compiling application-specific hardware mihai budiu seth copen goldstein carnegie mellon university
Post on 21-Dec-2015
219 views
TRANSCRIPT

Compiling Application-Specific Hardware
Mihai Budiu
Seth Copen Goldstein
Carnegie Mellon University

Resources

Problems
• Complexity
• Power
• Global Signals
• Limited issue window => limited ILP
We propose a scalable architecture

Outline
• Introduction• ASH: Application Specific Hardware
• Compiling for ASH• Conclusions

Application-Specific HardwareC program
Compiler
Dataflow IR
Reconfigurable hardware

Our Solution
General: applicable to today’s software - programming languages
- applications
Automatic: compiler-driven
Scalable: - run-time: with clock, hardware - compile-time: with program size
Parallelism: exploit application parallelism

Asynchronous Computation
+
data
datavalid
ack

New
• Entire C applications
• Dynamically scheduled circuits
• Custom dataflow machines
- application-specific
- direct execution (no interpretation)
- spatial computation

Outline
• Scalability• Application Specific Hardware• CASH: Compiling in ASH
• Conclusions

CASH: Compiling for ASH
Memory partitioning
Interconnection net
Circuits
C Program
RH

Primitives+Arithmetic/logic
Multiplexors
Merge
Eta (gateway)
Memory
data
predicates
datapredicate
ld st

Forward Branches
if (x > 0) y = -x;
elsey = b*x;
*
xb 0
y
!
- >
Decoded mux
Conditionals => Speculation

Critical Paths
if (x > 0) y = -x;
elsey = b*x;
*
xb 0
y
!
- >
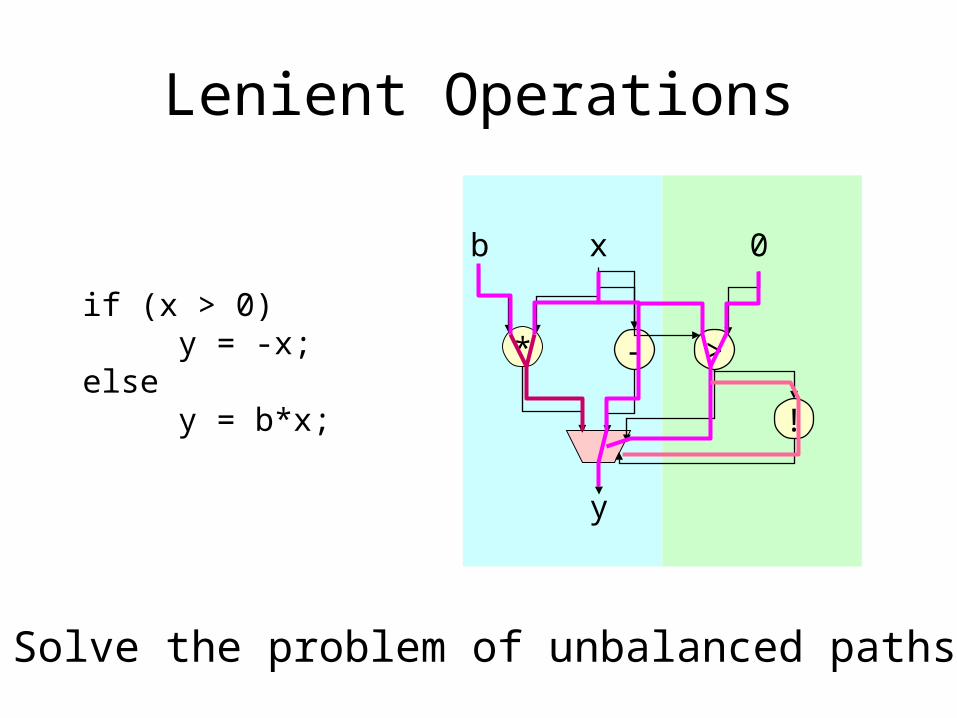
Lenient Operations
if (x > 0) y = -x;
elsey = b*x;
*
xb 0
y
!
- >
Solve the problem of unbalanced paths
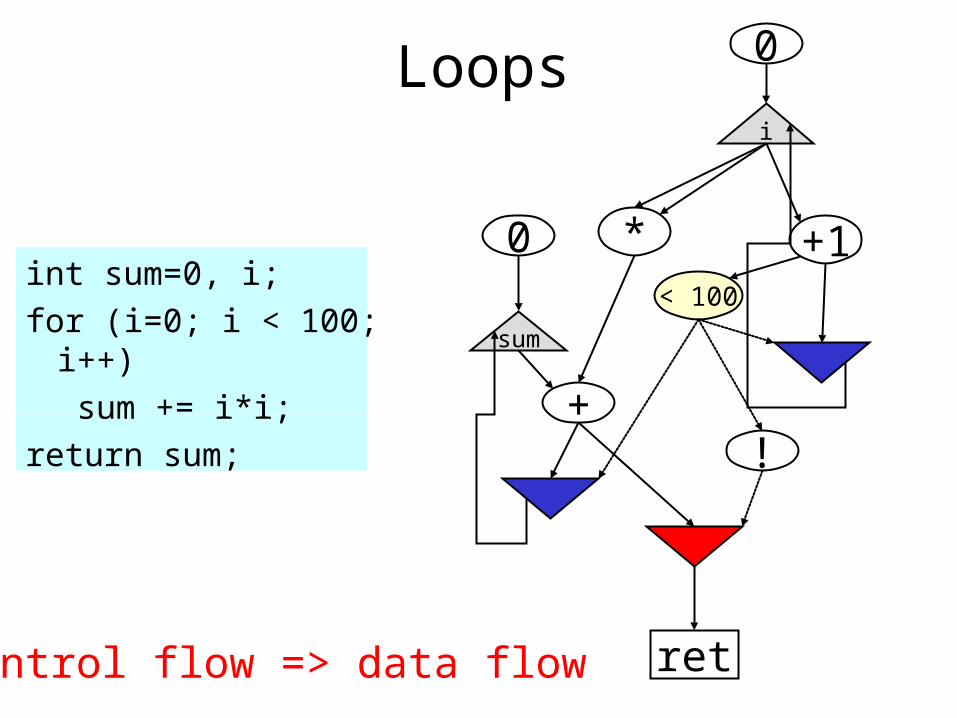
!
ret
i
+1< 100
0
*
+
sum
0
Loops
int sum=0, i;
for (i=0; i < 100; i++)
sum += i*i;
return sum;
Control flow => data flow

Compilation
• Translate C to dataflow machines
• Optimizationssoftware-, hardware-, dataflow-specific
• Expose parallelism – predication– speculation– localized synchronization– pipelining

Pipeliningi
+
<=
100
1
*
+
sum
pipelinedmultiplier
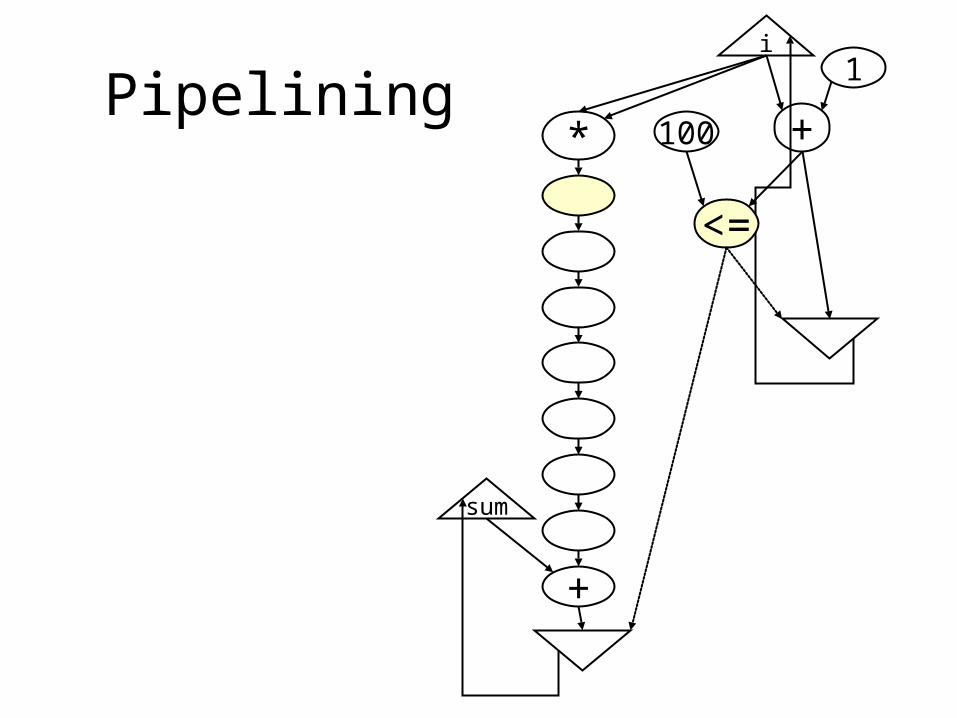
Pipeliningi
+
<=
100
1
*
+
sum

Pipeliningi
+
<=
100
1
*
+
sum

Pipeliningi
+
<=
100
1
*
+
sum

Pipeliningi
+
<=
100
1
*
+
sum
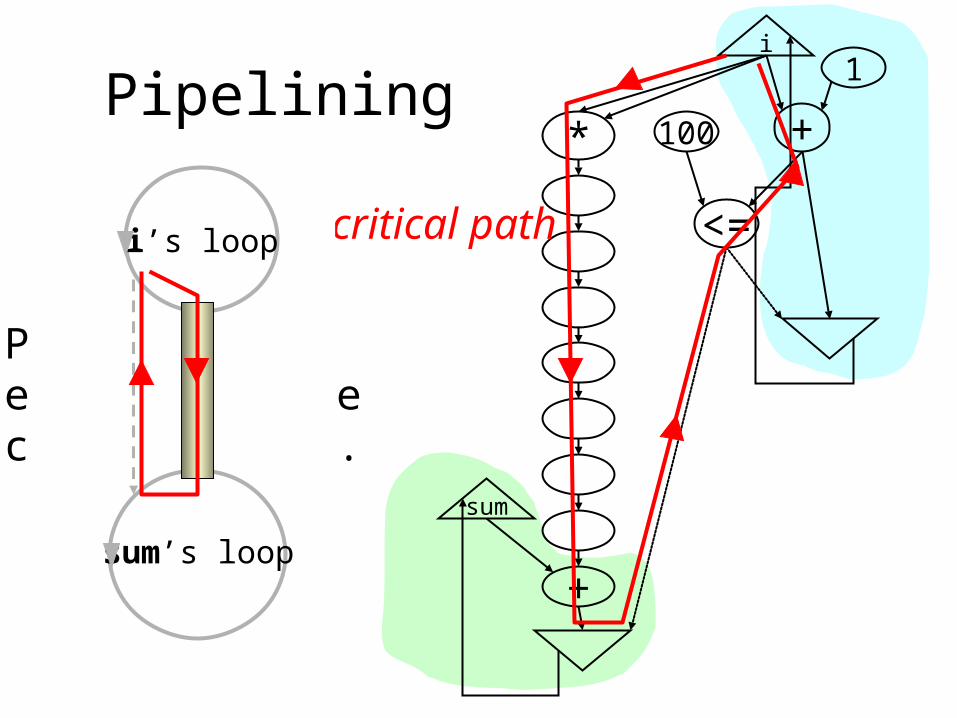
i’s loop
sum’s loop
Longlatency pipe

Pipeliningi
+
<=
100
1
*
+
sum

Pipeliningi
+
<=
100
1
*
+
sum
i’s loop
sum’s loop
Longlatency pipe
predicate
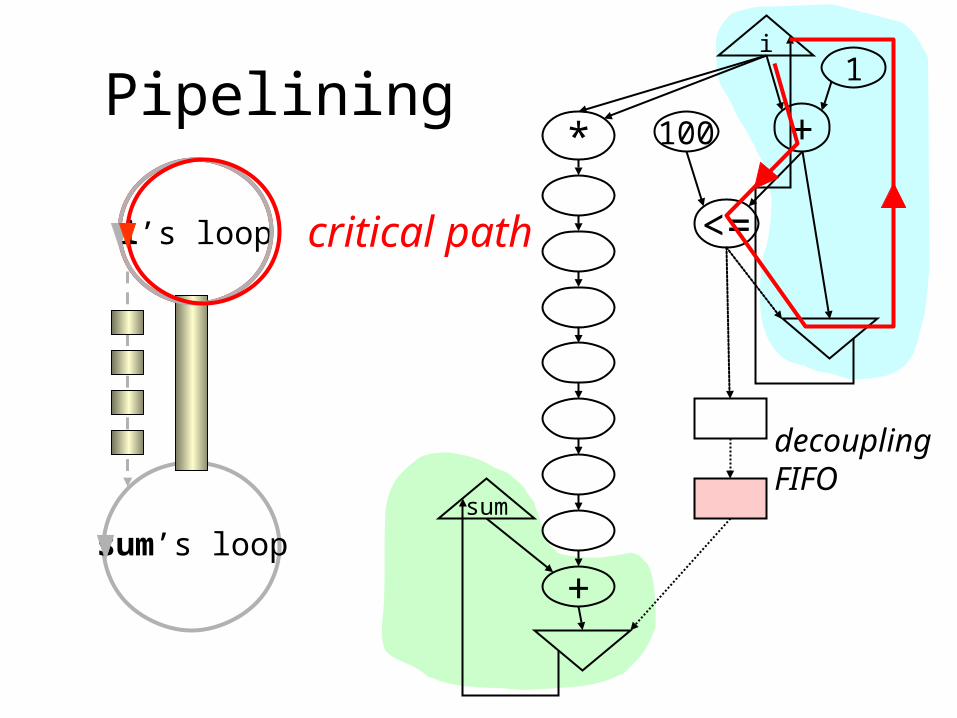
Predicate ackedge is on thecritical path.
Pipeliningi
+
<=
100
1
*
+
sum
critical pathi’s loop
sum’s loop
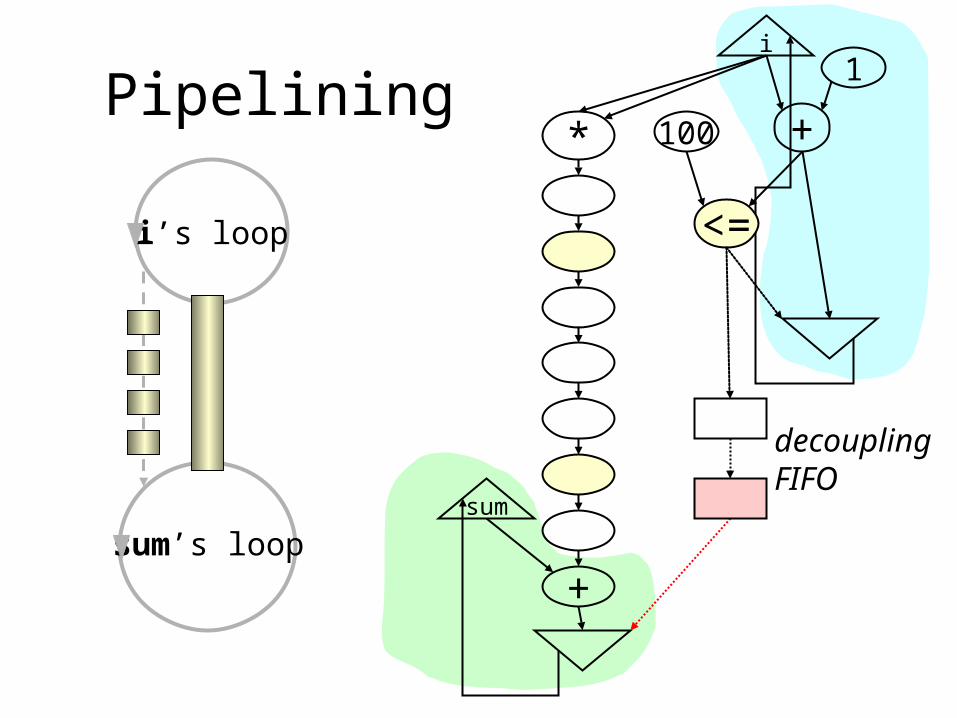
Pipeliningi
+
<=
100
1
*
+
sum
i’s loop
sum’s loop
decouplingFIFO
Pipeliningi
+
<=
100
1
*
+
sum
i’s loop
sum’s loop
critical path
decouplingFIFO

ASH Features
• What you code is what you get– no hidden control logic– lean hardware
(no CAM, multi-ported files, etc.)– no global signals
• Compiler has complete control
• Dynamic scheduling => latency tolerant
• Natural ILP and loop pipelining

Conclusions
• ASH: compiler-synthesized hardware from HLL
• Exposes program parallelism
• Dataflow techniques applied to hardware
• ASH promises to scale with:
– circuit speed
– transistors
– program size

Backup slides
• Hyperblocks• Predication• Speculation• Memory access• Procedure calls• Recursive calls• Resources• Performance

Hyperblocks
Procedure back
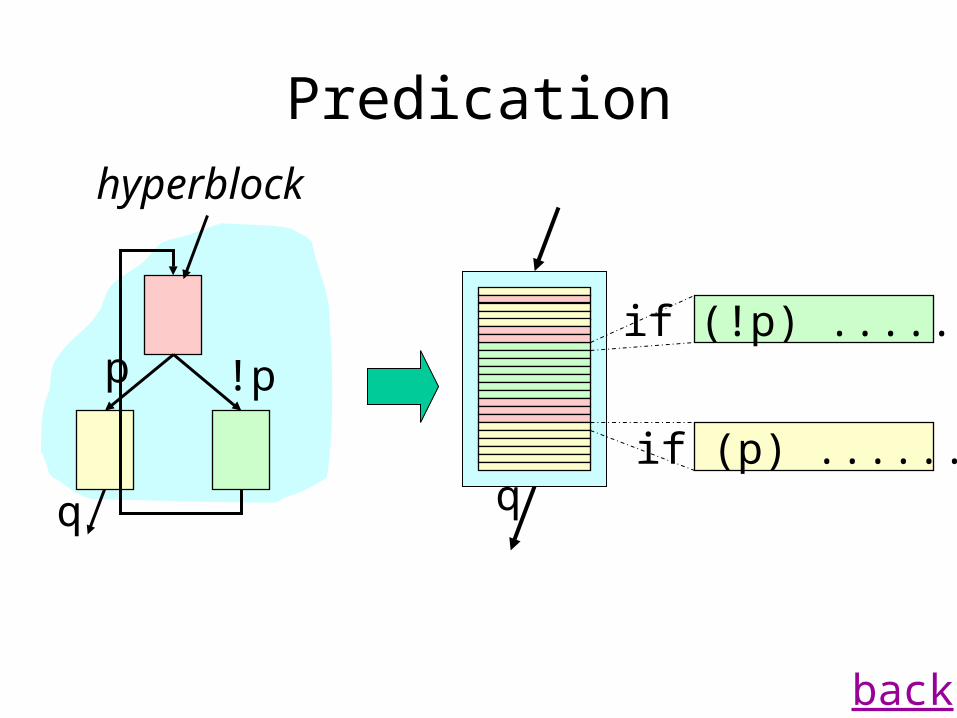
Predication
p !p
q
if (p) .......q
if (!p) .......
hyperblock
back

Speculation
q
if (!p) ......
q
if (!p) ......
ops w/ side-effects
back
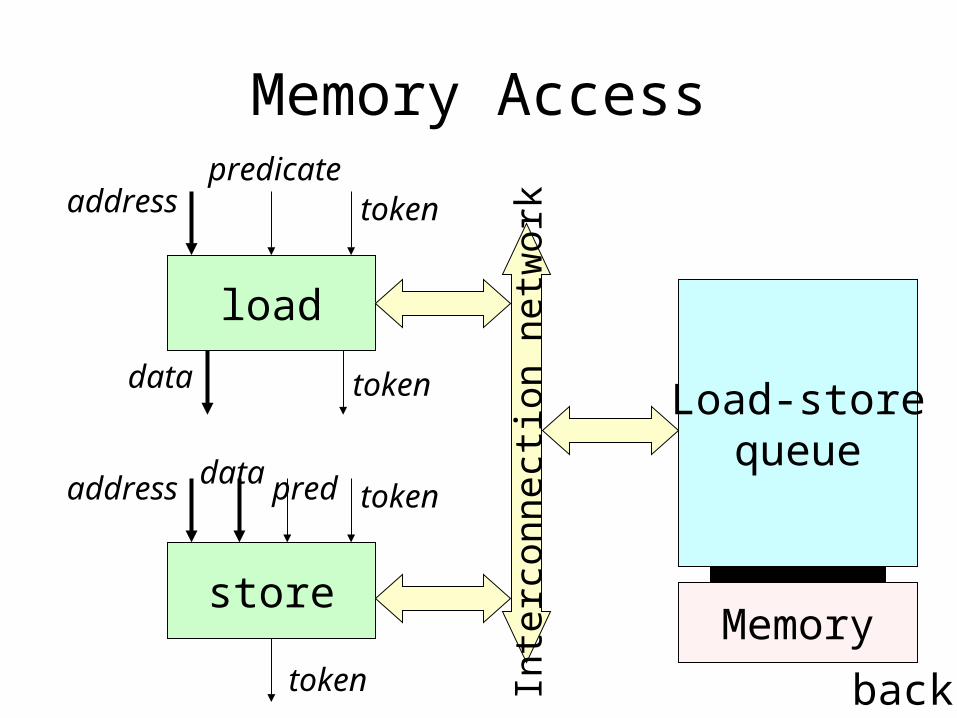
Memory Access
back
load
addresspredicate
token
tokendataLoad-store
queue
store
address pred token
token
data
Inte
rcon
nect
ion
netw
ork
Memory
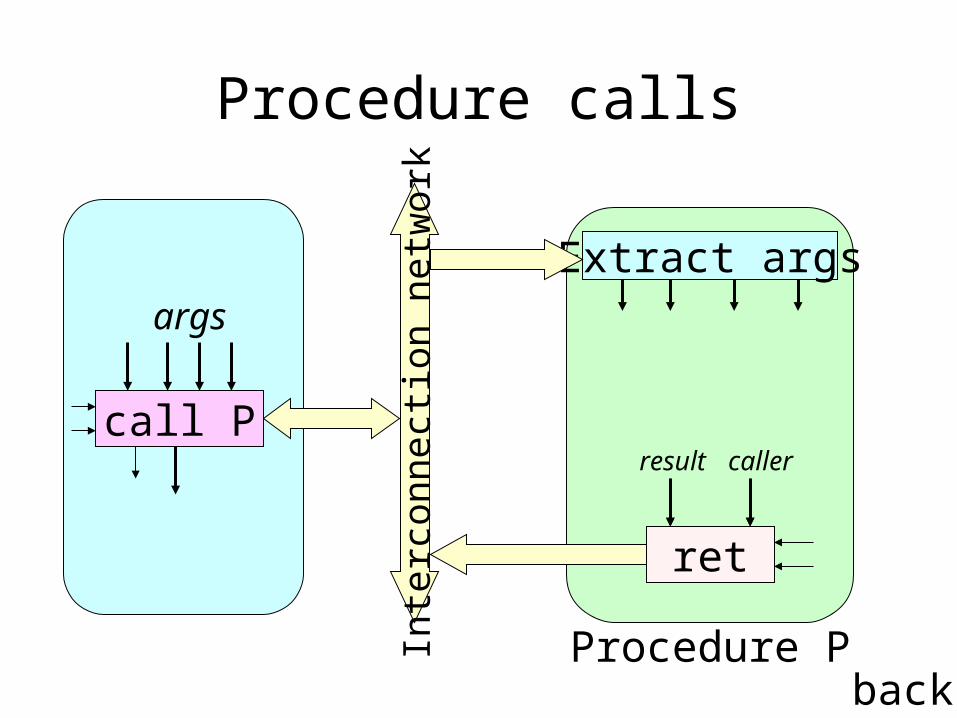
Procedure calls
back
Inte
rcon
nect
ion
netw
ork
Extract args
ret
result caller
Procedure P
call P
args

Recursion
recursive call
save live values
restore live values
hyperblock
stack
back

Resources
• Estimated SpecINT95 and Mediabench
• Average < 100 bit-operations/line of code
• Routing resources harder to estimate
• Detailed data in paper
back

Performance• Preliminary comparison with 4-wide OOO• Assumed same FU latencies• Speed-up on kernels from Mediabench
0
0.5
1
1.5
2
2.5
3
3.5
adpc
m_e
adpc
m_d
gsm
_e
gsm
_d
epic_
e
epic_
d
mpe
g2_d
jpeg_
e
pegw
it_e
pegw
it_d
g721
_e
g721
_d
back