cs179: gpu programming lecture 1: introduction. today course summary administrative details brief...
TRANSCRIPT

CS179: GPU ProgrammingLecture 1: Introduction

Today Course summary Administrative details Brief history of GPU computing Introduction to CUDA

Course Summary GPU Programming
What: GPU: Graphics processing unit -- highly parallel APIs for accelerated hardware
Why: Parallel processing
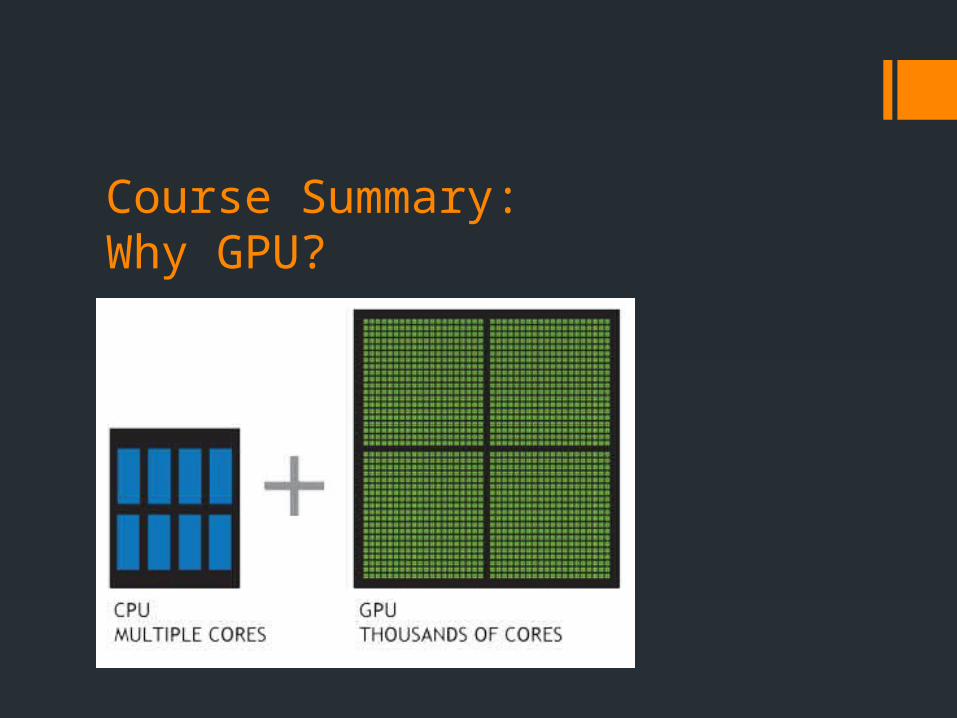
Course Summary:Why GPU?

Course Summary:Why GPU? How many cores, exactly?
GeForce 8800 Ultra (2007) - 128 GeForce GTX 260 (2008) - 192 GeForce GTX 295 (2009) - 480* GeForce GTX 480 (2010) - 480 GeForce GTX 590 (2011) - 1024* GeForce GTX 690 (2012) - 3072* GeForce GTX Titan Z (2014) - 5760*
* indicates these are cards shipped with 2 GPUs in them, effectively doubling the cores

Course Summary:Why GPU?

Course Summary:Why GPU?

Course Summary:Why GPU?
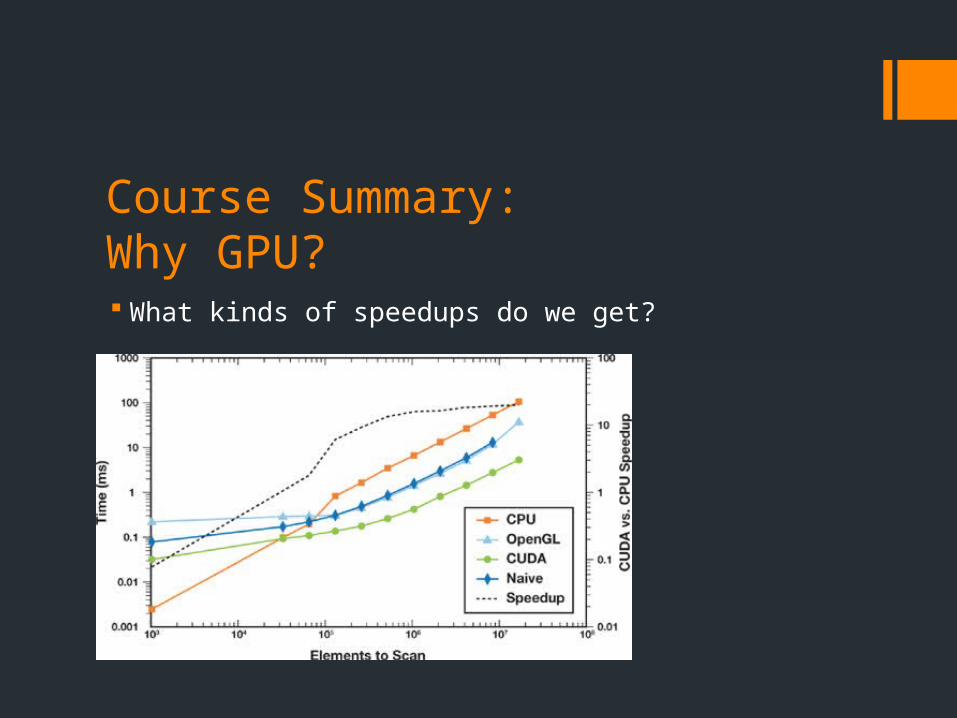
Course Summary:Why GPU? What kinds of speedups do we get?

Course Summary:Overview What will you learn?
CUDA Parallelizing problems Optimizing GPU code CUDA libraries
What will we not cover? OpenGL C/C++

Administrative:Course Details CS179: GPU Programming
Website: http://courses.cms.caltech.edu/cs179/ Course Instructors/TA’s:
Connor DeFanti ([email protected]) Kevin Yuh ([email protected])
Overseeing Instructor: Al Barr ([email protected])
Class time: MWF 5:00-5:55PM

Administrative:Assignments Homework:
8 assignments Each worth 10% of your grade (100 pts. each)
Final Project: 2 weeks for a custom final project Details are up to you! 20% of your grade (200 pts.)

Administrative:Assignments Assignments will be due Wednesday, 5PM Extensions may be granted…
Talk to TA’s beforehand! Office Hours: located in 104 ANB
Connor: Tuesday, 8-10PM Kevin: Monday, 8-10PM

Administrative:Assignments Doing the assignments:
CUDA-capable machine required! Must have NVIDIA GPU Setting up environment can be tricky Three options:
DIY with your own setup Use provided instructions with given environment Use lab machines

Administrative:Assignments Submitting assignments:
Due date: Wednesday 5PM Submit assignment as .tar/.zip, or similar Include README file!
Name, compilation instructions, answers to conceptual questions on sets, etc.
Submit all assignments to [email protected] Receiving graded assignments:
Assignments should get back 1 week after submission We will email you back with grade and comments

GPU History:Early Days Before GPUs:
All graphics run on the CPU Each pixel drawn in series
Super slow! (CS171, anyone?)
Early GPUs: 1980s: Blitters (fixed image sprites) allowed fast image memory
transfer 1990s: Introduction of DirectX and OpenGL
Brought fixed function pipeline for rendering

GPU History:Early Days Fixed Function Pipeline:
“Fixed” OpenGL states Phong or Gouraud shading? Render as wireframe or solid?
Very limiting, made early games look similar

GPU History:Shaders Early 2000’s: shaders introduced
Allow for much more interesting shading models

GPU History:Shaders Shaders: expanded world of rendering greatly
Vertex shaders: apply operations per-vertex Fragment shaders: apply operations per-pixel Geometry shaders: apply operations to add new geometry

GPU History:Shaders These are great when dealing with graphics data…
Vertices, faces, pixels, etc. What about general purpose?
Can trick GPU DirectX “compute” shader may be an option Anything slicker?

GPU History:CUDA 2007: NVIDIA introduces CUDA
C-style programming API for GPU Easier to do GPGPU Easier memory handling Better tools, libraries, etc.

GPU History:CUDA New advantages on the table:
Scattered reads Shared memory Faster memory transfer to/from the GPU

GPU History:Other APIs Plenty of other API’s exist for GPGPU
OpenCL/WebCL DirectX Compute Shader Other

Using the GPU Highly parallelizable parts of computational problems

A simple problem… Add two arrays
A[] + B[] -> C[]
On the CPU:(allocate memory for C)For (i from 1 to array length)
C[i] <- A[i] + B[i]
Operates sequentially… can we do better?

A simple problem… On the CPU (multi-threaded):
(allocate memory for C)Create # of threads equal to number of cores on processor (around 2, 4, perhaps 8)(Allocate portions of A, B, C to each thread...)
...
In each thread,For (i from beginning region of thread)
C[i] <- A[i] + B[i]//lots of waiting involved for memory reads, writes, ...
Wait for threads to synchronize...
Slightly faster – 2-8x (slightly more with other tricks)

A simple problem… How many threads? How does performance scale?
Context switching: High penalty on the CPU!

A simple problem… On the GPU:
(allocate memory for A, B, C on GPU)Create the “kernel” – each thread will perform one (or a few) additions
Specify the following kernel operation:
For (all i‘s assigned to this thread)C[i] <- A[i] + B[i]
Start ~20000 (!) threadsWait for threads to synchronize...
Speedup: Very high! (e.g. 10x, 100x)

GPU: Strengths Revealed Parallelism Low context switch penalty!
We can “cover up” performance loss by creating more threads!

GPU Computing: Step by Step Setup inputs on the host (CPU-accessible memory) Allocate memory for inputs on the GPU Copy inputs from host to GPU Allocate memory for outputs on the host Allocate memory for outputs on the GPU Start GPU kernel Copy output from GPU to host
(Copying can be asynchronous)

GPU: Internals Blocks: Groups of threads
Can cooperate via shared memory Can synchronize with each other Max size: 512, 1024 threads (hardware-dependent)
Warps: Subgroups of threads within block Execute “in-step” Size: 32 threads

GPU: InternalsBlock
SIMD processing unit
Warp

The Kernel Our “parallel” function Simple implementation (won’t work for lots of values)
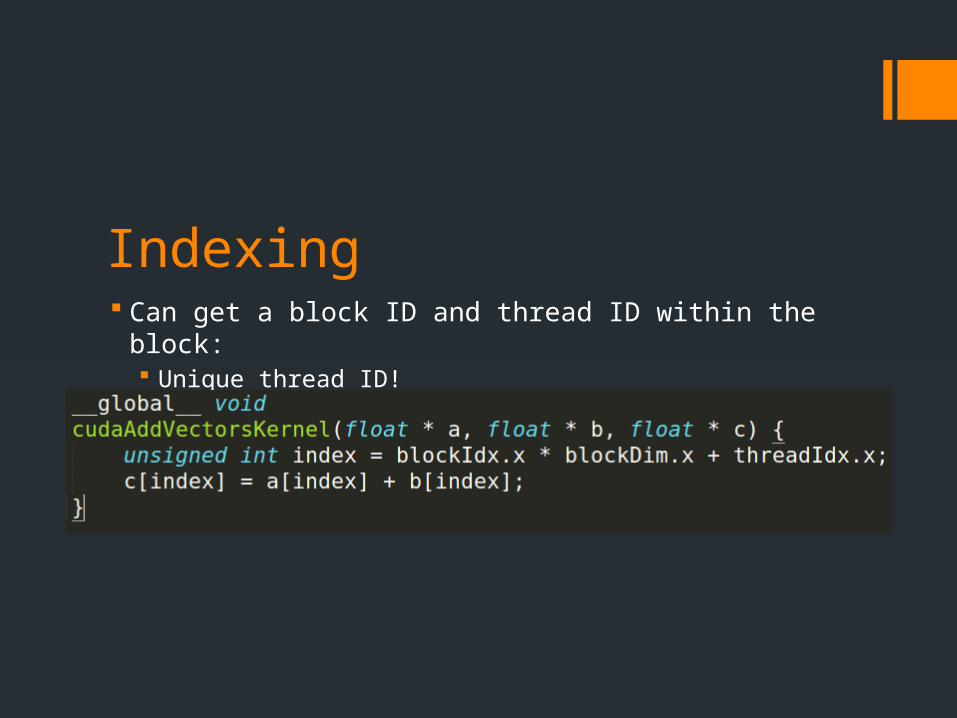
Indexing Can get a block ID and thread ID within the block:
Unique thread ID!

Calling the Kernel
…

Calling the Kernel (2)