concurrency. readings r tanenbaum and van steen: 3.1-3.3 r coulouris: chapter 6 r cs402 web page...
TRANSCRIPT

Concurrency

Readings
Tanenbaum and van Steen: 3.1-3.3 Coulouris: Chapter 6 cs402 web page links UNIX Network Programming by W.
Richard Stevens

Introduction
Consider a request for a file transfer. Client A requests a huge file from disk. This request means that the process is I/O bound. In the server program presented earlier, all other
client requests have to wait until client A’s request is processed.
Waste!
In writing distributed applications, it often necessary that a process be constructed such that communication and local processing can overlap.

Different Types of Servers
Iterative Server – The server cannot process a pending client until it has completely serviced the current client.
Concurrent Server – There are two basic versions: The fork systems call is used to spawn a
child process for every client. The server creates a thread for each client

Iterative Servers
Iterative servers process one request at a time.client 1 server client 2
call connect call acceptret connect
ret accept
call connect
call readwrite
ret readclose
closecall accept
ret connect
call read
ret read
close
write
ret accept
close

Iterative Servers
Solution: use concurrent servers instead. Concurrent servers use multiple concurrent flows to
serve multiple clients at the same time.
client 1 server client 2
call connectcall accept
call read
ret connectret accept
call connectcall fgets
User goesout
Client 1 blockswaiting for userto type in data
Client 2 blockswaiting to completeits connection request until afterlunch!
Server blockswaiting fordata fromClient 1
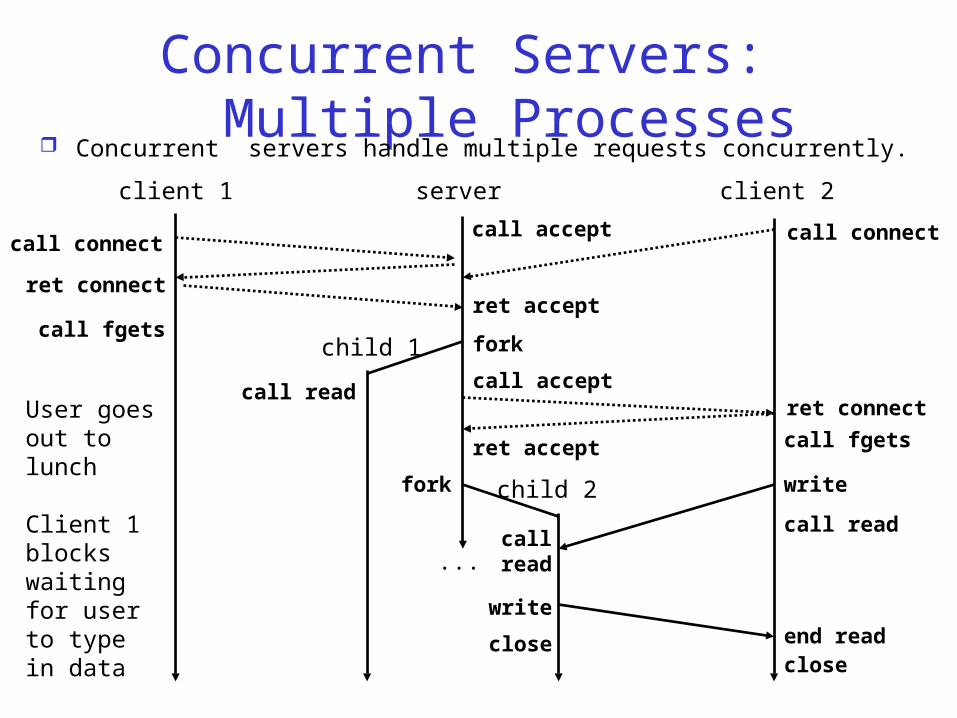
Concurrent Servers:Multiple Processes
Concurrent servers handle multiple requests concurrently.
client 1 server client 2
call connectcall accept
call read
ret connectret accept
call connect
call fgetsforkchild 1
User goesout to lunch
Client 1 blockswaiting for user to type in data
call acceptret connect
ret accept call fgets
writefork
call read
child 2
write
call read
end readclose
close
...

Using the Fork Systems Call
Traditionally, a concurrent TCP server calls fork to spawn a child to handle each client request.
The only limit on the number of clients is the operating system limit on the number of child processes for the user identifier under which the server is running.

Using the Fork System Call
The fork system call creates a UNIX process by copying a parent’s memory image.
Both processes continue execution at the instruction after the fork.
Creation of two completely identical processes is not useful. Need a way to distinguish between parent and child. The fork call returns 0 to the client process
and returns the child’s process identifier to the parent.

Using the Fork System Call
The child inherits most of the parent’s environment and context including scheduling parameters and the file descriptor table.
The parent and children share the same files that are opened by the parent prior to the fork.
When a program closes a file, the entry in the file descriptor table is freed.
To be safer, children and parent processes should close file descriptions of files they do not need immediately after fork() returns.

Using the Fork System Call…pid_t pid;int listenfd, connfd;listenfd = socket(…);
…listen(listenfd, queuesize);for (; ;) { connfd = accept(listenfd,…); if ( (pid = fork()) == 0) { close(listenfd); /*child closes listen socket*/ doit(connfd); /*process the request*/ close(connfd); /*child closes listening socket*/ exit(0); } close(connfd); /*parent closes connected socket */
… }

Zombies
When a program forks and the child finishes before the parent, the kernel still keeps some information about the child in case the parent needs it e.g., what is the child’s exit status.
The parent can get this information using wait().
In between terminating and the parent calling wait() the child process is referred to as a zombie.
Zombies stay in the system until they are waited for.

Zombies
Even though the child process is still not running, it still takes a place in the process descriptor table.
This is not good. Eventually we run out of processes.
If a parent terminates without calling wait(), the child process (now an orphan) is adopted by init() (which is the first process started up on a UNIX system).
The init process periodically waits for children so eventually orphan zombies are removed.

Zombies
You should make sure that the parent process calls wait() (or waitpid()) for each child process that terminates.
When a child process terminates, the child enters the zombie state. This sends the SIGCHLD signal to the parent process. A signal is an asynchronous notification to a process
that an event has occurred. A signal handler associated with the SIGCHLD
signal executes the wait() function.

Signal Handling
A signal is a notification to a process that an event has occurred.
Signals usually occur asynchronously i.e., the process does not know ahead of time exactly when a signal will occur.
Signals can be sent by one process to another process (or to itself) or by the kernel to a process.
Every signal has a disposition (action) associated with the signal.
There are about 32 signals in UNIX. Example signals: a child process terminates,
keyboard interrupt (e.g., ctrl-Z, ctrl-C).

Signal Handling
A function (called the signal handler) can be provided that is called whenever a specific signal occurs.
This function is called with a single integer argument that is the signal number. The function does not return anything.
Many signals can be ignored by setting its disposition to SIG_IGN. Two exceptions: SIGKILL and SIGSTOP.
The default disposition is SIG_DFL. The default normally terminates a process on the receipt of a signal.

Signal Handling
The signal function can be used to set the disposition for a signal. The first argument is the signal name and the second
argument is either a pointer to a function or one of the constants: SIG_IGN or SIG_DFL.
The signal function has different semantics depending on the OS.
One solution is to define your own signal function that calls the Posix sigaction function which has a clear semantics. Why not use sigaction to begin with? It is more
difficult to deal with than signal.

Signal Handling#include <signal.h>….int main(){ signal(SIGCHLD, reapchild);….}void reapchild(int s){ pid_t pid; int stat;
pid = wait(&stat); return;}

Signal Handling
wait returns two values: The return value of the function is the process
identifier of the terminated child The termination status of the child (an integer) is
returned through stat. This assumes that the caller did not pass NULL which indicates that wait is applied to terminated child processes.
Can also use waitpid() Gives better control since an input parameter of this
function specifies the process id of the child process to be waited upon.

Signal Handling
A few points about signal handling on a Posix-compliant system: Once a signal handler is installed, it remains
installed. While a signal handler is executing, the
signal being delivered is blocked. If a signal is generated one or more times
while it is blocked, it is normally delivered only one time after the signal is unblocked i.e., Unix signals are not queued.

Signal Handling
A slow system call is any system call that can block forever (e.g., accept(), read()/write() from sockets).
System calls may be interrupted by signals and should be restarted.
When a process is blocked in a slow system call and the process catches a signal and the signal handler returns: The system call can return an error EINTR (interrupted
system call) Some kernels automatically restart some system calls
For portability, when we write a program that catches signals, we must be prepared for slow system calls to return EINTR.

Signal Handling
…void main() {
… if ((connfd = accept(listenfd, (struct sockaddr *) &sin,
&sizeof(sin)) < 0) { if (errno==EINTR) continue; else { perror(“accept”); exit(1); } }
…

TCP Preforked Server
Instead of doing one fork per client, the server preforks some number of children when it starts and then the children are ready to service the clients as each client connection arrives.
Advantage: new clients can be handled without the cost of a fork by the parent.
Disadvantage: When it starts the parent process must guess how many children to prefork. If the number of clients at any time is greater than
the number of children, additional client requests are queued.

TCP Preforked Server
main(){ … for (i=0; i < nchildren; i++) pids[i] =
child_make(i,listenfd,addrlen); …}

TCP Preforked Server
The childmake() function is called by the main program to create each child.
As will be seen on the next slide, a call to fork in childmake() will be used to create a child; only the parent will return from childmake().

TCP Preforked Serverpid_t child_make(int i, int listenfd, int
addrlen){ pid_t pid; void child_main(int, int, int); if ( (pid = fork()) > 0) return (pid); child_main(i,listenfd,addrlen);}

TCP Preforked Servervoid child_main(int i, int listenfd, int addrlen){ … for (; ;) { connfd = accept(listenfd …); doit(connfd); close(connfd); }}

TCP Preforked Server
Note that in the example there are multiple processes calling accept on the same socket descriptor. This is allowed in Berkeley-derived kernels. If there are N children waiting on accept, then the
next incoming client connection is assigned to the next child process to run
There are other approaches. For example: The application places a lock of some form around
the call to accept, so that only one process at a time is blocked in the call to accept. The remaining children will be blocked trying to obtain the lock.
• There are various ways to provide the lock.

TCP Preforked Server
In this type of server, it is desirable to catch the SIGINT signal generated when we type a terminal interrupt key. The signal handler may kill all the child
processes.

TCP Preforked Servervoid sig_int(int signo){ int i; for (i = 0; i < nchildren; i++) kill(pids[i],SIGTERM); while (wait(NULL) > 0); /*wait for all children*/ ….}

Problem with Forking Processes
Process creation requires that the operating system creates a complete (almost) independent address space.
Allocation can mean initializing memory segments by zeroing a data segment, copying the associated program into a text segment, and setting up a stack for temporary data.
Switching the CPU between two processes may be relatively expensive as well, since the CPU context (which consists of register values, program counter, stack counter, etc) must be saved.
Context switching also requires invalidation of address translation caches.

Problem with Forking Processes
The problem with using the fork systems call is the amount of CPU time that it takes to fork a child for each client.
In the 80’s when a busy server handled hundreds or perhaps even a few thousand clients per day this wasn’t an issue.
The WWW has changed this since some web servers measure the number of TCP connections per day in the millions.

Using the Fork Systems Call
Advantages Handles multiple connections concurrently Simple and straightforward (compared to
other approaches) Clean sharing model except for descriptors
Disadvantages Overhead It is non-trivial to share data

Threads
An alternative to forking processes is to use threads.
A thread (sometimes called a lightweight process) does not require lots of memory or startup time.
A process may include many threads all sharing: Memory (program code and global data) Open file/socket descriptors Working environment (current directory, user ID, etc.)
Information needed for a thread includes CPU context and thread management information such as keeping track of the fact that a thread is currently blocked on a mutex variable (described later).

Threads
In contrast to processes, no attempt is made to achieve a high degree of concurrency transparency.
Implications In many cases, multithreading leads to a
performance gain. Multithreaded applications are more difficult
to design and implement than single threaded applications.

Process B
GlobalVariables
Code
Stack
Stack
Process A
GlobalVariables
Code
Stack
fork()Process A
GlobalVariables
Code
Stack
pthread_create()

Posix Threads We will focus on Posix Threads - most widely
supported threads programming API.
You need to link with “-lpthread”

Thread Creation
Thread identifiers Each thread has a unique identifier (ID), a thread
can find out its ID by calling pthread_self(). Thread IDs are of type pthread_t which is
usually an unsigned int. When debugging it's often useful to do something like this:
printf("Thread %u: blah\n",pthread_self());

Thread Creationpthread_create( pthread_t *tid,
const pthread_attr_t *attr, void *(*func)(void *), void *arg);
The thread id is returned to tid Return value is 0 for OK. Does not set errno; Error codes are returned. Thread attributes can be set using attr. You can
specify NULL and get the system attributes.

Thread Creation
func is the function to be called, when func() returns the thread is terminated; The function takes a single parameter specified by arg.
Thread arguments Complex parameters can be passed by
creating a structure and passing the address of the structure,
The structure cannot be a local variable.

Thread Creation
How can we have the main thread know when a child thread has terminated and it can now service a new client?
pthread_join (which is sort of like waitpid()) requires that we specify a thread id. We can wait for a specific thread, but we can't wait for "the next thread to exit".

Thread Example
main ()
{
pairint *foobar;
pthread_t threadid;
foobar->x = 8; foobar->y=10;
pthread_create(&threadid, NULL, blah, (void )foobar);
pthread_join(threadid,NULL);
printf("Parent is continuing....\n"); return 0;
}

Thread Exampletypedef struct {int x, y;} pairint;
void *blah(void *arg){
printf("now in thread blah\n");
pairint *foo = (pairint *) arg;
printf("thread id %u : sum of %d and %dis %d\n", thread_self(), foo->x, foo->y,
foo->x+foo->y);
return (NULL);
}

Thread Lifespan
Once a thread is created, it starts executing the function func() specified in the call to pthread_create().
If func() returns, the thread is terminated.
A thread can also be terminated by calling pthread_exit().
If main() returns or any thread calls exit()all threads are terminated.

Detached State Each thread can be either joinable or detached.
Joinable: On thread termination the thread ID and exit status are saved by the OS. One thread can "join" another by calling pthread_join - which waits (blocks) until a specified thread exits.
Detached: On termination all thread resources are released by the OS. A detached thread cannot be joined.

Shared Global VariablesAll threads within a process can access global
variables.int counter=0;
void *blah(void *arg) {
counter++;
printf("Thread %u is number %d\n",
pthread_self(),counter);
}
main() {
int i; pthread_t threadid;
for (i=0;i<10;i++)
pthread_create(&threadid,NULL,blah,NULL);
}

Problem
Sharing global variables is dangerous - two threads may attempt to modify the same variable at the same time.
pthreads includes support for mutual exclusion primitives that can be used to protect against this problem.
The general idea is to lock something before accessing global variables and to unlock as soon as you are done.

Support for Mutual Exclusion
A global variable of type pthread_mutex_t is required:
pthread_mutex_t counter_mtx=PTHREAD_MUTEX_INITIALIZER;
To lock use:pthread_mutex_lock(pthread_mutex_t &mutex);
To unlock use:pthread_mutex_unlock(pthread_mutex_t &mutex);

Threaded Server…for (;;) { printf("top of for loop\n"); connfd = accept(listenfd, 0, 0); if (connfd == -1) error("accept"); printf("accepted request\n"); pthread_create(&tid, NULL,
serverthread, (void *) connfd );
printf("waiting for more requests\n");
}
…

Threaded Servervoid * serverthread(void * parm)
{
…
fd = (int) parm;
pthread_detach(pthread_self());
/*code for process client request
placed here */
…
}

Summary We have looked at different ways to implement
concurrent servers. If the server is not heavily used, the traditional
concurrent server model with one fork per client is fine.
Creating a pool of child processes or threads can reduce CPU usage compared to the traditional concurrent server model.
Using threads is normally faster than using processes. Having child processes/threads call accept is usually
considered simpler and faster than having the parent process/main thread call accept and pass the descriptor to the child or thread.