contextual search and name disambiguation in email using graphs
DESCRIPTION
Contextual Search and Name Disambiguation in Email using Graphs. Einat Minkov William W. Cohen Andrew Y. Ng. SIGIR-2006. Outline. Extended similarity measure using graph walks Instantiation for Email Learning Evaluation Person Name Disambiguation Threading Summary and future directions. - PowerPoint PPT PresentationTRANSCRIPT

Contextual Search and Name Disambiguation in Email using
Graphs
Einat Minkov
William W. Cohen
Andrew Y. Ng
SIGIR-2006

Outline Extended similarity measure using graph walks Instantiation for Email Learning Evaluation
Person Name Disambiguation Threading
Summary and future directions

Object Similarity Textual similarity measures model D-D (or Q:D) similarity
However, in structured data, documents are not isolated.
We are interested in extending the text-based similarity measures to complex structure settings:
Represent structured data as a graph Derive object similarity using lazy graph walks.
We instantiate this framework for Email (a private case of structured data)
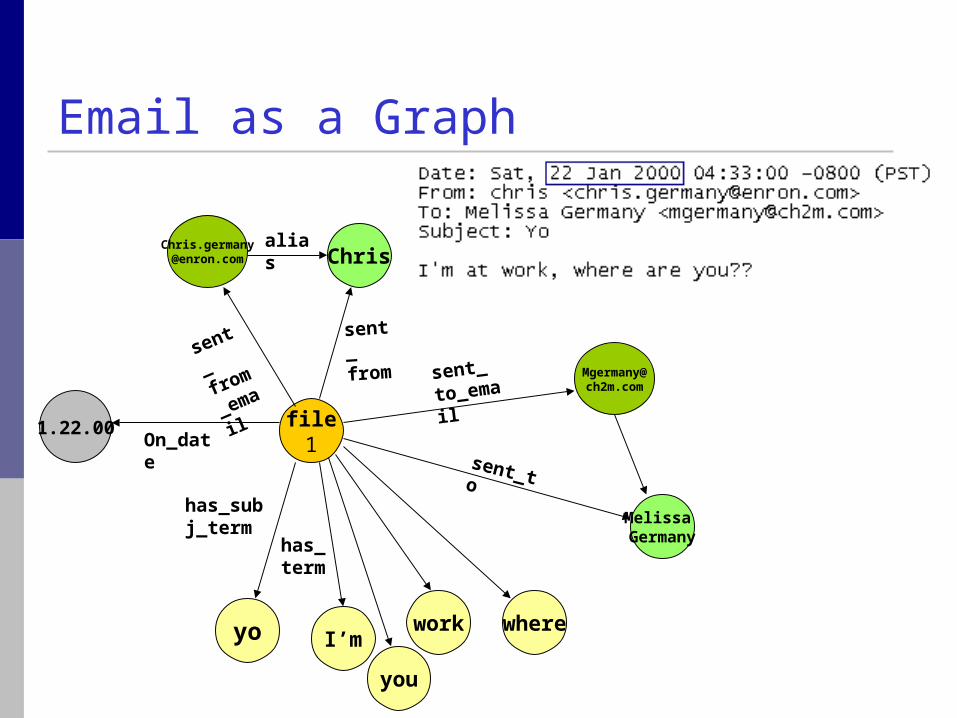
Email as a Graph
file1
[email protected] Chris
sent_
from_
alias
sent_from
Melissa Germany
sent_
to_email
sent_to
has_subj_term
yo I’mwork where
you
has_term
On_date1.22.00
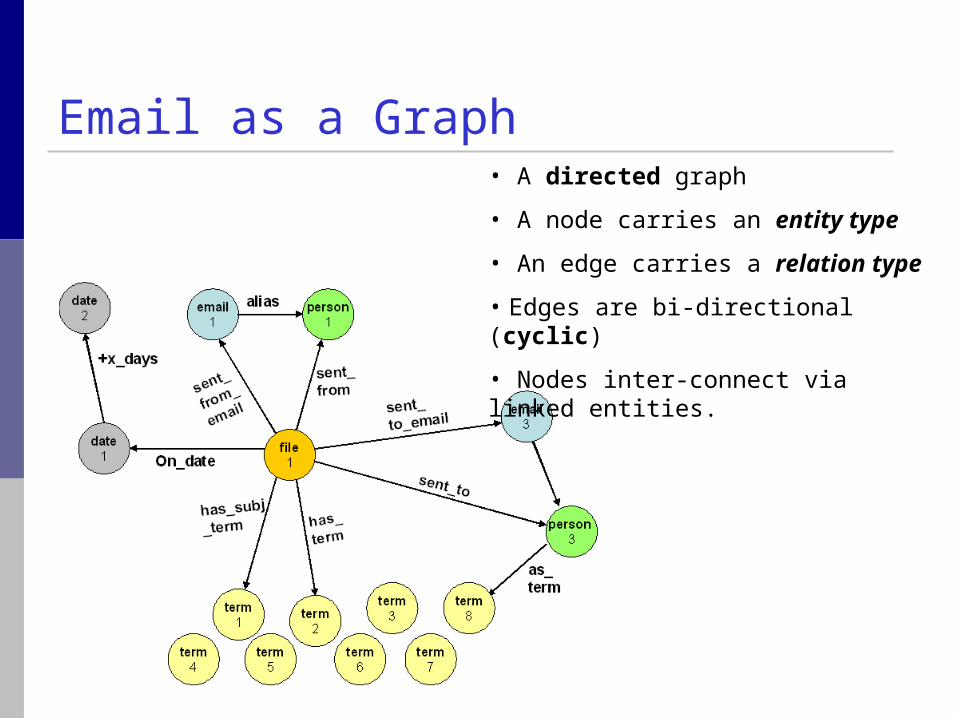
• A directed graph
• A node carries an entity type
• An edge carries a relation type
• Edges are bi-directional (cyclic)
• Nodes inter-connect via linked entities.
Email as a Graph

Edge Weights Graph G :
- nodes x, y, z - node types T(x), T(y), T(z)
- edge labels- parameters
Edge weight x y:
Prob. Distribution:
a. Pick an outgoing edge label b. Pick node y uniformly

Graph SimilarityDefined by lazy graph walks over k steps.
Given:
A transition matrix:
Stay probability: (larger values favor shorter paths)
Initial node distribution:
We use this platform to perform SEARCH of related items in the graph:
a query is initial distribution Vq over nodes and a desired output type Tout
Output node distribution:

Relation to IDF Reduce the graph to files and terms only.
One-dimensional search of files, over one step (Query = multiple source term nodes)
A natural IDF filter:terms occurring in multiple files will ‘spread’ their probability mass into small fractions over many file nodes.
file2
term5
term6
term4
term2
term3
term1
term7
file3
file1

Learning Learn how to better rank graph nodes per a particular task.
The parameters can be adjusted using gradient descent methods (Diligenti et-al, IJCAI 2005)
We suggest a re-ranking approach (Collins and Koo, Computational Linguistics, 2005)
take advantage of ‘global’ features
A training example includes: a ranked list of li nodes. Each node represented through m features At least one known correct node
Features will describe the graph walk paths

Path describing Features The full set of paths to a target node in step k can be recovered.
K=0 K=1 K=2
X1
X2
X3
X4
X5
Paths (x3, k=2):
x2 x3
x2 x1 x3
x4 x1 x3
x2 x2 x3
‘Edge unigrams’:was edge type l used in reaching x from Vq.
‘Edge bigrams’:were edge types l1 and l2 used (in that order) in reaching x from Vq.
‘Top edge bigrams’:were edge types l1 and l2 used (in that order) in reaching x from Vq, among the top two highest scoring paths.

Outline Extended similarity measure using graph walks Instantiation for Email Learning Evaluation
Person Name Disambiguation Threading
Summary and future directions
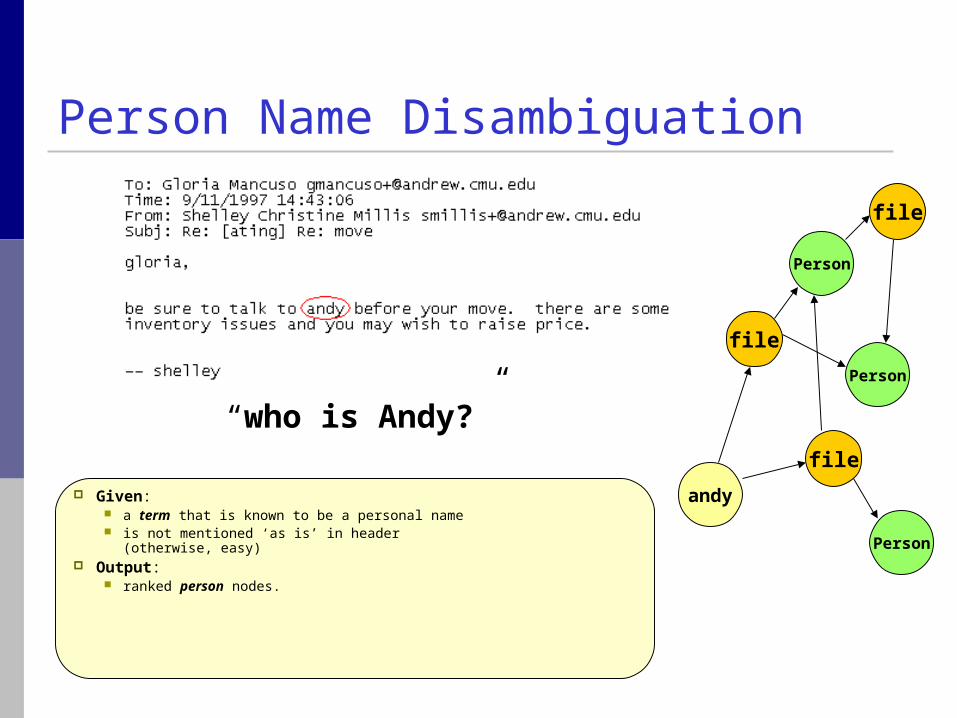
Person Name Disambiguation
Given: a term that is known to be a personal name is not mentioned ‘as is’ in header
(otherwise, easy) Output:
ranked person nodes.
“who is Andy?”
file
andy
file
Person
file
Person
Person

Corpora and Datasets
Example types : Andy Andrew Kai Keiko Jenny Xing
Two-fold problem: Map terms to person nodes (co-occurrence) Disambiguation (context)
Files Nodes Test Train
Mgmt. Game 821 6248 80 26
Sager-E 1632 9753 51 11
Shapiro-R 978 13174 49 11
Corpus Dataset

Methods
4. G: Term + File, Reranked
Re-rank (3), using:
- Path-describing features
- ‘source count’ : do the paths originate from a single/two source nodes
- string similarity
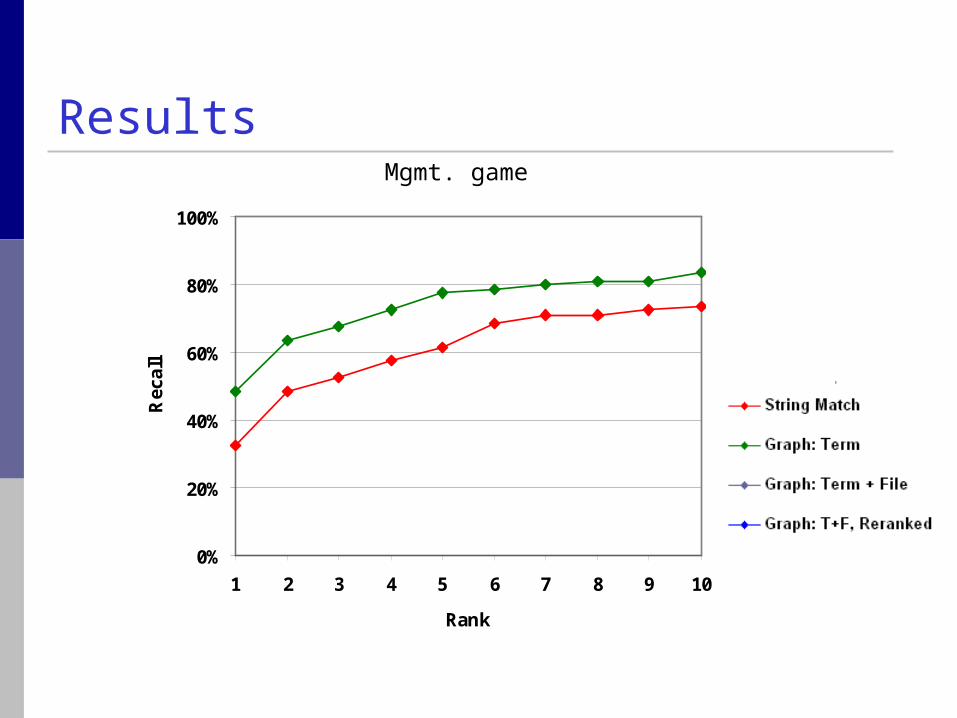
1. Baseline: String matching (& common nicknames)
Find persons that are similar to the name term (Jaro measure)
• Lexical similarity
2. Graph walk: Term
Vq: name term node
• Co-occurrence
3. Graph walk: Term + File
Vq: name term + file nodes
• Co-occurrence
• Ambiguity
• but, incorporates additional noise
Results
0%
20%
40%
60%
80%
100%
1 2 3 4 5 6 7 8 9 10
Rank
Rec
all
Mgmt. game
Results
0%
20%
40%
60%
80%
100%
1 2 3 4 5 6 7 8 9 10
Rank
Rec
all
Mgmt. game
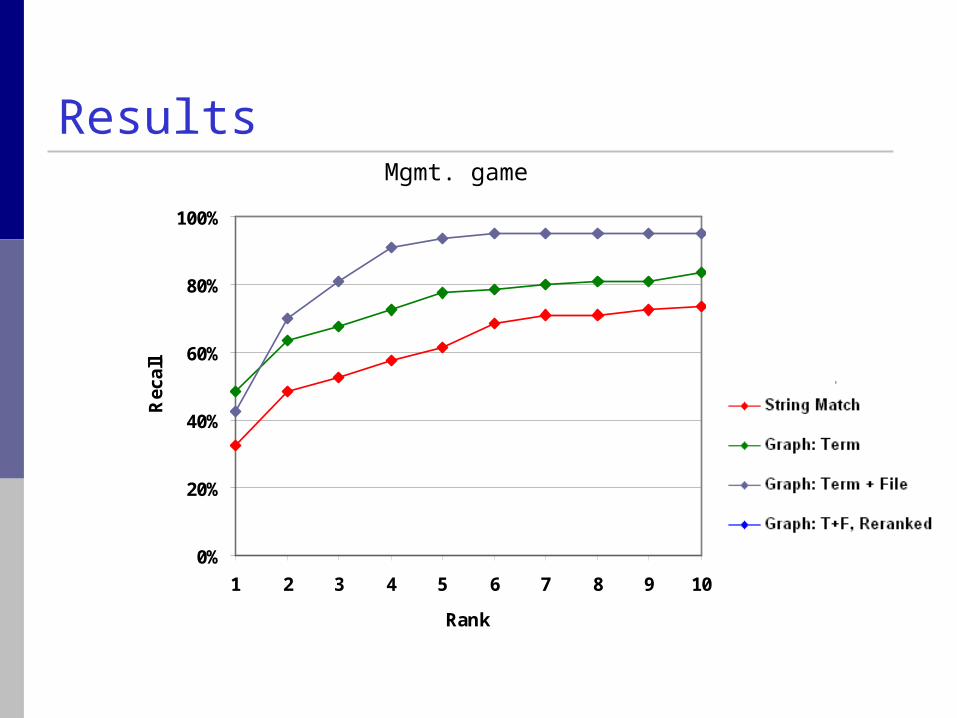
Results
0%
20%
40%
60%
80%
100%
1 2 3 4 5 6 7 8 9 10
Rank
Rec
all
Mgmt. game

Results
0%
20%
40%
60%
80%
100%
1 2 3 4 5 6 7 8 9 10
Rank
Rec
all
Mgmt. game
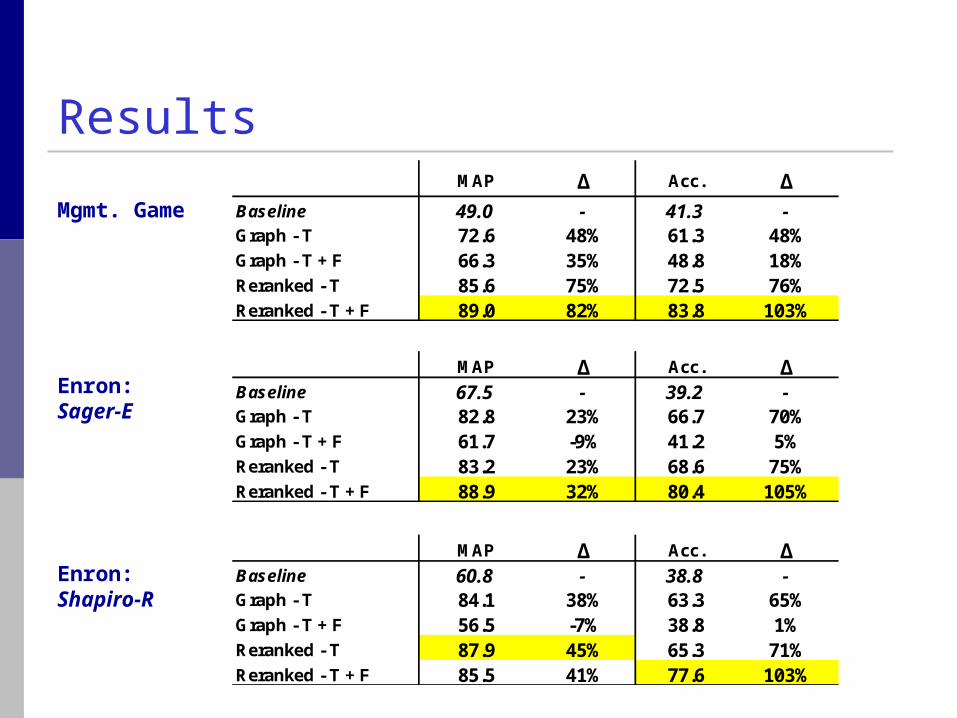
ResultsMAP Δ Acc. Δ
Baseline 49.0 - 41.3 -Graph - T 72.6 48% 61.3 48%Graph - T + F 66.3 35% 48.8 18%Reranked - T 85.6 75% 72.5 76%Reranked - T + F 89.0 82% 83.8 103%
MAP Δ Acc. ΔBaseline 67.5 - 39.2 -Graph - T 82.8 23% 66.7 70%Graph - T + F 61.7 -9% 41.2 5%Reranked - T 83.2 23% 68.6 75%Reranked - T + F 88.9 32% 80.4 105%
MAP Δ Acc. ΔBaseline 60.8 - 38.8 -Graph - T 84.1 38% 63.3 65%Graph - T + F 56.5 -7% 38.8 1%Reranked - T 87.9 45% 65.3 71%Reranked - T + F 85.5 41% 77.6 103%
Mgmt. Game
Enron:Sager-E
Enron:Shapiro-R

Threading There are often irregularities in thread structural information
(Lewis and Knowles, 1997)
Threading can improve message categorization into topical folders (Klimt and Yang, 2004)
Adjacent messages in a thread can be assumed to be most similar to each other in the corpus. An approximation for finding similar messages in a corpus.
Given: a file
Output: ranked file nodes adjacent files in a thread are correct answers
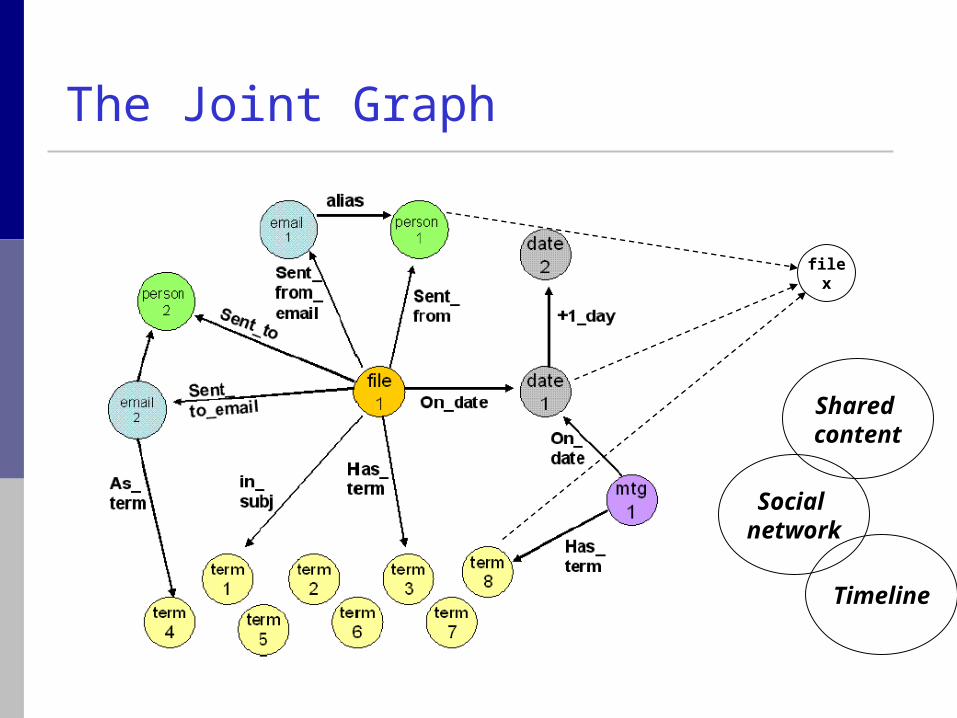
filex
Shared content
Social network
Timeline
The Joint Graph

Threading: experiments1. Baseline: TF-IDF Similarity
Consider all the available information (header & body) as text
2. Graph walk: Uniform weights Vq: file, 2 steps
3. Graph walk: Random weights Vq: file, 2 steps(best out of 10)
4. Graph walk: rerankedRerank the output of (3) using the graph-describing features

Results
20%
30%
40%
50%
60%
70%
80%
all no reply lines no reply lines no subj
20%
30%
40%
50%
60%
70%
80%
all no reply lines no reply lines no subj
Header & BodySubjectReply lines
Header & BodySubject-
Header & Body--
Header & BodySubjectReply lines
Header & BodySubject-
Header & Body--
Mgmt. Game
Enron:Farmer
MA
PM
AP
58.4
73.8
50.2
71.5
36.2
60.3
65.7
79.8
36.1
65.1

Main Contributions Presented an extended similarity measure incorporating
non-textual objects
Perform finite lazy random walks for typed search
A re-ranking paradigm to improve on graph walk results
Instantiation of this framework for Email
Enron Datasets and corpora are available online

Future directions Scalability:
Sampling-based approximation to iterative matrix multiplication
10-step walks on a million-node corpus in 10-15 seconds
Language Model Learning:
Adjust the weights Eliminate noise in contextual/complex queries
Timeline

Related Research IR:
Infinite walks for node centrality Graph walks for query expansion Spreading activation over semantic/association networks
Data Mining Relational data representation
Machine Learning Semi supervised learning in graphs

Thank you! Questions?