cracow grid workshop 09 13. october 2009 dipl.-ing. (m.sc.) marcus hilbrich...
TRANSCRIPT

Cracow Grid Workshop 0913. October 2009
Dipl.-Ing. (M.Sc.) Marcus Hilbrich
Center for Information Services and High Performance Computing (ZIH)
A Scalable Infrastructure for Job-centric Monitoring Data from
Distributed Systems

Marcus Hilbrich 2
Outline
Motivation
– Users view on the Grid
– How Grid jobs behave
AMon
– What kind of data is recorded
– How the user can access the data
– How to find the interesting data (problematic jobs)
Monitoring infrastructure
– Why centralized structures fail
– A layered and distributed solution
Summary

Marcus Hilbrich 3
Users View on the Grid
Grid is an environment to solve computing intensive problems
There is no need for users to be experts in computer since
The complexity of the Grid is mostly hidden from the user
– Middleware Globus gLite ...
– Web portals VO or community specific but easy access to the Grid
– Client applications Integration of the Grid in the user's desktop
– Automatic submission of processes Grid is part of a workflow
Marcus Hilbrich 4
?
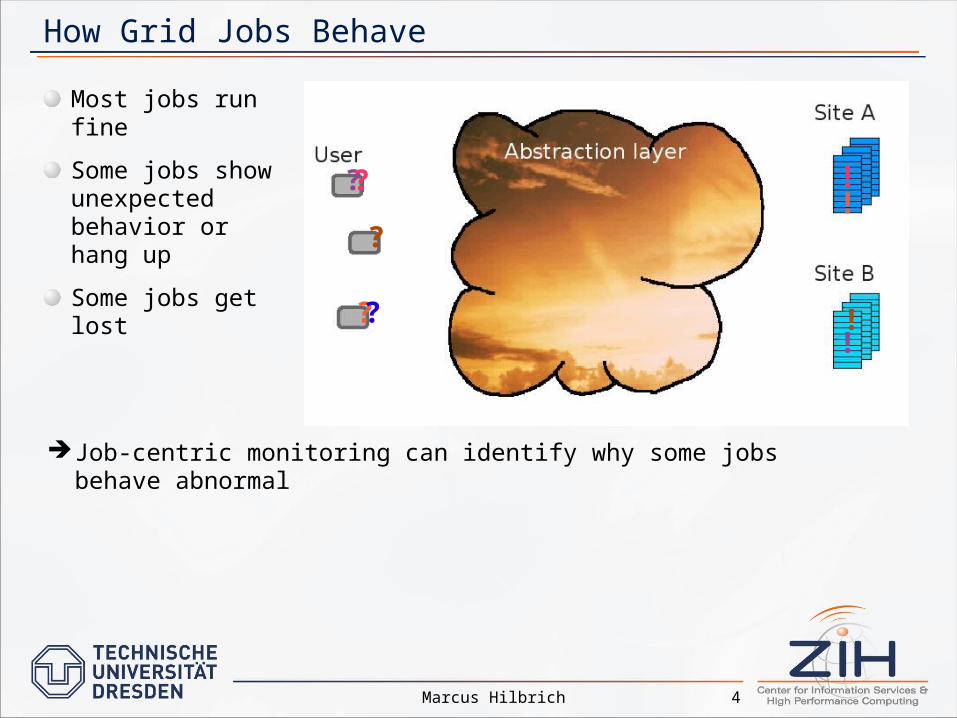
How Grid Jobs Behave
Most jobs run fine
Some jobs show unexpected behavior or hang up
Some jobs get lost
?
?
!?
!
!
!
?
Job-centric monitoring can identify why some jobs behave abnormal

Marcus Hilbrich 5
AMon
AMonA Tool for Job-centric Monitoring

Marcus Hilbrich 6
What Kind of Data is Recorded
Job-specific, system-specific and general information
Job information
– Job ID, username, computing element, worker node, ...
CPU information
– Wallclock time, CPU time, ...
Memory
– Used real/virtual main memory, free memory, SWAP, ...
Disk
– Free space HOME/TMP, disk usage, ...
File I/O
– I/O rate of used files
Network
– Send/received traffic
Marcus Hilbrich 7
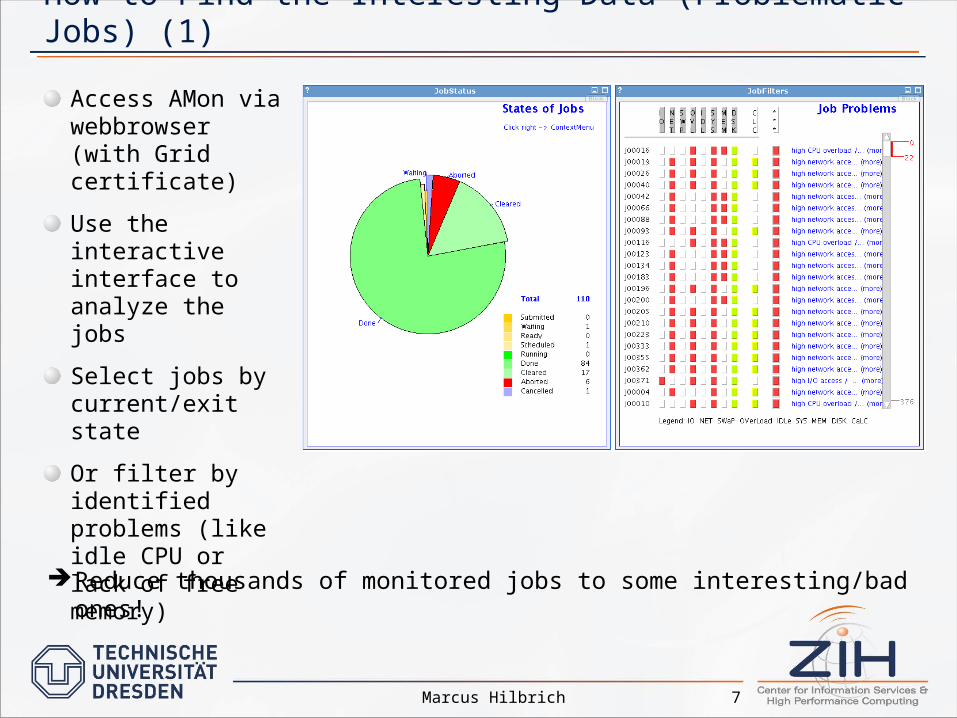
How to Find the Interesting Data (Problematic Jobs) (1)
Access AMon via webbrowser (with Grid certificate)
Use the interactive interface to analyze the jobs
Select jobs by current/exit state
Or filter by identified problems (like idle CPU or lack of free memory)
Reduce thousands of monitored jobs to some interesting/bad ones!

Marcus Hilbrich 8
How to Find the Interesting Data (Problematic Jobs) (2)
Color coded bars to compare multiple jobs
Identify differences over the whole runtime (for one parameter)
Look at a single job
Interactive scroll and zoom for analyzing details

Marcus Hilbrich 9
Monitoring Infrastructure
Monitoring Infrastructurefor Job-centric Monitoring Data of Huge,
Widely Distributed Computing Grids
Marcus Hilbrich 10
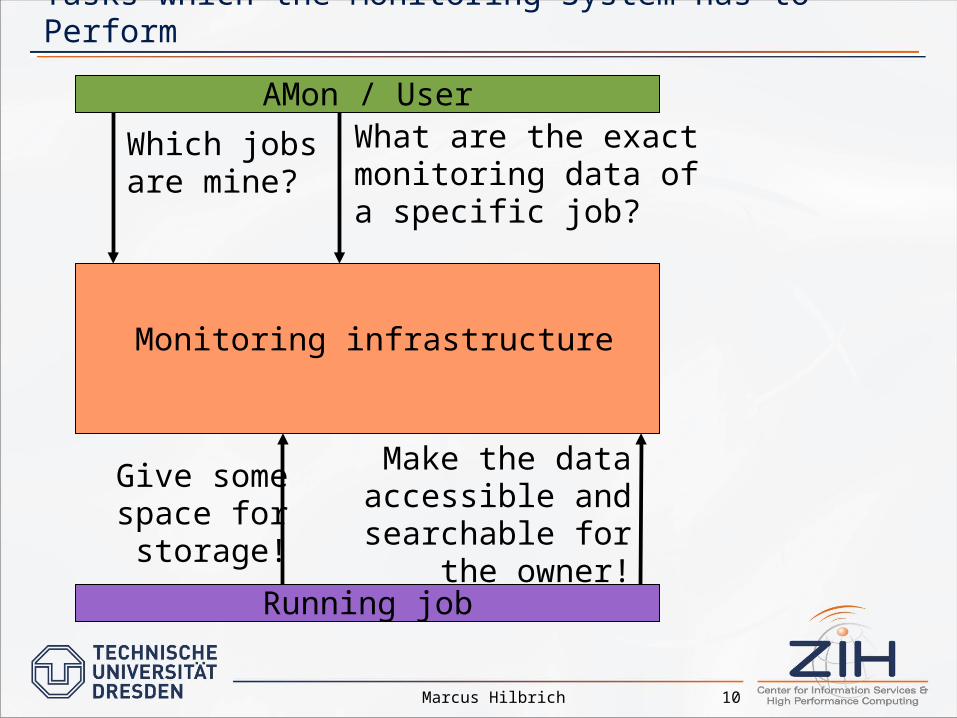
Tasks which the Monitoring System has to Perform
AMon / User
Running job
Monitoring infrastructure
Which jobsare mine?
What are the exactmonitoring data ofa specific job?
Give somespace forstorage!
Make the data accessible and
searchable for the owner!

Marcus Hilbrich 11
AMon / User
Running job
Monitoring infrastructure
Which jobsare mine?
What are the exactmonitoring data ofa specific job?
Give somespace forstorage!
Make the data accessible and
searchable for the owner!
Constraints of the Monitoring System
Authorization
Who canaccesswhose data?
Security
How to denyunauthorizedaccess?
Scalability /Performance
Single userup to hugeVOs
Authorization and Security can rely on Globus Toolkit 4 framework
Scalability has to be archived by using collaborating Globus Toolkit 4 instances

Marcus Hilbrich 12
Why Centralized Structures Fail
The storage performance has to be increased with the number of users or computing elements
Some performance criteria can be increased quite easily (e.g. storage capacity)
Other criteria cannot be increased (e.g. network bandwidth)
Network bandwidth tends to be a major bottleneck!
Distributed storage of data can avoid this problem!
Marcus Hilbrich 13
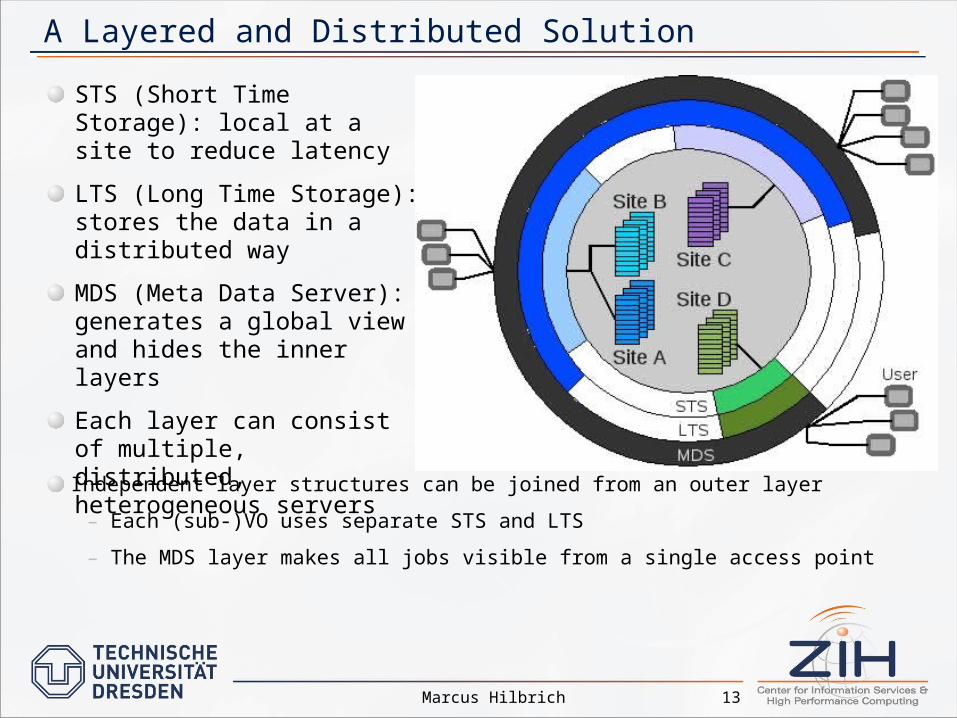
A Layered and Distributed Solution
Independent layer structures can be joined from an outer layer
– Each (sub-)VO uses separate STS and LTS
– The MDS layer makes all jobs visible from a single access point
STS (Short Time Storage): local at a site to reduce latency
LTS (Long Time Storage): stores the data in a distributed way
MDS (Meta Data Server): generates a global view and hides the inner layers
Each layer can consist of multiple, distributed, heterogeneous servers

Marcus Hilbrich 14
Summary
Using AMon
– Grid users get a tool to find out why some jobs behave unusual
– It is easy to take a look at jobs
– The Grid gets more transparent with respect to the jobs behavior
The new monitoring data infrastructure is scalable with
– The number of jobs
– The number of resource providers
– The increasing power of single resources
AMon already addresses the demands of future Grids

Marcus Hilbrich 15
Open Discussion
Open Discussion