conversational human robot interaction
TRANSCRIPT

Conversational Human–Robot Interaction
Speech and Language Technology Challenges
Gabriel Skantze
Professor in Speech Technology at KTHCo-founder & Chief scientist, Furhat Robotics

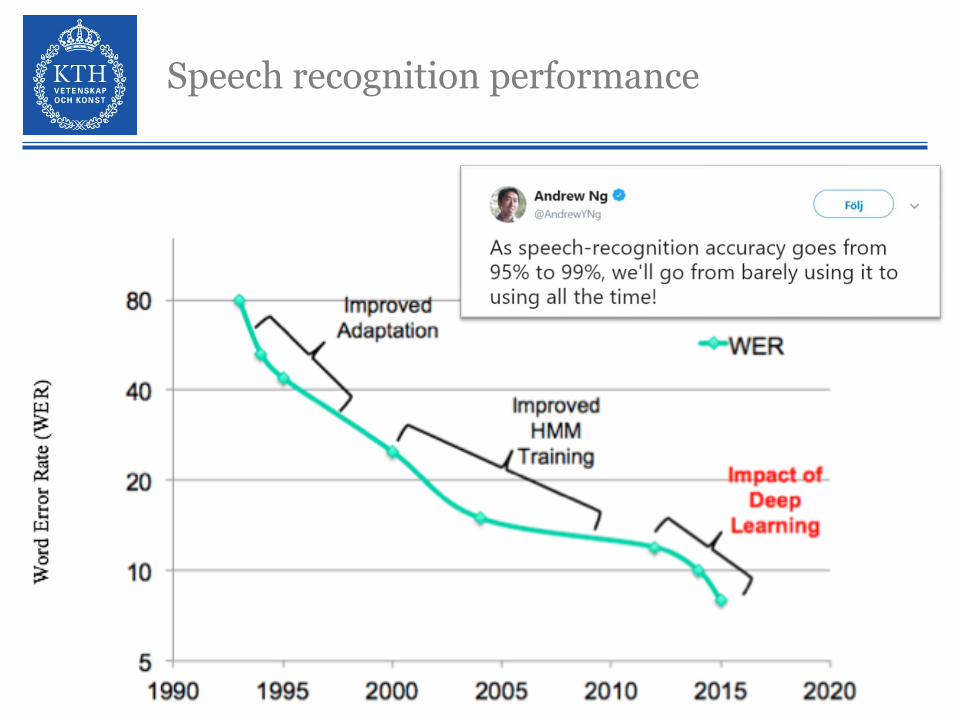
Speech recognition performance

The emergence of Social robots
Tutoring
Public spaces
Manufacturing
Health care

What’s the difference?

• Engaging• Feeling of presence• Situated
Output• Gaze (attention)• Facial expressions• Lip movements
Input• Speaker detection• Speaker recognition• Facial expressions (emotions)• Attention (gaze/headpose)
What the face adds to the conversation

JiboNAO
Giving the machine a face
Sophia Avatars/ECAs

Furhat – a backprojected robot head

Furhat as a concierge

Furhat at the Frankfurt airport

Furhat as an unbiased recruiter

Furhat for social simulation

Situated, Multi-party interaction
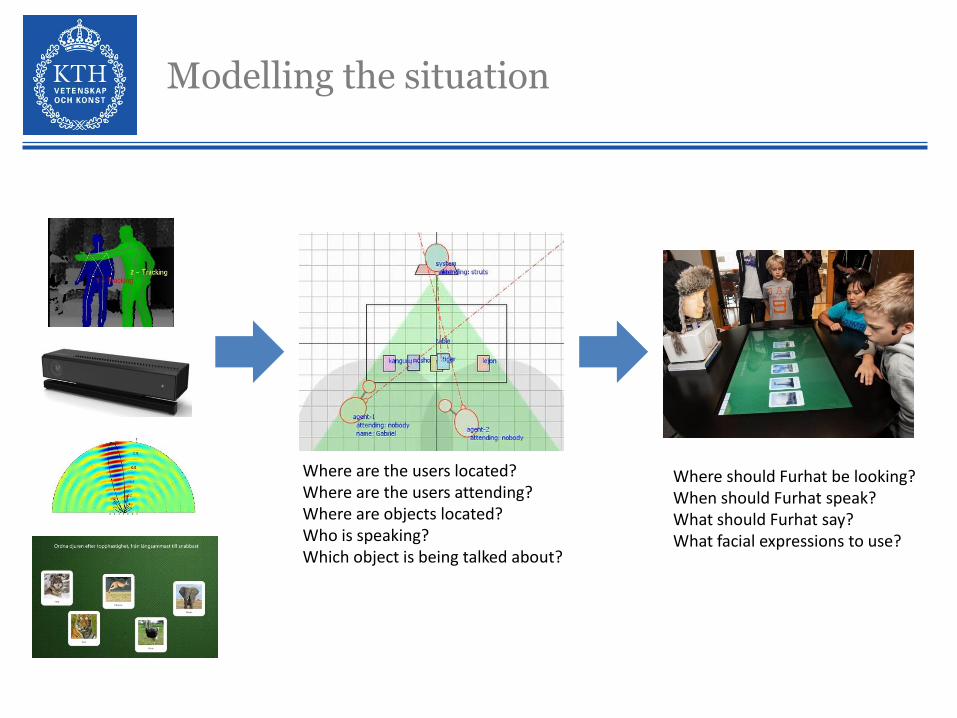
Modelling the situation
Where should Furhat be looking?When should Furhat speak?What should Furhat say?What facial expressions to use?
Where are the users located?Where are the users attending?Where are objects located? Who is speaking?Which object is being talked about?
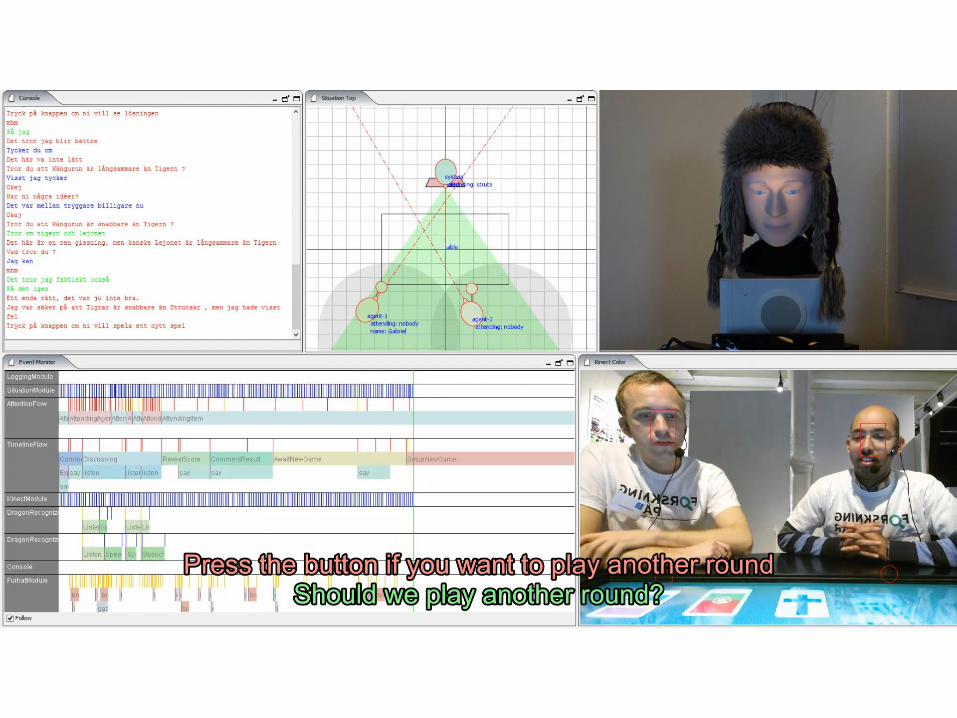

Current limitations and Challenges ahead
• Fluent Turn-taking (SSF/VR)• Learning symbol grounding through dialog (SSF/WASP)• Scaling beyond limited domains (Amazon)• Learning from interaction (VR)• Learning from human/Wizard-of-oz (SSF)
– Transfer learning• Managing shared spaces (ICT-TNG)
– Using Mixed/Augmented Reality for simulation
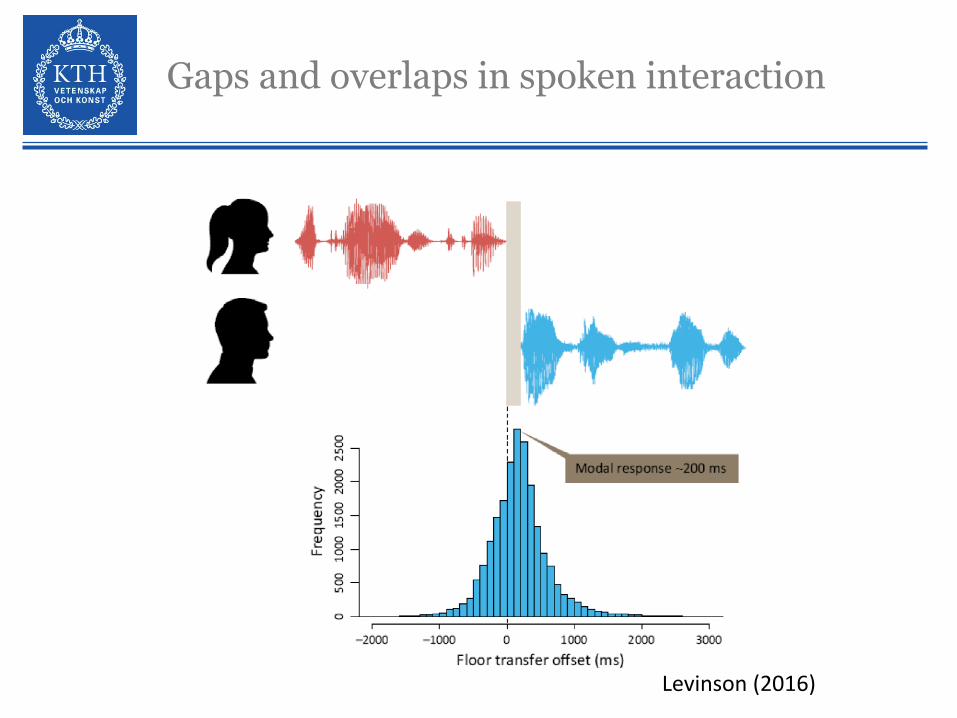
Gaps and overlaps in spoken interaction
Levinson (2016)

How is turn-taking coordinated?
The more cues, the stronger the signal! (Duncan, 1972)
Signal Turn-yielding cue Turn-holding cueSyntax Complete IncompleteProsody - Pitch Rising or Falling FlatProsody - Intensity Lower HigherProsody - Duration Shorter LongerBreathing Breathe out Breathe inGaze Looking at addressee Looking awayGesture Terminated Non-terminated
S1
S2
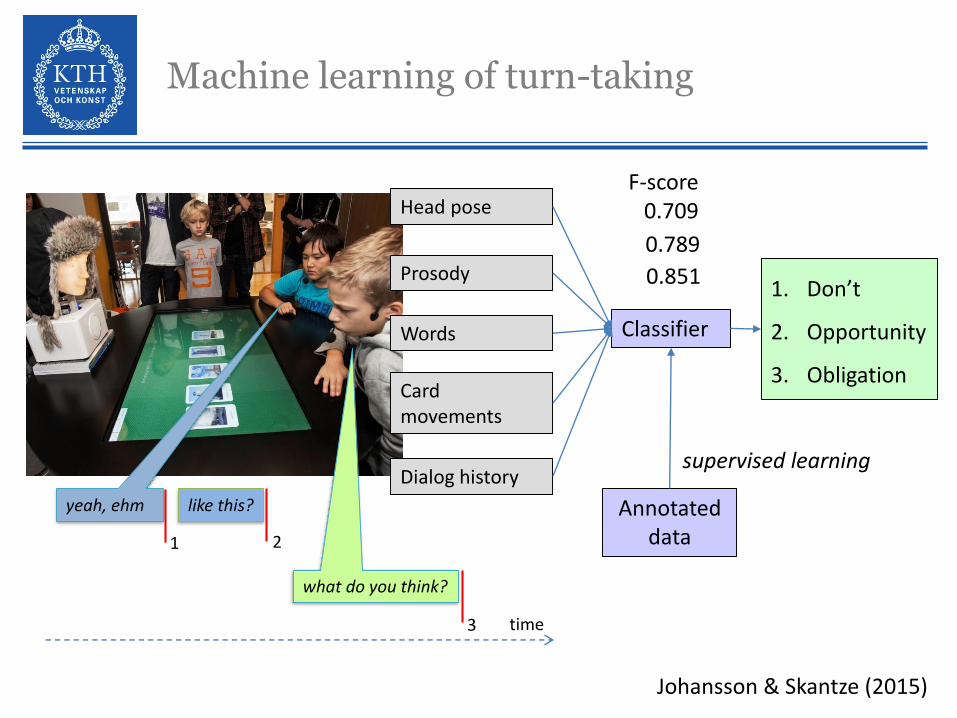
Machine learning of turn-taking
what do you think?
like this?
3
1 2
time
1. Don’t
2. Opportunity
3. ObligationCard movements
Words
Prosody
Head pose
Dialog history
Classifier
Annotated data
F-score0.709
0.8510.789
supervised learning
yeah, ehm
Johansson & Skantze (2015)

Towards a more general model
• Annotation of data is expensive and does not generalize– Can we learn from human-human interaction?
• Predictions are only made after IPUs (pauses)– Humans make continuous predictions
• Other turn-taking decisions are important as well– Overlap– Detecting backchannels
�Can we create a more general model?
Skantze (2017)
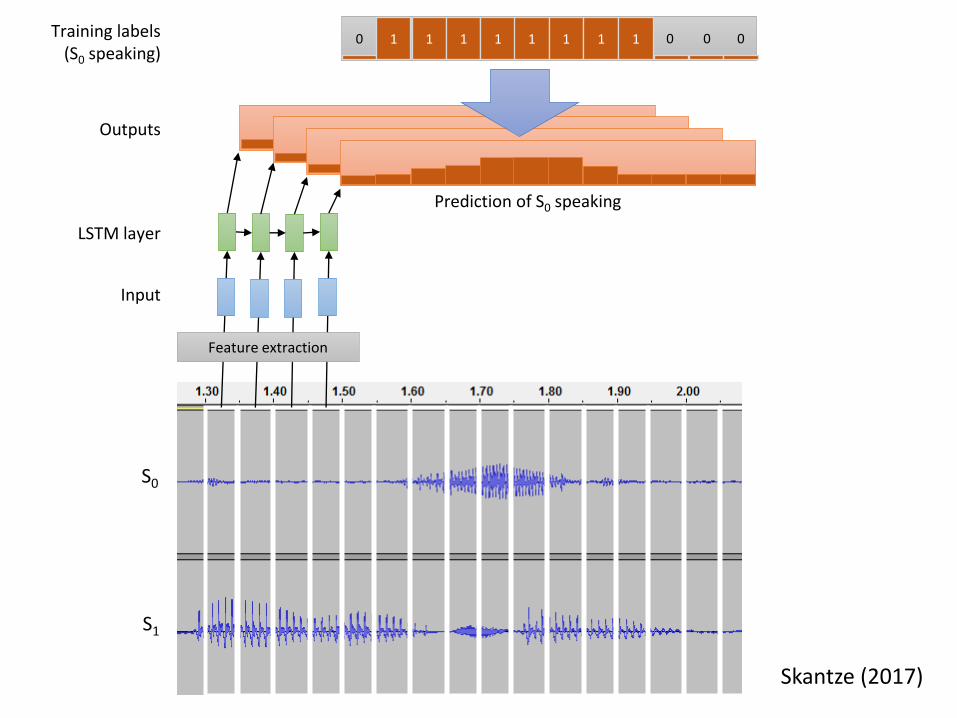
Outputs
LSTM layer
Prediction of S0 speaking
S0
S1
Input
Training labels(S0 speaking)
1 1 1 1 1 1 1 1
Feature extraction
0 0 00
Skantze (2017)
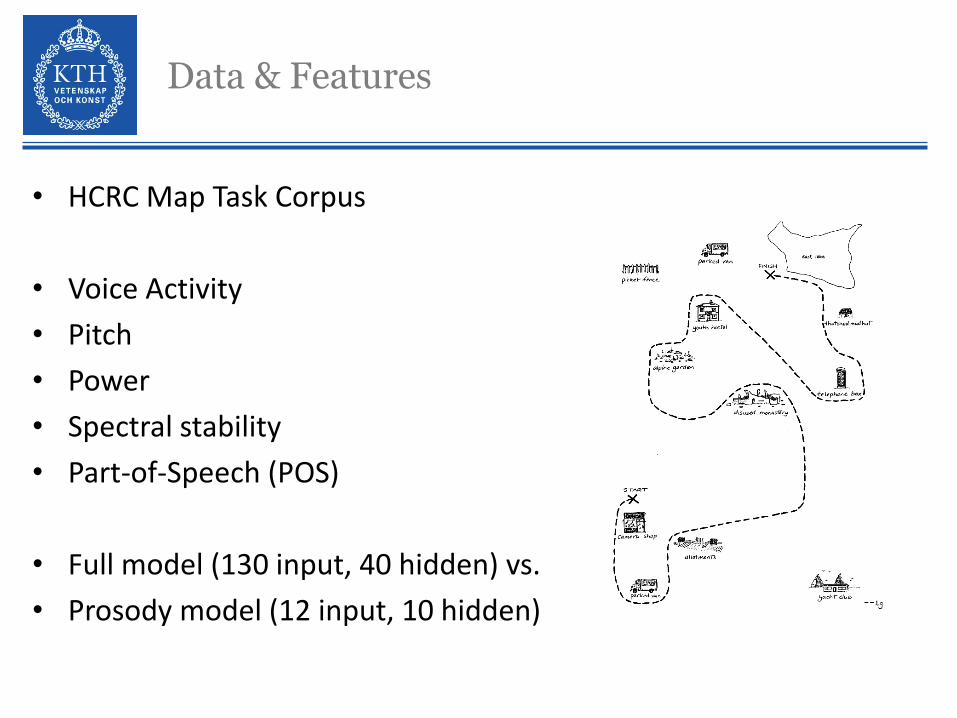
Data & Features
• HCRC Map Task Corpus
• Voice Activity• Pitch• Power• Spectral stability• Part-of-Speech (POS)
• Full model (130 input, 40 hidden) vs. • Prosody model (12 input, 10 hidden)
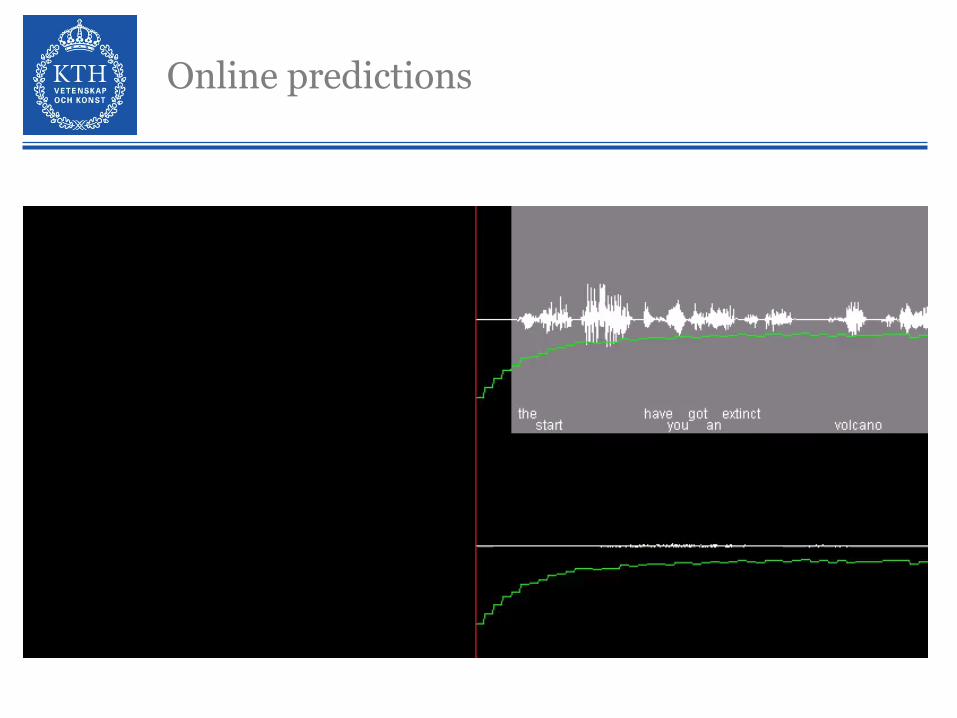
Online predictions
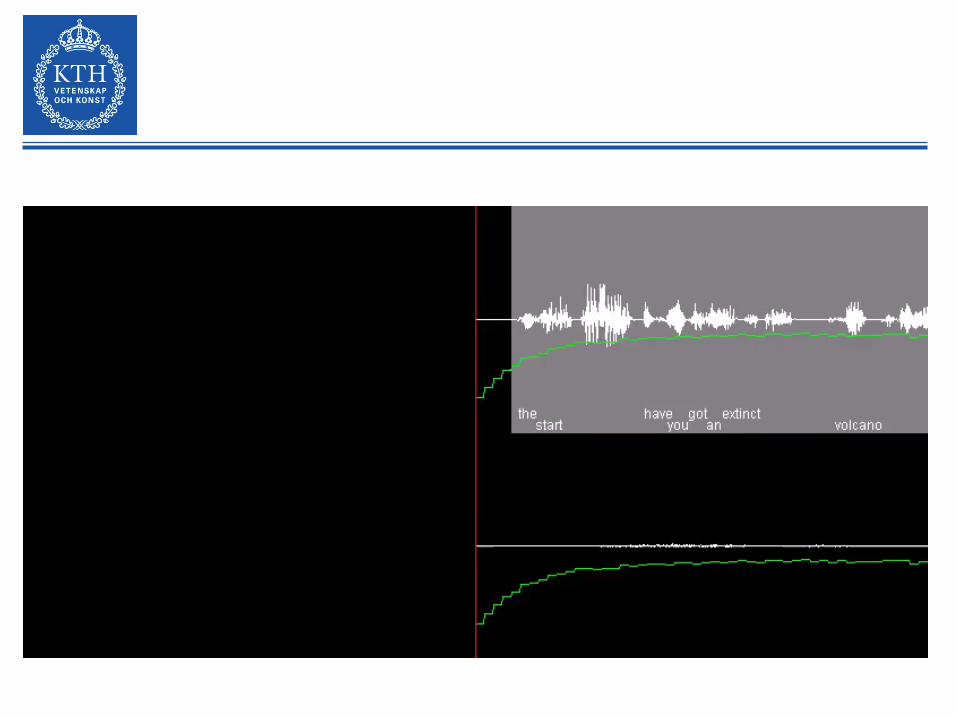

Prediction at pauses: HOLD vs SHIFT
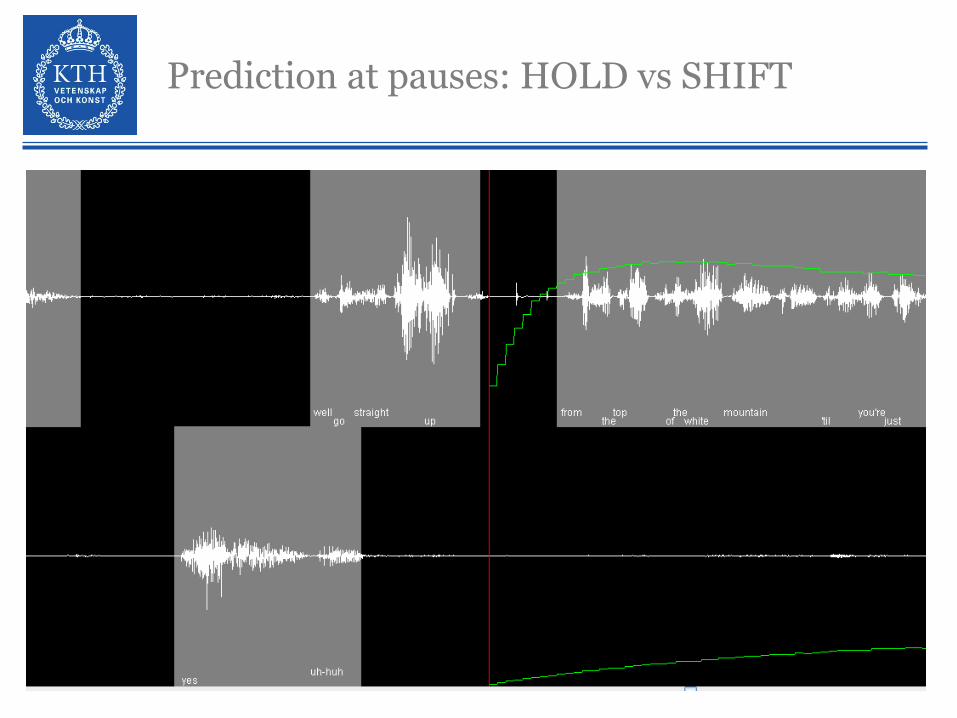
Prediction at pauses: HOLD vs SHIFT

Prediction at pauses: comparison
RNN, Prosody only (SigDial, 2017) 0.724
RNN, All features (SigDial, 2017) 0.762
Human performance (SigDial, 2017) 0.709
Majority-class baseline 0.421
Tuning speech parameters (Interspeech, 2018) 0.813
F-score for Prediction of turn-shifts at 500ms pauses
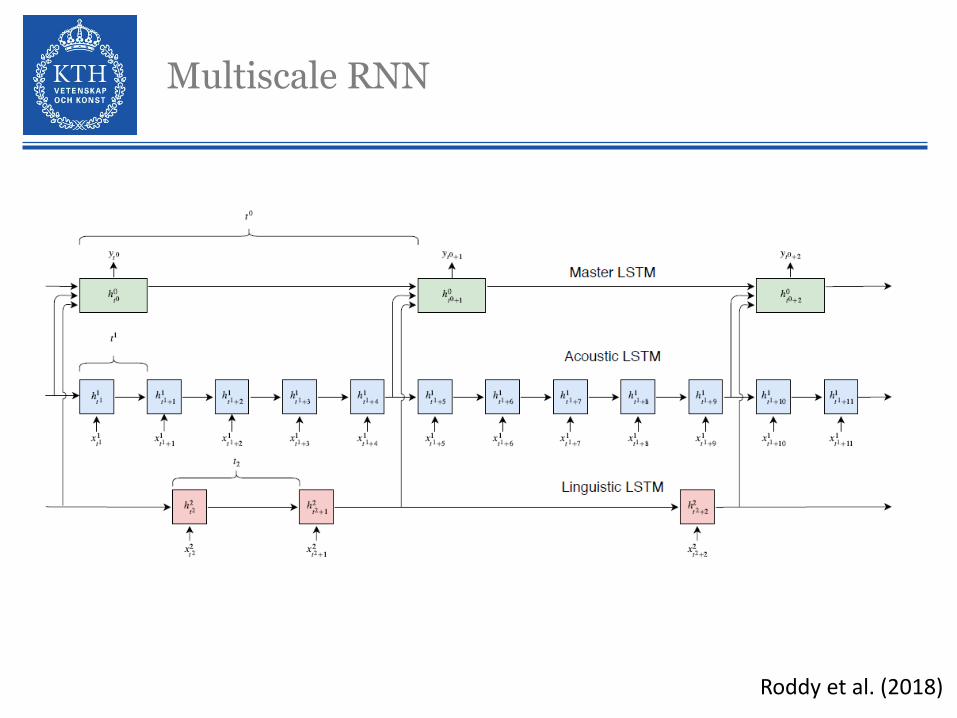
Multiscale RNN
Roddy et al. (2018)

Prediction at pauses: comparison
RNN, Prosody only (SigDial, 2017) 0.724
RNN, All features (SigDial, 2017) 0.762
Human performance (SigDial, 2017) 0.709
Majority-class baseline 0.421
Tuning speech parameters (Interspeech, 2018) 0.813
Multi-scale RNN (ICMI, 2018) 0.855
F-score for Prediction of turn-shifts at 500ms pauses

Current work: Application to HRI
• Applying to human-machine interaction– Human and synthetic voice– Various datasets of non-perfect
interactions
Tell me about yourself
Okay
mhm
I have had many interesting jobs
time

Current limitations and Challenges ahead
• Fluent Turn-taking (SSF/VR)• Learning symbol grounding through dialog (SSF/WASP)• Scaling beyond limited domains (Amazon)• Learning from interaction (VR)• Learning from human/Wizard-of-oz (SSF)
– Transfer learning• Managing shared spaces (ICT-TNG)
– Using Mixed/Augmented Reality for simulation

Referring to objects in situated interaction
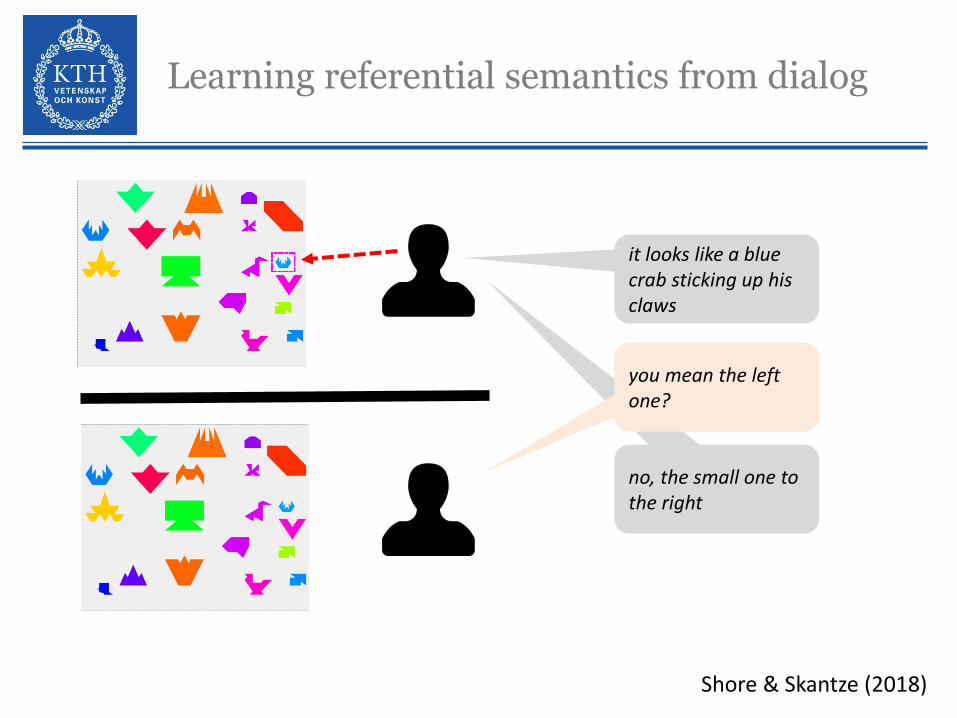
Learning referential semantics from dialog
it looks like a blue crab sticking up his claws
Shore & Skantze (2007). Enhancing reference resolution in dialogue using participant feedback. In Proceedings of Grounding Language Understanding GLU2017, Stockholm.
no, the small one to the right
you mean the left one?
Shore & Skantze (2018)

Data collection
• Referring-to-tangrams game• Repeated rounds
– Switching roles– Pieces move
• 42 dialogs, > 40 rounds each– Coreferences– Mean duration 15:25
minutes• Manual transcriptions• Train and evaluate using 42-
fold cross-validation
?
Instructor
Manipulator
It’s the blue crab

Data collection
• Referring-to-tangrams game• Repeated rounds
– Switching roles– Pieces move
• 42 dialogs, > 40 rounds each– Coreferences– Mean duration 15:25
minutes• Manual transcriptions• Train and evaluate using 42-
fold cross-validation
?
Instructor
Now it’s the pink chicken
Manipulator

Training a semantic model for words
“The small blue crab” Baseline• “words-as-classifiers”
Kennington & Schlangen (2015)• Train a logistic regression model
for each word• Negative sampling
• Use features of objects• Shape• Color• Size• Position
• Application: Rank the referents based on simple average of the world classifier scores
• Evaluate using MRR• 1/rank

Learning of color words
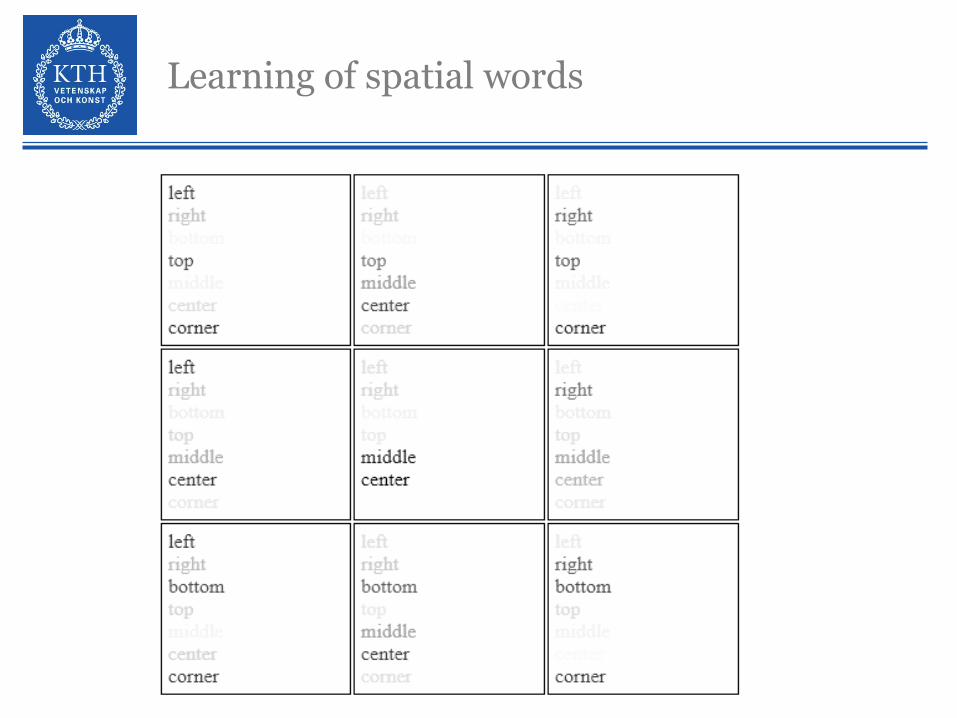
Learning of spatial words

Comparison to the previous results
• Applying the baseline model to our dataset gives MRR 0.682• Previous results using similar model and task: MRR 0.759
(Kennington & Schlangen, 2015)• Complicating factors:
– Dialog, not monolog– Using all language in the dialogs, not just manually annotated
Referring expressions– Non-trivial referring language, sparsity of data
• Weird shapes (“asteroid”, “a man with a hat”), atypical colors (“pinkish”)
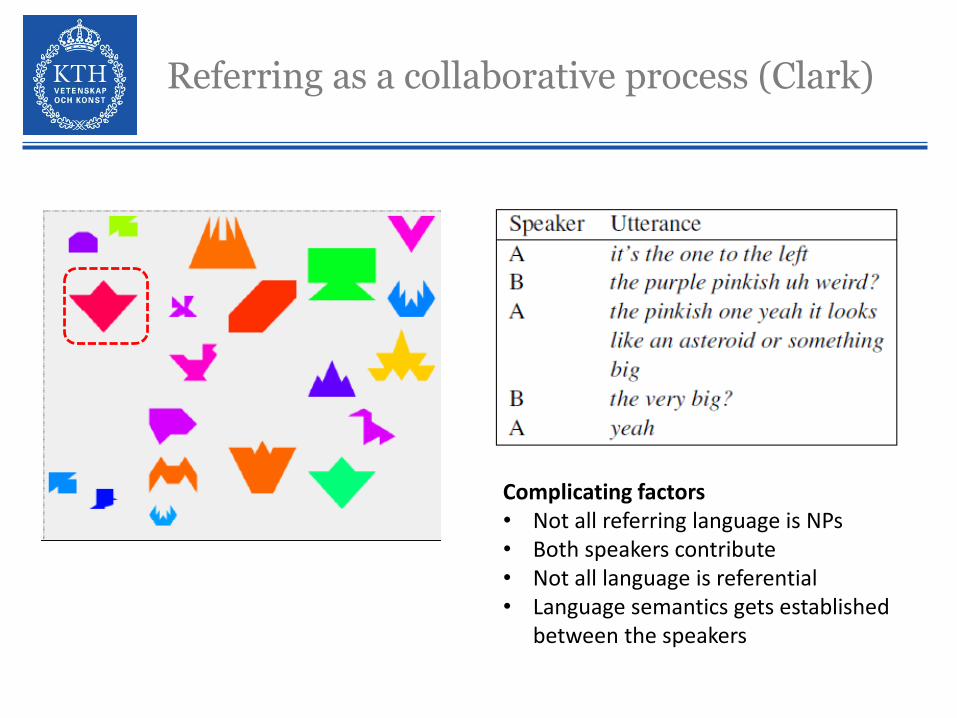
Referring as a collaborative process (Clark)
Complicating factors• Not all referring language is NPs• Both speakers contribute• Not all language is referential• Language semantics gets established
between the speakers
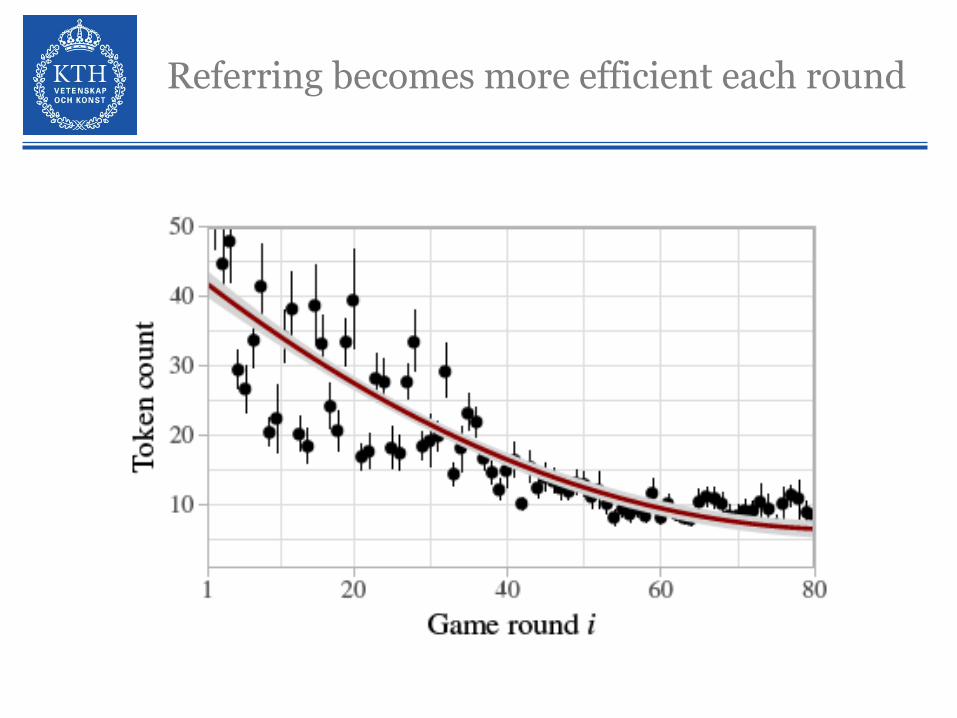
Referring becomes more efficient each round

Conceptual pacts/Lexical alignment

Model adaptation: Lexical alignment
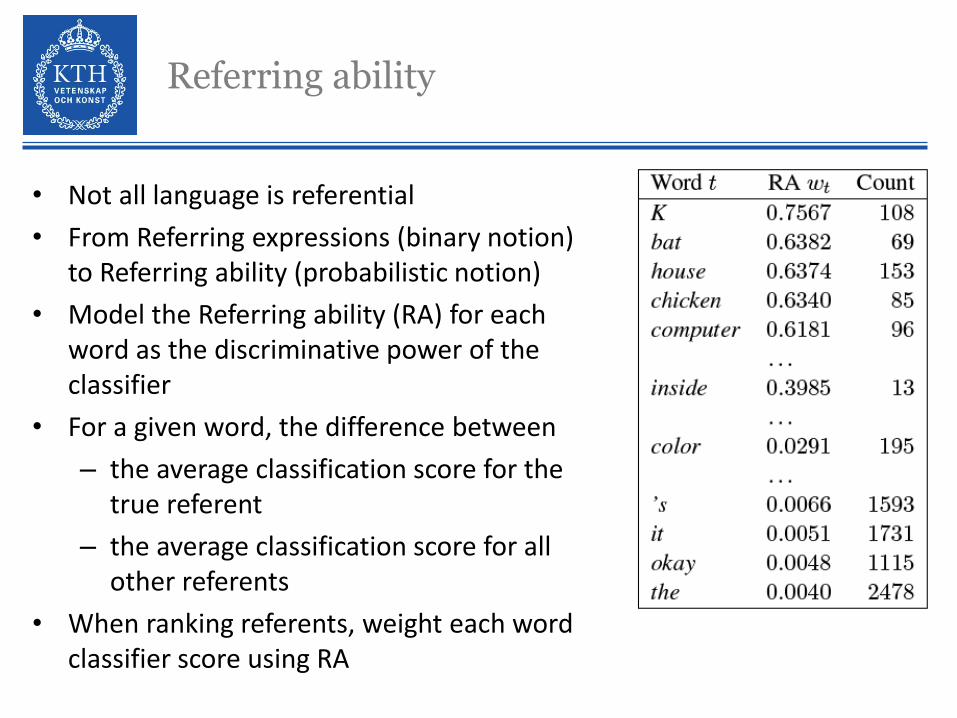
Referring ability
• Not all language is referential• From Referring expressions (binary notion)
to Referring ability (probabilistic notion)• Model the Referring ability (RA) for each
word as the discriminative power of the classifier
• For a given word, the difference between – the average classification score for the
true referent– the average classification score for all
other referents• When ranking referents, weight each word
classifier score using RA

Example

Weighting by Referring ability
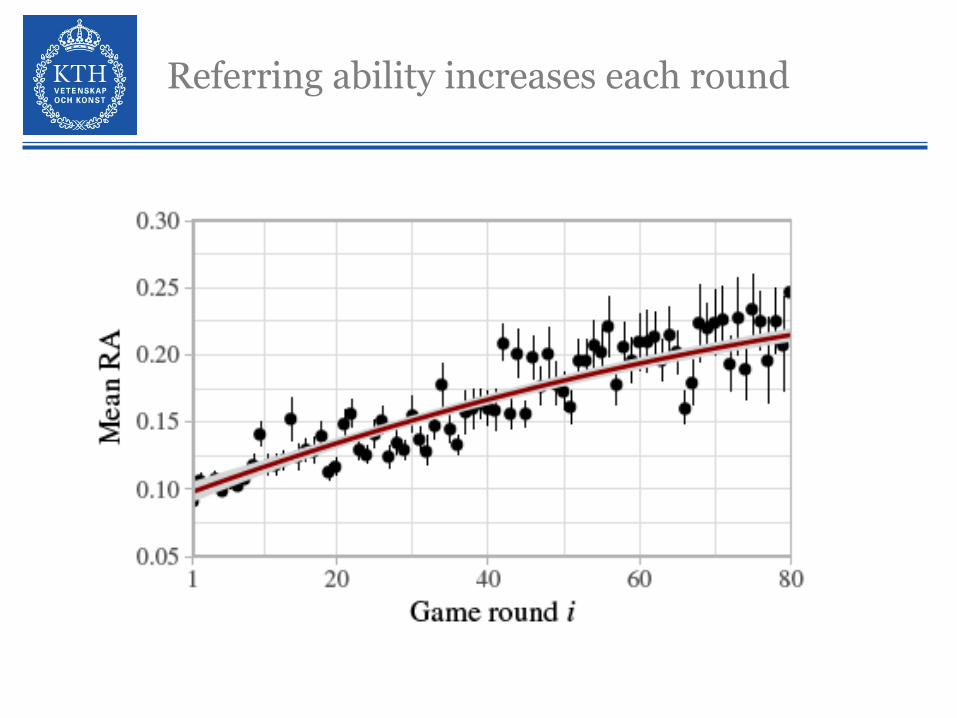
Referring ability increases each round
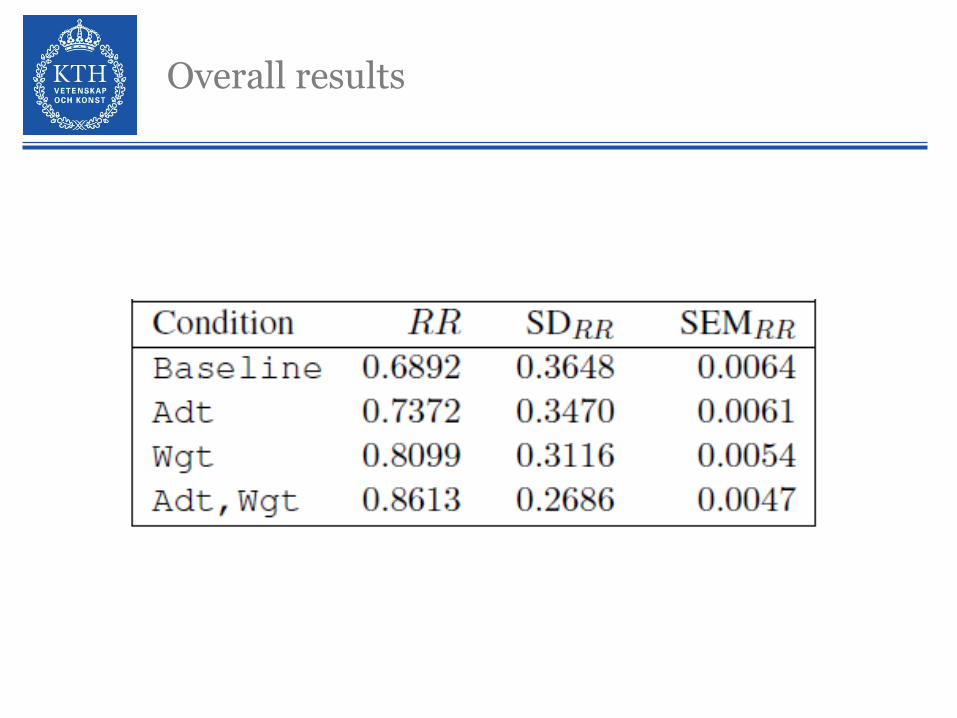
Overall results

Conclusions
• Semantics of referring language can be learned from observing situated dialog, even with relatively little data
• With non-typical properties of objects, data sparsity is an issue– We can leverage language entrainment between speakers to
adapt the model• Referring in dialog is a collaborative process�We cannot derive referential semantics from “Referring
expressions” alone� A more probabilistic notion of “Referring ability” of language
is useful, and can be derived from data

The End
Questions?