cs 152 computer architecture & engineering
DESCRIPTION
CS 152 Computer Architecture & Engineering. Section 8 Spring 2010. Andrew Waterman. University of California, Berkeley. Mystery Die. Mystery Die. DEC Alpha 21264 15M transistors 600 MHz in 350 nm Highly speculative OoO superscalar. Mystery Die. Map/IQ. FUs. Bus. FUs. FP Map/IQ. - PowerPoint PPT PresentationTRANSCRIPT

CS 152Computer Architecture &
Engineering
Andrew Waterman
University of California, Berkeley
Section 8Spring 2010

Mystery Die

Mystery Die
• DEC Alpha 21264• 15M transistors• 600 MHz in 350
nm• Highly speculative
OoO superscalar

Mystery Die
• DEC Alpha 21264• 15M transistors• 600 MHz in 350
nm• Highly speculative
OoO superscalar

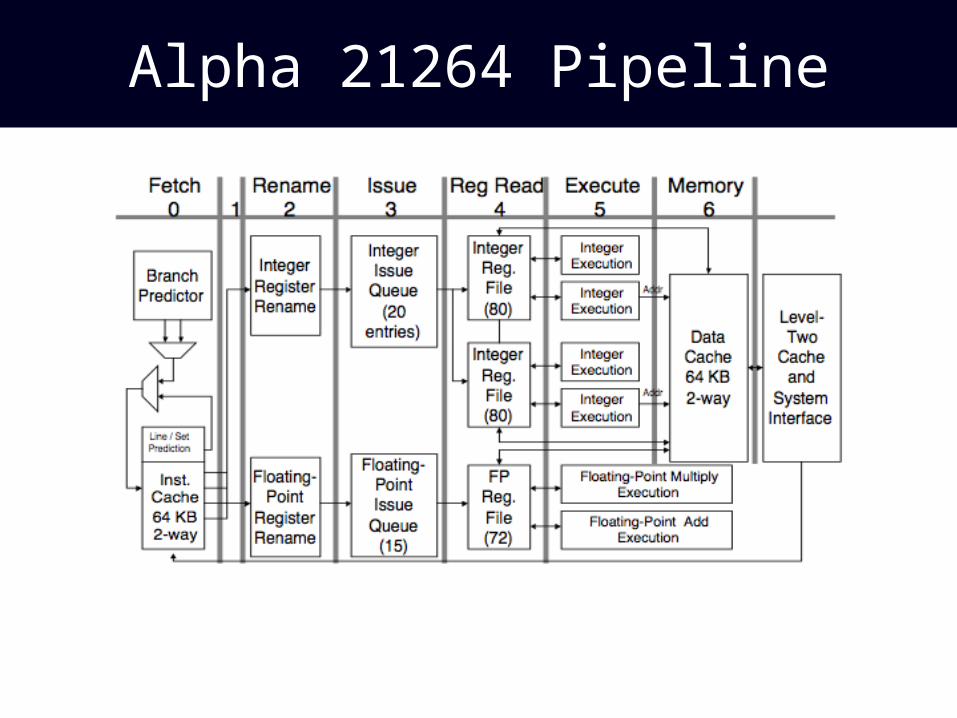
Alpha 21264 Pipeline

Branch Prediction
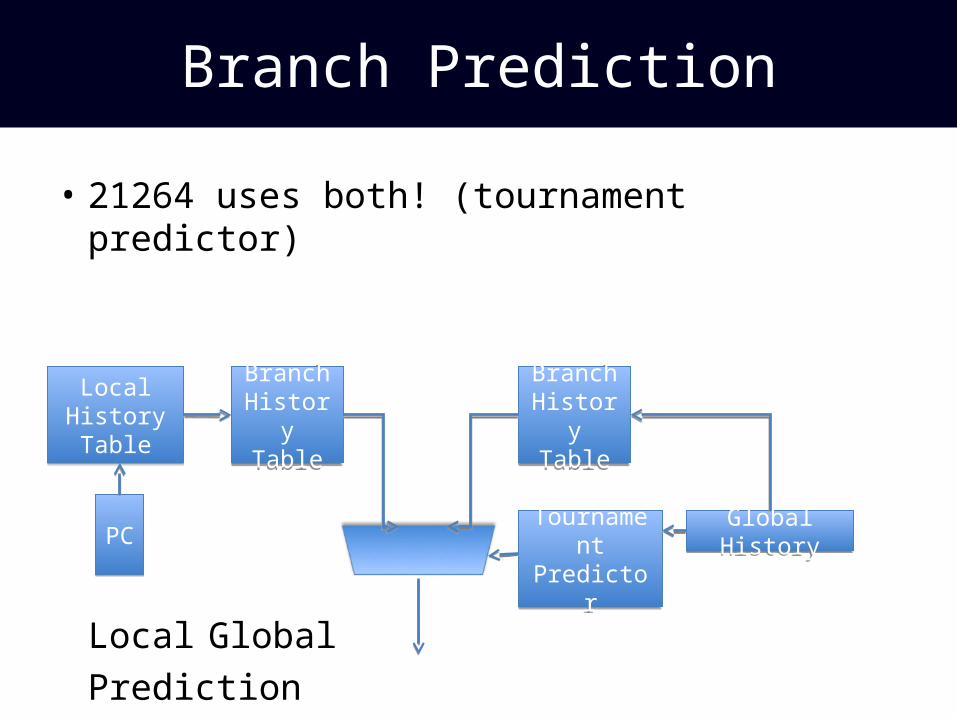
• Two kinds of correlating branch predictors:
Local Global
PCPC
Local History Table
Local History Table
Branch History Table
Branch History Table
Global HistoryGlobal History
Branch History Table
Branch History Table
Branch Prediction
• 21264 uses both! (tournament predictor)
Local GlobalPrediction
PCPC
Local History Table
Local History Table
Branch History Table
Branch History Table
Global HistoryGlobal History
Branch History Table
Branch History Table
Tournament Predictor
Tournament Predictor

21264 Fetch
• Line/way prediction keeps fetch loop short
Alpha 21264 Pipeline

21264 Register Renaming
• Registers are renamed, then instructions are inserted into the issue queue
• Map table backed up on every in-flight insn

21264 Register Renaming
• What hazards does renaming obviate?
• In what situations is renaming useful?
• If you had to choose between branch prediction and renaming, which would you pick?

21264 Register Renaming
• What hazards does renaming obviate?–WAR, WAW
• In what situations is renaming useful?
• If you had to choose between branch prediction and renaming, which would you pick?

21264 Register Renaming
• What hazards does renaming obviate?–WAR, WAW
• In what situations is renaming useful?– Code with ILP and name dependencies:
loops
• If you had to choose between branch prediction and renaming, which would you pick?

21264 Register Renaming
• What hazards does renaming obviate?–WAR, WAW
• In what situations is renaming useful?– Code with ILP and name dependencies: loops
• If you had to choose between branch prediction and renaming, which would you pick?– Not much ILP within a basic block, so
renaming isn’t too useful without branch prediction

Alpha 21264 Pipeline

21264 Superscalar Execution
• The 21264 can decode, rename, issue, execute, and commit 4 insns/cycle
• How does circuit complexity scale with W in the following operations?– Instruction decode– Register renaming– Result bypassing

21264 Superscalar Execution
• The 21264 can decode, rename, issue, execute, and commit 4 insns/cycle
• How does circuit complexity scale with W in the following operations?– Instruction decode: O(W)– Register renaming– Result bypassing

21264 Superscalar Execution
• The 21264 can decode, rename, issue, execute, and commit 4 insns/cycle
• How does circuit complexity scale with W in the following operations?– Instruction decode: O(W)– Register renaming: O(W2)– Result bypassing

21264 Superscalar Execution
• The 21264 can decode, rename, issue, execute, and commit 4 insns/cycle
• How does circuit complexity scale with W in the following operations?– Instruction decode: O(W)– Register renaming: O(W2)– Result bypassing: O(W2)

21264 Superscalar Execution
• The 21264 can decode, rename, issue, execute, and commit 4 insns/cycle
• How does circuit complexity scale with W in the following operations?– Instruction decode: O(W)– Register renaming: O(W2)– Result bypassing: O(W2)
• What about issue window complexity?

21264 Superscalar Execution
• 21264 couldn’t fit full bypassing into one clock cycle
• Instead, they fully bypass within each of two clusters; inter-cluster bypass takes another cycle

21264 Instruction Reordering
• As mentioned earlier, 21264 uses explicit renaming, as opposed to data-in-ROB design
• What does ROB hold?

Memory Ordering in the 21264
• To execute the critical instruction path quickly, want to execute loads ASAP
• Initially, loads speculatively bypass stores
• On a misspeculation, set a “wait” bit for that load’s PC, so it will behave conservatively from then on
• Clear wait bits periodically

Speculation in the 21264
• What does the 21264 speculate on?– Next I$ line/way– Branches, indirect jumps– Exceptions– Load/Store ordering– Load hit/miss• Shortens hit time by a cycle
– Anything else?