crescando: predictable performance for unpredictable workloads g. alonso, d. fauser, g. giannikis,...
TRANSCRIPT

Crescando: Predictable Performance for Unpredictable Workloads
G. Alonso, D. Fauser, G. Giannikis, D. Kossmann, J. Meyer, P. Unterbrunner
Amadeus S.A.ETH Zurich, Systems Group
(Funded by Enterprise Computing Center)

Overview
• Background & Problem Statement
• Approach
• Experiments & Results

Amadeus Workload• Passenger-Booking Database– ~ 600 GB of raw data (two years of bookings)– single table, denormalized– ~ 50 attributes: flight-no, name, date, ..., many flags
• Query Workload– up to 4000 queries / second– latency guarantees: 2 seconds– today: only pre-canned queries allowed
• Update Workload– avg. 600 updates per second (1 update per GB per sec)– peak of 12000 updates per second– data freshness guarantee: 2 seconds

Amadeus Query Examples• Simple Queries– Print passenger list of Flight LH 4711– Give me LH hon circle from Frankfurt to Delhi
• Complex Queries– Give me all Heathrow passengers that need special
assistance (e.g., after terror warning)• Problems with State-of-the Art– Simple queries work only because of mat. views• multi-month project to implement new query / process
– Complex queries do not work at all
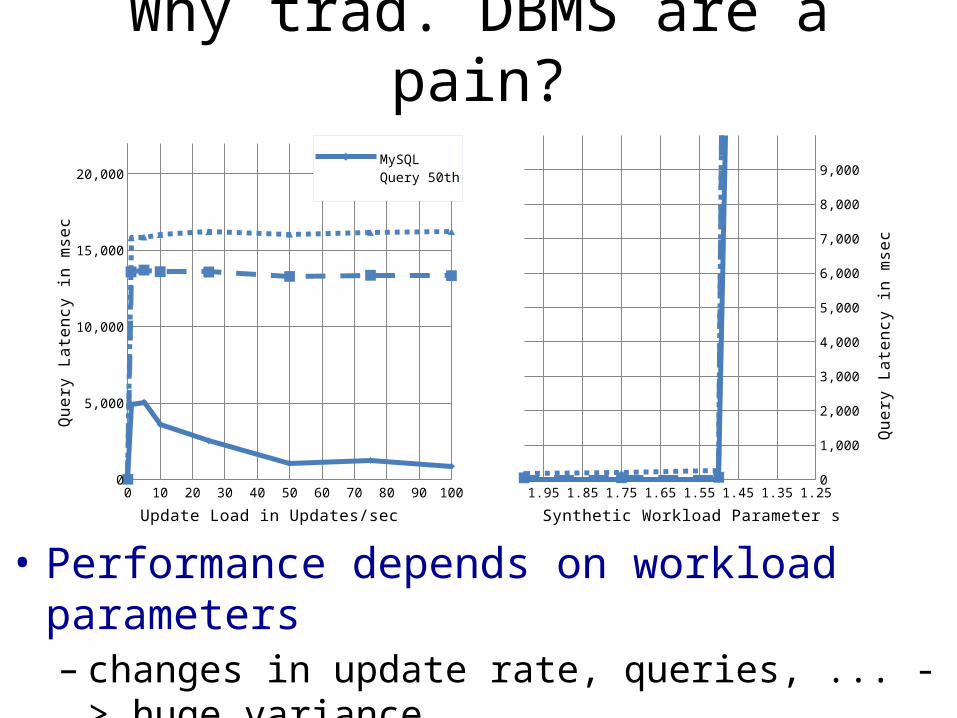
Why trad. DBMS are a pain?
• Performance depends on workload parameters– changes in update rate, queries, ... -> huge variance – impossible / expensive to predict and tune correctly
0 10 20 30 40 50 60 70 80 90 1000
5,000
10,000
15,000
20,000
MySQL Query 50thMySQL Query 90th
Update Load in Updates/sec
Que
ry L
aten
cy in
mse
c
1.251.351.451.551.651.751.851.950
1,000
2,000
3,000
4,000
5,000
6,000
7,000
8,000
9,000
Synthetic Workload Parameter s
Que
ry L
aten
cy in
mse
c

Goals• Predictable (= constant) Performance– independent of updates, query types, ...
• Meet SLAs– latency, data freshness
• Affordable Cost– ~ 1000 COTS machines are okay– (compare to mainframe)
• Meet Consistency Requirements– monotonic reads (ACID not needed)
• Respect Hardware Trends– main-memory, NUMA, large data centers

Selected Related Work• L. Qiao et. al. Main-memory scan sharing for multi-core CPUs.
VLDB '08– Cooperative main-memory scans for ad-hoc OLAP queries (read-only)
• P. Boncz, M. Zukowski, and N. Nes. MonetDB/X100: Hyper-pipelining query execution. CIDR ’05– Cooperative scans over vertical partitions on disk
• K. A. Ross. Selection conditions in main memory. In ACM TODS, 29(1), 2004.
• S. Chandrasekaran and M. J. Franklin. Streaming queries over streaming data VLDB '02– “Query-data join”
• G. Candea, N. Polyzotis, R. Vingralek. A Scalable, Predictable Join Operator for Highly Concurrent Data Warehouses. VLDB ’09– An “always on” join operator based on similar requirements and design principles

Overview
• Background & Problem Statement
• Approach
• Experiments & Results

What is Crescando?
• A distributed (relational) table: MM on NUMA– horizontally partitioned– distributed within and across machines
• Query / update interface– SELECT * FROM table WHERE <any predicate>– UPDATE table SET <anything> WHERE <any predicate>– monotonic reads / writes (SI within a single partition)
• Some nice properties– constant / predictable latency & data freshness– solves the Amadeus use case

Design• Operate MM like disk in shared-nothing architect.– Core ~ Spindle (many cores per machine & data center)– all data kept in main memory (log to disk for recovery)– each core scans one partition of data all the time
• Batch queries and updates: shared scans– do trivial MQO (at scan level on system with single table)– control read/update pattern -> no data contention
• Index queries / not data– just as in the stream processing world– predictable+optimizable: rebuild indexes every second
• Updates are processed before reads

Crescando in Data Center (N Machines)
...
AggregationLayers
Replication Groups
...
...
External Clients
Crescando
...

Crescando on 1 Machine (N Cores)
...
Split
Scan Thread
Scan Thread
Scan Thread
Scan Thread
Scan Thread
Merge
Input Queue(Operations)
Input Queue(Operations)
Output Queue(Result Tuples)
Output Queue(Result Tuples)

is
qs
ActiveQueries
Unindexed Queries
Predicate Indexes
Record 0
Read Cursor
Write Cursor
Snapshot n+1
Snapshot n
Queries + Upd.
records
results
{record, {query-ids} }
Crescando on 1 Core data partition

Record 0
Read Cursor
Write Cursor
Snapshot n+1
Snapshot n
Scanning a Partition

Record 0
Read Cursor
Write Cursor
Snapshot n+1
Snapshot n
Mergecursors
Scanning a Partition
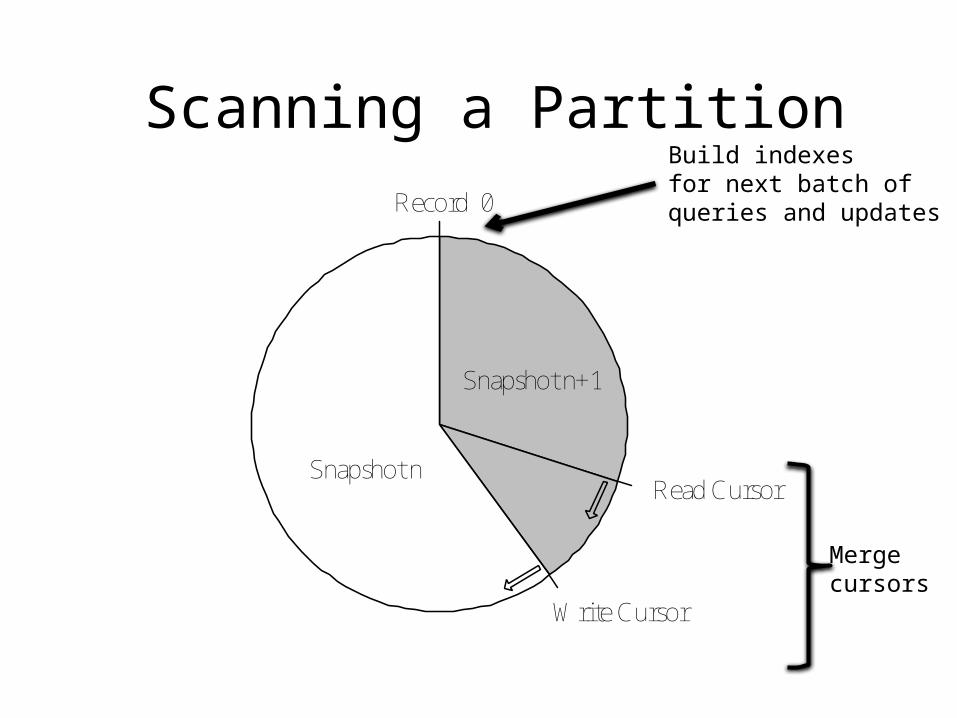
Record 0
Read Cursor
Write Cursor
Snapshot n+1
Snapshot n
Mergecursors
Build indexesfor next batch ofqueries and updates
Scanning a Partition

Crescando @ Amadeus
Mainframe
Transactions (OLTP)
Store (e.g., S3)Store (e.g., S3)Crescando Nodes
Update stream (queue)
AggregatorAggregator
AggregatorAggregator
Aggregator
Queries (Oper. BI)
Key / Value
Query / {Key}

Implementation Details• Optimization– decide for batch of queries which indexes to build– runs once every second (must be fast)
• Query + update indexes– different indexes for different kinds of predicates– e.g., hash tables, R-trees, tries, ...– must fit in L2 cache (better L1 cache)
• Probe indexes– Updates in right order, queries in any order
• Persistence & Recovery– Log updates / inserts to disk (not a bottleneck)

Crescando in the Cloud
Client
Store
HTTP
Web Server
App Server
DB Server
FCGI, ...
SQL
get/put block
records
XML, JSON, HTML
XML, JSON, HTML

Crescando in the Cloud
Client
Store
HTTP
Web Server
App Server
DB Server
FCGI, ...
SQL
get/put block
records
XML, JSON, HTML
XML, JSON, HTML
Client ClientClient
Workload Splitter
Store (e.g., S3)
Web/AppAggregator
Web/AppAggregator
XML, JSON, HTML
queries/updates <-> records
Store (e.g., S3)Crescando Nodes

Overview
• Background & Problem Statement
• Approach
• Experiments & Results

Benchmark Environment• Crescando Implementation
– Shared library for POSIX systems– Heavily optimized C++ with some inline assembly
• Benchmark Machines– 16 core Opteron machine with 32 GB DDR2 RAM– 64-bit Linux SMP kernel, ver. 2.6.27, NUMA enabled
• Benchmark Database– The Amadeus Ticket view (one record per passenger per flight)– ~350byte per record; 47 attributes, many of them flags– Benchmarks use 15 GB of net data
• Query + Update Workload– Current: Amadeus Workload (from Amadeus traces)– Predicted: Synthetic workload with varying predicate selectivity

Multi-core Scale-up
1.9 Q/s10.5 Q/s
558.5 Q/s
Round-robin partitioning, read-only Amadeus workload, vary number of threads

Latency vs. Query Volume
base latencyof scan
L1 cache
L2 cache
thrashing, queueoverflows
Hash partitioning, read-only Amadeus workload, vary queries/sec

Latency vs. Concurrent Writes
Hash partitioning, Amadeus workload, 2000 queries/sec, vary updates

Crescando vs. MySQL - Latency
updates + big queries cause massive queuing
s = 1.5: 1 / 10,000 queriesdo not hit an index
s = 1.4: 1 / 3,000 queriesdo not hit an index
16s = time for full-tablescan in MySQL
Amadeus workload, 100 q/sec, vary updates Synthetic read-only workload, vary skew

Crescando vs. MySQL - Throughput
read-only workload!
Amadeus workload, vary updates Synthetic read-only workload, vary skew
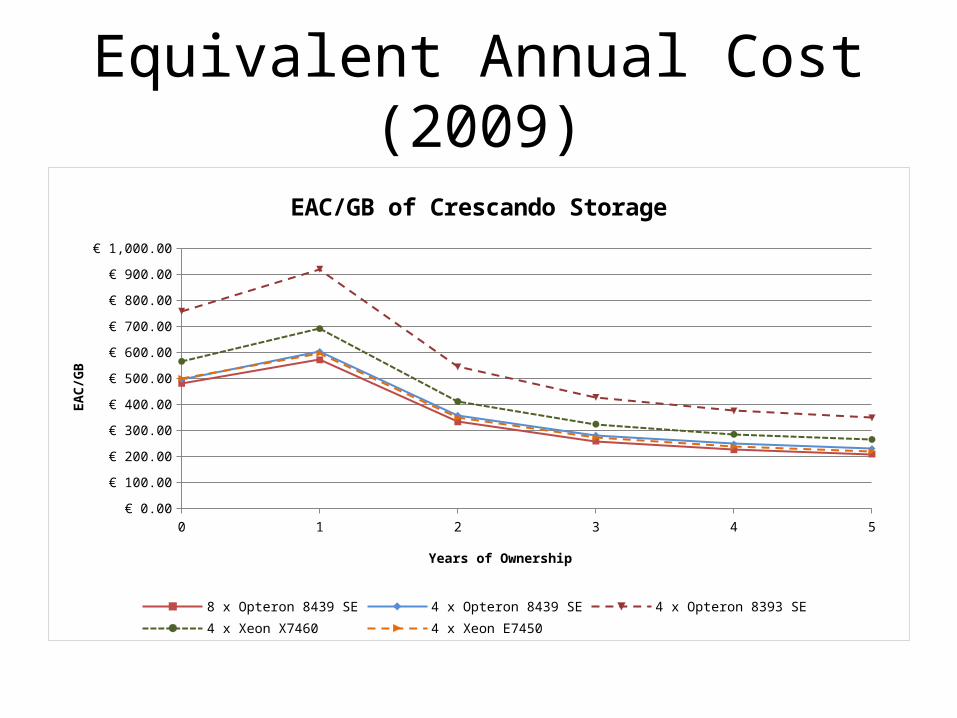
Equivalent Annual Cost (2009)
0 1 2 3 4 5€ 0.00
€ 100.00
€ 200.00
€ 300.00
€ 400.00
€ 500.00
€ 600.00
€ 700.00
€ 800.00
€ 900.00
€ 1,000.00
EAC/GB of Crescando Storage
8 x Opteron 8439 SE 4 x Opteron 8439 SE 4 x Opteron 8393 SE 4 x Xeon X7460 4 x Xeon E7450
Years of Ownership
EAC/
GB

Summary of Experiments• high concurrent query + update throughput – Amadeus: ~4000 queries/sec + ~1000 updates/sec– updates do not impact latency of queries
• predictable and guaranteed latency– depends on size of partition: not optimal, good enough
• cost and energy effeciency– depends on workload: great for hot data, heavy WL
• consistency: write monotonicity, can build SI on top• works great on NUMA! – controls read+write pattern– linear scale-up with number of cores

Status & Outlook
• Status– Fully operational system– Extensive experiments at Amadeus– Production: Summer 2011 (planned)
• Outlook– Column store variant of Crescando– Compression– E-cast: flexible partitioning & replication– Joins over normalized data, Aggregation, ...

Conclusion
• A new way to process queries– Massively parallel, simple, predictable– Not always optimal, but always good enough
• Ideal for operational BI– High query throughput– Concurrent updates with freshness guarantees
• Great building block for many scenarios– Rethink database and storage system architecture