compiler optimizations for memory hierarchy chapter 20 trishulc/ tseng/ high performance compilers
Post on 20-Dec-2015
222 views
TRANSCRIPT

Compiler Optimizations for Memory Hierarchy
Chapter 20
http://research.microsoft.com/~trishulc/ http://www.cs.umd.edu/~tseng/
High Performance Compilers forParellel Computing (Wolfe)
Mooly Sagiv

Outline
• Motivation
• Instruction Cache Optimizations
• Scalar Replacement of Aggregates
• Data Cache Optimizations
• Where does it fit in a compiler
• Complementary Techniques
• Preliminary Conclusion

Motivation
• Every year– CPUs are improving by 50%-60% – Main memory speed is improving 10%
• So what?• What can we do?
– Programmers– Compiler writers– Operating system designers– Hardware architectures
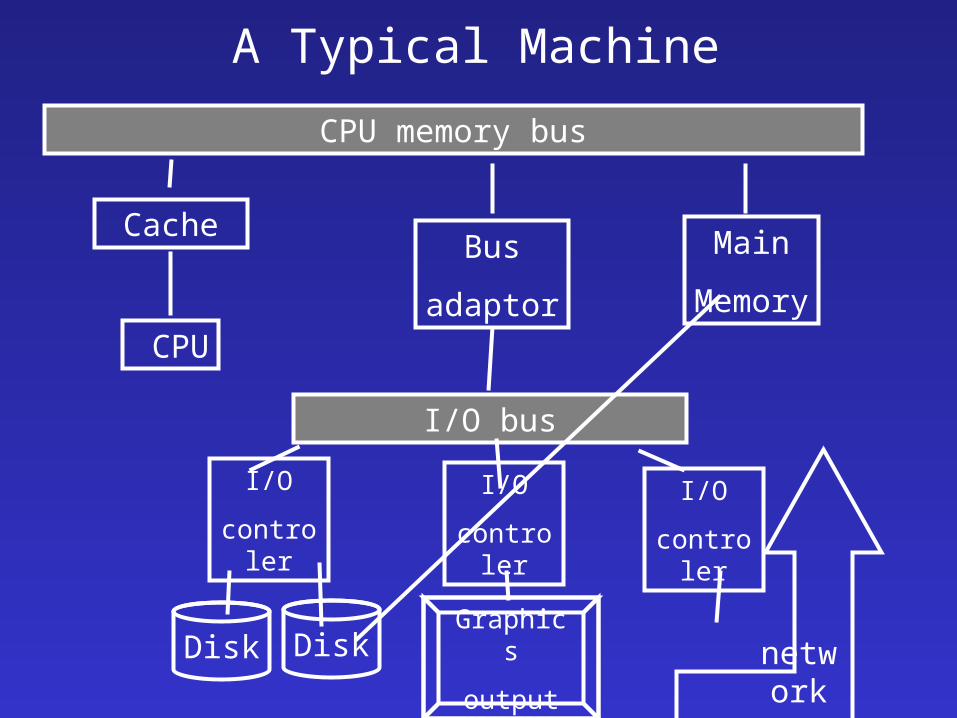
A Typical Machine
CPU memory bus
Cache
CPU
Bus
adaptor
Main
Memory
I/O bus
I/O
controler
Disk Disk
I/O
controler
Graphics
outputnetwo
rk
I/O
controler

Types of Locality in Programs• Temporal Locality
– The same data is accessed many times in successive instructions
– Example:while (…) { x = x + a;
}
• Spatial Locality– “Nearby” memory locations are accessed many times in
successive instructions– Example
for (i = 1; i < n; i++) { x[i] = x[i] + a; }

Compiler Optimizations forMemory Hierarchy
• Register allocation (Chapter 16)
• Improve locality
• Improve branch predication
• Software prefetching
• Improve memory allocation

A Reasonable Assumption
• The machine has two separate caches– Instruction cache– Data cache
• Employ different compiler optimizations– Instruction cache optimizations– Data Cache optimizations

Instruction-Cache Optimizations
• Instruction Prefecthing
• Procedure Sorting
• Procedure and Block Placement
• Intraprocedural Code Positioning(Pettis & Hensen 1990)
• Procedure Splitting
• Tailored for specific cache policy

Instruction Prefetching
• Many machines prefetch instruction of blocks predicted to be executed
• Some RISC architectures support “software” prefecth– iprefetch address (Sparc-V9)– Criteria for inserting prefetching
• Tprefetch - The latency of prefecting
• t - The time that the address is known

Procedure Sorting
• Interprocedural Optimization• Place the caller and the callee close to each
other• Applies for statically linked procedures• Create “undirected” call graph
– Label arcs with execution frequencies– Use a greedy approach to select neighboring
procedures
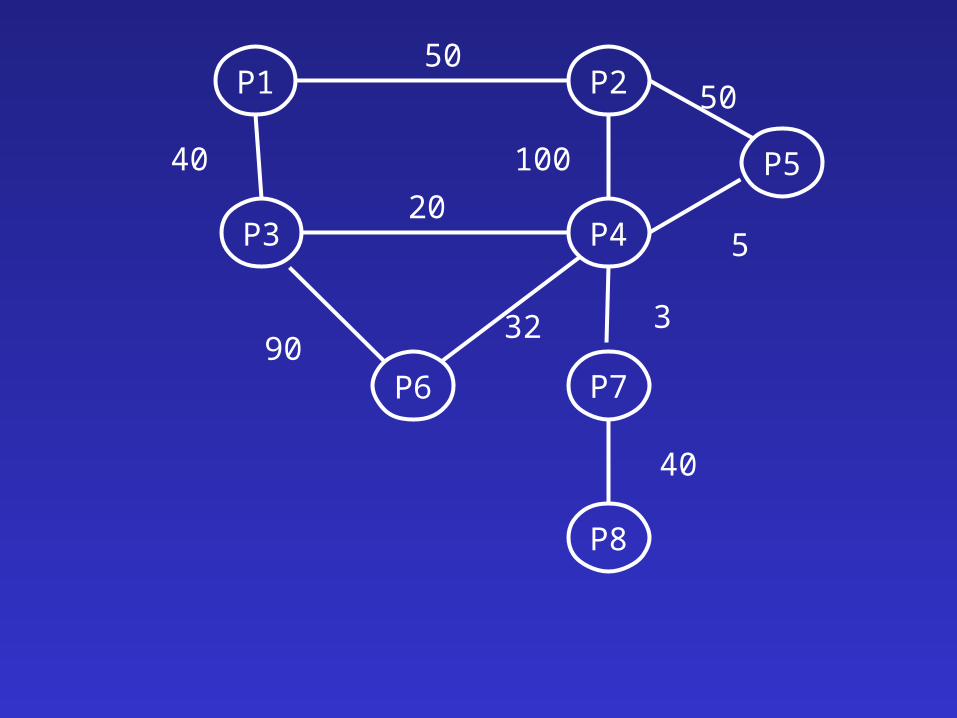
P1 P2
P3 P4
P5
P6 P7
P8
50
40
20
100
50
5
9032 3
40

Intraprocedural Code Positioning
• Move infrequently executed code out of main body
• “Straighten” the code• Higher fraction of fetched instructions are
actually executed• Operates on a control flow graph
– Edges are annotated with execution frequencies– Cover the graph with traces

Intraprocedural Code Positioning
• Input– Contrtol flow graph– Edges are annotated with execution frequencies
• Bottom-up trace selection– Initially each basic block is a trace– Combine traces with the maximal edge from tail to head
• Place traces from entry– Traces with many outgoing edges appear earlier– Successive traces are close
• Fix up the code by inserting and deleting branches
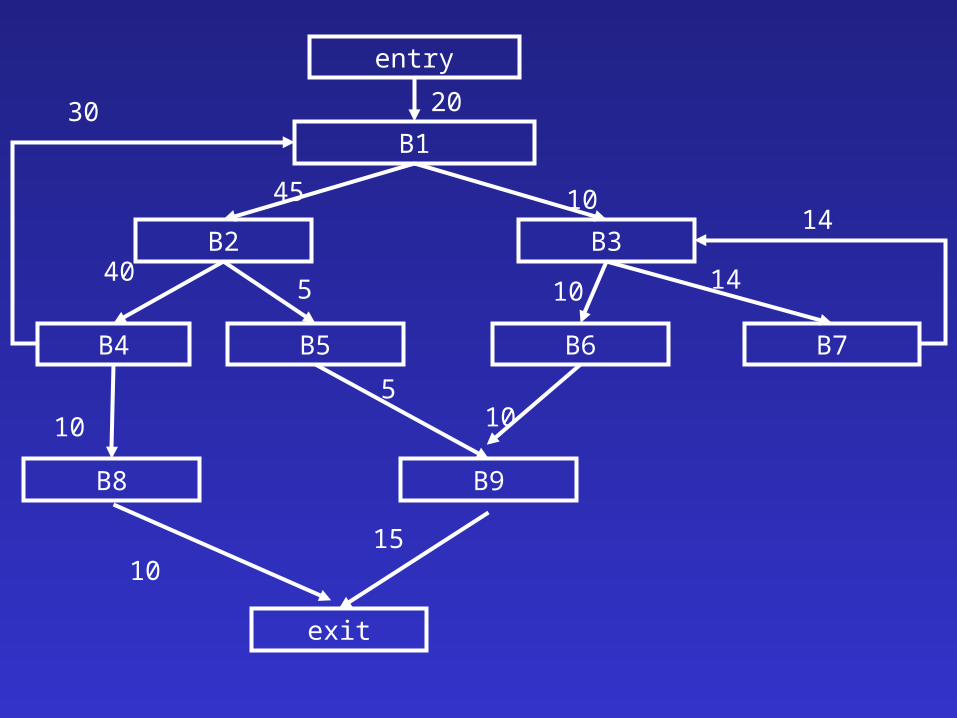
entry
B1
B2
B4 B5
B3
B7B6
B9B8
exit
20
4010
10
14
1445
30
10
5
510
1510

Procedure Splitting
• Enhances the effectiveness of – Procedure sorting– Code positioning
• Divides procedures into “hot” and “cold” parts
• Place hot code in a separate section

Scalar Replacement of Array Elements
• Reduce the number of memory accesses
• Improve the effectiveness of register allocation do i= 1..N
do j=1..N
do k=1..N
C(i, j)= C(i, j) + A(i, k) * B(k, j)
endo
endo
endo

Data-Cache Optimizations
• Loop transformations– Re-arrange loops in scientific code– Allow parallel/pipelined/vector execution– Improve locality
• Data placement of dynamic storage
• Software prefetching

Loop Transformations
• Loop interchange
• Loop permutation
• Loop skewing
• Loop fusion
• Loop distribution
• Loop tiling
Unimodular transformations

Tiling
• Perform array operations in small blocks
• Rearrange the loops so that innermost loops fits in cache (due to fewer iterations)
• Allow reuse in all tiled dimensions
• Padding may be required to avoid cache conflicts
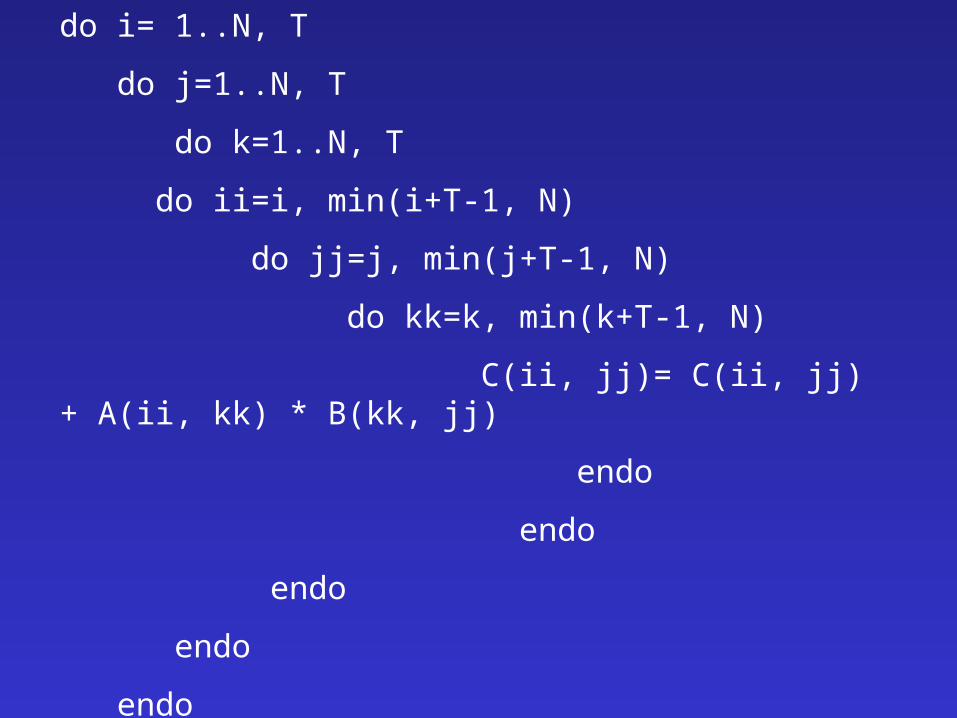
do i= 1..N, T
do j=1..N, T
do k=1..N, T
do ii=i, min(i+T-1, N)
do jj=j, min(j+T-1, N)
do kk=k, min(k+T-1, N)
C(ii, jj)= C(ii, jj) + A(ii, kk) * B(kk, jj)
endo
endo
endo
endo
endo
endo

Dynamic storage
• Improve special locality at allocation time• Examples
– Use type of data structure at malloc– Reorganize heap – Allocate the parent of tree node and the node close
• Useful information– Types– Traversal patterns
• Research Frontier
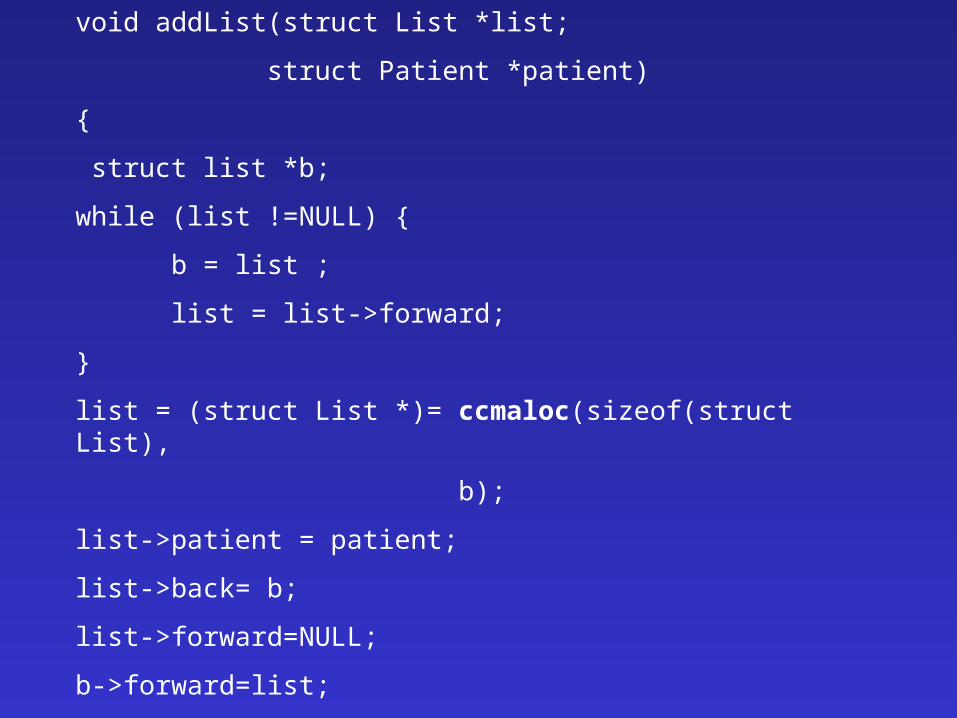
void addList(struct List *list;
struct Patient *patient)
{
struct list *b;
while (list !=NULL) {
b = list ;
list = list->forward;
}
list = (struct List *)= ccmaloc(sizeof(struct List),
b);
list->patient = patient;
list->back= b;
list->forward=NULL;
b->forward=list;
}

Software Prefetching
• Requires special hardware (Alpha, PowerPC, Sparc-V9)
• Reduces the cost of subsequent accesses in loops
• Not limited to scientific code
• More effective for large memory bandwidth

struct node {int val;
struct node *next ;
}
…
ptr= the_list->head;
while (ptr->next) {
…
ptr= ptr->next
struct node {int val;
struct node *next ;
struct node *jump;
}
…
ptr= the_list->head;
while (ptr->next) {
prefetch(ptr->jump);
…
ptr= ptr->next
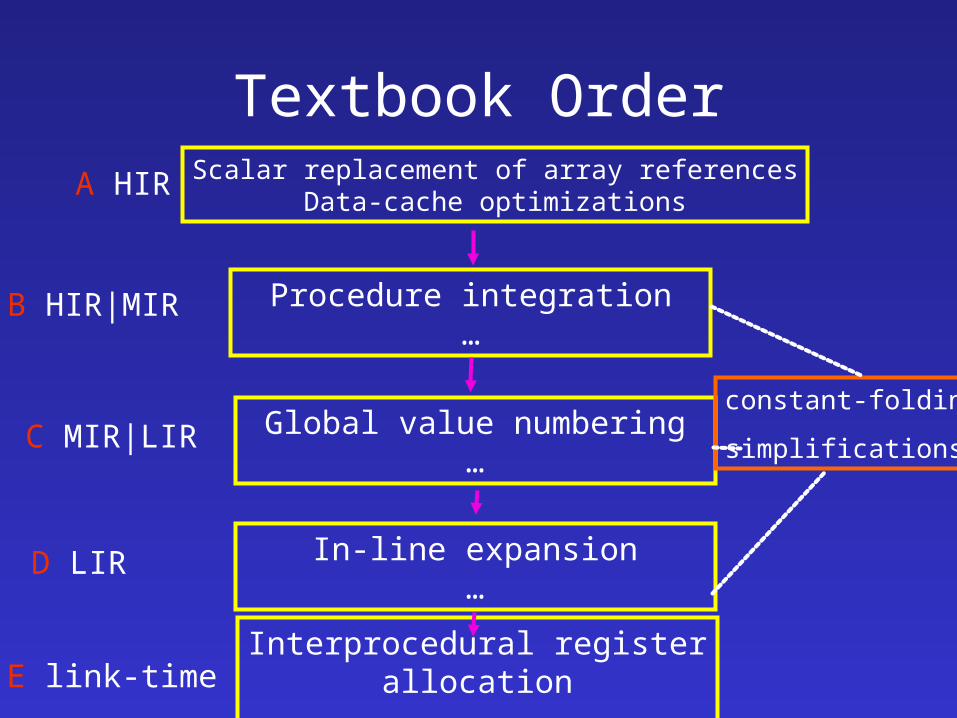
Textbook OrderScalar replacement of array references
Data-cache optimizationsA HIR
Global value numbering…
C MIR|LIR
Procedure integration…
B HIR|MIR
In-line expansion…
D LIR
Interprocedural register allocation…
E link-time
constant-folding
simplifications

LIR(D)
constant-folding
simplifications
Inline expansion
Leaf-routine optimizations
Shrink wrapping
Machine idioms
Tail merging
Branch optimization and conditional moves
Dead code elimination
Software pipelining, …
Instruction Scheduling 1
Register allocation
Instruction Scheduling 2
Intraprocedural I-cache optimizations
Instruction prefetching
Data prefertching
Branch predication

Link-time optimizations(E)
Interprocedural register allocation
Aggregation global references
Interprcudural I-cache optimizations

Complementary Techniques
• Cache aware data structures
• Smart hardware
• Cache aware garbage collection

Preliminary Conclusion
• For imperative programs current I-cache optimizations suffice to get good speed-ups (10%)
• For D-cache optimizations:– Locality optimizations are effective for regular
scientific code (46%)
– Software prefetching is effective with large memory bandwidth
– For pointer chasing programs more research is needed
• Memory optimizations is a profitable area