comparaciÓn de controladores data-driven para …
TRANSCRIPT

COMPARACIÓN DE CONTROLADORES DATA-DRIVEN PARAUN PROCESO CON INCERTIDUMBRES Y NO LINEALIDADESDEL LABORATORIO DE AUTOMATIZACIÓN Y CONTROL DE
LA UNIVERSIDAD EIA
Daniel Espinosa CárcamoSergio Andrés Pacheco Márquez
UNIVERSIDAD EIAESCUELA DE INGENIERÍA Y CIENCIAS
INGENIERÍA MECATRÓNICAENVIGADO, COLOMBIA
2021

COMPARACIÓN DE CONTROLADORES DATA-DRIVEN PARAUN PROCESO CON INCERTIDUMBRES Y NO LINEALIDADESDEL LABORATORIO DE AUTOMATIZACIÓN Y CONTROL DE
LA UNIVERSIDAD EIA
Daniel Espinosa CárcamoSergio Andrés Pacheco Márquez
Trabajo de grado para optar al título de:Ingeniero Mecatrónico
Directora de trabajo de grado:Tatiana Manrique EspíndolaPh.D. en Control Automático
Codirector de trabajo de grado:Juan Camilo Tejada Orjuela
M.Sc. en Ingeniería
UNIVERSIDAD EIAESCUELA DE INGENIERÍA Y CIENCIAS BÁSICAS
INGENIERÍA MECATRÓNICAENVIGADO, COLOMBIA
2021

Dedicatoria
Daniel Espinosa Cárcamo
Le dedico este trabajo a mis padres Antonio y Luz Mery,sin los cuales no habría podido llegar hasta este punto.
A mi hermana, mi tía Ofelia y su familia,que siempre estuvieron ahí para mí.
Sergio Andrés Pacheco Marquez
Este trabajo está dedicado a mi madre Zuny Marquez (Q.E.P.D),quien con dedicación dio todo para que cumpliera mis sueños.
Y a mi hermano, Henyelbert,mis tías Eury y Lola y demás familiares por su apoyo incondicional.
I

Agradecimientos
A nuestros compañeros de carrera, por apoyarnos entre todos para salir adelante.
A nuestros profesores, por su dedicación y empeño para transmitir sus conocimiento yexperiencias.
A nuestros directores Tatiana Manrique y Juan Camilo Tejada, por confiar en nosotros yacompañarnos en esta etapa final de nuestra carrera.
A nuestro director de carrera Georffrey Acevedo, por su apoyo y labor a lo largo de nues-tro proceso de formación.
A nuestros amigos cercanos, que a pesar de la distancia siempre se pudo encontrar elmomento para actividades lúdicas que nos permitieron liberar las sobrecargas de trabajo,en especial a Julián Andrés Marmolejo, por enseñarnos a conectar correctamente lasresistencias en la protoboard, y Juan Pablo Manco, por enseñarnos la diferencia entreroca y piedra.A ellos muchas gracias por permitirnos disfrutar momentos agradables dentro y fuera dela Universidad.
A todos ellos un infinito gracias, esto fue algo muy importante para nosotros y lo agrade-ceremos por siempre.

Índice general
1. Preliminares 31.1. Introducción . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.2. Formulación del problema . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61.3. Objetivos del proyecto . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
1.3.1. Objetivo general . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71.3.2. Objetivos específicos . . . . . . . . . . . . . . . . . . . . . . . . . . 8
1.4. Antecedentes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81.4.1. Estrategias de control basadas en Machine Learning (ML) . . . . . 91.4.2. Control Data Driven para manipuladores flexibles . . . . . . . . . . . 13
1.5. Marco Teórico . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 151.5.1. Control Model-based . . . . . . . . . . . . . . . . . . . . . . . . . . . 151.5.2. Control Data driven indirecto (DDI) . . . . . . . . . . . . . . . . . . . 151.5.3. Control Data driven Directo (DDD) . . . . . . . . . . . . . . . . . . . 19
2. Metodología 232.1. Exploración de procesos del laboratorio de Automatización y Control de la
Universidad EIA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 232.1.1. Planta de pH Amatrol . . . . . . . . . . . . . . . . . . . . . . . . . . 232.1.2. Péndulo doble invertido . . . . . . . . . . . . . . . . . . . . . . . . . 252.1.3. Robot de dos grados de libertad con articulaciones flexibles . . . . . 27
2.2. Estrategias de control data-driven indirecto . . . . . . . . . . . . . . . . . . 282.2.1. Control tradicional (PID) . . . . . . . . . . . . . . . . . . . . . . . . . 282.2.2. Espacio de estados . . . . . . . . . . . . . . . . . . . . . . . . . . . 292.2.3. Realimentación de estados . . . . . . . . . . . . . . . . . . . . . . . 292.2.4. Realimentación de estados con seguimiento de señal . . . . . . . . 30
2.3. Estrategias de control data-driven directo . . . . . . . . . . . . . . . . . . . 312.3.1. PID Neuronal . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 312.3.2. Control Adaptativo Base Radial . . . . . . . . . . . . . . . . . . . . . 322.3.3. Simplificación de datos algoritmo SVD . . . . . . . . . . . . . . . . . 34
2.4. Identificación experimental de sistemas . . . . . . . . . . . . . . . . . . . . 342.4.1. Identificación usando el toolbox Ident de MATLAB . . . . . . . . . . 35
2.5. Transformaciones cinemáticas del FJRM . . . . . . . . . . . . . . . . . . . . 352.5.1. Solución geométrica . . . . . . . . . . . . . . . . . . . . . . . . . . . 352.5.2. Solución analítica . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37

3. Presentación y discusión de resultados 393.1. Protocolo de pruebas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 393.2. Modelos hallados a partir de datos experimentales . . . . . . . . . . . . . . 403.3. Control Data-Driven Indirecto . . . . . . . . . . . . . . . . . . . . . . . . . . 44
3.3.1. Control PID . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 443.3.2. Control con Realimentación de estados con Observador de orden
completo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 603.4. Control Data-Driven Directo . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
3.4.1. Control PID Neuronal . . . . . . . . . . . . . . . . . . . . . . . . . . 763.4.2. Control Adaptativo Base Radial . . . . . . . . . . . . . . . . . . . . . 89
3.5. Comparación de controladores data-driven Directo y Data-driven Indirecto 1033.5.1. Comparación de controladores en sentido horario . . . . . . . . . . 1043.5.2. Comparación de controladores en sentido antihorario . . . . . . . . 107
4. Conclusiones y consideraciones finales 111

Índice de tablas
2.1. Parámetros D-H . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
3.1. Posición X - PID Neuronal . . . . . . . . . . . . . . . . . . . . . . . . . . . . 763.2. Posición Y - PID Neuronal . . . . . . . . . . . . . . . . . . . . . . . . . . . . 763.3. Posición X - Adaptativo Base Radial (ABR) . . . . . . . . . . . . . . . . . . 893.4. Posición Y - Adaptativo Base Radial (ABR) . . . . . . . . . . . . . . . . . . 893.5. Índices de desempeño - Hombro . . . . . . . . . . . . . . . . . . . . . . . . 1103.6. Índices de desempeño - Codo . . . . . . . . . . . . . . . . . . . . . . . . . 110

Índice de figuras
1.1. Artículos desarrollados a nivel mundial. . . . . . . . . . . . . . . . . . . . . 51.2. Artículos desarrollados a nivel mundial por países. . . . . . . . . . . . . . . 51.3. Uso de controladores data-driven en distintos campos del conocimiento . . 61.4. Estructuras de división de control de procesos industriales . . . . . . . . . 81.5. Diagrama de bloques de iteración actual del ILC utilizando redes neuronales 91.6. Diagrama en bloques sistema de control predictivo . . . . . . . . . . . . . . 101.7. Diagrama en bloques sistema de control predictivo . . . . . . . . . . . . . . 101.8. Tipos de señal de entrada . . . . . . . . . . . . . . . . . . . . . . . . . . . . 161.9. Metodología para la obtención de modelos híbridos . . . . . . . . . . . . . 171.10.Proceso de conversión análogo-Digital . . . . . . . . . . . . . . . . . . . . . 181.11.Proceso de conversión digital – análogo . . . . . . . . . . . . . . . . . . . . 191.12.Esquema de control: Modelo inverso. . . . . . . . . . . . . . . . . . . . . . . 201.13.Esquema de control directo sin uso de modelo. . . . . . . . . . . . . . . . . 211.14.Esquema de control directo con uso de modelo. . . . . . . . . . . . . . . . 211.15.Algoritmo de propagación de una red neuronal reconfigurable. . . . . . . . 22
2.1. Planta de PH de la Universidad EIA, Fabricante Amatrol . . . . . . . . . . . 242.2. Identificación de Planta de pH de la Pontificia Universidad Javeriana de
Bogotá . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 252.3. Pendulo Invertido Simple . . . . . . . . . . . . . . . . . . . . . . . . . . . . 262.4. Manipulador robótico con articulaciones flexibles . . . . . . . . . . . . . . . 272.5. Controlador PID Ideal en lazo cerrado . . . . . . . . . . . . . . . . . . . . . 282.6. Realimentación de estado . . . . . . . . . . . . . . . . . . . . . . . . . . . . 302.7. Realimentación de estado con seguimiento de señal . . . . . . . . . . . . . 312.8. Control Adaptativo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 332.9. Red neuronal de función de base radial . . . . . . . . . . . . . . . . . . . . 332.10.Solución geométrica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 362.11.Solución analítica, parámetros D-H . . . . . . . . . . . . . . . . . . . . . . . 37
3.1. Datos experimentales usados para la identificación del hombro . . . . . . . 403.2. Datos experimentales usados para la identificación del codo . . . . . . . . 403.3. Comportamiento no lineal del hombro respecto al sentido de giro . . . . . . 413.4. Comportamiento no lineal del codo respecto al sentido de giro . . . . . . . 413.5. Comportamiento no lineal del codo respecto al sentido de giro . . . . . . . 453.6. DDI: PID - Respuesta Escalón - Hombro (1) . . . . . . . . . . . . . . . . . . 463.7. DDI: PID - Respuesta Escalón - Hombro (0) . . . . . . . . . . . . . . . . . . 463.8. DDI: PID - Respuesta Escalón - Codo (1) . . . . . . . . . . . . . . . . . . . 473.9. DDI: PID - Respuesta Escalón - Codo (0) . . . . . . . . . . . . . . . . . . . 47

3.10.Controlador PID Tradicional implementando switcheo Hombro (1) . . . . . . 483.11.Derivada de de señal de hombro (1) . . . . . . . . . . . . . . . . . . . . . . 493.12.Controlador PID Tradicional implementando switcheo Hombro (0) . . . . . . 503.13.Derivada de señal de hombro (0) . . . . . . . . . . . . . . . . . . . . . . . . 513.14.Controlador PID Tradicional implementando switcheo Codo (1) . . . . . . . 523.15.Derivada de señal de Codo (1) . . . . . . . . . . . . . . . . . . . . . . . . . 533.16.Controlador PID Tradicional implementando switcheo Codo (0) . . . . . . . 543.17.Derivada de señal de codo (0) . . . . . . . . . . . . . . . . . . . . . . . . . 553.18.DDI: PID Tradicional - Posición X vs Y (1) sin switcheo . . . . . . . . . . . . 563.19.DDI: PID Tradicional - Posición X vs Y (0) sin switcheo . . . . . . . . . . . . 573.20.DDD: PID Tradicional - Posición X vs Y (1) con switcheo . . . . . . . . . . . 583.21.DDI: PID Tradicional - Posición X vs Y (0) con switcheo . . . . . . . . . . . 593.22.DDI: Realimentación SSFI - Respuesta Escalón - Hombro (1) . . . . . . . . 623.23.DDI: Realimentación SSFI - Respuesta Escalón - Hombro (0) . . . . . . . . 623.24.DDI: Realimentación SSFI - Respuesta Escalón - Codo (1) . . . . . . . . . 633.25.DDI: Realimentación SSFI - Respuesta Escalón - Codo (0) . . . . . . . . . 633.26.Controlador Realimentación SSFI implementando switcheo Hombro (1) . . 643.27.Derivada de de señal de hombro (1) . . . . . . . . . . . . . . . . . . . . . . 653.28.Controlador Realimentación SSFI implementando switcheo Hombro (0) . . 663.29.Derivada de señal de hombro (0) . . . . . . . . . . . . . . . . . . . . . . . . 673.30.Controlador Realimentación SSFI implementando switcheo Codo (1) . . . . 683.31.Derivada de señal de Codo (1) . . . . . . . . . . . . . . . . . . . . . . . . . 693.32.Controlador Realimentación SSFI implementando switcheo Codo (0) . . . . 703.33.Derivada de señal de codo (0) . . . . . . . . . . . . . . . . . . . . . . . . . 713.34.DDI: Realimentación SSFI - Posición X vs Y (1) sin switcheo . . . . . . . . 723.35.DDI: Realimentación SSFI - Posición X vs Y (0) sin switcheo . . . . . . . . 733.36.DDD: Realimentación SSFI - Posición X vs Y (1) con switcheo . . . . . . . 743.37.DDI: Realimentación SSFI - Posición X vs Y (0) con switcheo . . . . . . . . 753.38.DDD: PID Neuronal - Respuesta escalón - Hombro (1) - Codo (1) . . . . . . 773.39.DDD: PID Neuronal - Posición X (1) - Y(1) . . . . . . . . . . . . . . . . . . . 783.40.DDD: PID Neuronal - Posición X vs Y . . . . . . . . . . . . . . . . . . . . . 783.41.DDD: PID Neuronal - Posición X vs Y Seleccionadas . . . . . . . . . . . . . 793.42.Experimento seleccionado para hombro en sentido horario . . . . . . . . . 803.43.Derivadas para el hombro en sentido horario . . . . . . . . . . . . . . . . . 813.44.Experimento seleccionado para codo en sentido horario . . . . . . . . . . . 823.45.Derivadas para el codo en sentido horario . . . . . . . . . . . . . . . . . . . 833.46.Experimento seleccionado para hombro en sentido antihorario . . . . . . . 843.47.Derivadas para el hombro en sentido horario . . . . . . . . . . . . . . . . . 853.48.Experimento seleccionado para codo en sentido horario . . . . . . . . . . . 863.49.Derivadas para el codo en sentido antihorario . . . . . . . . . . . . . . . . . 873.50.DDD: PID Neuronal - Posición X vs Y (0) . . . . . . . . . . . . . . . . . . . 883.51.DDD: Adaptativo Base Radial - Respuesta escalón - Hombro (1) - Codo (1) 903.52.DDD: Adaptativo Base Radial - Posición X (1) - Y(1) . . . . . . . . . . . . . 913.53.DDD: Adaptativo Base Radial - Posición X vs Y . . . . . . . . . . . . . . . . 923.54.DDD: Adaptativo Base Radial - Posición X vs Y Seleccionadas . . . . . . . 933.55.Experimento seleccionado para hombro en sentido horario . . . . . . . . . 943.56.Derivadas para el hombro en sentido horario . . . . . . . . . . . . . . . . . 95

3.57.Experimento seleccionado para codo en sentido horario . . . . . . . . . . . 963.58.Derivadas para el codo en sentido horario . . . . . . . . . . . . . . . . . . . 973.59.Experimento seleccionado para hombro en sentido antihorario . . . . . . . 983.60.Derivadas para el hombro en sentido horario . . . . . . . . . . . . . . . . . 993.61.Experimento seleccionado para codo en sentido horario . . . . . . . . . . . 1003.62.Derivadas para el codo en sentido antihorario . . . . . . . . . . . . . . . . . 1013.63.DDD: Adaptativo Base Radial - Posición X vs Y (0) . . . . . . . . . . . . . . 1023.64.Comparación de controladores hombro (1) . . . . . . . . . . . . . . . . . . 1043.65.Comparación de controladores Codo(1) . . . . . . . . . . . . . . . . . . . . 1053.66.Comparación de posición Final X(1) Y(1) . . . . . . . . . . . . . . . . . . . 1063.67.Comparación de controladores X(1) . . . . . . . . . . . . . . . . . . . . . . 1063.68.Comparación de controladores hombro (0) . . . . . . . . . . . . . . . . . . 1073.69.Comparación de controladores Codo (0) . . . . . . . . . . . . . . . . . . . . 1083.70.Comparación de posición Final X(0) Y(0) . . . . . . . . . . . . . . . . . . . 1093.71.Comparación de controladores en sentido antihorario para efector final en
posición X-Y . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 109

Índice de anexos
Anexo 1: Control PID
Anexo 2: Control SSI con Observador

Resumen
En el presente trabajo se plantea la comparación de controladores data-driven direc-tos e indirectos en un proceso dinámico ubicado en el laboratorio de Automatización ycontrol de la Universidad EIA. Por esto se realizó una exploración de los procesos dispo-nibles y se definió cuál cumple con los requerimientos para esta actividad. Entre estosse encuentran sistemas como la planta de pH, el péndulo doble invertido de Furuta yel manipulador robótico de dos grados de libertad con articulaciones flexibles. Tenien-do en cuenta los objetivos del presente trabajo se escogerá el proceso adecuado quecumpla con las características de incertidumbres y no linealidades. Los conceptos delos sistemas data-driven son los principales insumos con los cuales se diseñaron estoscontroladores.
Además, se busca dar respuesta a la pregunta: ¿qué estrategias de control data-drivenson adecuadas para procesos con incertidumbres y/o no linealidades asociadas a sunaturaleza? Estos controladores son expuestos a criterios de desempeño respecto a lasseñales de error y esfuerzo de control, permitiendo así una comparación cuantitativa decada lazo de control.
Palabras claves: Control data-driven, Sistemas no lineales, Incertidumbre, PID Neuro-nal, Base Radial, Espacio de estados, Realimentación.
1

Abstract
In this work, the comparison between direct and indirect data-driven controllers for a dy-namic process from Automation and Control laboratory of EIA University is proposed.For this reason, an exploration of the available processes was carried out and it was de-fined which one meets the requirements for this activity. These included systems suchas the pH plant, Furuta’s inverted double pendulum, and the two-degree-of-freedom ro-botic manipulator with flexible joints. Taking into account the objectives of this work, theappropriate process that meets the characteristics of uncertainties and non-linearities ischosen. The concepts of data-driven systems are the main inputs with which these con-trollers were designed.
In addition, we want to answer the question: which data-driven control strategies are sui-table for processes with uncertainties and / or non-linearities associated with their nature?These controllers are exposed to performance criteria regarding error signals and controleffort, thus allowing a quantitative comparison of each control loop.
Keywords:Data-driven control, Non-linear systems, Uncertainty, Neural PID, RadialBase, State space, Feedback.
2

Capítulo 1
Preliminares
1.1. Introducción
El control clásico consta esencialmente de tratamiento de información a nivel numérico,lo cual deja de lado las contingencias derivadas por comportamientos impredecibles co-mo, por ejemplo: problemas de medición, adaptación del modelo numérico, errores deprecisión y problemas propios de los sistemas a controlar, incluyendo también los erroreshumanos en la toma de datos y aproximaciones utilizadas.
Steve Brunton, Autor de Libro Data-Driven Science and Engineering Machine Learning,Dynamical Systems, menciona que existen ciertas limitaciones dentro de los controla-dores tradicionales. Una de las características que destaca es la no linealidad. Puedenexistir procesos que requieran aumentar estás no linealidades, por ejemplo, en procesosquímicos donde se desea realizar un aumento en el nivel del tanque se generará unamayor no linealidad, por lo que un control que ya esté diseñado, no funcionaría en elnuevo sistema.
También menciona que existen sistemas que no se describen por medio de un modelomatemático, como es el caso de las señales emitidas por las neuronas donde se puededar el caso de que cada interacción con objetos conlleve a activaciones que no siganuna ecuación predefinida. Otro ejemplo es el clima, en particular la turbulencia. Uno delos casos donde más se evidencia es en las alas de un avión donde pueden generardiferentes tipos de turbulencia, teniendo en cuenta factores como temperatura, presión,humedad, entre otros; esto hace que el sistema tenga una dinámica desconocida.
La metodología de control basada en modelos, o model-based, es aquella a través de lacual se diseñan controladores tomando como base ecuaciones o modelos matemáticosque describen el comportamiento físico del sistema (funciones de transferencia, modelosde espacio de estados, etc.) Fink et al. (2015). Cuando se habla de control data-driven,se hace referencia a metodologías de diseño de controladores que utilizan datos expe-rimentales como base. Estos controladores pueden ser diseñados de dos formas: si seutilizan los datos experimentales para encontrar un modelo del sistema y, a partir de este,diseñar el controlador, se conoce como Data-Driven Indirecto (DDI). Si, por el contrario,no se utilizan los datos para hallar un modelo del sistema, sino que se utilizan para ali-mentar el controlador y que este se adapte al comportamiento del sistema, se conoce
3

como Data-Driven Directo (DDD), Wang et al. (2017). Dependiendo de la complejidadde los fenómenos asociados al sistema, los controladores DDI requieren de una identi-ficación adecuada para el diseño de controladores, Piga et al. (2018). También se debeconsiderar la carga computacional cuando se diseñan métodos de control DDD.
Los manipuladores robóticos industriales pueden realizar tareas que al ser humano co-mún se le pueden dificultar, por ejemplo, tareas repetitivas donde se requiere de altaprecisión o trabajo pesado. En la industria, la creciente demanda de manipuladores ro-bóticos crea la necesidad de seguridad para los operadores humanos cuando interactúancon robots, ya que los robots pueden representar un peligro para sus vidas. La robóticacolaborativa surge como un escenario en el que los robots interactúan con los huma-nos de forma segura en un entorno compartido para mejorar el proceso de fabricacióny las condiciones de trabajo, Robla-Gómez et al. (2017), Han et al. (2021), Behrens andElkmann (2021). Esto significa que los manipuladores robóticos deben mejorarse concierto nivel de conciencia para detectar al operador humano a fin de evitar colisiones, Land Chowdhury (2021), Palleschi et al. (2021). Además, si no pudiese evitar un impacto,el manipulador robótico debe estar diseñado para amortiguarlo y tener una baja iner-cia, es decir, sus uniones o articulaciones deben ser flexibles, Trung and Iwasaki (2021),Ullah et al. (2021). Esta característica introduce no linealidades y vibraciones en la di-námica del movimiento del manipulador robótico de articulaciones flexibles (FJRM porsus siglas en inglés, Flexible Joint Robotic Manipulator), Meng et al. (2020), Arteaga andSiciliano (2000). Por ejemplo, cuando se trata de manipuladores robóticos de articula-ciones flexibles, generalmente se utilizan resortes para transferir el movimiento de lasarticulaciones a los eslabones rígidos. Además de las vibraciones y las no linealidades,los resortes tienden a desgastarse con el tiempo, imponiendo también incertidumbres.Los fenómenos anteriores pueden derivar en modelos dinámicos y cinemáticos de altacomplejidad, lo que hace que el diseño de controladores basados en modelos sea muydifícil de manejar, Diao et al. (2021).
Las estrategias de Machine Learning (ML) son alternativas utilizadas para el diseño con-troladores data-driven, al mapear correctamente las no linealidades e incertidumbresen un modelo identificado (Data-Driven Indirecto) o directamente en los controladores(Data-Driven Directo), ambos a partir de datos experimentales.
El diseño de controladores data-driven directos permite el manejo de información dondelos sistemas no son lineales, también permiten el manejo de gran cantidad de datos pa-ra ir actualizando el sistema de control. Una de las ventajas más significativas es el norequerir de una identificación previa del proceso a controlar para realizar una aproxima-ción matemática de la dinámica del sistema, lo que ahorra trabajo al diseñador y evita lapresencia de errores al identificar una planta industrial. Además, un controlador directo,al funcionar con datos que se miden en tiempo real, puede funcionar con cualquier tipode planta, lo que ahorra la necesidad de diseñar múltiples controladores diferentes enuna industria, Santos (2011). Esta afirmación es apoyada por diferentes autores, dondese destaca que: el control inteligente comprende una serie de técnicas - tomadas funda-mentalmente de la inteligencia artificial - con las que se pretenden resolver problemasde control inabordables por los métodos clásicos, Galán et al. (2000).
4
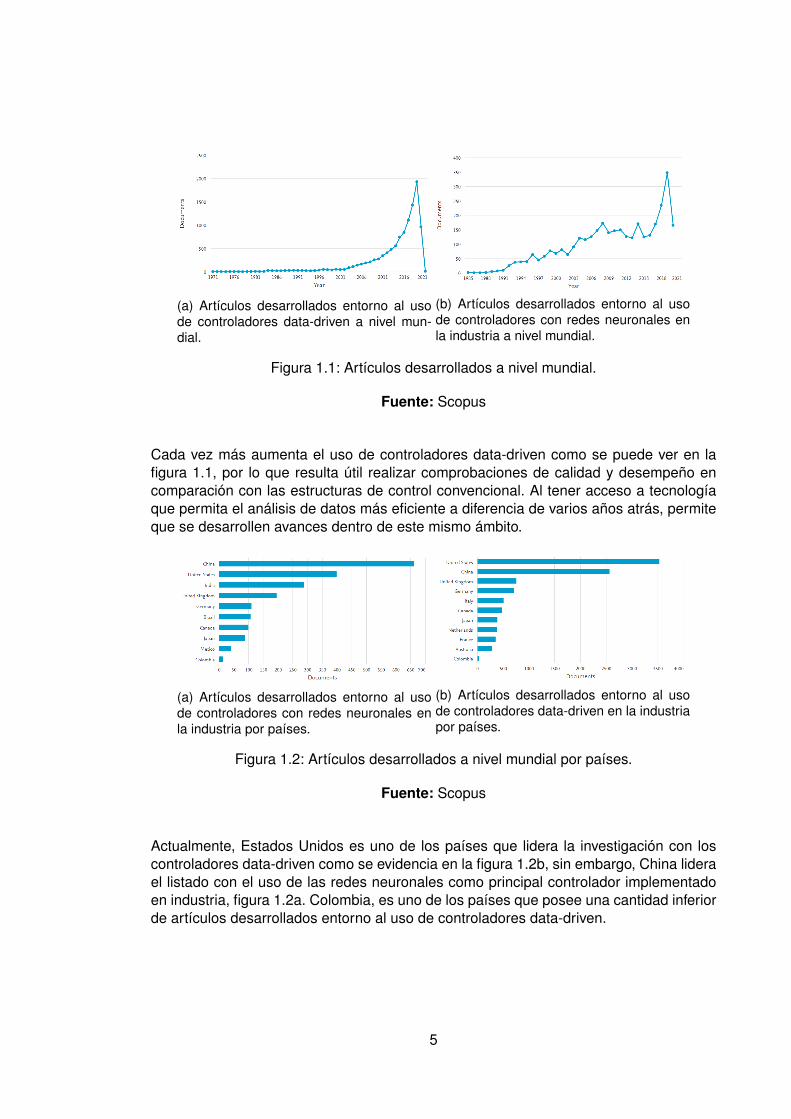
(a) Artículos desarrollados entorno al usode controladores data-driven a nivel mun-dial.
(b) Artículos desarrollados entorno al usode controladores con redes neuronales enla industria a nivel mundial.
Figura 1.1: Artículos desarrollados a nivel mundial.
Fuente: Scopus
Cada vez más aumenta el uso de controladores data-driven como se puede ver en lafigura 1.1, por lo que resulta útil realizar comprobaciones de calidad y desempeño encomparación con las estructuras de control convencional. Al tener acceso a tecnologíaque permita el análisis de datos más eficiente a diferencia de varios años atrás, permiteque se desarrollen avances dentro de este mismo ámbito.
(a) Artículos desarrollados entorno al usode controladores con redes neuronales enla industria por países.
(b) Artículos desarrollados entorno al usode controladores data-driven en la industriapor países.
Figura 1.2: Artículos desarrollados a nivel mundial por países.
Fuente: Scopus
Actualmente, Estados Unidos es uno de los países que lidera la investigación con loscontroladores data-driven como se evidencia en la figura 1.2b, sin embargo, China liderael listado con el uso de las redes neuronales como principal controlador implementadoen industria, figura 1.2a. Colombia, es uno de los países que posee una cantidad inferiorde artículos desarrollados entorno al uso de controladores data-driven.
5

Figura 1.3: Uso de controladores data-driven en distintos campos del conocimiento
Fuente: Scopus
El uso de controladores data-driven no es especialmente el ámbito de la ingeniería. En lafigura 1.3 se muestran las áreas de conocimiento donde se han implementado este tipode controladores, teniendo ingeniería el mayor porcentaje, seguida de ciencia compu-tacional; esto demuestra el gran uso que se puede dar al realizar un análisis basadoen datos. La implementación de controladores data-driven en una planta de la Univer-sidad EIA abre puertas a un mundo de conocimientos más avanzados para los nuevosestudiantes de Ingeniería Mecatrónica, ampliando enormemente sus conocimientos y,mejorando así, el nivel base educativo del área de conocimiento de sistemas de controlno convencional.
1.2. Formulación del problema
La teoría del control clásica ha sido usada y aplicada por tanto tiempo que, hasta hoy,todavía se siguen desarrollando nuevas estructuras y tipos de controladores, siemprebuscando cumplir con los mismos objetivos, y la mayoría de estas con una base común,como la necesidad de disponer de información sobre la planta, ya sea en forma de mode-lo analítico o representando su comportamiento de alguna otra forma, o teniendo accesoa los datos de esta.
Hay algunos factores que generan la necesidad de aplicar diseños de control que sebasan en el comportamiento de las neuronas del ser humano, es decir, la inteligenciaartificial y las redes neuronales: el constante crecimiento de la sociedad, y en conse-cuencia de la industria, demanda que el control pueda con mejores y más sofisticadassoluciones a los problemas que se dan hoy en día; a su vez, la automatización empiezaa dejar de lado la necesidad de los operarios en tareas repetitivas dentro de la industria(permitiendo que se desempeñen en tareas de mayor nivel), por lo que se comienza a
6

exigir a los controladores que consigan realizar el trabajo que sólo estos pueden haceren muchos casos, como conseguir características de alto nivel para el proceso, ej. laseguridad, la calidad y la optimización de la producción, Santos (2011).
Otro factor importante por el que surge la necesidad de utilizar el denominado controldata-driven es porque los controladores diseñados bajo la teoría de control convencionalsólo son capaces de realizar su trabajo adecuadamente en ciertos rangos de opera-ción en sistemas de control complejos, como pueden ser los sistemas que poseen pa-rámetros variantes en el tiempo o que dependen del ambiente externo, sistemas con nolinealidades, entre otros. Esto se debe principalmente a que los modelos analíticos o ma-temáticos de los sistemas con incertidumbres y no linealidades son complejos de hallar;incluso si se lograse modelar el sistema, el diseño del controlador sería muy complicado.Por último, existen ocasiones en los que las especificaciones de desempeño pueden serinciertas o poco concretas, por lo que se requeriría acercarse al problema de una formamás heurística que analítica, Santos (2011).
Con el paso del tiempo y los avances en la ciencia de datos, empiezan a aparecer mássistemas complejos que deben ser controlados por medio de sistemas data-driven, comopueden ser: turbulencia, el cerebro, el clima, epidemiología, finanzas, robótica y autono-mía, entre otros, Brunton and Kutz (2019).
El control de procesos analíticos requiere varias iteraciones de mediciones con el fin degarantizar una cantidad de datos que permita una varianza menor a un valor deseado;posterior a esto, se realiza una linealización del proceso. Desde la linealización encon-tramos a una función de transferencia que relaciona la salida con la entrada. Desde laparte teórica sabemos que los sistemas de tipo 1 en lazo cerrado poseen un error iguala cero en estado estable, pero existen casos donde es necesario agregar otro integra-dor para lograr las características deseadas, esto se debe a que la linealización de unsistema no abarca sus zonas atípicas de operación. Es bien sabido que las limitacionesde los controladores data-driven indirecto pueden generar que el sistema tenga error enestado estable. Además conlleva que se presente ineficiencia en el estado transitorio deestos mismos, lo que provoca que el sistema requiera un gasto computacional adicionalinnecesario.
¿Qué estrategias de control data-driven son las más apropiadas para implementar en unsistema dinámico con incertidumbres y no linealidades; además, qué plantas posee laUniversidad EIA con estas características?
1.3. Objetivos del proyecto
1.3.1. Objetivo general
Comparar controladores data-driven directo e indirecto para un proceso dinámico conincertidumbres y no linealidades, disponible en el laboratorio de Automatización y controlde la Universidad EIA.
7

1.3.2. Objetivos específicos
Escoger un proceso dinámico con incertidumbres y no linealidades apropiado parael desarrollo de controladores data-driven, de entre los procesos disponibles en ellaboratorio de Automatización y control de la Universidad EIA.
Establecer los requerimientos de desempeño deseados para el proceso escogido.
Seleccionar estrategias de control data-driven para ser implementadas en el pro-ceso escogido.
Diseñar controladores basados en sistemas data-driven directos teniendo en cuen-ta los requerimientos deseados del proceso escogido.
Comparar los controladores data-driven directos e indirectos desarrollados para elproceso escogido, usando identificación experimental de sistemas de caja negra ogris.
1.4. Antecedentes
A continuación, se presentan algunos artículos que poseen utilidad para el desarrollodel proyecto. La figura 1.4 muestra un resumen de la estructura de los distintos tipos decontroladores que existen, de los cuales se hace referencia en este trabajo.
Figura 1.4: Estructuras de división de control de procesos industriales
Fuente: Propios
8

1.4.1. Estrategias de control basadas en Machine Learning (ML)
Control de sistemas no lineales con aprendizaje iterativo basado en redes neuro-nales
Una de las ventajas de los controladores inteligentes es que no importa si el sistemaes lineal o no. Por eso, en el artículo “Control de sistemas no lineales con aprendizajeiterativo basado en redes neuronales” (Patan y Patan, 2019), se analiza la estructura deuna red neuronal del controlador inteligente para un sistema discreto en espacio de es-tados. El uso de redes neuronales en controladores hace posible obtener una respuestaflexible, debido a que este se adapta a las condiciones de la planta y aprende de esta.Se analiza la correcta formulación de suficientes condiciones para error nulo en estadoestable, así como la forma de incorporarlas de forma cuidadosa a la etapa de entrena-miento del controlador inteligente.La red neuronal mostrada se utiliza para controlar un sistema SISO (Single-input single-output), sin embargo, puede generalizarse para sistemas MIMO (Multiple-input multiple-output). La idea que se muestra es crear un controlador que se adapte a una planta concondiciones de trabajo variables en el tiempo.
Figura 1.5: Diagrama de bloques de iteración actual del ILC utilizando redes neuronales
Fuente: Krzysztof Patan y Maciej Patan.
Una característica interesante que se menciona es que, usando una representación pun-tual del vector (VVVVVV) del controlador adaptativo basado en redes neuronales, sepuede obtener un comportamiento de un tipo de control específico, como un controladorPD, un controlador de orden superior o un control dinámico.
Control predictivo/adaptativo de sistemas complejos utilizando técnicas de inge-niería neuronal
En la revista de la universidad de Medellín se desarrolló un artículo para desarrollar elcontrol de un sistema MIMO no lineal etapa posterior, la temperatura y el nivel en una
9

planta no lineal de tipo cónica. Dentro de este artículo se desarrolló un controlador queestá constituido por un optimizador como controlador primario y una red neuronal contro-ladora como controlador secundario. Esta red controladora se conecta en paralelo conel optimizador y una vez entrenada, puede constituirse en el controlador primario. Estaconfiguración otorga una mayor robustez al sistema desarrollado y aliviana la carga decómputo del optimizador con idéntico desempeño. Se ha incorporado una red neuro-nal como controlador secundario o de respaldo para dar una mayor robustez al sistemadesarrollado. La red neuronal controladora, consiste en una red backpropagation condinámica externa. (Gallardo Arancibia et al., 2018).
Figura 1.6: Diagrama en bloques sistema de control predictivo
Fuente: José Gallardo, Claudio Ayala y Rubén Castro.
El sistema que se implementó consistió en un controlador y optimizador, además selograron resultados donde el error cuadrático medio no excedía 10(-6).
Figura 1.7: Diagrama en bloques sistema de control predictivo
Fuente: José Gallardo, Claudio Ayala y Rubén Castro.
10

“Es importante destacar además que, dado que la red de predicción que modela el pro-ceso queda entrenando en línea, el sistema de control implementado también tiene elcarácter de adaptativo lo cual significa que permanentemente se actualizará el modeloante cambios de los parámetros de la planta si es que ello se produce” (Gallardo Aranci-bia et al., 2018).
La utilización de las redes neuronales y predicciones permite que la respuesta de siste-mas no lineales ante entradas diferentes a escalones se logren errores de aproximada-mente cero. Es aquí donde se evidencia la utilidad de las redes neuronales y su funcio-nalidad dentro de las industrias en especial pH, llenado de tanques con formas diferentesa las rectangulares.
Sincronización de redes neuronales recurrentes de tiempo discreto con retrasosvariantes en el tiempo, a través de control deslizante cuantificado
En este artículo se analiza a fondo la sincronización cuantizada de redes neuronalesrecurrentes de tiempo discreto con retrasos por medio de control deslizante. Este controldeslizante se pasó a tiempo discreto debido a su efectividad. Los principales resultadosse obtienen del uso de las propiedades de las funciones de Lyapunov y algunas tran-siciones matemáticas. Todo esto con el fin de mostrar la utilidad de implementar redesneuronales recurrentes en los sistemas de control, sobre todo en la respuesta de los pun-tos de equilibrio (Sun et al., 2020). La cuantización del sistema discreto es mucho máscomplicada que la del sistema discreto a la hora de realizar la sincronización, pero enel sistema discreto se pueden apreciar mucho mejor los resultados, y para visualizarlosmejor, se utilizaron distintos tiempos de muestreo. Esto quiere decir, que, seleccionandolos parámetros correctos, es posible hacer que el sistema de redes neuronales en tiempodiscreto logre la sincronización.
Modelado dinámico y control adaptativo en sistemas de boya inteligente con GPS(GIB) basados en redes neuronales difusas
En este artículo se muestra el uso de modelado dinámico para controlar la posición deboyas por medio de redes neuronales construidas con técnicas de backstepping. El es-tudio se centra en el desarrollo de un nuevo controlador basado en una técnica queutiliza redes neuronales adaptativas difusas para hacer un seguimiento dinámico de laposición de la boya sobre el agua con datos desconocidos, como las velocidades y otrosparámetros de control. Este diseño aplica una técnica de back-stepping vectorial en lassuperficies de las naves, que se posicionan dinámicamente con perturbaciones indeter-minadas y ambivalencias. El objetivo es, como en cualquier sistema de control, reducirel error de salida de la red neuronal en lazo cerrado (Zhang et al., 2020).Esto es útil porque en la actualidad se utiliza mucho el control para sistemas de posicio-namiento, además las técnicas utilizadas se pueden generalizar para sistemas dinámi-cos que no tengan que ver con posicionamiento, debido a la naturaleza adaptativa de loscontroladores implementados con redes neuronales.
11

Control neuronal predictivo por linealización instantánea
En este artículo se presenta el desarrollo de un esquema de Control Predictivo Gene-ralizado (GPC), que se basa en un modelo neuronal del proceso, aplicado a un reactorde neutralización de laboratorio. Este modelo neuronal se obtiene por medio de unaidentificación previa, y se linealiza en cada iteración dentro del algoritmo de control. Asíse combina la eficiencia del GPC con la capacidad adaptativa de ajuste de las redesneuronales, consiguiendo así un sistema con las ventajas de un control predictivo, peroutilizado en sistemas no lineales, teniendo una buena velocidad de respuesta y precisiónante la presencia de perturbaciones (Lamanna y Gimón, 2007). La salida estimada delsistema debe pasar por un optimizador para mejorar la respuesta del controlador, peroeste es un trabajo muy complejo para un sistema no lineal, lo que puede conllevar a queel diseño no se pueda implementar en tiempo real, cosa que no es deseada en muchoscasos. Por eso, se prueba la utilidad de las redes neuronales en los sistemas de control,ya que, en este caso, la red neuronal propuesta se encarga de linealizar el sistema encada iteración en tiempo real, pudiendo así utilizar el optimizador en tiempo real en unsistema no lineal con un control predictivo implementado.
Diseño de un sistema control de temperatura y pH, en el proceso de digestiónanaeróbica para residuos sólidos orgánicos en un bio-reactor tipo BATCH.
A partir de los datos de la dinámica del pH, se evidencian las no linealidades que se pre-sentan en el pH del sustrato, por lo que es necesario optar por un sistema de control quese adapte a esta dinámica. Para el control de pH encontramos trabajos que implementantécnicas de control como; Fuzzy de modo deslizante (FSMC), Fuzzy predictivo, Fuzzyadaptativo (Alvarado Moreno, 2015).Se evidencia, la necesidad de utilizar un método de control no tradicional, para poderrepresentar y cumplir con los requerimientos que establezca el usuario. Además, tocatener en cuenta que la selección de los controladores se realizó en base a los datos dela planta, es allí donde se puede evidenciar la no linealidad de los procesos de pH engeneral. Posterior a esto, se sacó un modelo matemático teniendo en cuenta las mezclasque se presentan dentro del procesos.Como resultado, se obtuvo que el pH en el biorreactor con el sistema de control presentóuna respuesta estable, con un tiempo de respuesta alrededor de 100 min, y sin sobreimpulso, el cual se acondiciono a las no linealidades del sistema. También, al realizar si-mulaciones donde se implementaba acciones de integrales y derivativas para un controldifuso, no se obtuvieron resultados adecuados, al incorporar este tipo de acciones decontrol debido a que ocasionaban inestabilidad en el sistema.
Control reset de un proceso de pH industrial en línea
En este trabajo se realizó la implementación de un controlador híbrido/reset de un proce-so de pH. “La dinámica de proceso no lineal se linealiza alrededor de diferentes puntos deoperación, y como resultado se obtiene una planta de segundo orden más tiempo muertocon ganancia y retardo inciertos para fines de control. Se diseña y ajusta un compen-sador PI estándar y un compensador de reset. El objetivo principal de este trabajo eracomparar el rendimiento de ambos compensadores mediante la experimentación prácti-ca.”(Carrasco y Baños, 2012)
12

Para las mediciones se definieron tipos de entrada denominadas: Entrada de paso ne-gativo, se considera un incremento de referencia de paso de 3,9 a 3,1 y entrada de pasopositivo donde se considera un incremento de referencia de paso de 3 a 3,8. Para es-te artículo, se desarrollaron los resultados en base a experimentaciones, de lo que seobtuvo que:• Demostraron que el compensador reset presentó mejor restablecimiento seguimientode referencia y rechazo de perturbaciones en comparador a un compensador PI.• Se implementó un filtro reset, como resultado se obtuvo una señal de control mássuave.
Data driven fuzzy c-means clustering basado en optimización de enjambre de par-tículas (PSO) para un proceso de pH.
El modelado y el control del proceso de pH se considera una tarea difícil porque uno ne-cesita tener conocimiento sobre los componentes y su naturaleza en el flujo de procesocon el fin de modelar su dinámica utilizando técnicas convencionales. En el aspecto delmodelado, se deben establecer modelos rigurosos donde se debe tener en cuenta ecua-ciones de equilibrio de masa y como esta varía entorno a porcentaje de concentracióndel soluto.La optimización del enjambre de partículas (PSO) es una técnica de optimización es-tocástica desarrollada por el Dr. Eberhart y el Dr. Kennedy en 1995, inspirada en elcomportamiento social del rebaño de aves o peces. En los resultados obtenido de la im-plementación de este método se obtuvo que:No se requiere ninguna información previa sobre el sistema, excepto el número de en-tradas y salidas. Al elegir el umbral adecuado podemos estimar el valor de retardo enpresencia de perturbaciones. Este método se puede utilizar como semi-online para ladetección de sistemas que poseen diferentes tipos de retardos. Es importante elegir eltiempo de muestreo adecuado y la señal de entrada para la recopilación de datos. Elalgoritmo diseñado fue probado en SISO, MIMO y escenario de variación de retardo,demostrando la eficacia del método.(Sivaraman et al., 2011)
1.4.2. Control Data Driven para manipuladores flexibles
A continuación se muestran algunos artículos donde se realiza el control del manipuladorde articulaciones flexibles.
Control difuso basado en reglas de Lyapunov y anticontrol caótico para un sistemade articulación flexible y análisis de la eficacia de la existencia de señales caóticascon validación experimental
En este estudio se propone un anticontrol caótico para el sistema con juntas flexibles.El controlador propuesto se compone de un control difuso basado en reglas Lyapunov yun anticontrol caótico para el seguimiento del objetivo del manipulador de articulacionesflexible.La señal caótica se utiliza para estudiar el efecto del anticontrol para reducir la desviacióndel sistema de unión flexible y la energía de la señal de control. Para ello se ha sincroni-zado la articulación flexible con el modelo caótico del sistema Lorenz. En este estudio se
13

cambia uno de los parámetros de Lorenz para analizar el efecto de las señales caóticas.Los resultados del enfoque propuesto muestran que en términos de nivel de reducción devibraciones y consumo de energía de la señal de control, podríamos encontrar un puntoóptimo basado en el valor del parámetro del sistema Lorenz. Finalmente, la eficacia delmétodo propuesto y los resultados de la existencia de diferentes comportamientos de nolinealidad se validan a través de experimentos con el manipulador de articulaciones fle-xibles de QUANSER. Sandgani and Shoorehdeli (2013) Se obtuvo un control adecuadodel sistema, ademá se evitaron oscilaciones del manipulador para las diferentes entra-das planteadas. Además se evidencia una señal de control mínima haciendo uso de estecontrol. Cabe destacar que para implementar este tipo de control se parten del modelocaótico de lorenz, cuya dinámica es representada por 3 ecuaciones en el espacio.
Control Neuronal en Línea para Regulación y Seguimiento de Trayectorias de Po-sición para un Quadrotor
En el artículo se presentan distintas estructuras de control tradicional para el modelono lineal de un Quadrotor, o helicóptero de cuatro hélices, ya que estos son simples yson suficientes para las tareas básicas de estabilización, sin embargo, se diseñan algo-ritmos basados en redes neuronales para mejorar su respuesta y su desempeño antesituaciones más complejas, y para optimizar los recursos de cómputo utilizados. La es-tructura de control propuesta, incluyendo los algoritmos de redes neuronales, se adaptaa las especificaciones de desempeño propuestas al inicio, y además sigue aprendiendocontinuamente y en línea ante irregularidades o cambios en las condiciones de trabajonormales del sistema Yañez-Badillo et al. (2017).De todo el estudio resultan dos casos con los que se verifica el desempeño del siste-ma de control neuronal. Estos son: el control adaptativo que se propuso, con gananciasvariables, y un controlador no lineal basado en modos deslizantes de segundo orden,donde al final se concluye que el uso de redes neuronales en controladores permiteobtener respuestas sin ruido en altas frecuencias.
Control estable del manipulador de unión flexible de un grado de libertad
Este articulo se presenta un acercamiento nuevo para el control estable de un manipula-dor de juntas flexibles con simple (Un grado de libertad) (por siglas del inglés SLFJM). Elobjetivo de control es estabilizar el SLFJM en la posición de equilibrio recto hacia arribadesde la posición de equilibrio recto hacia abajo y suprimir la vibración utilizando solola medición de posición. En primer lugar, la transformación homeomorfa diferencial seutiliza para convertir equivalentemente el sistema original en un nuevo sistema práctico.El sistema queda descrito en dos partes: lineal y no lineal. La parte no lineal se con-sidera como una perturbación virtual de la parte lineal. Entonces, el sistema de controlbasado en perturbaciones de entrada equivalente (basado en EID) está diseñado parasuprimir esta perturbación no lineal virtual en el punto de equilibrio cero. De esta manera,el objetivo de control del sistema original se realiza efectivamente. Yan et al. (2018)
14

1.5. Marco Teórico
En esta sección se definen ciertos elementos necesarios para afianzar la comprensiónde los temas que se tratan en el desarrollo del trabajo.
1.5.1. Control Model-based
Para el diseño de controladores model-based se debe hacer uso de los planteamientosfísicos que describan el sistema, es decir, sumatoria de fuerzas, energías, entre otros.Para el caso de manipuladores, se puede describir la dinámica con las matrices de trans-formación de Denavit-Hartenberg Aureliano et al. (2013). A pesar de que se describe latrayectoria del efector final, no se consideran las no linealidades generadas por los re-sortes.Además, puede que los modelos no describan la dinámica del sistema, debido que exis-ten parámetros que varían en el tiempo, por ejemplo, la constante del resorte o el desgas-te mecánico de la articulación. Estos parámetros generan que el sistema no sea descritoen su totalidad solo con el planteamiento de ecuaciones. Sin destacar que existen siste-mas en los cuales no se puede obtener un modelo, como es el caso de las neuronas deun humano, el clima, entre otros.
1.5.2. Control Data driven indirecto (DDI)
Para la implementación de los controladores DDI, se debe hacer uso de un modelo quedescriba la dinámica del sistema. Existen estrategias que permiten una identificacióna partir de datos. En sección se muestra la definición de los de modelos caja negra.También, se describe el funcionamiento de los modelos caja gris y como se deben im-plementar para la obtención de un modelo que parte de datos y del planteamiento defuerzas o energías.
Modelos caja negra
Una de las formas más comunes de conocer el comportamiento de un sistema sin co-nocer su modelo matemático es someterlo a una entrada y observar la señal de salida;existen dos tipos de respuesta en los sistemas: subamortiguadas y sobreamortiguadas.Cuando se obtiene un modelo de un sistema únicamente a partir de datos experimen-tales es cuando se habla de un modelo de caja negra. Para realizar un modelo de cajanegra adecuadamente es necesario excitar el sistema con una entrada que sea suficien-temente grande y que aporte información suficiente. Las entradas más utilizadas son:escalón, senoidales y señales pseudoaleatorias.
15

Figura 1.8: Tipos de señal de entrada
Fuente: (Ángel Martínez Bueno, 2011)
Las señales subamortiguadas indican que el proceso es de segundo orden y tiene mayorvelocidad de respuesta, pero posee sobreimpulso, por el contrario, las señales sobre-amortiguadas indican una menor velocidad de respuesta y que el sistema es de primerorden. Todo este proceso de observación debe hacerse cerrando previamente el lazopara que el sistema sea estable (Bueno, 2011).
Modelos caja gris
El método de identificación de caja gris es también conocido como modelo híbrido, tam-bién conocidos como modelos de caja gris son aquellos modelos que se obtienen me-diante la unión o combinación de modelos de conocimiento y modelos empíricos.
16
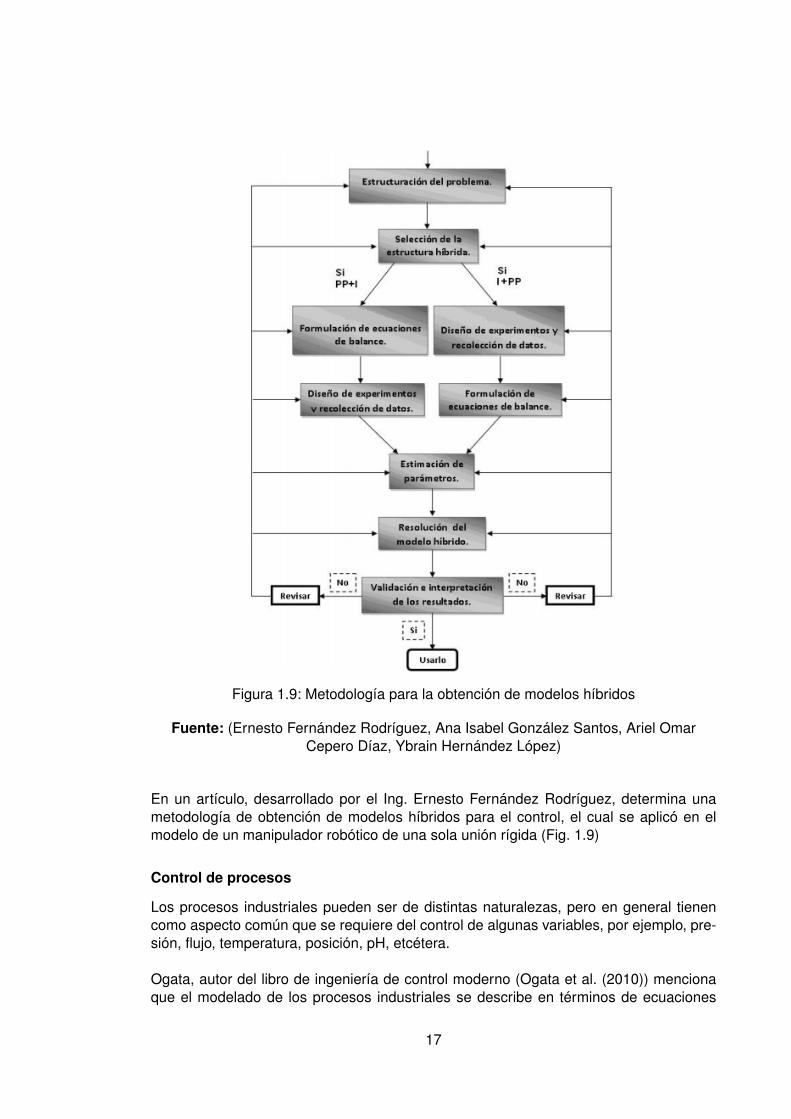
Figura 1.9: Metodología para la obtención de modelos híbridos
Fuente: (Ernesto Fernández Rodríguez, Ana Isabel González Santos, Ariel OmarCepero Díaz, Ybrain Hernández López)
En un artículo, desarrollado por el Ing. Ernesto Fernández Rodríguez, determina unametodología de obtención de modelos híbridos para el control, el cual se aplicó en elmodelo de un manipulador robótico de una sola unión rígida (Fig. 1.9)
Control de procesos
Los procesos industriales pueden ser de distintas naturalezas, pero en general tienencomo aspecto común que se requiere del control de algunas variables, por ejemplo, pre-sión, flujo, temperatura, posición, pH, etcétera.
Ogata, autor del libro de ingeniería de control moderno (Ogata et al. (2010)) mencionaque el modelado de los procesos industriales se describe en términos de ecuaciones
17

diferenciales. Estás ecuaciones parten de leyes físicas. Para el control tradicional la ob-tención de un modelo matemático es la parte más importante de todo el análisis.Partiendo de un modelo matemático se puede realizar un control sobre el proceso, estose denomina un sistema de control. Según Gilberto Enrique (Gilberto Enriquez Arper(2013)), un sistema de control puede definirse como un comparador de una variable acontrolar con un valor deseado y cuando existe una desviación se efectúa una acciónde corrección sin que exista la intervención humana. Esto garantiza una optimización yeficiencia de los procesos.
Para la implementación de un controlador se hace uso de los microprocesadores y pro-cesadores de señales digitales (DSP), esto ha permitido realizar tareas que durante añosfueron hechas por sistemas electrónicos analógicos. Por otro lado, nuestro mundo reales análogo, es por lo que se tienen que hacer uso de conversores análogo - digital (ADC-Analogue to Digital Converter) y conversores digital - análogo (DAC- Digital to AnalogueConverter).
Figura 1.10: Proceso de conversión análogo-Digital
Fuente: (Gilberto Enrique, 2013)
18

Figura 1.11: Proceso de conversión digital – análogo
Fuente: (Gilberto Enrique, 2013)
1.5.3. Control Data driven Directo (DDD)
En esta sección de dará la definición del control basado en datos y las ventajas queposee para el aprendizaje de no linealidades e incertidumbre.
Control basado en datos
El uso de datos es unos los grandes auges que se han evidenciado en la última década,es una de las características que menciona el libro Data-Driven Science and EngineeringMachine Learning, Dynamical Systems, and Control, (Brunton and Kutz (2019)) ademásdestaca que: Las técnicas de aprendizaje automático pueden usarse para:
1. Caracterizar un sistema para su uso posterior con control basado en modelos. Esteultimo es conocido por diferentes autores como Data-Driven indirecto. Se diseña uncontrolador estático con base al modelo hallado apartir de los datos.
2. Caracterizar directamente una ley de control que interactúa efectivamente con unsistema. Este es conocido como Data-Driven Directo, se puede hallar un modelopara partir de valores iniciales pero el control varía con respecto a la planta real,por lo cual siempre aprende el comportamiento de esta y se adapta a los cambiosque esta presente.
Control basado en redes neuronales
Según un artículo publicado en el 2006 por Damián Matich (Matich Damián, 2006), exis-ten numerosas formas de definir a las redes neuronales:
Una nueva forma de computación, inspirada en modelos biológicos.
Un modelo matemático compuesto por un gran número de elementos procesalesorganizados en niveles.
Un sistema de computación compuesto por un gran número de elementos simples,elementos de procesos muy interconectados, los cuales procesan información pormedio de su estado dinámico como respuesta a entradas externas.
19

Las Redes neuronales artificiales son redes interconectadas masivamente en para-lelo de elementos simples (usualmente adaptativos) y con organización jerárquica,las cuales intentan interactuar con los objetos del mundo real del mismo modo quelo hace el sistema nervioso biológico.
Actualmente el uso de las redes neuronales se ha desarrollado en múltiples ámbitos, porejemplo, el análisis de datos, control de procesos industriales, machine learning, entreotros campos. Según Damián Matich, en su artículo de redes neuronales: Conceptosbásicos y aplicaciones, se pueden destacar las siguientes ventajas:
Aprendizaje Adaptativo. Capacidad de aprender a realizar tareas basadas en unentrenamiento o en una experiencia inicial.
Autoorganización: Una red neuronal puede crear su propia organización o repre-sentación de la información que recibe mediante una etapa de aprendizaje.
Tolerancia a fallos: La destrucción parcial de una red conduce a una degradaciónde su estructura; sin embargo, algunas capacidades de la red se pueden retener,incluso sufriendo un gran daño.
Operación en tiempo real: Los cómputos neuronales pueden ser realizados en pa-ralelo; para esto se diseñan y fabrican máquinas con hardware especial para obte-ner esta capacidad.
Fácil inserción dentro de la tecnología existente: Se pueden obtener chips espe-cializados para redes neuronales que mejoran su capacidad en ciertas tareas. Ellofacilitará la integración modular en los sistemas existentes.
Las redes neuronales artificiales ocupan un lugar importante en el desarrollo de técnicasde control para procesos dinámicos no lineales. Cuando se habla de control de procesosutilizando redes de neuronas, generalmente, se entiende que es una red encargada decalcular la acción de control que hay que aplicar al proceso para que se alcance elobjetivo de control deseado. La revista Ingenierías de la universidad de Medellín, en suvolumen 17, da a conocer un resumen de estructuras de controladores basados en redesneuronales que desarrollaron dentro del artículo.
Figura 1.12: Esquema de control: Modelo inverso.
Fuente: (José Gallardo, Claudio Ayala y Rubén Castro)
La estructura de control basado en modelo inverso (Fig. 1.12) consiste en la cancelaciónde la dinámica de la planta, con el fin de garantizar que la salida sea igual a la entrada. Apesar de ser muy confiable, al no realizar un proceso de realimentación de puede llegara incurrir un posible error en estado estacionario.
20

Figura 1.13: Esquema de control directo sin uso de modelo.
Fuente: (José Gallardo, Claudio Ayala y Rubén Castro)
En la Figura 1.13, se evidencia uno usos de control híbrido donde se tiene en cuentael uso de control tradicional, en este caso la implementación de un control PID, peroen general podría ser un control ya mencionado con anterioridad. También se hace unode un lazo cerrado para tener una comparación de la salida de la planta con el valordeseado.La estructura de control directo sin uso de modelo se basa en trabajar solamente con losdatos de salida de la planta, por cual no es necesario una identificación de este mismopara un mejor rendimiento.
Figura 1.14: Esquema de control directo con uso de modelo.
Fuente: (José Gallardo, Claudio Ayala y Rubén Castro)
La utilización del esquema de control de la figura 1.15 evidencia la necesidad de utilizarun modelo aproximado del sistema, lo que realiza una estimación de la planta por mediode los valores de salida y el esfuerzo de control (Optimizador red).
La utilización de controladores basado en redes neuronales es ampliamente utilizado de-bido, a su rechazo de perturbaciones, esto se debe, a que la utilización de redes permiterealizar una constante validación de la salida versus la entrada.
Otro tipo de estructura de control es una red neuronal reconfigurables, está conformapara establecer el modelo del sistema de forma selectiva, se plantea la red neuronalcomo un estimador del comportamiento del sistema, la diferencia entre la salida de lared neuronal y(s) y la salida real de la planta y(p), se realimenta como el error para
21

el algoritmo de entrenamiento de la red. La red neuronal para el modelado del sistematiene como entradas: yr(s), correspondiente a la respuesta deseada (según los criteriosde control seleccionados) y, yp(s), respuesta de la planta, esquema presentado en laFigura 19.
Figura 1.15: Algoritmo de propagación de una red neuronal reconfigurable.
Fuente: Cecilia Sandoval-Ruiz
Se puede observar los componentes neuronales descritos en VHDL, así como el algo-ritmo de entrenamiento del controlador neuronal, con lo que se obtienen los parámetrosde la red neuronal que minimiza el error en la salida deseada (target) de la planta. Ental sentido, partiendo del comportamiento deseado del sistema a controlar se realiza eldiseño y entrenamiento del control neuronal para hardware reconfigurable.
En este trabajo se comparan metodologías de diseño de control DDD y DDI sobre un sis-tema no lineal, el FJRM, mostrando las ventajas y desventajas del diseño e implementa-ción de cada uno de ellos. Se desarrollan controladores DDD y DDI para el seguimientodel movimiento de un FJRM planar. El FJRM tiene 2 grados de libertad y dos juntasflexibles en una configuración de conexión rígida de junta flexible. Primero, se diseñancontroladores DDI utilizando modelos de la dinámica del FJRM identificados experimen-talmente por medio de la herramienta Ident de MATLAB. También se implementa uncontrolador PID neuronal y un control adaptativo de base radial haciendo control sobrela dinámica de manera heurística, como controladores DDD, dado que las redes neuro-nales requieren entrenamiento, debido principalmente a la inicialización aleatoria de lospesos de la red neuronal.
22

Capítulo 2
Metodología
2.1. Exploración de procesos del laboratorio de Automatiza-ción y Control de la Universidad EIA
A continuación, se presenta una descripción de algunos procesos no lineales disponiblesen los laboratorios de la Universidad EIA, y que se consideraron para ser estudiados ycontrolados en este trabajo de grado mediante metodologías de diseño de control DDDy DDI.
2.1.1. Planta de pH Amatrol
El control del proceso de pH es muy amplio dentro de la industria. Se pueden apreciaraplicaciones en el tratamiento de aguas residuales, procesos bioquímicos y electroquími-cos, la industria del papel, la industria farmacéutica, siendo esta última un sector donderequiere un mejor manejo de pH, entre otras. Sin embargo, la dinámica del proceso depH es altamente no lineal, presentando valores diferentes de ganancias en el tiempo.Es muy difícil investigar el comportamiento dinámico de estos sistemas utilizando técni-cas de modelado convencionales para los parámetros del controlador, Sivaraman et al.(2011).Otro de los sectores donde se refleja un importante uso de pH es en la industria del licor,La cerveza tiene un pH de entre [4.1-4.6] que inhibe el crecimiento de ciertos organis-mos; un pH más bajo puede indicar la proliferación de bacterias productoras de ácido,resultando en cervezas amargas, Hanna (2019).
23

Figura 2.1: Planta de PH de la Universidad EIA, Fabricante Amatrol
Dentro del marco de referencia respecto a la búsqueda de sistemas de control de unaplanta de procesos de pH, se encontró un modelo planteado dentro de una tesis demaestría donde se diseñó una PLATAFORMA DE APRENDIZAJE PARA CONTROLBATCH en la PONTIFICIA UNIVERSIDAD JAVERIANA, en la cual se hizo uso de laidentificación del sistema de pH por medio de una señal pseudoaleatoria.
Para esta identificación se tomó el muestreo de la planta en 1 segundo, y se obtuvo unnivel de confianza de 87.26 % (Ver figura 2.2).
24
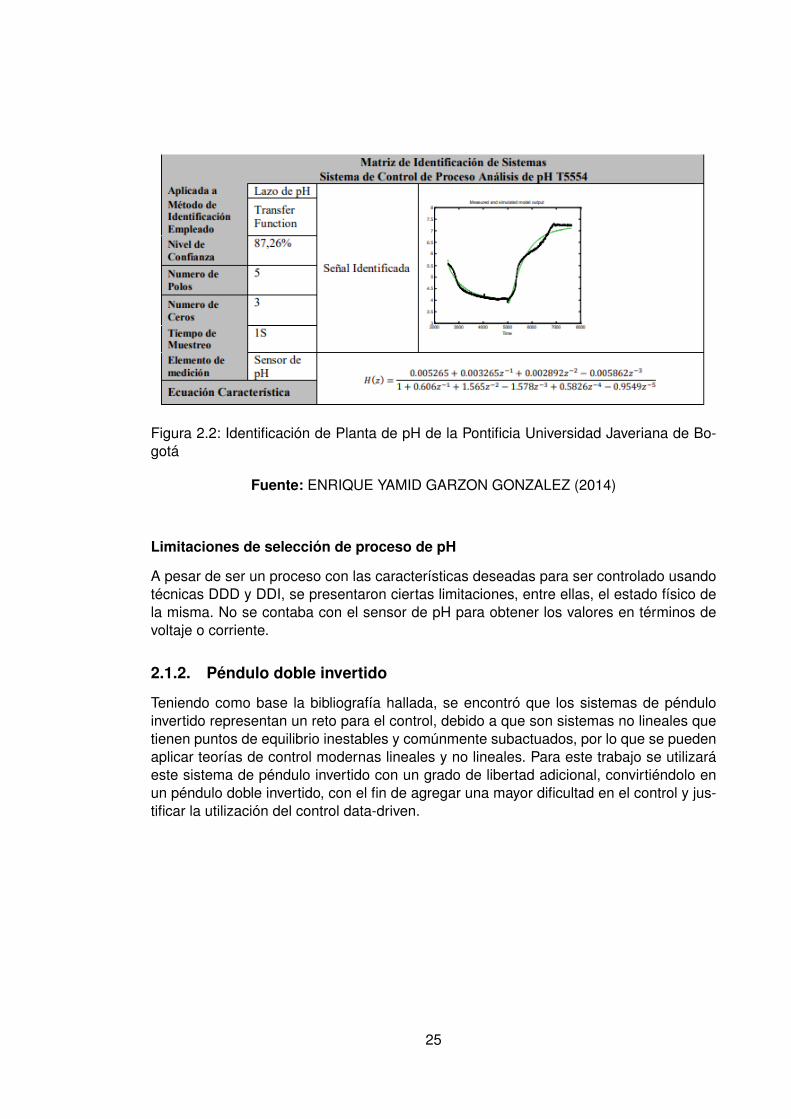
Figura 2.2: Identificación de Planta de pH de la Pontificia Universidad Javeriana de Bo-gotá
Fuente: ENRIQUE YAMID GARZON GONZALEZ (2014)
Limitaciones de selección de proceso de pH
A pesar de ser un proceso con las características deseadas para ser controlado usandotécnicas DDD y DDI, se presentaron ciertas limitaciones, entre ellas, el estado físico dela misma. No se contaba con el sensor de pH para obtener los valores en términos devoltaje o corriente.
2.1.2. Péndulo doble invertido
Teniendo como base la bibliografía hallada, se encontró que los sistemas de pénduloinvertido representan un reto para el control, debido a que son sistemas no lineales quetienen puntos de equilibrio inestables y comúnmente subactuados, por lo que se puedenaplicar teorías de control modernas lineales y no lineales. Para este trabajo se utilizaráeste sistema de péndulo invertido con un grado de libertad adicional, convirtiéndolo enun péndulo doble invertido, con el fin de agregar una mayor dificultad en el control y jus-tificar la utilización del control data-driven.
25

Figura 2.3: Pendulo Invertido Simple
Dentro del marco de referencia de la búsqueda de un modelo para un péndulo dobleinvertido, se encontró uno planteado dentro de una tesis donde se realiza el DISEÑO,CONSTRUCCIÓN Y CONTROL DE UN DOBLE PÉNDULO INVERTIDO ROTACIONALen la UNIVERSIDAD NACIONAL AUTÓNOMA DE MÉXICO, Ávila Ruiz (2013); tambiénse encontró otra tesis de THE UNIVERSITY OF ADELAIDE titulada DESIGN, BUILDAND CONTROL OF A SINGLE / DOUBLE ROTATIONAL INVERTED PENDULUM, dela cual se toman las ecuaciones planteadas para el péndulo doble invertido rotacional,Driver et al. (2004).
El modelo de las ecuaciones de movimiento de Euler-Lagrange encontrado en ambosdocumentos coincide, por lo que se concluye que estas son adecuadas para el desarrollode este trabajo.
Limitaciones de selección de una planta compuesta por 2 Péndulos Invertidos
El enfoque del presente trabajo de grado es la implementación de diferentes estrategiasde control. Como se puede apreciar en la figura 2.3, el péndulo con que se contabaen la Universidad era simple (un grado de libertad). Para anexar un grado adicional, sedebe realizar un análisis metodológico con matriz de selección y morfológica, teniendo
26

en cuenta el desempeño del motor. Por lo cual, se debía partir de estas limitaciones ysolucionarlas con metodologías diferentes.
2.1.3. Robot de dos grados de libertad con articulaciones flexibles
El robot de dos grados de libertad con articulaciones flexibles(FJRM por sus siglas eninglés) de Quanser consiste en dos motores DC con escobillas y cajas reductoras detransmisión armónica, así como una articulación de dos barras asignada a cada motor.Las dos articulaciones son rígidas. La primera articulación (hombro) está unida a la re-ducción por medio de la junta flexible, y esta conecta a la segunda reducción (codo), lacual está unida a la otra junta flexible. Tanto los motores como las articulaciones estáninstrumentadas con cuatro encoders ópticos de cuadratura. Cada articulación utiliza re-sortes que pueden ser cambiados.
Este sistema robótico emula el comportamiento de torsión y la flexibilidad de las articu-laciones, las cuales son características comunes en sistemas mecánicos, como transmi-siones armónicas de alta relación de engranajes y ejes de transmisión livianos QuanserInc. (2015). El FJRM se muestra en la Fig. 2.4.
Figura 2.4: Manipulador robótico con articulaciones flexibles
Debido a sus articulaciones flexibles, el sistema manipulador presenta oscilaciones al-rededor de un valor estable del motor de circuito cerrado. Esto se debe al hecho deque la energía cinética rotacional deforma los resortes y se transforma en energía po-tencial elástica. El FJRM se puede modelar como un sistema de múltiples entradas yúnica salida (SIMO) donde cada posición y vibración de la articulación se refleja en eldesplazamiento angular de la otra articulación.
27

Este sistema es el seleccionado para la implementación del trabajo de grado. Se realizael proceso de identificación y estudio de la dinámica. Este sistema cumple con las ca-racterísticas de no linealidades e incertidumbres para la aplicación de técnicas DDD yDDI. Además posee una conexión directa con Simulink por medio de QUARC (toolboxde MATLAB) lo que permitió agilidad al momento de implementar los controladores.
2.2. Estrategias de control data-driven indirecto
La implementación de estrategias de control tradicional, permite comparar la eficienciaque posee frente a los controladores Data-Driven Directo. Al hacer uso de un modeloidentificado, siendo este mismo una aproximación del sistema, se evalúa la robustas delcontrolador
2.2.1. Control tradicional (PID)
Uno de los controladores más utilizados es el PID, el cual consiste en un controladorproporcional, integrador y derivador. Cada parte de este mismo se encarga de funcionesmuy especificas dentro del sistema a controlar.El proporcional ayuda a aumentar o disminuir la ganancia estática de la planta y permitedisminuir o aumentar el tiempo de establecimiento del sistema, esto ya depende deldiseñador del controlador para el sistema. El integrador permite que el sistema, para unaentrada tipo escalón, posea un error en estado estable igual a cero. El derivador suavizala parte transitoria del sistema.Estas son las características más notorias que presenta este controlador. Cabe mencio-nar que existen diferentes estructuras de control PID, donde se pueden encontrar el PIDIdeal, PID Paralelo, I+PD (PID modificado) entre otros. Para este trabajo se optó por eldiseño de un controlador PID en configuración paralelo.
Figura 2.5: Controlador PID Ideal en lazo cerrado
Fuente: (Castaño Giraldo, Sergio s.f)
Haciendo uso de la herramienta MATLAB, se utilizó el toolbox mupad, que permite desa-rrollar operaciones algebraicas, geométricas, diferenciales, integrales entre otras. Estocon el fin de simplificar los cálculos algebraicos del modelo.
28

Para el diseño de este controlador se optó por utilizar el método de estructura fija, dondese parte de una estructura de control deseada con las incógnitas Kp, Ki y Kd en lazocerrado con el sistema, como se evidencia en la figura 2.9. Para la parte del derivador,se colocó un filtro donde el parámetro adicional es N.Posterior a esto, se realiza la simplificación del sistema con el fin de obtener el polino-mio característico de la planta con las incógnitas del controlador. Debido a que estamosbuscando un comportamiento particular del sistema, se utiliza una función de segundoorden, donde se puede tener control sobre el tiempo de establecimiento y máximo so-bre impulso del sistema para finalmente lograr igualar el polinomio característico y elpolinomio deseado.
Limitaciones en el diseño de controlador
Debido a que el sistema posee 4 incógnitas se deben colocar polos remanentes (no do-minantes) en el sistema deseado para obtener el mismo número de ecuaciones que deincógnitas.El sistema identificado es una linealización del proceso real. Consecuente a esta aproxi-mación, no se puede garantizar un control viable para todo el tramo de la trayectoria.Al partir de un modelo identificado experimentalmente, se evalúa la robustez de estemismo. Es por esto que en la realidad no se obtendrán resultados entorno a las especi-ficaciones de diseño.
2.2.2. Espacio de estados
Dentro de la literatura de Ogata, Control Moderno (Ogata et al. (2010)), se menciona undiseño de controlador muy útil para sistemas de aproximaciones de orden superior (ma-yores a 3), el cual es conocido como Espacio de estados. Este busca la representaciónde la dinámica del sistema en 4 Matrices A,B,C y D. Dependiendo del autor se puedenencontrar las matrices A y B en continuo y en discreto como G y H respectivamente, estocon el fin de diferenciar el tiempo en que se está desarrollando el diseño del controlador.Las matrices C y D son iguales en tiempo continuo y en discreto.
La matriz A es conocida como al matriz de estados del sistema, corresponde a una ma-triz cuadrada de tamaño nxn, donde n, es el numero de polos que posee el sistema,además tiene como característica que los eigen valores de esta matriz corresponde alos polos del sistema, y al realizar el determinante de la matriz A menos Is (Siendo I unamatriz identidad nxn, y s la variable en Laplace) se obtiene el polinomio característicodel sistema. B es un vector al vector de entrada del sistema. C corresponde al vector desalida del sistema y D la matriz de transmisión Directa
2.2.3. Realimentación de estados
Para la implementación de control en espacio de estados se tienen que evaluar doscaracterísticas básicas, observabilidad y controlabilidad del sistema. Esto se realiza pormedio de las matrices A y B.
29

Para determinar si un sistema es controlable, el rango de la matriz de controlabilidadtiene que ser igual al orden del sistema y su determinante ser diferente de cero. Estomismo sucede para la observabilidad del sistema. Si el sistema no es observable sepuede diseñar un controlador con observador de orden completo para la estimación delestado no medibles.
Figura 2.6: Realimentación de estado
Fuente: (Manrique, Tatiana 2020)
La implementación de control en espacio de estados parte de realimentar el sistema conun vector columna de tamaño n, siendo este valor los estados del sistema. Este vector esconocido como el vector K. Para encontrar este parámetro se se parte de un polinomiodeseado con polos no remanentes, tal que genere la misma cantidad de polos que delorden del sistema. Para encontrar este vector se puede hacer uso de la función Placede matlab, que tiene como argumento las matrices A,B y polos deseados. Esto entra losparámetros para la realimentación del sistema.
2.2.4. Realimentación de estados con seguimiento de señal
Para la implementación del controlador con seguimiento de señal, se parte de los tipoerrores en estado estable del sistema. Como teoría sacada del libro de Ogata se conoceque:Para un sistema tipo cero, el error en estado estable ante una entrada escalón es igual1kp
Para un sistema tipo uno, el error en estado estable ante una entrada tipo escalón esigual a cero.Es por esto que se implementa un integrador al espacio de estado, para esto también setoma la estructura de control demostrada en el libro Control Moderno de Ogata.
30

Figura 2.7: Realimentación de estado con seguimiento de señal
Fuente: (Manrique, Tatiana 2020)
Para la búsqueda de las constantes de realimentación e integral, se hizo uso de la función"place"de Matlab. Matlab define la función "placeçomo diseño de colocación de polos.Los parámetros que recibe esta función son la matrices (A,B) y el polinomio deseado.Como resultado se obtiene un vector K o vector de realimentación.
2.3. Estrategias de control data-driven directo
Las Redes Neuronales son un campo muy importante dentro de la Inteligencia Artifi-cial. Inspirándose en el comportamiento conocido del cerebro humano (principalmenteel referido a las neuronas y sus conexiones), trata de crear modelos artificiales que solu-cionen problemas difíciles de resolver mediante técnicas algorítmicas convencionales. Apesar de que una sola neurona puede realizar modelos simples de funciones, su mayorproductividad viene dada cuando se organizan en redes.De aquí se implementará controladores con lógica borrosa. Para esta sección se pondrána prueba un PID borroso y un PID neuronal para ver sus ventajas frente a los demáscontroladores.
2.3.1. PID Neuronal
Cuando se trata del diseño PID neuronal, la señal de control en el tiempo K viene dadapor:
UKc = UKc−1 + (Kpek +KIek +Kdek) (2.1)
Donde UKc es la señal de control en el tiempo K y UKc−1 la señal de control en el tiempoK-1. KI siendo la ganancia integral, Kd ganancia derivativa y Kp ganancia proporcional.La función de capas ocultas, representada por la letra c, se obtiene de:
∂e2k∂U2
k
= cjhj (2.2)
Donde,hj =
∑wjiX (2.3)
31

yX = [Kek,KIek,Kdek] (2.4)
Para el error de aprendizaje del sistema, el error entre la entrada y la salida se considerade la siguiente manera:
e2k =1
2((Sp − Ysk))
2 (2.5)
e2k =1
2
(0−
∂e2k∂U2
k
)2
(2.6)
Para actualizar los pesos wj y cj :
cjk = cji + αekhj (2.7)
wji = wji + αekcjxk (2.8)
Estas ecuaciones, más la función de activación lineal de la red neuronal, describen elfuncionamiento de un control PID neuronal. Este tipo de control data-driven se puedeadaptar para enfrentar variaciones de inercia y perturbaciones, ya que es una red neu-ronal que siempre actualiza los valores de los pesos. Se implementó una función de ac-tivación lineal para las redes de aprendizaje y control debido a que el sistema presentódivergencias en las simulaciones cuando se probaron las funciones tangentes hiperbóli-cas y sigmoideas. Esto se puede deber a los valores de las funciones.
2.3.2. Control Adaptativo Base Radial
El control adaptativo es un tipo de control, en el cual, los parámetros de su controladorpueden cambiar de acuerdo a la dinámica del proceso, logrando así que el compor-tamiento en el lazo cerrado conserve las características de diseño requeridas Ortega(2011). En general, se puede construir controladores adaptativos PID, PI, PD y sus mo-dificaciones, tal que permita, adaptar los cambios del proceso en linealidades conocidas.El enfoque del presente trabajo, es en analizar, estrategias nuevas de control, haciendouso de conceptos en estudios.En la figura 2.8 se evidencia la conexión que posee el sistema adaptativo con el fin derealizar el aprendizaje del proceso y modificación de los parámetros del controlador. Unade las ventajas que posee el controlador base radial y Adaptativos en general, es poseer2 redes de aprendizaje. La red neuronal del controlador, se utilizan los valores del error(Sp - yk) y también posee los pesos W, C y D de la red de aprendizaje en tiempo de laplanta. Con el fin que controlador conozca la dinámica de la planta en el tiempo.
32

Figura 2.8: Control Adaptativo
Fuente: (Godoy Ortega, Jannet 2011)
Las redes con funciones de base radial presentan un entrenamiento mucho más rápi-do que el que se logra con técnicas como la de back-propagations. Giraldo and Hoyos(2004)
Figura 2.9: Red neuronal de función de base radial
Fuente: Giraldo and Hoyos (2004)
El sistema posee 6 entradas que representan la dinámica del sistema, Esfuerzo de con-trol (uk), error (ek), y salida del sistema (yk). Cada parámetro posee 2 retardos, represen-tados como Xk1 y Xk2 haciendo relación al 1er retardos y 2do retardo de las variables.Se puede utilizar más valores, pero realizando un análisis con el diagrama de correlacióncon los modelos encontrados, 2 retardos pueden construir la dinámica de la planta.
X = [yk1, yk2, uk1, uk2, ek1, ek2] (2.9)
Los parámetros de aprendizaje del sistema, utiliza los valores de salida del sistema yesfuerzo de control. Con base a esto, se calculan los valores de W y C (Pesos de laNeuronas ocultas y salida).
cjk = cji + αekhj (2.10)
33

wji = wji + αekcjxk (2.11)
Para el esfuerzo de control, se parte que el controlador busca disminuir el error de laplanta y la referencia. Al igual, que en e PID Neuronal.
e2k =1
2(Sp − Ysk) (2.12)
e2k =1
2
(0−
∂e2k∂U2
k
)2
(2.13)
De donde se obtiene que la señal de esfuerzo de control es:
ukc = ukc1 + αcek; (2.14)
Para este sistema también se optó por una función de activación lineal. Al ser una redneuronal base radial, se utilizan los valores W y C, que se actualizan para la red D,donde:Donde,
hj =∑
wjiX (2.15)
yX = [Kek,KIek,Kdek] (2.16)
2.3.3. Simplificación de datos algoritmo SVD
La identificación de sistemas puede resumirse como la búsqueda de modelo matemáticode un sistema dinámico a partir de medidas entrada-salida, esta definición es tomada deautor por Daniel Adad. Pero existe un gran limitante, debido a que se pueden llegar atener volúmenes muy extensos de datos que pueden representar un exigencia mayor deprocesamiento, por lo cual se hace evidente una estrategia que permita disminuir estosvolúmenes de datos sin perder información valiosa.
El algoritmo SVD (Por sus siglas en inglés Singular Value Descompositions) permite larepresentación de una cantidad extensa de datos recolectados en 3 matrices, cuya re-presentación es U, (Sumatoria) y V. Este mismo, permitirá que se disminuya la cantidadde datos procesados, con el fin de obtener un modelo similar al real. No es una lineali-zación, es un procesos de simplificación con el fin de obtener los datos más dominantesdel sistema y representar toda la dinámica de este mismo.
2.4. Identificación experimental de sistemas
Mediante la identificación experimental se busca encontrar un modelo matemático querepresente lo más fielmente posible al sistema en cuestión, Bueno (2011). Esto es es-pecialmente útil cuando el proceso a controlar posee una dinámica difícil de hallar conmétodos clásicos de identificación, como es el caso de la propiedad visco-elástica de lasarticulaciones flexibles. Con el objetivo de simular el control de las articulaciones flexiblesdel brazo robótico, para su posterior implementación, se hace necesaria una adecuada
34

identificación de un modelo del sistema, el que más se aproxime a la dinámica real y,así, obtener los mejores resultados al implementar el controlador.Para esta identificación se planteó la utilización de la herramienta MATLAB, que poseeun Toolbox con el que se pueden utilizar distintas técnicas de identificación.
2.4.1. Identificación usando el toolbox Ident de MATLAB
El Toolbox de identificación de sistemas es un complemento de la herramienta MATLABque permite construir modelos matemáticos de sistemas dinámicos a partir de datos deentrada y salida. El control de procesos implica el uso de sensores que captan y transmi-ten datos de la variable del proceso en cuestión, y estos son el insumo principal para laidentificación y el control data-driven indirecto. La herramienta permite utilizar datos deentrada en el dominio del tiempo y la frecuencia para modelar funciones de transferenciay espacios de estados. También provee algoritmos para realizar estimación de paráme-tros en línea.Debido a la no linealidad de las articulaciones flexibles, se puede optar por utilizar méto-dos de identificación de modelos no lineales, como son los modelos ARX no lineales ylos modelos de Hammerstein-Weiner.Para este trabajo se optó por utilizar los datos medidos experimentalmente para hallarmodelos aproximados del sistema con espacio de estados de segundo orden.Al hacer estimaciones de espacio de estados, el toolbox permite incluir una componenteK donde se albergan elementos de perturbación o ruido del sistema. Si se decide noincluir esta componente para la estimación, los modelos calculados pueden resultar conbajos porcentajes de ajuste o fit, pero se obtienen modelos razonables para la dinámicadel sistema. Para los modelos del FJRM también se optó por no incluir esta componentede ruido, ya que complicaría el diseño de controladores PID y Espacio de estados conseguimiento de señal.
2.5. Transformaciones cinemáticas del FJRM
El objetivo de la implementación del control de movimiento en un manipulador robóticosuele ser alcanzar la posición deseada del efector final mediante control cinemático odinámico. El modelo cinemático inverso (TCI) y el modelo cinemático directo (TCD) sepueden utilizar con ese propósito. A continuación, el modelo cinemático del FJRM seobtiene mediante dos métodos: solución geométrica y solución analítica. El sistema seconsidera primero como un robot de junta rígida y, a continuación, se hacen las conside-raciones adecuadas para el caso de junta flexible.
2.5.1. Solución geométrica
La solución geométrica se puede obtener aplicando relaciones geométricas y trigonomé-tricas. En la Figura 2.10 se muestra un esquema simplificado para la posición del codohacia abajo y hacia arriba.La TCD describe el modelo para obtener una posición deseada (x, y) dados los valoresde las articulaciones θ1 y θ2. Este modelo se puede observar en la ec. (2.17) y (2.18).
Px = L1cos(θ1) + L2cos(θ1 + θ2) (2.17)
35

�
Figura 2.10: Solución geométrica
Py = L1sin(θ1) + L2sin(θ1 + θ2) (2.18)
La TCI describe el modelo para obtener los valores de las articulaciones θ1 y θ2 da-da una posición deseada (x, y). Para la Figura 2.10 se pueden obtener las siguientesexpresiones.Desplazamiento codo-arriba del FJRM:
θ1 = γ + α
θ2 = β − π(2.19)
Desplazamiento codo-abajo del FJRM:
θ1 = γ − α
θ2 = π − β(2.20)
Los valores de las variables se pueden obtener mediante:LT , distancia entre el punto final y el origen en un robot 2R.
LT =√P 2x + P 2
y (2.21)
β, ángulo entre L1 y L2 (longitud de hombro y codo respectivamente)
β = acos(−L2
T + L21 + L2
1
2L1L2) (2.22)
γ, ángulo entre LT y el eje x.γ = atan2(Py, Px) (2.23)
α, ángulo entre L1 y LT.
α = acos(−L2
2 + L2T + L2
1
2LTL1) (2.24)
36

2.5.2. Solución analítica
El método de Denavit-Hartenberg (D-H) se utiliza para la solución analítica Corke (2007).El primer paso es calcular los parámetros D-H del robot que se muestra en la Figura 2.11.Estos parámetros están definidos por las transformaciones homogéneas entre sistemascoordinados de articulaciones, la base y el efector final.
L1 L2
�� ��x0,x1
y0,y1 y2
x2z0,z1 z2
yT
xTzT
Figura 2.11: Solución analítica, parámetros D-H
Los parámetros de D-H son extraídos de la Figura 2.11 y se muestran en la Tabla 2.1.
Tabla 2.1: Parámetros D-H
Referencia αi−1 ai−1 di θi0-1 0 0 0 θ11-2 0 L1 0 θ22-T 0 L2 0 0
A partir de los parámetros extraídos se puede obtener la matriz de transformación ho-mogénea desde la base a la posición P descrita por T0 T dada en ec. 2.25.
ABR =
c(θ1 + θ2) −s(θ1 + θ2) 0 L1c(θ1) + L2c(θ1 + θ2)s(θ1 + θ2) c(θ1 + θ2) 0 L1s(θ1) + L2s(θ1 + θ2)
0 0 1 00 0 0 1
(2.25)
De esta matriz se pueden extraer la orientación y la matriz de posición descritas en laec. (2.26) y (2.27).
T0 R =
c(θ1 + θ2) −s(θ1 + θ2) 0s(θ1 + θ2) c(θ1 + θ2) 0
0 0 1
(2.26)
PxPyPz
=
L1c(θ1) + L2c(θ1 + θ2)L1s(θ1) + L2s(θ1 + θ2)
0
(2.27)
La TCD viene dada por la matriz de posición y la TCI se calcula a partir de la suma deelevar al cuadrado las ecuaciones Px y Py y resolver el sistema como en la ecuación.2.28.
Acosθ1 +Bsinθ1 = C (2.28)
donde,
37

A = 2PxL1
B = 2PyL1
C = P 2x + P 2
y + L21 − L2
2
(2.29)
aplicando cosθ1 =1−tan2(
θ12)
1+tan2(θ12)
y sinθ1 =2tan(
θ12)
1+tan2(θ12)
se puede obtener la TCI descrita por la
ec. 2.30.
tan(θ12) =
−Bb ±√Bb
2 − 4AbCb2Ab
θ1(a,b) = 2tan−1(−Bb ±
√Bb
2 − 4AbCb2Ab
)
θ2(a,b) = atan2(Py − L1sinθ1Px − L1cosθ1
)− θ1(a,b)
(2.30)
donde,
Ab = −A− C
Bb = 2B
Cb = A− C
(2.31)
Una vez que se utiliza la descripción cinemática presentada anteriormente para mapearlos datos de los encoders en la posición del efector final, se pueden utilizar como insumopara la referencia de los controladores de cada articulación.
38

Capítulo 3
Presentación y discusión deresultados
3.1. Protocolo de pruebas
Para aplicar la metodología DDI, se hace una identificación del FJRM por medio de unprecontrol de la planta, realizando una realimentación con ganancia igual a 1, ya queel FJRM presenta inestabilidad cuando se trata de la posición del codo y el hombro.Los datos se registran con entradas ascendentes de 0,3 radianes para un movimientoen sentido horario desde cero hasta 3 radianes. Luego, desde 3 radianes hasta cerocon paso de 0,3 radianes en sentido antihorario. Los datos para el hombro y el codo semuestran en la Figura 3.1 y en la Figura 3.2, respectivamente.
Se partió de un sobre-muestreo de la planta, con tiempo igual a 0.001 Segundos, vali-dando los datos se utilizó el tiempo de subida, aproximadamente el 70 % del valor establepara sacar el tiempo de muestro adecuado. El criterio rápido determina un décimo deltiempo de subida para reconstruir esa dinámica transitoria por lo menos con 10 datos. Eltiempo seleccionado es de 0.3 Segundos.
La TCD de la ec. (2.17) y la ec. (2.18), se aplica para obtener la posición del efector finala partir de datos experimentales de los encoders del codo y el hombro. Se obtiene laposición X e Y del efector final, con X = 25cm y Y = 40cm como entrada.
Al ser un sistema acoplado, un movimiento en el hombro se ve reflejado en el codoy en sentido opuesto, es por esto, que las perturbaciones aplicadas en articulacionesdiferentes, se ven reflejadas en sus respectivas gráficas.Para el nombre de las imágenes, se acogió un formato para encontrar con mayor facili-dad el controlador implementado. DDD: Controlador - Tipo de gráfica.
DDD o DDI: Se refiere a si es Data-Driven Directo o Data-Driven Indirecto.Controlador: Se especifica que tipo de controlador se implementó.Tipo de gráfica: Se menciona que datos se están graficando.
Para la parte de control se realizaron perturbaciones de los modelos escogidos paralos controladores data-driven Indirecto y Directo. Se aplicó una perturbación de 1 radian
39

constante en en esfuerzo de control para cada motor. Se realizó perturbación en untiempo de 50 segundos para el codo y 70 segundos para el hombro.
3.2. Modelos hallados a partir de datos experimentales
Debido a que el objetivo principal del trabajo es la comparación del comportamiento dedos tipos de control data-driven (directo e indirecto), para la sintonización de controlado-res indirectos es necesario obtener un modelo del sistema a controlar. Ya que el sistemaque se propuso controlar presenta comportamientos no lineales, la complejidad a la horade hallar un modelo para este aumenta. Por esto, la identificación experimental que sehizo sobre el sistema se basó en modelos de caja negra.
0 500 1000 1500 2000 2500 3000
Time [sec]
0
0.5
1
1.5
2
2.5
3
Angle
[ra
dia
n]
Shoulder Experimental Data
Input
Shoulder Joint Encoder
Figura 3.1: Datos experimentales usados para la identificación del hombroFuente: Propio
0 500 1000 1500 2000 2500 3000
Time [sec]
0
0.5
1
1.5
2
2.5
3
Angle
[ra
dia
n]
Elbow Experimental Data
Input
Elbow Joint Encoder
Figura 3.2: Datos experimentales usados para la identificación del codoFuente: Propio
El FJR es un producto de QUANSER®, por lo que, para realizar la conexión con Simulink
40

de Matlab y adquirir los datos, se requirió de un complemento llamado QUARC®.
Al graficar las entradas contra las salidas en estado estable, tanto para el codo comopara el hombro, se observa que el FJRM se comporta de manera diferente cuando giraen sentido antihorario o en sentido horario (ver Figuras 3.3 y 3.4). Por lo tanto, exhibeuna dinámica conmutada en la que la dinámica del FJRM actúa como el estado continuocuando gira en sentido antihorario o en sentido horario (dos estados), y el estado discre-to es el sentido de giro (1 si es horario, 0 si es antihorario), Manrique and Patiño (2010).
0 0.5 1 1.5 2 2.5 3
Input [rad]
-0.5
0
0.5
1
1.5
2
2.5
3
3.5
Outp
ut [r
ad]
Data
Counterclockwise
Clockwise
Figura 3.3: Comportamiento no lineal del hombro respecto al sentido de giro
0 0.5 1 1.5 2 2.5 3
Input [rad]
-0.5
0
0.5
1
1.5
2
2.5
3
3.5
Outp
ut [r
ad]
Data
Counterclockwise
Clockwise
Figura 3.4: Comportamiento no lineal del codo respecto al sentido de giro
Como se puede ver en la Figura 3.4, dado que la entrada no supera la fricción estáticadel motor se presenta un valor igual a cero para la coordenada de la primera entradaascendente.
Los modelos identificados correspondientes con mejor ajuste a los datos experimentalesse muestran en las ec. (3.4) - (3.16). Se obtiene el siguiente modelo de espacio deestados para el hombro en sentido horario:
41

A1_hombro =
[−0,7828 −0,0819−1,1758 −0,1245
](3.1)
B1_hombro =
[−1,9064−2,8676
](3.2)
C1_hombro =[−0,7605 0,1975
](3.3)
D1_hombro = 0 (3.4)
El modelo de espacio de estados para el hombro en sentido antihorario:
A0_hombro =
[−0,5890 0,20091,1678 −0,4136
](3.5)
B0_hombro =
[−1,24842,5025
](3.6)
C0_hombro =[−0,9870 −0,1142
](3.7)
D0_hombro = 0 (3.8)
En cuanto al codo, el modelo de espacio de estados para el sentido horario:
A1_codo =
[−0,1340 0,60080,4723 −2,1152
](3.9)
B1_codo =
[2,9237
−10,2934
](3.10)
C1_codo =[0,1877 −0,1851
](3.11)
D1_codo = 0 (3.12)
Finalmente, el modelo de espacio de estados para el codo en sentido antihorario:
A0_codo =
[−0,5890 0,20091,1678 −0,4136
](3.13)
B0_codo =
[−1,24842,5025
](3.14)
C0_codo =[−0,9870 −0,1142
](3.15)
D0_codo = 0 (3.16)
El sistema modelado para el Hombro está dado representado de la siguiente manera:
42

Ahombro = A0hombro(1− δ) +A1hombroδ
Bhombro = B0hombro(1− δ) +B1hombroδ
Chombro = C0hombro(1− δ) + C1hombroδ
Dhombro = D0hombro(1− δ) +D1hombroδ
(3.17)
Donde,
δ =
{1, Sentido horario0, Sentido Antihorario
El sistema modelado para el codo está dado representado de la siguiente manera:
Acodo = A0codo(1− ρ) +A1codoρ
Bcodo = B0codo(1− ρ) +B1codoρ
Ccodo = C0codo(1− ρ) + C1codoρ
Dcodo = D0codo(1− ρ) +D1codoρ
(3.18)
Donde,
ρ =
{1, Sentido horario0, Sentido Antihorario
Para desarrollar un control PID se hizo uso de una función de transferencia. Se tuvo encuenta 2 polos y 1 cero como parámetros para el toolbox de Matlab Ident. Se obtuvo 4funciones de transferencia, 2 para el hombro y 2 para el codo:Para el hombro en sentido horario se obtiene que:
H1(s) =−5,995s+ 10,13
s2 + 11,92s+ 12,2(3.19)
En sentido antihorario, el hombro está representado como:
H0(s) =−6,618s− 10
s2 + 11,92s+ 1(3.20)
En cuanto al codo, la función de transferencia para el sentido horario:
C1(s) =−0,7859s+ 22,46
s2 + 7,676s+ 21,67(3.21)
Finalmente, el modelo para el codo en sentido antihorario esta dado por:
C0(s) =−1,042s+ 23,4
s2 + 8,276s+ 21,5(3.22)
Estas funciones de transferencia se utilizaron para aplicar un controlador PID por estruc-tura fija.
43

3.3. Control Data-Driven Indirecto
Para el diseño de controladores DDI, se plantearon las mismas característica de diseñoencontradas heurísticamente con el PID Neuronal y Control adaptativo base radial.
Máximo sobreimpulso : %MP = 10%
Tiempo de establecimiento : tss = 10s
Factor de amortiguamiento : ζ =
√√√√√ Ln(Mp)−π
2
1 +Ln(Mp)
−π2
(3.23)
El sistema real se comporta como un modelo híbrido, por lo cual, se parte del diseñode 2 controladores. La implementación del control se debe tener en cuenta la señal delerror. El esfuerzo de control para el motor está definió como:
Uk = Uk0(1− γ) + Uk1γ (3.24)
γ =
{1, error > 0
0, error ≤ 0
Uk1 Hace referencia al controlador utilizado para el control del motor en sentido horario.
Uk0 Hace referencia al controlador utilizado para el control del motor en sentido Antiho-rario.
3.3.1. Control PID
Para el diseño de controlado PID se partió de una estructura fija, utilizando las caracte-rísticas de desempeño mencionadas con anterioridad (Ec. 3.23). Se utilizó un polinomiodeseado de segundo orden con polos remanentes para encontrar una solución matemá-tica. Para la sección del derivador se colocó un filtro pasa bajas de la forma (Ns + 1) talque se garantice una función de transferencia del controlador propia. Para el diseño delcontrolador se adjunta en anexos (ANEXO 1) un formato Mupad para calcular las cons-tante a partir de las funciones de transferencias mostradas en la sección de Modeloshallados.Las constante Proporcional, Derivativa con filtro, e Integral son:Hombro en sentido horario:
td = −0,1179000633
ti = 0,8330177215
kp = 0,6821163706
N = 0,647418544
(3.25)
44

Hombro en sentido antihorario:
td = 0,05449599678
ti = 0,3519049818
kp = 0,4683832714
N = 0,55711052
(3.26)
Codo en sentido horario:
td = −0,3214121914
ti = −1,334663512
kp = −0,4516061486
N = 0,6179813567
(3.27)
Codo en sentido antihorario:
td = 0,0767383766
ti = −1,347509329
kp = −0,5072142637
N = 0,09895480624
(3.28)
Para la implementación del switcheo del control se realizó de la siguiente manera (VerFig. 3.5),
Figura 3.5: Comportamiento no lineal del codo respecto al sentido de giro
Resultados de control PID sin Switcheo
En esta sección se mostrarán los controladores PID sin tener en cuenta el switcheocon la señal de error. Esto con el fin de comprobar la estabilidad del controlador PIDindividualmente.
45
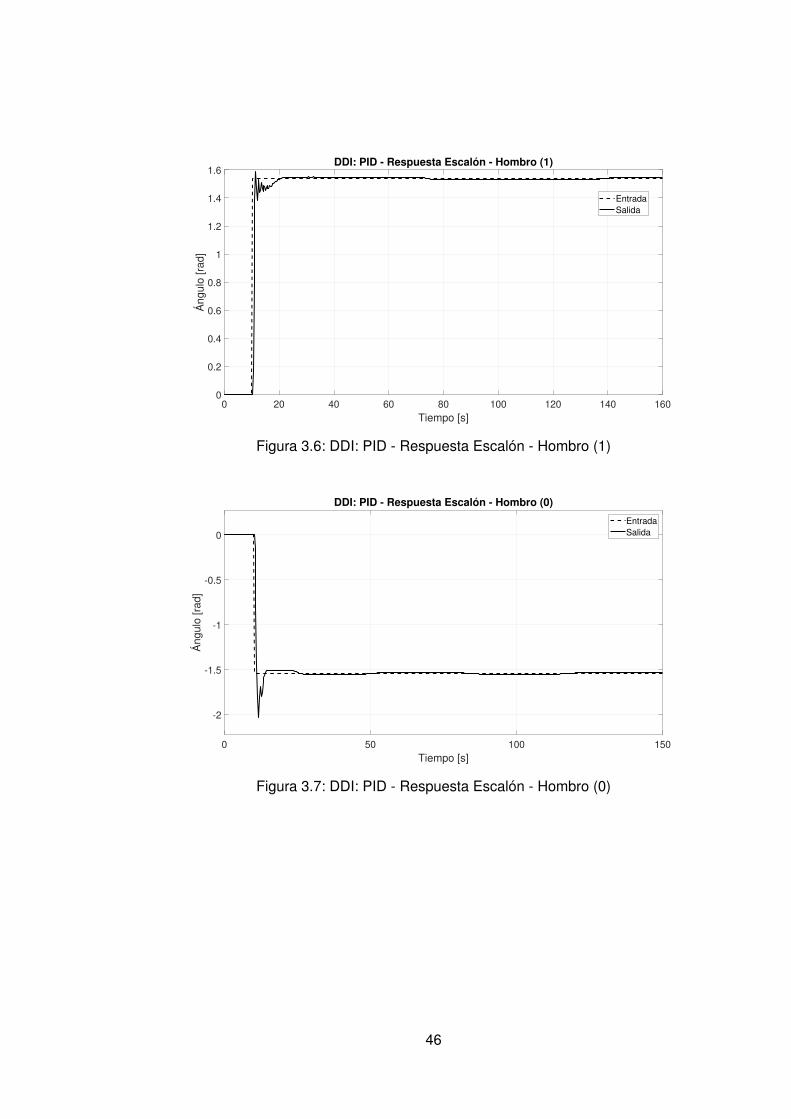
0 20 40 60 80 100 120 140 160Tiempo [s]
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
Áng
ulo
[rad
]
DDI: PID - Respuesta Escalón - Hombro (1)
EntradaSalida
Figura 3.6: DDI: PID - Respuesta Escalón - Hombro (1)
0 50 100 150Tiempo [s]
-2
-1.5
-1
-0.5
0
Áng
ulo
[rad
]
DDI: PID - Respuesta Escalón - Hombro (0)
EntradaSalida
Figura 3.7: DDI: PID - Respuesta Escalón - Hombro (0)
46
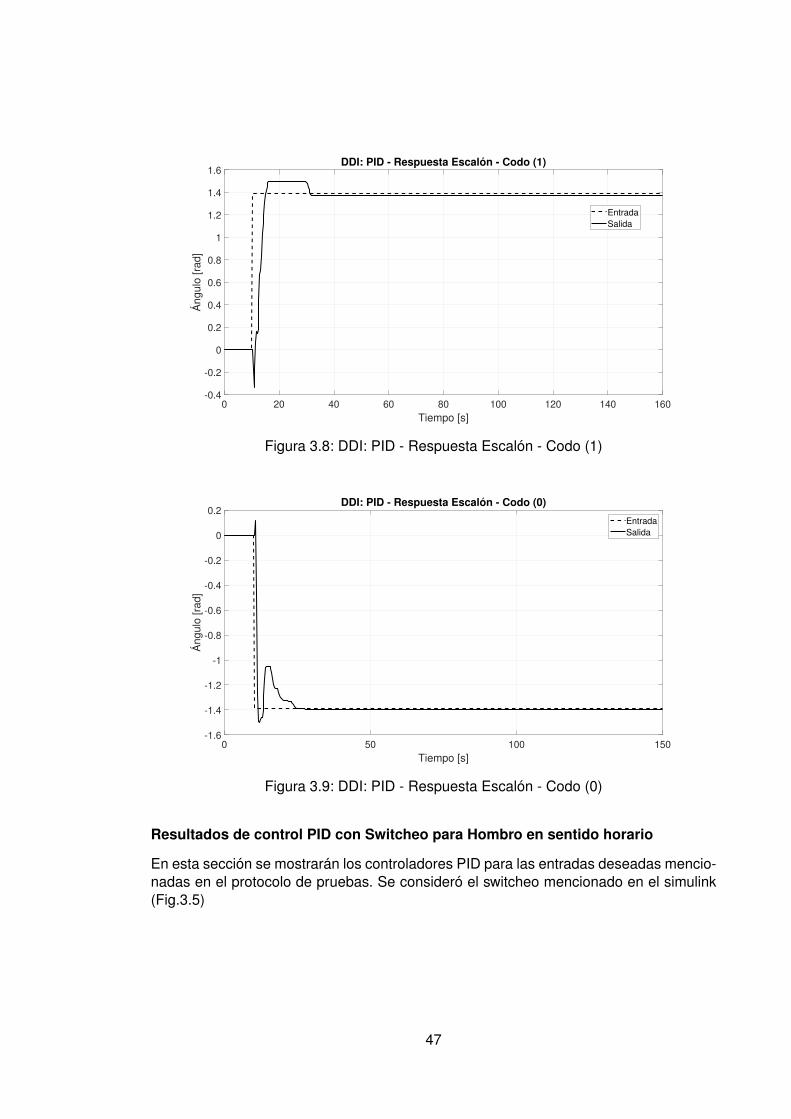
0 20 40 60 80 100 120 140 160Tiempo [s]
-0.4
-0.2
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
Áng
ulo
[rad
]
DDI: PID - Respuesta Escalón - Codo (1)
EntradaSalida
Figura 3.8: DDI: PID - Respuesta Escalón - Codo (1)
0 50 100 150Tiempo [s]
-1.6
-1.4
-1.2
-1
-0.8
-0.6
-0.4
-0.2
0
0.2
Áng
ulo
[rad
]
DDI: PID - Respuesta Escalón - Codo (0)
EntradaSalida
Figura 3.9: DDI: PID - Respuesta Escalón - Codo (0)
Resultados de control PID con Switcheo para Hombro en sentido horario
En esta sección se mostrarán los controladores PID para las entradas deseadas mencio-nadas en el protocolo de pruebas. Se consideró el switcheo mencionado en el simulink(Fig.3.5)
47

0 20 40 60 80 100 120 140 160Tiempo [s]
0
0.5
1
1.5
2
Áng
ulo
[rad
]
DDI: PID - Respuesta Escalón - Hombro (1)
EntradaSalida
(a) DDI: PID Tradicional - Respuesta escalón -Hombro (1)
0 20 40 60 80 100 120 140 160Tiempo [s]
0
0.2
0.4
0.6
0.8
1
Áng
ulo
[rad
]
DDI: PID - Perturbación - Hombro (1)
Perturbación
(b) DDI: PID Tradicional - Perturbación - Hombro(1)
0 20 40 60 80 100 120 140 160
Tiempo [s]
-1
-0.5
0
0.5
1
1.5
Voltaje
[V
]
DDI: PID - Esfuerzo de control (Motor) - Hombro (1)
Señal de control
(c) DDI: PID Tradicional - Esfuerzo de control(Motor) - Hombro (1)
Figura 3.10: Controlador PID Tradicional implementando switcheo Hombro (1)
48
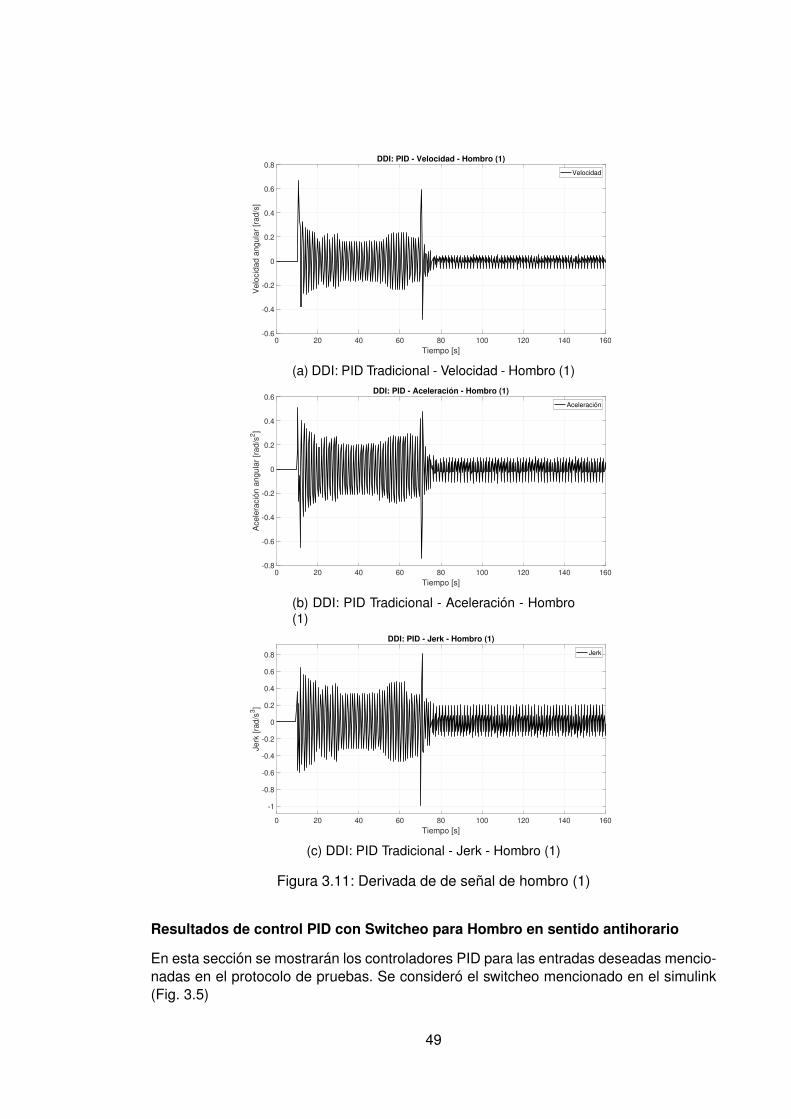
0 20 40 60 80 100 120 140 160
Tiempo [s]
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
0.8
Velo
cid
ad a
ngula
r [r
ad/s
]
DDI: PID - Velocidad - Hombro (1)
Velocidad
(a) DDI: PID Tradicional - Velocidad - Hombro (1)
0 20 40 60 80 100 120 140 160
Tiempo [s]
-0.8
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
Acele
ració
n a
ngula
r [r
ad/s
2]
DDI: PID - Aceleración - Hombro (1)
Aceleración
(b) DDI: PID Tradicional - Aceleración - Hombro(1)
0 20 40 60 80 100 120 140 160
Tiempo [s]
-1
-0.8
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
0.8
Jerk
[ra
d/s
3]
DDI: PID - Jerk - Hombro (1)
Jerk
(c) DDI: PID Tradicional - Jerk - Hombro (1)
Figura 3.11: Derivada de de señal de hombro (1)
Resultados de control PID con Switcheo para Hombro en sentido antihorario
En esta sección se mostrarán los controladores PID para las entradas deseadas mencio-nadas en el protocolo de pruebas. Se consideró el switcheo mencionado en el simulink(Fig. 3.5)
49
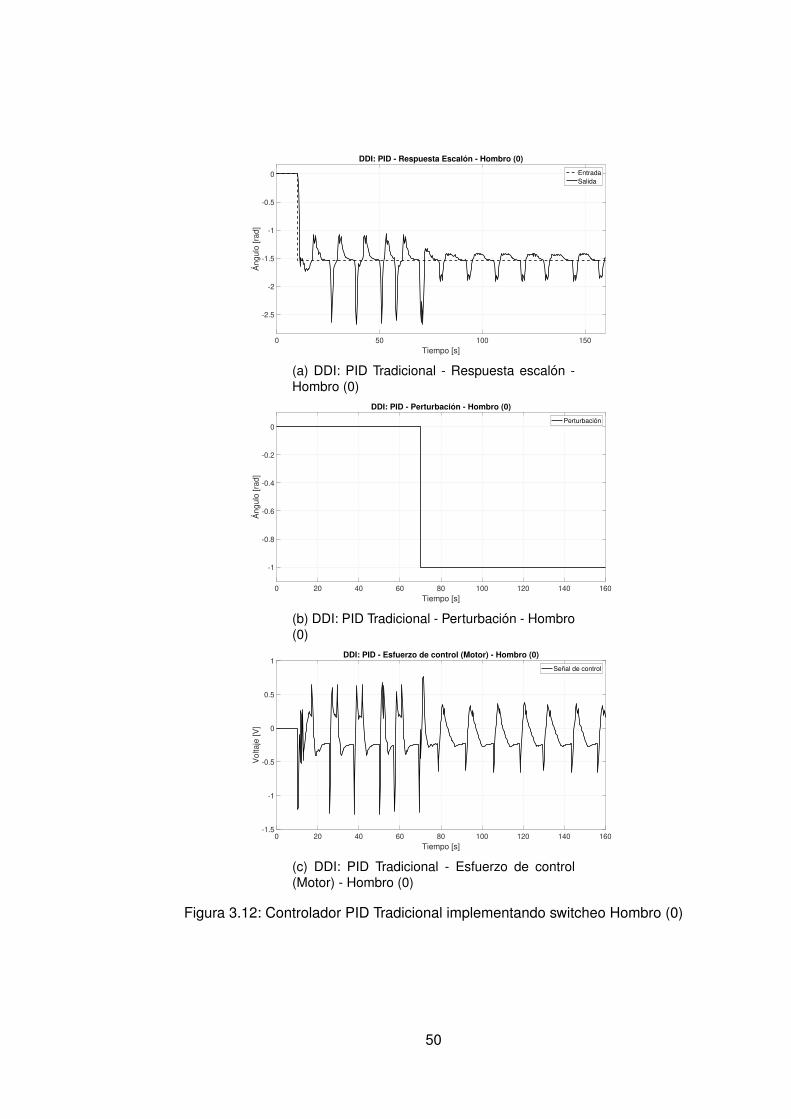
0 50 100 150Tiempo [s]
-2.5
-2
-1.5
-1
-0.5
0
Áng
ulo
[rad
]
DDI: PID - Respuesta Escalón - Hombro (0)
EntradaSalida
(a) DDI: PID Tradicional - Respuesta escalón -Hombro (0)
0 20 40 60 80 100 120 140 160Tiempo [s]
-1
-0.8
-0.6
-0.4
-0.2
0
Áng
ulo
[rad
]
DDI: PID - Perturbación - Hombro (0)
Perturbación
(b) DDI: PID Tradicional - Perturbación - Hombro(0)
0 20 40 60 80 100 120 140 160
Tiempo [s]
-1.5
-1
-0.5
0
0.5
1
Voltaje
[V
]
DDI: PID - Esfuerzo de control (Motor) - Hombro (0)
Señal de control
(c) DDI: PID Tradicional - Esfuerzo de control(Motor) - Hombro (0)
Figura 3.12: Controlador PID Tradicional implementando switcheo Hombro (0)
50
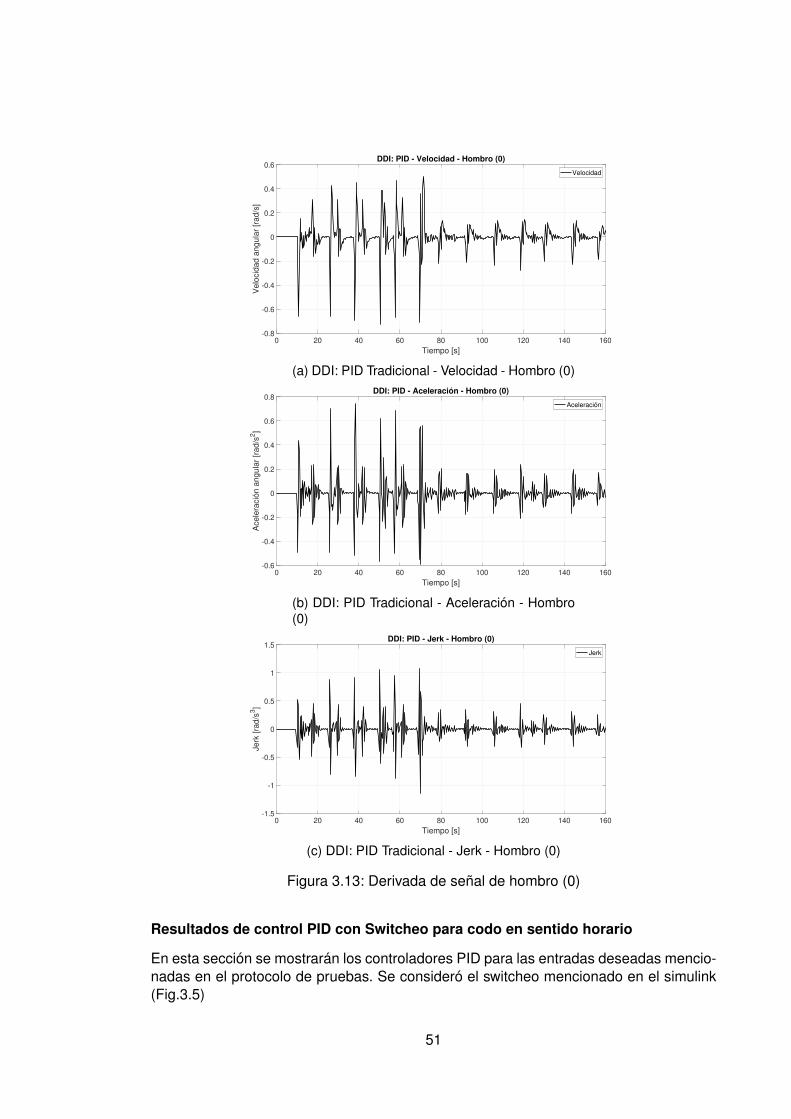
0 20 40 60 80 100 120 140 160
Tiempo [s]
-0.8
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
Velo
cid
ad a
ngula
r [r
ad/s
]
DDI: PID - Velocidad - Hombro (0)
Velocidad
(a) DDI: PID Tradicional - Velocidad - Hombro (0)
0 20 40 60 80 100 120 140 160
Tiempo [s]
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
0.8
Acele
ració
n a
ngula
r [r
ad/s
2]
DDI: PID - Aceleración - Hombro (0)
Aceleración
(b) DDI: PID Tradicional - Aceleración - Hombro(0)
0 20 40 60 80 100 120 140 160
Tiempo [s]
-1.5
-1
-0.5
0
0.5
1
1.5
Jerk
[ra
d/s
3]
DDI: PID - Jerk - Hombro (0)
Jerk
(c) DDI: PID Tradicional - Jerk - Hombro (0)
Figura 3.13: Derivada de señal de hombro (0)
Resultados de control PID con Switcheo para codo en sentido horario
En esta sección se mostrarán los controladores PID para las entradas deseadas mencio-nadas en el protocolo de pruebas. Se consideró el switcheo mencionado en el simulink(Fig.3.5)
51
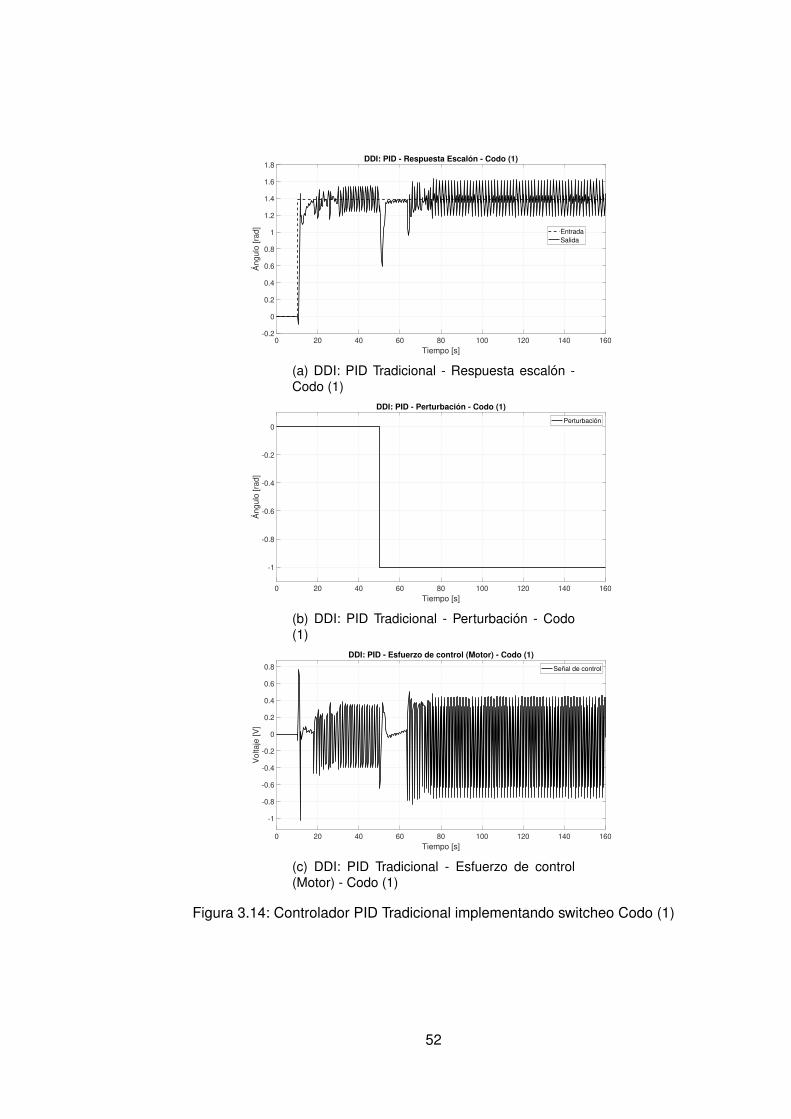
0 20 40 60 80 100 120 140 160Tiempo [s]
-0.2
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
Áng
ulo
[rad
]
DDI: PID - Respuesta Escalón - Codo (1)
EntradaSalida
(a) DDI: PID Tradicional - Respuesta escalón -Codo (1)
0 20 40 60 80 100 120 140 160Tiempo [s]
-1
-0.8
-0.6
-0.4
-0.2
0
Áng
ulo
[rad
]
DDI: PID - Perturbación - Codo (1)
Perturbación
(b) DDI: PID Tradicional - Perturbación - Codo(1)
0 20 40 60 80 100 120 140 160
Tiempo [s]
-1
-0.8
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
0.8
Voltaje
[V
]
DDI: PID - Esfuerzo de control (Motor) - Codo (1)
Señal de control
(c) DDI: PID Tradicional - Esfuerzo de control(Motor) - Codo (1)
Figura 3.14: Controlador PID Tradicional implementando switcheo Codo (1)
52

0 20 40 60 80 100 120 140 160
Tiempo [s]
-0.4
-0.2
0
0.2
0.4
0.6
0.8
1
Velo
cid
ad a
ngula
r [r
ad/s
]
DDI: PID - Velocidad - Codo (1)
Velocidad
(a) DDI: PID Tradicional - Velocidad - Codo (1)
0 20 40 60 80 100 120 140 160
Tiempo [s]
-1.2
-1
-0.8
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
0.8
Acele
ració
n a
ngula
r [r
ad/s
2]
DDI: PID - Aceleración - Codo (1)
Aceleración
(b) DDI: PID Tradicional - Aceleración - Hombro(1)
0 20 40 60 80 100 120 140 160
Tiempo [s]
-1.5
-1
-0.5
0
0.5
1
1.5
Jerk
[ra
d/s
3]
DDI: PID - Jerk - Codo (1)
Jerk
(c) DDI: PID Tradicional - Jerk - Codo (1)
Figura 3.15: Derivada de señal de Codo (1)
Resultados de control PID con Switcheo para Codo en sentido antihorario
En esta sección se mostrarán los controladores PID para las entradas deseadas mencio-nadas en el protocolo de pruebas. Se consideró el switcheo mencionado en el simulink(Fig. 3.5)
53
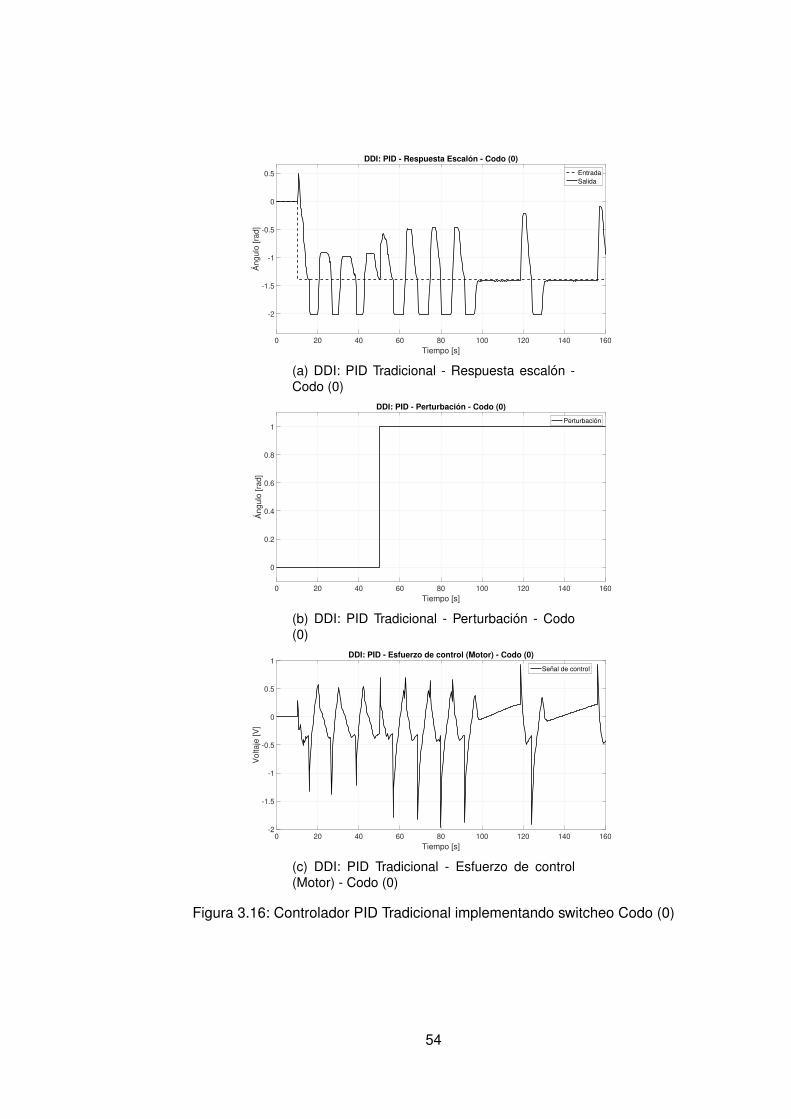
0 20 40 60 80 100 120 140 160Tiempo [s]
-2
-1.5
-1
-0.5
0
0.5
Áng
ulo
[rad
]
DDI: PID - Respuesta Escalón - Codo (0)
EntradaSalida
(a) DDI: PID Tradicional - Respuesta escalón -Codo (0)
0 20 40 60 80 100 120 140 160Tiempo [s]
0
0.2
0.4
0.6
0.8
1
Áng
ulo
[rad
]
DDI: PID - Perturbación - Codo (0)
Perturbación
(b) DDI: PID Tradicional - Perturbación - Codo(0)
0 20 40 60 80 100 120 140 160
Tiempo [s]
-2
-1.5
-1
-0.5
0
0.5
1
Voltaje
[V
]
DDI: PID - Esfuerzo de control (Motor) - Codo (0)
Señal de control
(c) DDI: PID Tradicional - Esfuerzo de control(Motor) - Codo (0)
Figura 3.16: Controlador PID Tradicional implementando switcheo Codo (0)
54
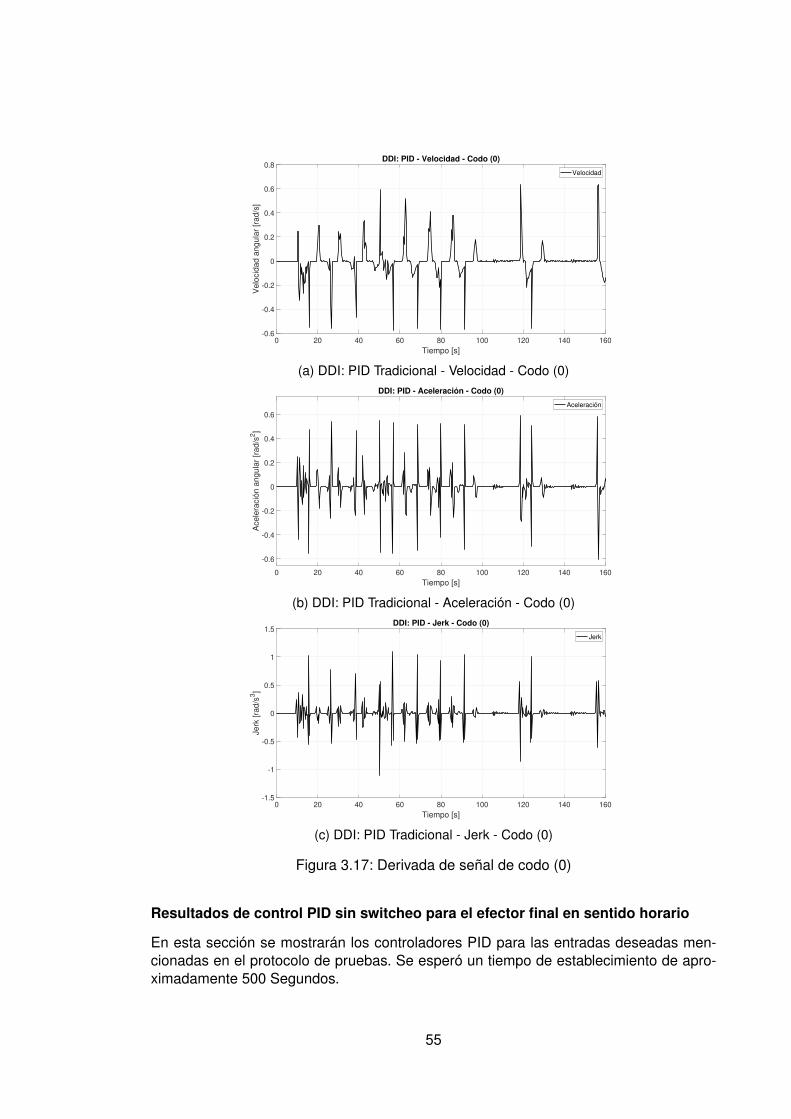
0 20 40 60 80 100 120 140 160
Tiempo [s]
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
0.8
Velo
cid
ad a
ngula
r [r
ad/s
]
DDI: PID - Velocidad - Codo (0)
Velocidad
(a) DDI: PID Tradicional - Velocidad - Codo (0)
0 20 40 60 80 100 120 140 160
Tiempo [s]
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
Acele
ració
n a
ngula
r [r
ad/s
2]
DDI: PID - Aceleración - Codo (0)
Aceleración
(b) DDI: PID Tradicional - Aceleración - Codo (0)
0 20 40 60 80 100 120 140 160
Tiempo [s]
-1.5
-1
-0.5
0
0.5
1
1.5
Jerk
[ra
d/s
3]
DDI: PID - Jerk - Codo (0)
Jerk
(c) DDI: PID Tradicional - Jerk - Codo (0)
Figura 3.17: Derivada de señal de codo (0)
Resultados de control PID sin switcheo para el efector final en sentido horario
En esta sección se mostrarán los controladores PID para las entradas deseadas men-cionadas en el protocolo de pruebas. Se esperó un tiempo de establecimiento de apro-ximadamente 500 Segundos.
55
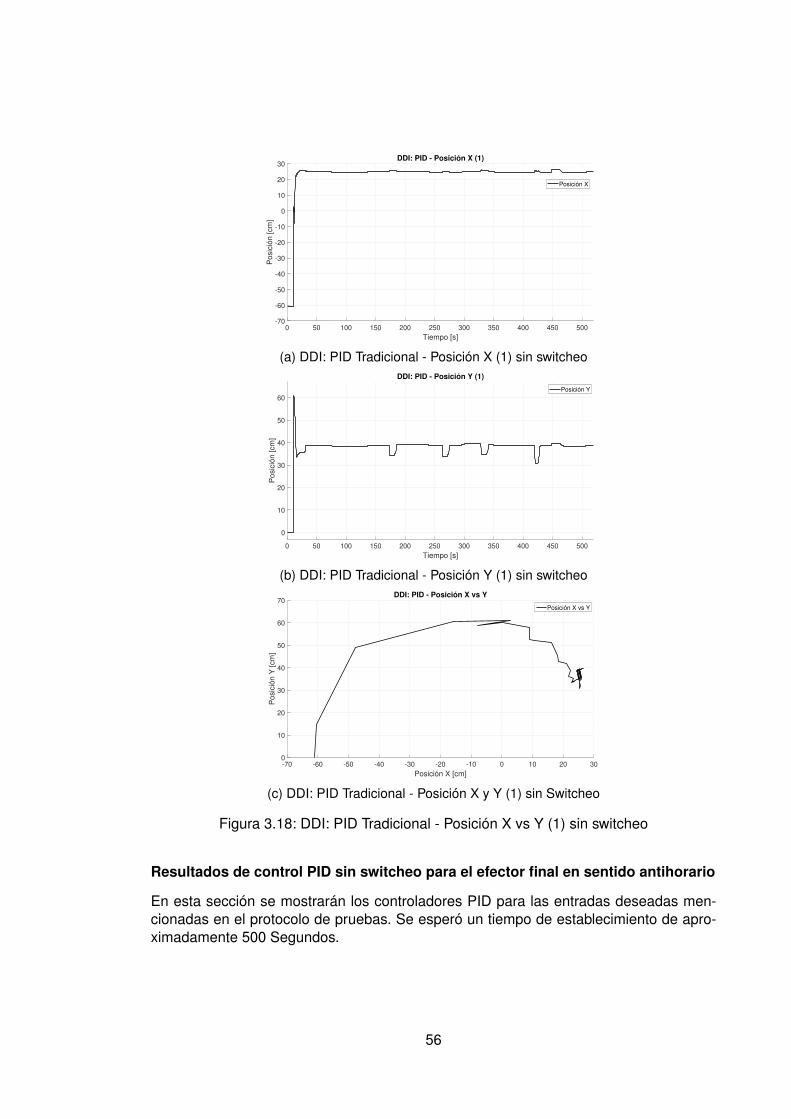
0 50 100 150 200 250 300 350 400 450 500
Tiempo [s]
-70
-60
-50
-40
-30
-20
-10
0
10
20
30
Po
sic
ión
[cm
]
DDI: PID - Posición X (1)
Posición X
(a) DDI: PID Tradicional - Posición X (1) sin switcheo
0 50 100 150 200 250 300 350 400 450 500
Tiempo [s]
0
10
20
30
40
50
60
Po
sic
ión
[cm
]
DDI: PID - Posición Y (1)
Posición Y
(b) DDI: PID Tradicional - Posición Y (1) sin switcheo
-70 -60 -50 -40 -30 -20 -10 0 10 20 30
Posición X [cm]
0
10
20
30
40
50
60
70
Po
sic
ión
Y [
cm
]
DDI: PID - Posición X vs Y
Posición X vs Y
(c) DDI: PID Tradicional - Posición X y Y (1) sin Switcheo
Figura 3.18: DDI: PID Tradicional - Posición X vs Y (1) sin switcheo
Resultados de control PID sin switcheo para el efector final en sentido antihorario
En esta sección se mostrarán los controladores PID para las entradas deseadas men-cionadas en el protocolo de pruebas. Se esperó un tiempo de establecimiento de apro-ximadamente 500 Segundos.
56

0 50 100 150
Tiempo [s]
-60
-40
-20
0
20
40
60
80
Posic
ión [cm
]
DDI: PID - Posición X (0)
Posición X
(a) DDI: PID Tradicional - Posición X (0) sin switcheo
0 50 100 150
Tiempo [s]
0
10
20
30
40
50
60
Posic
ión [cm
]
DDI: PID - Posición Y (0)
Posición Y
(b) DDI: PID Tradicional - Posición Y (0) sin switcheo
-60 -40 -20 0 20 40 60 80
Posición X [cm]
0
10
20
30
40
50
60
Posic
ión Y
[cm
]
DDI: PID - Posición X vs Y
Posición X vs Y
(c) DDI: PID Tradicional - Posición X y Y (0) sin Switcheo
Figura 3.19: DDI: PID Tradicional - Posición X vs Y (0) sin switcheo
57

Resultados de control PID con switcheo para el efector final en sentido horario
En esta sección se mostrarán los controladores PID para las entradas deseadas men-cionadas en el protocolo de pruebas.
0 20 40 60 80 100 120 140 160
Tiempo [s]
-80
-60
-40
-20
0
20
40
60P
osic
ión [cm
]DDI: PID - Posición X (1)
Posición X
(a) DDI: PID Tradicional - Posición X (1) con switcheo
0 20 40 60 80 100 120 140 160
Tiempo [s]
0
10
20
30
40
50
Posic
ión [cm
]
DDI: PID - Posición Y (1)
Posición Y
(b) DDI: PID Tradicional - Posición Y (1) con switcheo
-80 -60 -40 -20 0 20 40 60
Posición X [cm]
0
10
20
30
40
50
60
Posic
ión Y
[cm
]
DDI: PID - Posición X vs Y
Posición X vs Y
(c) DDI: PID Tradicional - Posición X y Y (1) con switcheo
Figura 3.20: DDD: PID Tradicional - Posición X vs Y (1) con switcheo
58
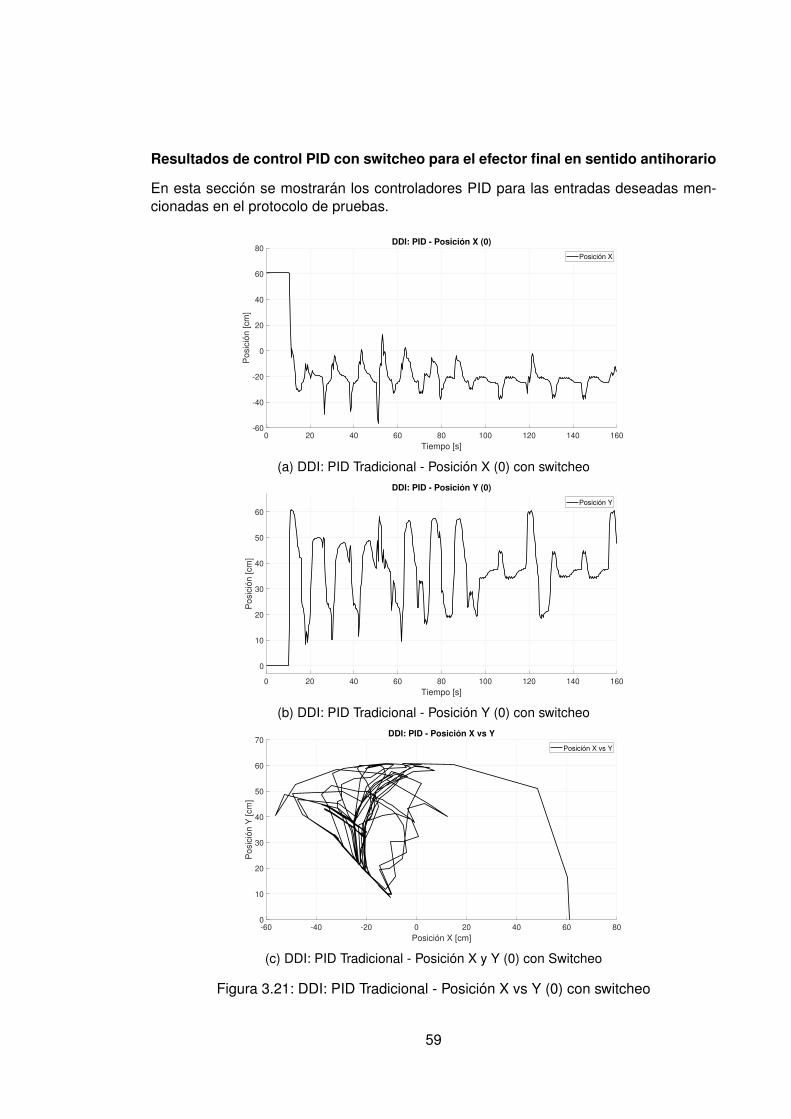
Resultados de control PID con switcheo para el efector final en sentido antihorario
En esta sección se mostrarán los controladores PID para las entradas deseadas men-cionadas en el protocolo de pruebas.
0 20 40 60 80 100 120 140 160
Tiempo [s]
-60
-40
-20
0
20
40
60
80P
osic
ión [cm
]DDI: PID - Posición X (0)
Posición X
(a) DDI: PID Tradicional - Posición X (0) con switcheo
0 20 40 60 80 100 120 140 160
Tiempo [s]
0
10
20
30
40
50
60
Posic
ión [cm
]
DDI: PID - Posición Y (0)
Posición Y
(b) DDI: PID Tradicional - Posición Y (0) con switcheo
-60 -40 -20 0 20 40 60 80
Posición X [cm]
0
10
20
30
40
50
60
70
Posic
ión Y
[cm
]
DDI: PID - Posición X vs Y
Posición X vs Y
(c) DDI: PID Tradicional - Posición X y Y (0) con Switcheo
Figura 3.21: DDI: PID Tradicional - Posición X vs Y (0) con switcheo
59

3.3.2. Control con Realimentación de estados con Observador de ordencompleto
Realimentación de estados con seguimiento de señal
Los modelos identificados en la sección anterior se utilizan en el diseño del controladordata-driven indirecto. Se propone un control por retroalimentación de estados con inte-grador mediante colocación de polos. El rendimiento deseado es basado en Ec. 3.23.Para encontrar el valor de Wn se utiliza el criterio de estabilidad planteado en el libro deOgata correspondiente a criterio en estado estable de 1 %:
Frecuencia natural :Wn =4,6
ζtss(3.29)
El desarrollo matemática se realizó desde matLab (ANEXO 2). Estos parámetros (Ec.3.29 y 3.23) se utilizaron para el desarrollo de las constante de realimentación de estadoy seguimiento de señal. Debido a que el sistema identificado, se realizó con un proce-sos de caja negra, los estados de estos mismos no son medibles. Se debe plantear unobservador de orden completo para la implementación de control.Para encontrar la ganancia del integrador del sistema, se debe adicionar un estado alsistema, que permita encontrar en la matriz de realimentación un valor adiciona. Sedebe trabajar con nuevas matrices que permitan describir los nuevos estados partiendodel diagrama de bloques (Fig. 2.7)
Aext =
[A [0; 0]−C −0
](3.30)
Bext =
[B0
](3.31)
Cext =[C −D
](3.32)
Dext = 0 (3.33)
Se hizo uso de un archivo de matlab para encontrar los parámetros. El código se en-cuentra en: (Anexo 2) A continuación, se muestran las constantes halladas para cadaarticulación, haciendo uso de la función Place y parámetros hallados en las Ec (3.30),(3.31), (3.32), (3.33) :
Hombro en sentido horario,
K1hombro =[−0,0432 −0,1574
]Kinteg1hombro = 0,2749
(3.34)
Hombro en sentido Antihorario,
K0hombro =[−0,0053 0,1454
]Kinteg1hombro = 0,2658
(3.35)
60

Codo en sentido horario,
K1codo =[0,2121 −0,0962
]Kinteg1codo = 0,1190
(3.36)
Codo en sentido Antihorario,
K0codo =[−0,2363 0,0904
]Kinteg0codo = 0,1240
(3.37)
Observador de orden completo
Para predecir los estados del sistemas, el observador debe ser más rápido que la plantareal, en este caso se parte de los modelos identificado con una confianza de aproximada-mente 91 %. Se plantea un observador con un tiempo de establecimiento 10 veces másrápido que el propuesto para la realimentación de estado. El sistema identificado posee2 estados, y se realizó el desarrollo para hallar el valor de realimentación del observador,es planteado por algunos autores como el valor de realimentación L.
Máximo sobreimpulso : %MP = 10%
Tiempo de establecimiento : tss = 1s
Factor de amortiguamiento : ζ =
√√√√√ Ln(Mp)−π
2
1 +Ln(Mp)
−π2
(3.38)
Para el valor de la frecuencia natural se utilizó se hizo uso del mismo criterio de estable-cimiento de 1 % (Ec. 3.29).Al igual para el desarrollo de la igualación de polos para el control por realimentaciónde estados se hace uso de la función place de Matlab, para encontrar las constante.Para encontrar las constante de la matriz L, Matlab recibe como parámetros en la mismafunción A’, C’ y P; Donde A’ es la matriz de estados transpuesta identificada, C’ matrizC identificada y P polinomio deseado del sistema, cabe recordar que tiene que ser 10veces más rápido que el diseño de la planta.Para cada articulación se pueden encontrar un vector de ganancia de realimentación deestado y una ganancia de integrador (al girar en sentido antihorario y horario).A continuación, se muestran las constantes halladas para cada articulación:
Hombro en sentido horario,
L1hombro =[6,0521 38,5674
](3.39)
Hombro en sentido Antihorario,
L0hombro =[−2,8471 −37,8635
](3.40)
Codo en sentido horario,L1codo =
[1,5711 43,8054
](3.41)
Codo en sentido Antihorario,
L0codo =[6,0521 38,5674
](3.42)
61
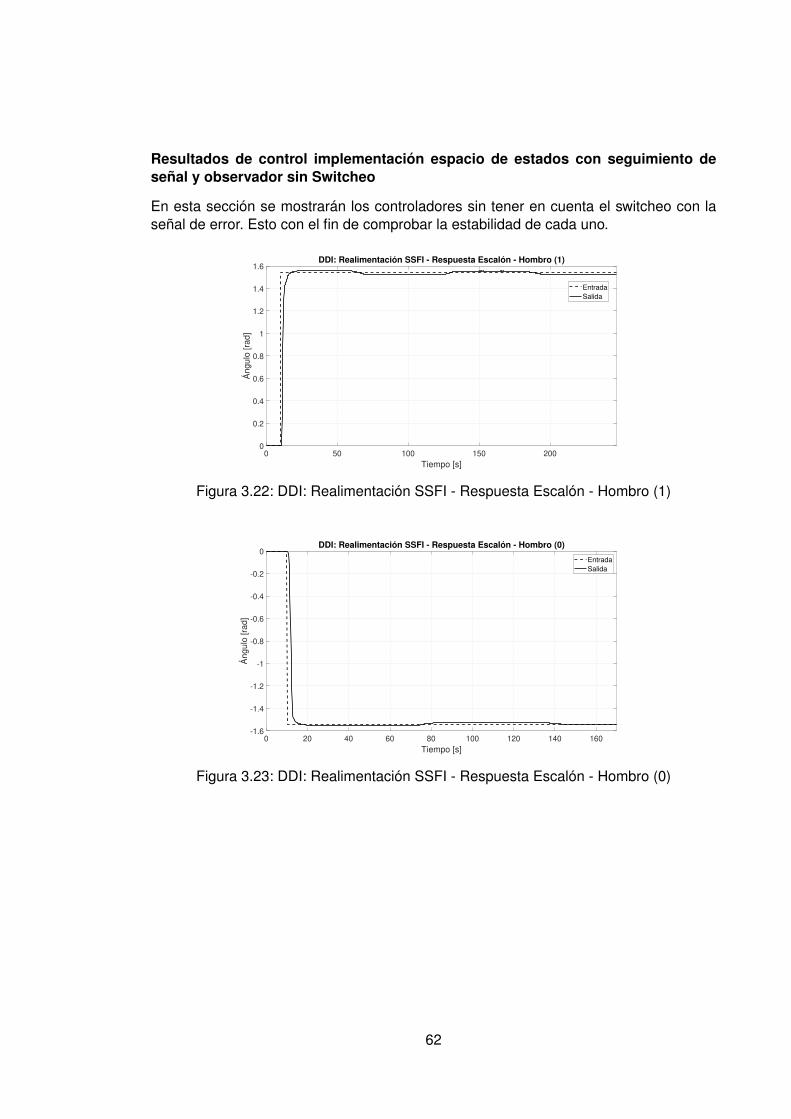
Resultados de control implementación espacio de estados con seguimiento deseñal y observador sin Switcheo
En esta sección se mostrarán los controladores sin tener en cuenta el switcheo con laseñal de error. Esto con el fin de comprobar la estabilidad de cada uno.
0 50 100 150 200Tiempo [s]
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
Áng
ulo
[rad
]
DDI: Realimentación SSFI - Respuesta Escalón - Hombro (1)
EntradaSalida
Figura 3.22: DDI: Realimentación SSFI - Respuesta Escalón - Hombro (1)
0 20 40 60 80 100 120 140 160Tiempo [s]
-1.6
-1.4
-1.2
-1
-0.8
-0.6
-0.4
-0.2
0
Áng
ulo
[rad
]
DDI: Realimentación SSFI - Respuesta Escalón - Hombro (0)
EntradaSalida
Figura 3.23: DDI: Realimentación SSFI - Respuesta Escalón - Hombro (0)
62

0 50 100 150 200Tiempo [s]
-0.2
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
Áng
ulo
[rad
]
DDI: Realimentación SSFI - Respuesta Escalón - Codo (1)
EntradaSalida
Figura 3.24: DDI: Realimentación SSFI - Respuesta Escalón - Codo (1)
0 20 40 60 80 100 120 140 160Tiempo [s]
-1.6
-1.4
-1.2
-1
-0.8
-0.6
-0.4
-0.2
0
0.2
Áng
ulo
[rad
]
DDI: Realimentación SSFI - Respuesta Escalón - Codo (0)
EntradaSalida
Figura 3.25: DDI: Realimentación SSFI - Respuesta Escalón - Codo (0)
Resultados de control de Espacio de estado con seguimiento de señal y observa-dor de orden completo y Switcheo para Hombro en sentido horario
En esta sección se mostrarán los controladores para las entradas deseadas menciona-das en el protocolo de pruebas.
63

0 20 40 60 80 100 120 140 160 180 200Tiempo [s]
0
0.5
1
1.5
2
2.5
Áng
ulo
[rad
]
DDI: Realimentación SSFI - Respuesta Escalón - Hombro (1)
EntradaSalida
(a) DDI: Realimentación SSFI Tradicional - Res-puesta escalón - Hombro (1)
0 20 40 60 80 100 120 140 160 180 200Tiempo [s]
0
0.2
0.4
0.6
0.8
1
Áng
ulo
[rad
]
DDI: Realimentación SSFI - Perturbación - Hombro (1)
Perturbación
(b) DDI: Realimentación SSFI - Perturbación -Hombro (1)
0 20 40 60 80 100 120 140 160 180 200
Tiempo [s]
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
0.8
1
Voltaje
[V
]
DDI: Realimentación SSFI - Esfuerzo de control (Motor) - Hombro (1)
Señal de control
(c) DDI: Realimentación SSFI - Esfuerzo de con-trol (Motor) - Hombro (1)
Figura 3.26: Controlador Realimentación SSFI implementando switcheo Hombro (1)
64
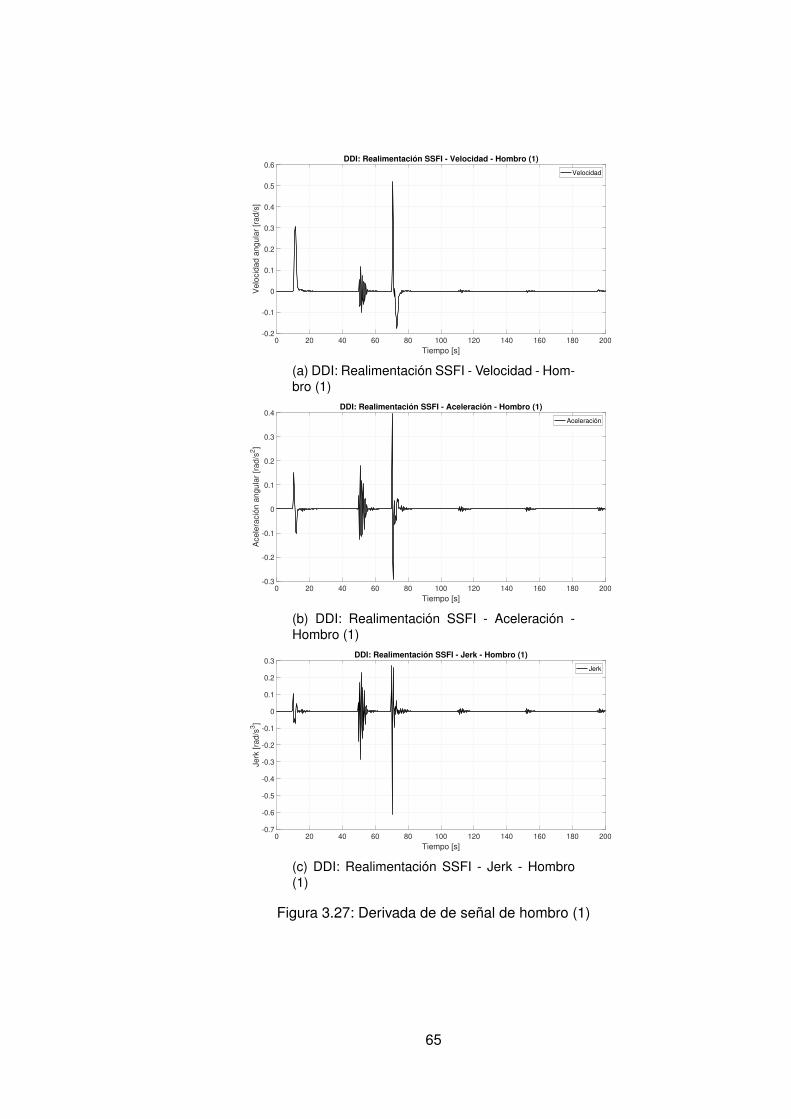
0 20 40 60 80 100 120 140 160 180 200
Tiempo [s]
-0.2
-0.1
0
0.1
0.2
0.3
0.4
0.5
0.6
Velo
cid
ad a
ngula
r [r
ad/s
]
DDI: Realimentación SSFI - Velocidad - Hombro (1)
Velocidad
(a) DDI: Realimentación SSFI - Velocidad - Hom-bro (1)
0 20 40 60 80 100 120 140 160 180 200
Tiempo [s]
-0.3
-0.2
-0.1
0
0.1
0.2
0.3
0.4
Acele
ració
n a
ngula
r [r
ad/s
2]
DDI: Realimentación SSFI - Aceleración - Hombro (1)
Aceleración
(b) DDI: Realimentación SSFI - Aceleración -Hombro (1)
0 20 40 60 80 100 120 140 160 180 200
Tiempo [s]
-0.7
-0.6
-0.5
-0.4
-0.3
-0.2
-0.1
0
0.1
0.2
0.3
Jerk
[ra
d/s
3]
DDI: Realimentación SSFI - Jerk - Hombro (1)
Jerk
(c) DDI: Realimentación SSFI - Jerk - Hombro(1)
Figura 3.27: Derivada de de señal de hombro (1)
65
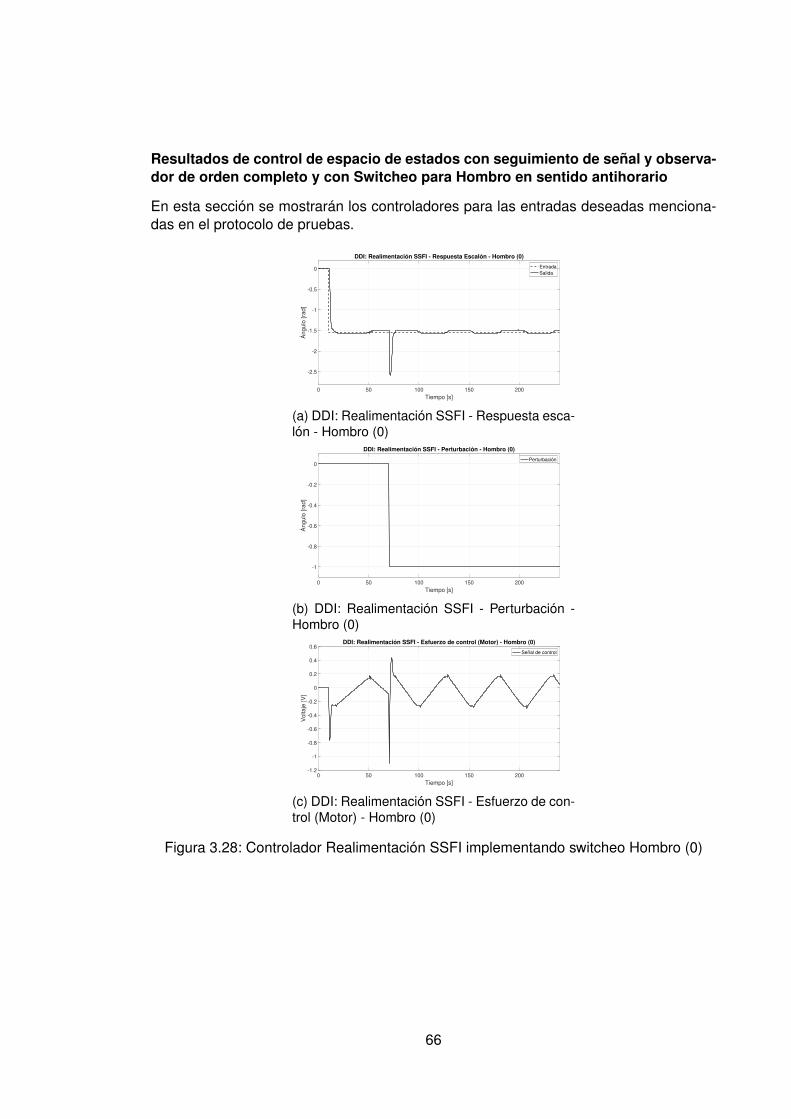
Resultados de control de espacio de estados con seguimiento de señal y observa-dor de orden completo y con Switcheo para Hombro en sentido antihorario
En esta sección se mostrarán los controladores para las entradas deseadas menciona-das en el protocolo de pruebas.
0 50 100 150 200Tiempo [s]
-2.5
-2
-1.5
-1
-0.5
0
Áng
ulo
[rad
]
DDI: Realimentación SSFI - Respuesta Escalón - Hombro (0)
EntradaSalida
(a) DDI: Realimentación SSFI - Respuesta esca-lón - Hombro (0)
0 50 100 150 200Tiempo [s]
-1
-0.8
-0.6
-0.4
-0.2
0
Áng
ulo
[rad
]
DDI: Realimentación SSFI - Perturbación - Hombro (0)
Perturbación
(b) DDI: Realimentación SSFI - Perturbación -Hombro (0)
0 50 100 150 200
Tiempo [s]
-1.2
-1
-0.8
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
Vo
lta
je [
V]
DDI: Realimentación SSFI - Esfuerzo de control (Motor) - Hombro (0)
Señal de control
(c) DDI: Realimentación SSFI - Esfuerzo de con-trol (Motor) - Hombro (0)
Figura 3.28: Controlador Realimentación SSFI implementando switcheo Hombro (0)
66
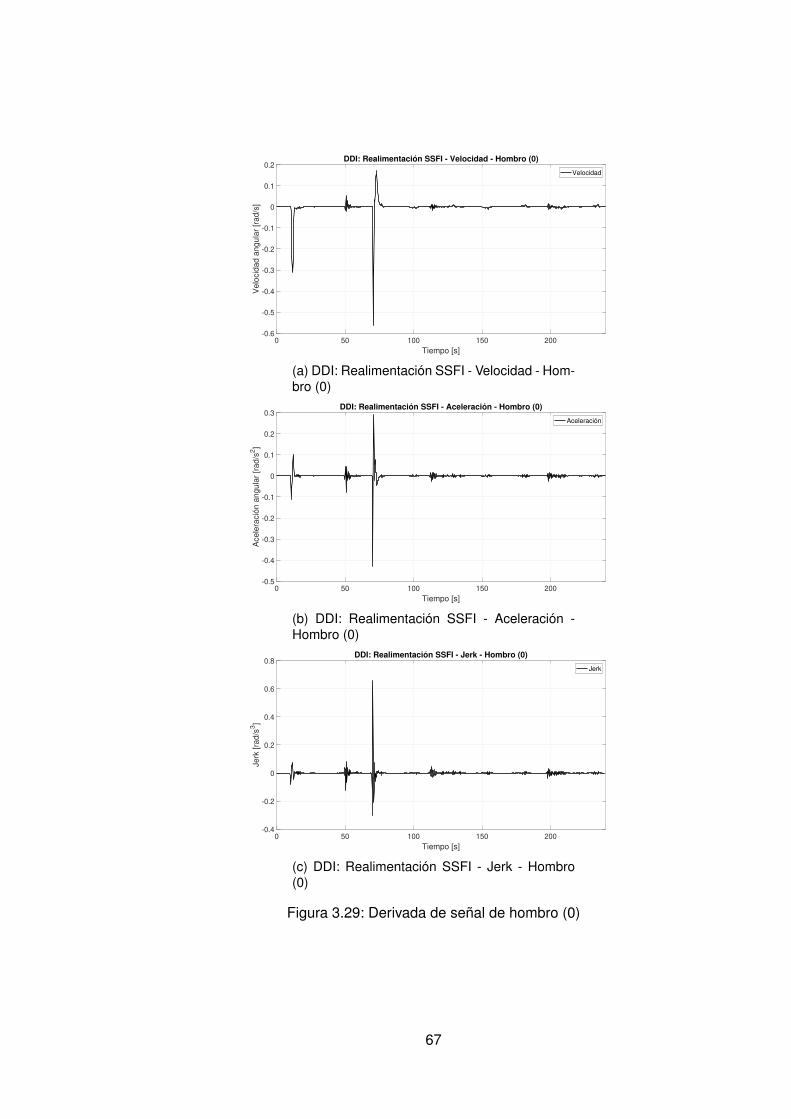
0 50 100 150 200
Tiempo [s]
-0.6
-0.5
-0.4
-0.3
-0.2
-0.1
0
0.1
0.2
Velo
cid
ad a
ngula
r [r
ad/s
]
DDI: Realimentación SSFI - Velocidad - Hombro (0)
Velocidad
(a) DDI: Realimentación SSFI - Velocidad - Hom-bro (0)
0 50 100 150 200
Tiempo [s]
-0.5
-0.4
-0.3
-0.2
-0.1
0
0.1
0.2
0.3
Acele
ració
n a
ngula
r [r
ad/s
2]
DDI: Realimentación SSFI - Aceleración - Hombro (0)
Aceleración
(b) DDI: Realimentación SSFI - Aceleración -Hombro (0)
0 50 100 150 200
Tiempo [s]
-0.4
-0.2
0
0.2
0.4
0.6
0.8
Jerk
[ra
d/s
3]
DDI: Realimentación SSFI - Jerk - Hombro (0)
Jerk
(c) DDI: Realimentación SSFI - Jerk - Hombro(0)
Figura 3.29: Derivada de señal de hombro (0)
67
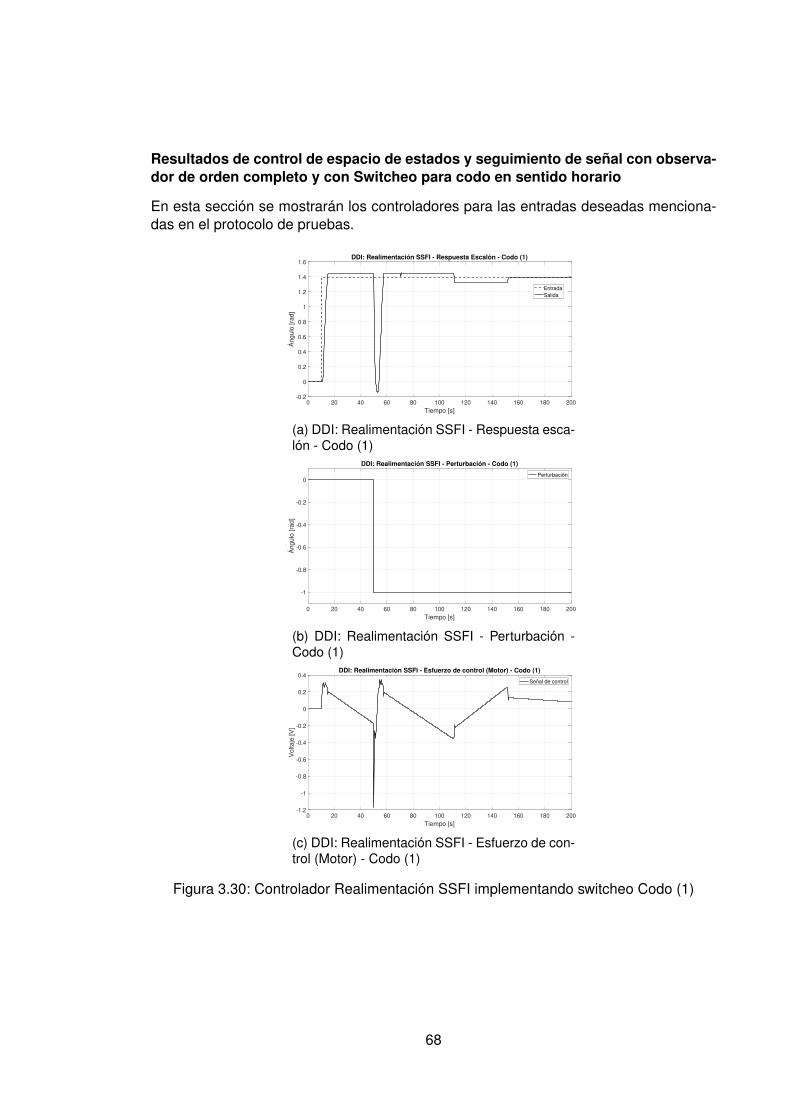
Resultados de control de espacio de estados y seguimiento de señal con observa-dor de orden completo y con Switcheo para codo en sentido horario
En esta sección se mostrarán los controladores para las entradas deseadas menciona-das en el protocolo de pruebas.
0 20 40 60 80 100 120 140 160 180 200Tiempo [s]
-0.2
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
Áng
ulo
[rad
]
DDI: Realimentación SSFI - Respuesta Escalón - Codo (1)
EntradaSalida
(a) DDI: Realimentación SSFI - Respuesta esca-lón - Codo (1)
0 20 40 60 80 100 120 140 160 180 200Tiempo [s]
-1
-0.8
-0.6
-0.4
-0.2
0
Áng
ulo
[rad
]
DDI: Realimentación SSFI - Perturbación - Codo (1)
Perturbación
(b) DDI: Realimentación SSFI - Perturbación -Codo (1)
0 20 40 60 80 100 120 140 160 180 200
Tiempo [s]
-1.2
-1
-0.8
-0.6
-0.4
-0.2
0
0.2
0.4
Voltaje
[V
]
DDI: Realimentación SSFI - Esfuerzo de control (Motor) - Codo (1)
Señal de control
(c) DDI: Realimentación SSFI - Esfuerzo de con-trol (Motor) - Codo (1)
Figura 3.30: Controlador Realimentación SSFI implementando switcheo Codo (1)
68
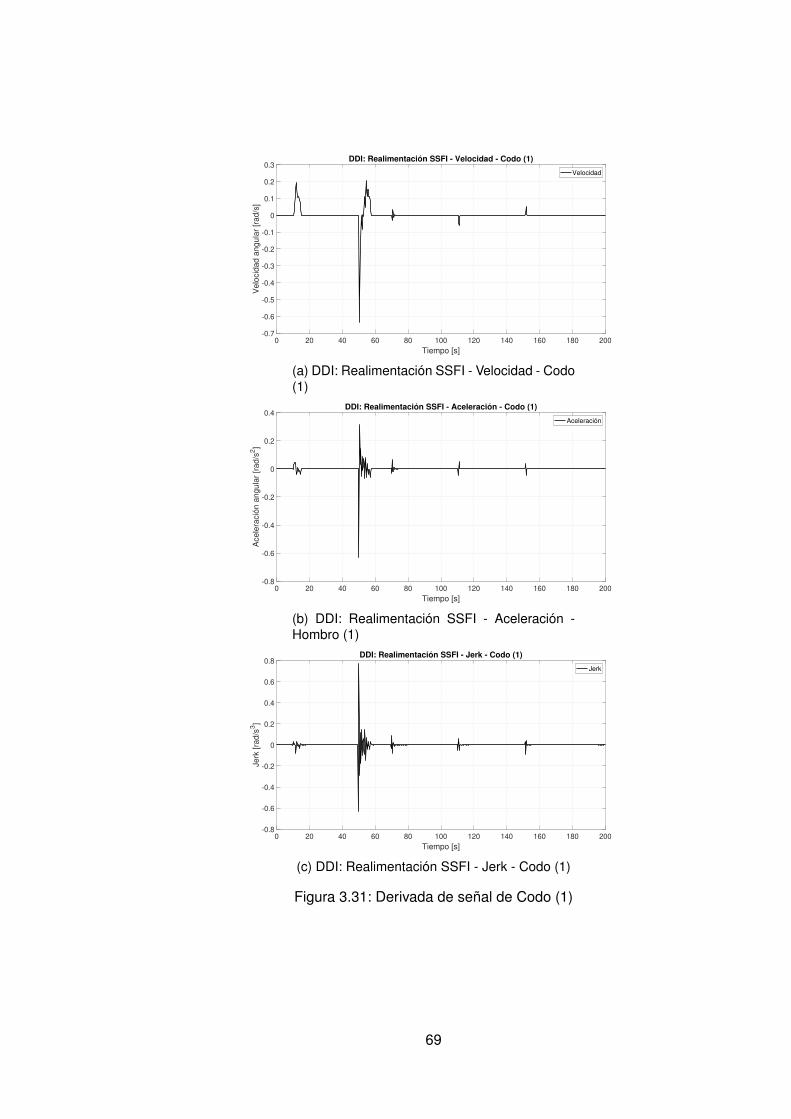
0 20 40 60 80 100 120 140 160 180 200
Tiempo [s]
-0.7
-0.6
-0.5
-0.4
-0.3
-0.2
-0.1
0
0.1
0.2
0.3
Velo
cid
ad a
ngula
r [r
ad/s
]
DDI: Realimentación SSFI - Velocidad - Codo (1)
Velocidad
(a) DDI: Realimentación SSFI - Velocidad - Codo(1)
0 20 40 60 80 100 120 140 160 180 200
Tiempo [s]
-0.8
-0.6
-0.4
-0.2
0
0.2
0.4
Acele
ració
n a
ngula
r [r
ad/s
2]
DDI: Realimentación SSFI - Aceleración - Codo (1)
Aceleración
(b) DDI: Realimentación SSFI - Aceleración -Hombro (1)
0 20 40 60 80 100 120 140 160 180 200
Tiempo [s]
-0.8
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
0.8
Jerk
[ra
d/s
3]
DDI: Realimentación SSFI - Jerk - Codo (1)
Jerk
(c) DDI: Realimentación SSFI - Jerk - Codo (1)
Figura 3.31: Derivada de señal de Codo (1)
69
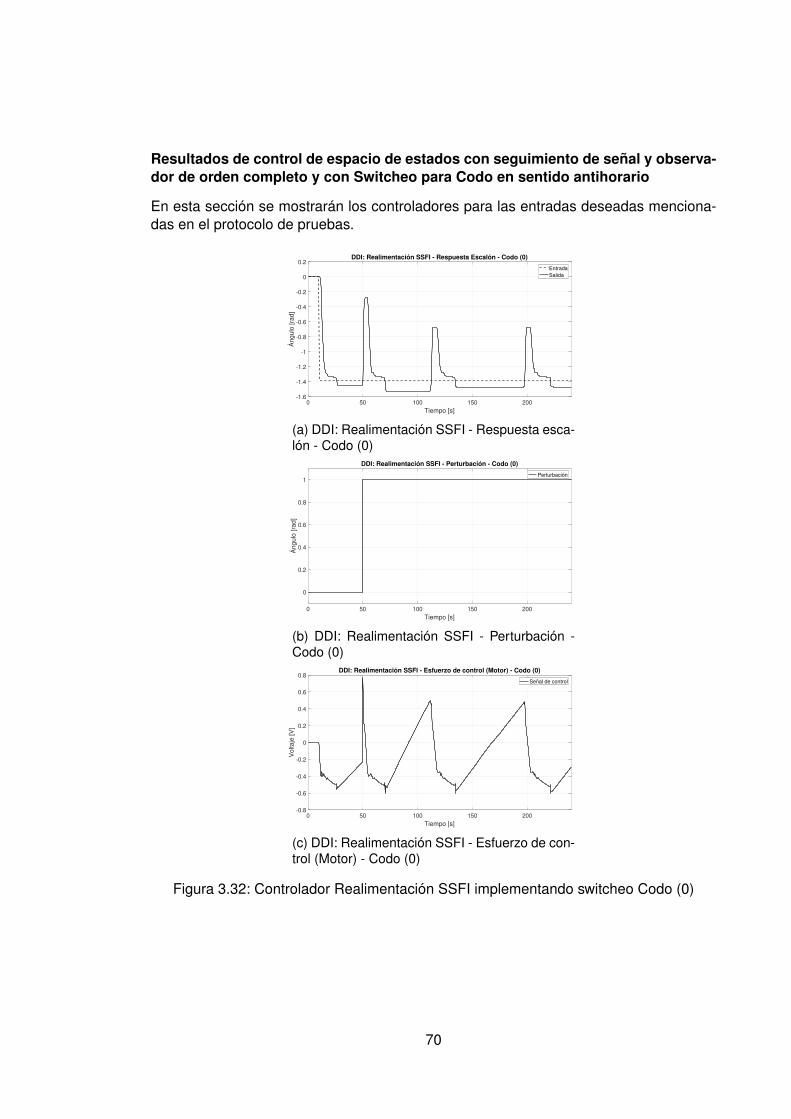
Resultados de control de espacio de estados con seguimiento de señal y observa-dor de orden completo y con Switcheo para Codo en sentido antihorario
En esta sección se mostrarán los controladores para las entradas deseadas menciona-das en el protocolo de pruebas.
0 50 100 150 200Tiempo [s]
-1.6
-1.4
-1.2
-1
-0.8
-0.6
-0.4
-0.2
0
0.2
Áng
ulo
[rad
]
DDI: Realimentación SSFI - Respuesta Escalón - Codo (0)
EntradaSalida
(a) DDI: Realimentación SSFI - Respuesta esca-lón - Codo (0)
0 50 100 150 200Tiempo [s]
0
0.2
0.4
0.6
0.8
1
Áng
ulo
[rad
]
DDI: Realimentación SSFI - Perturbación - Codo (0)
Perturbación
(b) DDI: Realimentación SSFI - Perturbación -Codo (0)
0 50 100 150 200
Tiempo [s]
-0.8
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
0.8
Voltaje
[V
]
DDI: Realimentación SSFI - Esfuerzo de control (Motor) - Codo (0)
Señal de control
(c) DDI: Realimentación SSFI - Esfuerzo de con-trol (Motor) - Codo (0)
Figura 3.32: Controlador Realimentación SSFI implementando switcheo Codo (0)
70
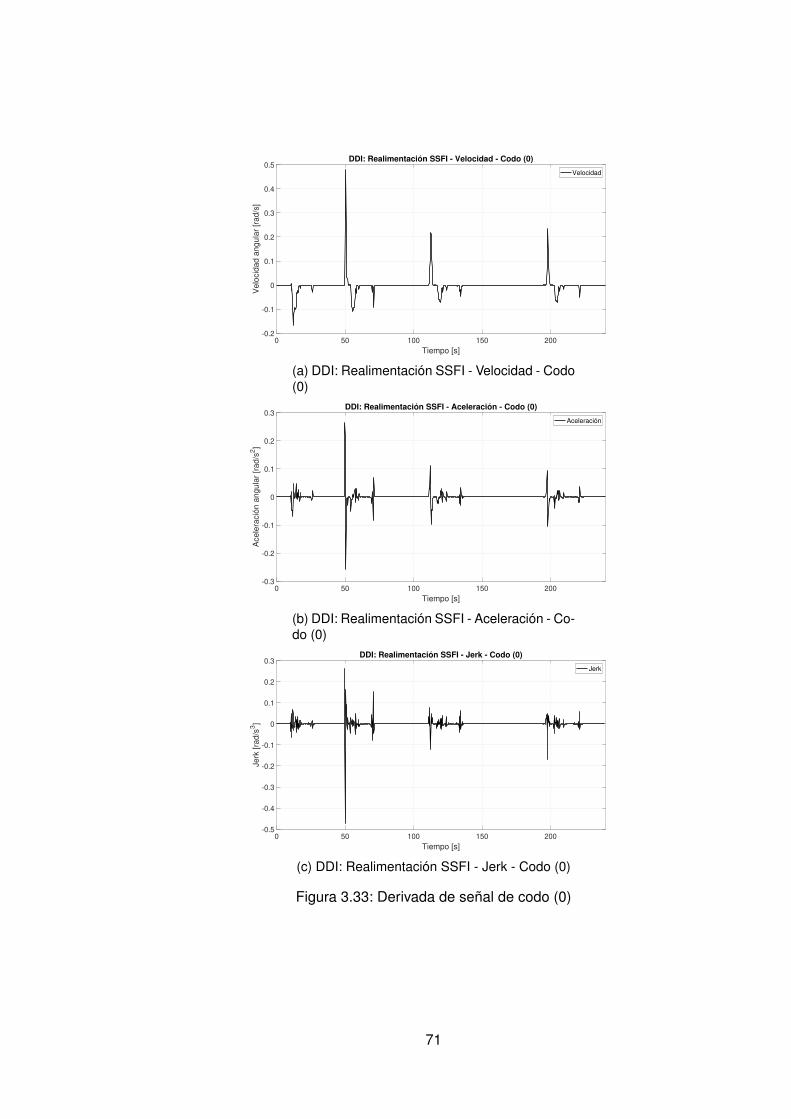
0 50 100 150 200
Tiempo [s]
-0.2
-0.1
0
0.1
0.2
0.3
0.4
0.5
Velo
cid
ad a
ngula
r [r
ad/s
]
DDI: Realimentación SSFI - Velocidad - Codo (0)
Velocidad
(a) DDI: Realimentación SSFI - Velocidad - Codo(0)
0 50 100 150 200
Tiempo [s]
-0.3
-0.2
-0.1
0
0.1
0.2
0.3
Acele
ració
n a
ngula
r [r
ad/s
2]
DDI: Realimentación SSFI - Aceleración - Codo (0)
Aceleración
(b) DDI: Realimentación SSFI - Aceleración - Co-do (0)
0 50 100 150 200
Tiempo [s]
-0.5
-0.4
-0.3
-0.2
-0.1
0
0.1
0.2
0.3
Jerk
[ra
d/s
3]
DDI: Realimentación SSFI - Jerk - Codo (0)
Jerk
(c) DDI: Realimentación SSFI - Jerk - Codo (0)
Figura 3.33: Derivada de señal de codo (0)
71

Resultados de control espacio de estados con seguimiento de señal y observadorde orden completo sin switcheo para el efector final en sentido horario
En esta sección se mostrarán los controladores para las entradas deseadas menciona-das en el protocolo de pruebas.
0 50 100 150 200
Tiempo [s]
-70
-60
-50
-40
-30
-20
-10
0
10
20
30P
osic
ión
[cm
]
DDI: Realimentación SSFI - Posición X (1)
Posición X
(a) DDI: Realimentación SSFI - Posición X (1) sin switcheo
0 50 100 150 200
Tiempo [s]
0
10
20
30
40
50
Po
sic
ión
[cm
]
DDI: Realimentación SSFI - Posición Y (1)
Posición Y
(b) DDI: Realimentación SSFI - Posición Y (1) sin switcheo
-70 -60 -50 -40 -30 -20 -10 0 10 20 30
Posición X [cm]
0
10
20
30
40
50
60
Po
sic
ión
Y [
cm
]
DDI: Realimentación SSFI - Posición X vs Y
Posición X vs Y
(c) DDI: Realimentación SSFI - Posición X y Y (1) sin Switcheo
Figura 3.34: DDI: Realimentación SSFI - Posición X vs Y (1) sin switcheo
72
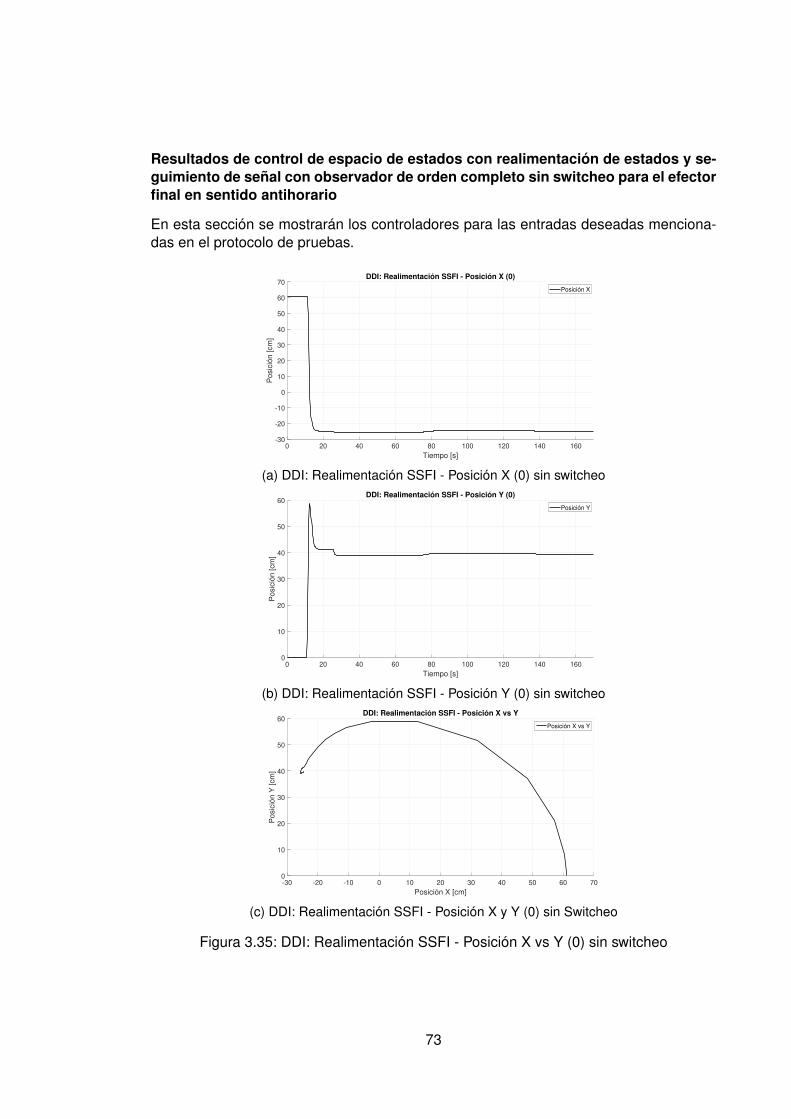
Resultados de control de espacio de estados con realimentación de estados y se-guimiento de señal con observador de orden completo sin switcheo para el efectorfinal en sentido antihorario
En esta sección se mostrarán los controladores para las entradas deseadas menciona-das en el protocolo de pruebas.
0 20 40 60 80 100 120 140 160
Tiempo [s]
-30
-20
-10
0
10
20
30
40
50
60
70
Po
sic
ión
[cm
]DDI: Realimentación SSFI - Posición X (0)
Posición X
(a) DDI: Realimentación SSFI - Posición X (0) sin switcheo
0 20 40 60 80 100 120 140 160
Tiempo [s]
0
10
20
30
40
50
60
Po
sic
ión
[cm
]
DDI: Realimentación SSFI - Posición Y (0)
Posición Y
(b) DDI: Realimentación SSFI - Posición Y (0) sin switcheo
-30 -20 -10 0 10 20 30 40 50 60 70
Posición X [cm]
0
10
20
30
40
50
60
Po
sic
ión
Y [
cm
]
DDI: Realimentación SSFI - Posición X vs Y
Posición X vs Y
(c) DDI: Realimentación SSFI - Posición X y Y (0) sin Switcheo
Figura 3.35: DDI: Realimentación SSFI - Posición X vs Y (0) sin switcheo
73
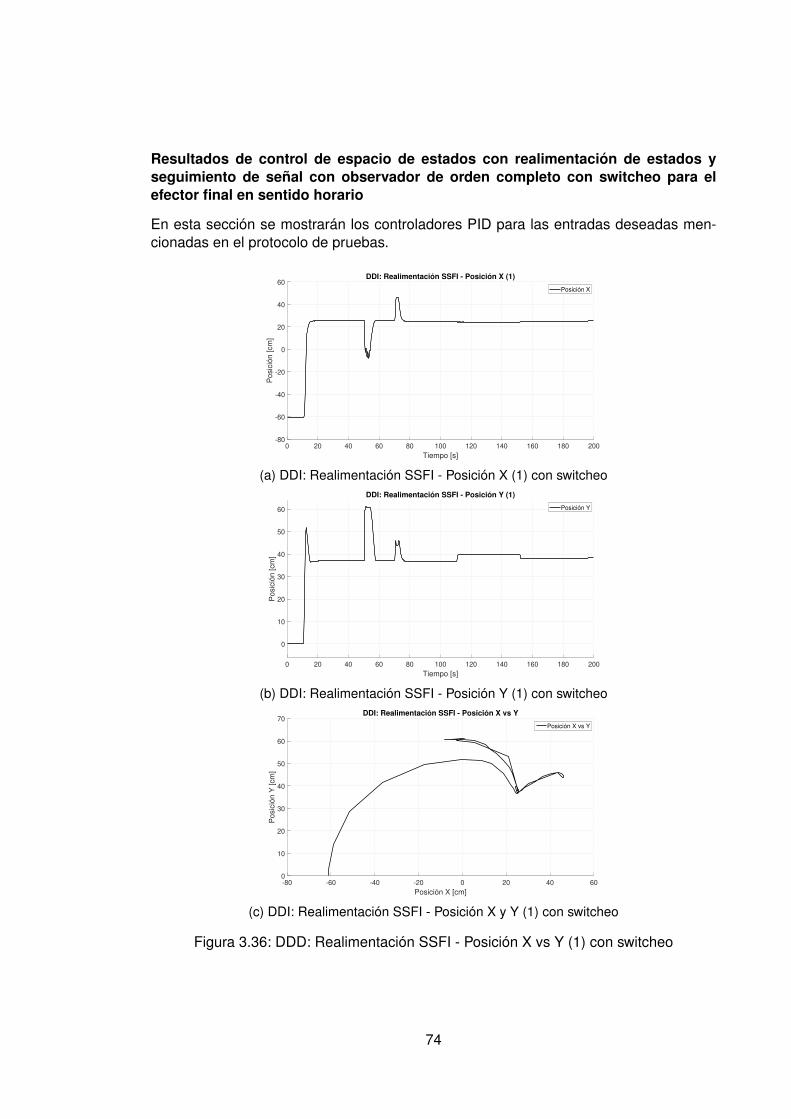
Resultados de control de espacio de estados con realimentación de estados yseguimiento de señal con observador de orden completo con switcheo para elefector final en sentido horario
En esta sección se mostrarán los controladores PID para las entradas deseadas men-cionadas en el protocolo de pruebas.
0 20 40 60 80 100 120 140 160 180 200
Tiempo [s]
-80
-60
-40
-20
0
20
40
60
Po
sic
ión
[cm
]DDI: Realimentación SSFI - Posición X (1)
Posición X
(a) DDI: Realimentación SSFI - Posición X (1) con switcheo
0 20 40 60 80 100 120 140 160 180 200
Tiempo [s]
0
10
20
30
40
50
60
Po
sic
ión
[cm
]
DDI: Realimentación SSFI - Posición Y (1)
Posición Y
(b) DDI: Realimentación SSFI - Posición Y (1) con switcheo
-80 -60 -40 -20 0 20 40 60
Posición X [cm]
0
10
20
30
40
50
60
70
Po
sic
ión
Y [
cm
]
DDI: Realimentación SSFI - Posición X vs Y
Posición X vs Y
(c) DDI: Realimentación SSFI - Posición X y Y (1) con switcheo
Figura 3.36: DDD: Realimentación SSFI - Posición X vs Y (1) con switcheo
74
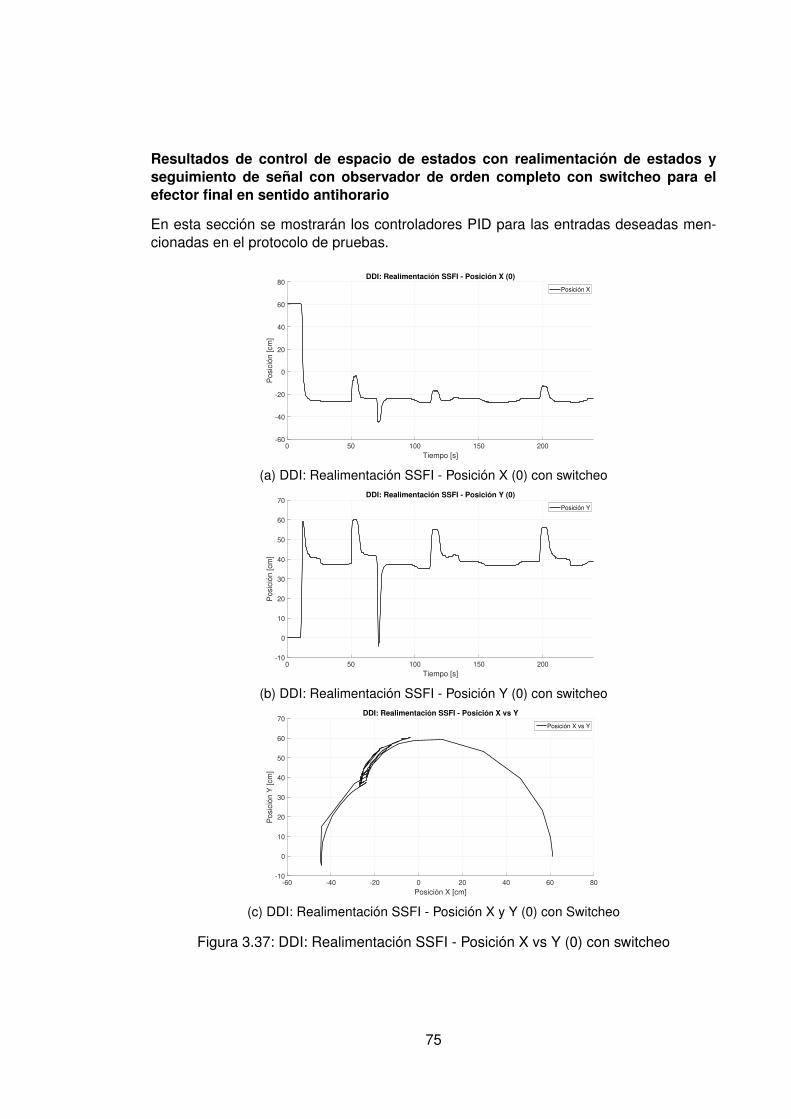
Resultados de control de espacio de estados con realimentación de estados yseguimiento de señal con observador de orden completo con switcheo para elefector final en sentido antihorario
En esta sección se mostrarán los controladores PID para las entradas deseadas men-cionadas en el protocolo de pruebas.
0 50 100 150 200
Tiempo [s]
-60
-40
-20
0
20
40
60
80
Po
sic
ión
[cm
]DDI: Realimentación SSFI - Posición X (0)
Posición X
(a) DDI: Realimentación SSFI - Posición X (0) con switcheo
0 50 100 150 200
Tiempo [s]
-10
0
10
20
30
40
50
60
70
Po
sic
ión
[cm
]
DDI: Realimentación SSFI - Posición Y (0)
Posición Y
(b) DDI: Realimentación SSFI - Posición Y (0) con switcheo
-60 -40 -20 0 20 40 60 80
Posición X [cm]
-10
0
10
20
30
40
50
60
70
Po
sic
ión
Y [
cm
]
DDI: Realimentación SSFI - Posición X vs Y
Posición X vs Y
(c) DDI: Realimentación SSFI - Posición X y Y (0) con Switcheo
Figura 3.37: DDI: Realimentación SSFI - Posición X vs Y (0) con switcheo
75

3.4. Control Data-Driven Directo
Se implementaron controladores PID Neuronal y Base Radial descritos en la sección demetodología.
3.4.1. Control PID Neuronal
El controlador PID neuronal se propone como uno de los controladores data-driven di-rectos. Al mapear datos en sentido antihorario y horario directamente en el diseño delcontrolador, se obtiene un solo controlador por articulación, a pesar de que los datosexperimentales mostraron que el sistema se comporta como un modelo híbrido con dosfunciones de transferencia lineal por articulación.
Una de las ventajas de aplicación de este tipo de controlador es el uso de señales deerror, donde se encuentran la constante integral del error, el error proporcional y el errorderivado.
Para establecer el alfa de aprendizaje (αL) y el alfa de control (αC) del controlador, sellevaron a cabo experimentos con siete configuraciones de PID neuronales diferentes.De manera similar, la comparación experimental de las siete configuraciones de PID serealiza trazando la posición X contra la posición Y para el efector final y perturbando elefector final.
La tabla 3.1 y la tabla 3.2, resumen el efecto de la selección de αL y αC en el desempeñodel controlador para las coordenadas X e Y.
Tabla 3.1: Posición X - PID Neuronal
PID αL αC tss [s] %OS %e_ss1 0.001 0.04 5 0 1.642 0.002 0.05 2.3 3.68 2.323 0.001 0.04 4.7 0 3.084 0.002 0.02 7.7 0 3.25 0.004 0.02 6.5 0 2.886 0.004 - 0.009 0.02 6.5 0 2.167 0.009 0.03 4.1 0 3.24
Tabla 3.2: Posición Y - PID Neuronal
PID αL αC tss [s] %OS %e_ss1 0.001 0.04 7.4 21.1 1.932 0.002 0.05 5 5.85 0.933 0.001 0.04 3.8 5.75 2.254 0.002 0.02 7.4 26.4 3.355 0.004 0.02 6.8 21.35 0.386 0.004 - 0.009 0.02 6.5 24.66 0.57 0.009 0.03 5.9 14.2 1.35
76
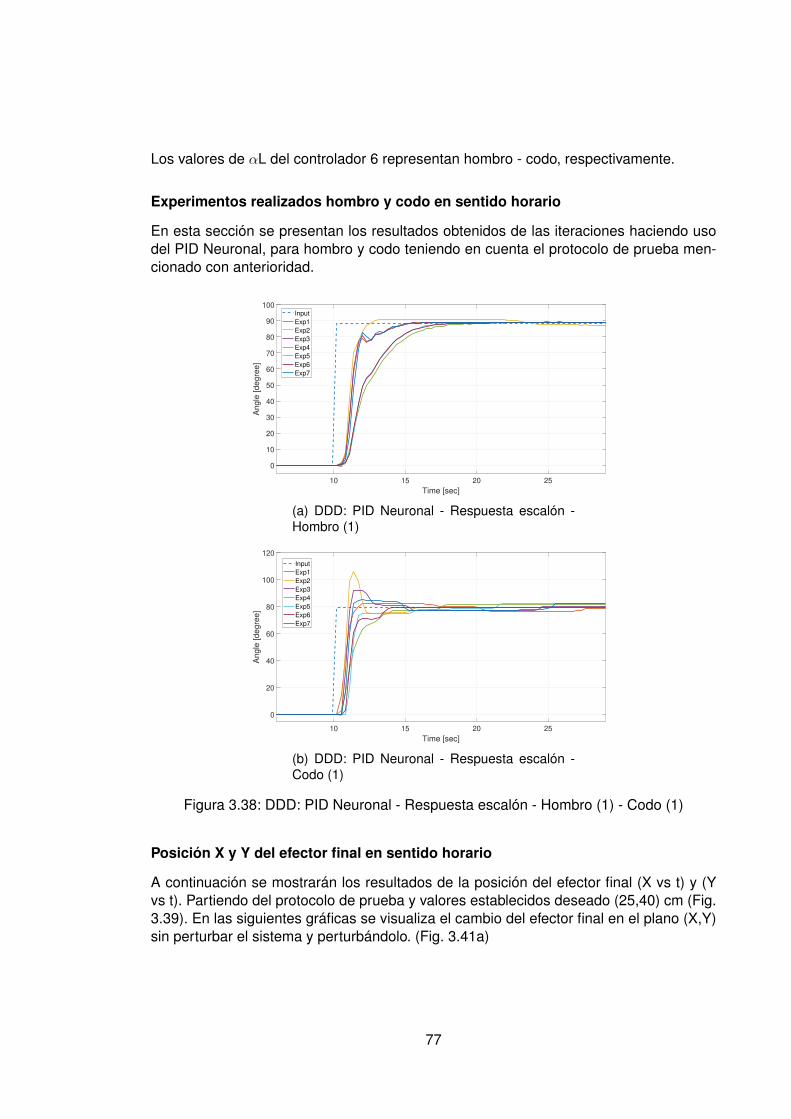
Los valores de αL del controlador 6 representan hombro - codo, respectivamente.
Experimentos realizados hombro y codo en sentido horario
En esta sección se presentan los resultados obtenidos de las iteraciones haciendo usodel PID Neuronal, para hombro y codo teniendo en cuenta el protocolo de prueba men-cionado con anterioridad.
10 15 20 25
Time [sec]
0
10
20
30
40
50
60
70
80
90
100
Angle
[degre
e]
Input
Exp1
Exp2
Exp3
Exp4
Exp5
Exp6
Exp7
(a) DDD: PID Neuronal - Respuesta escalón -Hombro (1)
10 15 20 25
Time [sec]
0
20
40
60
80
100
120
Angle
[degre
e]
Input
Exp1
Exp2
Exp3
Exp4
Exp5
Exp6
Exp7
(b) DDD: PID Neuronal - Respuesta escalón -Codo (1)
Figura 3.38: DDD: PID Neuronal - Respuesta escalón - Hombro (1) - Codo (1)
Posición X y Y del efector final en sentido horario
A continuación se mostrarán los resultados de la posición del efector final (X vs t) y (Yvs t). Partiendo del protocolo de prueba y valores establecidos deseado (25,40) cm (Fig.3.39). En las siguientes gráficas se visualiza el cambio del efector final en el plano (X,Y)sin perturbar el sistema y perturbándolo. (Fig. 3.41a)
77
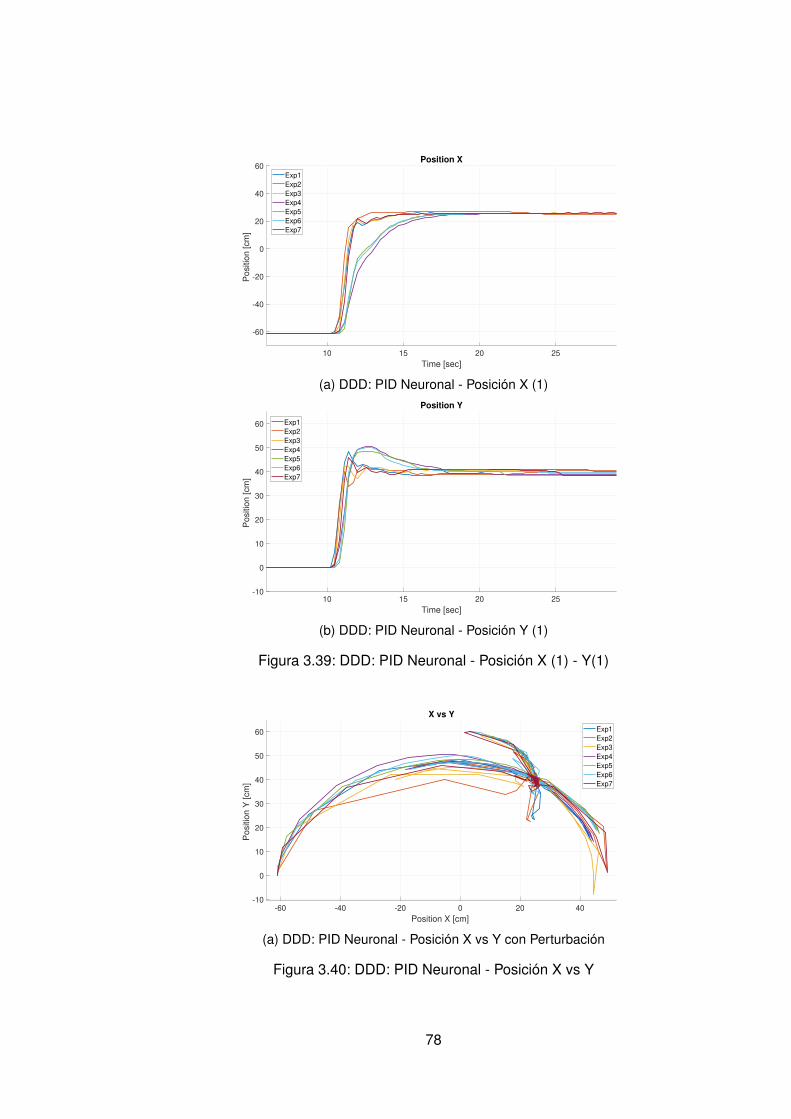
10 15 20 25
Time [sec]
-60
-40
-20
0
20
40
60
Positio
n [cm
]
Position X
Exp1
Exp2
Exp3
Exp4
Exp5
Exp6
Exp7
(a) DDD: PID Neuronal - Posición X (1)
10 15 20 25
Time [sec]
-10
0
10
20
30
40
50
60
Positio
n [cm
]
Position Y
Exp1
Exp2
Exp3
Exp4
Exp5
Exp6
Exp7
(b) DDD: PID Neuronal - Posición Y (1)
Figura 3.39: DDD: PID Neuronal - Posición X (1) - Y(1)
-60 -40 -20 0 20 40
Position X [cm]
-10
0
10
20
30
40
50
60
Positio
n Y
[cm
]
X vs Y
Exp1
Exp2
Exp3
Exp4
Exp5
Exp6
Exp7
(a) DDD: PID Neuronal - Posición X vs Y con Perturbación
Figura 3.40: DDD: PID Neuronal - Posición X vs Y
78
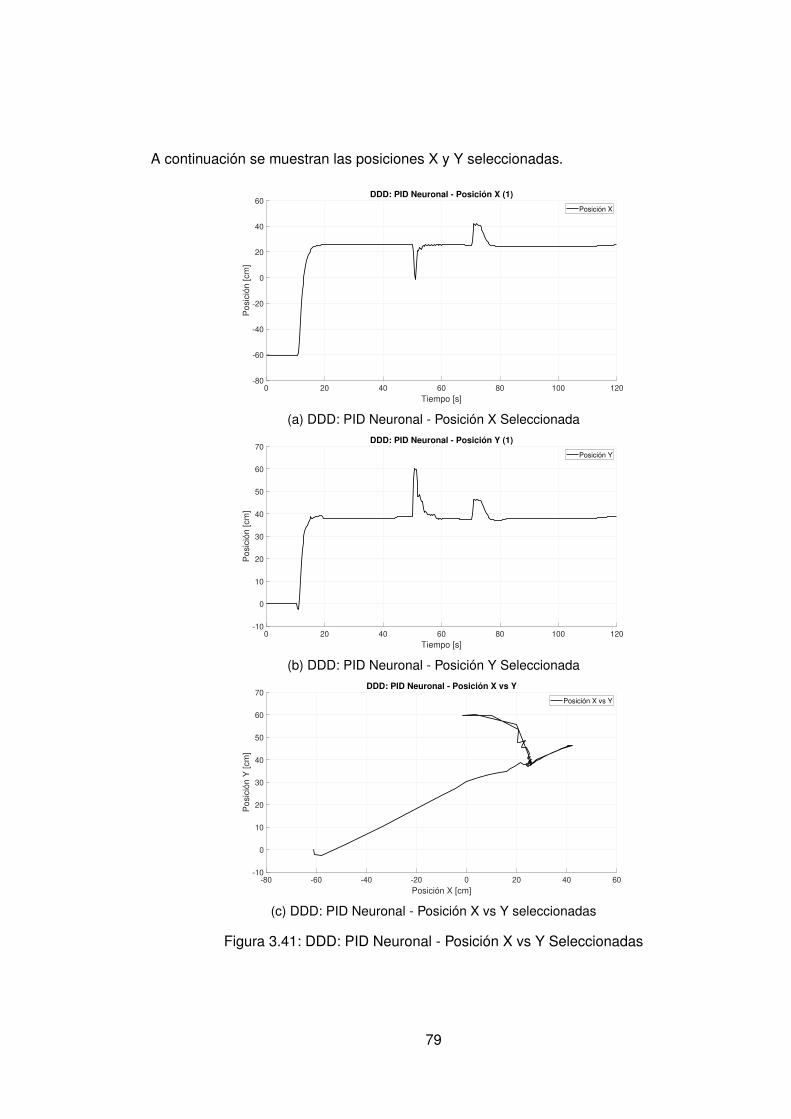
A continuación se muestran las posiciones X y Y seleccionadas.
0 20 40 60 80 100 120
Tiempo [s]
-80
-60
-40
-20
0
20
40
60
Posic
ión [cm
]
DDD: PID Neuronal - Posición X (1)
Posición X
(a) DDD: PID Neuronal - Posición X Seleccionada
0 20 40 60 80 100 120
Tiempo [s]
-10
0
10
20
30
40
50
60
70
Posic
ión [cm
]
DDD: PID Neuronal - Posición Y (1)
Posición Y
(b) DDD: PID Neuronal - Posición Y Seleccionada
-80 -60 -40 -20 0 20 40 60
Posición X [cm]
-10
0
10
20
30
40
50
60
70
Posic
ión Y
[cm
]
DDD: PID Neuronal - Posición X vs Y
Posición X vs Y
(c) DDD: PID Neuronal - Posición X vs Y seleccionadas
Figura 3.41: DDD: PID Neuronal - Posición X vs Y Seleccionadas
79
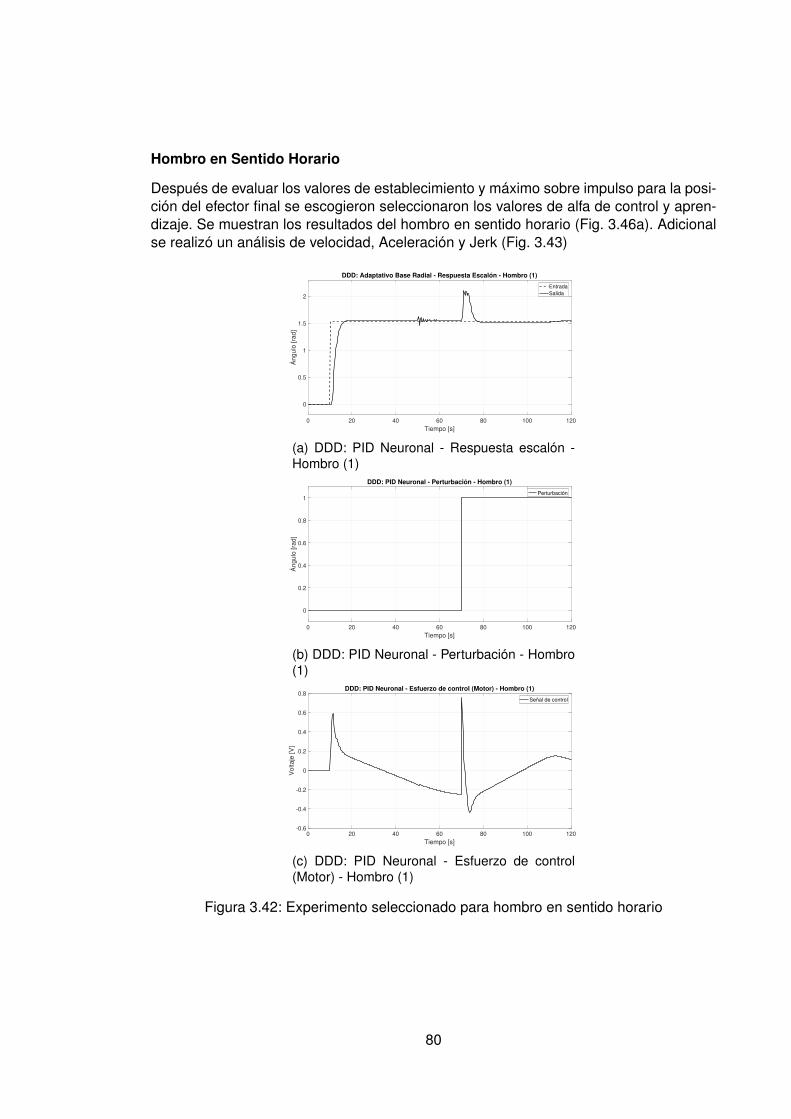
Hombro en Sentido Horario
Después de evaluar los valores de establecimiento y máximo sobre impulso para la posi-ción del efector final se escogieron seleccionaron los valores de alfa de control y apren-dizaje. Se muestran los resultados del hombro en sentido horario (Fig. 3.46a). Adicionalse realizó un análisis de velocidad, Aceleración y Jerk (Fig. 3.43)
0 20 40 60 80 100 120Tiempo [s]
0
0.5
1
1.5
2Á
ngul
o [r
ad]
DDD: Adaptativo Base Radial - Respuesta Escalón - Hombro (1)
EntradaSalida
(a) DDD: PID Neuronal - Respuesta escalón -Hombro (1)
0 20 40 60 80 100 120Tiempo [s]
0
0.2
0.4
0.6
0.8
1
Áng
ulo
[rad
]
DDD: PID Neuronal - Perturbación - Hombro (1)
Perturbación
(b) DDD: PID Neuronal - Perturbación - Hombro(1)
0 20 40 60 80 100 120
Tiempo [s]
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
0.8
Voltaje
[V
]
DDD: PID Neuronal - Esfuerzo de control (Motor) - Hombro (1)
Señal de control
(c) DDD: PID Neuronal - Esfuerzo de control(Motor) - Hombro (1)
Figura 3.42: Experimento seleccionado para hombro en sentido horario
80
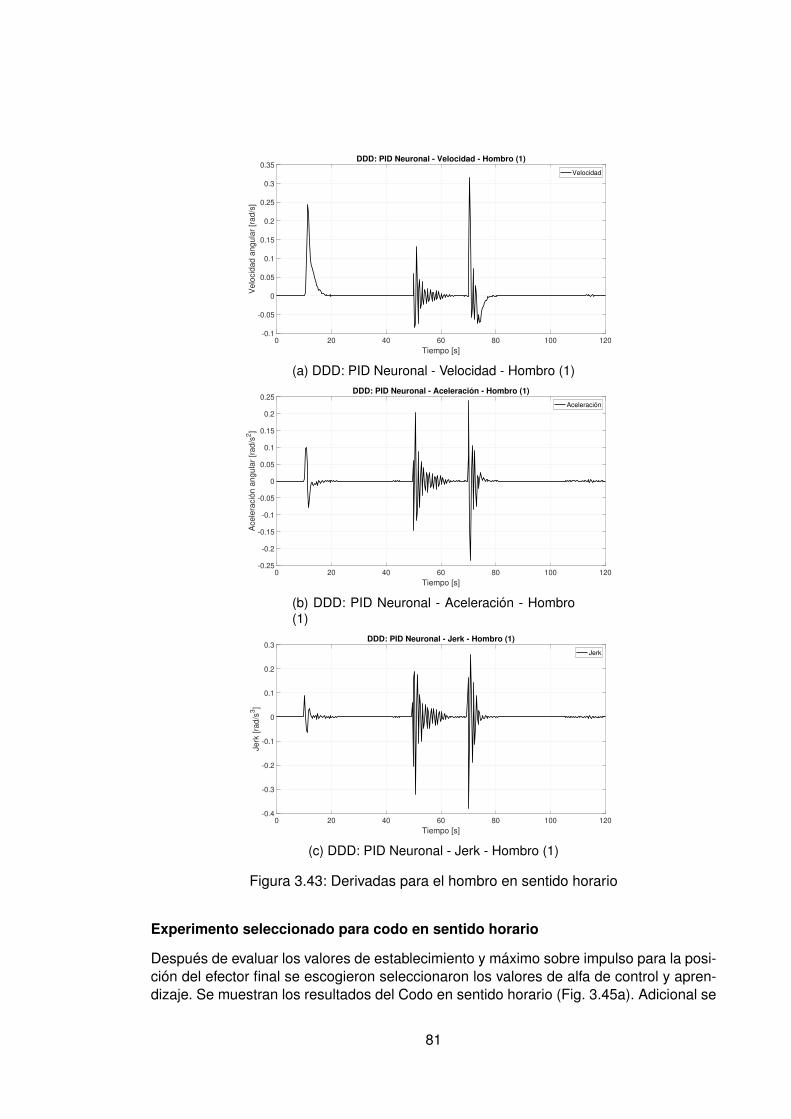
0 20 40 60 80 100 120
Tiempo [s]
-0.1
-0.05
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
Velo
cid
ad a
ngula
r [r
ad/s
]
DDD: PID Neuronal - Velocidad - Hombro (1)
Velocidad
(a) DDD: PID Neuronal - Velocidad - Hombro (1)
0 20 40 60 80 100 120
Tiempo [s]
-0.25
-0.2
-0.15
-0.1
-0.05
0
0.05
0.1
0.15
0.2
0.25
Acele
ració
n a
ngula
r [r
ad/s
2]
DDD: PID Neuronal - Aceleración - Hombro (1)
Aceleración
(b) DDD: PID Neuronal - Aceleración - Hombro(1)
0 20 40 60 80 100 120
Tiempo [s]
-0.4
-0.3
-0.2
-0.1
0
0.1
0.2
0.3
Jerk
[ra
d/s
3]
DDD: PID Neuronal - Jerk - Hombro (1)
Jerk
(c) DDD: PID Neuronal - Jerk - Hombro (1)
Figura 3.43: Derivadas para el hombro en sentido horario
Experimento seleccionado para codo en sentido horario
Después de evaluar los valores de establecimiento y máximo sobre impulso para la posi-ción del efector final se escogieron seleccionaron los valores de alfa de control y apren-dizaje. Se muestran los resultados del Codo en sentido horario (Fig. 3.45a). Adicional se
81
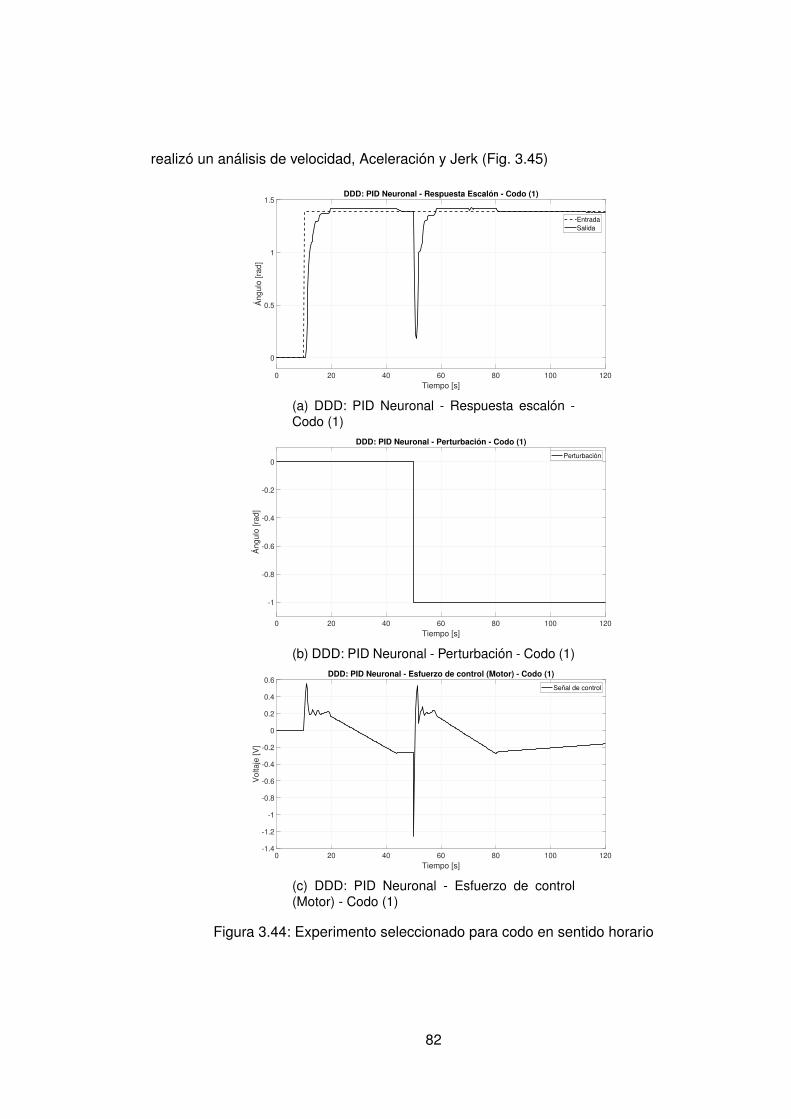
realizó un análisis de velocidad, Aceleración y Jerk (Fig. 3.45)
0 20 40 60 80 100 120Tiempo [s]
0
0.5
1
1.5
Áng
ulo
[rad
]
DDD: PID Neuronal - Respuesta Escalón - Codo (1)
EntradaSalida
(a) DDD: PID Neuronal - Respuesta escalón -Codo (1)
0 20 40 60 80 100 120Tiempo [s]
-1
-0.8
-0.6
-0.4
-0.2
0
Áng
ulo
[rad
]
DDD: PID Neuronal - Perturbación - Codo (1)
Perturbación
(b) DDD: PID Neuronal - Perturbación - Codo (1)
0 20 40 60 80 100 120
Tiempo [s]
-1.4
-1.2
-1
-0.8
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
Voltaje
[V
]
DDD: PID Neuronal - Esfuerzo de control (Motor) - Codo (1)
Señal de control
(c) DDD: PID Neuronal - Esfuerzo de control(Motor) - Codo (1)
Figura 3.44: Experimento seleccionado para codo en sentido horario
82
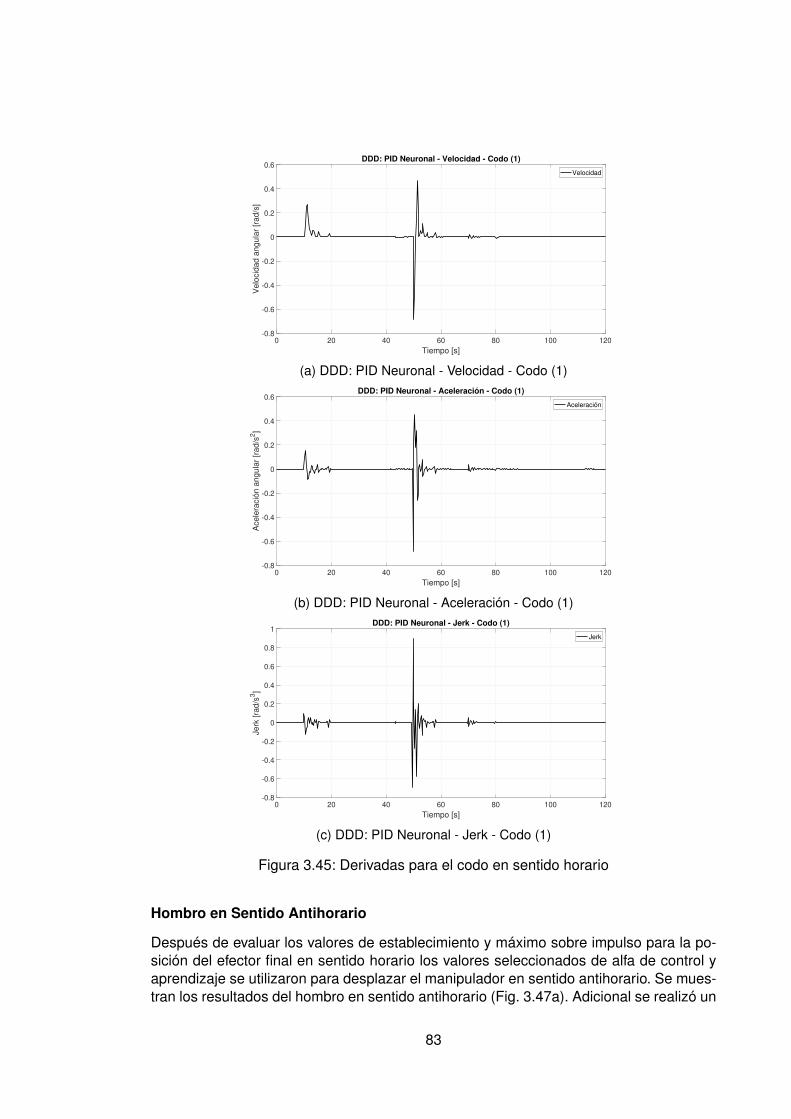
0 20 40 60 80 100 120
Tiempo [s]
-0.8
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
Velo
cid
ad a
ngula
r [r
ad/s
]
DDD: PID Neuronal - Velocidad - Codo (1)
Velocidad
(a) DDD: PID Neuronal - Velocidad - Codo (1)
0 20 40 60 80 100 120
Tiempo [s]
-0.8
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
Acele
ració
n a
ngula
r [r
ad/s
2]
DDD: PID Neuronal - Aceleración - Codo (1)
Aceleración
(b) DDD: PID Neuronal - Aceleración - Codo (1)
0 20 40 60 80 100 120
Tiempo [s]
-0.8
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
0.8
1
Jerk
[ra
d/s
3]
DDD: PID Neuronal - Jerk - Codo (1)
Jerk
(c) DDD: PID Neuronal - Jerk - Codo (1)
Figura 3.45: Derivadas para el codo en sentido horario
Hombro en Sentido Antihorario
Después de evaluar los valores de establecimiento y máximo sobre impulso para la po-sición del efector final en sentido horario los valores seleccionados de alfa de control yaprendizaje se utilizaron para desplazar el manipulador en sentido antihorario. Se mues-tran los resultados del hombro en sentido antihorario (Fig. 3.47a). Adicional se realizó un
83
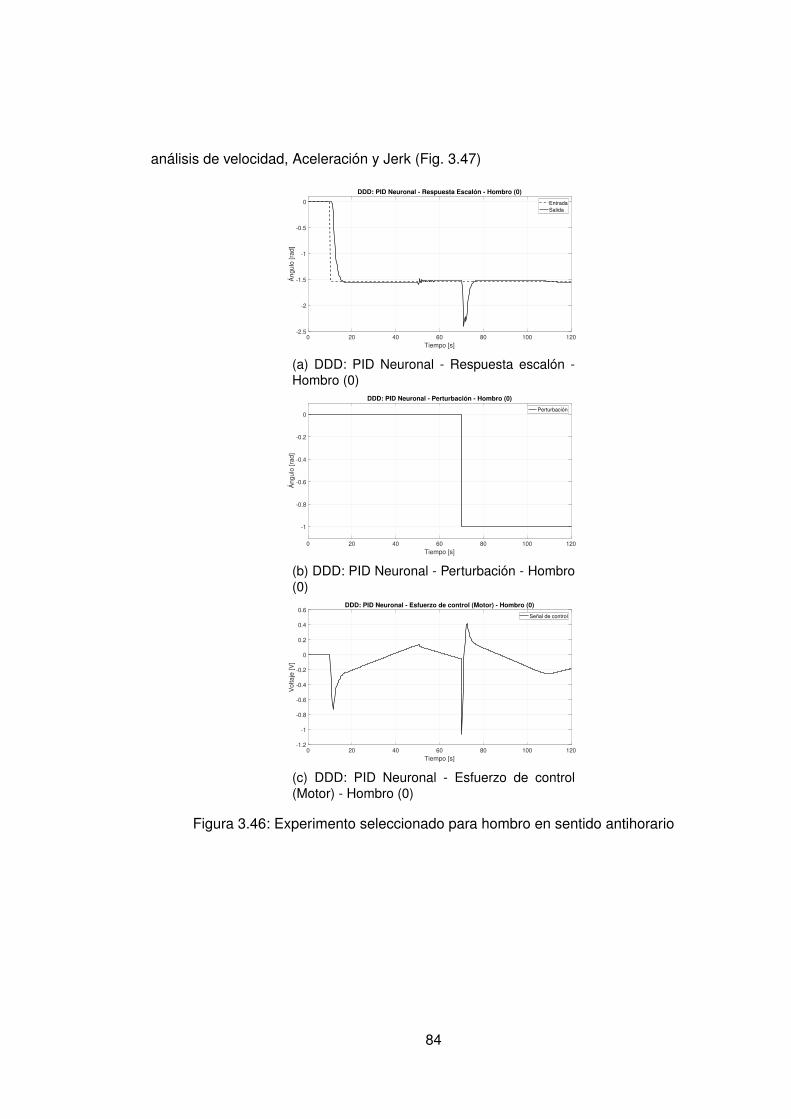
análisis de velocidad, Aceleración y Jerk (Fig. 3.47)
0 20 40 60 80 100 120Tiempo [s]
-2.5
-2
-1.5
-1
-0.5
0
Áng
ulo
[rad
]
DDD: PID Neuronal - Respuesta Escalón - Hombro (0)
EntradaSalida
(a) DDD: PID Neuronal - Respuesta escalón -Hombro (0)
0 20 40 60 80 100 120Tiempo [s]
-1
-0.8
-0.6
-0.4
-0.2
0
Áng
ulo
[rad
]
DDD: PID Neuronal - Perturbación - Hombro (0)
Perturbación
(b) DDD: PID Neuronal - Perturbación - Hombro(0)
0 20 40 60 80 100 120
Tiempo [s]
-1.2
-1
-0.8
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
Voltaje
[V
]
DDD: PID Neuronal - Esfuerzo de control (Motor) - Hombro (0)
Señal de control
(c) DDD: PID Neuronal - Esfuerzo de control(Motor) - Hombro (0)
Figura 3.46: Experimento seleccionado para hombro en sentido antihorario
84

20 40 60 80 100 120
Tiempo [s]
-0.5
-0.4
-0.3
-0.2
-0.1
0
0.1
Velo
cid
ad a
ngula
r [r
ad/s
]
DDD: PID Neuronal - Velocidad - Hombro (0)
Velocidad
(a) DDD: PID Neuronal - Velocidad - Hombro (0)
0 20 40 60 80 100 120
Tiempo [s]
-0.4
-0.3
-0.2
-0.1
0
0.1
0.2
0.3
0.4
Acele
ració
n a
ngula
r [r
ad/s
2]
DDD: PID Neuronal - Aceleración - Hombro (0)
Aceleración
(b) DDD: PID Neuronal - Aceleración - Hombro(0)
0 20 40 60 80 100 120
Tiempo [s]
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
0.8
Jerk
[ra
d/s
3]
DDD: PID Neuronal - Jerk - Hombro (0)
Jerk
(c) DDD: PID Neuronal - Jerk - Hombro (0)
Figura 3.47: Derivadas para el hombro en sentido horario
Experimento seleccionado para codo en sentido antihorario
Después de evaluar los valores de establecimiento y máximo sobre impulso para la posi-ción del efector final se escogieron seleccionaron los valores de alfa de control y apren-dizaje. Se muestran los resultados del Codo en sentido horario (Fig. 3.49a). Adicional se
85

realizó un análisis de velocidad, Aceleración y Jerk (Fig. 3.45)
0 20 40 60 80 100 120Tiempo [s]
-1.5
-1
-0.5
0
Áng
ulo
[rad
]
DDD: PID Neuronal - Respuesta Escalón - Codo (0)
EntradaSalida
(a) DDD: PID Neuronal - Respuesta escalón -Codo (0)
0 20 40 60 80 100 120Tiempo [s]
0
0.2
0.4
0.6
0.8
1
Áng
ulo
[rad
]
DDD: PID Neuronal - Perturbación - Codo (0)
Perturbación
(b) DDD: PID Neuronal - Perturbación - Codo (0)
0 20 40 60 80 100 120
Tiempo [s]
-0.8
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
0.8
1
Voltaje
[V
]
DDD: PID Neuronal - Esfuerzo de control (Motor) - Codo (0)
Señal de control
(c) DDD: PID Neuronal - Esfuerzo de control(Motor) - Codo (0)
Figura 3.48: Experimento seleccionado para codo en sentido horario
86
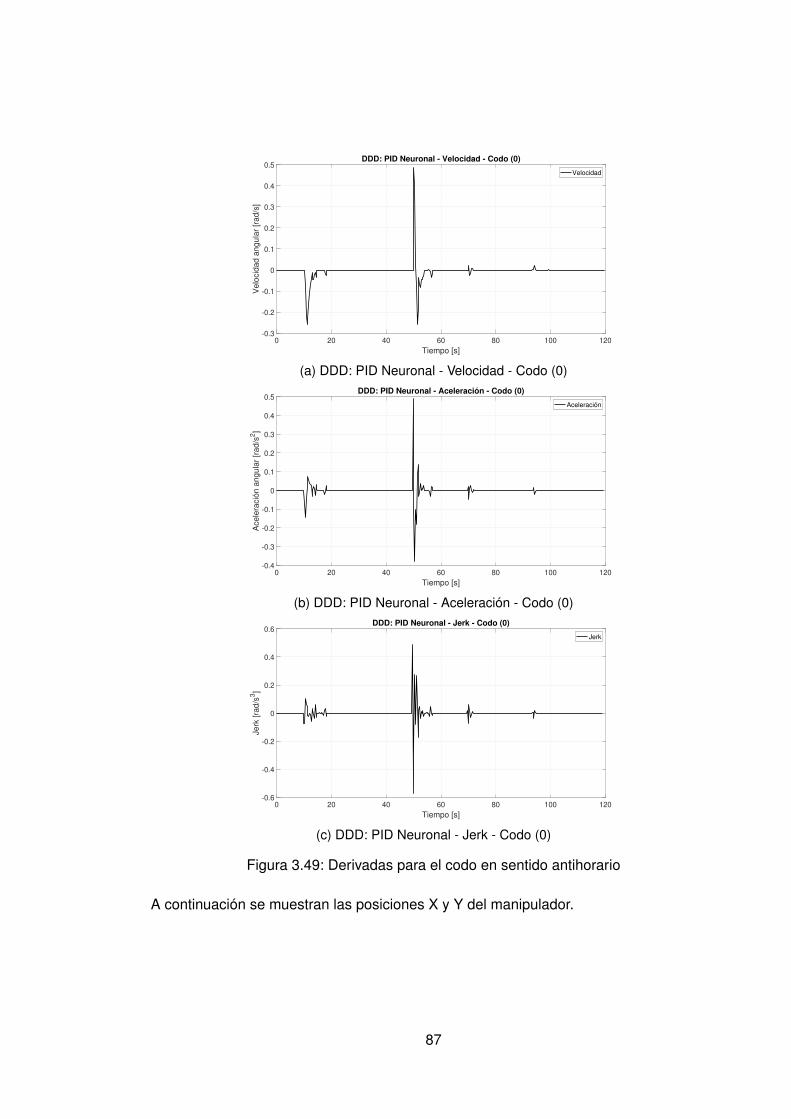
0 20 40 60 80 100 120
Tiempo [s]
-0.3
-0.2
-0.1
0
0.1
0.2
0.3
0.4
0.5
Velo
cid
ad a
ngula
r [r
ad/s
]
DDD: PID Neuronal - Velocidad - Codo (0)
Velocidad
(a) DDD: PID Neuronal - Velocidad - Codo (0)
0 20 40 60 80 100 120
Tiempo [s]
-0.4
-0.3
-0.2
-0.1
0
0.1
0.2
0.3
0.4
0.5
Acele
ració
n a
ngula
r [r
ad/s
2]
DDD: PID Neuronal - Aceleración - Codo (0)
Aceleración
(b) DDD: PID Neuronal - Aceleración - Codo (0)
0 20 40 60 80 100 120
Tiempo [s]
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
Jerk
[ra
d/s
3]
DDD: PID Neuronal - Jerk - Codo (0)
Jerk
(c) DDD: PID Neuronal - Jerk - Codo (0)
Figura 3.49: Derivadas para el codo en sentido antihorario
A continuación se muestran las posiciones X y Y del manipulador.
87

0 20 40 60 80 100 120
Tiempo [s]
-60
-40
-20
0
20
40
60
80
Posic
ión [cm
]
DDD: PID Neuronal - Posición X (0)
Posición X
(a) DDD: PID Neuronal - Posición X(0)
0 20 40 60 80 100 120
Tiempo [s]
-10
0
10
20
30
40
50
60
Posic
ión [cm
]
DDD: PID Neuronal - Posición Y (0)
Posición Y
(b) DDD: PID Neuronal - Posición Y (0)
-60 -40 -20 0 20 40 60 80
Posición X [cm]
-10
0
10
20
30
40
50
60
Posic
ión Y
[cm
]
DDD: PID Neuronal - Posición X vs Y
Posición X vs Y
(c) DDD: PID Neuronal - Posición X vs Y (0)
Figura 3.50: DDD: PID Neuronal - Posición X vs Y (0)
88
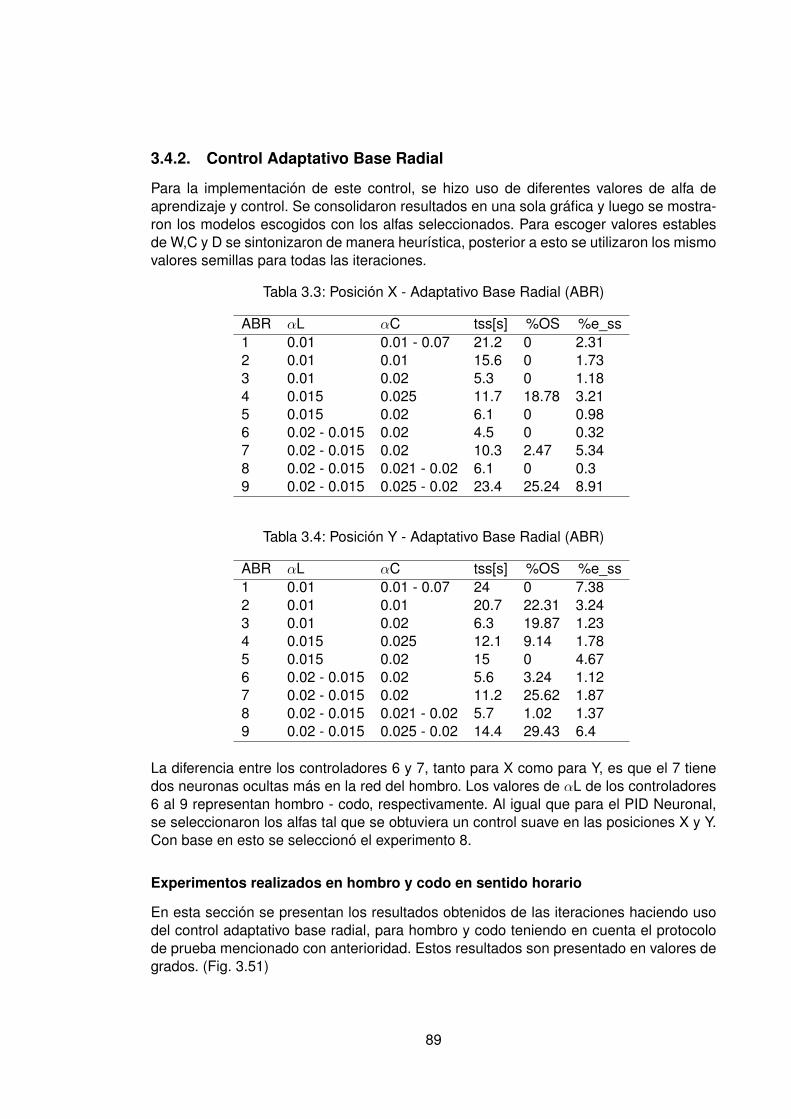
3.4.2. Control Adaptativo Base Radial
Para la implementación de este control, se hizo uso de diferentes valores de alfa deaprendizaje y control. Se consolidaron resultados en una sola gráfica y luego se mostra-ron los modelos escogidos con los alfas seleccionados. Para escoger valores establesde W,C y D se sintonizaron de manera heurística, posterior a esto se utilizaron los mismovalores semillas para todas las iteraciones.
Tabla 3.3: Posición X - Adaptativo Base Radial (ABR)
ABR αL αC tss[s] %OS %e_ss1 0.01 0.01 - 0.07 21.2 0 2.312 0.01 0.01 15.6 0 1.733 0.01 0.02 5.3 0 1.184 0.015 0.025 11.7 18.78 3.215 0.015 0.02 6.1 0 0.986 0.02 - 0.015 0.02 4.5 0 0.327 0.02 - 0.015 0.02 10.3 2.47 5.348 0.02 - 0.015 0.021 - 0.02 6.1 0 0.39 0.02 - 0.015 0.025 - 0.02 23.4 25.24 8.91
Tabla 3.4: Posición Y - Adaptativo Base Radial (ABR)
ABR αL αC tss[s] %OS %e_ss1 0.01 0.01 - 0.07 24 0 7.382 0.01 0.01 20.7 22.31 3.243 0.01 0.02 6.3 19.87 1.234 0.015 0.025 12.1 9.14 1.785 0.015 0.02 15 0 4.676 0.02 - 0.015 0.02 5.6 3.24 1.127 0.02 - 0.015 0.02 11.2 25.62 1.878 0.02 - 0.015 0.021 - 0.02 5.7 1.02 1.379 0.02 - 0.015 0.025 - 0.02 14.4 29.43 6.4
La diferencia entre los controladores 6 y 7, tanto para X como para Y, es que el 7 tienedos neuronas ocultas más en la red del hombro. Los valores de αL de los controladores6 al 9 representan hombro - codo, respectivamente. Al igual que para el PID Neuronal,se seleccionaron los alfas tal que se obtuviera un control suave en las posiciones X y Y.Con base en esto se seleccionó el experimento 8.
Experimentos realizados en hombro y codo en sentido horario
En esta sección se presentan los resultados obtenidos de las iteraciones haciendo usodel control adaptativo base radial, para hombro y codo teniendo en cuenta el protocolode prueba mencionado con anterioridad. Estos resultados son presentado en valores degrados. (Fig. 3.51)
89
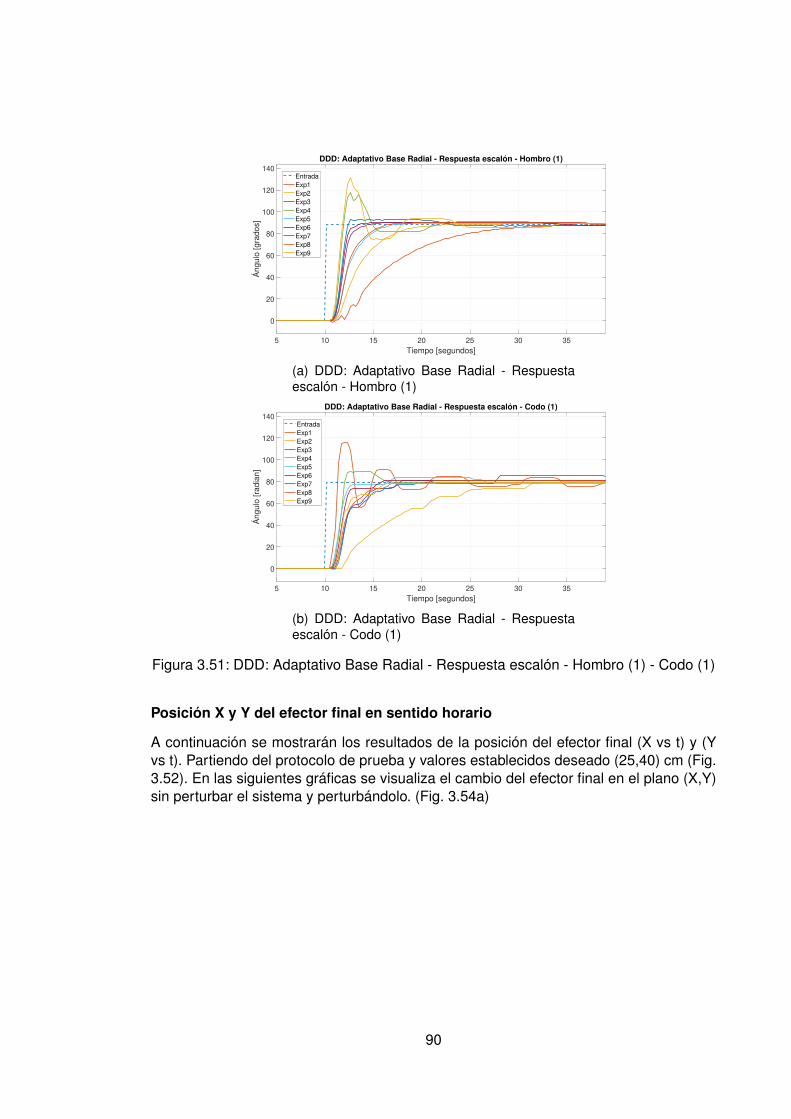
5 10 15 20 25 30 35Tiempo [segundos]
0
20
40
60
80
100
120
140
Áng
ulo
[gra
dos]
DDD: Adaptativo Base Radial - Respuesta escalón - Hombro (1)
EntradaExp1Exp2Exp3Exp4Exp5Exp6Exp7Exp8Exp9
(a) DDD: Adaptativo Base Radial - Respuestaescalón - Hombro (1)
5 10 15 20 25 30 35Tiempo [segundos]
0
20
40
60
80
100
120
140
Áng
ulo
[rad
ian]
DDD: Adaptativo Base Radial - Respuesta escalón - Codo (1)
EntradaExp1Exp2Exp3Exp4Exp5Exp6Exp7Exp8Exp9
(b) DDD: Adaptativo Base Radial - Respuestaescalón - Codo (1)
Figura 3.51: DDD: Adaptativo Base Radial - Respuesta escalón - Hombro (1) - Codo (1)
Posición X y Y del efector final en sentido horario
A continuación se mostrarán los resultados de la posición del efector final (X vs t) y (Yvs t). Partiendo del protocolo de prueba y valores establecidos deseado (25,40) cm (Fig.3.52). En las siguientes gráficas se visualiza el cambio del efector final en el plano (X,Y)sin perturbar el sistema y perturbándolo. (Fig. 3.54a)
90
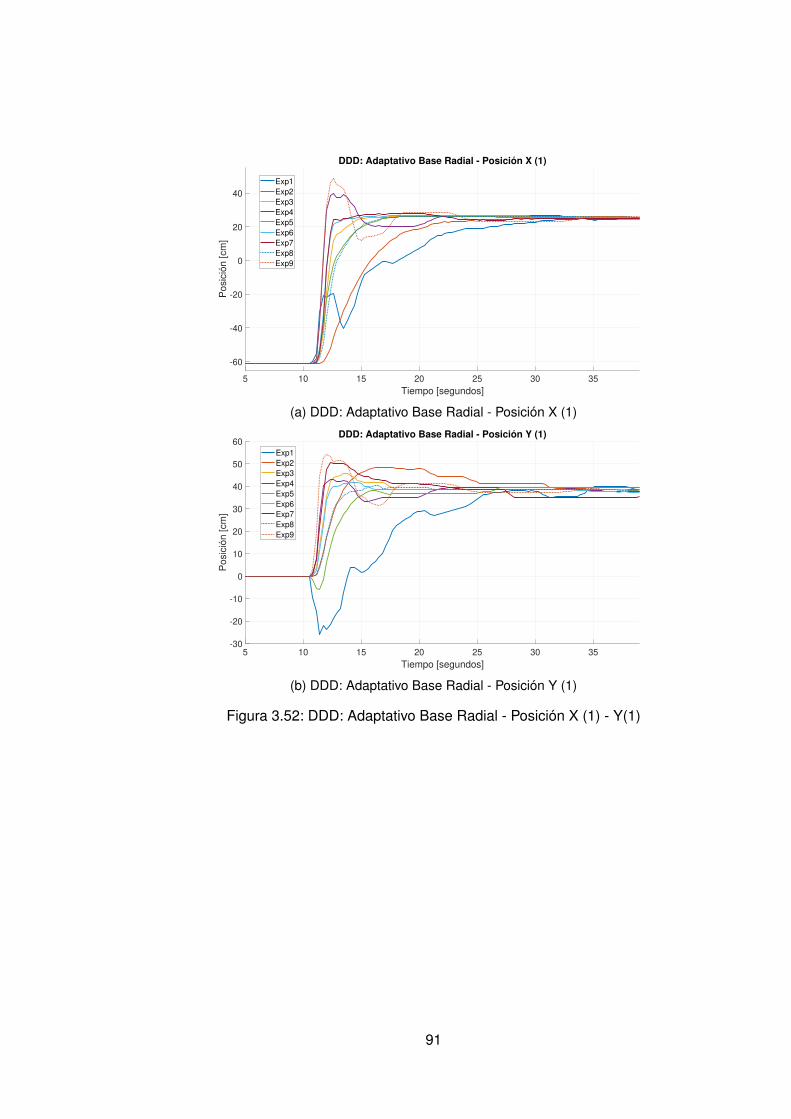
5 10 15 20 25 30 35
Tiempo [segundos]
-60
-40
-20
0
20
40
Po
sic
ión
[cm
]
DDD: Adaptativo Base Radial - Posición X (1)
Exp1
Exp2
Exp3
Exp4
Exp5
Exp6
Exp7
Exp8
Exp9
(a) DDD: Adaptativo Base Radial - Posición X (1)
5 10 15 20 25 30 35
Tiempo [segundos]
-30
-20
-10
0
10
20
30
40
50
60
Po
sic
ión
[cm
]
DDD: Adaptativo Base Radial - Posición Y (1)
Exp1
Exp2
Exp3
Exp4
Exp5
Exp6
Exp7
Exp8
Exp9
(b) DDD: Adaptativo Base Radial - Posición Y (1)
Figura 3.52: DDD: Adaptativo Base Radial - Posición X (1) - Y(1)
91

-60 -40 -20 0 20 40
Posición X [cm]
-30
-20
-10
0
10
20
30
40
50
60
Posic
ión Y
[cm
]
DDD: Adaptativo Base Radial - Posición X vs Y
Exp1
Exp2
Exp3
Exp4
Exp5
Exp6
Exp7
Exp8
Exp9
(a) DDD: Adaptativo Base Radial - Posición X vs Y
-60 -40 -20 0 20 40
Posición X [cm]
-30
-20
-10
0
10
20
30
40
50
60
Posic
ión Y
[cm
]
DDD: Adaptativo Base Radial - Posición X vs Y
Exp1
Exp2
Exp3
Exp4
Exp5
Exp6
Exp7
Exp8
Exp9
(b) DDD: Adaptativo Base Radial - Posición X vs Y con Perturbación
Figura 3.53: DDD: Adaptativo Base Radial - Posición X vs Y
A continuación se muestran las posiciones X y Y seleccionadas.
92
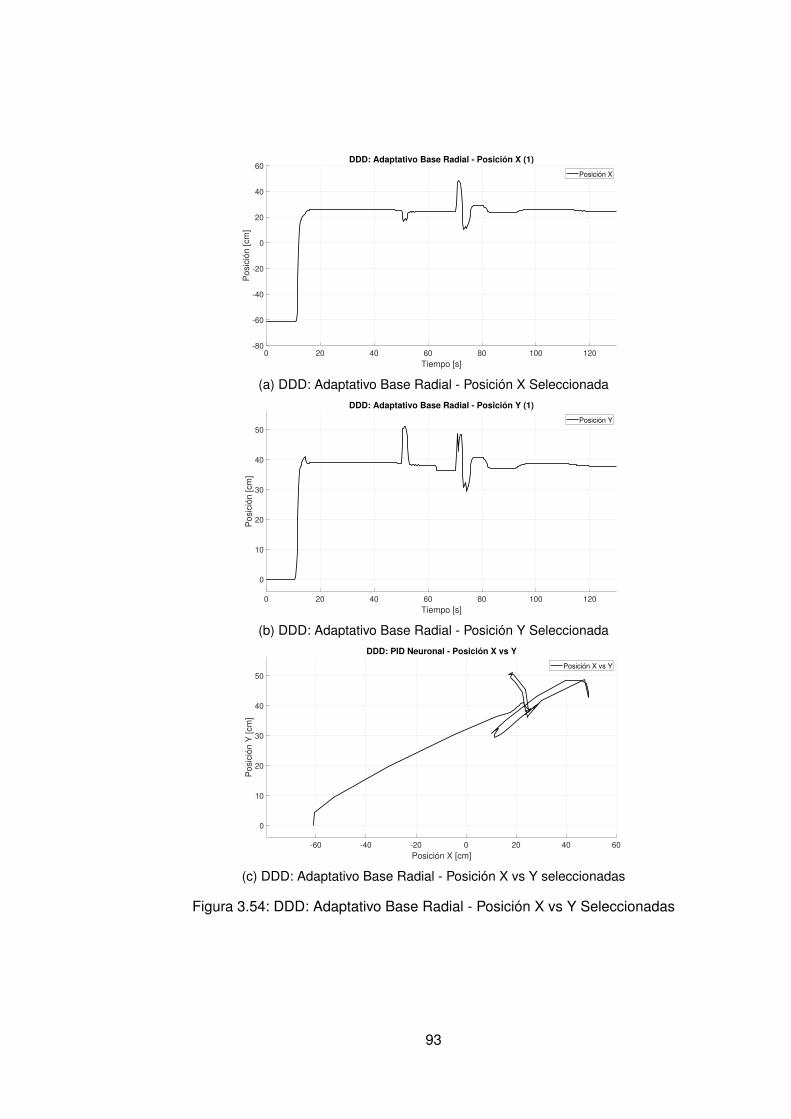
0 20 40 60 80 100 120
Tiempo [s]
-80
-60
-40
-20
0
20
40
60
Posic
ión [cm
]
DDD: Adaptativo Base Radial - Posición X (1)
Posición X
(a) DDD: Adaptativo Base Radial - Posición X Seleccionada
0 20 40 60 80 100 120
Tiempo [s]
0
10
20
30
40
50
Posic
ión [cm
]
DDD: Adaptativo Base Radial - Posición Y (1)
Posición Y
(b) DDD: Adaptativo Base Radial - Posición Y Seleccionada
-60 -40 -20 0 20 40 60
Posición X [cm]
0
10
20
30
40
50
Posic
ión Y
[cm
]
DDD: PID Neuronal - Posición X vs Y
Posición X vs Y
(c) DDD: Adaptativo Base Radial - Posición X vs Y seleccionadas
Figura 3.54: DDD: Adaptativo Base Radial - Posición X vs Y Seleccionadas
93
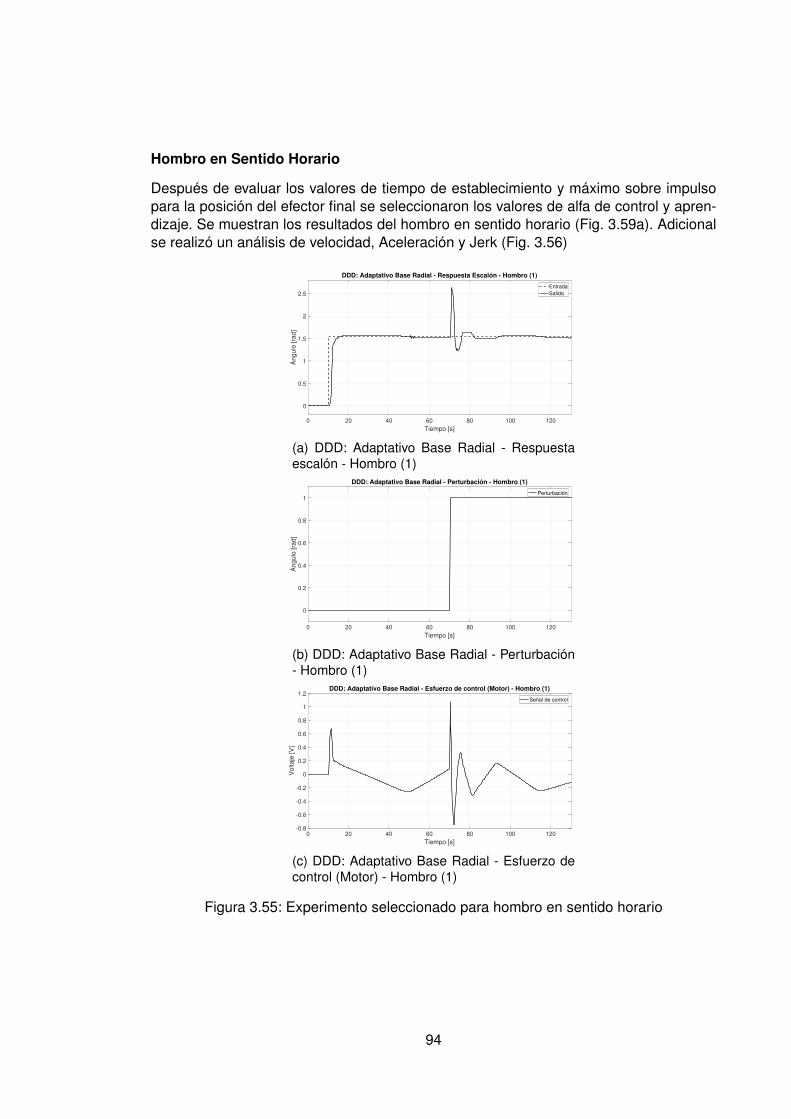
Hombro en Sentido Horario
Después de evaluar los valores de tiempo de establecimiento y máximo sobre impulsopara la posición del efector final se seleccionaron los valores de alfa de control y apren-dizaje. Se muestran los resultados del hombro en sentido horario (Fig. 3.59a). Adicionalse realizó un análisis de velocidad, Aceleración y Jerk (Fig. 3.56)
0 20 40 60 80 100 120Tiempo [s]
0
0.5
1
1.5
2
2.5Á
ngul
o [r
ad]
DDD: Adaptativo Base Radial - Respuesta Escalón - Hombro (1)
EntradaSalida
(a) DDD: Adaptativo Base Radial - Respuestaescalón - Hombro (1)
0 20 40 60 80 100 120Tiempo [s]
0
0.2
0.4
0.6
0.8
1
Áng
ulo
[rad
]
DDD: Adaptativo Base Radial - Perturbación - Hombro (1)
Perturbación
(b) DDD: Adaptativo Base Radial - Perturbación- Hombro (1)
0 20 40 60 80 100 120
Tiempo [s]
-0.8
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
0.8
1
1.2
Voltaje
[V
]
DDD: Adaptativo Base Radial - Esfuerzo de control (Motor) - Hombro (1)
Señal de control
(c) DDD: Adaptativo Base Radial - Esfuerzo decontrol (Motor) - Hombro (1)
Figura 3.55: Experimento seleccionado para hombro en sentido horario
94

0 20 40 60 80 100 120
Tiempo [s]
-0.4
-0.3
-0.2
-0.1
0
0.1
0.2
0.3
0.4
0.5
0.6
Velo
cid
ad a
ngula
r [r
ad/s
]
DDD: Adaptativo Base Radial - Velocidad - Hombro (1)
Velocidad
(a) DDD: Adaptativo Base Radial - Velocidad -Hombro (1)
0 20 40 60 80 100 120
Tiempo [s]
-0.5
-0.4
-0.3
-0.2
-0.1
0
0.1
0.2
0.3
0.4
0.5
Acele
ració
n a
ngula
r [r
ad/s
2]
DDD: Adaptativo Base Radial - Aceleración - Hombro (1)
Aceleración
(b) DDD: Adaptativo Base Radial - Aceleración -Hombro (1)
0 20 40 60 80 100 120
Tiempo [s]
-0.8
-0.6
-0.4
-0.2
0
0.2
0.4
Jerk
[ra
d/s
3]
DDD: Adaptativo Base Radial - Jerk - Hombro (1)
Jerk
(c) DDD: Adaptativo Base Radial - Jerk - Hombro(1)
Figura 3.56: Derivadas para el hombro en sentido horario
95
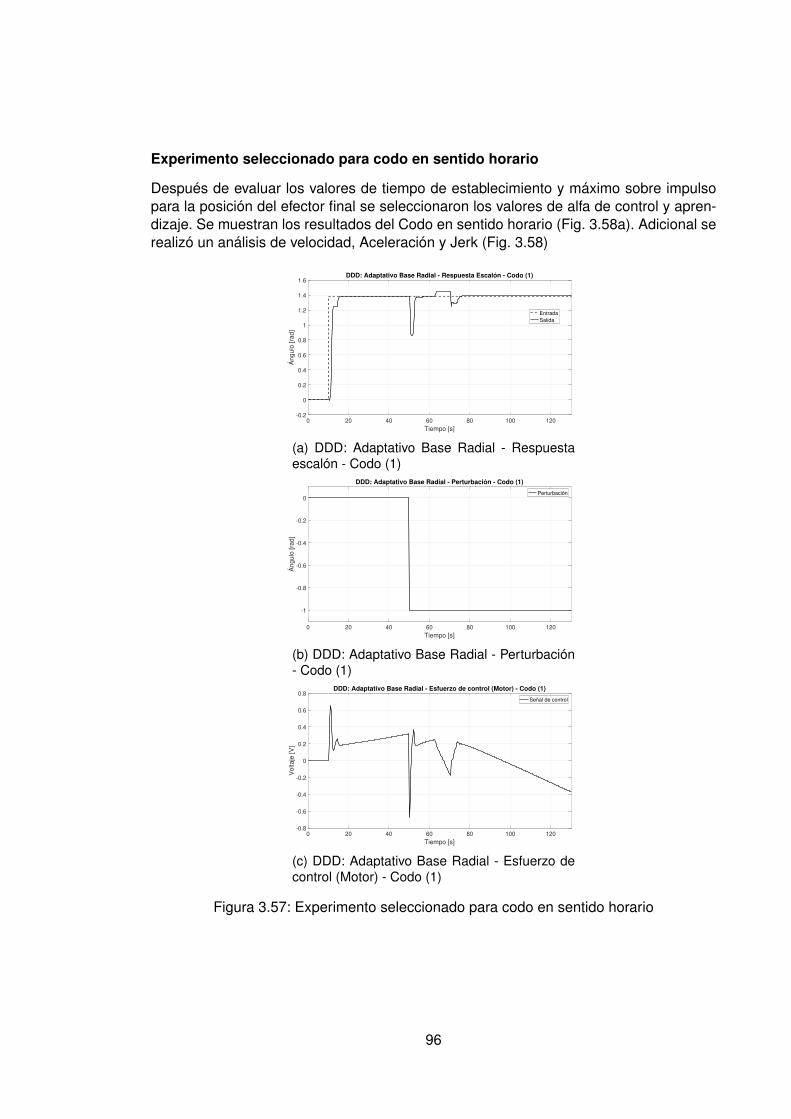
Experimento seleccionado para codo en sentido horario
Después de evaluar los valores de tiempo de establecimiento y máximo sobre impulsopara la posición del efector final se seleccionaron los valores de alfa de control y apren-dizaje. Se muestran los resultados del Codo en sentido horario (Fig. 3.58a). Adicional serealizó un análisis de velocidad, Aceleración y Jerk (Fig. 3.58)
0 20 40 60 80 100 120Tiempo [s]
-0.2
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
Áng
ulo
[rad
]
DDD: Adaptativo Base Radial - Respuesta Escalón - Codo (1)
EntradaSalida
(a) DDD: Adaptativo Base Radial - Respuestaescalón - Codo (1)
0 20 40 60 80 100 120Tiempo [s]
-1
-0.8
-0.6
-0.4
-0.2
0
Áng
ulo
[rad
]
DDD: Adaptativo Base Radial - Perturbación - Codo (1)
Perturbación
(b) DDD: Adaptativo Base Radial - Perturbación- Codo (1)
0 20 40 60 80 100 120
Tiempo [s]
-0.8
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
0.8
Voltaje
[V
]
DDD: Adaptativo Base Radial - Esfuerzo de control (Motor) - Codo (1)
Señal de control
(c) DDD: Adaptativo Base Radial - Esfuerzo decontrol (Motor) - Codo (1)
Figura 3.57: Experimento seleccionado para codo en sentido horario
96
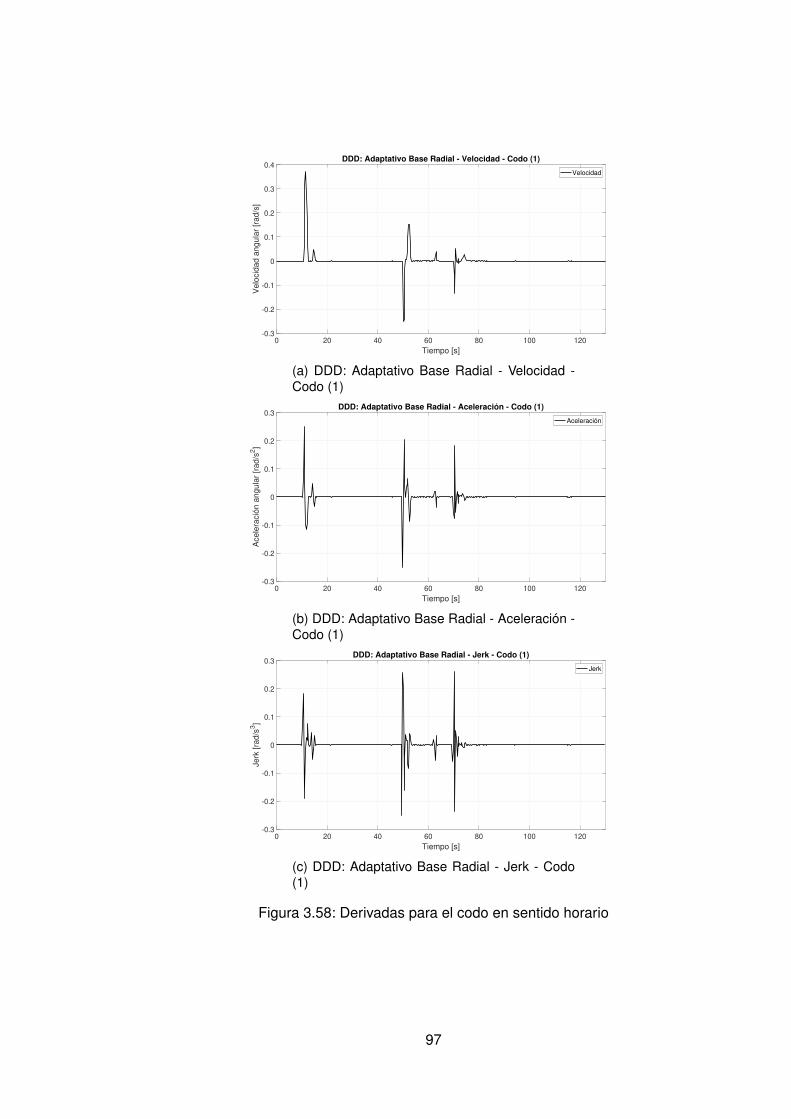
0 20 40 60 80 100 120
Tiempo [s]
-0.3
-0.2
-0.1
0
0.1
0.2
0.3
0.4
Velo
cid
ad a
ngula
r [r
ad/s
]
DDD: Adaptativo Base Radial - Velocidad - Codo (1)
Velocidad
(a) DDD: Adaptativo Base Radial - Velocidad -Codo (1)
0 20 40 60 80 100 120
Tiempo [s]
-0.3
-0.2
-0.1
0
0.1
0.2
0.3
Acele
ració
n a
ngula
r [r
ad/s
2]
DDD: Adaptativo Base Radial - Aceleración - Codo (1)
Aceleración
(b) DDD: Adaptativo Base Radial - Aceleración -Codo (1)
0 20 40 60 80 100 120
Tiempo [s]
-0.3
-0.2
-0.1
0
0.1
0.2
0.3
Jerk
[ra
d/s
3]
DDD: Adaptativo Base Radial - Jerk - Codo (1)
Jerk
(c) DDD: Adaptativo Base Radial - Jerk - Codo(1)
Figura 3.58: Derivadas para el codo en sentido horario
97

Hombro en Sentido Antihorario
Después de evaluar los valores de establecimiento y máximo sobre impulso para la po-sición del efector final en sentido horario los valores seleccionados de alfa de control yaprendizaje se utilizaron para desplazar el manipulador en sentido antihorario. Se mues-tran los resultados del hombro en sentido antihorario (Fig. 3.60a). Adicional se realizó unanálisis de velocidad, Aceleración y Jerk (Fig. 3.60)
0 20 40 60 80 100 120Tiempo [s]
-2
-1.5
-1
-0.5
0
Áng
ulo
[rad
]DDD: Adaptativo Base Radial - Respuesta Escalón - Hombro (0)
EntradaSalida
(a) DDD: Adaptativo Base Radial - Respuestaescalón - Hombro (0)
0 20 40 60 80 100 120Tiempo [s]
-1
-0.8
-0.6
-0.4
-0.2
0
Áng
ulo
[rad
]
DDD: Adaptativo Base Radial - Perturbación - Hombro (0)
Perturbación
(b) DDD: Adaptativo Base Radial - Perturbación- Hombro (0)
0 20 40 60 80 100 120
Tiempo [s]
-1
-0.8
-0.6
-0.4
-0.2
0
0.2
0.4
Voltaje
[V
]
DDD: Adaptativo Base Radial - Esfuerzo de control (Motor) - Hombro (0)
Señal de control
(c) DDD: Adaptativo Base Radial - Esfuerzo decontrol (Motor) - Hombro (0)
Figura 3.59: Experimento seleccionado para hombro en sentido antihorario
98

0 20 40 60 80 100 120
Tiempo [s]
-0.5
-0.4
-0.3
-0.2
-0.1
0
0.1
0.2
Velo
cid
ad a
ngula
r [r
ad/s
]
DDD: Adaptativo Base Radial - Velocidad - Hombro (0)
Velocidad
(a) DDD: Adaptativo Base Radial - Velocidad -Hombro (0)
0 20 40 60 80 100 120
Tiempo [s]
-0.4
-0.3
-0.2
-0.1
0
0.1
0.2
0.3
Acele
ració
n a
ngula
r [r
ad/s
2]
DDD: Adaptativo Base Radial - Aceleración - Hombro (0)
Aceleración
(b) DDD: Adaptativo Base Radial - Aceleración -Hombro (0)
0 20 40 60 80 100 120
Tiempo [s]
-0.3
-0.2
-0.1
0
0.1
0.2
0.3
0.4
0.5
Jerk
[ra
d/s
3]
DDD: Adaptativo Base Radial - Jerk - Hombro (0)
Jerk
(c) DDD: Adaptativo Base Radial - Jerk - Hombro(0)
Figura 3.60: Derivadas para el hombro en sentido horario
99
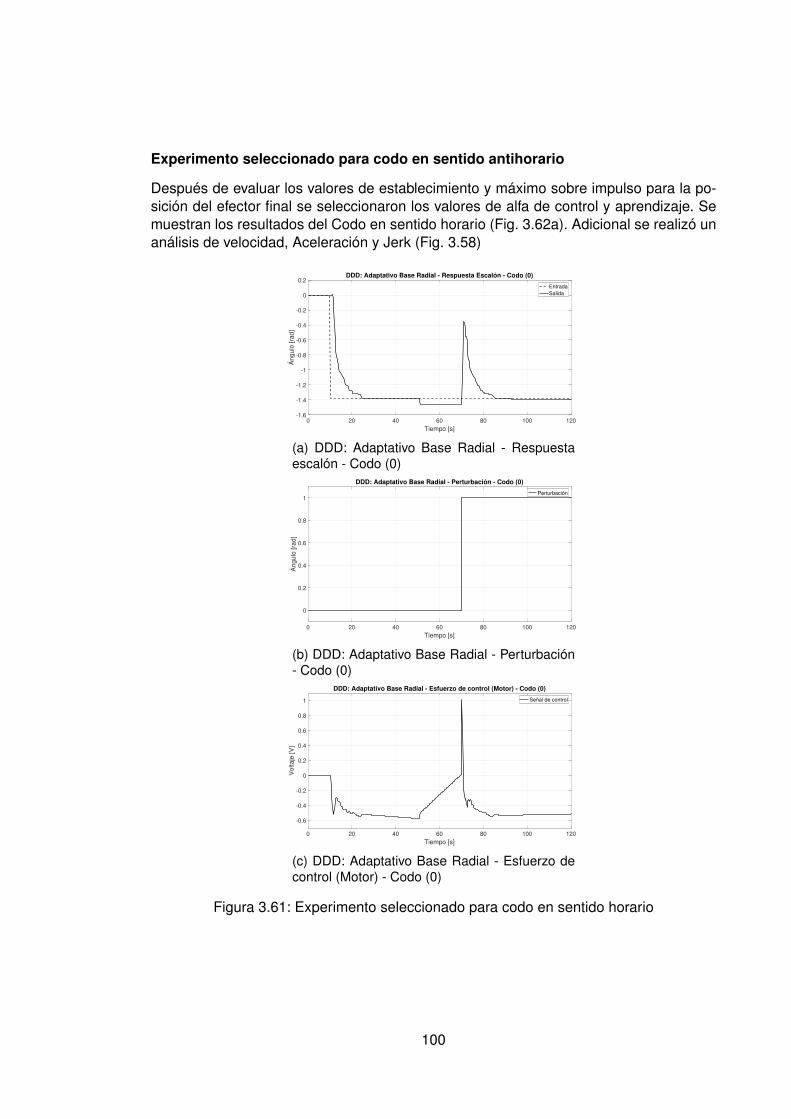
Experimento seleccionado para codo en sentido antihorario
Después de evaluar los valores de establecimiento y máximo sobre impulso para la po-sición del efector final se seleccionaron los valores de alfa de control y aprendizaje. Semuestran los resultados del Codo en sentido horario (Fig. 3.62a). Adicional se realizó unanálisis de velocidad, Aceleración y Jerk (Fig. 3.58)
0 20 40 60 80 100 120Tiempo [s]
-1.6
-1.4
-1.2
-1
-0.8
-0.6
-0.4
-0.2
0
0.2
Áng
ulo
[rad
]
DDD: Adaptativo Base Radial - Respuesta Escalón - Codo (0)
EntradaSalida
(a) DDD: Adaptativo Base Radial - Respuestaescalón - Codo (0)
0 20 40 60 80 100 120Tiempo [s]
0
0.2
0.4
0.6
0.8
1
Áng
ulo
[rad
]
DDD: Adaptativo Base Radial - Perturbación - Codo (0)
Perturbación
(b) DDD: Adaptativo Base Radial - Perturbación- Codo (0)
0 20 40 60 80 100 120
Tiempo [s]
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
0.8
1
Voltaje
[V
]
DDD: Adaptativo Base Radial - Esfuerzo de control (Motor) - Codo (0)
Señal de control
(c) DDD: Adaptativo Base Radial - Esfuerzo decontrol (Motor) - Codo (0)
Figura 3.61: Experimento seleccionado para codo en sentido horario
100
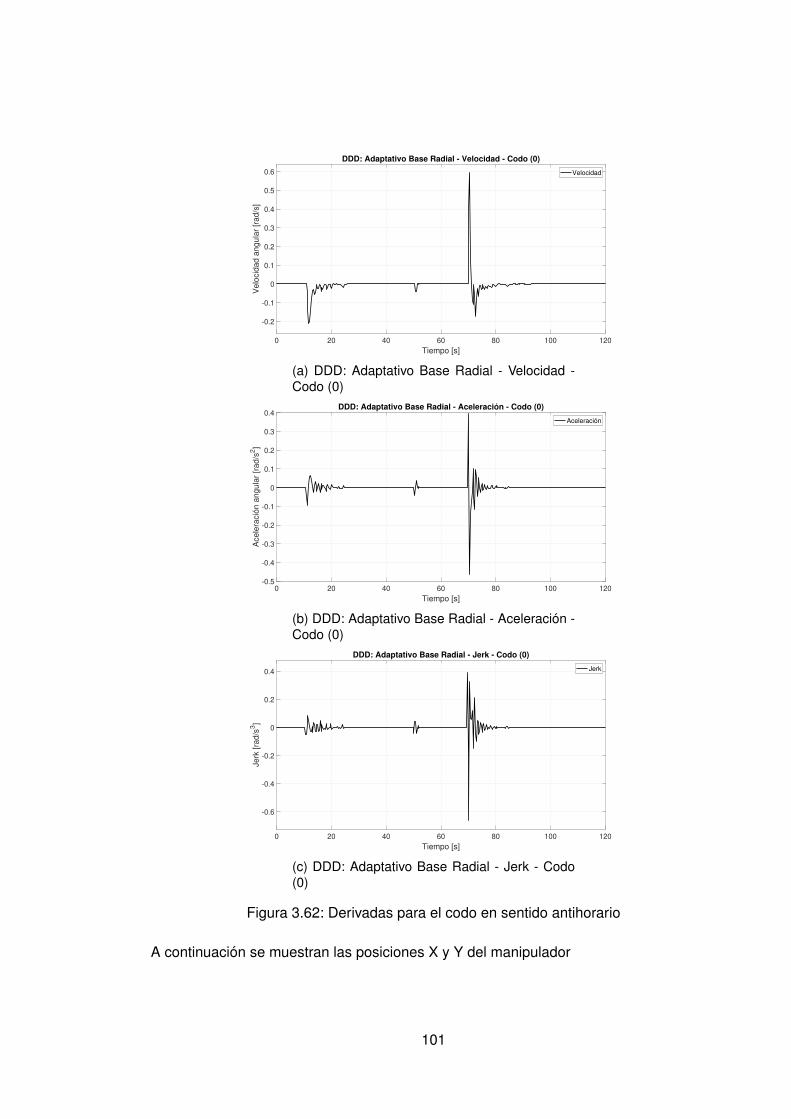
0 20 40 60 80 100 120
Tiempo [s]
-0.2
-0.1
0
0.1
0.2
0.3
0.4
0.5
0.6
Velo
cid
ad a
ngula
r [r
ad/s
]
DDD: Adaptativo Base Radial - Velocidad - Codo (0)
Velocidad
(a) DDD: Adaptativo Base Radial - Velocidad -Codo (0)
0 20 40 60 80 100 120
Tiempo [s]
-0.5
-0.4
-0.3
-0.2
-0.1
0
0.1
0.2
0.3
0.4
Acele
ració
n a
ngula
r [r
ad/s
2]
DDD: Adaptativo Base Radial - Aceleración - Codo (0)
Aceleración
(b) DDD: Adaptativo Base Radial - Aceleración -Codo (0)
0 20 40 60 80 100 120
Tiempo [s]
-0.6
-0.4
-0.2
0
0.2
0.4
Jerk
[ra
d/s
3]
DDD: Adaptativo Base Radial - Jerk - Codo (0)
Jerk
(c) DDD: Adaptativo Base Radial - Jerk - Codo(0)
Figura 3.62: Derivadas para el codo en sentido antihorario
A continuación se muestran las posiciones X y Y del manipulador
101
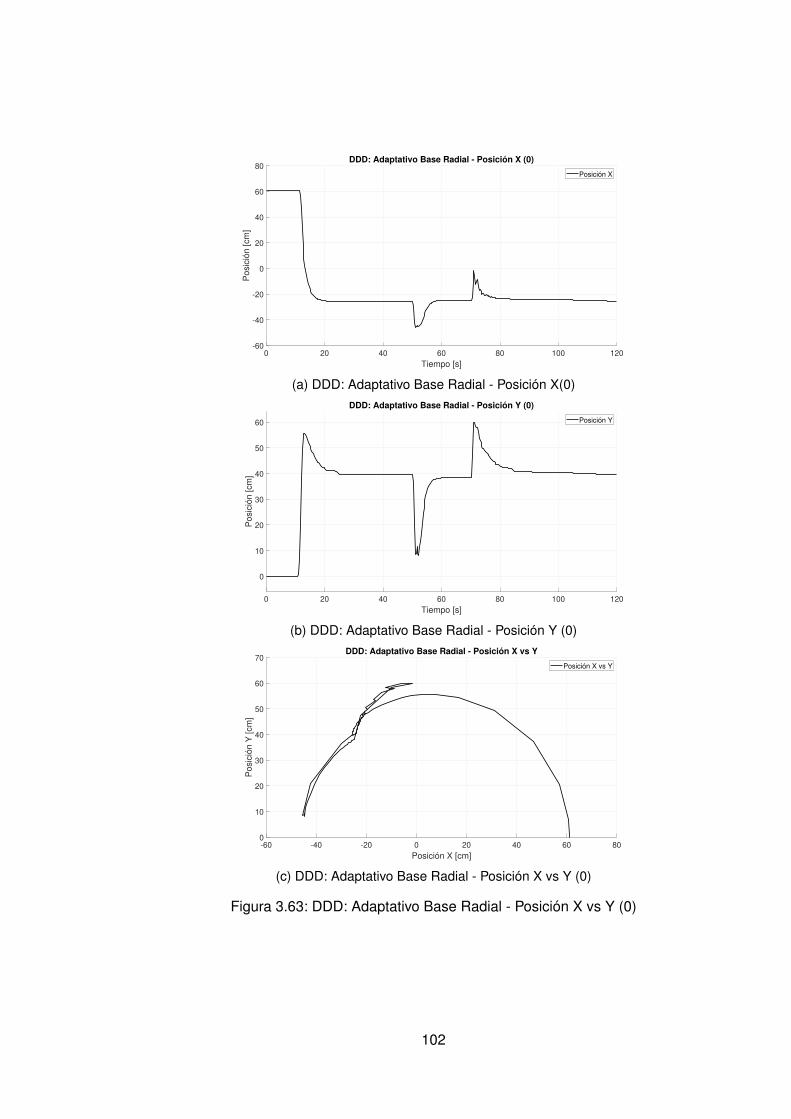
0 20 40 60 80 100 120
Tiempo [s]
-60
-40
-20
0
20
40
60
80
Posic
ión [cm
]
DDD: Adaptativo Base Radial - Posición X (0)
Posición X
(a) DDD: Adaptativo Base Radial - Posición X(0)
0 20 40 60 80 100 120
Tiempo [s]
0
10
20
30
40
50
60
Posic
ión [cm
]
DDD: Adaptativo Base Radial - Posición Y (0)
Posición Y
(b) DDD: Adaptativo Base Radial - Posición Y (0)
-60 -40 -20 0 20 40 60 80
Posición X [cm]
0
10
20
30
40
50
60
70
Posic
ión Y
[cm
]
DDD: Adaptativo Base Radial - Posición X vs Y
Posición X vs Y
(c) DDD: Adaptativo Base Radial - Posición X vs Y (0)
Figura 3.63: DDD: Adaptativo Base Radial - Posición X vs Y (0)
102

3.5. Comparación de controladores data-driven Directo y Data-driven Indirecto
Para la comparación de los controladores se graficaron las respuesta de cada contro-lador ante una misma entrada y perturbación, con el fin de visualizar la respuesta deestos mismos. Se mostrarán las gráficas en sentido horario y antihorario del codo y hom-bro. Además de las posiciones X y Y del efector final. Como se resultado se obtienenlos controladores diseñados a partir de un modelo (Control Data Driven - Indirecto) ycontroladores seleccionados heurísticamente (Control Data Driven - Directo) para cadaarticulación.
Se evidencian oscilaciones en el control del PID conmutado. Se puede concluir que segeneró por el rechazo de las perturbaciones, es decir, cuando se supera el setpoint elsistema cambia de controlador, por lo cual, el nuevo controlador interpreta esa diferenciacomo una perturbación y la rechaza, esto genera un máximo sobre impulso generandooscilaciones alrededor del setpoint.
Se presentan cada sección correspondiente a los controladores en sentido horario yantihorario.
103

3.5.1. Comparación de controladores en sentido horario
0 20 40 60 80 100 120Tiempo [s]
0
0.5
1
1.5
2
2.5
Áng
ulo
[rad
]
Comparación de controladores - Hombro (1)
EntradaPIDRealimentación SSFIAdaptativo Base RadialPID Neuronal
(a) Comparación de controladores en sentido horario para el hombro
0 20 40 60 80 100 120Tiempo [s]
0
0.2
0.4
0.6
0.8
1
Áng
ulo
[rad
]
Perturbación - Hombro (1)
Perturbación
(b) Perturbación aplicada a los controladores
Figura 3.64: Comparación de controladores hombro (1)
104

0 20 40 60 80 100 120Tiempo [s]
-0.2
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
Áng
ulo
[rad
]
Comparación de controladores - Codo (1)
EntradaPIDRealimentación SSFIAdaptativo Base RadialPID Neuronal
(a) Comparación de controladores en sentido horario para el Codo
0 20 40 60 80 100 120Tiempo [s]
-1
-0.8
-0.6
-0.4
-0.2
0
Áng
ulo
[rad
]
Perturbación - Codo (1)
Perturbación
(b) Perturbación aplicada a los controladores
Figura 3.65: Comparación de controladores Codo(1)
Comparación de controladores en para el efector final en sentido horario.
105
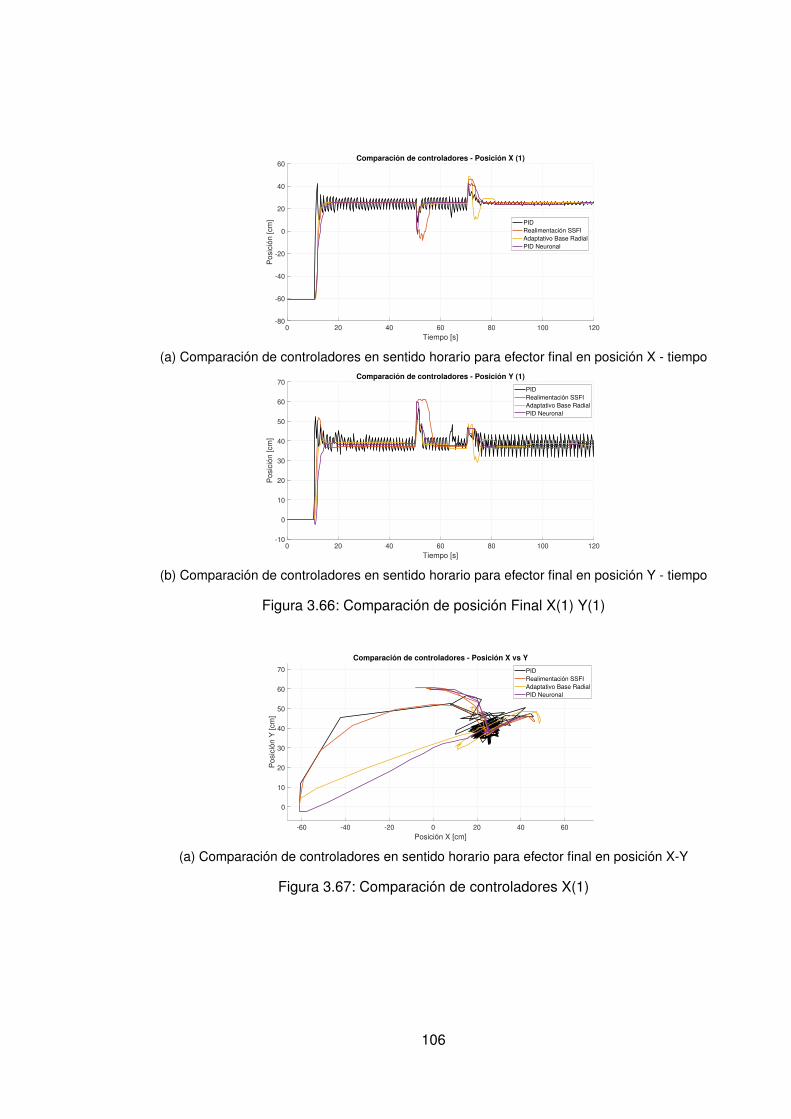
0 20 40 60 80 100 120
Tiempo [s]
-80
-60
-40
-20
0
20
40
60
Po
sic
ión
[cm
]
Comparación de controladores - Posición X (1)
PID
Realimentación SSFI
Adaptativo Base Radial
PID Neuronal
(a) Comparación de controladores en sentido horario para efector final en posición X - tiempo
0 20 40 60 80 100 120
Tiempo [s]
-10
0
10
20
30
40
50
60
70
Po
sic
ión
[cm
]
Comparación de controladores - Posición Y (1)
PID
Realimentación SSFI
Adaptativo Base Radial
PID Neuronal
(b) Comparación de controladores en sentido horario para efector final en posición Y - tiempo
Figura 3.66: Comparación de posición Final X(1) Y(1)
-60 -40 -20 0 20 40 60
Posición X [cm]
0
10
20
30
40
50
60
70
Po
sic
ión
Y [
cm
]
Comparación de controladores - Posición X vs Y
PID
Realimentación SSFI
Adaptativo Base Radial
PID Neuronal
(a) Comparación de controladores en sentido horario para efector final en posición X-Y
Figura 3.67: Comparación de controladores X(1)
106
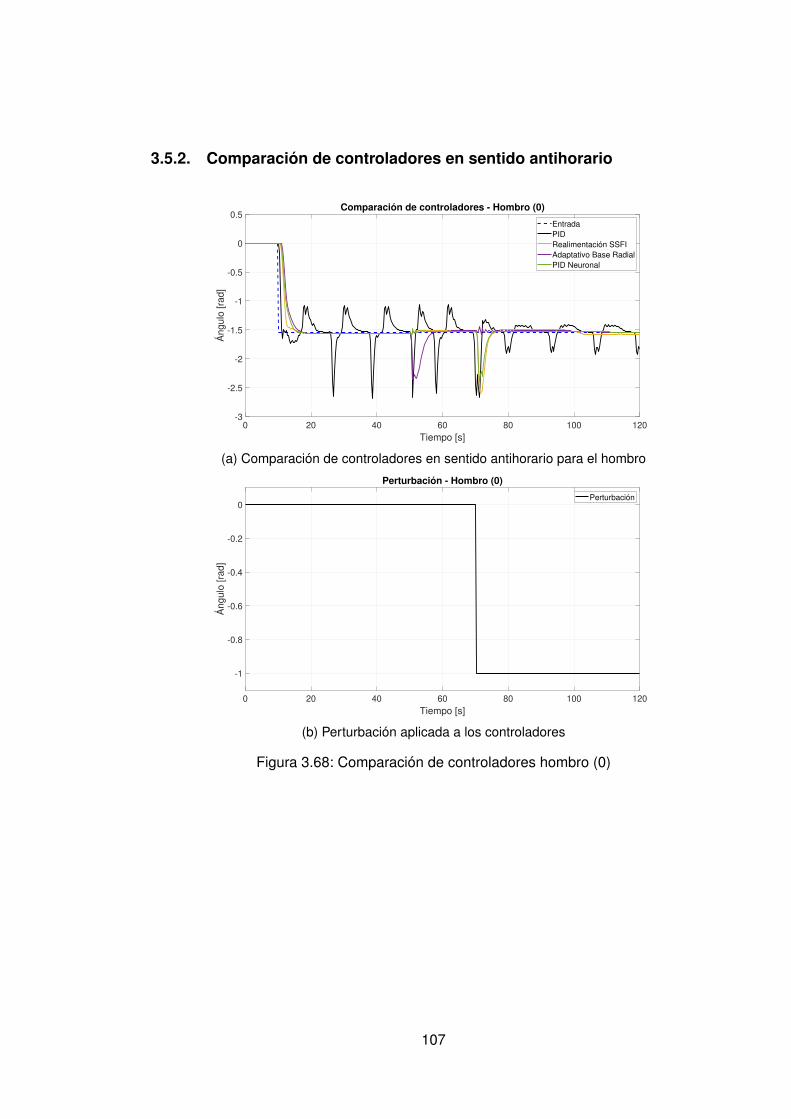
3.5.2. Comparación de controladores en sentido antihorario
0 20 40 60 80 100 120Tiempo [s]
-3
-2.5
-2
-1.5
-1
-0.5
0
0.5Á
ngul
o [r
ad]
Comparación de controladores - Hombro (0)
EntradaPIDRealimentación SSFIAdaptativo Base RadialPID Neuronal
(a) Comparación de controladores en sentido antihorario para el hombro
0 20 40 60 80 100 120Tiempo [s]
-1
-0.8
-0.6
-0.4
-0.2
0
Áng
ulo
[rad
]
Perturbación - Hombro (0)
Perturbación
(b) Perturbación aplicada a los controladores
Figura 3.68: Comparación de controladores hombro (0)
107
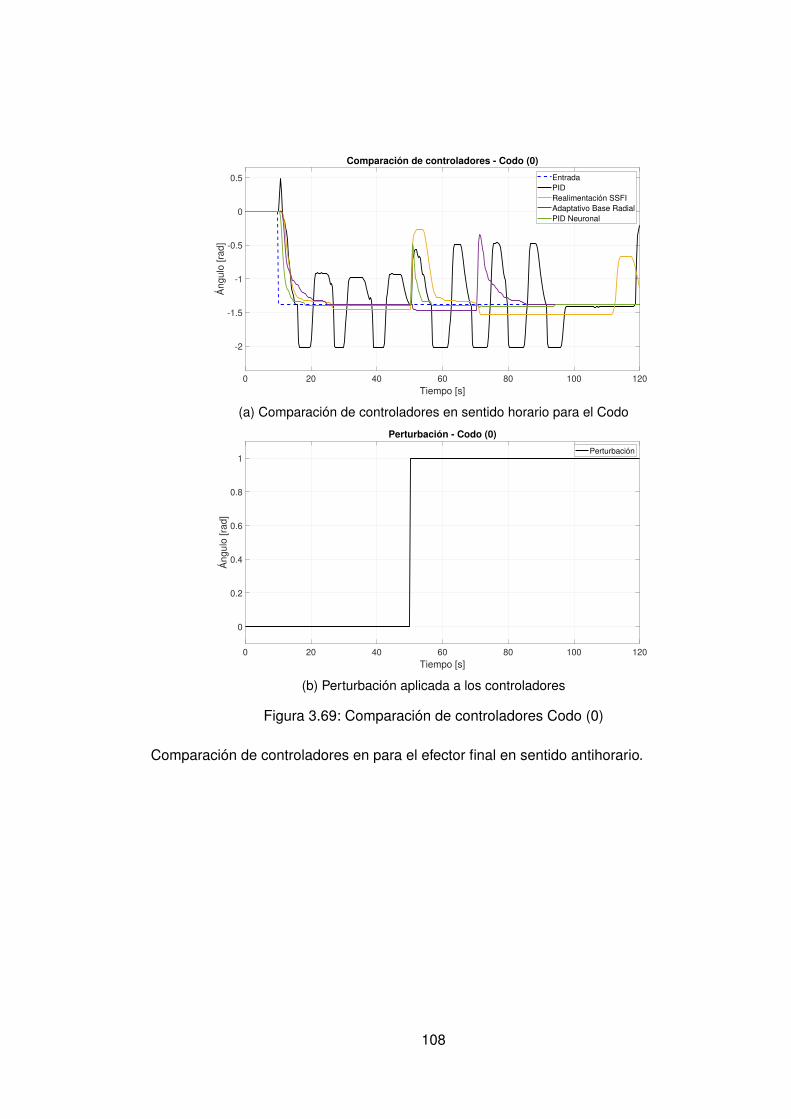
0 20 40 60 80 100 120Tiempo [s]
-2
-1.5
-1
-0.5
0
0.5
Áng
ulo
[rad
]
Comparación de controladores - Codo (0)
EntradaPIDRealimentación SSFIAdaptativo Base RadialPID Neuronal
(a) Comparación de controladores en sentido horario para el Codo
0 20 40 60 80 100 120Tiempo [s]
0
0.2
0.4
0.6
0.8
1
Áng
ulo
[rad
]
Perturbación - Codo (0)
Perturbación
(b) Perturbación aplicada a los controladores
Figura 3.69: Comparación de controladores Codo (0)
Comparación de controladores en para el efector final en sentido antihorario.
108
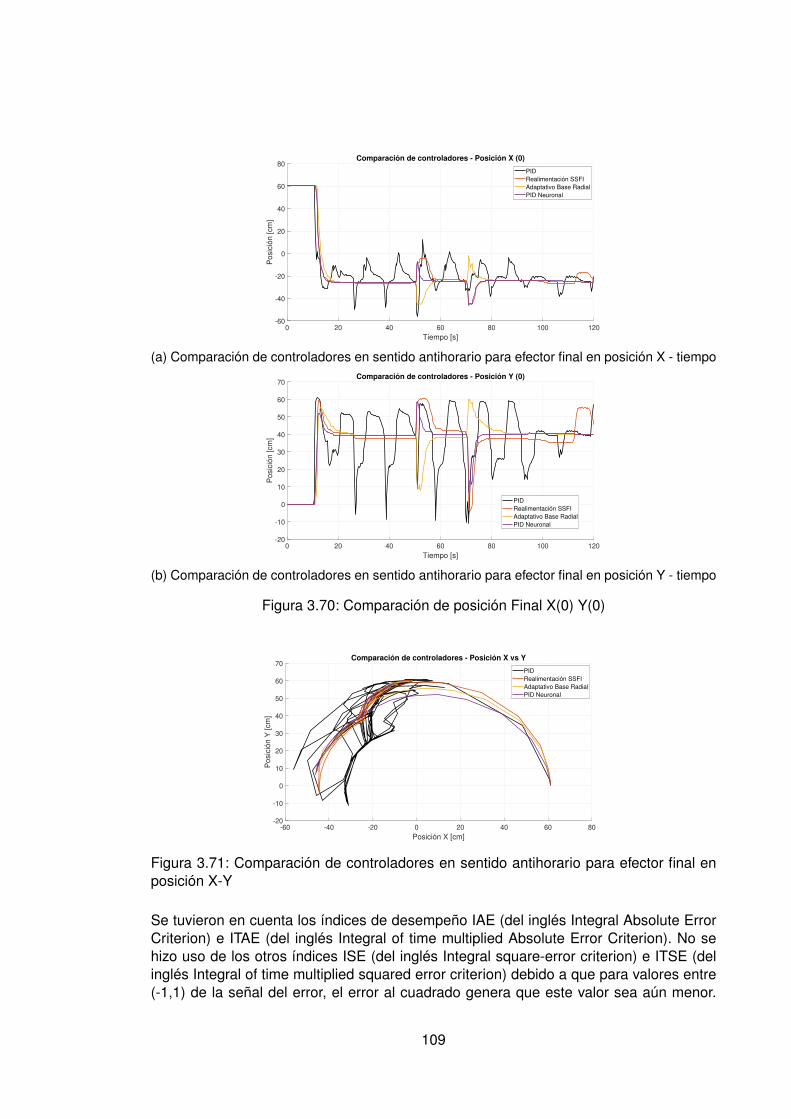
0 20 40 60 80 100 120
Tiempo [s]
-60
-40
-20
0
20
40
60
80
Po
sic
ión
[cm
]
Comparación de controladores - Posición X (0)
PID
Realimentación SSFI
Adaptativo Base Radial
PID Neuronal
(a) Comparación de controladores en sentido antihorario para efector final en posición X - tiempo
0 20 40 60 80 100 120
Tiempo [s]
-20
-10
0
10
20
30
40
50
60
70
Po
sic
ión
[cm
]
Comparación de controladores - Posición Y (0)
PID
Realimentación SSFI
Adaptativo Base Radial
PID Neuronal
(b) Comparación de controladores en sentido antihorario para efector final en posición Y - tiempo
Figura 3.70: Comparación de posición Final X(0) Y(0)
-60 -40 -20 0 20 40 60 80
Posición X [cm]
-20
-10
0
10
20
30
40
50
60
70
Po
sic
ión
Y [
cm
]
Comparación de controladores - Posición X vs Y
PID
Realimentación SSFI
Adaptativo Base Radial
PID Neuronal
Figura 3.71: Comparación de controladores en sentido antihorario para efector final enposición X-Y
Se tuvieron en cuenta los índices de desempeño IAE (del inglés Integral Absolute ErrorCriterion) e ITAE (del inglés Integral of time multiplied Absolute Error Criterion). No sehizo uso de los otros índices ISE (del inglés Integral square-error criterion) e ITSE (delinglés Integral of time multiplied squared error criterion) debido a que para valores entre(-1,1) de la señal del error, el error al cuadrado genera que este valor sea aún menor.
109

Tabla 3.5: Índices de desempeño - Hombro
HombroSentido de Giro Controlador IAE ITAE
Horario
PID Neuronal 24.5584 1011.4322Adaptativo Base Radial 25.0951 1217.0936PID Tradicional 31.9417 1614.1815Realimentación SSFI 21.4659 1184.4285
Antihorario
PID Neuronal 23.7518 950.5350Adaptativo Base Radial 28.4417 1017.4962PID Tradicional 89.2423 8340.6861Realimentación SSFI 42.1124 3979.6777
Tabla 3.6: Índices de desempeño - Codo
CodoSentido de Giro Controlador IAE ITAE
Horario
PID Neuronal 21.7291 776.3805Adaptativo Base Radial 17.7931 688.8018PID Tradicional 58.5729 4730.6786Realimentación SSFI 61.7361 3687.6234
Antihorario
PID Neuronal 19.4492 741.5408Adaptativo Base Radial 38.5431 1667.6368PID Tradicional 258.7928 25591.1661Realimentación SSFI 126.3564 1382.7549
Para el PID Tradicional que presenta oscilaciones entre este rango, puede provocar queeste valor sea menor en la comparación. Generando así un criterio no adecuado parala comparación de estos controladores. Se hizo uso de la función de matlab "trapz"querecibe un vector y realiza la aproximación de una integral con el método trapezoidal.
Para la comparación de estos parámetros y selección del controlador óptimo se escoge elvalor más pequeño. Debido a que se si parte de un caso ideal, donde la planta respondeigual al escalón, el valor de estos índices sería aproximadamente cero. Es por esto quese escoge el menor.Con las tablas 3.5 y 3.6 se evidencia que el controlador que presenta mejor desempeñoes el PID Neuronal. A pesar de que para el hombro en sentido horario el control porrealimentación de estados con seguimiento de señal obtuvo un valor menor en el criterioIAE. Pero en el criterio ITAE, donde se tiene en cuenta el vector de tiempo posee un valormayor al del PID Neuronal. Es decir, la parte transitaría posee mayor error en compara-ción al PID Neuronal.
Estas comparaciones tuvieron en cuenta las perturbaciones realizadas en los mismosperiodos de tiempo.
110

Capítulo 4
Conclusiones y consideracionesfinales
Se exploraron dos metodologías diferentes de diseño de controladores, DDD (Data-Driven Directo) y DDI (Data-Driven Indirecto). Se implementaron controladores de es-pacio de estados con observador y seguimiento de señal y PID en configuración paralelapara el control DDI. Para esta parte de implementación de control se hizo uso del toolboxde matlab ident para encontrar un modelo híbrido que represente la dinámica del proce-so. Para este control fue necesario diseñar dos controles por articulación. En el controlde espacio de estado con seguimiento de señal fue necesario un observador de ordencompleto; debido a que nuestro sistema es el motor pre-controlado para la identificaciónde un modelo estable caja negra esto conlleva que los estados medidos, no correspon-dan a posición y velocidad, si no unos estados no medibles pero observables. Esto seevidencia en la matriz de salida.
Las oscilaciones presentadas por los controladores PID son propias de los sistemas con-mutados y del controlador, debido a que un controlador, al tener un valor de referencia deerror y conmutarlo, genera valores diferentes de esfuerzo de control. Estas oscilacionesse pueden reducir de dos maneras: con histéresis, o garantizando que el controlador nogenere un máximo sobre impulso en el sistema.Los modelos cinemáticos clásicos no describen completamente los fenómenos en FJRMya que no se consideran algunas no linealidades como lo son las impuestas por las ar-ticulaciones flexibles. Hoy en día, los comportamientos suaves y no lineales son muycomunes en robótica, especialmente en robótica colaborativa, donde la seguridad deloperador impone características que garantizan este ítem en el mismo. El uso del apren-dizaje automático puede ayudar a utilizar modelos simplificados para controlar robots nolineales sin necesidad de calcular modelos dinámicos y cinemáticos robustos y comple-jos.
El uso de controladores data-driven directo permite adaptar un aprendizaje en tiemporeal del sistema, lo que brinda la ventaja de no presentar problemas ante no lineali-dad e incertidumbres. Sin embargo, cuando se diseñaron los controladores data-drivenindirectos, esto derivó en modelos compuestos que generan la necesidad de utilizar con-troladores híbridos, debido al comportamiento lineal de subida y lineal de bajada.
111

Por otro lado, si bien los parámetros iniciales del PID Neural y Adaptativo Base Radial seencontraron heurísticamente, existe una configuración de alfa de aprendizaje y controlque tiene valores estables para el sistema y se evidencia un control ante una perturba-ción constante de 57.2958° (1 radián).
Para la comparación de los controladores se tuvo en cuenta los índices de desempeñoIAE e ITAE. No se tuvieron en cuenta los otros índices debido que al elevar el error alcuadrado puede provocar un valor menor para el control PID Tradicional que oscila enel intervalo (-1,1). Teniendo en cuenta esto, se obtuvo que el PID Neuronal generó unmejor desempeño en comparación los otros controladores.
Recomendaciones para futuros trabajos
Implementación de controladores en plataformas diferentes a Simulink, por ejemploLabView, Raspberry, entre otros.
Implementar controlador conmutado con desempeño tal que no se genere máximosobre impulso, en este trabajo se exigieron estos desempeños para compararloscon los controladores Data-Driven Directos. Se permitió un máximo sobre-impulsode 10 % consecuente a presentar inestabilidad para un tiempo de establecimientode 10 Segundos con máximo sobre impulso cercano a 1 %.
Validar otros valores de alfas de aprendizaje y de controlabilidad, se puede mejorarla respuesta de los controladores data driven directo, pero se necesitan realizarvarias iteraciones.
112

Bibliografía
Arteaga, M. and Siciliano, B. (2000). On tracking control of flexible robot arms. IEEETransactions on Automatic Control, 45(3):520–527.
Aureliano, J., Cárdenas, E., Tello, J. R., and Maltos, G. R. (2013). Metodología para en-contrar matrices de transformación homogénea para la cinemática de mecanismos conmatlab y vrml metodología para encontrar matrices de transformación homogénea pa-ra la cinemática de mecanismos con matlab y vrml methodology to find homogeneoustranformation matrices for kinematics of mechanisms with matlab and vrml.
Ávila Ruiz, M. A. (2013). DISEÑO, CONSTRUCCIÓN Y CONTROL DE UN DOBLE PÉN-DULO INVERTIDO ROTACIONAL. PhD thesis, Universidad Nacional Autónoma deMéxico.
Behrens, R. and Elkmann, N. (2021). A revised framework for managing the complexityof contact hazards in collaborative robotics. In 2021 IEEE International Conference onIntelligence and Safety for Robotics (ISR), pages 252–258.
Brunton, S. L. and Kutz, J. N. (2019). Data-Driven Science and Engineering: MachineLearning, Dynamical Systems, and Control. Cambridge University Press.
Bueno, A. M. (2011). Sistemas de Control Automático Identificación experimental desistemas. Technical report.
Corke, P. I. (2007). A simple and systematic approach to assigning denavit–hartenbergparameters. IEEE Transactions on Robotics, 23(3):590–594.
Diao, S., Sun, W., Su, S.-F., and Xia, J. (2021). Adaptive fuzzy event-triggered control forsingle-link flexible-joint robots with actuator failures. IEEE Transactions on Cybernetics,pages 1–11.
Driver, M. J., Thorpe, M. D., Cazzolato, B., and Rohin Wood, M. (2004). DESIGN, BUILDAND CONTROL OF A SINGLE / DOUBLE ROTATIONAL INVERTED PENDULUM.Technical report.
ENRIQUE YAMID GARZON GONZALEZ (2014). PLATAFORMA DE APRENDIZAJE PA-RA CONTROL BATCH.
Fink, A., Nelles, O., and Fischer, M. (2015). Linearization based and local model basedcontroller design. pages 3540–3545. Institute of Electrical and Electronics EngineersInc.
113

Galán, R., Jiménez, A., Sanz, R., and Martía, F. (2000). Control Inteligente. INTELIGEN-CIA ARTIFICIAL, 4(10):44–48.
Gilberto Enriquez Arper (2013). EL ABC DE LA INSTRUMENTACIÓN EN EL CONTROLDE PROCESOS INDUSTRIALES - Enríquez, Gilberto - Google Libros.
Giraldo, M. and Hoyos, J. G. (2004). Control por redes neuronales de base radial y planosdeslizantes. Scientia Et Technica, X:43–46.
Han, D., Park, M. Y., Choi, J., Shin, H., and Rhim, S. (2021). Analysis of human-robotphysical interaction at collision. In 2021 IEEE International Conference on Intelligenceand Safety for Robotics (ISR), pages 153–156.
Hanna (2019). pH, cerveza y usted; La importancia del pH en la elaboración de cerveza| HANNA Instruments Colombia.
L, A. and Chowdhury, A. R. (2021). Human aware robot motion planning using rrt algo-rithm in industry4.0 environment. In 2021 IEEE International Conference on Intelligen-ce and Safety for Robotics (ISR), pages 351–358.
Manrique, T. and Patiño, D. (2010). Mathematical modelling on hybrid dynamical systems:An application to the bouncing ball and a two-tanks system. In 2010 IEEE ANDESCON,pages 1–8.
Meng, Q., Lai, X., Yan, Z., and Wu, M. (2020). Tip position control and vibration suppres-sion of a planar two-link rigid-flexible underactuated manipulator. IEEE Transactionson Cybernetics, pages 1–13.
Ogata, K., Pinto Bermúdez, E., Matía, F., Pearson, E., Hall, P., Dorf, R. C., and Pearson,R. H. B. (2010). Ingeniería de control moderna.
Ortega, J. C. G. (2011). Control adaptativo en tiempo real.
Palleschi, A., Hamad, M., Abdolshah, S., Garabini, M., Haddadin, S., and Pallottino,L. (2021). Fast and safe trajectory planning: Solving the cobot performance/safetytrade-off in human-robot shared environments. IEEE Robotics and Automation Letters,6(3):5445–5452.
Piga, D., Formentin, S., and Bemporad, A. (2018). Direct data-driven control of constrai-ned systems. IEEE Transactions on Control Systems Technology, 26(4):1422–1429.
Quanser Inc. (2015). 2-DOF Serial Flexible Joint Robot User Manual.
Robla-Gómez, S., Becerra, V. M., Llata, J. R., González-Sarabia, E., Torre-Ferrero, C.,and Pérez-Oria, J. (2017). Working together: A review on safe human-robot collabora-tion in industrial environments. IEEE Access, 5:26754–26773.
Sandgani, M. R. and Shoorehdeli, M. A. (2013). Lyapunov rule-based fuzzy control andchaotic anti-control for flexible joint system and analysis of chaotic signal existenceeffectiveness with experimental validation. IEEE Computer Society.
Santos, M. (2011). Un enfoque aplicado del control inteligente. RIAI - Revista Iberoame-ricana de Automatica e Informatica Industrial, 8(4):283–296.
114

Sivaraman, E., Arulselvi, S., and Babu, K. (2011). Data driven fuzzy C-means clusteringbased on particle swarm optimization for pH process. In 2011 International Conferenceon Emerging Trends in Electrical and Computer Technology, ICETECT 2011, pages220–225.
Trung, T. V. and Iwasaki, M. (2021). Double-disturbance compensation design for full-closed cascade control of flexible robots. In 2021 IEEE International Conference onMechatronics (ICM), pages 1–6.
Ullah, H., Malik, F. M., Raza, A., Ahmad, I., Mazhar, N., and Khan, R. (2021). Trackingcontrol of flexible joint single link robotic manipulator via extended high-gain obser-ver. In 2021 International Bhurban Conference on Applied Sciences and Technologies(IBCAST), pages 630–635.
Wang, Z., Lu, R., Gao, F., and Liu, D. (2017). An indirect data-driven method for trajectorytracking control of a class of nonlinear discrete-time systems. IEEE Transactions onIndustrial Electronics, 64:4121–4129.
Yan, Z., Lai, X., and Meng, Q. (2018). Stable control of single-link flexible-joint manipula-tor. volume 2018-July, pages 575–578. IEEE Computer Society.
Yañez-Badillo, H., Tapia-Olvera, R., Aguilar-Mejía, O., and Beltran-Carbajal, F. (2017).Control Neuronal en Línea para Regulación y Seguimiento de Trayectorias de Posi-ción para un Quadrotor. RIAI - Revista Iberoamericana de Automatica e InformaticaIndustrial, 14(2):141–151.
115

ANEXOS

ANEXOS 1: CONTROL PID

reset()
----------------------------------------------------------------------------------------------------------------------Planta----------------------------------------------------------------------------------------------------------------------
gp:=(-5.995*s+10.13)/(s^2+11.92*s+12.2)
-5.995s - 10.13s2 + 11.92s + 12.2
----------------------------------------------------------------------------------------------------------------------Polinomiodeseado----------------------------------------------------------------------------------------------------------------------Máximosobreimpulsode10%mp:=0.10.1
Tiempodeestablecimiento10Segundostsd:=1010
FactordeAmortiguamientozitad:=simplify(sqrt((log(mp)^2)/(PI^2+(log(mp)^2))))0.5911550338
FrecuenciaNaturalwnd:=(4.6/(zitad*tsd));0.778137669
PolinomioDeseadoPolosremanentesa10décadasde2*zita*wnBD:=collect((s^2+2*zitad*wnd*s+wnd^2)*(s+20*zitad*wnd)^2,s)s4 + 19.32s3 + 102.1734982s2 + 89.00996747s + 51.24937035
coffbd:=coeff(BD,s)1, 19.32, 102.1734982, 89.00996747, 51.24937035
----------------------------------------------------------------------------------------------------------------------ControladorPID----------------------------------------------------------------------------------------------------------------------C:=collect(kp*(1+1/(ti*s)+td*s/(N*s+1)),s)Nkpti + kptdtis2 + Nkp + kptis + kp
Ntis2 + tis
----------------------------------------------------------------------------------------------------------------------LazoCerrado----------------------------------------------------------------------------------------------------------------------SimplificaciónLazoCerrado+ControladorLC:=collect(simplify((gp*C)/(1+gp*C)),s)

LC:=collect(simplify((gp*C)/(1+gp*C)),s)1199.0Nkpti + 1199.0kptdtis3 + 1199.0Nkp + 1199.0kpti - 2026.0Nkpti - 2026.0kptdti
s2 + 1199.0kp - 2026.0Nkp - 2026.0kptis - 2026.0kp
- 200.0Ntis4
+ 1199.0Nkpti - 2384.0Nti - 200.0ti + 1199.0kptdtis3
+ 1199.0Nkp - 2384.0ti - 2440.0Nti + 1199.0kpti - 2026.0Nkpti - 2026.0kptdtis2
+ 1199.0kp - 2440.0ti - 2026.0Nkp - 2026.0kptis - 2026.0kp
Bc:=(collect(denom(LC)/(200*N*ti),s))
1.0s4 + 200.0ti + 2384.0Nti - 1199.0Nkpti - 1199.0kptdti200Nti
s3
+2384.0ti - 1199.0Nkp + 2440.0Nti - 1199.0kpti + 2026.0Nkpti + 2026.0kptdti
200Nti s2
+2440.0ti - 1199.0kp + 2026.0Nkp + 2026.0kpti
Nti200 s + 10.13kp
Nti
coeffbc:=coeff(Bc,s)
1.0,200.0ti + 2384.0Nti - 1199.0Nkpti - 1199.0kptdti
200Nti ,
2384.0ti - 1199.0Nkp + 2440.0Nti - 1199.0kpti + 2026.0Nkpti + 2026.0kptdti200Nti
,
2440.0ti - 1199.0kp + 2026.0Nkp + 2026.0kpti200Nti
, 10.13kpNti
----------------------------------------------------------------------------------------------------------------------Procesodeigualacióndepolinomios----------------------------------------------------------------------------------------------------------------------
a0:=coeff(Bc[1],s);a1:=coeff(Bc[4],s);a2:=coeff(Bc[5],s);a3:=coeff(Bc[3],s);a4:=coeff(Bc[2],s)1.0
200.0ti + 2384.0Nti - 1199.0Nkpti - 1199.0kptdti200Nti
2384.0ti - 1199.0Nkp + 2440.0Nti - 1199.0kpti + 2026.0Nkpti + 2026.0kptdti200Nti
2440.0ti - 1199.0kp + 2026.0Nkp + 2026.0kpti200Nti
10.13kpNti
b0:=coeff(BD[1],s);b1:=coeff(BD[2],s);b2:=coeff(BD[3],s);b3:=coeff(BD[4],s);b4:=coeff(BD[4],s)

b0:=coeff(BD[1],s);b1:=coeff(BD[2],s);b2:=coeff(BD[3],s);b3:=coeff(BD[4],s);b4:=coeff(BD[4],s)1
19.32
102.1734982
89.00996747
89.00996747
SolucióndeParámetrosKp,Td,TiyNsolve([a1=b1,a2=b2,a3=b3,a4=b4],[td,ti,kp,N])td = 0.003729613709, ti = 0.2539434612, kp = 0.2494429656, N = 0.1117905337

ANEXOS 2: CONTROL SSIOBSERVADOR

%--------------------------------------------------------------------------% Simulación de FJR% Realimentación de estados con Observador%--------------------------------------------------------------------------
PlantaAc = ss2.ABc = ss2.BCc = ss2.CDc = ss2.D
% Matriz de ControlabilidadMc_c = obsv(Ac, Cc);% Matriz de ObservabilidadMo_c = ctrb(Ac, Bc);
% Verificación de la Matriz de Controlabilidaddet(Mc_c)rank(Mc_c)% Verificación de la Matriz de Observabilidaddet(Mo_c)rank(Mo_c)
%--------------------------------------------------------------------------% Simulación del sistema FJR con Integrador%--------------------------------------------------------------------------Cnew_c = [Cc -Dc]Anew_c = [Ac [0;0];-Cc 0]Bnew_c = [Bc; 0]
% Polinomio deseado% Criterios de diseno: 10% Maximo sobreimpulso, ts : 10s% Se parte de un polinomio deseado de 2 orden con 1 polo remanete
pnew_c= [ -4.6000 + 0.0000i -0.4600 + 0.6276i -0.4600 - 0.6276i];
% Matriz de ControlabilidadMonew_c = obsv(Anew_c, Cnew_c);% Matriz de ObservabilidadMcnew_c = ctrb(Anew_c, Bnew_c);
% Verificación de la Matriz de Controlabilidaddet(Mcnew_c)rank(Mcnew_c)
% Verificación de la Matriz de Observabilidaddet(Monew_c)rank(Monew_c)
1

% Constante de realimentaciónKnew_c= place(Anew_c,Bnew_c,pnew_c)
k1_c = [Knew_c(1,1) Knew_c(1,2)];
k2_c = -Knew_c(1,3);
% Lazo cerradoStateSpaceFeedbackController = ss([Ac-Bc*k1_c Bc*k2_c;-Cc+Dc*k1_c -Dc*k2_c],[zeros(2,1);1],[Cc-Dc*k1_c Dc*k2_c],0);
step(StateSpaceFeedbackController)
%--------------------------------------------------------------------------% Observador de Orden completo%--------------------------------------------------------------------------
% Se plantea un sistema más rápido que el identificado con el mismo% Máximo sobreimpulso de 10%
% Parametros para contrucción del polinomio deseadozita_o = 0.5911550338ts_o = 1 % 10 veces más rápidown_o = 4.6/(ts_o*zita_o)
% Polinomio deseado del observador% Raices de un polinomio de segundo ordenp_o = [-4.6000 + 6.2761i; -4.6000 - 6.2761i]
% Matriz de realimentación del observador "L"L = place(Ac',Cc',p_o)
Ac =
-0.0179 -2.4790 8.6864 -7.6582
Bc =
-5.3357 -37.7950
Cc =
0.3941 -0.0348
Dc =
0
2

ans =
-0.2906
ans =
2
ans =
2.2477e+03
ans =
2
Cnew_c =
0.3941 -0.0348 0
Anew_c =
-0.0179 -2.4790 0 8.6864 -7.6582 0 -0.3941 0.0348 0
Bnew_c =
-5.3357 -37.7950 0
ans =
-5.0479e+04
ans =
3
ans =
0
3

ans =
2
Knew_c =
-0.2363 0.0904 -0.1240
zita_o =
0.5912
ts_o =
1
wn_o =
7.7814
p_o =
-4.6000 + 6.2761i -4.6000 - 6.2761i
L =
0.4649 -38.4807
4
Published with MATLAB® R2019b
5