computational challenges sean eddy hhmi janelia farm research campus
TRANSCRIPT

Computational challenges
Sean Eddy
HHMI Janelia Farm Research Campus

My charge
2008: 2 Tb 2009: 32 Tb 2010: 150 Tb 2011: 165 Tb
How will we keep up with this?
• maintaining/annotating quality • storage• communication (network bandwidth)• analysis (including software and databases)• integration

Ewan BirneyMichael BrentJeremy BuhlerGoran CericBarak CohenRichard DurbinJonathan EisenRob FinnPaul GardnerIan HolmesScott Hunicke-SmithRob KnightDavid KonerdingSaul KravitzAnthony LeonardoRob MitraRyan RichtJason StajichLincoln SteinGranger Sutton George WeinstockRick Wilson
Dan Meiron Dept. of Applied & Computational Mathematics and Aeronautics, Caltech
Steven Brenner UC Berkeley
David Dooling WashU Genome Center
Vivien Bonazzi and Adam Felsenfeld NIH NHGRI
http://cryptogenomicon.org

FY09 NHGRI: $488M about 40M databases
about 60M informatics
FY09 NIH: $29,000M
HHMI: $760MJanelia Farm alone: $120M
• Informatics challenges affect all biomedical research
• NHGRI lacks resources to solve these problems alone
• First planning priority is dealing with NHGRI’s own data well
At the same time:
• lead and catalyze -- show others how to do it; best practices
• work together -- NCBI, EBI, NCI, others share our problems.
CERN: $1000MSLAC: $300MLSST: $45M (start 2015)

Data volume per se is not the problem.

250 TB12 TB
GIG Data Capacity (Services, Transport & Storage)
UUVsSe
nsor
Dat
a Vo
lum
e2000 Today 2010 2015 & Beyond
PREDATOR UAV VIDEO
GLOBAL HAWK DATAGLOBAL HAWK DATA
Future Sensor XFuture Sensor X
Future Sensor YFuture Sensor Y
Larg
e Data JC
TD
Future Sensor ZFuture Sensor Z
Theater Data Stream (2006):~270 TB of NTM data / year
Example: One Theater’s Storage Capacity:
2006 2010
1018
1012
1024
Yottabytes
Exabytes
Terabytes
1015
Petabytes
1021
Zettabytes
FIRESCOUT VTUAV DATAFIRESCOUT VTUAV DATA
Capability Gap
Bob Gourleyhttp://ctovision.typepad.com/InfoSharingTechnologyFutures.ppt
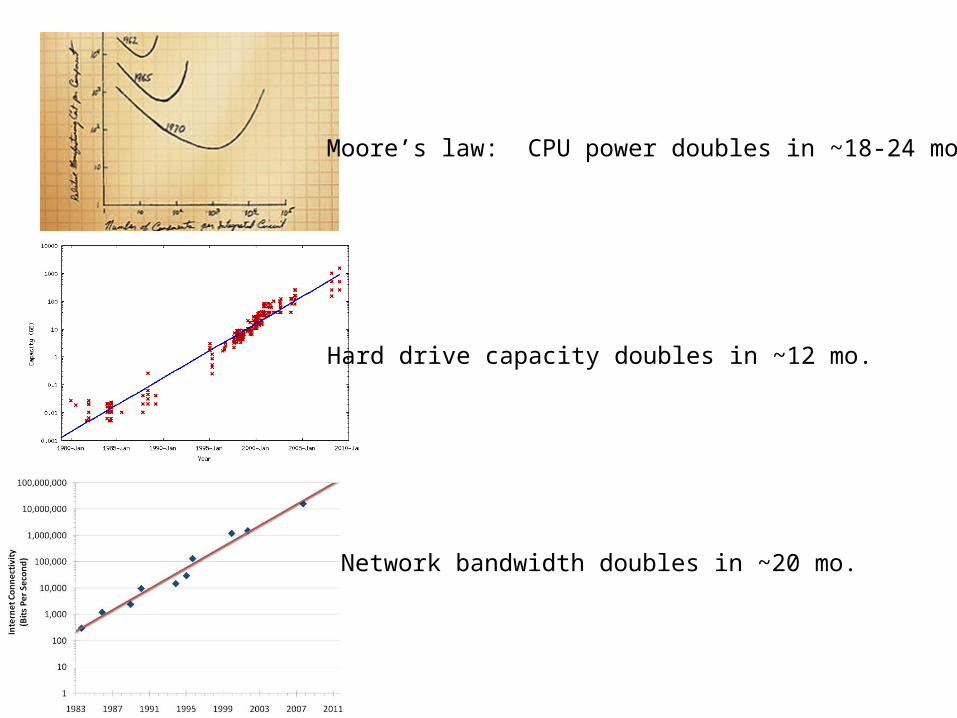
Moore’s law: CPU power doubles in ~18-24 mo.
Hard drive capacity doubles in ~12 mo.
Network bandwidth doubles in ~20 mo.

Fundamental computing capabilities should increase:7-10x in 5 years
50-100x in 10 years
We project in 3-5 years:100x increase in sequencing volume
Therefore: yes, next-gen sequencing tech bumps us up;
and we can’t just sit on our hands; but we only have to be a little more clever

Fortunately, we are not alone.

For example: Microsoft is constructing a new $500M data center in Chicago. Four new electrical substations totalling 168 MW power.
About 200 40’ truckable containers, each containing ~1000-2000 servers.Estimated 200K-400K servers total.
Comparisons to Google, Microsoft, etc. aren’t entirely appropriate;scale of their budgets vs. ours aren’t comparable.
Google FY2007: 11.5B; ~ $1B to computing hardware
Though they do give us early warning of coming trends:(container data centers; cloud computing)
Private sector datasets and computing capacity are already huge.
Google, Yahoo!, Microsoft: probably ~100 PB or soEbay, Facebook, Walmart: probably ~10 PB or so

CERN Large Hadron Collider (LHC)
~10 PB/year at start~1000 PB in ~10 years
2500 physicists collaborating
http://www.cern.ch

Pan-STARRS (Haleakala, Hawaii)US Air Forcenow: 800 TB/year soon: 4 PB/year
Large Synoptic Survey Telescope (LSST)NSF, DOE, and private donors
~5-10 PB/year at start in 2012~100 PB by 2025
http://www.lsst.org; http://pan-starrs.ifa.hawaii.edu/public/

1. Petabyte data volumes are manageable using commodity tech
Pan STARRS: 80 “data bricks”, RAID-6; 3 PB for ~$1M

2. Just because you can store raw data doesn’t mean you should
data filtering at the sourceand at every stop along the way
using strategy appropriate to a particular experiment/analysis
CERN LHC Atlas detector generates 105 more data than is stored
(40 million events/sec 200/sec stored)
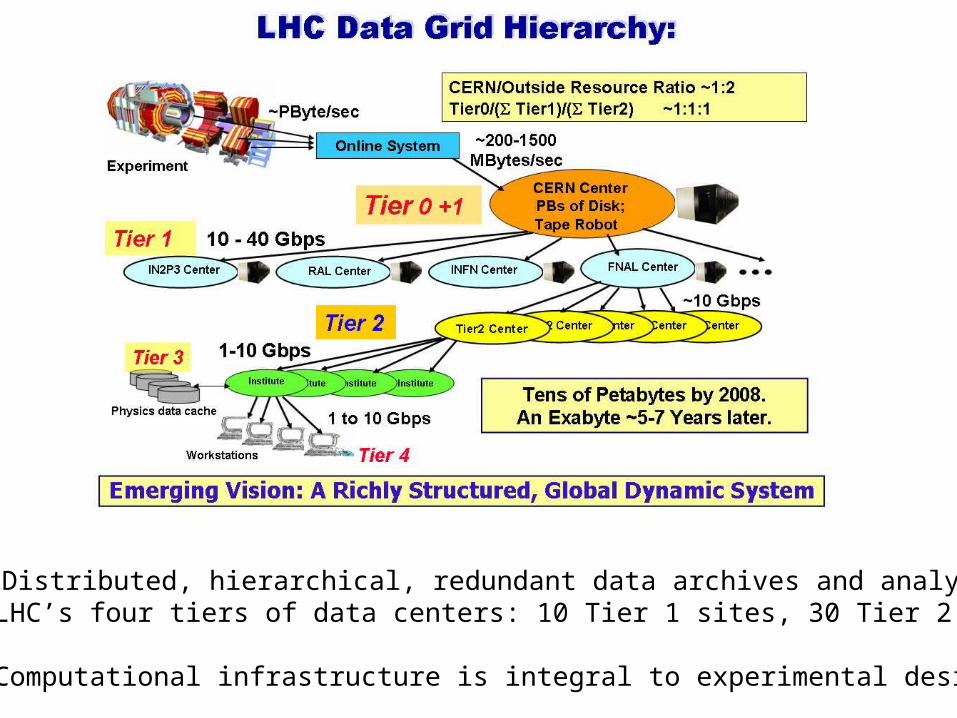
3. Distributed, hierarchical, redundant data archives and analysis(CERN LHC’s four tiers of data centers: 10 Tier 1 sites, 30 Tier 2 sites)
4. Computational infrastructure is integral to experimental design

Hardware technology is important, but is not where we are stressed.
Our single most important problem is
the democratization of sequence analysis.
Biology has become an informatics- and data-heavy science,but we lack a culture that supports pervasive computational analysis
Our weak links are computational infrastructure and the training and expertise of bench scientists.

one genome
cloning, mapping, sequencing
assembly
ge
no
me
cen
ter
international DNA databases
The good old days:

PI’s lab
genome centers
ENCODE centers,CEGS
departmentalcore sequencers
international databases
genome browsers
model organismdatabases
boutique databases
supplementary material
referencegenome assemblies
comparative sequence
transcript sequence
ChIP-seq, CLIP-seq
resequencing(mutants, variants)
phenotype data
1. Evolving toward a tiered structure (like physics/astronomy)
2. Must integrate lots of different data (unlike physics/astronomy)

A return to a paper as a unit of advance, not a genome
The output of genome sequencing and assembly is simple, modular, and well-understood, including the associated quality metrics
This meant we could shoot pre-publication data into the databasesand it was useful
Now that next-gen sequencing is a multipurposed digital assay tool:Details of methods, experimental design, and analysis all matter again
we’ve been calling this information “metadata”,as if it were merely a db format issue to solve with XML;it is not. it’s the information in a properly written paper.

For an individual PI’s lab to generate reliable/reusable datasets, integrate them with other datasets, conduct large-scale computational analyses, and write great papers, with results that can in turn be integrated with others;
Those individual labs need good software for mapping/assembling sequenceaccess to reliable, modular, well-annotated datasets good software for integrated data analysisefficient means of sharing/distributing their datasets
Democratization means:

Availability of good software.
Availability of other datasets in a form that can be most readily integrated into analysis workflows.
Computing infrastructure to do the work.
Bottlenecks (challenges, opportunities):

Software and database infrastructure requiresengineering discipline and science
Our culture values science, not engineering
Commercialization path largely hasn’t worked: why? market too small? too dynamic? poisoned by open source?
The main challenge with software:
The result: a software literature full ofgood ideas that don’t get fully baked;
tools that work in one place but aren’t portable
Commercialization isn’t a complete answer anyway:tools themselves are research, require open publication

Suggested approach to better software:
There is currently little support niche forthe engineering of robust research software inbiology (exceptions include NCI caBIG; NCBI)
“Centers of excellence” in software engineeringcould be established to harden/productize research
tools while they’re still in R&D phase:reward engineering for its own sake
(compare Tech D funding at genome centers)
Encourage commercialization of stable tools oncethey’ve left R&D phase: SBIR mechanisms
compare Road Map NCBCs: http://www.ncbcs.org

One desired outcome:earlier, more widespread adoption
of analysis best practices
(no more using BLAST to map short reads)
more efficient use of time and computational resources;
less big iron and less global warming required.

The main challenges with datasets:
overly reliant on monolithic, overly centralized international databases
versioning: instability of coordinate systemsinterferes with data integration
poor ability to improve annotation and qualityof archived data

An aggregated monolithic database makes senseif you’re going to search it all at once
Historically, we think in terms of the sequence databases and homology searches
Literature, text search also makes sense (Google)
But does a monolithic archive make sense for all data?
For example: is the Short Read Archive useful?

An approach for better datasets: modularity
Do one thing well; define standards for input/output so tools can be chained
together in powerful combinations.
Akin to CERN/LHC tiered structure, where each tier digests data from previous tier, addingnew information while compressing the previous.
Example: I really don’t want the raw short reads from your ChIP-seq experiment; I want the histogramof them mapped to a reference genome, with defined
methods and reliability measures
modularity rather than tiers because our data isn’ta hierarchical single experiment like the LHC

The lowest level of modularity is supplementary material
Supplementary material should be electronicdatasets in standard exchange formatssuitable for integration with other data
(not an unreviewed, wordy alternative version of the same paper to circumvent page limits)
Not an NHGRI problem; a community problem requiring consciousness-raising and commitment at journals
R. Gentleman, Reproducible research: a case study. Stat Appl Genet Mol Biol 4:Article2 (2005)
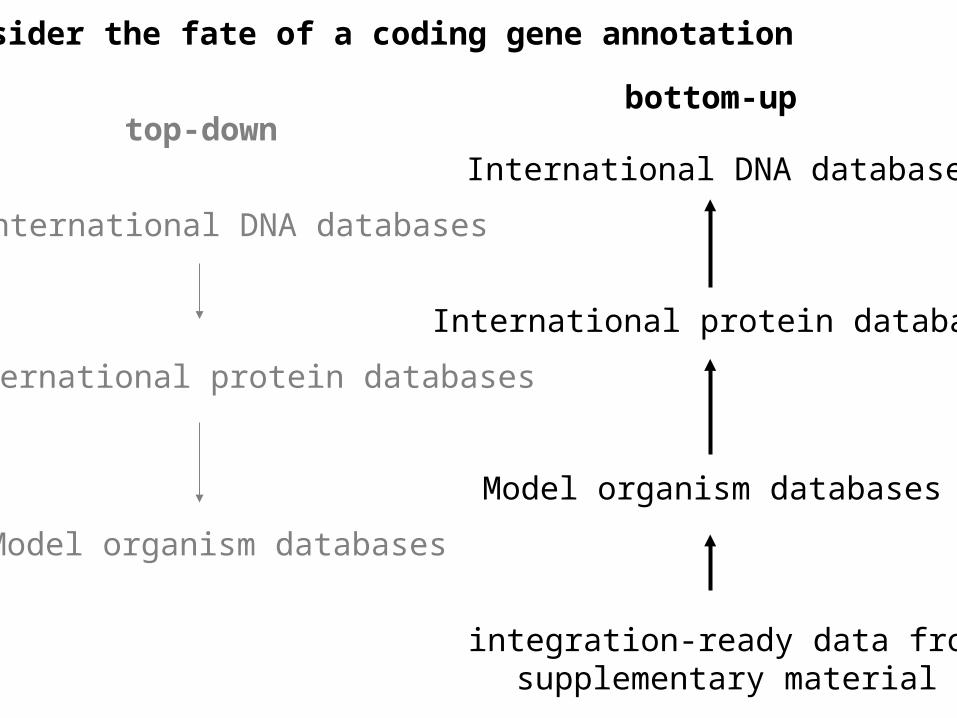
top-downbottom-up
International DNA databases
International protein databases
Model organism databases
consider the fate of a coding gene annotation
integration-ready data fromsupplementary material
Model organism databases
International protein databases
International DNA databases

main challenge with computing infrastructure:
Efficient large-scale analysis and data requires data centers
Data centers exhibit strong economies of scale,due to load balancing, space, cooling, power, staffing
Most individual labs cannot justify cost of anefficient data center, nor can they keep it loaded
NIH traditionally funds at individual lab level
Individual labs are wasting money on subscaled computing

Example: the Janelia Farm data center
circa 2006:528 nodes (1056 cores): 480 w/ 4 GB RAM,
40 w/ 8 GB RAM, 8 w/ 64 GB RAM
1 gigabit to each node; 10 gigabit between racks
EMC DMX-3 + 8 EMC Celerra file servers;MPFSi (parallel NFS)
200 TB disk; 1 PB offline backup
crucially: entire datacenter is accessibleon our desktops (no transfer lag in/out)
2 full time staff (including one demigod); $3M capital expense, recurring every 3 years;
serves ~40 labs with widely mixed needs

Approaches to computational infrastructure:
• Enable department- or institute-level data centers (NCRR? however, requires plan for the 3-year technology refresh rate; more a consumable than a capital expense)
• Web services (“SOA”, “service-oriented architecture”) For certain well-defined computational tasks, a remote server can process a query and return a formatted answer. includes annotation/integration problems: DAS, for example.
• Cloud computing For arbitrary computational tasks, you can create a virtual machine image, send it to a remote server, and have it execute there. “move the compute to the data”: large datasets can be hosted

Recommendations:
1. Develop “centers of excellence” for software engineering.
2. Modularize the organization of databases for key genomic resources, reduce reliance on monolithic centralized archives: think tiers, except not in a hierarchy.
3. Strengthen that modularity all the way down to the level of supplementary material in publications: reproducible methods, integration-ready results
4. Plan for hardware infrastructure at department, institute level
5. Catalyze development of web services and cloud computing resources, especially on hosted large datasets
6. Engage resources outside traditional biology: create “grand challenges” attractive to high-performance computing community