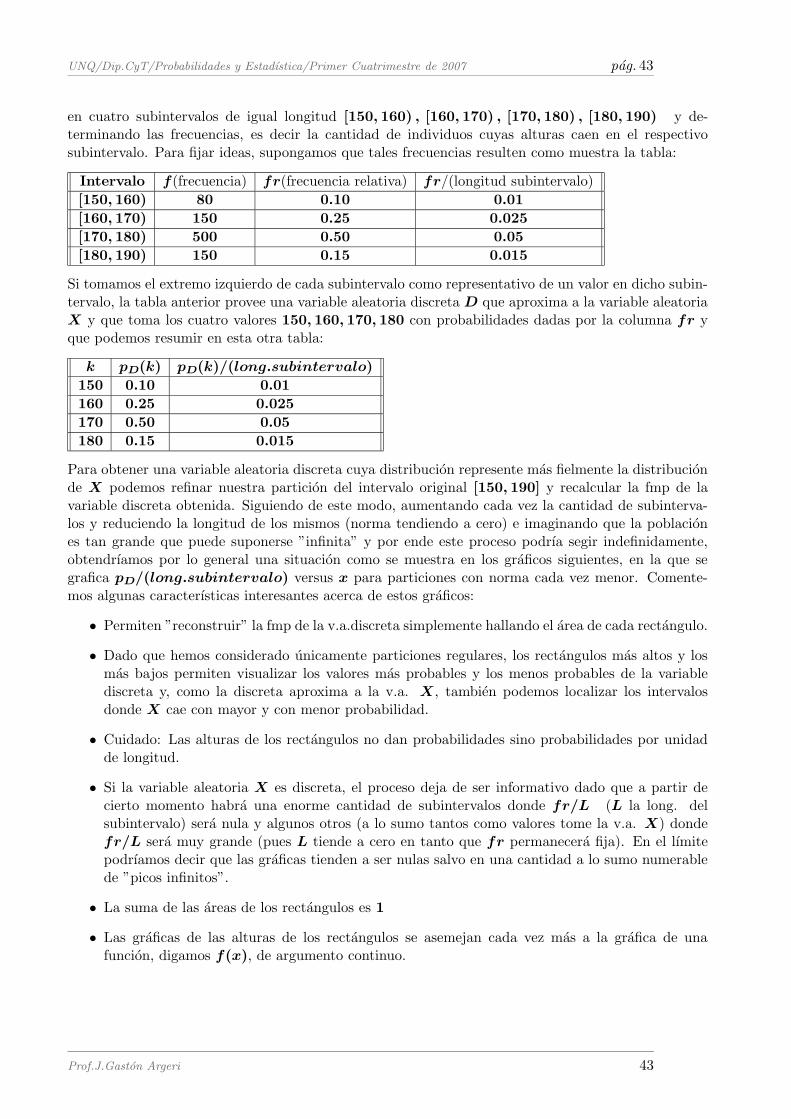
UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 43
en cuatro subintervalos de igual longitud [150, 160) , [160, 170) , [170, 180) , [180, 190) y de-terminando las frecuencias, es decir la cantidad de individuos cuyas alturas caen en el respectivosubintervalo. Para fijar ideas, supongamos que tales frecuencias resulten como muestra la tabla:
Intervalo f(frecuencia) fr(frecuencia relativa) fr/(longitud subintervalo)
[150, 160) 80 0.10 0.01
[160, 170) 150 0.25 0.025
[170, 180) 500 0.50 0.05
[180, 190) 150 0.15 0.015
Si tomamos el extremo izquierdo de cada subintervalo como representativo de un valor en dicho subin-tervalo, la tabla anterior provee una variable aleatoria discreta D que aproxima a la variable aleatoriaX y que toma los cuatro valores 150, 160, 170, 180 con probabilidades dadas por la columna fr yque podemos resumir en esta otra tabla:
k pD(k) pD(k)/(long.subintervalo)
150 0.10 0.01
160 0.25 0.025
170 0.50 0.05
180 0.15 0.015
Para obtener una variable aleatoria discreta cuya distribucion represente mas fielmente la distribucionde X podemos refinar nuestra particion del intervalo original [150, 190] y recalcular la fmp de lavariable discreta obtenida. Siguiendo de este modo, aumentando cada vez la cantidad de subinterva-los y reduciendo la longitud de los mismos (norma tendiendo a cero) e imaginando que la poblaciones tan grande que puede suponerse ”infinita” y por ende este proceso podrıa segir indefinidamente,obtendrıamos por lo general una situacion como se muestra en los graficos siguientes, en la que segrafica pD/(long.subintervalo) versus x para particiones con norma cada vez menor. Comente-mos algunas caracterısticas interesantes acerca de estos graficos:
• Permiten ”reconstruir” la fmp de la v.a.discreta simplemente hallando el area de cada rectangulo.
• Dado que hemos considerado unicamente particiones regulares, los rectangulos mas altos y losmas bajos permiten visualizar los valores mas probables y los menos probables de la variablediscreta y, como la discreta aproxima a la v.a. X, tambien podemos localizar los intervalosdonde X cae con mayor y con menor probabilidad.
• Cuidado: Las alturas de los rectangulos no dan probabilidades sino probabilidades por unidadde longitud.
• Si la variable aleatoria X es discreta, el proceso deja de ser informativo dado que a partir decierto momento habra una enorme cantidad de subintervalos donde fr/L (L la long. delsubintervalo) sera nula y algunos otros (a lo sumo tantos como valores tome la v.a. X) dondefr/L sera muy grande (pues L tiende a cero en tanto que fr permanecera fija). En el lımitepodrıamos decir que las graficas tienden a ser nulas salvo en una cantidad a lo sumo numerablede ”picos infinitos”.
• La suma de las areas de los rectangulos es 1
• Las graficas de las alturas de los rectangulos se asemejan cada vez mas a la grafica de unafuncion, digamos f(x), de argumento continuo.
Prof.J.Gaston Argeri 43
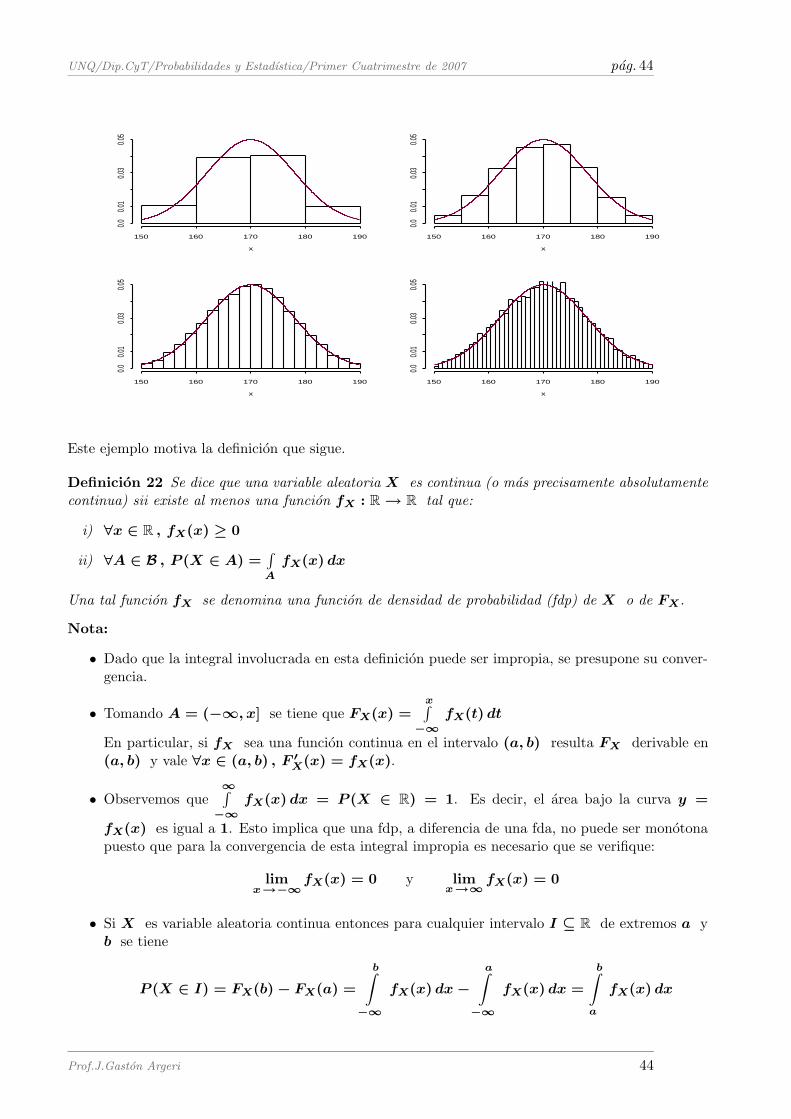
UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 44
150 160 170 180 190
0.00.0
10.0
30.0
5
x
150 160 170 180 190
0.00.0
10.0
30.0
5
x
150 160 170 180 190
0.00.0
10.0
30.0
5
x
150 160 170 180 190
0.00.0
10.0
30.0
5
x
Este ejemplo motiva la definicion que sigue.
Definicion 22 Se dice que una variable aleatoria X es continua (o mas precisamente absolutamentecontinua) sii existe al menos una funcion fX : R → R tal que:
i) ∀x ∈ R , fX(x) ≥ 0
ii) ∀A ∈ B , P (X ∈ A) =∫
A
fX(x) dx
Una tal funcion fX se denomina una funcion de densidad de probabilidad (fdp) de X o de FX .
Nota:
• Dado que la integral involucrada en esta definicion puede ser impropia, se presupone su conver-gencia.
• Tomando A = (−∞, x] se tiene que FX(x) =x∫
−∞fX(t) dt
En particular, si fX sea una funcion continua en el intervalo (a, b) resulta FX derivable en(a, b) y vale ∀x ∈ (a, b) , F ′
X(x) = fX(x).
• Observemos que∞∫
−∞fX(x) dx = P (X ∈ R) = 1. Es decir, el area bajo la curva y =
fX(x) es igual a 1. Esto implica que una fdp, a diferencia de una fda, no puede ser monotonapuesto que para la convergencia de esta integral impropia es necesario que se verifique:
limx →−∞
fX(x) = 0 y limx →∞
fX(x) = 0
• Si X es variable aleatoria continua entonces para cualquier intervalo I ⊆ R de extremos a yb se tiene
P (X ∈ I) = FX(b) − FX(a) =
b∫
−∞
fX(x) dx −a∫
−∞
fX(x) dx =
b∫
a
fX(x) dx
Prof.J.Gaston Argeri 44

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 45
• Si fX es continua en x, entonces fX(x) = F ′X(x) de modo que se tiene la siguiente
interpretacion de la fdp:
fX(x) = limh → 0+
fX(x+h)−FX(x)h
= limh → 0+
P (X≤x+h)−P (X≤x)h
=
= limh → 0+
P (x<X<x +h)h
Es decir que fX(x) representa la probabilidad de que X pertenezca al intervalo (x, x +h) dividida por la longitud de dicho intervalo. De ahı el nombre ”densidad” de probabilidad.
Ejemplo: Sea F : R → R dada por F (x) = 11+e− x . Comprueben que F satisface las condiciones
de una fda, es decir que existe una variable aleatoria X tal que F = FX . Esta va es continua.Hallemos su fdp:
fX(x) = F ′X(x) = d
dx1
1+e− x = e− x
(1+e− x)2 = ex
(1+ex)2
Propiedad 36 Sea f : R → R una funcion satisfaciendo las siguientes condiciones:
i) ∀x ∈ R , f(x) ≥ 0
ii)∞∫
−∞f(x) dx = 1
Entonces f una fdp.
Dem: Definamos F : R → R por F (x) =x∫
−∞f(t) dt. Vamos a verificar que esta F es una fda.
• F es no decreciente pues si x, y ∈ R con x < y se tiene:
F (x) =
x∫
−∞
f(t) dt ≤y∫
−∞
f(t) dt = F (y)
ya que f ≥ 0 y (−∞, x) ⊆ (−∞, y)
• Para cualquier x ∈ R es F continua en x. Solo demostraremos esto en el caso partirular enque f es continua en x. En tal caso el teorema fundamental del calculo asegura que:
limh → 0
1
h
x+h∫
x
f(t) dt = f(x)
Entonces:
limh → 0
F (x + h) − F (x) = limh → 0
(x+h∫
−∞f(t) dt −
x∫
−∞f(t) dt
)
= limh → 0
x+h∫
xf(t) dt =
= limh → 0
(
h · 1h
x+h∫
xf(t) dt
)
= 0 · f(x) = 0
Por lo tanto limh → 0
F (x + h) − F (x) = 0. Es decir: limh → 0
F (x + h) = F (x)
Prof.J.Gaston Argeri 45

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 46
• Finalmente:
limx →−∞
F (x) = limx →−∞
x∫
−∞f(t) dt =
−∞∫
−∞f(t) dt = 0
limx →∞
F (x) = limx →∞
x∫
−∞f(t) dt =
∞∫
−∞f(t) dt = 1
Esto demuestra que F es una fda. Entonces por teorema 1 existe una variable aleatoria con fda F (ypor ende, con fdp f) ¥
Definicion 23 Sea f una fdp. Se denomina soporte de f al menor conjunto cerrado que contieneal conjunto x ∈ R : f(x) > 0. Anotaremos RX al soporte de f .
Propiedad 37 Sean X v.a. continua con fdp fX y sea B ∈ B. Entonces: P (X ∈ B) = P (X ∈B ∩ RX)
Dem:P (X ∈ B) =
∫
B fX(x) dx =∫
B∩RXfX(x) dx +
∫
B∩RcX
fX(x) dx =∫
B∩RXfX(x) dx =
P (X ∈ B ∩ RX) puesto que∫
B∩RcX
fX(x) dx =∫
B∩RcX
0 dx = 0 ¥
Propiedad 38 La funcion f(x) = 1√2π
· e− x2/2 es una fdp.
Dem:Claramente: ∀x ∈ R , f(x) > 0. Por otra parte:
(∞∫
−∞
1√2π
· e− x2/2 dx
)2
=
(∞∫
−∞
1√2π
· e− x2/2 dx
)
·(
∞∫
−∞
1√2π
· e− y2/2 dy
)
=
=∞∫
−∞
∞∫
−∞
12π
· e− (x2+y2)/2 dy dx =∞∫
0
2π∫
0
12π
· e− r2/2 r dθ dr =
=∞∫
0
e− r2/2 r dr =∞∫
0
e− t dt = − e− t∣∣∞0
= 1
En lo anterior hemos utilizado coordenadas polares (se multiplico por r, el modulo del jacobiano).Luego, el cuadrado de la integral es 1. Pero siendo positiva la integral (pues f es positiva), resultanecesariamente: ∞∫
−∞
1√2π
· e− x2/2 dx = 1
Esta fdp es sumamente importante en estadıstica y se denomina densidad gaussiana (es frecuentellamarla tambien densidad normal standard). Suele anotarse ϕ(x).
Ejemplo: Sea
f(x) =
kx si 0 < x < 10 si x ≤ 0 ∨ x ≥ 1
Determinar el valor de la constante k de modo que f resulte ser una fdp. Hallar tambien la fda.
En primer lugar debe ser∞∫
−∞f(x) dx = 1. En este caso:
1 =
1∫
0
kx dx = kx2
2
∣∣∣∣
1
0
=k
2
Prof.J.Gaston Argeri 46

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 47
Por lo tanto k = 2. Hallemos la fda asociada:
F (x) =
x∫
−∞
f(t) dt =
0 si x ≤ 0x∫
0
2t dt si 0 < x < 1
1 si x ≥ 1
=
0 si x ≤ 0x2 si 0 < x < 11 si x ≥ 1
Nota: El soporte de f en este ejemplo es [0, 1].
Ejemplo: El tiempo T en horas que funciona una computadora antes de descomponerse es una v.a.continua con fdp dada por:
fT (t) =
λe− t/100 si t ≥ 0
0 si t < 0
Calcular la probabilidad de que una computadora funcione entre 50 y 150 horas antes de descompon-erse. Calcular tambien la probabilidad de que funciones menos de 100 horas.Rta: Primero debemos hallar λ. Siendo fT una fdp se tiene:
1 =
∫ ∞
− ∞fT (t) dt =
∫ ∞
0λe− t/100 dt = −100λ e− t/100
∣∣∣
∞
0= 100λ
Luego λ = 1/100. Entonces la probabilidad de funcionar entre 50 y 150 horas es:
P (50 < T < 150) =
∫ 150
50
1
100e− t/100 dt = − e− t/100
∣∣∣
150
50= e−0.5 − e−1.5 ≈ 0.384
La probabilidad de que funcione menos de 100 horas viene dada por:
P (T < 100) =
∫ 100
0
1
100e− t/100 dt = − e− t/100
∣∣∣
100
0= 1 − e−1 ≈ 0.633
18 Cuantiles de una distribucion
Definicion 24 Sea X una variable aleatoria con fda FX . Dado α ∈ R , 0 < α < 1, un numeroreal xα se dice un α-cuantil de FX o de X sii se verifican:
P (X < xα) ≤ α y P (X > xα) ≤ 1 − α
Equivalentemente, xα es un α-cuantil de FX sii se cumplen:
P (X < xα) ≤ α y P (X ≤ xα) ≥ α
Suponiendolos unicos, cuando α = 0.5 hablamos de la mediana de FX , cuando α = 0.25 hablamosdel primer cuartil de FX y para α = 0.75 hablamos del tercer cuartil de X. Cuando se considerancuantiles asociados a una division del intervalo (0, 1) en cien partes iguales es frecuente hablar depercentiles de FX .
Nota: Cuando X es variable aleatoria continua (es decir que FX es funcion continua) la condicionanterior se expresa de manera mas simple:
xα es cuantil α de FX sii F (xα) = α sii
∫ xα
− ∞fX(x) dx = α sii P (X ≤ xα) = α
De manera mas grafica, el cuantil α de una distribucion continua es el punto del eje de abscisas quedeja a su izquierda y por debajo de la grafica de fX (obviamente por encima del eje de abscisas) un
Prof.J.Gaston Argeri 47

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 48
area exactamente igual a α. Equivalentemente si se grafica FX (siempre supuesta continua), hallarel cuantil α de FX es hallar la abscisa del punto de la grafica que posee ordenada igual a α
Ejemplo: Si X es una variable aleatoria con distribucion gaussiana standard entonces la mediana esx0.5 = 0 pues debido a la paridad de la fdp ϕ se tiene:
FX(0) =
0∫
−∞
ϕ(x) dx =1
2
∞∫
−∞
ϕ(x) dx = 0.5
El cuantil α = 0.05 se determina planteando Φ(x0.05) = 0.05. Entonces x0.05 = Φ−1(0.05). Paracalcularlo en forma concreta podemos utilizar tablas normales acumulativas o podemos por ejemplorecurrir al SPlus. Para ilustrar un poco mas, veamos la siguiente tabla (junto con los comandosutilizados):p_c(0.01,0.05,0.1)
alfa_c(p,0.5,1-rev(p))
round(qnorm(alfa),3)
α xα
0.01 −2.3260.05 −1.6450.1 −1.2820.5 0.0000.9 1.2820.95 1.6450.99 2.326
Ejemplo: Sea X ≈ Bi(n, 0.5). Veamos que la mediana es unica cuando n par pero deja de serlocuando n es impar.
• Si n = 2r entonces x0.5 = r pues:
P (X < r) =r−1∑
k=0
(2rk
) (12
)2r=
(12
)2rr−1∑
k=0
(2rk
)
P (X > r) =2r∑
j=r+1
(2rj
) (12
)2r=
(12
)2r 2r∑
j=r+1
(2rj
)=
=(12
)2r 2r∑
j=r+1
( 2r2r−j
)=
(12
)2rr−1∑
k=0
(2rk
)
Entonces P (X < r) = P (X > r). Pero P (X < r) + P (X = r) + P (X > r) = 1. Luego:
P (X < r) = 1−P (X=r)2
≤ 0.5 y P (X > r) = P (X < r) ≤ 0.5 = 1 − 0.5
• Si n = 2r − 1 entonces cualquier punto del intervalo (r − 1, r] es una posible mediana de X.En efecto: Sea x∗ ∈ (r − 1, r]. Se tiene
P (X < x∗) =r−1∑
k=0
(2r−1k
) (12
)2r−1=
(12
)2r−1r−1∑
k=0
(2r−1k
)
P (X > x∗) =2r−1∑
j=r
(2r−1j
) (12
)2r−1=
(12
)2r−12r−1∑
j=r
(2r−1j
)=
=(12
)2r−12r−1∑
j=r
( 2r−12r−1−j
)=
(12
)2r−1r−1∑
k=0
(2r−1k
)
Prof.J.Gaston Argeri 48

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 49
Luego: P (X < x∗) = P (X > x∗). Pero como P (X < x∗) + P (X > x∗) = 1,necesariamente es P (X < x∗) = P (X > x∗) = 1/2. Luego: P (X < x∗) ≤ 0.5 yP (X > x∗) ≤ 1 − 0.5 = 0.5
Prof.J.Gaston Argeri 49

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 50
Familias parametricas de distribuciones univariadas
19 Distribuciones discretas
19.1 Distribucion uniforme discreta
Dado N ∈ N, se dice que una v.a. tiene distribucion uniforme discreta en 1, · · · , N sii su fmpviene dada por:
pX(X = k) =1
N(1 ≤ k ≤ N)
Observese que RX = 1, · · · , N y esta distribucion de probabilidades es uniforme en el sentidoque deposita la misma masa de probabilidad en cada uno de los N posibles valores 1, · · · , N de X.Podemos comprobar que pX verifica los axiomas de una fmp:
• ∀k ∈ RX , pX(k) = 1/N ≥ 0
•
N∑
k=1
pX(k) =N∑
k=1
1N
= N · 1N
= 1
Ejemplo: Se arroja un dado equilibrado. Sea X el puntaje obtenido. En este caso X poseedistribucion uniforme discreta en 1, · · · , 6Ejemplo: Se extrae una carta al azar de un mazo de cartas espanolas. Sea X la v.a. definida por
X =
1 si sale carta de oro2 si sale carta de copa3 si sale carta de espada4 si sale carta de basto
Entonces X posee distribucion uniforme discreta en 1, 2, 3, 4Ejemplo: Un sereno tiene un llavero con n llaves y solo una de ellas abre la puerta de su habitacion,pero no recuerda cual. Decide probarlas una por una (separando las que no abren) hasta lograrabrir la puerta. Sea X el numero de ensayos que necesita hasta abrir la puerta, de manera queRX = 1, 2, · · · , n. Veamos que X posee distribucion uniforme discreta en 1, 2, · · · , n. Enefecto:
P (X = 1) = 1n
P (X = 2) = (n−1)1n(n−1)
= 1n
P (X = 3) = (n−1)(n−2)1n(n−1)(n−2)
= 1n
......
......
...
P (X = n) = (n−1)(n−2)···2·1n!
= 1n
19.2 Distribucion binomial
Una variable aleatoria X se dice con distribucion binomial de parametros n, p, siendo n ∈ N yp ∈ R , 0 < p < 1, sii su fmp viene dada por:
pX(k) =
(n
k
)
pk(1 − p)n−k (0 ≤ k ≤ n)
En tal caso anotamos X ∼ Bi(n, p). Observese que RX = 0, 1, · · · , n. Comprobemos quepX verifica los axiomas de una fmp:
Prof.J.Gaston Argeri 50

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 51
• ∀k ∈ RX , pX(k) =(n
k
)pk(1 − p)n−k ≥ 0
•
n∑
k=0
pX(k) =n∑
k=0
(nk
)pk(1 − p)n−k = (p + (1 − p))n = 1
Ademas la fda de X viene dada por:
FX(x) =
[x]∑
k=0
(n
k
)
pk(1 − p)n−k
Cuando p = 1/2 la fmp resulta simetrica con centro de simetrıa x∗ = n/2. En efecto: Consideremospor separado los casos n par e impar.
• n impar. Anotemos n = 2r − 1. En este caso el simetrico de x = r − j respecto dex∗ = r − 1/2 es x = 2x∗ − (r − j) = 2
(r − 1
2
) − (r − j) = 2r − 1 − r + j = r + j − 1
pX(r − j) =
(2r − 1
r − j
) (1
2
)n
pX(r + j − 1) =
(2r − 1
r + j − 1
) (1
2
)n
Pero (2r − 1
r − j
)
=
(2r − 1
(2r − 1) − (r − j)
)
=
(2r − 1
r + j − 1
)
• n par. Anotemos n = 2r. En este caso el simetrico de x = r − j respecto de x∗ = r esx = 2x∗ − (r − j) = 2 2r
2− (r − j) = 2r − (r − j) = r + j
pX(r − j) =
(2r
r − j
) (1
2
)n
pX(r + j) =
(2r
r + j
) (1
2
)n
Pero (2r
r − j
)
=
(2r
(2r) − (r − j)
)
=
(2r
r + j
)
La distribucion binomial Bi(n, p) frecuentemente surge cuando se mide la cantidad de exitos enuna sucesion de n ensayos de Bernoulli con probabilidad de exito p en cada ensayo individual.Notese que en tal caso la distribucion del numero de fracasos es una variable aleatoria con distribucionBi(n, 1 − p).
Ejemplo: Se lanza 8 veces un dado equilibrado. Sea
X = ”cantidad de ensayos en los que se obtiene multiplo de 3”
Se trata de una sucesion de 8 ensayos de Bernoulli, donde en cada ensayo: ”exito”=”sale multiplode 3”. la probabilidad de exito en cada ensayo es pues p = 1/3. La distribucion de X es entoncesBi(8, 1/3). Calculemos las probabilidades de los siguientes eventos:
a) ”Cinco veces sale multiplo de 3”
Rta: P (X = 5) =(85
) (13
)5 (23
)3= 0.0683
Prof.J.Gaston Argeri 51

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 52
b) ”Al menos dos veces sale multiplo de 3”
Rta: P (X ≥ 2) = 1−P (X < 2) = 1−P (X = 0)−P (X = 1) = 1−(80
) (23
)8−(81
)13·(2
3
)7
c) ”A lo sumo cinco veces sale multiplo de 3”Rta: P (X ≤ 5) = 1 − P (X > 5) = 1 − P (X = 6) − P (X = 7) − P (X = 8) =
1 − (86
) (13
)6 · (23
)2 − (87
) (13
)7 · 23
− (88
) (13
)8
Propiedad 39 La fmp de una v.a. con distribucion Bi(n, p) alcanza un maximo en el puntox∗ = [(n + 1)p]
Dem:Dado que la fmp es discontinua, no es posible aplicar tecnicas de calculo (derivada) para obtenersu maximo. Sin embargo el siguiente procedimiento es viable: Calculemos el cociente C(k) =pX(k)/pX(k −1) Mientras este cociente se mantenga mayor que la unidad sera pX creciente comofuncion de k. En cambio mientras el cociente permanezca menor que la unidad entonces pX seradecreciente. Ante todo hallemos este cociente:
C(k) =
(nk
)
( nk−1
) =n!(k − 1)!(n − k + 1)!pkqn−k
k!(n − k)!n!pk−1qn−k+1=
(n − k + 1)p
kq
Luego:C(k) > 1 ⇔ (n − k + 1)p > k(1 − p) ⇔ k < (n + 1)p
C(k) = 1 ⇔ (n − k + 1)p > k(1 − p) ⇔ k = (n + 1)p
C(k) < 1 ⇔ (n − k + 1)p > k(1 − p) ⇔ k > (n + 1)p
Si (n + 1)p no es entero, lo anterior muestra que la fmp alcanza su maximo en un unico punto(unimodal), a saber x∗ = [(n + 1)p]. Si, en cambio, (n + 1)p es entero, lo anterior muestra que lafmp alcanza su maximo en dos puntos (bimodal), a saber: x∗ = (n + 1)p y x∗∗ = x∗ − 1 ¥
Esta situacion se puede comprobar en los siguientes graficos:
0 1 2 3 4 5 6
0.00.1
0.20.3
fmp de una Bi(6,1/3)
0 1 2 3 4 5 6 7 8
0.00.0
50.1
00.1
50.2
00.2
5
fmp de una Bi(8,1/3)
Nota: Los siguientes comandos de SPlus son utiles: Sea X ∼ Bi(n, p). Sea k un vector, k =(k1, · · · , ks) (cuando s = 1 es un vector de longitud 1, o sea un numero).
dbinom(k,n,p)
da como resultado el vector (pX(k1), · · · pX(ks)).Por ejemplo:
Prof.J.Gaston Argeri 52

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 53
> n <- 8
> p <- 0.25
> k <- c(3, 4, 6, 7)
> dbinom(k, n, p)
[1] 0.2076416016 0.0865173340 0.0038452148 0.0003662109
> round(dbinom(k, n, p), 5)
[1] 0.20764 0.08652 0.00385 0.00037
> k <- 0:8
> dbinom(k, n, p)
[1] 0.10011291504 0.26696777344 0.31146240234 0.20764160156 0.08651733398
[6] 0.02307128906 0.00384521484 0.00036621094 0.00001525879
> round(dbinom(k, n, p), 5)
[1] 0.10011 0.26697 0.31146 0.20764 0.08652 0.02307 0.00385 0.00037 0.00002
pbinom(k,n,p)
da como resultado el vector (FX(k1), · · · FX(ks)).
19.3 Distribucion geometrica
Dado p ∈ (0, 1), una v.a. X se dice con distribucion geometrica de parametro p sii su fmp vienedada por:
pX(k) = (1 − p)k−1 · p (k ∈ N)
En tal caso anotamos X ∼ G(p). Observemos que RX = N. Verifiquemos que pX satisface losaxiomas de una fmp. Para abreviar anotemos q = 1 − p:
• ∀k ∈ N , pX(k) = qk−1p ≥ 0
•
∞∑
k=1
pX(k) =∞∑
k=1
qk−1p = p∞∑
k=1
qk−1 = p1−q
= pp
= 1
Calculemos su fda:
FX(x) = P (X ≤ x) =[x]∑
k=1
(1 − p)k−1p = p[x]−1∑
j=0
(1 − p)j =
= p · 1−(1−p)[x]
1−(1−p)= 1 − (1 − p)[x] = 1 − q[x]
Algunas de estas graficas se muestran en la figura siguiente: Graficamos tambien algunas fmp:
Una propiedad interesante de esta distribucion es la siguiente.
Propiedad 40 (”Ausencia de memoria”) Sea X una v.a. con distribucion geometrica deparametro p ∈ (0, 1). Sean s, t ∈ N con s > t. Se verifica:
P (X > s|X > t) = P (X > s − t)
Dem:En efecto, anotemos q = 1 − p. Como s > t resulta X > s ⊆ X > t. Por lo tanto:
X > s ∩ X > t = X > sLuego:
P (X > s|X > t) = P (X>s , X>t )P (X>t)
= P (X>s)P (X>t)
= 1−FX(s)1−FX(t)
= qs
qt = qs−t = 1 − (1 − qs−t
)=
= 1 − FX(s − t) = P (X > s − t) ¥
Prof.J.Gaston Argeri 53

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 54
fda de una G( 0.2 )
k
P( X =
k )
0 5 10 15 20
0.00.2
0.40.6
0.81.0
fda de una G( 0.4 )
k
P( X =
k )
0 2 4 6 8 10 12
0.00.2
0.40.6
0.81.0
fda de una G( 0.6 )
k
P( X =
k )
0 2 4 6 8
0.00.2
0.40.6
0.81.0
fda de una G( 0.8 )
k
P( X =
k )
0 1 2 3 4 5
0.00.2
0.40.6
0.81.0
1 2 3 4 5 6 7 8 9
0.00.0
50.1
00.1
50.2
0
fmp de una G( 0.2 )
k
P( X =
k )
1 2 3 4 5 6 7 8 9
0.00.1
0.20.3
0.4fmp de una G( 0.4 )
k
P( X =
k )
1 2 3 4 5 6 7 8 9
0.00.2
0.40.6
fmp de una G( 0.6 )
k
P( X =
k )
1 2 3 4 5 6 7 8 9
0.00.2
0.40.6
0.8
fmp de una G( 0.8 )
k
P( X =
k )
Ejemplo: La distribucion geometrica surge tambien en el contexto de ensayos de Bernoulli con proba-bilidad de exito p en cada ensayo. Si X = ”cantidad de ensayos hasta obtener el primer exito” entoncesX posee distribucion geometrica con parametro p. Por ejemplo, si se arroja un dado equilibrado hastaque sale el numero 6 y X representa la cantidad de lanzamientos necesarios, entonces RX = N yX = k sii en los primeros k − 1 lanzamientos no sale 6 y en el k-esimo sale 6. Dado que loslanzamientos son independientes entre sı, es claro que P (X = k) = (1 − p)k−1p, siendo p = 1/6.
Nota: Los siguientes comandos de SPlus son utiles: Sea X ∼ G(p). Sea k un vector, k =(k1, · · · , ks) (cuando s = 1 es un vector de longitud 1, o sea un numero).
dgeom(k,p)
da como resultado el vector (pX(k1), · · · pX(ks)).Por ejemplo:
> p <- 0.25
> k <- c(1, 4, 6, 7)
> dgeom(k, p)
[1] 0.18750000 0.07910156 0.04449463 0.03337097
> round(dgeom(k, p), 5)
[1] 0.18750 0.07910 0.04449 0.03337
Prof.J.Gaston Argeri 54

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 55
> k <- 4:10
> dgeom(k, p)
[1] 0.07910156 0.05932617 0.04449463 0.03337097 0.02502823 0.01877117
[7] 0.01407838
> round(dgeom(k, p), 5)
[1] 0.07910 0.05933 0.04449 0.03337 0.02503 0.01877 0.01408
pgeom(k,p)
da como resultado el vector (FX(k1), · · · FX(ks)).
19.4 Distribucion hipergeometrica
Dados n, D, N ∈ N con n < N , D < N , se dice que una v.a. X posee distribucion hiper-geometrica con parametros n, D, N sii su fmp viene dada por:
pX(k) =
(Dk
)(N−Dn−k
)
(Nn
) para max 0, D − (N − n) ≤ k ≤ min n, D
En tal caso anotaremos X ∼ H(n, D, N). Observemos que cuando n ≤ min D, N − D resultaRX = 0, 1, · · · , n .
Ejemplo: Un lote de tamano N de cierta clase de artıculos contiene D artıculos defectuosos (yN − D artıculos no defectuosos). Se extrae al azar una muestra de artıculos de tamano n, sinreposicion. Sea X la cantidad de artıculos defectuosos presentes en dicha muestra. Evidentementeel rango de X es de la forma RX = m, · · · , M, donde m = max n − (N − D), 0 yM = min D, n. Dado k ∈ RX calculemos P (X = k). Abreviemos In = 1, · · · , n. Elespacio muestral puede pensarse como
Ω = A ⊆ M1, · · · , MD, B1, · · · , BN−D : #(A) = ndonde M indica defectuoso y B indica no defectuoso. Puesto que la extraccion se realiza al azar,resulta natural considerar a los eventos elementales en este espacio muestral como equiprobables.Entonces:
P (X = k) =# X = k
#Ω
Contar la cantidad de elementos en Ω equivale a contar la cantidad de posibles subconjuntos detamano n elegidos entre N elementos diferentes. Hay
(Nn
)formas diferentes. Contemos ahora
en cuantas de ellas hay exactamente k objetos defectuosos. Para ello debemos contar de cuantasformas es posible elegir los k objetos defectuosos que participaran, a saber
(Dk
), y por cada una de
estas elecciones habra que determinar de cuantas formas es posible elegir los otros n − k elementosparticipantes no defectuosos, a saber
(N−Dn−k
). Por lo tanto # X = k =
(Dk
)(N−Dn−k
). Por lo tanto:
P (X = k) =
(Dk
)(N−Dn−k
)
(Nn
)
Es decir, efectivamente X posee distribucion hipergeometrica de parametros n, D, N . Anotaremosesta distribucion como H(n, D, N).
Nota: Los siguientes comandos de SPlus son utiles: Sea X ∼ H(n, D, N). Sea k un vector,k = (k1, · · · , ks) (cuando s = 1 es un vector de longitud 1, o sea un numero).
dhyper(k,D,N-D,n)
da como resultado el vector (pX(k1), · · · pX(ks)).Por ejemplo:
Prof.J.Gaston Argeri 55
UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 56
> D <- 6
> ND <- 8
> n <- 4
> k <- 0:3
> round(dhyper(k, D, ND, n), 4)
[1] 0.0699 0.3357 0.4196 0.1598
phyper(k,D,N-D,n)
da como resultado el vector (FX(k1), · · · FX(ks)).
La fmp de una v.a. H(n, D, N) alcanza un maximo cuando k = k∗ =[(n+1)(D+1)
N+2
]
, como puede
demostrarse y comprobarse en los siguientes graficos. Notese que si (n+1)(D+1)N+2
no es entero, el
maximo se alcanza unicamente en k∗ (unimodal), mientras que si (n+1)(D+1)N+2
es entero, entonces
pX alcanza su maximo en los dos puntos k∗ = (n+1)(D+1)N+2
y k∗∗ = k∗ − 1 (bimodal)
0 1 2 3 4 5 6 7 8 9 10
fmp de H(10,12,26)
k
P( X
=k )
0.0
0.05
0.10
0.15
0.20
0.25
0.30
0 1 2 3 4 5 6 7
fmp de H(7,6,10)
k
P( X
=k )
0.0
0.1
0.2
0.3
0.4
19.5 Distribucion de Poisson - Procesos de Poisson
Dado λ ∈ R , λ > 0, se dice que una v.a. X posee distribucion de Poisson con parametro λ sii sufmp viene dada por:
pX(k) = e− λ · λk
k!(k = 0, 1, 2, · · · )
En tal caso anotaremos X ∼ P(λ). El parametro λ suele llamarse intensidad. Observemos queRX = N ∪ 0. Verifiquemos que efectivamente pX es una fmp:
• ∀k ∈ N ∪ 0 , pX(k) = e− λ · λk
k!≥ 0
•
∞∑
k=0
pX(k) =∞∑
k=0
e− λ · λk
k!= e− λ
∞∑
k=0
λk
k!= e− λeλ = e0 = 1
Cuando λ no es entero, la distribucion P(λ) alcanza su maximo en el unico (unimodal) puntok = [λ]. En cambio cuando λ es entero, la distribucion alcanza su maximo en dos puntos (bimodal),a saber k = λ y k = λ − 1. Grafiquemos algunas fmp de v.a. Poisson:
Uno de los contextos donde surgen naturalmente variables Poisson es en situaciones en las que deter-minado evento de interes ocurre aleatoriamente en puntos del eje temporal. Por ejemplo, si estamosen una parada de micros y el evento es la llegada de un micro a la parada, tal eventos ocurrira en de-terminados instantes (horas). Supongamos que para cierta constante λ > 0 se verifican las siguientessuposiciones:
Prof.J.Gaston Argeri 56

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 57
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
fmp de una P( 1.5 )
k
P( X = k
)
0.00.1
0.20.3
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
fmp de una P( 3 )
k
P( X = k
)
0.00.0
50.1
00.1
50.2
0
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
fmp de una P( 4.5 )
k
P( X = k
)
0.00.0
50.1
00.1
5
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
fmp de una P( 6 )
k
P( X = k
)
0.00.0
50.1
00.1
5
1. La probabilidad de que ocurra exactamente un evento en un intervalo de tiempo dado y delongitud h es de la forma: λh + o(h)
2. La prbabilidad de que dos o mas eventos ocurran en un intervalo de tiempo dado y de longitudh de la forma: o(h)
3. Dados cualesquiera numeros n ∈ N , j1, · · · , jn ∈ N∪0 y cualquier conjunto de n intervalostemporales disjuntos dos a dos, si se define Ei como el suceso que exactamente ji de los eventosbajo consideracion ocurran en el i-esimo intervalo temporal (i = 1, · · · , n), entonces los sucesosE1, · · · , En son mutuamente independientes.
Intuitivamente hablando, el supuesto 1 significa que para valores pequenos de h, la probabilidad deocurrencia de exactamente uno de los eventos en un lapso de duracion h es λh mas una cantidaddespreciable respecto de h. Observese que podemos interpretar λ como la tasa o razon instantaneade ocurrencia de un evento. El supuesto 2 significa que la probabilidad de que ocurran dos o maseventos en un lapso de tiempo de duracion h es despreciable respecto de h. El supuesto 3 significaque la cantidad de ocurrencias de eventos en un intervalo temporal no afecta ni es influenciada por lacantidad de ocurrencias del evento en intervalos de tiempo disjuntos con el primero.Antes de continuar vamos a establecer un lema que nos resultara util dentro de poco.
Lema 1 Sea αn una sucesion de numeros reales tal que existe α ∈ R con limn →∞
αn = α.
Entonces se cumple:
limn →∞
(
1 − αn
n
)n
= e− α
Dem:Sea f(x) = ln (1 − x). Desarrollemos por Taylor de primer orden alrededor de x = 0. Se obtiene:
f(x) = −x − x2
2· 1
(1 − c)2con c entre 0 y x
Evaluando en x = αn/n y multiplicando por n se obtiene:
n · ln
(
1 − αn
n
)
= −αn − α2n
2n· 1
(1 − cn)2(3)
Dado que cn se encuentra entre 0 y αn/n y como limn →∞
αn = α, resulta limn →∞
cn = 0. Luego,
tomando lımite para n → ∞ en (3) vemos que la sucesion (3) tiene lımite − α. Tomando exponencialy teniendo en cuenta que esta funcion es continua, resulta lo afirmado en el teorema ¥
Prof.J.Gaston Argeri 57

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 58
Teorema 7 Bajo los supuestos 1,2 y 3, la cantidad de ocurrencias de eventos en un lapso de tiempode duracion h es una variable aleatoria con distribucion de Poisson de parametro λh.
Dem:Designemos N(t) el numero de ocurrencias de eventos en el intervalo [0, t). Formemos una par-ticion regular del intervalo [0, t] en n subintervalos: [0, t/n) , [t/n, 2t/n) · · · [(n − 1)t/n, t) .Consideremos los siguientes sucesos:
A = ”k de los subint. contienen exact. un evento y n-k contienen 0 eventos”Bi = ”el subint. i-esimo contiene dos o mas eventos” (i = 1, · · · , n)B = ”al menos uno de los subint. contiene dos o mas eventos”C = N(t) = k ∩ B
Entonces claramente:
B =n⋃
i=1
Bi (union no disjunta)
P (N(t) = k) = P (A ∪ C) = P (A) + P (C) pues A y C son disjuntos
Pero:
P (C) ≤ P (B) ≤n∑
i=1
P (Bi) =n∑
i=1
o
(t
n
)
= n · o
(t
n
)
= t ·(
o(t/n)
t/n
)
Para cada t fijo es limn →∞
o(t/n)t/n
= 0. Luego: limn →∞
P (C) = 0. Por otra parte, si I es un intervalo
de duracion h, los supuestos 1 y 2 implican que:
P (”ocurren 0 eventos en I”) = 1 − P (”ocurre exact. un evento en I”)−−P (”ocurren dos o mas eventos en I”) =
= 1 − (λh + o(h)) − o(h) = 1 − λh − o(h)
Ademas en virtud del supuesto 3 se tiene:
P (A) =(n
k
) [λtn
+ o(
tn
)]k [
1 − λtn
− o(
tn
)]n−k=
= n(n−1)···(n−k+1)k!
· 1nk
n[
λtn
+ o(
tn
)]k
1 −[
λtn
+ o(
tn
)]n−k=
= n(n−1)···(n−k+1)nk · 1
k!
n[
λtn
+ o(
tn
)]k
1 −[
λtn
+ o(
tn
)]n−k=
= 1k!
n[
λtn
+ o(
tn
)]k
1 −[
λtn
+ o(
tn
)]n
1 −[
λtn
+ o(
tn
)]−k k∏
i=1
(
1 − i−1n
)
(4)
Pero como
limn →∞
n
[λt
n+ o
(t
n
)]
= λt + limn →∞
t
[o(t/n)
t/n
]
= λt
se deduce del lema 1 con αn = n[
λtn
+ o(
tn
)]
que:
limn →∞
1 −[λt
n+ o
(t
n
)]n
= e− λt
La primera expresion entre llaves en la ultima de las expresiones en (4) tiende a λk y la terceraexpresion entre llaves tiende a 0. La productoria consta de un numero fijo de factores y cada uno deellos tiende a 1. Por lo tanto:
limn →∞
P (A) = e− λt · (λt)k
k!¥
Prof.J.Gaston Argeri 58

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 59
Nota: Definamos para cada t > 0 la variable aleatoria
Xt = ”cantidad de ocurrencias del evento en el intervalo de tiempo [0,t)”
La coleccion de variables aleatorias Xt : t > 0 se denomina porceso de Poisson de parametroλ. Notese que para cada t > 0 es Xt ∼ P(λt). Volveremos a los procesos de Poisson cuandopresentemos las distribuciones exponencial y gama.
Corolario 4 (Aproximacion de Poisson a la distribucion binomial)Sea λ ∈ R , λ > 0. Para cada k ∈ N ∪ 0 se verifica:
limn →∞
(n
k
) (λ
n
)k (
1 − λ
n
)n−k
= e− λ · λk
k!
Nota: Este corolario suele utilizarse de la manera siguiente. Sea X ∼ Bi(n, p). Supongamosn grande, p pequeno y np es moderado. Entonces la fmp de X es aproximadamente igual a lafmp de Y , siendo Y ∼ P(np). La recomendacion suele ser el uso de la aproximacion cuando:
n ≥ 100 ; p ≤ 0, 01 ; np ≤ 20
Mencionemos que las variables Poisson no ocurren unicamente contando ocurrencias de eventos en eltiempo. Damos algunos ejemplos de otras v.a. que usualmente tienen distribucion de Poisson:
• La cantidad de errores de impresion en cierta/s pagina/s de un libro.
• La cantidad de bacterias en cierta region de cierto cultivo.
Ejemplo: Supongamos que la cantidad de errores tipograficos por pagina de apuntes teorico-practicostipeados por Gaston Argeri posee distribucion P(0.25) (i.e. en promedio Gaston comete un errorde tipeo cada cuatro paginas). Si se escoge al azar un apunte teorico-practico de Gaston, calcular laprobabilidad de que la primera pagina presente al menos un error tipografico.Rta: Si anotamos X a la cantidad de errores en la primera pagina entonces:
P (X ≥ 1) = 1 − P (X = 0) = 1 − e−0.25 ≈ 0.221
Ejemplo: Supongamos que en promedio uno de cada diez artıculos producidos por cierta maquinaresultan defectuosos. Se eligen al azar 20 artıculos producidos por la maquina. Hallar la probabilidadde que al menos 3 de ellos resulten defectuosos.Rta: Se trata de una sucesion de n = 20 ensayos de Bernoulli, donde ”exito=se produce artıculodefectuoso”, con p = 1/10 = 0.1 en cada ensayo. Si X representa la cantidad de defectuosos entre20, entonces X ∼ Bi(20, 0.1) de modo que la probabilidad pedida es:
P (X ≥ 3) = 1 − P (X = 0) − P (X = 1) − P (X = 2) =
= 1 − (200
)(0.9)20 − (20
1
)(0.1)(0.9)19 − (20
2
)(0.1)2(0.9)18 ≈
≈ 1 − 0.1215767 − 0.2701703 − 0.2851798 ≈ 0.3231
Utilizando la aproximacion de Poisson con λ = np = 20(0.1) = 2 se obtiene:
P (X ≥ 3) ≈ 1 −2∑
k=0
e− 2 · 2k
k!≈ 1 − 0.1353353 − 0.2706706 − 0.2706706 ≈ 0.3233
En este caso la aproximacion ha resultado muy buena.
Prof.J.Gaston Argeri 59

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 60
19.6 Distribucion binomial negativa
Dados r ∈ N y p ∈ (0, 1), se dice que una variable aleatoria X posee distribucion binomial negativacon parametros r y p sii su fmp esta dada por:
pX(k) =
(k − 1
r − 1
)
pr(1 − p)k−r (k = r, r + 1, · · · )
En tal caso anotaremos X ∼ BN (r, p). Obseervese que RX = r, r + 1, · · · . Verifiquemos queefectivamente pX es una fmp:
• pX(k) =(k−1r−1
)pr(1 − p)k−r ≥ 0 (k = r, r + 1, · · · )
•
∞∑
k=r
pX(k) =∞∑
k=r
(k−1r−1
)pr(1 − p)k−r = pr
∞∑
k=r
(k−1r−1
)(1 − p)k−r
Consideremos la funcion g(q) =∞∑
j=0
qj = 11−q
Si la derivamos r − 1 veces obtenemos:
∞∑
j=1
jqj−1 = 1(1−q)2
∞∑
j=2
j(j − 1)qj−2 = 2(1−q)3
· · · · · ·∞∑
j=r−1
j(j − 1) · · · (j − r + 2)qj−r+1 = (r−1)!(1−q)r
Es decir (r − 1)!∞∑
j=r−1
( jr−1
)qj−r+1 = (r−1)!
(1−q)r Por lo tanto, tomando q = 1 − p se tiene:
pr∞∑
k=r
(k − 1
r − 1
)
(1 − p)k−r = pr∞∑
j=r−1
(j
r − 1
)
(1 − p)j−r+1 =pr
pr= 1
La distribucin binomial negativa surge naturalmente en el contexto de ensayos de Bernoulli con prob-abilidad de exito p en cada ensayo individual. Recordemos que en dicho contexto la Bi(n, p) es ladistribucion de la cantidad de exitos en los n ensayos. En cambio, la BN (r, p) es la distribucionde la v.a. X definida como la cantidad de ensayos necesarios hasta obtener el r-esimo exito (esdecir, la cantidad de ensayos es ahora aleatoria). En efecto, decir que X = k equivale a decir queel r-esimo exito ocurre en el k-esimo ensayo. Por lo tanto en los k − 1 ensayos anteriores debehaber exactamente r − 1 exitos y k − r fracasos. Entonces para calcular la probabilidad del eventoX = k utilizamos asignacion de probabilidad por ensayos independientes: Hay
(k−1r−1
)maneras
de ubicar los r − 1 exitos entre los k − 1 primeros ensayos (los lugares para los fracasos quedanautomaticamente determinados). Cada ordenamiento de r exitos y k−r fracasos tiene probabilidadpr(1 − p)k−r. Luego P (X = k) =
(k−1r−1
)pr(1 − p)k−r Es decir X ∼ BN (r, p).
Nota: Comandos utiles eb SPlus son dnbinom , pnbinom
Presentamos algunos ejemplos de fmp binomiales negativas: Observese que la fmp de una v.a. BN (r, p)
alcanza su maximo en el punto k∗ =[
r+p−1p
]
. Cuando r+p−1p
no es entero, el maximo se alcanza
unicamente (unimodal) en k = k∗. En cambio, cuando r+p−1p
es entero, el maximo se alcanza en
k = k∗ y en k = k∗ − 1 (bimodal).
Prof.J.Gaston Argeri 60

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 61
3 4 5 6 7 8 9 10 11 12 13 14 15
fmp de BN( 3 , 0.25 )
k
P(
X=
k )
0.0
0.0
20
.04
0.0
60
.08
3 4 5 6 7 8 9 10 11 12 13 14 15
fmp de BN( 3 , 0.45 )
k
P(
X=
k )
0.0
0.0
50
.10
0.1
5
3 4 5 6 7 8 9 10 11 12 13 14 15
fmp de BN( 3 , 0.7 )
k
P(
X=
k )
0.0
0.1
0.2
0.3
20 Distribuciones continuas
20.1 Distribucion uniforme
Sean a, b ∈ R con a < b. Se dice que una variable aleatoria X posee distribucion uniforme en elintervalo [a, b] sii X posee fdp fX dada por
fX(x) =
1b−a
si a ≤ x < b
0 si x < a ∨ x ≥ b
Anotamos X ∼ U(a, b) para indicar que X posee distribucion uniforme en [a, b]. Verifiquemosque fX es realmente un fdp:
• ∀x ∈ R , fX(x) ≥ 0
•
∞∫
− ∞fX(x) dx =
b∫
a
1b−a
dx = 1b−a
b∫
adx = b−a
b−a= 1
Obtengamos la fda. FX(x) =x∫
− ∞fX(t) dt. Debemos distinguir tres casos, segun el valor de x:
• Si x < a: FX(x) = 0
• Si a ≤ x < b: FX(x) =∫ xa
1b−a
dt = x−ab−a
• Si x ≥ b: FX(x) =∫ ba
1b−a
dt = 1
Es decir:
FX(x) =
0 si x < ax−ab−a
si a ≤ x < b
1 si x ≥ b
Las graficas de la fdp y la fda tienen el siguiente aspecto:
20.2 Distribucion gaussiana
Sean µ, σ ∈ R , σ > 0. Se dice que una variable aleatoria X posee distribucion gaussiana (tambienllamada distribucion normal) de parametros µ, σ sii X posee fdp dada por
fX(x) =1√2π σ
· e− 12(x−µ)2/σ2
; x ∈ R
Prof.J.Gaston Argeri 61

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 62
fdp de U(a,b)
x
y
0 1 2
0.00.2
0.40.6
0.81 / ( b - a )
fda de U(a,b)
x
y
0 1 2
0.00.2
0.40.6
0.81.0
1.2
a b
Para indicar que X posee distribucion gaussiana de parametros µ, σ anotamos X ∼ N (µ, σ). Enparticular, cuando µ = 0 y σ = 1 se habla de la distribucion gaussiana (o normal) standard. Sufdp suele anotarse con la letra ϕ. Ası, la fdp gaussiana standard esta dada por
ϕ(x) =1√2π
· e− 12
x2; x ∈ R
Mediante calculo es posible estudiar las caracterısticas de la grafica de ϕ. Resulta simetrica respectodel eje de ordenadas (funcion par), con maximo en el origen. Ademas tiene la conocida forma de”campana de Gauss”. Volviendo al caso general, observese que:
fX(x) =1√2π σ
ϕ
(x − µ
σ
)
Es decir que fX se puede obtener a partir de ϕ mediante una traslacion paralela al eje de abscisasy cambios de escala en los ejes coordenados. Tales transformaciones conservan la forma acampanadade la fdp. Grafiquemos algunos ejemplos de fdp gaussianas:
La fda asociada viene dada por:
FX(x) =
x∫
− ∞
1√2π σ
e−12(t−µ)2/σ2
dt
La fda de una v.a. gaussiana standard suele anotarse Φ y viene dada por:
Φ(x) =
x∫
− ∞
1√2π
e−12
x2dt
Dado que esta funcion no es elemental (no puede expresarse elementalmente la integral indefinidacorrespondiente), para evaluarla en un punto se debe recurrir a tablas o se debe utilizar algun softwareo formula que aproxime sus valores. En el caso general, observemos que:
FX(x) = Φ
(x − µ
σ
)
si X ∼ N (µ, σ)
Nota: Comandos de SPlus dnorm , pnorm , qnorm. Ver el help del SPlus. Por ejemplo: help(dnorm)o simplemente resaltando ”dnorm” y clickeando sobre la flechita ”run”.
Prof.J.Gaston Argeri 62

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 63
misma sigma, distintas mu
x
y
-2 0 2 4 6 8 10 12
0.0
0.1
0.2
0.3
0.4
0.5 N(4,1.5)
N(2,1.5)N(7,1.5)
misma mu, distintas sigma
x
y
-2 0 2 4 6 8 10 12
0.0
0.1
0.2
0.3
0.4
0.5 N(4,1.5)
N(4,3)N(4,0.75)
Familia de densidades gaussianas
20.3 Distribucion exponencial
Dado λ ∈ R , λ > 0, se dice que una variable aleatoria X posee distribucion exponencial conparametro λ sii su fdp vien dada por:
fX(x) = λe− λx (x > 0)
En tal caso anotaremos X ∼ E(λ). El parametro λ suele denominarse parametro de intensidad.Verifiquemos que fX es efectivamente una fdp:
• Para todo x ∈ R, fX(x) = λe− λx ≥ 0
• Efectuando el cambio de variables t = λx se obtiene:∫ ∞
0λe− λx dx =
∫ ∞
0e−t dt = − lim
c →∞e−t
∣∣c
0= − lim
c →∞(e− c − 1) = 1
Hallemos al fda de X:
• Si x ≤ 0 entonces FX(x) =∫ x− ∞ fX(t) dt = 0 pues fX(t) = 0 si t ≤ 0
• Si x > 0 se tiene: FX(x) =∫ x− ∞ fX(t) dt =
∫ x0 λe− λt dt = − e− λt
∣∣x
0= 1 − e− λx
Por lo tanto la fda viene dada por:
FX(x) =
0 si x ≤ 0
1 − e− λt si x > 0
Prof.J.Gaston Argeri 63
UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 64
fdp
x
y
0 2 4 6 8 10 12 14
0.00.1
0.20.3
0.40.5
0.6
lambda=0.2lambda=0.4lambda=0.6
fda
x
y
0 2 4 6 8 10 12 14
0.00.2
0.40.6
0.81.0
lambda=0.2lambda=0.4lambda=0.6
Familia de densidades exponenciales
Para observar las caracterısticas mas importantes de la distribucion exponencial, grafiquemos algunosejemplos de fdp y fda en el caso exponencial:
Propiedad 41 (”Ausencia de memoria”) Supongamos que X ∼ E(λ). Sean s, t ∈ R , s > t ≥0. Se verifica:
P (X > s | X > t) = P (X > s − t)
Dem:
P (X > s|X > t) = P (X>s , X>t )P (X>t)
= P (X>s)P (X>t)
= 1−FX(s)1−FX(t)
= e− λs
e− λt = e− λ(s−t) = P (X > s − t) ¥
Ejemplo: Consideremos un proceso de conteo (de ocurrencias de cierto evento) tipo Poisson Xt : t > 0de parametro λ, es decir que Xt ∼ E(λ). Definamos la variable aleatoria:
T1 = ”tiempo hasta la primera ocurrencia del evento”
Hallemos la fda de T1. Para ello calculemos:
P (T1 ≥ t) = P (”la primera ocurrencia se produce luego del instante t”) =
= P (”no hay ocurrencias en [0, t]”) = P (Xt = 0) = e− λt · (λt)0
0!= e− λt
Por lo tanto FT1(t) = 1 − e− λt si t > 0. Naturalmente FT1(t) = 0 si t ≤ 0. Por lo tanto lavariable aleatoria T1 tiene distribucion exponencial de parametro λ.Nota: Comandos de SPlus dexp , pexp , qexp
20.4 Distribucion gamma
Se denomina funcion gama a la funcion Γ : (0, ∞) → R definida por:
Γ(x) =
∞∫
0
tx−1e−t dt (5)
Para ver que esta funcion esta correctamente definida es necesario demostrar que la integral impropiaen (5) es convergente. Observese que el integrando es positivo y que cuando x ≥ 1 la integral esimpropia en el infinito, en tanto que si 0 < x < 1 la integral es impropia tanto en el infinito comoen el origen.
Prof.J.Gaston Argeri 64

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 65
Lema 2 Para cada u ∈ R , u ≥ 0 y para cada n ∈ N se verifica
eu ≥ 1 + u +u2
2!+
u3
3!+ · · · +
un
n!(6)
Dem:Por induccion sobre nPaso base:Dado que ∀u ≥ 0 , eu ≥ 0, la monotonıa de la integral definida garantiza que
∫ u0 eu du ≥ 0. Luego:
eu − 1 ≥ 0. Por lo tanto eu ≥ 1Hipotesis inductiva (HI): Consiste en suponer que para todo u ≥ 0 la desigualdad (6) es verdadera.En base a la HI queremos probar que:
eu ≥ 1 + u +u2
2!+
u3
3!+ · · · +
un+1
(n + 1)!(u ≥ 0)
Pero integrando ambos miembros de (6) en el intervalo [0, u] y teniendo en cuenta la monotonıa dela integral, se deduce que
eu − 1 ≥ u +u2
2!+
u3
3!+ · · · +
un+1
(n + 1)!
que es precisamente lo que queremos demostrar. Luego, la desigualdad es verdadera para tonon natural ¥
Corolario 5 Para cada u ≥ 0 y cada n natural (o cero) se verifica la siguiente desigualdad
eu ≥ un
n!
Dem:Siendo u ≥ 0, todos los terminos en el mienbro de la derecha de la desigualdad (6) son no negativos.Luego, la suma de los mismos es mayor o igual que cualquiera de ellos. En particular es mayor o igualque el ultimo termino. Este hecho, junto con la desigualdad (6) terminan de demostrar este lema ¥
Propiedad 42 Para cada x ∈ R , x > 0, la integral en (5) es convergente.
Dem:Consideramos dos casos por separado.
• Caso x ≥ 1En el corolario anterior tomemos n = 1 + [x] de manera que n − x + 1 > 1. Entonces parat > 0 se verifica
tx−1e−t =tx−1
et≤ tx−1n!
tn=
n!
tn−x+1
Como la integral impropia∫ ∞1
n!tn−x+1 dt es convergente, por criterio de comparacion resulta
∫ ∞1 tx−1e−t dt tambien convergente. Puesto que
∫ 10 tx−1e−t dt es propia (finita), se deduce
que∫ ∞0 tx−1e−t dt es convergente.
• Caso 0 < x < 1
Prof.J.Gaston Argeri 65

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 66
– Para t ≥ 1 resulta t1−x = e(1−x) ln t ≥ 1 dado que (1 − x) ln t > 0. Entonces:
tx−1e−t =1
t1−xet≤ 1
et= e−t
Pero como∫ ∞1 e−t dt es convergente, por criterio de comparacion resulta
∫ ∞1 tx−1e−t dt
convergente.
– Para 0 < t < 1 resulta e−t ≤ 1. Luego tx−1e−t ≤ tx−1 = 1t1−x . Puesto que
∫ 10
1t1−x dt es convergente por ser 0 < x < 1, el criterio de comparacion asegura que
∫ 10 tx−1e−t dt es convergente ¥
Propiedad 43 La funcion gama verifica:
i) ∀x ∈ R, x > 0, Γ(x + 1) = xΓ(x)
ii) ∀n ∈ N , Γ(n) = (n − 1)!
Dem:
i) Integrando por partes con u = e−t, dv = tx−1 se tiene du = − e−t, v = tx/x
∫
tx−1e−t dt =txe−t
x+
1
x
∫
txe−t dt =1
x
(
txe−t +
∫
t(x+1)−1e−t dt
)
Entonces:∫ h1 tx−1e−t dt = 1
x
(
txe−t∣∣h
1+
∫ h1 t(x+1)−1e−t dt
)
=
= 1x
(
hxe−h − e−1 +∫ h1 t(x+1)−1e−t dt
)
Tomando lımite para h → ∞ se obtiene:
∫ ∞
1tx−1e−t dt =
1
x
(
−e−1 +
∫ ∞
1t(x+1)−1e−t dt
)
(7)
Analogamente:
∫ 1h tx−1e−t dt = 1
x
(
txe−t∣∣1
h+
∫ 1h t(x+1)−1e−t dt
)
=
= 1x
(
e−1 − hxe−h +∫ 1h t(x+1)−1e−t dt
)
Tomando lımite para h → 0+ se obtiene:
∫ 1
0tx−1e−t dt =
1
x
(
e−1 +
∫ 1
0t(x+1)−1e−t dt
)
(8)
Juntando los resultados (7) y (8) se tiene Γ(x) = 1xΓ(x + 1) como se querıa demostrar.
ii) Para n ∈ N podemos aplicar repetidamente el resultado probado en el item anterior. Masformalmente, utilicemos induccion completa:
• Paso base:
Γ(1) =
∫ ∞
0e−t dt =
∫ 1
0e−t dt +
∫ ∞
1e−t dt = lim
h → 0+e−h + lim
k →∞e−k = 1 = 0!
• Hipotesis inductiva (HI): Suponemos Γ(n) = (n − 1)!
Prof.J.Gaston Argeri 66

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 67
• En base a la HI queremos demostrar que Γ(n + 1) = n!. Para ello:
Γ(n + 1) = nΓ(n) = n(n − 1)! = n!
Por lo tanto Γ(n) = (n − 1)! es verdadera para todo n ∈ N ¥
Dados α, λ ∈ R , α, λ > 0 se dice que una variable aleatoria X posee distribucion gama deparametros α, λ sii posee fdp dada por
fX(x) =λα
Γ(α)xα−1e− λx (x > 0)
En tal caso anotaremos X ∼ Γ(α, λ). El parametro α suele llamarse parametro de forma (”shape”)y el parametro λ se suele denominar parametro de intensidad (”rate”). Verifiquemos que fX esefectivamente una fdp:
• Para todo x ∈ R es fX(x) = λα
Γ(α)xα−1e− λx ≥ 0
• Debemos verificar que la integral de fX sobre R es 1. Si en la integral se realiza el cambio devariables t = λx se tendra:
∫ ∞
0
λα
Γ(α)xα−1e− λx dx =
1
Γ(α)
∫ ∞
0tα−1e−t dt =
Γ(α)
Γ(α)= 1
Grafiquemos algunos ejemplos de densidades gama:
alfa= 0.5
x
y
0.0 0.02 0.04 0.06 0.08 0.10
02
46
810
1214 lambda=0.2
lambda=0.4lambda=0.6
alfa= 1
x
y
0 2 4 6
0.0
0.1
0.2
0.3
0.4
0.5
0.6 lambda=0.2
lambda=0.4lambda=0.6
alfa= 1.5
x
y
0 5 10 15
0.0
0.05
0.10
0.15
0.20
0.25
0.30
lambda=0.2lambda=0.4lambda=0.6
Familia de densidades gama
Examinando los distintos graficos se dara cuenta porque α y λ se dicen parametros de ”forma” e”intensidad” (para α ≥ 1, λ controla la rapidez con la cual la cola a derecha de la fdp tiende a ceropara x → ∞), respectivamente.Observemos que la distribucion Γ(1, λ) es precisamente la distribucion exponencial de parametro λ.En efecto, sea X ∼ Γ(1, λ):
fX(x) =λ1
Γ(1)x1−1e− λx = λe− λx
Nota: Comandos de SPlus dgamma , pgamma , qgamma
Vamos a vincular las distribuciones gamma y Poisson.
Prof.J.Gaston Argeri 67

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 68
Propiedad 44 Sean n ∈ N, x > 0. Sea X ∼ Γ(n, λ). Si Y ∼ P(λx) entonces se cumple:
FX(x) = P (X ≤ x) = P (Y ≥ n) = 1 − FY (n − 1)
Dem:Mediante integracion por partes, con u = tn−1 y dv = e− λtdt, se tiene:
∫
tn−1e− λt dt = −λ−1
tn−1e− λt + (n − 1)
∫
tn−2e− λt dt
Aplicando la regla de Barrow entre t = 0 y t = x y anotando In(x) =∫ x0 tn−1e− λt dt resulta:
λIn(x) = (n − 1)In−1(x) − xn−1e− λx (9)
Queremos demostrar (lo haremos por induccion sobre n):
∀n ∈ N , ∀x > 0 ,
∫ x
0
λn
(n − 1)!tn−1e− λt dt = 1 −
n−1∑
k=0
(λx)k
k!e− λx
En otro terminos, queremos probar que:
λn
(n − 1)!In(x) = 1 −
n−1∑
k=0
(λx)k
k!e− λx (10)
Entonces:
• Paso base: I1(x) =∫ x0 λe− λt dt = 1− e− λt
∣∣x
0= 1−e− λx Esto es precisamente (10) cuando
n = 1
• Hipotesis inductiva (HI): Supongamos (10) es verdadera.
• Utilizando (9) junto con (HI) se tiene:
λn+1
n!In+1(x) = λn
n!
(nIn(x) − xne− λx
)= λn
(n−1)!In(x) − (λx)n
n!e− λx =
= 1 −n−1∑
k=0
(λx)k
k!e− λx − (λx)n
n!e− λx = 1 −
n∑
k=0
(λx)k
k!e− λx
¥
20.5 Distribucion chi cuadrado
Esta distribucion es un caso particular de la distribucion gama. Si en la familia de distribuciones gamase considera α = n/2, siendo n natural, y se toma λ = 1/2 se obtiene la llamada distribucion chicuadrado con n grados de libertad (g.l.). Es decir:Dado n ∈ N, se dice que una variable aleatoria X posee distribucion chi cuadrado con n grados delibertad sii posee fdp dada por:
fX(x) =1
2n/2Γ(n/2)x(n/2)−1e− x/2 (x > 0)
En tal caso anotamos X ∼ χ2(n). La distribucion chi cuadrado con g.l.=2 tambiense denominadistribucion de Raleygh y la chi cuadrado con g.l.=3 tambien se llama distribucion de Maxwell-Boltzman (Estos terminos son mas frecuentes en mecanica estadıstica).Presentamos algunos ejemplos de fdp chi cuadrado con distintos grados de libertad asociados:Nota: En SPlus los comandos utiles son dchisq , pchisq , qchisq.
Prof.J.Gaston Argeri 68

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 69
x
y
0.0 0.5 1.0 1.5 2.0
0.0
0.5
1.0
1.5
g.l=1g.l=2
x
y0 5 10 15
0.0
0.05
0.10
0.15
0.20
0.25
g.l=3g.l=4g.l=8
Familia de densidades chi cuadrado
20.6 Distribucion beta
Se denomina funcion beta la fuencion B : (0, ∞) × (0, ∞) → R dada por
B(α, β) =
∫ 1
0xα−1(1 − x)β−1 dx
Observese que segun los valores de α, β la integral que define a la funcion beta puede ser impropiaen el origen (cuando 0 < α < 1) y/o en x = 1 (cuando 0 < β < 1), o directamente ser propia.Una aplicacion trivial del creiterio de comparacion muestra que la integral impropia es convergentepara cualesquiera α, β > 0. Mencionemos dos propiedades utiles de la funcion beta.
Propiedad 45 Para cualesquiera α, β ∈ R, α > 0, β > 0 se verifican:
i) B(α, β) = Γ(α)Γ(β)Γ(α+β)
ii) B(β, α) = B(α, β)
Dados α, β ∈ R , α > 0, β > 0 se dice que una variable aleatoria X posee distribucion beta conparamteros α, β si posee fdp dada por:
fX(x) =1
B(α, β)xα−1(1 − x)β−1 (0 < x < 1)
En tal caso anotaremos X ∼ B(α, β). Verifiquemos que fX es realmente una fdp:
• Para x ∈ (0, 1) , 1B(α,β)
xα−1(1 − x)β−1 ≥ 0
•
∫ 10
1B(α,β)
xα−1(1 − x)β−1 dx = 1B(α,β)
B(α, β) = 1
Grafiquemos algunos ejemplos de fdp para distribuciones beta:
Prof.J.Gaston Argeri 69

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 70
alfa= 0.5
x
y
0.0 0.2 0.4 0.6 0.8 1.0
01
23
4 beta= 0.4beta= 1beta= 1.5
alfa= 0.7
x
y
0.0 0.2 0.4 0.6 0.8 1.0
01
23
45
beta= 0.4beta= 1beta= 1.5
alfa= 1
x
y
0.0 0.2 0.4 0.6 0.8 1.0
01
23
45
6
beta= 0.4beta= 1beta= 1.5
alfa= 1.3
x
y
0.0 0.2 0.4 0.6 0.8 1.0
02
46
beta= 0.4beta= 1beta= 1.5
Familia de densidades beta
Cuando α = β la distribucion beta es simetrica respecto de x = 0.5 Un caso particular (evidente)de la distribucion beta es la U(0, 1). Esto tambien se aprecia en el grafico correspondiente a losvalores α = 1 , β = 1
20.7 Distribucion de Cauchy
Dados λ ∈ R, θ ∈ R, θ > 0, se dice que una variable aleatoria tiene distribucion de Cauchy conparametros λ, θ sii posee fdp dada por:
fX(x) =θ
π
1
θ2 + (x − λ)2(x ∈ R)
En tal caso anotamos X ∼ C(λ, θ). Se dice que λ es el parametro de posicion y θ el parametro deescala. La fdp tiene forma similar a la gaussiana (acampanada) pero sus colas son mucho mas pesadas,como veremos posteriormente. Esta familia de distribuciones es importante en estudios teoricos y desimulacion. En la grafica se observan fdp Cauchy para distintos valores de los parametros: Nota: EnSPlus los comandos interesantes son dcauchy , pcauchy , qcauchy.
Prof.J.Gaston Argeri 70

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 71
misma theta, distintas lambda
x
y
-2 0 2 4 6 8 10 120.0
0.05
0.10
0.15
0.20 C(4,1.5)
C(2,1.5)C(7,1.5)
misma lambda, distintas theta
x
y
0 2 4 6 8
0.00.1
0.20.3
0.4 C(4,0.75)C(4,1.5)C(4,2.25)
Familia de densidades Cauchy
20.8 Distribucion lognormal
Sean µ, σ ∈ R , σ > 0. Se dice que una variable aleatoria X tiene distribucion lognormal conparametros µ, σ sii ln X posee distribucion N (µ, σ2). Para hallar la fdp de X, llamemos Y =ln X de manera que Y ∼ N (µ, σ2), y procedamos como sigue:
FX(x) = P (X ≤ x) = P (eY ≤ x) = P (Y ≤ ln x) = FY (ln x)
Derivando ambos miembros respecto de x (usamos la regla de la cadena) obtenemos:
fX(x) = fY (ln x) · 1
x=
1√2π σx
e− 12
(ln x−µ)2/σ2
Las caracterısticas salientes de la grafica de una fdp lognormal puede estudiarse analıticamente. Pre-sentamos algunos ejemplos: Nota: Los comandos utiles en SPlus son dlnorm , plnorm , qlnorm.
misma mu,distintas sigma
x
y
0 1 2 3 4 5 6
0.00.1
0.20.3
logN(1,0.25)logN(1,1)logN(1,2.25)
misma sigma,distintas mu
x
y
0 1 2 3 4 5 6
0.00.1
00.2
00.3
0 logN(0.7,1)logN(1,1)logN(1.3,1)
Familia de densidades lognormales
Prof.J.Gaston Argeri 71
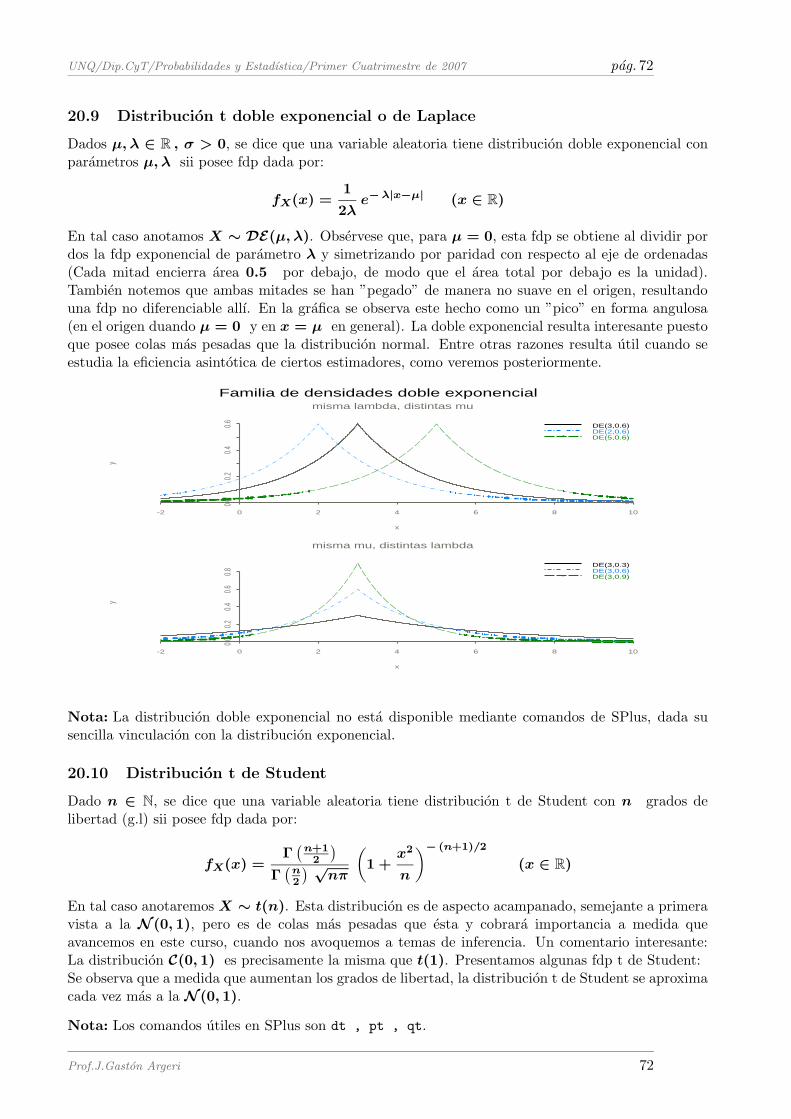
UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 72
20.9 Distribucion t doble exponencial o de Laplace
Dados µ, λ ∈ R , σ > 0, se dice que una variable aleatoria tiene distribucion doble exponencial conparametros µ, λ sii posee fdp dada por:
fX(x) =1
2λe− λ|x−µ| (x ∈ R)
En tal caso anotamos X ∼ DE(µ, λ). Observese que, para µ = 0, esta fdp se obtiene al dividir pordos la fdp exponencial de parametro λ y simetrizando por paridad con respecto al eje de ordenadas(Cada mitad encierra area 0.5 por debajo, de modo que el area total por debajo es la unidad).Tambien notemos que ambas mitades se han ”pegado” de manera no suave en el origen, resultandouna fdp no diferenciable allı. En la grafica se observa este hecho como un ”pico” en forma angulosa(en el origen duando µ = 0 y en x = µ en general). La doble exponencial resulta interesante puestoque posee colas mas pesadas que la distribucion normal. Entre otras razones resulta util cuando seestudia la eficiencia asintotica de ciertos estimadores, como veremos posteriormente.
misma lambda, distintas mu
x
y
-2 0 2 4 6 8 10
0.00.2
0.40.6 DE(3,0.6)
DE(2,0.6)DE(5,0.6)
misma mu, distintas lambda
x
y
-2 0 2 4 6 8 10
0.00.2
0.40.6
0.8
DE(3,0.3)DE(3,0.6)DE(3,0.9)
Familia de densidades doble exponencial
Nota: La distribucion doble exponencial no esta disponible mediante comandos de SPlus, dada susencilla vinculacion con la distribucion exponencial.
20.10 Distribucion t de Student
Dado n ∈ N, se dice que una variable aleatoria tiene distribucion t de Student con n grados delibertad (g.l) sii posee fdp dada por:
fX(x) =Γ
(n+1
2
)
Γ(
n2
) √nπ
(
1 +x2
n
)− (n+1)/2
(x ∈ R)
En tal caso anotaremos X ∼ t(n). Esta distribucion es de aspecto acampanado, semejante a primeravista a la N (0, 1), pero es de colas mas pesadas que esta y cobrara importancia a medida queavancemos en este curso, cuando nos avoquemos a temas de inferencia. Un comentario interesante:La distribucion C(0, 1) es precisamente la misma que t(1). Presentamos algunas fdp t de Student:Se observa que a medida que aumentan los grados de libertad, la distribucion t de Student se aproximacada vez mas a la N (0, 1).
Nota: Los comandos utiles en SPlus son dt , pt , qt.
Prof.J.Gaston Argeri 72
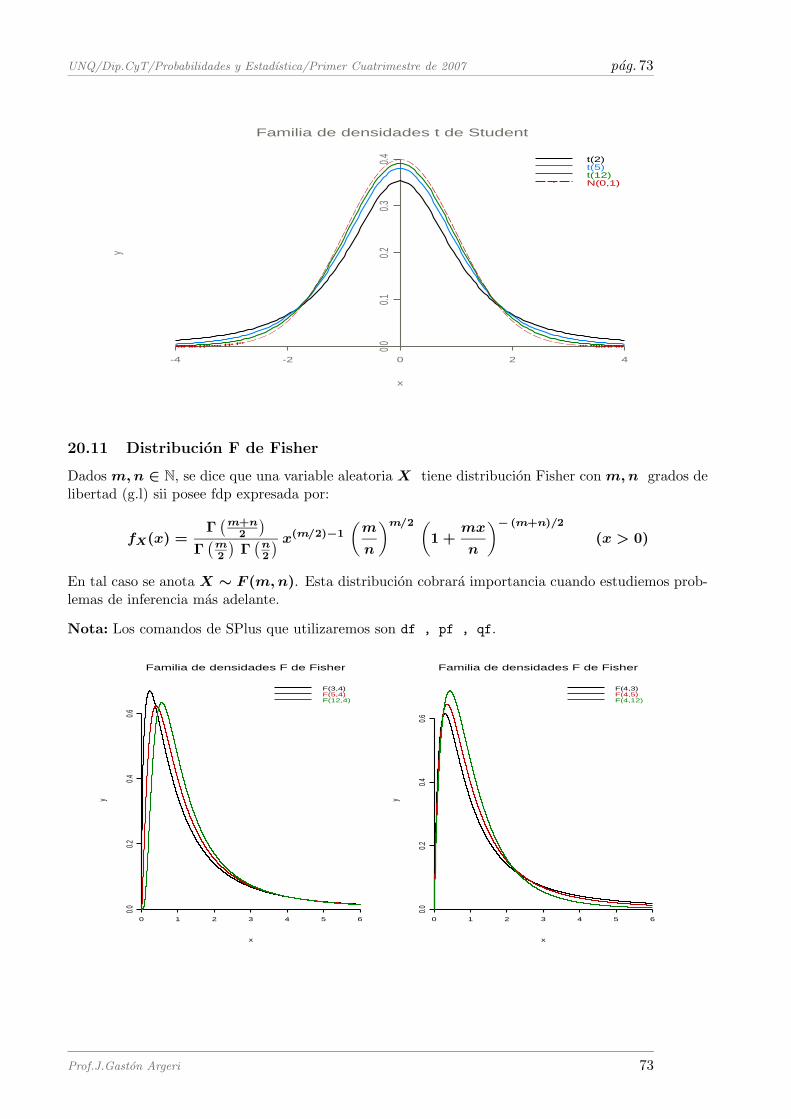
UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 73
Familia de densidades t de Student
x
y
-4 -2 0 2 4
0.00.1
0.20.3
0.4 t(2)t(5)t(12)N(0,1)
20.11 Distribucion F de Fisher
Dados m, n ∈ N, se dice que una variable aleatoria X tiene distribucion Fisher con m, n grados delibertad (g.l) sii posee fdp expresada por:
fX(x) =Γ
(m+n
2
)
Γ(
m2
)Γ
(n2
) x(m/2)−1
(m
n
)m/2 (
1 +mx
n
)− (m+n)/2
(x > 0)
En tal caso se anota X ∼ F (m, n). Esta distribucion cobrara importancia cuando estudiemos prob-lemas de inferencia mas adelante.
Nota: Los comandos de SPlus que utilizaremos son df , pf , qf.
Familia de densidades F de Fisher
x
y
0 1 2 3 4 5 6
0.00.2
0.40.6
F(3,4)F(5,4)F(12,4)
Familia de densidades F de Fisher
x
y
0 1 2 3 4 5 6
0.00.2
0.40.6
F(4,3)F(4,5)F(4,12)
Prof.J.Gaston Argeri 73

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 74
20.12 Distribucion Weibull
Dados α, β ∈ R , α > 0, β > 0, se dice que una variable aleatoria X tiene distribucion Weibull deparametros α, β si posee fdp dada por:
fX(x) =1
βαxα−1 e− (x/β)α (x > 0)
En tal caso anotamos X ∼ W(α, β). La distribucion Weibull es importante en el estudio de tiemposde sobrevida. El aspecto de la grafica de una fdp Weibull puede observarse en las siguientes figuras:
x
y
0 1 2 3 4
0.00.5
1.01.5
W(0.5,1)W(1,1)W(1.5,1)
x
y
0 1 2 3 4
0.00.5
1.01.5
W(1,0.5)W(1,1)W(1,1.5)
Familia de densidades Weibull
Nota: Como caso particular, observemos que tomando α = 1 y λ = β−1 se obtiene la distribucionexponencial de parametro λ.
20.13 Distribucion logıstica
Dados θ, λ ∈ R , θ > 0, se dice que una variable aleatoria X tiene distribucion logıstica deparametros λ, θ si posee fdp dada por:
fX(x) =1
θ
e− (x−λ)/θ
[1 + e− (x−λ)/θ
]2
En tal caso anotamos X ∼ L(λ, θ). Las graficas de las fdp logısticas asemejan a la gaussiana, perocon colas mas pesadas. Presentemos algunas figuras comparativas:
Prof.J.Gaston Argeri 74

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 75
misma theta, distintas lambda
x
y
-4 -2 0 2 4 6 8
0.00.1
0.20.3
0.4 L(2,1)L(3,1)L(5,1)N(0,1)
misma lambda, distintas theta
x
y
-4 -2 0 2 4 6 8
0.00.1
0.20.3
0.40.5 L(0,0.5)
L(0,1)L(0,1.5)N(0,1)
Familia de densidades logisticas
Prof.J.Gaston Argeri 75

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 76
Funciones de variables aleatorias
21 Transformaciones de variables aleatorias
21.1 Distribucion de una funcion de una variable aleatoria
Supongamos que un experimento aleatorio esta disenado para estudiar el area de la seccion transver-sal de una poblacion de tubos cilındricos (circulares). Posiblemente cuando se estudia una muestraaleatoria de tubos se mida el radio de su seccion transversal, en lugar del area de dicha seccion. Delmismo modo, podrıamos conocer la distribucion poblacional del radio de un tubo y estar interesadosen investigar la distribucion poblacional del area de la seccion transversal del mismo. Si anotamosX a la variable aleatoria ”radio del tubo” e Y a la variable aleatoria ”area de la seccion transver-sal del tubo”, existe una relacion funcional determinıstica entre ambas variables aleatorias, a saber:Y = πX2. Dado que la distribucion de X queda determinada por FX , es de esperar que estatambien determine la distribucion FY .
Definicion 25 Sean Σ una σ-algebra de subconjuntos de Ω, X una variable aleatoria sobre
(Ω, Σ) con rango RX y Dg→ R una funcion con RX ⊆ D. Definimos Ω
g(X)→ R como
la funcion compuesta g(X) = g X. Es decir, para cada ω ∈ Ω se define (g(X)) (ω)def=
(g X) (ω) = g (X(ω))
Recordemos que B designa la σ-algebra de Borel en R, es decir la mınima σ-algebra de subconjuntosde R que contiene a todos los abiertos.Nos preguntamos que caracterıstica debe tener la funcion g en la def. anterior de modo que g(X) seauna variable aleatoria sobre (Ω, Σ). Para responder a esta pregunta necesitamos una definicion previa.
Definicion 26 Diremos que una funcion Dg→ R, con D ⊆ R, es boreliana sii se verifica:
∀B ∈ B , g−1(B) ∈ B
Las funciones continuas son solo un ejemplo de la amplısima variedad de funciones borelianas.
Propiedad 46 Sean X , g como en la primera definicion. Anotemos Y = g(X). Si g es unafuncion boreliana entonces Y es una variable aleatoria sobre (Ω, Σ).
Dem:Sea B ∈ B. Para ver que Y es variable aleatoria sobre (Ω, Σ) debemos verificar que Y −1(B) ∈ Σ.Pero:
Y ∈ B = Y −1(B) = ω ∈ Ω : Y (ω) ∈ B = ω ∈ Ω : g (X(ω)) ∈ B =
=ω ∈ Ω : X(ω) ∈ g−1(B)
=
ω ∈ Ω : ω ∈ X−1
(g−1(B)
)
=X ∈ g−1(B)
Siendo g boreliana y B ∈ B se cumple g−1(B) ∈ B. Pero puesto que X es variable aleatoriasobre (Ω, Σ) resulta X−1
(g−1(B)
) ∈ Σ. Esto demuestra que Y −1(B) ∈ Σ, como deseabamosver ¥
Investiguemos la relacion entre la fda de X y la fda de Y = g(X) (suponiendola v.a.). Notemosante todo que RY = g (RX) = g(x) : x ∈ RX. Fijado y ∈ R hemos visto que
Y ≤ y =X ∈ g−1 ((− ∞, y])
Prof.J.Gaston Argeri 76

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 77
Por lo tanto:FY (y) = P
(X ∈ g−1 ((− ∞, y])
)
Ası, cuando X es v.a.discreta, digamos con RX = xn, resulta tambien Y discreta con RY =g(xn) (Notar que como g no necesita ser 1-1, los valores g(xn) pueden estar repetidos). Sianotamos RY = yn se tiene:
FY (y) =∞∑
n=1yn≤y
pY (yn) =∞∑
n=1yn≤y
P (Y = yn) =∞∑
n=1yn≤y
P(X ∈ g−1 (yn)
)=
=∞∑
n=1g(xn)≤y
pX(xn)
Analogamente:
pY (yn) = P (Y = yn) = P(X ∈ g−1(yn)
)=
∞∑
n=1g(xn)=yn
P (X = xn) =
=∞∑
n=1g(xn)=yn
pX(xn)
En cambio, si X es v.a. continua con fdp fX , resulta:
FY (y) = P(X ∈ g−1 ((− ∞, y])
)=
∫
g−1((− ∞,y])
fX(x) dx
En este caso no queda claro si Y posee fdp. Esta situacion se analizara mas adelante. Por ahora nosdedicaremos a presentar algunos ejemplos concretos de lo que acabamos de ver.Nota: Cuando X discreta, la funcion g no necesita ser boreliana puesto que en este caso esΣ = P(Ω).
Ejemplo: Sea X ≈ Bi(n, p). Para fijar ideas podemos pensar en n lanzamientos independientes eidenticos de una moneda, con probabilidad de salir cara en cada lanxamiento igual a p, donde X midela cantidad de caras que salen. Sea Y la cantidad de cecas que se obtienen. Entonces Y = n − X.Aca g(x) = n − x. Como RX = 0, 1, · · · , n resulta RY = RX . Para k ∈ RY se tiene:
pY (k) = P (Y = k) = P (n − X = k) =
= P (X = n − k) = pX(n − k) =( nn−k
)pn−k(1 − p)k =
(nk
)(1 − p)kpn−k
Esto muestra (aunque es obvio) que Y ≈ Bi(n, 1 − p).
Ejemplo: Sea X ≈ E(λ). Determinemos la distribucion de Y = 1X
. Evidentemente RY = (0, ∞).Se tiene para y > 0:
FY (y) = P (Y ≤ y) = P(
1X
≤ y)
= P(
X ≥ 1y
)
=
=∞∫
1/y
λe− λx dx = − e− λx∣∣∞1/y
= e− λ/y
Por lo tanto:
fY (y) = F ′Y (y) =
λe− λ/y
y2(para Y > 0)
Prof.J.Gaston Argeri 77

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 78
Ejemplo: Sea X ≈ N (0, 1). Definamos Y = X2. Hallemos la fda de Y . Naturalmente RY =(0, ∞). Fijado y > 0 se tiene:
FY (y) = P (Y ≤ y) = P (X2 ≤ y) = P (|X| ≤√
(y)) = P (−√y ≤ X ≤ √
y) =
=
√y
∫
−√y
1√2π
· e− x2/2 dx = Φ(√
y) − Φ(−√y) = 2Φ(
√y) − 1
Luego:
fY (y) = F ′Y (y) =
(2Φ(
√y) − 1
)′=
2ϕ(√
y)
2√
y=
ϕ(√
y)√y
=
= 1√2π
· y− 1/2e−y/2 (para y > 0)
Habran reconocido que esta es la fdp de una v.a. chi-cuadrado con 1 grado de libertad, verdad? Esdecir:
X ≈ N (0, 1) ⇒ X2 ≈ χ2(1)
Hay dos casos donde la relacion entre FX y FY es muy sencilla: Cuando la funcion g es estrictamente
monotona sabemos que existe la funcion inversa g(D)g−1
→ D la cual verifica:
• ∀x ∈ D , g−1 (g(x)) = x
• ∀y ∈ g(D) , g(g−1(y)
)= y
Consideremos por separado los casos g creciente y g decreciente:
• Cuando g es creciente tambien g−1 lo es. En efecto: Si y, u ∈ g(D) , y < u entoncesno puede ser g−1(y) ≥ g−1(u) porque en tal caso, sabiendo que g crece resultarıa la con-tradiccion y = g(g−1(y)) ≥ g(g−1(u)) = u. Luego, necesariamente es g−1(y) < g−1(u).Por lo tanto podemos reescribir:
X ∈ g−1 ((− ∞, y]) ⇔ g(X) ∈ (− ∞, y] ⇔ g(X) ≤ y ⇔ g−1 (g(X)) ≤ g−1(y)
⇔ X ≤ g−1(y)
Entonces se obtiene:
FY (y) = P (Y ≤ y) = P (g(X) ≤ y) = P (X ≤ g−1(y)) = FX(g−1(y))
Dicho de otro modo: FY = FX g−1
• Cuando g es decreciente tambien g−1 lo es (sencillo de demostrar) y en tales casos la relacionentre FX y FY viene dada por: FY (y) = 1 − lim
t g−1(y)FX(t). Si ademas FX es continua
en el punto x = g−1(y) esto se simplifica aun mas: FY (y) = 1 − FX(g−1(y))
Teorema 8 Sea X ∼ N (µ, σ2) y sean a, b ∈ R , a 6= 0. Entonces:
Y = aX + b ∼ N (aµ + b, a2σ2)
Prof.J.Gaston Argeri 78

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 79
Dem:Consideremos primeramente el caso a > 0. Se tiene: FY (y) = P (Y ≤ y) = P (aX + b ≤y) = P (aX ≤ y − b) = P
(
X ≤ y−ba
)
= FX
(y−b
a
)
. Esto mismo se podıa obtener a partir
de g(x) = ax + b hallando la inversa: g−1(y) = (y − b)/a. Entonces segun las observaciones
anteriores es FY (y) = FX(g−1(y)) = FX
(y−b
a
)
.
Luego, derivando respecto de y se obtiene:
fY (y) = 1a
F ′X
(y−b
a
)
= 1a
1√2π σ
e− 1/2
( y−ba −µ
σ
)2
= 1√2π aσ
e− 1/2
(
y−(aµ+b)aσ
)2
Pero esta es precisamente la fdp N (aµ + b, a2σ2)Ahora consideremos el caso a < 0. Se tiene: FY (y) = P (Y ≤ y) = P (aX + b ≤ y) = P (aX ≤y − b) = P
(
X ≥ y−ba
)
= 1 − FX
(y−b
a
)
. Por lo tanto, derivando respecto de y se tiene:
fY (y) = − 1a
F ′X
(y−b
a
)
= 1|a|
1√2π σ
e− 1/2
( y−ba −µ
σ
)2
= 1√2π |a|σ e
− 1/2(
y−(aµ+b)|a|σ
)2
Reconocemos aquı nuevamente la fdp N (aµ + b, (|a| σ)2) es decir N (aµ + b, a2σ2) ¥
Corolario 6
X ∼ N (µ, σ2) ⇔ X − µ
σ∼ N (0, 1)
Nota: A partir de una variable aleatoria X ∼ N (µ, σ2), el proceso de restarle mu y dividir elresultado por σ, es decir obtener la nueva variable aleatoria Z = X−µ
σ, se denomina standarizar X.
O sea, Z es la standarizacion de X.
Ejemplo: Si X ∼ N (2, 9) calcular:
a) P (1 < X < 5)Rta:P (1 < X < 5) = P
(1−23
< X−23
< 5−23
)
= P (− 1/3 < Z < 1) = Φ(1) − Φ(− 1/3) ≈0.841 − 0.369 = 0.472
b) P (|X − 3| > 6)Rta:
P (|X − 3| > 6) = 1 − P (|X − 3| ≤ 6) = 1 − P (−6 ≤ X − 3 ≤ 6) =
= 1 − P (−6 + 3 ≤ X ≤ 6 + 3) = 1 − P(
−3−23
≤ X−23
≤ 9−23
)
=
= 1 − P (−5/3 ≤ Z ≤ 7/3) = 1 − [Φ(7/3) − Φ(−5/3)] ≈
≈ 1 − 0.990 + 0.048 = 0.058
Teorema 9 (Teorema de cambio de variables) Sea [c, d]g→ R diferenciable con continuidad
en [c, d] (es decir g′ existe y es continua en [c, d]). Sea f continua en g ([c, d]). Se verifica:
∫ g(d)
g(c)f(x) dx =
∫ d
cf (g(t)) g′(t) dt
Prof.J.Gaston Argeri 79

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 80
Nota: Siendo g continua en [c, d] resulta g ([c, d]) intervalo. Este intervalo contiene al intervalode extremos g(c) y g(d).Dem:
Por hipotesis las funciones [c, d]g′,fg−→ R son continuas. Definamos [c, d]
G→ R y g ([c, d])F→ R por
G(t) =∫ tc f (g(s)) g′(s) ds ; F (x) =
∫ xg(c) f(w) dw
Por el teorema fundamental del calculo se tiene:
G′(t) = f (g(t)) g′(t) para todo t ∈ [c, d]F ′(x) = f(x) para todo x ∈ g ([c, d])
Las funciones G y F g son dos primitivas de (f g)g′ en [c, d]. Por lo tanto existe algunaconstante k tal que G = F g + k. Pero evaluando en t = c resulta G(c) = 0 = F (g(c)). Luegok = 0. Entonces G = F g. En particular, tomando t = d se obtiene lo deseado ¥
Corolario 7 Sea X una v.a. continua con fdp fX . Anotemos SX al soporte de fX y supongamosque es un intervalo. Sea g una funcion continua y estrictamente monotona en §X . Definamos
SYdef= g(SX). Supongamos que g−1 es diferenciable con continuidad en SY Entonces la variable
aleatoria Y = g(X) es continua y su fdp viene dada por:
fY (y) =
fX(g−1(y)) ·∣∣∣
ddy
(g−1(y)
)∣∣∣ si y ∈ RY
0 si y 6∈ RY
Dem:Consideremos el caso en que g es estrictamente decreciente en RX Como g es continua re-sulta que g(RX) es un intervalo. Anotemos IX e IY a las funciones indicadoras de SX yde SY respectivamente. Entonces:
FY (y) = P (Y ≤ y) = P (g(X) ≤ y) = P (g(X) ≤ y, X ∈ RX) = P (X ≥ g−1(y)) =
=∫ ∞g−1(y) fX(x)IX(x) dx =
∫ − ∞y fX
(g−1(y)
) (g−1
)′(y)IY (y) dy =
= − ∫ y− ∞ fX
(g−1(y)
)d
dy
(g−1(y)
)IY (y) dy =
=∫ y− ∞ fX
(g−1(y)
) [
− ddy
(g−1(y)
)]
IY (y) dy =
=∫ y− ∞ fX
(g−1(y)
)∣∣∣
ddy
(g−1(y)
)∣∣∣ IY (y) dy
El otro caso es similar ¥
Ejemplo: Veamos que si X ∼ U(0, 1) entonces Y = − ln(1 − X) ∼ E(1)Notemos que SX = (0, 1) Ademas en este caso Y = g(X) siendo y = g(x) = − ln(1 − x) Estafuncion es estrictamente creciente en SX como puede comprobarse vıa grafica o evaluando el signo
de g′ en SX Se tiene: (0, 1)g→ (0, ∞) , g−1(y) = 1 − e− y es diferenciable con continuidad,
siendo ddy
(g−1(y)
)= e− y Por el teorema resulta:
fY (y) = fX(1 − e− y)e−yI(0,∞)(y) = e−yI(0,∞)(y)
que es precisamente la densidad de una E(1)
Ejemplo: Mostrar que si X ∼ U(0, 1) entonces Y = βX1/α ∼ W(α, β)
Prof.J.Gaston Argeri 80

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 81
Se tiene SX = (0, ∞) En este caso (0, ∞)g→ (0, ∞) es estrictamente creciente con inversa
continuamente diferenciable: g−1(y) = (y/β)α , ddy
(g−1(y)
)= α
βα yα−1 Por el teorema se tiene:
fY (y) = fX ((y/β)α) · α
βαyα−1I(0,∞)(y) =
α
βαyα−1I(0,∞)(y)
que es precisamente la densidad W(α, β)
Ejemplo: Si X ∼ U(0, 1) y si Φ es la fda normal standard entonces Y = Φ−1(X) ∼ N (0, 1)Por ejemplo con Splus o R podrıamos generar n = 100 observaciones normales standard del modosiguiente:x_runif(100)
y_qnorm(x)
y
qqnorm(y)
qqline(y)
cuyo resultado es:> y
[1] 1.439656209 -0.153820818 -0.973364545 -2.670822995 1.573157002
[6] -1.515236540 -0.017587315 -0.277855490 1.522914668 0.805903825
[11] 1.390965278 1.081745384 -0.940007847 1.806211842 1.385184211
[16] 0.789081143 -0.572512513 -0.426706851 -1.619519525 -0.163684787
[21] 0.363264580 3.509691190 -0.358246089 -0.618651099 -0.440391503
[26] -0.463496951 -0.528399068 0.343278381 -0.798728454 -0.858057270
[31] -0.114529089 0.014408313 0.711339651 -0.702370373 1.151716769
[36] 1.222205661 0.553613844 -1.291154983 1.576725352 1.274922705
[41] 2.373343271 0.023516669 -1.179085855 0.376860986 0.837743375
[46] 0.638265270 0.200955245 -1.227181790 0.226847841 0.092363984
[51] -0.202351448 -1.194020555 -0.031555431 -0.276199872 -0.522546189
[56] -0.821240291 -0.829233179 -1.420151004 -0.018863978 1.071702472
[61] 0.952116827 -0.481977529 0.013052120 2.576981022 -0.240945446
[66] 1.061576194 -0.429587065 1.177723298 1.517133775 0.747041757
[71] -0.302776745 -0.606648062 0.159249318 -0.727483736 -0.209902629
[76] -1.468940054 -0.384172801 -1.107982526 1.475101839 0.794312989
[81] -1.684586480 -0.847926953 0.244018386 -0.143598695 0.614903554
[86] 0.592337464 0.417235128 1.225940136 1.156041361 0.214837671
[91] -0.005689715 -0.291107554 1.142520415 -0.036015666 1.284851222
[96] 0.343150051 0.431397104 -0.260146350 -0.297678363 0.857941106
Quantiles of Standard Normal
y
-2 -1 0 1 2
-2-1
01
23
Prof.J.Gaston Argeri 81

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 82
El teorema anterior tiene el inconveniente de requerir la monotonıa de g Presentamos a continuacionuna version menos restrictiva del mismo teorema.
Teorema 10 ddd
Prof.J.Gaston Argeri 82

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 83
Esperanza y varianza
22 Valor esperado de una variable aleatoria
22.1 Motivacion
Los ejemplos siguientes aclaran la situacion que vamos a considerar.
Ejemplo: Una prueba es calificada en una escala de puntajes 0, 1, 2, 3. Un curso de 35 alumnosrealiza la prueba, con los siguientes resultados (en la tabla X indica el puntaje):
Al. X Al. X Al. X Al. X Al. X
1 2 8 1 15 2 22 1 29 02 1 9 2 16 2 23 1 30 13 1 10 1 17 1 24 2 31 14 0 11 1 18 2 25 1 32 25 2 12 1 19 1 26 1 33 26 2 13 0 20 1 27 2 34 27 2 14 3 21 0 28 1 35 1
Supongamos que se extrae al azar un alumno entre los 35 evaluados ¿Que puntaje se espera observar?Dicho en otro terminos, ¿ que numero podemos tomar como representativo del puntaje del curso?Naturalmente esperamos que el puntaje promedio del curso sirva a tales efectos. Sea X la variablealeatoria que mide el puntaje (de un alumno, en nuestro experimento aleatorio de extraer un alumnoal azar y observar su puntaje). El rango de X es RX = 0, 1, 2, 3. El puntaje promedio del cursoes (n = 35):
X = 2+1+1+0+2+2+2+1+2+1+1+1+0+3+2+2+1+2+1+1+0+1+1+2+1+1+2+2+1+135
Para calcular el numerador de esta expresion podemos agrupar puntajes iguales, es decir que podemosagrupar de acuerdo a los distintos valores de la variable aleatoria X. Entonces el calculo anterioradopta la forma:
X = 0·f(X=0)+1·f(X=1)+2·f(X=2)+3·f(X=3)35
=
= 0·4+1·18+2·12+3·135
En los calculos f(k) = f(X = k) representa la frecuencia del valor X = k (k = 0, 1, 2, 3). Siahora distribuimos el denominador, se obtiene:
X = 0·4+1·18+2·12+3·135
= 0 · 435
+ 1 · 1835
+ 2 · 1235
+ 3 · 135
=
= 0 · f(X=0)35
+ 1 · f(X=1)35
+ 2 · f(X=2)35
+ 3 · f(X=3)35
==
=n∑
k=0
k · f(X=k)n
Ahora bien, los numeros f(X=k)n
vienen dados precisamente por la fmp de X, es decir pX(k) =P (X = k). Entonces obtenemos el siguiente resultado:
X =n∑
k=0
k · pX(k) =n∑
k=0
k · P (X = k) =∑
k∈RX
k · P (X = k)
Ejemplo: Supongamos (para modelizar) que la altura X de un individuo adulto de cierta poblacion
Prof.J.Gaston Argeri 83

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 84
sigue una distribucion N (1.70, 0.01). Si se extrae un individuo al azar de esta poblacion, ¿ quealtura esperada tendra? Es decir, ¿ que numero podrıamos tomar como representativo de la altura deun individuo en dicha poblacion? A diferencia del ejemplo anterior, en este caso la variable aleatoriaX es continua. Podemos considerar un rango razonable [L, U ] de alturas (por ejemplo podrıamostomar L = 1, U = 2 por decir algo). Dividamos este intervalo [L, U ] en cierta cantidad n desubintervalos, mediante una particion regular:
L = xo < x1 < · · · < xn = U
y llamemos h a la norma de esta particion, es decir h = (U − L)/n. Recordemos que:
fX(x) = limh → 0+
P (x ≤ X < x + h)
h
Por lo tanto podemos escribir:
P (x ≤ X < x + h) = hfX(x) + o(h) para h → 0+
o aproximadamente para h pequeno: P (x ≤ X < x + h) ≈ hfX(x). En cada subintervalo[x, x + h) es razonable considerar a x o a cualquier otro valor en tal intervalo, como represetativode las alturas allı (h pequeno). Luego, imitando los calculos del ejemplo anterior, tomarıamos comoaltura representativa aproximada:
n∑
k=1
xkP (xk−1 ≤ X < xk) ≈n∑
k=1
xkfX(xk)h =n∑
k=1
xkfX(xk) · h
El calculo resultara mas representativo cuanto mas pequeno sea h. En el lımite el calculo resultaraexacto. Pero de acuerdo a la definicion de integral definida se tiene:
limh → 0+
n∑
k=1
xkfX(xk) · h =
∫ U
LxfX(x) dx
Pero hemos introducido un intervalo ”razonable” de alturas posibles. Si nos atenemos estrictamentea nuestro modelo N (1.70, 0.01), no hay razones por las cuales no debamos considerar cualesquieraposibles valores de X en su rango RX = R (recordemos que esto es solo un modelo para la poblacionreal). Entonces lo logico sera tomar como representativo de la altura de la poblacion al numero:
∫ ∞
− ∞xfX(x) dx
22.2 Definicion y ejemplos
Definicion 27 Sea X una variable aleatoria discreta con rango RX = xk (finito o infinitonumerable) y sea pX su fmp. Se define el valor esperado o la esperanza de X como el numero real:
E(X) =∑
x∈RX
xP (X = x) =∑
x∈RX
xpX(x)
siempre y cuando la serie converja absolutamente. En caso contrario se dice que X no posee esperanzao que la esperanza de X no esta definda. Al hablar de convergencia absoluta queremos significar quela serie de los valores absolutos debe converger (suma finita), es decir:
∑
x∈RX
|x| pX(x) < ∞
Prof.J.Gaston Argeri 84

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 85
Nota: Cuando RX es finito siempre existira E(X) puesto que la serie en cuestion solo consta deun numero finito de terminos.
Definicion 28 Sea X una variable aleatoria continua y sea fX su fdp. Se define el valor esperadoo la esperanza de X como el numero real:
E(X) =
∞∫
− ∞
xfX(x) dx
siempre y cuando la integral converja absolutamente. En caso contrario se dice que X no poseeesperanza o que la esperanza de X no esta definda.
Nota: La integral puede ser propia o impropia, dependiendo de las caracterısticas y del soporte de fX .En todo caso, siempre debe analizarse su covergencia. Al hablar de convergencia absoluta queremossignificar que la integral del valor absoluto debe converger (valor finito), es decir:
∞∫
− ∞
|x| fX(x) dx < ∞
Vamos a ilustrar estas definiciones calculando la esperanza de algunas de las distribuciones que hemosintroducido anteriormente. Calcularemos tambien la esperanza del cuadrado de cada variable aleatoria,dado que nos resultara util en el futuro (cuando definamos el concepto de varianza de una variablealeatoria)
Ejemplo: GeometricaSea X ∼ G(p). En este caso RX = N. Anotemos q = 1 − p. La esperanza se calcula como:
E(X) =
∞∑
k=1
kP (X = k) =
∞∑
k=1
kqk−1p = p
∞∑
k=1
kqk−1
Para sumar esta serie podemos recurrir al truco siguiente (que ya hemos utilizado):
S(q) =∞∑
k=0
qk =1
1 − q(11)
Derivado respecto de q (justificaran el intercambio de derivada con suma en alguno de los cursos deAnalisis Matematico) se obtiene:
S′(q) =∞∑
k=1
kqk−1 =d
dq
(1
1 − q
)
=1
(1 − q)2=
1
p2
Luego:
E(X) = p1
p2=
1
p
Por otra parte:
E(X2) =∞∑
k=1
k2P (X = k) =∞∑
k=1
k2qk−1p = p∞∑
k=1
k2qk−1
Para hallar la suma de esta serie, derivemos (11) pero en este caso dos veces:
S′′(q) =∞∑
k=2
k(k − 1)qk−2 =d
dq
(1
(1 − q)2
)
=2
(1 − q)3=
2
p3
Prof.J.Gaston Argeri 85

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 86
Si separamos la suma obtenemos:
S′′(q) =∞∑
k=2
k2qk−2 −∞∑
k=2
kqk−2 = q−1
( ∞∑
k=1
k2qk−1 − 1 −∞∑
k=2
kqk−1
)
=
= q−1
[ ∞∑
k=1
k2qk−1 − 1 − (S′(q) − 1)
]
=
= q−1
( ∞∑
k=1
k2qk−1 − S′(q)
)
Despejando:∞∑
k=1
k2qk−1 = qS′′(q) + S′(q) =2q
p3+
1
p2=
2q + p
p3
Por lo tanto:
E(X2) = p∞∑
k=1
k2qk−1 =2q + p
p2
Ejemplo: BinomialSea X ∼ Bi(n, p). En este caso RX = 0, 1, · · · , n. Anotemos q = 1 − p. Entonces:
E(X) =n∑
k=0
k(n
k
)pkqn−k =
n∑
k=1
kn!k!(n−k)!
pkqn−k =n∑
k=1
n(n−1)!(k−1)!(n−k)!
pkqn−k =
= npn∑
k=1
(n−1k−1
)pk−1qn−k = np
n∑
k=1
(n−1k−1
)pk−1qn−k =
= np(p + q)n−1 = np
Para calcular la esperanza del cuadrado de una binomial:
E(X2) =n∑
k=0
k2(n
k
)pkqn−k =
n∑
k=1
k2(n
k
)pkqn−k =
n∑
k=1
k2n!k!(n−k)!
pkqn−k =
=n∑
k=1
nk(n−1)!(k−1)!(n−k)!
pkqn−k = npn∑
k=1
k(n−1
k−1
)pk−1qn−k =
= np
[n∑
k=1
(k − 1)(n−1
k−1
)pk−1qn−k +
n∑
k=1
(n−1k−1
)pk−1qn−k
]
=
= np
[n∑
k=1
(k − 1)(n−1
k−1
)pk−1qn−k + 1
]
= np
[n−1∑
s=0s(n−1
s
)psqn−1−s + 1
]
=
= np [(n − 1)p + 1] = np(np + 1 − p) = np(np + q)
donde hemos utilizado que la ultima suma entre corchetes es la expresion de la esperanza de unaBi(n − 1, p), es decir (n − 1)p.
Ejemplo: PoissonSea X ∼ P(λ) de modo que RX = N
⋃ 0. Calculemos su esperanza:
E(X) =∞∑
k=0
kλk
k!e− λ = λe− λ
∞∑
k=1
λk−1
(k − 1)!= λe− λ
∞∑
s=0
λs
s!= λe− λeλ = λ
Prof.J.Gaston Argeri 86

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 87
Calculemos la esperanza de su cuadrado:
E(X2) =∞∑
k=0
k2 λk
k!e− λ = λe− λ
∞∑
k=1
k λk−1
(k−1)!= λe− λ
∞∑
s=0(s + 1) λs
s!=
= λ
[ ∞∑
s=0s λs
s!e− λ + e− λ
∞∑
s=0
λs
s!
]
= λ(λ + e− λeλ
)= λ(1 + λ)
Ejemplo: Gaussiana standardSea X ∼ N (0, 1). Su esperanza se calcula como:
E(X) =
∫ ∞
− ∞x
1√2π
e− x2/2 dx =1√2π
∫ ∞
− ∞x e− x2/2 dx
Afortunadamente el integrando posee primitiva elemental. En efecto: Sustituyendo t = −x2/2 setiene dt = − x dx
∫
x e− x2/2 dx = −∫
et dt = −et + C = −e− x2/2 + C
Por lo tanto: ∫ b0 x e− x2/2 dx = 1 − e− b2/2 −→
b →∞1
∫ 0a x e− x2/2 dx = e− a2/2 − 1 −→
a →− ∞−1
De manera que:∫ ∞− ∞ x e− x2/2 dx = −1 + 1 = 0. Esto muestra que E(X) = 0
Calculemos ahora E(X2), es decir:
E(X2) =
∫ ∞
− ∞x2 1√
2πe− x2/2 dx =
1√2π
∫ ∞
− ∞x2 e− x2/2 dx
Planteamos la integral indefinida por partes: u = x , dv = xe− x2/2 dx. Entonces: du = dx , v =∫
xe− x2/2 dx = −e− x2/2. Luego:
∫
x2 e− x2/2 dx = xe− x2/2 +
∫
e− x2/2 dx
Por lo tanto:
∫ b
ax2 e− x2/2 dx = xe− x2/2
∣∣∣
b
a+
∫ b
ae− x2/2 dx = be− b2/2 − ae− a2/2 +
∫ b
ae− x2/2 dx
Luego:∫ 0a x2 e− x2/2 dx −→
a →− ∞+
∫ 0− ∞ e− x2/2 dx
∫ b0 x2 e− x2/2 dx −→
b →∞+
∫ ∞0 e− x2/2 dx
Por lo tanto: ∫ ∞
− ∞x2 e− x2/2 dx =
∫ ∞
− ∞e− x2/2 dx =
√2π
Finalmente: Por lo tanto:
E(X2) =1√2π
∫ ∞
− ∞x2 e− x2/2 dx =
1√2π
√2π = 1
Prof.J.Gaston Argeri 87

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 88
Ejemplo: ExponencialSea X ∼ E(λ). Calculemos su esperanza:
E(X) =
∫ ∞
0xλe− λx dx = λ
∫ ∞
0xe− λx dx
Planteamos la integral indefinida por partes: u = x , dv = λe− λx dx∫
xe− λx dx = −x e− λx +
∫
e− λx dx = −x e− λx − 1
λe− λx
Entonces:
E(X) = − x e− λx∣∣∣
∞
0− 1
λe− λx
∣∣∣
∞
0=
1
λ
En cuanto a la esperanza del cuadrado, planteamos:
E(X2) =
∫ ∞
0x2λe− λx dx = λ
∫ ∞
0x2e− λx dx
Nuevamente aca planteamos la integral indefinida por partes: u = x2 , dv = λe− λx dx∫
x2e− λx dx = −x2 e− λx + 2
∫
xe− λx dx
Entonces:
E(X2) =∫ ∞0 x2e− λx dx = − x2 e− λx
∣∣∞0
+ 2∫ ∞0 xe− λx dx = 2
∫ ∞0 xe− λx dx =
= 2 E(X)λ
= 2/λ2
Ejemplo: Binomial negativaSea X ∼ BN (r, p). Su esperanza se calcula como:
E(X) =∞∑
k=r
k(k−1r−1
)prqk−r =
∞∑
k=r
k(k−1)!(r−1)!(k−r)!
prqk−r =
= r∞∑
k=r
k!r!(k−r)!
prqk−r = r∞∑
k=r
(kr
)prqk−r =
= rp
∞∑
k=r
(kr
)pr+1qk−r = r
p
∞∑
s=r+1
(s − 1
(r + 1) − 1
)
pr+1qs−(r+1)
︸ ︷︷ ︸
1
= rp
Para hallar la esperanza del cuadrado:
E(X2) =∞∑
k=r
k2(k−1r−1
)prqk−r =
∞∑
k=r
rkk!r!(k−r)!
prqk−r =
= r∞∑
k=r
k(kr
)prqk−r = r
∞∑
s=r+1(s − 1)
(s−1r
)pr+1qs−r−1 =
= rp
∞∑
s=r+1
s
(s − 1
r
)
pr+1qs−r−1
︸ ︷︷ ︸
(r+1)/p
−∞∑
s=r+1
(s − 1
r
)
pr+1qs−r−1
︸ ︷︷ ︸
1
= rp
(r+1
p− 1
)
Prof.J.Gaston Argeri 88

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 89
Ejemplo: GamaSea X ∼ Γ(α, λ). Calculemos su esperanza:
E(X) =∫ ∞0 x λα
Γ(α)xα−1 e− λx dx =
∫ ∞0
λα
Γ(α)x(α+1)−1 e− λx dx =
= αλ
∫ ∞0
λα+1
Γ(α+1)x(α+1)−1 e− λx dx = α
λ
En cuanto a la esperanza del cuadrao, los calculos son similares:
E(X2) =∫ ∞0 x2 λα
Γ(α)xα−1 e− λx dx =
∫ ∞0
λα
Γ(α)x(α+2)−1 e− λx dx =
= α(α+1)λ2
∫ ∞0
λα+2
Γ(α+2)x(α+2)−1 e− λx dx = α(α+1)
λ2
Ejemplo: BetaSea X ∼ Be(α, β). Su esperanza viene dada por:
E(X) =∫ 10 x 1
B(α,β)xα−1 (1 − x)β−1 dx =
∫ 10
1B(α,β)
x(α+1)−1 (1 − x)β−1 dx =
=∫ 10
1B(α,β)
x(α+1)−1 (1 − x)β−1 dx = αα+β
∫ 10
1B(α+1,β)
x(α+1)−1 (1 − x)β−1 dx = αα+β
Calculemos la esperanza de su cuadrado:
E(X2) =∫ 10 x2 1
B(α,β)xα−1 (1 − x)β−1 dx =
∫ 10
1B(α,β)
x(α+2)−1 (1 − x)β−1 dx =
= α(α+1)(α+β)(α+β+1)
∫ 10
1B(α+2,β)
x(α+2)−1 (1 − x)β−1 dx = α(α+1)(α+β)(α+β+1)
Ejemplo: HipergeometricaSea X ∼ H(n, D, N). Sean m = max 0, n − N + D , M = min n, D. Entonces si anota-mos m∗ = max 0, (n − 1) − (N − 1) + (D − 1) , M∗ = min n − 1, D − 1 resulta:
m∗ =
0 si m = 0
m − 1 si m ≥ 1= max m − 1, 0 = max m, 1 − 1 ; M∗ = M − 1
La esperanza de X viene dada por:
E(X) =M∑
k=m
k(D
k)(N−Dn−k )
(Nn)
=M∑
k=maxm,1k
(Dk)(
N−Dn−k )
(Nn)
=
= nN
M∑
k=maxm,1
D(D−1k−1 )(
(N−1)−(D−1)(n−1)−(k−1) )
(N−1n−1 )
= nDN
M∑
k=maxm,1
(D−1k−1 )(
(N−1)−(D−1)(n−1)−(k−1) )
(N−1n−1 )
=
= nDN
M−1∑
s=maxm,1−1
(D−1s )((N−1)−(D−1)
(n−1)−s )
(N−1n−1 )
= nDN
M∗∑
s=m∗
(D−1s )((N−1)−(D−1)
(n−1)−s )
(N−1n−1 )
= n DN
Prof.J.Gaston Argeri 89

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 90
Calculemos la esperanza de su cuadrado:
E(X2) =M∑
k=m
k2 (Dk)(
N−Dn−k )
(Nn)
=M∑
k=maxm,1k2 (D
k)(N−Dn−k )
(Nn)
=
= nN
M∑
k=maxm,1k
D(D−1k−1 )(
(N−1)−(D−1)(n−1)−(k−1) )
(N−1n−1 )
= nDN
M∑
k=maxm,1k
(D−1k−1 )(
(N−1)−(D−1)(n−1)−(k−1) )
(N−1n−1 )
=
= nDN
M−1∑
s=maxm,1−1
(s + 1)(D−1
s )((N−1)−(D−1)(n−1)−s )
(N−1n−1 )
= nDN
M∗∑
s=m∗(s + 1)
(D−1s )((N−1)−(D−1)
(n−1)−s )
(N−1n−1 )
=
= nDN
[M∗∑
s=m∗s
(D−1s )((N−1)−(D−1)
(n−1)−s )
(N−1n−1 )
+M∗∑
s=m∗
(D−1s )((N−1)−(D−1)
(n−1)−s )
(N−1n−1 )
]
=
= nDN
[
(n − 1) D−1N−1
+ 1]
= nDN
(n−1)(D−1)+(N−1)N−1
= n DN
(
1 + (n − 1) D−1N−1
)
=
= NN−1
(
1 + n(D−1)N−D
)
n DN
(
1 − DN
)
Ejemplo: Chi cuadradoSea X ∼ χ2(n) = Γ
(n2, 1
2
). Entonces por lo visto para la gamma, se tiene:
E(X) = n/21/2
= n ; E(X2) =n2 (n
2+1)
(1/2)2= n(n + 2)
Ejemplo: UniformeSea X ∼ U(a, b). En este caso:
E(X) =∫ ba x 1
b−adx = 1
b−a
∫ ba x dx = 1
b−ax2
2
∣∣∣
b
a= b2−a2
2(b−a)= (b−a)(b+a)
2(b−a)= a+b
2
E(X2) =∫ ba x2 1
b−adx = 1
b−a
∫ ba x2 dx = 1
b−ax3
3
∣∣∣
b
a= b3−a3
3(b−a)= (b−a)(a2+ab+b2)
3(b−a)= a2+ab+b2
3
Ejemplo: t de StudentSea X ∼ t(n). Para calcular su esperanza observemos antes algunas particularidades. Debemosanalizar ante todo la convergencia de la integral impropia. Por simetrıa y dado que dicha integrales propia en el origen, vamos a estudiarla en [
√n, ∞). De hecho, para que nos sirva despues,
estudiaremos la convergencia de la siguiente (un poco mas general):
Ik,n =
∫ ∞
√n
xk
(
1 + x2
n
)(n+1)/2dx
Hacemos el cambio de variables (para deshacernos del n ”molesto”): t = x/√
n. Entonces dt =dx/
√n. Luego:
Ik,n = n(k+1)/2
∫ ∞
1
tk
(1 + t2)(n+1)/2dt
Pero si t ≥ 1 se cumple:
•tk
(1+t2)(n+1)/2 ≤ tk
tn+1 = 1tn+1−k pues 1 + t2 ≥ t2
•tk
tk
(1+t2)(n+1)/2
≥ tn
(1+t2)(n+1)/2 ≥ tn
(2t2)(n+1)/2 = 12(n+1)/2 t
pues 1 + t2 ≤ t2 + t2 = 2t2
Prof.J.Gaston Argeri 90

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 91
Luego: Ik,n es convergente sii n + 1 − k > 1 sii k < n. Deducimos inmediatamente que siX ∼ t(1) entonces X carece de esperanza (finita). Si X ∼ t(2) entonces E(X) existe peroE(X2) no existe. En cambio si X ∼ t(n) con n ≥ 3 entonces existen E(X) y E(X2).
Vamos a calcularlas: Para alivianar notacion denotemos An =Γ(n+1
2 )Γ(n
2 )√
nπ. Tengamos presente que
por definicion de fdp (su integral sobre toda la recta es 1 ) se tiene para n ∈ N:
∫ ∞
−∞
dt
(1 + t2)(n+1)/2= n− 1/2
∫ ∞
− ∞
dx(
1 + x2
n
)(n+1)/2=
(
n1/2An
)−1
Entonces usando consecutivamente las sustituciones t = x/√
n , s = 1 + t2 se obtiene para n ≥ 2:
E(X) = An
∫ ∞− ∞
x(
1+x2
n
)(n+1)/2 dx = nAn
∫ ∞− ∞
t
(1+t2)(n+1)/2 dt =
= nAn
[∫ 0− ∞
t
(1+t2)(n+1)/2 dt +∫ ∞0
t
(1+t2)(n+1)/2 dt]
=
= 12
nAn
[∫ 0∞
dss(n+1)/2 +
∫ ∞0
dss(n+1)/2
]
= 12
nAn
[
− ∫ ∞0
dss(n+1)/2 +
∫ ∞0
dss(n+1)/2
]
= 0
Analogamente, para n ≥ 3 se tiene:
E(X2) = An
∫ ∞− ∞
x2
(
1+x2
n
)(n+1)/2 dx = n3/2An
∫ ∞− ∞
t2
(1+t2)(n+1)/2 dt =
= n3/2An
∫ ∞− ∞
(1+t2)−1
(1+t2)(n+1)/2 dt =
= n3/2An
[∫ ∞− ∞
1
(1+t2)(n−1)/2 dt − ∫ ∞− ∞
1
(1+t2)(n+1)/2 dt]
=
= n3/2An
[1
(n−2)1/2An−2− 1
n1/2An
]
=
= n
[(n
n−2
)1/2An
An−2− 1
]
Utilizando las propiedades de la funcion gamma se puede verificar facilmente que An/An−2 = (n −1)/
[n(n − 2)1/2
]. Reemplazando resulta:
E(X2) = n
(n
n−2
)1/2n−1
[n(n−2)]1/2 − 1
= n(
n−1n−2
− 1)
= nn−2
Ejemplo: F de Fisher-SnedecorEl calculo de E(X) y E(X2) es un poco engorroso y lo omitiremos. El resultado es el siguiente:
E(X) = nn−2
para n ≥ 3
E(X2) =(
nn−2
)2 [
1 + 2m+n−2m(n−4)
]
para n ≥ 5
Ejemplo: LognormalSea X ∼ logN (µ, σ). Calculemos su esperanza: Para la integral realizamos la sustitucion t = ln x.
Prof.J.Gaston Argeri 91

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 92
Luego: dt = dx/x , x = et. Entonces:
E(X) =∫ ∞0
x√2π σx
e− (ln x−µ)2/(2σ2) dx = 1√2π σ
∫ ∞0 e− (ln x−µ)2/(2σ2) dx =
= = 1√2π σ
∫ − ∞∞ e− (t−µ)2/(2σ2) et dt = 1√
2π σ
∫ ∞− ∞ e−(t2−2µt+µ2−2σ2t)/(2σ2) dt =
= 1√2π σ
e− µ2/(2σ2)∫ ∞− ∞ e−[t2−2(µ+σ2)t]/(2σ2) dt =
= 1√2π σ
e− µ2/(2σ2)∫ ∞− ∞ e−[t2−2(µ+σ2)t+(µ+σ2)2−(µ+σ2)2]/(2σ2) dt =
= 1√2π σ
e− µ2/(2σ2)∫ ∞− ∞ e−[t−(µ+σ2)]
2/(2σ2)e(µ+σ2)2/(2σ2) dt =
= e− µ2/(2σ2) e(µ+σ2)2/(2σ2)∫ ∞− ∞
1√2π σ
e−[t−(µ+σ2)]2/(2σ2) dt =
= e− µ2/(2σ2) e(µ+σ2)2/(2σ2) = eµ+σ2/2
El calculo de la esperanza del cuadrado es completamente similar:
E(X2) =∫ ∞0
x2√
2π σxe− (ln x−µ)2/(2σ2) dx = 1√
2π σ
∫ ∞0 x e− (ln x−µ)2/(2σ2) dx =
= = 1√2π σ
∫ − ∞∞ e− (t−µ)2/(2σ2) e2t dt = 1√
2π σ
∫ ∞− ∞ e−(t2−2µt+µ2−4σ2t)/(2σ2) dt =
= 1√2π σ
e− µ2/(2σ2)∫ ∞− ∞ e−[t2−2(µ+2σ2)t]/(2σ2) dt =
= 1√2π σ
e− µ2/(2σ2)∫ ∞− ∞ e−[t2−2(µ+2σ2)t+(µ+2σ2)2−(µ+2σ2)2]/(2σ2) dt =
= 1√2π σ
e− µ2/(2σ2)∫ ∞− ∞ e−[t−(µ+2σ2)]
2/(2σ2)e(µ+2σ2)2/(2σ2) dt =
= e− µ2/(2σ2) e(µ+2σ2)2/(2σ2)∫ ∞− ∞
1√2π σ
e−[t−(µ+2σ2)]2/(2σ2) dt =
= e− µ2/(2σ2) e(µ+2σ2)2/(2σ2) = e2(µ+σ2)
22.3 Propiedades de la esperanza
Propiedad 47 (Linealidad de la esperanza) Sean X e Y variables aleatorias definidas sobreun mismo espacio de probabilidad. Supongamos ademas que E(X) , E(Y ) estan definidas. Entoncespara cualesquiera constantes a, b ∈ R la esperanza E(aX + bY ) existe y se verifica:
E(aX + bY ) = aE(X) + bE(Y )
Dem: Esta demostracion se dara mas adelante, cuando desarrollemos la teorıa de vectores aleatorios. ¥
Propiedad 48 Sea X una variable aleatoria. Dados m, n ∈ N , m < n se cumple:
E(Xn) existe ⇒ E(Xm) existe
Dem:Solo demostramos el caso discreto (El caso continuo se demustra de manera completamente analoga,
Prof.J.Gaston Argeri 92

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 93
reemplazando sumas por integrales). Tengamos en cuenta que: ∀x ≥ 0 , xm ≤ xn ⇔ x ≥ 1
E (|Xm|) =∑
x∈RX
|x|m pX(x) =∑
x∈RX|x|>1
|x|m pX(x) +∑
x∈RX|x|≤1
|x|m pX(x) ≤
≤ ∑
x∈RX|x|>1
|x|n pX(x) +∑
x∈RX|x|≤1
pX(x) ≤
≤ ∑
x∈RX
|x|n pX(x) +∑
x∈RX
pX(x) = E (|Xn|) + 1
Por lo tanto si E(Xn) existe entonces E (|Xn|) < ∞ por lo cual E (|Xm|) < ∞ de manera queE(Xm) existe. ¥
Propiedad 49 Sea X una variable aleatoria tal que E(X) existe. Se cumple:
P (X ≥ 0) = 1 ⇒ E(X) ≥ 0
Dem:Caso discreto:pX(x) = P (X = x) = P (X = x, X ≥ 0) + P (X = x, X < 0)Pero: P (X < 0) = 1 − P (X ≥ 0) = 1 − 1 = 0 Entonces como X = x, X < 0 ⊆X < 0 resulta P (X = x, X < 0) = 0 Por lo tanto: pX(x) = P (X = x, X ≥ 0) =pX(x)I[0,∞)(x) Entonces:
E(X) =∑
x∈RX
xpX(x) =∑
x∈RX
xpX(x)I[0,∞)(x) =∑
x∈RXx≥0
xpX(x) ≥ 0
El caso continuo es similar. ¥
Corolario 8 Sean X, Y variables aleatorias tales que existen E(X), E(Y ) Se cumple:
P (X ≥ Y ) = 1 ⇒ E(X) ≥ E(Y )
Dem: Consideremos Z = X −Y Aplicandole directamente la propiedad anterior y utilizando luegola linealidad de la esperanza, se deduce el resultado a probar. ¥
Propiedad 50 (Desigualdad de Markov) Sea X una variable aleatoria tal que X ≥ 0 y E(X)existe. Entonces para cualquier numero real c > 0 se verifica:
P (X ≥ c) ≤ E(X)
c
Dem: Sea A = [c, ∞) La funcion indicadora de A es
IA(x) =
1 si x ∈ A0 si x 6∈ A
La variable aleatoria IA(X) es discreta con rango 0, 1 Calculemos su esperanza:
E(IA(X)) = 0·P (IA(X) = 0)+1·P (IA(X) = 1) = P (IA(X) = 1) = P (X ∈ A) = P (X ≥ c)
Ademas: x ∈ A ⇒ x ≥ c ⇒ x/c ≥ 1 Por lo tanto:
∀x ∈ R , IA(x) ≤ x
cIA(x) ≤ x
c
Luego: IA(X) ≤ Xc
Tomando esperanzas y utilizando el corolario anterior se tiene:
P (X ≥ c) = E(IA(X)) ≤ E
(X
c
)
=E(X)
c¥
Prof.J.Gaston Argeri 93

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 94
Propiedad 51 Sea X una variable aleatoria. Se verifica:
X ≥ 0 y E(X) = 0 ⇒ P (X = 0) = 1
Dem: Fijemos x > 0 Por la desigualdad de Markov y utilizando que E(X) = 0 se tiene:
P (X ≥ x) ≤ E(X)x
= 0Entonces: ∀x > 0 , P (X ≥ x) = 0 Por lo tanto, si x > 0 vale: FX(x) = 1 puesto que:
FX(x) = P (X ≤ x) = limn →∞
P (X < x + 1/n) = limn →∞
1 − P (X ≥ x + 1/n)︸ ︷︷ ︸
0
= 1
Utilizando que X ≥ 0 tambien se tiene: ∀x > 0 , FX(−x) = 0 Por lo tanto:
P (X = 0) = limx → 0+
FX(x)︸ ︷︷ ︸
1
− FX(−x)︸ ︷︷ ︸
0
= 1
como querıamos demostrar. ¥
23 Varianza de una variable aleatoria
23.1 Motivacion y definicion
Consideremos una variable aleatoria X que representa una caracterıstica numerica de los individuosde cierta poblacion. Supongamos ademas que existe E(X2) Elijamos al azar un individuo dentro detal poblacion e intentemos ”predecir” el valor que tomara la variable aleatoria X en dicho individuo.Lo mas razonable serıa predecir el valor de X mediante el numero E(X) ¿Porque? Supongamosque decidimos predecir el valor de X mediante un numero c Tal prediccion tendra asociado un error(absoluto) aleatorio expresado por |X − c| Naturalmente ningun numero c minimizara este error paratodos los valores posibles de X precisamente por ser aleatorio el error. Pero podemos intentar buscarel numero c que minimice la esperanza del error. Para evitar valores absolutos, busquemos el numeroc que minimice la esperanza del cuadrado del error, denominada error cuadratico medio(ECM):
ECM(c) = E((X − c)2
)= E(X2 − 2cX + c2) = E(X2) − 2cE(X) + c2
La expresion anterior es cuadratica en c Podemos reexpresarla como:
E((X − c)2
)= E
[(X − E(X)) + (E(X) − c)]2
=
= E((X − E(X))2
)+ 2 (E(X) − c) E (X − E(X)) + E
((X − E(X))2
)=
= E((X − E(X))2
)+ E
((E(X) − c)2
)
Como el primer termino en esta expresion no depende de c y el segundo termino se hace mınimotomando c = E(X) deducimos que el mejor predictor constante de X es el numero E(X) Ademas, elECM de E(X) como predictor de X resulta ser E
((X − E(X))2
)Esta magnitud es tan importante
en probabilidades y estadıstica que recibe un nombre especial.
Definicion 29 Dada una variable aleatoria X se define la varianza de X como:
V (X) = E((X − E(X))2
)
Prof.J.Gaston Argeri 94

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 95
siempre y cuando tal esperanza exista.Otras notaciones comunes para la varianza de X son V ar(X) , σXX , σ2
X
El desvıo standard o tıpico de X se define como la raız cuadrada de su varianza:
SD(X) =√
V (X)
El desvıo standard de X tambien se anota σX
Observese que:
• Si E(X2) existe entonces V (X) existe puesto que por propiedades vistas anteriormente sededuce que E(X) existe y por lo tanto, utilizando la propiedad de linealidad de la esperanzatiene: V (X) = E
((X − E(X))2
)= E(X2 − 2E(X)X + E2(X)) existe.
• Siendo V (X) la esperanza de un cuadrado, resulta siempre: V (X) ≥ 0
• Por propiedades vistas anteriormente se deduce que: V (X) = 0 ⇔ P (X = E(X)) = 1
• Si X se expresa en ciertas unidades, entonces V (X) se expresa en dichas unidades al cuadrado.Por ejemplo, si X representa altura y se expresa en cm entonces V (X) queda expresada encm2 En cambio SD(X) queda espresada en las mismas unidades que X
Tanto V (X) como SD(X) miden en cierto sentido cuan alejados se encuentran, en promedio, losvalores de la variable aleatoria X respecto de su ”centro” o valor esperado E(X) Por ello decimosque V (X) y SD(X) representan medidas de dispersion de la variable aleatoria.
23.2 Calculo y propiedades
Propiedad 52 Sea X una variable aleatoria con E(X2) finita. Se cumple:
V (X) = E(X2) − E2(X)
Dem: Notemos que como E(X2) < ∞ entonces por una propiedad anterior E(X) existe. Por lotanto, utilizando la linealidad de la esperanza se obtiene:V (X) = E
((X − E(X))2
)= E(X2 − 2E(X)X + E2(X)) = E(X2) − 2E2(X) + E2(X) =
E(X2) − E2(X) ¥
Ejemplo: X ∼ Bi(n, p)Ya calculamos E(X) = np , E(X2) = np(q + np) de modo que se tiene: V (X) = np(q + np) −(np)2 = npq = np(1 − p)
Ejemplo: X ∼ G(p)En este caso sabemos que E(X) = 1/p y E(X2) = (2q + p)/p2 Por lo tanto V (X) =(2q + p)/p2 − 1/p2 = q/p2 = (1 − p)/p2
Ejemplo: X ∼ H(n, D, N)
Vimos que E(X) = n DN
y E(X2) = NN−1
(
1 + n(D−1)N−D
)
n DN
(
1 − DN
)
Entonces luego de operar se obtiene: V (X) = n DN
(
1 − DN
) N − n
N − 1︸ ︷︷ ︸
(∗)
El factor (∗) se denomina factor de correccion por poblacion finita, en tanto que los tres primerosfactores coinciden con la esperanza de una variable aleatoria con distribucion Bi(n, D/N) Esto nodebe sorprendernos ya que la hipergeometrica surgio al contar la cantidad de objetos distinguidosen una muestra sin reposicion de tamano n de una poblacion de N individuos entre los que hay untotal de D distinguidos. Entonces cuando N es grande respecto de n y este es pequeno respecto
Prof.J.Gaston Argeri 95

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 96
de D es razonable que la no reposicion afecte muy poco el resultado, de manera que contar la can-tidad de distinguidos entre los n deberıa dar resultados similares ya sea que la extraccion se realicecon o sin reposicion. Pero si se realiza con reposicion, la cantidad de distinguidos posee distribucionBi(n, D/N)
Ejemplo: X ∼ P(λ)En este caso vimos que E(X) = λ , E(X2) = λ(λ + 1) Luego: V (X) = λ(λ + 1) − λ2 = λ
Ejemplo: X ∼ N (µ, σ2)Vimos que E(X) = µ , E(X2) = µ2 + σ2 Por lo tanto: V (X) = µ2 + σ2 − µ2 = σ2
Ejemplo: X ∼ Γ(λ, α)Probamos antes que E(X) = λ/α , E(X2) = λ(λ + 1)/α2 Luego: V (X) = λ(λ + 1)/α2 −(λ/α)2 = λ/α
Propiedad 53 Sea X una variable aleatoria tal que V (X) es finita y sean a, b constantes. Vale:
V (aX + b) = a2V (X)
Dem:
V (aX + b) = E((aX + b)2
) − E2(aX + b) = E(a2X2 + 2abX + b2) − (aE(X) + b)2 =
= a2E(X2) + 2abE(X) + b2 − a2E2(X) − 2abE(X) − b2 =
= a2E(X2) − a2E2(X) = a2(E(X2) − E2(X)
)= a2V (X) ¥
24 Esperanza y varianza de una funcion de una variable aleatoria
Propiedad 54 Sea X una variable aleatoria y sea SX el soporte de su distribucion. La esperanza dela variable aleatoria g(X) puede calcularse, siempre que exista, como:
i) Caso discreto:
E(g(X)) =∑
x∈SX
g(x)pX(x)
ii) Caso continuo:
E(g(X)) =
∫
SX
g(x)fX(x) dx
Dem:Caso discreto: La fmp de Y = g(X) viene dada por pY (y) =
∑
x∈RXg(x)=y
pX(x) Por lo tanto:
E(Y ) =∑
y∈RY
ypY (y) =∑
y∈RY
y∑
x∈RXg(x)=y
pX(x) =∑
y∈RY
∑
x∈RXg(x)=y
ypX(x) =
=∑
y∈RY
∑
x∈RXg(x)=y
g(x)pX(x) =∑
x∈RX
g(x)pX(x)
En el caso continuo la demostracion es similar a la del teorema de cambio de variables que se demostrocuando se dedujo, bajo condiciones de regularidad, que Y = g(X) posee densidad. Omitimos laprueba. ¥
Prof.J.Gaston Argeri 96

UNQ/Dip.CyT/Probabilidades y Estadıstica/Primer Cuatrimestre de 2007 pag. 97
Ejemplo: Calculemos E(− ln X) siendo X ∼ U(0, 1)Sea Y = − ln X Anotando SX = (0, 1) y SY = (0, ∞) los soportes de X e Y respectivamente,se tiene:
E(Y ) =
∫ 1
0(− ln x) fX(x) dx = −
∫ 1
0ln x dx = − x ln x|10 +
∫ 1
0dx = 1
Prof.J.Gaston Argeri 97