cost-effective compiler directed memory prefetching and
TRANSCRIPT

Cost-Effective Compiler Directed Memory Prefetching and Bypassing
Daniel Ortegat, Eduard Ayguadet, Jean-Loup Baert and Mateo Valerot
tDepartamento de Arquitectura de Computadores, tDepartment of Computer Science and Engineering,
Universidad Politecnica de Cataluiia -Barcelona, Spain University of Washington -Seattle, WA
{ dortega,eduard,mateo }@ac. upc.es baer@cs. washington.edu
mance processors.
Prefetching is generally defined as the action ofbringing a data item closer to the processor before it isaccessed by a load instruction, thus reducing the load'soverall latency. Prefetching relies on address predic-tion, i.e., the prediction of the effective address of theoperand of a (predicted to be executed) subsequentload instruction, thus making prefetching speculative.If prefetching is limited to bringing data in the cachehierarchy, processor state is not affected and there isno need for microarchitectural recovery mechanisms.
Prefetching can be extended by considering thephysical registers to be part of the memory hierarchy.That is, even if the data is present in the lower levelcache (11), more can be gained by bringing it closer tothe processor. This technique is referred to as bindingprefetching when it is performed in a non-speculativeway [7]. There exist several ways to perform this bind-ing speculatively [10], including value prediction.
Initiation of the prefetching can be done by eitherthe software, the hardware, or a hybrid combinationof both. In software-based prefetching, the compiler[7] can insert a pref instruction which, when executed,will bring the referenced data into the 11 cache. Thisexplicit prefetching has no semantic implication andcan be ignored by the hardware, e.g. for binary com-patibility. The compiler can also advance a load aheadin the instruction stream and in this case, the (implicit )prefetching becomes binding since data is brought intoa register. If the load instruction has been advancedacross basic block boundaries, it can become specula-tive and a recovery mechanism is required [6]. Thisconcept, akin to forwarding mechanisms [3] used to al-leviate the latency of dependent instructions, can beextended to the case of non-speculative pref instruc-tions. In [8], a novel mechanism was introduced thattransforms non-binding prefetches into binding, thusbypassing the execution of the load instructions thateffectively bring data into the register file. This bypass-ing, defined as memory instruction bypassing, extracts
Abstract
Ever increasing memory latencies and deeper
pipelines push memory farther from the processor.Prefetching techniques aim is to bridge these two gaps
by fetching data in advance to both the L1 cache andthe register file. Our main contribution in this paper
is a hybrid approach to the prefetching problem that
combines both software and hardware prefetching in a
cost-effective way by needing very little hardware sup-port and impacting minimally the design of the proces-
sor pipeline. The prefetcher is built on-top of a static
memory instruction bypassing, which is in charge of
bringing prefetched values in the register file. In thispaper we also present a thorough analysis of the limits
of both prefetching and memory instruction bypassing.
We also compare our prefetching technique with a prior
speculative proposal that attacked the same problem,and we show that at much lower cost, our hybrid solu-
tion is better than a realistic implementation of specu-
lative prefetching and bypassing. In average, our hybrid
implementation achieves a 13% speed-up improvementover a version with software prefetching in a subset of
numerical applications and an average of 43% over a
version with no software prefetching ( achieving up to a
102% for specific benchmarks).
1 Introduction and Related Work
Memory operations represent over 20% of all dy-namic instructions [3] and while other types of instruc-
tions have fixed latencies, loads have latencies that de-
pend on the placement of the data in the memory hier-
archy. When the data is not in the cache closest to the
processor, stalls may occur. In scientific applications
this stalling effect has been measured [7] and representsa significant amount of total application time.
Technological trends point towards relatively longer
latencies at all levels of the memory hierarchy, there-
fore techniques to tolerate them better become increas-
ingly important. In particular, larger and more efficientcache hierarchies and more precise prefetching tech-
niques have become necessary to sustain high perfor-
Proceedings of the 2002 International Conference on Parallel Architectures and Compilation Techniques (PACT’02) 1089-795X/02 $17.00 © 2002 IEEE
c.;:J LO~....c.
(I; .,
D No Prefetching No Bypassing
-No Prefetching Perfect Bypassing
-Perfect Prefetching No Bypassing
-Perfect Prefetching Pertect Bypassing
tomcatv
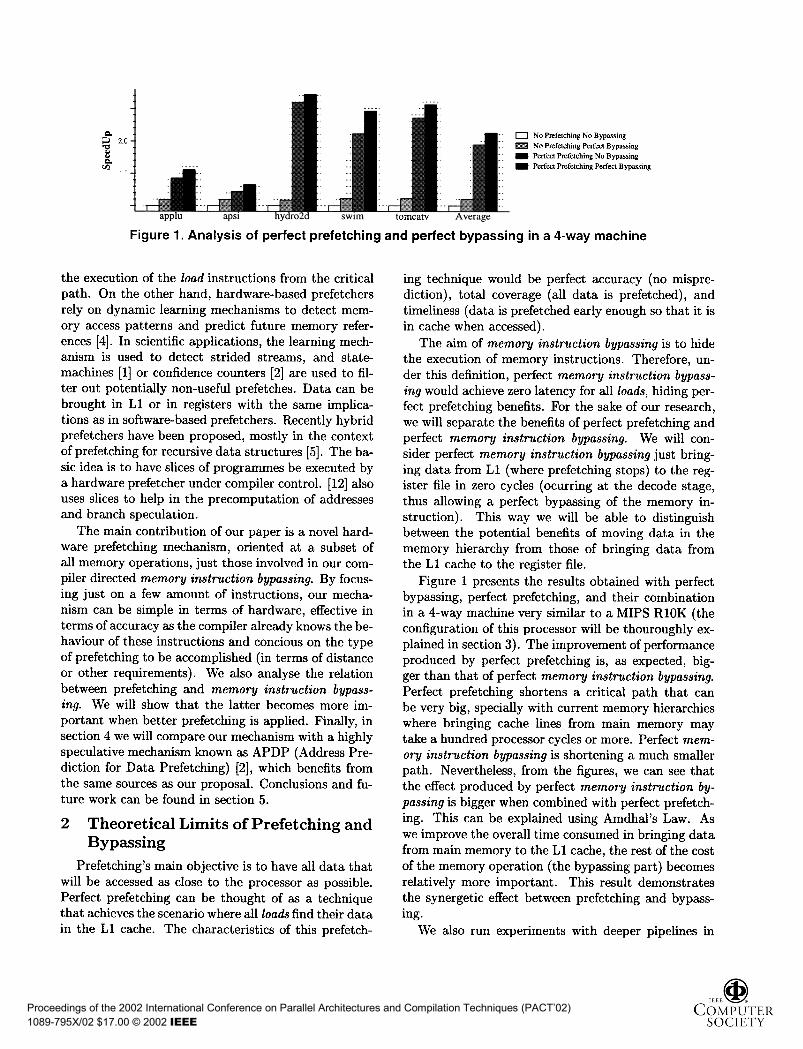
Figure 1. Analysis of perfect prefetching and perfect bypassing in a 4-way machine
the execution of the load instructions from the criticalpath. On the other hand, hardware-based prefetchersrely on dynamic learning mechanisms to detect mem-ory access patterns and predict future memory refer-ences [4]. In scientific applications, the learning mech-anism is used to detect strided streams, and state-machines [1] or confidence counters [2] are used to fil-ter out potentially non-useful prefetches. Data can bebrought in Ll or in registers with the same implica-tions as in software-based prefetchers. Recently hybridprefetchers have been proposed, mostly in the contextof prefetching for recursive data structures [5] .The ba-sic idea is to have slices of programmes be executed bya hardware prefetcher under compiler control. [12] alsouses slices to help in the precomputation of addressesand branch speculation.
The main contribution of our paper is a novel hard-ware prefetching mechanism, oriented at a subset ofall memory operations, just those involved in our com-piler directed memory instruction bypassing. By focus-ing just on a few amount of instructions, our mecha-nism can be simple in terms of hardware, effective interms of accuracy as the compiler already knows the be-haviour of these instructions and concious on the typeof prefetching to be accomplished (in terms of distanceor other requirements). We also analyse the relationbetween prefetching and memory instruction bypass-ing. We will show that the latter becomes more im-portant when better prefetching is applied. Finally, insection 4 we will compare our mechanism with a highlyspeculative mechanism known as APDP (Address Pre-diction for Data Prefetching) [2] , which benefits fromthe same sources as our proposal. Conclusions and fu-ture work can be found in section 5.
2 Theoretical Limits of Prefetching and
Bypassing
Prefetching's main objective is to have all data thatwill be accessed as close to the processor as possible.Perfect prefetching can be thought of as a techniquethat achieves the scenario where all loads find their datain the Ll cache. The characteristics of this prefetch-
ing technique would be perfect accuracy (no mispre-diction), total coverage (all data is prefetched), andtimeliness ( data is prefetched early enough so that it isin cache when accessed).
The aim of memory instruction bypassing is to hidethe execution of memory instructions. Therefore, un-der this definition, perfect memory instruction bypass-ing would achieve zero latency for all loads, hiding per-fect prefetching benefits. Fot the sake of our research,we will separate the benefits of perfect prefetching andperfect memory instruction bypassing. We will con-sider perfect memory instruction bypassing just bring-ing data from Ll (where prefetching stops) to the reg-ister file in zero cycles (ocurring at the decode stage,thus allowing a perfect bypassing of the memory in-struction). This way we will be able to distinguishbetween the potential benefits of moving data in thememory hierarchy from those of bringing data fromthe Ll cache to the register file.
Figure 1 presents the results obtained with perfectbypassing, perfect prefetching, and their combinationin a 4-way machine very similar to a MIPS RlOK (theconfiguration of this processor will be thouroughly ex-plained in section 3). The improvement of performanceproduced by perfect prefetching is, as expected, big-ger than that of perfect memory instruction bypassing.Perfect prefetching shortens a critical path that canbe very big, specially with current memory hierarchieswhere bringing cache lines from main memory maytake a hundred processor cycles or more. Perfect mem-ory instruction bypassing is shortening a much smallerpath. Nevertheless, from the figures, we can see thatthe effect produced by perfect memory instruction by-passing is bigger when combined with perfect prefetch-ing. This can be explained using Amdhal's Law. Aswe improve the overall time consumed in bringing datafrom main memory to the Ll cache, the rest of the costof the memory operation (the bypassing part) becomesrelatively more important. This result demonstratesthe synergetic effect between prefetching and bypass-
ing.We also run experiments with deeper pipelines in
Proceedings of the 2002 International Conference on Parallel Architectures and Compilation Techniques (PACT’02) 1089-795X/02 $17.00 © 2002 IEEE

D 02 1 port
D 02 2 ports
.03 (no prefetch) 1 port
.03 (no prefetch) 2 ports
.03 (prefetch) I port
.03 (prefetch) 2 ports
=-;;J 1.5
1=-rIJ
1.0
apsl swim tomcatv
Figure 2. Effect of compiler optimisations and the number of ports in a 4-way machine
which both the Lllatency and the memory stage wereincreased from 1 to 2 cycles. We found out thatthe relative improvement of bypassing with respect toprefetching increases, which shows that bypassing willbecome more important with deeper pipelines.
3 Prefetching and memory instructionbypassing implementation techniques
Software Prefetching3.1
Initiating prefetching can be done automatically bythe hardware or can be driven by the insertion or place-ment of memory operations in the code, i.e. softwareprefetching, which itself can be decided by the compileralone or may require the aid of the programmer .
Software prefetching can be classified as being bind-ing or non-binding. Binding prefetch brings data fromthe memory to the register file before it is needed.In order to achieve this, the load instruction mustbe advanced far enough in the instruction stream sothat the contents of the register are updated before itsconsumers start executing. This advancement can beachieved, for example, by executing the load instruc-tion a few iterations ahead of where it is needed.
Sometimes hiding the total latency of the load isnot possible and in many architectures load instruc-tions cannot be executed speculatively because theymay access memory locations that trigger exceptions,modifying the normal execution of the application (spe-cially if it should have never been executed). In certaincodes the moment in which we know that a particularload is going to be executed is too near to the use ofthe data to completely hide its latency. In other sit-uations it is the lack of resources that the load needs(such as logical registers) that inhibits us from expand-ing the lifetime of the load. In these two latter scenariosthough, the benefits produced from hiding partially theload latency are far better than no prefetching at all.
Non-binding software prefetch tries to overcome thelimitations of the binding case. A new instruction,namely pref instruction, is used to inform the hardware
which data will potentially be accessed in the near fu-ture, which is consequently brought to the L1 cache(thus allocating no registers). In most architectures,this pref instruction is speculative, thus raising no ex-ceptions at all. This pref instruction ( and the non-binding prefetch it represents) does not have the draw-backs of the binding load, but on the other hand hasother drawbacks. As it leaves the data in the L1 cache,a conventional load instruction must still be present inthe code to bring the data to the register file. Thisimplies the overhead of two memory operations to dothe work of one. Moreover, the conventional load in-struction is usually found near its dependent use, andtherefore, the cost of bringing data from the L1 to theregister file ( what we have called memory instructionbypassing) is not hidden at all.
The choice of when to aply either is not simple. Nor-mally the compiler will combine both techniques tryingto achieve the best performance. In all our simulations,we have used code produced by the MIPSpro compiler(Version 7.30), which is considered to be a very goodcompiler in terms of prefet<!hing and which combinesboth binding and non-binding prefetch. We have anal-ysed two base machines, roughly based on the MIPSR10K processor. The first one assumes a 4-way out-of-order core and the second, more aggressive, assumesan 8-way out-of-order core. The number of functionalunits and the rest of the resources have been lever-aged to the issue width. The base memory hierarchyanalysed consists of a 32K direct mapped L1 cache ac-cessible in 1 cycle, a 4-way 2Mb L2 cache with hit in13 cycles and main memory with an 88 cycles latency.
In figures 2 and 3 we can see the effects that softwareprefetching has on five numerical applications runningon our base machines. All five applications were chosenfrom the SPECfp95 suite d1ile to their amenability tosimulation.
The compiler produced three different versions ofeach application. In the compiler framework used forour experiments, prefetching can only be inserted in-03 mode. This is why we have chosen to produce
Proceedings of the 2002 International Conference on Parallel Architectures and Compilation Techniques (PACT’02) 1089-795X/02 $17.00 © 2002 IEEE
£'~t 1.2Q,
"J
D 02 2 ports
.02 4 ports
.03 (no prefetch) 2 ports
.03 (no prefetch) 4 ports
.03 (prefetch) 2 ports
.03 (prefetch) 4 ports1.0
08
apSl swIm tomcatv
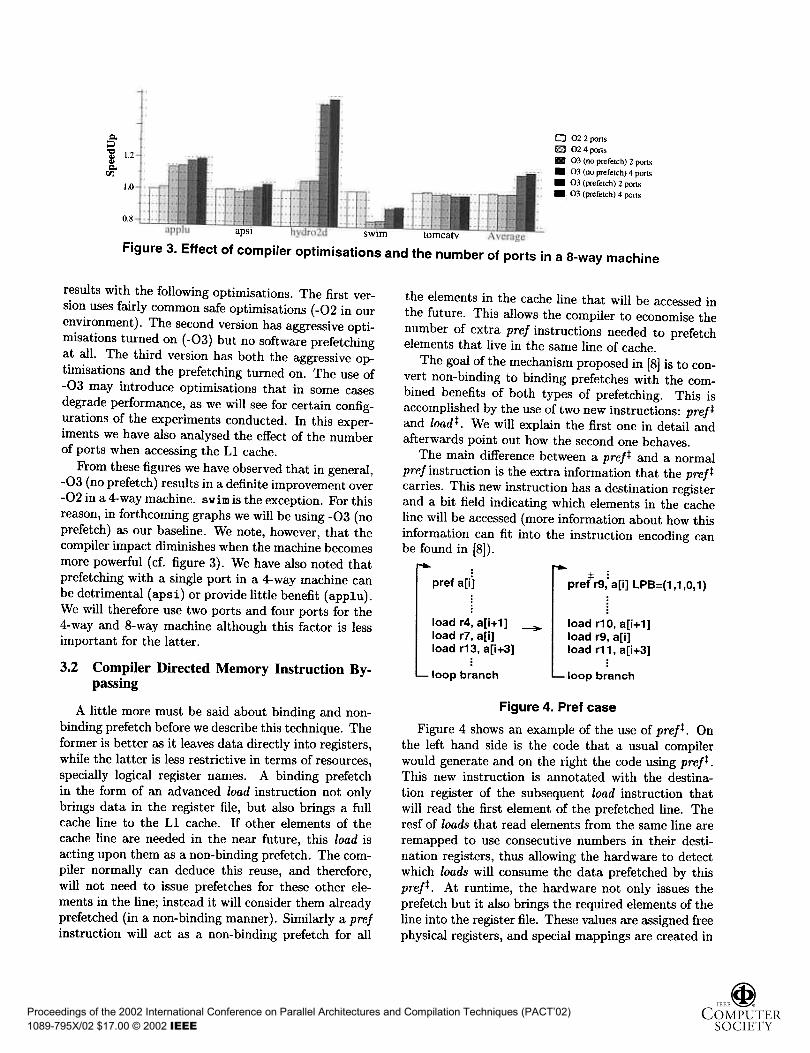
Figure 3. Effect of compiler optimisations and the number of ports in a S-way machine
the elements in the cache line that will be accessed inthe future. This allows the compiler to economise thenumber of extra pre! instructions needed to prefetchelements that live in the same line of cache.
The goal of the mechanism proposed in [8] is to con-vert non-binding to binding prefetches with the com-bined benefits of both types of prefetching. This isaccomplished by the use of two new instructions: pre!*and load * .We will explain the first one in detail and
afterwards point out how the second one behaves.The main difference between a pre!* and a normal
pre! instruction is the extra information that the pre!*carries. This new instruction has a destination registerand a bit field indicating which elements in the cacheline will be accessed (more information about how thisinformation can fit into the instruction encoding canbe found in [8]).
results with the following optimisations. The first ver-sion uses fairly common safe optimisations ( -02 in our
environment). The second version has aggressive opti-misations turned on ( -03) but no software prefetchingat all. The third version has both the aggressive op-timisations and the prefetching turned on. The use of-03 may introduce optimisations that in some cases
degrade performance, as we will see for certain config-urations of the experiments conducted. In this exper-iments we have also analysed the effect of the numberof ports when accessing the 11 cache.
From these figures we have observed that in general,-03 (no prefetch) results in a definite improvement over-02 in a 4-way machine. swim is the exception. For thisreason, in forthcoming graphs we will be using -03 (noprefetch) as our baseline. We note, however, that thecompiler impact diminishes when the machine becomesmore powerful (cf. figure 3). We have also noted thatprefetching with a single port in a 4-way machine canbe detrimental (apsi) or provide little benefit (applu).We will therefore use two ports and four ports for the4-way and S-way machine although this factor is lessimportant for the latter .
3.2 Compiler Directed Memory Instruction By-
passing
pref a[i]
load r4, a[i+1] -load r7, a[i]load r13, a[i+3]
loop branch
;1: :pref r9, a[i] LPB=(1 ,1,0,1 )
load r10, a[i+1]load r9, a[i]load r11 , a[i+3]
loop branch
A little more must be said about binding and non-binding prefetch before we describe this technique. Theformer is better as it leaves data directly into registers,while the latter is less restrictive in terms of resources,specially logical register names. A binding prefetchin the form of an advanced load instruction not onlybrings data in the register file, but also brings a fullcache line to the L1 cache. If other elements of thecache line are needed in the near future, this load isacting upon them as a non-binding prefetch. The com-piler normally can deduce this reuse, and therefore,will not need to issue prefetches for these other ele-ments in the line; instead it will consider them alreadyprefetched (in a non-binding manner). Similarly a prefinstruction will act as a non-binding prefetch for all
Figure 4. Pref case
Figure 4 shows an example of the use of pre!+. Onthe left hand side is the code that a usual compilerwould generate and on the right the code using pre!+ .This new instruction is annotated with the destina-tion register of the subsequent load instruction thatwill read the first element of the prefetched line. Theresf of loads that read elements from the same line areremapped to use consecutive numbers in their desti-nation registers, thus allowing the hardware to detectwhich loads will consume the data prefetched by thispre!+ .At runtime, the hardware not only issues theprefetch but it also brings the required elements of theline into the register file. These values are assigned freephysical registers, and special mappings are created in
Proceedings of the 2002 International Conference on Parallel Architectures and Compilation Techniques (PACT’02) 1089-795X/02 $17.00 © 2002 IEEE

~-0""Q. 10
"'
D 024 way LoadStore
.03 (ptefetch) 4 way LoadStore
.03 (prefetch) Memory Instruction Bypassing
08 apsl tomcatv average
Figure 5. Improvement due to compiler-directed memory instruction bypassing
present. The mechanism presented in [8] relies on soft-ware prefetching, which in many cases is not enough toallow all the potential benefits that memory instruc-tion bypassing may offer. To boost the prefetchingcapabilities of the software prefetcher, we propose acompiler-controlled hardware prefetcher that is simpleand thus cost-effective. This hardware prefetcher willassist the compiler instructions preft and loadt whenappropriate. We call this prefetching scheme decoupledbecause the actual prefetching of the data is sharedamong different resources. The compiler inserts soft-ware prefetching instructions, responsible for bringingdata closer to the processor. The compiler also in-structs the special prefetching hardware as to whichinstructions should be prefetched with greater dis-tances and without extra software intervention. Thesesupplementary prefetches will bring data into the 11cache. The memory instruction bypassing mechanism(also compiler directed) is responsible for bringing thedata from the 11 cache to the register file in a non-
speculative way.
A documented drawback of hardware prefetchers istrying to prefetch for too many load instructions un-less some (complex) filtering is implemented [9]. Ourmechanism issues as few useless prefetches as possible.This is accomplished by issuing only one prefetch percache line and in a conservative manner since it is con-trolled by relying on the new type of preft and loadtinstructions. Each time one of these instructions ar-rives in its execution phase, it is executed normally( which includes the binding of all the requested ele-ments of the line), and a special prefetching hardwareassist starts the process of prefetching successive ele-ments. The purpose of this hardware is to improve thetimeline of the prefetch by increasing the chance thatfuture executions of this same instruction will hit incache, making the most out of the bypassing effect.
The nature of our prefetching mechanism allows thework of prefetching and memory instruction bypassingto be separated among the hardware and the software.Our hardware prefetcher is in charge of non-bindingprefetching into the 11 cache, while the software con-
a separate table. When the loads reach the decodingstage, the hardware recognises them and instead of is-suing and executing them in a load-store unit, it movesthe special mappings from the separate table to thenormal renaming table. This way, any instruction be-fore the loads will see those logical registers as havingtheir normal value, and after the loads they will be di-rected to the values brought by the preff instruction.Notice that these values may not have reached the reg-ister file at the decoding of the loads, in which casethe dependent instructions on the values produced bythe loads should wait just as if they were waiting forthe loads to complete (i.e. some form of scoreboard-ing is still necessary). In the case that the values havearrived to the register file, the dependent instructionsmay consume them inmediately, thus allowing for thememory instruction bypassing to occur .
Although the number of logical registers is fixed inany given ISA (possibly preventing the compiler of in-serting more binding prefetches) , the number of physi-cal registers may vary with each implementation of theISA. This mechanism dynamically makes use of freephysical registers when the compiler lacks logical ones.The mechanism behaves very similarly with the newload f instruction. The only difference with respect to
what we have just explained is that the primary databrought by the loadf is renamed normally, as it wouldhave been if it were a normal load instruction.
In figure 5 we can see the results observed whenthis particular memory bypassing mechanism is imple-mented in a 4 way out-of-order processor. This mem-ory instruction bypassing mechanism based on renam-ing shows speed-ups ranging from 5% to 22%. As wasexpected, memory instruction bypassing yields verygood benefits when combined with software prefetchingalone. We will show that this relation becomes strongerin the presence of hardware prefetching. The results ofthis figure have been extracted from [8].
3.3 Our proposal: A decoupled prefetcher
As was noted in section 2, memory instruction by-
passing produces better benefits when prefetching is
Proceedings of the 2002 International Conference on Parallel Architectures and Compilation Techniques (PACT’02) 1089-795X/02 $17.00 © 2002 IEEE

20
O 03 (no prefelch) LoadStore(base)O 03 (prefelCh) LoadStore(ba&)m 03 (prefelCh) Bypassing + PrefelChing O entriesm 03 (prefelCh) Bypassing + Prefelching 16 entries lookahead (pref I.load I).03 (prelelCh) Bypassing + Prefelching 16 entries lookahead (pref I.lnad 2).03 (prefelCb) Bypassing + Prefelching 16entries lookahead (pref2.load I).03 (prefelCh) Bypassing + Prefelching 32 entries lookahead (pref 1, load I).03 (prefelCh) Bypassing + PrefelChing 32 entries lookahead (pref I, load 2).03 (prefelCh) Bypassing + PrefelChing 32 entries lookahead (pref 2.load I)
apsl tomcatv,
Figure 6. Influence of the number of entries and lookahead policies (4-way)
hierarchy with requests. Since our mechanism is drivenby a subset of all memory operations we do not havethis problem and do not have to introduce any hard-ware filtering mechanism. Moreover, the renaming by-passing mechanism on which the hardware prefetchingrelies has been shown to minimise the need of ports byutilising them more intelligently. We also note that theprocess of looking in the table and prefetching can bedivided into several stages, therefore not impacting cy-cle time. As prefetched data is not used immediately,we can be more lax in choosing the time to issue theprefetch without impacting severely the performancebenefits.
The cost of our decoupled prefetching and memoryinstruction bypassing mechanism consists of the num-ber of entries in the CLPT and the necessary circuitryto handle prefetches, plus the hardware associated withthe memory instruction bypassing mechanism. Thememory instruction bypassing mechanism relies on asecondary renaming mapping table and on an increasein the number of physical registers. The cost in size andimpact on cycle time has been shown to be minimal[8].
In figures 6 and 7 we can see the performance resultsobtained for our decoupled prefetching and memoryinstruction bypassing mechanism. The first two barsrepresent the improvement due to software prefetchingalone. The next bars represent the different configura-tions for our decoupled prefetching mechanism on topof the memory instruction bypassing mechanims. Thefirst bar (0 entries) is the memory instruction bypassingmechanism alone. The other bars represent the resultsobtained by our prefetching and memory instructionbypassing mechanism with varying number of entries(16 and 32) and different lookahead depths (1 and 2).We can see that all applications except apsi benefitfrom our hybrid approach averaging a 43% speed-upover an execution without software prefetching and a15% speed-up over software prefetching in the case ofa 4-way processor. With respect to the varying depthparameters, in average, the best combination of depthsis 1 for prep and 2 for loadt. This observation agreeswith the fact that our compiler framework usually in-
trolled prep and load+ instructions bypass the datainto registers. This leaves the compiler with more free-dom, as it does not need to insert binding prefetchtoo far away from its use, thus reducing logical registerpressure. Moreover, as our prefetcher leaves data in theLl cache, our hardware mechanism is non-speculativeand does not require recovery mechanisms.
Our hardware consists of a small PC tagged tablecalled Cache-Line Prefetching Table (CLPT). In ourexperiments we have chosen to make it very small (from8 to 32 entries) and fully associative with least recentlyused (LRU) replacement policy. Each entry in this ta-ble has two fields (besides the tag): (1) Last EffectiveAddress, which contains the last address produced bythis instruction, and (2) Type Bit which allows us to dif-ferentiate among preft and loads t. This bit is strictlynecessary as we could keep different instructions in dif-ferent tables. We have kept them together to simplifythe understanding of the mechanism.
When a preft or a loadt is decoded, the hardwaremechanism is activated. If there is a tag match in theCLPT table, the current stride ( difference between ef-fective address and last effective address) is computed.The address of the next line to prefetch is computedadding N x stride to the effective address and a prefetchis initiated. N, the depth of prefetching, is a param-eter and we have performed experiments with N = 1and N = 2, and with either value for preft and load+
instructions (thus the need for the Type Bit). In thispaper we kept N fixed for the whole application. Weare planning future experiments in which the depthmay vary dynamically or even be compiler directed onan instruction per instruction basis.
In the second case, if the instruction has no allo-cated entry in the CLPT, the hardware assists sim-ply allocates one (using LRU replacement policy). Inboth cases, the effective address in the CLPT is up-dated. Once our mechanism decides to prefetch a cacheline, the request is maintained until it effectively findsa free port to the memory hierarchy and can be exe-cuted. Some prefetching mechanisms filter prefetcheswhen the ports are busy, not to exhaust the memory
Proceedings of the 2002 International Conference on Parallel Architectures and Compilation Techniques (PACT’02) 1089-795X/02 $17.00 © 2002 IEEE
c. l4~
~
"
~
rIJ l2
O 03 (no prefelCh) LoadS,nre(base)O 03 (prefe",h) LoadStore(base)13 03 (prefe",h) Bypassing + Prefe'ching O enlrie,13 03 (prefe",h) Bypassing + Prefe",hing 16 enlrie, lookahead (pref 1, load I).03 (prefe",h) Bypassing + Prefe",hing 16 enlrie, lookahead (pref 1, load 2).03 (prefe",h) Bypassing + Prefe'ching 16 eolrie, lookahead (pref 2, load I ).03 (prefe",h) Bypassing + Prefe,ching 32 enlrie, lookahead (pref I, load 1).03 (prefe",h) Bypassing + Prefe",hing 32 enlrie, lookahead (pref I, load 2).03 (prefe",h) Bypassing + Prefe'ching 32 enlrie, lookahead (pref 2, load 1)
tomcatv
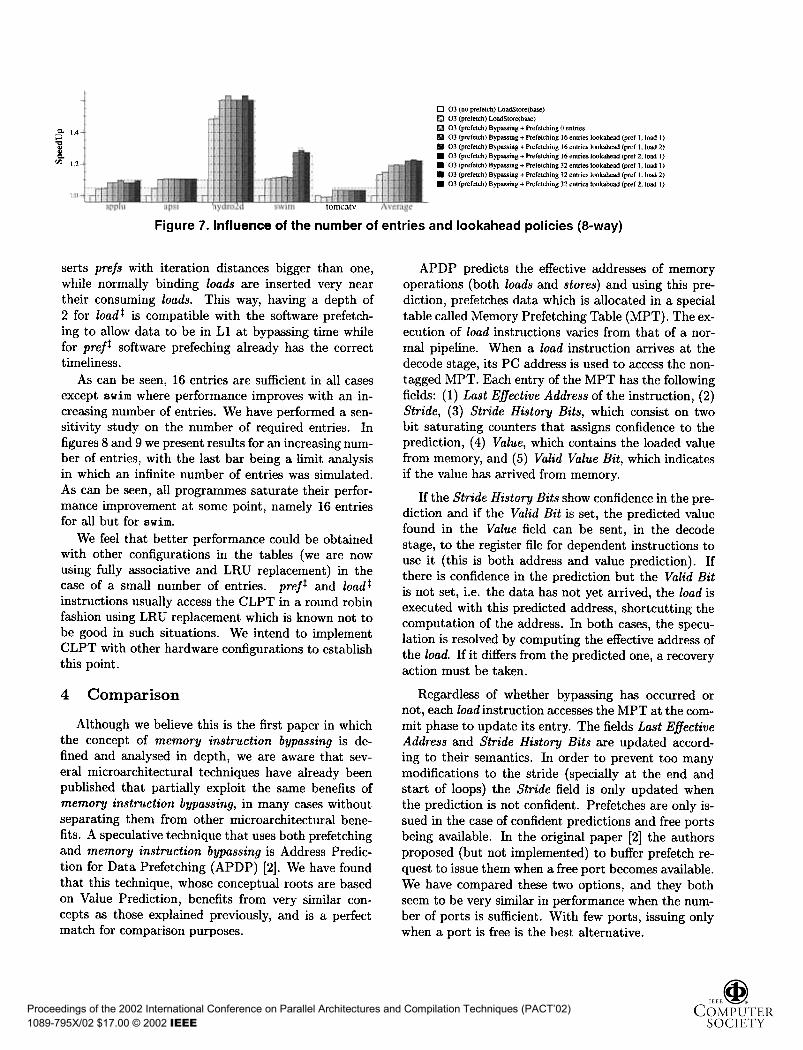
Figure 7. Influence of the number of entries and lookahead policies (S-way)
serts prefs with iteration distances bigger than one,while normally binding loads are inserted very neartheir consuming loads. This way, having a depth of2 for loadt is compatible with the software prefetch-ing to allow data to be in 11 at bypassing time whilefor preft software prefeching already has the correcttimeliness.
As can be seen, 16 entries are sufficient in all casesexcept swim where performance improves with an in-creasing number of entries. We have performed a sen-sitivity study on the number of required entries. Infigures 8 and 9 we present results for an increasing num-ber of entries, with the last bar being a limit analysisin which an infinite number of entries was simulated.As can be seen, all programmes saturate their perfor-mance improvement at some point, namely 16 entriesfor all but for swim.
We feel that better performance could be obtainedwith other configurations in the tables (we are nowusing fully associative and 1RU replacement) in thecase of a small number of entries. preft and loadtinstructions usually access the C1PT in a round robinfashion using 1RU replacement which is known not tobe good in such situations. We intend to implementC1PT with other hardware configurations to establishthis point.
4 Comparison
APDP predicts the effective addresses of memoryoperations (both loads and stores) and using this pre-diction, prefetches data which is allocated in a specialtable called Memory Prefetching Table (MPT). The ex-ecution of toad instructions varies from that of a nor-mal pipeline. When a load instruction arrives at thedecode stage, its PC address is used to access the non-tagged MPT. Each entry of the MPT has the followingfields: (1) Last Effective Address of the instruction, (2)Stride, (3) Stride History Bits, which consist on twobit saturating counters that assigns confidence to theprediction, (4) Value, which contains the loaded valuefrom memory, and (5) Valid Value Bit, which indicatesif the value has arrived from memory.
If the Stride History Bits show confidence in the pre-diction and if the Valid Bit is set, the predicted valuefound in the Value field can be sent, in the decodestage, to the register file for dependent instructions touse it (this is both address and value prediction). Ifthere is confidence in the prediction but the Valid Bitis not set, i.e. the data has not yet arrived, the toad isexecuted with this predicted address, shortcutting thecomputation of the address. In both cases, the specu-lation is resolved by computing the effective address ofthe load. If it differs from the predicted one, a recoveryaction must be taken.
Regardless of whether bypassing has occurred ornot, each load instruction accesses the MPT at the com-mit phase to update its entry. The fields Last EffectiveAddress and Stride History Bits are updated accord-ing to their semantics. In order to prevent too manymodifications to the stride (specially at the end andstart of loops) the Stride field is only updated whenthe prediction is not confident. Prefetches are only is-sued in the case of confident predictions and free portsbeing available. In the original paper [2] the authorsproposed (but not implemented) to buffer prefetch re-quest to issue them when a free port becomes available.We have compared these two options, and they bothseem to be very similar in performance when the num-ber of ports is sufficient. With few ports, issuing onlywhen a port is free is the best alternative.
Although we believe this is the first paper in whichthe concept of memory instruction bypassing is de-fined and analysed in depth, we are aware that sev-eral microarchitectural techniques have already beenpublished that partially exploit the same benefits ofmemory instruction bypassing, in many cases withoutseparating them from other microarchitectural bene-fits. A speculative technique that uses both prefetchingand memory instruction bypassing is Address predic-tion for Data Prefetching (APDP) [2]. We have foundthat this technique, whose conceptual roots are basedon Value Prediction, benefits from very similar con-cepts as those explained previously, and is a perfectmatch for comparison purposes.
Proceedings of the 2002 International Conference on Parallel Architectures and Compilation Techniques (PACT’02) 1089-795X/02 $17.00 © 2002 IEEE

O 03 (no p'efetch) wadStore(OOse)O 03 (p'efetch) LoadStore(hase)m 03 (p'efetch) Bypassing + Prefetching O entriesm 03 (prefetch) Bypassing + Prefetching 8 entries lookahead (p,ef ,. load 2)m 03 (p'efetch) Bypassing + Prefetching 16 entries tookahead (pref t.load 2)m 03 (p'efetch) Bypassing + Prefetching 32 entries lookahead (pref 1.lnad 2)m 03 (p'efetch) Bypassing + Prefetching 64 entries lookahead (p,ef 1.load 2)m 03 (p'efetch) Bypassing + Prefetching infini(e en"ies lookahead (pref 1.load 2)
I"
apsl swim
Figure 8. Influence of increasing the number of entries in our decoupled prefetcher (4-way)
c. 14~
~"c.
"'
O 03 (00 prefetch) LoadSIore(base)
O 03 (prefetch) LoadStore(hase)
m 03 (prefetch) Bypassing + Prefetching O entries
m 03 (prefetch) Bypassing + Prefetching 8 entries lookahead (ptef I, load 2)
.03 (ptefetch) Bypassing + Prefetchtrig 16 entries lookahead (pref " load 2)
.03 (ptefetch) Bypassing + Prefetching 32 entries lookahead (pref " load 2)
.03 (ptefetch) Bypassing + Prefetching 64 entries lookahead (pref " load 2)
.03 (ptefetch) Bypassing + Prefetching inlinite entries lookahead (pref " load 2)
apsl swIm
Figure 9. Influence of increasing the number of entries in our decoupled prefetcher (S-way)
The last issue regarding the implementation ofAPDP is the recovery mechanism. A good explana-tion of recovery mechanisms can be found in [11] whererecovery schemes are divided into: (1) squashing re-covery, similar in spirit to branch prediction recoverywhereby all instructions following the mispredicted loadare reexecuted; and (2) selective recovery where onlythose instructions dependent on the mispredicted loadare reexecuted. While neither of these two mechanismsis easy to implement, selective recovery is much morecomplex for an out-of-order processor. To our knowl-edge, no such cost-effective implementation has beenproposed. We will show that APDP is very sensitiveto the choice of recovery mechanisms (only selectiverecovery was analysed in [2]).
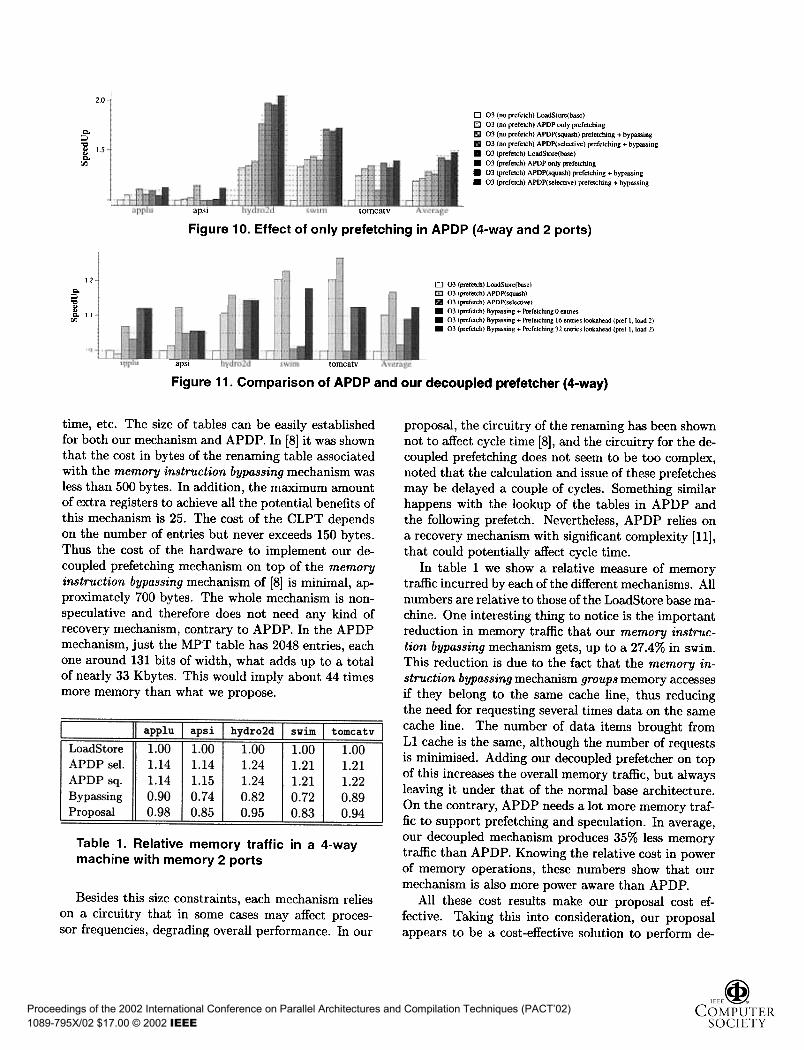
The original paper on APDP did not quantify sep-arately the performance benefits due to prefetching tothose due to memory instruction bypassing. In figure10 we present results for various simulations with re-spect to our 4-way base machine described previously.The configuration parameters for the APDP were takenfrom [2]: in particular the MPT table has 2048 entries.These results (cf. figure 10) show the relative contribu-tions of prefetching and memory instruction bypassingin the APDP scheme. We did simulations with theexecutables highly optimised (-03) with and withoutsoftware prefetching. With these two executables werun simulations for the base machine (1oadStore) andfor three versions of the APDP, namely: (1) Prefetch-ing only; (2) Prefetching and memory instruction by-passing with squash recovery; and (3) Prefetching andmemory instruction bypassing with selective recovery.
As can be seen in the figure prefetching only to 11
can cover up to 75% of the total performance bene-fits of APDP with selective recovery. It can be notedthat APDP with squash recovery may be worse (upto a 5% in applu) than just bringing data to the 11cache, specially in applications with software prefetch-ing. In these applications squash recovery mechanismsseems to produce a very small benefit (in avg. a 2%)over prefetching only to 11. A possible explanation forthis behaviour is that when the compiler introducessoftware prefetching, it usually unrolls loops. This un-rolling converts one memory operation into a series ofmemory operations besides cutting down the total iter-ations of the loop. When the loop finishes and is reexe-cuted, in the first iteration, not only one, but all mem-ory operations will fail their speculation, resulting in aseries of squashes, which, due to the shorter number ofiterations of the loop, represent a bigger handicap forAPDP. What is gained through value prediction andspeculation is almost totally counterbalanced by thecost of the series of squashes.
In figure 11 we compare relative performance re-suits of a subset of the configurations presented sofar. In average, it can be seen that having a decoupledprefetching and memory instruction bypassing mecha-nism as introduced in section 3 behaves midway APDPwith squash recovery and APDP with selective recov-ery mechanism.
In order to fully understand these results and whywe consider that our mechanism is a cost-effective so-lution, we must take into consideration the costs ofboth mechanisms. Cost cannot be measured in a sim-ple way with just one number. Cost implies sizes oftables, power consumption, potential increase in cycle
Proceedings of the 2002 International Conference on Parallel Architectures and Compilation Techniques (PACT’02) 1089-795X/02 $17.00 © 2002 IEEE
20
Q,~'Q..15
~01)
O 03 (no prefelCh) LoadSlore(base)O 03 (no prefetch) APDP only prefetchingm 03 (nn prefetch) APDP(squash) prefetching + bypassing
m 03 (no prefetch) APDP(selective) prefetching + bypassing
.03 (prefetch) LoadStore(base)
.03 (prefetch) APDP only prefetching
.03 (prefetch) APDp(squash) prefetching + bypassing
.03 (prefetch) APDP(selective) prefetching + bypassing
apsl tomcatv
Figure 10. Effect of only prefetching in APDP (4-way and 2 ports)
D 03 (prefeICh) LoadSIO'e(hasel
m 03 (prefe'ch) APDP(squash)
m 03 (prefe'ch) APDP(selecuve)
m 03 (prefetch) Bypass;ng + Prefe'ch;ng O entries
m 03 (prefeICh) Bypassmg + Prefe,ch;ng 16 entries lnokahead (pref I, load 2)
m 03 (prcfetch) Bypassmg + Prefe,chmg 32 cntrics lnokahead (pref I, load 2)
12c.
;J"0
tC.U
"'
apsl tomcatv
Figure 11. Comparison of APDP and our decoupled prefetcher (4-way)
time, etc. The size of tables can be easily establishedfor both our mechanism and APDP. In [8] it was shownthat the cost in bytes of the renaming table associatedwith the memory instruction bypassing mechanism wasless than 500 bytes. In addition, the maximum amountof extra registers to achieve all the potential benefits ofthis mechanism is 25. The cost of the CLPT dependson the number of entries but never exceeds 150 bytes.Thus the cost of the hardware to implement our de-coupled prefetching mechanism on top of the memoryinstruction bypassing mechanism of [8] is minimal, ap-proximately 700 bytes. The whole mechanism is non-speculative and therefore does not need any kind ofrecovery mechanism, contrary to APDP. In the APDPmechanism, just the MPT table has 2048 entries, eachone around 131 bits of width, what adds up to a totalof nearly 33 Kbytes. This would imply about 44 timesmore memory than what we propose.
~u I apsi I hydr~2d I swim I tomcatv
LoadStore
APDP sel
APDP sq.
Bypassing
Proposal
1.001.141.140.900.98
1.001.141.150.740.85
1.00
1.24
1.24
0.82
0.95
1.00
1.21
1.21
0.72
0.83
1.00
1.21
1.22
0.89
0.94
Table 1. Relative memory traffic in a 4-waymachine with memory 2 ports
Besides this size constraints, each mechanism relieson a circuitry that in some cases may affect proces-sor frequencies, degrading overall performance. In our
proposal, the circuitry of the renaming has been shownnot to affect cycle time [8], and the circuitry for the de-coupled prefetching does not seem to be too complex,noted that the calculation and issue of these prefetchesmay be delayed a couple of cycles. Something similarhappens with the lookup of the tables in APDP andthe following prefetch. Nevertheless, APDP relies ona recovery mechanism with significant complexity [11],that could potentially affect cycle time.
In table 1 we show a relative measure of memorytraffic incurred by each of the different mechanisms. Allnumbers are relative to those of the 1oadStore base ma-chine. One interesting thing to notice is the importantreduction in memory traffic that our memory instruc-tion bypassing mechanism gets, up to a 27.4% in swim.This reduction is due to the fact that the memory in-struction bypassing mechanism groups memory accessesif they belong to the same cache line, thus reducingthe need for requesting several times data on the samecache line. The number of data items brought from11 cache is the same, although the number of requestsis minimised. Adding our decoupled prefetcher on topof this increases the overall memory traffic, but alwaysleaving it under that of the normal base architecture.On the contrary, APDP needs a lot more memory traf-fic to support prefetching and speculation. In average,our decoupled mechanism produces 35% less memorytraffic than APDP. Knowing the relative cost in powerof memory operations, these numbers show that ourmechanism is also more power aware than APDP.
All these cost results make our proposal cost ef-fective. Taking this into consideration, our proposalappears to be a cost-effective solution to perform de-
Proceedings of the 2002 International Conference on Parallel Architectures and Compilation Techniques (PACT’02) 1089-795X/02 $17.00 © 2002 IEEE

increase the potential improvements of our decoupledprefetching and memory instruction bypassing mecha-nism, reaching those of APDP.
6 Acknowledgements
This work has been supported by the Spanish Min-istry of Science and Technology and the EuropeanUnion FEDER contract TIC2001-0995-CO2-01, by theNSF Grant CCR-OO72948 and the CEPBA.
References
coupled prefetching on top of memory instruction by-passing. At much lower cost our proposal is betterthan a realistic APDP (with squash recovery) and closeto a highly complex APDP (with selective recovery).Our decoupled prefetching mechanism would get bet-ter with better compiler technology and we are confi-dent it would close the gap with respect to the compleximplementation of APDP.
5 Conclusions
In this paper we have presented a cost effective de-coupled prefetcher driven by the compiler insertion ofspecial prefetching instructions. We have achieved verygood performance results while keeping the cost low be-cause the hardware mechanism is limited by what thecompiler can predict. For a subset of SPECfp bench-marks we have achieved a 13% speed-up in average overa version with software prefetching and a 43% speed-upover a version without software prefetching.
The insertion of new pref/load instructions allowsthe hardware to bypass the execution of successive loadinstructions, allowing subsequent instructions to havetheir source operands ready earlier. As this bypassingphase is not speculative, it needs no recovery action.This property in conjunction with the prefetching toL1 done by a compiler-controlled simple stride basedhardware prefetcher, makes our mechanism very easyto implement.
Besides this main contribution, we have also dis-cussed in detail the concept of memory instruction by-passing and its relation with prefetching. We haveshown that memory instruction bypassing combinedwith both software and hardware prefetching, can ef-fectively increase performance, with the advantage thatit implies no recovery action since it is non-speculative.
We have also analysed a previously proposed mech-anism, APDP [2], with respect to its prefetchingand memory instruction bypassing implementations.APDPs motivation for improving performance camefrom a different angle, namely value prediction andspeculation. We have analysed APDP sources of im-provement and compared them with those in our mech-anism. Our mechanism can achieve better performancethan a realistic implementation of APDP with squashrecovery, and is close to a much more complex APDP.We have also compared our mechanism in terms ofcost: sizes of tables, complexity of the hardware in-volved, memory traffic, etc. Our mechanism utilisesless than 40 times the amount of real estate than thetables that APDP use, has a minimal impact in thedesign of the processors pipeline and has in average a35% less memory traffic than a realistic APDP. More-over, as our mechanism relies on compiler technology,we expect that compiler improvements will eventually
[1] T. Chen and J. Baer. Effective hardware-based dataprefetching for high performance processors. IEEE11-ansactions on Computers, May 1995.
[2] J. Gonzalez and A. Gonzalez. Speculative executionvia address prediction and data prefetching. 1997 In-ternational Conference on Supercomputing, July 1997.
[3] J. Hennessy and D. Patterson. Computer Architec-ture. A Quantitative Approach. Second Edition. Mor-gan Kaufmann Publishers, San Francisco, 1996.
[4] N. Jouppi. Improving direct-mapped cache perfor-mance by the addition of a small fully-associativecache and prefetch buffers. 17th Annual Symposiumon Computer Architecture, May 1990.
[5] C. Luk and T. Mowry. Compiler-based prefetching forrecursive data structures. tth International Confer-ence on Architectural Support for Programming Lan-guages and Operating Systems, October 1996.
[6] S. Mahlke, W. Chen, W. Hwu, B. Rau, andM. Schlanker. Sentinel scheduling for vliw and su-perscalar processors. Sth International Conference onArchitectural Support for Programming Languages andOperating Systems, October 1992.
[7] T. Mowry, M. Lam, and A. Gupta. Design and eval-uation of a compiler algorithm for prefetching. SthInternational Conference on Architectural Support forProgramming Languages and Operating Systems, Oc-tober 1992.
[8] D. Ortega, M. Valero, and E. Ayguade. A novelrenaming mechanism that boosts software prefetch-ing. 2001 International Conference on Supercomput-ing, June 2001.
[9] S. Pinter and A. Yoaz. Tango: a hardware-based dataprefetching technique for superscalar processors. InProceedings of the 29th annual IEEEIACM interna-tional symposium on Microarchitecture, 1996.
[10] G. Reinman, B. Calder, D. Tullsen, G. Tyson, andT. Austin. Classifying load and store instructions for
memory renaming. 1999 International Conference onSupercomputing, June 1999.
[11] H. Zhou, C. Fu, E. Rotenberg, and T. Conte. A studyof value speculative execution and misspeculation re-covery in superscalar microprocessors. Research re-port, North Carolina State University, January 2001.
[12] C. Zilles and G. Sohi. Execution-based prediction us-ing speculative slices. International Symposium onComputer Architecture, June 2001.
Proceedings of the 2002 International Conference on Parallel Architectures and Compilation Techniques (PACT’02) 1089-795X/02 $17.00 © 2002 IEEE