correlation and simple linear regression - s5 - nki · 1/39 basic medical statistics course...
TRANSCRIPT

1/39
Basic Medical Statistics Course
Correlation and simple linear regression
S5
Patrycja [email protected]
November 4, 2015

2/39
Introduction
I So far we have looked at the association between:I Two categorical variables (chi-square test)I Numerical variable and categorical variable (independent
samples t-test and ANOVA)
I We will now look at the association between two numerical(continuous) variables, say x and y

3/39
Introduction
Example 1: Brain size versus body weight
Brain size WeightSubject id (count per 10,000) (pounds)
1 81.69 1182 96.54 1723 92.88 1464 90.49 1345 95.55 1726 83.39 1187 92.41 155...
......
24 79.06 12225 98.00 190
How do we investigate the association between these two variables?

4/39
Scatter plot
Subject 4
Subject 24
There is a roughly linear association

5/39
Relationship between two numerical variables
If a linear relationship between x and y appears to be reasonablefrom the scatter plot, we can take the next step and
1. Calculate Pearson’s product moment correlation coefficientbetween x and yI Measures how closely the data points on the scatter plot resemble a
straight line
2. Perform a simple linear regression analysisI Finds the equation of the line that best describes the relationship
between variables seen in a scatter plot

6/39
Correlation
Sample Pearson’s product moment correlation coefficient, orcorrelation coefficient, between variables x and y is calculated as
r(x , y) =1
n − 1
n∑i=1
(xi − x
sx
)(yi − y
sy
)=
1n − 1
n∑i=1
zxi zyi
where:I {(xi , yi ) : i = 1, . . . ,n} is a random sample of n observations on x
and y ,I x and y are the sample means of respectively x and y ,I sx and sy are the sample standard deviations of respectively x and
y , andI zxi and zyi are z-scores of x and y for i-th observation.

7/39
Correlation
Properties of r :
I r estimates the true population correlation coefficient ρI r takes on any value between −1 and 1I Magnitude of r indicates the strength of a linear relationship
between x and y :I r = −1 or 1 means perfect linear associationI r = 0 indicates no linear association (but can be e.g. non-linear)I The closer r is to -1 or 1, the stronger the linear association
(e.g. r = -0.1 (weak association) vs r = 0.85 (strong association))I Sign of r indicates the direction of association:
I r > 0 implies positive relationshipi.e. the two variables tend to move in the same direction
I r < 0 implies negative relationshipi.e. the two variables tend to move in opposite directions

8/39
Correlation
Properties of r (cont’d):
I r(a · x + b, c · y + d) = r(x , y), where a > 0, c > 0, and b and d areconstants
I r(x , y) = r(y , x)
I r 6= 0 does not imply causation! Just because two variables arecorrelated does not necessarily mean that one causes the other!
I r2 is called the coefficient of determinationI 0 ≤ r 2 ≤ 1I Represents the proportion of total variation in one variable that is
explained by the otherI For example: the coefficient of determination between body weight and
age of 0.60 means that 60% of total variation in body weight is explainedby age alone and the remaining 40% is explained by other factors

9/39
CorrelationCorrelation
r= -1 r= 1 r= 0.8 r= -0.8
r= 0 r= 0 0 < r< 1 -1 < r< 0
6 / 49
Don’t interpret r without looking at the scatter plot!

10/39
Correlation
Hypothesis test for the population correlation coefficient ρ:
H0 : ρ = 0(there is no linear relationship between y and x)
H1 : ρ 6= 0(there is a linear relationship between y and x)
Under H0, the test statistic
T = r√
n−21−r2
follows a Student-t distribution with n − 2 degrees of freedom.
Note:I This test assumes that the variables x and y are normally distributed

11/39
Correlation
Example 1 revisited: brain size vs weight
What is the magnitude and sign of correlation coefficient betweenbrain size and weight?

12/39
Correlation
Example 1 revisited: brain size vs weight
r
p‐value
n

13/39
Simple linear regression
I Pearson’s product moment correlation coefficient measures thestrength and direction of the linear association between x and y
I But often times we are also interested in predicting the value of onevariable given the value of the other
I This requires finding an equation (or mathematical model) thatdescribes the relationship between the variables
I If a scatter plot of data shows an approximately linear relationshipbetween x and y we can use simple linear regression to estimatethe equation of this line
I Unlike correlation, regression requires that we haveI a dependent variable (or outcome or response variable), i.e. the
variable being predicted (always on the vertical or y -axis)I an independent variable (or explanatory or predictor variable), i.e. the
variable used for prediction (always on the horizontal or x-axis)I We will assume that x and y are the independent variable and the
dependent variable, respectively

14/39
Simple linear regression
Simple linear regression postulates that in the population
y = (α + β · x) + ε,
where:I y is the dependent variableI x is the independent variableI α and β are parameters called population regression
coefficientsI ε is a random error term

15/39
Simple linear regression
x
y
x1 x2 x3 x4 x5

16/39
Simple linear regression
x
y E(y|xi)
x1 x2 x3 x4 x5
E(y|x) = α + β·x
E(y |xi) is the mean value of y when x = xi
E(y |x) = α+ β · x is the population regression function

17/39
Simple linear regression
x
y
1 2 3 4 5
E(y|x) = α + β·x
0
α
6
β
3β
I α is the y -intercept of the population regression function, i.e. the meanvalue of y when x equals 0
I β is the slope of the population regression function, i.e. the mean (orexpected) change in y associated with a 1-unit increase in the value of x
I c · β is the mean change in y for a c-unit increase in the value of xI α and β are estimated from the sample data using the least squares
method (usually)

18/39
Simple linear regression
x
y
xi 0
= a + b·x
i
yi ei ei = yi - i = residual i
Least squares method chooses a and b (estimates for α and β) tominimize the sum of the squares of the residuals
n∑i=1
e2i =
n∑i=1
(yi − yi )2 =
n∑i=1
[yi − (a + b · xi )]2

19/39
Simple linear regression
The least squares estimates for β and α are:
b =
∑ni=1(xi − x)(yi − y)∑n
i=1(xi − x)2
and
a = y − b · x ,
where x and y are the respective sample means of x and y .
Note that:b = r(x , y) ·
sy
sx,
where r(x , y) is the sample product moment correlation between xand y , and sx and sy are the sample standard deviations of x and y .

20/39
Simple linear regression
Relationship between slope b and correlation coefficient r
I r 6= b unless sx = sy
I r measures the strength of a linear association between x and ywhile b measures the size of the change in the mean value of ydue to a unit change in x
I r does not distinguish between x and y while b doesI r is scale-free while b is not
But:I r and b have the same signI both r and b do not imply causationI both r and b can be affected by outliersI r = 0 if and only if b = 0, thus test of β = 0 is equivalent to the test
of ρ = 0 (i.e. no linear relationship)

21/39
Simple linear regression
Test of H0 : β = 0 versus H1 : β 6= 0
1. t-test:I Test statistic: T = b
SE(b) , where SE(b) is the standard error of bcalculated from the data
I Under H0, T follows a Student-t distribution with n − 2 degrees offreedom
2. F-test:I Test statistic: F =
(b
SE(b)
)2= T 2, where SE(b) and T are as above
I Under H0, F follows an F distribution with 1 and n − 2 degrees offreedom
I The t-test and the F-test lead to the same outcome
Note: The test of zero intercept α is of less interest, unless x = 0 ismeaningful

22/39
Simple linear regression
Example 2: blood pressure (mmHg) versus body weight (kg) in 20patients with hypertension1
Weight
105.00100.0095.0090.0085.00
BP
125.00
120.00
115.00
110.00
105.00
Page 1
1Daniel, W.W. and Cross, C.L.(2013). Biostatistics: a foundation for analysis in the health sciences, 10th edition.

23/39
Simple linear regression
SPSS output:
Coefficientsa
Model
Unstandardized Coefficients
t Sig.B Std. Error Beta
1 (Constant)
Weight
2.205 8.663 .255 .802
1.201 .093 .950 12.917 .000
a.
Page 1
From above, the regression equation is BP = 2.20 + 1.20 ·Weight
ANOVAa
Model Sum of Squares df Mean Square F Sig.
1
Regression 505,472 1 505,472 166,859 ,000b
Residual 54,528 18 3,029
Total 560,000 19
a. Dependent Variable: BP
b. Predictors: (Constant), Weight
F-test

24/39
Simple linear regression
Standardized coefficientsI Obtained by standardizing both y and x (i.e. converting into
z-scores) and re-running the regressionI After standardization, the intercept will be equal to zero and the
slope for x will be equal to the sample correlation coefficientI Of greater concern in multiple linear regression (next lecture)
where the predictors are expressed in different unitsI Standardization removes the dependence of regression coefficients on
the units of measurements of y and x ’s so they can be meaningfullycompared
I The larger the standardized coefficient (in absolute value) the greaterthe contribution of the respective variable in the prediction of y

25/39
Simple linear regression
Simple linear regression is only appropriate when the followingassumptions are satisfied:
1. Independence: the observations are independent, i.e. there is onlyone pair of observations per subject
2. Linearity: the relationship between x and y is linear3. Constant variance: the variance of y is constant for all values of x4. Normality: y has a Normal distribution

26/39
Simple linear regression
Checking linearity assumption:
1. Make a scatter plot of y versus xI If the assumption of linearity is met, the points in this plot should
generally form a straight line
2. Plot the residuals against the explanatory variable xI If the assumption of linearity is met, we should see a random scatter of
points around zero rather than any systematic pattern
x x
x
x
x x
x x
x x
x
x
x
x x
x
x x
x
x x x
x
x x
0
x
e
Linearity
x
x x
x
x
x
x x
x x
x x
x x
x
x
x
x
x
x
x
x
x
x
x
0
Lack of linearity
x
e
27/39
Simple linear regression
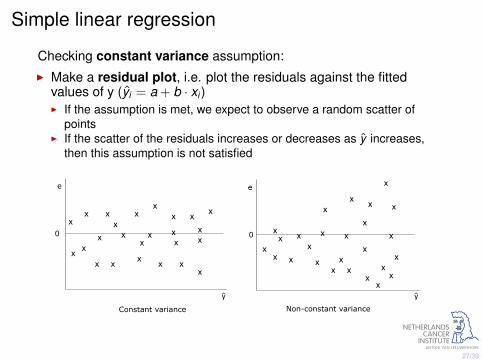
Checking constant variance assumption:I Make a residual plot, i.e. plot the residuals against the fitted
values of y (yi = a + b · xi )I If the assumption is met, we expect to observe a random scatter of
pointsI If the scatter of the residuals increases or decreases as y increases,
then this assumption is not satisfied
x x
x
x
x x
x x
x
x
x
x
x
x
x
x
x x
x
x x x
x
x x
0
e
Constant variance
0
Non-constant variance
e
x
x
x x
x
x
x
x x
x
x x x
x
x x
x
x x
x x
x x
x
x
x

28/39
Simple linear regression
Example 2 revisited: blood pressure vs body weight
Residual plot

29/39
Simple linear regression
Checking normality assumption:
1. Draw a histogram of y or the residuals and “eyeball” the result2. Make a normal probability plot (P–P plot) of the residuals,
i.e. plot the expected cumulative probability of a normal distributionversus the observed cumulative probability at each value of theresidualI If the assumption of normality is met, the points in this plot should form a
straight diagonal line

30/39
Simple linear regression
Example 2 revisited: blood pressure vs body weight
What can we do when assumptions 1–4 are violated?

31/39
Simple linear regression
Assessing goodness of fit
I The estimated regression line is the “best” one available (in theleast-squares sense)
I Yet, it can still be a very poor fit to the observed data
x
x
x
x x
x x
x
x x
x
x
x
x x
x
x
x x
x
x
x
x x
x
x
y
Good fit
x x
x
x
x
x
x
x
x
x x x
x x x
x
x x
x x
x
x
x
x
x
Bad fit
x
y

32/39
Simple linear regression
To assess goodness of fit of a regression line (i.e. how well does theline fit the data) we can:
1. Calculate the correlation coefficient between the predicted andobserved values of y , RI A higher absolute value of R indicates better fit (predicted and observed
values of y are closer to each other)
2. Calculate R2 (R Square in SPSS)I 0 ≤ R2 ≤ 1I A higher value of R2 indicates better fitI R2 = 1 indicates perfect fit (i.e. yi = yi for each i)I R2 = 0 indicates very poor fit

33/39
Simple linear regression
Alternatively, R2 can be calculated as
R2 =
∑ni=1(yi − y)2∑ni=1(yi − y)2
=variation in y explained by x
total variation in y
I We interpret R2 as the proportion of total variability in y that isexplained by the explanatory variable xI An R2 of 1 means that x explains all variability in yI An R2 of 0 indicates that x does not explain any variability in y
I R2 is usually expressed as a percentage. For example, R2 = 0.93indicates that 93% of total variation in y can be explained by x
I In SPSS, R2 can be found in Model Summary table or it can becalculated from ANOVA table; both tables are produced whenrunning linear regression

34/39
Simple linear regression
Example 2 revisited: blood pressure vs body weight
Model Summary
Model R R Square Adjusted R
Square
Std. Error of the
Estimate
1 ,950a ,903 ,897 1,74050
a. Predictors: (Constant), Weight

35/39
Simple linear regressionPrediction: interpolation versus extrapolation
y
Range of actual data
x
Possible patterns of additional data
Extrapolation beyond the range of the data is risky!!

36/39
Categorical explanatory variable
I So far we assumed that the predictor variable is numericalI But what if we want to study an association between y and a
categorical x , e.g. between blood pressure and gender or betweenbrain size and ethnicity?
I Categorical variables can be incorporated into a regression modelthrough dummy variables that take on the values 0 and 1
I In general, to include a variable with p categories p − 1 dummyvariables are required

37/39
Categorical explanatory variable
Example: variable with 4 categories, e.g. blood group (A, B, AB, 0)
Basic steps:1. Create dummy variables for all categories
xA =
{1, if blood group is A0, otherwise
xB =
{1, if blood group is B0, otherwise
xAB =
{1, if blood group is AB0, otherwise
x0 =
{1, if blood group is 00, otherwise
2. Select one category as a reference categoryI category that results in useful comparisons (e.g. exposed versus
non-exposed, experimental versus standard treatment) or a categorywith large number of subjects
3. Include in the model all dummies except the one corresponding tothe reference category

38/39
Categorical explanatory variable
Taking blood group 0 as reference category, the model becomes
y = α + βA · xA + βB · xB + βAB · xAB + ε
and its estimated counterpart is
y = a + bA · xA + bB · xB + bAB · xAB
I Estimation of model parameters requires running multiple linearregression (next lecture), unless the explanatory variable has onlytwo categories (e.g. gender)
I Given that y represents IQ score, the estimated coefficients areinterpreted as follows:I a is the mean IQ for subjects with blood group 0, i.e. the reference
categoryI Each b represents the mean difference in IQ between subjects with a
blood group represented by the respective dummy variable and subjectswith blood group 0 (the reference category)

39/39
Categorical explanatory variable
Specifically:I bA is the mean difference in IQ between subjects with blood group
A and subjects with blood group 0I bB is the mean difference in IQ between subjects with blood group
B and subjects with blood group 0I bAB is the mean difference in IQ between subjects with blood group
AB and subjects with blood group 0
Note:A test for the significance of a categorical explanatory variable with plevels involves the hypothesis that the coefficients of all p − 1 dummyvariables are zero. For that purpose, we need to use an overall F-test(next lecture) and not a t-test. The t-test can be used only when thevariable is binary.