cs 414 review. 2 operating system: definition definition an operating system (os) provides a virtual...
Post on 20-Dec-2015
216 views
TRANSCRIPT

CS 414 Review

2
Operating System: DefinitionDefinition
An Operating System (OS) provides a virtual machine on top of the real hardware, whose interface is more
convenient than the raw hardware interface.
Hardware
Applications
Operating System
OS interface
Physical machine interface
Advantages
Easy to use, simpler to code, more reliable, more secure, …
You can say: “I want to write XYZ into file ABC”

3
What is in an OS?
Operating System Services
Interrupts, Cache, Physical Memory, TLB, Hardware Devices
Generic I/O File System
Memory Management
Process Management
Virtual MemoryNetworking
Naming
Access Control
Windowing & graphics
Windowing & Gfx
Applications
OS Interface
Physical m/c Intf
Device Drivers
ShellsSystem Utils
Quake Sql Server
Logical OS Structure

4
Crossing Protection Boundaries
• User calls OS procedure for “privileged” operations• Calling a kernel mode service from user mode program:
– Using System Calls– System Calls switches execution to kernel mode
User process System Call
TrapMode bit = 0
Save Caller’s state Execute system call Restore state
ReturnMode bit = 1
Resume process
User ModeMode bit = 1
Kernel ModeMode bit = 0

5
What is a process?
• The unit of execution
• The unit of scheduling
• Thread of execution + address space
• Is a program in execution– Sequential, instruction-at-a-time execution of a program.
The same as “job” or “task” or “sequential process”

6
Process State Transitions
New
Ready Running
Exit
Waiting
admitted
interrupt
I/O o
r eve
nt w
aitI/O
or event
completion
dispatch done
Processes hop across states as a result of:
• Actions they perform, e.g. system calls
• Actions performed by OS, e.g. rescheduling
• External actions, e.g. I/O

7
Context Switch
• For a running process– All registers are loaded in CPU and modified
• E.g. Program Counter, Stack Pointer, General Purpose Registers
• When process relinquishes the CPU, the OS– Saves register values to the PCB of that process
• To execute another process, the OS– Loads register values from PCB of that process
Context Switch Process of switching CPU from one process to another Very machine dependent for types of registers

8
Threads and Processes
• Most operating systems therefore support two entities:– the process,
• which defines the address space and general process attributes
– the thread, • which defines a sequential execution stream within a process
• A thread is bound to a single process. – For each process, however, there may be many threads.
• Threads are the unit of scheduling • Processes are containers in which threads execute

9
Schedulers
• Process migrates among several queues– Device queue, job queue, ready queue
• Scheduler selects a process to run from these queues• Long-term scheduler:
– load a job in memory– Runs infrequently
• Short-term scheduler:– Select ready process to run on CPU– Should be fast
• Middle-term scheduler– Reduce multiprogramming or memory consumption

10
CPU Scheduling
• FCFS• LIFO• SJF• SRTF• Priority Scheduling• Round Robin• Multi-level Queue• Multi-level Feedback Queue

Race conditions• Definition: timing dependent error involving shared state
– Whether it happens depends on how threads scheduled
• Hard to detect:– All possible schedules have to be safe
• Number of possible schedule permutations is huge
• Some bad schedules? Some that will work sometimes?
– they are intermittent
• Timing dependent = small changes can hide bug

12
The Fundamental Issue: Atomicity
• Our atomic operation is not done atomically by machine– Atomic Unit: instruction sequence guaranteed to execute indivisibly– Also called “critical section” (CS)
When 2 processes want to execute their Critical Section,– One process finishes its CS before other is allowed to enter

13
Critical Section Problem
• Problem: Design a protocol for processes to cooperate, such that only one process is in its critical section– How to make multiple instructions seem like one?
Processes progress with non-zero speed, no assumption on clock speed
Used extensively in operating systems:Queues, shared variables, interrupt handlers, etc.
Process 1
Process 2
CS1
Time
CS2

14
Solution StructureShared vars:
Initialization:
Process:. . . . . .
Entry Section
Critical Section
Exit Section
Added to solve the CS problem

15
Solution Requirements
• Mutual Exclusion– Only one process can be in the critical section at any time
• Progress– Decision on who enters CS cannot be indefinitely postponed
• No deadlock
• Bounded Waiting– Bound on #times others can enter CS, while I am waiting
• No livelock
• Also efficient (no extra resources), fair, simple, …

16
Semaphores
• Non-negative integer with atomic increment and decrement• Integer ‘S’ that (besides init) can only be modified by:
– P(S) or S.wait(): decrement or block if already 0– V(S) or S.signal(): increment and wake up process if any
• These operations are atomic
semaphore S;
P(S) { while(S ≤ 0) ; S--;}
V(S) { S++;}

17
Semaphore Types
• Counting Semaphores:– Any integer– Used for synchronization
• Binary Semaphores– Value 0 or 1– Used for mutual exclusion (mutex)
Shared: semaphore S
Init: S = 1;
Process i
P(S);
Critical Section
V(S);

18
Mutexes and Synchronizationsemaphore S;
P(S) { while(S ≤ 0) ; S--;}
V(S) { S++;}
Process i
P(S);
Code XYZ
V(S);
Process j
P(S);
Code ABC
V(S);
Init: S = 0;Init: S = 1;

19
Classical Synchronization Problems using Semaphores

20
Producer-Consumer ProblemShared: Semaphores mutex, empty, full;
Init: mutex = 1; /* for mutual exclusion*/ empty = N; /* number empty buf entries */ full = 0; /* number full buf entries */
Producer
do { . . . // produce an item in nextp . . . P(empty); P(mutex); . . . // add nextp to buffer . . . V(mutex); V(full);} while (true);
Consumer
do { P(full); P(mutex); . . . // remove item to nextc . . . V(mutex); V(empty); . . . // consume item in nextc . . . } while (true);
607-256-4000

21
Readers-Writers Problem
• Courtois et al 1971• Models access to a database
– A reader is a thread that needs to look at the database but won’t change it.
– A writer is a thread that modifies the database
• Example: making an airline reservation– When you browse to look at flight schedules the web site is
acting as a reader on your behalf– When you reserve a seat, the web site has to write into the
database to make the reservation

22
Readers-WritersShared variables: Semaphore mutex, wrl; integer rcount;
Init: mutex = 1, wrl = 1, rcount = 0;
Writerdo {
P(wrl); . . . /*writing is performed*/ . . . V(wrl);
}while(TRUE);
Readerdo { P(mutex); rcount++; if (rcount == 1) P(wrl); V(mutex); . . . /*reading is performed*/ . . . P(mutex); rcount--; if (rcount == 0) V(wrl); V(mutex);}while(TRUE);

23
Readers-Writers Notes
• If there is a writer– First reader blocks on wrl– Other readers block on mutex
• Once a reader is active, all readers get to go through– Which reader gets in first?
• The last reader to exit signals a writer– If no writer, then readers can continue
• If readers and writers waiting on wrl, and writer exits– Who gets to go in first?
• Why doesn’t a writer need to use mutex?

24
Does this work as we hoped?
• If readers are active, no writer can enter– The writers wait doing a P(wrl)
• While writer is active, nobody can enter– Any other reader or writer will wait
• But back-and-forth switching is buggy:– Any number of readers can enter in a row– Readers can “starve” writers
• With semaphores, building a solution that has the desired back-and-forth behavior is really, really tricky!– We recommend that you try, but not too hard…

25
Common programming errors
Process i
P(S)CSP(S)
Process j
V(S)CSV(S)
Process k
P(S)CS
A typo. Process I will get stuck (forever) the second time it does the P() operation. Moreover, every other process will freeze up too when trying
to enter the critical section!
A typo. Process J won’t respect mutual exclusion even if the other
processes follow the rules correctly. Worse still, once we’ve done two
“extra” V() operations this way, other processes might get into the CS
inappropriately!
Whoever next calls P() will freeze up. The bug might be confusing
because that other process could be perfectly correct code, yet that’s the one you’ll see hung when you use the debugger to look at its state!

26
More common mistakes
• Conditional code that can break the normaltop-to-bottom flow of codein the critical section
• Often a result of someonetrying to maintain aprogram, e.g. to fix a bugor add functionality in codewritten by someone else
P(S)if(something or other) return;CSV(S)

27
What if buffer is full?
Producer
do { . . . // produce an item in nextp . . . P(mutex); P(empty); . . . // add nextp to buffer . . . V(mutex); V(full);} while (true);
What’s wrong?Shared: Semaphores mutex, empty, full;
Init: mutex = 1; /* for mutual exclusion*/ empty = N; /* number empty bufs */ full = 0; /* number full bufs */
Consumer
do { P(full); P(mutex); . . . // remove item to nextc . . . V(mutex); V(empty); . . . // consume item in nextc . . . } while (true);
Oops! Even if you do the correct operations, the order in which you do semaphore operations can have an
incredible impact on correctness

28
Language Support for Concurrency

29
Monitors
• Hoare 1974• Abstract Data Type for handling/defining shared resources• Comprises:
– Shared Private Data• The resource• Cannot be accessed from outside
– Procedures that operate on the data• Gateway to the resource• Can only act on data local to the monitor
– Synchronization primitives• Among threads that access the procedures

30
Synchronization Using Monitors
• Defines Condition Variables:– condition x;– Provides a mechanism to wait for events
• Resources available, any writers
• 3 atomic operations on Condition Variables– x.wait(): release monitor lock, sleep until woken up
condition variables have waiting queues too
– x.notify(): wake one process waiting on condition (if there is one)• No history associated with signal
– x.broadcast(): wake all processes waiting on condition• Useful for resource manager
• Condition variables are not Boolean– If(x) then { } does not make sense

31
Types of Monitors
What happens on notify():• Hoare: signaler immediately gives lock to waiter (theory)
– Condition definitely holds when waiter returns– Easy to reason about the program
• Mesa: signaler keeps lock and processor (practice)– Condition might not hold when waiter returns– Fewer context switches, easy to support broadcast
• Brinch Hansen: signaler must immediately exit monitor– So, notify should be last statement of monitor procedure

32
Monitor Semantics
• Monitors guarantee mutual exclusion– Only one thread can execute monitor procedure at any time
• “in the monitor”
– If second thread invokes monitor procedure at that time• It will block and wait for entry to the monitor
Need for a wait queue
– If thread within a monitor blocks, another can enter
• Effect on parallelism?

33
Structure of a MonitorMonitor monitor_name{ // shared variable declarations
procedure P1(. . . .) { . . . . }
procedure P2(. . . .) { . . . . } . . procedure PN(. . . .) { . . . . }
initialization_code(. . . .) { . . . . }}
For example:
Monitor stack{ int top; void push(any_t *) { . . . . }
any_t * pop() { . . . . }
initialization_code() { . . . . }}only one instance of stack can be modified at a time

34
Condition Variables & Semaphores
• Condition Variables != semaphores• Access to monitor is controlled by a lock
– Wait: blocks on thread and gives up the lock• To call wait, thread has to be in monitor, hence the lock• Semaphore P() blocks thread only if value less than 0
– Signal: causes waiting thread to wake up• If there is no waiting thread, the signal is lost• V() increments value, so future threads need not wait on P()• Condition variables have no history
• However they can be used to implement each other

35
Monitor Solutions to Classical Problems

36
Producer Consumer using Monitors
Monitor Producer_Consumer { any_t buf[N]; int n = 0, tail = 0, head = 0; condition not_empty, not_full;
void put(char ch) {if(n == N) wait(not_full);buf[head%N] = ch;head++;n++;
signal(not_empty); }}
char get() {if(n == 0)
wait(not_empty);ch = buf[tail%N];tail++; n--;signal(not_full);return ch;
}

37
Readers and WritersMonitor ReadersNWriters { int WaitingWriters, WaitingReaders,NReaders, NWriters; Condition CanRead, CanWrite;
Void BeginWrite() { if(NWriters == 1 || NReaders > 0) { ++WaitingWriters; wait(CanWrite); --WaitingWriters; } NWriters = 1; } Void EndWrite() { NWriters = 0; if(WaitingReaders) Signal(CanRead); else Signal(CanWrite); }
Void BeginRead() { if(NWriters == 1 || WaitingWriters > 0) { ++WaitingReaders; Wait(CanRead);
--WaitingReaders; } ++NReaders; Signal(CanRead); }
Void EndRead() { if(--NReaders == 0) Signal(CanWrite);
}

38
Deadlocks
Definition:
Deadlock exists among a set of processes if – Every process is waiting for an event – This event can be caused only by another process in the set
• Event is the acquire of release of another resource
Kansas 20th century law: “When two trains approach each other at a crossing, both shall come to a full stop and neither shall start up again until the other has gone”

39
Four Conditions for Deadlock
• Coffman et. al. 1971• Necessary conditions for deadlock to exist:
– Mutual Exclusion• At least one resource must be held is in non-sharable mode
– Hold and wait• There exists a process holding a resource, and waiting for another
– No preemption• Resources cannot be preempted
– Circular wait• There exists a set of processes {P1, P2, … PN}, such that
– P1 is waiting for P2, P2 for P3, …. and PN for P1
All four conditions must hold for deadlock to occur

40
Dealing with Deadlocks
• Proactive Approaches:– Deadlock Prevention
• Negate one of 4 necessary conditions• Prevent deadlock from occurring
– Deadlock Avoidance• Carefully allocate resources based on future knowledge• Deadlocks are prevented
• Reactive Approach:– Deadlock detection and recovery
• Let deadlock happen, then detect and recover from it
• Ignore the problem– Pretend deadlocks will never occur– Ostrich approach

41
Safe State
• A state is said to be safe, if it has a process sequence
{P1, P2,…, Pn}, such that for each Pi,
the resources that Pi can still request can be satisfied by the currently available resources plus the resources held by all Pj, where j < i
• State is safe because OS can definitely avoid deadlock – by blocking any new requests until safe order is executed
• This avoids circular wait condition– Process waits until safe state is guaranteed

42
Banker’s Algorithm
• Decides whether to grant a resource request. • Data structures:
n: integer # of processesm: integer # of resourcesavailable[1..m] available[i] is # of avail resources of type imax[1..n,1..m] max demand of each Pi for each Riallocation[1..n,1..m] current allocation of resource Rj to Pineed[1..n,1..m] max # resource Rj that Pi may still request
let request[i] be vector of # of resource Rj Process Pi wants

43
Basic Algorithm
1. If request[i] > need[i] then error (asked for too much)
2. If request[i] > available[i] then wait (can’t supply it now)
3. Resources are available to satisfy the request
Let’s assume that we satisfy the request. Then we would have:
available = available - request[i]
allocation[i] = allocation [i] + request[i]
need[i] = need [i] - request [i]
Now, check if this would leave us in a safe state:
if yes, grant the request,
if no, then leave the state as is and cause process to wait.
44
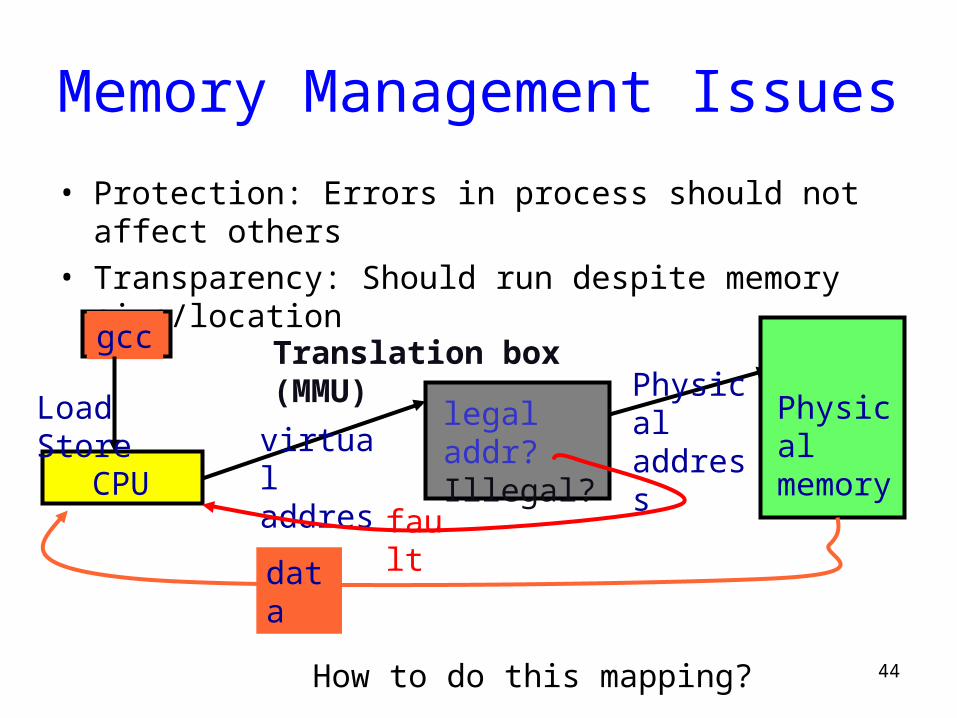
Memory Management Issues
• Protection: Errors in process should not affect others• Transparency: Should run despite memory size/location
gcc
virtual address
CPU
Load Store
legal addr?Illegal?
Physicaladdress
Physicalmemory
faultdat
a
Translation box (MMU)
How to do this mapping?

45
Segmentation
• Processes have multiple base + limit registers• Processes address space has multiple segments
– Each segment has its own base + limit registers– Add protection bits to every segment
gcc
Text seg r/o
Stack seg r/w
0x1000
0x3000
0x5000
0x6000
Real memory
0x2000
0x8000
0x6000
Base&Limit?
How to do the mapping?
46
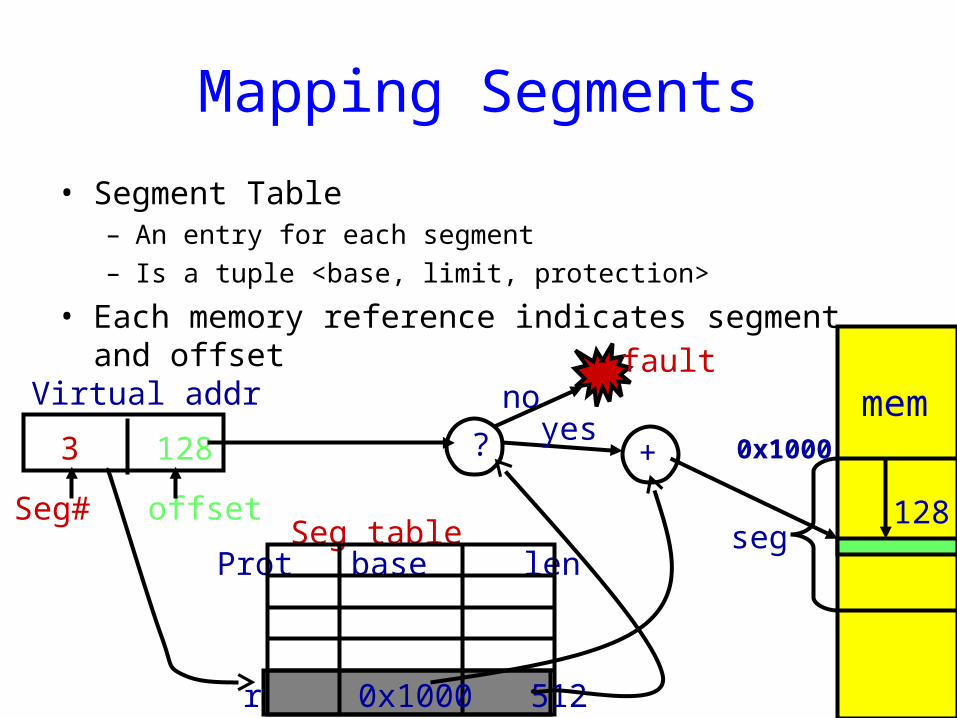
Mapping Segments
• Segment Table– An entry for each segment– Is a tuple <base, limit, protection>
• Each memory reference indicates segment and offset
Virtual addr
Seg# offset
3 128
Seg tableProt base len
r 0x1000 512
mem
seg128
+ 0x1000? yesno
fault

47
Fragmentation
• “The inability to use free memory”• External Fragmentation:
– Variable sized pieces many small holes over time
• Internal Fragmentation:– Fixed sized pieces internal waste if entire piece is not used
gcc
emacs
doomstackallocated
Unused (“internal fragmentation”)
ExternalfragmentationWord ??

48
Paging
• Divide memory into fixed size pieces– Called “frames” or “pages”
• Pros: easy, no external fragmentation
gcc
emacs internal frag
Pages typical: 4k-8k

49
Mapping Pages
• If 2m virtual address space, 2n page size (m - n) bits to denote page number, n for offset within page
Translation done using a Page Table
Virtual addr
VPN page offset
3 128 (12bits)
page tableProt VPN PPN
r 3 1
mem
seg128
0x1000((1<<12)|128)
“invalid”
? PPN

50
Paging + Segmentation
• Paged segmentation– Handles very long segments– The segments are paged
• Segmented Paging– When the page table is very big– Segment the page table– Let’s consider System 370 (24-bit address space)
Seg # page # (8 bits) page offset (12 bits)(4 bits)

51
What is virtual memory?
• Each process has illusion of large address space– 232 for 32-bit addressing
• However, physical memory is much smaller• How do we give this illusion to multiple processes?
– Virtual Memory: some addresses reside in disk
page table
Physical memory
disk

52
Virtual Memory
• Load entire process in memory (swapping), run it, exit– Is slow (for big processes)– Wasteful (might not require everything)
• Solutions: partial residency– Paging: only bring in pages, not all pages of process– Demand paging: bring only pages that are required
• Where to fetch page from?– Have a contiguous space in disk: swap file (pagefile.sys)

53
Page Faults
• On a page fault:– OS finds a free frame, or evicts one from memory (which one?)
• Want knowledge of the future?
– Issues disk request to fetch data for page (what to fetch?)
• Just the requested page, or more?
– Block current process, context switch to new process (how?)
• Process might be executing an instruction
– When disk completes, set present bit to 1, and current process in ready queue

54
Page Replacement Algorithms
• Random: Pick any page to eject at random– Used mainly for comparison
• FIFO: The page brought in earliest is evicted– Ignores usage– Suffers from “Belady’s Anomaly”
• Fault rate could increase on increasing number of pages
• E.g. 0 1 2 3 0 1 4 0 1 2 3 4 with frame sizes 3 and 4
• OPT: Belady’s algorithm– Select page not used for longest time
• LRU: Evict page that hasn’t been used the longest– Past could be a good predictor of the future

55
Thrashing
• Processes in system require more memory than is there– Keep throwing out page that will be referenced soon– So, they keep accessing memory that is not there
• Why does it occur?– No good reuse, past != future– There is reuse, but process does not fit– Too many processes in the system

56
Approach 1: Working Set
• Peter Denning, 1968– Defines the locality of a program
pages referenced by process in last T seconds of execution considered to comprise its working set
T: the working set parameter
• Uses:– Caching: size of cache is size of WS– Scheduling: schedule process only if WS in memory– Page replacement: replace non-WS pages

57
Working Sets
• The working set size is num pages in the working set – the number of pages touched in the interval (t, t-Δ).
• The working set size changes with program locality.– during periods of poor locality, you reference more pages.
– Within that period of time, you will have a larger working set size.
• Don’t run process unless working set is in memory.

58
Approach 2: Page Fault Frequency
• thrashing viewed as poor ratio of fetch to work• PFF = page faults / instructions executed • if PFF rises above threshold, process needs more memory
– not enough memory on the system? Swap out.
• if PFF sinks below threshold, memory can be taken away

59
What does the disk look like?

60
Disk overheads• To read from disk, we must specify:
– cylinder #, surface #, sector #, transfer size, memory address
• Transfer time includes: – Seek time: to get to the track – Latency time: to get to the sector and – Transfer time: get bits off the disk
Track
Sector
Seek Time
RotationDelay

61
Disk Scheduling
• FCFS• SSTF• SCAN• C-SCAN• LOOK• C-LOOK

62
RAID Levels
• 0: Striping• 1: Mirroring• 2: Hamming Codes• 3: Parity Bit• 4: Block Striping• 5: Spread parity blocks across all disks• 0+1 and 1+0

63
Stable Storage Algo• Use 2 identical disks
– corresponding blocks on both drives are the same
• 3 operations:– Stable write: retry on 1st until successful, then try 2nd disk– Stable read: read from 1st. If ECC error, then try 2nd – Crash recovery: scan corresponding blocks on both disks
• If one block is bad, replace with good one
• If both are good, replace block in 2nd with the one in 1st

64
File System Layout• File System is stored on disks
– Disk is divided into 1 or more partitions– Sector 0 of disk called Master Boot Record– End of MBR has partition table (start & end address of partitions)
• First block of each partition has boot block– Loaded by MBR and executed on boot

65
Implementing Files• Contiguous Allocation: allocate files contiguously on disk

66
Linked List Allocation
• Each file is stored as linked list of blocks– First word of each block points to next block– Rest of disk block is file data

67
Using an in-memory table• Implement a linked list allocation using a table
– Called File Allocation Table (FAT)– Take pointer away from blocks, store in this table

68
I-nodes• Index-node (I-node) is a per-file data structure
– Lists attributes and disk addresses of file’s blocks– Pros: Space (max open files * size per I-node)– Cons: what if file expands beyond I-node address space?

69
Implementing Directories
• When a file is opened, OS uses path name to find dir– Directory has information about the file’s disk blocks
• Whole file (contiguous), first block (linked-list) or I-node
– Directory also has attributes of each file
• Directory: map ASCII file name to file attributes & location• 2 options: entries have all attributes, or point to file I-node

70
Implementing Directories
• What if files have large, variable-length names?• Solution:
– Limit file name length, say 255 chars, and use previous scheme• Pros: Simple Cons: wastes space
– Directory entry comprises fixed and variable portion• Fixed part starts with entry size, followed by attributes
• Variable part has the file name
• Pros: saves space
• Cons: holes on removal, page fault on file read, word boundaries
– Directory entries are fixed in length, pointer to file name in heap• Pros: easy removal, no space wasted for word boundaries
• Cons: manage heap, page faults on file names

71
Managing Free Disk Space
• 2 approaches to keep track of free disk blocks– Linked list and bitmap approach

72
File System Consistency
• System crash before modified files written back– Leads to inconsistency in FS– fsck (UNIX) & scandisk (Windows) check FS consistency
• Algorithm:– Build 2 tables, each containing counter for all blocks (init to 0)
• 1st table checks how many times a block is in a file
• 2nd table records how often block is present in the free list– >1 not possible if using a bitmap
– Read all i-nodes, and modify table 1– Read free-list and modify table 2– Consistent state if block is either in table 1 or 2, but not both

73
FS Performance
• Access to disk is much slower than access to memory– Optimizations needed to get best performance
• 3 possible approaches: caching, prefetching, disk layout• Block or buffer cache:
– Read/write from and to the cache.

74
Block Cache Replacement
• Which cache block to replace?– Could use any page replacement algorithm– Possible to implement perfect LRU
• Since much lesser frequency of cache access
• Move block to front of queue
– Perfect LRU is undesirable. We should also answer:• Is the block essential to consistency of system?
• Will this block be needed again soon?
• When to write back other blocks?– Update daemon in UNIX calls sync system call every 30 s– MS-DOS uses write-through caches

75
LFS Basic Idea
• Structure the disk a log– Periodically, all pending writes buffered in memory are collected
in a single segment– The entire segment is written contiguously at end of the log
• Segment may contain i-nodes, directory entries, data– Start of each segment has a summary– If segment around 1 MB, then full disk bandwidth can be utilized
• Note, i-nodes are now scattered on disk– Maintain i-node map (entry i points to i-node i on disk)– Part of it is cached, reducing the delay in accessing i-node
• This description works great for disks of infinite size

76
LFS Cleaning
• Finite disk space implies that the disk is eventually full– Fortunately, some segments have stale information– A file overwrite causes i-node to point to new blocks
• Old ones still occupy space
• Solution: LFS Cleaner thread compacts the log– Read segment summary, and see if contents are current
• File blocks, i-nodes, etc.
– If not, the segment is marked free, and cleaner moves forward– Else, cleaner writes content into new segment at end of the log– The segment is marked as free!
• Disk is a circular buffer, writer adds contents to the front, cleaner cleans content from the back

77
FS Examples
• DOS• Win98• WinXP• UNIX FS• Linux ext2FS• NFS, AFS, LFS• P2P FSes

78
Network Stack: Layering
Presentation
Transport
Network
Data Link
Physical
Application
Presentation
Transport
Network
Data Link
Physical
ApplicationNode A Node B
Network

79
End-to-End Argument
• What function to implement in each layer?• Saltzer, Reed, Clarke 1984
– A function can be correctly and completely implemented only with the knowledge and help of applications standing at the communication endpoints
– Argues for moving function upward in a layered architecture
• Should the network guarantee packet delivery ?– Think about a file transfer program
– Read file from disk, send it, the receiver reads packets and writes them to the disk

80
Packet vs. Circuit Switching
• Reliability: no congestion, in-order data in circuit-switch• Packet switching: better bandwidth use• State, resources: packet switching has less state
– Good: less control plane processing resources along the way
– More data plane (address lookup) processing
• Failure modes (routers/links down)– Packet switch reconfigures sub-second timescale
– Circuit switching: more complicated• Involves all switches in the path

81
Link level Issues
• Encoding: map bits to analog signals• Framing: Group bits into frames (packets)• Arbitration: multiple senders, one resource• Addressing: multiple receivers, one wire

82
Repeaters and Bridges
• Both connect LAN segments• Usually do not originate data• Repeaters (Hubs): physical layer devices
– forward packets on all LAN segments– Useful for increasing range– Increases contention
• Bridges: link layer devices– Forward packets only if meant on that segment– Isolates congestion– More expensive

83
Network Layer
Two important functions:• routing: determine path from source to dest. • forwarding: move packets from router’s input to output
T1T3
Sts-1
T3
T1

84
Two connection models• Connectionless (or “datagram”):
– each packet contains enough information that routers can decide how to get it to its final destination
• Connection-oriented (or “virtual circuit”)– first set up a connection between two nodes– label it (called a virtual circuit identifier (VCI))– all packets carry label
BAb b
C
BA1 1
C
1

85
DNS name servers
Name server: process running on a host that processes DNS requests
local name servers:– each ISP, company has
local (default) name server– host DNS query first goes to
local name server
authoritative name server:– can perform name/address
translation for a specific domain or zone
How could we provide this service? Why not centralize DNS?
• single point of failure• traffic volume• distant centralized database• maintenance
doesn’t scale!
• no server has all name-to-IP address mappings
86
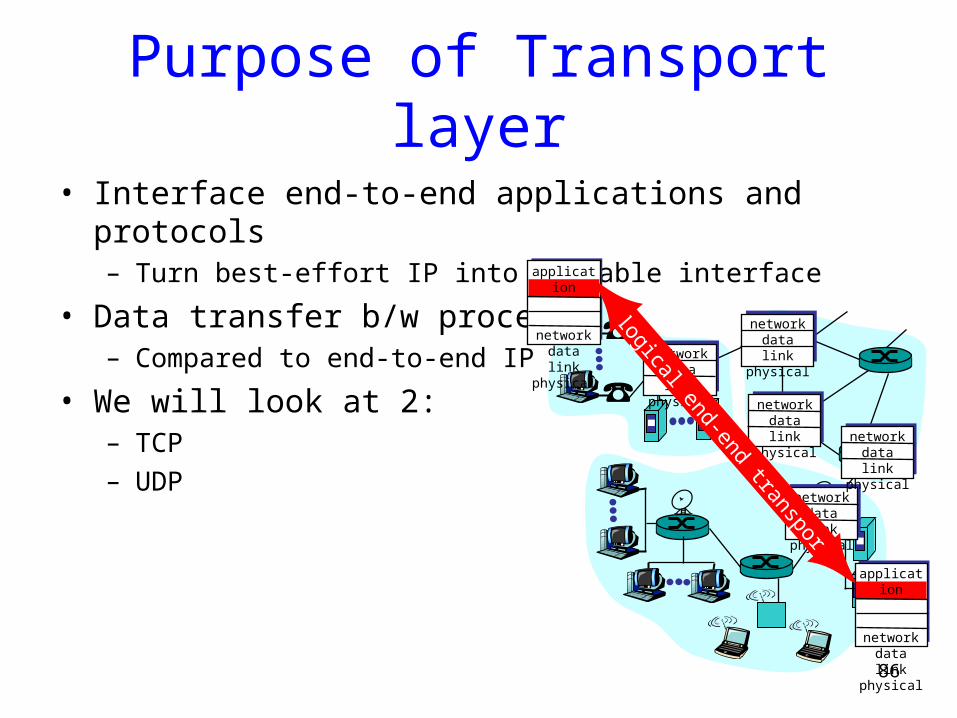
Purpose of Transport layer
• Interface end-to-end applications and protocols– Turn best-effort IP into a usable interface
• Data transfer b/w processes:– Compared to end-to-end IP
• We will look at 2:– TCP– UDP
application
transport
networkdata link
physical
application
transport
networkdata link
physical
networkdata link
physical
networkdata link
physical
networkdata link
physical
networkdata link
physicalnetworkdata link
physical
logical end-end transport

87
UDP
• Unreliable Datagram Protocol
• Best effort data delivery between processes– No frills, bare bones transport protocol
– Packet may be lost, out of order
• Connectionless protocol:– No handshaking between sender and receiver
– Each UDP datagram handled independently

88
UDP Functionality
• Multiplexing/Demultiplexing– Using ports
• Checksums (optional)– Check for corruption
applicationtransportnetwork
MP2
applicationtransportnetwork
receiver
HtHnsegment
segment Mapplicationtransportnetwork
P1M
M MP4
segmentheader
application-layerdata
P3

89
TCP
• Transmission Control Protocol– Reliable, in-order, process-to-process, two-way byte stream
• Different from UDP– Connection-oriented– Error recovery: Packet loss, duplication, corruption, reordering
• A number of applications require this guarantee– Web browsers use TCP

90
TCP Summary
• Reliable ordered message delivery
– Connection oriented, 3-way handshake
• Transmission window for better throughput
– Timeouts based on link parameters
• Congestion control
– Linear increase, exponential backoff
• Fast adaptation
– Exponential increase in the initial phase

91
Security in Computer Systems
• In computer systems, this translates to:– Authorization– Authentication– Audit
• This is the Gold Standard for Security (Lampson)• Some security goals:
– Data confidentiality: secret data remains secret– Data integrity: no tampering of data– System availability: unable to make system unusable– Privacy: protecting from misuse of user’s information

92
Cryptography Overview
• Encrypt data so it only makes sense to authorized users– Input data is a message or file called plaintext– Encrypted data is called ciphertext
• Encryption and decryption functions should be public– Security by obscurity is not a good idea!

93
Secret-Key Cryptography
• Also called symmetric cryptography– Encryption algorithm is publicly known– E(message, key) = ciphertext D(ciphertext, key) = message
• Naïve scheme: monoalphabetic substitution– Plaintext : ABCDEFGHIJKLMNOPQRSTUVWXYZ– Ciphertext: QWERTYUIOPASDFGHJKLZXCVBNM– So, attack is encrypted to: qzzqea– 26! possible keys ~ 4x1026 possibilities
• 1 µs per permutation 10 trillion years to break
– easy to break this scheme! How?• ‘e’ occurs 14%, ‘t’ 9.85%, ‘q’ 0.26%

94
Public Key Cryptography
• Diffie and Hellman, 1976• All users get a public key and a private key
– Public key is published– Private key is not known to anyone else
• If Alice has a packet to send to Bob,– She encrypts the packet with Bob’s public key– Bob uses his private key to decrypt Alice’s packet
• Private key linked mathematically to public key– Difficult to derive by making it computationally infeasible (RSA)
• Pros: more security, convenient, digital signatures• Cons: slower

95
Digital Signatures
• Hashing function hard to invert, e.g. MD5, SHA• Apply private key to hash (decrypt hash)
– Called signature block
• Receiver uses sender’s public key on signature block– E(D(x)) = x should work (works for RSA)

96
Authentication
• Establish the identity of user/machine by– Something you know (password, secret)– Something you have (credit card, smart card)– Something you are (retinal scan, fingerprint)
• In the case of an OS this is done during login– OS wants to know who the user is
• Passwords: secret known only to the subject– Simplest OS implementation keeps (login, password) pair– Authenticates user on login by checking the password– Try to make this scheme as secure as possible!
• Display the password when being typed? (Windows, UNIX)

97
Salting Example
• If the hacker guesses Dog, he has to try Dog0001, …• UNIX adds 12-bit of salt• Passwords should be made secure:
– Length, case, digits, not from dictionary– Can be imposed by the OS! This has its own tradeoffs

98
One time passwords
• Password lasts only once– User gets book with passwords– Each login uses next password in list
• Much easier approach (Lamport 1981)– Uses one-way hash functionsUser stores Server storesuid, passwd uid, n, m, H=
hm(passwd)
n=n-1S = hn(password)
if(hm-n(S) == H)then
m=n;H=S;acceptelse reject
uid
nS

99
Security Attacks & Defenses
• Attacks– Trojan Horses– Login spoofing– Logic bombs– Trapdoors– Buffer overflows– Viruses, worms– Denial of Service
• Defenses– Virus Scanners– Lures– Intrusion Detection

100
Mobile Code Protection
• Can we place extension code in the same address space as the base system, yet remain secure ?
• Many techniques have been proposed– SFI– Safe interpreters– Language-based protection– PCC

101
Encoding Security
• Depends on how a system represents the Matrix– Not much sense in storing entire matrix!– ACL: column for each object stored as a list for the object– Capabilities: row for each subject stored as list for the subject
Cs414 grades Cs415 grades Emacs
Ranveer r/w r/w Kill/resume
Tom r r/w None
Mohamed r r None

102
Protecting Capabilities
• Prevent users from tampering with capabilities
• Tagged Architecture– Each memory word has extra bit indicating that it is a capability
– These bits can only be modified in kernel mode
– Cannot be used for arithmetic, etc.
• Sparse name space implementation– Kernel stores capability as object+rights+random number
– Give copy of capability to the user; user can transfer rights
– Relies on inability of user to guess the random number
• Need a good random number generator

103
Protecting Capabilities
• Kernel capabilities: per-process capability information– Store the C-list in kernel memory
– Process access capabilities by offset into the C-list
– Indirection used to make capabilities unforgeable
– Meta instructions to add/delete/modify capabilities

104
Protecting Capabilities
• Cryptographically protected capabilities– Store capabilities in user space; useful for distributed systems
– Store <server, object, rights, f(object, rights, check)> tuple
– The check is a nonce,
• unique number generated when capability is created;
• kept with object on the server; never sent on the network
• Language-protected capabilities– SPIN operating system (Mesa, Java, etc.)

105
Capability Revocation
• Kernel based implementation– Kernel keeps track of all capabilities; invalidates on revocation
• Object keeps track of revocation list– Difficult to implement
• Timeout the capabilities– How long should the expiration timer be?
• Revocation by indirection– Grant access to object by creating alias; give capability to alias– Difficult to review all capabilities
• Revocation with conditional capabilities– Object has state called “big bag”– Access only if capability’s little bag has sth. in object’s big bag

106
Why Distributed Systems?
• Resource sharing
• Computational speedup
• Reliability

107
Happens-Before• Define a Happens-before relation
(denoted by ).– 1) If A and B are events in the same
process, and A was executed before B, then A B.
– 2) If A is the event of sending a message by one process and B is the event of receiving that message by another process, then A B.
– 3) If A B and B C then A C.

108
Partial Ordering
Pi ->Pi+1; Qi -> Qi+1; Ri -> Ri+1R0->Q4; Q3->R4; Q1->P4; P1->Q2

109
Impossibility of Consensus
• Network characteristics:– Synchronous - some upper bound on network/processing
delay.– Asynchronous - no upper bound on network/processing
delay.
• Fischer Lynch and Paterson showed:– With even just one failure possible, you cannot guarantee
consensus.– Essence of proof: Just before a decision is reached, we can
delay a node slightly too long to reach a decision.
• Real world solutions:– Paxos, Randomized Consensus (P==1 is good enough)

110
Good luck!