computer science integrity assurance for outsourced databases without dbms modification dbsec 2014...
TRANSCRIPT

Computer Science
Integrity Assurance for Outsourced Databases without DBMS Modification
DBSec 2014
Wei Wei, Ting Yu
1

Computer Science
Overview
Motivationo Database outsourcing is a cost-effective solutiono Integrity for Outsourced Databases
It has been an active research area in decades Existing solutions requires modifying DBMSs No existing cloud database services support integrity checking
Our Focuso Provide integrity assurance for outsourced databases without DBMS
modification
Basic Ideao Build a Merkle Hash Tree based Authenticated Data Structure per tableo De-serialize authentication data into tables with well-designed format
Support highly efficient authentication data retrieval
2

Computer Science
Database Outsourcing Model
3
id col1 … coln
0 Alice … 1000
10 Ben … 2000
… … … …
70 Smith … 4500
• Database Service Provider
(DSP)
• Data Owner
• Clients
• Upload Data and Authentication Data
• Send Data Queries and Authentication Data Queries
• Update Data and Authentication Data
• Query Results Including Data and Authentication Data

Computer Science
System Model
Assumptionso DSPs are not fully trusted by data owners and clientso The data owner has a public/private key pair, and public key is known
to allo The data owner is the only party who can update datao Public communications are through a secure channel
Attacks from a DSPo Return incorrect data by tampering some datao Return incomplete data result by discarding some datao Report that data doesn’t exist or return old data
4

Computer Science
System Model cont’d
Goalo Provide integrity assurance for outsourced databases without DBMS
modification
Design Goalso Security (Integrity)
Correctness, completeness, freshness
o Practicability Simplicity, flexibility, efficiency
5

Computer Science
Running Example
6
id col1 col2 col3 col4 … coln
0 Alice F 20 NC … 1000
10 Ben M 30 NY … 2000
20 Cary F 42 CA … 1500
30 Lisa F 15 CA … 3000
40 Kate F 18 NY … 2300
50 Mike M 24 SC … 4000
60 Nancy F 36 VA … 2300
70 Smith M 12 TA … 4500
• A Relational Data Table

Computer Science
System Design
Authentication Data Structure Identify Authentication Data Store Authentication Data Extract Authentication Data
7

Computer Science
Authentication Data Structure
8
id col1 … coln
0 Alice … 1000
10 Ben … 2000
20 Cary … 1500
30 Lisa … 3000
40 Kate … 2300
50 Mike … 4000
60 Nancy … 2300
70 Smith … 4500
• 40
• 20
• 10
• 30
• 60
• 0• 1
0• 3
0• 2
060 7040 50
• 50
• Data Table • Merkle B-tree
• p
i
• k
i
• … • …• hi=H(h1|…|hf)
Signature Aggregation based ADS Merkle Hash Tree based ADS

Computer Science
Identify Authentication Data
9
Existing Approacheso Adjacency list
Multiple steps to find ancestor, no order of pointers or records in a node
o Path enumeration No order of pointers or records in a node, inefficient string operation
o Nested set Require joining two tables to find parent node, hard to find siblings
o Closure table Consume more storage, no order of pointers or records in a node
Our Approacho Radix-Path Identifier
Combine Radix-based labeling and Dewey labeling

Computer Science
Identify Authentication Data
10
4020
10 30 60
0 10 3020 60 7040 50
50
000
00 01 10 11 20 21 22
0 1 2
010 100 110 200 210 220 221
• Radix-Path Identifier

Computer Science
Identify Authentication Data
11
4020
10 30 60
0 10 3020 60 7040 50
50
0
0 1 4 5 8 9 10
0 1 2
4 16 20 32 36 40 41
• Radix-Path Identifier (rb = 4)

Computer Science
Identify Authentication Data
12
Radix-Path Identifier Properties1. Identifiers in a node are continuous, but not continuous between
sibling nodes
2. =
3. Min = Max =
4. Easy to find the index in a node, which is

Computer Science
Store Authentication Data
13
SAT: Single Authentication Table
id rpid hash level
-1 0 TvJtus 2
20 1 asdwS 2
40 2 DFsQ 2
-1 0 Kjdaw 1
10 1 Ujrw 1
-1 4 JHds 1
30 5 iueDs 1
-1 8 Jdiw. 1
50 9 .dkaw 1
id rpid hash level
60 10 Udew 1
0 0 nudg 0
10 4 Q9ej 0
20 16 wVi2 0
30 20 kidDs 0
40 32 Kdie* 0
50 36 8dFes 0
60 40 Iurw 0
70 41 KJdw 0
data_auth (max level - 2)

Computer Science
Store Authentication Data
14
SAT: Single Authentication Tableo Pros
Simple and straightforward
o Cons Index is built based on all records (inefficient queries) Updates could be inefficient Concurrent updates may cost more resources

Computer Science
Store Authentication Data
15
LBAT: Level-based Authentication Table
id rpid hash
-1 0 Kjdaw
10 1 Ujrw
-1 4 JHds
30 5 iueDs
-1 8 Jdiw.
50 9 .dkaw
60 10 Udew
id col1 … coln rpid hash
0 Alice … 1000 0 nudg
10 Ben … 2000 4 Q9ej
20 Cary … 1500 16 wVi2
30 Lisa … 3000 20 kidDs
40 Kate … 2300 32 Kdie*
50 Mike … 4000 36 8dFes
60 Nancy … 2300 40 Iurw
70 Smith … 4500 41 KJdw
id rpid hash
-1 0 TvJtus
20 1 asdwS
40 2 DFsQ
• data_auth0 (Level 2) • data_auth1 (Level 1) • data (Level 0)
level table
2 data_auth0
1 data_auth1
0 data
• data_mapping

Computer Science
Store Authentication Data
16
LBAT: Level-based Authentication Tableo Pros
Indexes are more efficient Updates could be more efficient (root split) Enable concurrent updates with table level lock
o Cons Multiple authentication tables Relatively complicated for authentication data generation

Computer Science
Extract Authentication Data
17
• Retrieval of Authentication Data
4020
10 30 60
0 10 3020 60 7040 50
50
• Authentication Data for 50

Computer Science
Extract Authentication Data
18
SingleJoin
id rpid hash
-1 0 Kjdaw
10 1 Ujrw
-1 4 JHds
30 5 iueDs
-1 8 Jdiw.
50 9 .dkaw
60 10 Udew
id col1 … coln rpid hash
0 Alice … 1000 0 nudg
10 Ben … 2000 4 Q9ej
20 Cary … 1500 16 wVi2
30 Lisa … 3000 20 kidDs
40 Kate … 2300 32 Kdie*
50 Mike … 4000 36 8dFes
60 Nancy … 2300 40 Iurw
70 Smith … 4500 41 KJdw
id rpid hash
-1 0 TvJtus
20 1 asdwS
40 2 DFsQ
• data_auth0 (Level 0) • data_auth1 (Level 1) • data (Level 2)
• select l1.rpid,l1.hash from data t0 • left join data l1 on l1.rpid/4 = t0.rpid/(4) • where t0.id=50;
• select l1.rpid,l1.hash from data t0 • left join data_auth1 l1 on l1.rpid/4 = t0.rpid/(4*4) • where t0.id=50;
• select l1.rpid,l1.hash from data t0 • left join data_auth0 l1 on l1.rpid/4 =
t0.rpid/(4*4*4) • where t0.id=50;

Computer Science
Extract Authentication Data
19
RangeCondition
• -- find the rpid of the data record with the id 50• declare @rowrpid AS int; • set @rowrpid=(select top 1 rpid from data where id=50);
• -- level 2, 1, 0 (from leaf level to root level)• select rpid,hash from data • where rpid>=(@rowrpid/(4))*4 and rpid<(@rowrpid/(4))*4+4;• select rpid,hash from data_auth1 • where rpid>=(@rowrpid/(4*4))*4 and rpid<(@rowrpid/(4*4))*4+4;• select rpid,hash from data_auth0 • where rpid>=(@rowrpid/(4*4*4))*4 and rpid<(@rowrpid/(4*4*4))*4+4;

Computer Science
Extract Authentication Data
20
SingleJoin
RangeCondition

Computer Science
Data Operations
21
Selecto Unique Selecto Range Select
Updateo Single Record Updateo Batch Update and Optimization
Inserto Single Record Inserto Batch Insert and Optimization
Computer Science
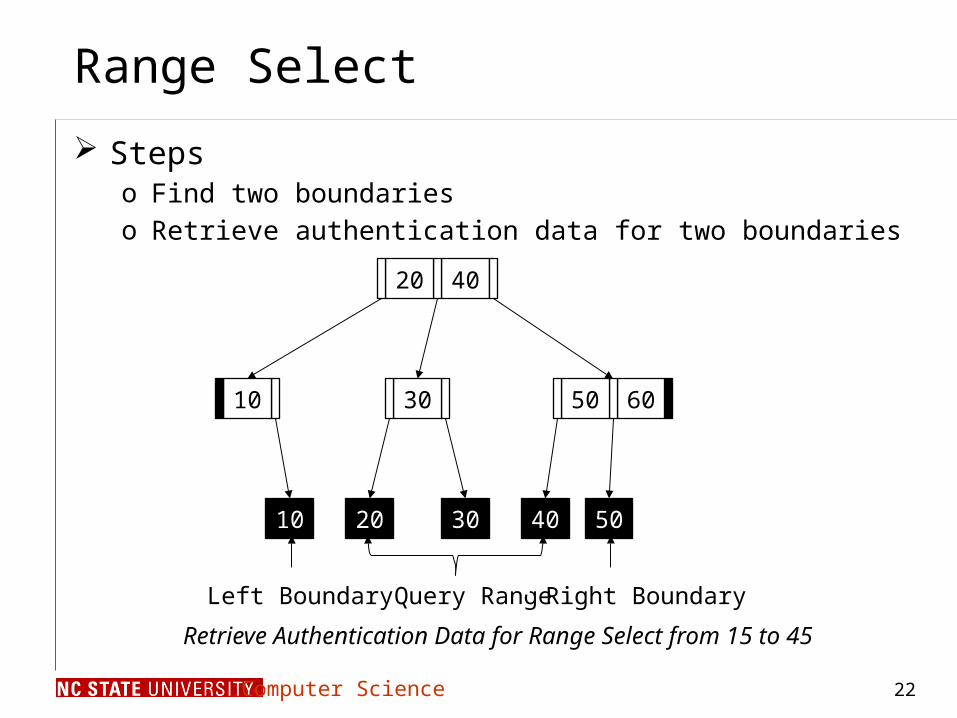
Range Select
22
Stepso Find two boundarieso Retrieve authentication data for two boundaries
• Retrieve Authentication Data for Range Select from 15 to 45
4020
10 30 60
10 3020 40 50
50
• Query Range• Left Boundary • Right Boundary

Computer Science
Range Select
23
Stepso Find two boundarieso Retrieve authentication data for two boundaries
• Retrieve Authentication Data for Range Select from 15 to 45

Computer Science
Single Record Update
24
Stepso Retrieve authentication datao Generate update statements
o h updates, (h – tree height)
o Execute updates in one transaction
4020
30
20
4020
30
20
VO for 20 VO update for 20
• Update 20

Computer Science
Batch Update and Optimization
25
Update x recordso x * h update statementso Some of them update the same authentication data record
4020
10 30 60
0 10 3020 60 7040 50
50
• # of updates is 4 * 3 = 12
• Actually, 8 updates are necessary

Computer Science
Batch Update and Optimization
26
Optimization – MergeUpdateo Track all updates to each tableo Find the set of updates to one authentication data recordo Keep the latest one and remove others

Computer Science
Experimental Evaluation
System Implementationo Implementation based on .NET and SQL Servero Merkle B-tree based on .NETo MultiJoin, SingleJoin, ZeroJoin and RangeConditiono Query rewrite algorithmo A tool to generate authentication data
Experiment Setupo A synthetic database containing one table with 100,000 recordso Each record is about 1KBo .NET3.5, SQL Server 2008 R2, Windows OSo Client network with 30Mbps download and 4Mbps upload
27

Computer Science
Experiments – Unique Select
Setupo Run a select statement based on the primary key to retrieve one data
recordo Compute the overhead of our scheme when using different
authentication retrieval methods
28
Results1. RangeCondition is much more efficient
than others2. The overhead of our scheme could be as
low as 5%
Computer Science
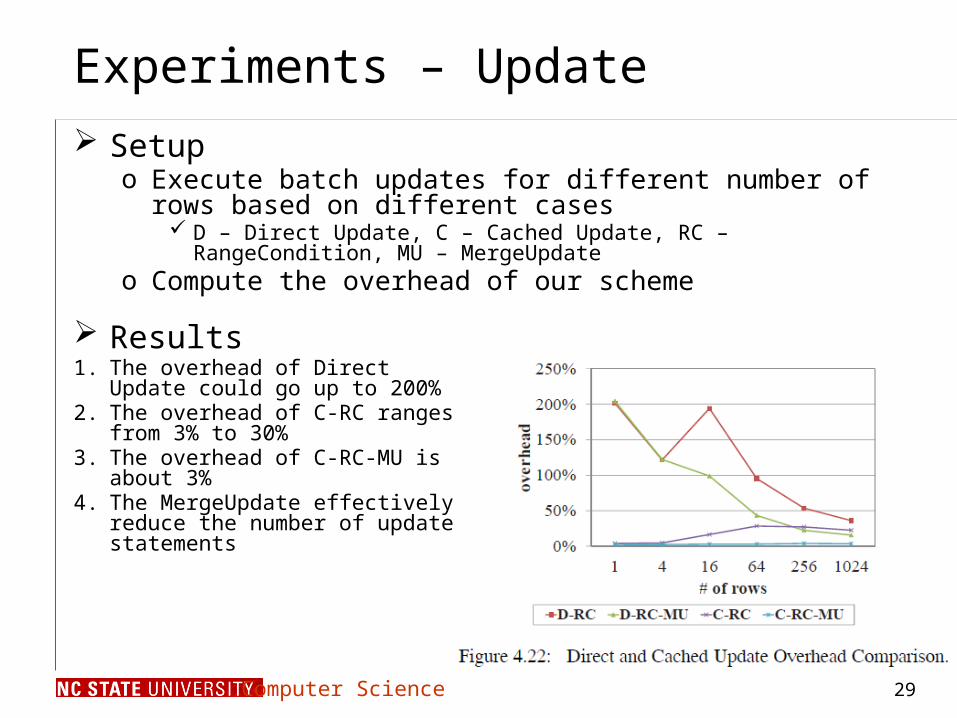
Experiments – Update
Setupo Execute batch updates for different number of rows based on different
cases D – Direct Update, C – Cached Update, RC – RangeCondition, MU – MergeUpdate
o Compute the overhead of our scheme
29
Results1. The overhead of Direct Update could go
up to 200%2. The overhead of C-RC ranges from 3%
to 30%3. The overhead of C-RC-MU is about 3%4. The MergeUpdate effectively reduce the
number of update statements

Computer Science
Experiments – Scalability
Setupo Run a range query to select 512 rows as # of rows changes in the data
tableo Record time spent to complete the select query
30
Results1. The overhead of our scheme is about 2 ~
3% in all cases

Computer Science
Experiments – Comparison
Setupo Run queries to retrieve authentication data as # of rows in table
increases for three schemes: our scheme, OPEN-XML and DT-XMLo Record time spent to retrieve authentication data
31
Results1. Our scheme takes about 250ms in all
cases2. Our scheme is about 100 times faster
than two XML-based schemes

Computer Science
Related Work
Authentication Data Structureo Verifiable B-tree [Pang et al. ICDE 2004]o Embedded Merkle B-tree [Hakan et al. SIGMOD 2006]o Signature aggregation and chaining [Narasimha et al. DASFFA 2006]
Otherso Protect data privacy [Hakan et al. SIGMOD 2002]o Only handle read-only queries [Sion et al.VLDB 2005]o Authenticated join processing [Yin et al.SIGMOD 2009]o Partially materialized digest scheme [Mouratidis et al.VLDB 2009]
Similar to our worko Probabilistic approaches [Xie et al.VLDB 2007]o Tamper-Evident Database System [Gerome et al. ASIAN 2005]o Authenticated Relational Tables [Giuseppe et al. DBSec 2007]
32

Computer Science
Conclusion
Contributionso Proposed a novel approach called Radix-Path Identifier to serialize/de-
serialize MHT-based authentication datao Explored the efficiency of different methods to retrieve authentication
data, and optimize the update processingo Build a proof-of-concept prototype and conduct extensive experiments
to evaluate the performance overhead and efficiency
33

Computer Science
•Thank you•Questions?
34