combined human and computer scoring of student writing · 3 acknowledgments this small scoring...
TRANSCRIPT

Combined Human and Computer Scoringof Student Writing
October 2014

2
Table of ContentsAcknowledgments . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
Background . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
Rationale for the Scoring Approach . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
Design of the Study . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5The Essays Used . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5Human Scoring. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6Computer/Automated Scoring . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
Results of Analyses . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7Preliminary Analyses . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7Reliability Analyses. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9Decision Accuracy/Consistency and Standard Errors of Measurement . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10Scorer Discrepancies (>1) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
Findings, Conclusions, and Recommendations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
References . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
Appendix A: NECAP Prompts and Rubrics . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
Appendix B: Scoring Study Rubrics . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
This document was prepared by Measured Progress, Inc. with funding from the Bill and Melinda Gates Foundation, Grant Number OPP1037341. The content of the publication does not necessarily reflect the views of the Foundation.
© 2014 Measured Progress. All rights reserved.

3
AcknowledgmentsThis small scoring study was part of a larger project entitled Teacher Moderated Scoring Systems (TeaMSS). The TeaMSS team at Measured Progress wishes to thank members of the leadership team of the New England Common Assessment Program (NECAP), who allowed us to use student essays in response to released prompts from previous years of NECAP testing. Our thanks also goes to staff from the Educational Testing Service for the automated scoring of over 4500 essays using the e-rater® system, and to Yigal Attali, who provided invaluable advice on the project. We also appreciate the involvement of Pearson Education, Inc., who used the Intelligent Essay AssessorTM to score over 1000 Grade 11 essays for the project, and the significant data analysis efforts of Dr. Lisa Keller and the Abelian Group, LLC.
It is appropriate to acknowledge the efforts of staff in departments within Measured Progress who contributed to the effort – particularly Scoring Services and Data and Reporting Services. Finally, our greatest appreciation is extended to the Bill and Melinda Gates Foundation whose commitment to education and support of teachers have been considerable. For the support, patience, and wisdom of the Gates Project Officer, Ash Vasudeva, we are especially grateful.
BackgroundIn this age of the Common Core State Standards, large state assessment consortia, Race to the Top programs, and college and career readiness initiatives, there is renewed interest in performance assessments, measures involving the demonstration of higher order skills through the production of significant products or performances. Heretofore, in many school subjects, there has been general satisfaction with, or at least acceptance of, indirect multiple-choice measures of isolated content and skills, the overemphasis on which research has shown has had a negative impact on instruction (Pecheone et al, 2010). Teachers focus on the kinds of knowledge emphasized in the high stakes tests and strive to emulate those measures in their own tests. Although challenges associated with the measurement quality of performance assessments can be addressed in situations in which testing time and scoring logistics and costs are of lesser concern, efficiency has all too often been valued more than authenticity and higher order skills.
Interestingly, the scenario described above has not been the case with the assessment of writing. While it can be argued that many students are not asked to write enough in school, when the time comes to assess writing, there has generally not been an acceptable substitute for direct measures – writing assignments or prompts calling for writing samples such as essays, letters, reports, etc. Sometimes a testing program will include multiple-choice items addressing isolated writing skills (grammar and mechanics), but these are often in addition to direct writing assessments. It seems that in the area of writing, educators are not willing to assume students who can respond successfully to multiple-choice questions dealing with specific knowledge and skills in isolation can or will necessarily apply the knowledge and skills addressed by such items when asked to write an essay. More importantly, however, there are other aspects of good writing – such as topic development, organization, attention to audience – that are not so readily assessed by the multiple-choice format.
That educators embrace direct writing assessment does not mean that the problems associated with the measurement quality of this form of performance assessment have been solved. While there are those who believe we should think differently about reliability and validity for performance assessments than we do for multiple-choice tests, in fact we cannot. In general terms, consistency of measurement and measuring the right construct are no less important for either type of test, and they are accomplished the same way for both types. Any test samples a large domain of knowledge and skills. A good sampling of the domain (a large number of “items” and a broad representation of the knowledge and skills in the domain) is what leads to a reliable test exhibiting content validity.
Because a multiple-choice item usually taps such a small piece of a subject domain, a multiple-choice test must contain a large number of items to achieve an acceptable level of reliability. However, the production of an essay

4
requires the application of many skills and the synthesis of a great deal of information; therefore far fewer tasks are required to achieve the same level of reliability. Time constraints have led many assessment programs to demand a single essay from students. While such a one-item test can produce far more generalizable results than a very short multiple-choice test, there is still variability of student performance across writing prompts/tasks. Therefore, more than one task are desirable. Dunbar, Koretz, and Hoover (1991) showed very clearly that a second prompt or even two more, increases reliability considerably. Beyond three, the situation is one of diminishing returns.
Of course, from a content validity perspective, representation of the domain to which results are to be generalized is a concern. The domain of writing can be considered quite large and diverse, encompassing essays, letters, reports, stories, directions, and many other forms of writing. However, the Common Core State Standards helps us here as the writing standards, oriented toward college and career readiness, focus on essays in the expository and argumentation modes, and the writing traits of interest in scoring are almost identical for both modes. Even where they would logically differ, for example in “support,” they are similar in that expository essays should support a theme or main idea while an argumentation essay should present evidence to support a position on an issue. Thus, if one is interested in generalizing to the narrow subdomain of writing defined by the CCSS, then the number of essays required from students can be very small.
Dunbar et al also addressed the contribution of multiple readings of essays to the reliability of writing scores. Their results were similar to those for the number of tasks: the more readings (scorers), the more reliable the measure, but after three scorings, there are diminishing returns. The study described in this report investigates an approach to scoring writing that combines the notions of more “items” and more “readings,” accomplishing each in a different way from that of the more common scoring approaches. The approach involves the use of both human and automated (computer) scoring, with the computer scoring different writing attributes than the humans, rather than being “trained” to provide the best estimate of human holistic scores (linear combination of computer trait scores). It has application to summative assessments of writing at the state level for state accountability programs or at the district level where common writing assessments across schools or districts might be used for a variety of purposes, including contributing to information used in the evaluation of teaching effectiveness.
Rationale for the Scoring ApproachHolistic scoring is commonly used for summative assessments of writing involving large numbers of students. By this method, two readers each independently assign a single score, often from 1 to 6, to a student essay. Discrepant scores, scores that differ by more than one point, are typically arbitrated by a third reader. Automated computer scoring is also used in some writing assessment programs. It is intended to reduce scoring time and expense, these economies being more significant when the number of students responding to a prompt is greater. Probably because there is not absolute faith in computer scoring yet, there are some who would argue that computer scoring can take the place of second human readers, but should not be relied on solely for student scores. In fact, there is some evidence that computer scoring is less capable than humans at distinguishing among papers at the extremes of the writing performance continuum (Goldsmith et al, 2012). Zhang (2013) points out that automated scoring systems can be “tricked” by test takers who realize that such things as sophistication of vocabulary and greater length, even if text is incoherent, can lead to higher scores.
In programs combining direct writing assessment with multiple-choice writing components, there is an irony in that students can earn perhaps ten independent points for their multiple-choice responses, which take five minutes to provide, whereas they might spend two hours planning, drafting, and revising an essay to present considerably more evidence of specific skills, yet only receive up to six points for this much greater effort and output. (Double scoring can produce up to twelve points, but they are far from independent points since the two readers’ scores pertain to the same essay.) There is even further irony in computer second scoring since the computer is actually evaluating independent analytic traits, but then combining them statistically in such a way to produce the best estimate of the single human scores.

5
To get more independent points for each essay and more useful information for reports, analytic scoring has been used, whereby readers assign separate scores for typically three to six writing traits or attributes, such as topic development, organization, support, language, and conventions. Of course, human analytic scoring takes longer than holistic scoring and yields more discrepant scores that need arbitrating. Furthermore, there has long been concern that human scorers have difficulty distinguishing among the traits or, more accurately, have difficulty preventing scores on one trait from influencing scores on another. Thus, human analytic scoring fails at providing more independent points and more useful information. Analytic scoring, particularly with annotations, is a more reasonable approach for formative classroom assessment.
The scoring approach being investigated in this study has the humans providing no more than two scores – for attributes humans can score readily – and has the computer scoring the attributes it can score effectively, but leaving them as independent scores of different attributes, rather than combining them to produce an estimate of what a human would assign as a holistic score. This accomplishes several things. It produces more independent score points per essay, which better reflect the amount of evidence in an essay than a holistic score; and it saves on human scoring time for second readings. The human and computer scores are like scores on different items in a multi-item test. (The more items or independent score points, the more reliable the test.) It is recognized that these points a student earns are not totally independent since they pertain to the same response to a single prompt or task. Clearly, it is desirable to use a second prompt or even three prompts, but maximizing the independent points for each student essay also is desirable. Actually, at the same time the computer is generating trait scores that can ultimately be combined with the human scores to produce a total writing score, it can generate a holistic score as a check on the human scores. While this holistic score would not be counted since the trait scores that go into it are counted as independent scores, it can be used to identify human scores that need to be arbitrated.
Design of the StudyThe primary research question addressed by this study was: Are two human scores from one reader, combined with computer analytic scores, better than six human analytic scores with double scoring? “Better” was defined in terms of discrepancy rates, correlations across tasks (reliability), decision accuracy, decision consistency, and standard errors at cut points. A secondary research question was: Is a single human holistic score combined with independent computer analytic scores more reliable than a single human holistic score combined with a computer holistic score? Different kinds of reliability coefficients, applied to direct writing results, were also investigated.
The Essays UsedThe general approach of this study was to score large samples of student essays multiple times in different ways, yielding results for comparative analyses. It was desirable to gather two different pieces of writing from each student in response to common prompts so that cross-task correlations could be computed as estimates of alternative forms reliability. Essays from Grade 8 and 11 students gathered in conjunction with the New England Common Assessment Program were used. NECAP is a common state accountability assessment program used by the several New England states that belong to the NECAP consortium. For this program, at Grade 8 each student writes both a long and a short essay each year in response to two common prompts. At Grade 11, each student produces two long essays, one in response to a common prompt and one in response to a matrix-sampled prompt. The matrix-sampling of prompts is used for the piloting of prompts for use as common prompts in later years. So as to not jeopardize the security of prompts intended for future use, the study used Grade 11 essays from several years ago so that the matrix-sampled prompt was one that was used more recently as a common prompt and subsequently released to the public. The four NECAP prompts and their associated scoring rubrics are provided in Appendix A.
NECAP does not score all the essays associated with the matrix-sampled prompts being field tested. Consequently, the study’s Grade 11 essays were those of only 590 students, many fewer than the number of Grade 8 students whose

6
essays were used. At Grade 8, to take advantage of the benefits of IRT scaling and linking to the NECAP writing scale, the work of 1694 students was used. That work included not only the essays of the 8th graders, but also their responses to non-essay-related test items in writing (multiple-choice, short-answer, and 4-pt constructed-response items worth a total of 25 raw points.) The linkage to the NECAP scale enabled the use of the NECAP cut scores for proficiency levels for analysis of decision accuracy and consistency. The scores on the Grade 11 pilot prompts were not scaled in with the other writing measures for NECAP. However, for generating comparative data from NECAP, the raw cut scores for proficiency levels used for NECAP were used, along with the NECAP operational rubrics and procedures.
Human ScoringAlthough the essays had already been scored for NECAP, they were rescored by humans using two different methods for purposes of the study. Double scoring (independent scoring by two readers) was done for each method. The scoring was accomplished by temporary scoring staff employed for other Measured Progress projects and trained by regular, full-time scoring staff who followed routine benchmarking and training procedures. These scoring leaders also monitored scorer accuracy during the scoring process by standard read-behind procedures, and they arbitrated paired scores from double scoring that differed by more than one point.
One scoring method called for readers to assign one holistic score and five analytic scores to each essay. The analytic scores were for organization, support, focus, language, and conventions. The second scoring method required each reader to provide only two scores: a holistic score and a score for support. (Even though holistic scoring does not focus on a single analytic trait, it was chosen as a basis for one of the human scores because writing experts have argued that only humans can take into account “intangibles” that can and should influence holistic scores.) The rubrics designed specifically for this study are presented in Appendix B.
Essays were scored one prompt at a time. The scorers and essays were divided into two groups such that half the scorers used the first method first, while the other half used the second method first. (Thus, half the essays were scored by the first method first, while the other half were scored by the second method first.) There were eighteen experienced scorers involved in the study.
Computer/Automated ScoringThe essays at both grade levels were scored by the ETS e-rater® system, which yielded four analytic scores: word choice, conventions, fluency/organization, and topical vocabulary (content). The system also produced a holistic score, which for this study was not based on “training” to produce best estimates of human holistic scores. The eleventh graders’ essays were also scored by Pearson’s Intelligent Essay AssessorTM (IEA). From this system, the researchers obtained a holistic score (based on “training”) and three analytic scores: mechanics, content, and style.
The list below summarizes the score data that were available for each student essay:
�� MP/Gates human scores – holistic and 5 traits (organization, support, focus, language, conventions), double-scored
�� MP/Gates human scores – holistic and 1 trait (support), double-scored
�� e-rater® scores – holistic and 4 traits (word choice, conventions, fluency/organization, topical vocabulary/content)
�� NECAP human scores – holistic, double-scored
�� (grade 11 only) IEA scores – holistic and 3 traits (mechanics, content, style)

7
Results of AnalysesPreliminary AnalysesAs an initial check of the reliabilities of human and computer scoring, cross-task correlations between holistic scores were computed for both types of scoring. (The human scores were the sums of two readers’ scores.) These alternative form reliabilities for human holistic scores were .59 at grade 8 and .78 at grade 11 (from the 6-score method). The corresponding reliabilities for computer scoring were .82 and .90 respectively. The lower values at grade 8 are not surprising since one of the essays at that grade was a short one.
Tables 1 through 6 address the contention that human scorers tend to not differentiate among analytic traits well. It should be noted that in these tables, the terms “Scorer 1” and “Scorer 2” actually refer to the first scoring and the second scoring. There were many more than two scorers working on the project, and scorers were randomly assigned essays to score. During the course of double scoring, a particular scorer was paired with many different scorers and was sometimes a first reader, and sometimes a second reader of essays. Scorer 1 scores were used in analyses in which single scoring was of interest.
The correlations in Tables 1 and 2 are average intercorrelations among the analytic traits. These correlations are extremely high for human scorers as compared to those for the automated scoring systems. Some researchers have argued that such high correlations between two measures have two explanations: either one measure is a direct cause of the other, or the two measures are really measures of the same thing. This logic supports the notion that the human scorers cannot easily separate the analytic traits in their minds as they are scoring. The correlations among analytic traits from automated scoring are much more reasonable for variables that should be correlated, but that are truly independent of one another. Clearly, the factors the computer scoring considers are different from one another. Even though writing experts do not consider these factors ideal measures of the traits named, they are good, correlated proxies that are easily “counted” or evaluated by computers. For example, vocabulary level is a basis for e-rater®’s word choice, and essay length contributes to analytic traits scored by various computer systems.

8
TABLE 1: AVERAGE INTERCORRELATIONS OF ANALYTIC TRAITS – GRADE 8
Passage Scorer Correlation
LightningScorer 1Scorer 2e-rater®
.937
.938
.290*
School LunchScorer 1Scorer 2e-rater®
.926
.924
.615
* e-rater® Lightning intercorrelations being lower than e-rater® School Lunch intercorrelations is to be expected because the Lightning essays are much shorter essays.
TABLE 2: AVERAGE INTERCORRELATIONS OF ANALYTIC TRAITS* – GRADE 11
Passage Scorer Correlation
Ice Age
Scorer 1Scorer 2e-rater®
IEA
.947
.946
.614
.753
Reflection
Scorer 1Scorer 2e-rater®
IEA
.916
.918
.535
.648
*Human scorers scored five analytic traits, while e-rater® and the IEA system scored four and three respectively.
It was hypothesized that if human scorers had fewer traits to score, then they could more easily separate traits in their minds. Tables 3 and 4 suggest that this is not the case. They show the correlations between holistic scores and support scores obtained via the two human scoring methods. While we would expect these correlations to be high because support obviously contributes to holistic scores, the hypothesis mentioned above would lead one to expect a lower correlation by the 2-score method. Such was not obtained.
TABLE 3: CORRELATIONS BETWEEN HUMAN HOLISTIC AND SUPPORT SCORES – GRADE 8
Passage Scorer 6-Score Method
2-Score Method
Lightning Scorer 1Scorer 2
.907
.906.905.903
School Lunch Scorer 1Scorer 2
.921
.924.924.926
TABLE 4: CORRELATIONS BETWEEN HOLISTIC AND SUPPORT SCORES – GRADE 11
Passage Scorer 6-Score Method
2-Score Method
Ice Age Scorer 1Scorer 2
.946
.937.945.941
Reflection Scorer 1Scorer 2
.930
.933.946.930

9
Tables 5 and 6 show all the correlations between first and second human scorings. While these are high as expected, they are consistently lower than the intercorrelations among different trait scores from single scoring. In other words, correlations between scores from different scorers on the same traits are not as high as correlations between scores from the same scorers on different traits (refer to Tables 1 and 2). All of the analyses in these six tables lend credence to the concern about the lack of independence of human analytic scores. Statistical tests of the significance of differences among these correlations from “dependent populations” were not computed as the distribution of such differences is not known, but the statistics speak for themselves.
TABLE 5: CORRELATIONS BETWEEN SCORES FROM SCORER 1 AND SCORER 2 – GRADE 8
Passage Holistic Organization Support Focus Language Conventions
Lightning .844 .807 .813 .800 .810 .810
School Lunch .905 .846 .840 .853 .857 .862
TABLE 6: CORRELATIONS BETWEEN SCORES FROM SCORER 1 AND SCORER 2 – GRADE 11
Passage Holistic Organization Support Focus Language Conventions
Ice Age .907 .870 .866 .871 .892 .899
Reflection .907 .881 .882 .865 .875 .862
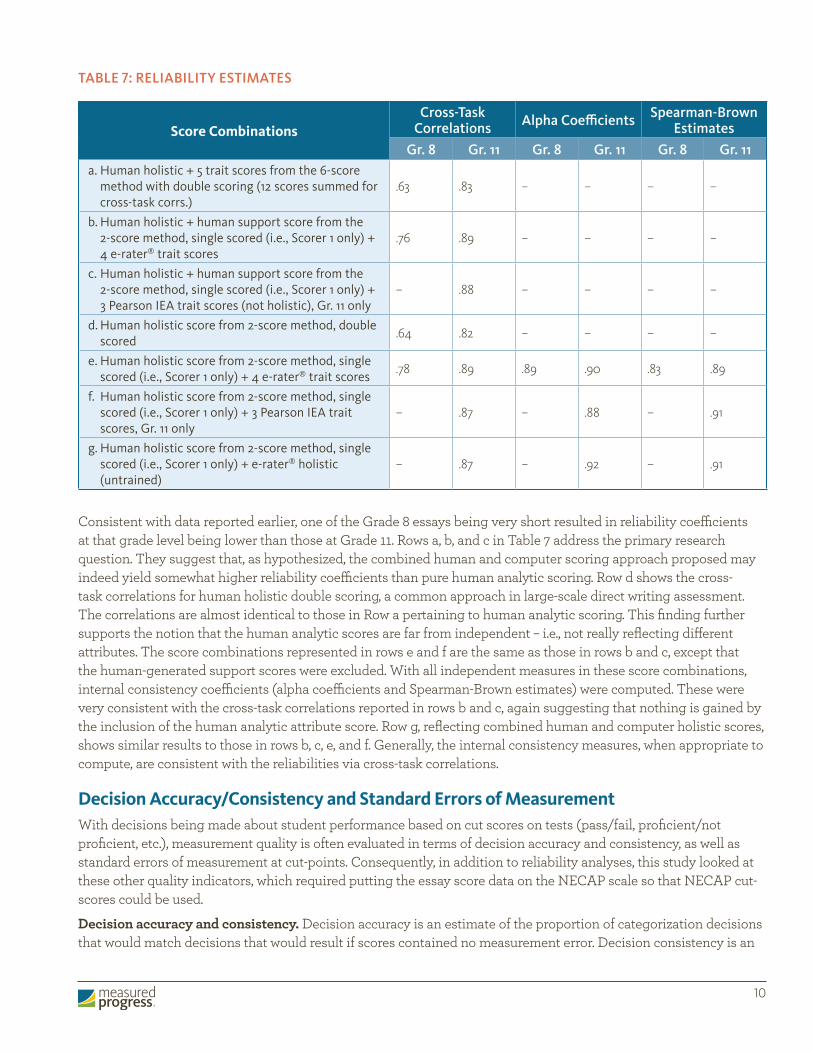
Reliability AnalysesEstimating the reliability of direct writing assessments can be challenging, largely because the assessments are often one-item tests – single writing prompts. NECAP has an advantage in that two prompts are administered to each student in that program. This allows the computation of correlations between scores on two essays – an alternative form reliability estimate for either of the two measures. For this study, these are reported in the first two columns of Table 7. Interestingly, if the two essays were written in conjunction with different programs, one might consider their correlation to be validity evidence. (Validity of scoring could be demonstrated by the correlation between results of scoring the essays in response to the same prompt by two different scoring methods.)
As can be concluded from the Grade 8 results, the short essay, being a weaker measure of writing, resulted in a lower cross-task correlation. Of course, the NECAP assessments are two-prompt tests, so the reliability of the total tests could be estimated by applying the Spearman-Brown Prophecy Formula to .63 and .83, thereby estimating the reliabilities of tests twice as long. However, that is not what was done to obtain the values in the Spearman-Brown columns of Table 7. The alpha coefficients and Spearman-Brown estimates treated the score components as separate items in multi-item tests. Reliability estimates by these two methods were computed separately for each prompt, then the two estimates at a grade level were averaged. Thus, all the reliability estimates in Table 7 pertain to a one-prompt test. Alpha coefficients and Spearman-Brown estimates are not shown for rows a through d because of the lack of independence of the component scores which inflates internal consistency measures. The alpha coefficient for the 6-score method at Grade 11, for example, was 0.99 (not shown).
10
TABLE 7: RELIABILITY ESTIMATES
Score CombinationsCross-Task
Correlations Alpha Coefficients Spearman-Brown Estimates
Gr. 8 Gr. 11 Gr. 8 Gr. 11 Gr. 8 Gr. 11a. Human holistic + 5 trait scores from the 6-score
method with double scoring (12 scores summed for cross-task corrs.)
.63 .83 – – – –
b. Human holistic + human support score from the 2-score method, single scored (i.e., Scorer 1 only) + 4 e-rater® trait scores
.76 .89 – – – –
c. Human holistic + human support score from the 2-score method, single scored (i.e., Scorer 1 only) + 3 Pearson IEA trait scores (not holistic), Gr. 11 only
– .88 – – – –
d. Human holistic score from 2-score method, double scored
.64 .82 – – – –
e. Human holistic score from 2-score method, single scored (i.e., Scorer 1 only) + 4 e-rater® trait scores
.78 .89 .89 .90 .83 .89
f. Human holistic score from 2-score method, single scored (i.e., Scorer 1 only) + 3 Pearson IEA trait scores, Gr. 11 only
– .87 – .88 – .91
g. Human holistic score from 2-score method, single scored (i.e., Scorer 1 only) + e-rater® holistic (untrained)
– .87 – .92 – .91
Consistent with data reported earlier, one of the Grade 8 essays being very short resulted in reliability coefficients at that grade level being lower than those at Grade 11. Rows a, b, and c in Table 7 address the primary research question. They suggest that, as hypothesized, the combined human and computer scoring approach proposed may indeed yield somewhat higher reliability coefficients than pure human analytic scoring. Row d shows the cross-task correlations for human holistic double scoring, a common approach in large-scale direct writing assessment. The correlations are almost identical to those in Row a pertaining to human analytic scoring. This finding further supports the notion that the human analytic scores are far from independent – i.e., not really reflecting different attributes. The score combinations represented in rows e and f are the same as those in rows b and c, except that the human-generated support scores were excluded. With all independent measures in these score combinations, internal consistency coefficients (alpha coefficients and Spearman-Brown estimates) were computed. These were very consistent with the cross-task correlations reported in rows b and c, again suggesting that nothing is gained by the inclusion of the human analytic attribute score. Row g, reflecting combined human and computer holistic scores, shows similar results to those in rows b, c, e, and f. Generally, the internal consistency measures, when appropriate to compute, are consistent with the reliabilities via cross-task correlations.
Decision Accuracy/Consistency and Standard Errors of MeasurementWith decisions being made about student performance based on cut scores on tests (pass/fail, proficient/not proficient, etc.), measurement quality is often evaluated in terms of decision accuracy and consistency, as well as standard errors of measurement at cut-points. Consequently, in addition to reliability analyses, this study looked at these other quality indicators, which required putting the essay score data on the NECAP scale so that NECAP cut-scores could be used.
Decision accuracy and consistency. Decision accuracy is an estimate of the proportion of categorization decisions that would match decisions that would result if scores contained no measurement error. Decision consistency is an

11
estimate of the proportion of categorization decisions that would match decisions based on scores from a parallel form. Tables 8 and 9 show the decision accuracy and consistency statistics for various combinations of Grade 8 and Grade 11 writing score data. The Grade 8 combinations included the NECAP non-essay scores since they were used in the NECAP scaling. What was varied in the different score combinations were the human and computer scoring components of interest. The first two data rows in Table 8 and the first three data rows in Table 9 pertain to the two models of most interest in this study: 6 human-generated scores versus 2 human-generated scores augmented by automated analytic scores. While it might appear that differences in those two statistics (relative to the proficient cut) favor the 6-score method, the actual differences are practically negligible. The last data row in each table shows results for a score combination in which the human scoring contribution is only a holistic score. As with previous analyses, the results suggest that human scores on a second trait do not make a difference.
TABLE 8: DECISION ACCURACY (AND CONSISTENCY) – GRADE 8
Score Combination Overall Near Proficient vs Proficient
MP/Gates human holistic + 5 traits (double scoring both long and short essays) + NECAP non-essay scores
0.92(0.88) 0.95(0.93)
MP/Gates human holistic + 1 trait (single scoring both essays) + e-rater® 4 traits (both essays) + NECAP non-essay scores
0.79(0.71) 0.92(0.88)
NECAP holistic (single scoring both essays) + e-rater® 4 traits (both essays) + NECAP non-essay scores
0.77(0.68) 0.92(0.89)
TABLE 9: DECISION ACCURACY (AND CONSISTENCY) – GRADE 11
Score Combination Overall Near Proficient vs Proficient
MP/Gates human holistic + 5 traits (double scoring both essays) 0.91(0.87) 0.97(0.95)
MP/Gates human holistic + 1 trait (single scoring both essays) + e-rater® 4 traits (both essays) 0.79(0.71) 0.93(0.90)
MP/Gates human holistic + 1 trait (single scoring both essays) + Pearson IEA automated 3 traits (both essays) 0.87(0.81) 0.96(0.94)
NECAP holistic (single scoring both essays) + e-rater® 4 traits (both essays) 0.76(0.68) 0.92(0.88)
NECAP holistic (single scoring both essays) + Pearson IEA 3 traits (both essays) 0.84(0.78) 0.95(0.93)
Standard errors at cut-points. The same combinations of scores corresponding to the rows in Tables 8 and 9 are used in Tables 10 and 11 below. The latter tables report the standard errors of measurement at the cut points, the second cut being the one that separates proficient performance from not-proficient performance.
TABLE 10: STANDARD ERRORS AT CUTS* – GRADE 8
Score CombinationStandard Error (% of Range)
C1 C2 C3MP/Gates human holistic + 5 traits (double scoring both long and short essays) + NECAP non-essay scores .87(1.09) 1.01(1.26) 1.40(1.75)
MP/Gates human holistic+1 trait (single scoring both essays) + e-rater® 4 traits (both essays) + NECAP non-essay scores 1.94(2.41) 2.07(2.59) 2.51(3.14)
NECAP holistic (single scoring both essays) + e-rater® 4 traits (both essays) + NECAP non-essay scores 1.69(2.11) 2.66(3.32) 3.00(3.75)
* All standard errors are on the scale score metric. NECAP uses an 80-point scale.

12
TABLE 11: STANDARD ERRORS AT CUTS* – GRADE 11
Score CombinationStandard Error (% of Range)
C1 C2 C3
MP/Gates human holistic + 5 traits (double scoring both essays) 1.09(1.36) 1.10(1.38) 1.24(1.56)
MP/Gates human holistic + 1 trait (single scoring both essays) + e-rater® 4 traits (both essays) 1.59(1.99) 1.64(2.05) 1.90(2.38)
MP/Gates human holistic + 1 trait (single scoring both essays) + Pearson IEA automated 3 traits (both essays) 1.55(1.94) 1.58(1.98) 1.74(2.18)
NECAP holistic (single scoring both essays) + e-rater® 4 traits (both essays) 2.04(2.55) 2.06(2.58) 2.20(2.75)
NECAP holistic (single scoring both essays) + Pearson IEA 3 traits (both essays) 1.97(2.46) 1.93(2.41) 1.96(2.45)
*All standard errors are on the scale score metric. NECAP uses an 80-point scale.
The results depicted in Table 10 and Table 11 suggest that the primary scoring methods of interest do make a difference, with lower standard errors associated with 6 human-generated scores as opposed to 2 human-generated scores (or a single human holistic score) augmented by automated analytic scores. Again, however, the differences (and the standard errors themselves) are small.
The finding of slightly better results for the 6-score method (although the actual differences in decision accuracy/consistency and standard errors were not great) was not expected, particularly in light of the reliability analyses. However, it is unclear just what the impact is of the spurious, extremely high intercorrelations among human analytic scores on these statistics for the 6-human-score method. (This situation approaches that of having a one-item test, but counting that item many times as if each time it is a different item, which would inappropriately inflate internal consistency measures and deflate standard errors. This is why internal consistency coefficients were not reported for the 6-score method in Table 7.) Investigating the impact of greatly inflated internal consistency on decision accuracy/consistency and standard errors was beyond the scope of this study.
Scorer Discrepancies (>1)Typically, when two scorers award scores that differ by more than one point, a third reading is required to arbitrate the discrepancy and determine final scores of record. The analyses leading to the results reported in Tables 12 and 13 used original, unarbitrated scores. Looking at frequencies of discrepancies is another way of evaluating agreement rates. It was hypothesized that human agreement rates would be greater (and discrepancy rates lower) if there were fewer analytic traits to score. The data in the Table 12 pertain to just the holistic and support scores awarded using both the 6-trait and 2-trait methods – the two scores common to both methods. Indeed the discrepancy rates (rates of score differences greater than one point) between scorers for these two scores appeared to be greater when scorers had to award six analytic scores than when they awarded only the two scores.
TABLE 12: HUMAN SCORING DISCREPANCIES BY METHOD
Grade Number of Essays
Holistic and Support Scores from 6-Score Method
Holistic and Support Scores from 2-Score Method
# Discrep. % Discrep. # Discrep. % Discrep.
8 3376 303 8.98 221 6.55
11 1168 74 6.34 55 4.71

13
Since the Pearson IEA system produced holistic scores after “training” of the computer to mimic human scores, a common practice, the study could compare human-to-human with human-to-computer discrepancy rates. Table 13 shows that the discrepancies between human holistic scores and computer holistic scores (2.08% on average) are fewer than those between two human scorers (3.21% on average). However, that difference is not large enough to make a big difference in the expense of third readings for arbitrations, even recognizing that there would likely be three times as many human discrepancies when scoring six traits rather than two traits. What would make a meaningful monetary difference for large projects, however, is not the time to remedy discrepant scores, but rather the time it takes humans to score six traits rather than two – roughly 25 percent more time. (This is a rough approximation based on review of scorer time sheet information recorded during this study.)
TABLE 13: FREQUENCY OF HOLISTIC SCORE DISCREPANCIES >1 – GRADE 11
Human Discrepancies > 1 (S1 vs S2) Human (S1) vs IEA Discrepancies
# Scorings # Discrep. % Discrep. # Scorings # Discrep. % Discrep.
2336* 75 3.21 2066 43 2.08
*For each student, there were two essays double scored by humans by two methods.

14
Findings, Conclusions, and RecommendationsThe primary purpose of this study was to investigate a method of scoring student writing that:
�� addressed the problem of the lack of independence of human-generated analytic scores;
�� produced more independent score points per essay in order to enhance measurement quality;
�� engaged humans in scoring that they could do better than computers and engaged computers in scoring that they could do better than humans; and
�� capitalized on the efficiencies of computer scoring of essays.
That method, as implemented in this study, required (1) human scorers to assign two scores to each student essay: one a holistic score, and the second a score for the analytic trait typically called “support” (single reader scoring) and (2) an automated scoring system to generate multiple trait scores. The primary comparison method was all-human double scoring that yielded a holistic score and five trait scores. Other combinations of writing scores were examined to address other aspects of the scoring of writing relevant to the primary focus.
The key findings of analyses are summarized below:
1. Intercorrelations among human-generated and among computer-generated analytic writing scores strongly supported the long-held concern that human scorers do not differentiate analytic traits effectively. There was an extreme “halo effect.”
2. The combined human-computer scoring approach produced somewhat more reliable scores than the all-human holistic plus analytic (double) scoring.
3. The combined human-computer approach including a human holistic score only was just as reliable as the approach which included both human holistic and support scores.
4. The reliability of combined human holistic and human analytic double scoring was no greater than the reliability of human holistic double scoring by itself.
5. With human holistic and computer analytic scores being clearly independent measures, internal consistency measures of reliability were justified, and they were consistent with reliability estimates based on cross-task correlations.
6. Small differences between the two primary methods in decision accuracy and consistency and standard errors at the proficiency cut-points favored the human analytic scoring approach. It is unclear what impact the inflated internal consistency of human analytic scores has on these three statistics.
7. As anticipated, when humans had only two scores to award, the scoring discrepancy rate was lower than the discrepancy rate for those same two scores when scorers had to award six scores.
8. Discrepancy rates between human and computer-generated scores were lower than discrepancy rates between two human scorers.
9. Although not studied precisely, perusal of timesheet data suggested that 6-score human scoring took approximately 25 percent more time than the 2-score human scoring method.
Generally, the findings of this study support combined human holistic and computer analytic scoring, particularly for programs requiring large scoring projects. There are writing traits that computers cannot score and unusual features writers might create that computers cannot take into account. Clearly, however, computer analytic scoring can provide more independent score points than human-generated trait scores, thereby enhancing reliability and at the same time offering time- and cost-efficiencies. Single scoring of student essays by the human readers is sufficient, if computer-generated holistic scores or a simple combination of the computer-generated analytic scores is used to identify human scores that should be arbitrated. Of course, if there are high stakes for individual students associated with the writing test results, more than one task/prompt are advisable.

15
Because the study design was partially dictated by large-scale assessment procedures and because of the particular statistics computed, statistical hypothesis tests were not performed. However, since combined single human holistic and computer holistic scoring are already accepted practice, the results of this study would easily justify a state testing program employing on a trial basis the recommended approach of single human holistic scoring with computer analytic scoring, at the same time as the human/computer holistic approach with the “training” of the computer. If the results of the two are similar and the reliability of the “new” approach is the same as or better than that of the other, then future assessments could employ the “new” approach without the need to train” the computer, thus saving time and expense.
The study results are not a justification for abandoning human analytic scoring altogether. For classroom formative and summative assessment and for district testing for which there is adequate time for scorers to provide annotations along with scores, analytic scoring can be especially useful. It focuses teachers/readers on analytic traits and can help them provide rich, meaningful feedback on how students can improve their essays. For example, pointing out to a student specifically where clearer wording or a particular example might have enhanced an argument is far more helpful than a simple numerical score on a trait. Computer-generated trait scores contribute to overall test reliability, and can also provide some useful diagnostic information. However, educators should be mindful that the computer uses proxy measures of the attributes the writing experts value, and can be “outsmarted” the more knowledgeable the test takers become regarding those proxy measures.
Direct writing assessment has been the most accepted form of performance assessment implemented in our schools. Yet even with our many years of experience, we have managed to shortchange basic measurement principals in practicing it. It is not unusual for a single writing assignment to be a component in a broader assessment of English language arts. Yet treating it as a one-item test, the only evidence of technical quality many programs provide for their writing component is information on scorer agreement rates. This is NOT test reliability. There is a lot of evidence of many aspects of effective writing in student essays, and independent computer-generated trait scores, combined with human holistic scores, can help tap that evidence and make a total writing test score range (and reliability estimates) more reflective of that large amount of evidence. The measurement quality of direct writing assessments is as much a function of how we score the student work as it is a function of the quality of the tasks.
ReferencesDunbar, S., Koretz, D. and Hoover, H.D. (1991). Quality control in the development and use of performance assessments. Applied Measurement
in Education, 4(4) 289-303.
Goldsmith, J., Davis, E., Kahl, S., DeVito, P. (2012). Can a Machine Cry? Current Research on Using Software to Grade Complex Essays. Presentation delivered at the National Conference on Student Assessment, CCSSO, Minneapolis, June 28.
Pecheone, R., Kahl, S., Hamma, J., Jaquith, A. (2010). Through a Looking Glass: Lessons Learned and Future Directions for Performance Assessment. Stanford, CA: Stanford University, Stanford Center for Opportunity Policy in Education.
Zhang, M. (2013). Contrasting automated and human scoring of essays. R&D Connections, No. 21. Princeton, NJ: ETS.

16
Appendix A: NECAP Prompts and Rubrics

17
Grade 8 NECAP Prompt—LightningFor a class report, a student wrote this fact sheet about lightning. Read the fact sheet and then write a response to the prompt that follows.
Lightning
Facts about lightning
��thunder is made from the sound waves produced by lightning
��lightning causes air to heat rapidly and then cool, producing sound waves
��lightning happens mostly within clouds, but it can also happen between a cloud and Earth
��causes more than 10,000 forest fires in the United States each year
��Earth is struck by lightning 50 to 100 times each second worldwide
��can strike up to 20 miles away from a storm
��temperature of a lightning bolt hotter than the Sun
��about 100,000 thunderstorms in the United States each year
��chances of being struck by lightning 1 in 600,000
��average flash of lightning could turn on a 100-watt bulb for three months
��can strike more than once in the same place
��“blitz” is the German word for lightning
��moves 60,000 miles a second
��kills or injures several hundred people in the United States each year
Write your response to prompt 13 on page 23 in your Student Answer Booklet.
13. Use the fact sheet to write an introductory paragraph for a report about the dangers of lightning. Your paragraph should��contain a lead sentence/hook that will interest the reader in the report,��set the context for the report, and��include a clear focus/controlling idea.
Select only the facts you need for your introduction.

18
Grade 8 NECAP Scoring Rubric for Lightning
Scoring Guide:
Score Description
4
Response provides an introduction to a report about the dangers of lightning. The paragraph contains an appropriate and effective lead sentence, clearly sets the context for the report, and contains a clearly stated focus/controlling idea. The paragraph includes only relevant facts from the fact sheet. The response is well-organized. The response includes a variety of correct sentence structures and demonstrates sustained control of grade-appropriate grammar, usage, and mechanics.
3
Response provides an introduction to a report about the dangers of lightning. There is a lead sentence, although it may serve more to introduce the topic than to capture the reader’s interest. The paragraph sets the context and contains a focus/controlling idea, but there may be minor lapses in focus or clarity. The paragraph includes mostly relevant facts from the fact sheet. The response is generally well-organized. The response includes some sentence variety and demonstrates general control of grade-appropriate grammar, usage, and mechanics.
2
Response is an attempt at a paragraph that is an introduction to a report on the dangers of lightning. The paragraph may have no lead sentence, may not clearly set the context, or may lack a consistent focus or clear organization. The paragraph includes some relevant facts from the fact sheet. The response includes some attempt at sentence variety and may demonstrate inconsistent control of grammar, usage, and mechanics.
1 Response is undeveloped or contains an unclear focus. There is little evidence of logical organization.
0 Response is totally incorrect or irrelevant.
Blank No response

19
Grade 8 NECAP Prompt—School Lunch
Write your response to prompt 17 on pages 24 through 26 in your Student Answer Booklet.
When writing a response to prompt 17, remember to
��read the prompt carefully,��develop a complete response to the prompt,��proofread and edit your writing, and��write only in the space provided.
17. Do you think that making your school lunch period longer is a good idea? Write to your principal to persuade him or her to agree with your point of view.
Grade 8 NECAP Scoring Rubric for School Lunch
Scoring Guide:
Score Description
6
� purpose/position is clear throughout; strong focus/position OR strongly stated purpose/opinion focuses the writing� intentionally organized for effect� fully developed arguments and reasons; rich, insightful elaboration supports purpose/opinion� distinctive voice, tone, and style effectively support position� consistent application of the rules of grade-level grammar, usage, and mechanics
5
� purpose/position is clear; stated focus/opinion is maintained consistently throughout � well organized and coherent throughout� arguments/reasons are relevant and support purpose/opinion; arguments/reasons are sufficiently elaborated� strong command of sentence structure; uses language to support position� consistent application of the rules of grade-level grammar, usage, and mechanics
4
� purpose/position and focus are evident but may not be maintained� generally well organized and coherent � arguments are appropriate and mostly support purpose/opinion� well-constructed sentences; uses language well� may have some errors in grammar, usage, and mechanics
3
� purpose/position may be general� some sense of organization; may have lapses in coherence� some relevant details support purpose; arguments are thinly developed� generally correct sentence structure; uses language adequately � may have some errors in grammar, usage, and mechanics
2
� attempted or vague purpose/position� attempted organization; lapses in coherence� generalized, listed, or undeveloped details/reasons� may lack sentence control or may use language poorly� may have errors in grammar, usage, and mechanics that interfere with meaning
1
� minimal evidence of purpose/position� little or no organization� random or minimal details� rudimentary or deficient use of language� may have errors in grammar, usage, and mechanics that interfere with meaning
0 Response is totally incorrect or irrelevant.
Blank No response

20
Grade 11 NECAP Prompt—Ice Age
Everyday Life at the End of the Last Ice AgeInformational Writing (Report)
A student wrote this fact sheet about life 12,000 years ago, at the end of the last ice age. Read the fact sheet. Then write a response to the prompt that follows.
Everyday Life at the End of the Last Ice Age
��people lived in bands of about 25 members��lived mainly by hunting and gathering��shared decision-making fairly equally among members in a band��each person skilled in every type of job��diet: small and large mammals, fish, shellfish, fruits, wild greens and vegetables, grains, roots, and nuts��approximately 10,000 years ago wooly mammoth became extinct��nomadic based on time of year or movement of animal herds��cooked meat by roasting it on a spit over a fire or by boiling it inside a piece of leather secured by a twig��gathered herbs��made everything themselves: tools, homes, clothing, medicines, etc.��worked about 2-3 hours a day getting food��worked about 2-3 hours a day making and repairing tools and clothes��spent remainder of day relaxing with family and friends��told stories, danced, sang, and played games��owned very few possessions��no concept of rich or poor��communicated through art (painting and sculpture) and the spoken word��buried their dead and had concepts of religion and an afterlife��sometimes adorned themselves with ornaments and decorations such as jewelry, tattoos, body painting, and
elaborate hairstyles
1. What would a person from 12,000 years ago find familiar and/or different about life today? Select relevant information from the fact sheet and use your own knowledge to write a report.
Before writing, consider��the focus/thesis of your report��the supporting details in your report��the significance of the information in your report
A complete response to the prompt will include
✔ a clear purpose/focus✔ coherent organization✔ details/elaboration✔ well-chosen language and a variety of sentence structures✔ control of conventions

21
Grade 11 NECAP Prompt—Ice Age (continued)
Grade 11 NECAP Scoring Rubric for Ice Age
Scoring Guide:
Score Description
6
� purpose is clear throughout; strong focus/controlling idea OR strongly stated purpose focuses the writing� intentionally organized for effect� fully developed details, rich and/or insightful elaboration supports purpose� distinctive voice, tone, and style enhance meaning� consistent application of the rules of grade-level grammar, usage, and mechanics
5
� purpose is clear; focus/controlling idea is maintained throughout � well organized and coherent throughout� details are relevant and support purpose; details are sufficiently elaborated� strong command of sentence structure; uses language to enhance meaning� consistent application of the rules of grade-level grammar, usage, and mechanics
4
� purpose is evident; focus/controlling idea may not be maintained� generally organized and coherent � details are relevant and mostly support purpose� well-constructed sentences; uses language well� may have some errors in grammar, usage, and mechanics
3
� writing has a general purpose� some sense of organization; may have lapses in coherence� some relevant details support purpose� uses language adequately; may show little variety of sentence structures � may have some errors in grammar, usage, and mechanics
2
� attempted or vague purpose� attempted organization; lapses in coherence� generalized, listed, or undeveloped details � may lack sentence control or may use language poorly� may have errors in grammar, usage, and mechanics that interfere with meaning
1
� minimal evidence of purpose� little or no organization� random or minimal details� rudimentary or deficient use of language� may have errors in grammar, usage, and mechanics that interfere with meaning
0 Response is totally incorrect or irrelevant.
Blank No response

22
Grade 11 NECAP Prompt—Reflective Essay
Reflective EssayRead this quotation. Think about what it means and how it applies to your life.
“The cure for boredom is curiosity. There is no cure for curiosity.” —Dorothy Parker
Write your response to prompt 1 on pages 3 through 5 in your Student Answer Booklet.
1. What does this quotation mean to you? Write a reflective essay using personal experience or observations to show how the quotation applies to your life.
Before writing, consider��what the quotation means to you��what experience/observations support your ideas��how your ideas connect to the larger world
A complete response to the prompt will include
✔ a clear purpose/focus✔ coherent organization✔ details/elaboration✔ well-chosen language and a variety of sentence structures✔ control of conventions

23
Grade 11 NECAP Scoring Rubric for Reflective Essay
Scoring Guide:
Score Description
6
� purpose is clear throughout; strong focus/controlling idea OR strongly stated purpose focuses the writing� intentionally organized for effect� fully developed details, rich and/or insightful elaboration supports purpose� distinctive voice, tone, and style enhance meaning� consistent application of the rules of grade-level grammar, usage, and mechanics
5
� purpose is clear; focus/controlling idea is maintained throughout � well organized and coherent throughout� details are relevant and support purpose; details are sufficiently elaborated� strong command of sentence structure; uses language to enhance meaning� consistent application of the rules of grade-level grammar, usage, and mechanics
4
� purpose is evident; focus/controlling idea may not be maintained� generally organized and coherent � details are relevant and mostly support purpose� well-constructed sentences; uses language well� may show inconsistent control of grade-level grammar, usage, and mechanics
3
� writing has a general purpose� some sense of organization; may have lapses in coherence� some relevant details support purpose� uses language adequately; may show little variety of sentence structures � may contain some serious errors in grammar, usage, and mechanics
2
� attempted or vague purpose; stays on topic� little evidence of organization; lapses in coherence� generalizes or lists details� lacks sentence control; uses language poorly� errors in grammar, usage, and mechanics are distracting
1
� lack of evident purpose; topic may not be clear� incoherent or underdeveloped organization� random information� rudimentary or deficient use of language� serious and persistent errors in grammar, usage, and mechanics throughout
0 Response is totally incorrect or irrelevant.
Blank No response

24
Appendix B: Scoring Study Rubrics

25
Scor
ing
Rub
ric
— H
olis
tic
and
Supp
ort
Hol
isti
c R
atin
g1
23
45
6O
vera
ll Eff
ecti
vene
ss o
f Exp
lana
tion
of
Arg
umen
t in
Acc
ompl
ishi
ng P
urpo
seN
ot e
ffect
ive
at a
llLi
mite
d
effec
tiven
ess
Inco
nsis
tent
ly
effec
tive
Gen
eral
ly
effec
tive
Hig
hly
effec
tive
Hig
hly
effec
tive
with
di
stin
ctiv
e qu
aliti
es
Org
aniz
atio
nSu
ppor
tFo
cus/
Coh
eren
ceLa
ngua
ge/T
one/
Styl
eC
onve
ntio
ns
1
Far f
rom
M
eeti
ng
Expe
ctat
ions
Ove
rall
stru
ctur
e la
ckin
g, id
eas
diso
r-ga
nize
d, fe
w o
r no
tran
sitio
ns.
Idea
s/cl
aim
s/po
sitio
n ar
e in
suffi
cien
tly o
r poo
rly
supp
orte
d w
ith li
ttle
, am
bigu
ous,
or n
o de
tails
/ ev
iden
ce.
Lack
s foc
us,
ofte
n off
topi
c.La
ngua
ge/v
ocab
ular
y an
d to
ne in
cons
isten
t or g
ener
-al
ly in
appr
opria
te fo
r aud
i-en
ce a
nd p
urpo
se; l
ittle
or
no v
aria
tion
in s
ente
nce
stru
ctur
e.
Man
y er
rors
(maj
or
and
min
or) i
n gr
amm
ar,
usag
e, a
nd m
echa
nics
, fr
eque
ntly
inte
rfer
ing
with
mea
ning
.
1
2
App
roac
hing
Ex
pect
atio
nsIn
cons
isten
t org
ani-
zatio
n an
d se
quen
c-in
g of
idea
s, so
me
tran
sitio
ns, b
ut so
me
notic
eabl
y la
ckin
g.
Idea
s/cl
aim
s/po
sitio
n ar
e un
even
ly s
uppo
rted
with
som
e de
tails
/evi
denc
e.
Inco
nsist
ent o
r un
even
focu
s,
som
e st
rayi
ng
from
topi
c.
Lang
uage
/voc
abul
ary
and
tone
som
ewha
t inc
on-
siste
nt fo
r aud
ienc
e an
d pu
rpos
e; so
me
varia
tion
in
sent
ence
str
uctu
re.
Man
y er
rors
in g
ram
mar
, us
age,
and
mec
hani
cs,
som
e in
terf
erin
g w
ith
mea
ning
.2
3
Mee
ts
Expe
ctat
ions
Adeq
uate
org
aniz
a-tio
n, m
ostly
logi
cal
orde
ring
of id
eas,
su
ffici
ent t
rans
ition
s.
Idea
s/cl
aim
s/po
sitio
n ar
e su
p-po
rted
with
ade
quat
e re
leva
nt
deta
ils/e
vide
nce.
In a
rgum
enta
tion,
iden
tifies
co
unte
rcla
im(s
).
Clea
r foc
us
thro
ugho
ut
mos
t of e
ssay
.
Lang
uage
/voc
abul
ary
and
tone
mos
tly a
ppro
pria
te
for a
udie
nce
and
purp
ose;
ad
equa
te v
aria
tion
in s
en-
tenc
e st
ruct
ure.
Som
e er
rors
in g
ram
mar
, us
age,
and
mec
hani
cs,
but f
ew, i
f any
, int
erfe
r-in
g w
ith m
eani
ng.
3
4
Exce
eds
Expe
ctat
ions
Clea
r, ov
eral
l org
a-ni
zatio
n st
ruct
ure
(dis
cour
se u
nits
), lo
gica
l seq
uenc
ing
of id
eas,
effec
tive
tran
sitio
ns.
Idea
s/cl
aim
s/po
sitio
n ar
e fu
lly
supp
orte
d w
ith c
onvi
ncin
g, re
l-ev
ant,
clea
r det
ails
/evi
denc
e.
In a
rgum
enta
tion,
cle
arly
dis-
tingu
ishes
cla
ims
and
coun
ter-
clai
ms,
refu
ting
latt
er.
Stro
ng fo
cus
thro
ugho
ut
essa
y.
Lang
uage
/voc
abul
ary
and
tone
con
siste
ntly
app
ro-
pria
te fo
r aud
ienc
e an
d pu
rpos
e; e
ffect
ive
varia
tion
in s
ente
nce
stru
ctur
e.
Few
, if a
ny, e
rror
s in
gr
amm
ar, u
sage
, and
m
echa
nics
, and
non
e in
terf
erin
g w
ith m
ean-
ing.
4

26
Scor
ing
Rub
ric
— H
olis
tic
and
Five
Ana
lyti
c Tr
aits
Hol
isti
c R
atin
g1
23
45
6O
vera
ll Eff
ecti
vene
ss o
f Exp
lana
tion
of
Arg
umen
t in
Acc
ompl
ishi
ng P
urpo
seN
ot e
ffect
ive
at a
llLi
mite
d
effec
tiven
ess
Inco
nsis
tent
ly
effec
tive
Gen
eral
ly
effec
tive
Hig
hly
effec
tive
Hig
hly
effec
tive
with
di
stin
ctiv
e qu
aliti
es
Org
aniz
atio
nSu
ppor
tFo
cus/
Coh
eren
ceLa
ngua
ge/T
one/
Styl
eC
onve
ntio
ns
1
Far f
rom
M
eeti
ng
Expe
ctat
ions
Ove
rall
stru
ctur
e la
ckin
g, id
eas
diso
r-ga
nize
d, fe
w o
r no
tran
siti
ons.
Idea
s/cl
aim
s/po
siti
on a
re
insu
ffici
ently
or p
oorl
y
supp
orte
d w
ith
little
, am
bigu
ous,
or n
o de
tails
/ev
iden
ce.
Lack
s foc
us,
ofte
n off
topi
c.La
ngua
ge/v
ocab
ular
y an
d to
ne in
cons
iste
nt o
r ge
nera
lly in
appr
opri
ate
for a
udie
nce
and
pur-
pose
; litt
le o
r no
vari
atio
n in
sen
tenc
e st
ruct
ure.
Man
y er
rors
(maj
or
and
min
or) i
n gr
am-
mar
, usa
ge, a
nd
mec
hani
cs, f
requ
ently
in
terf
erin
g w
ith
mea
n-in
g.
1
2
App
roac
hing
Ex
pect
atio
nsIn
cons
iste
nt o
rgan
i-za
tion
and
seq
uenc
-in
g of
idea
s, so
me
tran
siti
ons,
but
so
me
notic
eabl
y la
ckin
g.
Idea
s/cl
aim
s/po
siti
on a
re
unev
enly
sup
port
ed w
ith
som
e de
tails
/evi
denc
e.
Inco
nsis
tent
or
unev
en fo
cus,
so
me
stra
ying
fr
om to
pic.
Lang
uage
/voc
abul
ary
and
tone
som
ewha
t in
cons
iste
nt fo
r aud
i-en
ce a
nd p
urpo
se; s
ome
vari
atio
n in
sen
tenc
e st
ruct
ure.
Man
y er
rors
in
gram
mar
, usa
ge, a
nd
mec
hani
cs, s
ome
inte
r-fe
ring
wit
h m
eani
ng.
2
3
Mee
ts
Expe
ctat
ions
Ade
quat
e or
gani
za-
tion
, mos
tly lo
gica
l or
deri
ng o
f ide
as,
suffi
cien
t tra
nsi-
tion
s.
Idea
s/cl
aim
s/po
siti
on a
re
supp
orte
d w
ith
adeq
uate
re
leva
nt d
etai
ls/e
vide
nce.
In a
rgum
enta
tion
, ide
ntifi
es
coun
terc
laim
(s).
Cle
ar fo
cus
thro
ugho
ut
mos
t of e
ssay
.
Lang
uage
/voc
abul
ary
and
tone
mos
tly a
ppro
-pr
iate
for a
udie
nce
and
purp
ose;
ade
quat
e va
riat
ion
in s
ente
nce
stru
ctur
e.
Som
e er
rors
in
gram
mar
, usa
ge, a
nd
mec
hani
cs, b
ut fe
w, i
f an
y, in
terf
erin
g w
ith
mea
ning
.
3
4
Exce
eds
Expe
ctat
ions
Cle
ar, o
vera
ll or
ga-
niza
tion
str
uctu
re
(dis
cour
se u
nits
), lo
gica
l seq
uenc
ing
of id
eas,
eff
ectiv
e tr
ansi
tion
s.
Idea
s/cl
aim
s/po
siti
on a
re
fully
sup
port
ed w
ith
conv
inc-
ing,
rele
vant
, cle
ar d
etai
ls/
evid
ence
.
In a
rgum
enta
tion
, cle
arly
di
stin
guis
hes c
laim
s an
d co
unte
rcla
ims,
refu
ting
latt
er.
Stro
ng fo
cus
thro
ugho
ut
essa
y.
Lang
uage
/voc
abul
ary
and
tone
con
sist
ently
ap
prop
riat
e fo
r aud
ienc
e an
d pu
rpos
e; e
ffec
tive
vari
atio
n in
sen
tenc
e st
ruct
ure.
Few
, if a
ny, e
rror
s in
gr
amm
ar, u
sage
, and
m
echa
nics
, and
non
e in
terf
erin
g w
ith
mea
n-in
g.4

