cs 252 graduate computer architecture lecture 10 ...cs252/fa07/lectures/l10-multiproc... · cs 252...
TRANSCRIPT

CS 252 Graduate Computer Architecture
Lecture 10: Multiprocessors
Krste AsanovicElectrical Engineering and Computer Sciences
University of California, Berkeley
http://www.eecs.berkeley.edu/~krstehttp://inst.eecs.berkeley.edu/~cs252
10/9/2007 2
Recap: Virtual Memory
• Virtual memory support standard on general-purposeprocessors
– Gives each user (or program) illusion of a separate large protectedmemory
– Programs can be written independent of machine memoryconfiguration
• Hierarchical page tables exploit sparseness of virtualaddress usage to reduce size of mapping information
• TLB caches translation/protection information tomake VM practical
– Would not be acceptable to have multiple additional memoryreferences for each instruction
• Interaction between TLB lookup and cache tag lookup– Want to avoid inconsistencies from virtual address aliases
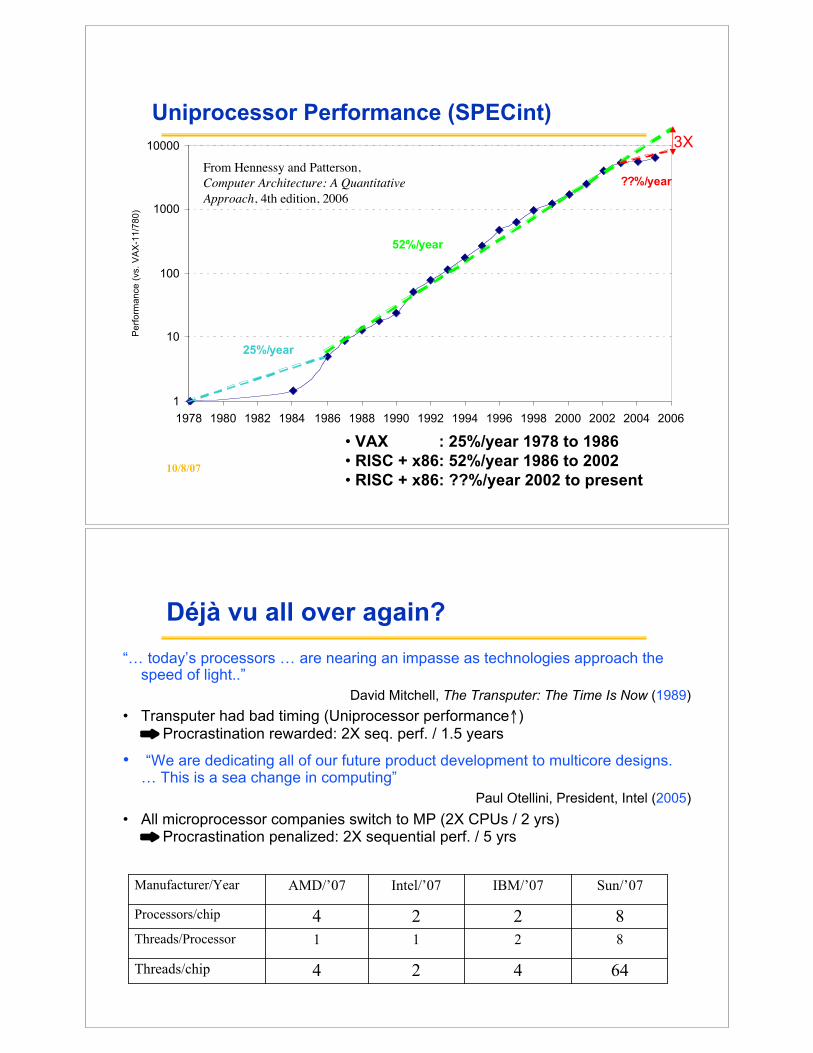
10/8/07 3
1
10
100
1000
10000
1978 1980 1982 1984 1986 1988 1990 1992 1994 1996 1998 2000 2002 2004 2006
Pe
rfo
rma
nce
(vs.
VA
X-1
1/7
80
)
25%/year
52%/year
??%/year
Uniprocessor Performance (SPECint)
• VAX : 25%/year 1978 to 1986
• RISC + x86: 52%/year 1986 to 2002
• RISC + x86: ??%/year 2002 to present
From Hennessy and Patterson,
Computer Architecture: A Quantitative
Approach, 4th edition, 2006
3X
10/8/07 4
Déjà vu all over again?
“… today’s processors … are nearing an impasse as technologies approach thespeed of light..”
David Mitchell, The Transputer: The Time Is Now (1989)
• Transputer had bad timing (Uniprocessor performance!)" Procrastination rewarded: 2X seq. perf. / 1.5 years
• “We are dedicating all of our future product development to multicore designs.… This is a sea change in computing”
Paul Otellini, President, Intel (2005)
• All microprocessor companies switch to MP (2X CPUs / 2 yrs)" Procrastination penalized: 2X sequential perf. / 5 yrs
64424Threads/chip
8211Threads/Processor
8224Processors/chip
Sun/’07IBM/’07Intel/’07AMD/’07Manufacturer/Year

10/8/07 5
Other Factors " Multiprocessors
• Growth in data-intensive applications– Data bases, file servers, …
• Growing interest in servers, server perf.
• Increasing desktop perf. less important– Outside of graphics
• Improved understanding in how to usemultiprocessors effectively
– Especially server where significant natural TLP
• Advantage of leveraging design investment byreplication
– Rather than unique design
10/8/07 6
Flynn’s Taxonomy
• Flynn classified by data and control streams in 1966
• SIMD " Data-Level Parallelism
• MIMD " Thread-Level Parallelism
• MIMD popular because– Flexible: N programs or 1 multithreaded program
– Cost-effective: same MPU in desktop & MIMD machine
Multiple Instruction, MultipleData MIMD
(Clusters, SMP servers)
Multiple Instruction, SingleData (MISD)
(????)
Single Instruction, MultipleData SIMD
(single PC: Vector, CM-2)
Single Instruction, Single Data(SISD)
(Uniprocessor)
M.J. Flynn, "Very High-Speed Computers",
Proc. of the IEEE, V 54, 1900-1909, Dec. 1966.

10/8/07 7
Back to Basics
• “A parallel computer is a collection of processing elements thatcooperate and communicate to solve large problems fast.”
• Parallel Architecture = Computer Architecture + CommunicationArchitecture
10/8/07 8
Two Models for Communication andMemory Architecture
1. Communication occurs by explicitly passing messages among theprocessors:message-passing multiprocessors (aka multicomputers)• Modern cluster systems contain multiple stand-alone computers communicating
via messages
2. Communication occurs through a shared address space (via loadsand stores):shared-memory multiprocessors either
• UMA (Uniform Memory Access time) for shared address,centralized memory MP
• NUMA (Non-Uniform Memory Access time multiprocessor) forshared address, distributed memory MP
• In past, confusion whether “sharing” means sharing physicalmemory (Symmetric MP) or sharing address space
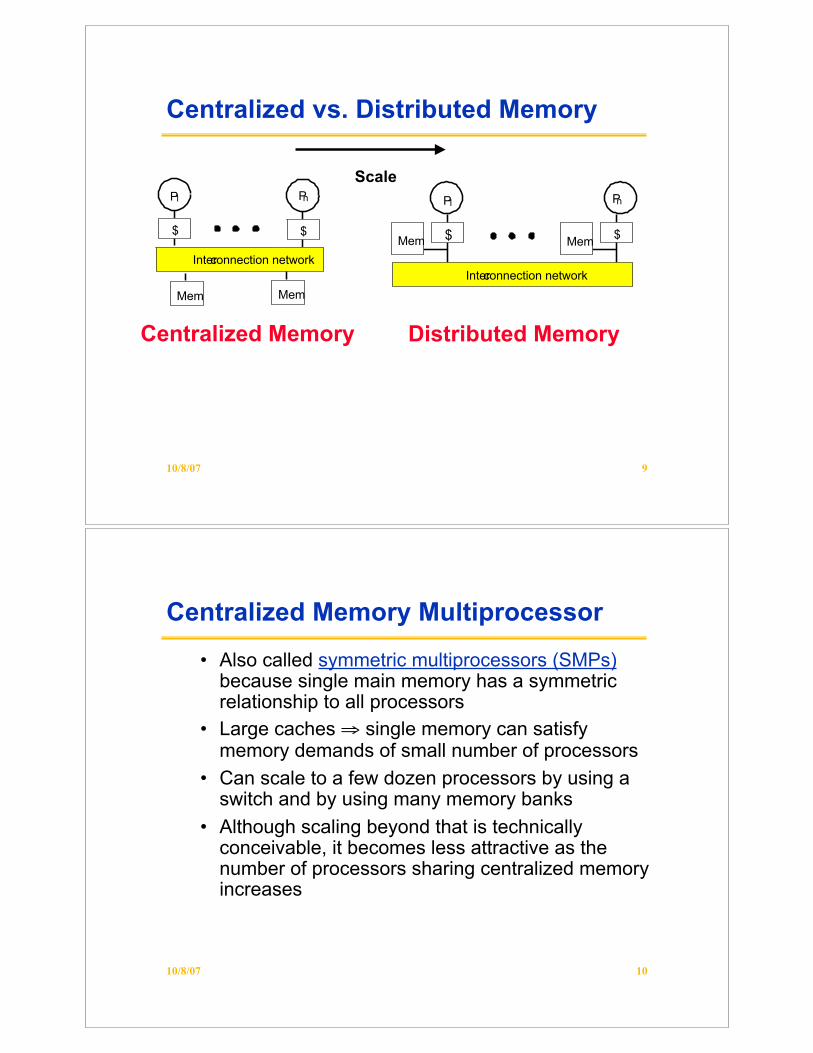
10/8/07 9
Centralized vs. Distributed Memory
P1
$
Interconnection network
$
Pn
Mem Mem
P1
$
Interconnection network
$
Pn
Mem Mem
Centralized Memory Distributed Memory
Scale
10/8/07 10
Centralized Memory Multiprocessor
• Also called symmetric multiprocessors (SMPs)because single main memory has a symmetricrelationship to all processors
• Large caches " single memory can satisfymemory demands of small number of processors
• Can scale to a few dozen processors by using aswitch and by using many memory banks
• Although scaling beyond that is technicallyconceivable, it becomes less attractive as thenumber of processors sharing centralized memoryincreases

10/8/07 11
Distributed Memory Multiprocessor
• Pro: Cost-effective way to scale memorybandwidth
• If most accesses are to local memory
• Pro: Reduces latency of local memoryaccesses
• Con: Communicating data between processorsmore complex
• Con: Software must be aware of dataplacement to take advantage of increasedmemory BW
10/8/07 12
Challenges of Parallel Processing
• Big challenge is % of program that isinherently sequential– What does it mean to be inherently sequential?
• Suppose 80X speedup from 100processors. What fraction of originalprogram can be sequential?
a.10%
b.5%
c. 1%
d.<1%

10/8/07 14
Communication and Synchronization
• Parallel processes must co-operate to complete a singletask faster
• Requires distributed communication andsynchronization
– Communication is for data values, or “what”
– Synchronization is for control, or “when”
– Communication and synchronization are often inter-related
» i.e., “what” depends on “when”
• Message-passing bundles data and control– Message arrival encodes “what” and “when”
• In shared-memory machines, communication usually viacoherent caches & synchronization via atomic memoryoperations
– Due to advent of single-chip multiprocessors, it is likely cache-coherentshared memory systems will be the dominant form of multiprocessor
– Today’s lecture focuses on the synchronization problem
10/9/2007 15
CS252 Administrivia
• Haven’t received many project website URLs, pleaseforward to both Rose and me
– We will use this for 2nd project meetings, week of October 22
• Midterm #1, Thursday, in class, 9:40AM-11:00AM– Closed book, no calculators/computers/iPhones…
– Based on material and assigned readings from lectures 1-9
– Practice problems and solutions on website
• Meet in La Vals for pizza/drinks at 7pm after midtermon Thursday
– Show of hands for RSVP
• Slight change in course calendar– All final project presentations on Thursday December 6th (no class
on December 4th)
– Gives all groups same amount of time before final presentation
– Reminder: final report due Monday December 10th, no extensions

10/9/2007 16
symmetric• All memory is equally far away from all processors• Any processor can do any I/O (set up a DMA transfer)
Symmetric Multiprocessors
MemoryI/O controller
Graphicsoutput
CPU-Memory bus
bridge
Processor
I/O controller I/O controller
I/O bus
Networks
Processor
10/9/2007 17
Synchronization
The need for synchronization arises whenever there are concurrent processes in a system
(even in a uniprocessor system)
Forks and Joins: In parallel programming, a parallel process may want to wait until several events have occurred
Producer-Consumer: A consumer process must wait until the producer process has produced data
Exclusive use of a resource: Operating system has to ensure that only one process uses a resource at a given time
producer
consumer
fork
join
P1 P2

10/9/2007 18
A Producer-Consumer Example
The program is written assuminginstructions are executed in order.
Producer posting Item x:Load Rtail, (tail)Store (Rtail), xRtail=Rtail+1Store (tail), Rtail
Consumer:Load Rhead, (head)
spin: Load Rtail, (tail)if Rhead==Rtail goto spinLoad R, (Rhead)Rhead=Rhead+1Store (head), Rhead
process(R)
Producer Consumertail head
RtailRtail Rhead R
Problems?
10/9/2007 19
A Producer-Consumer Examplecontinued
Producer posting Item x:Load Rtail, (tail)Store (Rtail), xRtail=Rtail+1Store (tail), Rtail
Consumer:Load Rhead, (head)
spin: Load Rtail, (tail)if Rhead==Rtail goto spinLoad R, (Rhead)Rhead=Rhead+1Store (head), Rhead
process(R)Can the tail pointer get updatedbefore the item x is stored?
Programmer assumes that if 3 happens after 2, then 4happens after 1.
Problem sequences are:2, 3, 4, 14, 1, 2, 3
1
2
3
4

10/9/2007 20
Sequential ConsistencyA Memory Model
“ A system is sequentially consistent if the result ofany execution is the same as if the operations of allthe processors were executed in some sequential order, and the operations of each individual processorappear in the order specified by the program”
Leslie Lamport
Sequential Consistency = arbitrary order-preserving interleavingof memory references of sequential programs
M
P P P P P P
10/9/2007 21
Sequential Consistency
Sequential concurrent tasks: T1, T2Shared variables: X, Y (initially X = 0, Y = 10)
T1: T2:Store (X), 1 (X = 1) Load R1, (Y) Store (Y), 11 (Y = 11) Store (Y’), R1 (Y’= Y)
Load R2, (X) Store (X’), R2 (X’= X)
what are the legitimate answers for X’ and Y’ ?
(X’,Y’) # {(1,11), (0,10), (1,10), (0,11)} ?
If y is 11 then x cannot be 0

10/9/2007 22
Sequential Consistency
Sequential consistency imposes more memory orderingconstraints than those imposed by uniprocessorprogram dependencies ( )
What are these in our example ?
T1: T2:Store (X), 1 (X = 1) Load R1, (Y) Store (Y), 11 (Y = 11) Store (Y’), R1 (Y’= Y)
Load R2, (X) Store (X’), R2 (X’= X)additional SC requirements
Does (can) a system with caches or out-of-orderexecution capability provide a sequentially consistentview of the memory ?
10/9/2007 23
Multiple Consumer Example
Producer posting Item x:Load Rtail, (tail)Store (Rtail), xRtail=Rtail+1Store (tail), Rtail
Consumer:Load Rhead, (head)
spin: Load Rtail, (tail)if Rhead==Rtail goto spinLoad R, (Rhead)Rhead=Rhead+1Store (head), Rhead
process(R)
What is wrong with this code?
Critical section:Needs to be executed atomicallyby one consumer ! locks
tail headProducer
Rtail
Consumer1
R Rhead
Rtail
Consumer2
R Rhead
Rtail

10/9/2007 24
Locks or SemaphoresE. W. Dijkstra, 1965
A semaphore is a non-negative integer, with thefollowing operations:
P(s): if s>0, decrement s by 1, otherwise wait
V(s): increment s by 1 and wake up one of the waiting processes
P’s and V’s must be executed atomically, i.e., without• interruptions or• interleaved accesses to s by other processors
initial value of s determines the maximum no. of processesin the critical section
Process iP(s) <critical section>V(s)
10/9/2007 25
Implementation of Semaphores
Semaphores (mutual exclusion) can be implemented using ordinary Load and Store instructions in the Sequential Consistency memory model. However, protocols for mutual exclusion are difficult to design...
Simpler solution:atomic read-modify-write instructions
Test&Set (m), R: R $ M[m];
if R==0 then M[m] $ 1;
Swap (m), R:Rt $ M[m];M[m] $ R;R $ Rt;
Fetch&Add (m), RV, R:R $ M[m];M[m] $ R + RV;
Examples: m is a memory location, R is a register

10/9/2007 26
CriticalSection
P: Test&Set (mutex),Rtemp
if (Rtemp!=0) goto PLoad Rhead, (head)
spin: Load Rtail, (tail)if Rhead==Rtail goto spinLoad R, (Rhead)Rhead=Rhead+1Store (head), Rhead
V: Store (mutex),0process(R)
Multiple Consumers Example using the
Test&Set Instruction
Other atomic read-modify-write instructions (Swap, Fetch&Add, etc.) can also implement P’s and V’s
What if the process stops or is swapped out whilein the critical section?
10/9/2007 27
Nonblocking Synchronization
Compare&Swap(m), Rt, Rs:if (Rt==M[m]) then M[m]=Rs;
Rs=Rt ;status $ success;
else status $ fail;
try: Load Rhead, (head)spin: Load Rtail, (tail)
if Rhead==Rtail goto spinLoad R, (Rhead)Rnewhead = Rhead+1Compare&Swap(head), Rhead, Rnewhead
if (status==fail) goto tryprocess(R)
status is animplicitargument

10/9/2007 28
Load-reserve & Store-conditional
Special register(s) to hold reservation flag and address, and the outcome of store-conditional
try: Load-reserve Rhead, (head)spin: Load Rtail, (tail)
if Rhead==Rtail goto spinLoad R, (Rhead)Rhead = Rhead + 1Store-conditional (head), Rhead
if (status==fail) goto tryprocess(R)
Load-reserve R, (m):<flag, adr> $ <1, m>; R $ M[m];
Store-conditional (m), R:if <flag, adr> == <1, m> then cancel other procs’
reservation on m; M[m] $ R; status $ succeed;
else status $ fail;
10/9/2007 29
Performance of Locks
Blocking atomic read-modify-write instructionse.g., Test&Set, Fetch&Add, Swap
vsNon-blocking atomic read-modify-write instructions
e.g., Compare&Swap, Load-reserve/Store-conditional
vsProtocols based on ordinary Loads and Stores
Performance depends on several interacting factors:degree of contention, caches, out-of-order execution of Loads and Stores
later ...

10/9/2007 30
Issues in ImplementingSequential Consistency
Implementation of SC is complicated by two issues
• Out-of-order execution capabilityLoad(a); Load(b) yesLoad(a); Store(b) yes if a % bStore(a); Load(b) yes if a % bStore(a); Store(b) yes if a % b
• CachesCaches can prevent the effect of a store from being seen by other processors
M
P P P P P P
10/9/2007 31
Memory FencesInstructions to sequentialize memory accesses
Processors with relaxed or weak memory models (i.e.,permit Loads and Stores to different addresses to be reordered) need to provide memory fence instructions to force the serialization of memory accesses
Examples of processors with relaxed memory models:Sparc V8 (TSO,PSO): Membar Sparc V9 (RMO):
Membar #LoadLoad, Membar #LoadStoreMembar #StoreLoad, Membar #StoreStore
PowerPC (WO): Sync, EIEIO
Memory fences are expensive operations, however, one pays the cost of serialization only when it is required
10/9/2007 32
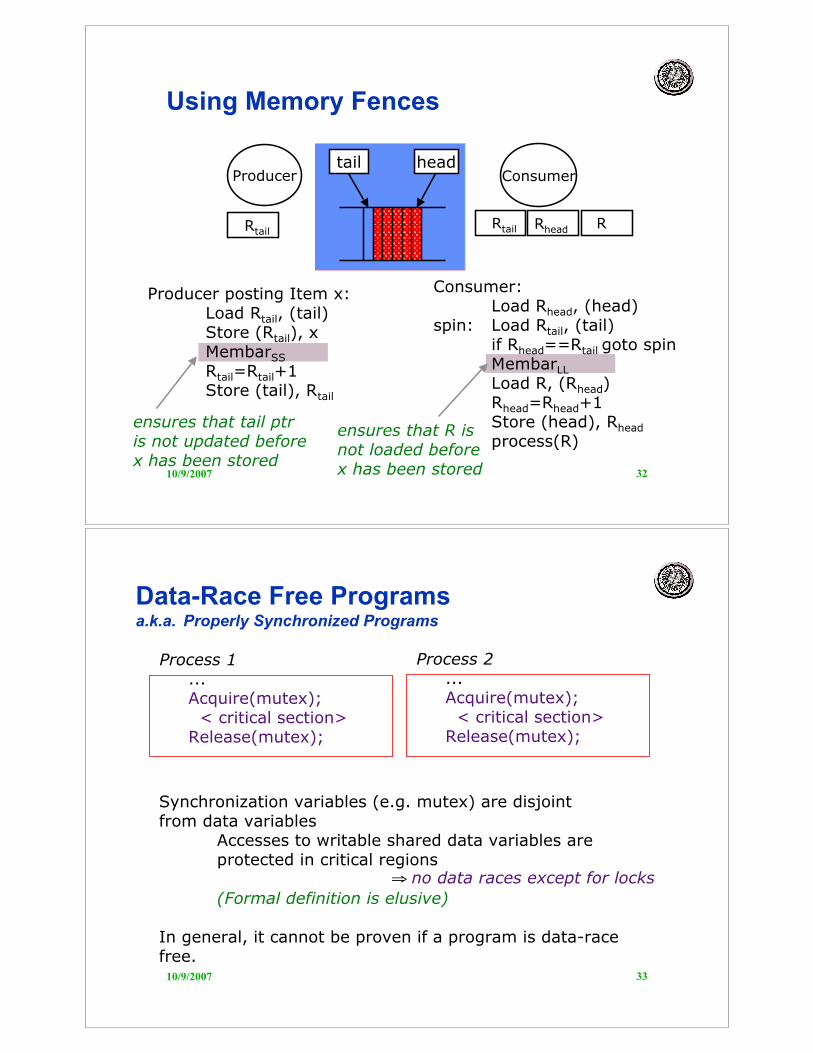
Using Memory Fences
Producer posting Item x:Load Rtail, (tail)Store (Rtail), xMembarSS
Rtail=Rtail+1Store (tail), Rtail
Consumer:Load Rhead, (head)
spin: Load Rtail, (tail)if Rhead==Rtail goto spinMembarLL
Load R, (Rhead)Rhead=Rhead+1Store (head), Rhead
process(R)
Producer Consumertail head
RtailRtail Rhead R
ensures that tail ptris not updated before x has been stored
ensures that R isnot loaded before x has been stored
10/9/2007 33
Data-Race Free Programsa.k.a. Properly Synchronized Programs
Process 1...Acquire(mutex); < critical section>Release(mutex);
Process 2...Acquire(mutex); < critical section>Release(mutex);
Synchronization variables (e.g. mutex) are disjointfrom data variables Accesses to writable shared data variables are
protected in critical regions" no data races except for locks
(Formal definition is elusive)
In general, it cannot be proven if a program is data-race free.

10/9/2007 34
Fences in Data-Race Free Programs
Process 1...Acquire(mutex);membar;
< critical section>membar;Release(mutex);
Process 2...Acquire(mutex);membar;
< critical section>membar;Release(mutex);
• Relaxed memory model allows reordering of instructions by the compiler or the processor as long as the reordering is not done across a fence
• The processor also should not speculate or prefetch across fences
10/9/2007 35
Mutual Exclusion Using Load/Store
A protocol based on two shared variables c1 and c2. Initially, both c1 and c2 are 0 (not busy)
What is wrong?
Process 1 ...c1=1;
L: if c2=1 then go to L < critical section>c1=0;
Process 2 ...c2=1;
L: if c1=1 then go to L < critical section>c2=0;
Deadlock!

10/9/2007 36
Mutual Exclusion: second attempt
To avoid deadlock, let a process give up the reservation (i.e. Process 1 sets c1 to 0) while waiting.
• Deadlock is not possible but with a low probability a livelock may occur.
• An unlucky process may never get to enter the critical section " starvation
Process 1 ...
L: c1=1;if c2=1 then
{ c1=0; go to L} < critical section>c1=0
Process 2 ...
L: c2=1;if c1=1 then
{ c2=0; go to L} < critical section>c2=0
10/9/2007 37
A Protocol for Mutual ExclusionT. Dekker, 1966
Process 1...c1=1;turn = 1;
L: if c2=1 & turn=1 then go to L
< critical section>c1=0;
A protocol based on 3 shared variables c1, c2 and turn. Initially, both c1 and c2 are 0 (not busy)
• turn = i ensures that only process i can wait • variables c1 and c2 ensure mutual exclusion
Solution for n processes was given by Dijkstra and is quite tricky!
Process 2...c2=1;turn = 2;
L: if c1=1 & turn=2 then go to L
< critical section>c2=0;

10/9/2007 38
Analysis of Dekker’s Algorithm
... Process 1c1=1;turn = 1;
L: if c2=1 & turn=1 then go to L
< critical section>c1=0;
... Process 2c2=1;turn = 2;
L: if c1=1 & turn=2 then go to L
< critical section>c2=0;
Scenario 1
... Process 1c1=1;turn = 1;
L: if c2=1 & turn=1 then go to L
< critical section>c1=0;
... Process 2c2=1;turn = 2;
L: if c1=1 & turn=2 then go to L
< critical section>c2=0;
Scenario 2
10/9/2007 39
N-process Mutual ExclusionLamport’s Bakery Algorithm
Process i
choosing[i] = 1;num[i] = max(num[0], …, num[N-1]) + 1;choosing[i] = 0;
for(j = 0; j < N; j++) {while( choosing[j] );while( num[j] && ( ( num[j] < num[i] ) || ( num[j] == num[i] && j < i ) ) );
}
num[i] = 0;
Initially num[j] = 0, for all jEntry Code
Exit Code